
VQ-InfraTrans: A Unified Framework for RGB-IR Translation with Hybrid Transformer


Abstract
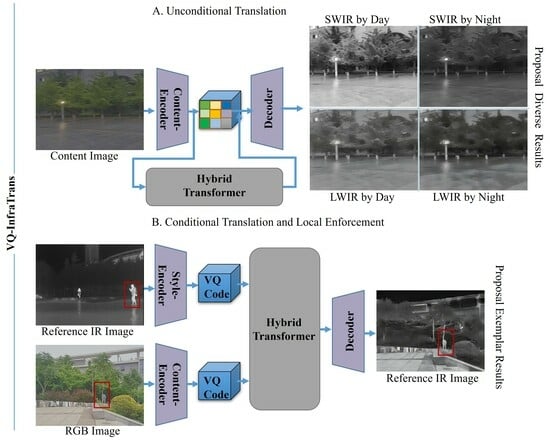
:
1. Introduction
- We propose a unified transfer learning framework that can generate multi-modal and multi-scene IR images from an RGB image. We introduce multi-modal transfer learning into IR image generation, achieving the best generalization and performance currently available through vectorized reconstruction and hybrid transformer models;
- We propose a reference-based image translation model containing vectorized encoders and instance segmentation. The IR radiation distribution and instance mask from the model can enhance local target features with similar semantics in the IR Synthetic image. When dealing with targets exhibiting high radiation features, our framework demonstrates the capability to produce high-quality infrared images.
2. Related Work
3. Method
3.1. A Unified Framework
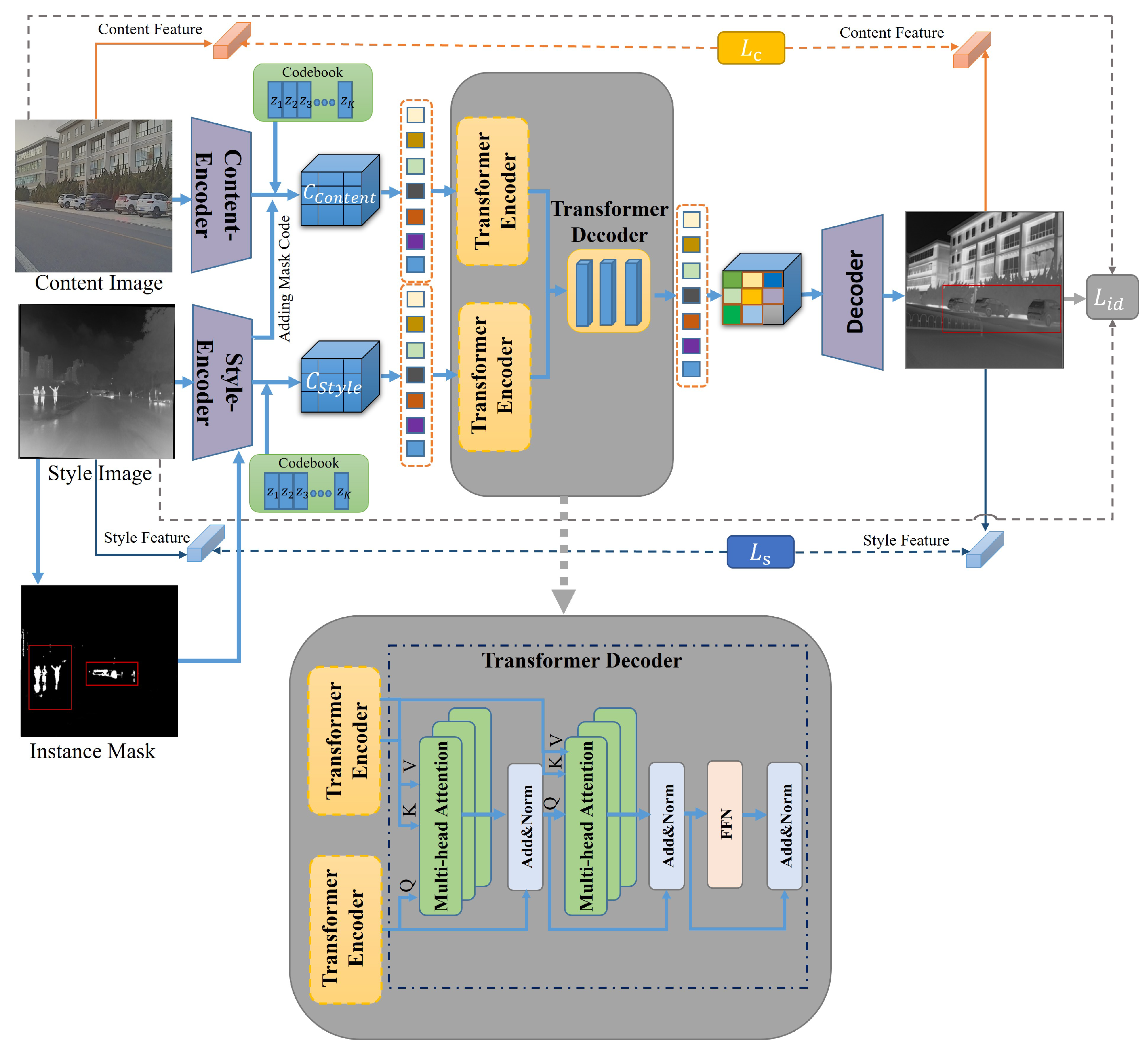
3.1.1. Vector Quantized Content Representation
3.1.2. Hybrid-Transformer Translation
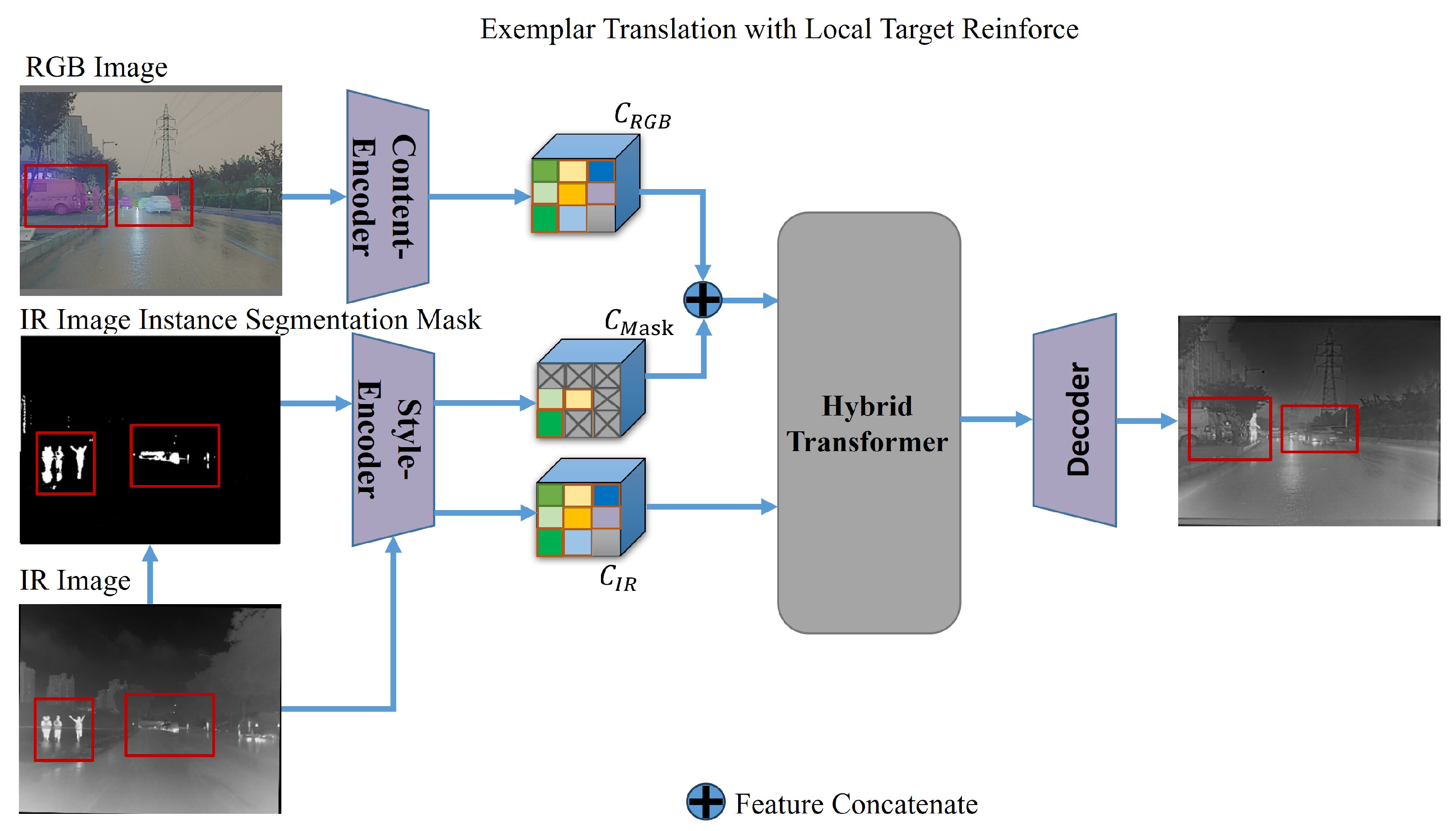
3.2. Local Target Reinforcement
4. Experiments
4.1. Compared Baselines and Datasets
4.2. Qualitative Evaluation
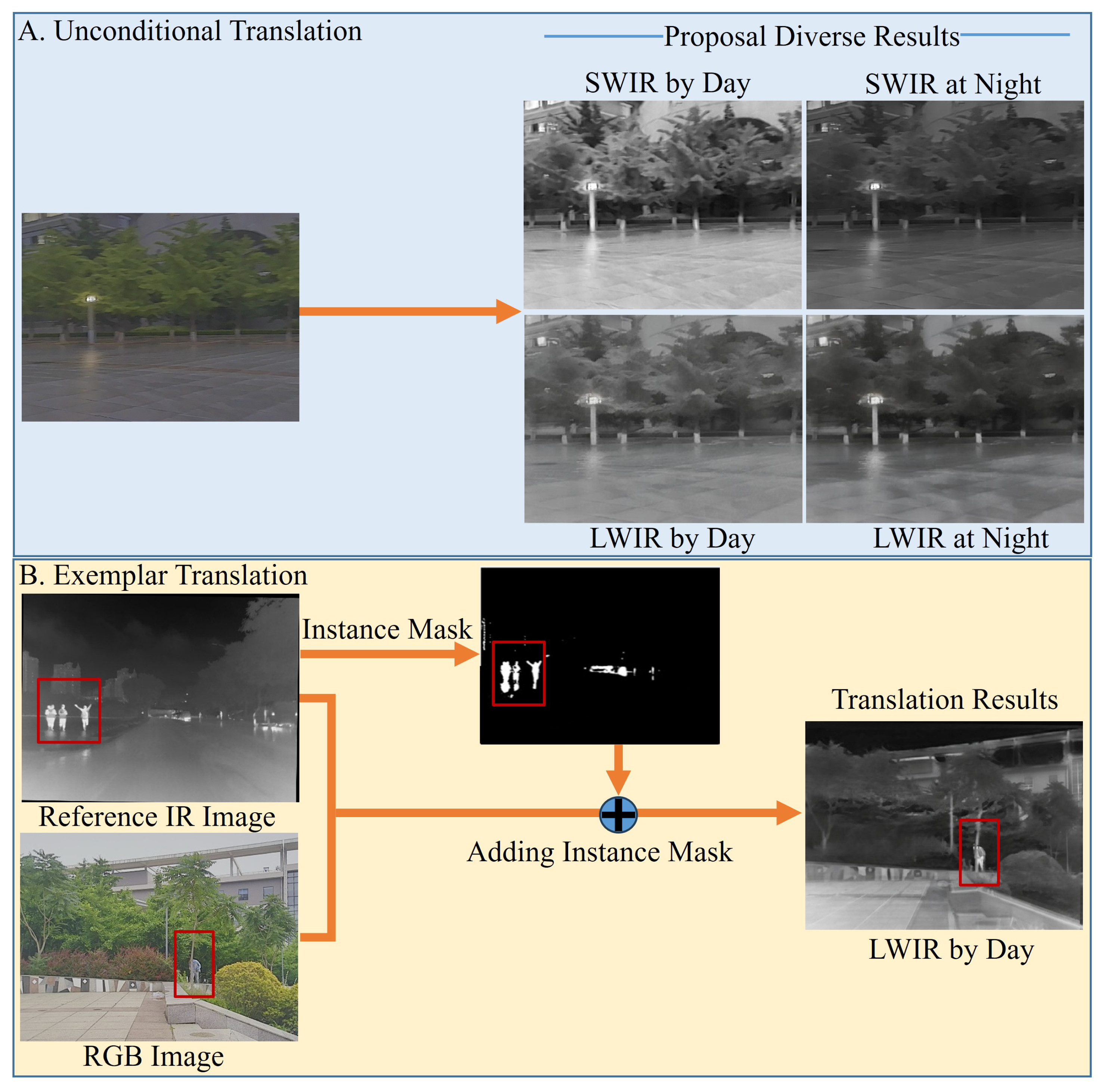
4.2.1. Unconditional Translation
4.2.2. Exemplar Translation
4.3. Quantitative Evaluation
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings, Part V 13, Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Chang, Y.; Luo, B. Bidirectional convolutional LSTM neural network for remote sensing image super-resolution. Remote Sens. 2019, 11, 2333. [Google Scholar] [CrossRef]
- Gu, J.; Sun, X.; Zhang, Y.; Fu, K.; Wang, L. Deep residual squeeze and excitation network for remote sensing image super-resolution. Remote Sens. 2019, 11, 1817. [Google Scholar] [CrossRef]
- Lu, T.; Wang, J.; Zhang, Y.; Wang, Z.; Jiang, J. Satellite image super-resolution via multi-scale residual deep neural network. Remote Sens. 2019, 11, 1588. [Google Scholar] [CrossRef]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Pla, F. A new deep generative network for unsupervised remote sensing single-image super-resolution. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6792–6810. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Zou, Z. Coupled adversarial training for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3633–3643. [Google Scholar] [CrossRef]
- Xiong, Y.; Guo, S.; Chen, J.; Deng, X.; Sun, L.; Zheng, X.; Xu, W. Improved SRGAN for remote sensing image super-resolution across locations and sensors. Remote Sens. 2020, 12, 1263. [Google Scholar] [CrossRef]
- Zhang, D.; Shao, J.; Li, X.; Shen, H.T. Remote sensing image super-resolution via mixed high-order attention network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5183–5196. [Google Scholar] [CrossRef]
- Salvetti, F.; Mazzia, V.; Khaliq, A.; Chiaberge, M. Multi-image super resolution of remotely sensed images using residual attention deep neural networks. Remote Sens. 2020, 12, 2207. [Google Scholar] [CrossRef]
- Zhang, S.; Yuan, Q.; Li, J.; Sun, J.; Zhang, X. Scene-adaptive remote sensing image super-resolution using a multiscale attention network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4764–4779. [Google Scholar] [CrossRef]
- Yang, S.; Sun, M.; Lou, X.; Yang, H.; Zhou, H. An unpaired thermal infrared image translation method using GMA-CycleGAN. Remote Sens. 2023, 15, 663. [Google Scholar] [CrossRef]
- Huang, S.; Jin, X.; Jiang, Q.; Liu, L. Deep learning for image colorization: Current and future prospects. Eng. Appl. Artif. Intell. 2022, 114, 105006. [Google Scholar] [CrossRef]
- Liang, W.; Ding, D.; Wei, G. An improved DualGAN for near-infrared image colorization. Infrared Phys. Technol. 2021, 116, 103764. [Google Scholar] [CrossRef]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12873–12883. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhang, L.; Gonzalez-Garcia, A.; Van De Weijer, J.; Danelljan, M.; Khan, F.S. Synthetic data generation for end-to-end thermal infrared tracking. IEEE Trans. Image Process. 2018, 28, 1837–1850. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Pan, J.; Zhang, S.; Xiao, L.; Yang, J. Intelligence Science and Big Data Engineering. Visual Data Engineering. In Proceedings, Part I, Proceedings of the 9th International Conference, IScIDE 2019, Nanjing, China, 17–20 October 2019; Springer Nature: Berlin/Heidelberg, Germany, 2019; Volume 11935. [Google Scholar]
- Lee, H.Y.; Tseng, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
- Lee, H.Y.; Tseng, H.Y.; Mao, Q.; Huang, J.B.; Lu, Y.D.; Singh, M.; Yang, M.H. Drit++: Diverse image-to-image translation via disentangled representations. Int. J. Comput. Vis. 2020, 128, 2402–2417. [Google Scholar] [CrossRef]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive learning for unpaired image-to-image translation. In Proceedings, Part IX 16, Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 319–345. [Google Scholar]
- Mao, Q.; Lee, H.Y.; Tseng, H.Y.; Ma, S.; Yang, M.H. Mode seeking generative adversarial networks for diverse image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1429–1437. [Google Scholar]
- Mao, Q.; Tseng, H.Y.; Lee, H.Y.; Huang, J.B.; Ma, S.; Yang, M.H. Continuous and diverse image-to-image translation via signed attribute vectors. Int. J. Comput. Vis. 2022, 130, 517–549. [Google Scholar] [CrossRef]
- Lee, H.Y.; Li, Y.H.; Lee, T.H.; Aslam, M.S. Progressively Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation. Sensors 2023, 23, 6858. [Google Scholar] [CrossRef] [PubMed]
- Kuang, X.; Zhu, J.; Sui, X.; Liu, Y.; Liu, C.; Chen, Q.; Gu, G. Thermal infrared colorization via conditional generative adversarial network. Infrared Phys. Technol. 2020, 107, 103338. [Google Scholar] [CrossRef]
- Kniaz, V.V.; Knyaz, V.A.; Hladuvka, J.; Kropatsch, W.G.; Mizginov, V. Thermalgan: Multimodal color-to-thermal image translation for person re-identification in multispectral dataset. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, H.; Cheng, C.; Zhang, X.; Sun, H. Towards high-quality thermal infrared image colorization via attention-based hierarchical network. Neurocomputing 2022, 501, 318–327. [Google Scholar] [CrossRef]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.H. Universal style transfer via feature transforms. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Sheng, L.; Lin, Z.; Shao, J.; Wang, X. Avatar-net: Multi-scale zero-shot style transfer by feature decoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8242–8250. [Google Scholar]
- Gu, S.; Chen, C.; Liao, J.; Yuan, L. Arbitrary style transfer with deep feature reshuffle. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8222–8231. [Google Scholar]
- Jing, Y.; Liu, X.; Ding, Y.; Wang, X.; Ding, E.; Song, M.; Wen, S. Dynamic instance normalization for arbitrary style transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4369–4376. [Google Scholar]
- An, J.; Li, T.; Huang, H.; Shen, L.; Wang, X.; Tang, Y.; Ma, J.; Liu, W.; Luo, J. Real-time universal style transfer on high-resolution images via zero-channel pruning. arXiv 2020, arXiv:2006.09029. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings, Part II 14, Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In Proceedings, Part II 14, Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 702–716. [Google Scholar]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. Stylebank: An explicit representation for neural image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1897–1906. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A learned representation for artistic style. arXiv 2016, arXiv:1610.07629. [Google Scholar]
- Lin, M.; Tang, F.; Dong, W.; Li, X.; Xu, C.; Ma, C. Distribution aligned multimodal and multi-domain image stylization. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–17. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Z.; Zhang, H.; Zuo, Z.; Li, A.; Xing, W.; Lu, D. Artistic style transfer with internal-external learning and contrastive learning. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 26561–26573. [Google Scholar]
- Razavi, A.; Van den Oord, A.; Vinyals, O. Generating diverse high-fidelity images with vq-vae-2. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Han, L.; Ren, J.; Lee, H.Y.; Barbieri, F.; Olszewski, K.; Minaee, S.; Metaxas, D.; Tulyakov, S. Show me what and tell me how: Video synthesis via multimodal conditioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3615–3625. [Google Scholar]
- Van Den Oord, A.; Vinyals, O. Neural discrete representation learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Deng, Y.; Tang, F.; Dong, W.; Ma, C.; Pan, X.; Wang, L.; Xu, C. Stytr2: Image style transfer with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11326–11336. [Google Scholar]
- Jiang, Y.; Chang, S.; Wang, Z. Transgan: Two pure transformers can make one strong gan, and that can scale up. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 14745–14758. [Google Scholar]
- Bruckner, S.; Gröller, M.E. Style transfer functions for illustrative volume rendering. In Proceedings of the Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2007; Volume 26, pp. 715–724. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Huang, Z.; Zhao, N.; Liao, J. UniColor: A Unified Framework for Multi-Modal Colorization with Transformer. ACM Trans. Graph. 2022, 41, 1–16. [Google Scholar] [CrossRef]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Wang, Y.; Tang, S.; Zhu, F.; Bai, L.; Zhao, R.; Qi, D.; Ouyang, W. Revisiting the Transferability of Supervised Pretraining: An MLP Perspective. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9173–9183. [Google Scholar]
- Hu, X.; Zhou, X.; Huang, Q.; Shi, Z.; Sun, L.; Li, Q. Qs-attn: Query-selected attention for contrastive learning in i2i translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18291–18300. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Fardoulis, J.; Depreytere, X.; Gallien, P.; Djouhri, K.; Abdourhmane, B.; Sauvage, E. Proof: How Small Drones Can Find Buried Landmines in the Desert Using Airborne IR Thermography. J. Conv. Weapons Destr. 2020, 24, 15. [Google Scholar]
- Özkanoğlu, M.A.; Ozer, S. InfraGAN: A GAN architecture to transfer visible images to infrared domain. Pattern Recognit. Lett. 2022, 155, 69–76. [Google Scholar] [CrossRef]
- An, J.; Huang, S.; Song, Y.; Dou, D.; Liu, W.; Luo, J. Artflow: Unbiased image style transfer via reversible neural flows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 862–871. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FLIR | SSIM ↑ | PSNR ↑ | FID ↓ |
| CUT | 0.7707 | 33.360 | 71.962 |
| QSA | 0.7768 | 42.869 | 70.648 |
| VQ-InfraTrans | 0.7876 | 39.873 | 69.445 |
| M3FD | SSIM ↑ | PSNR ↑ | FID ↓ |
| CUT | 0.7326 | 17.281 | 81.30 |
| QSA | 0.8077 | 37.193 | 74.55 |
| VQ-InfraTrans | 0.8258 | 40.539 | 71.23 |
| VEDAI | SSIM ↑ | PSNR ↑ | FID ↓ |
| InfraGAN | 0.898 | 27.64 | 50.485 |
| CUT | 0.792 | 19.83 | 121.557 |
| QSA | 0.7815 | 17.10 | 116.659 |
| VQ-InfraTrans | 0.881 | 28.31 | 73.79 |
| FLIR | Vehicle | People |
|---|---|---|
| Metric | SSIM ↑/FID ↓ | PSNR ↑/FID ↓ |
| InfraGAN | 0.66/222.575 | 0.65/123.033 |
| CUT | 0.72/87.44 | 0.76/84.78 |
| QSA | 0.74/80.09 | 0.75/83.17 |
| VQ-InfraTrans | 0.72/77.82 | 0.80/80.15 |
| Method | SSIM ↑ | PSNR ↑ | FID ↓ |
|---|---|---|---|
| Condition-VQGAN | 0.771 | 34.8 | 70.6 |
| TransGAN | 0.735 | 37.2 | 80.09 |
| VQ-InfraTrans | 0.787 | 39.87 | 69.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Q.; Wang, X.; Yan, C.; Zhang, X. VQ-InfraTrans: A Unified Framework for RGB-IR Translation with Hybrid Transformer. Remote Sens. 2023, 15, 5661. https://doi.org/10.3390/rs15245661
Sun Q, Wang X, Yan C, Zhang X. VQ-InfraTrans: A Unified Framework for RGB-IR Translation with Hybrid Transformer. Remote Sensing. 2023; 15(24):5661. https://doi.org/10.3390/rs15245661
Chicago/Turabian StyleSun, Qiyang, Xia Wang, Changda Yan, and Xin Zhang. 2023. "VQ-InfraTrans: A Unified Framework for RGB-IR Translation with Hybrid Transformer" Remote Sensing 15, no. 24: 5661. https://doi.org/10.3390/rs15245661
APA StyleSun, Q., Wang, X., Yan, C., & Zhang, X. (2023). VQ-InfraTrans: A Unified Framework for RGB-IR Translation with Hybrid Transformer. Remote Sensing, 15(24), 5661. https://doi.org/10.3390/rs15245661