


Focal Combo Loss for Improved Road Marking Extraction of Sparse Mobile LiDAR Scanning Point Cloud-Derived Images Using Convolutional Neural Networks

Abstract
1. Introduction
2. Materials and Methods
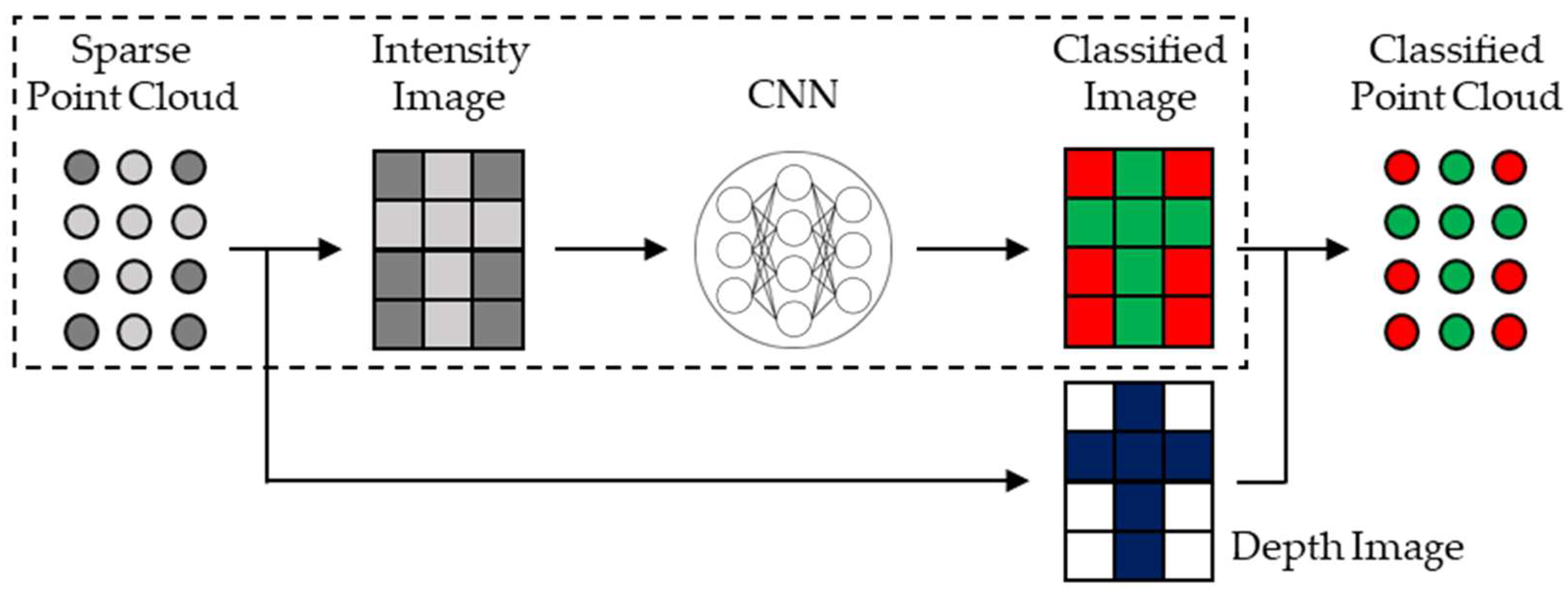
2.1. Dataset Preparation
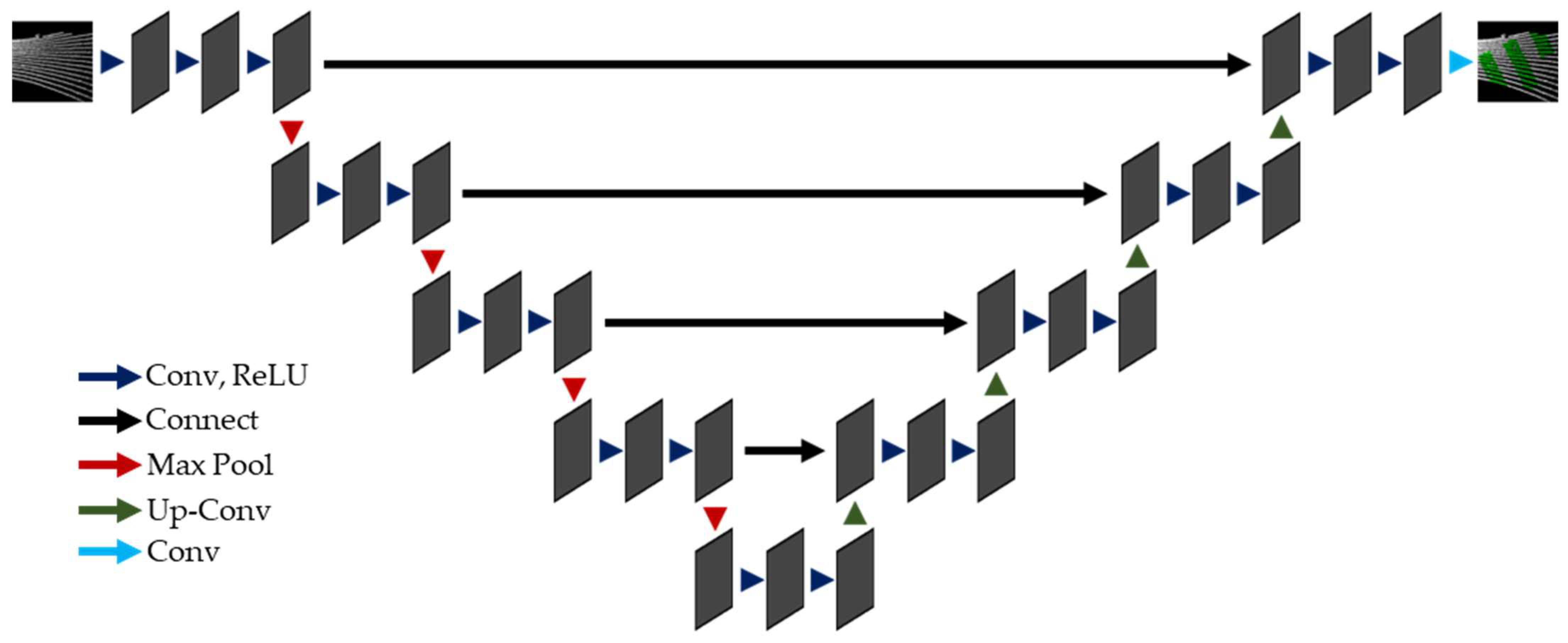
2.2. Convolutional Neural Network Models
2.3. Loss Functions
2.4. Model Training
3. Results
3.1. Generated Dataset
3.2. Resulting Images of Extracted Road Markings
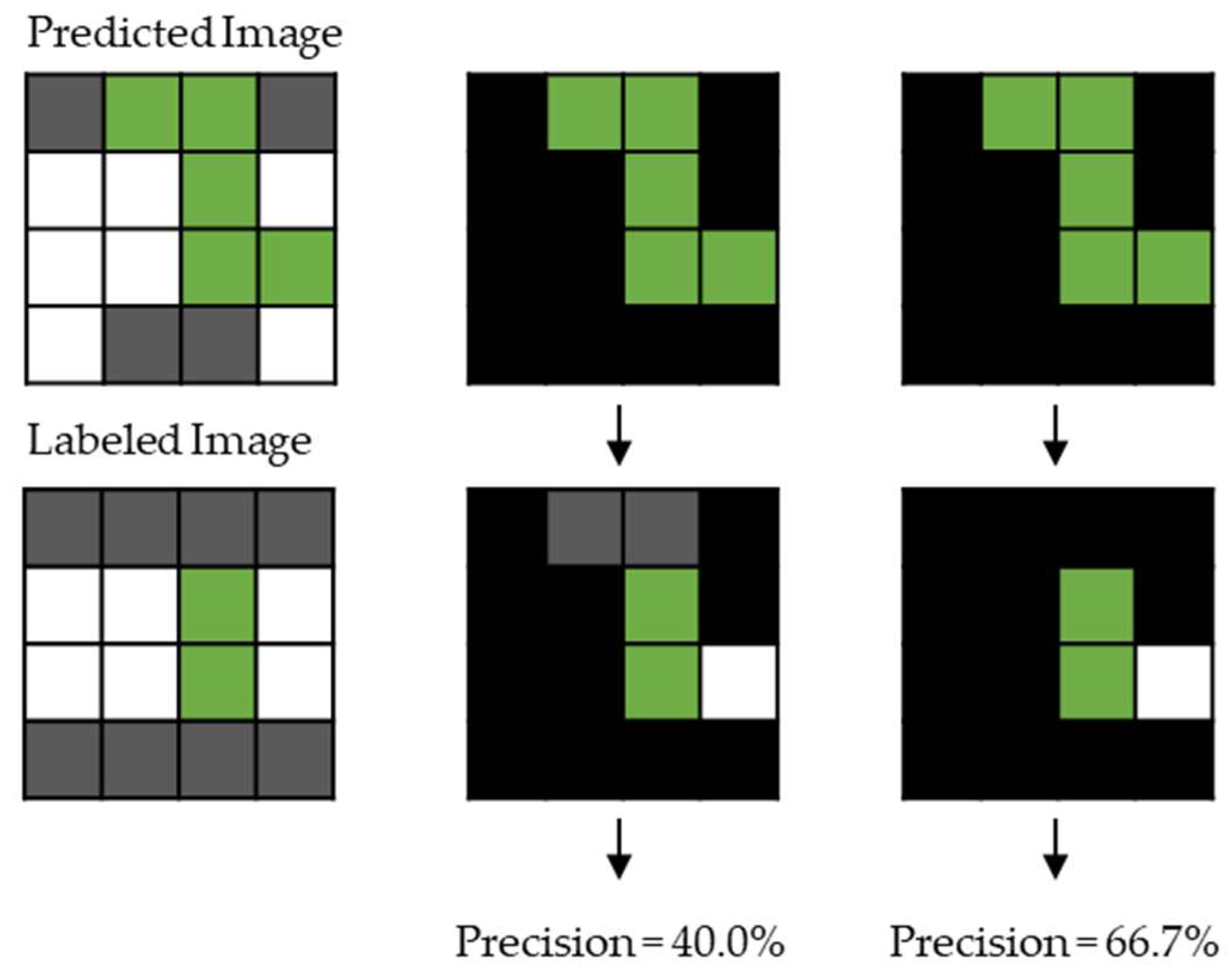
3.3. Assessment Criteria
3.4. Assessment after ‘Black’ Pixel Omission
3.5. Analyzing the Weighted Sum Combinations
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, L.; Li, Y.; Li, J.; Wang, C.; Wang, R.; Chapman, M. Mobile Laser Scanned Point-Clouds for Road Object Detection and Extraction: A Review. Remote Sens. 2018, 10, 1531. [Google Scholar] [CrossRef]
- Chiang, K.; Zeng, J.; Tsai, M.; Darweesh, M.; Chen, P.; Wang, C. Bending the Curve of HD Maps Production for Autonomous Vehicle Applications in Taiwan. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8346–8359. [Google Scholar] [CrossRef]
- Seif, H.; Hu, X. Autonomous Driving in the iCity–HD Maps as a Key Challenge of the Automotive Industry. Engineering 2016, 2, 159–162. [Google Scholar] [CrossRef]
- Liu, R.; Wang, J.; Zhang, B. High Definition Map for Automated Driving: Overview and Analysis. J. Navig. 2020, 73, 324–341. [Google Scholar] [CrossRef]
- Kashani, A.; Olsen, M.; Parrish, C.; Wilson, N. A Review of LIDAR Radiometric Processing: From Ad Hoc Intensity Correction to Rigorous Radiometric Calibration. Sensors 2015, 15, 28099–28128. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Liu, B.; Feng, C.; Vallespi-Gonzales, C.; Wellington, C. 3D Point Cloud Processing and Learning for Autonomous Driving. IEEE Signal Process. Mag. 2021, 38, 68–86. [Google Scholar] [CrossRef]
- Cheng, M.; Zhang, H.; Wang, C.; Li, J. Extraction and Classification of Road Markings Using Mobile Laser Scanning Point Clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1182–1196. [Google Scholar] [CrossRef]
- Pan, Y.; Yang, B.; Li, S.; Yang, H.; Dong, Z.; Yang, X. Automatic Road Marking Extraction, Classification and Vectorization from Mobile Laser Scanning Data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W13, 1089–1096. [Google Scholar] [CrossRef]
- Soilan, M.; Riveiro, B.; Martinez-Sanchez, J.; Arias, P. Segmentation and Classification of Road Markings using MLS Data. ISPRS J. Photogramm. Remote Sens. 2017, 123, 94–103. [Google Scholar] [CrossRef]
- Wen, C.; Sun, X.; Li, J.; Wang, C.; Guo, Y.; Habib, A. A Deep Learning Framework for Road Marking Extraction, Classification and Completion from Mobile Laser Scanning Point Clouds. ISPRS J. Photogramm. Remote Sens. 2019, 14, 178–192. [Google Scholar] [CrossRef]
- Lagahit, M.; Tseng, Y. Using Deep Learning to Digitize Road Arrow Markings from LIDAR Point Cloud Derived Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 123–129. [Google Scholar] [CrossRef]
- Lagahit, M.; Tseng, Y. Road Marking Extraction and Classification from Mobile LIDAR Point Clouds Derived Imagery using Transfer Learning. J. Photogramm. Remote Sens. 2021, 26, 127–141. [Google Scholar]
- Ma, L.; Li, Y.; Li, J.; Yu, Y.; Junior, J.M.; Goncalves, W.N.; Chapman, M. Capsule-Based Networks for Road Marking Extraction and Classification from Mobile LiDAR Point Clouds. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1981–1995. [Google Scholar] [CrossRef]
- Elhashash, M.; Albanwan, H.; Qin, R. A Review of Mobile Mapping Systems: From Sensors to Applications. Sensors 2022, 22, 4262. [Google Scholar] [CrossRef]
- Masiero, A.; Fissore, F.; Guarnieerri, A.; Vettore, A.; Coppa, U. Development and Initial Assessment of a Low Cost Mobile Mapping System. R3 Geomat. Res. Results Rev. 2020, 1246, 116–128. [Google Scholar]
- Lagahit, M.; Matsuoka, M. Boosting U-Net with Focal Loss for Road Marking Classification on Sparse Mobile LIDAR Point Cloud Derived Images. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 5, 33–38. [Google Scholar] [CrossRef]
- Lagahit, M.; Matsuoka, M. Exploring FSCNN + Focal Loss: A Faster Alternative for Road Marking Classification on Mobile LIDAR Sparse Point Cloud Derived Images. In Proceedings of the 2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3135–3138. [Google Scholar]
- Jadon, S. A Survey of Loss Functions for Semantic Segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology, Vina del Mar, Chile, 27–29 October 2020. [Google Scholar]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A Comprehensive Survey of Loss Functions in Machine Learning. Ann. Data Sci. 2022, 9, 187–212. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T. A survey on Image Data Augmentation for Deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Poudel, R.; Liwicki, S.; Cipolla, R. Fast-SCNN: Fast Semantic Segmentation Network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Kohonen, T.; Barna, G.; Chrisley, R. Statistical Pattern Recognition with Neural Networks: Benchmarking Studies. In Proceedings of the IEEE 1988 International Conference on Neural Networks, San Diego, CA, USA, 24–27 July 1988; Volume 1, pp. 61–68. [Google Scholar]
- Picek, S.; Heuser, A.; Jovic, A.; Bhasin, S.; Regazzoni, F. The Curse of Class Imbalance and Conflicting Metrics with Side-Channel Evaluations. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 1, 209–237. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Sudre, C.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalized Dice Overlap as a Deep Learning Loss Function for highly Unbalanced Segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10553, pp. 240–248. [Google Scholar]
- Taghanaki, S.; Zheng, Y.; Zhou, S.K.; Georgescu, B.; Sharma, P.; Xu, D.; Comaniciu, D.; Hamarneh, G. Combo Loss: Handling Input and Output Imbalance in Multi-Organ Segmentation. Comput. Med. Imaging Graph. 2019, 75, 24–33. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Chung, A.C. Focal Dice Loss and Image Dilation for Brain Tumor Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11045, pp. 119–127. [Google Scholar]
- Tharwat, A. Classification Assessment Methods. Appl. Comput. Inform. 2018, 17, 168–192. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Images | Number of Pixels per Class | ||
|---|---|---|---|---|
| Black | Others | Road Marking | ||
| Training | 1000 | 99.03% | 0.88% | 0.09% |
| Validation | 100 | 99.04% | 0.76% | 0.20% |
| Testing | 100 | 99.03% | 0.94% | 0.03% |
| Loss | Recall | Precision | F1-Score | IoU | |
|---|---|---|---|---|---|
| [23] | Cross Entropy | 7.3 ± 4.5 | 67.2 ± 6.1 | 12.8 ± 7.6 | 6.9 ± 4.2 |
| [24] | Weighted Cross Entropy | 46.9 ± 5.4 | 42.7 ± 5.2 | 44.3 ± 0.6 | 28.4 ± 0.5 |
| [25] | Weighted Focal (γ = 1) | 52.5 ± 6.0 | 37.9 ± 5.7 | 44.0 ± 5.9 | 28.3 ± 4.9 |
| [26] | Dice | 3.0 ± 5.0 | 1.2 ± 1.4 | 0.7 ± 0.8 | 0.3 ± 0.4 |
| [28] | Focal Dice (β = 3) | 8.3 ± 14.1 | 5.4 ± 6.2 | 1.3 ± 1.8 | 0.7 ± 0.9 |
| [27] | Combo (α = 0.50) | 96.2 ± 2.7 | 10.5 ± 2.2 | 18.8 ± 3.4 | 10.4 ± 2.1 |
| Focal Combo (γ = 1, β = 3, α = 0.25) | 95.3 ± 1.3 | 9.9 ± 0.8 | 18.0 ± 1.3 | 9.9 ± 0.8 |
| Loss | Recall | Precision | F1-Score | IoU | |
|---|---|---|---|---|---|
| [23] | Cross Entropy | 0.0 ± 0.0 | --- | --- | 0.0 ± 0.0 |
| [24] | Weighted Cross Entropy | 55.4 ± 12.2 | 6.4 ± 0.6 | 11.4 ± 1.0 | 6.0 ± 0.6 |
| [25] | Weighted Focal (γ = 5) | 52.7 ± 8.8 | 5.9 ± 0.4 | 10.5 ± 0.7 | 5.6 ± 0.4 |
| [26] | Dice | 56.8 ± 46.9 | 3.3 ± 1.0 | 4.6 ± 1.2 | 2.4 ± 0.6 |
| [28] | Focal Dice (β = 1.5) | 57.4 ± 48.4 | 3.4 ± 0.7 | 4.8 ± 2.5 | 2.5 ± 1.3 |
| [27] | Combo (α = 0.25) | 61.5 ± 10.4 | 5.2 ± 0.4 | 9.6 ± 0.8 | 5.0 ± 0.4 |
| Focal Combo (γ = 5, β = 1.5, α = 0.25) | 66.6 ± 1.7 | 5.5 ± 0.8 | 10.1 ± 1.3 | 5.3 ± 0.7 |
| Loss | Recall | Precision | F1-Score | IoU | |
|---|---|---|---|---|---|
| [23] | Cross Entropy | 7.3 ± 4.5 | 97.1 ± 0.2 | 13.3 ± 8.0 | 25.3 ± 15.2 |
| [24] | Weighted Cross Entropy | 46.9 ± 5.4 | 95.6 ± 0.5 | 62.8 ± 4.7 | 50.7 ± 4.9 |
| [25] | Weighted Focal (γ = 1) | 52.5 ± 6.0 | 94.3 ± 1.7 | 67.3 ± 55.2 | 5.2 ± 7.9 |
| [26] | Dice | 3.0 ± 5.0 | 2.2 ± 1.9 | 1.8 ± 2.7 | 0.9 ± 1.4 |
| [28] | Focal Dice (β = 3) | 8.3 ± 14.1 | 14.3 ± 16.7 | 3.9 ± 6.3 | 2.1 ± 3.3 |
| [27] | Combo (α = 0.50) | 96.2 ± 2.7 | 76.4 ± 6.7 | 84.9 ± 3.1 | 73.9 ± 4.6 |
| Focal Combo (γ = 1, β = 3, α = 0.25) | 95.3 ± 1.3 | 77.4 ± 2.7 | 85.4 ± 1.1 | 74.5 ± 1.7 |
| Loss | Recall | Precision | F1-Score | IoU | |
|---|---|---|---|---|---|
| [23] | Cross Entropy | 0.0 ± 0.0 | --- | --- | --- |
| [24] | Weighted Cross Entropy | 55.4 ± 12.2 | 80.9 ± 10.6 | 64.6 ± 6.5 | 48.2 ± 6.9 |
| [25] | Weighted Focal (γ = 5) | 52.7 ± 8.8 | 85.2 ± 3.3 | 64.9 ± 6.7 | 48.7 ± 7.7 |
| [26] | Dice | 56.8 ± 46.9 | 41.3 ± 5.2 | 37.7 ± 28.7 | 26.3 ± 19.3 |
| [28] | Focal Dice (β = 1.5) | 57.4 ± 48.4 | 43.4 ± 10.0 | 40.0 ± 32.9 | 28.8 ± 23.7 |
| [27] | Combo (α = 0.25) | 61.5 ± 10.4 | 78.2 ± 4.1 | 68.6 ± 7.6 | 53.7 ± 6.8 |
| Focal Combo (γ = 5, β = 1.5, α = 0.25) | 66.6 ± 1.9 | 71.4 ± 6.9 | 68.9 ± 4.2 | 52.9 ± 4.8 |
| α | Recall | Precision | F1-Score | IoU |
|---|---|---|---|---|
| 0.25 | 95.3 ± 1.3 | 77.4 ± 2.7 | 85.4 ± 1.1 | 74.5 ± 1.7 |
| 0.50 | 66.7 ± 19.3 | 79.0 ± 5.1 | 70.9 ± 8.1 | 55.3 ± 10.1 |
| 0.75 | 23.4 ± 10.5 | 85.7 ± 7.8 | 36.2 ± 13.4 | 22.7 ± 10.5 |
| α | Recall | Precision | F1-Score | IoU |
|---|---|---|---|---|
| 0.25 | 66.6 ± 1.9 | 71.4 ± 6.9 | 68.9 ± 4.2 | 52.9 ± 4.8 |
| 0.50 | 68.0 ± 3.9 | 69.0 ± 10.7 | 68.0 ± 4.4 | 51.9 ± 5.1 |
| 0.75 | 60.0 ± 21.7 | 70.5 ± 10.2 | 61.9 ± 11.1 | 45.7 ± 11.3 |
| Method | Recall | Precision | F1-Score | IoU | |
|---|---|---|---|---|---|
| [11] | U-Net + Cross Entropy | 7.3 ± 4.5 | 97.1 ± 0.2 | 13.3 ± 8.0 | 25.3 ± 15.2 |
| [12] | U-Net + Cross Entropy (Transfer Learning) | 6.7 ± 1.1 | 97.9 ± 0.9 | 12.5 ± 2.0 | 30.2 ± 1.5 |
| [13] | U-Net + Weighted Focal | 52.5 ± 6.0 | 94.3 ± 1.7 | 67.3 ± 55.2 | 5.2 ± 7.9 |
| [10] | U-Net + IoU | 8.4 ± 14.5 | --- | --- | 2.4 ± 4.2 |
| U-Net + Focal Combo | 95.3 ± 1.3 | 77.4 ± 2.7 | 85.4 ± 1.1 | 74.5 ± 1.7 | |
| [14] | Fast-SCNN + Weighted Focal | 52.7 ± 8.8 | 85.2 ± 3.3 | 64.9 ± 6.7 | 48.7 ± 7.7 |
| Fast-SCNN + Focal Combo | 66.6 ± 1.7 | 71.4 ± 6.9 | 68.9 ± 4.2 | 52.9 ± 4.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lagahit, M.L.R.; Matsuoka, M. Focal Combo Loss for Improved Road Marking Extraction of Sparse Mobile LiDAR Scanning Point Cloud-Derived Images Using Convolutional Neural Networks. Remote Sens. 2023, 15, 597. https://doi.org/10.3390/rs15030597
Lagahit MLR, Matsuoka M. Focal Combo Loss for Improved Road Marking Extraction of Sparse Mobile LiDAR Scanning Point Cloud-Derived Images Using Convolutional Neural Networks. Remote Sensing. 2023; 15(3):597. https://doi.org/10.3390/rs15030597
Chicago/Turabian StyleLagahit, Miguel Luis R., and Masashi Matsuoka. 2023. "Focal Combo Loss for Improved Road Marking Extraction of Sparse Mobile LiDAR Scanning Point Cloud-Derived Images Using Convolutional Neural Networks" Remote Sensing 15, no. 3: 597. https://doi.org/10.3390/rs15030597
APA StyleLagahit, M. L. R., & Matsuoka, M. (2023). Focal Combo Loss for Improved Road Marking Extraction of Sparse Mobile LiDAR Scanning Point Cloud-Derived Images Using Convolutional Neural Networks. Remote Sensing, 15(3), 597. https://doi.org/10.3390/rs15030597