
Fast, Efficient, and Viable Compressed Sensing, Low-Rank, and Robust Principle Component Analysis Algorithms for Radar Signal Processing


Abstract
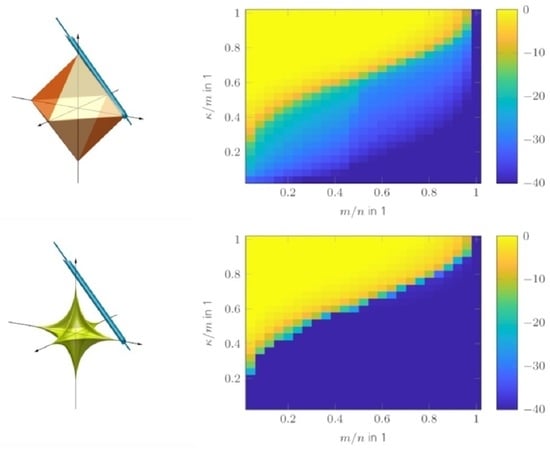
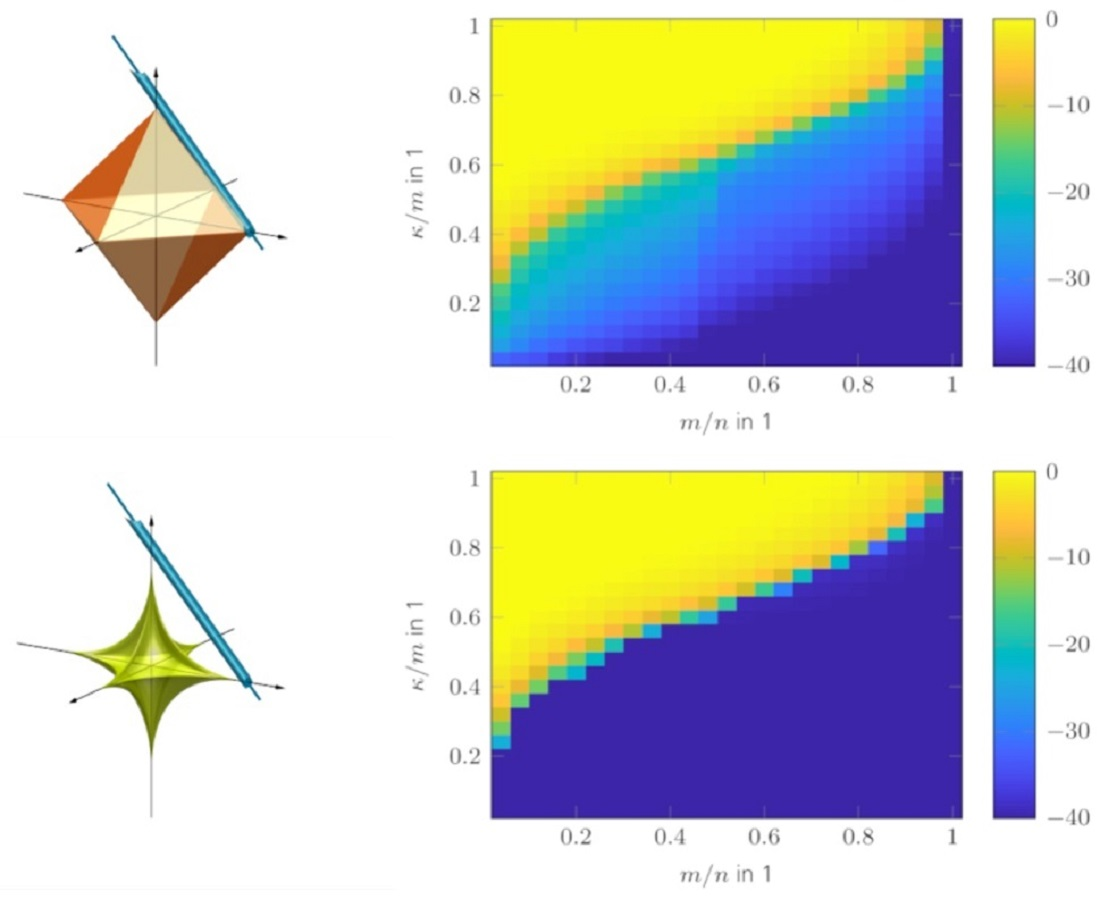{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
- Turbo shrinkage-thresholding (TST)
- Complex successive concave sparsity approximation (CSCSA)
- Turbo singular value thresholding (TSVT)
- Complex smoothed rank approximation (CSRA)
- Turbo compressed robust principal component analysis (TCRPCA)
1.1. Background
1.2. State of the Art
1.2.1. Greedy Algorithms
1.2.2. Hard Thresholding Algorithms
1.2.3. Convex Relaxations Algorithms
1.2.4. Approximated Message-Passing Algorithms
1.2.5. Smoothed -Algorithms
1.3. Contribution
1.4. Outline of the Paper
2. Compressed Sensing
2.1. Turbo Shrinkage Thresholding
| Algorithm 1 The TST algorithm. |
| Input: A, y, λ, I Initialization:
|
2.2. Complex Successive Concave Sparsity Approximation
| Algorithm 2 The CSCSA algorithm. |
| Input: A, y, λ, I, J Initialization:
|
3. Affine Rank Minimization
3.1. Turbo Singular Value Thresholding
| Algorithm 3 The TSVT algorithm. |
| Input: , y, λ, I Initialization:
|
3.2. Complex Smoothed Rank Approximation
| Algorithm 4 The CSRA algorithm. |
| Input: , y, λ, J, P Initialization:
|
4. Compressed Robust Principle Component Analysis
Turbo Compressed Robust Principle Component Analysis
| Algorithm 5 Part 1 of TCRPCA algorithm delivering convex solution. |
| Input: , y, λs, λl, κs, φl, I Initialization:
|
| Algorithm 6 Part 2 of TCRPCA algorithm delivering refined solution. |
| Input: Initialization:
|
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Divergence of the Complex Soft-Thresholding Operator
Appendix B. Complex Smoothed Rank Approximation
References
- Ender, J.H. On compressive sensing applied to radar. Signal Process. 2010, 90, 1402–1414. [Google Scholar] [CrossRef]
- Weng, Z.; Wang, X. Low-rank matrix completion for array signal processing. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 2697–2700. [Google Scholar] [CrossRef]
- Ender, J. A brief review of compressive sensing applied to radar. In Proceedings of the 2013 14th International Radar Symposium (IRS), Dresden, Germany, 19–21 June 2013; Volume 1, pp. 3–16. [Google Scholar]
- de Lamare, R.C. Low-Rank Signal Processing: Design, Algorithms for Dimensionality Reduction and Applications. arXiv 2015, arXiv:1508.00636. [Google Scholar] [CrossRef]
- Sun, S.; Mishra, K.V.; Petropulu, A.P. Target Estimation by Exploiting Low Rank Structure in Widely Separated MIMO Radar. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Xiang, Y.; Xi, F.; Chen, S. LiQuiD-MIMO Radar: Distributed MIMO Radar with Low-Bit Quantization. arXiv 2023, arXiv:eess.SP/2302.08271. [Google Scholar]
- Rangaswamy, M.; Lin, F. Radar applications of low rank signal processing methods. In Proceedings of the Thirty-Sixth Southeastern Symposium on System Theory, Atlanta, GA, USA, 16 March 2004; pp. 107–111. [Google Scholar] [CrossRef]
- Prünte, L. GMTI on short sequences of pulses with compressed sensing. In Proceedings of the 2015 3rd International Workshop on Compressed Sensing Theory and its Applications to Radar, Sonar and Remote Sensing (CoSeRa), Pisa, Italy, 17–19 June 2015; pp. 66–70. [Google Scholar] [CrossRef]
- Sen, S. Low-Rank Matrix Decomposition and Spatio-Temporal Sparse Recovery for STAP Radar. IEEE J. Sel. Top. Signal Process. 2015, 9, 1510–1523. [Google Scholar] [CrossRef]
- Prünte, L. Compressed sensing for the detection of moving targets from short sequences of pulses: Special section “sparse reconstruction in remote sensing”. In Proceedings of the 2016 4th International Workshop on Compressed Sensing Theory and its Applications to Radar, Sonar and Remote Sensing (CoSeRa), Aachen, Germany, 19–22 September 2016; pp. 85–89. [Google Scholar] [CrossRef]
- Prünte, L. Detection of Moving Targets Using Off-Grid Compressed Sensing. In Proceedings of the 2018 19th International Radar Symposium (IRS), Bonn, Germany, 20–22 June 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Dao, M.; Nguyen, L.; Tran, T.D. Temporal rate up-conversion of synthetic aperture radar via low-rank matrix recovery. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 2358–2362. [Google Scholar] [CrossRef]
- Cerutti-Maori, D.; Prünte, L.; Sikaneta, I.; Ender, J. High-resolution wide-swath SAR processing with compressed sensing. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 3830–3833. [Google Scholar] [CrossRef]
- Mason, E.; Son, I.-Y.; Yazici, B. Passive synthetic aperture radar imaging based on low-rank matrix recovery. In Proceedings of the 2015 IEEE Radar Conference (RadarCon), Arlington, VA, USA, 10–15 May 2015; pp. 1559–1563. [Google Scholar]
- Kang, J.; Wang, Y.; Schmitt, M.; Zhu, X.X. Object-Based Multipass InSAR via Robust Low-Rank Tensor Decomposition. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3062–3077. [Google Scholar] [CrossRef]
- Hamad, A.; Ender, J. Three Dimensional ISAR Autofocus based on Sparsity Driven Motion Estimation. In Proceedings of the 2020 21st International Radar Symposium (IRS), Warsaw, Poland, 5–8 October 2020; pp. 51–56. [Google Scholar] [CrossRef]
- Qiu, W.; Zhou, J.; Fu, Q. Jointly Using Low-Rank and Sparsity Priors for Sparse Inverse Synthetic Aperture Radar Imaging. IEEE Trans. Image Process. 2020, 29, 100–115. [Google Scholar] [CrossRef]
- Wagner, S.; Ender, J. Scattering Identification in ISAR Images via Sparse Decomposition. In Proceedings of the 2022 IEEE Radar Conference (RadarConf22), New York, NY, USA, 21–25 March 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Tang, V.H.; Bouzerdoum, A.; Phung, S.L.; Tivive, F.H.C. Radar imaging of stationary indoor targets using joint low-rank and sparsity constraints. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 1412–1416. [Google Scholar] [CrossRef]
- Sun, Y.; Breloy, A.; Babu, P.; Palomar, D.P.; Pascal, F.; Ginolhac, G. Low-Complexity Algorithms for Low Rank Clutter Parameters Estimation in Radar Systems. IEEE Trans. Signal Process. 2016, 64, 1986–1998. [Google Scholar] [CrossRef]
- Wang, J.; Ding, M.; Yarovoy, A. Interference Mitigation for FMCW Radar with Sparse and Low-Rank Hankel Matrix Decomposition. IEEE Trans. Signal Process. 2022, 70, 822–834. [Google Scholar] [CrossRef]
- Brehier, H.; Breloy, A.; Ren, C.; Hinostroza, I.; Ginolhac, G. Robust PCA for Through-the-Wall Radar Imaging. In Proceedings of the 2022 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; pp. 2246–2250. [Google Scholar] [CrossRef]
- Yang, D.; Yang, X.; Liao, G.; Zhu, S. Strong Clutter Suppression via RPCA in Multichannel SAR/GMTI System. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2237–2241. [Google Scholar] [CrossRef]
- Guo, Y.; Liao, G.; Li, J.; Chen, X. A Novel Moving Target Detection Method Based on RPCA for SAR Systems. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6677–6690. [Google Scholar] [CrossRef]
- A Clutter Suppression Method Based on NSS-RPCA in Heterogeneous Environments for SAR-GMTI. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5880–5891. [CrossRef]
- Yang, J.; Jin, T.; Xiao, C.; Huang, X. Compressed Sensing Radar Imaging: Fundamentals, Challenges, and Advances. Sensors 2019, 19, 3100. [Google Scholar] [CrossRef] [PubMed]
- Zuo, L.; Wang, J.; Zhao, T.; Cheng, Z. A Joint Low-Rank and Sparse Method for Reference Signal Purification in DTMB-Based Passive Bistatic Radar. Sensors 2021, 21, 3607. [Google Scholar] [CrossRef] [PubMed]
- De Maio, A.; Eldar, Y.; Haimovich, A. Compressed Sensing in Radar Signal Processing; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Amin, M. Compressive Sensing for Urban Radar; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Manchanda, R.; Sharma, K. A Review of Reconstruction Algorithms in Compressive Sensing. In Proceedings of the 2020 International Conference on Advances in Computing, Communication Materials (ICACCM), Dehradun, India, 21–22 August 2020; pp. 322–325. [Google Scholar] [CrossRef]
- Cai, J.F.; Candès, E.J.; Shen, Z. A Singular Value Thresholding Algorithm for Matrix Completion. arXiv 2008, arXiv:math.OC/0810.3286. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust Principal Component Analysis? CoRR 2009. abs/0912.3599. [Google Scholar] [CrossRef]
- Eldar, Y.; Kutyniok, G. Compressed Sensing: Theory and Applications; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Pilastri, A.; Tavares, J. Reconstruction Algorithms in Compressive Sensing: An Overview. In Proceedings of the FAUP-11th Edition of the Doctoral Symposium in Informatics Engineering, Porto, Portugal, 3 February 2016. [Google Scholar]
- Park, D.; Kyrillidis, A.; Caramanis, C.; Sanghavi, S. Finding Low-Rank Solutions via Non-Convex Matrix Factorization, Efficiently and Provably. arXiv 2016, arXiv:1606.03168. [Google Scholar] [CrossRef]
- Chandrasekaran, V.; Sanghavi, S.; Parrilo, P.A.; Willsky, A.S. Rank-Sparsity Incoherence for Matrix Decomposition. SIAM J. Optim. 2011, 21, 572–596. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Donoho, D.L.; Tsaig, Y.; Drori, I.; Starck, J.L. Sparse solution of underdetermined systems of linear equations by stagewise orthogonal matching pursuit. IEEE Trans. Inf. Theory 2012, 58, 1094–1121. [Google Scholar] [CrossRef]
- Needell, D.; Vershynin, R. Signal recovery from incomplete and inaccurate measurements via regularized orthogonal matching pursuit. IEEE J. Sel. Top. Signal Process. 2010, 4, 310–316. [Google Scholar] [CrossRef]
- Needell, D.; Tropp, J.A. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef]
- Dai, W.; Milenkovic, O. Subspace pursuit for compressive sensing signal reconstruction. IEEE Trans. Inf. Theory 2009, 55, 2230–2249. [Google Scholar] [CrossRef]
- Boche, H.; Calderbank, R.; Kutyniok, G.; Vybiral, J. A Survey of Compressed Sensing; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar] [CrossRef]
- Lee, K.; Bresler, Y. ADMiRA: Atomic Decomposition for Minimum Rank Approximation. IEEE Trans. Inf. Theory 2010, 56, 4402–4416. [Google Scholar] [CrossRef]
- Waters, A.; Sankaranarayanan, A.; Baraniuk, R. SpaRCS: Recovering low-rank and sparse matrices from compressive measurements. In Proceedings of the Advances in Neural Information Processing Systems; Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2011; Volume 24. [Google Scholar]
- Xiang, J.; Yue, H.; Xiangjun, Y.; Guoqing, R. A Reweighted Symmetric Smoothed Function Approximating L0-Norm Regularized Sparse Reconstruction Method. Symmetry 2018, 10, 583. [Google Scholar] [CrossRef]
- Xiang, J.; Yue, H.; Xiangjun, Y.; Wang, L. A New Smoothed L0 Regularization Approach for Sparse Signal Recovery. Math. Probl. Eng. 2019, 2019, 1978154. [Google Scholar] [CrossRef]
- Blumensath, T.; Davies, M.E. Normalized Iterative Hard Thresholding: Guaranteed Stability and Performance. IEEE J. Sel. Top. Signal Process. 2010, 4, 298–309. [Google Scholar] [CrossRef]
- Meka, R.; Jain, P.; Dhillon, I.S. Guaranteed Rank Minimization via Singular Value Projection. arXiv 2009, arXiv:cs.LG/0909.5457. [Google Scholar]
- Zhang, X.; Wang, L.; Gu, Q. A Unified Framework for Low-Rank plus Sparse Matrix Recovery. arXiv 2017, arXiv:1702.06525. [Google Scholar] [CrossRef]
- Blanchard, J.D.; Tanner, J. Performance comparisons of greedy algorithms in compressed sensing. Numer. Linear Algebra Appl. 2015, 22, 254–282. [Google Scholar] [CrossRef]
- Mansour, H. Beyond ℓ1-norm minimization for sparse signal recovery. In Proceedings of the 2012 IEEE Statistical Signal Processing Workshop (SSP), Ann Arbor, MI, USA, 5–8 August 2012; pp. 337–340. [Google Scholar] [CrossRef]
- Aravkin, A.; Becker, S.; Cevher, V.; Olsen, P. A variational approach to stable principal component pursuit. arXiv 2014, arXiv:1406.1089. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Panhuber, R.; Prünte, L. Complex Successive Concave Sparsity Approximation. In Proceedings of the 2020 21st International Radar Symposium (IRS), Warsaw, Poland, 5–8 October 2020; pp. 67–72. [Google Scholar] [CrossRef]
- Ma, J.; Yuan, X.; Ping, L. Turbo Compressed Sensing with Partial DFT Sensing Matrix. IEEE Signal Process. Lett. 2015, 22, 158–161. [Google Scholar] [CrossRef]
- Xue, Z.; Ma, J.; Yuan, X. Denoising-Based Turbo Compressed Sensing. IEEE Access 2017, 5, 7193–7204. [Google Scholar] [CrossRef]
- Xue, Z.; Yuan, X.; Ma, J.; Ma, Y. TARM: A Turbo-Type Algorithm for Affine Rank Minimization. IEEE Trans. Signal Process. 2019, 67, 5730–5745. [Google Scholar] [CrossRef]
- Xue, Z.; Yuan, X.; Yang, Y. Turbo-Type Message Passing Algorithms for Compressed Robust Principal Component Analysis. IEEE J. Sel. Top. Signal Process. 2018, 12, 1182–1196. [Google Scholar] [CrossRef]
- He, X.; Xue, Z.; Yuan, X. Learned Turbo Message Passing for Affine Rank Minimization and Compressed Robust Principal Component Analysis. IEEE Access 2019, 7, 140606–140617. [Google Scholar] [CrossRef]
- Kang, Z.; Peng, C.; Cheng, J.; Cheng, Q. LogDet Rank Minimization with Application to Subspace Clustering. Comput. Intell. Neurosci. 2015, 2015, 824289. [Google Scholar] [CrossRef]
- Malek-Mohammadi, M.; Babaie-Zadeh, M.; Amini, A.; Jutten, C. Recovery of Low-Rank Matrices Under Affine Constraints via a Smoothed Rank Function. IEEE Trans. Signal Process. 2014, 62, 981–992. [Google Scholar] [CrossRef]
- Malek-Mohammadi, M.; Babaie-Zadeh, M.; Skoglund, M. Iterative Concave Rank Approximation for Recovering Low-Rank Matrices. IEEE Trans. Signal Process. 2014, 62, 5213–5226. [Google Scholar] [CrossRef]
- Malek-Mohammadi, M.; Koochakzadeh, A.; Babaie-Zadeh, M.; Jansson, M.; Rojas, C. Successive Concave Sparsity Approximation for Compressed Sensing. IEEE Trans. Signal Process. 2016, 64, 5657–5671. [Google Scholar] [CrossRef]
- Ye, H.; Li, H.; Yang, B.; Cao, F.; Tang, Y. A Novel Rank Approximation Method for Mixture Noise Removal of Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4457–4469. [Google Scholar] [CrossRef]
- Bickel, P.J.; Ritov, Y.; Tsybakov, A.B. Simultaneous analysis of Lasso and Dantzig selector. arXiv 2008, arXiv:0801.1095. [Google Scholar] [CrossRef]
- Donoho, D.; Tanner, J. Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processing. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2009, 367, 4273–4293. [Google Scholar] [CrossRef] [PubMed]
- Candès, E.J.; Sing-Long, C.A.; Trzasko, J.D. Unbiased Risk Estimates for Singular Value Thresholding and Spectral Estimators. IEEE Trans. Signal Process. 2013, 61, 4643–4657. [Google Scholar] [CrossRef]
- Bouwmans, T.; Sobral, A.; Javed, S.; Jung, S.K.; Zahzah, E.H. Decomposition into low-rank plus additive matrices for background/foreground separation: A review for a comparative evaluation with a large-scale dataset. Comput. Sci. Rev. 2017, 23, 1–71. [Google Scholar] [CrossRef]
- Foucart, S.; Rauhut, H. A Mathematical Introduction to Compressive Sensing; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- Zill, D.; Wright, W. Differential Equations with Boundary-Value Problems; Cengage Learning: Boston, MA, USA, 2012. [Google Scholar]

























Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panhuber, R. Fast, Efficient, and Viable Compressed Sensing, Low-Rank, and Robust Principle Component Analysis Algorithms for Radar Signal Processing. Remote Sens. 2023, 15, 2216. https://doi.org/10.3390/rs15082216
Panhuber R. Fast, Efficient, and Viable Compressed Sensing, Low-Rank, and Robust Principle Component Analysis Algorithms for Radar Signal Processing. Remote Sensing. 2023; 15(8):2216. https://doi.org/10.3390/rs15082216
Chicago/Turabian StylePanhuber, Reinhard. 2023. "Fast, Efficient, and Viable Compressed Sensing, Low-Rank, and Robust Principle Component Analysis Algorithms for Radar Signal Processing" Remote Sensing 15, no. 8: 2216. https://doi.org/10.3390/rs15082216
APA StylePanhuber, R. (2023). Fast, Efficient, and Viable Compressed Sensing, Low-Rank, and Robust Principle Component Analysis Algorithms for Radar Signal Processing. Remote Sensing, 15(8), 2216. https://doi.org/10.3390/rs15082216