1. Introduction
With the advancement of remote sensing observation technology and image processing technology, more and more high-resolution remote sensing images can be acquired and utilized. As a kind of crucial element in images, the spatial distribution of buildings holds significant importance for applications such as land management, urban planning, and disaster prevention and control. Extracting buildings from remote sensing images is essentially a binary semantic segmentation task, which has become a key research direction in the field of remote sensing image processing.
Traditional building extraction methods can be divided into methods based on artificial features, methods based on objects, and methods based on auxiliary information. The method based on artificial features refers to selecting one or more feature sets from important features such as texture [
1,
2], spectrum [
3,
4], and geometry [
5,
6,
7,
8] in remote sensing images based on professional knowledge as the standard for extracting buildings. Gu et al. [
4] proposed the usage of the normalized spectral building index (NSBI) and the difference spectral building index (DSBI) for building extraction from remote sensing images with eight spectral bands and four spectral bands, respectively. The object-based method [
9,
10] refers to the division of remote sensing images into different objects, and each object contains pixels aggregated according to features such as spectrum, texture, color, and other features. Finally, the building and background are determined by classifying the objects. Compared with other methods, these methods have good spatial scalability and robustness to multi-source information. Attarzadeh R et al. [
10] used the optimal scale parameters to segment remote sensing images and then classified objects through the extracted stable features and variable features. The method based on auxiliary information [
11,
12] refers to using height, shadow, and other information to assist in building extraction. Maruyama et al. [
12] established a digital surface model (DSM) to detect collapsed buildings through aerial images before and after earthquakes. In summary, traditional building extraction methods are essentially classified according to the underlying feature, exhibiting weak anti-interference capabilities. However, these methods fail to accurately extract buildings when similar objects possess distinct features or dissimilar objects exhibit identical features.
In recent years, deep learning-based methods have been widely used in automatic building extraction. Compared with traditional methods, they can automatically, accurately, and quickly extract buildings. Currently, many segmentation models mainly use single-branch structures derived from the fully convolutional network (FCN). Long et al. [
13] proposed the FCN for end-to-end pixel-level prediction. It is based on an encoder-decoder structure, encoding and decoding features through convolution and deconvolution, respectively. On the basis of FCN, many studies [
14,
15,
16,
17,
18] are committed to improving the expansion of receptive fields and multi-scale feature fusion. Yang et al. [
14] proposed DenseASPP, which combines the atrous spatial pyramid pooling (ASPP) module with dense connections to achieve an expanded receptive field and address the issue of insufficiently dense sampling points. Wang et al. [
15] added a global feature information awareness (GFIA) module to the last layer of the encoder, which combines skip connections, dilated convolutions with different dilation rates, and non-local [
16] units to capture multi-scale contextual information and integrate global semantic information. However, using a simple upsampling method in the decoding process of FCN-based structures can only obtain smooth and blurred boundaries, as it leads to insufficient expression of low-level detail features. In addition, these networks are all based on convolutional neural network (CNN), making it difficult to capture long-distance dependencies and global contexts, and they also have shortcomings in interpretability.
More recently, Transformer-based methods [
19,
20,
21,
22,
23,
24,
25,
26,
27] have achieved remarkable results in remote sensing images with large-scale changes, relying on their strong encoders. Guo et al. [
28] elaborated on the importance of strong encoders for semantic segmentation tasks. Zheng et al. [
23] proposed SETR. Based on the Vision Transformer as the encoder, a lightweight decoder was designed to handle semantic segmentation tasks, demonstrating the superiority of treating semantic segmentation tasks as sequence-to-sequence prediction tasks. He et al. [
24] proposed a dual-encoder architecture that combines Swin Transformer [
25] with a U-shaped network for semantic segmentation tasks in remote sensing images, addressing the challenge faced by CNNs in capturing global context. However, Transformers bring high complexity while establishing global connections, and some methods focus on lightweight Transformers. Segformer [
26] employed depthwise convolution in place of position encodings, enhancing efficiency and enabling the network to accommodate various image sizes seamlessly. Chen et al. [
27] proposed STT, which utilized sparse sampling in spatial and channel dimensions to reduce the input of the Transformer, thereby reducing complexity.
Overall, existing methods for image segmentation mainly focus on large models and datasets, which may not be suitable for building extraction tasks due to the high cost of remote sensing image capture and annotation, as well as the small and densely distributed features of buildings. In terms of model design, building extraction models often use relatively lightweight designs, which emphasize the separation of foreground and background with the assistance of features such as boundaries and tend to maintain the high resolution of feature maps in feature learning to preserve detail features.
Although deep learning-based methods have raised the performance and efficiency of extraction tasks to new heights now, there are still two problems: first, there is a serious foreground–background imbalance in remote sensing images. In the traditional methods, excessive learning of background pixels not only results in higher computational complexity, but also interferes with foreground learning, especially when employing strong encoder structures such as the Transformer. Second, boundary features are prone to be lost during model learning, especially in the downsampling and upsampling processes. Traditional methods focus on extracting multi-scale contextual features and expanding receptive fields while neglecting the refinement of low-level boundary details. If boundary learning is not supervised in a judicious manner, it will cause blurred boundaries and significantly affect the segmentation performance.
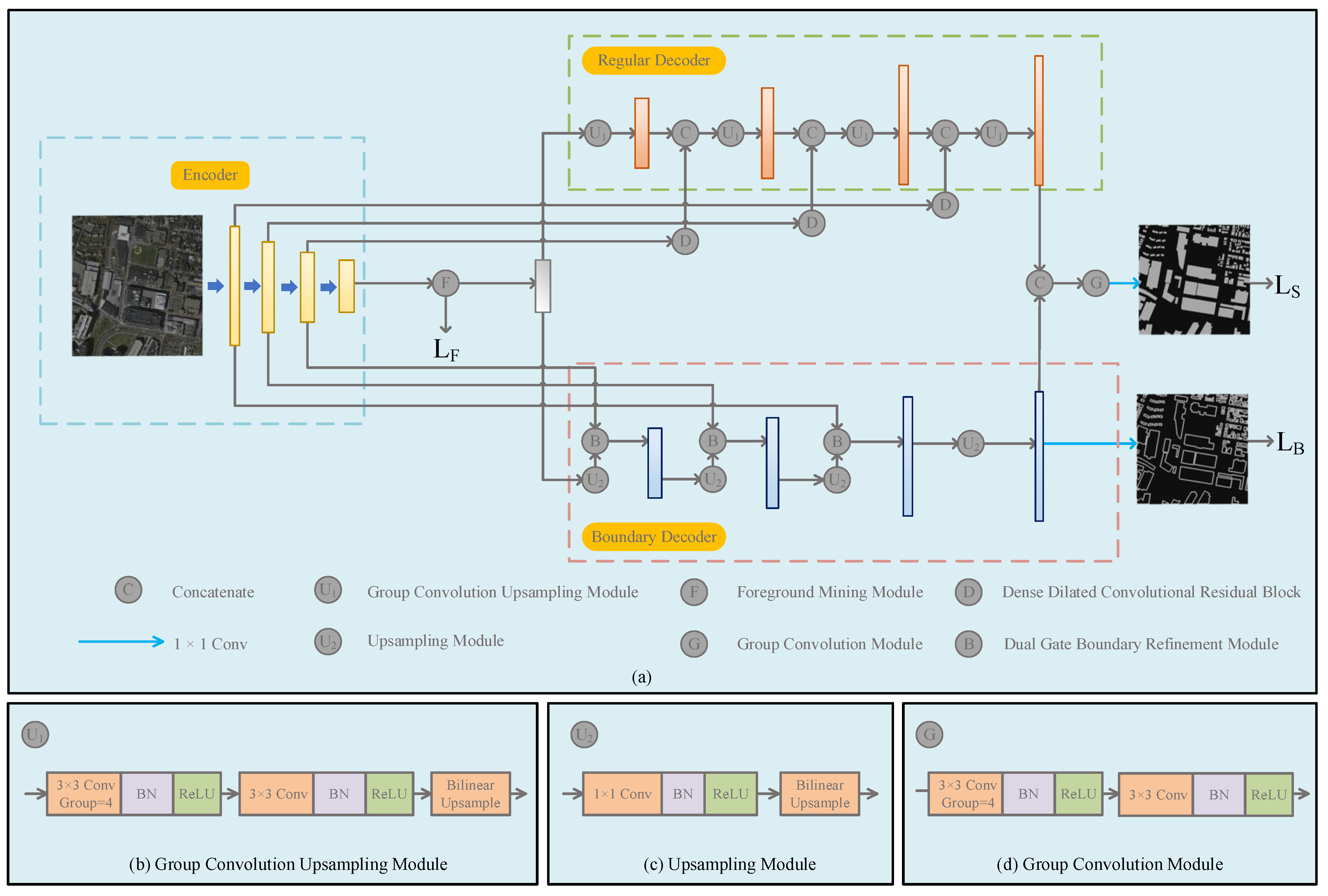
In order to solve the above two problems and improve the performance of building extraction, we propose a multi-task learning building extraction network in this paper. The main contributions are as follows:
- (1)
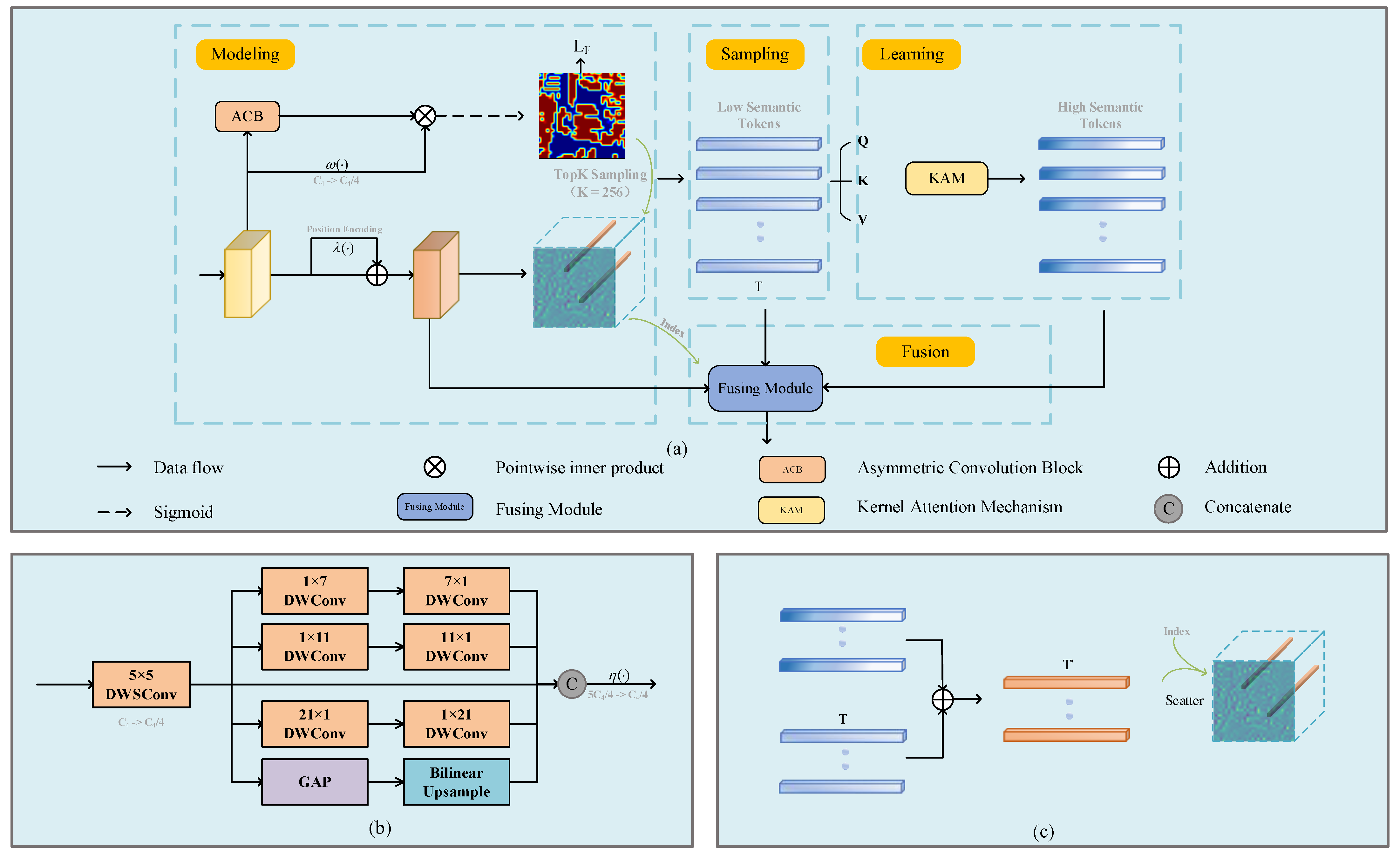
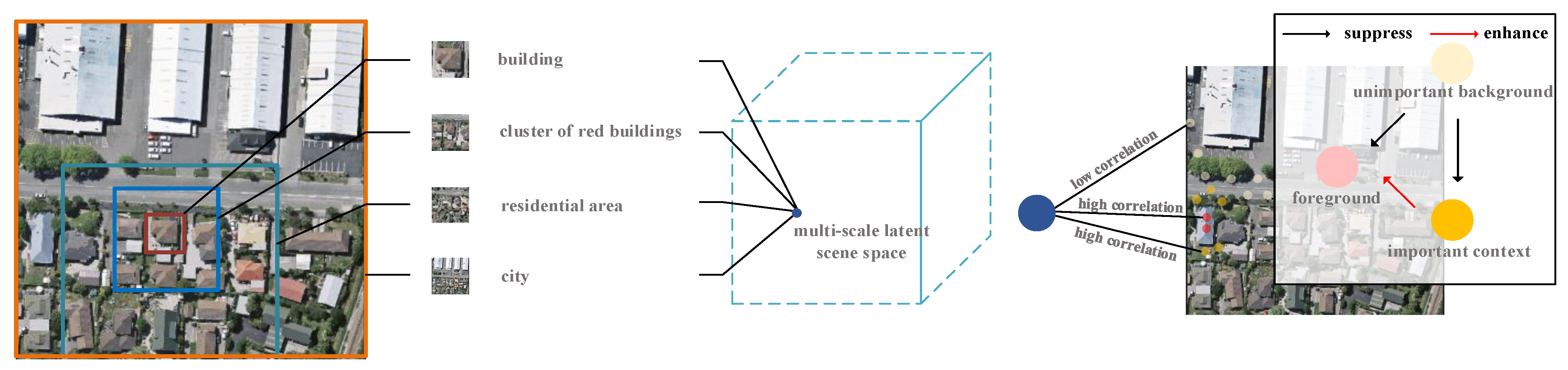
The Foreground Mining Module (FMM) is proposed. A multi-scale relationship-based foreground modeling method is used to learn foreground features, including explicit modeling, sampling, and learning of foreground features, which can reduce model complexity while reducing background pixel interference;
- (2)
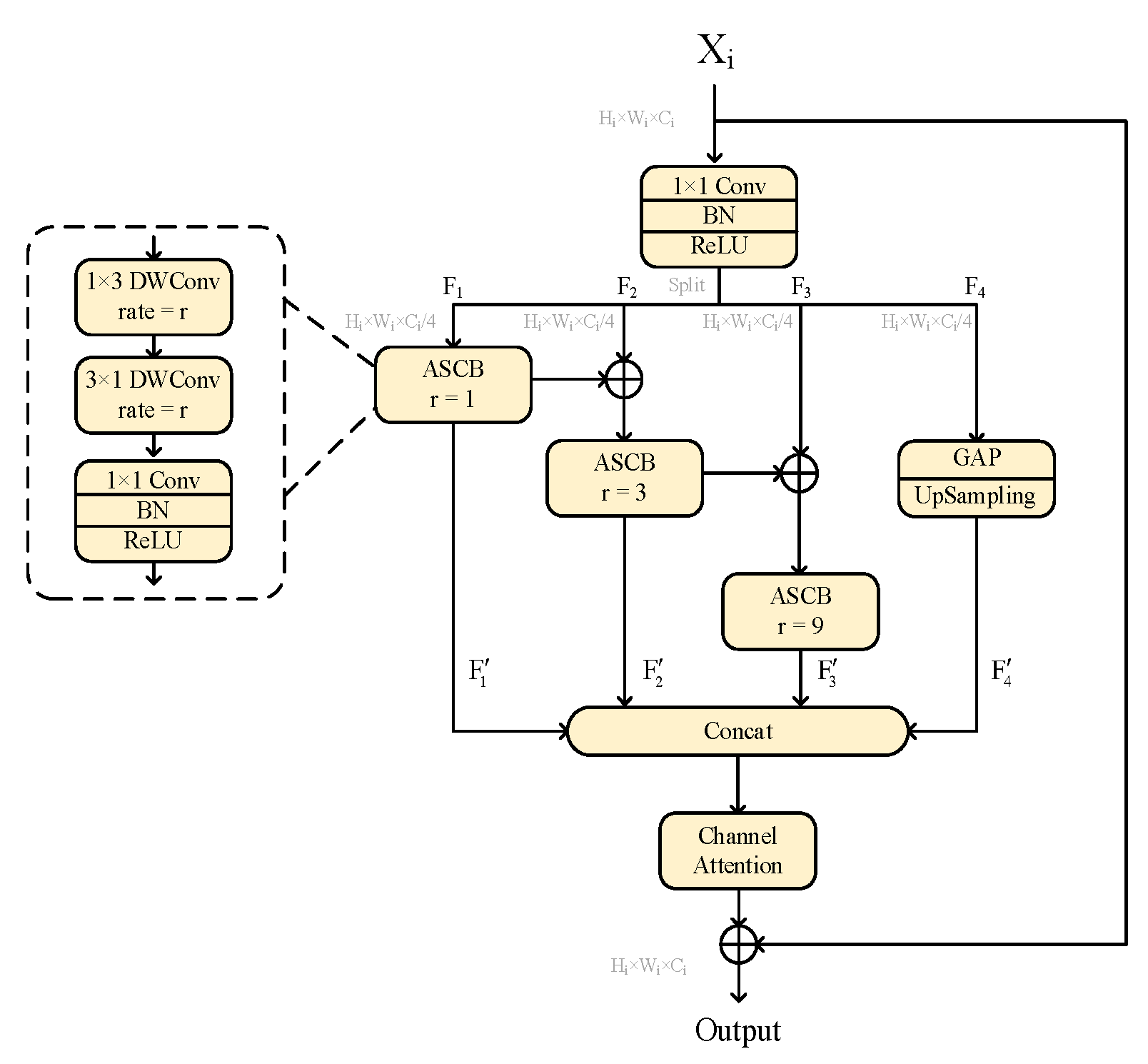
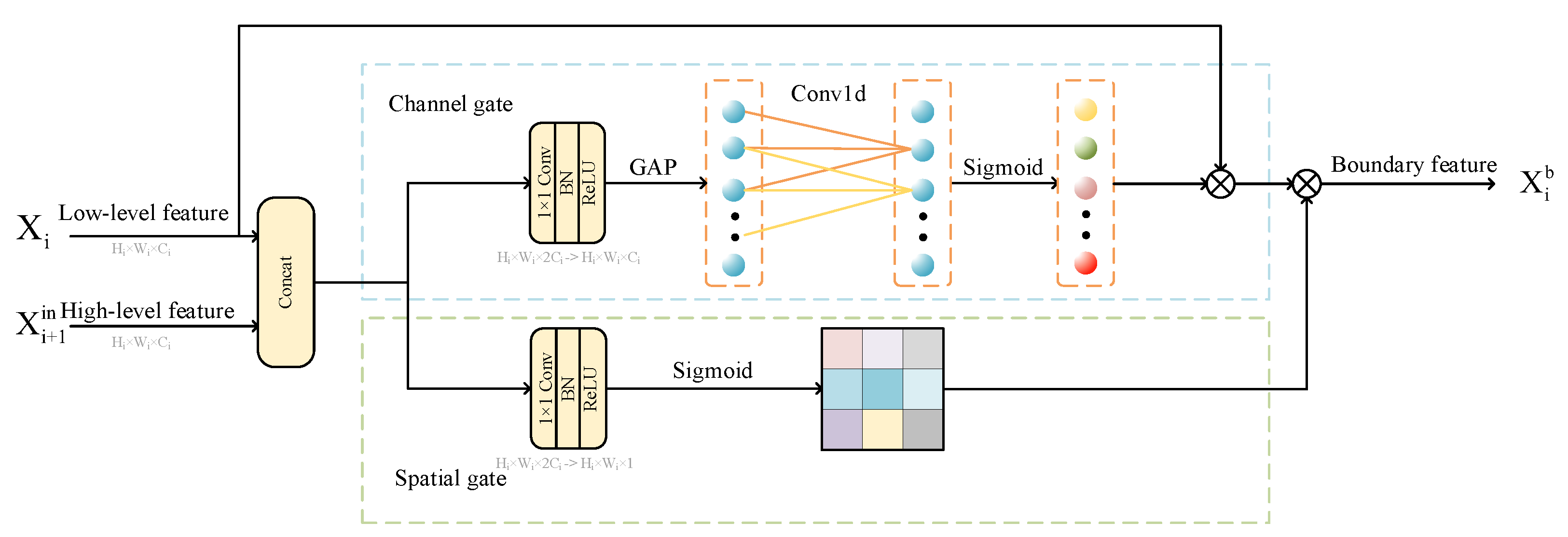
The Dual Gate Boundary Refinement Module (DGBRM) and the Dense Dilated Convolutional Residual Block (DDCResBlock) are proposed to handle the boundary branch and the regular branch, respectively. DGBRM refines the boundary through spatial and channel gates. DDCResBlock efficiently extracts and integrates multi-scale semantic features from low-level feature maps, thereby expanding the receptive field of the feature maps;
- (3)
We conducted experiments on two public datasets, the WHU Building Aerial Imagery Dataset and the Massachusetts Buildings Dataset. The ablation experiment has demonstrated the effectiveness of each module. The results of the comparative experiment indicate that our method outperforms the other compared methods in terms of performance while maintaining a relatively low computational complexity.
4. Results and Analysis
4.1. Datasets
The WHU Building Aerial Imagery Dataset includes satellite datasets and aerial image datasets, with a spatial resolution of 0.3 m–2.5 m. We only conducted experiments on the aerial image dataset, which was mainly filmed from Christchurch, New Zealand, covering 220,000 buildings of various forms with a coverage area of 450 .
The Massachusetts Building dataset was mainly captured in the urban and suburban areas of Boston, USA, with a spatial resolution of 1 m. Each image covers 2.25 , and all images cover approximately 350 .
4.2. Data Preprocessing
Before the experiment, we preprocessed both datasets. We set the pixel with the semantic meaning of building in the label to 1 and the pixel with the semantic meaning of background to 0 as the segmentation label and foreground label and used the findContours function in OpenCV to obtain the boundary label of the image. WHU Building dataset images have a size of 512 × 512 pixels, and the training set, validation set, and test set have been divided. We will not perform any operations. Massachusetts Building dataset images have a size of 1500 × 1500 pixels. We cropped the original image to 512 × 512 pixels, with an overlap of 256 pixels. Each image has been divided into 25 images. Due to the presence of a large number of blank pixels in some images, we removed them for training efficiency. The divisions of the processed dataset are listed in
Table 1.
4.3. Evaluation Metrics
In this paper, we use four commonly used metrics for semantic segmentation: Intersection over Union (IoU), F1-score, Recall, and Precision to evaluate the performance of building extraction. IoU is the ratio of the intersection and union of pixels predicted as buildings and pixels labeled as buildings. Recall reflects the model’s recognition ability for positive samples, Precision reflects the model’s recognition ability for negative samples, and F1-score is the harmonic average of Recall and Precision, which is a comprehensive reflection of Recall and Precision. The calculation formulas are as follows:
where TP, FP, TN, and FN represent true positive samples, false positive samples, true negative samples, and false negative samples, respectively.
4.4. Experimental Settings
In this paper, all models were implemented based on Python-3.8 and PyTorch-1.11.0, and all experiments were conducted on a single Nvidia GeForce RTX 3090 GPU. L2 regularization and data augmentation methods, including random horizontal flipping, random vertical flipping, random rotation, and random Gaussian blur, were used to avoid overfitting. During training, we used the Adam optimizer with an initial learning rate of 0.0005, and the Poly learning rate was used to decay the learning rate. The batch size was set to 12. In the WHU dataset and the Massachusetts dataset, the number of epochs is set to 200 and 300, respectively.
4.5. Comparative Experiments
4.5.1. Introduction of the Models for Comparison
We compare our proposed model with state-of-the-art models to demonstrate the advancement of our model. The comparison model selection process is as follows: because the overall structure of our model is based on a U-shaped structure, U-Net++ is chosen as the comparison. HRNet is the classic model in natural image segmentation, which have been widely used in research and industry. FarSeg, PFNet, and FactSeg are models that have achieved significant results in remote sensing image segmentation in recent years. They can solve the imbalance problem in tasks such as building extraction to a certain extent. MANet improves the problem of insufficient information utilization in feature fusion of U-Net through a linear complexity of attention, achieving state-of-the-art performance in multiple remote sensing image datasets. STT, AFL-Net, and MEC-Net are models that have achieved significant results in building extraction from remote sensing images in recent years.
4.5.2. Comparisons with State-of-the-Art Methods
For all methods, official codes were used for experimentation. Due to the lack of code provided by AFL-Net, we implemented the code based on the original paper.
The results of the comparative experiments on the WHU dataset and the Massachusetts dataset are shown in
Table 2. On the WHU dataset, our model achieved the best in IoU, Precision, and F1-score, with improvements of 0.55%, 0.41%, and 0.3% compared to the second-ranked model, respectively. MEC-Net achieved the best in Recall, surpassing the second-ranked model by 0.45%. On the Massachusetts dataset, our model achieved the best in IoU, Precision, and F1-score, with improvements of 0.61%, 0.83%, and 0.41% compared to the second-ranked model, respectively. MEC-Net achieved the best in Recall, surpassing the second-ranked model by 4.28%. Overall, our model achieved the best results on both datasets. This fully demonstrates the effectiveness of our model. In addition, models optimized for the imbalance of foreground and background in remote sensing images, such as FarSeg and PFNet, as well as FactSeg and BFL-Net, achieved stable performance on both datasets by reducing background interference. In addition, networks specifically designed for extracting buildings from remote sensing images, such as AFL-Net and MEC-Net, also perform well. On the contrary, some networks used for natural image segmentation or multi-class semantic segmentation of remote sensing images, such as MANet and U-Net++, have achieved poor performance on one or two datasets. Therefore, not all semantic segmentation models are suitable for building extraction tasks. Finally, it is worth noting that our proposed BFL-Net outperforms other models in terms of Precision on both datasets and is higher than Recall by 1.09% and 5.44%, respectively. The reason may be that BFL-Net has explicitly modeled and independently learned foreground features, thereby reducing the interference of background features of suspected buildings, reducing misjudgment to a certain extent, and making a significant contribution to Precision, making it very suitable for tasks with high Precision requirements.
4.5.3. Comparison of Different Foreground Modeling Methods
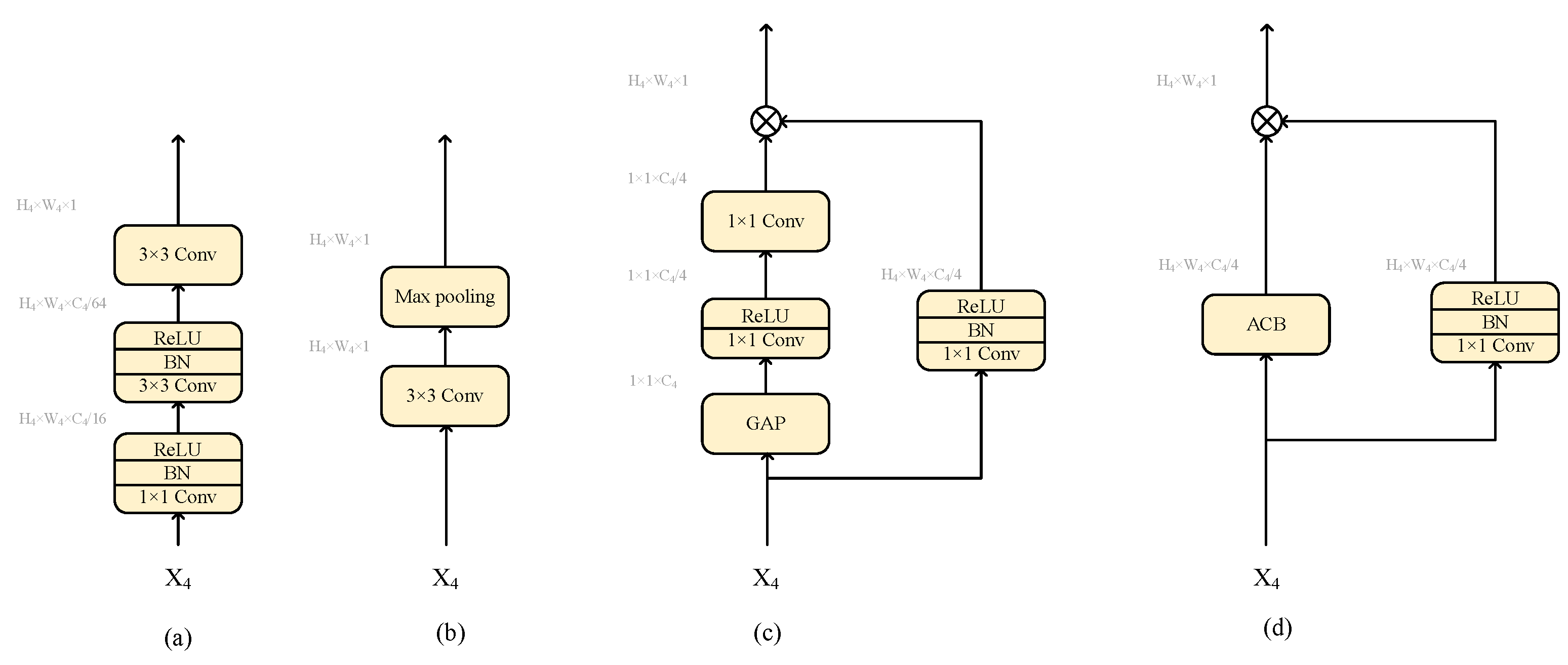
As shown in
Figure 6, we compared four foreground modeling methods. (a) [
27] and (b) [
45] are convolution-based methods, while (c) [
44] and (d) are relationship-based methods. Foreground-Recall (F-Recall) and IoU are employed as evaluation metrics in this experiment. F-Recall is used to measure the performance of methods in foreground localization, while IoU is used to measure the contribution of the method to the final prediction result. For F-Precision, we set the 256 points with the highest score in the foreground modeling stage to 1 and the remaining points to 0. After nearest upsampling, the Recall is calculated from the foreground predictions and the foreground labels. The IoU is calculated from final predictions and building labels.
Table 3 shows a comparison of different mainstream foreground modeling methods. The results show that relationship-based methods are superior to convolution-based methods, and our foreground modeling method achieves the best performance in both F-Recall and IoU metrics, which proves that FMM can not only locate the foreground position in the middle of learning, but also bring positive improvements to the final prediction results by enhancing foreground and beneficial context. It is worth noting that all foreground modeling methods do not perform well in F-Recall on the Massachusetts dataset. The reason is that the buildings in the Massachusetts dataset are small and dense, and the features in the foreground modeling stage lack the integration of low-level features, which leads to only rough positioning of these buildings.
4.5.4. Visualization of Experimental Results
To more intuitively reflect the performance of each model, we visualized their building prediction results on the WHU dataset and Massachusetts dataset. The two datasets have buildings of different styles and densities. Specifically, the buildings on the WHU dataset are larger and more dispersed, and the buildings on the Massachusetts dataset are smaller and denser. The visualization results on both datasets can fully reflect the model’s ability to extract architectural clusters of different styles. We selected four representative images on each of the two datasets.
The visualization results of each model on the WHU dataset are shown in
Figure 7. Overall, our proposed BFL-Net has fewer pixels for incorrect prediction and is visually superior to other models. Specifically, in (a)
, due to the small and dense buildings, all models had missed extractions. However, BFL-Net had the fewest pixels of false extractions, with only a few pixels being overlooked. In (a)
, only BFL-Net, FarSeg, and U-Net++ accurately predicted boundaries because the color of the edges on the right side of the building was different from the overall color. The above results indicate that BFL-Net has better predictive ability in building details, boundaries, and easily overlooked small buildings. In (d)
, in the prediction of large buildings, U-Net++, MANet, STT, MEC-Net, PFNet, and AFL-Net all showed a large number of missed pixels inside the building, possibly due to changes in the texture inside the large building and the model could not effectively recognize as the same building. HRNet showed a small number of missed pixels inside the building. FarSeg does not predict smoothly and accurately on the right boundary, while BFL-Net predicts more accurately on both internal pixels and boundaries. However, it is also noteworthy that all models generated numerous incorrect predictions in the areas marked within the red circles in the image. This might be attributed to certain angles in the capture, causing an inclination in the imaging of buildings, thereby resulting in false predictions. Overall, the above results indicate that BFL-Net can predict large buildings more accurately and stably through large receptive fields and multi-scale perception, with fewer missed detections inside buildings.
The visualization results of each model on the Massachusetts dataset are shown in
Figure 8. Overall, our proposed BFL-Net outperforms other models visually. Specifically, in (b)
, the five buildings are small and scattered. Only BFL-Net, U-Net++, FactSeg, MEC-Net, PFNet, and AFL-Net accurately predicted five buildings. The above results indicate that BFL-Net can predict details in images more accurately by utilizing low-level features reasonably. In (c)
, except for BFL-Net, all models had missed detections inside the building, and BFL-Net almost perfectly predicted the building, indicating that BFL-Net improved the prediction ability inside the building through multi-scale receptive fields. However, it is worth noting that the presence of densely distributed buildings with considerable background clutter (as shown in the red circle area in
Figure 8b) or complex structures on building rooftops (as shown in the red circle area in
Figure 8c) can result in the occurrence of shadows and occlusions. Shadows and occlusions in remote sensing images are critical factors that affect the performance of building extraction.
The visualization results of various models on the WHU dataset and Massachusetts dataset indicate that BFL-Net has advantages in predicting building details, small buildings, and internal pixels of large buildings, and the model has strong robustness and is not easily affected by factors such as building textures.
To verify the effectiveness of FMM in foreground prediction, we visualized the sampling points in foreground prediction. Specifically, we will represent the sampled points in white and the unsampled points in black. To improve visualization quality, we upsampled the prediction results to a size of 512 × 512 using the nearest-neighbor interpolation method. The visualization results on the WHU dataset and the Massachusetts dataset are shown in
Figure 9 and
Figure 10, respectively. The visualization results indicate that FMM can relatively accurately locate foreground pixels in the mid-term of model learning. In addition, for small buildings that are difficult to extract, FMM can also enhance the expression of these features by locating their relevant important contexts.
4.5.5. Comparison of Complexity
The WHU dataset is a widely used and highly accurate dataset for building extraction in remote sensing images. Therefore, we use the results of the model on the WHU dataset as a basis for measuring the model’s ability to extract buildings in this section. The IoU, the number of parameters (Params), and the floating-point operations (FLOPs) are used as evaluation metrics. IoU is an evaluation metric used to evaluate the performance of model predictions. The higher the IoU, the more accurately the model can extract buildings. Params and FLOPs are metrics for evaluating model complexity, and lower Params and FLOPs demonstrate that the model is lighter and more conducive to practical applications. All metrics were computed using code either open-sourced by the authors or code implemented by us.
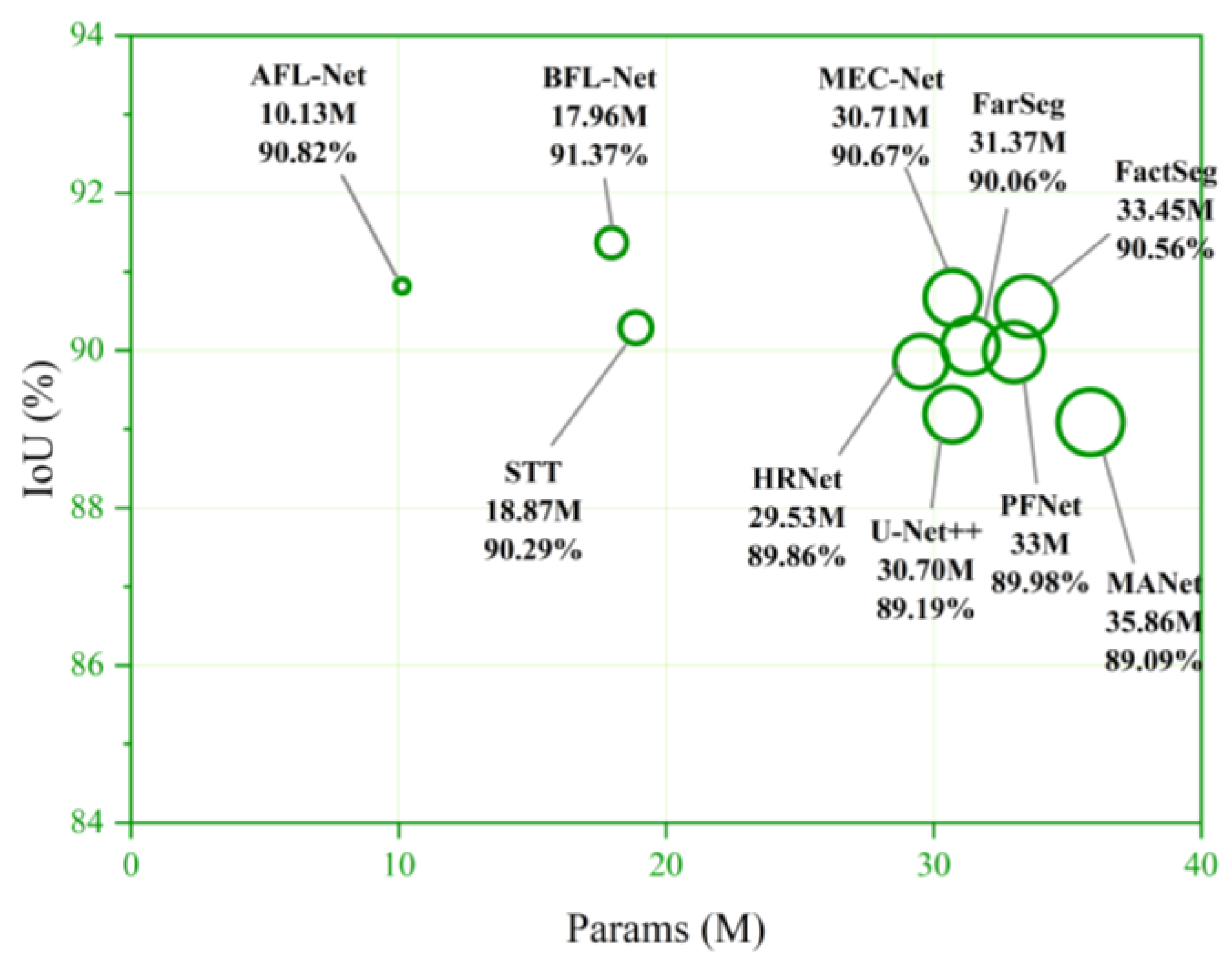
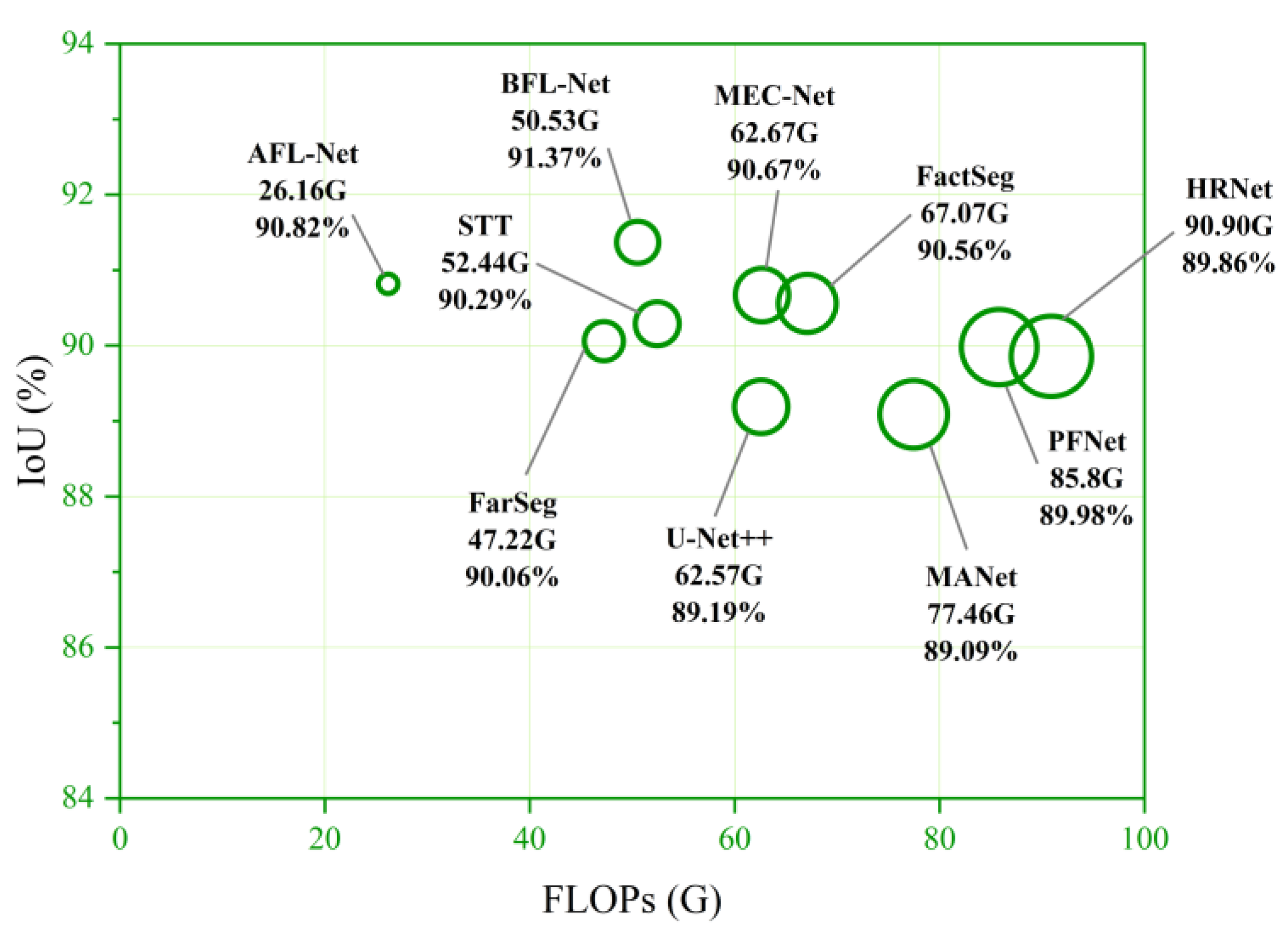
The comparison of IoU, Params, and FLOPs of each model is shown in
Figure 11 and
Figure 12. Each dot represents the performance of a model on evaluation metrics, and the larger the diameter of the circle, the larger the Params or FLOPs of the model. Our proposed BFL-Net achieved the best performance on IoU, surpassing the second-place AFL-Net by 0.55%. On Params, our model has the second smallest Params among all comparative models, only 17.96 M. On FLOPs, our model ranks third smallest FLOPs among all comparative models, with only 50.53 G. Overall, BFL-Net achieved a better balance between efficiency and performance.
4.6. Ablation Study
4.6.1. Ablation on Each Module
To verify the effectiveness of the proposed module in this paper, we split and combine modules for verification. We conducted experiments on the WHU dataset and the Massachusetts dataset. First, we use a dual decoder structure similar to FactSeg as the baseline. Specifically, we have replaced the feature fusion and upsampling modules in the decoding process of FactSeg with the same structure as BFL-Net. We have modified the foreground branch of FactSeg to a boundary prediction branch and added a feature fusion module in BFL-Net to fuse the features of the two branches. Next, we added the Foreground Mining Module (F), Dense Dilated Convolutional Residual Block (D), spatial gate (S), and channel gate (C) in the Dual Gate Boundary Refinement Module on the baseline to verify the effectiveness of each module. Finally, all modules were integrated together to verify the overall effectiveness of the model.
The experimental results on the WHU dataset are shown in
Table 4, which can fully demonstrate the effectiveness of each module. Firstly, we used FactSeg with Resnet 50 (R
4) as the baseline for the experiment, with an IoU of 87.96%. Then, we added FMM on the baseline, and the IoU increased by 2.01% to 89.97%. It is worth noting that the addition of FMM has a significant improvement in Precision, with a 2.17% increase compared to baseline, indicating that FMM can effectively enhance the expression of foreground information through foreground learning, reduce misjudgment caused by background pixel interference, and improve Precision. Next, we added DDCResBlock, which increased IoU by 2.80% compared to baseline and 0.79% compared to “Baseline + F”. This indicates that DDCResBlock can increase the model’s perception of large buildings by expanding the receptive field, thereby improving performance. Then, we added spatial gate and channel gate, respectively, with IoU increasing by 3.19% and 3.09% compared to baseline and 0.39% and 0.29%, respectively, compared to “Baseline + FD”. This indicates the necessity of adding gates in both spatial and channel dimensions, which can help the model more comprehensively separate and restore boundary information. Finally, we added FMM, DDCResBlock, and DGBRM together to the baseline, resulting in an IoU increase of 0.22% and 0.32%, respectively, compared to “Baseline + FDS” and “Baseline + FDC”. The above experiments fully demonstrate that each module is effective while combining them not only does not create conflicts but also has positive effects. The above results indicate that using all modules together in our model achieves optimal performance.
The effectiveness of each module was once again verified through the experimental results of the model on the Massachusetts dataset in
Table 5. The addition of F, D, S, and C resulted in improvements of 3.09%, 0.85%, 0.73%, and 0.61% on IoU, respectively. The incorporation of all four modules together has increased by 5.25%, 3.72%, 3.41%, and 3.56% compared to baseline on IoU, Precision, Recall, and F1-Score, respectively.
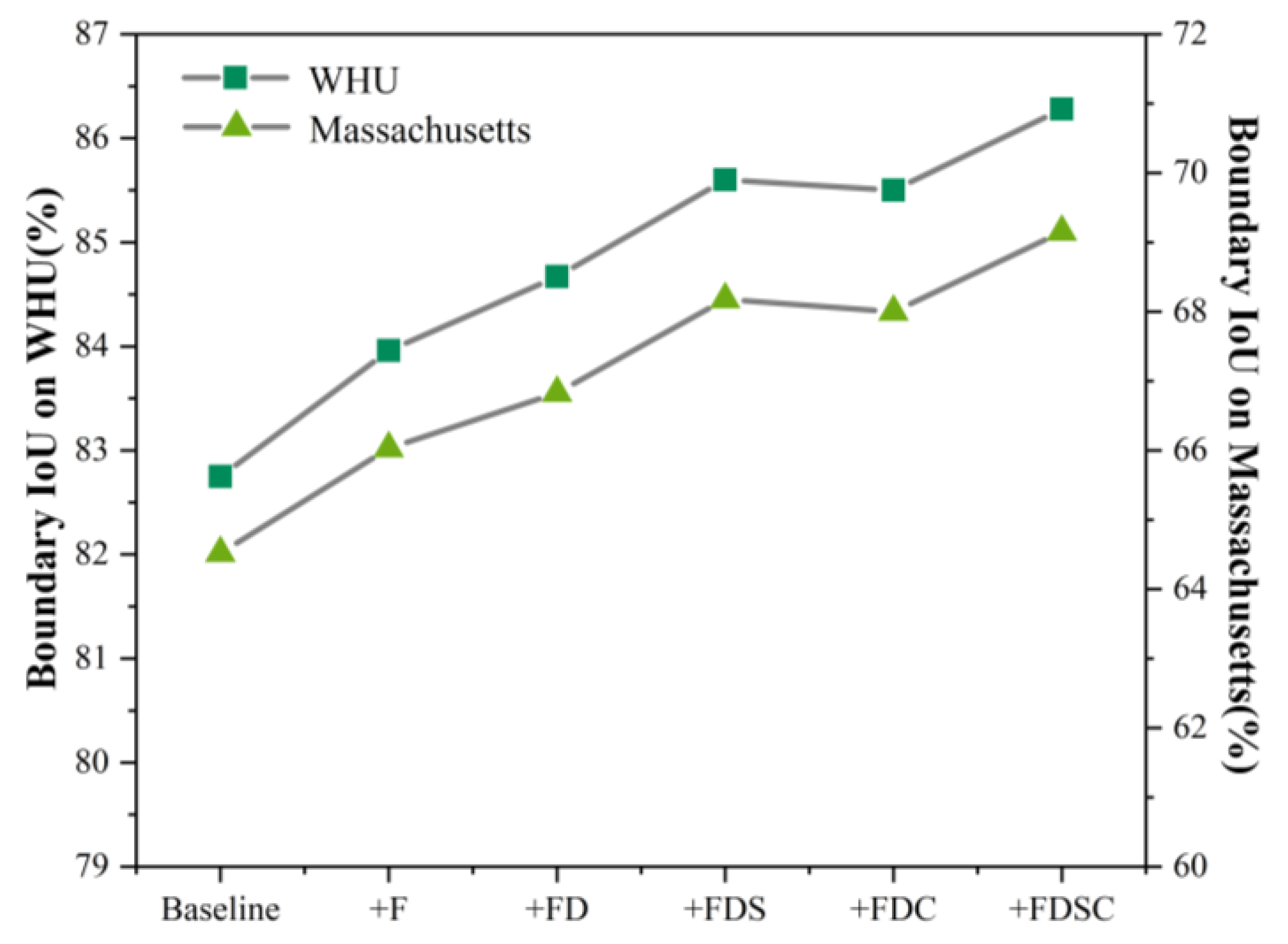
To verify that our proposed DGBRM can effectively extract boundary information, we evaluated the results of the above ablation experiments using the Boundary IoU [
61] as an evaluation metric, as shown in
Figure 13. On the WHU dataset, compared to the baseline, the boundary IoU of each group showed varying degrees of improvement, with the most significant improvement being the “Baseline + F” group. We analyzed the reason for this because the structure of the baseline was too simple, and the receptive field was small. FMM not only expanded the receptive field to a certain extent but also allowed the model to learn diverse foreground features, which enabled numerous unrecognizable buildings to be identified. Even if the boundaries are not precise and fine enough, it also enhances the Boundary IoU. In addition, the modules that contribute the most to the boundary IoU are SC, S, C, and D in order. Especially based on improving the receptive field and being able to comprehensively learn building features through “Baseline + FD,” SC still increased the Boundary IoU by 1.61%, indicating that boundary details have indeed been refined. Then, the results of “Baseline + FDS” and “Baseline + FDC” indicate that both spatial gate and channel gate contribute to the improvement in boundary IoU. The situation in the Massachusetts dataset is similar to that in the WHU dataset, where the spatial gate and channel gate respectively increase Boundary IoU by 1.35% and 1.17% compared to “Baseline + FD”, and the combined use of the two modules increases Boundary IoU by 2.32%.
4.6.2. Ablation on Different Backbones
We compared the effects of different backbones on the experimental results. The notations used in the following experiments are described as follows:
As shown in
Table 6, on the WHU dataset, the proposed BFL-Net with ResNet50 (R
4) achieved the best performance across all metrics. On the Massachusetts dataset, BFL-Net with ResNet50 (R
4) performed the best in IoU, Precision, and F1-score, while BFL-Net with ResNet50 (R
5) achieved the best in Recall. Overall, using ResNet50 as the Backbone outperforms ResNet18 because ResNet50 uses more ResBlocks and has stronger feature extraction ability. BFL-Net with ResNet50 (R
4) is better than ResNet50 (R
5). The reasons can be listed as follows: (i) ResNet50 (R
4) has higher resolution, preserves more detailed features, and is more conducive to extracting dense small buildings. (ii) ResNet50 (R
5) has advantages in receptive fields and large-scale building extraction. However, the advantage is weakened due to the capture of global contextual information through KAM after the backbone and may be overfitting due to a large number of parameters.
4.6.3. Ablation on Dilated Convolutions with Different Structures
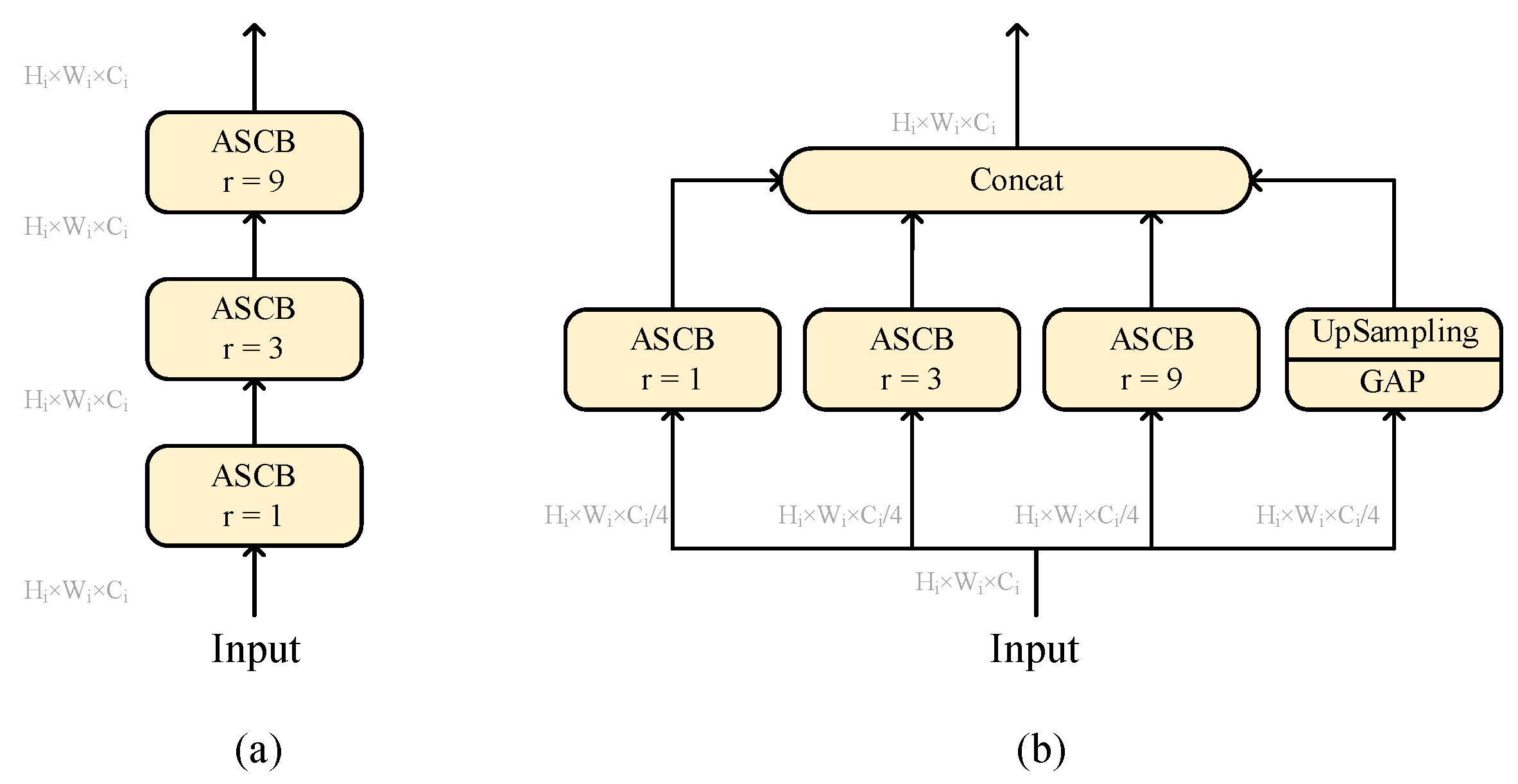
As shown in
Figure 4 and
Figure 14, we compared three different structures of ASCB in DDCResBlock: serial, parallel, and dense cascade structures. Note that in the experiment, we only changed the cascade structure of ASCB in DDCResBlock, and the rest of the structures remained consistent. As shown in
Table 7, the performance of the dense cascade structure on both the WHU dataset and the Massachusetts dataset is optimal, indicating that the dense cascade structure exhibits notable advantages in feature extraction, and it can effectively improve performance through dense feature representation and more receptive field scales.
4.6.4. Ablation on Dilation Rates
A small receptive field can lead to the model being unable to extract complex high-level features, while a large receptive field can lead to the loss of local detail information and increase the difficulty of training. In order to find a more suitable receptive field, we conducted ablation experiments on the setting of dilation rates in ASCB. Specifically, due to equipment limitations, while avoiding the gridding effect, we only set five different expansion rates. The experimental results are shown in
Table 8. The experimental results indicate that using dilation rates of 1, 3, and 9 can achieve the best performance on the WHU dataset and Massachusetts dataset due to their suitable receptive field.
4.6.5. Ablation on Number of Sampled Points
In order to select the appropriate number of sampling points, we conducted ablation experiments on the number of sampling points. The experimental results are shown in
Table 9. On the WHU dataset, the optimal performance was achieved when the number of sampling points was 256. On the Massachusetts dataset, when the number of sampling points was 256, the IoU, Precision, and F1-scores reached the best. The experimental results show that an excess of sampling points not only leads to interference resulting from sampling too many background pixels, which contradicts the original design intention, but also increases the complexity of the model. On the contrary, too few sampling points can lead to insufficient foreground information extraction and affect segmentation performance.
4.7. Hyperparameter Experiments
The loss function mainly involves three hyperparameters:
,
and
, which respectively represent the weight of segmentation loss, boundary loss, and foreground loss. In order to optimize the predictive performance of the model, although it is not possible to iterate through all possible parameters, we try our best to obtain the local optimal values of the parameters through experiments. First, we fixed the value of
to 1 and conducted experiments on the values of
and
. Because of equipment limitations, we only used five values for each parameter for experiments. The experimental results are shown in
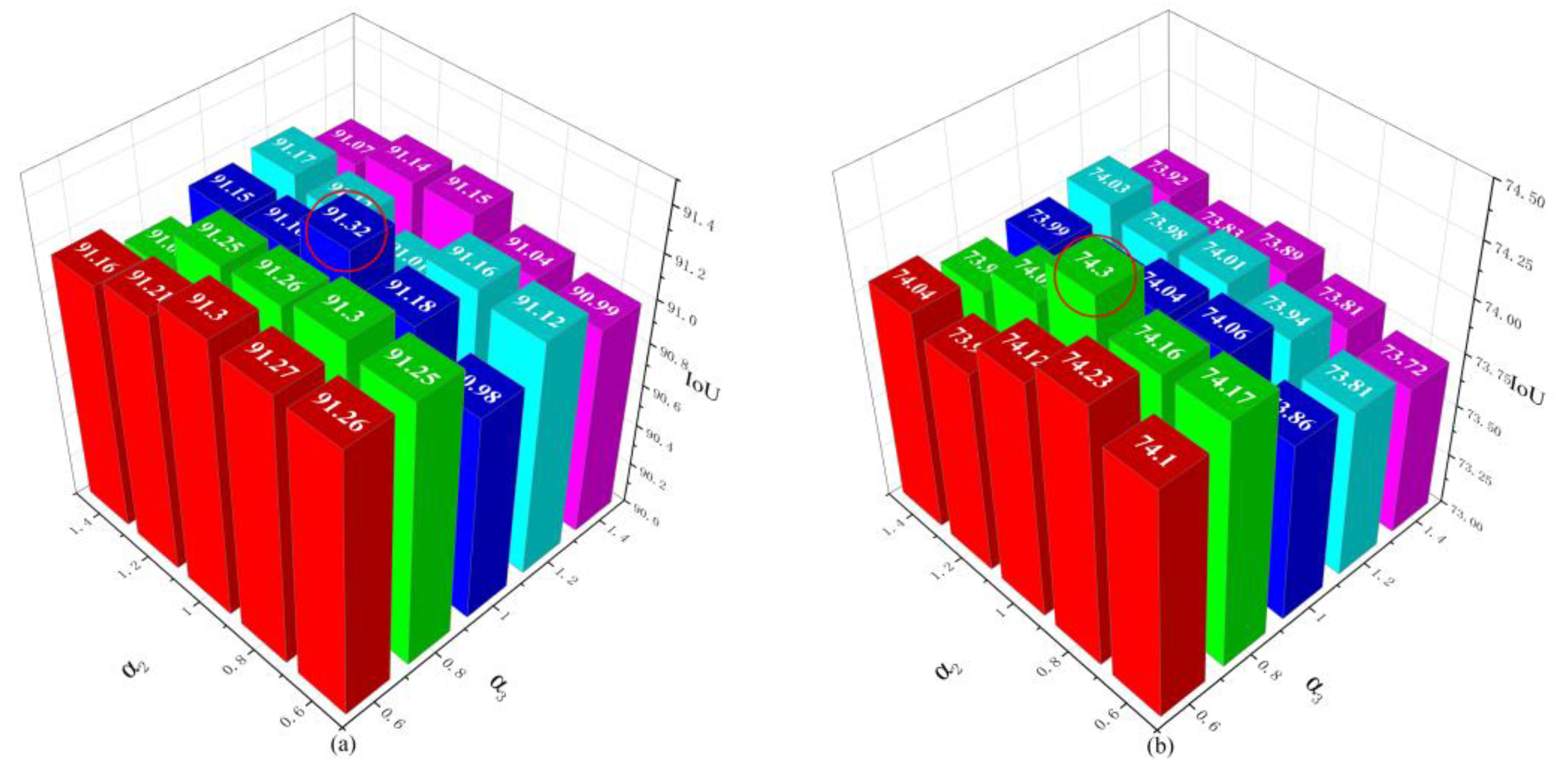
Figure 15.
The influence of the values of
and
on the WHU dataset is shown in
Figure 15a. When the values of
and
are both 1, the result is optimal. The influence of the values of
and
on the Massachusetts dataset is shown in
Figure 15b. When
= 1 and
= 0.8, the result is optimal. On the whole, on the two datasets, when
≥
, the prediction performance is generally better than when
<
. The reason is speculated that the boundary details are more important for predicting dense and complex buildings. In addition, the optimal values all appear when
,
≤ 1, and the reason is speculated that the weight of auxiliary tasks should not be greater than that of the main task.
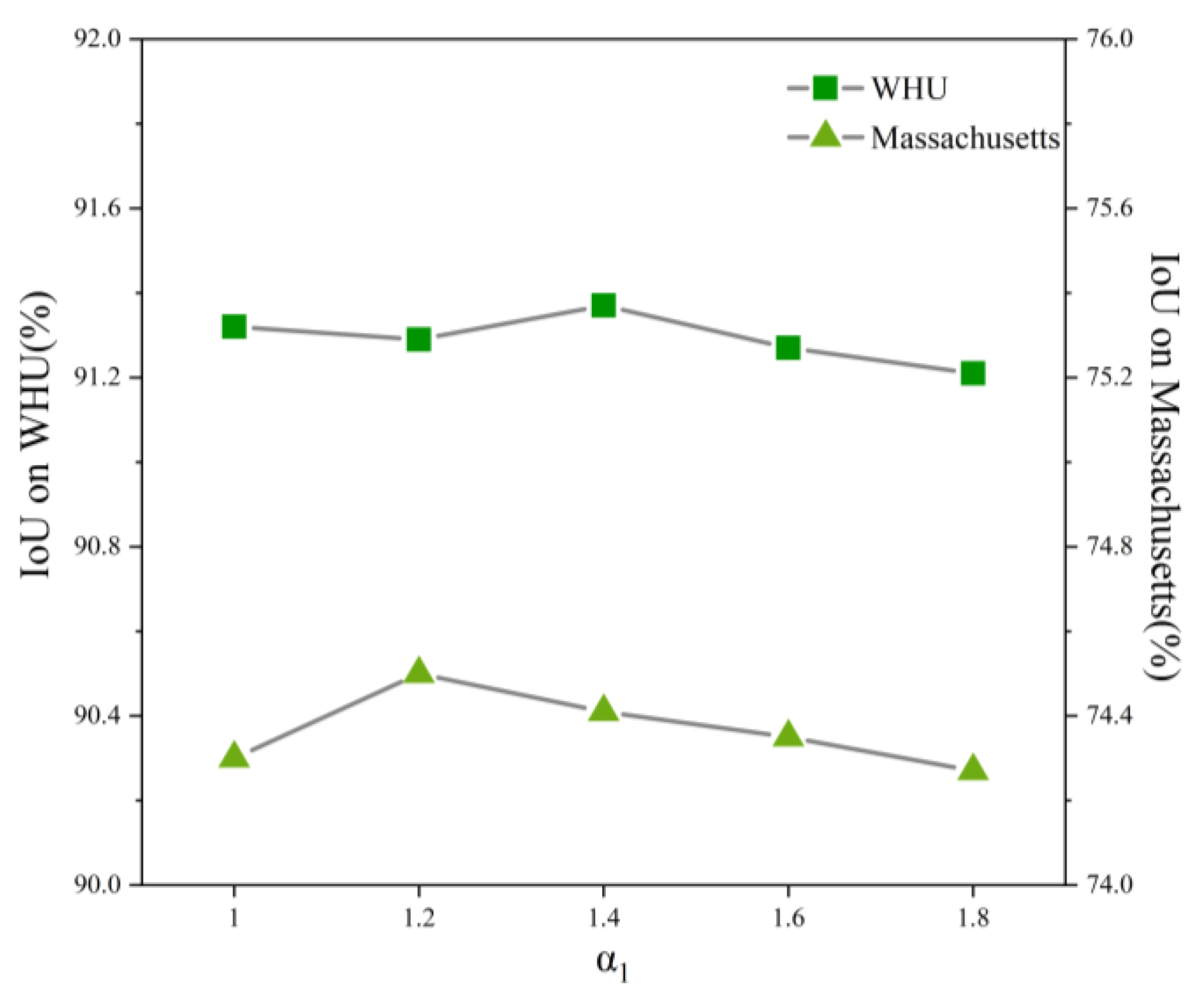
On the WHU dataset and Massachusetts dataset, the impact of the value of
on the prediction results is shown in
Figure 16. Both
and
are set to the best values. Specifically, on the WHU dataset,
= 1,
= 1, and on the Massachusetts dataset,
= 1,
= 0.8. Experimental results show that on the WHU dataset, the best result is obtained when
= 1.4; on the Massachusetts dataset, the best result is obtained when
= 1.2. To sum up, on the WHU dataset, when
,
, and
are 1.4, 1, and 1, the model achieves a local optimum. On the Massachusetts dataset, when
,
, and
are 1.2, 1, and 0.8, respectively, the model achieves a local optimum.
4.8. Limitations and Future Work
Although our proposed BFL-Net has advantages in various aspects, such as performance, Params, and FLOPs, we found in the experiment that there is still room for improvement in the model’s inference speed. Specifically, we use Frames Per Second (FPS) as the evaluation metric, using a tensor of dimension 1 × 3 × 512 × 512 to calculate FPS. The higher the FPS, the faster the inference speed and the stronger the real-time performance.
The experimental results are shown in
Table 10, where the inference speed of BFL-Net only exceeds HRNet, MANet, PFNet, and AFL-Net, but is not as fast as MEC-Net, STT, FactSeg, U-Net++, and FarSeg. This indicates that BFL-Net has limitations in tasks that require high real-time performance. In future work, we should aim to improve the model’s inference speed through means such as enhancing the model architecture or employing model pruning techniques. For example, we can choose a lighter and more efficient backbone or activation function based on the difficulty of the prediction task.
In the visualization experiments (as shown in
Figure 7 and
Figure 8), we found that when there are shadows or occlusion in the image, the probability of the model making incorrect predictions increases. Our analysis suggests that the reasons may be as follows: firstly, shadows and occlusion can cause partial information loss or deformation in the image, which reduces the effective features of the building and makes it difficult for the model to make accurate predictions. Secondly, partial occlusion may lead to annotation errors in the dataset, affecting the evaluation of the model. Thirdly, the generalization ability of the model needs to be improved, especially for the recognition ability of some features that rarely appear. In future work, we can increase the number of samples with shadows or occlusion in the training set or design new loss functions or post-processing methods to optimize prediction results through data augmentation. In addition, we believe that when the training data is insufficient, the performance of our method will be greatly affected, which can be alleviated by applying features and knowledge learned from other fields to building extraction tasks through transfer learning methods.
Our model has achieved good performance in most complexity and predictive performance metrics, which proves that our model achieves a better balance between efficiency and performance in building extraction tasks. In addition, we believe that our model has a certain degree of flexibility, which means that the model can be adapted to a wider range of scenarios and tasks with some modifications. Most of our pipeline steps are not specific to optical remote sensing images and building extraction tasks, and this method can be readily applied to other types of images and tasks. Furthermore, phenomena such as feature redundancy, pixel imbalance, and blurred boundaries exist in multiple fields. Outstanding key features and clear boundaries are beneficial for many tasks. We envision that our method may be applied in fields such as hyperspectral remote sensing images and medical images. In recent years, there has been a lot of research on hyperspectral remote sensing images, which have been widely applied in fields such as change detection [
62] and anomaly detection [
63,
64,
65]. However, there is still redundancy in the features of hyperspectral remote sensing images, leading to the submergence of discriminative features. In addition, it is difficult to effectively express the differences between feature classes and distinguish feature boundaries in images. Based on the above issues, extracting distinguishing features between background and target in complex scenes and reducing noise features are key. Lin et al. [
63] proposed a dynamic low-rank sparse priors constrained deep autoencoder for extracting discriminative features while enhancing self-interpretability. Cheng et al. [
64] proposed a novel subspace recovery autoencoder, which is combined with robust principal component analysis for better optimization of background reconstruction. Therefore, we believe that it is feasible to apply our method to these tasks in the future. It can effectively help models focus on foreground and discriminative features in hyperspectral remote sensing images, reduce anomalies or noise, and by strengthening boundary features, better capture the shape, structure, and spatial distribution of objects, helping to detect targets more accurately.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}