

ESatSR: Enhancing Super-Resolution for Satellite Remote Sensing Images with State Space Model and Spatial Context


Abstract

1. Introduction
- We propose ESatSR, an SR model designed for remote sensing images based on state space models. It can effectively conduct super-resolution in satellite remote sensing image scenarios, and our experiments demonstrate that ESatSR outperforms several state-of-the-art methods, including CNNs as well as Transformers, on public remote sensing datasets.
- We design a module utilizing the state space model (SSM) as a solution to enhancing long-range dependencies, named RVMB. Benefiting from the SSM’s wide receptive field, RVMBs exhibit powerful long-range modeling capabilities compared to modules based on CNNs or Transformers, and perform well in both global and local feature extraction tasks, thereby enhancing the model’s overall performance.
- We propose the Spatial Context Interaction Module to address the lack of prior assumptions. By introducing spatial prior information, ESatSR can utilize image prior knowledge to guide the image feature extraction process, and the interaction between multi-scale spatial context and image features enhance the network’s capability in capturing small targets, thereby leading to enhanced model performance on remote sensing images.
2. Related Work
2.1. Image Restoration
2.2. Image Super-Resolution for Remote Sensing
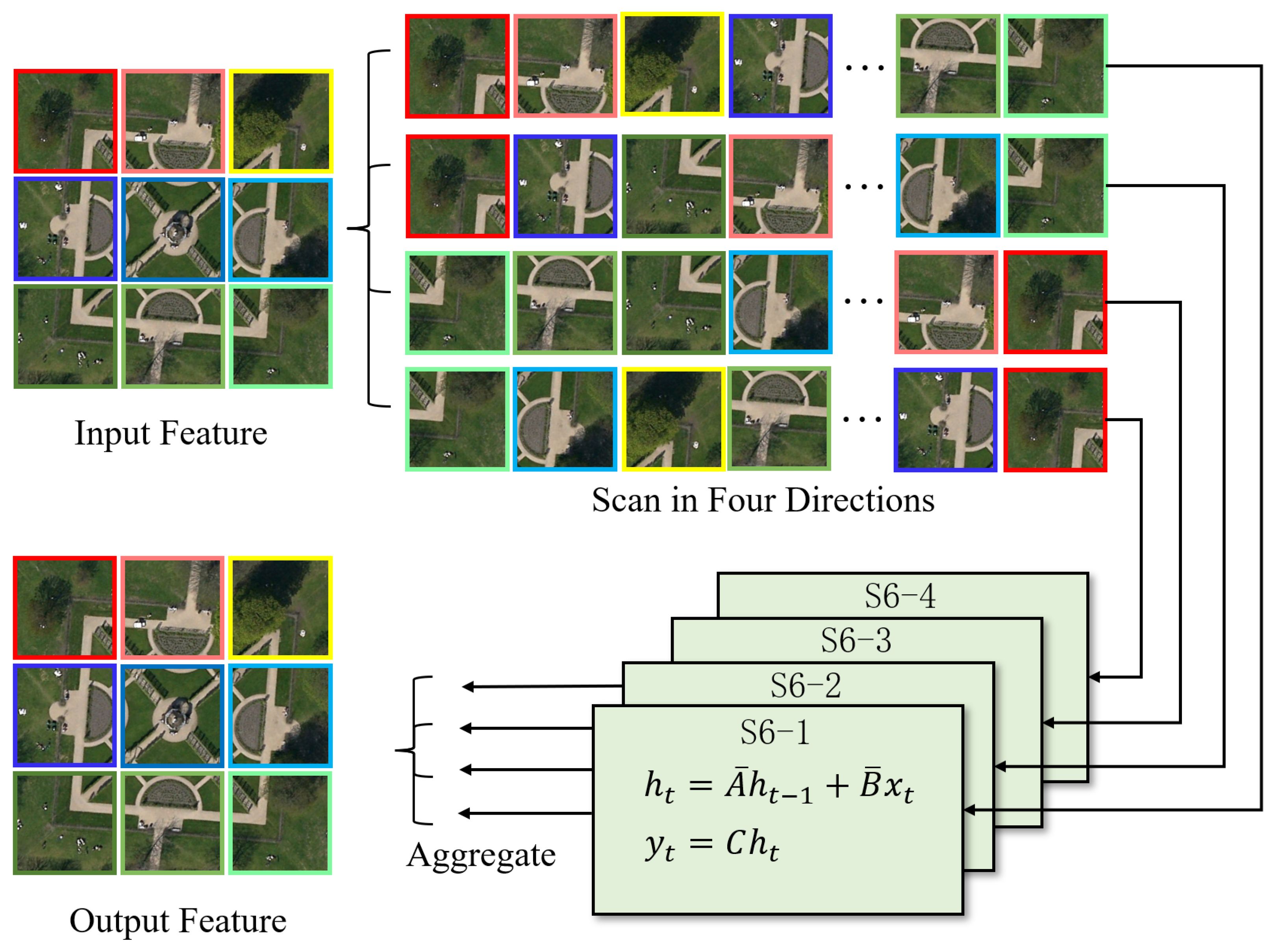
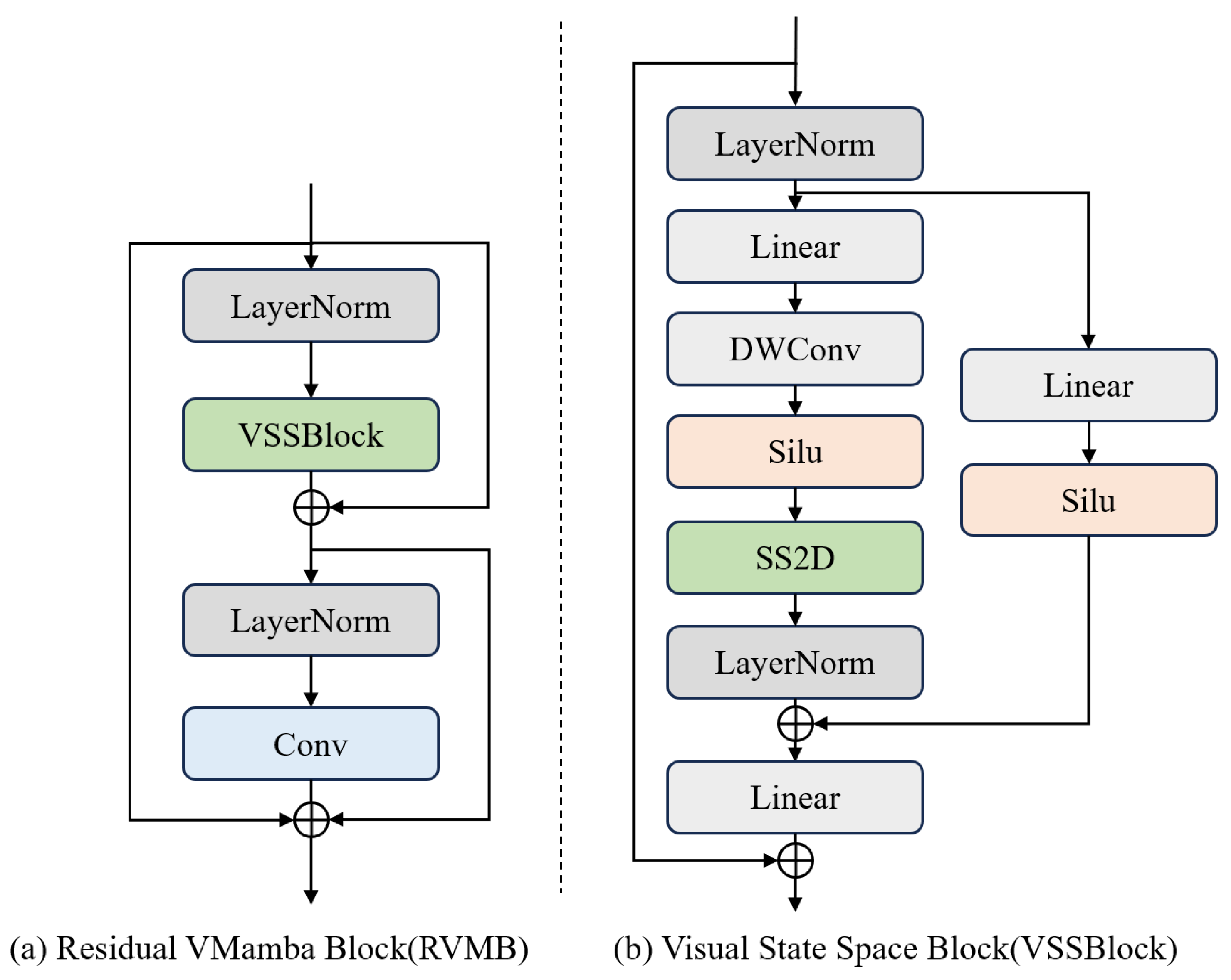
2.3. State Space Model
3. Methods
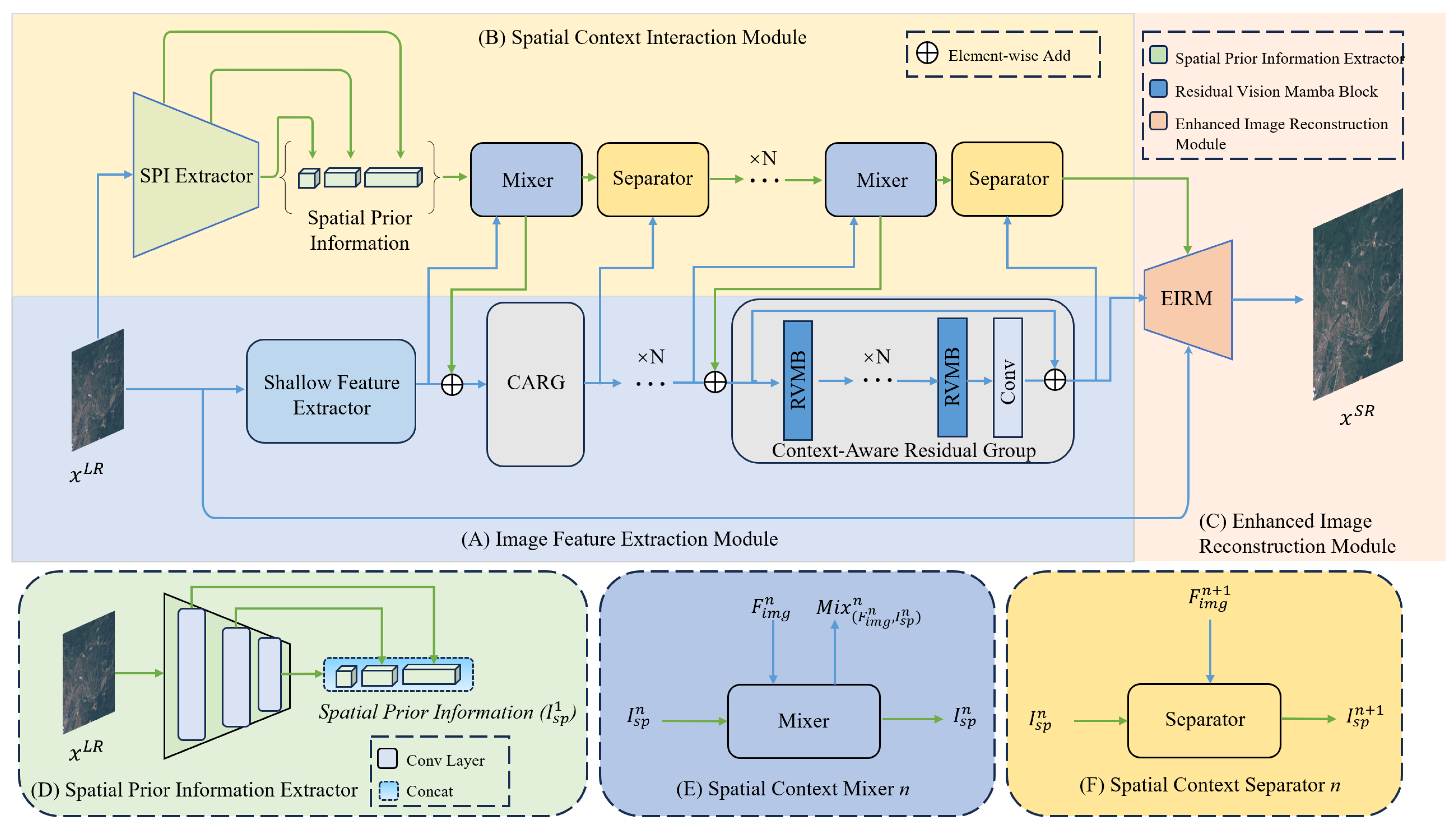
3.1. Overview of Network Architecture
3.2. Image Feature Extraction Module
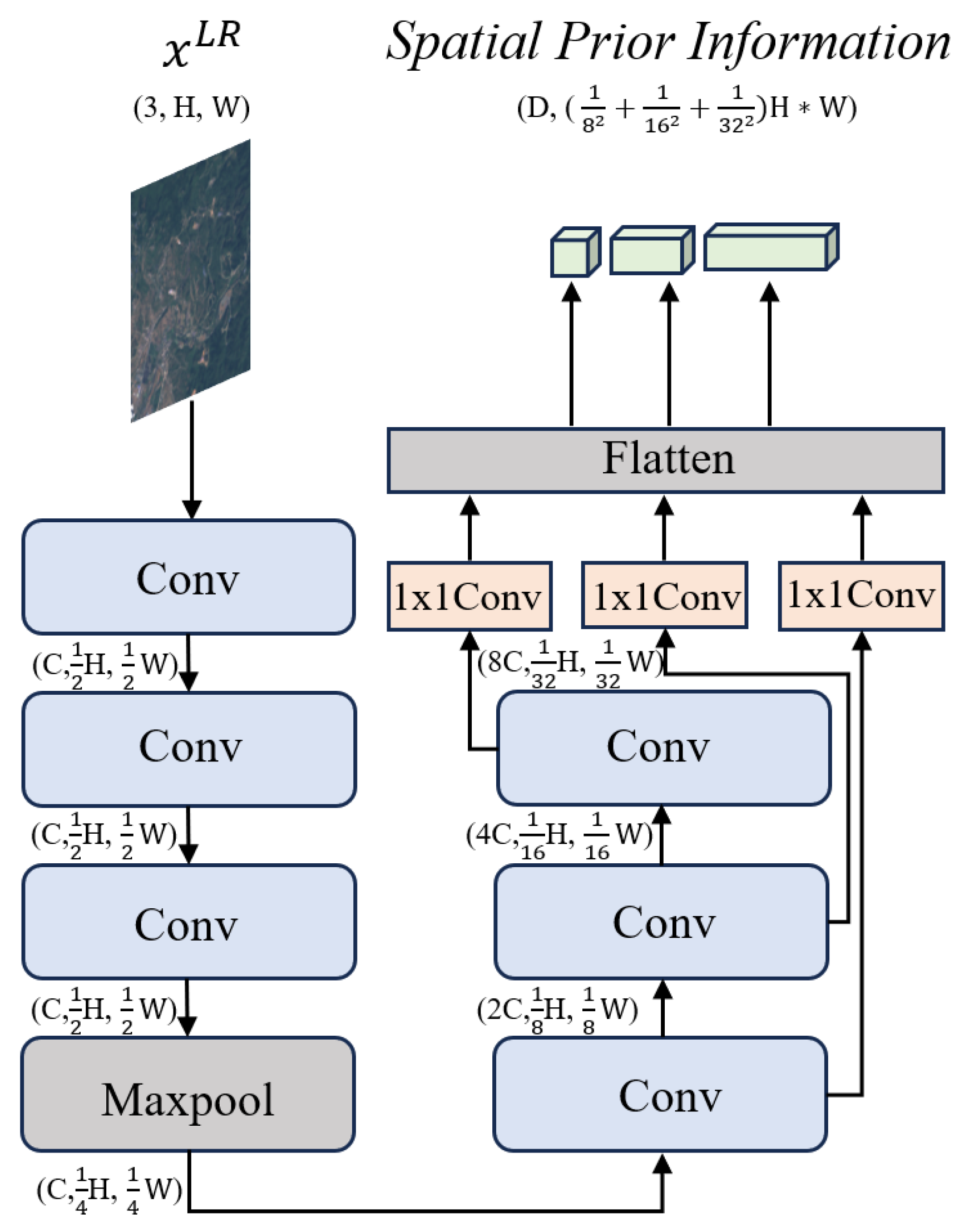
3.3. Spatial Context Interaction Module
3.3.1. Spatial Prior Information Extractor
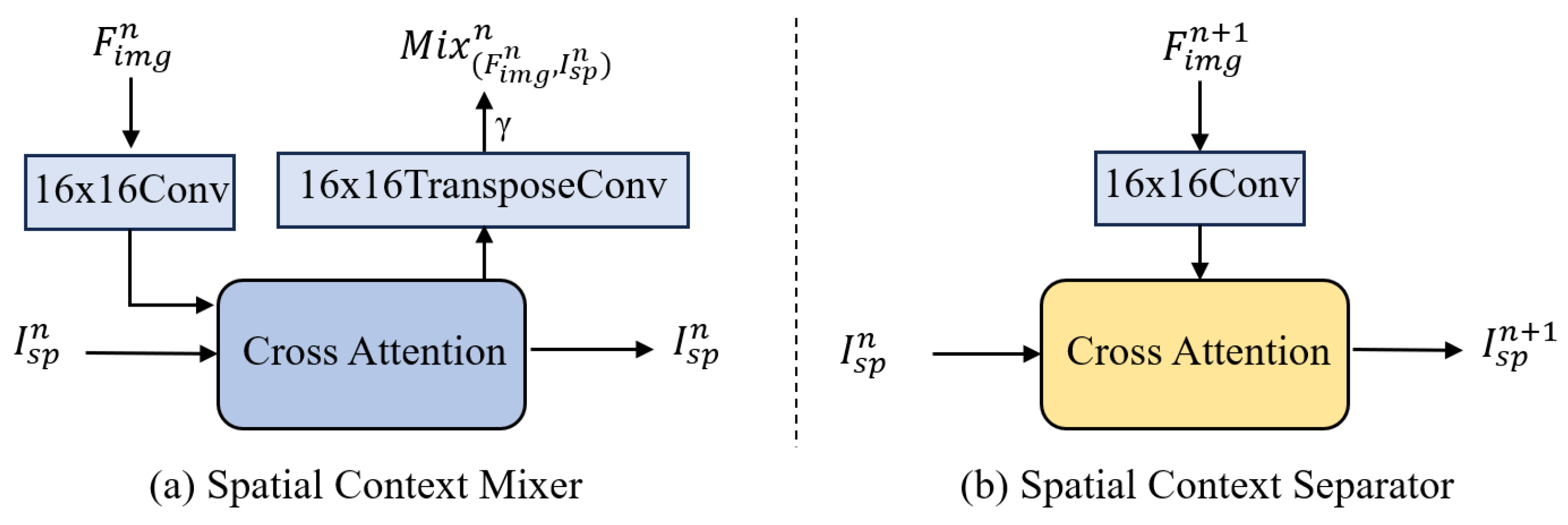
3.3.2. Spatial Context Mixer
3.3.3. Spatial Context Separator
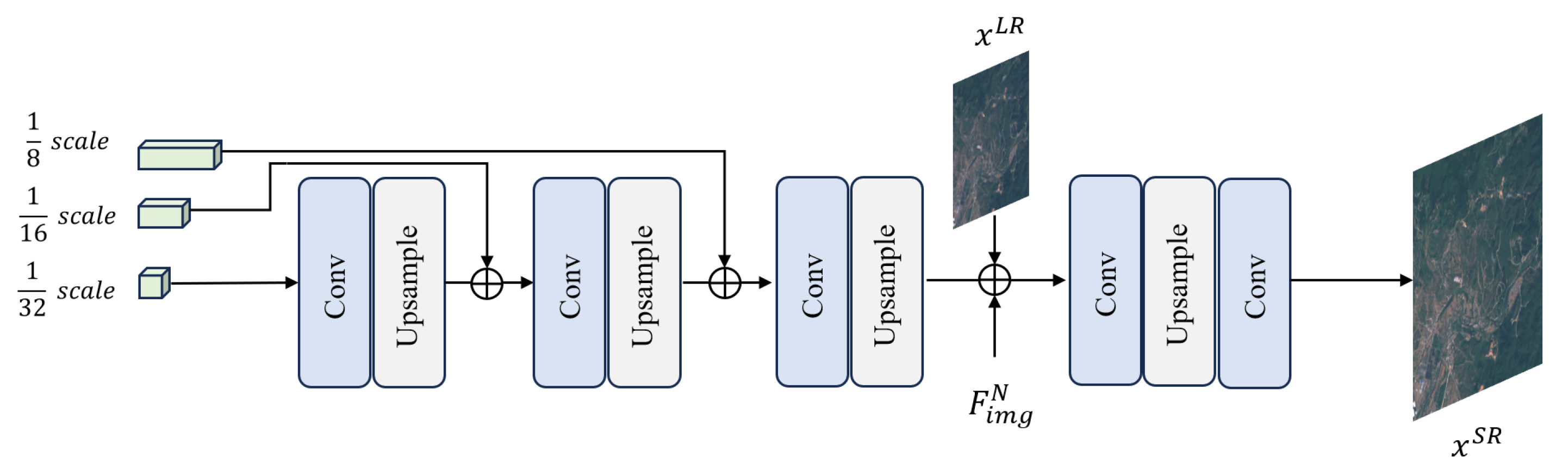
3.4. Enhanced Image Restoration Module
4. Experiments
4.1. Datasets
- DIV2K [50]: The DIV2K dataset includes 800 training images, 100 validation images, and 100 test images, all of which have 2K resolution. We divided the images into 480 × 480 sub-images with non-overlapping regions, and obtained LR images through bicubic downsampling.
- OLI2MSI [51]: The OLI2MSI is a real-world remote sensing image dataset, containing 5225 training LR-HR image pairs and 100 test LR-HR image pairs. The HR images have 480 × 480 resolution and the LR images have a resolution of 180 × 180. The LR images are ground images with a spatial resolution of 30 m, captured by the Operational Land Imager Landsat-8 satellite, and the HR images are ground images with a spatial resolution of 10 m, captured by the Multispectral Instrument Sentinel-2 satellite. Since the original scale factor of the dataset is 3, we used bicubic to obtain LR images for other scale factors.
- RSSCN7 [52]: The RSSCN7 contains 2800 remote sensing images collected from Google Earth, covering various classic remote sensing scenarios, including grasslands, forests, fields, lakes, parking lots, residential areas, and factory areas. Bicubic is used here to generate corresponding LR images.
4.2. Comparison Methods
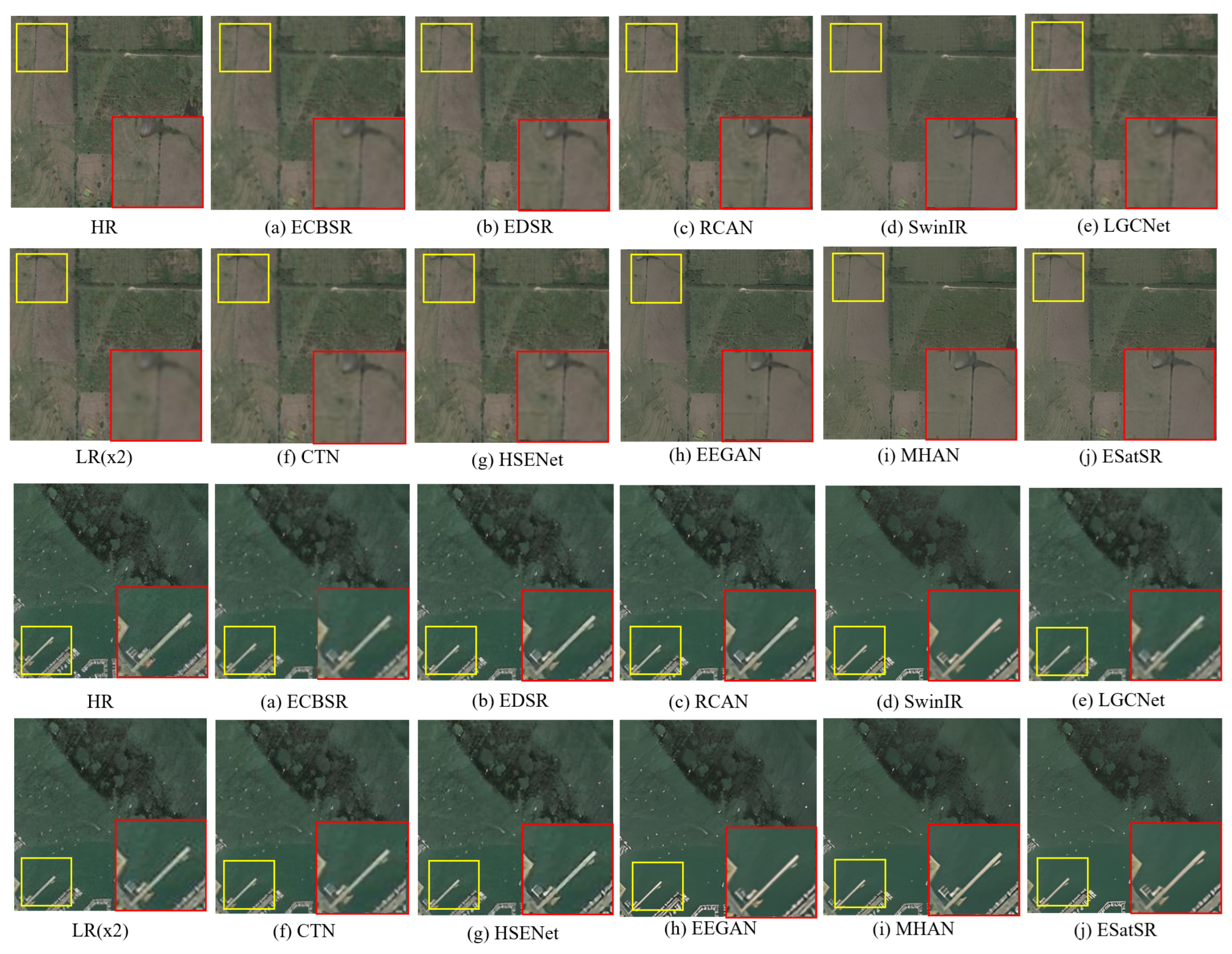
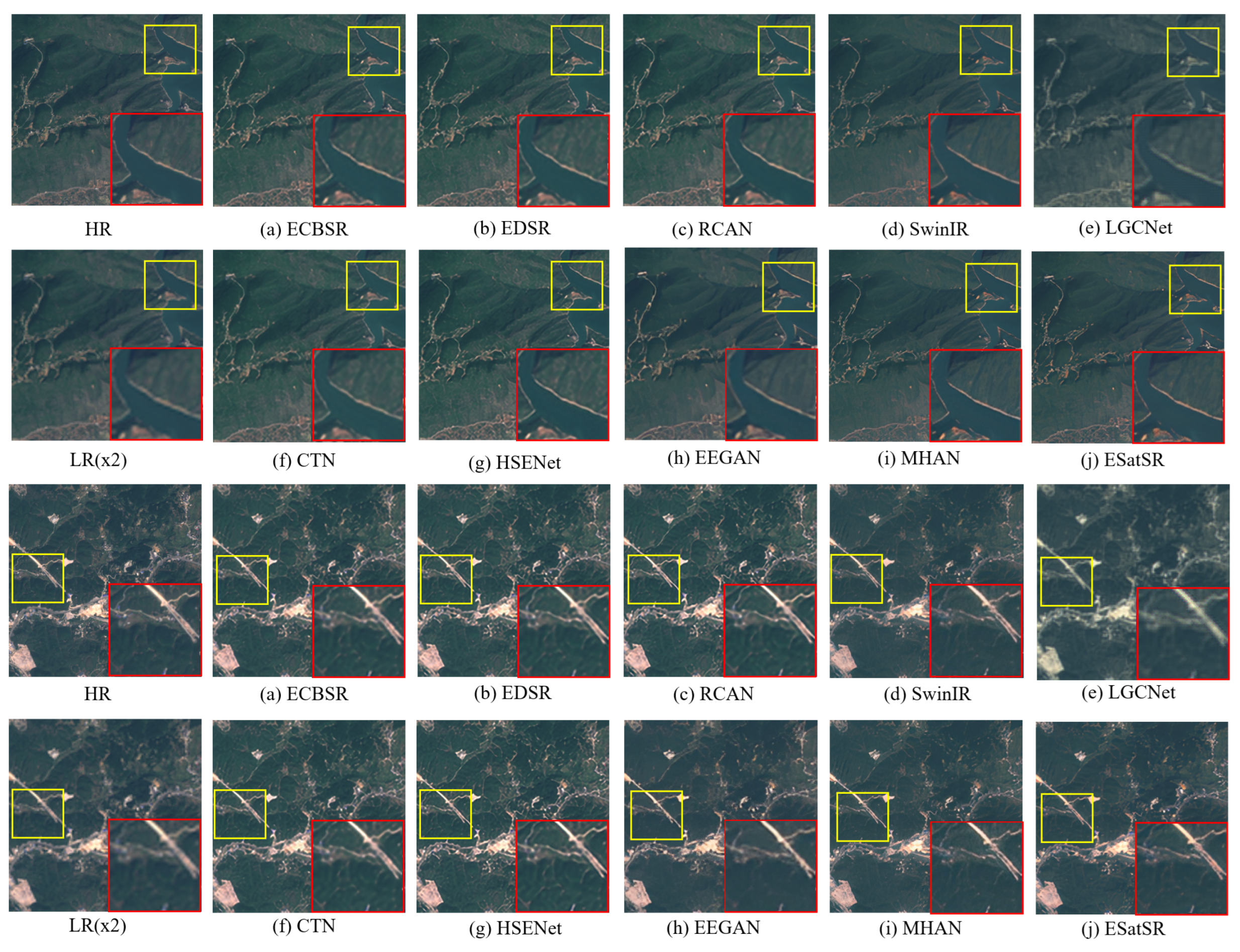
- ECBSR [53]: ECBSR is a lightweight SR model built with ECB, which is an improved convolution block. After replacing simple convolutional layers with ECB, the model’s inference is sped up, and the performance is also comparable to the popular SR methods.
- RCAN [20]: RCAN proposes a Residual-in-Residual module that can be used to build a deeper residual network. A channel attention mechanism is also added to RCAN to enhance the representation ability.
- SwinIR [16]: Introducing shifted window into the field of image restoration, SwinIR utilizes the attention among windows to enhance its local feature extraction capability, demonstrating state-of-the-art performance.
- LGCNet [36]: LGCNet fuses the outputs of different convolutional layers, which can improve the quality of SR images.
- CTN [37]: CTN extracts image features through a hierarchical architecture. Through a context aggregation module, the features are enhanced and combined to reconstruct SR images.
- HSENet [40]: An observation of remote sensing images is that lots of similar targets usually occur concurrently. To take advantage of that, HSENet designed a self-similarity utilization module to calculate the correlation of features at the same scale. Residual connections are set so that the network can refer to the features of similar targets in other scales during image reconstruction.
- EEGAN [54]: The usual GAN-based method produces a high-resolution result that looks sharp but is eroded with artifacts and noises. EEGAN uses edge-enhancement sub-networks to extract and enhance the image contours by purifying the noise-contaminated components with mask processing. The contours and purified image are combined to generate the final SR output.
- MHAN [55]: MHAN consists of two sub-networks bridged by a frequency-aware connection. One network is responsible for feature extraction, and it replaces the element-wise addition with weighted channel-wise concatenation in all skip connections, greatly facilitating the flow of information. The other network introduces a high-order attention module instead of the usual spatial or channel attention to restore missing details. MHAN exhibits superior performance among various SR methods tailored for remote sensing images.
4.3. Implementation Details
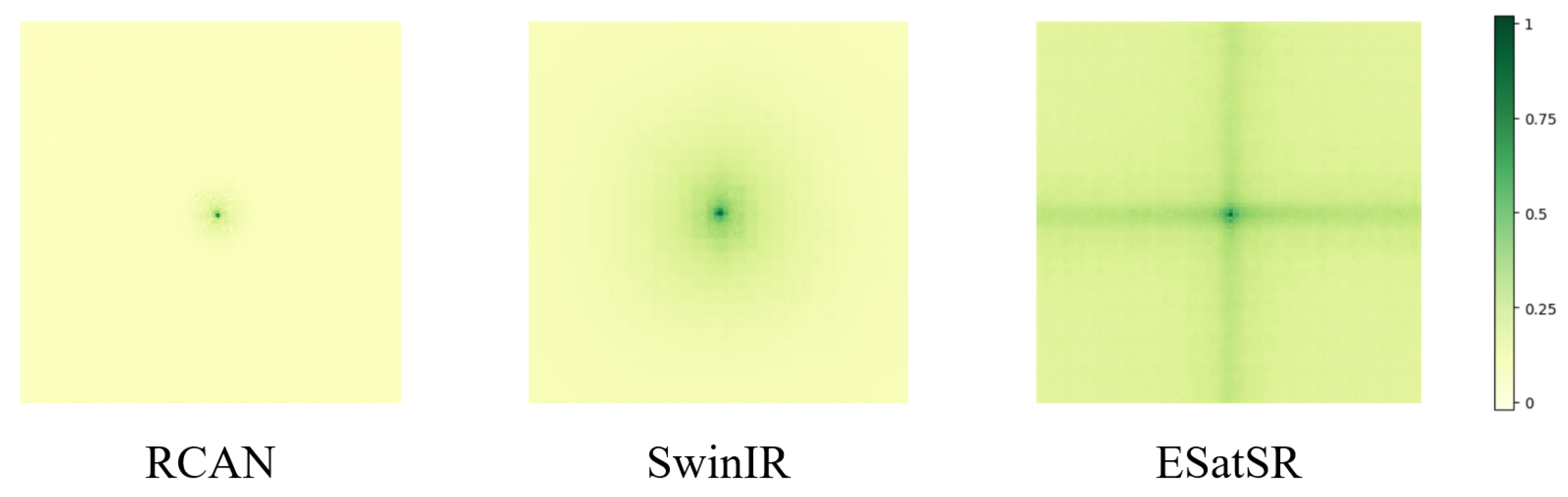
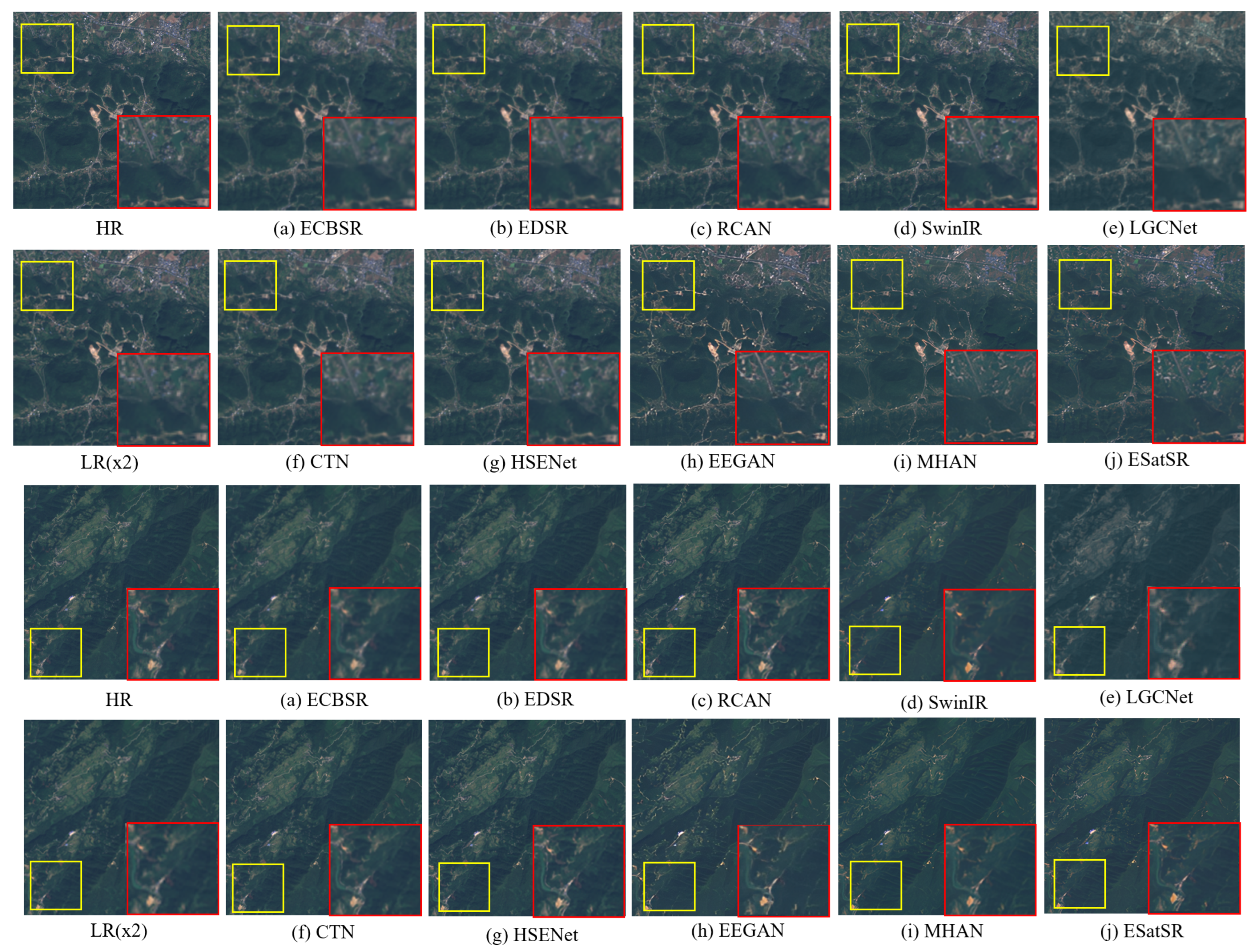
4.4. Quantitative and Qualitative Comparisons
4.5. Ablation Studies
4.5.1. The Effectiveness of Spatial Context Interaction Module
4.5.2. The Effectiveness of Enhanced Image Reconstruction Module and the Multi-Scale Design of Spatial Context
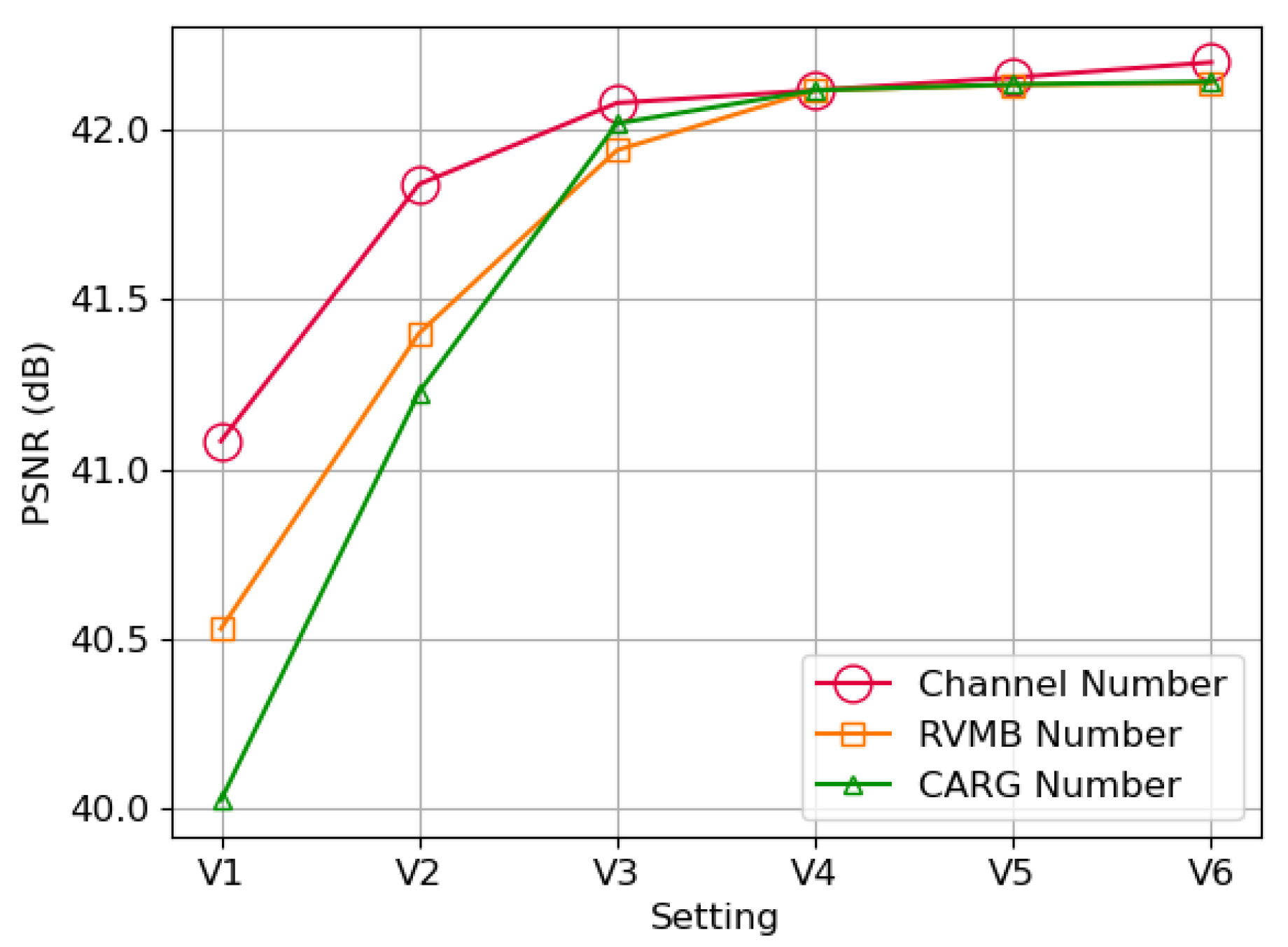
4.5.3. The Impact of Channel Number, RVMB Number, and CARG Number
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Gong, H.; Dai, H.; Li, C.; He, Z.; Wang, W.; Feng, Y.; Han, F.; Tuniyazi, A.; Li, H.; et al. Unsupervised hyperspectral image change detection via deep learning self-generated credible labels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9012–9024. [Google Scholar] [CrossRef]
- Gong, M.; Jiang, F.; Qin, A.K.; Liu, T.; Zhan, T.; Lu, D.; Zheng, H.; Zhang, M. A spectral and spatial attention network for change detection in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Wang, Y.; Bashir, S.M.A.; Khan, M.; Ullah, Q.; Wang, R.; Song, Y.; Guo, Z.; Niu, Y. Remote sensing image super-resolution and object detection: Benchmark and state of the art. Expert Syst. Appl. 2022, 197, 116793. [Google Scholar] [CrossRef]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H.; et al. Swin-transformer-enabled YOLOv5 with attention mechanism for small object detection on satellite images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Ngo, T.D.; Bui, T.T.; Pham, T.M.; Thai, H.T.; Nguyen, G.L.; Nguyen, T.N. Image deconvolution for optical small satellite with deep learning and real-time GPU acceleration. J. Real-Time Image Process. 2021, 18, 1697–1710. [Google Scholar] [CrossRef]
- Ye, Y.; Yang, C.; Gong, G.; Yang, P.; Quan, D.; Li, J. Robust optical and SAR image matching using attention-enhanced structural features. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–12. [Google Scholar] [CrossRef]
- Zhao, Q.; Dong, L.; Liu, M.; Kong, L.; Chu, X.; Hui, M.; Zhao, Y. Visible/Infrared Image Registration Based on Region-Adaptive Contextual Multi-Features. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Cao, J.; Li, Y.; Zhang, K.; Liang, J.; Van Gool, L. Video super-resolution transformer. arXiv 2021, arXiv:2106.06847. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating more pixels in image super-resolution transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. Vmamba: Visual state space model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–207. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y. Image super-resolution with non-local sparse attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtually, 19–25 June 2021; pp. 3517–3526. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Zhou, S.; Zhang, J.; Zuo, W.; Loy, C.C. Cross-scale internal graph neural network for image super-resolution. Adv. Neural Inf. Process. Syst. 2020, 33, 3499–3509. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2019; pp. 63–79. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual Event, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–218. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtually, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, T.; Lu, Y.; Di, H. Contextual transformation network for lightweight remote-sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Gu, J.; Sun, X.; Zhang, Y.; Fu, K.; Wang, L. Deep residual squeeze and excitation network for remote sensing image super-resolution. Remote Sens. 2019, 11, 1817. [Google Scholar] [CrossRef]
- Wang, Z.; Li, L.; Xue, Y.; Jiang, C.; Wang, J.; Sun, K.; Ma, H. FeNet: Feature enhancement network for lightweight remote-sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z. Hybrid-scale self-similarity exploitation for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–10. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Mo, W. Transformer-based multistage enhancement for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach to linear filtering and prediction problems. Trans. ASME D 1960, 82, 35–44. [Google Scholar] [CrossRef]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Gu, A.; Johnson, I.; Goel, K.; Saab, K.; Dao, T.; Rudra, A.; Ré, C. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Adv. Neural Inf. Process. Syst. 2021, 34, 572–585. [Google Scholar]
- Gupta, A.; Gu, A.; Berant, J. Diagonal state spaces are as effective as structured state spaces. Adv. Neural Inf. Process. Syst. 2022, 35, 22982–22994. [Google Scholar]
- Li, Y.; Cai, T.; Zhang, Y.; Chen, D.; Dey, D. What makes convolutional models great on long sequence modeling? arXiv 2022, arXiv:2210.09298. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Wang, J.; Gao, K.; Zhang, Z.; Ni, C.; Hu, Z.; Chen, D.; Wu, Q. Multisensor remote sensing imagery super-resolution with conditional GAN. J. Remote Sens. 2021, 2021, 9829706. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Zhang, X.; Zeng, H.; Zhang, L. Edge-oriented convolution block for real-time super resolution on mobile devices. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 4034–4043. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Wang, G.; Lu, T.; Jiang, J. Edge-enhanced GAN for remote sensing image superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5799–5812. [Google Scholar] [CrossRef]
- Zhang, D.; Shao, J.; Li, X.; Shen, H.T. Remote Sensing Image Super-Resolution via Mixed High-Order Attention Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5183–5196. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 158–168. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | FLOPs | #Param | RSSCN7 ×2 | OLI2MSI ×2 | ||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |||
| ECBSR [53] | 1.334 G | 0.036 M | 28.5243 | 0.7759 | 0.1298 | 38.1320 | 0.9453 | 0.0547 |
| EDSR [25] | 398.629 G | 10.806 M | 29.8445 | 0.8053 | 0.1169 | 40.6730 | 0.9721 | 0.0346 |
| RCAN [20] | 496.414 G | 13.559 M | 29.9278 | 0.8071 | 0.1146 | 40.8589 | 0.9730 | 0.0331 |
| SwinIR [16] | 432.409 G | 11.704 M | 31.2012 | 0.8147 | 0.1176 | 41.9301 | 0.9779 | 0.0336 |
| ESatSR (Ours) | 624.507 G | 23.751 M | 31.4243 | 0.8267 | 0.1145 | 42.1131 | 0.9784 | 0.0335 |
| CTN [37] | 9.412 G | 0.349 M | 28.7204 | 0.7811 | 0.1196 | 38.3098 | 0.9501 | 0.0394 |
| LGCNet [36] | 222.695 G | 6.042 M | 29.1485 | 0.7822 | 0.1174 | 38.5721 | 0.9529 | 0.0541 |
| HSENet [40] | 150.332 G | 5.286 M | 29.7957 | 0.8035 | 0.1153 | 40.4228 | 0.9708 | 0.0341 |
| EEGAN [54] | 214.248 G | 5.686 M | 30.5782 | 0.8105 | 0.1169 | 41.5793 | 0.9714 | 0.0338 |
| MHAN [55] | 416.803 G | 11.203 M | 30.9461 | 0.8148 | 0.1156 | 41.8747 | 0.9760 | 0.0342 |
| ESatSR (Ours) | 624.507 G | 23.751 M | 31.4243 | 0.8267 | 0.1145 | 42.1131 | 0.9784 | 0.0335 |
| Method | FLOPs | #Param | RSSCN7 ×3 | OLI2MSI ×3 | ||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |||
| ECBSR [53] | 0.593 G | 0.362 M | 26.2436 | 0.6492 | 0.1814 | 31.7960 | 0.8282 | 0.1168 |
| EDSR [25] | 201.454 G | 12.265 M | 27.7112 | 0.6965 | 0.1686 | 33.0270 | 0.9119 | 0.1012 |
| RCAN [20] | 223.416 G | 13.721 M | 27.7572 | 0.6981 | 0.1745 | 33.2142 | 0.9177 | 0.1004 |
| SwinIR [16] | 195.343 G | 11.889 M | 29.0517 | 0.7150 | 0.1690 | 34.9030 | 0.9268 | 0.0956 |
| ESatSR (Ours) | 280.720 G | 23.756 M | 29.2552 | 0.7262 | 0.1624 | 35.1744 | 0.9276 | 0.0951 |
| CTN [37] | 5.835 G | 0.349 M | 26.5870 | 0.6511 | 0.1763 | 32.2243 | 0.8404 | 0.1128 |
| LGCNet [36] | 98.975 G | 6.042 M | 26.6685 | 0.6526 | 0.1676 | 32.2528 | 0.8441 | 0.1170 |
| HSENet [40] | 69.976 G | 5.470 M | 27.6348 | 0.6925 | 0.1672 | 33.3470 | 0.9098 | 0.1150 |
| EEGAN [54] | 152.269 G | 5.870 M | 28.5782 | 0.7052 | 0.1691 | 34.5793 | 0.9114 | 0.1029 |
| MHAN [55] | 191.427 G | 11.387 M | 28.9461 | 0.7109 | 0.1647 | 34.8747 | 0.9160 | 0.0913 |
| ESatSR (Ours) | 280.720 G | 23.756 M | 29.2552 | 0.7262 | 0.1624 | 35.1744 | 0.9276 | 0.0951 |
| Setting | SCIM | EIRM | PSNR | SSIM | ||
|---|---|---|---|---|---|---|
| SPIE | Mixer | Separator | ||||
| baseline | 41.9583 | 0.9771 | ||||
| Variant 1 | √ | Single | 41.9613 | 0.9772 | ||
| Variant 2 | √ | √ | Single | 42.0493 | 0.9778 | |
| Variant 3 | √ | √ | √ | Single | 42.0855 | 0.9782 |
| ESatSR (Ours) | √ | √ | √ | Multi | 42.1131 | 0.9784 |
| Setting | Channel Number | RVMB Number | CARG Number |
|---|---|---|---|
| V1 | 90 | 1 | 1 |
| V2 | 120 | 2 | 2 |
| V3 | 150 | 4 | 4 |
| V4 | 180 | 6 | 6 |
| V5 | 210 | 8 | 8 |
| V6 | 240 | 10 | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Yuan, W.; Xie, F.; Lin, B. ESatSR: Enhancing Super-Resolution for Satellite Remote Sensing Images with State Space Model and Spatial Context. Remote Sens. 2024, 16, 1956. https://doi.org/10.3390/rs16111956
Wang Y, Yuan W, Xie F, Lin B. ESatSR: Enhancing Super-Resolution for Satellite Remote Sensing Images with State Space Model and Spatial Context. Remote Sensing. 2024; 16(11):1956. https://doi.org/10.3390/rs16111956
Chicago/Turabian StyleWang, Yinxiao, Wei Yuan, Fang Xie, and Baojun Lin. 2024. "ESatSR: Enhancing Super-Resolution for Satellite Remote Sensing Images with State Space Model and Spatial Context" Remote Sensing 16, no. 11: 1956. https://doi.org/10.3390/rs16111956
APA StyleWang, Y., Yuan, W., Xie, F., & Lin, B. (2024). ESatSR: Enhancing Super-Resolution for Satellite Remote Sensing Images with State Space Model and Spatial Context. Remote Sensing, 16(11), 1956. https://doi.org/10.3390/rs16111956