


An Improved Multi-Source Data-Driven Landslide Prediction Method Based on Spatio-Temporal Knowledge Graph



Abstract
1. Introduction
2. Materials and Methods
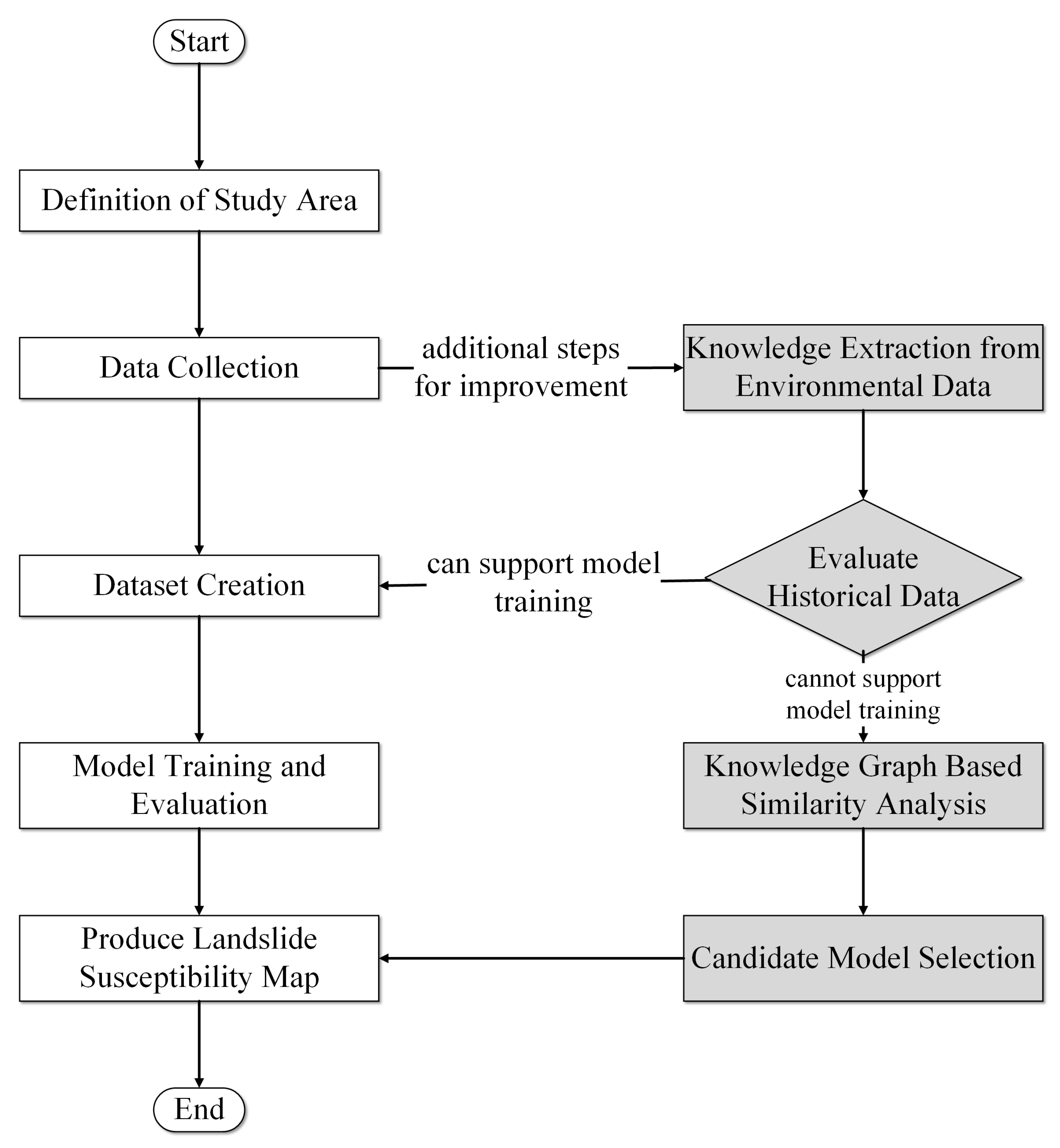
2.1. Workflow for Landslide Prediction
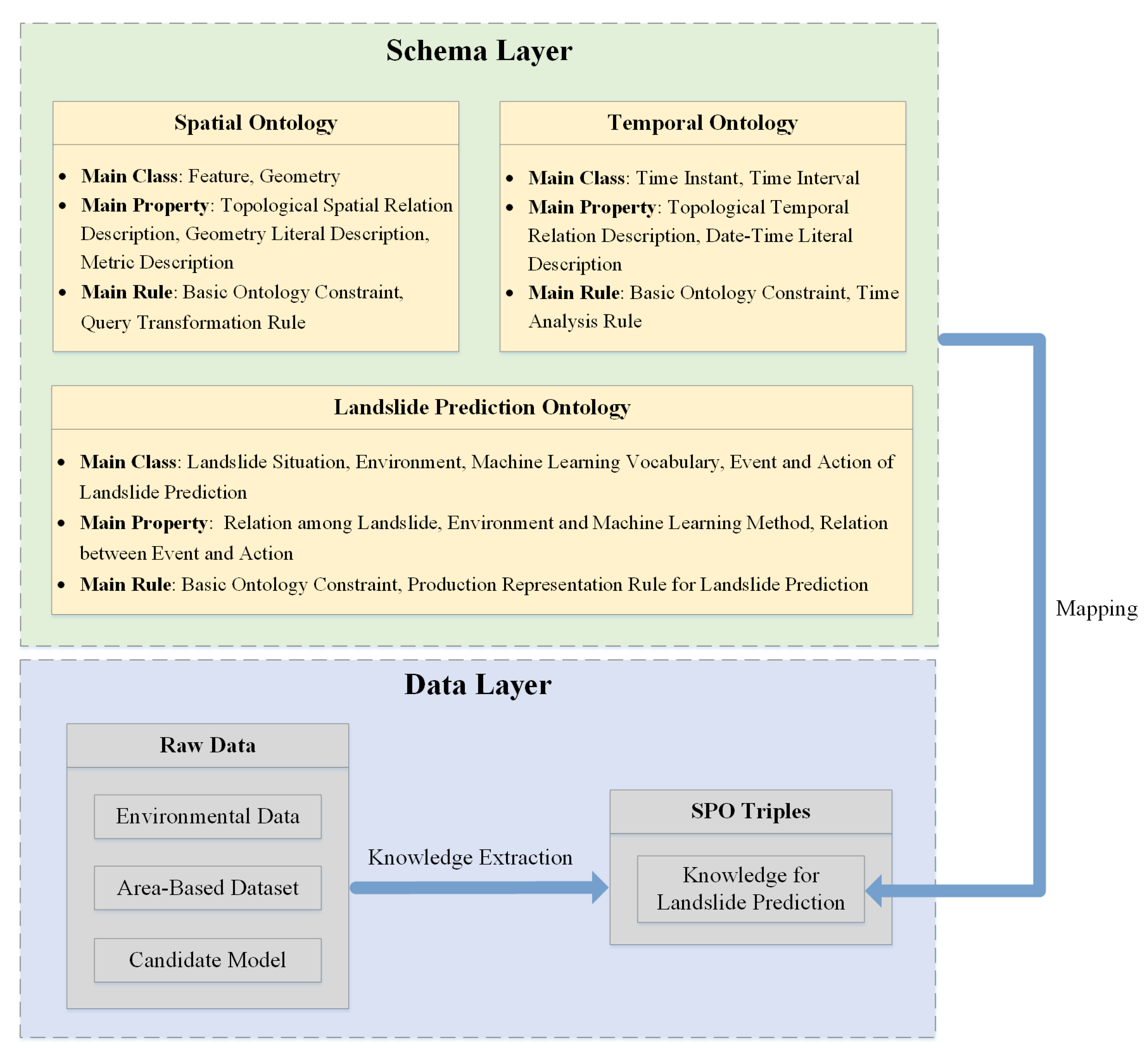
2.2. Design of Spatio-Temporal Knowledge Graph for Landslide Prediction
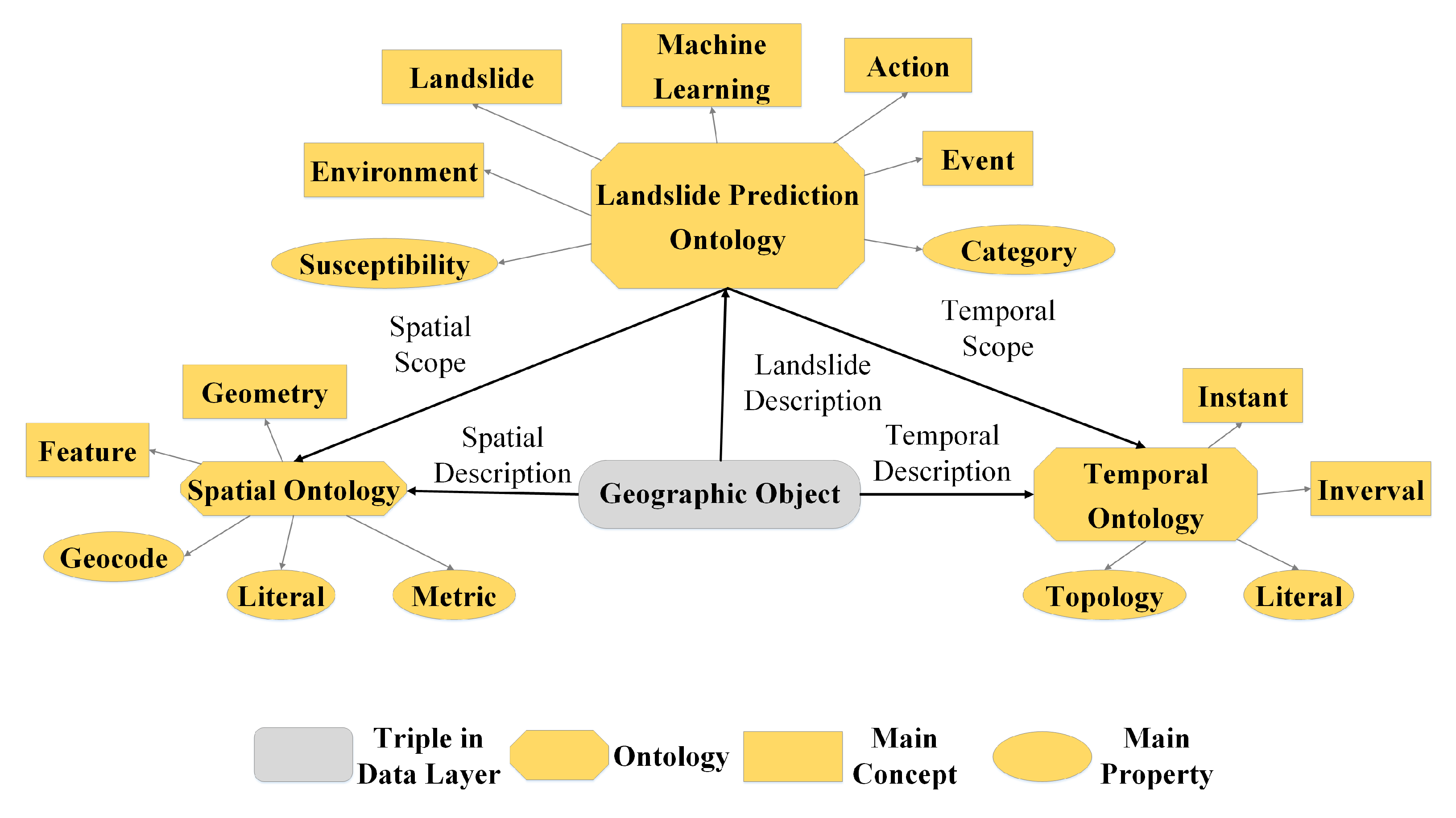
2.2.1. Schema Layer
- Spatial ontology
- Temporal ontology
- Landslide prediction ontology
2.2.2. Data Layer
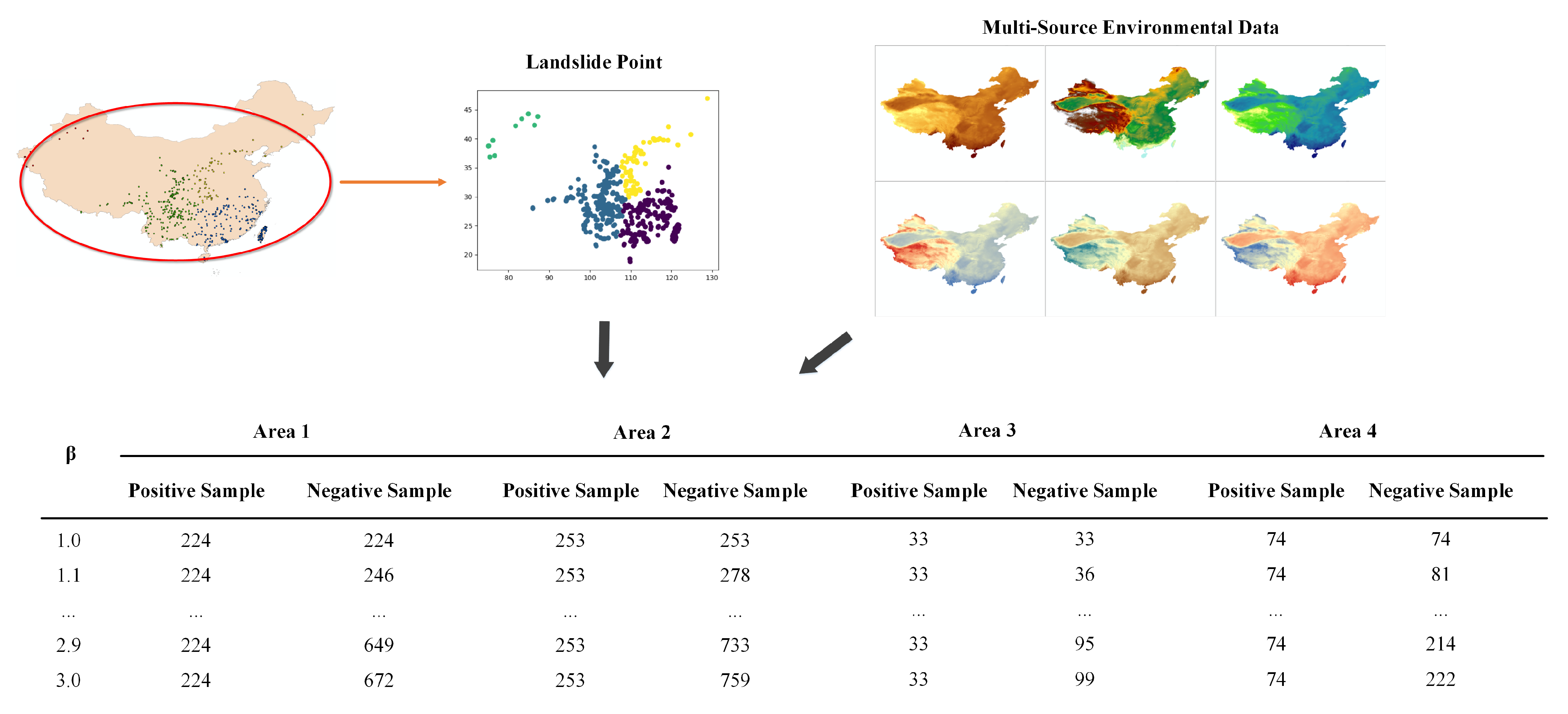
- Environmental Data: Environmental data record the causative factors of landslides in the area, with each type of environmental data corresponding to a specific causative factor. We extract both the environmental data and the environmental features in the area to generate SPO triples, which are used as the basis for analyzing environmental similarities between areas.
- Area-based Dataset: Area-based dataset refers to the dataset used for model training in specific areas. During the knowledge extraction process, we extract instances of dataset features to generate SPO triples. The features of the dataset include the number of samples, the sample area, and the statistical parameters of the causative factors contained in the samples.
- Candidate Model: Candidate model is the model trained based on the area-based dataset. We extract instances of model features to generate SPO triples, which include the name of the model, the address of the parameters, and the name of the samples used for model training.
2.3. Landslide Prediction Using Spatio-Temporal Knowledge Graph
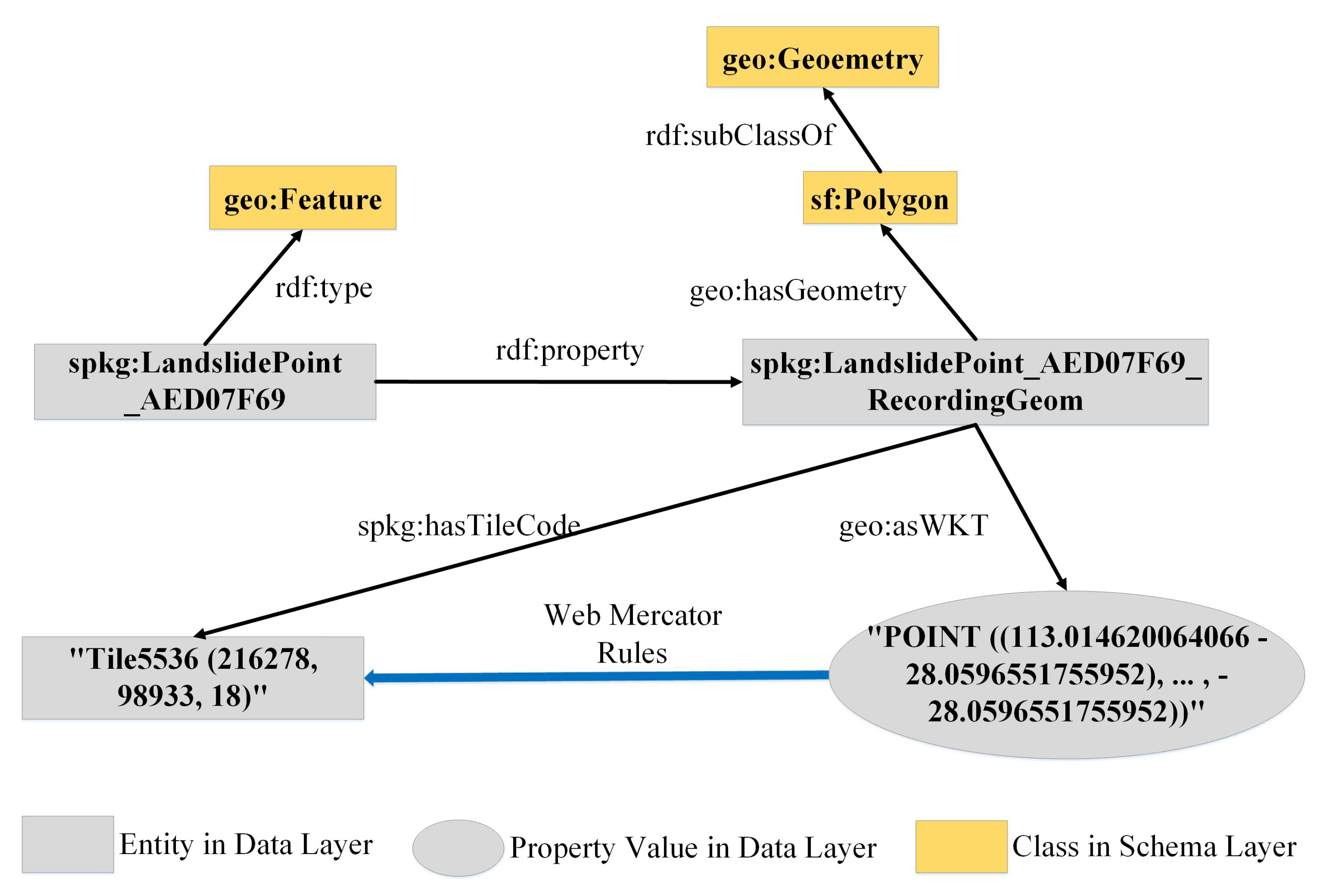
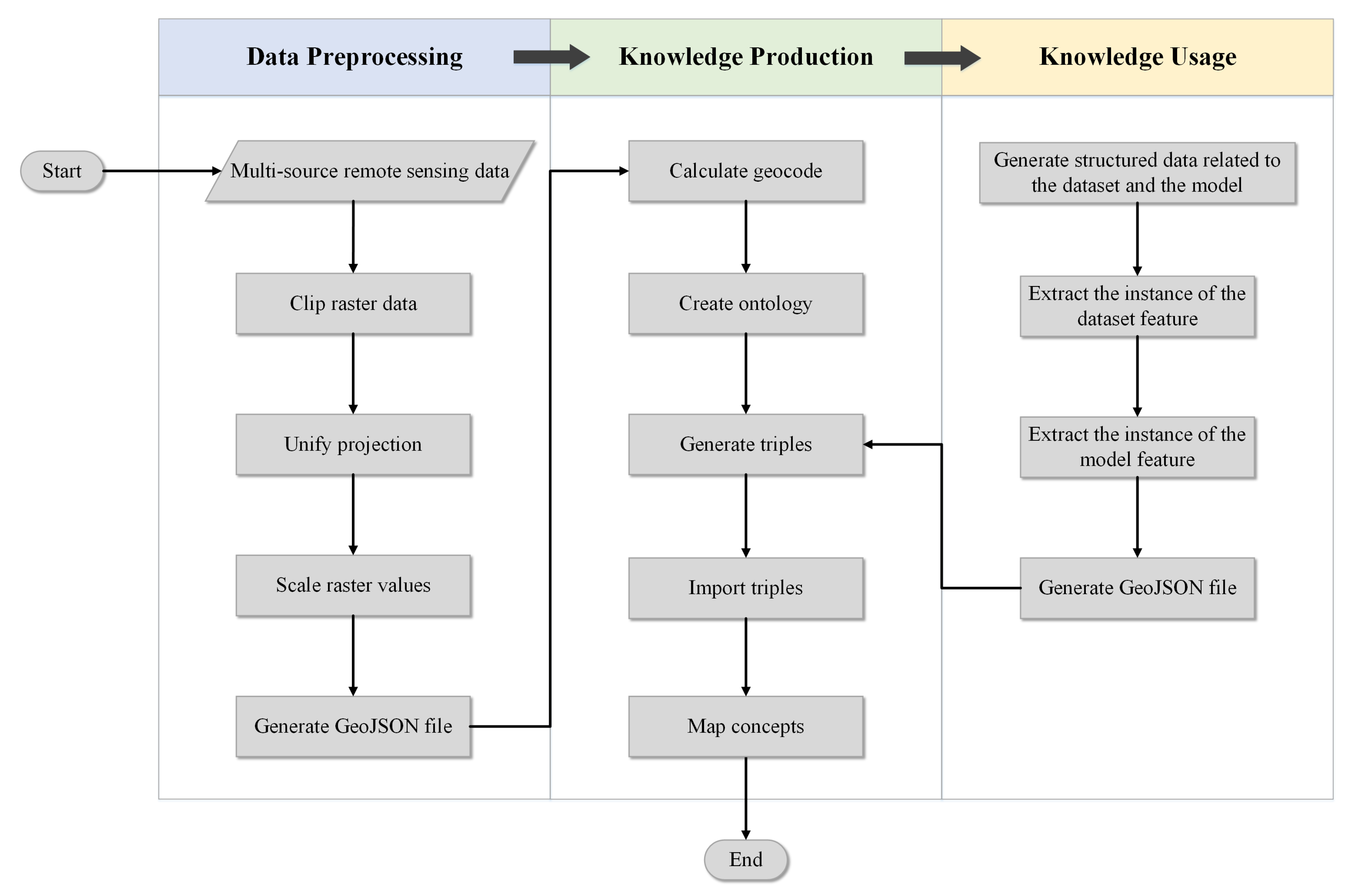
2.3.1. Knowledge Extraction and Storage
- Data preprocessing
- Knowledge production
- Knowledge usage
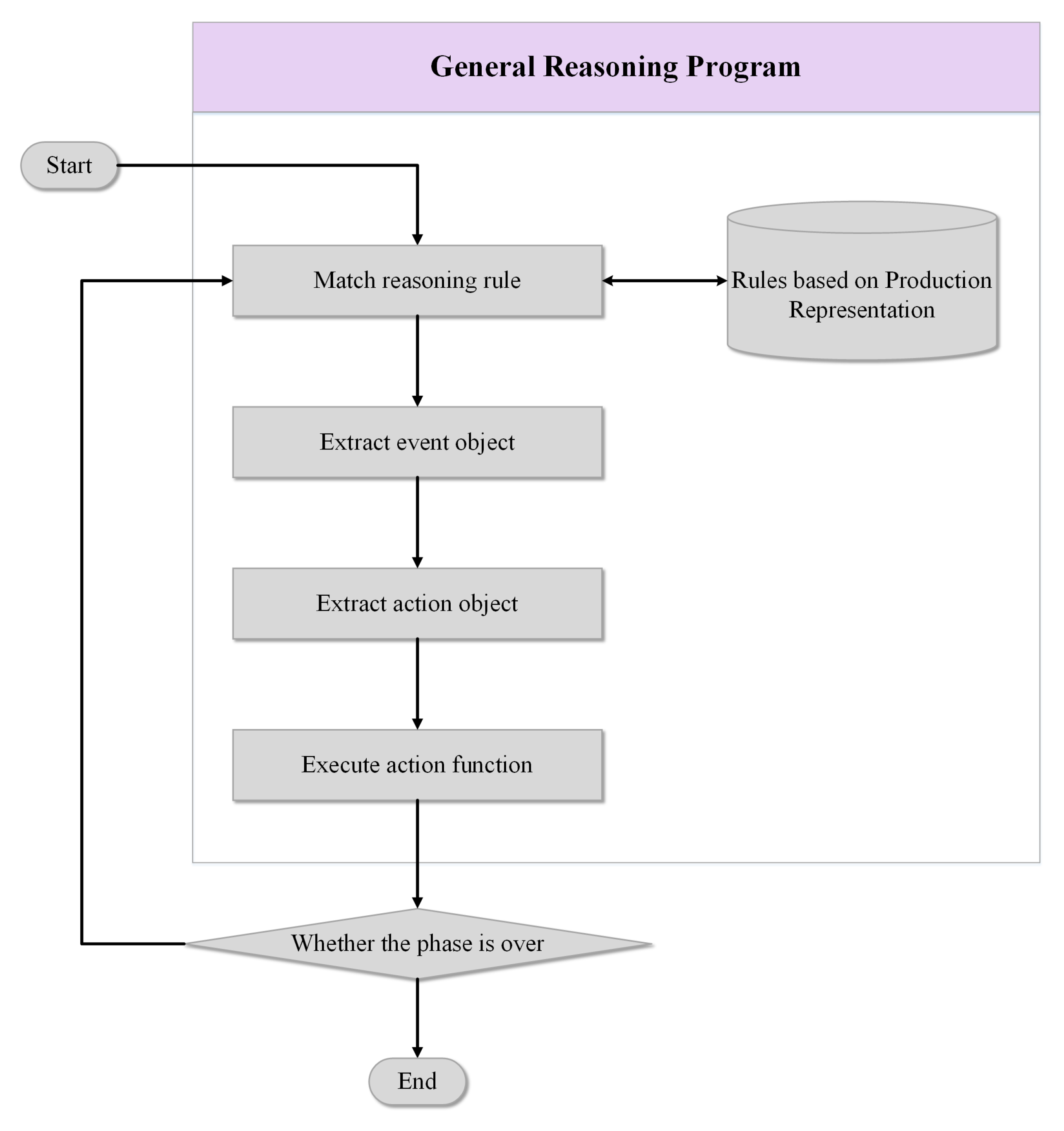
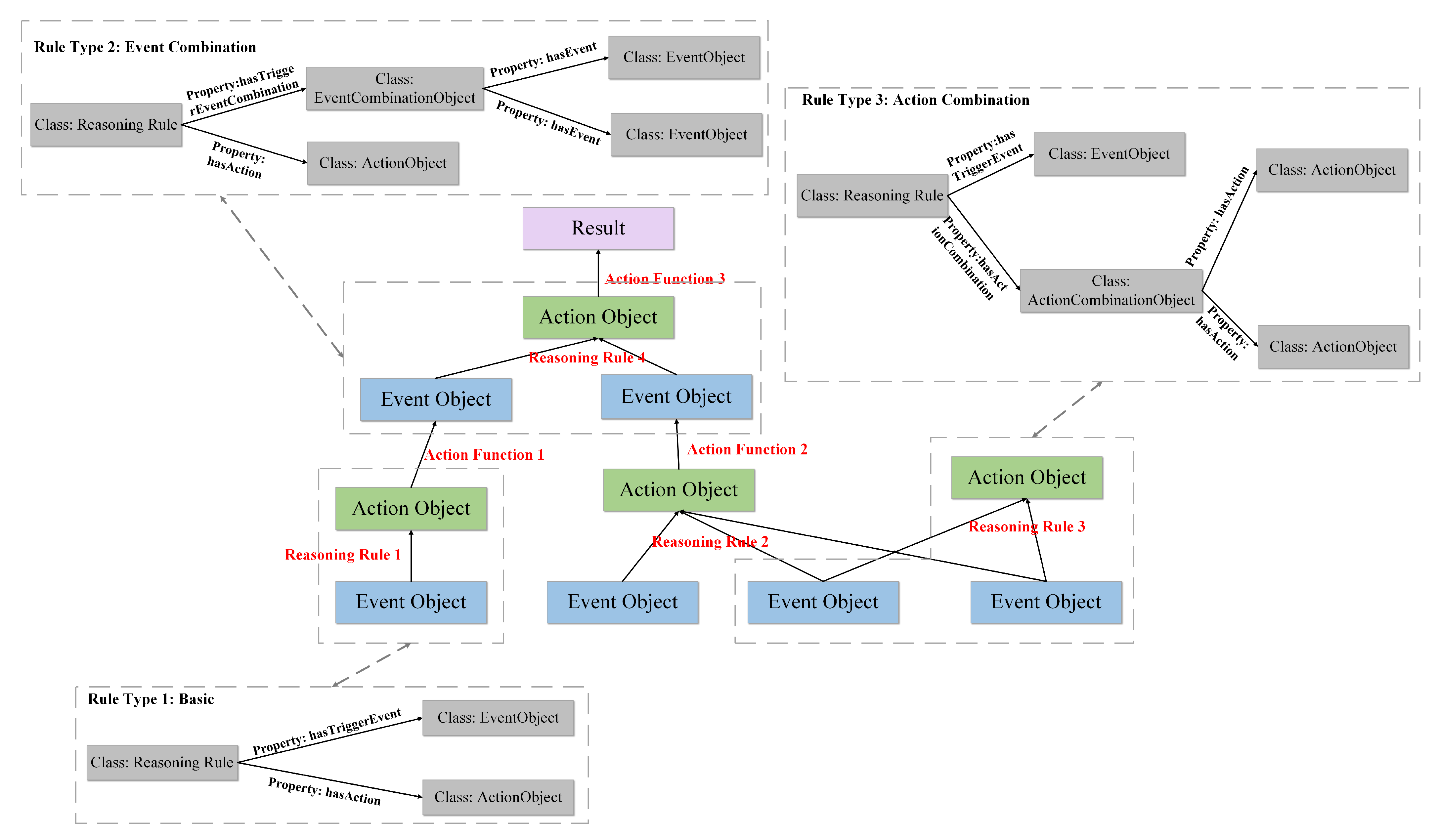
2.3.2. Semantic Reasoning
3. Experiment and Result
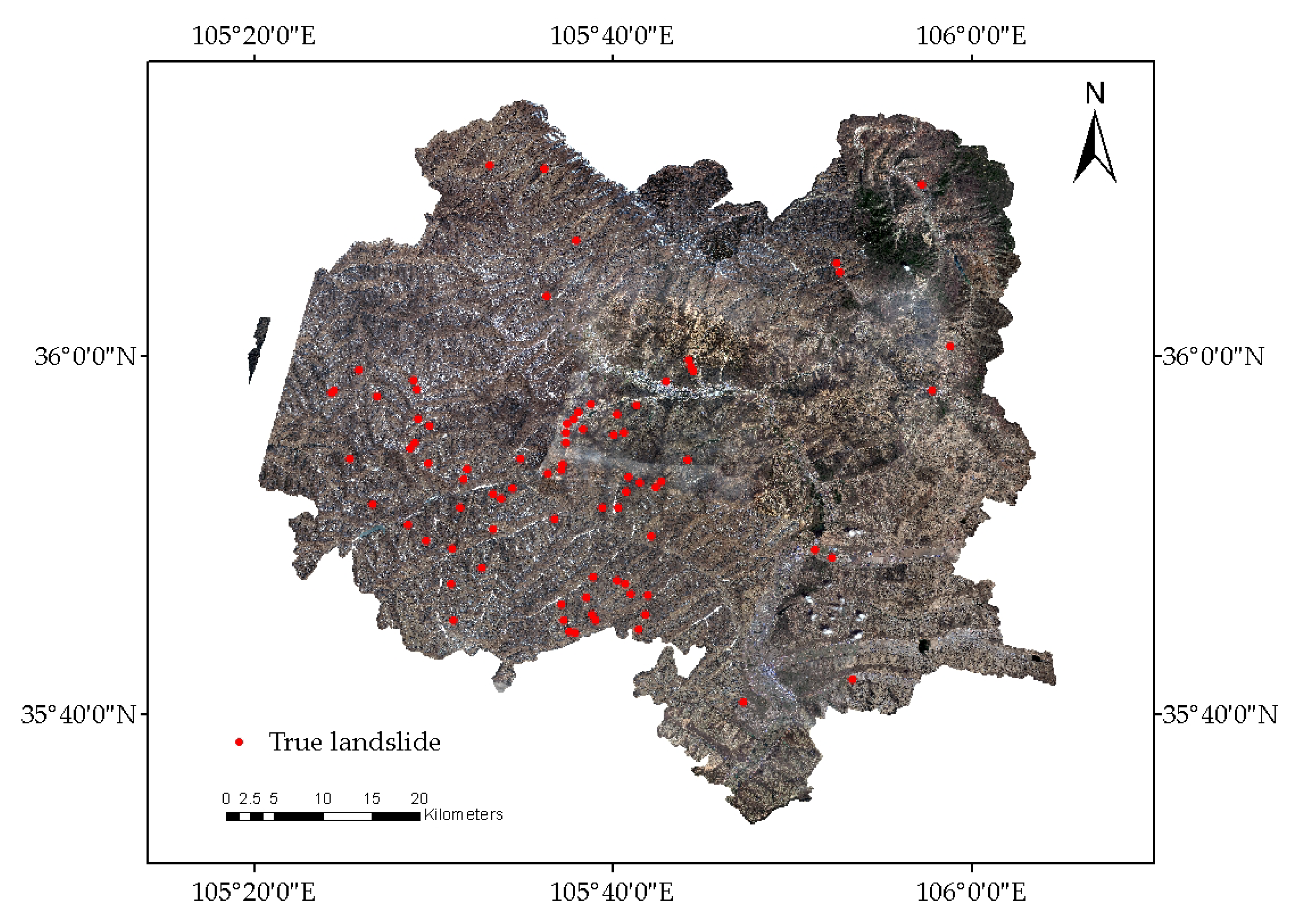
3.1. Study Area
3.2. Machine Learning Model
- Support Vector Machine: The SVM algorithm is a supervised learning binomial classifier based on the risk minimization principle of structured architecture. It can accurately deal with complex nonlinear boundary models.
- Random Forest: The RF algorithm is a combination algorithm based on the classification and regression tree (CART) proposed by Breiman. By randomly selecting k samples from the training set and putting them back into the ground, a decision tree corresponding to the training samples is generated; thus, a random forest composed of k decision trees is generated. According to the prediction result of each tree, the final prediction result is obtained according to the category with the most votes.
- K-Nearest Neighbors: The KNN algorithm is a supervised machine learning classification algorithm. In the K-nearest neighbor method, the K value and distance measure are determined in advance, and the training set and test set are prepared in advance. Through the training set, the feature space is divided into subspaces, and every sample in the training set occupies a part of a space.
- Multigraded Cascade Forest: The GCF algorithm is a supervised ensemble learning method that combines the theory of random forests and a deep neural network. The GCF is composed of a multilevel random forest model, and each level of the random forest model contains many different types of random forests. This multilevel and multidimensional random forest processes the probabilistic eigenvector of the input data, and can effectively enhance the performance of the prediction algorithm for the input data and help to improve the prediction accuracy. Each stage uses the output of the upper stage and the original probability feature vector as its input; that is, it uses the feature information after the upper stage is processed, combined with the original probability feature vector. The new information is processed at this level and passed on to the next level.
3.3. Metrics
3.4. Experimental Results
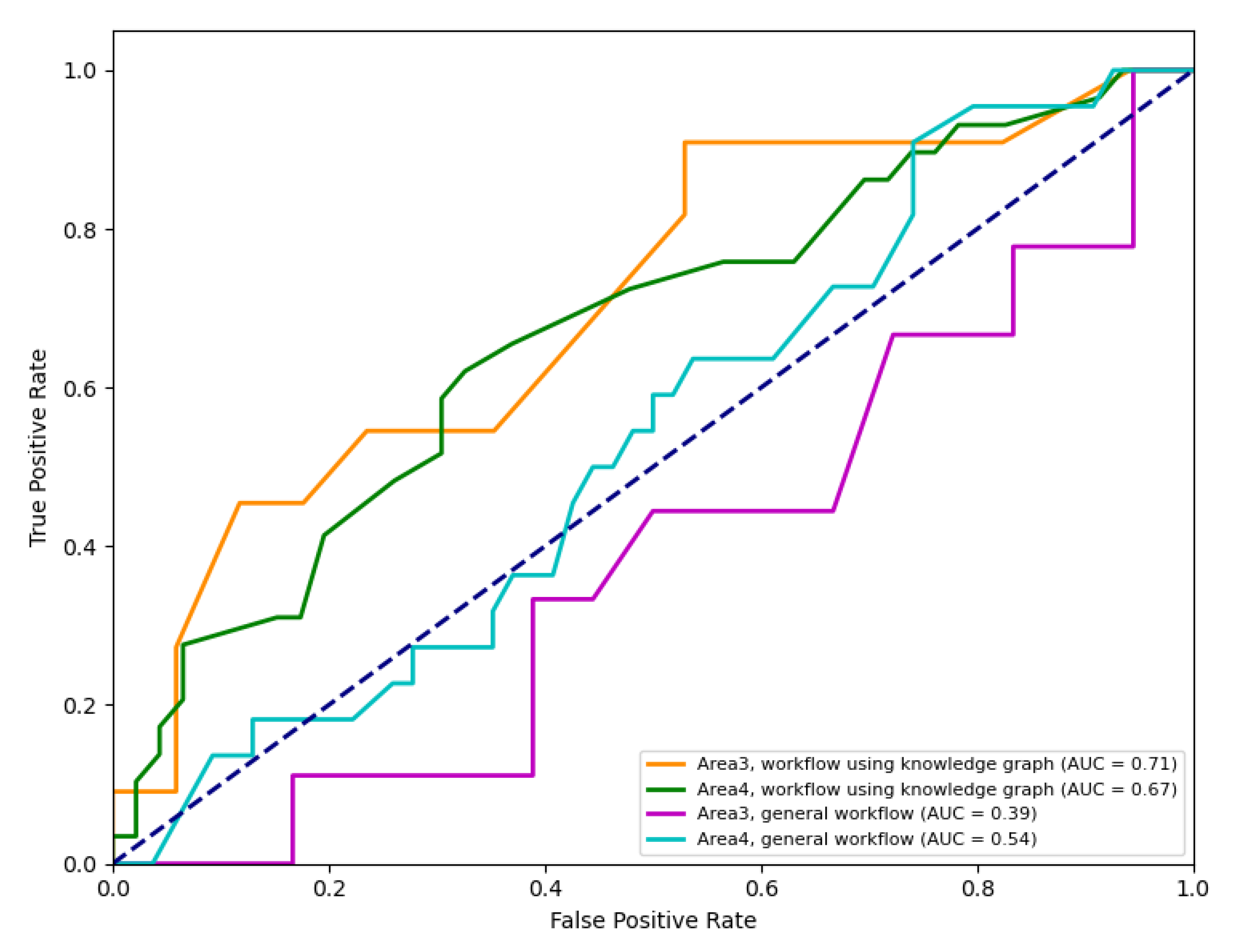
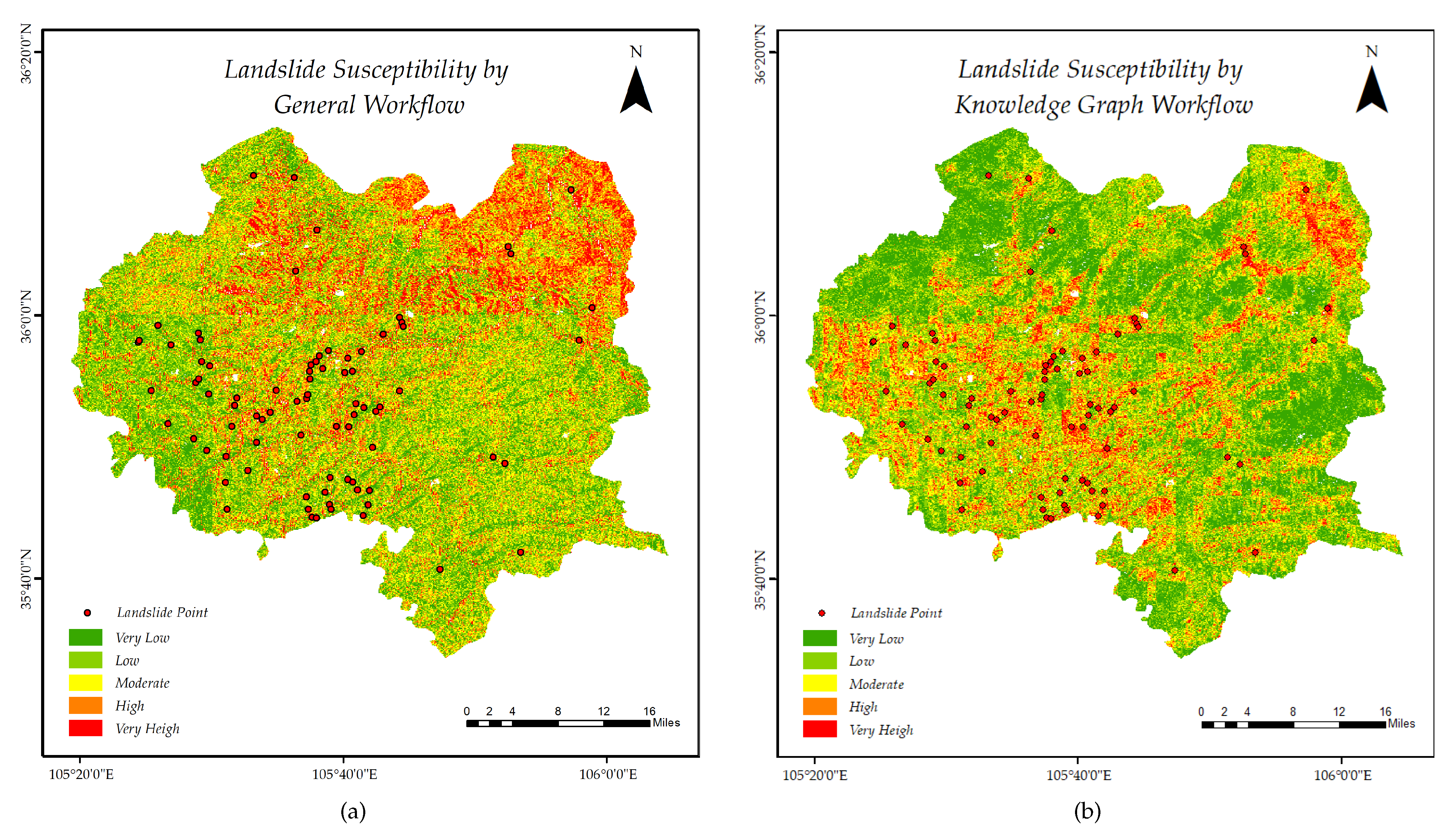
3.4.1. Effectiveness of the Method
3.4.2. Validation in Xiji
4. Discussion
5. Conclusions
- This paper proposes an efficient method for disaster analysis in the field of geohazard management by combining knowledge-driven and data-driven approaches.
- The problem of data-driven methods being over-sensitive to data is alleviated by semantic modeling and knowledge fusion.
- A novel paradigm is defined for the standardized integration of multi-source remote sensing resources, which helps to share and reuse formalized remote sensing resources and demonstrates the potential of spatio-temporal knowledge graphs in the field of remote sensing.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yilmaz, I. Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from Kat landslides (Tokat—Turkey). Comput. Geosci. 2009, 35, 1125–1138. [Google Scholar] [CrossRef]
- Liu, H.; Liu, J.; Chen, J.; Qiu, L. Experimental study on tilting deformation and a new method for landslide prediction with retaining-wall locked segment. Sci. Rep. 2023, 13, 5149. [Google Scholar] [CrossRef] [PubMed]
- Capparelli, G.; Versace, P. Analysis of landslide triggering conditions in the Sarno area using a physically based model. Hydrol. Earth Syst. Sci. 2014, 18, 3225–3237. [Google Scholar] [CrossRef]
- Mandal, B.; Mandal, S. Analytical hierarchy process (AHP) based landslide susceptibility mapping of Lish river basin of eastern Darjeeling Himalaya, India. Adv. Space Res. 2018, 62, 3114–3132. [Google Scholar] [CrossRef]
- Akgun, A.; Dag, S.; Bulut, F. Landslide susceptibility mapping for a landslide-prone area (Findikli, NE of Turkey) by likelihood-frequency ratio and weighted linear combination models. Environ. Geol. 2008, 54, 1127–1143. [Google Scholar] [CrossRef]
- Đurić, U.; Marjanović, M.; Radić, Z.; Abolmasov, B. Machine learning based landslide assessment of the Belgrade metropolitan area: Pixel resolution effects and a cross-scaling concept. Eng. Geol. 2019, 256, 23–38. [Google Scholar] [CrossRef]
- Ma, Z.; Mei, G.; Piccialli, F. Machine learning for landslides prevention: A survey. Neural Comput. Appl. 2021, 33, 10881–10907. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Peng, J.; Wang, J.; Duan, Z.; Hong, H. GIS-based landslide susceptibility modelling: A comparative assessment of kernel logistic regression, Naïve-Bayes tree, and alternating decision tree models. Geomat. Nat. Hazards Risk 2017, 8, 950–973. [Google Scholar] [CrossRef]
- Tian, Y.; Xu, C.; Hong, H.; Zhou, Q.; Wang, D. Mapping earthquake-triggered landslide susceptibility by use of artificial neural network (ANN) models: An example of the 2013 Minxian (China) Mw 5.9 event. Geomat. Nat. Hazards Risk 2019, 10, 1–25. [Google Scholar] [CrossRef]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženílek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.J.; Thai Pham, B.; Dou, J.; Talebpour Asl, D.; Bin Ahmad, B.; et al. New ensemble models for shallow landslide susceptibility modeling in a semi-arid watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Dou, J.; Singh, S.K.; Trinh, P.T.; Tran, H.T.; Le, T.M.; Van Phong, T.; Khoi, D.K.; Shirzadi, A.; et al. A novel hybrid approach of landslide susceptibility modelling using rotation forest ensemble and different base classifiers. Geocarto Int. 2020, 35, 1267–1292. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.W.; Han, Z.; Pham, B.T. Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 2020, 17, 641–658. [Google Scholar] [CrossRef]
- Hong, H.; Liu, J.; Bui, D.T.; Pradhan, B.; Acharya, T.D.; Pham, B.T.; Zhu, A.X.; Chen, W.; Ahmad, B.B. Landslide susceptibility mapping using J48 Decision Tree with AdaBoost, Bagging and Rotation Forest ensembles in the Guangchang area (China). Catena 2018, 163, 399–413. [Google Scholar] [CrossRef]
- Al-Najjar, H.A.; Pradhan, B.; Sarkar, R.; Beydoun, G.; Alamri, A. A new integrated approach for landslide data balancing and spatial prediction based on generative adversarial networks (GAN). Remote Sens. 2021, 13, 4011. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, L.; Hu, H.; Pirasteh, S.; Li, H.; Xie, X. Unsupervised feature learning to improve transferability of landslide susceptibility representations. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3917–3930. [Google Scholar] [CrossRef]
- Ai, X.; Sun, B.; Chen, X. Construction of small sample seismic landslide susceptibility evaluation model based on Transfer Learning: A case study of Jiuzhaigou earthquake. Bull. Eng. Geol. Environ. 2022, 81, 116. [Google Scholar] [CrossRef]
- Gutierrez, C.; Sequeda, J.F. Knowledge graphs. Commun. ACM 2021, 64, 96–104. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Singhal, A. Introducing the knowledge graph: Things, not strings. Off. Google Blog 2012, 5, 16. [Google Scholar]
- Nayyeri, M.; Vahdati, S.; Khan, M.T.; Alam, M.M.; Wenige, L.; Behrend, A.; Lehmann, J. Dihedron Algebraic Embeddings for Spatio-Temporal Knowledge Graph Completion. In Proceedings of the European Semantic Web Conference, Crete, Greece, 29 May–2 June 2022; Springer: Cham, Switzerland, 2022; pp. 253–269. [Google Scholar]
- Ge, X.; Yang, Y.; Peng, L.; Chen, L.; Li, W.; Zhang, W.; Chen, J. Spatio-temporal knowledge graph based forest fire prediction with multi source heterogeneous data. Remote Sens. 2022, 14, 3496. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Ye, P.; Du, M.; Lu, Y.; Xue, H. Geographic knowledge graph (GeoKG): A formalized geographic knowledge representation. ISPRS Int. J. Geo-Inf. 2019, 8, 184. [Google Scholar] [CrossRef]
- Yan, B.; Janowicz, K.; Mai, G.; Gao, S. From itdl to place2vec: Reasoning about place type similarity and relatedness by learning embeddings from augmented spatial contexts. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; pp. 1–10. [Google Scholar]
- Battle, R.; Kolas, D. Enabling the geospatial semantic web with parliament and geosparql. Semant. Web 2012, 3, 355–370. [Google Scholar] [CrossRef]
- Car, N.J.; Homburg, T. GeoSPARQL 1.1: Motivations, Details and Applications of the Decadal Update to the Most Important Geospatial LOD Standard. ISPRS Int. J. Geo-Inf. 2022, 11, 117. [Google Scholar] [CrossRef]
- Battersby, S.E.; Finn, M.P.; Usery, E.L.; Yamamoto, K.H. Implications of web Mercator and its use in online mapping. Cartogr. Int. J. Geogr. Inf. Geovis. 2014, 49, 85–101. [Google Scholar] [CrossRef]
- Time Ontology in OWL. Available online: https://www.w3.org/TR/owl-time/ (accessed on 8 August 2022).
- Allen, J.F.; Ferguson, G. Actions and events in interval temporal logic. J. Log. Comput. 1994, 4, 531–579. [Google Scholar] [CrossRef]
- Westra, E. Python Geospatial Development; Packt Publishing: Birmingham, UK, 2010. [Google Scholar]
- Tudorache, T.; Noy, N.F.; Tu, S.; Musen, M.A. Supporting collaborative ontology development in Protégé. In Proceedings of the International Semantic Web Conference, Karlsruhe, Germany, 26–30 October 2008; pp. 17–32. [Google Scholar]
- Virtuoso Universal Server. Available online: https://virtuoso.openlinksw.com (accessed on 8 August 2022).
- Kirschbaum, D.; Stanley, T.; Zhou, Y. Spatial and temporal analysis of a global landslide catalog. Geomorphology 2015, 249, 4–15. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]
- LP DAAC—Homepag. Available online: https://lpdaac.usgs.gov (accessed on 8 August 2022).
- Chinese Academy of Sciences Resource and Environmental Science Data Center. Available online: http://www.resdc.cn (accessed on 8 August 2022).
- Global Lithological Map Database v1.0 (Gridded to 0.5° Spatial Resolution). Available online: https://doi.pangaea.de/10.1594/PANGAEA.788537 (accessed on 8 August 2022).
- Panagos, P.; Van Liedekerke, M.; Borrelli, P.; Köninger, J.; Ballabio, C.; Orgiazzi, A.; Lugato, E.; Liakos, L.; Hervas, J.; Jones, A.; et al. European Soil Data Centre 2.0: Soil data and knowledge in support of the EU policies. Eur. J. Soil Sci. 2022, 73, e13315. [Google Scholar] [CrossRef]
- Meybeck, M.; Green, P.; Vörösmarty, C. A new typology for mountains and other relief classes. Mt. Res. Dev. 2001, 21, 34–45. [Google Scholar] [CrossRef]
- Iwahashi, J.; Pike, R.J. Automated classifications of topography from DEMs by an unsupervised nested-means algorithm and a three-part geometric signature. Geomorphology 2007, 86, 409–440. [Google Scholar] [CrossRef]
- Yang, J.; Huang, X. The 30 m annual land cover dataset and its dynamics in China from 1990 to 2019. Earth Syst. Sci. Data 2021, 13, 3907–3925. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Feng, J. Deep Forest: Towards An Alternative to Deep Neural Networks. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3553–3559. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Source | Spatial Resolution | Temporal Resolution | Acquisition Method or Sensor Used |
|---|---|---|---|---|
| Landslide | NASA Global Landslide Catalog [33] | Nationwide vector data | Acquired 1915–2021 | Crowdsourcing |
| Terrain | Shuttle Radar Topography Mission DEM [35] | 30 m × 30 m | Acquired 11–22 February 2000 | STS Endeavour OV-105, SIR-C/X-SAR |
| Precipitation | Annual spatial interpolation dataset of Chinese meteorological elements [36] | 1 km × 1 km | Update annual | Multi-element weather station |
| Lithology | Global Lithological Map [37] | 0.5° × 0.5°; Rasterized at 250 m resolution | Released 2014 | Assembled from existing regional geological maps |
| Landform | Global Landform classification from ESDAC [38] | 500 m × 500 m | Released 2008 | Applied two algorithms [39,40] on global DEM datasets |
| Land Cover | Landsat-derived annual land cover product of China [41] | 30 m × 30 m | Update annual | Landsat |
| Road | OpenStreetMap [42] | Nationwide vector data | Update daily | Crowdsourcing |
| Normalized Difference Vegetation Index (NDVI) | China Annual NDVI Spatial Distribution Dataset [36] | 1 km × 1 km | Update annual | SPOT/VEGETATION |
| Area Number | Model Number | Jaccard Index | Precision | Recall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | RF | KNN | GCF | SVM | RF | KNN | GCF | SVM | RF | KNN | GCF | |||
| 1 | 1 | - | 0.61 | 0.66 | 0.63 | 0.75 | 0.60 | 0.60 | 0.63 | 0.60 | 0.60 | 0.63 | 0.63 | 0.67 |
| 2 | 2 | - | 0.66 | 0.73 | 0.63 | 0.78 | 0.60 | 0.62 | 0.61 | 0.60 | 0.63 | 0.67 | 0.62 | 0.68 |
| 3 | 3 | - | 0.34 | 0.33 | 0.46 | 0.38 | 0.34 | 0.42 | 0.40 | 0.45 | 0.34 | 0.38 | 0.43 | 0.41 |
| 4 | 4 | - | 0.52 | 0.52 | 0.48 | 0.52 | 0.50 | 0.52 | 0.42 | 0.53 | 0.51 | 0.52 | 0.45 | 0.52 |
| 3 | 1 | 0.2 | 0.52 | 0.54 | 0.78 | 0.61 | 0.52 | 0.55 | 0.53 | 0.57 | 0.52 | 0.54 | 0.63 | 0.59 |
| 3 | 2 | 0.6 | 0.86 | 0.67 | 0.58 | 0.85 | 0.62 | 0.62 | 0.60 | 0.60 | 0.72 | 0.64 | 0.59 | 0.70 |
| 4 | 1 | 0.6 | 0.61 | 0.60 | 0.81 | 0.72 | 0.56 | 0.61 | 0.57 | 0.60 | 0.58 | 0.60 | 0.67 | 0.65 |
| 4 | 2 | 0.5 | 0.58 | 0.63 | 0.58 | 0.67 | 0.58 | 0.60 | 0.58 | 0.61 | 0.58 | 0.61 | 0.58 | 0.64 |
| Sample Scarcity Area Number | of General Workflow | of Workflow Using Knowledge Graph |
|---|---|---|
| 3 | 0.43 (Sample size too small to fit) | 0.72 |
| 4 | 0.52 | 0.67 |
| Workflow | Tools | Manual Steps | Calculation Time |
|---|---|---|---|
| General workflow | ArcGIS, Anaconda platform, Scikit-Learn package |
| 17.5 accumulated hours |
| Workflow with additional knowledge graph steps | Virtuoso database, Anaconda platform, Scikit-Learn package |
| 1.2 hours |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Ge, X.; Yang, L.; Li, W.; Peng, L. An Improved Multi-Source Data-Driven Landslide Prediction Method Based on Spatio-Temporal Knowledge Graph. Remote Sens. 2023, 15, 2126. https://doi.org/10.3390/rs15082126
Chen L, Ge X, Yang L, Li W, Peng L. An Improved Multi-Source Data-Driven Landslide Prediction Method Based on Spatio-Temporal Knowledge Graph. Remote Sensing. 2023; 15(8):2126. https://doi.org/10.3390/rs15082126
Chicago/Turabian StyleChen, Luanjie, Xingtong Ge, Lina Yang, Weichao Li, and Ling Peng. 2023. "An Improved Multi-Source Data-Driven Landslide Prediction Method Based on Spatio-Temporal Knowledge Graph" Remote Sensing 15, no. 8: 2126. https://doi.org/10.3390/rs15082126
APA StyleChen, L., Ge, X., Yang, L., Li, W., & Peng, L. (2023). An Improved Multi-Source Data-Driven Landslide Prediction Method Based on Spatio-Temporal Knowledge Graph. Remote Sensing, 15(8), 2126. https://doi.org/10.3390/rs15082126