
Detection of Changes in Buildings in Remote Sensing Images via Self-Supervised Contrastive Pre-Training and Historical Geographic Information System Vector Maps



Abstract
:
1. Introduction
- (1)
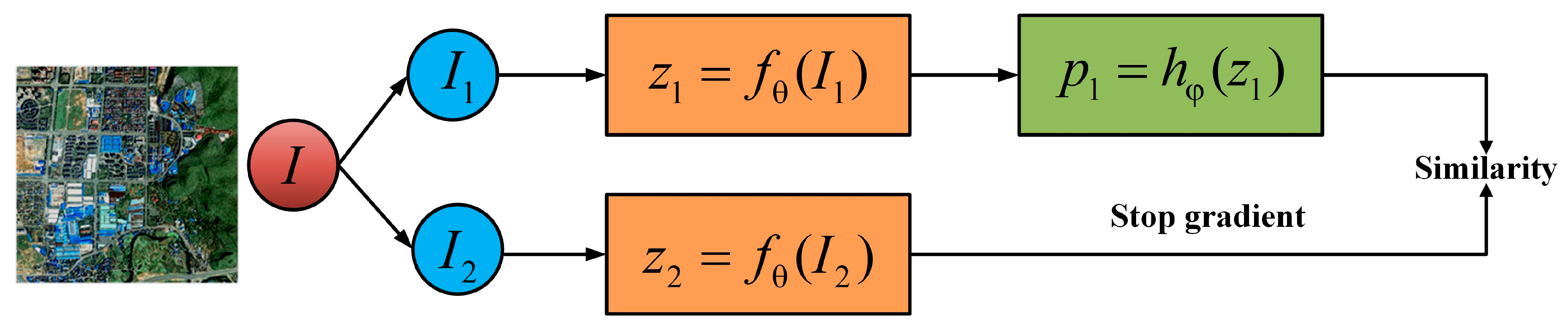
- This paper has explored the SimSiam algorithm’s generalisation ability to learn visual representations from remote sensing images. SimSiam leverages unlabelled samples of old temporal building images to acquire effective feature representations when extracting buildings from new temporal imagery. Initially pre-trained by a self-supervised contrastive learning approach, the encoder undergoes fine-tuning, thereby significantly enhancing downstream building extraction networks through well-initialised parameters.
- (2)
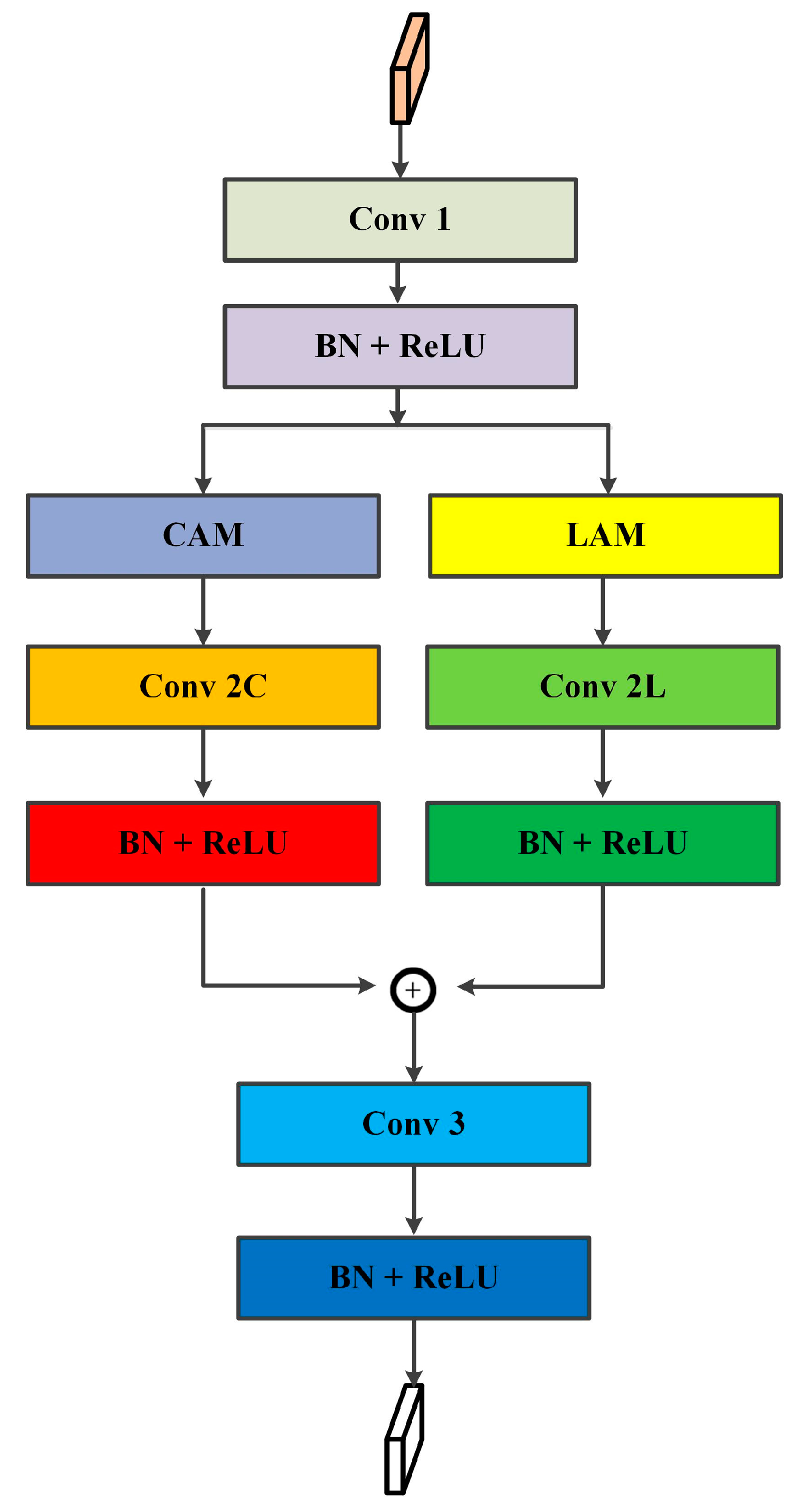
- We devised an MS-ResUNet network that incorporates an MIP and multi-layer attention modules, resulting in superior overall accuracy in building extraction compared to SOTA methods.
- (3)
- We introduced a novel spatial analysis rule to detect changes in building vectors. By leveraging domain knowledge from HGVMs and building upon the spatial analysis of building vectors in bi-temporal images, we achieved an automated BCD.
2. Related Work
2.1. Brief Overview of BCD Datasets and Methods
2.2. Use of SSL in Remote Sensing CD
3. Materials and Methods
3.1. Self-Supervised Contrastive Pre-Training Using SimSiam
3.2. New Temporal Building Extraction Based on MS-ResUNet
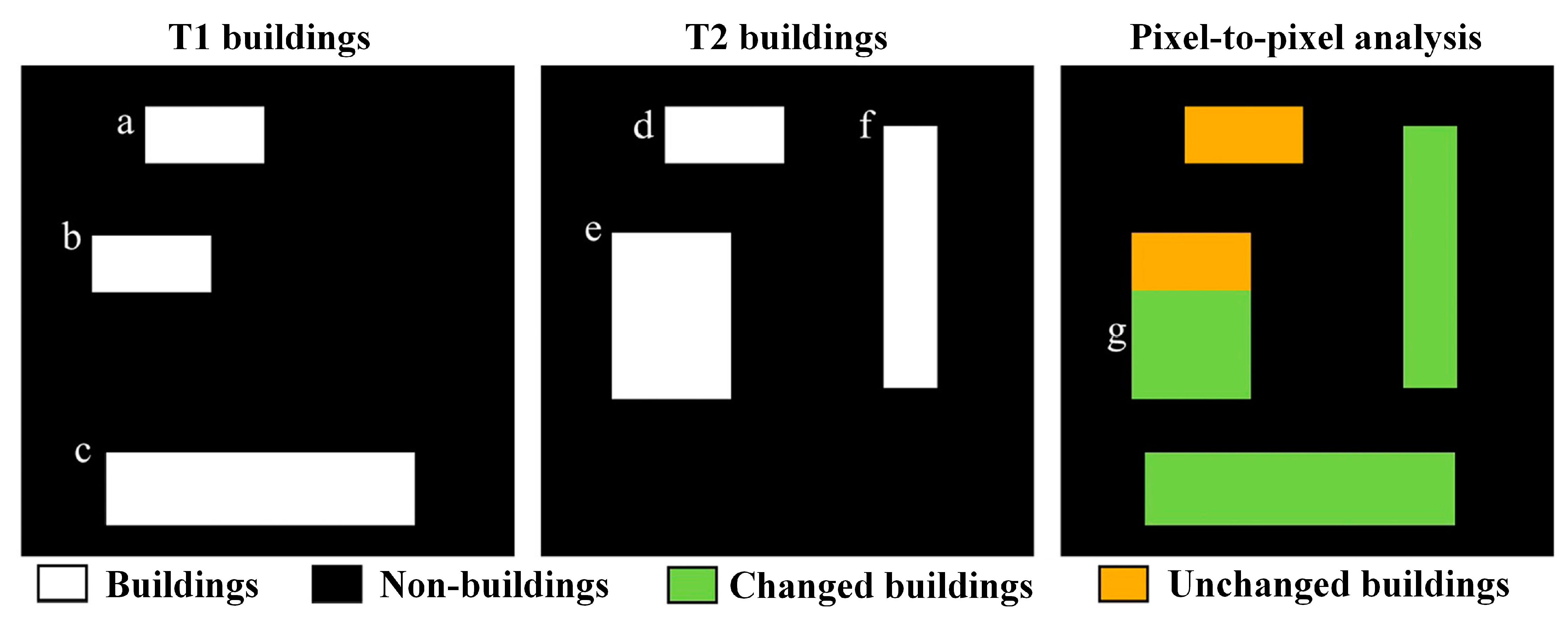
3.3. BCD Based on A Spatial Analysis
- (1)
- The T2 temporal remote sensing images are overlaid with HGVMs through raster–vector integration. This is followed by meticulous segmentation within vector boundaries, bolstering the building boundary and rooftop integrity using GIS vector constraints to yield segmented objects of varying scales. In this study, we utilised the Estimation of Scale Parameter tool (a plug-in based on the eCognition software 8.7 [65]) for optimal segmentation.
- (2)
- Following the extraction of buildings from the T2 temporal image, spatial analysis is conducted following the pixel-to-pixel comparison rules shown in Figure 5 to determine BCD between the T1 and T2 temporal image buildings.
- (3)
- To further preserve the integrity of changed building objects, a majority voting strategy is employed to achieve the final BCD and building extraction outcome.
3.4. Experimental Datasets
3.5. Implementation Details and Evaluation Metrics
3.6. Comparison with SOTA Approaches
4. Experimental Analyses and Discussion
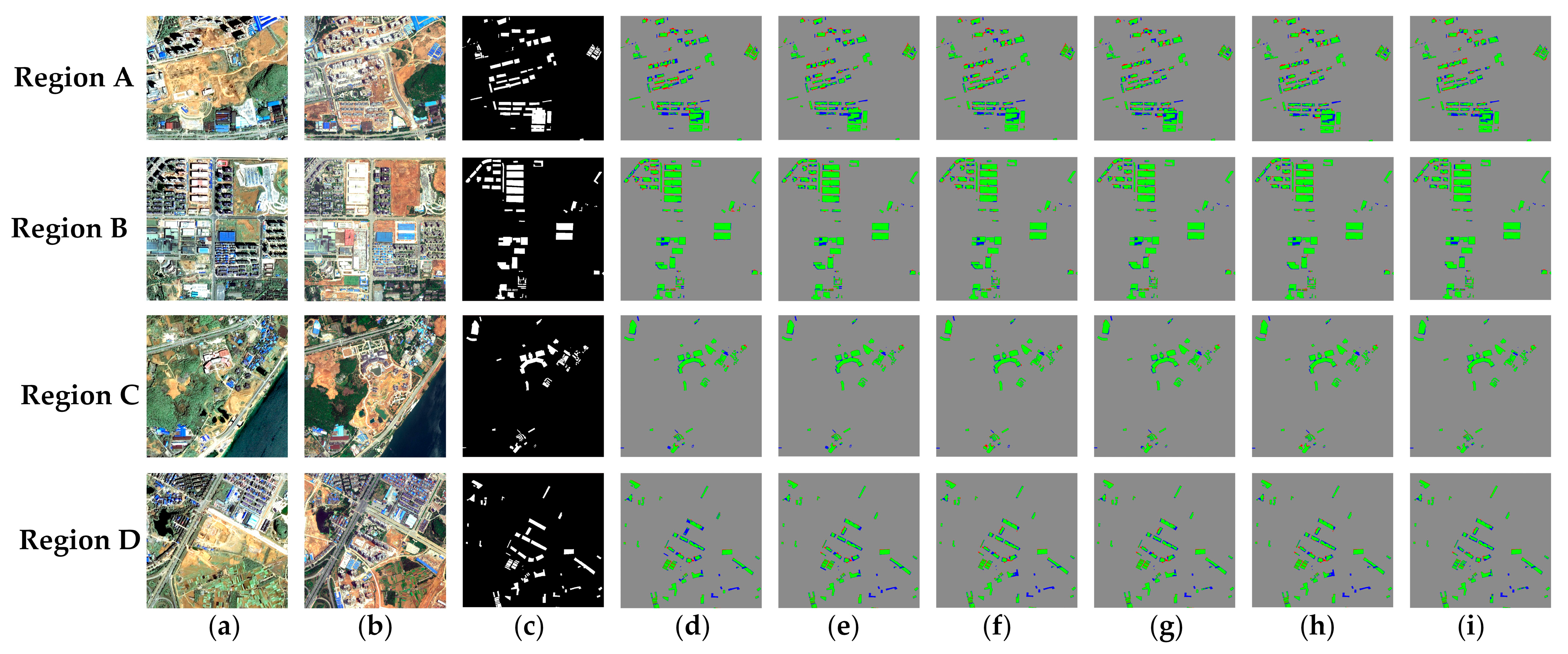
4.1. Performance Comparison for DS1
4.1.1. Comparison with SOTA Methods
4.1.2. Comparison with Recent SSL Methods
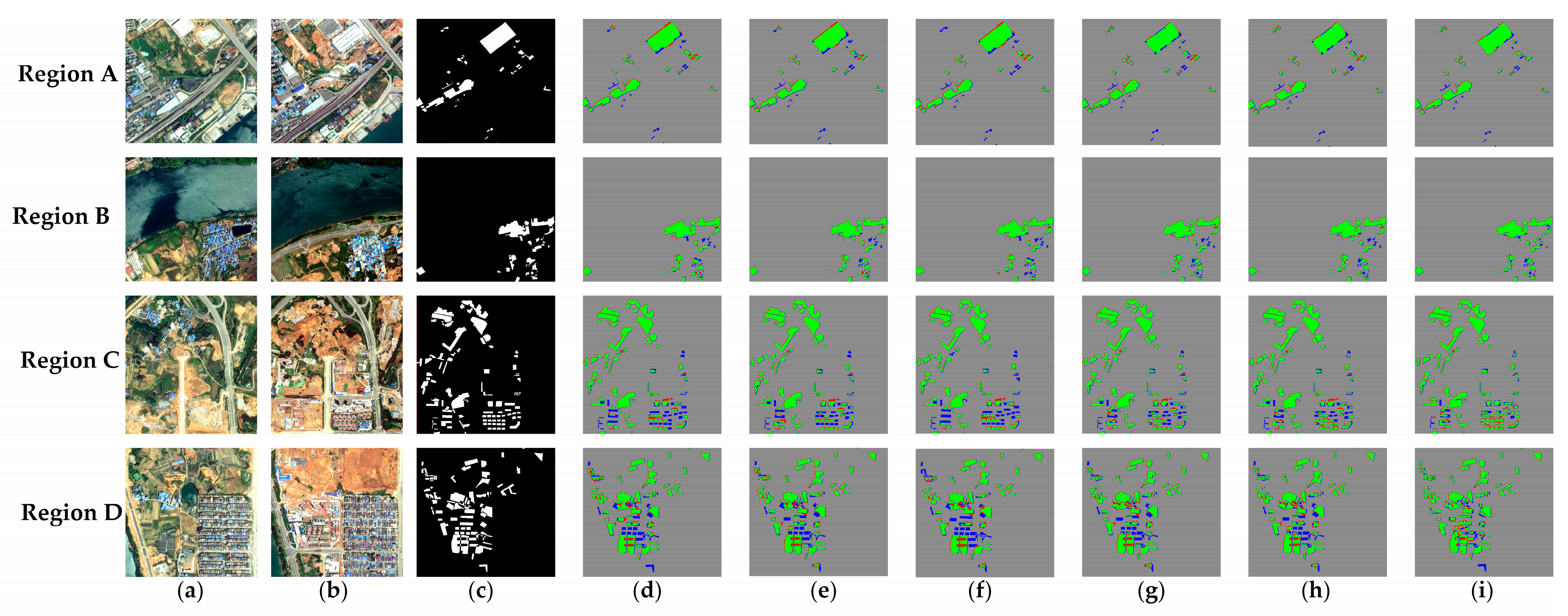
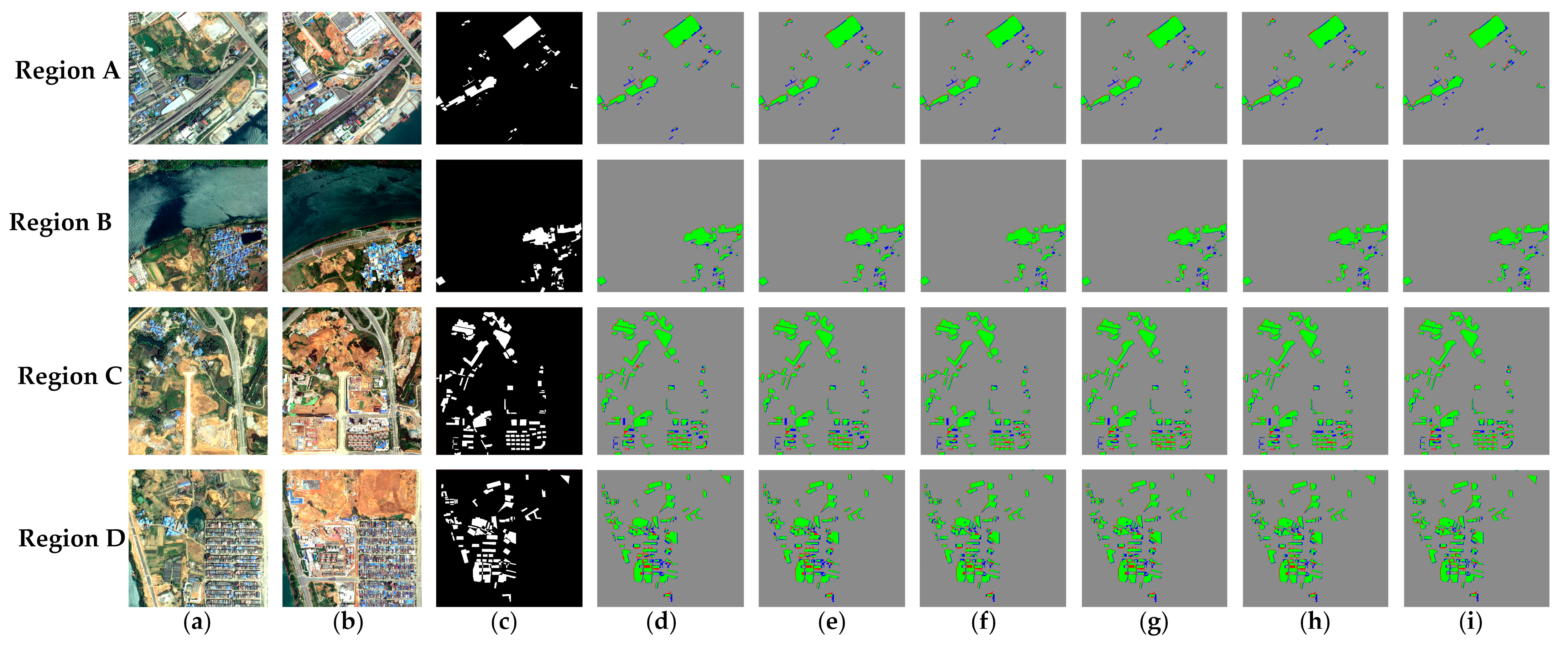
4.2. Performance Comparison for DS2
4.2.1. Comparison with SOTA Methods
4.2.2. Comparison with Recent SSL Methods
4.3. Discussion
4.3.1. Ablation Experiment
4.3.2. Efficiency under Limited Labels
4.3.3. Model Complexity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, Y.; Huang, X.; Weng, Q. A multi-scale weakly supervised learning method with adaptive online noise correction for high-resolution change detection of built-up areas. Remote Sens. Environ. 2023, 297, 113779. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, H.; Feng, L.; Lyu, S. China Building Rooftop Area: The first multi-annual (2016–2021) and high-resolution (2.5 m) building rooftop area dataset in China derived with super-resolution segmentation from Sentinel-2 imagery. Earth Syst. Sci. Data 2023, 15, 3547–3572. [Google Scholar] [CrossRef]
- Guo, H.; Shi, Q.; Marinoni, A.; Du, B.; Zhang, L. Deep building footprint update network: A semi-supervised method for updating existing building footprint from bi-temporal remote sensing images. Remote Sens. Environ. 2021, 264, 112589. [Google Scholar] [CrossRef]
- Cao, Y.; Huang, X. A full-level fused cross-task transfer learning method for building change detection using noise-robust pre-trained networks on crowd-sourced labels. Remote Sens. Environ. 2023, 284, 113371. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Li, M.; Yu, W. GIS-supervised building extraction with label noise-adaptive fully convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2020, 17, 2135–2139. [Google Scholar] [CrossRef]
- Guo, Z.; Du, S. Mining parameter information for building extraction and change detection with very high-resolution imagery and GIS data. GIScience Remote Sens. 2017, 54, 38–63. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, L.; Wu, Y.; Wu, G.; Guo, Z.; Waslander, S. Aerial imagery for roof segmentation: A large-scale dataset towards automatic mapping of buildings. ISPRS J. Photogramm. Remote Sens. 2019, 147, 42–55. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Ji, S.; Shen, Y.; Lu, M.; Zhang, Y. Building Instance Change Detection from Large-Scale Aerial Images using Convolutional Neural Networks and Simulated Samples. Remote Sens. 2019, 11, 1343. [Google Scholar] [CrossRef]
- Liu, M.; Shi, Q.; Marinoni, A.; He, D.; Liu, X.; Zhang, L. Super-resolution-based change detection network with stacked attention module for images with different resolutions. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4403718. [Google Scholar] [CrossRef]
- Shen, L.; Lu, Y.; Chen, H.; Wei, H.; Xie, D.; Yue, J.; Chen, R.; Lv, S.; Jiang, B. S2looking: A satellite side-looking dataset for building change detection. Remote Sens. 2021, 13, 5094. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Marsocci, V.; Coletta, V.; Ravanelli, R.; Scardapane, S.; Crespi, M. Inferring 3D change detection from bi-temporal optical images. ISPRS J. Photogramm. Remote Sens. 2023, 196, 325–339. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Scene Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Med. Image Comput. Comput.-Assist. Interv. (MICCAI) 2015, 9351, 234–241. [Google Scholar]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Li, R.; Zheng, S.; Duan, C.; Su, J.; Zhang, C. Multi-stage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 8009205. [Google Scholar]
- Xia, L.; Chen, J.; Luo, J.; Zhang, J.; Yang, D.; Shen, Z. Building Change Detection Based on an Edge-Guided Convolutional Neural Network Combined with a Transformer. Remote Sens. 2022, 14, 4524. [Google Scholar] [CrossRef]
- Liu, M.; Shi, Q.; Chai, Z.; Li, J. PA-Former: Learning Prior-Aware Transformer for Remote Sensing Building Change Detection. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 6515305. [Google Scholar] [CrossRef]
- Song, X.; Hua, Z.; Li, J. GMTS: GNN-based multi-scale transformer siamese network for remote sensing building change detection. Int. J. Digit. Earth 2023, 16, 1685–1706. [Google Scholar] [CrossRef]
- Mohammadian, A.; Ghaderi, F. SiamixFormer: A fully-transformer Siamese network with temporal Fusion for accurate building detection and change detection in bi-temporal remote sensing images. Int. J. Remote Sens. 2023, 44, 3660–3678. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Multiview Coding. arXiv 2019, arXiv:1906.05849. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. arXiv 2019, arXiv:1911.05722. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. arXiv 2021, arXiv:2006.09882. [Google Scholar]
- Jure, Z.; Li, J.; Ishan, M.; Yann, L.C.; Stéphane, D. Barlow twins: Self-supervised learning via redundancy reduction. arXiv 2021, arXiv:2103.03230. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Ghanbarzade, A.; Soleimani, H. Supervised and Contrastive Self-Supervised In-Domain Representation Learning for Dense Prediction Problems in Remote Sensing. arXiv 2023, arXiv:2301.12541. [Google Scholar]
- Ghanbarzade, A.; Soleimani, H. Self-Supervised In-Domain Representation Learning for Remote Sensing Image Scene Classification. arXiv 2023, arXiv:2302.01793. [Google Scholar]
- Dimitrovski, I.; Kitanovski, I.; Simidjievski, N.; Kocev, D. In-Domain Self-Supervised Learning Can Lead to Improvements in Remote Sensing Image Classification. arXiv 2023, arXiv:2307.01645. [Google Scholar]
- Chopra, M.; Chhipa, P.C.; Mengi, G.; Gupta, V.; Liwicki, M. Domain Adaptable Self-supervised Representation Learning on Remote Sensing Satellite Imagery. arXiv 2023, arXiv:2304.09874. [Google Scholar]
- Daudt, R.C.; Saux, B.L.; Boulch, A. Fully convolutional Siamese networks for change detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8007805. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional Siamese networks for change detection in high-resolution satellite images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2022, 14, 1194–1206. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5604816. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Verma, S.; Vakalopoulou, M.; Gupta, S.; Karantzalos, K. Detecting urban changes with recurrent neural networks from multitemporal Sentinel-2 data. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 214–217. [Google Scholar]
- Song, L.; Xia, M.; Jin, J.; Qian, M.; Zhang, Y. SUACDNet: Attentional change detection network based on Siamese U-shaped structure. Int. J. Appl. Earth Observ. Geoinf. 2021, 105, 102597. [Google Scholar] [CrossRef]
- Lee, H.; Kee, K.S.; Kim, J.; Na, Y.; Hwang, J. Local Similarity Siamese Network for Urban Land Change Detection on Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4139–4149. [Google Scholar] [CrossRef]
- Yin, H.; Weng, L.; Li, Y.; Xia, M.; Hu, K.; Lin, H.; Qian, M. Attention-guided siamese networks for change detection in high resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 117, 103206. [Google Scholar] [CrossRef]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Chen, Y.; Bruzzone, L. A Self-Supervised Approach to Pixel-Level Change Detection in Bi-Temporal RS Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4413911. [Google Scholar] [CrossRef]
- Chen, Y.; Bruzzone, L. Self-Supervised Change Detection in Multiview Remote Sensing Images. IEEE Trans. Geo-Sci. Remote Sens. 2022, 60, 5402812. [Google Scholar] [CrossRef]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. arXiv 2021, arXiv:2104.14294. [Google Scholar]
- Yan, L.; Yang, J.; Wang, J. Domain Knowledge-Guided Self-Supervised Change Detection for Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4167–4179. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders arescalable vision learners. arXiv 2021, arXiv:2111.06377. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Wei, Y.; Dai, Q.; Hu, H. On Data Scaling in Masked Image Modeling. arXiv 2022, arXiv:2206.04664. [Google Scholar]
- Sun, X.; Wang, P.; Lu, W.; Zhu, Z.; Lu, X.; He, Q.; Li, J.; Rong, X.; Yang, Z.; Chang, H.; et al. RingMo: A Remote Sensing Foundation Model With Masked Image Modeling. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5612822. [Google Scholar] [CrossRef]
- Saha, S.; Ebel, P.; Zhu, X. Self-Supervised Multisensor Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4405710. [Google Scholar] [CrossRef]
- Dong, H.; Ma, W.; Wu, Y.; Zhang, J.; Jiao, L. Self-Supervised Representation Learning for Remote Sensing Image Change Detection Based on Temporal Prediction. Remote Sens. 2020, 12, 1868. [Google Scholar] [CrossRef]
- Ou, X.; Liu, L.; Tan, S.; Zhang, G.; Li, W.; Tu, B. A Hyperspectral Image Change Detection Framework With Self-Supervised Contrastive Learning Pretrained Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7724–7740. [Google Scholar] [CrossRef]
- Ramkumar, V.R.T.; Bhat, P.; Arani, E.; Zonooz, B. Self-supervised pre-training for scene change detection. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Sydney, Australia, 6–14 December 2021; pp. 1–13. [Google Scholar]
- Ramkumar, V.R.T.; Arani, E.; Zonooz, B. Differencing based self-supervised pre-training for scene change detection. arXiv 2022, arXiv:2208.05838. [Google Scholar]
- Jiang, F.; Gong, M.; Zheng, H.; Liu, T.; Zhang, M.; Liu, J. Self-Supervised Global–Local Contrastive Learning for Fine-Grained Change Detection in VHR Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4400613. [Google Scholar] [CrossRef]
- Wang, J.; Zhong, Y.; Zhang, L. Change Detection Based on Supervised Contrastive Learning for High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5601816. [Google Scholar] [CrossRef]
- Chen, H.; Li, W.; Chen, S.; Shi, Z. Semantic-Aware Dense Representation Learning for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5630018. [Google Scholar] [CrossRef]
- Lucian, D.; Dirk, T.; Shaun, R. ESP: A tool to estimate scale parameter for multi-resolution image segmentation of remotely sensed data. Int. J. Geogr. Inf. Sci. 2010, 24, 859–871. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Methods | ImageNet Pre-Training | DS1 | |||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | IoU | |||
| Supervised method | UNet++ | ✔ | 77.97 | 86.42 | 81.98 | 69.46 |
| ResUNet | ✔ | 78.04 | 87.81 | 82.64 | 70.42 | |
| PSPNet | ✔ | 74.74 | 86.40 | 80.15 | 66.87 | |
| DeeplabV3+ | ✔ | 79.86 | 87.95 | 83.71 | 71.98 | |
| HRNet | ✔ | 80.83 | 87.33 | 83.96 | 72.35 | |
| MS-ResUNet | ✔ | 83.16 | 89.75 | 86.32 | 75.94 | |
| Type | Methods | SSL Pre-Training | DS1 | |||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | IoU | |||
| Self-supervised method | SimCLR | ✔ | 83.26 | 89.73 | 86.38 | 76.02 |
| CMC | ✔ | 83.94 | 90.21 | 86.96 | 76.93 | |
| BT | ✔ | 84.64 | 89.85 | 87.16 | 77.25 | |
| MoCo v2 | ✔ | 84.59 | 90.54 | 87.46 | 77.72 | |
| BYOL | ✔ | 84.84 | 90.39 | 87.53 | 77.82 | |
| SimSiam | ✔ | 85.59 | 91.26 | 88.34 | 79.11 | |
| Type | Methods | ImageNet Pre-Training | DS2 | |||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | IoU | |||
| Supervised method | UNet++ | ✔ | 75.27 | 85.29 | 79.97 | 66.62 |
| ResUNet | ✔ | 75.87 | 85.55 | 80.42 | 67.25 | |
| PSPNet | ✔ | 73.49 | 85.28 | 78.95 | 65.22 | |
| DeeplabV3+ | ✔ | 76.89 | 85.83 | 81.11 | 68.22 | |
| HRNet | ✔ | 77.27 | 87.45 | 82.20 | 69.34 | |
| MS-ResUNet | ✔ | 80.03 | 87.49 | 83.59 | 71.81 | |
| Type | Methods | SSL Pre-Training | DS2 | |||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | IoU | |||
| Self-supervised method | SimCLR | ✔ | 80.35 | 87.34 | 83.70 | 71.96 |
| CMC | ✔ | 79.92 | 87.50 | 83.54 | 71.73 | |
| BT | ✔ | 80.44 | 88.17 | 84.13 | 72.61 | |
| MoCo v2 | ✔ | 80.50 | 87.79 | 83.99 | 72.40 | |
| BYOL | ✔ | 80.37 | 88.15 | 84.08 | 72.53 | |
| SimSiam | ✔ | 80.75 | 88.54 | 84.47 | 73.11 | |
| Model | SimSiam Pre-Training | DS1 | DS2 | ||
|---|---|---|---|---|---|
| F1 | IoU | F1 | IoU | ||
| MS-ResUNet without MIP | ✔ | 85.45 | 76.87 | 80.84 | 68.92 |
| MS-ResUNet without attention block | ✔ | 86.67 | 77.15 | 81.93 | 70.95 |
| MS-ResUNet | ✔ | 88.34 | 79.11 | 84.47 | 73.11 |
| Pre-Training Type | 5% of the Labelled Samples | |||||||
|---|---|---|---|---|---|---|---|---|
| DS1 | DS2 | |||||||
| Precision | Recall | F1 | IoU | Precision | Recall | F1 | IoU | |
| ImageNet supervised | 69.43 | 37.02 | 48.30 | 31.84 | 66.14 | 50.84 | 57.49 | 40.34 |
| SimCLR | 68.91 | 39.66 | 50.35 | 33.64 | 67.29 | 55.75 | 60.98 | 43.87 |
| CMC | 70.67 | 39.58 | 50.74 | 34.01 | 66.57 | 55.87 | 60.75 | 43.63 |
| BT | 70.19 | 40.52 | 51.38 | 34.57 | 68.30 | 59.68 | 63.70 | 46.74 |
| MoCo v2 | 70.49 | 40.81 | 52.01 | 35.58 | 68.31 | 57.97 | 62.71 | 45.68 |
| BYOL | 71.10 | 41.59 | 52.49 | 35.61 | 67.44 | 60.11 | 63.57 | 46.59 |
| SimSiam | 70.09 | 42.05 | 52.57 | 35.65 | 67.85 | 60.52 | 63.98 | 47.03 |
| Method | UNet++ | ResUNet | PSPNet | DeeplabV3+ | HRNet | MS-ResUNet |
|---|---|---|---|---|---|---|
| Inference time | 0.029 s | 0.021 s | 0.013 s | 0.035 s | 0.098 s | 0.033 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, W.; Guan, F.; Tu, J.; Sun, C.; Xu, W. Detection of Changes in Buildings in Remote Sensing Images via Self-Supervised Contrastive Pre-Training and Historical Geographic Information System Vector Maps. Remote Sens. 2023, 15, 5670. https://doi.org/10.3390/rs15245670
Feng W, Guan F, Tu J, Sun C, Xu W. Detection of Changes in Buildings in Remote Sensing Images via Self-Supervised Contrastive Pre-Training and Historical Geographic Information System Vector Maps. Remote Sensing. 2023; 15(24):5670. https://doi.org/10.3390/rs15245670
Chicago/Turabian StyleFeng, Wenqing, Fangli Guan, Jihui Tu, Chenhao Sun, and Wei Xu. 2023. "Detection of Changes in Buildings in Remote Sensing Images via Self-Supervised Contrastive Pre-Training and Historical Geographic Information System Vector Maps" Remote Sensing 15, no. 24: 5670. https://doi.org/10.3390/rs15245670
APA StyleFeng, W., Guan, F., Tu, J., Sun, C., & Xu, W. (2023). Detection of Changes in Buildings in Remote Sensing Images via Self-Supervised Contrastive Pre-Training and Historical Geographic Information System Vector Maps. Remote Sensing, 15(24), 5670. https://doi.org/10.3390/rs15245670