
Vehicle Detection in UAV Images via Background Suppression Pyramid Network and Multi-Scale Task Adaptive Decoupled Head


Abstract
:
1. Introduction
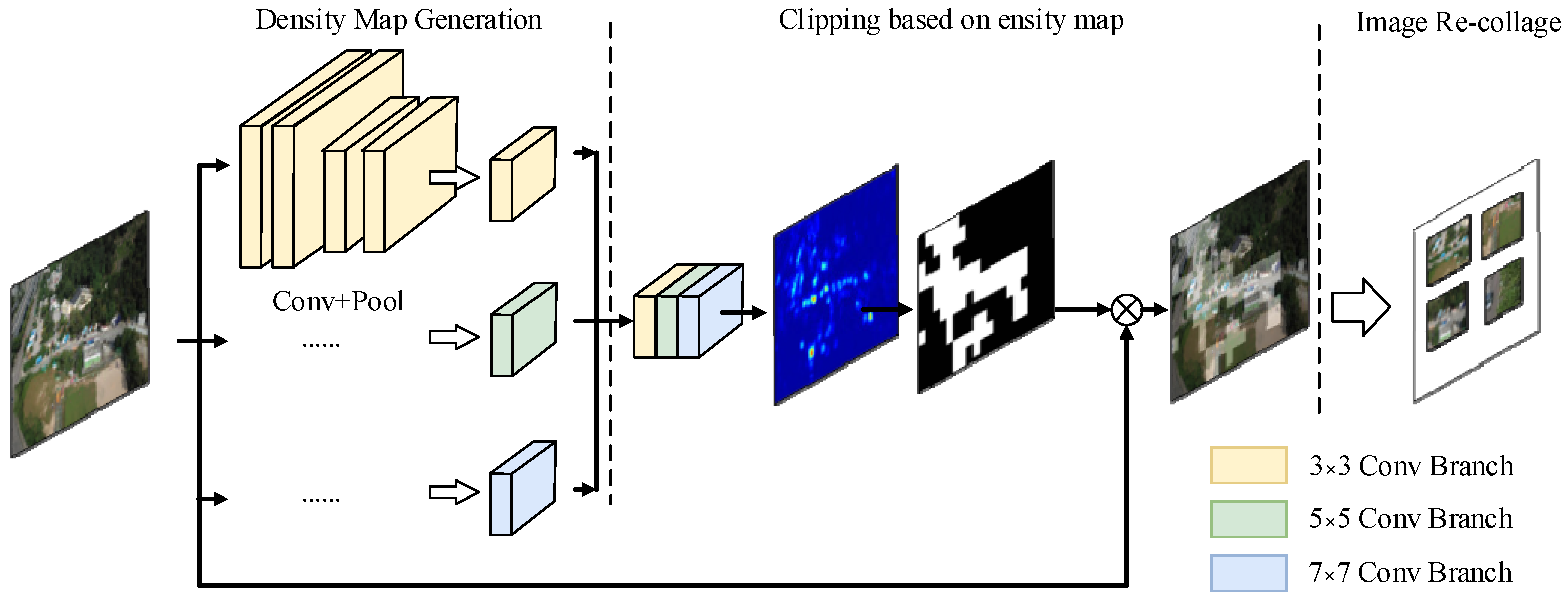
- Long-tail feature resampling algorithm: This algorithm generates target prediction density maps and resamples small-sample targets based on these maps to alleviate the issue of imbalanced target category distribution.
- Background suppression module: This module integrates spatial and channel attention mechanisms. Spatial attention focuses on key image regions to highlight targets, while channel attention emphasizes important features. The combined use of these attention methods can reduce the interference of the background in object detection.
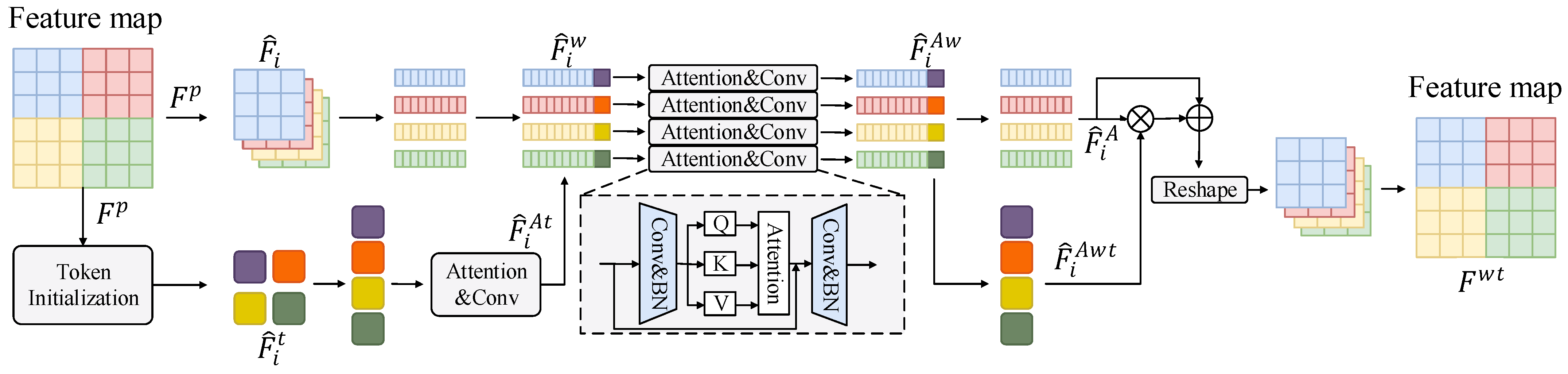
- Lightweight Transformer module: This module uses the concept of lightweight to divide input features into blocks, each then processed by a transformer. This design not only improves the ability of the model to detect small targets but also reduces computational requirements.
- Multi-scale task adaptive decoupled head: This module processes multi-scale features from different receptive fields through dynamic convolution to extract target scale features, selecting the most optimal features. This approach addresses the problem of drastic target scale changes in unmanned aerial vehicle target detection.
2. Related Work
3. Proposed Approach
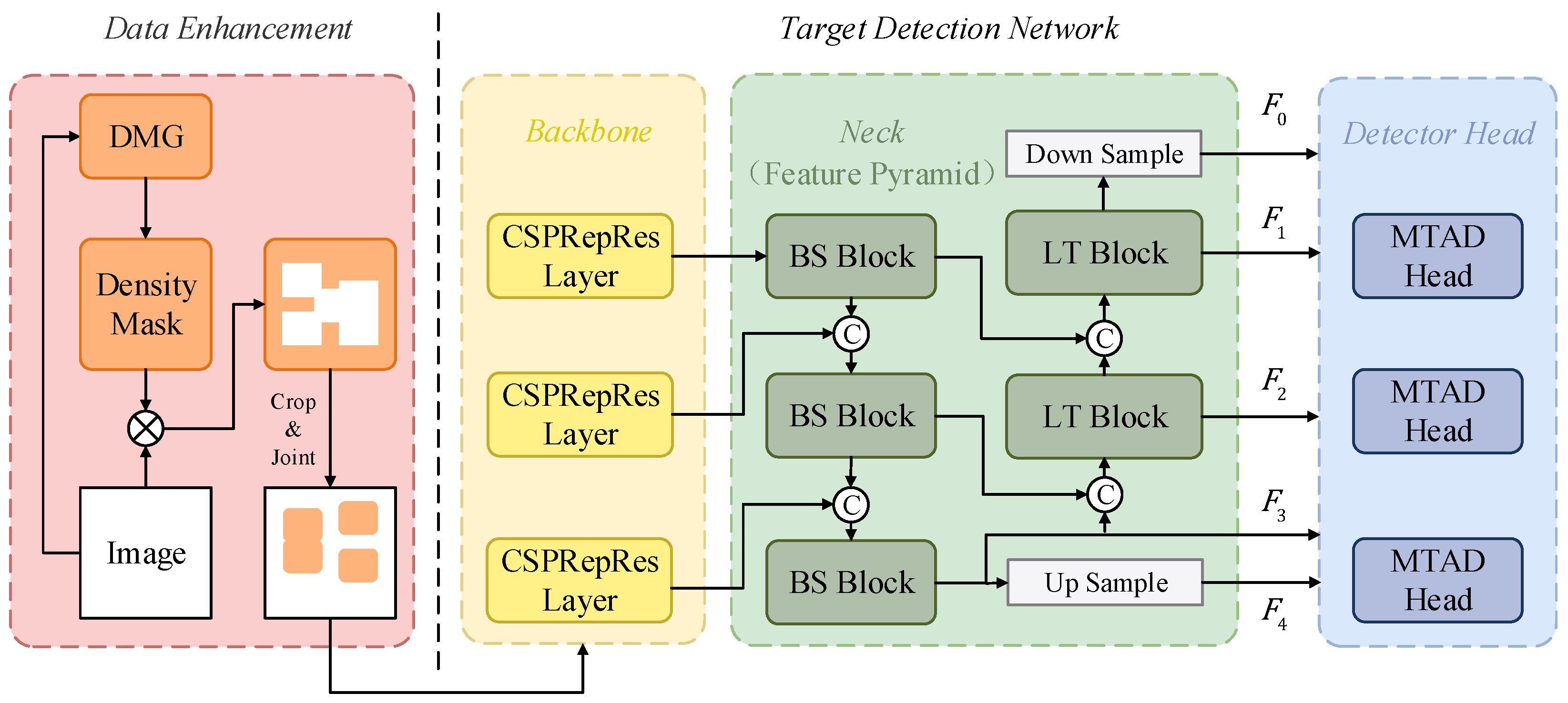
3.1. Overall Framework of the Model
3.2. Data Enhancement
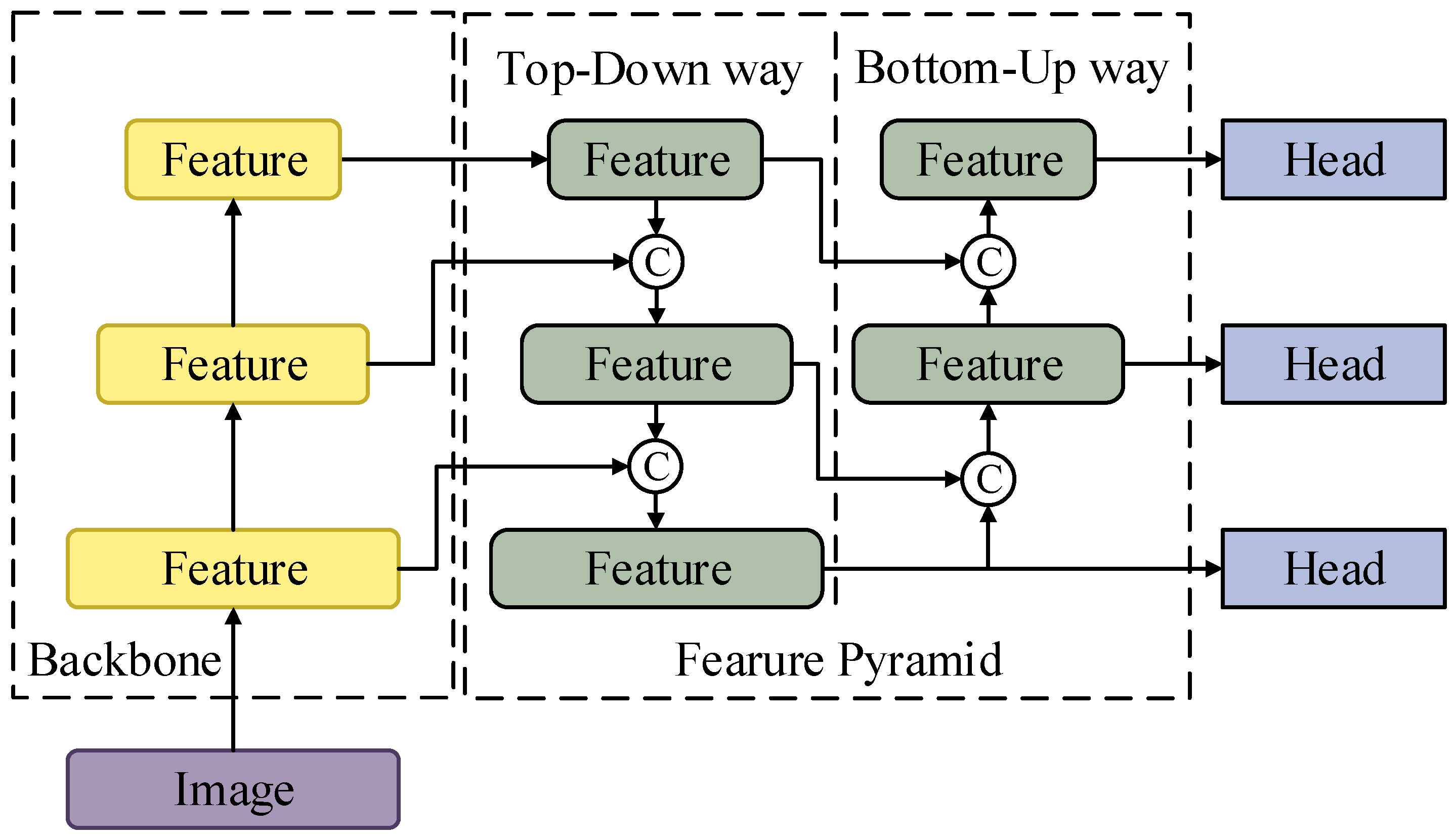
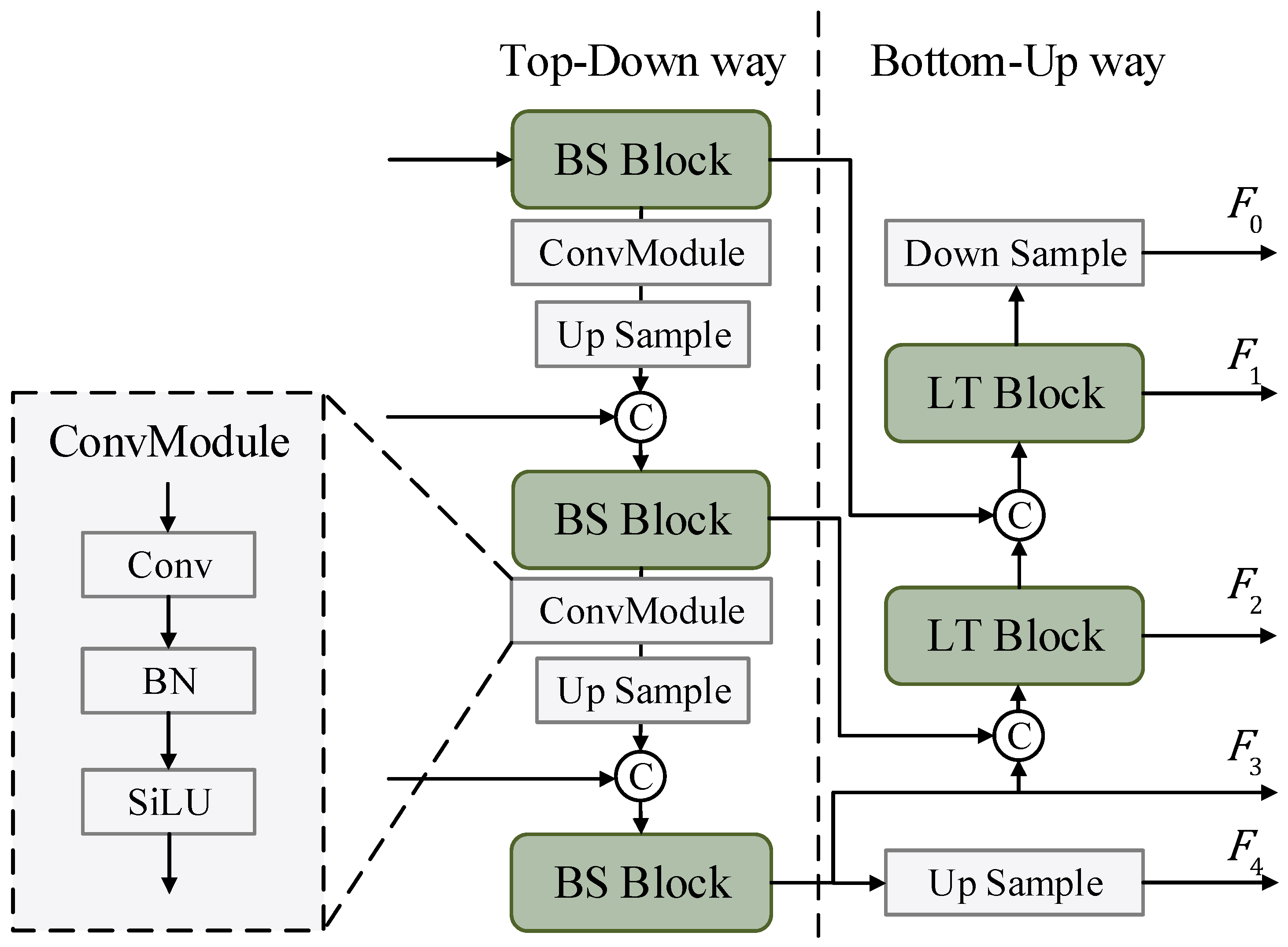
3.3. Background Suppression Pyramid Network
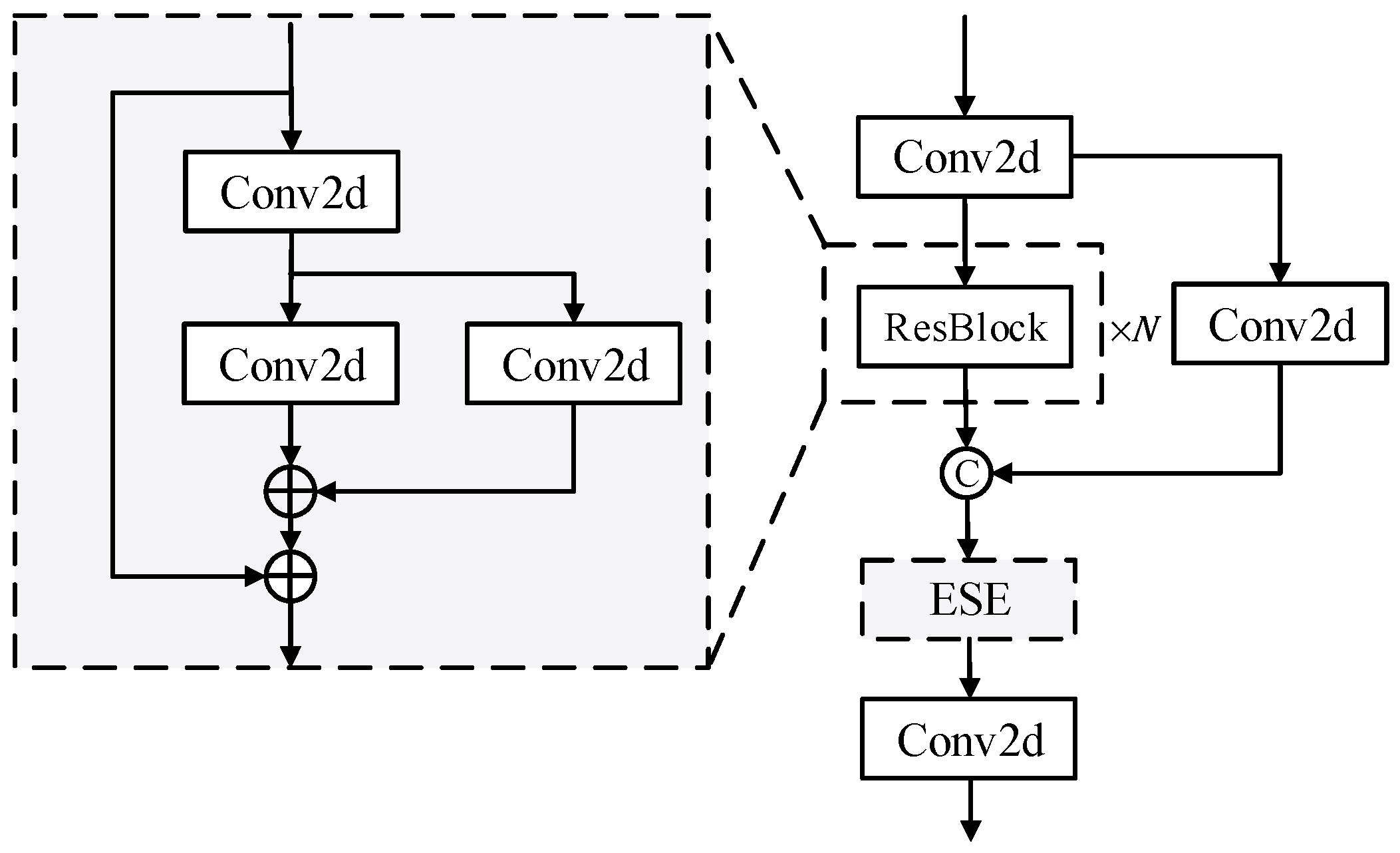
3.3.1. Background Suppression Block
3.3.2. Lightweight Transformer Block
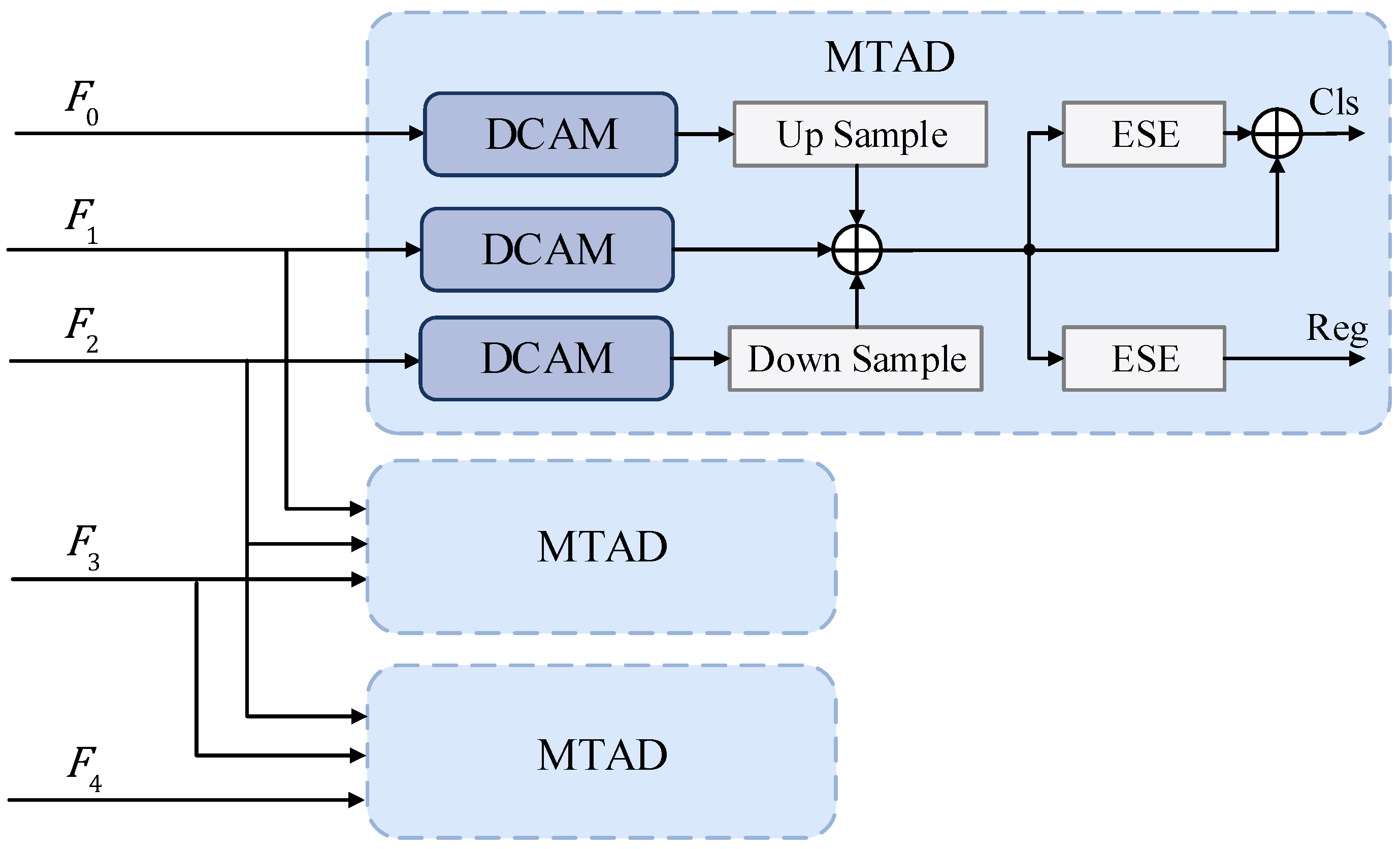
3.4. Detection Head Network
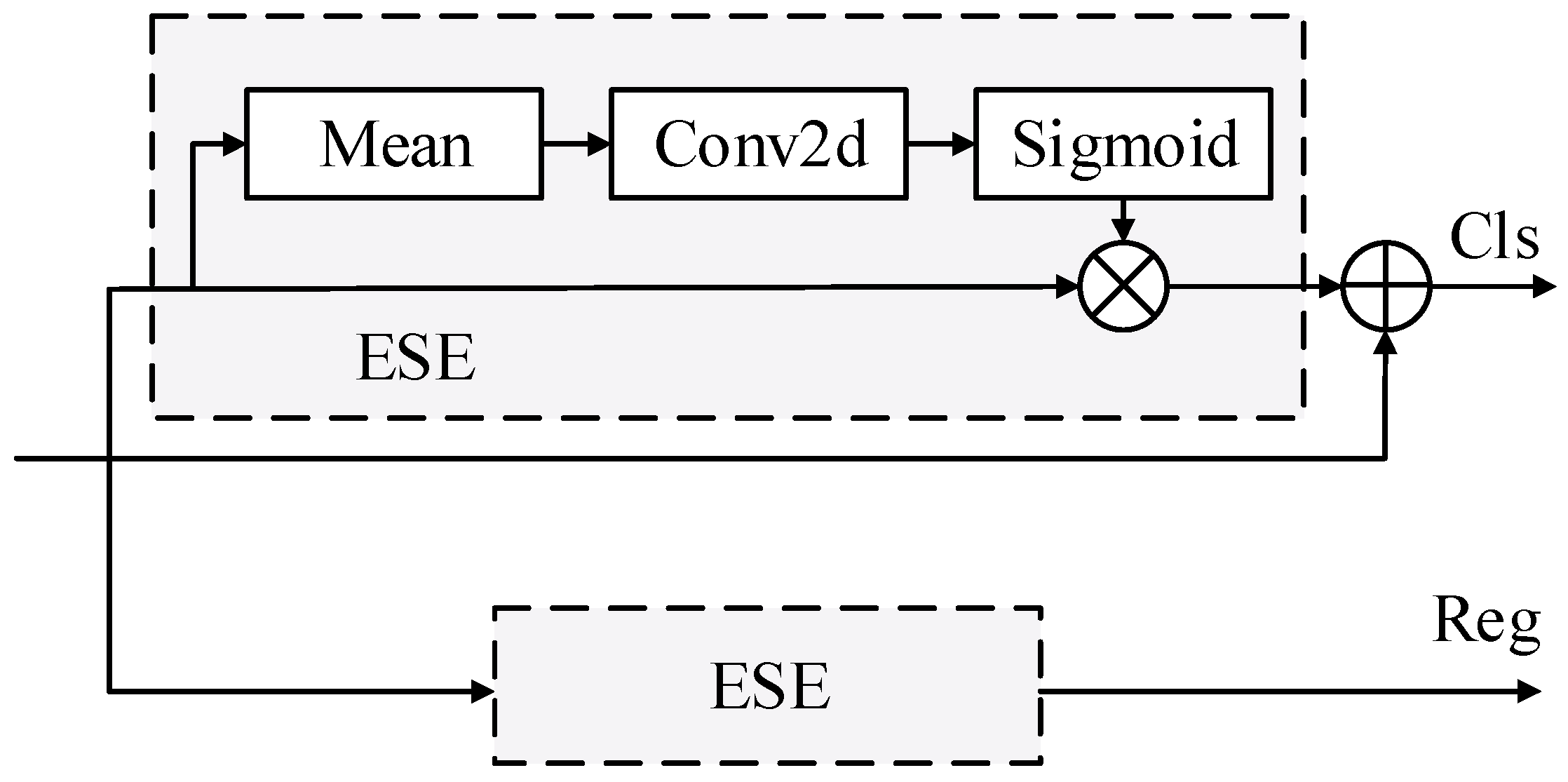
3.4.1. Multi-Scale Task Adaptive Decoupled Head
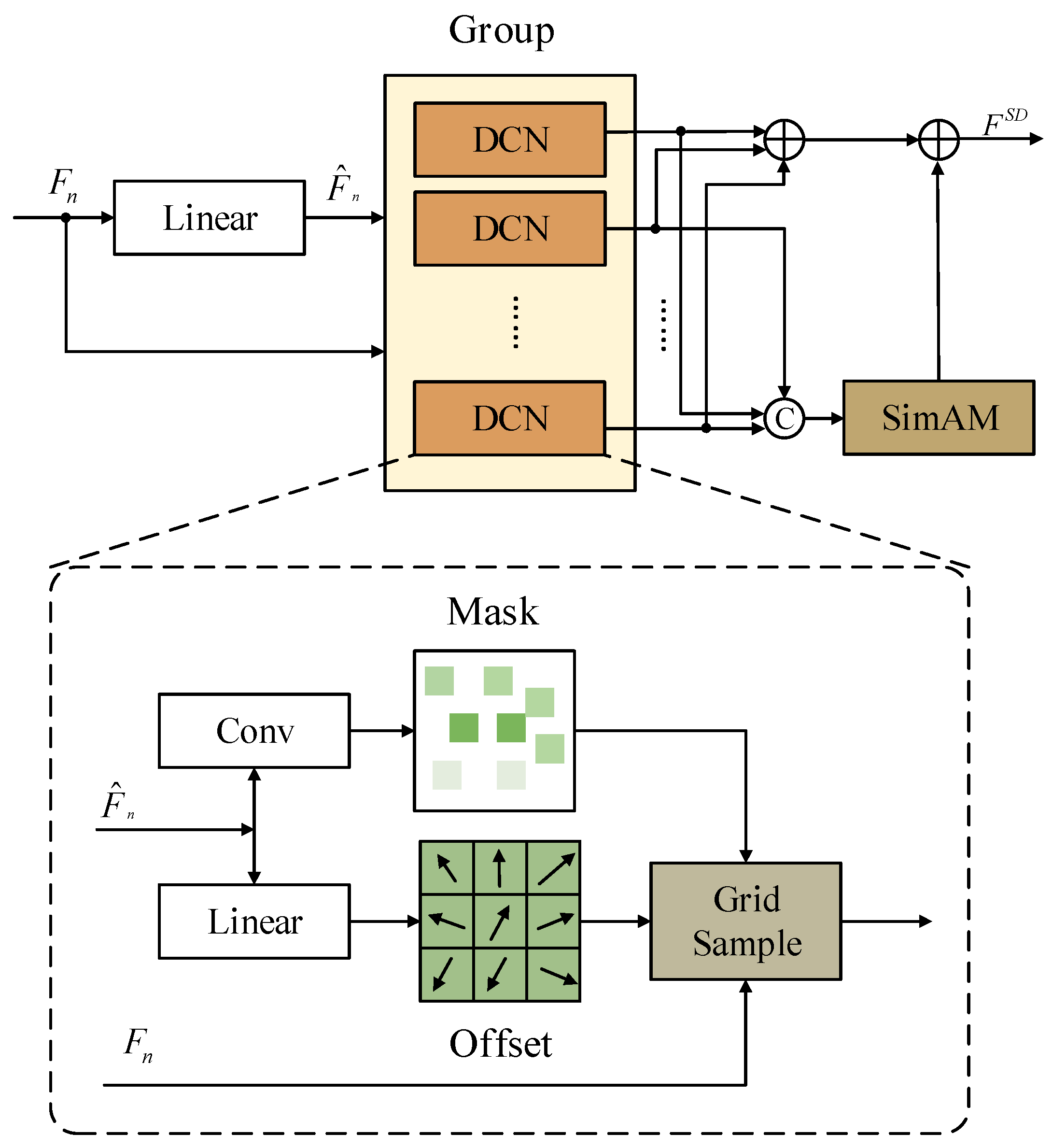
3.4.2. Dynamic Convolutional Attention Block
3.5. Loss Function
3.5.1. Density Map
3.5.2. Object Detection
4. Experiments
4.1. VisDrone-Vehicle Dataset
4.2. Experimental Setup
4.3. Ablation Study
4.4. Overall Model Performance Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mueller, M.; Smith, N.; Ghanem, B. A Benchmark and Simulator for UAV Tracking. In Computer Vision—ECCV 2016: Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 445–461. [Google Scholar]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning Social Etiquette: Human Trajectory Understanding in Crowded Scenes. In Computer Vision—ECCV 2016: Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9912, pp. 549–565. [Google Scholar]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision Meets Drones: A Challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Zhu, J.; Sun, K.; Jia, S.; Li, Q.; Hou, X.; Lin, W.; Liu, B.; Qiu, G. Urban Traffic Density Estimation Based on Ultrahigh-Resolution UAV Video and Deep Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4968–4981. [Google Scholar] [CrossRef]
- Betti Sorbelli, F.; Palazzetti, L.; Pinotti, C.M. YOLO-based detection of Halyomorpha halys in orchards using RGB cameras and drones. Comput. Electron. Agric. 2023, 213, 108–228. [Google Scholar] [CrossRef]
- Mishra, V.; Avtar, R.; Prathiba, A.P.; Mishra, P.K.; Tiwari, A.; Sharma, S.K.; Singh, C.H.; Chandra Yadav, B.; Jain, K. Uncrewed Aerial Systems in Water Resource Management and Monitoring: A Review of Sensors, Applications, Software, and Issues. Adv. Civ. Eng. 2023, 2023, e3544724. [Google Scholar] [CrossRef]
- Wang, X.; Yao, F.; Li, A.; Xu, Z.; Ding, L.; Yang, X.; Zhong, G.; Wang, S. DroneNet: Rescue Drone-View Object Detection. Drones 2023, 7, 441. [Google Scholar] [CrossRef]
- Półka, M.; Ptak, S.; Kuziora, Ł. The Use of UAV’s for Search and Rescue Operations. Procedia Eng. 2017, 192, 748–752. [Google Scholar] [CrossRef]
- Singh, C.H.; Mishra, V.; Jain, K.; Shukla, A.K. FRCNN-Based Reinforcement Learning for Real-Time Vehicle Detection, Tracking and Geolocation from UAS. Drones 2022, 6, 406. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems: Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Advances in Neural Information Processing Systems: Proceedings of the Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016: Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Alexey, B.; Wang, C.-Y.; Liao, H.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chen, C.; Zheng, Z.; Xu, T.; Guo, S.; Feng, S.; Yao, W.; Lan, Y. YOLO-Based UAV Technology: A Review of the Research and Its Applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision—ECCV 2014: Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Dong, Z.; Xu, K.; Yang, Y.; Xu, W.; Lau, R.W. Location-aware single image reflection removal. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5017–5026. [Google Scholar]
- Zhang, X.; Izquierdo, E.; Chandramouli, K. Dense and Small Object Detection in UAV Vision Based on Cascade Network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 118–126. [Google Scholar]
- Li, X.; Li, X. Robust Vehicle Detection in Aerial Images Based on Image Spatial Pyramid Detection Model. In Proceedings of the 2019 IEEE 4th International Conference on Advanced Robotics and Mechatronics (ICARM), Toyonaka, Japan, 3–5 July 2019; pp. 850–855. [Google Scholar]
- Wang, L.; Liao, J.; Xu, C. Vehicle Detection Based on Drone Images with the Improved Faster R-CNN. In Proceedings of the 2019 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–24 February 2019; ACM: New York, NY, USA, 2019; pp. 466–471. [Google Scholar]
- Brkić, I.; Miler, M.; Ševrović, M.; Medak, D. An Analytical Framework for Accurate Traffic Flow Parameter Calculation from UAV Aerial Videos. Remote Sens. 2020, 12, 3844. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Pan, H. Multi-Scale Vehicle Detection in High-Resolution Aerial Images with Context Information. IEEE Access 2020, 8, 208643–208657. [Google Scholar] [CrossRef]
- Zhou, J.; Vong, C.-M.; Liu, Q.; Wang, Z. Scale adaptive image cropping for UAV object detection. Neurocomputing 2019, 366, 305–313. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Li, Z.; Xiong, X.; Khyam, M.O.; Sun, C. Robust Vehicle Detection in High-Resolution Aerial Images with Imbalanced Data. IEEE Trans. Artif. Intell. 2021, 2, 238–250. [Google Scholar] [CrossRef]
- Pandey, V.; Anand, K.; Kalra, A.; Gupta, A.; Roy, P.P.; Kim, B.-G. Enhancing object detection in aerial images. Math. Biosci. Eng. 2022, 19, 7920–7932. [Google Scholar] [CrossRef] [PubMed]
- Tang, T.; Zhou, S.; Deng, Z.; Lei, L.; Zou, H. Fast multidirectional vehicle detection on aerial images using region based convolutional neural networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1844–1847. [Google Scholar]
- Sommer, L.; Schumann, A.; Schuchert, T.; Beyerer, J. Multi Feature Deconvolutional Faster R-CNN for Precise Vehicle Detection in Aerial Imagery. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 635–642. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward Fast and Accurate Vehicle Detection in Aerial Images Using Coupled Region-Based Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Xie, X.; Yang, W.; Cao, G.; Yang, J.; Zhao, Z.; Chen, S.; Liao, Q.; Shi, G. Real-Time Vehicle Detection from UAV Imagery. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Tayara, H.; Gil Soo, K.; Chong, K.T. Vehicle Detection and Counting in High-Resolution Aerial Images Using Convolutional Regression Neural Network. IEEE Access 2018, 6, 2220–2230. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, J.; Zhuo, L.; Li, Y.; Tian, Q. Small Object Detection in Unmanned Aerial Vehicle Images Using Feature Fusion and Scaling-Based Single Shot Detector with Spatial Context Analysis. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1758–1770. [Google Scholar] [CrossRef]
- Xi, Y.; Jia, W.; Miao, Q.; Liu, X.; Fan, X.; Li, H. FiFoNet: Fine-Grained Target Focusing Network for Object Detection in UAV Images. Remote Sens. 2022, 14, 3919. [Google Scholar] [CrossRef]
- Ma, Y.; Chai, L.; Jin, L.; Yu, Y.; Yan, J. AVS-YOLO: Object Detection in Aerial Visual Scene. Int. J. Patt. Recogn. Artif. Intell. 2022, 36, 2250004. [Google Scholar] [CrossRef]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An evolved version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A Practical Object Detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss v2: Learning reliable localization quality estimation for dense object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–24 June 2021; pp. 11632–11641. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density Map Guided Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 190–191. [Google Scholar]
- Li, X.; Sun, W.; Wu, T. Attentive Normalization. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVII; Springer: Cham, Switzerland, 2020; pp. 70–87. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. FoveaBox: Beyound Anchor-Based Object Detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. YOLOv6 v3.0: A Full-Scale Reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection. arXiv 2022, arXiv:2110.13389. [Google Scholar]
- Meethal, A.; Granger, E.; Pedersoli, M. Cascaded Zoom-In Detector for High Resolution Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 2046–2055. [Google Scholar]
- Lv, W.; Zhao, Y.; Xu, S.; Wei, J.; Wang, G.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. DETRs Beat YOLOs on Real-time Object Detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Size | Total | Category | Number |
|---|---|---|---|
| Small | 132,484 | Car | 84,913 |
| Van | 13,643 | ||
| Truck | 4761 | ||
| Bus | 4984 | ||
| Motor | 26,808 | ||
| Medium | 110,752 | Car | 74,976 |
| Van | 14,212 | ||
| Truck | 8169 | ||
| Bus | 4984 | ||
| Motor | 8411 | ||
| Large | 20,323 | Car | 13,051 |
| Van | 2872 | ||
| Truck | 2604 | ||
| Bus | 1523 | ||
| Motor | 273 |
| Method | LFRA | BSPN | MTAD | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Baseline | 30.9 | 49.7 | 33.3 | 13.8 | 40.7 | 52.4 | |||
| M1 | 31.6 | 50.2 | 34.0 | 14.3 | 41.3 | 53.3 | |||
| M2 | 31.5 | 50.0 | 33.9 | 14.0 | 41.6 | 53.5 | |||
| M3 | 31.7 | 50.4 | 34.5 | 14.1 | 41.8 | 53.6 | |||
| M4 | 32.4 | 51.0 | 35.2 | 14.5 | 42.5 | 54.2 | |||
| M5 | 32.0 | 50.6 | 34.8 | 14.2 | 41.9 | 53.9 | |||
| M6 | 32.1 | 50.8 | 34.9 | 14.3 | 42.3 | 53.8 | |||
| M7 | 32.8 | 51.7 | 36.0 | 14.6 | 43.4 | 54.7 |
| Method | Param | GFlops | FPS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Faster RCNN [13] | 26.2 | 41.4 | 29.5 | 10.3 | 36.5 | 45.9 | 41.1 | 202 | 11.6 |
| Cascade RCNN [47] | 27.9 | 42.7 | 31.6 | 11.2 | 38.5 | 50.4 | 68.9 | 230 | 16.3 |
| FSAF [48] | 19.4 | 35.4 | 19.1 | 6.8 | 26.3 | 39.5 | 36.0 | 201 | 20.7 |
| GFL [43] | 20.4 | 35.1 | 21.5 | 6.9 | 27.8 | 42.0 | 32.0 | 203 | 20.6 |
| FCOS [49] | 18.4 | 32.2 | 18.8 | 4.9 | 25.6 | 40.1 | 31.9 | 196 | 21.4 |
| Fovea [50] | 17.5 | 30.5 | 18.2 | 3.3 | 25.1 | 41.2 | 36.0 | 201 | 21.1 |
| YOLOX [51] | 23.7 | 40.1 | 25.2 | 9.3 | 32.2 | 33.9 | 8.94 | 13.4 | 46.2 |
| YOLOv6-n [52] | 24.9 | 40.7 | 26.7 | 9.3 | 33.7 | 47.5 | 4.30 | 5.49 | 33.4 |
| YOLOv6-t [52] | 28.4 | 45.6 | 31 | 11.1 | 38.1 | 49.2 | 9.67 | 12.3 | 34.8 |
| YOLOv7-t [53] | 25.4 | 43.3 | 26.7 | 9.9 | 33.7 | 46.9 | 6.02 | 6.89 | 65.5 |
| YOLOv8-n | 25.3 | 41.4 | 27.1 | 9.5 | 34.5 | 45.6 | 3.01 | 4.40 | 64.7 |
| YOLOv8-s | 30.2 | 48.2 | 32.7 | 12.7 | 40.4 | 51.8 | 11.1 | 14.3 | 63.2 |
| Faster RCNN NWD [54] | 30.3 | 32.8 | 49.8 | 15.9 | 39.5 | 46.5 | 41.14 | 202 | 11.2 |
| CZ Det [55] | 24.8 | 26.3 | 41.3 | 12.2 | 30.9 | 35.2 | 45.9 | 210 | 7.0 |
| RT-DETR-s [56] | 28.9 | 31.8 | 46.0 | 11.2 | 39.1 | 51.3 | 8.87 | 14.8 | 16.7 |
| PPYOLOE-s [41] | 30.9 | 49.7 | 33.3 | 13.6 | 40.4 | 51.5 | 7.46 | 7.95 | 45.1 |
| Our method | 32.8 | 51.7 | 36 | 14.6 | 43.4 | 54.7 | 10.3 | 13.1 | 20.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, M.; Xia, W.; Yu, H.; Hu, X.; Cai, W.; Shi, J. Vehicle Detection in UAV Images via Background Suppression Pyramid Network and Multi-Scale Task Adaptive Decoupled Head. Remote Sens. 2023, 15, 5698. https://doi.org/10.3390/rs15245698
Pan M, Xia W, Yu H, Hu X, Cai W, Shi J. Vehicle Detection in UAV Images via Background Suppression Pyramid Network and Multi-Scale Task Adaptive Decoupled Head. Remote Sensing. 2023; 15(24):5698. https://doi.org/10.3390/rs15245698
Chicago/Turabian StylePan, Mian, Weijie Xia, Haibin Yu, Xinzhi Hu, Wenyu Cai, and Jianguang Shi. 2023. "Vehicle Detection in UAV Images via Background Suppression Pyramid Network and Multi-Scale Task Adaptive Decoupled Head" Remote Sensing 15, no. 24: 5698. https://doi.org/10.3390/rs15245698
APA StylePan, M., Xia, W., Yu, H., Hu, X., Cai, W., & Shi, J. (2023). Vehicle Detection in UAV Images via Background Suppression Pyramid Network and Multi-Scale Task Adaptive Decoupled Head. Remote Sensing, 15(24), 5698. https://doi.org/10.3390/rs15245698