1. Introduction
As a high-resolution microwave imaging radar, synthetic aperture radar (SAR) has unique strengths in various planetary observation tasks, such as its excellent all-day and all-weather working capacity, especially in marine observation [
1]. As a part of marine missions, SAR ship detection is of great value in marine monitoring [
2,
3,
4,
5,
6]. Thus, the detection basis of ships using SAR has become a focus of marine research.
The pixel intensity information of an SAR image is related to the target’s scattering cross-section. Oceans often appear dark black in images, while ships are bright white. However, offshore islands and background noise will also appear in a similar bright white, and the defocusing produced by a ship moving at speed when an SAR image is taken will also cause serious geometric distortion, showing an irregular shape. Therefore, it is a challenging task to accurately distinguish and precisely locate ships from other targets in SAR images under real conditions. Traditional SAR ship target detection methods such as CFAR [
7,
8], and template matching-based methods [
9,
10] are generally divided into three steps: preprocessing, manual feature extraction, and setting thresholds or classifiers for detection to obtain the final result [
11,
12,
13]. CFAR establishes the best decision by estimating the noise threshold and information, such as the statistical characteristics of signal and noise. However, the probability of a false alarm in the clutter edge area is higher than the center area. The algorithm based on template matching distinguishes ships according to the size, area, and texture features, which need to be matched according to the template library established by experts. Template matching algorithms will always be affected by the background statistical area. In general, traditional SAR ship detectors generally use complex algorithms, have weak transfer ability, and have cumbersome manual features. In addition, due to the backscatter imaging mechanism, the traditional algorithm is highly sensitive to the geometric features of the target extracted from the SAR image, and the defocusing caused by the motion of the ship relative to the radar platform will dramatically reduce the performance of the algorithm.
At present, with the continuous development of neural network theory [
14], SAR ship detection based on deep-learning models has become a current mainstream method [
15,
16,
17,
18]. For instance, Li et al. [
19] proposed a new dataset and four strategies to improve detection performance based on the Faster RCNN [
20] algorithm. Lin et al. [
21] designed a squeeze and excitation rank mechanism to improve detection performance. Based on You Only Look Once v4 (YOLOv4) [
22], Jiang et al. [
23] integrated a multi-channel-fusion SAR image processing method that makes full use of image information and the network’s ability to extract features and refined the network for three-channel images to compensate for the loss of accuracy. Based on the Swin Transformer [
24], Li et al. [
25] adopted a feature enhancement Swin transformer (FESwin) and an adjacent feature fusion (AFF) module to boost performance. Based on RetinaNet [
26], Gao et al. [
27] proposed a polarization-feature-driven neural network for compact polarimetric (CP) SAR data. Based on FCOS [
28], Zhu et al. [
29] redesigned the feature extraction module.
CNN-based algorithms have better feature extraction and generalization capabilities than traditional detectors. However, due to the differences in scale between ships, small targets lack detailed information on a scaled feature map and cause false alarms. Therefore, designing a detection model for small targets that adapt to multi-scale and complex backgrounds has become the main research direction in the field of SAR ship detection in recent years. The feature pyramid network (FPN) [
30] has been the best method to solve multi-objective problems since it was proposed by Lin et al. For different incident angles, resolutions, satellites, etc., SAR ships possess various sizes. FPN uses feature maps of different scales to extract information at different levels of the picture and uses multi-scale feature information fusion to enhance the expression ability of ship targets, which enables better performance. For the ship detection problem, many scholars have made improvements on the basis of FPN. Zhu et al. [
31] combined DB-FPN with YOLO to improve overall detection capability. Cui et al. [
15] adopted an attention-guided balanced feature pyramid network (A-BFPN) to better exploit semantic and multi-level complementary features.
Compared to ordinary optical images, SAR echo signals contain complex features. Deep-learning SAR ship inspection models mostly use the amplitude information of SAR image as input, and the underutilization of complex information restricts the upper limits of these models. In order to further improve the utilization of the characteristics of SAR data, Xiang et al. [
32] proposed a ship detection method in range-compressed SAR data that employs complex signal kurtosis (CSK) to prescreen potential ship areas and then apply a convolutional neural network (CNN) based discrimination to obtain potential ship areas. The results show that the algorithm works well on range-compressed SAR data. Zhang et al. [
33] proposed a Polarization Fusion Network with Geometric Feature Embedding (PFGFE-NET) to comprehensively scan SAR ships using VV and VH polarized pictures and proposed a method to describe SAR ships between different polarization modes. Zhang et al. [
34] designed a complex-valued CNN network (CV-CNN) specially used for SAR image interpretation using the amplitude and phase information of SLC data. All elements in the CNN, including input and output layers, volume convolution layers, activation functions, and pooling layers, are all extended to the complex domain, but these methods are only applicable to PolSAR images. In order to utilize the target feature information contained in the monopolar SAR phase, Huang et al. [
35] introduced a deep-learning framework dedicated to complex-valued radar images. Using CNN to extract spatial features from intensity images and ResNet-18 as the pre-training model, they generated feature maps with scales of 64, 128, 256, and 512 to learn hierarchical features at different scales. The joint time-frequency analysis method was used to learn the physical characteristics of the target in the frequency domain, reveal the relationship between the backscatter diversity of the ground target and the range and azimuth frequency, and align the target for a final prediction along with spatial texture features.
At present, complex value-based networks are mostly used in the classification task of open-source ship datasets, such as Opensarship. The selected ship slices often have obvious geometric characteristics, and the position of the ship slices can be distinguished easily. However, for the ship detection task, ships moving at high speeds are more likely to lose geometric features in the SAR imaging process, so it is therefore necessary to employ more abundant auxiliary features to help with target recognition. So far, few works have attempted to solve the moving ship detection task using doppler features. Therefore, a novel doppler feature matrix fused with a multi-layer feature pyramid network is proposed in this paper. Our work focuses on three areas. The first is the establishment of the dataset. To extract doppler features, we detail a single-look complex image ship dataset composed of Gaofen-3 satellite image ship slices. Secondly, we propose a detection framework that fuses doppler features. We extract the doppler center frequency and frequency modulation rate offset to characterize the ship’s motion state from the doppler domain, and construct the doppler characteristic matrix. We then fuse it with spatial features to carry out a ship inspection. Finally, there is an improvement in the network structure for the image branch, and a bottom-up pyramid structure is designed to transmit the position information for large ships. This combines external attention (EA) and coordinate attention (CA) modules to solve the multi-scale moving ship detection problem.
Based on the above three points, we propose an SAR ship detection pipeline and conduct an experiment on the complex SAR ship dataset. The experimental results show that, compared with other deep-learning target detection algorithms, the D-MFPN can obtain the best performance in both inshore and offshore scenarios.
The main contributions of this paper are as follows:
An SAR single-look complex ship dataset is constructed.
We design a network structure based on FPN, using a bottom-up pyramid to transfer position information and refining features by combining CA and EA modules.
An SAR ship detection framework that integrates doppler features and spatial features is proposed, combining them to improve the performance of the model.
The rest of the paper is organized as follows:
Section 2 presents the entire detection model.
Section 3 presents the the dataset used, experiments, and results.
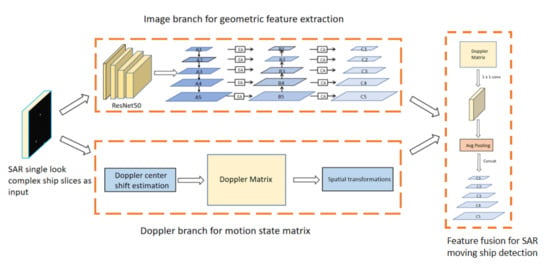
2. D-MFPN
The D-MFPN consists of two branches. The image branch designs a multi-layer feature pyramid network to enhance the positioning capacity for large ships. The doppler branch aims to build a feature matrix that characterizes a ship’s motion state by estimating the doppler center frequency and the frequency modulation rate offset. The overall structure of the D-MFPN is shown in
Figure 1.
In this section, the implementation steps of the D-MFPN for SAR ship detection are described. Firstly, the motivation and overall structure of the multi-layer feature pyramid, which is designed for magnitude images is described. The method of using the complex matrix to obtain the doppler feature matrix is also given. At the end of this section, the method of combining the two is introduced in detail.
2.1. Multi-Layer Feature Pyramid Network
For the SAR ship detection task, small-scale targets, multi-scale feature imbalance, and complex background interference are all important factors that hinder the accuracy of the model. The CNN-based convolutional neural network is a composite structure composed of multiple convolutional layers. With the continuous increase in the network depth, high-level feature representations can be learned, but the small ship characteristics will be weakened with the increasing receptive field, leading to missed detections. In addition, the deep network structure will generate multiple nonlinear activation function partial derivatives or continuous multiplication of weight parameters during back propagation, which can easily cause gradient disappearance or gradient explosion. For small objects, the pyramid structure adopted by the FPN uses feature maps of different scales to be sent to the detection head, which alleviates the multi-scale problem to a certain extent, although its feature weakening remains unresolved. The top-down structure causes the direction of semantic information of the top layer to flow downward.However, the position information of the bottom layer is not propagated to the top layer, which also leads to inaccurate positioning of large ships.
To solve the above problems, the D-MFPN uses resnet-50 as a backbone. The CNN structure independently extracts the features of the labeled data, effectively avoiding the traditional complex feature design. The residual block module also prevents overfitting and vanishing gradient problems, greatly increasing the network depth. The residual structure of resnet50 consists of multiple structures called a “bottlenet” (as shown in
Figure 2), and finally, five feature maps of different scales (conv1, conv2, conv3, conv4, conv5) are obtained.
With the continuous increase in the convolution stride and the number of residual network layers, the spatial resolution of the feature map gradually decreases, and the number of channels increases accordingly. The underlying feature maps contain accurate strong location information but lack semantic information. Therefore, the FPN uses the information to obtain the final combined features from different layers in the CNN network. As shown in
Figure 3, the FPN adopts horizontal connections and adds top-down paths to improve the expressiveness of the entire pyramid. However, low-level location information from the bottom of the pyramid is not transferred to the top. This directly leads to the wrong localization of the bounding boxes of large ships, thus degrading the performance. To solve this problem, the D-MFPN designs a bottom-up pyramid structure to enhance information flow. The location information of the bottom layer is passed upwards using a bottom-up pyramid structure. In addition to strengthening the positioning effect of large ships, in order to further improve the expression ability of feature maps of each layer, we also use two attention modules to enhance the association between each pixel and channel.
The attention methods are inspired by the human visual attention mechanism, the essence of which is to let the model ignore irrelevant information through a series of related calculations, pay more attention to the key information we want it to focus on, and obtain long-distance correlations between pixels. Usually, the way to obtain the attention weight is to imagine the constituent elements in the source as a series of key and value data pairs, and for an element query in the target, calculate the similarity between the query and each key or correlation, obtain the weight coefficient of the value corresponding to each key, and then weight and sum the value to obtain the final attention value. In the ship detection task, the background of the far sea is relatively monotonous. Different port backgrounds near the coast can also have a certain degree of similarity. Therefore, if an attention mechanism can be found to learn the implicit relationship between different samples, it will greatly improve the detection performance. Considering the above perspectives, we use the EA module, which uses two linear layers to replace the inputs that make the network learnable from the obtained keys and values. A normalization layer is used to obtain the similarity matrix between query and key. A learnable weight matrix is used to replace the key and value obtained by linear transformation according to the input itself so that the EA module can update the parameters according to the entire training set to better fit the data characteristics. At the same time, EA has linear complexity, which implicitly considers the relationship between different samples.
Figure 4 shows the implementation process of EA. In order to also make the attention mechanism consider the influence from other samples, EA designs two feature layers shared by all samples,
and
. First, in the same way as the self-attention mechanism, the input feature map F is flattened as a query and then multiplied with the
matrix using softmax normalization to obtain the correlation matrix between query and key. Finally, the same operation is performed with
to obtain the output. The formula for this process is as follows:
As shown in
Figure 5, the location information of the bottom of the pyramid is transferred to the top (B5 → B4 → B3 → B2 → B1). In this way, the high-level feature map will contain more location information, which will improve the feature expression ability of large ships to a certain extent. In addition, before downsampling, the low-level feature maps are refined by EA, which improves the effect of upsampling.
After the feature map is obtained, it is fused with the underlying information. In order to further refine the location features of each layer in the feature pyramid and solve the problem of the low recognition rate of overlapping ships of different scales, the D-MFPN adds the CA module at this step. Research on attention mechanisms shows that inter-channel attention has a significant effect on improving model performance, but it often ignores the location information between pixels. As shown in
Figure 6. CA encodes the relationship between channels and long-range location information, and the overall structure is divided into two steps: coordinated information embedding and coordinated attention generation.
Channel attention often uses global pooling to encode spatial attention information, but it is often difficult to preserve the position information between pixels. The location information is crucial for the detection task to capture the local spatial structure. Therefore, coordinate information embedding decomposes the global pooling into average pooling along the direction of height H and width W of the input feature map. Encoded along the horizontal and vertical coordinates, it can be expressed as:
The difference between aggregating features along the horizontal and vertical directions separately and using global pooling directly is that these two transformations can help to obtain distance dependencies along one direction at the same time. Along the other direction, accurate location information can be preserved.
In order to make full use of the positional features obtained by coordinate information embedding, the coordinated attention generation step concatenates the two and then passes the 1 × 1 convolution function
F
where
represents the concatenation along spatial dimension;
denotes the h_swish activation function; the shape of output
f is (
C/
r,(
H +
W)); and
r is the reduction ratio for controlling the block size as in the SE block. Then, we decompose f into components in the
h and
w directions and go through another 1 × 1 convolutional layer to turn it into a tensor with the same number of channels as the input X:
where
and
are tensors with the same channels obtained with the decomposed vector after 1 × 1 convolution,
is the sigmoid function, and
and
are the final attention weights. The output of the CA module can be expressed as:
2.2. Doppler Domain Feature Estimation
In the process of processing SAR detection echo data, due to the movement of the target, the doppler modulation frequency rate and center frequency of the signal will shift, and the deviation of the modulation frequency will result in a defocused image. Conversely, the feature matrix composed of offsets can be used to describe the motion characteristics of the target. Therefore, by estimating the doppler feature offset of the echo signal, the information that characterizes the motion state of the target can be obtained.
The geometric relationship between the satellite and target moving in the direction of
is shown in
Figure 7, where T represents the target point. According to the spaceborne SAR echo theory, the distance history of the stationary target T can be obtained as:
In which
where
,
, and
represent the satellite position, velocity, and acceleration vectors at the beam center time, respectively;
,
, and
represent the beam center time target position, velocity, and acceleration vectors, respectively; and
,
, and
represent the relative satellite position, velocity, and acceleration vector, respectively. If target T moves in a straight line at a uniform speed along the vector
, the distance between the moving target and the radar is:
The instantaneous slant range error caused by the moving target is:
where
is the incident angle, and the phase error changes the doppler information of the azimuth signal. According to the expression of the slant range error, the error of the azimuth doppler frequency can be described as:
From the above formula, the changes in the doppler center frequency and doppler modulation frequency rate can be shown as:
From Equation (
12), it can be seen that the doppler-center shift in the azimuth direction is related to the radial velocity of the target. In the D-MFPN, the processing flow of doppler migration for a complex image matrix is as follows. First, slice the data and perform the azimuth Fourier transform. Then, obtain the azimuth spectrum through fftshift. Since the characteristics represented by a single spectrum are not obvious, we adopt the range block method to incoherently stack the azimuth spectrum. The fitted parameters are given in
Section 3. In order to eliminate the influence of outliers, a high-order fitting on the spectral features is conducted to obtain the doppler center shift features and finally make the doppler feature matrix the same size as the original image. In the D-MFPN, the input doppler center frequency shift matrix will first undergo a normalization process to map the eigenvalues between 0 and 1.
The shift in doppler center frequency can be used to describe the radial velocity of the ship relative to the radar platform, while the frequency shift due to the lateral velocity resulting in defocusing can be estimated using the mapdrift algorithm. Suppose the ideal azimuth signal is:
where
denotes the azimuth time,
denotes the doppler modulation frequency,
denotes the doppler center, and
denotes the synthetic aperture time. The azimuth signal with quadratic phase error is:
The mapdrift algorithm divides the entire synthetic aperture time into two sub-apertures that do not coincide with each other, as follows:
In the above formula, . Neglecting constant quantities that are insignificant to focus quality, the second-order components of the quadratic phase error within the two sub-apertures are exactly the same, and the first-order components are the same in magnitude but opposite in sign. Among them, the effect of the second-order component on the matched filter is defocusing, and the effect of the first-order component on the matched filter is to change the peak position. When pulse-compressing both sub-apertures with the same matched filter, the signals of both sub-apertures are defocused, but the peaks are shifted at different positions. The deviation in the two peak positions can be calculated by cross-correlating the amplitudes of the compressed signals of the two sub-apertures.
The quadratic phase error of the chirp signal is the main cause of defocusing, which is mapped to the motion relationship and corresponds to the lateral motion of the target relative to the radar platform. However, the moving direction of the sea surface target is not completely perpendicular to the radar platform, and there are often both radial and lateral components. Therefore, the D-MFPN simultaneously estimates the offset of both as a feature to characterize the motion state.
2.3. Feature Fusion
Feature maps will take on multi-scale shapes after feature extraction from the magnitude image. Each point in the feature map maps the receptive field of different regions in the original image. After obtaining the doppler domain feature, they need to be spatially aligned with the points in the feature map. The magnitude image needs to transfer the convolutional and pooled spatial transformation information to the doppler domain, and average pooling can then be performed on the resulting doppler information matrix to ensure it has the same receptive field as the feature map. In order to preserve the ship’s motion state information contained in the doppler matrix, during the feature fusion process, the D-MFPN does not perform additional convolution operations on the doppler branch after spatial alignment but directly concatenates space and doppler features as the input of the detection head. The entire feature fusion and spatial alignment module process is shown in
Figure 8:
The fusion module firstly aligns the doppler domain feature matrix and its channel number with the last pyramid channel number using a 1 × 1 convolution. Then, for different feature map sizes of each layer, average pooling is used to spatially align them.
2.4. Loss Function
The D-MFPN is based on the Faster RCNN, so the loss function is similar to most two-stage object detection models. It is divided into classification loss and regression loss for optimization:
where
indicates the probability that the i-th anchor is predicted to be the true label,
is 1 for positive samples and 0 for negative samples,
represents the parameter of the ith regression box,
represents the GT box of ith anchor,
denotes the number of mini-batches,
denotes the number of anchor positions, and
represents the cross-entropy (CE) loss
using smooth L1 as regression loss
. Compared with L1 loss, smooth L1 loss improves the problem of zero-point unsmoothing. Compared with L2 loss, it is not as sensitive to outliers when the value is large. The gradient changes are relatively smaller, and the training process is more stable.
4. Discussion
The detection performance of the D-MFPN is compared with five algorithms, such as the FPN, Cascade RCNN, DCN, PAFPN, and Guide Anchoring. The visualization results of various detection models in offshore and onshore scenarios are shown in
Figure 12 and
Figure 13, and the index results on the dataset are shown in
Table 5.
As can be seen in
Figure 12, after adding a large number of defocused ship slices with insignificant geometric features, other detection models become unusually sensitive to ship-like noise and island regions. In
Figure 12b–e, the other four algorithms mistakenly detect the noise and island parts in the background as targets, and the overall network has a low degree of discrimination for the ship area. The loss of accuracy caused numerous false alarms, while on the other hand, the D-MFPN successfully detected almost all pictures, even in the case of strong noise interference or low signal-to-noise ratio, which shows that the D-MFPN is very suitable for the ship area and has sharp judgment and robust noise reduction performance. In
Figure 12f, compared with other methods, the D-MFPN strengthens the feature structure and can effectively distinguish dense ship features. After adding the doppler domain features, an enhanced judgment ability of defocused pixel blocks is obtained that is less sensitive to defocusing-like areas. Based on the above, the D-MFPN achieves the best performance among all algorithms in the marine background.
The detection results of various methods in nearshore scenarios are shown in
Figure 13.
Figure 13a shows the corresponding ground truth. As scenarios become more complex, the number of false positives and false positives from other detection algorithms increases. Due to the similarity between ports, land buildings, and ship targets, the redundant box problem becomes more obvious, which further restricts the improvement of model precision. As an important indicator to measure the SAR ship detection algorithm, the false alarm rate may directly affect the actual effect of the detection algorithm. In this scenario, the D-MFPN can still distinguish between complex backgrounds and objects with excellent performance. As can be seen from
Figure 13d, when the ship is in the nearshore scene, there are only a few redundant detection boxes. This is because, for the different blocks along the distance, the doppler domain matrix can effectively distinguish the area where the ship is located, and, for the ships and background pixels in the same block, the attention module and the multi-layer pyramid refinement feature also provide a guarantee of the correct distinction of ships. It can be proven that the proposed method has good performance in both sea and land scenarios.
The comparison results of different models are shown in
Table 5. The D-MFPN achieves the highest detection accuracy on the dataset, with huge advantages. In particular, the mAP reaches
, which is
higher than the second-best CASCADE RCNN. The recall rate reaches
, which is also the best indicator among all the models. As the network gradually comes to understand the doppler features and accurately expresses amplitude features during the training process, the D-MFPN not only highlights the features of the target ship area but also suppresses noise and other influences. The proposed method also has good discrimination ability for similar defocused areas. Thus, robust detection performance for moving ships in SAR images is obtained.
Table 5.
Comparison results of the other state-of-the-art CNN-based methods.
Table 5.
Comparison results of the other state-of-the-art CNN-based methods.
| Method | mAP | P | R | F1-Score |
|---|
| Faster RCNN | 0.873 | 0.834 | 0.928 | 0.878 |
| FPN | 0.924 | 0.863 | 0.937 | 0.898 |
| DCN [37] | 0.907 | 0.822 | 0.954 | 0.883 |
| GUIDE ANCHORING [38] | 0.884 | 0.798 | 0.914 | 0.852 |
| CASCADE RCNN | 0.936 | 0.823 | 0.958 | 0.885 |
| PAFPN | 0.905 | 0.785 | 0.955 | 0.862 |
| Proposed method | 0.968 | 0.919 | 0.963 | 0.940 |



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












