

P2FEViT: Plug-and-Play CNN Feature Embedded Hybrid Vision Transformer for Remote Sensing Image Classification
 ,
, 
Abstract
1. Introduction
- (1)
- A new hybrid classification architecture according to CNN and ViT is proposed for RSIC, which can be applied to complicated remote sensing scene classification and fine-grained target recognition tasks.
- (2)
- To address the limitations of existing methods in terms of feature representation, a novel approach embedding plug-and-play CNN features to ViT model is proposed, which can make full use of the local feature description capability of CNN and the representation ability of ViT for global context information to achieve better classification performance, as well as to reduce the high dependence of ViT models on large-scale pre-training data volume.
- (3)
- Considering that a large number of datasets are constructed based on the remote sensing scene classification task and relatively few datasets for the fine-grained target recognition task, a new fine-grained target recognition dataset is constructed in this paper, which contains 50 categories of aircraft targets aiming to facilitate scholars to carry out research on fine-grained target recognition.
2. Related Work
2.1. Review of Remote Sensing Image Classification Methods
2.2. Remote Sensing Image Classification Benchmarks
3. Materials and Methods
3.1. Analysis on the CNN and ViT
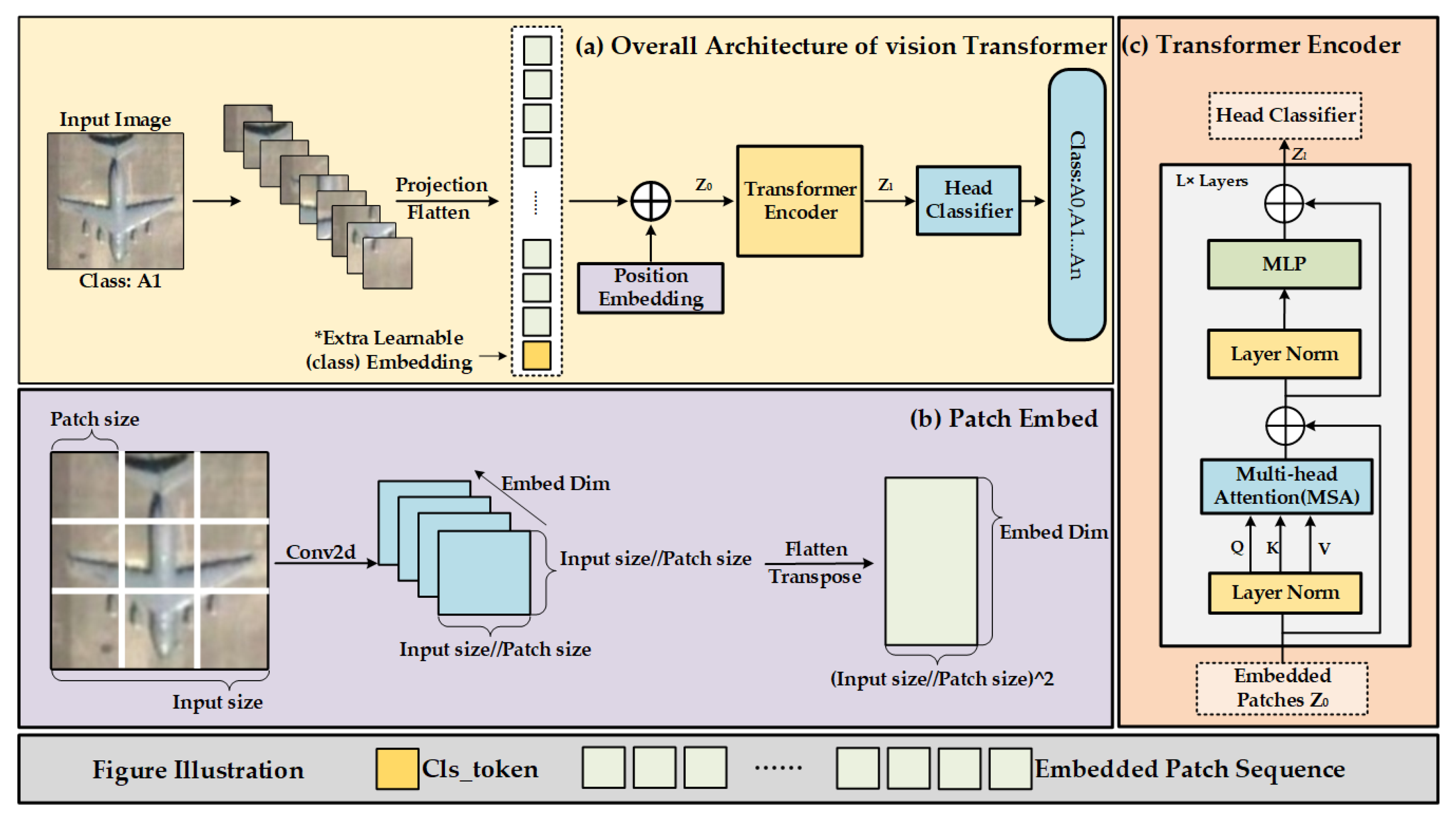
3.2. Review of Vision Transformer
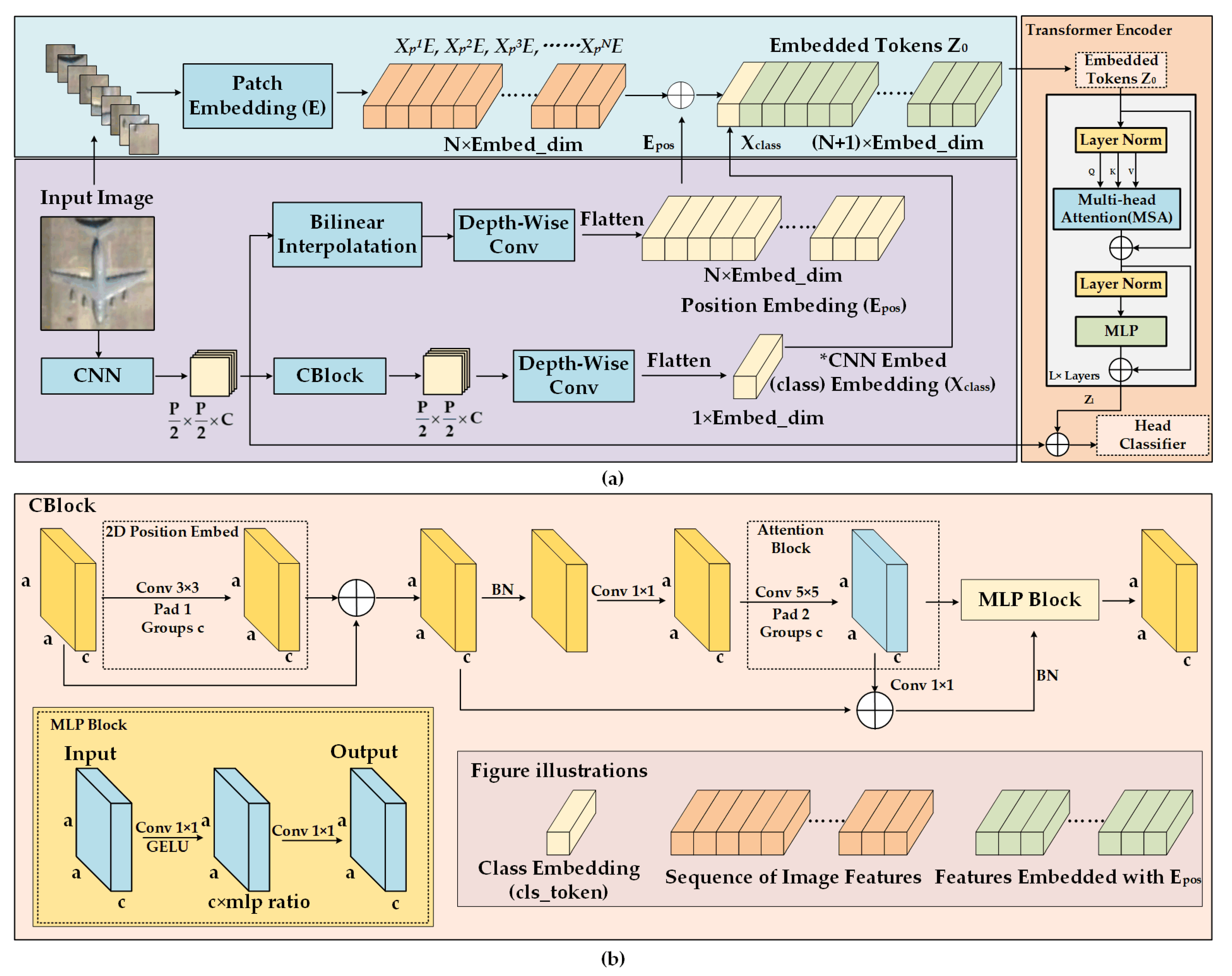
3.3. Plug-and-Play CNN Feature Embedded Hybrid Vision Transformer
3.4. Head Classifier
4. Experiments and Analysis
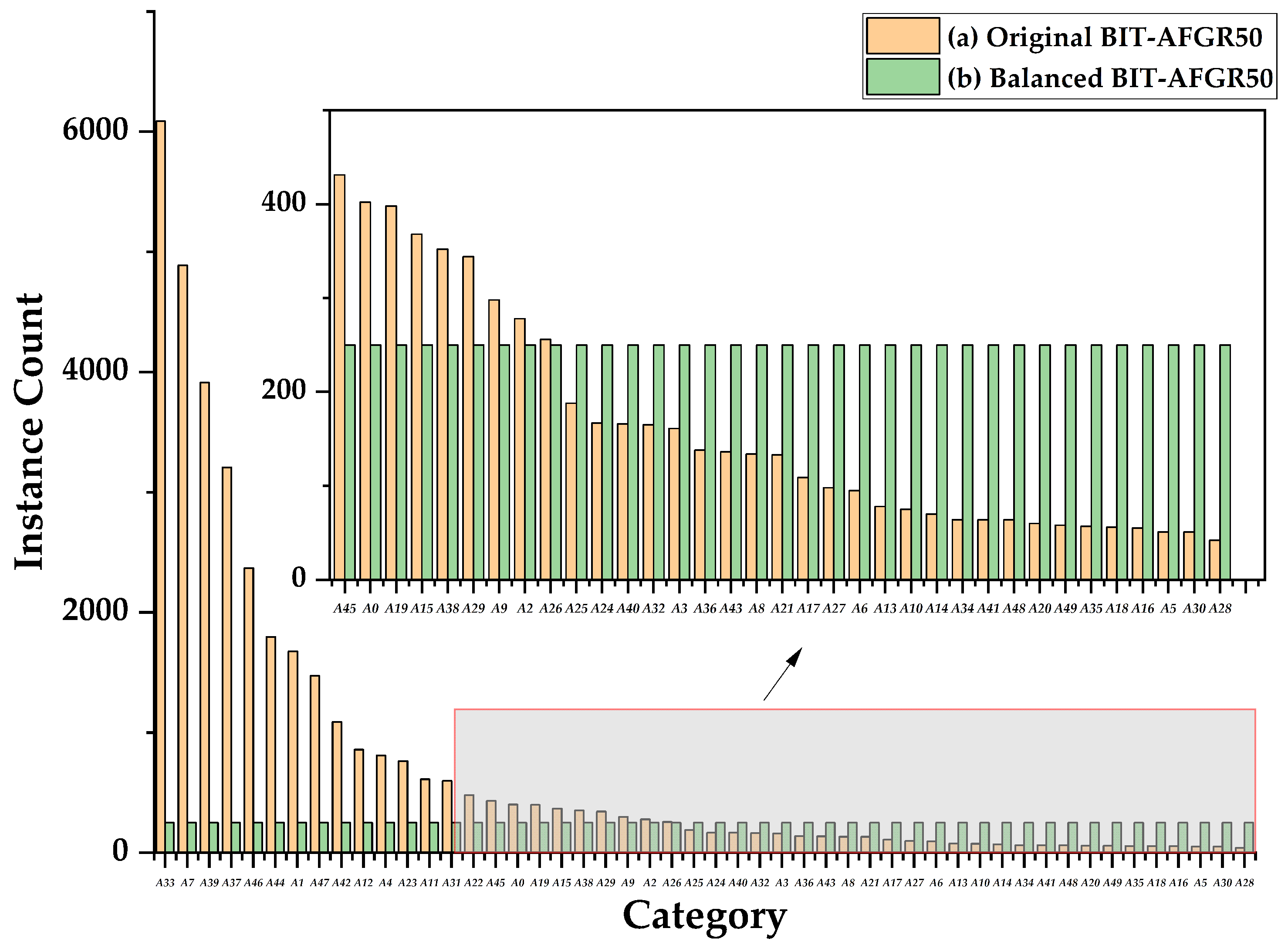
4.1. Establishment of BIT-AFGR50
4.2. Datasets
4.3. Experiment Setup
4.4. Evaluation Metrics
- (1)
- OA: overall accuracy (OA) is defined as the ratio of correctly classified and total samples. It can be calculated as follows:where N represents the total number of image samples in the dataset. f(i) refers to the classification accuracy of the ith sample. If correctly classified, then f(i) equals 1 and vice versa 0. In addition, the OA on each remote sensing classification dataset is the average of five repeated runs.
- (2)
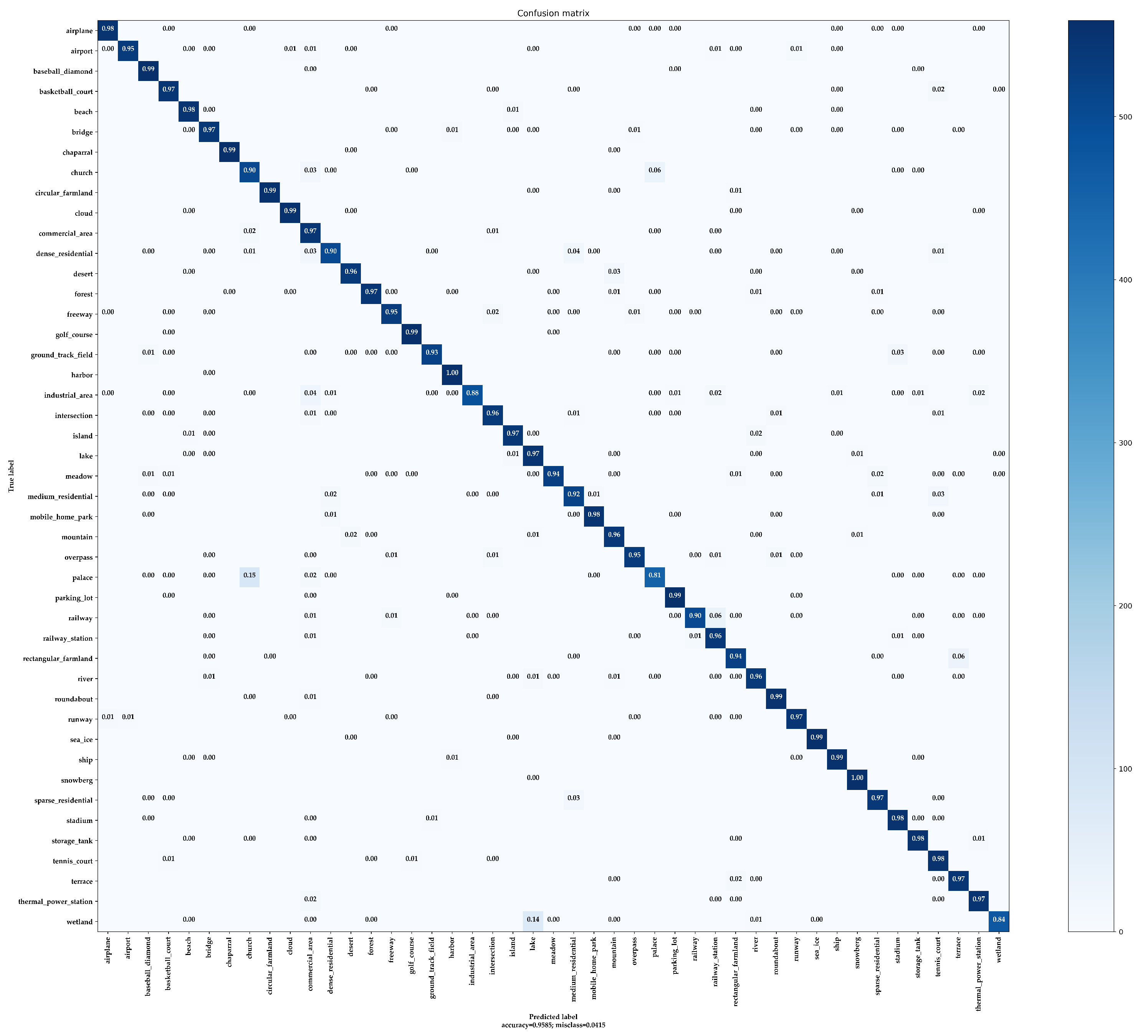
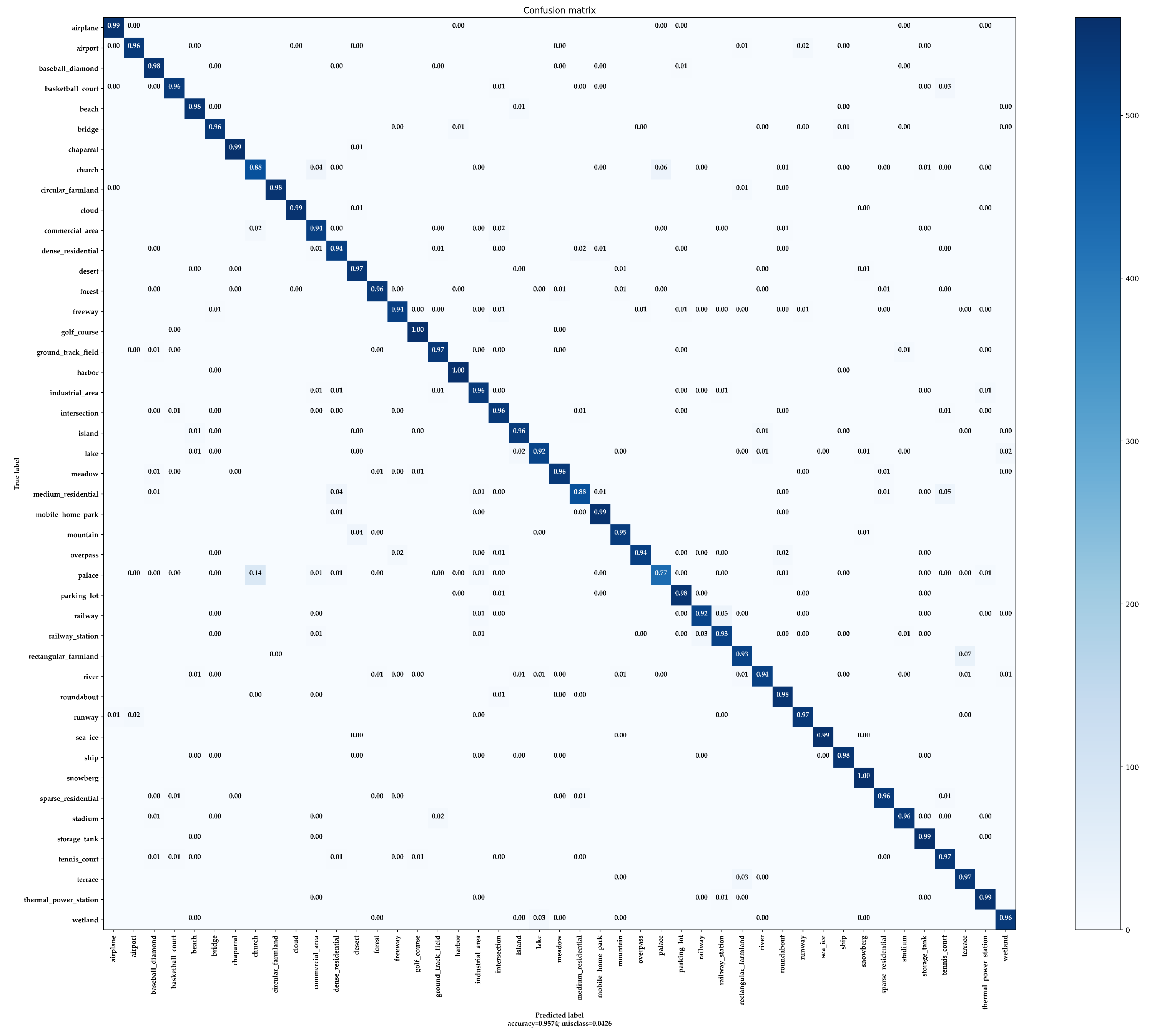
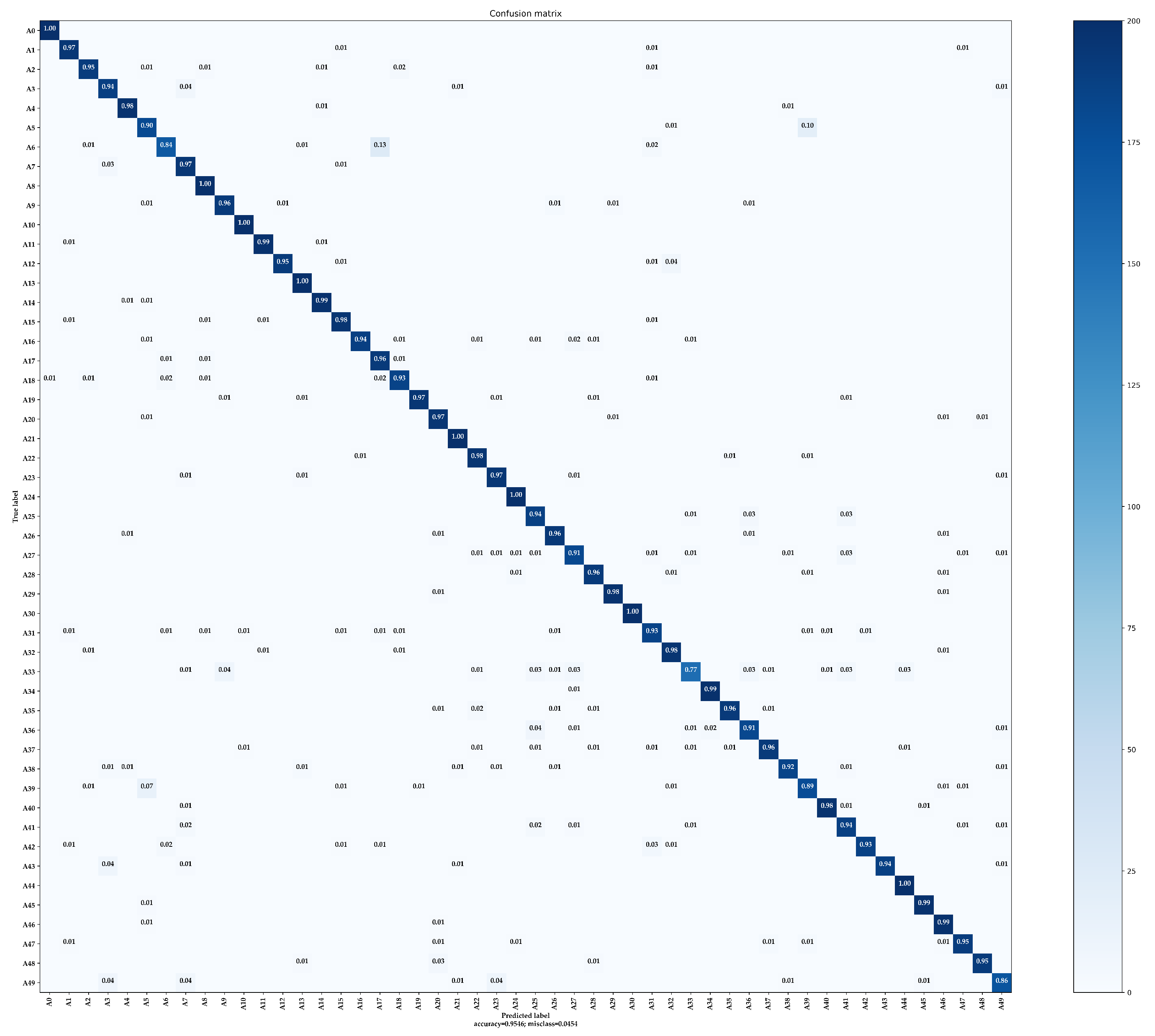
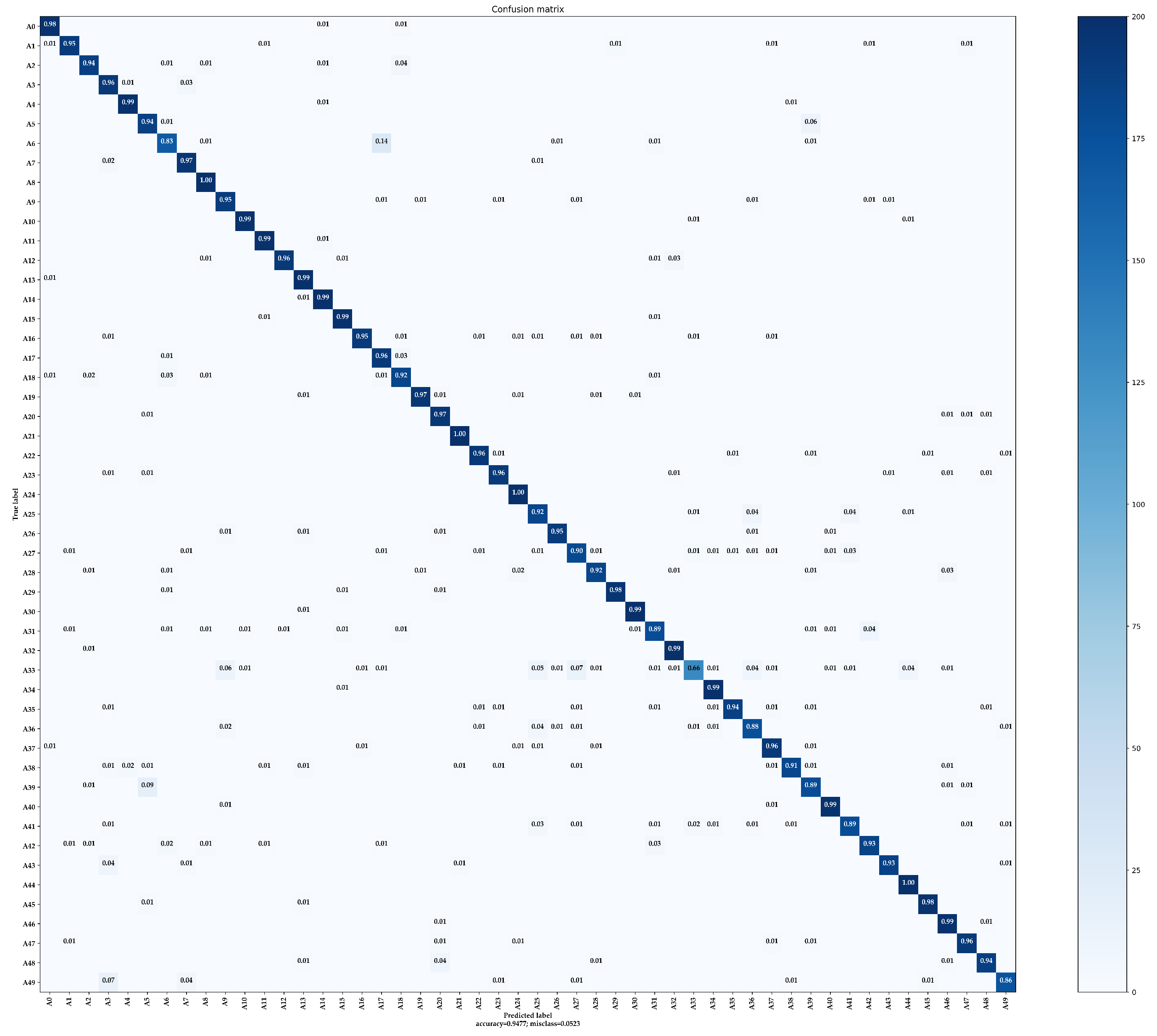
- CM: The confusion matrix is a standard format for image classification accuracy evaluation and consists of a matrix with N rows and N columns, where N denotes the total number of categories. The columns in the confusion matrix represent the predicted categories, and the total number of each column represents the total number of images predicted for that category. The rows indicate the ground truth attribution category, and the total number of each row indicates the total number of images belonging to that category in the test set. The confusion matrix is mainly used to visually compare the classification prediction results with the ground truth values.
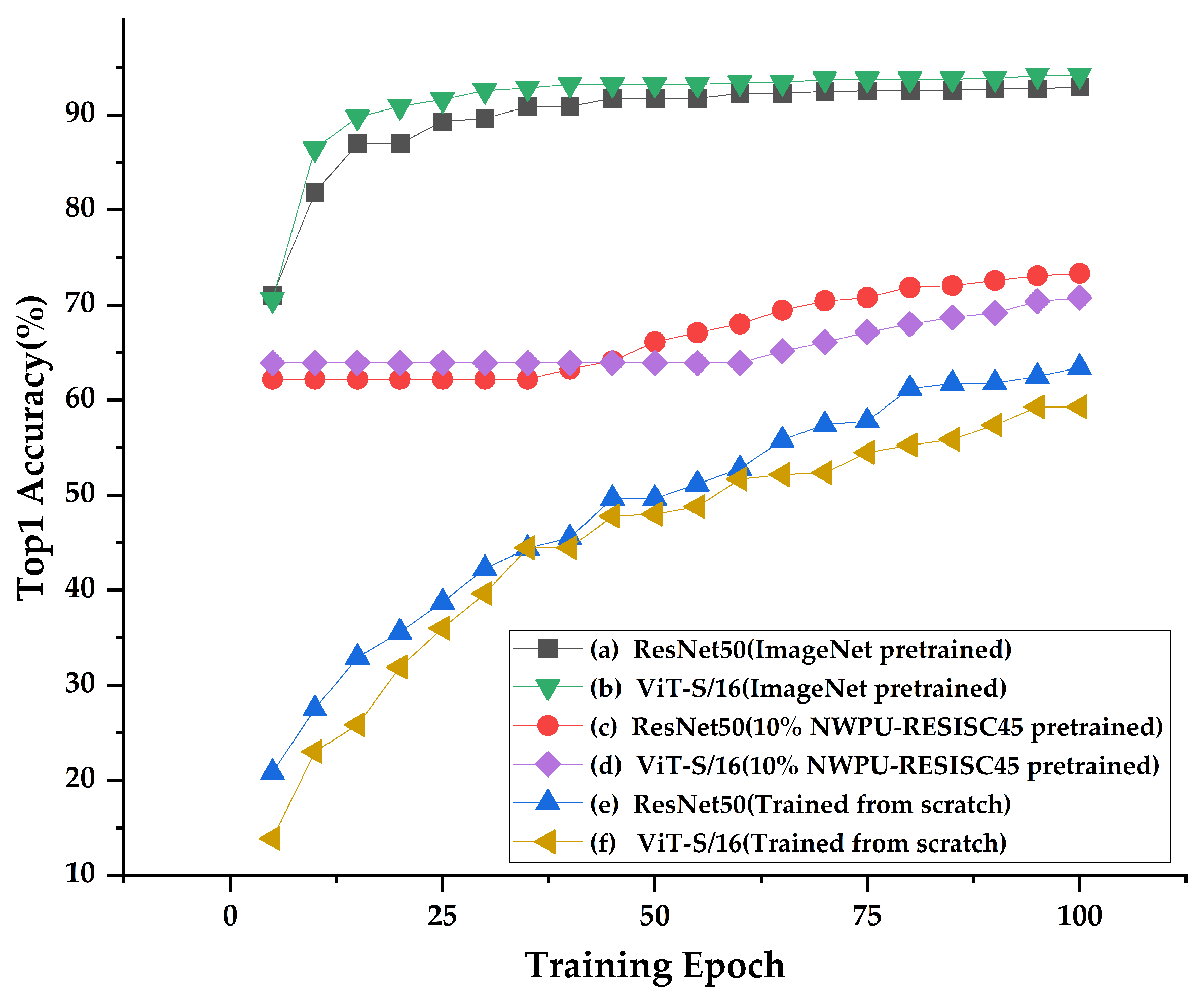
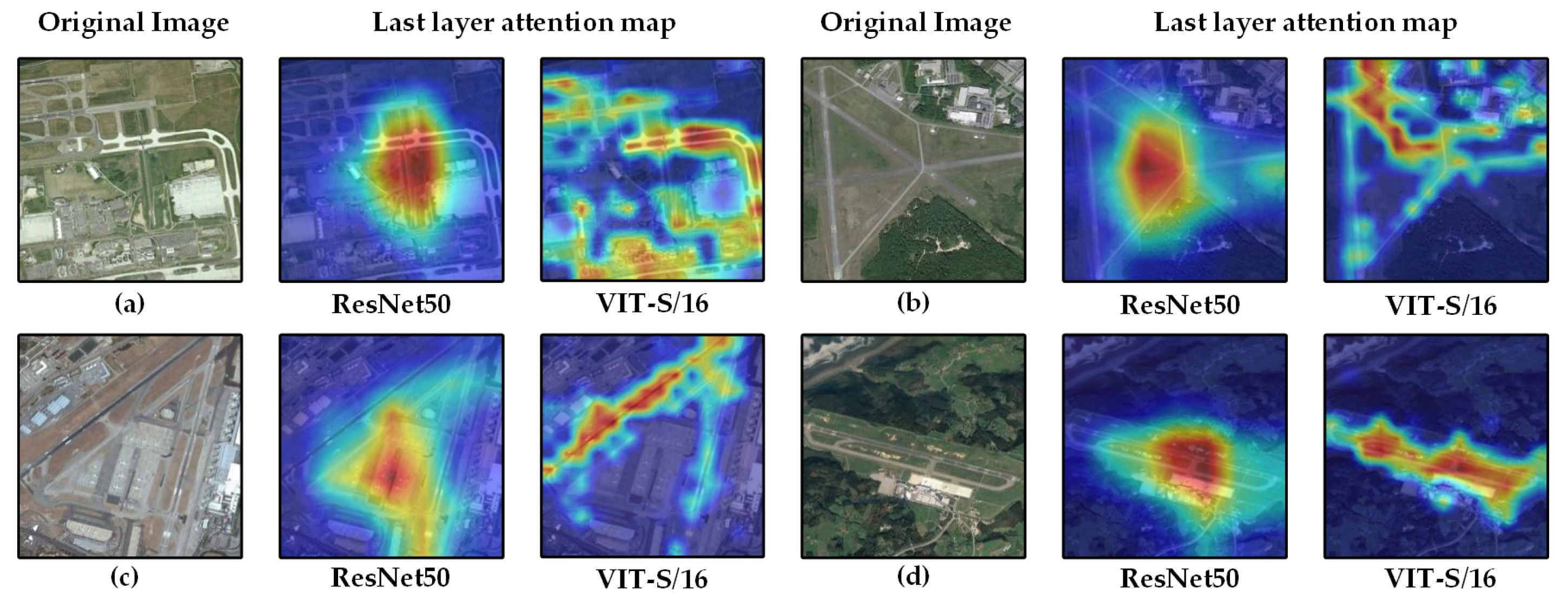
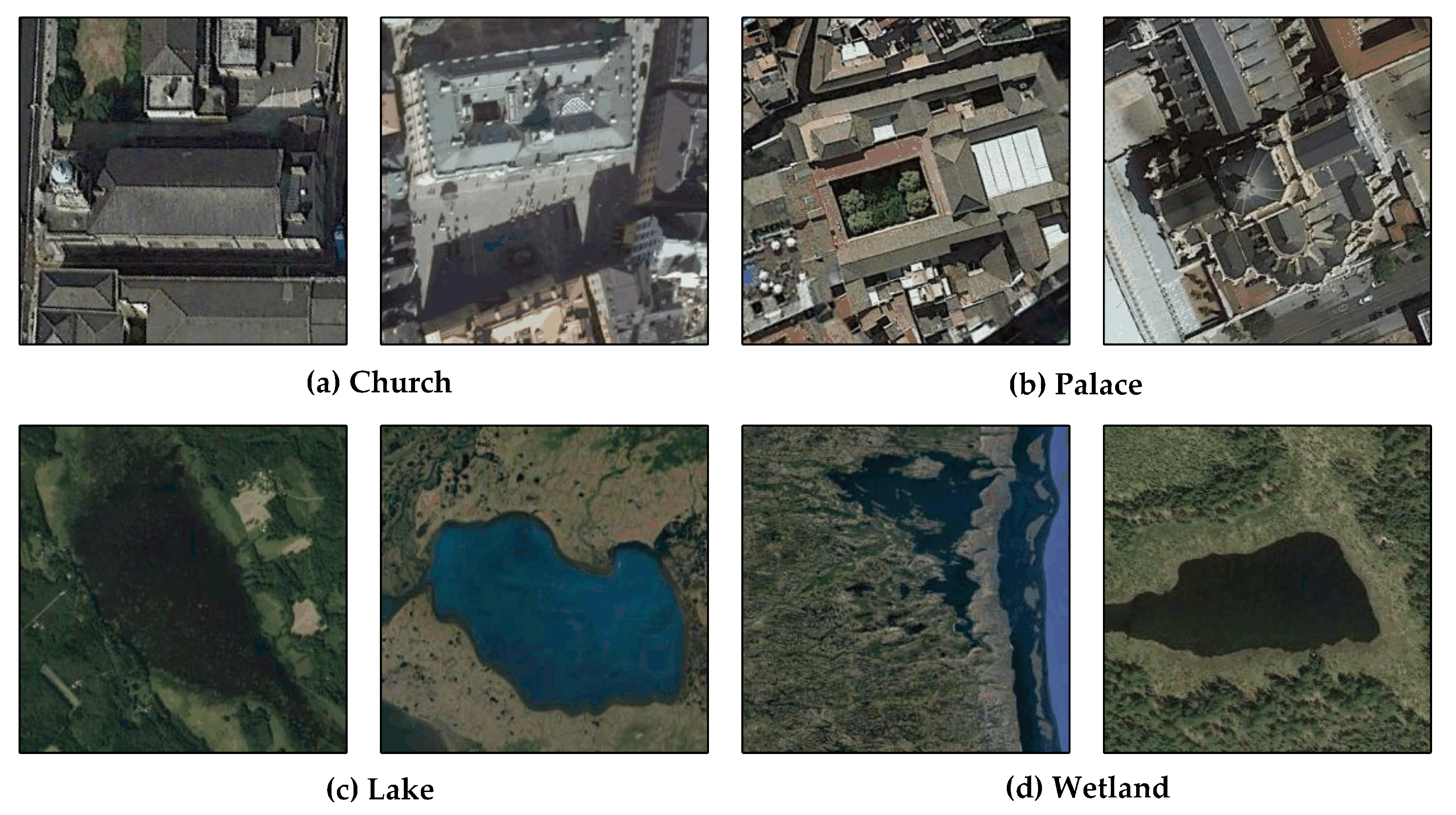
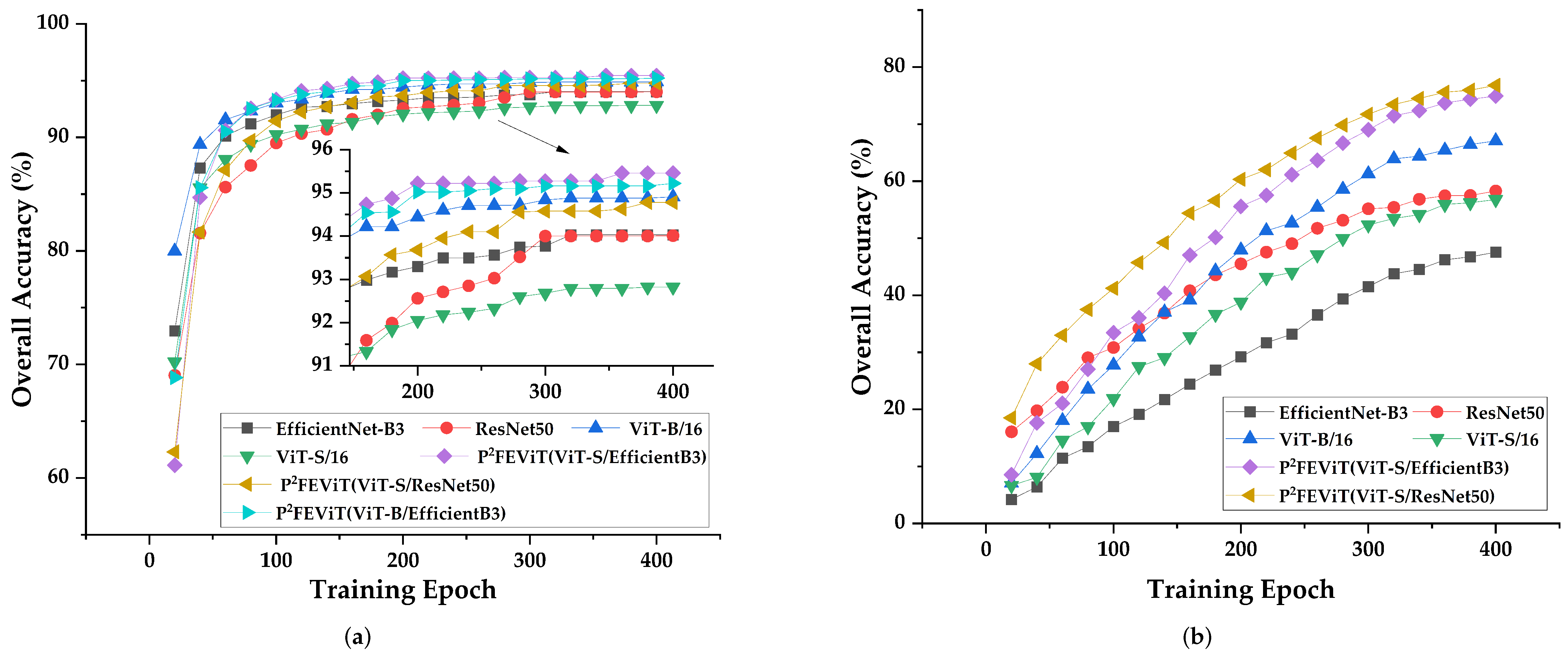
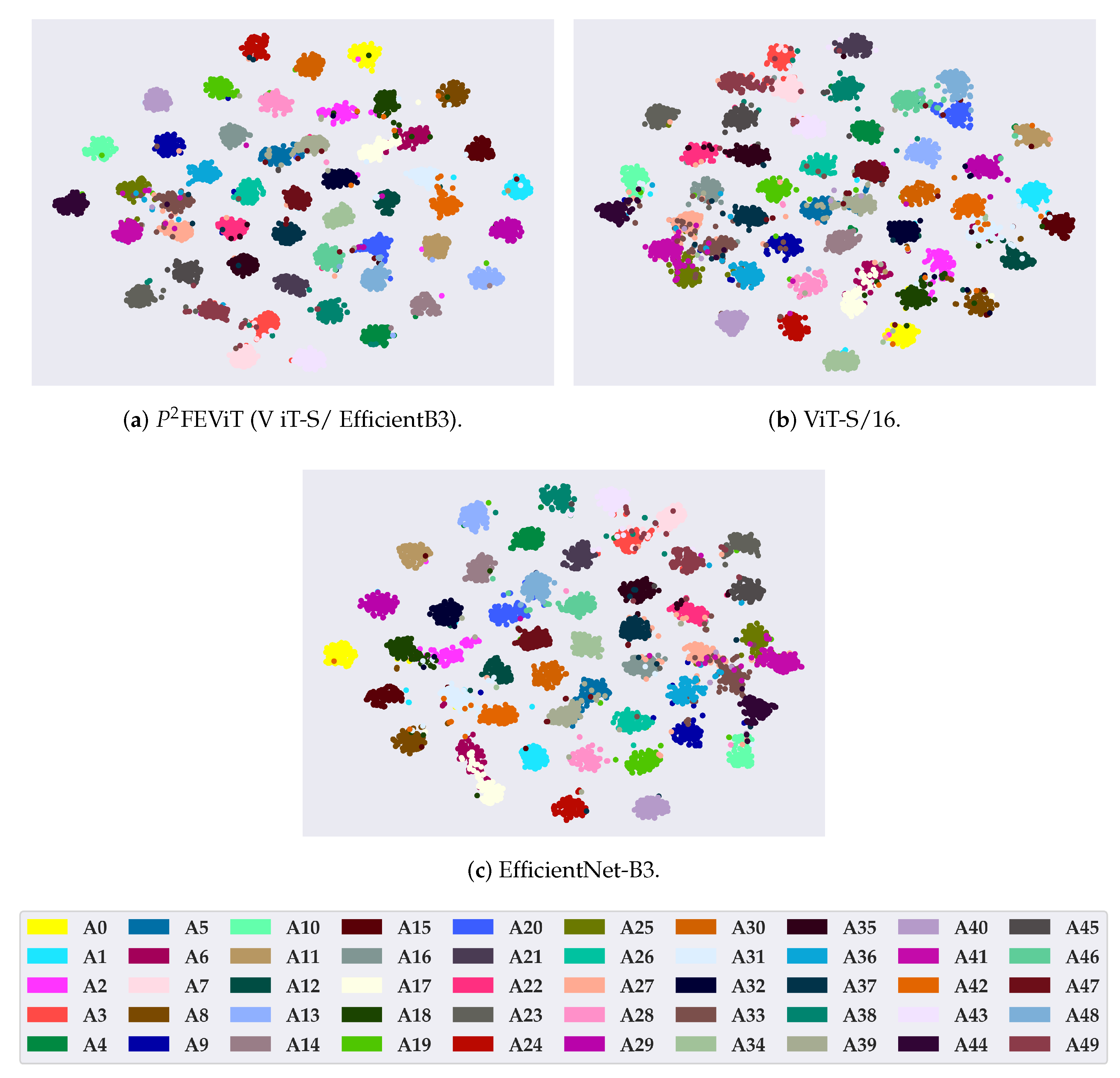
4.5. Performance Evaluation and Ablation Studies
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Chen, L.; Wang, C.; Zhuo, L.; Tian, Q.; Liang, X. Road recognition from remote sensing imagery using incremental learning. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2993–3005. [Google Scholar] [CrossRef]
- Abdullahi, H.S.; Sheriff, R.; Mahieddine, F. Convolution neural network in precision agriculture for plant image recognition and classification. In Proceedings of the 2017 Seventh International Conference on Innovative Computing Technology (INTECH), Luton, UK, 16–18 August 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 10, pp. 256–272. [Google Scholar]
- Nielsen, M.M. Remote sensing for urban planning and management: The use of window-independent context segmentation to extract urban features in Stockholm. Comput. Environ. Urban Syst. 2015, 52, 1–9. [Google Scholar] [CrossRef]
- Qin, P.; Cai, Y.; Liu, J.; Fan, P.; Sun, M. Multilayer feature extraction network for military ship detection from high-resolution optical remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11058–11069. [Google Scholar] [CrossRef]
- Mirik, M.; Ansley, R.J. Utility of Satellite and Aerial Images for Quantification of Canopy Cover and Infilling Rates of the Invasive Woody Species Honey Mesquite (Prosopis Glandulosa) on Rangeland. Remote. Sens. 2012, 4, 1947–1962. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. Lect. Notes Comput. Sci. 2006, 3951, 404–417. [Google Scholar]
- DARAL, N. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Brock, A.; De, S.; Smith, S.L.; Simonyan, K. High-performance large-scale image recognition without normalization. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 1059–1071. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2736–2746. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Cheng, X.; Lei, H. Remote sensing scene image classification based on mmsCNN–HMM with stacking ensemble model. Remote Sens. 2022, 14, 4423. [Google Scholar] [CrossRef]
- Wang, D.; Lan, J. A deformable convolutional neural network with spatial-channel attention for remote sensing scene classification. Remote Sens. 2021, 13, 5076. [Google Scholar] [CrossRef]
- Li, L.; Liang, P.; Ma, J.; Jiao, L.; Guo, X.; Liu, F.; Sun, C. A multiscale self-adaptive attention network for remote sensing scene classification. Remote Sens. 2020, 12, 2209. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, Y.; Yang, X.; Gao, S.; Li, F.; Kong, A.; Zu, D.; Sun, L. Improved remote sensing image classification based on multi-scale feature fusion. Remote Sens. 2020, 12, 213. [Google Scholar] [CrossRef]
- Shen, J.; Yu, T.; Yang, H.; Wang, R.; Wang, Q. An Attention Cascade Global–Local Network for Remote Sensing Scene Classification. Remote Sens. 2022, 14, 2042. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Deng, P. Remote Sensing Image Scene Classification Based on Global–Local Dual-Branch Structure Model. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Lv, P.; Wu, W.; Zhong, Y.; Du, F.; Zhang, L. SCViT: A Spatial-Channel Feature Preserving Vision Transformer for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhang, Y.; Wu, L.; Neggaz, N.; Wang, S.; Wei, G. Remote-Sensing Image Classification Based on an Improved Probabilistic Neural Network. Sensors 2009, 9, 7516–7539. [Google Scholar] [CrossRef] [PubMed]
- Han, M.; Liu, B. Ensemble of extreme learning machine for remote sensing image classification. Neurocomputing 2015, 149, 65–70. [Google Scholar] [CrossRef]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in Spectral-Spatial Classification of Hyperspectral Images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef]
- Song, W.; Cong, Y.; Zhang, Y.; Zhang, S. Wavelet Attention ResNeXt Network for High-resolution Remote Sensing Scene Classification. In Proceedings of the 2022 17th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 11–13 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 330–333. [Google Scholar]
- Wang, H.; Gao, K.; Min, L.; Mao, Y.; Zhang, X.; Wang, J.; Hu, Z.; Liu, Y. Triplet-Metric-Guided Multi-Scale Attention for Remote Sensing Image Scene Classification with a Convolutional Neural Network. Remote Sens. 2022, 14, 2794. [Google Scholar] [CrossRef]
- Shi, C.; Zhao, X.; Wang, L. A multi-branch feature fusion strategy based on an attention mechanism for remote sensing image scene classification. Remote Sens. 2021, 13, 1950. [Google Scholar] [CrossRef]
- Miao, W.; Geng, J.; Jiang, W. Multi-Granularity Decoupling Network with Pseudo-Label Selection for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1. [Google Scholar] [CrossRef]
- Singh, A.; Bruzzone, L. Data Augmentation Through Spectrally Controlled Adversarial Networks for Classification of Multispectral Remote Sensing Images. In Proceedings of the IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 651–654. [Google Scholar] [CrossRef]
- Stivaktakis, R.; Tsagkatakis, G.; Tsakalides, P. Deep learning for multilabel land cover scene categorization using data augmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1031–1035. [Google Scholar] [CrossRef]
- Xiao, Q.; Liu, B.; Li, Z.; Ni, W.; Yang, Z.; Li, L. Progressive data augmentation method for remote sensing ship image classification based on imaging simulation system and neural style transfer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9176–9186. [Google Scholar] [CrossRef]
- Yu, X.; Wu, X.; Luo, C.; Ren, P. Deep learning in remote sensing scene classification: A data augmentation enhanced convolutional neural network framework. GIScience Remote Sens. 2017, 54, 741–758. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, K.; Dong, Y.; Wu, K.; Hu, X. Semisupervised Classification Based on SLIC Segmentation for Hyperspectral Image. IEEE Geosci. Remote. Sens. Lett. 2020, 17, 1440–1444. [Google Scholar] [CrossRef]
- Yessou, H.; Sumbul, G.; Demir, B. A comparative study of deep learning loss functions for multi-label remote sensing image classification. In Proceedings of the IGARSS 2020-2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1349–1352. [Google Scholar]
- Bazi, Y.; Al Rahhal, M.M.; Alhichri, H.; Alajlan, N. Simple yet effective fine-tuning of deep CNNs using an auxiliary classification loss for remote sensing scene classification. Remote Sens. 2019, 11, 2908. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.; Wang, J.; Yue, X.G.; Lim, S.J.; Al-Makhadmeh, Z.; Tolba, A. Training convolutional neural networks with multi-size images and triplet loss for remote sensing scene classification. Sensors 2020, 20, 1188. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, M.; Pan, B.; Shi, Z. Semisupervised center loss for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1362–1373. [Google Scholar] [CrossRef]
- Wei, T.; Wang, J.; Liu, W.; Chen, H.; Shi, H. Marginal center loss for deep remote sensing image scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 968–972. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Q.; Xu, Y.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Advancing plain vision transformer towards remote sensing foundation model. IEEE Trans. Geosci. Remote. Sens. 2022. [Google Scholar] [CrossRef]
- Sha, Z.; Li, J. MITformer: A Multiinstance Vision Transformer for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Deng, P.; Xu, K.; Huang, H. When CNNs Meet Vision Transformer: A Joint Framework for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Gao, P.; Lu, J.; Li, H.; Mottaghi, R.; Kembhavi, A. Container: Context aggregation network. arXiv 2021, arXiv:2106.01401. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Long, Y.; Xia, G.S.; Li, S.; Yang, W.; Yang, M.Y.; Zhu, X.X.; Zhang, L.; Li, D. On creating benchmark dataset for aerial image interpretation: Reviews, guidances, and million-aid. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4205–4230. [Google Scholar] [CrossRef]
- Di, Y.; Jiang, Z.; Zhang, H. A public dataset for fine-grained ship classification in optical remote sensing images. Remote Sens. 2021, 13, 747. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Al-Rfou, R.; Choe, D.; Constant, N.; Guo, M.; Jones, L. Character-level language modeling with deeper self-attention. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3159–3166. [Google Scholar]
- Guo, Y.; Ji, J.; Lu, X.; Huo, H.; Fang, T.; Li, D. Global-local attention network for aerial scene classification. IEEE Access 2019, 7, 67200–67212. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-connected covariance network for remote sensing scene classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1461–1474. [Google Scholar] [CrossRef]
- Guo, D.; Xia, Y.; Luo, X. Scene classification of remote sensing images based on saliency dual attention residual network. IEEE Access 2020, 8, 6344–6357. [Google Scholar] [CrossRef]
- Tang, X.; Ma, Q.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. Attention consistent network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2030–2045. [Google Scholar] [CrossRef]
- Li, Q.; Yan, D.; Wu, W. Remote sensing image scene classification based on global self-attention module. Remote Sens. 2021, 13, 4542. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Categories | Images | Image Width |
|---|---|---|---|
| NWPU-R45 [24] | 45 | 31,500 | 256 |
| UC Merced Land-Use [36] | 21 | 2100 | 256 |
| Aerial Image Dataset [61] | 30 | 10,000 | 600 |
| FGSCR-42 [63] | 42 | 9320 | 50∼1500 |
| BIT-AFGR50 1 | 50 | 12,500 | 128 |
| Method | 10% Training Ratio | 20% Training Ratio | Year, Publication |
|---|---|---|---|
| ResNet50 [16] | 92.40 ± 0.07 | 94.22 ± 0.20 | 2016, CVPR |
| EfficientNet-B0 [73] | 91.79 ± 0.19 | 94.71 ± 0.13 | 2019, ICML |
| EfficientNet-B1 [73] | 91.84 ± 0.18 | 94.36 ± 0.14 | 2019, ICML |
| EfficientNet-B2 [73] | 92.17 ± 0.12 | 94.65 ± 0.16 | 2019, ICML |
| EfficientNet-B3 [73] | 93.23 ± 0.17 | 95.03 ± 0.17 | 2019, ICML |
| GLANet [68] | 91.03 ± 0.18 | 93.45 ± 0.17 | 2019, IEEE Access |
| SCCov [69] | 89.30 ± 0.35 | 91.10 ± 0.25 | 2019, IEEE TNNLS |
| ViT-S/16 [20] | 92.48 ± 0.11 | 94.17 ± 0.05 | 2020, ICLR |
| ViT-B/16 [20] | 93.25 ± 0.08 | 94.95 ± 0.07 | 2020, ICLR |
| SDAResNet50 [70] | 89.40 | 92.28 | 2020, IEEE Access |
| ACNet [71] | 91.09 ± 0.13 | 92.42 ± 0.16 | 2021, IEEE JSTARS |
| Li et al. [72] | 92.11 ± 0.06 | 94.00 ± 0.13 | 2021, Remote Sensing |
| SCViT [34] | 92.72 ± 0.04 | 94.66 ± 0.10 | 2021, IEEE TGRS |
| Cheng et al. [25] | 93.43 ± 0.25 | 95.51 ± 0.21 | 2022, Remote Sensing |
| CTNet(ResNet34) [56] | 93.86 ± 0.22 | 95.49 ± 0.12 | 2022, IEEE GRSL |
| CTNet(MobileNet_v2) [56] | 93.90 ± 0.14 | 95.40 ± 0.15 | 2022, IEEE GRSL |
| FEViT (ViT-S 1 /ResNet50) | 93.43 ± 0.12 | 94.79 ± 0.08 | ours |
| FEViT (ViT-S 1 /EfficientB0) | 93.52 ± 0.11 | 95.41 ± 0.12 | |
| FEViT (ViT-S 1/EfficientB1) | 93.54 ± 0.08 | 95.31 ± 0.13 | |
| FEViT (ViT-S 1 /EfficientB2) | 94.65 ± 0.10 | 95.38 ± 0.12 | |
| FEViT (ViT-S 1 /EfficientB3) | 94.43 ± 0.09 | 95.24 ± 0.18 | |
| FEViT(ViT-B 1 /EfficientB0) | 94.72 ± 0.04 | 95.85 ± 0.15 | |
| FEViT(ViT-B 1/ResNet50) | 94.97 ± 0.13 | 95.74 ± 0.19 |
| Method | Initial State | OA | Training Epoch | |
|---|---|---|---|---|
| Pretrained | Scratch | |||
| ResNet50 [16] | ✓ | 94.01 ± 0.17 | 400 | |
| EfficientNet-B0 [73] | ✓ | 91.94 ± 0.07 | 400 | |
| EfficientNet-B1 [73] | ✓ | 92.90 ± 0.12 | 400 | |
| EfficientNet-B2 [73] | ✓ | 92.96 ± 0.09 | 400 | |
| EfficientNet-B3 [73] | ✓ | 94.03 ± 0.06 | 400 | |
| ViT-S/16 [20] | ✓ | 92.82 ± 0.11 | 400 | |
| ViT-B/16 [20] | ✓ | 94.91 ± 0.13 | 400 | |
| FEViT 1 | ✓ | 92.94 ± 0.13 | 150 | |
| FEViT 2 | ✓ | 93.04 ± 0.11 | 90 | |
| FEViT 3 | ✓ | 95.02 ± 0.08 | 200 | |
| FEViT 1 | ✓ | 94.78 ± 0.15 | 400 | |
| FEViT 2 | ✓ | 95.46 ± 0.17 | 400 | |
| FEViT 3 | ✓ | 95.22 ± 0.13 | 400 | |
| ResNet50 [16] | ✓ | 58.29 ± 0.17 | 400 | |
| EfficientNet-B3 [73] | ✓ | 47.55 ± 0.17 | 400 | |
| ViT-S/16 [20] | ✓ | 56.79 ± 0.11 | 400 | |
| ViT-B/16 [20] | ✓ | 67.07 ± 0.13 | 400 | |
| FEViT 2 | ✓ | 57.53 ± 0.11 | 220 | |
| FEViT 2 | ✓ | 67.18 ± 0.15 | 280 | |
| FEViT 2 | ✓ | 74.92 ± 0.13 | 400 | |
| FEViT 1 | ✓ | 57.24 ± 0.05 | 180 | |
| FEViT 1 | ✓ | 67.57 ± 0.11 | 250 | |
| FEViT 1 | ✓ | 76.80 ± 0.17 | 400 | |
| Method | 10% Training Ratio | 20% Training Ratio | 30% Training Ratio |
|---|---|---|---|
| EfficientNet-B0 [73] | 81.61 ± 0.13 | 91.94 ± 0.07 | 94.93 ± 0.03 |
| EfficientNet-B1 [73] | 82.21 ± 0.12 | 92.90 ± 0.12 | 95.27 ± 0.10 |
| EfficientNet-B2 [73] | 84.28 ± 0.19 | 92.96 ± 0.09 | 95.29 ± 0.05 |
| EfficientNet-B3 [73] | 84.98 ± 0.03 | 94.03 ± 0.06 | 96.11 ± 0.05 |
| ResNet50 [16] | 86.65 ± 0.13 | 94.01 ± 0.17 | 96.20 ± 0.09 |
| ViT-S/16 [20] | 84.72 ± 0.16 | 92.82 ± 0.11 | 95.36 ± 0.08 |
| ViT-B/16 [20] | 88.55 ± 0.17 | 94.91 ± 0.13 | 96.75 ± 0.08 |
| FEViT (ViT-S 1/EfficientB3) | 88.50 ± 0.11 | 95.46 ± 0.17 | 97.22 ± 0.08 |
| FEViT (ViT-S 1/ResNet50) | 89.30 ± 0.07 | 94.78 ± 0.15 | 97.12 ± 0.09 |
| FEViT (ViT-B 1/EfficientB3) | 89.24 ± 0.10 | 95.22 ± 0.13 | 97.27 ± 0.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Chen, H.; Chen, L.; Zhuang, Y.; Zhang, S.; Zhang, T.; Dong, H.; Gao, P. P2FEViT: Plug-and-Play CNN Feature Embedded Hybrid Vision Transformer for Remote Sensing Image Classification. Remote Sens. 2023, 15, 1773. https://doi.org/10.3390/rs15071773
Wang G, Chen H, Chen L, Zhuang Y, Zhang S, Zhang T, Dong H, Gao P. P2FEViT: Plug-and-Play CNN Feature Embedded Hybrid Vision Transformer for Remote Sensing Image Classification. Remote Sensing. 2023; 15(7):1773. https://doi.org/10.3390/rs15071773
Chicago/Turabian StyleWang, Guanqun, He Chen, Liang Chen, Yin Zhuang, Shanghang Zhang, Tong Zhang, Hao Dong, and Peng Gao. 2023. "P2FEViT: Plug-and-Play CNN Feature Embedded Hybrid Vision Transformer for Remote Sensing Image Classification" Remote Sensing 15, no. 7: 1773. https://doi.org/10.3390/rs15071773
APA StyleWang, G., Chen, H., Chen, L., Zhuang, Y., Zhang, S., Zhang, T., Dong, H., & Gao, P. (2023). P2FEViT: Plug-and-Play CNN Feature Embedded Hybrid Vision Transformer for Remote Sensing Image Classification. Remote Sensing, 15(7), 1773. https://doi.org/10.3390/rs15071773