1. Introduction
The Doppler weather radar is an essential tool for nowcasting, warning of severe storms and hazardous weather phenomena such as thunderstorms, blizzards, and hail [
1]. For pulsed weather radars, a long aliasing range (
), also known as the maximum unambiguous range, is desirable for surveillance. In direct conflict with this desire, a high aliasing velocity
, also known as the Nyquist velocity, is essential to obtaining storm dynamics. The Doppler dilemma is the manifestation of this conflict—a long-lasting challenge where
and
are in a fixed trade-off relation [
1]. The Doppler dilemma becomes more severe for shorter-wavelength radars such as the X-band compared to C- and S-band. Many efforts have been attempted to mitigate the Doppler dilemma (e.g., [
2,
3,
4,
5,
6,
7]). Because the performance of automated dealiasing algorithms can be poor at critical locations in a sweep, labor-intensive manual dealiasing is still being practiced (e.g., [
8,
9,
10]). For that reason, an automated algorithm is still an important area of study, which is the primary motivation of the current work.
The Doppler dilemma can be derived as shown in Equation (
1).
For a specific combination of
and
, the Doppler dilemma dictates the
value. There are two common approaches to dealias the velocity measurements, which are (1) the post-processing method and (2) the waveform design method. In the first approach, aliased velocities are found by searching for velocity discontinuities (typically
, where
n is −2, −1, 1, 2, and so on). Subsequently, dealiasing is accomplished by adding/subtracting
to the aliased velocities. One assumption is that the initial velocity measurement, e.g., first cell, first range gate, first azimuth, etc., is non-aliased. The velocity measurement of this cell is also known as the reference velocity, and there have been numerous attempts to determine the discontinuity [
2,
3,
4,
5,
6,
7]. In the second approach, two (or more) PRT values are used, and the aliased velocities are found by searching for disagreements between the two measurements. The approach is known as the dual-PRF method [
1,
11]. Dealiasing is accomplished with the waveform design approaches by solving a least-common-multiplier problem. There is a similar method known as the staggered PRT (Pulse Repetition Time) [
12,
13]. Both methods use two pulse repetition frequencies (or periods). The key difference is how the periods are arranged. The dual-PRF method collects a radial by splitting it into two halves; one half uses one period while the other half uses the other. The staggered-PRT method, however, collects a radial by staggering the two periods; hence the name staggered PRT [
14,
15,
16,
17,
18].
It must be emphasized that the post-processing method allows the system to operate everything else, e.g., ground clutter filter, contiguous pulse-pair processing, etc., as is. The waveform design methods require modifications to the existing ground clutter filters due to the dwell discontinuity [
17]. In this work, the main focus will be on the post-processing approach, and the key is to detect the aliasing. Once detected successfully, it can be dealiased correctly [
2,
3,
4,
19].
The detection of velocity aliasing is comparable to classification and one can see how a machine learning (ML) algorithm can be applied to mitigate velocity aliasing. In principle, a classification ML algorithm to determine how many times the velocity aliasing has occurred allows us to identify the regions where velocity dealiasing is necessary. In essence, the ML processing replaces what human intervention often is needed, i.e., identification of the velocity aliasing region and classification of the velocity aliasing count. ML can perform these two tasks in one pass, much like what a human is capable of. ML is a data-fitting method. In ML, model parameters, i.e., weights and biases, are optimized through an iterative training process. Optimization is performed to minimize a cost function. Each couple of weights and biases is a neuron, and multiple neurons form a neural network (1 layer). Neural networks that contain more than one layer are considered deep neural networks. Deep learning is the training process of deep neural networks [
20]. A single-layer neural network is similar to the current technique (one threshold); however, the deep neural network is more complex, with the promise of better performance.
Image segmentation is performed through a CNN (Convolutional Neural Network); here, concatenated layers of filters operate like convolution. CNN-based image classification can produce a single label that represents the whole image, e.g., facial recognition [
21], or an output image that indicates multiple labels (segments) within an image, e.g., medical diagnosis [
22], object recognition, and so on. It is also applied in meteorological data processing, e.g., to classify spatially localized climate patterns from Community Atmospheric Model v5 (CAM5) simulation [
23], to detect the cold and warm fronts from the reanalysis data [
24], to classify the tropical cyclone intensity from satellite images [
25], to predict the probability of severe hail [
26], and to detect the birds roosts from combined radar products [
27]. Like these examples, a CNN segments and labels the images. In this work, the label represents whether a velocity cell is aliased. The input is the raw velocity field, and the output is a map of flags indicating whether the velocity of a cell is aliased and, by extension, how many times the velocity is aliased. Therefore, aliasing detection can be converted into a labeling problem.
Our training goal is to encourage the model to learn the aliasing concept, rather than to memorize a set of patterns. It is important to provide a diverse set of data that cover most scenarios, e.g., Nyquist velocity, local mean velocity, storm pattern, scan elevation, etc. Just like how a human can dealias a velocity map regardless of these variables, the goal is to produce a CNN model that is capable of identifying aliasing count regardless of these variables. To that end, some high-level features, such as segments and abrupt changes of Doppler velocity are used to identify regions of aliasing.
The evaluation of velocity dealiasing performance is commonly performed by calculating the accuracy or error rate (1 − accuracy). Some studies calculate the error rate based on the error-included scan [
2,
28,
29] and some studies evaluated the error rate based on error gates [
19,
30]. Case studies are also performed by analyzing specific PPI (Plan Position Indicator of one elevation angle) scans [
6,
19,
28,
29,
30]. In this study, the mean of accuracy (
) and the standard deviation of accuracy (
) averaged by scans are employed to evaluate the performance. The
indicates the consistency of performance. For example, a low
with low
means poor performance most of the time. However, a high
with high
means performance can vary widely and there are times the performance is unacceptable.
The overarching goal of this work is to exploit CNN for velocity dealiasing (aliasing detection/classification/labeling). This is a post-processing approach since even dual-PRF or staggered-PRT methods resulted in aliased velocity. The promise of using a CNN is to achieve human-level performance. Through this process, it is expected that the labor-intensive task of velocity dealiasing could be automated.
This paper is organized as follows.
Section 2 describes the background, materials, and proposed methodology, including the data pre-processing, algorithm description, and training. Then,
Section 3 explains the evaluation method and statistical results, presents an analysis of the sensitivity test of a selection of
values and template sizes, and analyzes with specific examples. In
Section 4, the limitations and future works will be discussed, and the conclusions of this paper are in
Section 5.
3. Results
Figure 3 illustrates the velocity dealiasing process with two synthetic velocity fields with a different
. This is an example of mostly filled precipitation, with a homogeneous wind field and a broad continuous precipitation field.
Figure 3a shows the radar reflectivity
Z, and
Figure 3b is the ground truth data (
) from the S-band radar velocity field. The second column is the input (aliased) velocity (
), which is manually aliased by
using Equation (
2). The third column is the predicted aliased label (
), and the last column is the dealiased velocity using Equation (
9). In
Figure 3c,
is aliased by
, where
Figure 3e
includes
,
, and
.
Figure 3d is the
aliased by
, and
is not included as shown in
Figure 3f. Regardless of different
, dealiased velocity
is shown as similar to ground truth
for both
(
Figure 3g,h), illustrating the efficacy of using a CNN model to label the velocity aliasing count correctly.
3.1. Evaluation Method and Metrics
Evaluation is performed with synthesized X-band radar velocity field values from the NEXRAD S-band radar since the ground truth is readily available. However, false labels in clutter and undesirable echoes such as planes and biological echoes with high velocity could survive the filters. Data from these speckles from the false ground truths could have a negative impact on the evaluation of meteorological echoes. Occasionally, CNN output appears correct; in our experience, most humans would prefer the CNN output compared to ground truth data from the NEXRAD S-band radar velocity field because the CNN output is spatially continuous, i.e., contains fewer speckles. Therefore, masking is employed in the evaluation stage while training is performed without masking. In a training process, even non-meteorological echoes could help predict more complicated storms, such as sparsely filled precipitation, by giving wider coverage since CNN is less prone to noise or bad pixels. However, as we explained above, non-meteorological echoes or speckles from the false labels are not considered in the evaluation. For a fair comparison, common masking conditions, which are the reflectivity filter, HCA mask, and SNR thresholding, are applied to both CNN and region-based dealiasing methods. In the region-based method, reflectivity filtering is pre-applied, which filters the velocity where the reflectivity is less than 0 dBZ or greater than 80 dBZ. NEXRAD HCA mask is applied to focus on precipitation by excluding the non-precipitation echoes and SNR thresholding is utilized for the data quality control.
In a training process, all scans are trained at the same time. However, evaluation is performed on two categories: mostly filled and sparsely filled precipitation, where the classification is manually performed. In evaluation, test data are further divided into three groups such as
,
, and
, based on the
used. It is because if we analyze all labels at the same time, it is hard to see the impact on less populated aliased labels when the
is higher.
is the combined performance of
and
,
is combined with
and
, and
is combined with
and
. Separation is based on the label population;
includes
,
does not include
, but it has a higher portion of
, and
consists of mostly
. The label population ratio is shown in
Table 2.
Performance is measured by and , where A is the accuracy of one scan, which is the number of correctly predicted cells of the total valid number of cells for one scan. is the mean A averaged by the number of scans and is the scan-averaged standard deviation of A to check how the accuracy is varied and dispersed. Because it could mitigate the performance on the less populated label, it is also evaluated on each label (, , and ).
3.2. Statistical Results
In
Figure 4,
and
of CNN and the region-based dealiasing method from each
group are compared. The region-based method has the option to utilize the environmental background wind to aid the first-guess field; however, in this study, environmental background wind is not utilized for a fair comparison. In mostly filled precipitation scans, in
, the CNN method has the lower
and higher
than the region-based method. In
and
, it shows the similar performance on both methods of
and
. However, in sparsely filled precipitation scans, in
and
, the CNN method has the higher
and lower
than the region-based method. In
,
is similar on both methods, but the
is still lower on CNN than the region-based method. Typical X-band radars that are set up to provide a 60-km coverage (
) have a
at approximately
. For that configuration, performance on
is most representative. It includes a reasonable amount of
and shows high performance on both mostly filled and sparsely filled precipitation scans.
Error analysis is conducted by separating the measurement type as speckles and non-speckles. Separation is performed by grouping the connected error pixels first, and if the number of error pixels in each group has less than a threshold (here, 10 pixels are used), it is classified as a speckle. Otherwise, it is regarded as a non-speckle.
Figure 5 shows an example of an incorrect prediction. From
Figure 5, panel (a) shows an image of the true labels, and panel (b) is an image of the predicted labels using the CNN model. Panels (c)–(h) are the softmax classifier outputs, i.e., it normalizes a vector to the [0, 1] range for each label, and the sum of each softmax output is 1. Therefore, it shares many characteristics of a probability distribution of a random variable. There are significant overlaps between labels ‘−1’ and ‘0’. Some ‘0’ labels are predicted as ‘−1’ labels. In these instances, the otherwise correct label ‘0’ has the second highest probability. In order to obtain more insight into the incorrect prediction, a similar scan, which is at around the same time but from a different elevation angle is compared. In
Figure 6, the predicted label is mostly correct, but it somewhat overlaps between the label ‘−1’ and ‘0’. It shows a low probability area, which is lighter than adjacent pixels, in the correct label ‘0’, and the second highest probability, which is darker than adjacent pixels, is shown in the incorrect label ‘−1’.
If one replaces the incorrect pixels with labels that have the second highest probability, the accuracy would have increased from 88.1% to 99.7%. The replaced result is shown in
Figure 7. Panel (a) represents the true label, panel (b) shows the raw predicted label, and panel (c) is the replaced label from panel (b) by ones with the second most probable prediction on failed ones. Out of the 168 scans among the total of 495 test data (non-speckle), 80.9% of them have the correct label as the second most probable prediction. Because of the complexity of the CNN model, it is extremely difficult to find an explanation for these false predictions. However, it is clear that the performance of the CNN model can be improved significantly if the second most probable predictions were selected under these circumstances. It must be emphasized here that this cannot be recovered in practice. This example is presented here only to illustrate the potential for improvements.
In
Table 3, the overall performance, which is the weighted sum of
,
, and
, are calculated with Equation (
10) from each aliasing label, i.e., labels in the sets of non-aliased (
), once-aliased (
) and twice-aliased (
).
where
represents the weight of labels in group
and set
l, which are iterated through all groups (
,
, and
) and all label sets (
,
, and
). The weights, which are the population ratio of each
group, are shown in
Table 4, where the sum of the weights is ‘1’ for each label, and the overall performance of the CNN and region-based methods are compared against each other.
For the mostly filled precipitation scans, both methods have similarly high (>99%), but the region-based method shows slightly better performance, and the performances between the methods are similar with a discrepancy of less than 1% for each label.
For the sparsely filled precipitation, which has a higher complexity than the mostly filled precipitation scans, the CNN method achieves higher , and with much lower , compared to the region-based method. For both methods, the overall accuracy is higher than the group specific accuracy () since is derived with more elements in as the set includes groups and .
The overall performances of the three aliasing labels are in the order of . That is, the CNN model is effective at identifying non-aliased regions, then the once-aliased regions, and finally, the twice-aliased regions. Identifying the twice-aliased regions requires the correct identification of the once-aliased regions that they are adjacent to. As such, it is unsurprising that is lower than . Similar argument can be made for .
3.3. Sensitivity Test
In this study, training variables are evaluated on
in three configurations:
,
, and
. In
, the population ratio of
:
:
equals 110:48:1, and the corresponding class weight ratio is 1:2.28:110. In
,
:
:1, and the corresponding class weight is the inverse of the population ratio, i.e., 1:
. In
,
:
:1, and the corresponding class weight ratio is 1:119.
Figure 8 shows the performance with different training
and evaluation using
,
, and
. In
,
and
show the highest performance among five different models since both include
in training, which has the largest number of aliased labels (
and
) in training. However, in
, training with
resulted in lower
than
model since
consists of the highest
values with the least aliased label.
model shows a relatively poor performance than others for its extremely skewed class weights (1:
:555) because the
population is deficient. Therefore, it diminishes the non-aliased and once-aliased performance by highly focusing the optimization on
. From this experiment,
model is chosen for our final training condition.
Figure 9 shows the scan-averaged
and
as a function of
T. The left panels provide results on the mostly filled precipitation scans, and the right panels correspond to the sparsely filled precipitation scans. In general, using a larger
T produces better results (higher
and lower
), with the only exception on mostly filled precipitation with
and
, which are in reverse order but the difference is less than
. In
and
, all four different template sizes show similar performances. These results are expected because the mostly filled precipitation scans are spatially continuous and have relatively simple features in contrast to the sparsely filled precipitation. It is noteworthy that training with
, which is relatively short-range coverage, also shows high performance (
> 96%) since it still has 360° coverage and a more homogeneous wind field, which makes it easier to predict the aliased label. Mostly filled precipitation is less impacted by template size since these are spatially continuous and mostly filled. In contrast, more spatially complicated cases can be negatively impacted by template size. A larger template size covers a wider area, and it is beneficial for predicting the aliased label
L.
Figure 10 shows the
performance of the trained model using different template sizes as a function of range. The top panels provide the results on the mostly filled precipitation scans, and the bottom panels are on the sparsely filled precipitation scans. For the mostly filled precipitation, in range gates 0–127, all four template sizes show similar performances. However, in range gates 128–256, the performances are shown in this order:
. For the sparsely filled precipitation, the performances are shown in this order:
. It is noteworthy that the performance reduction is shown at each template boundary, unlike for the mostly filled precipitation. The sparsely filled precipitation scans include the non-uniform wind field, spatially discontinuous, and isolated storms. For these scans, the wider coverage would certainly help determine the dealiasing decisions.
and
are similarly performed. However,
shows the boundary reduction on range gate 128, while
is not, and
can be performed in one prediction to cover the 64 km while
needs two predictions.
In
Figure 10, velocity dealiasing results with different template sizes as a function of the range are compared against the traditional region-based method. The region-based method can utilize the environmental background wind for estimating the first-guess field velocity aliasing. As mentioned before, environmental background wind is not utilized for the sake of fairness. For the mostly filled precipitation scans, the region-based dealiasing method properly dealiases the velocity and shows a stable performance along the range compared to the CNN method. However, for the sparsely filled precipitation scans, the region-based dealiasing method performs poorly at the initial range gate compared to the
model. It does not show any measurable performance reduction at the far range. In contrast, the CNN method shows significant performance reduction. In the region-based method, if it correctly estimates the first-guess velocity aliasing field, the performance is consistent along the range. However, if not, it leads to failing the aliasing prediction of the entire storm cell. Since the sparsely filled precipitation includes the multiple isolated storm precipitation scans, a more significant number of first-guess field predictions are required than a single-storm case. When the storm is isolated and far from the radar, it is more difficult to estimate the first-guess field aliasing, even for a human-expert implementation. For the higher
groups (
and
), the overall performance is gradually improved, and the performance differences among different template sizes are also reduced. Although class weight helps equalize the less populous labels to be trained by weighting them higher, the distribution of the labels in the evaluation sets is different. That is,
contains more
than in
and
; therefore, evaluation using
results in higher overall performance than
and
. The same explanations can be applied to comparisons between
and
.
3.4. Case Study
In this subsection, a case study will be presented to illustrate the performance of the two dealiasing methods under the conditions with mostly filled and sparsely filled precipitation.
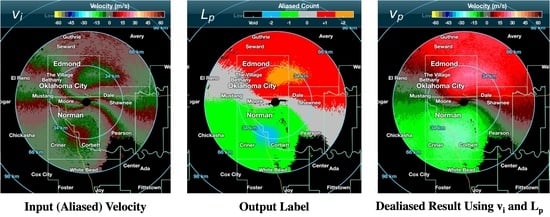
Figure 11 shows an example PPI scan with mostly filled precipitation and
=
, which includes
, and
. The wind field is spatially continuous, which can be seen in
. Both CNN and region-based methods dealiased the
with over 99% accuracy since the storm is wide, spatially continuous, and mostly filled.
Figure 12 shows an example PPI scan with sparsely filled precipitation and
=
. This is a case with multiple isolated storms that are well separated. As one can see in
, the wind field is discontinuous, and extremely challenging to distinguish the aliased area even for a human. The proposed CNN method successfully dealiased most of the aliased isolated storms. However, the region-based method failed at many isolated storms, which are circled in a yellow dashed line. For the isolated storms, if the region-based method fails at the first-guess field, it leads to failure to decide the aliasing of whole isolated storms. With isolated storms, the assumption that the first-guess field is non-aliased can be problematic, as illustrated in this example.
On the other hand, a wide processing window can aid the decision of aliasing label. Compared to the region-based method, the CNN model has a much wider view. In the domain of CNN processing, there is a notion of the receptive field, which is defined as the region that each particular CNN layer is looking at [
43]. This region is essentially a 2-D processing window that results from multiple layers of convolution. As one would expect, more successive convolution results in a wider processing region. With the CNN model that processes each radar cell through multiple layers, the receptive field is wide. In the case of the proposed CNN architecture, the receptive field includes the whole PPI and the entire scan range, effectively the whole radar coverage. As such, in a way, the model is able to comprehend the big picture of a storm and identify aliasing regions like a human. Through the wide view, the CNN is trained to identify large-scale features.
4. Discussion
Generating a training dataset is arguably one of the most important steps in producing a successful deep-learning model. One method of designing a deep-learning model is to include the Nyquist velocity and mean wind as part of the input metadata. Conceptually, knowing the scan elevation and the mean wind allows us to roughly expect where aliasing can occur. So, using these two variables could help identify where aliasing occurs. A different approach was taken in this work. That is, data normalization and augmentation. In our opinion, both accomplish a similar result. The data normalization would eliminate the need to include Nyquist velocity as a part of the metadata while the data augmentation (rotating the PPI and negating the velocity values) would remove the mean wind so that the model no longer needs these variables.
Wind speed changes rapidly as a function of altitude. The probability of aliasing can change depending on the scan elevation and range. One could argue that including all scan elevations is necessary for the training datasets. However, as mentioned previously, our hope is to let the CNN model learn the aliasing concept rather than memorize the specific patterns. Just as how a human learns the aliasing concept, having all scan elevation is not necessary. Therefore, including all scan elevations in the training dataset is, in principle, unnecessary. Nonetheless, a future work to investigate the real-world outcome may be worthwhile.
On the portions where CNN failed, the accuracy could improve from to if one replaces the output with the label with the second-highest probability. This suggests that some velocity discontinuity features are not identified properly. There is no obvious solution at the moment but if portions of these errors can be recovered, the overall performance would greatly improve.
One of the concerns of utilizing a deep learning model is the cost of computing. The training time of our design is on the order of tens of hours while the inference time is only a fraction of a second, which is feasible for real-time applications.
5. Conclusions
In this study, velocity dealiasing using a CNN method is proposed, implemented, and evaluated. For the training, input velocity and true label fields are generated using the NEXRAD S-band radar velocity field, which is assumed to be non-aliased. The velocity field is artificially aliased to produce the aliased velocity fields, as one would collect using an X-band radar. Since the collected dataset has an inherent mean bias due to the regional dominant wind direction, data augmentation is performed by rotating the velocity field in azimuth, and negating the sign. Class weight is also applied to equalize the less populous labels, which are mostly the aliased labels. Cross-entropy is used as the cost function (loss). Essentially, the optimization is targeted to minimize the difference between the true and the predicted labels during the training. Velocity dealiasing is performed with input velocity , predicted output label , and the Nyquist velocity . Through the sensitivity test, template size and training are selected as the best training conditions.
Evaluation is performed by comparison to the region-based method, which is a part of the Py-ART software collection. The performance evaluation is partitioned into three groups: , , and , which are the used and analyzed on mostly filled and sparsely filled precipitation scans. The grouping provides insights about the real-world performance of the algorithm when the certain distribution of aliasing conditions are present. Group represents a collection with a severe aliasing condition, group represents a typical aliasing condition from an X-band radar, and represents a collection with velocity fields that are the easiest to process.
For mostly filled precipitation, both the CNN and the region-based methods are able to successfully produce the dealiasing label and, hence, the dealiased velocity fields, with <1% performance difference. This illustrates that the CNN method can be used under conditions with mostly filled precipitation. For the sparsely filled precipitation, however, the CNN method shows a substantially better performance than the region-based method.
The performance difference can be attributed to the discontinuity of the storms, which the region-based greatly suffers as the first-guess field cannot be produced correctly. There is an option to utilize external wind measurements to aid this process but not practiced in this work, for the sake of fairness for comparisons. The CNN model, which has a receptive field of the entire scan, is capable of processing the entire scan in one shot. Through the large collection of velocity fields in the training dataset, one can surmise that the CNN model has learned what a proper velocity field and the corresponding aliasing label should look like and, thus, is capable of producing the correct labels despite the discontinuity of the storms. This level of data comprehension and processing is what a human would do during a hand dealiasing process.
Of course, even the CNN model fails in some instances. When it does fail, it was found that more than 80% of the errors (from the non-speckle echoes) could be eliminated if they were identified as the label with the second highest probability. An investigation to recover this type of error can be investigated in future work.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}