Abstract
Attenuation is often significant during seismic wave propagation in the subsurface, leading to the reduced resolution and narrower bandwidth of seismic images. Traditional corrections for such effects are inverse-Q filtering and deconvolution, which require a high signal-to-noise ratio (SNR) to avoid noise boost-up. Here, we propose a time-domain method offering advantages in the resolution and interpretational quality of the resulting images. Similar to wavelet transforms, the iterative time-domain deconvolution (ITD) represents the seismogram by a superposition of non-stationary source wavelets modeled in the appropriate attenuation model. Arbitrary frequency-dependent Q and velocity dispersion laws can be used and non-Q type attenuation can be caused by focusing, defocusing, scattering, effects of fine layering, and fluctuations of the wavefield. Compared to inverse-Q filtering and some deconvolution methods, the method does not boost high-frequency noise and is less sensitive to the accuracy of the Q model. We illustrate and compare this method to inverse-Q filtering by using several synthetic and real data examples. The tests include noise-contaminated data, inaccurate Q models, and variable source wavelets. The examples show that the ITD is a practical and effective tool for Q-compensation with a broad scope of potential applications, albeit with some defects. An important benefit of ITD that other methods may not possess could be the ability to utilize geological information, such as locations and sparseness of major reflectors or the presence of interpreted Q contrasts, which might be able to further improve the performance of ITD.
1. Introduction
Seismic waves are affected by attenuation and dispersion caused by the inelasticity of the subsurface. In reflection seismic imaging, these effects are adverse and result in frequency-dependent amplitude reduction, the narrowing down of the frequency bandwidths, and phase distortions. Attenuation effects decrease the resolution of reflection seismic images, especially within deeper parts of the sections [1,2]. Attenuation effects may also cause difficulties in imaging and interpretation, such as in horizontal event tracking and the identification of fine structures.
By studying the attenuation and dispersion in seismic records, two complementary objectives can be achieved: (1) measuring these effects and including them in interpretation and (2) their removal from final images. For the first objective, detailed knowledge of attenuation mechanisms is required [3,4,5,6]. However, in most practical studies, detailed knowledge of the layering or the rock-physics mechanisms of internal friction is not available, and its determination is a subject of many studies. Nevertheless, even when the physical mechanisms are poorly known, attenuation and dispersion effects can be modeled (and corrected) empirically by constructing time-dependent attenuation operators (Section 2) [1,2,7,8]. Generally, this correction represents a type of deconvolution of the empirical attenuation filter from the data [7,8].
In seismology, the term deconvolution in general is related to inverse filtering where the filter operator is designed to change the shape of the primary source wavelet. The deconvolution of attenuation and dispersion effects is an inverse filtering process that attempts to remove the linear filtering imposed on the wavelet by the Earth. By removing such linear filtering, deconvolution results are likely to provide more recognizable reflection events with higher resolution [9]. Numerous methods of deconvolution exist, each offering certain advantages in specific applications. In particular, for amplitude-only corrections in Q-compensation, time-variant spectral whitening is a simple and convenient method not requiring the knowledge of a Q. In this case, the time-variant deconvolution is zero-phase, with power response approximated by an inverse of the time-variant power of the data (which is close to Wiener deconvolution). To implement this deconvolution, time-domain seismic data are first decomposed into time-frequency panels by using a series of narrow band-pass filters, and then the spectral amplitudes are equalized at all times [10]. Another broadly used method for correcting attenuation and dispersion effects is inverse-Q filtering [7]. This filtering can also be viewed as deconvolution [11], although Hargreaves and Calvert note that its treatment of frequency components is also analogous to Stolt migration [12]. As with all types of frequency-domain deconvolutions, this method faces problems of noise and instabilities related to amplifying high-frequency components of records.
In this paper, we propose a simple iterative algorithm popular in earthquake seismology [13,14] that is less sensitive to high-frequency noise and can use arbitrary frequency-dependent Q and velocity dispersion law and non-Q type attenuation. This algorithm is called the iterative time-domain deconvolution (ITD) hereafter in this paper. ITD represents the seismogram as a superposition of non-stationary source wavelets modeled using an appropriate empirical attenuation model. Due to the use of an iterative data-fitting procedure in the time domain, this approach can be viewed as a wavelet transform or matching-pursuit algorithm based on modeling the source waveform propagating throughout the section. Time-domain formulation encourages the application of numerous ideas beyond the traditional Q-compensation, such as combining multiple, true physical mechanisms of attenuation, scattering, geometrical spreading, or deconvolution starting from stronger reflectors (as conducted by ITD). As a method using time-domain waveform matching, ITD can (in principle) incorporate additional information derived from geology, stacked seismic data, or well logs, such as positions and sparseness of major reflectors or their sharp or gradational characters.
2. Methods
In time-variant deconvolution, a recorded seismic waveform can be regarded as a function of two times defined at different scales: the two-way reflection time t0 characterizing the depth of recording and the “local” wave time t near t0. The phase of the wave quickly varies with t, whereas the amplitude and spectral attributes (such as Q) vary comparatively slowly with t0. We implemented this hierarchy of time scales by windowing the data using a sequence of overlapping time windows, as is often done in time-variant filtering of seismic records [10]. Each windowed data (denoted ) and reflectivity () record was characterized by the time at its center t0 and contained a Hanning taper applied to the respective continuous record. The tapered time windows were constructed so that the continuous reflectivity series represented a sum of windowed records: , with analogous relations for data records before and after correction for attenuation [8].
Linear interpolation of the windowed records was conducted using the dependences at relatively sparsely sampled times t0, which greatly reduced the computational cost [8]. The sufficiency of a sparsely-sampled sequence of times t0 implied a relatively smooth variation of Q with depth. This requirement may appear somewhat stringent and unexpected, considering that layered Q models are often used in inverse-Q filtering [1,12]. However, based on fundamental observations by White [15], Morozov and Baharvand Ahmadi suggested that Q is not a property of the medium but always an apparent property of a wave in it [16]. Therefore, the Q cannot be rigorously defined as a localized physical parameter of the medium, and it can only be measured by averaging over significant time intervals (coherence length of the wave) [15]. Due to this averaging, measurable Q models are always inherently smooth in time and space. Arbitrarily layered viscoelastic-Q models can still be formally used in ITD, similarly to inverse-Q filtering [1,12]; however, uncertainties in interpreting the reflectivity on sharp Q contrasts arise in this case [17].
The seismogram within a window centered at time t0 can be represented by a convolution of the propagating source waveform and the reflectivity series :
where dependences on t are now implied in all factors, and symbol ‘∗’ denotes the convolution operation with respect to time t. For simplicity, we omitted the additive noise in this convolutional model. Note that the “reflectivity” series may not necessarily represent only the normal-incidence reflection coefficients within the subsurface. The only definitive property required by Equation (1) is that the record contains all information from that is not accounted for by the modeled attenuating source waveform . For example, can be the propagating waveform of a direct wave, in which case would represent the near-source reverberations and multiples. If contains amplitude and/or Q variations with offset (AVO or QVO) effects [18], multiples, or other types of coherent noise, these effects would be corrected in . However, in common practice and examples in this paper, predominantly layered Q models are considered, and, consequently, the AVO and QVO effects remain in and the resulting Q-compensated below.
The notion of the “source waveform” in Equation (1) must also be carefully understood. The seismic wavefield is formed at a significant distance from the source (“far field”), where the deformation of the medium becomes linear and reflections, conversions, and reverberations within the near-surface form a consistent spreading pattern [9]. Scattering, attenuation (Q−1), and spectral-fluctuation effects can also be extremely high in the proximity of the weathering layer [16,19,20]. Thus, can only be assessed at a certain distance from the source. As a practical proxy for this distance, we used the time of the uppermost portion of the reflection record. As discussed below and in Section 5, this source waveform can generally be estimated from the data and denoted . By increasing the two-way time t0, this waveform is modified through multiple propagation mechanisms (refraction, reflection, mode conversion, and attenuation) and becomes the time-variant waveform [8].
Let us now denote an analogous “elastic” source waveform (defined in the sense of the preceding paragraph) that would have been observed in the absence of attenuation. The corresponding seismic record would be related to it by the same convolutional model:
The actual and can then be related to and by a linear attenuation filter [7,8]:
The goal of attenuation compensation is to invert the second equation in (3) for the “elastic” data . This inversion is conventionally conducted in the frequency domain, in which the local time t is replaced with angular frequency and the convolution becomes multiplication:
According to the usual convention, uppercase letters here represent Fourier transforms of the corresponding time-domain functions. Note that in contrast to the Fourier formulation of time-variant filtering by Margrave [21], we did not transform t0 to its counterpart frequency variable, and the multiplication in the right-hand side of Equation (4) did not become convolution.
Frequency dependences of the complex-valued attenuation/dispersion spectrum can be complex and contain effects such as source-receiver coupling, geometric spreading, tuning, and inelasticity. Morozov et al. described all these effects as a superposition of linear filters [8]. In this paper, we only focus on the “attenuation” filter, the action of which can be lumped in a phenomenological quality factor Q. Such filters are usually taken in several standard forms determined by the Q-factor alone [1]. For example, the constant-Q model is as follows [22]:
where ω0 is a reference frequency.
Equation (5) shows that in an anelastic medium, the source wavelet and data amplitudes are reduced by a factor of after a two-way travel time t0. The phases of the wave are shifted by , which must be compared to for an elastic medium. Therefore, the phase shift due to dispersion equals . From Equations (4) and (5), the Q-compensated waveform is as follows:
The frequency-domain inverse (6) is used in the inverse-Q filtering of seismic data [1,7]. However, the evaluation of in Equation (7) contains a division of the spectra, which is often unstable and increases noise at high frequencies. Such undesirable effects can be reduced by restricting the maximum amplitude of (7) or using other regularization approaches [1,7,12,23]. For the following discussion, note that this regularization is always achieved by replacing the exact inverse operator (7) with some approximation, reducing its response at high frequencies, such as by using the stabilization factor or restricting the maximum gain by [1].
Here, we propose a different approximate solution for Q-compensated data (6) by using an iterative time-domain deconvolution (ITD) method. Instead of solving the inverse problem for operator A−1 in (7) in the frequency domain, this method performs the transformation (or equivalently, ) directly by iteratively performing cross-correlations with the forward-modeled wavelet in the time domain. In this method, the “reflectivity” series within a window centered at t0 is approximated by a series of pulses with amplitudes located at times :
where is the delta function. The number of pulses N per time window is either set by the analyst or selected adaptively based on the waveform energy criteria described below. With few pulses, only the strongest reflections are reproduced, and with large N, the complete reflection series is retained. By substituting Equation (8) for (1), the seismic record is presented by a superposition of wavelets of amplitudes ri and placed at times τi:
Instead of seeking a potentially unstable inverse of the wavelet (7), we solved Equation (9) for the “reflectivity” series by using a synthetic wavelet modeled at time t0 by utilizing an appropriate combination of attenuation mechanisms. The search for ri(t0) and was iterative, starting from the largest value of [14]. The corresponding time τ1 was found by the maximum cross-correlation between the data and the modeled (attenuated) source waveform: . The associated reflectivity amplitude was then given by the peak of cross-correlation:
The remaining reflectivity parameters, and , were found by subtracting the prediction of the first peak from the waveform as follows:
The same operations were then repeated with d1(t,t0) and continued iteratively, with residual waveforms at the n-th step defined by .
In ITD procedures (10) and (11), the strongest contributors to signal (9) were found first and the iteration could be stopped based on several criteria. The simplest practical approach is to restrict the number of pulses N in the resulting solution (Equation (9)). The selection of N not only helps promote the sparsity of the restored signal but also possesses the advantage of preferential recovery of the strongest reflections. The residual energy after the n-th iteration is defined as follows:
It can be used to evaluate what portion of the input signal is passed by the ITD filter. This parameter can also be used as a threshold for stopping the iterations.
By convolving the resulting “reflectivity” series with the “elastic” source waveform , we obtained the desired Q-compensated data record :
Note that a different “shaping” wavelet can be used instead of in this equation, enabling, for example, wavelet phase transformations [8].
As shown in Equations (13) through (15) and (17), the result of ITD depends on the estimated source waveform . Thus, the ITD can be described as not purely a Q-correction procedure but rather attenuated-signal detection or shaping to the signal that would have been observed in an elastic medium. This difference leads to additional requirements for the algorithm but also somewhat different goals and advantages compared to inverse-Q filtering. The additional requirements of ITD are the need to set the waveform and specify the parameters of the iterative search, such as the selection of the cutoff. In reflection seismic data processing, the source waveform can be estimated by blind or well-log-based methods for stationary and non-stationary signals [24,25]. Some of these methods are discussed in Section 5. In real-data examples (Section 4), we bypass the complications due to signal non-stationarity by measuring the near-source waveform ( at small t0) in inverse-Q filtered records [8]. After inverse-Q filtering, the underlying source waveform becomes near-stationary and can be estimated with greater confidence by making zero- or minimum-phase assumptions [24]. Once the near-source waveform is estimated, the ITD can be used to produce an “elastic” section.
The key advantages of deconvolution (13) compared to (6) are the absence of inverse operator and the identification of the underlying “reflection” sequence that can be analyzed and potentially interpreted. As shown in Section 3 and Section 4, spectral properties of the ITD-corrected wavefield are principally controlled by the source waveform, and, hence, the ITD does not boost the high-frequency noise more than the low-frequency one. Due to its working from the stronger reflections to the weaker ones, the procedure is also less sensitive to errors in Q.
3. Numerical Experiments
To illustrate the operation and performance of ITD in reflection imaging, we conducted a series of simple numerical tests using 1-D synthetic seismograms (Section 3.1, Section 3.2, Section 3.3, Section 3.4 and Section 3.5) and employed a more realistic example using one common mid-point (CMP) from the Marmousi-II model (Section 3.6). In the sparse-reflector tests, we arbitrarily selected 1500-ms long records containing five reflectors (Table 1) illuminated by a 30-Hz zero-phase Ricker wavelet as the source. An elastic waveform with Q = ∞ is shown in Figure 1a. The lengths of overlapping time windows for ITD were selected equal 200 ms. The results were compared to those of the conventional inverse-Q filtering method.

Table 1.
Reflection amplitude model for numerical experiments.
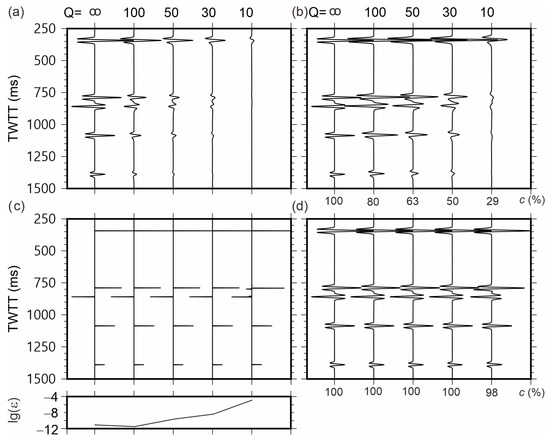
Figure 1.
Test of Q-compensation methods using noise-free data: (a) data with Q = ∞, 100, 50, 30, and 10 (trace labels) obtained by forward modeling in the reflectivity model in Table 1; (b) stabilized inverse-Q filtering; (c) reflectivity model produced by ITD; (d) waveforms Q-corrected by ITD. For Q ≥ 30, this model also exactly corresponded to the input reflectivity model labeled by Q = ∞. Below plot (c), a graph of logarithms of residual data energies is shown (Equation (12)). Label TWTT denotes the two-way travel time.
3.1. Test with Noise-Free Data
For noise-free input data (Figure 1a), ITD results are shown in Figure 1c,d and compared to inverse-Q filtering results (Figure 1b). Inverse-Q filtering with a stabilization factor equal to 0.005 showed good corrections for most of the energy loss for weak attenuation (Q = 100; Figure 1b). For relatively strong attenuation (Q = 50, 30, and 10), the inverse-Q filter recovered the shallow parts of the records well, but the deeper parts were no as well recovered (Figure 1b). With Q = 100, the signal was recovered reasonably well. For these inverse-Q filtered results, the imperfect correction was due to high-frequency signal components being limited by the stabilization factor [1]. This phenomenon became stronger with decreasing Q or increasing travel times (Figure 1b). The amplitudes recovered by ITD equaled the true reflectivities at all attenuation rates Q > 10 (Figure 1d). This was expected because the times of reflections were practically accurately identified already in the first iteration of the procedure (11). For Q = 10, the reflectivities of the two opposite-polarity reflections within the range of t = 790 to 860 ms were over-estimated (Figure 1d). This overestimation was caused by the interference of these reflections at low frequencies. By convolving the ITD-inverted reflectivity with the known source wavelet, Q-corrected waveforms were obtained (Figure 1c). The low levels of residual energy are shown below.
Figure 1c indicates that all events were detected in the data well. A comparison of Figure 1b,d shows that ITD accurately corrected the amplitudes and phases of the high-frequency components that were affected by regularization in inverse-Q filtering.
This example suggests that a distinctive feature of the ITD over inverse-Q filtering is that a reflectivity model can be inverted by the ITD. Then, the compensated signals can be obtained by convolving this reflectivity model with a source wavelet. In principle, one can also apply a broadband filter to convolve with the reflectivity model so that reflections with much higher resolutions can be obtained. This feature can be practically useful for the high-resolution data processing usually implemented for fine structure detection.
3.2. Tests with Noisy Data
To test the sensitivity of the method to additive noise, white Gaussian noise was added to the seismograms with Q = 10 and 50 in Figure 1a. The SNR was defined in these tests as follows:
where and are the powers of the signal and noise, respectively, evaluated over the entire time interval. With strong attenuation (Q = 10, Figure 2a), all levels of noise strongly affected the reflections below 0.5 s. When Q = 50, the reflections were strongly affected when SNR was below 9 dB.

Figure 2.
Seismograms with (a) Q = 10, (b) Q = 50 in Figure 1a with added Gaussian random noise. Trace labels show the signal-to-noise ratios (SNR) in the records.
Figure 3 and Figure 4 compare the results of Q-compensation of the data in Figure 2 by using the inverse-Q filtering and ITD approaches, respectively. In these cases, the stabilization factor in inverse-Q filtering selected was equal 0.04 and an additional bandpass filter was applied to reduce the boosted high-frequency noise. Compared to Figure 3, the ITD with N = 8 achieved better results (Figure 4). For Q = 10, inverse-Q filtering recovered the reflection at t = 344 ms (Figure 3a) reasonably well, but reflections below this time level were barely recovered, and the noise was also amplified. Even with high SNR, the reflections below 0.5 s still could not be recovered well. Due to the selected length of the inverse-Q filter and its regularization, the records resembled those processed by automatic gain control (AGC) (Figure 3). This AGC-like effect occurred because the travel time increased and the SNR reduced within the later time windows, and, consequently, the relative boosting of high-frequency noise increased in the inverse-Q filter. By contrast, ITD recovered the first three reflections well at all SNR levels (Figure 4a). When SNR > 5 dB, ITD recovered the first four reflections, and for SNR = 21 dB, all reflections were recovered.

Figure 3.
Results obtained by stabilized inverse-Q filtering: (a) Q = 10, (b) Q = 50. Note that the amplitudes of noise increase to the bottom of the section, resembling an automatic gain control (AGC) effect.

Figure 4.
Seismograms obtained by ITD inversion of the data in Figure 3: (a) model with Q = 10, (b) Q = 50. The curve below each graph is the logarithm of the residual energy defined by Equation (12).
For weaker attenuation with Q = 50, inverse-Q filtering recovered the first four reflections at almost all SNRs. However, at low SNR levels, the inverse-Q filter still over-amplified the noise (for example, for SNR < 13 dB). By contrast, the ITD not only recovered the reflections but also filtered out the noise, which helped improve the images (Figure 4b).
The residual data error ε(N) below each graph in Figure 4 showed a decreasing trend with increasing SNR levels but did not depend on Q. For low SNR levels, the increased ε(N) values were due to two factors: biases in measuring reflectivity amplitudes and misdetection of noise pulses as signals. With increasing SNRs, the signal was recovered more accurately, and the noise was rejected.
Seismic data interpretation can benefit not only from corrections for Q effects but also from direct deconvolution for reflectivity, which is an intermediate step of ITD (Equation (10)). Figure 5 shows that, as expected, such reflectivity images became clearer and more accurate with increasing SNR and Q. Such reflectivity images with stronger reflectors can be useful for interpretation.
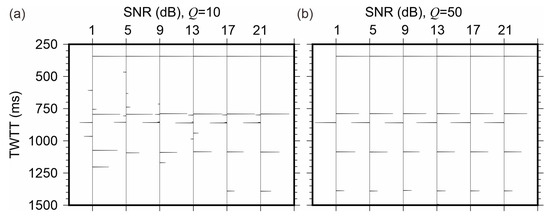
Figure 5.
Reflectivity records obtained by ITD inversion, corresponding to Q-compensated waveforms in Figure 4: (a) Q = 10, (b) Q = 50.
3.3. Test of Inaccurate Q
The causes of wave attenuation are complex and often poorly understood. As a result, Q is usually an apparent (wave-dependent) property, and its measurements have an inherently limited accuracy [15,16]. It is, therefore, important to check how the different Q-compensation methods respond to inaccurate Q models. In Figure 6a, we re-plotted the noise-free waveform with Q = 50 (Figure 1a). Then, we assumed that the Q used in ITD forward modeling and inversion equaled 20, 40, 50, 60, or 80 (Section 2; Figure 6b–f). In each of these examples, the error in the modeled level of attenuation was defined as follows:
ranging from −38% to +150%.

Figure 6.
Test for an inaccurate Q used in ITD: (a) noise-free and noise-contaminated data with Q = 50 and SNR = 10 dB; (b) inverse-Q filtering result using noise-free data; (c) reflectivity model inverted by ITD; (d) ITD-corrected waveform using noise-free data; (e) reflectivity model inverted by ITD with noise-contaminated data; (f) the corresponding ITD-corrected waveforms. Trace labels show the relative errors of the Q−1 used for modeling and inversion.
Both inverse-Q filtering and ITD were applied to the synthetic data with variable assumed Q levels (Figure 6). When the assumed Q was much smaller than the correct one (error = +150%), inverse-Q filtering showed very good compensation results in the deeper part (Figure 6b) but overcorrected the shallow part. To measure the quality of compensation, we used the correlation coefficient c defined by
Here, d and del denote the vector form of d(t, t0) and del(t, t0), respectively, ‘∙’ denotes the inner product of two such vectors, and “∥d∥” is the Euclidean norm of d. The correlation coefficient (denoted by c in the bottom of each graph in Figure 6) shows that, with error ranging from +150% to −38%, the similarity between source waveform and those obtained by inverse-Q filtering increased (Figure 6b), and the correlation coefficient changed from 0.31 to 0.76.
With the assumed Q value much lower than the correct one (error = +150%), ITD over-amplified the reflection from the deeper parts of the record but reasonably recovered the shallower reflections (Figure 6c,d). When the assumed Q approached its correct value, both the waveforms and reflectivity were close to the reference waveform and reflectivity, and the correlation coefficient approached 1. For Q errors from −38% to +25% (Figure 6d), the correlation coefficient c for waveforms was above 0.90. This appeared to be a good level of tolerance to Q uncertainty for practical applications, and, therefore, we suggest that the correlation level of c ≥ 0.90 can be used as a waveform criterion of model-parameter sensitivity. When applied to inverting for reflectivity (Figure 6c), this criterion shows that ITD can tolerate −38% to almost +25% errors in Q.
It is also important to assess the influence of noise in the presence of inaccurately known Q within the subsurface. To measure this influence, white Gaussian noise is added to the record in Figure 6a with SNR = 10 dB, which is also shown in Figure 6a. With these strongly noise-contaminated data, the corrected waveforms and reflectivity with inaccurately known Qs are shown in Figure 6c,f. Again, considering the correlation coefficient above 90% as acceptable, the ITD tolerated Q−1 errors from −38% to 25% for waveforms and reflectivity. Because random noise was suppressed by ITD deconvolution, even with accurately estimated Q (error equals 0% in Equation (15)), the correlation coefficient for reflectivity was only 91%. A closer inspection of the records showed that this reduced correlation was mainly due to the inverted reflectivity within the deeper part being shifted by one or two milliseconds in the presence of noise. However, Figure 6e shows that when the error in Q−1 ranged from approximately −38% to +25%, the reflectivity was recovered very well except for several weak spurious values. The restored waveform had a high correlation coefficient (between 97% and 99%) if the estimated Q lay from –38% to 25% away from the exact Q (Figure 6f). This reduced sensitivity to Q was due to convolution with the source wavelet, reducing the effects of high-frequency differences among the reflectivity series in Figure 6e. This reduced sensitivity was related to the limited accuracy of measuring Q from time-range limited records [15,16].
In summary of the above noise and Q testing, compared to inverse-Q filtering, the ITD appeared to be less sensitive to inaccurate Q models even in the presence of random noise. Additionally, the character of noise remaining in ITD-filtered sections differed from the one in inverse-Q filtered records. Instead of amplifying high-frequency noise, the ITD made the noise more “sparse”, appearing like uncorrelated random pulses in the seismic section. Interestingly, uncertainties in the assumed background Q led to inverting for fine layering with alternating polarities near the reflectors (Figure 6c,e) [17]. Due to the absence of direct sensitivity to frequency, the ITD did not increase the “ringiness” of seismic records.
3.4. Test of Inaccurate Source Wavelet
ITD requires the knowledge of a source wavelet, and the wavelet estimated from seismic data may be inaccurate (a discussion of wavelet estimation methods is provided in Section 5). Therefore, it is necessary to understand how the accuracy of wavelet parameters influences the performance of ITD. In this subsection, two numerical tests for the effects of wavelet phase and peak frequency are discussed. For these two experiments, a noise-free record with a 30-Hz zero-phase Ricker wavelet was utilized. The quality factor Q of the propagating medium was set as equal to 50. The reflectivity model for forward modeling is given in Table 1. In contrast to the preceding numerical experiments, two values of the number of iterations, N = 20 and N = 1000, were tested (Figure 7 and Figure 8). The results using unperturbed source wavelets are shown by gray lines in Figure 7 and Figure 8.

Figure 7.
ITD results with N = 20 of iterations by using variable source wavelets (black lines): (a) ITD compensation results with inaccurate wavelet phases and (b) the associated reflectivity model; (c) ITD compensation results with inaccurate dominant frequency and (d) the associated reflectivity model. Trace labels show the phase rotations (plots a) and (b) dominant-frequency variations (plots c) (d) applied to source wavelets. Red lines show the results for an unperturbed wavelet.

Figure 8.
Wavelet sensitivity tests for ITD as in Figure 7 but with N = 1000.
In Figure 7 and Figure 8, two parameters are used for characterizing the shape of the inferred wavelet: its phase and the characteristic length, which is represented by the dominant frequency. Note that it is generally insufficient to only constrain the amplitude spectra of the source waveform, and the phase may have a significant impact on the recovered seismic section. For the maximum iteration limit N = 20, ITD results with wavelet phases varying from −80° to +80° are shown in Figure 7a, and the inverted reflectivity series are shown in Figure 7b. The waveforms (Figure 7a) show that the corrected reflection at t = 344 ms is closer to the accurate source-wavelet shape than those from the deeper parts. This could be due to dispersion effects increasing with time and being added to the phase rotations of the source waveforms. Figure 7b suggests that the reflectivity series can be identified accurately by ITD with phase errors of up to ±20º. With phase errors beyond ±20°, the reflectivity series was significantly different from the exact one at ϕ = 0°. This sensitivity of to the wavelet phase was of course expected and is common to all types of deconvolution.
In the second test, we assumed the correct zero phase of the wavelet and checked the influence of inaccurately estimated peak frequency (Figure 7c,d). For the Ricker wavelet, the peak frequency determined the scaling of each part of the waveform. Figure 7c shows that with N = 20, if the assumed peak frequency was above or below the exact value, the result was respectively over- or under-compensated. This bias occurred due to the waves with higher dominant frequencies attenuating faster than those at lower frequencies. Overall, Figure 7c,d shows that ITD performed very well with assumed dominant frequencies lying within 0.8 to 1.4 times the true values.
3.5. Sensitivity to the Number of ITD Iterations
As described in Section 2, ITD filtering was based on an approximate deconvolution (Equation (9)), which was controlled by the number of iterations N and/or the data-error threshold ε. With N → ∞, the deconvolution became exact and perfectly reproduced the seismic record (ε = 0). Figure 8 shows that for noise-free data, a large N = 1000 also enabled the recovery of the “elastic” response, even with inaccurately estimated phases and peak frequencies of the source wavelet. With an increasing number of iterations, the ITD became progressively less sensitive to wavelet estimates (Figure 8).
Depending on the number of iterations, the ITD behaved differently and achieved somewhat different goals. For small N compared to the number of samples within the analysis window, the ITD represented a signal-detection method extracting a set of strongest, usually “sparse” events and correcting them for attenuation and dispersion. By contrast, for large N, the inverted events were no longer sparse but still corrected for attenuation, and, therefore, the ITD became analogous to frequency-domain Q-compensation. Similar to inverse-Q filtering, large-N ITD was independent of the choice of the source wavelet but sensitive to noise and errors in Q. Nevertheless, large-N ITD still did not boost the noise above the frequency band of the source waveform.
3.6. Realistic Waveform Synthetics
To illustrate the performance of the algorithm on a realistic reflection waveform, a single 1200 ms-long trace was selected from Marmousi-II synthetics and modeled for Q = ∞, 10, and 50 (Figure 9). The synthetics were modeled by using the convolutional model and only considering the primary reflections. The noise level in this example was low (resulting from numerical synthetics). We were only interested in the recovery of complex reflection waveforms. Both modeling and ITD were performed by using a 30-Hz Ricker wavelet. To perform the post-stack ITD iterations, we selected 200-ms time windows, threshold parameter N = 200, and residual energy ε = 10−7. In the inverse-Q algorithm, the stabilization factor was set as equal to 0.005 [1].

Figure 9.
Comparisons between the attenuated reflection records modeled in Marmousi II model and its inverse-Q-filtered and ITD-corrected records (black lines, labels). Panels (a,b) correspond to modeled Q = 10 and 50, respectively. The identical red lines in all plots are the models in an elastic structure (Q = ∞). All records are scaled equally, and, therefore, the attenuated records (labels “Modeled”) show low amplitudes in these plots, particularly in (a).
For Q = 50 (Figure 9b), comparisons of the filtered records (black lines) to the record modeled in an elastic model (gray lines) show that ITD accurately recovered almost the complete elastic record (Figure 9b). For very strong attenuation (Q = 10; Figure 9a), ITD recovered well the reflections above approximately 700 ms and the stronger reflections from the deeper part of the trace (for example, near 1050, 1150, and 1450 ms) (Figure 9a). As expected in Section 2, with a large number of pulses in r(t) series (N = 200), the ITD showed no instabilities, required no regularization, and recovered the elastic waveform with good accuracy.
Compared to inverse-Q filtering, the ITD results appear to be preferable in both cases (Figure 9a,b). For Q = 50, the quality of inverse-Q correction was good above approximately 800 ms and reduced with depth (Figure 9b). The strong reflection packages near 850–900 ms and 1400 ms were somewhat under-corrected in amplitudes and shifted in phases. For very strong attenuation, the inverse-Q filtering result was unsuccessful (Figure 9a). These difficulties in inverse-Q filtering were apparently caused by the selection of the stabilization factor required for suppressing the high-frequency noise in these records. In this low-noise example, this stabilization factor or gain limiting could of course be adjusted and results could be obtained that are comparable to those of ITD. However, our goal in this example was to illustrate the inverse-Q and ITD filtering with “typical” parameters not tailored for a noise-free case.
4. Application to Real Data
To illustrate the ITD method on field seismic data, we applied it to a stacked 2-D seismic line (the owner and location of the data are confidential; Figure 10a). This line contains 400 CMPs with two-way travel times ranging from 400 to 5000 ms (Figure 10a). Standard 2-D seismic processing was applied to the data, with an emphasis on preserving the attenuation characteristics (time-variant spectra) for Q-compensation. The stacked data (Figure 10a) showed significant attenuation effects, resulting in a dominant frequency of approximately 15 Hz for the whole data. The data were somewhat contaminated with linear large-moveout noise, which could be observed above 1000-ms, near 1500-ms, and below 2500-ms travel times. The hatch noise could be easily removed by many filtering methods. Here, we did not attempt to reduce this or any other type of noise and only focused on Q-compensation.

Figure 10.
Field data example: (a) a fragment of a stacked real-data section; (b) interval Q model at CMP = 200; (c) the estimated wavelet (gray shading) and a simplified Gaussian wavelet (dotted line) used for shaping in ITD.
As for many other reflection datasets, no independent measurements of Q were available, and the spatially-variable Q was estimated from seismic-processing velocities by using the following empirical equation [26]:
where V is the interval velocity in km/s. Although this Gardner-type equation is certainly inaccurate, it reproduces the commonly-observed positive correlation of seismic velocities with Qs [27]. Sharp layering resulting from Equation (17) was smoothed in accordance with the expected smooth Q variability (Section 2). A vertical profile of Q(t0) at the location of CMP = 200 is shown in Figure 10b.
Figure 11 shows post-stack Q-compensation results by using the inverse-Q filtering method and ITD [1]. As described in Section 2, the records (Figure 11a) obtained from inverse-Q filtering (with a stabilization factor equal to 0.02) could be used for estimating the source wavelet for ITD. We estimated the wavelet from the upper part of the section in Figure 11a, assuming its zero phase and using the method by Oppenheim and Schafer [24]. This wavelet is shown by gray shading in Figure 10c. Further, because the Q values in the upper portion of the section were relatively low (Figure 10b), significant attenuation was present between the effective “source” zone and the times at which the wavelet was measured. To approximately account for this attenuation, we constructed a Gaussian wavelet (dotted line in Figure 10c), which was utilized for ITD. The width of this wavelet was near 6 ms, and it was used for both waveform cross-correlation and the shaping included in ITD [8].
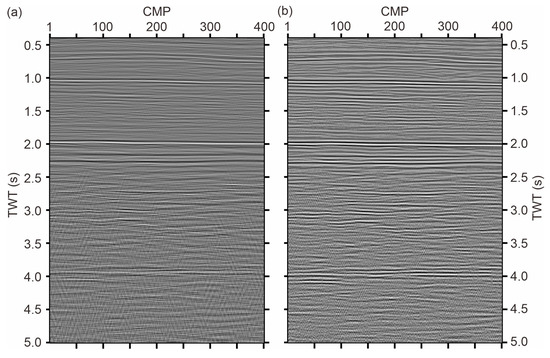
Figure 11.
A fragment of a stacked data section (Figure 10a) after corrections by using (a) stabilized inverse-Q filtering [1] and (b) ITD.
Figure 11 shows that the appearance, resolution, and apparently the SNR of the data section were improved after both inverse-Q filtering and ITD. The ITD appeared to recover more reflectors and enhance their sharpness, although, in the deeper parts of the section, the amplitudes of the linear steep-moveout noise remained comparable to the original section (Figure 11b and Figure 10a). Compared to (stabilized) inverse-Q filtering (Figure 10a), this linear noise in Figure 11b was enhanced below approximately 3 s because, at these times, the ITD was significantly more effective in recovering all waveforms close to those of the attenuated source signal. Coherent linear noise could not be suppressed by any of the post-stack Q-compensation techniques, but it could be addressed by pre-stack or post-stack filtering, such as f-x deconvolution. The coherent steep-moveout linear noise could also be isolated at the interpretational stages. Apart from this noise, the improvements by ITD compared to inverse-Q filtering were clear throughout the whole section (Figure 11a,b). Figure 12 shows the traces at CMP = 200 before and after attenuation in detail. Both stabilized inverse-Q filtering and ITD (Figure 12b,c) enhanced the high-frequency content of the records and increased the relative amplitudes of reflections compared to unfiltered records (Figure 12a). Simultaneously, the events corrected by ITD (Figure 12c) showed much higher resolution (particularly below approximately 2 s) and suggest closely-spaced reflectors. Some of the events enhanced by ITD below approximately 3 s may be due to the aforementioned linear noise, which could be identified by analyzing the 2-D record section. However, high-frequency reflections from ~1.8 s to 2.4 s are consistent across the stacked section (Figure 11 and Figure 12). In addition, the reflections in the ITD-filtered section became zero-phase due to the zero-phase wavelet used for deconvolution (Figure 10c).

Figure 12.
Record at CMP = 200 in Figure 11: (a) field data before Q-compensation, (b) after compensation by using stabilized inverse-Q filtering, and (c) Q-compensation by using ITD. For plotting, all records were normalized by the root-mean-square amplitudes.
Figure 13 compares the average spectra of the data before and after compensation by using inverse-Q filtering and ITD. These spectra were normalized by the peak power of the data before compensation within 400–1400 ms. To avoid busy lines, the spectra were separated by shifting. Prior to Q-compensation, the high-frequency components (above approximately 40 Hz) decayed with reflection times faster than the low-frequency components (below approximately 40 Hz). Consequently, the peak spectral powers shifted to lower frequencies at increased depths (red lines in Figure 13). Both the inverse-Q filtering and ITD boosted the higher-frequency components of the data (black solid and blue dotted lines, respectively, Figure 13). For the shallow part (400–1400 ms, Figure 13a), inverse-Q filtering and ITD achieved similar compensation results in the power spectra. It should again be noted that this compensation was achieved differently by these methods: for inverse-Q filtering, it was a result of Q correction, but for ITD, this was principally achieved by selecting the shaping wavelet. Assuming that the source was accurately approximated by the Gaussian pulse (Figure 10c) and that the reflection sequences were “white” and noise-free, the recovery of the source spectrum by ITD was near-perfect at all depths (Figure 13a–c). However, the effects of noise still increased with depth; the contamination of the deconvolved record with random and coherent noise can be judged from the 2-D record (Figure 11). In addition, the trade-off of Q with sub-wavelength scale structures caused further uncertainties in the recovery of the spectrum [17]. This trade-off could only be constrained by using ground truth data, such as well logs.

Figure 13.
Power spectra of the data before (red lines) and after (black and blue lines) compensation within reflection-time ranges: (a) 400–1400 ms, (b) 1400–3900 ms, and (c) 3900–5000 ms. Black solid lines indicate the spectra measured for ITD compensation and blue dotted lines are the spectra after inverse-Q filtering. Identical green dashed lines are the spectrum of the Gaussian wavelet (Figure 10c). Please note that the spectra were shifted up or down to separate the curves for a better view.
Within the intermediate and deeper parts of the section (1400 to 5000 ms; Figure 13b,c), inverse-Q filtering may have under-corrected the high-frequency components (above 40 Hz) where the SNR was low, and ITD provided stronger enhancements of the spectra (Figure 13b,c). The time-domain images in Figure 11 and Figure 12 also show that the intermediate and deeper parts (1400–5000 ms) of the ITD-filtered records revealed more and sharper reflected events, albeit with some enhancement of the linear large-moveout noise.
5. Discussion
Selections of time-, frequency- or mixed-domain (such as wavelet-based) deconvolution methods emphasize different aspects of the data and may be significant for the success of deconvolution. Conventional inverse-Q filtering is performed in the frequency domain so that each frequency component of the data is restored independently. However, for long wave propagation, the highest-frequency components can become lost in noise and cannot be recovered by inverse-Q filtering (Figure 1b). By contrast, due to its time-domain (or wavelet-based) algorithm (Equations (10) and (11)), the ITD method detects reflections principally by their dominant-frequency components. Thus, ITD operates in the most advantageous part of the spectrum and has lower sensitivity to frequencies at which the signal is weak. By identifying the time of the signal, this method is able to recover all frequency components (Figure 1c,d). ITD also makes no selective use of any frequencies, and, consequently, it is stable and does not boost high-frequency noise.
The principal advantage of ITD is principally due to the fact that this algorithm focuses on recovering the strongest reflections first. However, if necessary, the entire waveform can be transformed by taking large values of cutoff parameter N. The ITD seeks the highest similarity of the recorded signals with the propagating source waveforms. Such similarity is expected from true reflections and not from (random) noise. By contrast, inverse-Q filtering does not differentiate the signal from noise, and, consequently, always boosts and phase-shifts the high-frequency noise.
Although offering some advantages over frequency-domain inverse-Q filtering, ITD has some limitations when applied to low-SNR data. As shown in Figure 4 and Figure 5, in cases where inverse-Q filtering strongly boosts noise (low Q and/or low SNR), ITD images can contain noise in the form of spurious random reflectivity (Figure 4b and Figure 5b). This effect is, of course, unavoidable in a single-channel record where weak (attenuated) reflection waveforms cannot be differentiated from strong noise. With multichannel recording and data processing, the SNR can be improved by various techniques (such as slant filtering or f-x deconvolution) before or after applying Q-compensation. In addition, as a time-domain waveform processing method, ITD can readily be extended to fully multichannel operation.
Although ITD requires an estimation of the source wavelet, such estimates can be produced in seismic processing. Assuming the randomness of the reflectivity and zero phase of the wavelet, a statistical wavelet can be derived from the autocorrelation of the recorded data [10,28]. By tying seismic data to well logs, the phase and amplitude spectrum of the wavelet can be further adjusted [29]. Stone reviewed several approaches for estimating the phase of the wavelet from seismic data alone based on statistical models of reflectivity [30]. Recently, van der Baan and Pham and Berkhout and Verschuur proposed further developments of these methods [25,31], and Edgar and van der Baan compared them with well-log-guided deconvolution [32]. All of the above methods derive stationary wavelets that remain invariant throughout the data record. In the presence of attenuation, this requirement of stationarity is not satisfied; however, the source wavelet becomes stationary after a correction for attenuation. Therefore, to derive a source wavelet for ITD corrections, we propose to (1) perform iterative analysis starting from an initial wavelet estimated by one of the methods above, (2) repeat the determination of the source wavelet after ITD filtering, and (3) repeat both steps until a consistent estimate of the wavelet is obtained. As attenuation effects are usually relatively weak, this iteration should converge in two to three steps. A simple example of such an estimation was given in Section 4.
Although playing similar roles in seismic data processing, ITD is conceptually different from inverse-Q filtering. ITD can be described as adaptive signal detection rather than correction of a Q-factor in the model. In inverse-Q filtering, the high-frequency components of noise are taken as signal and become amplified. Stabilization and gain limiting reduce this noise amplification [1,2] but also reduce the accuracy of Q-compensation and make it approximate. In ITD, the restriction on the number of iterations similarly reduces the accuracy of waveform matching, but this reduction is not for stabilization but for promoting the identification of stronger reflections. A significant portion of the noise (especially incoherent noise) is rejected by ITD because it does not match the source waveform (Figure 4). Seeking the strongest events first, the major events are secured early in the process and weaker secondary events can be filtered out on the processor’s demand. Alternatively, major events can be identified and then removed to uncover the interested weak reflections in the target zone. Compared to frequency-domain methods (such as inverse-Q filtering), this may be a major advantage of time-domain waveform decomposition methods. This advantage appears to be most important and analogous to the advantages of τ-p filtering over f-k.
The numerical experiments with inaccurate Qs and source waveforms (Section 3) show that accurate dispersion relations are required in order to constrain detailed structures. As with any other seismic processing method, Q-compensation cannot exceed the resolution limits imposed by the bandwidth of seismic data and by limited knowledge of the subsurface structure. However, the character of uncertainties and noise in the images produced by inverse-Q filtering and ITD are different, which may be useful in interpretation. Inverse-Q filtering and other frequency-domain methods are insensitive to the shape of the source wavelet but rely on accurate models of Q and dispersion relations that may be difficult to measure from the data. Such accurate Q models may not even exist ab initio [16]. Frequency-domain methods are also prone to boosting noise and exhibit instabilities at high frequencies, and may sometimes increase the ringiness of sections. By contrast, the ITD is stable and less sensitive to model uncertainties and its noise has the appearance of mis-detected reflections rather than high-frequency waveforms. Generally, it appears best to use a combination of such methods, as in the examples in this paper.
6. Conclusions
We presented a simple scheme called the iterative time-domain deconvolution (ITD) with a number of unique advantages for Q-compensation of reflection seismic records. A series of numerical experiments were conducted to evaluate the performance of ITD. Tests on noise-contaminated data suggested that compared to inverse-Q filtering, ITD is stable and has the ability to filter out random noise. By virtue of its time-domain operation, ITD can increase the sparseness of the Q-compensated images, which may be an attractive feature for interpretation. ITD is performed on a trace-by-trace basis, and, consequently, it can be used in both post- and pre-stack processing and potentially included in the migration. The method is illustrated on numerical examples and real data. Numerical experiments show that ITD is relatively weakly sensitive to inaccurate attenuation and velocity models. For example, with Q ≈ 50, ITD can tolerate approximately ±40% errors in Q with or without noise in the data. Because ITD requires an estimate of the source wavelet, we recommend combining this method with inverse-Q filtering and wavelet estimation.
Author Contributions
Conceptualization, W.D., I.B.M. and L.-Y.F.; Data curation, W.D.; Formal analysis, Q.C.; Funding acquisition, W.D. and L.-Y.F.; Investigation, W.D. and Q.C.; Methodology, W.D., I.B.M. and L.-Y.F.; Project administration, I.B.M. and L.-Y.F.; Resources, I.B.M. and L.-Y.F.; Software, W.D. and Q.C.; Supervision, I.B.M. and L.-Y.F.; Validation, W.D. and Q.C.; Visualization, W.D., Q.C., I.B.M. and L.-Y.F.; Writing—original draft, W.D., I.B.M. and L.-Y.F.; Writing—review & editing, W.D., I.B.M. and L.-Y.F. All authors have read and agreed to the published version of the manuscript.
Funding
The research is supported by the National Natural Science Foundation of China (Grant Nos. 42274161 and 42230803) and 111 project “Deep-Superdeep Oil & Gas Geophysical Exploration” (B18055).
Data Availability Statement
The data are available upon request.
Acknowledgments
We would like to thank the anonymous reviewers whose comments and questions have helped improve the manuscript greatly.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, Y. Seismic Inverse Q Filtering; Blackwell: Oxford, UK, 2008; ISBN 978-1-4051-8540-0. [Google Scholar]
- Van Der Baan, M. Bandwidth enhancement: Inverse Q filtering or time-varying Wiener deconvolution? Geophysics 2012, 77, V133–V142. [Google Scholar] [CrossRef]
- Han, L.; Liu, C.; Yuan, S. Can we use wavelet phase change due to attenuation for hydrocarbon detection? In Proceedings of the SEG Annual Meeting, New Orleans, LA, USA, 18–23 October 2015; pp. 2962–2966. [Google Scholar] [CrossRef]
- Huang, F.; Juhlin, C.; Han, L.; Sopher, D.; Ivandic, M.; Norden, B.; Deng, W.; Zhang, F.; Kempka, T.; Lüth, S. Feasibility of utilizing wavelet phase to map the CO2 plume at the Ketzin pilot site, Germany. Geophys. Prospect. 2016, 65, 523–543. [Google Scholar] [CrossRef]
- Deng, W.; Morozov, I.B. Macroscopic mechanical properties of porous rock with one saturating fluid. Geophysics 2019, 84, MR223–MR239. [Google Scholar] [CrossRef]
- Deng, W.; Morozov, I.B. A simple and general macroscopic model for local-deformation effects in fluid-saturated porous rock. Geophys. J. Int. 2020, 220, 1893–1903. [Google Scholar] [CrossRef]
- Hale, D. An inverse Q-filter. Stanf. Explor. Proj. 1981, 26, 231–244. [Google Scholar]
- Morozov, I.; Haiba, M.; Deng, W. Inverse attenuation filtering. Geophysics 2018, 83, V135–V147. [Google Scholar] [CrossRef]
- Sheriff, R.E. Encyclopedic Dictionary of Applied Geophysics; Geophysical References Series; Society of Exploration Geophysicists: Houston, TX, USA, 2002; ISBN 978-1-56080-296-9. [Google Scholar]
- Yilmaz, O. Seismic Data Processing Society of Exploration Geophysicists; Society of Exploration Geophysicists: Tulsa, OK, USA, 2001; ISBN 978-1-56080-094-1. [Google Scholar]
- Bickel, S.H.; Natarajan, R.R. Plane-wave Q deconvolution. Geophysics 1985, 50, 1426–1439. [Google Scholar] [CrossRef]
- Hargreaves, N.D.; Calvert, A.J. Inverse Q filtering by Fourier transform. Geophysics 1991, 56, 519–527. [Google Scholar] [CrossRef]
- Kikuchi, M.; Kanamori, H. Inversion of complex body waves—III. Bull. Seism. Soc. Am. 1982, 72, 491–506. [Google Scholar] [CrossRef]
- Ligorría, J.P.; Ammon, C.J. Iterative deconvolution and receiver-function estimation. Bull. Seism. Soc. Am. 1999, 89, 1395–1400. [Google Scholar] [CrossRef]
- White, R.E. The accuracy of estimating Q from seismic data. Geophysics 1992, 57, 1508–1511. [Google Scholar] [CrossRef]
- Morozov, I.; Ahmadi, A.B. Taxonomy of Q. Geophysics 2015, 80, T41–T49. [Google Scholar] [CrossRef]
- Deng, W.; Morozov, I.B. Trade-off of Elastic Structure and Q in Interpretations of Seismic Attenuation. Pure Appl. Geophys. 2017, 174, 3853–3867. [Google Scholar] [CrossRef]
- Dasgupta, R.; Clark, R.A. Estimation of Q from surface seismic reflection data. Geophysics 1998, 63, 2120–2128. [Google Scholar] [CrossRef]
- Al-Shukri, H.J.; Pavlis, G.L.; Vernon, F.L. Site effect observations from broadband arrays. Bull. Seismol. Soc. Am. 1995, 85, 1758–1769. [Google Scholar] [CrossRef]
- Wilson, D.C.; Pavlis, G.L. Near-surface site effects in crystalline bedrock: A comprehensive analysis of spectral amplitudes determined from a dense, three-component seismic array. Earth Interact. 2000, 4, 1–31. [Google Scholar] [CrossRef]
- Margrave, G.F. Theory of nonstationary linear filtering in the Fourier domain with application to time-variant filtering. Geophysics 1998, 63, 244–259. [Google Scholar] [CrossRef]
- Kjartansson, E. Constant Q-wave propagation and attenuation. J. Geophys. Res. Atmos. 1979, 84, 4737–4748. [Google Scholar] [CrossRef]
- Zhang, C.; Ulrych, T.J. Seismic absorption compensation: A least squares inverse scheme. Geophysics 2007, 72, R109–R114. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Schafer, R.W. Digital Signal Processing; Prentice-Hall, Inc.: Englewood Cliffs, NJ, USA, 1975; p. 584. ISBN 0-13-214635-5. [Google Scholar]
- van der Baan, M.; Pham, D.-T. Robust wavelet estimation and blind deconvolution of noisy surface seismics. Geophysics 2008, 73, V37–V46. [Google Scholar] [CrossRef]
- Li, Q. The Way to High Precision Exploration; Petroleum Industry Press: Beijing, China, 1993; ISBN 9787502109967. (In Chinese) [Google Scholar]
- Zhang, Z.; Stewart, R.R. Seismic Attenuation and Rock Property Analysis in a Heavy Oilfield; CREWES Research Report: Ross Lake, Saskatchewan, Canada, 2007; Volume 19. [Google Scholar]
- Clayton, R.W.; Wiggins, R.A. Source shape estimation and deconvolution of teleseismic body waves. Geophys. J. R. Astron. Soc. 1976, 47, 151–177. [Google Scholar] [CrossRef]
- Walden, A.T.; White, R.E. On errors of fit and accuracy in matching synthetic seismograms and seismic traces. Geophys. Prospect. 1984, 32, 871–891. [Google Scholar] [CrossRef]
- Stone, D.G. Wavelet estimation. Proc. IEEE 1984, 72, 1394–1402. [Google Scholar] [CrossRef]
- Berkhout, A.J.; Verschuur, D.J. A scientific framework for active and passive seismic imaging, with applications to blended data and micro-earthquake responses. Geophys. J. Int. 2011, 184, 777–792. [Google Scholar] [CrossRef]
- Edgar, J.A.; van der Baan, M. How reliable is statistical wavelet estimation? Geophysics 2011, 76, V59–V68. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).