

SIGNet: A Siamese Graph Convolutional Network for Multi-Class Urban Change Detection



Abstract
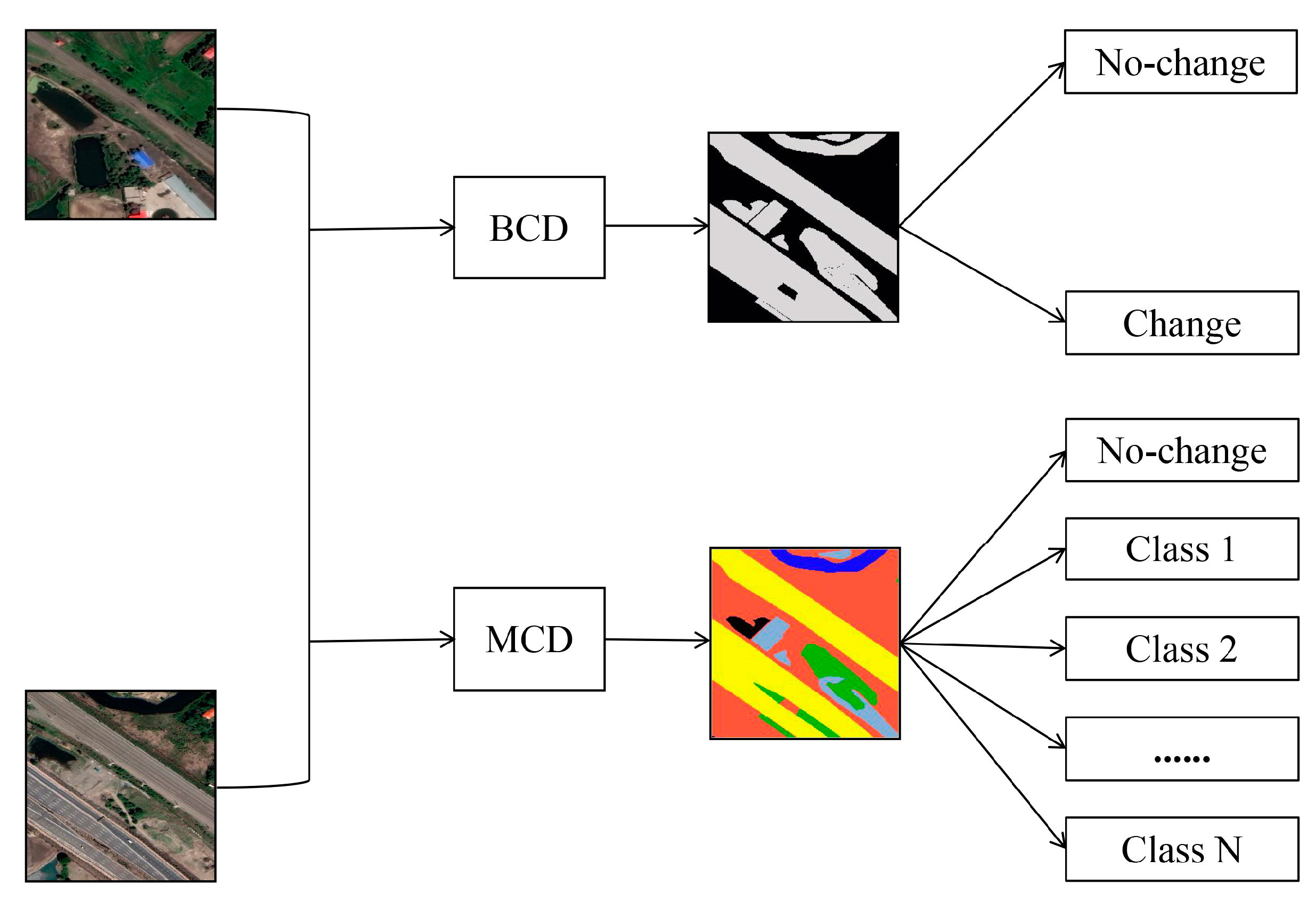
1. Introduction
- (1)
- A Siamese graph convolutional network (SIGNet) is proposed for urban MCD tasks. SIGNet combines the outputs of the Siamese network through joint pyramid upsampling and uses graph convolution to establish reliable and robust spatial connections to achieve pixel-level MCD results.
- (2)
- In the process of spatial relationship reasoning, we utilize the cross-attention mechanism to establish semantic associations with the category information in the dataset and incorporate the semantic association information between categories into the spatial context relationships, which provides new inspiration for MCD research.
- (3)
- A large-scale pixel-level MCD dataset (CNAM-CD) is presented, which collects images from 12 different urban scenes over the last decade. Compared with previously released datasets, CNAM-CD has more refined labels and a more balanced distribution of categories, thus providing the possibility to evaluate each category individually.
2. Methods
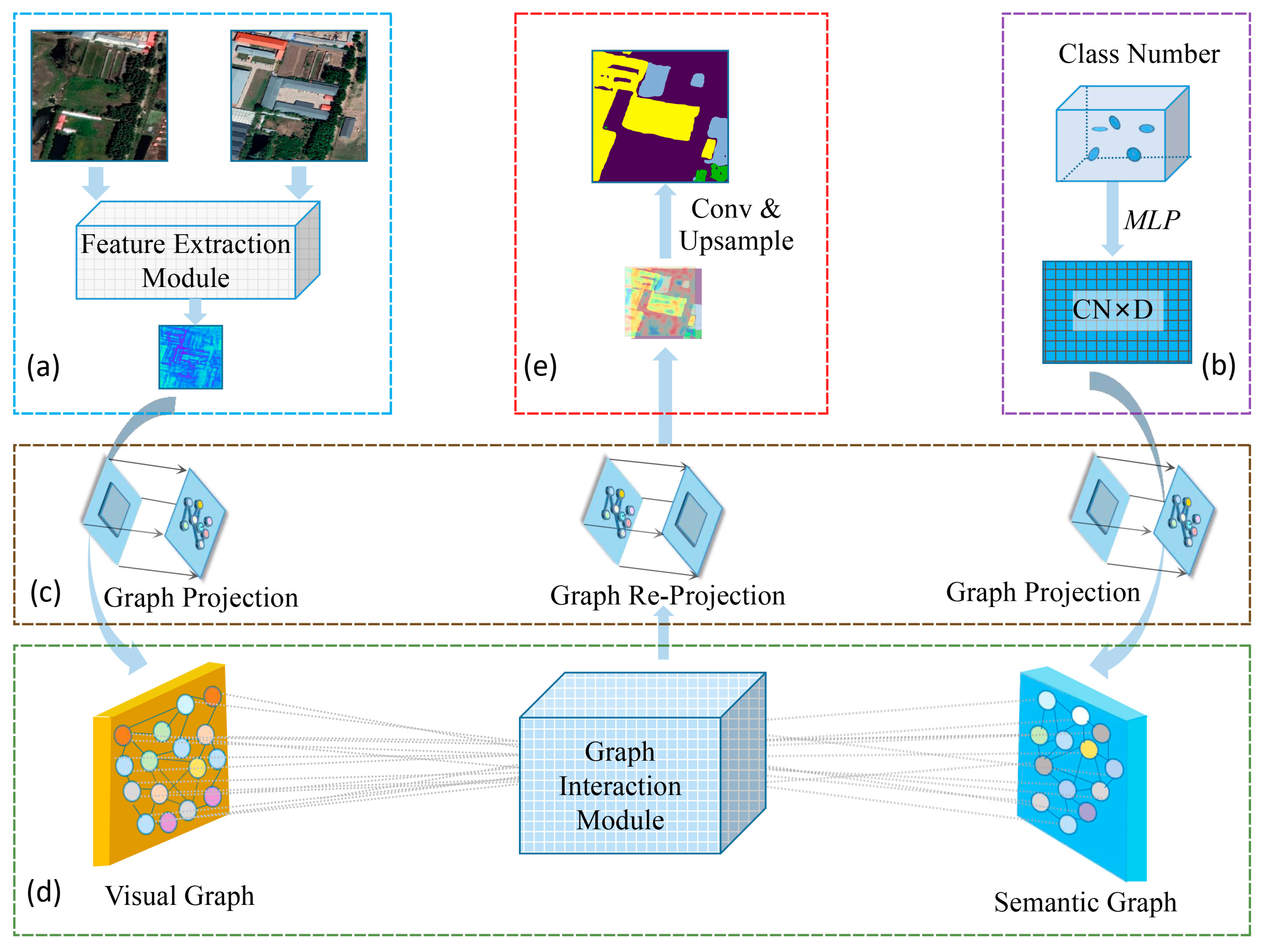
2.1. SIGNet: A Siamese Graph Convolutional Neural Network
2.2. Model Architecture
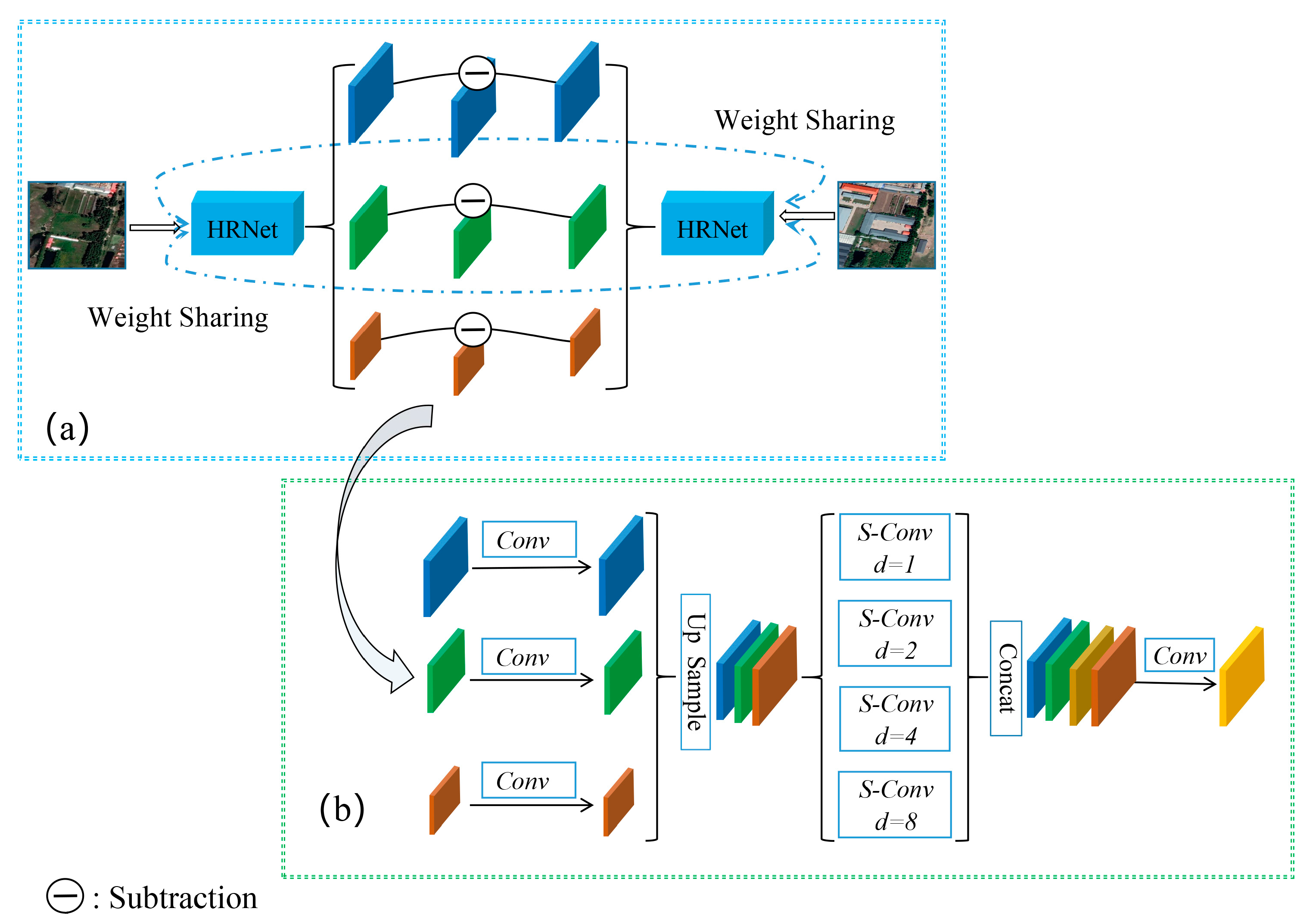
2.2.1. Feature Extraction Module
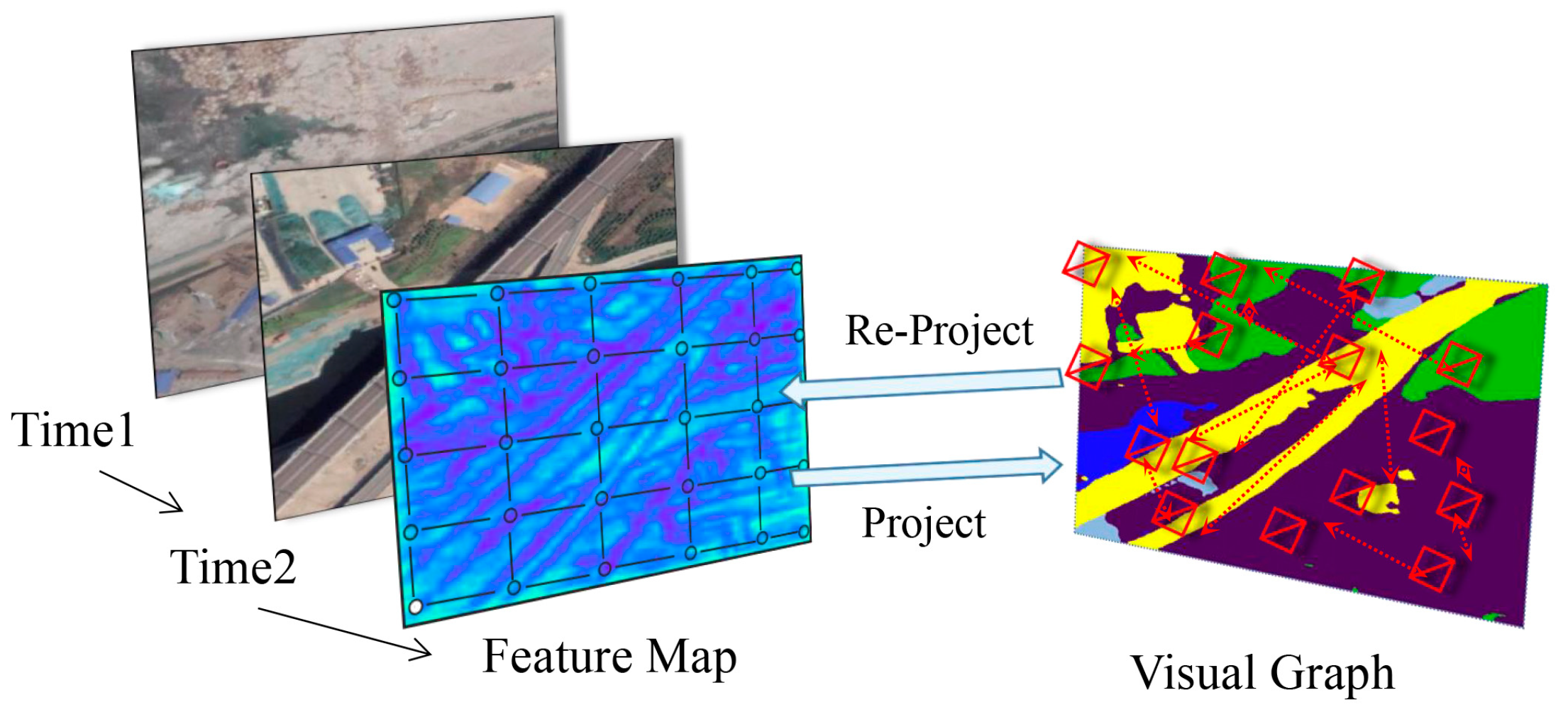
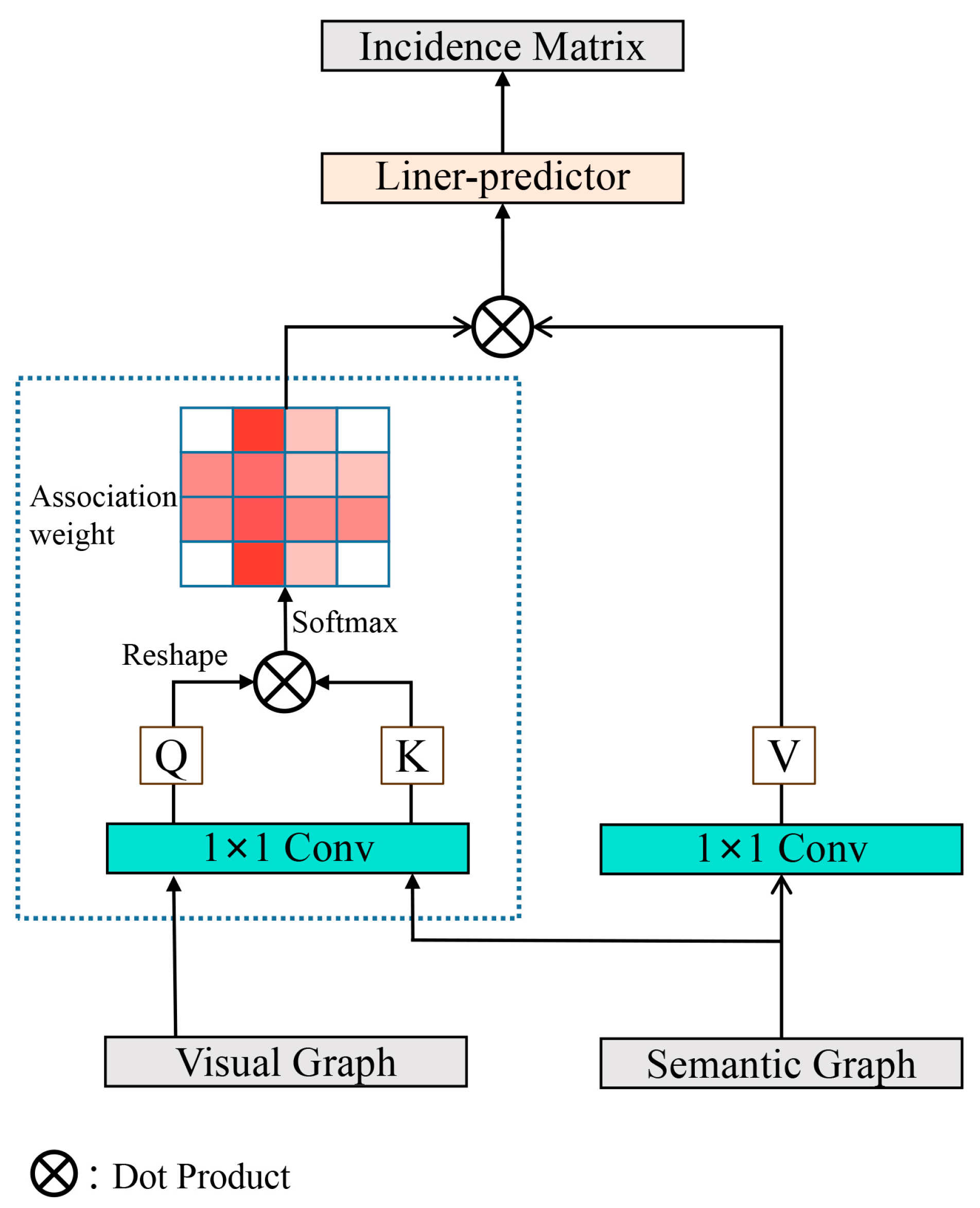
2.2.2. Graph Projection
2.2.3. Graph Interaction Module
2.2.4. Graph Re-Projection
2.2.5. Loss Function
3. Datasets and Experiment
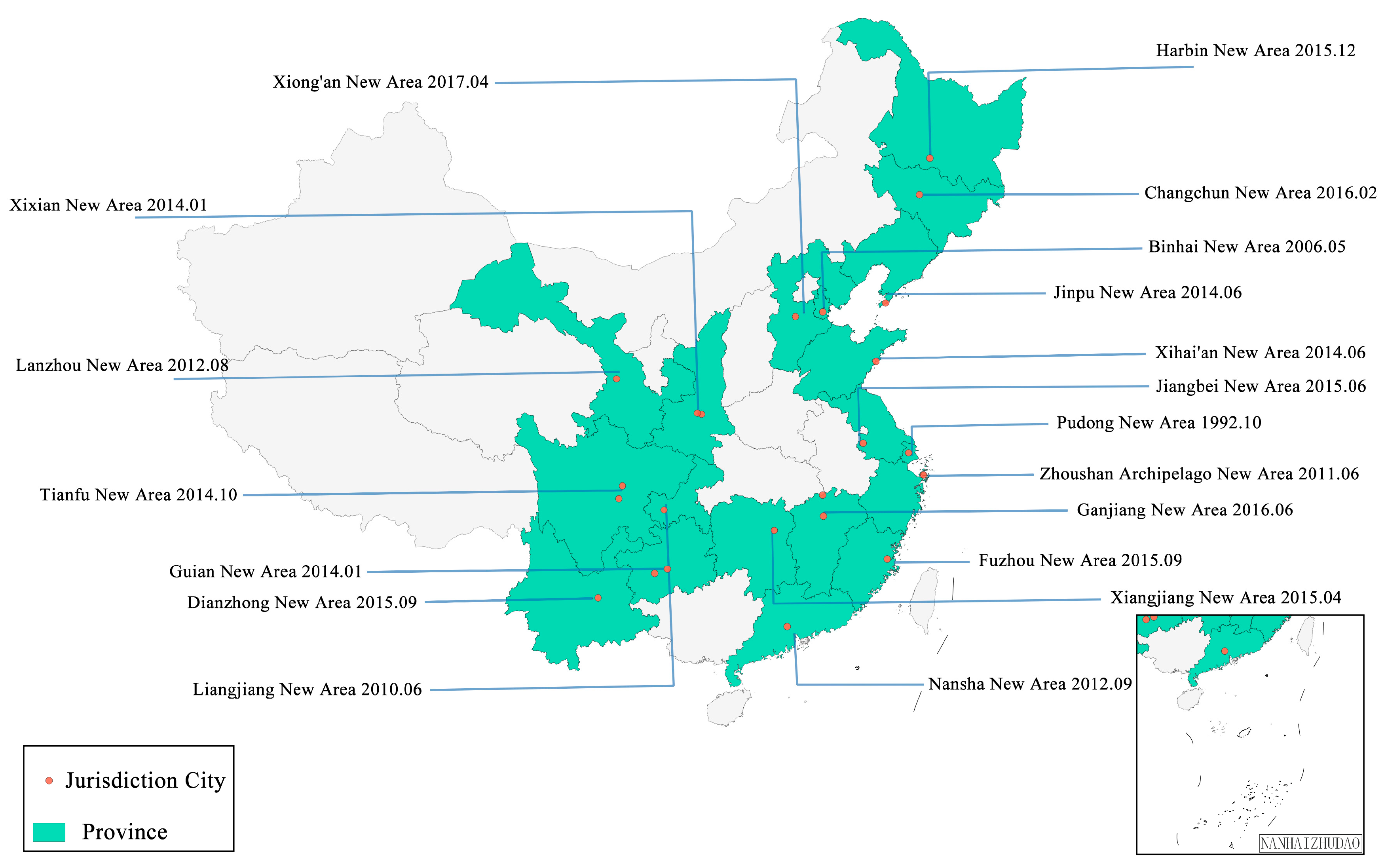
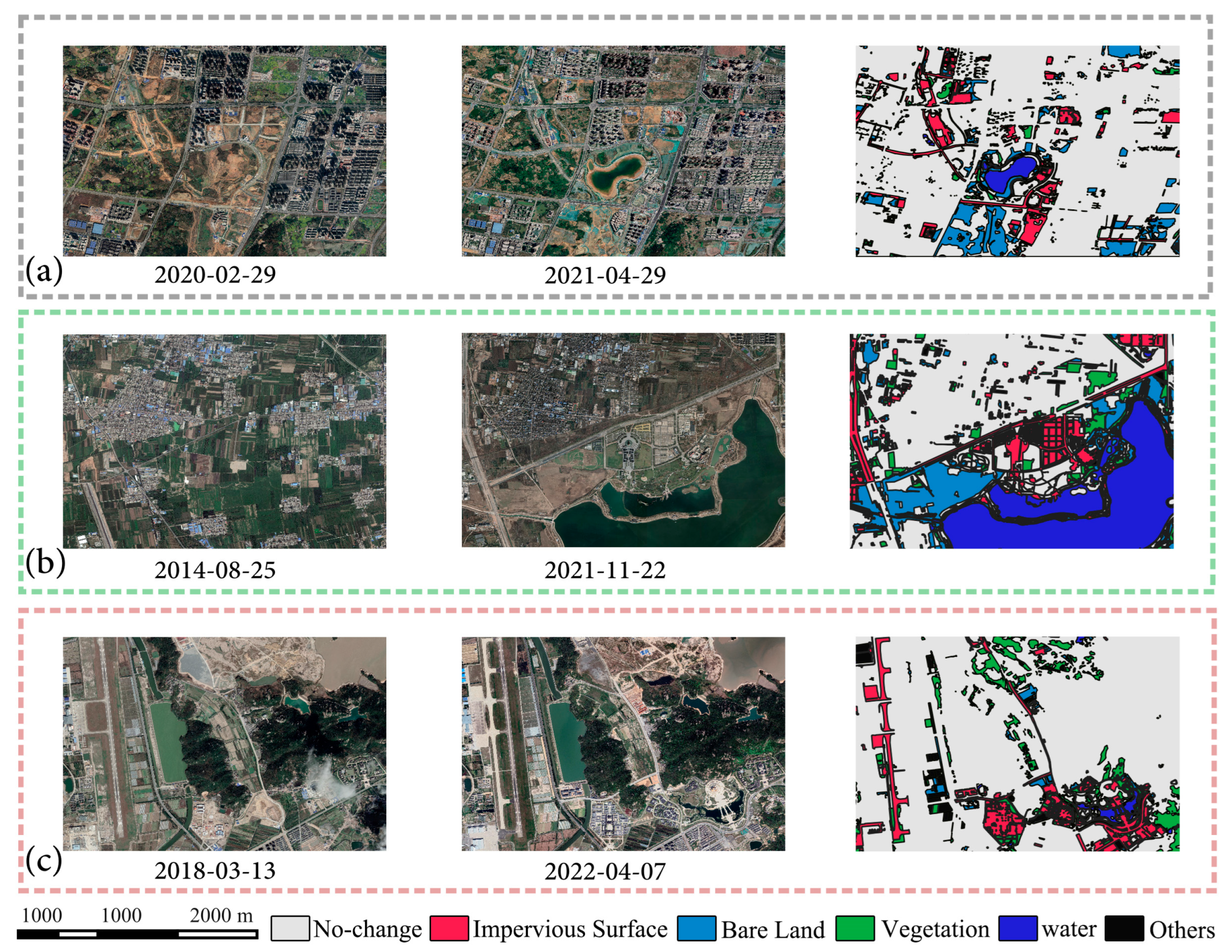
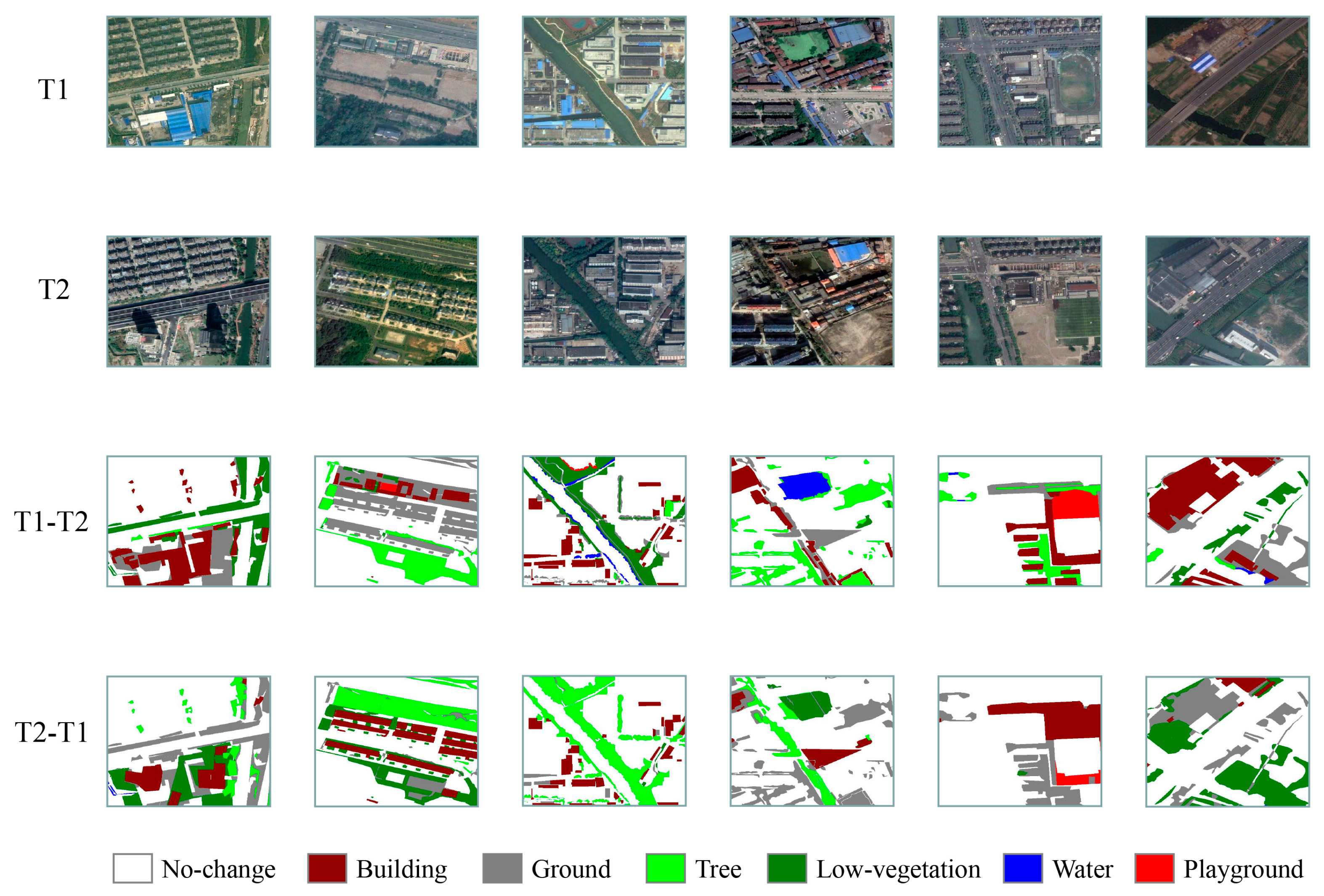
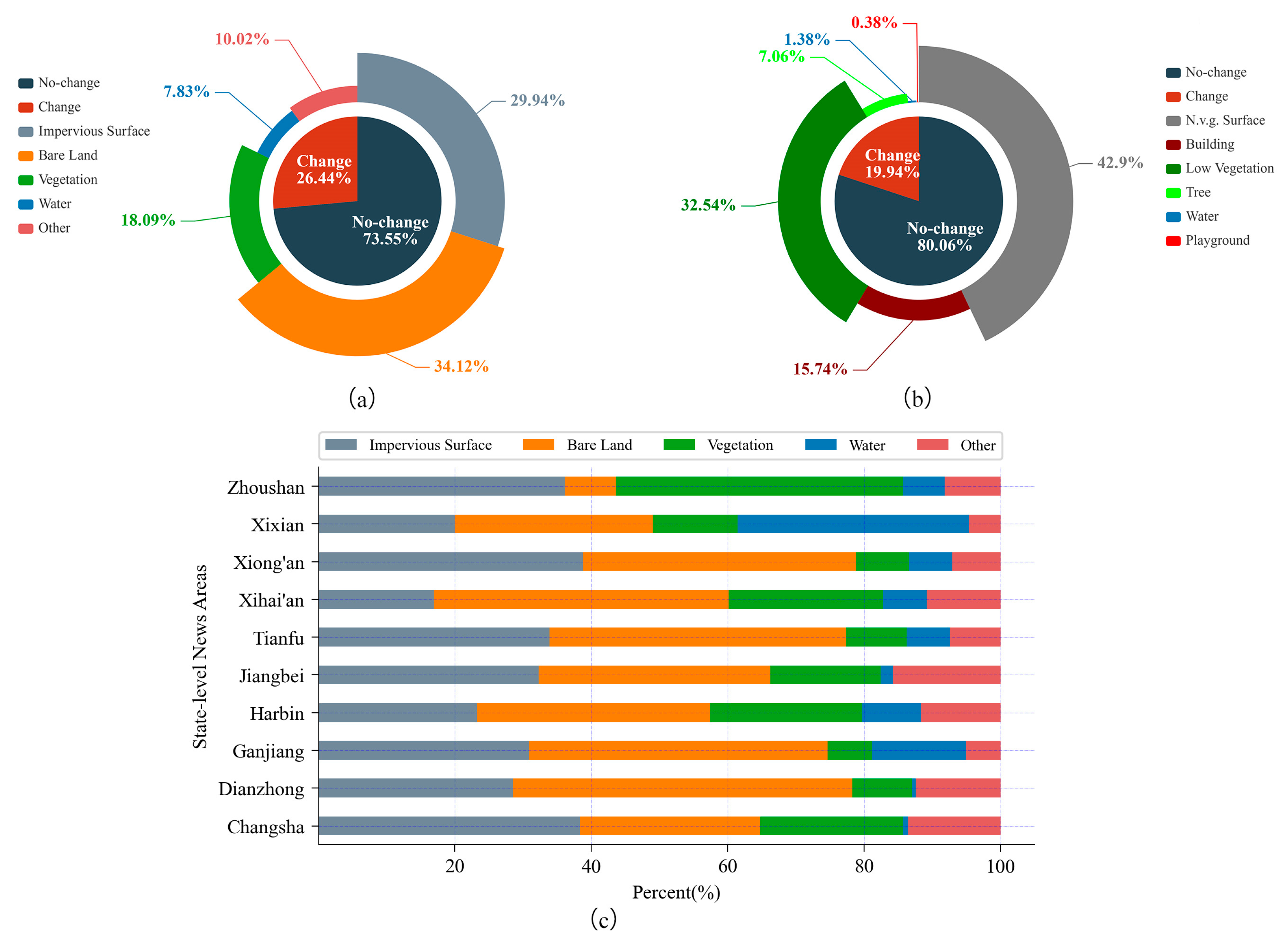
3.1. CNAM-CD: A Multi-Class Change Detection Dataset
3.2. Study Area
3.3. Data Sources and Categories
3.4. SECOND Dataset
3.5. Categorical Distribution
3.6. Experiment
3.6.1. Evaluation Metrics
3.6.2. Data Enhancement
3.6.3. Training Details
4. Results
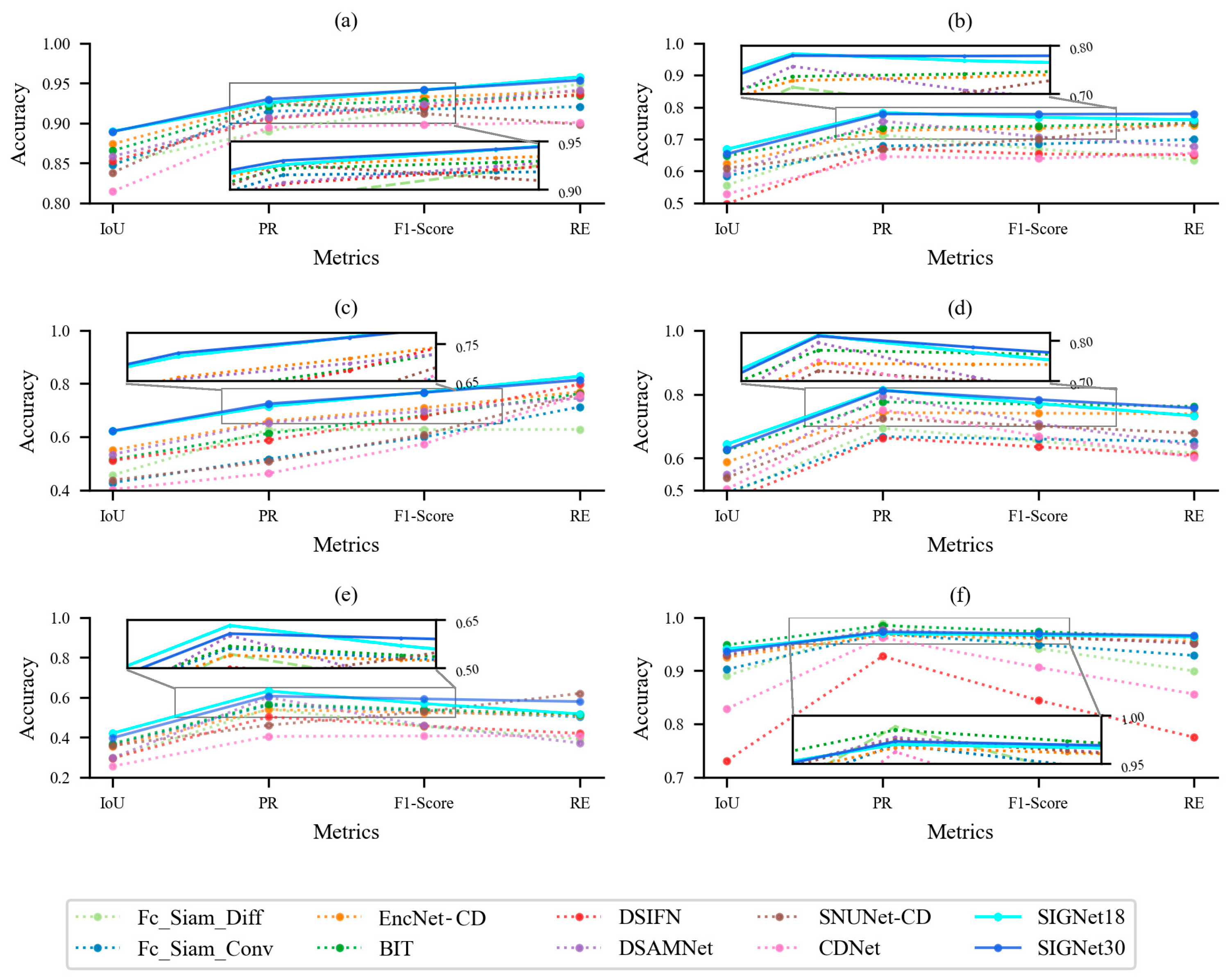
4.1. Model Comparison
4.1.1. CNAM-CD Dataset
4.1.2. SECOND Dataset
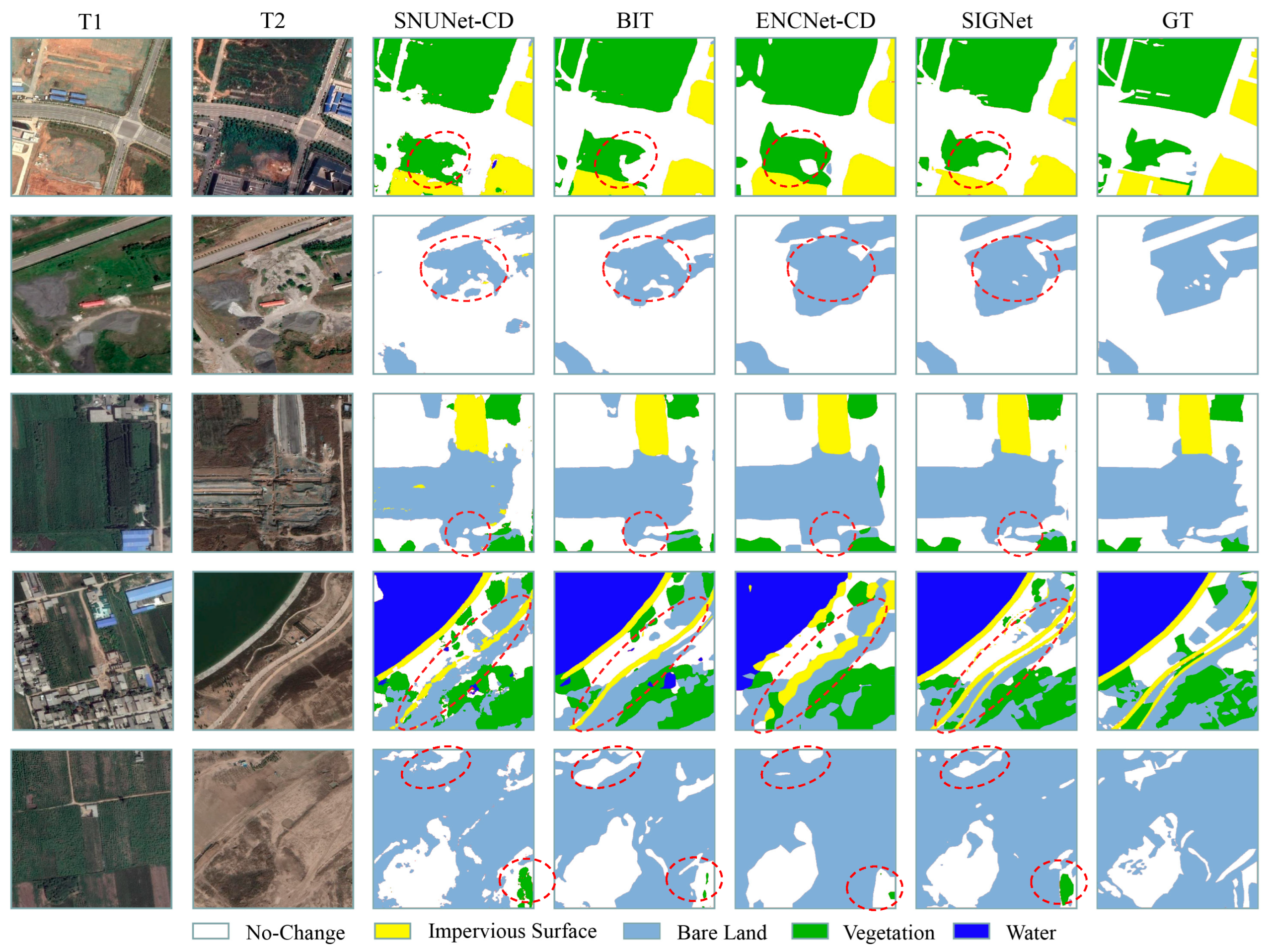
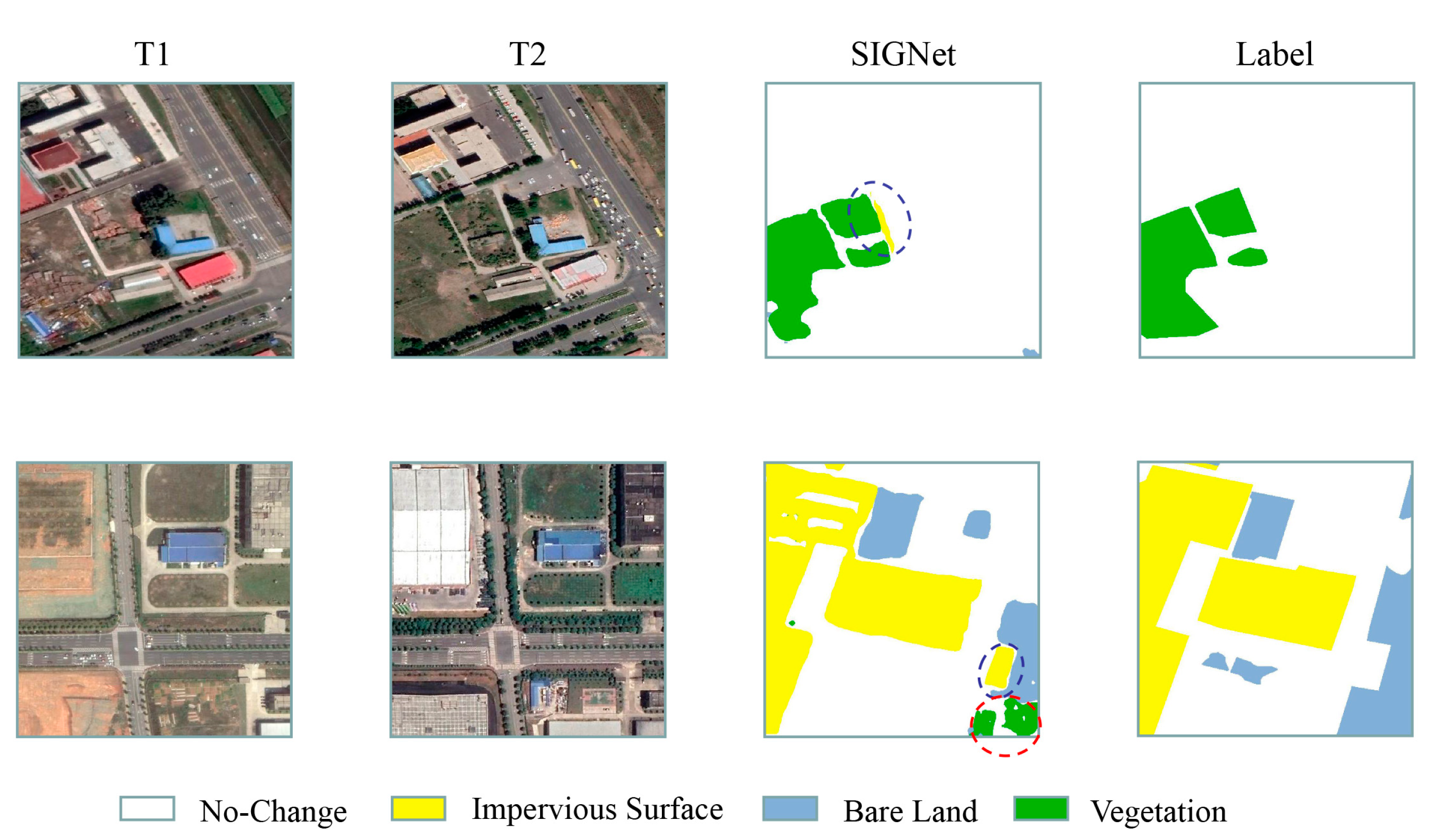
4.2. Model Inference
4.3. Ablation Experiment
5. Discussion
5.1. Attention Visualization of the Model in Different Stages
5.2. The Impact of the Characteristics of Different Categories on the Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alberti, M.; Marzluff, J.M.; Shulenberger, E.; Bradley, G.; Ryan, C.; Zumbrunnen, C. Integrating humans into ecology: Opportunities and challenges for studying urban ecosystems. BioScience 2003, 53, 1169–1179. [Google Scholar] [CrossRef]
- Ridd, M.K. Exploring a VIS (vegetation-impervious surface-soil) model for urban ecosystem analysis through remote sensing: Comparative anatomy for cities. Int. J. Remote Sens. 1995, 16, 2165–2185. [Google Scholar] [CrossRef]
- Fu, P.; Weng, Q. A time series analysis of urbanization induced land use and land cover change and its impact on land surface temperature with Landsat imagery. Remote Sens. Environ. 2016, 175, 205–214. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, Y. Seasonal change of land-use/land-cover (LULC) detection using modis data in rapid urbanization regions: A case study of the Pearl River Delta region (China). IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1913–1920. [Google Scholar] [CrossRef]
- Shafique, A.; Cao, G.; Khan, Z.; Asad, M.; Aslam, M. Deep learning-based change detection in remote sensing images: A review. Remote Sens. 2022, 14, 871. [Google Scholar] [CrossRef]
- Jiang, H.; Peng, M.; Zhong, Y.; Xie, H.; Hao, Z.; Lin, J.; Ma, X.; Hu, X. A survey on deep learning-based change detection from high-resolution remote sensing images. Remote Sens. 2022, 14, 1552. [Google Scholar] [CrossRef]
- Du, B.; Ru, L.; Wu, C.; Zhang, L. Unsupervised deep slow feature analysis for change detection in multi-temporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9976–9992. [Google Scholar] [CrossRef]
- Du, B.; Wang, Y.; Wu, C.; Zhang, L. Unsupervised scene change detection via latent Dirichlet allocation and multivariate alteration detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4676–4689. [Google Scholar] [CrossRef]
- Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised deep change vector analysis for multiple-change detection in VHR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3677–3693. [Google Scholar] [CrossRef]
- Ferraris, V.; Dobigeon, N.; Wei, Q.; Chabert, M. Detecting changes between optical images of different spatial and spectral resolutions: A fusion-based approach. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1566–1578. [Google Scholar] [CrossRef]
- Dai, X.; Khorram, S. The effects of image misregistration on the accuracy of remotely sensed change detection. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1566–1577. [Google Scholar]
- Bai, T.; Sun, K.; Deng, S.; Li, D.; Li, W.; Chen, Y. Multi-scale hierarchical sampling change detection using Random Forest for high-resolution satellite imagery. Int. J. Remote Sens. 2018, 39, 7523–7546. [Google Scholar] [CrossRef]
- Gao, F.; Dong, J.; Li, B.; Xu, Q.; Xie, C. Change detection from synthetic aperture radar images based on neighborhood-based ratio and extreme learning machine. J. Appl. Remote Sens. 2016, 10, 046019. [Google Scholar] [CrossRef]
- Hao, M.; Shi, W.; Zhang, H.; Li, C. Unsupervised change detection with expectation-maximization-based level set. IEEE Geosci. Remote Sens. Lett. 2013, 11, 210–214. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Li, B.; Guo, Y.; Yang, J.; Wang, L.; Wang, Y.; An, W. Gated recurrent multiattention network for VHR remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Khelifi, L.; Mignotte, M. Deep learning for change detection in remote sensing images: Comprehensive review and meta-analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, S.; Ji, S.; Lu, M. Detecting large-scale urban land cover changes from very high resolution remote sensing images using CNN-based classification. ISPRS Int. J. Geo-Inf. 2019, 8, 189. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected Siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Lyu, H.; Lu, H.; Mou, L. Learning a transferable change rule from a recurrent neural network for land cover change detection. Remote Sens. 2016, 8, 506. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, Z.; Feng, J.; Liu, L.; Jiao, L. Remote Sensing Image Change Detection Based on Deep Multi-Scale Multi-Attention Siamese Transformer Network. Remote Sens. 2023, 15, 842. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Chicco, D. Siamese neural networks: An overview. Artif. Neural Netw. 2021, 2190, 73–94. [Google Scholar]
- Zhu, Q.; Guo, X.; Li, Z.; Li, D. A review of multi-class change detection for satellite remote sensing imagery. Geo-Spat. Inf. Sci. 2022, 1–15. [Google Scholar] [CrossRef]
- Kotaridis, I.; Lazaridou, M. Remote sensing image segmentation advances: A meta-analysis. ISPRS J. Photogramm. Remote Sens. 2021, 173, 309–322. [Google Scholar] [CrossRef]
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 7151–7160. [Google Scholar]
- Yu, C.; Wang, J.; Gao, C.; Yu, G.; Shen, C.; Sang, N. Context prior for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12416–12425. [Google Scholar]
- Chen, K.; Zou, Z.; Shi, Z. Building extraction from remote sensing images with sparse token transformers. Remote Sens. 2021, 13, 4441. [Google Scholar] [CrossRef]
- Chen, Y.; Rohrbach, M.; Yan, Z.; Shuicheng, Y.; Feng, J.; Kalantidis, Y. Graph-based global reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 433–442. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R.S. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. arXiv 2017, arXiv:1701.04128. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters--improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yuan, Y.; Chen, X.; Chen, X.; Wang, J. Segmentation transformer: Object-contextual representations for semantic segmentation. arXiv 2019, arXiv:1909.11065. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Chen, C.-F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 357–366. [Google Scholar]
- Ma, J.; Bai, Y.; Zhong, B.; Zhang, W.; Yao, T.; Mei, T. Visualizing and understanding patch interactions in vision transformer. arXiv 2022, arXiv:2203.05922. [Google Scholar]
- Zhang, D.; Tang, J.; Cheng, K.-T. Graph Reasoning Transformer for Image Parsing. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 2380–2389. [Google Scholar]
- Yan, J.; Ji, S.; Wei, Y. A combination of convolutional and graph neural networks for regularized road surface extraction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Li, B.; Fu, K. Multi-object tracking in satellite videos with graph-based multitask modeling. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Li, Y.; Gupta, A. Beyond Grids: Learning Graph Representations for Visual Recognition. In Proceedings of the (NeurIPS) Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; p. 11. [Google Scholar]
- Wu, T.; Lu, Y.; Zhu, Y.; Zhang, C.; Wu, M.; Ma, Z.; Guo, G. GINet: Graph interaction network for scene parsing. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 34–51. [Google Scholar]
- Liang, X.; Hu, Z.; Zhang, H.; Lin, L.; Xing, E.P. Symbolic graph reasoning meets convolutions. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 2–8 December 2018; pp. 1853–1863. [Google Scholar]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Meng, Y.; Zhang, H.; Zhao, Y.; Yang, X.; Qiao, Y.; MacCormick, I.J.; Huang, X.; Zheng, Y. Graph-based region and boundary aggregation for biomedical image segmentation. IEEE Trans. Med. Imaging 2021, 41, 690–701. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Gupta, A. Videos as space-time region graphs. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 399–417. [Google Scholar]
- Su, Y.; Cheng, J.; Wang, W.; Bai, H.; Liu, H. Semantic segmentation for high-resolution remote-sensing images via dynamic graph context reasoning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Diao, W.; Yan, Z.; Yin, D.; Fu, K. Transformer-induced graph reasoning for multimodal semantic segmentation in remote sensing. IEEE Trans. Geosci. Remote Sens. 2022, 193, 90–103. [Google Scholar] [CrossRef]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 924–935. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Multitask learning for large-scale semantic change detection. Comput. Vis. Image Underst. 2019, 187, 102783. [Google Scholar] [CrossRef]
- Yang, K.; Xia, G.-S.; Liu, Z.; Du, B.; Yang, W.; Pelillo, M.; Zhang, L. Asymmetric siamese networks for semantic change detection in aerial images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Tian, S.; Zhong, Y.; Zheng, Z.; Ma, A.; Tan, X.; Zhang, L. Large-scale deep learning based binary and semantic change detection in ultra high resolution remote sensing imagery: From benchmark datasets to urban application. ISPRS J. Photogramm. Remote Sens. 2022, 193, 164–186. [Google Scholar] [CrossRef]
- Ding, L.; Guo, H.; Liu, S.; Mou, L.; Zhang, J.; Bruzzone, L. Bi-Temporal Semantic Reasoning for the Semantic Change Detection in HR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; He, P. SCDNET: A novel convolutional network for semantic change detection in high resolution optical remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102465. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Tian, S.; Ma, A.; Zhang, L. ChangeMask: Deep multi-task encoder-transformer-decoder architecture for semantic change detection. ISPRS J. Photogramm. Remote Sens. 2022, 183, 228–239. [Google Scholar] [CrossRef]
- Xia, H.; Tian, Y.; Zhang, L.; Li, S. A Deep Siamese Postclassification Fusion Network for Semantic Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, X.; Deng, W.; Shi, S.; Guan, Q.; Zhong, Y.; Zhang, L.; Li, D. Land-use/land-cover change detection based on a Siamese global learning framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 63–78. [Google Scholar] [CrossRef]
- Xiang, S.; Wang, M.; Jiang, X.; Xie, G.; Zhang, Z.; Tang, P. Dual-task semantic change detection for remote sensing images using the generative change field module. Remote Sens. 2021, 13, 3336. [Google Scholar] [CrossRef]
- Niu, Y.; Guo, H.; Lu, J.; Ding, L.; Yu, D. SMNet: Symmetric Multi-Task Network for Semantic Change Detection in Remote Sensing Images Based on CNN and Transformer. Remote Sens. 2023, 15, 949. [Google Scholar] [CrossRef]
- Cui, F.; Jiang, J. MTSCD-Net: A network based on multi-task learning for semantic change detection of bitemporal remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103294. [Google Scholar] [CrossRef]
- Braimoh, A.K.; Onishi, T. Spatial determinants of urban land use change in Lagos, Nigeria. Land Use Policy 2007, 24, 502–515. [Google Scholar] [CrossRef]
- Davies, R.G.; Barbosa, O.; Fuller, R.A.; Tratalos, J.; Burke, N.; Lewis, D.; Warren, P.H.; Gaston, K.J. City-wide relationships between green spaces, urban land use and topography. Urban Ecosyst. 2008, 11, 269–287. [Google Scholar] [CrossRef]
- Herold, M.; Couclelis, H.; Clarke, K.C. The role of spatial metrics in the analysis and modeling of urban land use change. Comput. Environ. Urban Syst. 2005, 29, 369–399. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. Fastfcn: Rethinking dilated convolution in the backbone for semantic segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Zhang, S.; Guan, Z.; Liu, Y.; Zheng, F. Land Use/Cover Change and Its Relationship with Regional Development in Xixian New Area, China. Sustainability 2022, 14, 6889. [Google Scholar] [CrossRef]
- Luo, J.; Ma, X.; Chu, Q.; Xie, M.; Cao, Y. Characterizing the up-to-date land-use and land-cover change in Xiong’an New Area from 2017 to 2020 using the multi-temporal sentinel-2 images on Google Earth Engine. ISPRS Int. J. Geo-Inf. 2021, 10, 464. [Google Scholar] [CrossRef]
- Malarvizhi, K.; Kumar, S.V.; Porchelvan, P. Use of high resolution Google Earth satellite imagery in landuse map preparation for urban related applications. Procedia Technol. 2016, 24, 1835–1842. [Google Scholar] [CrossRef]
- Miyazaki, H.; Bhushan, H.; Wakiya, K. Urban Growth Modeling using Historical Landsat Satellite Data Archive on Google Earth Engine. In Proceedings of the 2019 First International Conference on Smart Technology & Urban Development (STUD), Chiang Mai, Thailand, 13–14 December 2019; pp. 1–5. [Google Scholar]
- Ma, Y.; Yu, D.; Wu, T.; Wang, H. PaddlePaddle: An open-source deep learning platform from industrial practice. Front. Data Domputing 2019, 1, 105–115. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Stent, S.; Ros, G.; Arroyo, R.; Gherardi, R. Street-view change detection with deconvolutional networks. Auton. Robot. 2018, 42, 1301–1322. [Google Scholar] [CrossRef]
- Wen, D.; Huang, X.; Bovolo, F.; Li, J.; Ke, X.; Zhang, A.; Benediktsson, J.A. Change detection from very-high-spatial-resolution optical remote sensing images: Methods, applications, and future directions. IEEE Geosci. Remote Sens. Mag. 2021, 9, 68–101. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
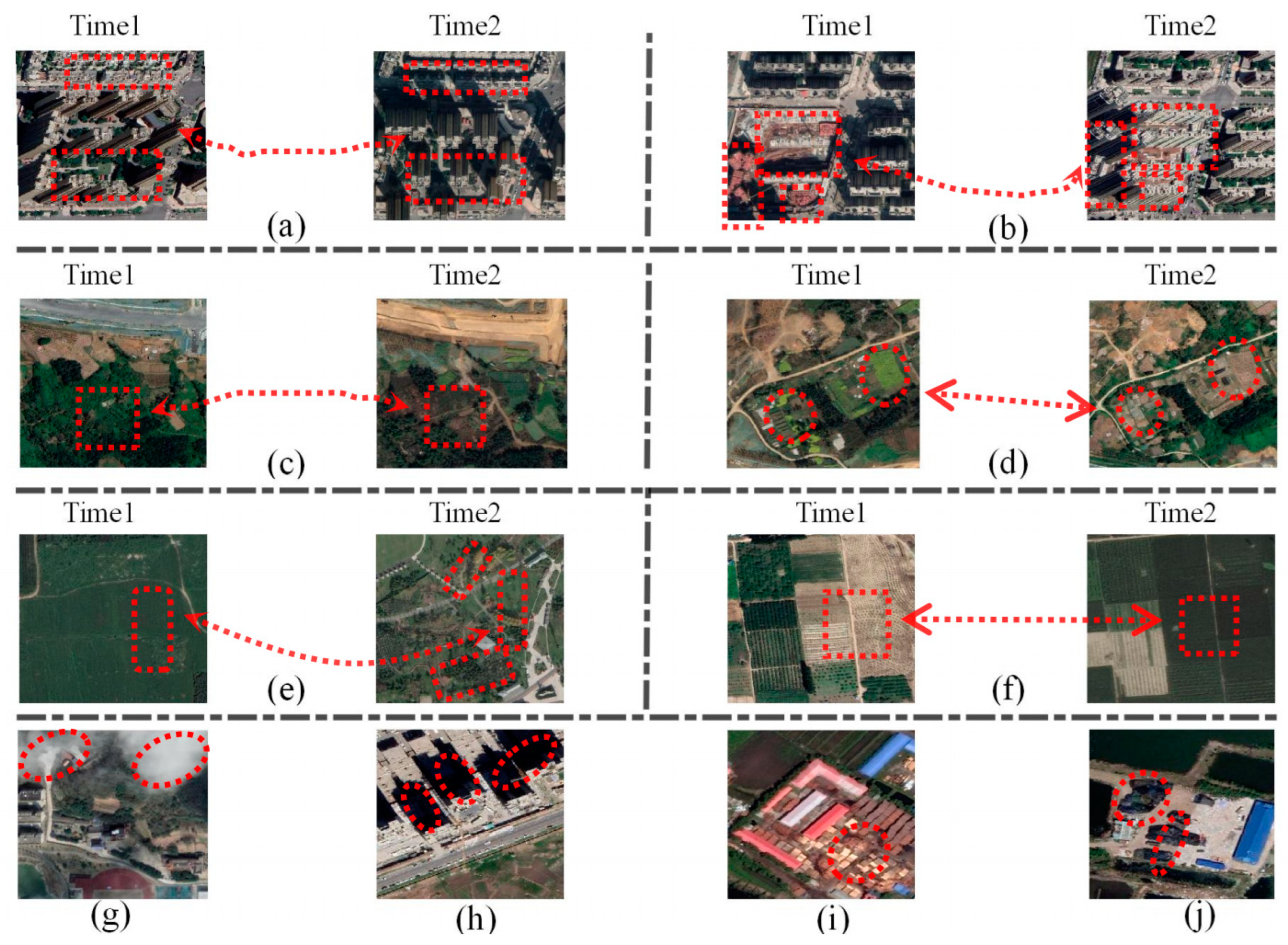{kind=link}
| ID | Source | Jurisdiction City | Time1 (Y/M/D) | Time2 (Y/M/D) | Area (km2) |
|---|---|---|---|---|---|
| 1 | Xihai’an New Area | Qingdao | 2014/09/25 | 2019/09/18 | 14.6 |
| 2 | Jiangbei New Area | Nanjing | 2013/07/13 | 2018/10/11 | 12.7 |
| 3 | Xiangjiang New Area | Changsha | 2018/04/07 | 2021/05/09 | 12 |
| 4 | Binghai New Area | Tianjin | 2015/09/13 | 2020/06/05 | 20.5 |
| 5 | Dianzhong New Area | Kunming | 2018/03/03 | 2022/01/05 | 18.7 |
| 6 | Zhoushan Archipelago New Area | Zhoushan | 2018/03/13 | 2022/04/07 | 13 |
| 7 | Harbin New Area | Harbin | 2015/06/13 | 2021/05/19 | 18 |
| 8 | Tianfu New Area | Chengdu &Meishan | 2020/02/19 | 2021/04/29 | 16.6 |
| 9 | Xixian New Area | Xi’an &Xianyang | 2014/08/25 | 2021/11/22 | 18.4 |
| 10 | Xiong’an New Area | Baoding | 2015/08/22 | 2021/06/19 | 15.7 |
| 11 | Changchun New Area | Changchun | 2016/07/03 | 2020/06/11 | 19.9 |
| 12 | Ganjiang New Area | Nanchang &Jiujiang | 2017/12/26 | 2020/11/15 | 18.7 |
| Model | Backbone | Type | MIoU (%) | MR (%) | MP (%) | MF (%) | PA (%) | Kappa |
|---|---|---|---|---|---|---|---|---|
| Fc-Siam-Diff | Unet | All | 59.51 | 69.69 | 74.83 | 71.91 | 85.55 | 0.70 |
| No-change | 84.96 | 94.90 | 89.02 | 91.87 | ||||
| Change | 53.15 | 63.38 | 71.29 | 66.92 | ||||
| Fc-Siam-Conv | Unet | All | 60.62 | 74.34 | 72.59 | 73.11 | 85.09 | 0.75 |
| No-change | 84.78 | 92.03 | 91.50 | 91.77 | ||||
| Change | 54.58 | 69.92 | 67.86 | 68.45 | ||||
| EncNet-CD | HRNet-W18 | All | 65.86 | 78.30 | 76.65 | 77.38 | 87.83 | 0.77 |
| No-change | 87.40 | 93.97 | 92.59 | 93.28 | ||||
| Change | 60.48 | 74.38 | 72.67 | 73.41 | ||||
| BIT | ResNet18 | All | 66.46 | 77.26 | 78.72 | 77.80 | 87.69 | 0.76 |
| No-change | 86.56 | 93.45 | 92.16 | 92.80 | ||||
| Change | 61.44 | 75.04 | 73.53 | 74.05 | ||||
| DSIFN | VGGNet16 | All | 57.15 | 70.77 | 71.73 | 70.70 | 84.67 | 0.69 |
| No-change | 85.28 | 93.58 | 90.57 | 92.05 | ||||
| Change | 50.12 | 65.07 | 67.02 | 65.36 | ||||
| DSAMNet | ResNet18 | All | 63.41 | 72.99 | 78.67 | 75.05 | 87.90 | 0.72 |
| No-change | 85.85 | 94.13 | 90.70 | 92.39 | ||||
| Change | 57.80 | 67.70 | 75.66 | 70.71 | ||||
| SNUNet-CD | Unet++ | All | 62.06 | 78.18 | 71.87 | 74.26 | 84.77 | 0.71 |
| No-change | 83.80 | 89.84 | 92.57 | 91.19 | ||||
| Change | 56.63 | 75.27 | 66.69 | 70.03 | ||||
| CDNet | De-Conv | All | 56.08 | 70.49 | 69.53 | 69.08 | 82.52 | 0.65 |
| No-change | 81.46 | 90.09 | 89.48 | 89.78 | ||||
| Change | 49.73 | 65.59 | 64.54 | 63.91 | ||||
| SIGNet18 | HRNet-W18 | All | 69.45 | 79.99 | 81.12 | 80.31 | 89.51 | 0.80 |
| No-change | 88.98 | 95.79 | 92.55 | 94.14 | ||||
| Change | 65.67 | 76.04 | 78.26 | 76.85 | ||||
| SIGNet30 | HRNet-W30 | All | 70.33 | 81.40 | 80.90 | 81.07 | 89.63 | 0.80 |
| No-change | 88.93 | 95.37 | 92.99 | 94.17 | ||||
| Change | 64.58 | 77.90 | 77.87 | 77.79 |
| Model | Backbone | MIoU (%) | Sek (%) | Score (%) |
|---|---|---|---|---|
| FC-Siam-conv | UNet | 70.10 | 12.89 | 30.05 |
| FC-Siam-diff | UNet | 70.22 | 12.51 | 29.82 |
| DSIFN | VGGNet | 69.07 | 5.90 | 24.85 |
| BIT | ResNet18 | 72.43 | 15.62 | 32.66 |
| HRSCD-str.2 [61] | FCNN | 59.70 | 5.70 | 21.90 |
| HRSCD-str.3 [61] | FCNN | 62.10 | 8.40 | 24.51 |
| HRSCD-str.4 [61] | FCNN | 67.20 | 13.00 | 29.26 |
| ANS-ATL [61] | ANS | 70.20 | 17.30 | 33.17 |
| HBSCD | HRNet-W40 | 70.40 | 15.46 | 31.94 |
| SCDNet | UNet | 72.75 | 16.86 | 33.63 |
| SIGNet18 | HRNet-W18 | 74.41 | 18.48 | 35.26 |
| SIGNet30 | HRNet-W30 | 74.64 | 18.85 | 35.59 |
| Model | GCN | CSI | AL | MIoU (%) | PA (%) | MP (%) | MF (%) | MR (%) | KAPPA |
|---|---|---|---|---|---|---|---|---|---|
| SIGNet | √ | √ | √ | 69.45 | 89.51 | 81.12 | 80.31 | 79.99 | 0.80 |
| SIGNet-GCN | √ | √ | 68.30 | 89.37 | 81.00 | 79.23 | 78.53 | 0.80 | |
| SIGNet-CSI | √ | √ | 68.06 | 89.12 | 81.16 | 79.33 | 77.88 | 0.79 | |
| SIGNet-AL | √ | √ | 67.49 | 88.62 | 78.43 | 78.77 | 79.12 | 0.78 | |
| Backbone | 64.26 | 87.24 | 76.76 | 75.64 | 75.23 | 0.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Wang, J.; Ding, J.; Liu, B.; Weng, N.; Xiao, H. SIGNet: A Siamese Graph Convolutional Network for Multi-Class Urban Change Detection. Remote Sens. 2023, 15, 2464. https://doi.org/10.3390/rs15092464
Zhou Y, Wang J, Ding J, Liu B, Weng N, Xiao H. SIGNet: A Siamese Graph Convolutional Network for Multi-Class Urban Change Detection. Remote Sensing. 2023; 15(9):2464. https://doi.org/10.3390/rs15092464
Chicago/Turabian StyleZhou, Yanpeng, Jinjie Wang, Jianli Ding, Bohua Liu, Nan Weng, and Hongzhi Xiao. 2023. "SIGNet: A Siamese Graph Convolutional Network for Multi-Class Urban Change Detection" Remote Sensing 15, no. 9: 2464. https://doi.org/10.3390/rs15092464
APA StyleZhou, Y., Wang, J., Ding, J., Liu, B., Weng, N., & Xiao, H. (2023). SIGNet: A Siamese Graph Convolutional Network for Multi-Class Urban Change Detection. Remote Sensing, 15(9), 2464. https://doi.org/10.3390/rs15092464