



Wavelet Integrated Convolutional Neural Network for Thin Cloud Removal in Remote Sensing Images


Abstract
1. Introduction
- 1.
- We propose a novel wavelet-integrated CNN for thin cloud removal in RS images, which we call WaveCNN-CR. WaveCNN-CR can obtain multi-scale and multi-frequency features as well as larger receptive fields without any information loss. In addition, it can generate cloud-free results with more accurate details by directly processing the high-frequency features.
- 2.
- We design a novel EFEM consisting of an attentive residual block (ARB) and gated residual block (GRB) in WaveCNN-CR, enabling stronger feature representation ability. ARB enhances features by capturing long-range interactive global information based on an attention mechanism, while GRB enhances features by exploiting local information based on a gating mechanism.
- 3.
- We conduct extensive experiments on three public datasets, T-CLOUD, RICE1, and WHUS2-CR, which respectively include Landsat 8, Google Earth, and Sentinel-2A images. Compared with existing thin cloud removal methods, WaveCNN-CR achieves state-of-the-art (SOTA) results both qualitatively and quantitatively.
2. Related Works
2.1. Network Architecture of Existing DL-Based Methods
2.2. Wavelet Transform in DL-Based Computer Vision
3. Method
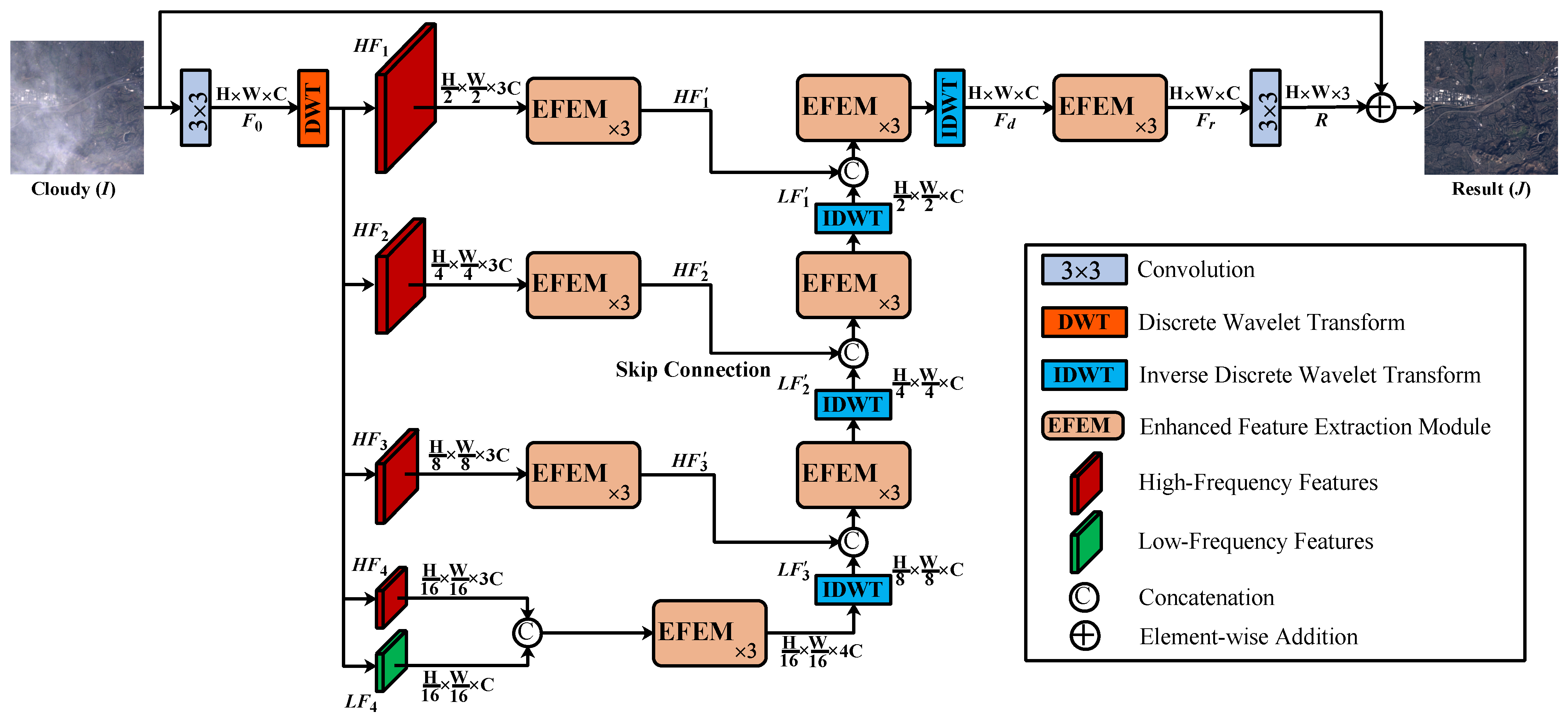
3.1. Overall Framework
3.2. Hierarchical Wavelet Transform
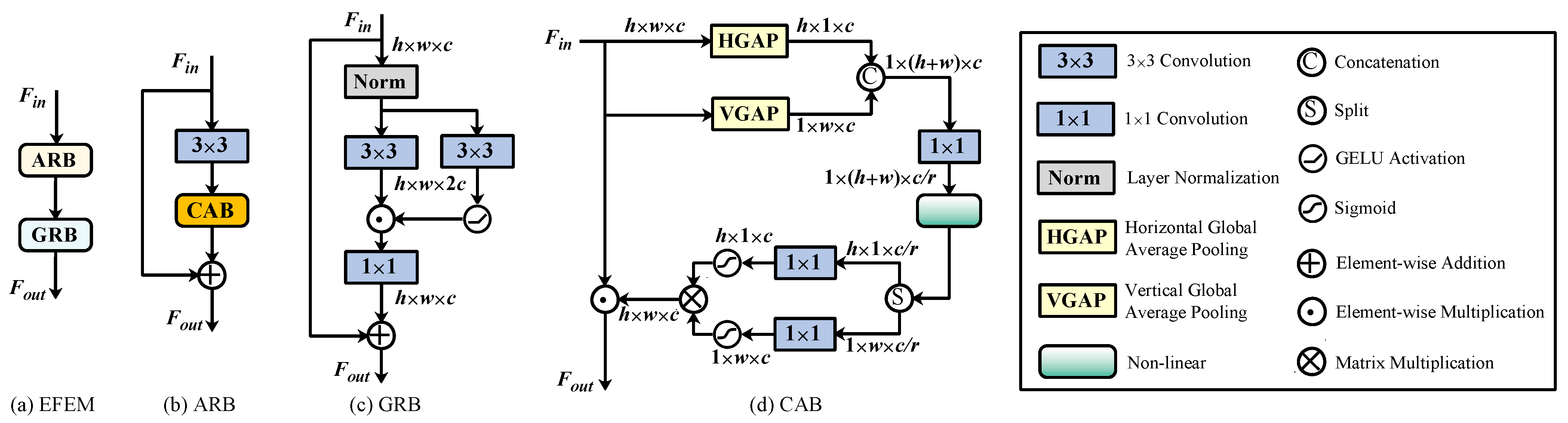
3.3. Attentive Residual Block
3.4. Gated Residual Block
3.5. Loss Function
4. Results and Discussion
4.1. Experimental Setting
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Ablation Study
4.2.1. Analysis of Overall Architecture
4.2.2. Effectiveness of EFEM
4.2.3. Analysis of ARB
4.2.4. Analysis of GRB
4.3. Comparisons with SOTA Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pan, B.; Shi, Z.; Xu, X.; Shi, T.; Zhang, N.; Zhu, X. CoinNet: Copy initialization network for multispectral imagery semantic segmentation. IEEE Geosci. Remote Sens. Lett. 2018, 16, 816–820. [Google Scholar] [CrossRef]
- Shi, L.; Wang, Z.; Pan, B.; Shi, Z. An end-to-end network for remote sensing imagery semantic segmentation via joint pixel-and representation-level domain adaptation. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1896–1900. [Google Scholar] [CrossRef]
- Chen, J.; Xie, F.; Lu, Y.; Jiang, Z. Finding arbitrary-oriented ships from remote sensing images using corner detection. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1712–1716. [Google Scholar] [CrossRef]
- Liu, E.; Zheng, Y.; Pan, B.; Xu, X.; Shi, Z. DCL-Net: Augmenting the capability of classification and localization for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7933–7944. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Benz, U.C.; Hofmann, P.; Willhauck, G.; Lingenfelder, I.; Heynen, M. Multi-resolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready information. ISPRS J. Photogramm. Remote Sens. 2004, 58, 239–258. [Google Scholar] [CrossRef]
- Zhang, Y.; Rossow, W.B.; Lacis, A.A.; Oinas, V.; Mishchenko, M.I. Calculation of radiative fluxes from the surface to top of atmosphere based on ISCCP and other global data sets: Refinements of the radiative transfer model and the input data. J. Geophys. Res. Atmos. 2004, 109. [Google Scholar] [CrossRef]
- King, M.D.; Platnick, S.; Menzel, W.P.; Ackerman, S.A.; Hubanks, P.A. Spatial and temporal distribution of clouds observed by MODIS onboard the Terra and Aqua satellites. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3826–3852. [Google Scholar] [CrossRef]
- Shen, H.; Li, H.; Qian, Y.; Zhang, L.; Yuan, Q. An effective thin cloud removal procedure for visible remote sensing images. ISPRS J. Photogramm. Remote Sens. 2014, 96, 224–235. [Google Scholar] [CrossRef]
- Pan, X.; Xie, F.; Jiang, Z.; Yin, J. Haze removal for a single remote sensing image based on deformed haze imaging model. IEEE Signal Process. Lett. 2015, 22, 1806–1810. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. Haze and thin cloud removal via sphere model improved dark channel prior. IEEE Geosci. Remote Sens. Lett. 2018, 16, 472–476. [Google Scholar] [CrossRef]
- Makarau, A.; Richter, R.; Muller, R.; Reinartz, P. Haze detection and removal in remotely sensed multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5895–5905. [Google Scholar] [CrossRef]
- Makarau, A.; Richter, R.; Schlapfer, D.; Reinartz, P. Combined haze and cirrus removal for multispectral imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 379–383. [Google Scholar] [CrossRef]
- He, M.; Wang, B.; Sheng, W.; Yang, K.; Hong, L. Thin cloud removal method in color remote sensing image. Opt. Tech. 2017, 43, 503–508. [Google Scholar]
- Hu, G.; Li, X.; Liang, D. Thin cloud removal from remote sensing images using multidirectional dual tree complex wavelet transform and transfer least square support vector regression. J. Appl. Remote Sens. 2015, 9, 095053. [Google Scholar] [CrossRef]
- Shen, Y.; Wang, Y.; Lv, H.; Qian, J. Removal of thin clouds in Landsat-8 OLI data with independent component analysis. Remote Sens. 2015, 7, 11481–11500. [Google Scholar] [CrossRef]
- Lv, H.; Wang, Y.; Gao, Y. Using independent component analysis and estimated thin-cloud reflectance to remove cloud effect on Landsat-8 oli band data. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 915–918. [Google Scholar] [CrossRef]
- Xu, M.; Jia, X.; Pickering, M.; Jia, S. Thin cloud removal from optical remote sensing images using the noise-adjusted principal components transform. ISPRS J. Photogramm. Remote Sens. 2019, 149, 215–225. [Google Scholar] [CrossRef]
- Hong, G.; Zhang, Y. Haze removal for new generation optical sensors. Int. J. Remote Sens. 2018, 39, 1491–1509. [Google Scholar] [CrossRef]
- Lv, H.; Wang, Y.; Shen, Y. An empirical and radiative transfer model based algorithm to remove thin clouds in visible bands. Remote Sens. Environ. 2016, 179, 183–195. [Google Scholar] [CrossRef]
- Lv, H.; Wang, Y.; Yang, Y. Modeling of thin-cloud TOA reflectance using empirical relationships and two Landsat-8 visible band data. IEEE Trans. Geosci. Remote Sens. 2018, 57, 839–850. [Google Scholar] [CrossRef]
- Xu, M.; Jia, X.; Pickering, M. Automatic cloud removal for Landsat 8 OLI images using cirrus band. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 2511–2514. [Google Scholar] [CrossRef]
- Zhou, B.; Wang, Y. A thin-cloud removal approach combining the cirrus band and RTM-based algorithm for Landsat-8 OLI data. In Proceedings of the 2019 IEEE Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 1434–1437. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Que, Y.; Dai, Y.; Jia, X.; Leung, A.K.; Chen, Z.; Tang, Y.; Jiang, Z. Automatic classification of asphalt pavement cracks using a novel integrated generative adversarial networks and improved VGG model. Eng. Struct. 2023, 277, 115406. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Wu, F.; Duan, J.; Ai, P.; Chen, Z.; Yang, Z.; Zou, X. Rachis detection and three-dimensional localization of cut off point for vision-based banana robot. Comput. Electron. Agric. 2022, 198, 107079. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar] [CrossRef]
- Li, W.; Li, Y.; Chen, D.; Chan, J.C.W. Thin cloud removal with residual symmetrical concatenation network. ISPRS J. Photogramm. Remote Sens. 2019, 153, 137–150. [Google Scholar] [CrossRef]
- Wen, X.; Pan, Z.; Hu, Y.; Liu, J. An effective network integrating residual learning and channel attention mechanism for thin cloud removal. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6507605. [Google Scholar] [CrossRef]
- Li, J.; Wu, Z.; Hu, Z.; Li, Z.; Wang, Y.; Molinier, M. Deep learning based thin cloud removal fusing vegetation red edge and short wave infrared spectral information for Sentinel-2A imagery. Remote Sens. 2021, 13, 157. [Google Scholar] [CrossRef]
- Zhou, Y.; Jing, W.; Wang, J.; Chen, G.; Scherer, R.; Damaševičius, R. MSAR-DefogNet: Lightweight cloud removal network for high resolution remote sensing images based on multi scale convolution. IET Image Process. 2022, 16, 659–668. [Google Scholar] [CrossRef]
- Ding, H.; Zi, Y.; Xie, F. Uncertainty-based thin cloud removal network via conditional variational autoencoders. In Proceedings of the 2022 Asian Conference on Computer Vision (ACCV), Macau SAR, China, 4–8 December 2022; pp. 469–485. [Google Scholar]
- Zheng, J.; Liu, X.Y.; Wang, X. Single image cloud removal using U-Net and generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6371–6385. [Google Scholar] [CrossRef]
- Xu, Z.; Wu, K.; Huang, L.; Wang, Q.; Ren, P. Cloudy image arithmetic: A cloudy scene synthesis paradigm with an application to deep-learning-based thin cloud removal. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Enomoto, K.; Sakurada, K.; Wang, W.; Fukui, H.; Matsuoka, M.; Nakamura, R.; Kawaguchi, N. Filmy cloud removal on satellite imagery with multispectral conditional generative adversarial nets. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 48–56. [Google Scholar] [CrossRef]
- Zhang, R.; Xie, F.; Chen, J. Single image thin cloud removal for remote sensing images based on conditional generative adversarial nets. In Proceedings of the Tenth International Conference on Digital Image Processing (ICDIP), Shanghai, China, 11–14 May 2018; Volume 10806, pp. 1400–1407. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar] [CrossRef]
- Wen, X.; Pan, Z.; Hu, Y.; Liu, J. Generative adversarial learning in YUV color space for thin cloud removal on satellite imagery. Remote Sens. 2021, 13, 1079. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, X.; Yu, Q.; Ma, C. An improved method for removal of thin clouds in remote sensing images by generative adversarial network. In Proceedings of the 2022 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 6706–6709. [Google Scholar] [CrossRef]
- Pan, H. Cloud removal for remote sensing imagery via spatial attention generative adversarial network. arXiv 2020, arXiv:2009.13015. [Google Scholar] [CrossRef]
- Chen, H.; Chen, R.; Li, N. Attentive generative adversarial network for removing thin cloud from a single remote sensing image. IET Image Process. 2021, 15, 856–867. [Google Scholar] [CrossRef]
- Xu, M.; Deng, F.; Jia, S.; Jia, X.; Plaza, A.J. Attention mechanism-based generative adversarial networks for cloud removal in Landsat images. Remote Sens. Environ. 2022, 271, 112902. [Google Scholar] [CrossRef]
- Xu, Z.; Wu, K.; Ren, P. Recovering thin cloud covered regions in GF satellite images based on cloudy image arithmetic+. In Proceedings of the 2022 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 1800–1803. [Google Scholar] [CrossRef]
- Zi, Y.; Xie, F.; Zhang, N.; Jiang, Z.; Zhu, W.; Zhang, H. Thin cloud removal for multispectral remote sensing images using convolutional neural networks combined with an imaging model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3811–3823. [Google Scholar] [CrossRef]
- Yu, W.; Zhang, X.; Pun, M.O.; Liu, M. A hybrid model-based and data-driven approach for cloud removal in satellite imagery using multi-scale distortion-aware networks. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 7160–7163. [Google Scholar] [CrossRef]
- Yu, W.; Zhang, X.; Pun, M.O. Cloud removal in optical remote sensing imagery using multiscale distortion-aware networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5512605. [Google Scholar] [CrossRef]
- Li, J.; Wu, Z.; Hu, Z.; Zhang, J.; Li, M.; Mo, L.; Molinier, M. Thin cloud removal in optical remote sensing images based on generative adversarial networks and physical model of cloud distortion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 373–389. [Google Scholar] [CrossRef]
- Zi, Y.; Xie, F.; Song, X.; Jiang, Z.; Zhang, H. Thin cloud removal for remote sensing images using a physical-model-based CycleGAN with unpaired data. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Yu, H.; Zheng, N.; Zhou, M.; Huang, J.; Xiao, Z.; Zhao, F. Frequency and spatial dual guidance for image dehazing. In Proceedings of the 2022 European Conference on Computer Vision (ECCV), Tel-Aviv, Israel, 23–27 October 2022; pp. 181–198. [Google Scholar] [CrossRef]
- Li, Q.; Shen, L.; Guo, S.; Lai, Z. Wavelet integrated CNNs for noise-robust image classification. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7243–7252. [Google Scholar] [CrossRef]
- Huang, H.; He, R.; Sun, Z.; Tan, T. Wavelet-SRNet: A wavelet-based CNN for multi-scale face super resolution. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1698–1706. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level wavelet-CNN for image restoration. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 773–782. [Google Scholar] [CrossRef]
- Chang, Y.; Chen, M.; Yan, L.; Zhao, X.L.; Li, Y.; Zhong, S. Toward universal stripe removal via wavelet-based deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2880–2897. [Google Scholar] [CrossRef]
- Guan, J.; Lai, R.; Xiong, A. Wavelet deep neural network for stripe noise removal. IEEE Access 2019, 7, 44544–44554. [Google Scholar] [CrossRef]
- Chen, W.T.; Fang, H.Y.; Hsieh, C.L.; Tsai, C.C.; Chen, I.H.; Ding, J.J.; Kuo, S.Y. ALL snow removed: Single image desnowing algorithm using hierarchical dual-tree complex wavelet representation and contradict channel loss. In Proceedings of the 2021 IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 4176–4185. [Google Scholar] [CrossRef]
- Yang, M.; Wang, Z.; Chi, Z.; Feng, W. WaveGAN: Frequency-aware GAN for high-fidelity few-shot image generation. In Proceedings of the 2022 European Conference on Computer Vision (ECCV), Tel-Aviv, Israel, 23–27 October 2022; pp. 1–17. [Google Scholar] [CrossRef]
- Haar, A. Zur theorie der orthogonalen funktionensysteme. Math. Ann. 1911, 71, 38–53. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar] [CrossRef]
- Gondal, M.W.; Scholkopf, B.; Hirsch, M. The unreasonable effectiveness of texture transfer for single image super-resolution. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 80–97. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar] [CrossRef]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A remote sensing image dataset for cloud removal. arXiv 2019, arXiv:1901.00600. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Luo, M.R.; Cui, G.; Rigg, B. The development of the CIE 2000 colour-difference formula: CIEDE2000. Color Res. Appl. 2001, 26, 340–350. [Google Scholar] [CrossRef]
- Sharma, G.; Wu, W.; Dalal, E.N. The CIEDE2000 color-difference formula: Implementation notes, supplementary test data, and mathematical observations. Color Res. Appl. 2005, 30, 21–30. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Source | Size | Training | Test | Type |
|---|---|---|---|---|---|
| T-CLOUD | Landsat 8 | 2351 | 588 | Nonuniform | |
| RICE1 | Google Earth | 400 | 100 | Uniform | |
| WHUS2-CR | Sentinel-2A | 4000 | 1000 | Nonuniform |
| Architecture | PSNR↑ | SSIM↑ | CIEDE2000↓ |
|---|---|---|---|
| Plane | 30.15 | 0.8681 | 3.7293 |
| Hourglass1 | 29.45 | 0.8492 | 4.1804 |
| Hourglass2 | 30.43 | 0.8676 | 3.6911 |
| WaveCNN-CR | 31.01 | 0.8813 | 3.4262 |
| EFEM | PSNR↑ | SSIM↑ | CIEDE2000↓ |
|---|---|---|---|
| ARB_ARB | 28.41 | 0.8440 | 4.3556 |
| GRB_GRB | 30.58 | 0.8783 | 3.5269 |
| GRB_ARB | 30.85 | 0.8792 | 3.4644 |
| Ours(ARB_GRB) | 31.01 | 0.8813 | 3.4262 |
| Block | PSNR↑ | SSIM↑ | CIEDE2000↓ |
|---|---|---|---|
| CB | 28.65 | 0.8547 | 4.2068 |
| AB | 29.14 | 0.8359 | 4.3878 |
| RB | 28.84 | 0.8600 | 4.1158 |
| ARB_SE | 30.64 | 0.8777 | 3.5421 |
| ARB_CBAM | 30.27 | 0.8742 | 3.6667 |
| Ours(ARB_CAB) | 31.01 | 0.8813 | 3.4262 |
| Block | PSNR↑ | SSIM↑ | CIEDE2000↓ |
|---|---|---|---|
| CB | 26.80 | 0.8134 | 5.2177 |
| GB | 25.50 | 0.7727 | 5.9063 |
| RB | 29.68 | 0.8626 | 3.9105 |
| Ours(GRB) | 31.01 | 0.8813 | 3.4262 |
| Method | PSNR↑ | SSIM↑ | CIEDE2000↓ |
|---|---|---|---|
| RSC-Net [33] | 23.98 | 0.7596 | 7.0502 |
| MCRN [50] | 26.60 | 0.8091 | 5.5816 |
| MSAR-DefogNet [36] | 28.84 | 0.8432 | 4.1862 |
| RCA-Net [34] | 28.69 | 0.8443 | 4.3708 |
| SpA-GAN [45] | 27.15 | 0.8145 | 4.9107 |
| UNet-GAN [38] | 23.71 | 0.7630 | 7.6156 |
| MS-GAN [39] | 24.04 | 0.7228 | 7.8543 |
| Color-GAN [44] | 24.01 | 0.7490 | 6.9769 |
| AMGAN-CR [47] | 27.85 | 0.8317 | 4.5691 |
| WaveCNN-CR | 31.21 | 0.8838 | 3.3479 |
| Method | PSNR↑ | SSIM↑ | CIEDE2000↓ |
|---|---|---|---|
| RSC-Net [33] | 21.34 | 0.8150 | 8.3078 |
| MCRN [50] | 31.09 | 0.9465 | 3.3767 |
| MSAR-DefogNet [36] | 33.58 | 0.9534 | 2.7066 |
| RCA-Net [34] | 32.49 | 0.9537 | 2.2334 |
| SpA-GAN [45] | 29.62 | 0.8844 | 4.3374 |
| UNet-GAN [38] | 23.92 | 0.8085 | 7.6766 |
| MS-GAN [39] | 27.74 | 0.8796 | 5.6267 |
| Color-GAN [44] | 21.57 | 0.8065 | 8.5284 |
| AMGAN-CR [47] | 29.05 | 0.8965 | 4.4694 |
| WaveCNN-CR | 35.74 | 0.9650 | 1.7922 |
| Method | PSNR↑ | SSIM↑ | CIEDE2000↓ |
|---|---|---|---|
| RSC-Net [33] | 29.03 | 0.9056 | 4.6571 |
| MCRN [50] | 28.81 | 0.9163 | 4.7939 |
| MSAR-DefogNet [36] | 29.89 | 0.9168 | 5.2028 |
| RCA-Net [34] | 29.57 | 0.9128 | 4.4211 |
| SpA-GAN [45] | 28.78 | 0.8887 | 4.7904 |
| UNet-GAN [38] | 29.58 | 0.9008 | 5.1388 |
| MS-GAN [39] | 27.59 | 0.8560 | 6.2101 |
| Color-GAN [44] | 29.24 | 0.9020 | 4.7212 |
| AMGAN-CR [47] | 28.82 | 0.8672 | 4.9061 |
| WaveCNN-CR | 30.29 | 0.9318 | 4.1469 |
| Method | T-CLOUD | RICE1 | WHUS2-CR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Red | Green | Blue | Red | Green | Blue | Red | Green | Blue | |
| Input | 101.31 | 96.71 | 106.93 | 131.09 | 130.98 | 127.39 | 80.89 | 87.73 | 98.41 |
| RSC-Net [33] | 67.12 | 62.52 | 69.52 | 128.08 | 124.34 | 114.84 | 64.54 | 68.89 | 75.71 |
| MCRN [50] | 70.55 | 63.31 | 69.93 | 118.80 | 118.29 | 105.75 | 66.20 | 69.84 | 75.30 |
| MSAR-DefogNet [36] | 71.77 | 65.64 | 71.95 | 122.96 | 120.69 | 110.56 | 66.18 | 70.49 | 76.18 |
| RCA-Net [34] | 69.64 | 64.42 | 70.24 | 121.06 | 119.94 | 108.56 | 66.64 | 71.25 | 76.99 |
| SpA-GAN [45] | 69.96 | 64.27 | 70.78 | 121.56 | 121.36 | 110.28 | 66.52 | 72.74 | 78.78 |
| UNet-GAN [38] | 67.24 | 62.31 | 72.29 | 125.87 | 123.24 | 117.82 | 64.08 | 69.22 | 75.87 |
| MS-GAN [39] | 66.92 | 62.19 | 69.60 | 118.87 | 116.90 | 107.60 | 62.92 | 67.85 | 73.04 |
| Color-GAN [44] | 69.94 | 63.96 | 71.16 | 119.16 | 123.26 | 108.43 | 64.18 | 68.28 | 75.67 |
| AMGAN-CR [47] | 70.14 | 64.48 | 70.93 | 122.04 | 120.38 | 109.37 | 66.01 | 69.75 | 74.57 |
| WaveCNN-CR | 70.78 | 64.88 | 71.13 | 122.34 | 120.43 | 109.70 | 65.05 | 69.79 | 75.00 |
| Reference | 71.09 | 65.14 | 71.35 | 122.48 | 120.68 | 109.85 | 64.59 | 70.03 | 76.45 |
| Image | Parameters (M) | FLOPs (G) | Test Time (ms) |
|---|---|---|---|
| RSC-Net [33] | 0.11 | 14.84 | 8.06 |
| MCRN [50] | 1.41 | 94.90 | 44.68 |
| MSAR-DefogNet [36] | 0.80 | 104.90 | 6.11 |
| RCA-Net [34] | 2.27 | 401.79 | 21.33 |
| SpA-GAN [45] | 0.21 | 33.97 | 19.03 |
| UNet-GAN [38] | 3.31 | 11.83 | 4.89 |
| MS-GAN [39] | 8.08 | 44.27 | 10.83 |
| Color-GAN [44] | 0.51 | 9.95 | 5.58 |
| AMGAN-CR [47] | 0.29 | 96.96 | 16.05 |
| WaveCNN-CR | 30.38 | 395.09 | 40.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zi, Y.; Ding, H.; Xie, F.; Jiang, Z.; Song, X. Wavelet Integrated Convolutional Neural Network for Thin Cloud Removal in Remote Sensing Images. Remote Sens. 2023, 15, 781. https://doi.org/10.3390/rs15030781
Zi Y, Ding H, Xie F, Jiang Z, Song X. Wavelet Integrated Convolutional Neural Network for Thin Cloud Removal in Remote Sensing Images. Remote Sensing. 2023; 15(3):781. https://doi.org/10.3390/rs15030781
Chicago/Turabian StyleZi, Yue, Haidong Ding, Fengying Xie, Zhiguo Jiang, and Xuedong Song. 2023. "Wavelet Integrated Convolutional Neural Network for Thin Cloud Removal in Remote Sensing Images" Remote Sensing 15, no. 3: 781. https://doi.org/10.3390/rs15030781
APA StyleZi, Y., Ding, H., Xie, F., Jiang, Z., & Song, X. (2023). Wavelet Integrated Convolutional Neural Network for Thin Cloud Removal in Remote Sensing Images. Remote Sensing, 15(3), 781. https://doi.org/10.3390/rs15030781