
Binary Noise Guidance Learning for Remote Sensing Image-to-Image Translation



Abstract
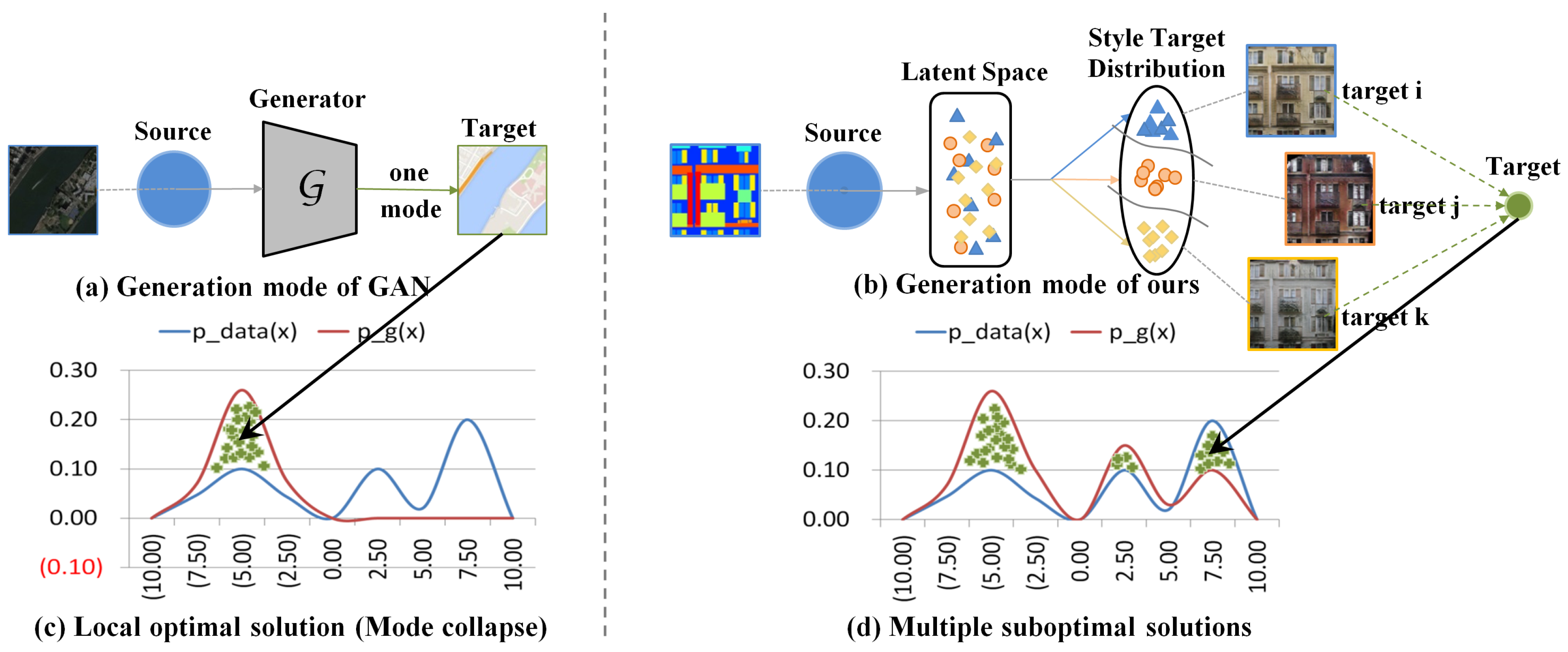
:1. Introduction
- This work proposes a binary-noise guidance learning (BnGLGAN) model to achieve more reliable conditions for generating image dependencies and a more robust prior distribution to restore images.
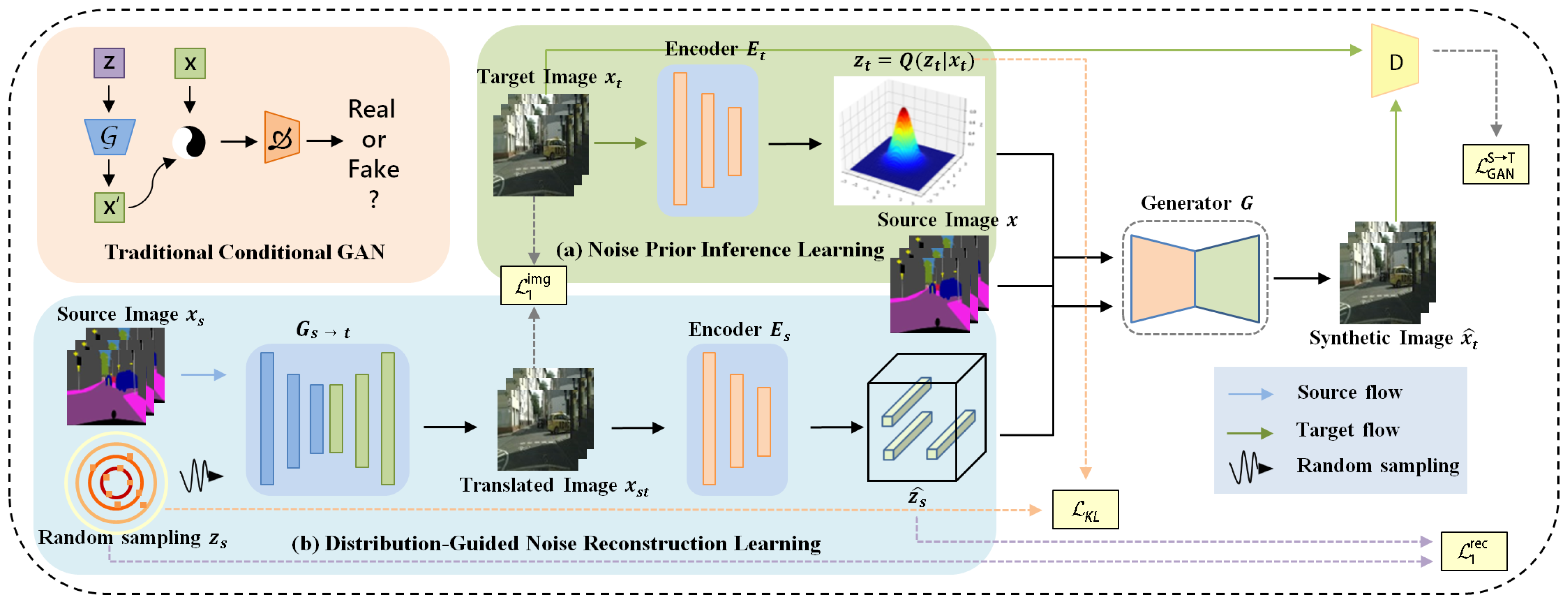
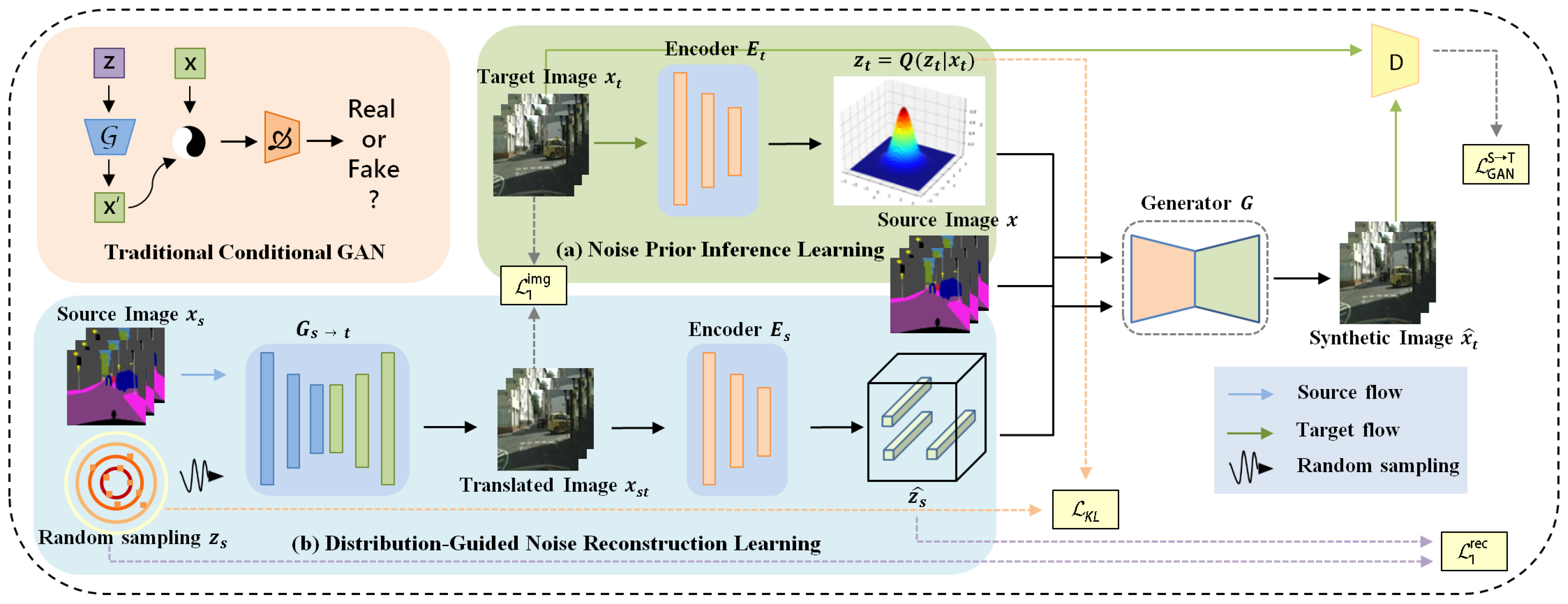
- This work designs a noise prior inference learning (NPIL) module to reduce the uncertainty of the mapping relationships under the co-supervision of a generator and an encoder so as to improve the robustness of image restoration.
- A distribution-guided noise reconstruction learning (DgNRL) module is designed to reduce the distortion of generated images by reconstructing the noise in the source domain with semantic information. Notably, as far as we know, this is the first I2IT method that uses reconstruction noise as a network condition.
- Comparisons with some state-of-the-art I2IT methods to reveal the transcendence of our method and ablation experiments are conducted to prove the efficiency of each proposed module.
2. Related Work
2.1. Image-to-Image Translation
2.2. Supervised Image-to-Image Translation
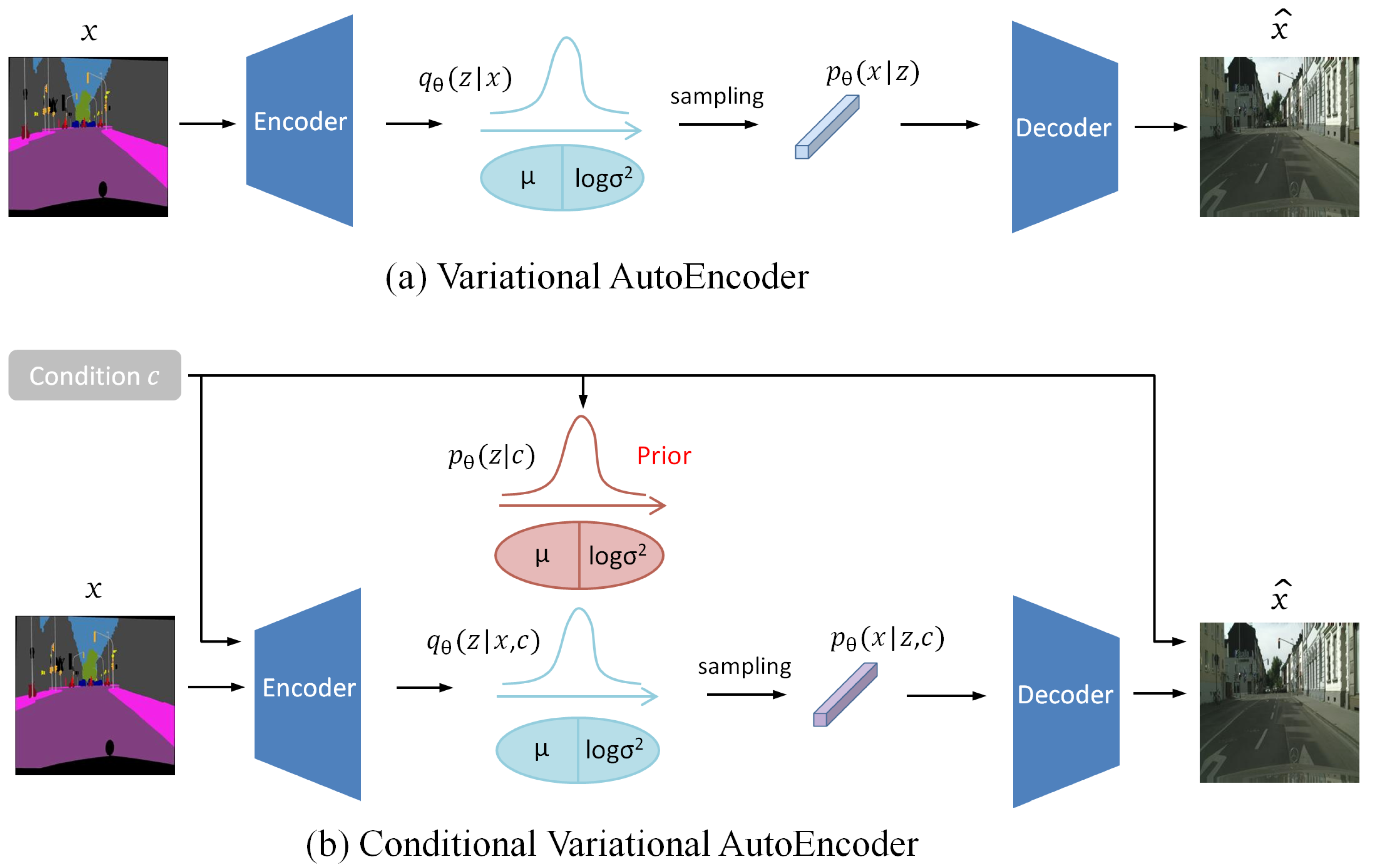
2.3. Variational Autoencoder
3. Proposed Method
3.1. Framework Overview
3.2. Noise Prior Inference Learning Module
3.3. Distribution-Guided Noise Reconstruction Learning Module
4. Experiment
4.1. Experiment Setup
4.1.1. Training Details
4.1.2. Datasets
4.1.3. Evaluation Metrics
4.2. Qualitative Evaluation
4.3. Quantitative Evaluation
4.4. Ablation Study
4.5. Activation Map Visualization
4.5.1. Higher Intra-Class Variation
4.5.2. Smaller Inter-Class Dissimilarity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A. Image-To-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhang, Z.; Sun, J.; Chen, J. Caster: Cartoon style transfer via dynamic cartoon style casting. Neurocomputing 2023, 556, 126654. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A. Colorful image colorization. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 649–666. [Google Scholar]
- Zhao, J.; Yang, D.; Li, Y.; Xiao, P.; Yang, J. Intelligent Matching Method for Heterogeneous Remote Sensing Images Based on Style Transfer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6723–6731. [Google Scholar] [CrossRef]
- Xiao, Q.; Liu, B.; Li, Z.; Ni, W.; Yang, Z.; Li, L. Progressive data augmentation method for remote sensing ship image classification based on imaging simulation system and neural style transfer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9176–9186. [Google Scholar] [CrossRef]
- Fu, L.; Zhang, D.; Ye, Q. Recurrent thrifty attention network for remote sensing scene recognition. IEEE Trans. Geosci. Remote Sens. 2020, 59, 8257–8268. [Google Scholar] [CrossRef]
- Merugu, S.; Jain, K.; Mittal, A. Sub-scene target detection and recognition using deep learning convolution neural networks. In ICDSMLA 2019: Proceedings of the 1st International Conference on Data Science, Machine Learning and Applications; Springer: Singapore, 2020; pp. 1082–1101. [Google Scholar]
- Zhang, G.; Ge, Y.; Dong, Z. Deep high-resolution representation learning for cross-resolution person re-identification. IEEE Trans. Image Process. 2021, 8913–8925. [Google Scholar] [CrossRef] [PubMed]
- Ye, Q.; Li, Z.; Fu, L. Nonpeaked discriminant analysis for data representation. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3818–3832. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Shoeiby, M.; Malthus, T. Single underwater image restoration by contrastive learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2385–2388. [Google Scholar]
- Skandha, S.; Saba, L.; Gupta, S. Magnetic resonance based Wilson’s disease tissue characterization in an artificial intelligence framework using transfer learning. In Multimodality Imaging, Volume 1: Deep Learning Applications; IOP Publishing: Bristol, UK, 2022; pp. 1–5. [Google Scholar]
- Saba, L.; Skandha, S.; Gupta, S. Artificial Intelligence Based Carotid Plaque Tissue Characterisation and Classification from Ultrasound Images Using a Deep Learning Paradigm. In Multimodality Imaging, Volume 1: Deep Learning Applications; IOP Publishing: Bristol, UK, 2022; pp. 1–6. [Google Scholar]
- Zhang, G.; Fang, W.; Zheng, Y. SDBAD-Net: A Spatial Dual-Branch Attention Dehazing Network based on Meta-Former Paradigm. IEEE Trans. Circuits Syst. Video Technol. 2023. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Chao, H. Image blind denoising with generative adversarial network based noise modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3155–3164. [Google Scholar]
- Ian, G.; Jean, P.; Mehdi, M. Generative adversarial networks. Commun. ACM 2020, 139–144. [Google Scholar]
- Lin, J.; Xia, Y.; Liu, S. Zstgan: An adversarial approach for unsupervised zero-shot image-to-image translation. Neurocomputing 2021, 461, 327–335. [Google Scholar] [CrossRef]
- Pang, Y.; Lin, J.; Qin, T. Image-to-image translation: Methods and applications. IEEE Trans. Multimed. 2021, 24, 3859–3881. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, J.; Chen, Y. Multi-biometric unified network for cloth-changing person re-identification. IEEE Trans. Image Process. 2023, 4555–4566. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Zhang, H.; Lin, W. Camera contrast learning for unsupervised person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4096–4107. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, G.; Chen, Y. Global relation-aware contrast learning for unsupervised person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8599–8610. [Google Scholar] [CrossRef]
- Zhang, G.; Luo, Z.; Chen, Y. Illumination unification for person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6766–6777. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Che, T.; Li, Y.; Jacob, A. Mode regularized generative adversarial networks. arXiv 2016, arXiv:1612.02136. [Google Scholar]
- Srivastava, A.; Valkov, L.; Russell, C.; Gutmann, M.; Sutton, C. Veegan: Reducing mode collapse in gans using implicit variational learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2347–2356. [Google Scholar]
- Bang, D.; Shim, H. Mggan: Solving mode collapse using manifold-guided training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2347–2356. [Google Scholar]
- Sohn, K.; Lee, H.; Yan, X. Learning structured output representation using deep conditional generative models. Adv. Neural Inf. Process. Syst. 2015, 28, 3483–3491. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 994–1003. [Google Scholar]
- Richardson, E.; Alaluf, Y.; Patashnik, O. Encoding in style: A stylegan encoder for image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2287–2296. [Google Scholar]
- Zhou, X.; Zhang, B.; Zhang, T. Cocosnet v2: Full-resolution correspondence learning for image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11465–11475. [Google Scholar]
- Mustafa, A.; Mantiuk, R. Transformation consistency regularization–a semi-supervised paradigm for image-to-image translation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVIII 16. Springer International Publishing: Cham, Switzerland, 2020; pp. 599–615. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Lee, H.; Tseng, H.; Huang, J. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
- Wang, T.; Liu, M.; Zhu, J. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Wang, C.; Zheng, H.; Yu, Z. Discriminative region proposal adversarial networks for high-quality image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 770–785. [Google Scholar]
- AlBahar, B.; Huang, J. Guided image-to-image translation with bi-directional feature transformation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 9016–9025. [Google Scholar]
- Yan, L.; Fan, B.; Liu, H. Triplet adversarial domain adaptation for pixel-level classification of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3558–3573. [Google Scholar] [CrossRef]
- Tang, H.; Xu, D.; Sebe, N. Multi-channel attention selection gan with cascaded semantic guidance for cross-view image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2417–2426. [Google Scholar]
- Shaham, T.; Gharbi, M.; Zhang, R. Spatially-adaptive pixelwise networks for fast image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14882–14891. [Google Scholar]
- Zhang, P.; Zhang, B.; Chen, D. Cross-domain correspondence learning for exemplar-based image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5143–5153. [Google Scholar]
- Park, T.; Liu, M.; Wang, T. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Mou, L.; Ghamisi, P.; Zhu, X. Deep recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Van, D.; Kalchbrenner, N.; Espeholt, L. Conditional image generation with pixelcnn decoders. Adv. Neural Inf. Process. Syst. 2016, 29, 4797–4805. [Google Scholar]
- Liu, M.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. Adv. Neural Inf. Process. Syst. 2017, 30, 700–708. [Google Scholar]
- Bepler, T.; Zhong, E.; Kelley, K. Explicitly disentangling image content from translation and rotation with spatial-VAE. Adv. Neural Inf. Process. Syst. 2019, 32, 15409–15419. [Google Scholar]
- Zhang, J.; Lang, X.; Huang, B. VAE-CoGAN: Unpaired image-to-image translation for low-level vision. Signal Image Video Process. 2023, 17, 1019–1026. [Google Scholar] [CrossRef]
- Kearney, V.; Ziemer, B.; Perry, A. Attention-aware discrimination for MR-to-CT image translation using cycle-consistent generative adversarial networks. Radiol. Artif. Intell. 2020, 2, e190027. [Google Scholar] [CrossRef] [PubMed]
- Duchi, J. Introductory lectures on stochastic optimization. Math. Data 2018, 25, 99–186. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Volpi, M.; Ferrari, V. Semantic segmentation of urban scenes by learning local class interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhu, J.; Gao, L.; Song, J. Label-guided generative adversarial network for realistic image synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3311–3328. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Xie, S.; Wu, W. Maximum spatial perturbation consistency for unpaired image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18311–18320. [Google Scholar]
- Hu, X.; Zhou, X.; Huang, Q. Qs-attn: Query-selected attention for contrastive learning in i2i translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18291–18300. [Google Scholar]
- Torbunov, D.; Huang, Y.; Yu, H. Uvcgan: Unet vision transformer cycle-consistent gan for unpaired image-to-image translation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 702–712. [Google Scholar]
- He, J.; Zhang, X.; Lei, S. Semantic inpainting on segmentation map via multi-expansion loss. Neurocomputing 2022, 501, 306–317. [Google Scholar] [CrossRef]
- Shang, Y.; Yuan, Z.; Xie, B. Post-training quantization on diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1972–1981. [Google Scholar]
- Huang, S.; He, C.; Cheng, R. SoloGAN: Multi-domain Multimodal Unpaired Image-to-Image Translation via a Single Generative Adversarial Network. IEEE Trans. Artif. Intell. 2022, 3, 722–737. [Google Scholar] [CrossRef]
- Gao, F.; Xu, X.; Yu, J. Complementary, heterogeneous and adversarial networks for image-to-image translation. IEEE Trans. Image Process. 2021, 30, 3487–3498. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cityscapes | Face2comics | CMP Facades | Google Maps | Night2day | Shoes | Handbag | |
|---|---|---|---|---|---|---|---|
| # total images (image pairs) | 3475 | 20,000 | 506 | 2194 | 20,110 | 50,025 | 138,767 |
| # training images (image pairs) | 2975 | 15,000 | 400 | 1096 | 17,823 | 49,825 | 13,8567 |
| # testing images (image pairs) | 500 | 5000 | 106 | 1098 | 2287 | 200 | 200 |
| image crop size | 1024 × 1024 | 512 × 512 | 256 × 256 | 600 × 600 | 256 × 256 | 256 × 256 | 256 × 256 |
| # training epochs | 300 | 400 | 400 | 400 | 200 | 60 | 60 |
| Method | FID ↓ | Per-Class Acc. | MIoU | PSNR | SSIM | LPIPS ↓ |
|---|---|---|---|---|---|---|
| pix2pix [1] | 61.2 | 25.5 | 8.41 | 15.193 | 0.279 | 0.379 |
| DRIT++ [32] | 57.4 | 25.7 | 11.60 | 15.230 | 0.287 | 0.384 |
| LSCA [50] | 45.5 | 29.1 | 27.33 | 15.565 | 0.369 | 0.325 |
| MSPC [51] | 39.1 | 29.6 | 33.67 | 15.831 | 0.425 | 0.397 |
| Qs-Attn [52] | 48.8 | 32.6 | 37.45 | 16.235 | 0.401 | 0.334 |
| UVCGAN [53] | 54.7 | 33.0 | 40.16 | 16.333 | 0.524 | 0.351 |
| PTQ [55] | 37.6 | 34.2 | 41.47 | 16.739 | 0.532 | 0.322 |
| BnGLGAN (512 × 512) | 35.9 | 35.6 | 42.60 | 16.839 | 0.547 | 0.319 |
| BnGLGAN (1024 × 1024) | 36.3 | 35.6 | 44.30 | 16.843 | 0.550 | 0.321 |
| Method | 512 × 512 | 1024 × 1024 | MOS | B |
|---|---|---|---|---|
| cycleGAN | 0.325 | 0.562 | 2.295 | 1.6 GB |
| pix2pix | 0.293 | 0.485 | 2.331 | 1.6 GB |
| DRIT++ | 0.336 | 0.512 | 2.372 | 1.6 GB |
| LSCA | 0.301 | 0.499 | 2.462 | 1.8 GB |
| BnGLGAN | 0.287 | 0.431 | 2.657 | 1.6 GB |
| Method | Face2comics | Edges2shoes | Edges2handbag | ||||||
|---|---|---|---|---|---|---|---|---|---|
| FID↓ | SSIM | LPIPS↓ | FID↓ | SSIM | LPIPS↓ | FID↓ | SSIM | LPIPS↓ | |
| pix2pix [1] | 49.96 | 0.298 | 0.282 | 66.69 | 0.625 | 0.598 | 43.02 | 0.736 | 0.286 |
| DRIT++ [32] | 28.87 | 0.287 | 0.285 | 53.37 | 0.692 | 0.498 | 43.67 | 0.688 | 0.411 |
| Qs-Attn [52] | 31.28 | 0.283 | 0.247 | 47.10 | - | 0.244 | 37.30 | 0.682 | - |
| MSPC [51] | - | 0.360 | - | 34.60 | 0.682 | 0.240 | - | 0.741 | - |
| SoloGAN [56] | - | 0.450 | - | 37.94 | 0.691 | 0.234 | 33.20 | 0.771 | 0.265 |
| UVCGAN [53] | 32.40 | 0.536 | 0.217 | - | 0.684 | 0.246 | 35.94 | - | 0.244 |
| PTQ [55] | 30.94 | 0.584 | 0.210 | 25.36 | 0.732 | 0.231 | 29.67 | 0.801 | 0.254 |
| BnGLGAN (Ours) | 27.39 | 0.586 | 0.205 | 21.07 | 0.782 | 0.228 | 28.35 | 0.793 | 0.182 |
| Method | Facades | Google Maps | Night2day | ||||||
|---|---|---|---|---|---|---|---|---|---|
| FID↓ | SSIM | LPIPS↓ | FID↓ | SSIM | LPIPS↓ | FID↓ | SSIM | LPIPS↓ | |
| pix2pix [1] | 96.1 | 0.365 | 0.438 | 140.1 | 0.177 | 0.321 | 121.2 | 0.441 | 0.433 |
| CHAN [57] | 93.7 | 0.387 | 0.422 | 131.5 | 0.187 | 0.287 | 117.9 | 0.558 | 0.303 |
| Qs-Attn [52] | 90.2 | 0.417 | 0.399 | 129.7 | 0.191 | 0.309 | 99.9 | - | 0.287 |
| SISM [54] | 91.7 | 0.422 | 0.401 | 110.4 | 0.196 | 0.294 | - | 0.668 | - |
| MSPC [51] | 87.3 | 0.501 | 0.384 | 104.3 | 0.203 | 0.311 | 91.2 | 0.654 | 0.246 |
| LSCA [50] | 88.0 | 0.434 | 0.359 | 99.8 | 0.212 | 0.283 | - | 0.659 | - |
| UVCGAN [53] | 85.3 | 0.459 | 0.344 | 101.1 | 0.216 | 0.297 | 89.8 | 0.701 | 0.223 |
| BnGLGAN (Ours) | 81.2 | 0.488 | 0.335 | 91.2 | 0.233 | 0.298 | 85.5 | 0.670 | 0.214 |
| Method | FID ↓ | SSIM | LPIPS ↓ |
|---|---|---|---|
| Baseline | 39.0 | 0.478 | 0.336 |
| Baseline + NPIL | 37.6 | 0.514 | 0.329 |
| Baseline + DgNRL | 37.1 | 0.523 | 0.324 |
| Baseline + NPIL + DgNRL (Ours) | 36.3 | 0.550 | 0.321 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Zhou, R.; Zheng, Y.; Li, B. Binary Noise Guidance Learning for Remote Sensing Image-to-Image Translation. Remote Sens. 2024, 16, 65. https://doi.org/10.3390/rs16010065
Zhang G, Zhou R, Zheng Y, Li B. Binary Noise Guidance Learning for Remote Sensing Image-to-Image Translation. Remote Sensing. 2024; 16(1):65. https://doi.org/10.3390/rs16010065
Chicago/Turabian StyleZhang, Guoqing, Ruixin Zhou, Yuhui Zheng, and Baozhu Li. 2024. "Binary Noise Guidance Learning for Remote Sensing Image-to-Image Translation" Remote Sensing 16, no. 1: 65. https://doi.org/10.3390/rs16010065
APA StyleZhang, G., Zhou, R., Zheng, Y., & Li, B. (2024). Binary Noise Guidance Learning for Remote Sensing Image-to-Image Translation. Remote Sensing, 16(1), 65. https://doi.org/10.3390/rs16010065