
Improvements in Forest Segmentation Accuracy Using a New Deep Learning Architecture and Data Augmentation Technique


Abstract
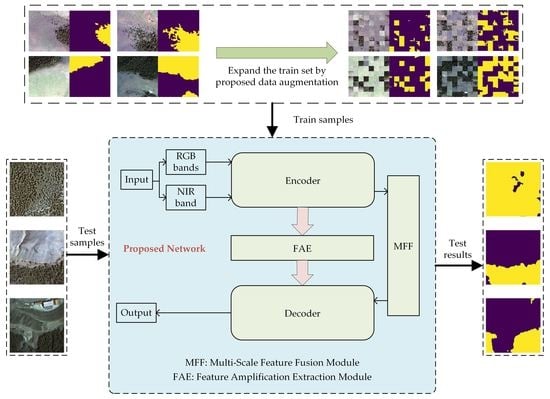
1. Introduction
2. Materials and Methods
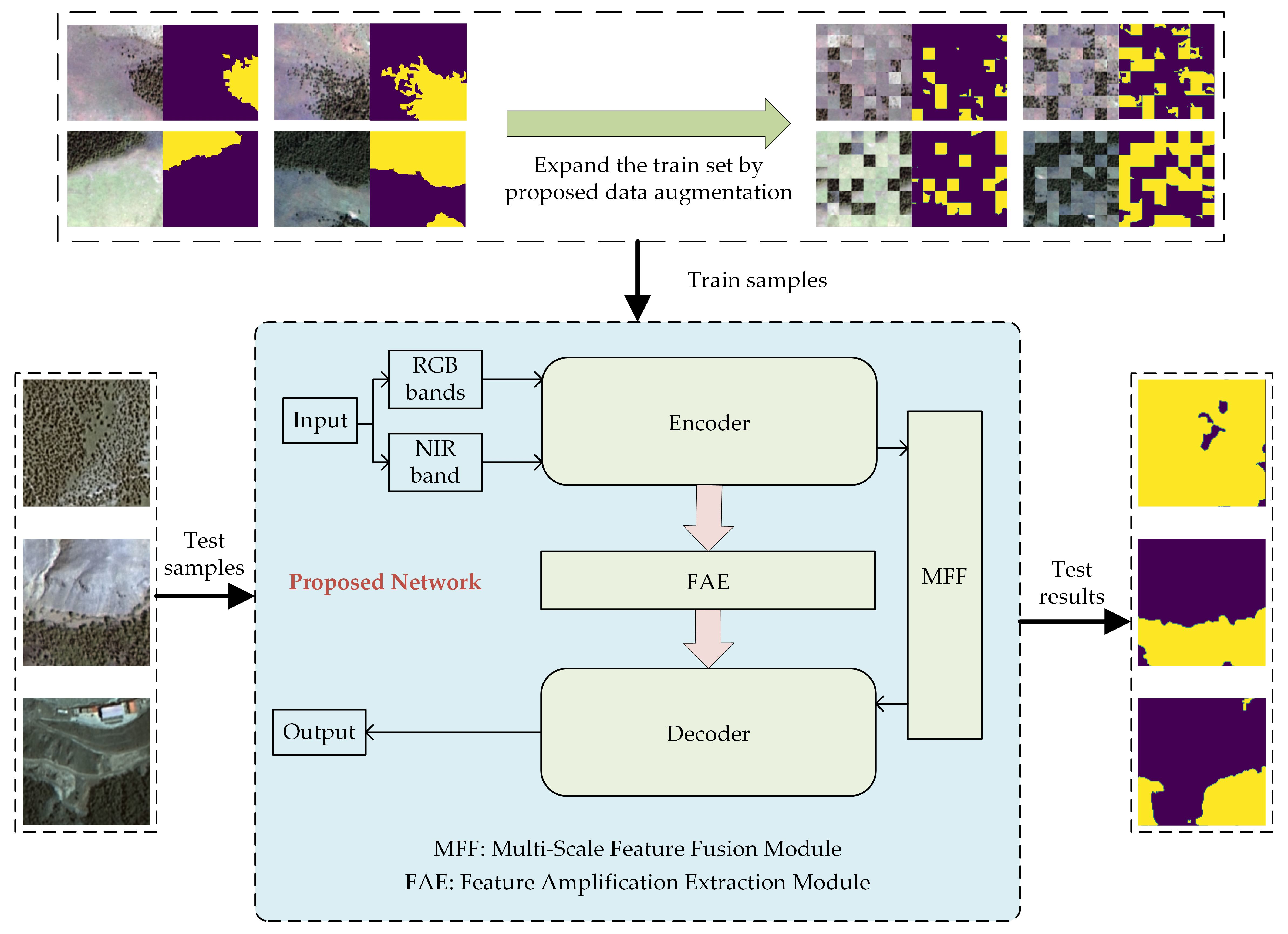
2.1. Study Area and Data
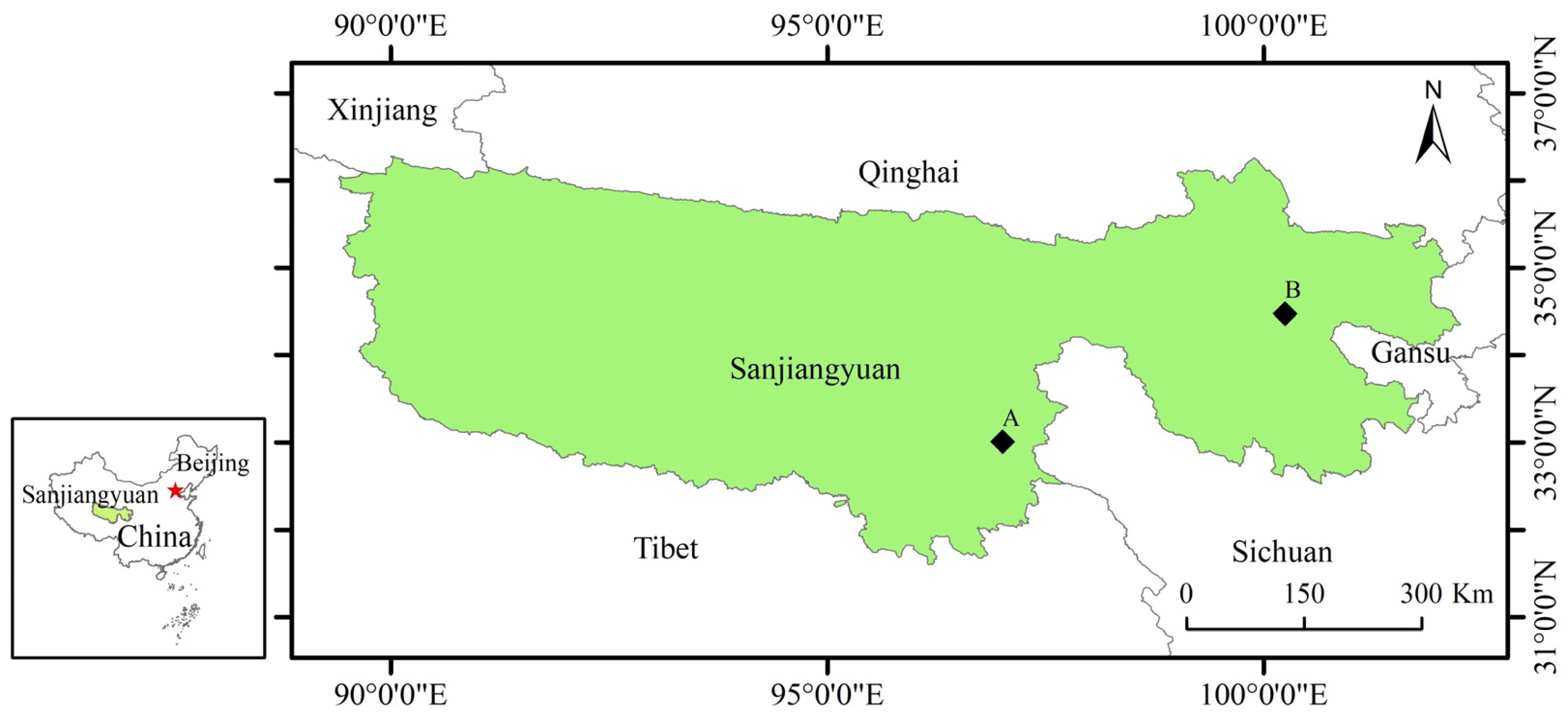
2.2. Proposed Network
2.2.1. Overview of Proposed Network
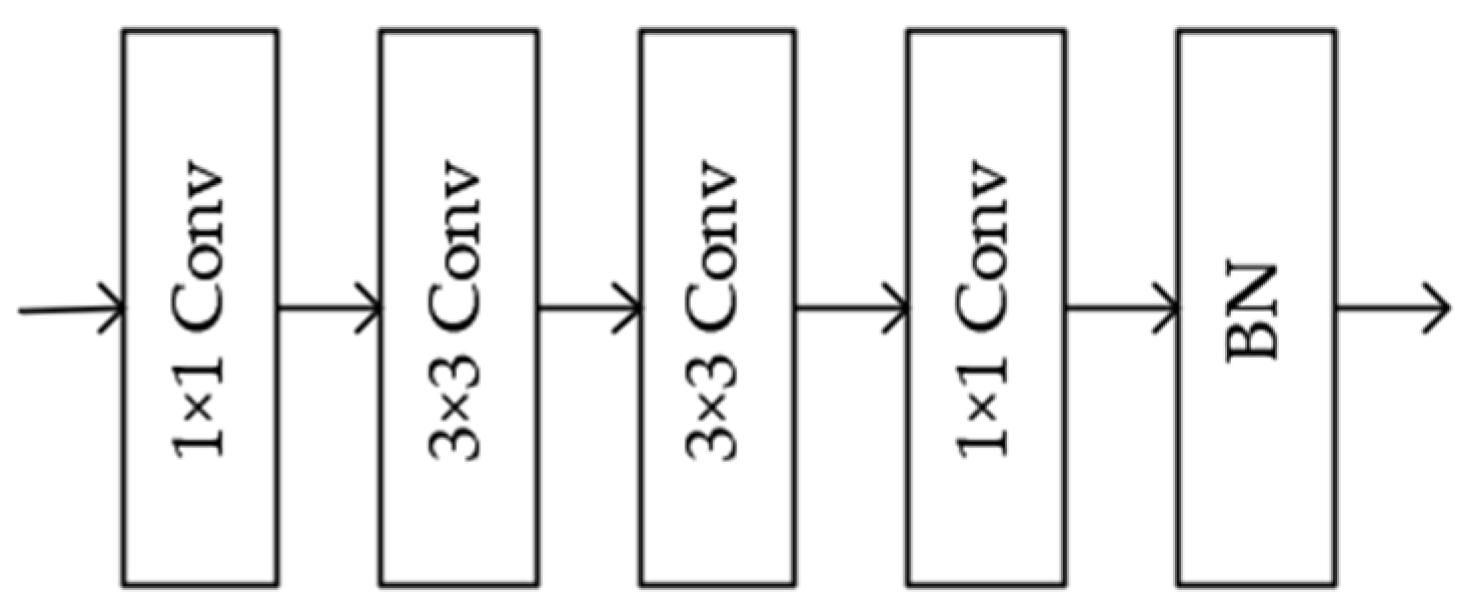
2.2.2. Convolution Block
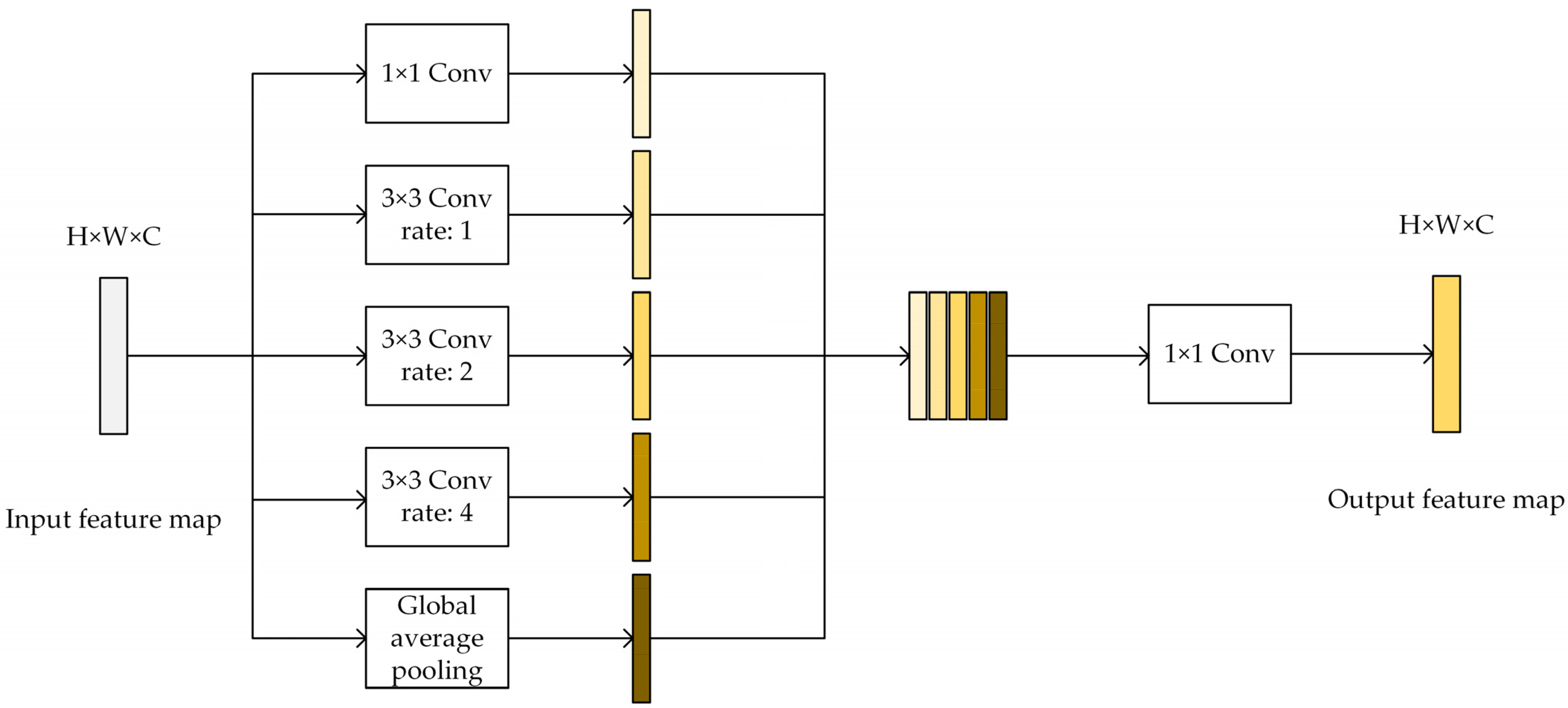
2.2.3. Multi-Scale Feature Fusion Module
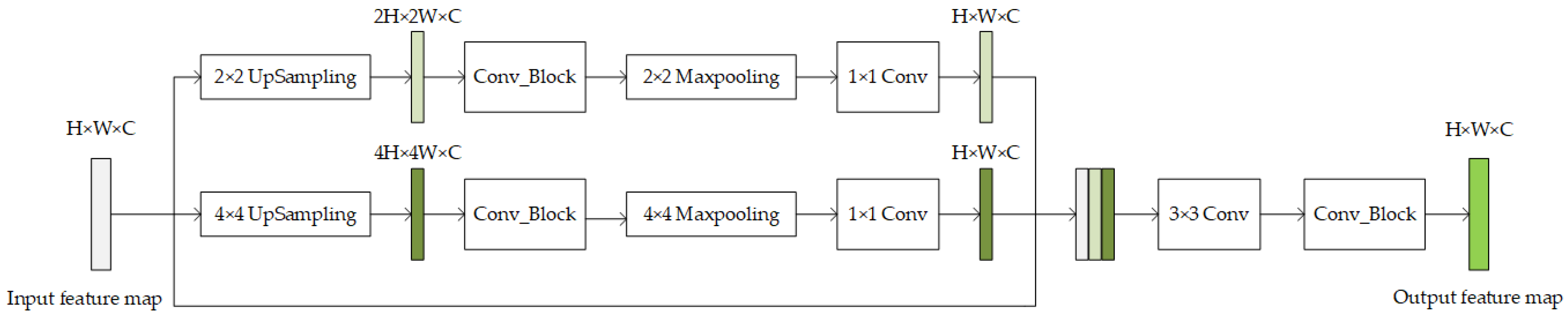
2.2.4. Feature Amplification Extraction Module
2.3. Proposed Data Augmentation
2.4. Comparison with Existing Methods
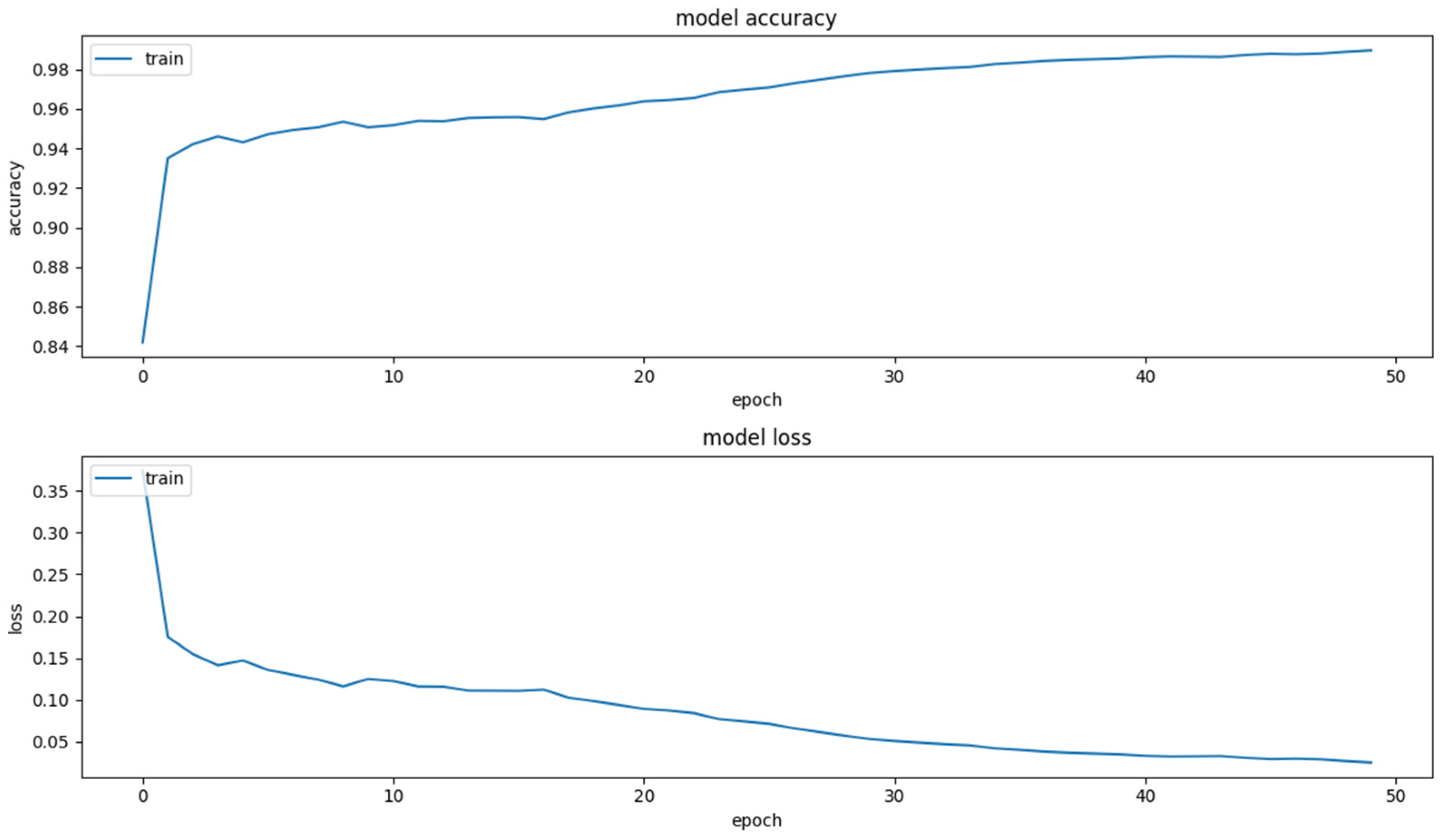
2.5. Network Training
2.6. Accuracy Evaluation Metrics
3. Results
3.1. Segmentation Accuracy Assessment
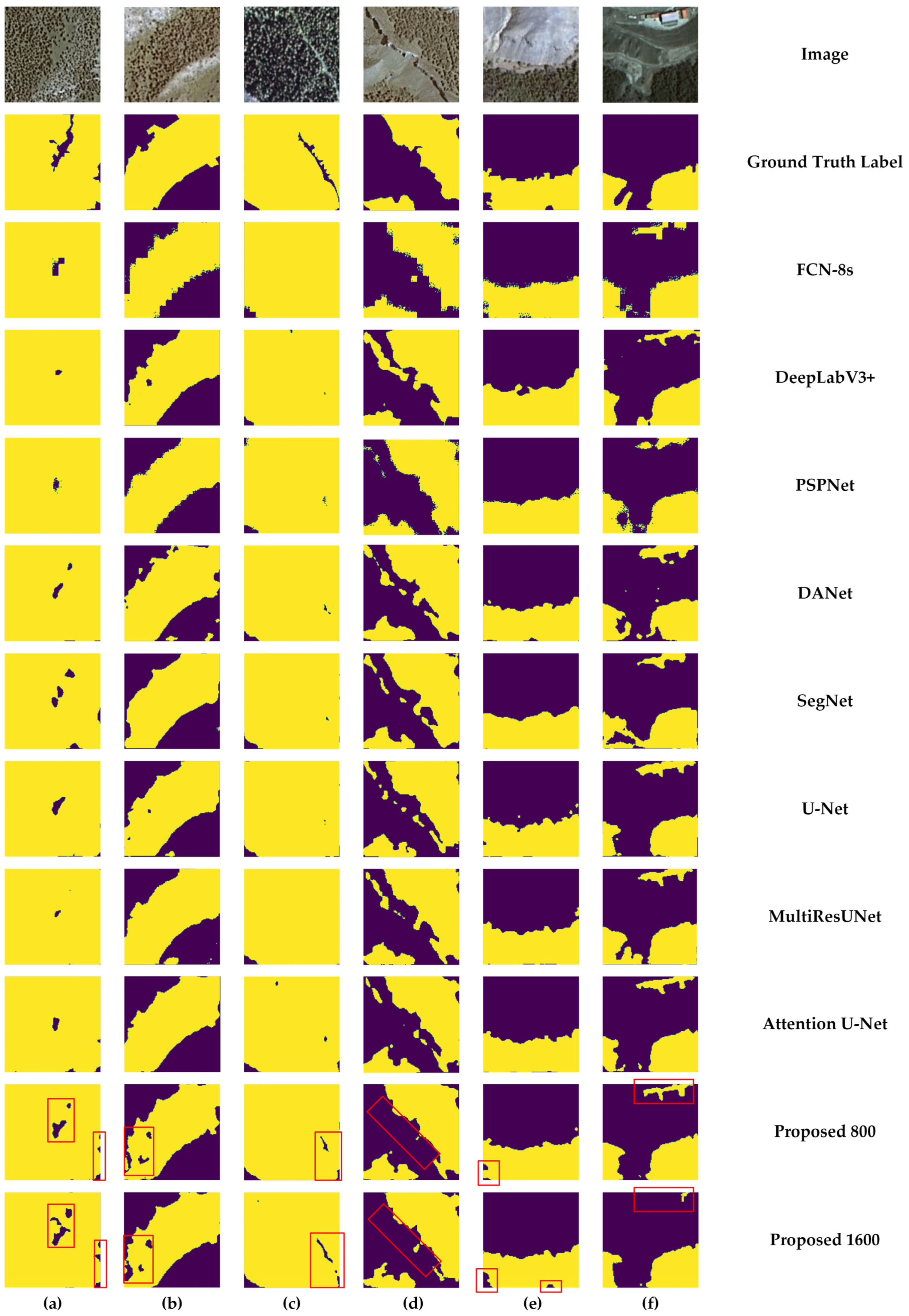
3.2. Segmentation Visual Assessment
3.3. Data Augmentation Assessment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bonan, G.B. Forests and climate change: Forcings, feedbacks, and the climate benefits of forests. Science 2008, 320, 1444–1449. [Google Scholar] [CrossRef]
- Xiao, J.-L.; Zeng, F.; He, Q.-L.; Yao, Y.-X.; Han, X.; Shi, W.-Y. Responses of Forest Carbon Cycle to Drought and Elevated CO2. Atmosphere 2021, 12, 212. [Google Scholar] [CrossRef]
- Shaheen, H.; Khan, R.W.A.; Hussain, K.; Ullah, T.S.; Nasir, M.; Mehmood, A. Carbon stocks assessment in subtropical forest types of Kashmir Himalayas. Pak. J. Bot 2016, 48, 2351–2357. [Google Scholar]
- Raymond, C.M.; Bryan, B.A.; MacDonald, D.H.; Cast, A.; Strathearn, S.; Grandgirard, A.; Kalivas, T. Mapping community values for natural capital and ecosystem services. Ecol. Econ. 2009, 68, 1301–1315. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Nguyen, T.-A.; Kellenberger, B.; Tuia, D. Mapping forest in the Swiss Alps treeline ecotone with explainable deep learning. Remote Sens. Environ. 2022, 281, 113217. [Google Scholar] [CrossRef]
- AHoscilo, A.; Lewandowska, A. Mapping Forest Type and Tree Species on a Regional Scale Using Multi-Temporal Sentinel-2 Data. Remote Sens. 2019, 11, 929. [Google Scholar] [CrossRef]
- Camarretta, N.; Harrison, P.A.; Bailey, T.; Potts, B.; Lucieer, A.; Davidson, N.; Hunt, M. Monitoring Forest Structure to Guide Adaptive Management of Forest Restoration: A Review of Remote Sensing Approaches. New For. 2020, 51, 573–596. [Google Scholar] [CrossRef]
- Huete, A.R. Vegetation Indices, Remote Sensing and Forest Monitoring. Geogr. Compass 2012, 6, 513–532. [Google Scholar] [CrossRef]
- Shimu, S.; Aktar, M.; Afjal, M.; Nitu, A.; Uddin, M.; Al Mamun, M. NDVI based change detection in Sundarban Mangrove Forest using remote sensing data. In Proceedings of the 2019 4th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 20–22 December 2019; pp. 1–5. [Google Scholar]
- Pesaresi, S.; Mancini, A.; Casavecchia, S. Recognition and Characterization of Forest Plant Communities through Remote-Sensing NDVI Time Series. Diversity 2020, 12, 313. [Google Scholar] [CrossRef]
- Spruce, J.P.; Hicke, J.A.; Hargrove, W.W.; Grulke, N.E.; Meddens, A.J.H. Use of MODIS NDVI Products to Map Tree Mortality Levels in Forests Affected by Mountain Pine Beetle Outbreaks. Forests 2019, 10, 811. [Google Scholar] [CrossRef]
- Pesaresi, S.; Mancini, A.; Quattrini, G.; Casavecchia, S. Mapping Mediterranean Forest Plant Associations and Habitats with Functional Principal Component Analysis Using Landsat 8 NDVI Time Series. Remote Sens. 2020, 12, 1132. [Google Scholar] [CrossRef]
- Piragnolo, M.; Pirotti, F.; Zanrosso, C.; Lingua, E.; Grigolato, S. Responding to Large-Scale Forest Damage in an Alpine Environment with Remote Sensing, Machine Learning, and Web-GIS. Remote Sens. 2021, 13, 1541. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Mansaray, L.R.; Wang, F.; Huang, J.; Yang, L.; Kanu, A.S. Accuracies of support vector machine and random forest in rice mapping with Sentinel-1A, Landsat-8 and Sentinel-2A datasets. Geocarto Int. 2020, 35, 1088–1108. [Google Scholar] [CrossRef]
- Zagajewski, B.; Kluczek, M.; Raczko, E.; Njegovec, A.; Dabija, A.; Kycko, M. Comparison of random forest, support vector machines, and neural networks for post-disaster forest species mapping of the Krkonoše/Karkonosze Transboundary Biosphere Reserve. Remote Sens. 2021, 13, 2581. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [PubMed]
- Zafari, A.; Zurita-Milla, R.; Izquierdo-Verdiguier, E. Integrating support vector machines and random forests to classify crops in time series of Worldview-2 images. Image Signal Process. Remote Sens. XXIII 2017, 10427, 243–253. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in Remote Sensing Applications: A Meta-Analysis and Review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Xia, M.; Cui, Y.; Zhang, Y.; Xu, Y.; Liu, J.; Xu, Y. DAU-Net: A novel water areas segmentation structure for remote sensing image. Int. J. Remote Sens. 2021, 42, 2594–2621. [Google Scholar] [CrossRef]
- Jiang, B.; An, X.; Xu, S.; Chen, Z. Intelligent Image Semantic Segmentation: A Review Through Deep Learning Techniques for Remote Sensing Image Analysis. J. Indian Soc. Remote Sens. 2022, 1–14. [Google Scholar] [CrossRef]
- Wei, Z.; Jia, K.; Jia, X.; Liu, P.; Ma, Y.; Chen, T.; Feng, G. Mapping Large-Scale Plateau Forest in Sanjiangyuan Using High-Resolution Satellite Imagery and Few-Shot Learning. Remote Sens. 2022, 14, 388. [Google Scholar] [CrossRef]
- Boston, T.; Van Dijk, A.; Larraondo, P.R.; Thackway, R. Comparing CNNs and Random Forests for Landsat Image Segmentation Trained on a Large Proxy Land Cover Dataset. Remote Sens. 2022, 14, 3396. [Google Scholar] [CrossRef]
- Freudenberg, M.; Nölke, N.; Agostini, A.; Urban, K.; Wörgötter, F.; Kleinn, C. Large scale palm tree detection in high resolution satellite images using U-Net. Remote Sens. 2019, 11, 312. [Google Scholar] [CrossRef]
- Wagner, F.H.; Sanchez, A.; Tarabalka, Y.; Lotte, R.G.; Ferreira, M.P.; Aidar, M.P.M.; Gloor, E.; Phillips, O.L.; Aragão, L.E.O.C. Using the U-net convolutional network to map forest types and disturbance in the Atlantic rainforest with very high resolution images. Remote Sens. Ecol. Conserv. 2019, 5, 360–375. [Google Scholar] [CrossRef]
- Wagner, F.H.; Dalagnol, R.; Tagle Casapia, X.; Streher, A.S.; Phillips, O.L.; Gloor, E.; Aragão, L.E. Regional mapping and spatial distribution analysis of canopy palms in an amazon forest using deep learning and VHR images. Remote Sens. 2020, 12, 2225. [Google Scholar] [CrossRef]
- Flood, N.; Watson, F.; Collett, L. Using a U-net convolutional neural network to map woody vegetation extent from high resolution satellite imagery across Queensland, Australia. Int. J. Appl. Earth Obs. 2019, 82, 101897. [Google Scholar] [CrossRef]
- Cao, K.; Zhang, X. An Improved Res-UNet Model for Tree Species Classification Using Airborne High-Resolution Images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef]
- Wei, Z.; Jia, K.; Jia, X.; Xie, Y.; Jiang, Z. Large-Scale River Mapping Using Contrastive Learning and Multi-Source Satellite Imagery. Remote Sens. 2021, 13, 2893. [Google Scholar] [CrossRef]
- Rendenieks, Z.; Nita, M.D.; Nikodemus, O.; Radeloff, V.C. Half a century of forest cover change along the Latvian-Russian border captured by object-based image analysis of Corona and Landsat TM/OLI data. Remote Sens. Environ. 2020, 249, 112010. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, W.; Tang, X.; Li, H.; Hu, H.; Wang, X. Classification of Alpine Grasslands in Cold and High Altitudes Based on Multispectral Landsat-8 Images: A Case Study in Sanjiangyuan National Park, China. Remote Sens. 2022, 14, 3714. [Google Scholar] [CrossRef]
- Chen, D.; Li, Q.; Li, C.; He, F.; Huo, L.; Chen, X.; Zhang, L.; Xu, S.; Zhao, X.; Zhao, L. Density and Stoichiometric Characteristics of Carbon, Nitrogen, and Phosphorus in Surface Soil of Alpine Grassland in Sanjiangyuan. Pol. J. Environ. Stud. 2022, 31, 3531–3539. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yao, X.; Zhou, S.; Zhang, D. Glacier changes in the Sanjiangyuan Nature Reserve of China during 2000–2018. J. Geogr. Sci. 2022, 32, 259–279. [Google Scholar] [CrossRef]
- Han, Z.; Dian, Y.; Xia, H.; Zhou, J.; Jian, Y.; Yao, C.; Wang, X.; Li, Y. Comparing Fully Deep Convolutional Neural Networks for Land Cover Classification with High-Spatial-Resolution Gaofen-2 Images. ISPRS Int. J. Geo-Inf. 2020, 9, 478. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve Restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Sergey, I.; Christian, S. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Oubara, A.; Wu, F.; Amamra, A.; Yang, G. Survey on Remote Sensing Data Augmentation: Advances, Challenges, and Future Perspectives. International Conference on Computing Systems and Applications (CSA), Algiers, Algeria, 17–18 May 2022; Springer: Cham, Switzerland, 2022; pp. 95–104. [Google Scholar]
- He, C.; Li, S.; Xiong, D.; Fang, P.; Liao, M. Remote Sensing Image Semantic Segmentation Based on Edge Information Guidance. Remote Sens. 2020, 12, 1501. [Google Scholar] [CrossRef]
- Moolayil, J. An Introduction to Deep Learning and Keras: A Fast-Track Approach to Modern Deep Learning with Python; Apress: Thousand Oaks, CA, USA, 2018; pp. 1–16. [Google Scholar]
- Drakopoulos, G.; Liapakis, X.; Spyrou, E.; Tzimas, G.; Sioutas, S. Computing long sequences of consecutive fibonacci integers with tensorflow. In Proceedings of the International Conference on Artificial Intelligence Applications and Innovations, Dubai, United Arab Emirates, 30 November 2019; pp. 150–160. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Usha Ruby, A. Binary cross entropy with deep learning technique for Image classification. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 5393–5397. [Google Scholar]
- Cui, H.; Chen, S.; Hu, L.; Wang, J.; Cai, H.; Ma, C.; Liu, J.; Zou, B. HY1C/D-CZI Noctiluca scintillans Bloom Recognition Network Based on Hybrid Convolution and Self-Attention. Remote Sens. 2023, 15, 1757. [Google Scholar] [CrossRef]
- Kim, J.; Chi, M. SAFFNet: Self-Attention-Based Feature Fusion Network for Remote Sensing Few-Shot Scene Classification. Remote Sens. 2021, 13, 2532. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, Y.; Wang, F.; Wang, S.; Xu, Z. SDGH-Net: Ship Detection in Optical Remote Sensing Images Based on Gaussian Heatmap Regression. Remote Sens. 2021, 13, 499. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, Z. Remote Sensing Image Road Extraction Network Based on MSPFE-Net. Electronics 2023, 12, 1713. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, X.; Zhang, Y.; Zhao, G. MSLWENet: A Novel Deep Learning Network for Lake Water Body Extraction of Google Remote Sensing Images. Remote Sens. 2020, 12, 4140. [Google Scholar] [CrossRef]
- Xiang, K.; Yuan, W.; Wang, L.; Deng, Y. An LSWI-Based Method for Mapping Irrigated Areas in China Using Moderate-Resolution Satellite Data. Remote Sens. 2020, 12, 4181. [Google Scholar] [CrossRef]
- Jenčo, M.; Fulajtár, E.; Bobáľová, H.; Matečný, I.; Saksa, M.; Kožuch, M.; Gallay, M.; Kaňuk, J.; Píš, V.; Oršulová, V. Mapping Soil Degradation on Arable Land with Aerial Photography and Erosion Models, Case Study from Danube Lowland, Slovakia. Remote Sens. 2020, 12, 4047. [Google Scholar] [CrossRef]
- Li, M.; Stein, A. Mapping Land Use from High Resolution Satellite Images by Exploiting the Spatial Arrangement of Land Cover Objects. Remote Sens. 2020, 12, 4158. [Google Scholar] [CrossRef]
- Chehreh, B.; Moutinho, A.; Viegas, C. Latest Trends on Tree Classification and Segmentation Using UAV Data—A Review of Agroforestry Applications. Remote Sens. 2023, 15, 2263. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Type | Details |
|---|---|
| temporal resolution | 5 days |
| spatial resolution | 2 m |
| spectral range | 0.45–0.89 μm |
| orbital altitude | 505.984 km |
| Parameter Type | Details |
|---|---|
| data sources | ZY-3 satellite imagery |
| number of samples | 38,708 |
| number of manual ground truth labels | 1187 |
| sample size | 128 × 128 pixels |
| number of spectral bands | 4 |
| manual ground truth size | 128 × 128 pixels |
| resolution for each pixel | 2 m |
| time period of the data | January 2017–December 2017 |
| period of the manual ground truth | May 2017–June 2017 |
| Train Samples | 800 | 1600 | ||||||
|---|---|---|---|---|---|---|---|---|
| Evaluation Metrics | P | R | F1 | IoU | P | R | F1 | IoU |
| FCN-8s [20] | 93.05 | 89.92 | 91.06 | 84.58 | 93.63 | 92.39 | 92.77 | 87.05 |
| DeepLab V3+ [24] | 88.26 | 87.67 | 86.92 | 78.28 | 91.79 | 90.42 | 90.53 | 83.60 |
| PSPNet [22] | 92.74 | 93.73 | 92.98 | 87.44 | 92.51 | 95.05 | 93.48 | 88.29 |
| DANet [25] | 92.87 | 93.93 | 93.04 | 87.65 | 92.14 | 94.84 | 93.18 | 87.90 |
| SegNet [23] | 92.38 | 93.74 | 92.76 | 87.11 | 92.51 | 94.17 | 93.09 | 87.61 |
| U-Net [21] | 93.31 | 93.84 | 93.30 | 87.95 | 92.60 | 94.86 | 93.41 | 88.20 |
| MultiResUNet [45] | 92.45 | 94.09 | 93.00 | 87.57 | 92.58 | 94.47 | 93.35 | 88.11 |
| Attention U-Net [44] | 94.09 | 93.98 | 93.72 | 88.74 | 93.82 | 94.70 | 94.00 | 89.14 |
| Proposed | 94.37 | 94.80 | 94.36 | 89.71 | 94.59 | 95.12 | 94.62 | 90.19 |
| Evaluation Metrics | P | R | F1 | IoU |
|---|---|---|---|---|
| FCN-8s [20] | 92.29 | 92.32 | 92.01 | 85.82 |
| DeepLab V3+ [24] | 88.32 | 92.30 | 89.16 | 81.78 |
| PSPNet [22] | 92.75 | 94.07 | 93.15 | 87.70 |
| DANet [25] | 92.53 | 94.34 | 93.13 | 87.76 |
| SegNet [23] | 93.16 | 92.97 | 92.81 | 87.18 |
| U-Net [21] | 93.69 | 93.43 | 93.29 | 87.99 |
| MultiResUNet [45] | 93.70 | 93.15 | 93.10 | 87.65 |
| Attention U-Net [44] | 93.31 | 94.93 | 93.77 | 88.83 |
| Proposed | 94.08 | 95.16 | 94.40 | 89.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Jia, K.; Wei, Z. Improvements in Forest Segmentation Accuracy Using a New Deep Learning Architecture and Data Augmentation Technique. Remote Sens. 2023, 15, 2412. https://doi.org/10.3390/rs15092412
He Y, Jia K, Wei Z. Improvements in Forest Segmentation Accuracy Using a New Deep Learning Architecture and Data Augmentation Technique. Remote Sensing. 2023; 15(9):2412. https://doi.org/10.3390/rs15092412
Chicago/Turabian StyleHe, Yan, Kebin Jia, and Zhihao Wei. 2023. "Improvements in Forest Segmentation Accuracy Using a New Deep Learning Architecture and Data Augmentation Technique" Remote Sensing 15, no. 9: 2412. https://doi.org/10.3390/rs15092412
APA StyleHe, Y., Jia, K., & Wei, Z. (2023). Improvements in Forest Segmentation Accuracy Using a New Deep Learning Architecture and Data Augmentation Technique. Remote Sensing, 15(9), 2412. https://doi.org/10.3390/rs15092412