1. Introduction
More recently, extensive research on intelligent driving vehicles has revealed the significance of environmental perception systems. As the bases for downstream tasks such as vehicle positioning, path planning and 3D reconstruction, environmental perception systems are crucial parts of intelligent driving vehicles. It facilitates a comprehensive understanding of the surrounding environment through various vehicle-mounted sensors such as LiDAR, cameras, millimeter-wave radar, and GPS/IMU. Two commonly used sensors are LiDAR and camera. LiDAR-based perception systems can effectively capture information about the distance and speed of surrounding objects, but they are expensive. In contrast, a camera-based visual perception system can capture rich semantic information from the surrounding environment at a lower cost, enabling vehicles to make optimal driving decisions. Consequently, the visual perception system finds wider application in intelligent driving vehicles.
In practice, to satisfy the safety and stability requirements of intelligent driving vehicles, researchers [
1,
2,
3,
4,
5] commonly agree that visual perception systems should possess three basic perception capabilities: Firstly, traffic object detection aims at recognizing specific traffic objects within images and locating their positions, thus empowering vehicles to anticipate and respond to the potential risks of collision. Secondly, drivable area segmentation serves as a typical semantic segmentation task that can delineate the road regions suitable for vehicle navigation. Thirdly, lane detection seeks to locate lanes in the current vehicle driving environment, thereby providing accurate lane-keeping operations for safe driving. These capabilities jointly empower intelligent driving systems with a holistic view of the environment, contributing to safe navigation and intelligent decision-making. Over recent years, deep learning has advanced rapidly and made significant achievements. Many excellent methods can be utilized to tackle these tasks separately. For instance, SSD [
6], FCOS [
7] and YOLO [
8] are used for object detection; U-Net [
9], SegNet [
10], PSPNet [
11] and DeeplabV3+ [
12] for performing semantic segmentation; and LaneNet [
13], SCNN [
14], ENet-SAD [
15] and ENet [
16] to detect lanes. The above approaches achieve remarkable achievements in their respective tasks. Nevertheless, due to the inherent limitation of resources of the intelligent driving system, significant delays caused by continuous image processing via multiple different models pose a significant challenge to safe driving. To tackle this challenge, researchers have introduced multi-task learning methods to speed up image processing as well as enhance network generalization via accomplishing multiple related visual tasks simultaneously. For example, YOLOP [
2], built upon the lightweight one-stage detector YOLOv4, enables simultaneous traffic object detection, drivable area segmentation and lane detection. The subsequent HybridNets [
3] and YOLOPv2 [
4] retain the fundamental design concepts in YOLOP, and employ effective network architectures as well as training strategies for better multi-task prediction performance on the BDD100K dataset [
17]. The recent YOLOPX [
5] replaces the anchor-based detection head utilized in previous works with an anchor-free decoupled detection head, thus improving the flexibility and extensibility of the multi-task network. However, this anchor-free manner typically requires complex optimization strategies and large computational costs to achieve optimal performance, thus making the multi-task network harder to train. Therefore, this paper focuses on anchor-based multi-task networks and seeks to simplify training and improve the prediction performance of the networks.
For this purpose, a thorough study of existing multi-task visual perception methods is conducted. We recognize that despite the commendable performances exhibited by existing methods, they still suffer from the following drawbacks. Firstly, they fail to fully leverage multi-scale high-resolution features. For example, YOLOP [
2] and YOLOPv2 [
4] fail to utilize high-resolution features. HybridNets [
3] and YOLOPX [
5] only employ them for semantic segmentation. This manner is not conducive for the network to detect small objects that are prevalent in intelligent driving scenarios. Secondly, current anchor-based multi-task networks suffer from difficulties in capturing non-local (i.e., long-distance) contextual information. They generally adopt Path Aggregation Networks (PANs) [
18], Feature Pyramid Networks (FPNs) [
19], or Bidirectional Feature Pyramid Networks (BiFPNs) [
20] for obtaining contextual dependencies. Nevertheless, the convolutional layer’s constrained receptive field hinders information propagation over long distances, thus impairing network performance. Thirdly, training optimization remains a significant challenge, such as HybridNets [
3], which employs a stage-wise training strategy and numerous pre-defined anchors for optimal results, leading to increased computing expense. Existing anchor-based works [
2,
3,
4] typically utilize a hand-crafted label assignment strategy that results in ambiguous matching between the prior anchors and the ground truth, thus impairing detection performance. The training strategy of YOLOPX [
5] primarily focuses on an anchor-free multi-task network and fails to be directly applied to an anchor-based one.
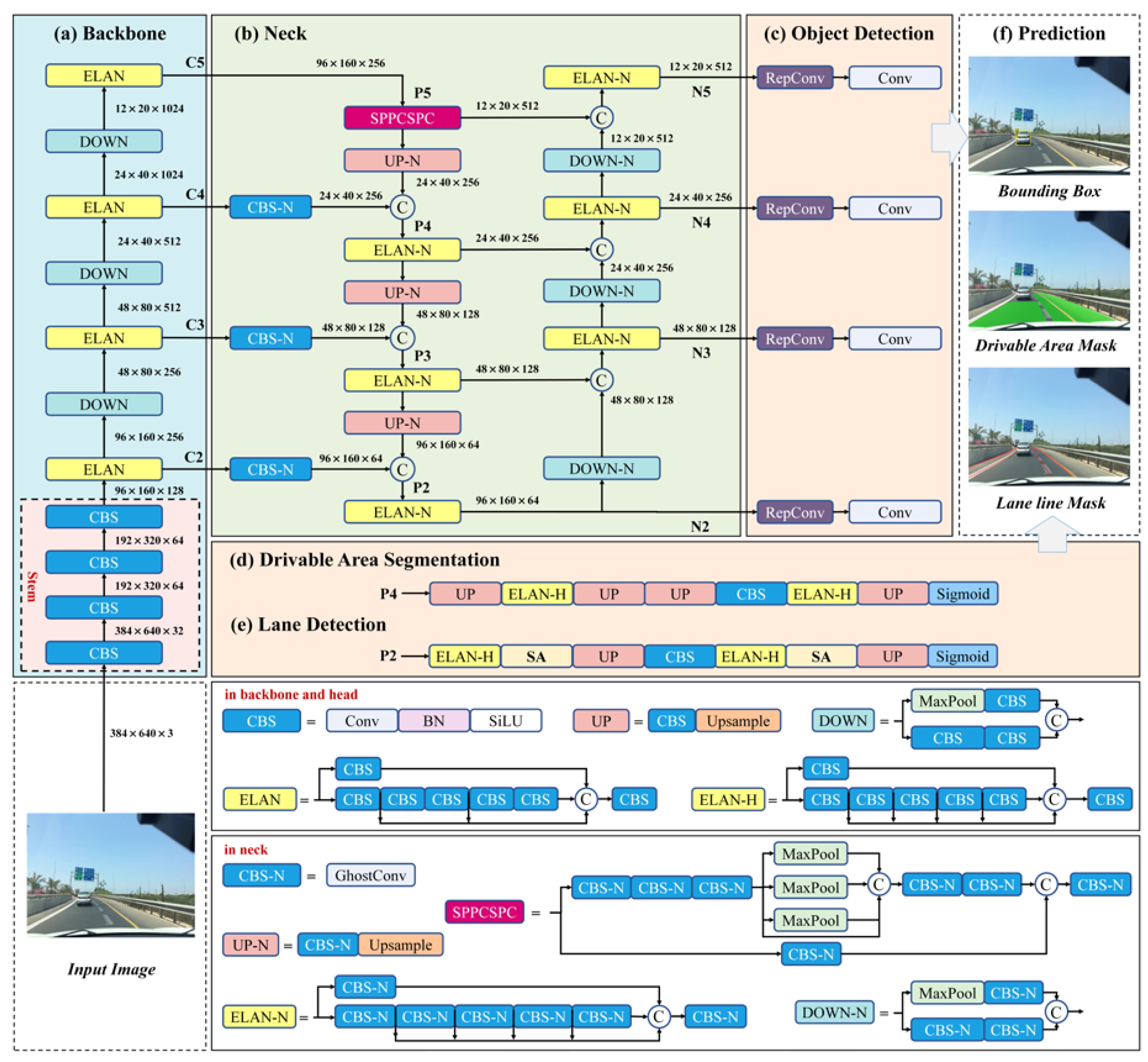
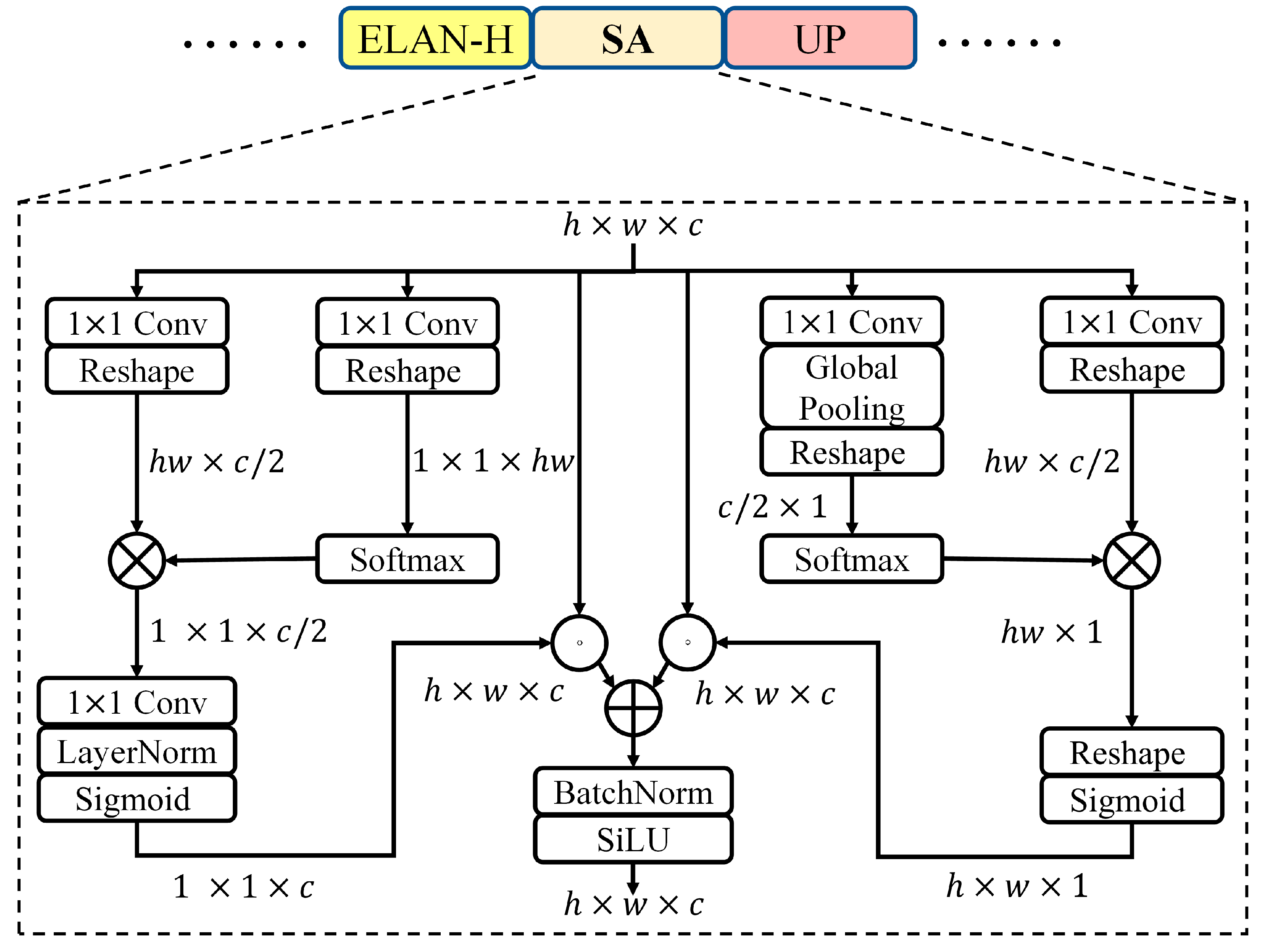
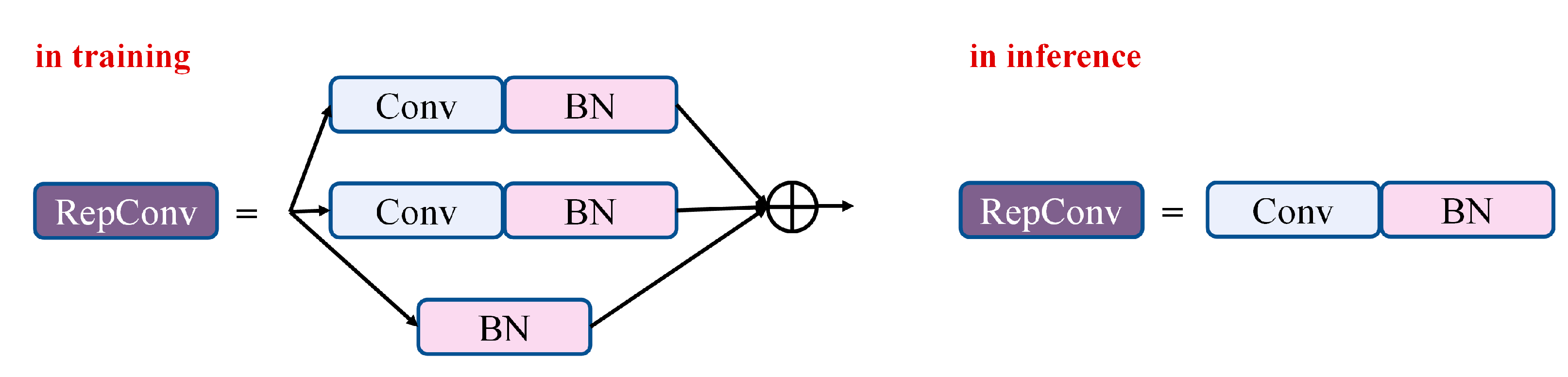
To tackle these shortcomings, we propose YOLOPv3, an efficient anchor-based multi-task visual perception network, which can jointly handle object detection, drivable area segmentation and lane detection, thus saving computing expense and speeding up inference. YOLOPv3, built upon the one-stage detector YOLOv7, is a classical encoder–decoder architecture. We have made the improvements as follows: (1) We design a novel multi-task learning architecture that can effectively leverage multi-scale high-resolution features to enhance network performance in small object detection and small region segmentation. (2) We propose a lightweight self-attention (SA)-based refined module and integrate it into the lane detection head. This module can capture non-local contextual dependencies and further enhance lane detection with little computing expense. (3) We propose optimization improvements (e.g., hybrid data augmentation, model re-parameterization, dynamic label assignment, and new multi-task loss function) that can optimize network training without increasing inference expense, thus allowing the anchor-based YOLOPv3 to attain best results via straightforward end-to-end training instead of stage-wise training as in HybridNets [
3]. In addition, we only utilize 12 anchors (significantly less than HybridNets which has 45 anchors), making the memory consumption acceptable for users with limited computational resources. Following [
2,
3,
4,
5], we train and evaluate YOLOPv3 on three visual tasks of the BDD100K dataset, which is a large and prevalent driving video dataset and can support the research of multi-task learning in the field of intelligent driving. The experimental results demonstrate that YOLOPv3 sets a new state of the art (SOTA): 96.9% recall and 84.3% mAP50 for traffic object detection, 93.2% mIoU for drivable area segmentation, and 88.3% accuracy and 28.0% IoU for lane detection. Compared to the lightweight networks YOLOP and HybridNets, the proposed YOLOPv3 obviously surpasses them. Furthermore, YOLOPv3 achieves an inference speed of 37 FPS, which is faster than HybridNets (17 FPS) and comparable to YOLOP (39 FPS) on the NVIDIA RTX 3080. These results indicate that YOLOPv3 is suitable for real-time operation. Compared to previous anchor-based SOTA YOLOPv2 and anchor-free SOTA YOLOPX, our YOLOPv3 demonstrates better performance with fewer parameters. Specifically, YOLOPv3 possesses 8.7 million fewer parameters than YOLOPv2 and 2.7 million fewer parameters than YOLOPX.
The main contributions can be summarized as follows:
We propose YOLOPv3, an efficient anchor-based multi-task visual perception network capable of simultaneously handling object detection, drivable area segmentation, and lane detection.
We propose architecture enhancements to utilize multi-scale high-resolution features and non-local contextual dependencies to improve network performance.
We propose optimization improvements aiming at enhancing network training, allowing our YOLOPv3 to achieve optimal performance via straightforward end-to-end training.
We empirically validate the effectiveness of our proposed method by achieving superior performance to most current SOTA methods on the BDD100K dataset.
2. Related Work
Traffic Object Detection. Object detection aims to locate and classify objects within images. Significant advancements in deep learning have established a robust foundation for its application in diverse fields such as intelligent driving vehicles [
21], medical healthcare [
22], agricultural robots [
23], and remote sensing [
24,
25,
26]. Currently, object detection methods are mainly categorized into two-stage and one-stage methods. Two-stage methods such as the R-CNN series [
27,
28,
29] first obtain the regions of interest (ROIs), then predict categories and perform boundary box regression based on these ROIs. These methods perform well but are training complex and computationally intensive. In contrast, one-stage methods like SSD [
6] and YOLO [
8] can directly and concurrently perform object classification and bounding box regression, leading to a simpler procedure and faster processing. Recently, certain researchers have argued that anchor-based schemes restrict the performance limits of detection methods to some extent. Therefore, they advocate for anchor-free one-stage methods such as CenterNet [
30], FCOS [
7] and YOLOX [
31], which are effective in improving the facilitation of object detection. Furthermore, the emergence of transformer-based structures has opened up new avenues for one-stage object detection. DETR series [
32,
33] are typical transformer-based methods that simplify the object detection pipeline and eliminate the need for hand-crafted anchors. However, these methods are computationally intensive and may require substantial training data to achieve optimal results. Thus, it is essential to consider the speed, accuracy, and computational complexity to ensure a method meets our practical needs.
In this work, we employ the one-stage detector YOLOv7 [
34], which achieves an excellent balance between accuracy and speed.
Semantic Segmentation. Semantic segmentation is essential for understanding image context at a pixel-wise level. Early methods, such as FCN [
35] and SegNet [
10], perform end-to-end but coarse prediction. To acquire comprehensive contextual information and promote accurate pixel-wise predictions, subsequent researchers introduce multi-scale high-resolution features into the semantic segmentation pipeline. Numerous methods leverage these features for excellent results. For instance, PSPNet [
11] employs the Pyramid Pooling Module (PPM) to consolidate context information across various scales, thereby enhancing the network’s capability to capture global information. Deeplab v3+ [
12] introduces atrous convolutions and Atrous Spatial Pyramid Pooling (ASPP) to account for both local detail and global context, yielding remarkable achievements in accuracy and scale awareness. In addition, it introduces additional high-resolution feature maps that are 1/4 of the size of the input image into ASPP, thus improving segmentation results for small regions and producing smoother boundaries. However, the convolutional layer’s constrained receptive field hinders information propagation over long distances, thus impairing network performance. To tackle this problem, researchers introduce non-local operations [
36]. For example, CrossViT [
37] explores the fusion of vision transformers and CNN to further improve segmentation capabilities. SETR [
38] regards semantic segmentation as the prediction task of Seq2Seq and proposes a novel transformer-based architecture to capture extensive contextual information.
In this study, drivable area segmentation and lane detection are classical pixel prediction tasks, where pixel-wise binary classifications are usually performed to determine whether a pixel belongs to a drivable area or a lane line [
13,
14,
15,
16,
39]. Consequently, it is very beneficial to introduce multi-scale high-resolution features and non-local contextual dependencies for improving network performance.
Multi-task Learning. Multi-task learning seeks to train a single model capable of simultaneously addressing multiple related tasks. In this model, each task branch shares information to improve the generalization of the model and accelerate convergence. In practice, the simultaneous execution of multiple related tasks by multi-task networks can efficiently leverage available resources and substantially diminish computational redundancy. This can confer significant advantages for the edge-side intelligent driving system with limited resources. Current works generally employ the encoder–decoder architectures. A good example is Mask R-CNN [
29], which adds a parallel instance segmentation head based on Faster R-CNN to handle classification, object detection, and instance segmentation in a unified manner. MultiNet [
40] simultaneously implements scene classification, object detection, and drivable area segmentation through a simple encoder–decoder architecture. DLT-Net [
1] designs a context tensor to fuse features from multiple task branches, thus enabling the network to efficiently identify traffic objects, lane lines, and drivable areas according to extensive features. YOLOP [
2], built upon the one-stage detector YOLOv4, achieves remarkable performance on three visual tasks of the BDD100K dataset. However, the simplicity of its network architecture leaves room for further improvements. HybridNets [
3] enhances YOLOP by employing a more robust network architecture, automatically customized anchor technology, and a new loss function and optimization strategy. YOLOPv2 [
4] retains the core design concepts of prior works [
2,
3], but employs more efficient network architecture and training strategy for better multi-task prediction performance. The recent YOLOPX [
5] replaces the anchor-based detection head utilized in previous works with an anchor-free decoupled one, which improves the flexibility and extensibility of the network. Moreover, YOLOPX also employs a lightweight lane detection head and optimization strategy to obtain better network performance.
Although these multi-task networks demonstrate commendable performance, they still suffer from several drawbacks such as suboptimal network architecture and training optimization. Therefore, there is a need to design a new multi-task visual perception network seeking to simplify training and further enhance network performance.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}