1. Introduction
Currently, inertial navigation systems are the primary navigation tools used for underwater vehicles. They do not rely on external information and can provide real-time, continuous, autonomous, and all-weather data such as position, velocity, acceleration, and attitude, meeting the requirements of underwater navigation for concealment and reliability [
1,
2,
3,
4]. However, the drift error of inertial devices accumulates over time, leading to a gradual decrease in the navigation accuracy of the inertial navigation system, which cannot meet the accuracy requirements for long-duration missions. Therefore, regular calibration using other navigation methods is necessary [
5,
6].
Gravity matching navigation utilizes variations in the Earth’s gravity field for positioning and does not require signal transmission and reception. It possesses strong anti-interference capabilities and can meet the requirements of underwater navigation for concealment and positioning reliability, making it one of the most suitable navigation methods for aiding inertial navigation systems [
7,
8,
9]. Gravity matching navigation acquires the gravity-related information of the current position using a gravity sensor. By comparing the real-time measurements with a prestored gravity field reference map and employing suitable matching and solving algorithms, the position of the vehicle is estimated, thus correcting the navigation errors of the inertial navigation system. The positioning accuracy and success rate of gravity matching navigation are closely related to the distribution of gravity field characteristics in the navigation area. The same matching algorithm exhibits different matching effects in regions with different gravity features, and areas with rich gravity features can significantly improve the matching accuracy [
10]. Therefore, to ensure the effectiveness of gravity matching navigation, it is necessary to evaluate the suitability of the navigational area based on gravity features and plan the trajectory in accordance with the distribution of suitability, ensuring that the trajectory remains within the suitable region.
Traditional underwater gravity matching navigation path planning algorithms are typically based on two-dimensional maps and cannot effectively adapt to the complex underwater terrain and obstacles [
11,
12,
13]. Researching and applying path planning algorithms for underwater three-dimensional space is of great significance in advancing underwater autonomous navigation technology and enhancing the safety and reliability of underwater devices. Despite significant achievements in two-dimensional path planning algorithms, extending them directly to three-dimensional space is not a straightforward task. Compared to the two-dimensional plane, a three-dimensional space involves more degrees of freedom and a more complex physical environment, which imposes higher requirements on path planning algorithms. For instance, in terms of computational complexity and storage space, three-dimensional path planning algorithms need to overcome greater challenges. Currently, the commonly used three-dimensional path planning algorithms include the artificial potential field method, A* algorithm, ant colony algorithm, and rapidly exploring random tree (RRT) algorithm. The artificial potential field method is a path planning approach that mimics natural potential fields. It constructs an artificial potential field where the target exerts attraction on objects and obstacles exert repulsion, causing objects to move in the direction of the potential field gradient to reach the destination. However, this method can sometimes result in objects becoming trapped in local minima and being unable to reach the target location, thus not guaranteeing a solution [
14,
15]. The A* algorithm is a heuristic-based path planning method that utilizes cost functions to obtain information about the distance to the goal, directing the search towards finding the path with the minimum cost and shortest distance. However, this method has limited real-time performance, with large computational requirements and long processing times for each node. As the number of nodes increases, the efficiency of the algorithm decreases [
16,
17]. The ant colony algorithm is a heuristic path planning method that simulates the foraging behavior of ants, treating the target as a food source and obstacles as impassable regions. It finds the optimal path by updating the pheromone concentration. The ant colony algorithm has strong robustness and can be combined with other algorithms. However, its convergence speed is relatively slow in the initial stage, and it is sensitive to the selection of initial solutions [
18,
19].
The RRT algorithm is a randomized search-based path planning method that constructs a random tree to explore the state space and quickly find a feasible path from the start point to the goal. The algorithm starts with an initial state as the root node and randomly samples a state at each iteration, attempting to connect it with the nearest state in the tree. If the connection is successful (without intersecting obstacles and satisfying other constraints), the new state is added to the tree [
20,
21]. Traditional RRT algorithms can find feasible paths, but they are not necessarily optimal and have slow convergence speeds and long search times. The RRT* algorithm improves upon this by introducing the process of reselecting the parent node for new nodes within a certain radius and rewiring nearby nodes. This modification enables the RRT* algorithm to exhibit asymptotic optimality, meaning that as the number of iterations increases indefinitely, the found path tends to be optimal. However, the convergence speed of the algorithm is influenced by the size of the bounding hyperball. Increasing the radius leads to a significant increase in the number of nodes within the hyperball, resulting in longer computation times [
22,
23,
24,
25]. To improve the search efficiency of the RRT* algorithm, the Q-RRT* algorithm extends the range of parent node selection for new nodes and nearby nodes based on the triangle inequality, which can generate better initial paths and achieve a faster convergence speed [
26,
27]. RRT-based algorithms exhibit significantly reduced search efficiency when dealing with high-dimensional spaces and complex obstacles, leading to a substantial increase in the required number of iterations and computation time [
28,
29,
30,
31,
32]. The Depth Sorting Fast Search (DSFS) algorithm enhances the efficiency of the parent node reselection process and rewiring process by utilizing the inequality relationship between ancestor nodes and their descendants. It achieves this by selecting candidate nodes in depth-first order, thereby reducing the number of nodes that require collision detection and effectively saving computation time [
33].
Differing from previous research, this paper proposes a novel Three-Dimensional Along-Path Obstacle Profiling (TAOP) algorithm aimed at further enhancing the efficiency of underwater gravity-matching navigation in three-dimensional environments. The TAOP algorithm decomposes three-dimensional path planning into two-dimensional planning and a height planning phases. It can be seamlessly integrated with existing planar path planning algorithms, thereby circumventing the low computational efficiency issue of current path planning methods in three-dimensional scenarios. Additionally, by combining gravity anomaly data and seafloor terrain data, a three-dimensional planning environment that is suitable for underwater gravity-matching navigation is established, and performance simulation tests for route planning are conducted within this environment. Through a comparison of the RRT*, Q-RRT*, and DSFS algorithms, various factors including the initial path quality and computation time are evaluated. This validation demonstrates that the TAOP algorithm is capable of achieving rational path planning for underwater gravity-matching navigation and effectively improving planning efficiency.
2. Three-Dimensional Along-Path Obstacle Profiling Algorithm
When performing three-dimensional path planning for underwater gravity-matching navigation, it is necessary to consider both gravity suitability, to ensure the normal operation of the navigation system, and seamount constraints, to ensure safe navigation. When RRT-based algorithms directly sample in three-dimensional space, the collision detection of the edges of the random tree requires both being in a gravity suitability grid and maintaining a safe distance from the seamount in the height direction, which places high demands on the nodes. The number of invalid nodes sampled in a three-dimensional space far exceeds that in the plane, which leads to a very high failure rate of collision detection, an excessive computational load, and a slow convergence of the planning algorithm. The calculation time is too long, and even feasible solutions cannot be found. Moreover, when the sampling range covers the entire three-dimensional planning space, the effective nodes are dispersed, resulting in large path volatility and a high path cost. In addition, each time collision detection is performed, it is necessary to interpolate the water depth at each detection point on the path to ensure a safe distance from obstacles. However, interpolation in large-scale terrain data is a time-consuming computational step, which greatly affects the computation time.
To address these issues, this paper proposes the Three-Dimensional Along-Path Obstacle Profiling (TAOP) algorithm, which transforms three-dimensional path planning into two separate processes: two-dimensional planar planning and height planning. First, based on the gravity suitability distribution map, a two-dimensional planning algorithm is employed to plan the planar path points. Next, obstacles along the path are unfolded along the planar path axis, and interpolation is used to generate a seamount obstacle profile graph with the distance from the starting point along the path as the horizontal axis and the elevation information as the vertical axis. Finally, by utilizing the obstacle profile information, the height of the path points is planned to ensure safety in the height direction. The TAOP algorithm separates height planning from planar planning, and gravity suitability actually only acts on the planar directions of the latitude and longitude, where planar planning is directly related to gravity suitability. Using planar planning to sample in a two-dimensional plane can reduce the number of invalid sampling nodes significantly, and it does not require the consideration of the impact of seamounts on the height, which greatly reduces the amount of collision detection calculations. The interpolation operation is only performed once in the preprocessing stage to generate the profile of the obstacle, effectively shortening the calculation time. The TAOP algorithm unfolds the profile of the obstacle along the path after planar planning, and it generates a three-dimensional path based on the profile contour according to height planning, which can be used in combination with most two-dimensional planning algorithms.
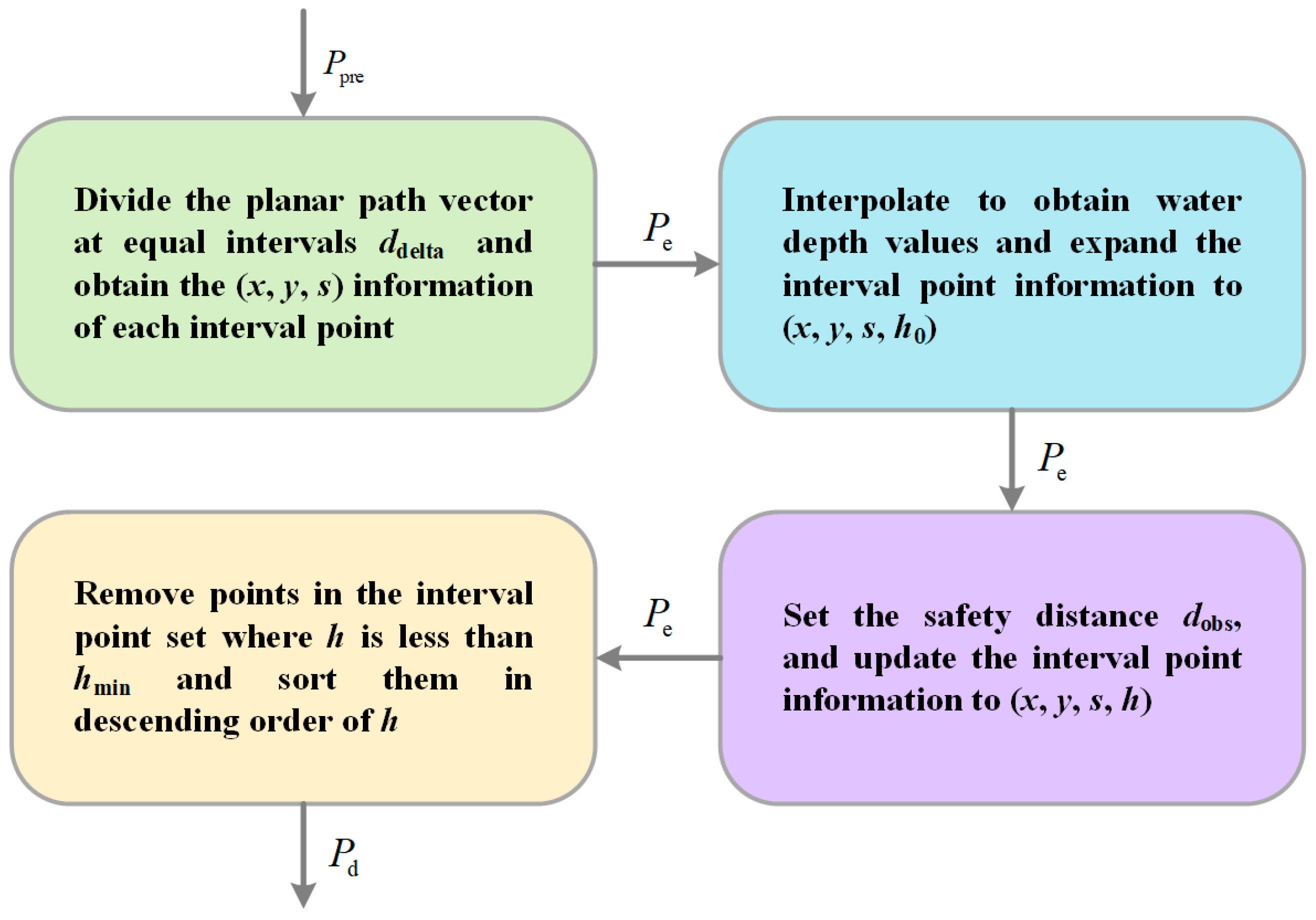
The TAOP algorithm mainly includes four steps, with the basic procedure shown in Algorithm 1 and the schematic diagram shown in
Figure 1: planar path point data preprocessing (
), path coarse planning (
), path secondary optimization (
), and path point integration (
).
| Algorithm 1 |
;
;
;
;
return ; |
Explanation of parameters in Algorithm 1:
: The set of planar path points;
: The safe distance from terrain obstacles;
: The interval distance when generating the obstacle profile;
: The set of location points to be verified;
: The set of coarse planned path points;
: The set of secondary optimization path points;
: The set of integrated path points.
The first step is planar path point data preprocessing. After obtaining the planar polyline path from two-dimensional planning, the TAOP algorithm performs a ‘straightening’ operation on the path. ‘Straightening’ is equivalent to coordinate transformation. The points on the planar path are no longer represented by the latitude and longitude or the coordinates in the two-dimensional planning space, but by the two-dimensional path distance
(not Euclidean distance) between them and the starting point of the path. Specifically, let
be the set of planar path points generated by the two-dimensional planning algorithm, let
be the total number of path points obtained via two-dimensional planning, and let each point
contain position information
in the two-dimensional space. In each vector segment formed by adjacent path points (i.e.,
,
,…,
), divide the vector into equal intervals of given interval distance
and uniformly insert interval points. Calculate the positions of each interval point, as well as its distance
from the starting point
, in the two-dimensional plane. Include the
information for each point
and add it to the interval point set
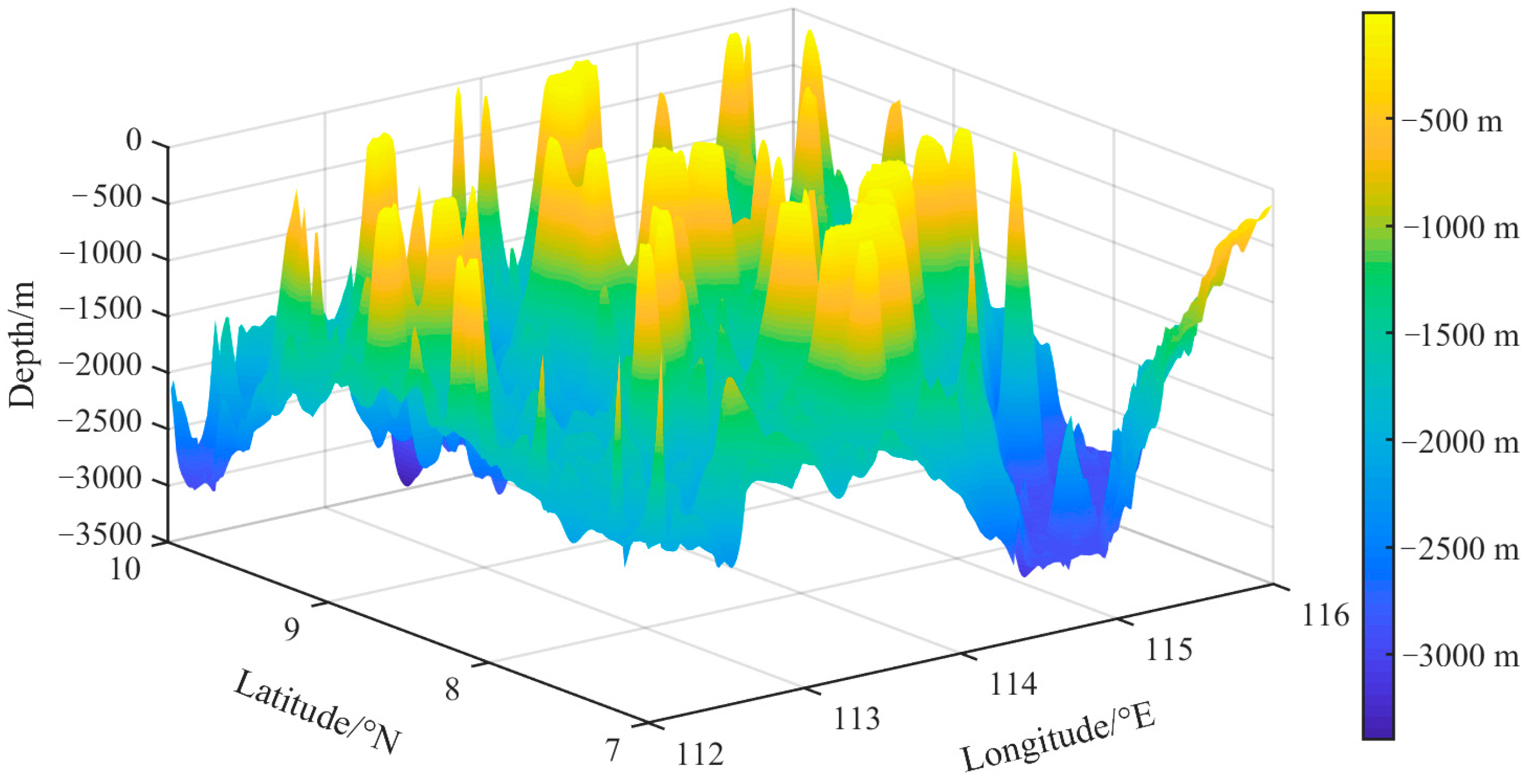
. Then, unfold the obstacles along the path onto a plane, which is equivalent to ‘slicing’ the obstacles in a three-dimensional space. To obtain the height information of the obstacles along the path, obtain the depth
at the location corresponding to each interval point by interpolating the downloaded terrain data based on the latitude and longitude. Expand the information of point
to
. Then, set the distance of each point on the ‘straightened’ path from the starting point as the horizontal axis, and set the depth value of the path points as the vertical axis, as shown in
Figure 2. Point A and point B represent the starting point and target point of the path planning, respectively. The solid line contour in the figure represents the profiles of obstacles along a path generated via two-dimensional planning.
To ensure the safety of navigation, the planned path needs to maintain a certain safe distance
from the obstacles. Therefore, the obstacle profile is dilated. The original depth
of each interval point is extended by a distance
along the outer normal direction of the profile edge to obtain the dilated depth
, and the information for the point
is updated to
. The dashed line contour in
Figure 2 represents the dilated profiles of the obstacles.
In the subsequent coarse planning phase, the TAOP algorithm will continuously adjust the height of the path by comparing the obstacle’s dilation depth at interval points with the height of the current planned path at that location. Therefore, the smaller value between the starting point depth and the target point depth is set as
, and the intervals with a puffed depth value of less than
in the interval point set
are deleted, as they do not affect the path direction. The remaining interval points are sorted in descending order based on their corresponding puffed water depth values, and these interval points are used as the set of points
for verification. The pseudocode for the preprocessing process of the planar path point data is described in detail in Algorithm 2, and the schematic diagram is shown in
Figure 3.
| Algorithm 2 |
;
;
;
for to do
;
;
;
;
end for
;
;
for all do
if then
;
end if
end for
return ; |
The second step is the coarse planning of the path. After establishing a profile map of the obstacles along the path segment, connect the path starting point
with the target point
as the highly planned initial path, and initialize the planned path point set
to
. For each position point
in the set
to be verified, locate the minimum interval
of the planned path based on its two-dimensional path distance
from the path starting point. Here,
and
are, respectively, the serial numbers of the front and rear ends of the path segment. Based on the two-dimensional path distance and the height between the path points at both ends of the interval and the starting point, as shown in
Figure 4, calculate the height
(the height of intersection in
Figure 4) of the path at the horizontal coordinate of the position to be verified according to the principle of similar triangles:
where
represents the location point to be verified,
and
represent the path points before and after the smallest interval of the planned path that has been located,
and
represent the path distance and water depth from the starting point, respectively, and
represents the height of the planned path at the abscissa of the location point to be verified.
Compare the calculated path height
with the
value of the position to be verified. If
, this indicates that the current planned path passes through obstacles or cannot maintain a safe distance from the obstacles at this position, and the path needs to be corrected. Take
as a new path point and insert it into the middle of the front and rear end points of the located minimum interval,
and
. The
value at this position is the new path height, as shown in
Figure 5.
If
, this indicates that the current planned path can maintain a safe distance from the obstacles at this position and no path correction is necessary. The pseudo code of the path coarse planning process is shown in Algorithm 3.
| Algorithm 3 |
;
for all do
for to () do
if then
;
if then
;
break
end if
end if
end for
end for
return ; |
The third step is the secondary optimization of the path. After traversing the point set to be verified, a set of path points that can safely pass through obstacles is obtained. However, this path may contain a certain number of redundant points, resulting in an increase in the total length of the path and the number of turns, which affects the efficiency of path planning. The optimization process can be used to identify and remove redundant points in a path. If there are no obstacles on the line between two path points, one of the points can be directly removed, thereby reducing unnecessary points on the path and making the path smoother, simpler, and more efficient.
For each path point
in the path point set
, check whether each point can directly connect with all non-adjacent points behind it. Suppose that the path points passed by the non-adjacent path points,
and
, are
(where
), and that the corresponding planning height is
. After connecting
and
, the height
(where
) at the intersection point of the intermediate path point’s horizontal coordinate on this line can be calculated according to the similarity triangle principle, as shown in
Figure 6. Therefore, the intermediate path point’s horizontal coordinate corresponding to the height
(the height of intersection in
Figure 6) on this line can be obtained according to the similarity triangle principle:
Compare the planning height
of all intermediate path points with the height
at their horizontal coordinates on the connecting line. If
, this indicates that the path between the path points
and
can be optimized, so delete the intermediate path points and directly connect
and
; if
, the path between
and
remains unchanged. The optimized path is
, and the pseudo code of the secondary optimization is shown in Algorithm 4.
| Algorithm 4 |
while do
;
for to do
;
for to do
;
if then
break
else
;
end if
end for
if then
;
;
break
end if
end for
if then
;
end if
end while
;
return ; |
The fourth step is path point integration. Due to the fact that the obstacle profile along the route is obtained based on the ‘straightened’ planar planning path points, which is equivalent to the artificial omission of the turning points in the
plane, the path point set
after the second optimization only contains the turning points in the
plane. It is necessary to integrate the path points from the height planning and the two-dimensional planar planning to obtain a complete path
that includes all of the turning points in the three-dimensional space. The specific implementation of the path point integration algorithm is given in Algorithm 5.
| Algorithm 5 |
;
;
for all do
if not then
for to do
if then
;
break
end if
end for
end if
end for
return ; |
The TAOP algorithm involves the following function explanations:
: Given two points, and , and a distance, , divide the vector with equal intervals starting from , calculate the positions of all the interval points and their distances from , and return the set of all the interval points that contain the point .
: Given a struct array containing position information and a terrain array containing latitude, longitude, and altitude information, convert the position coordinates in into latitude, longitude, and altitude , interpolate the latitude and longitude values into the terrain array to obtain the height values for all of the coordinates in and return it.
: Given an array , return the length of .
: Given a set , a point , and a positive integer , insert the point into the th position of the set .
: Given an array containing the values of , an array containing the values of , and an array containing the values of to be queried, use linear interpolation to calculate and return the corresponding values for all elements in .
: Given a struct array and a field in it, sort the elements of the array in ascending order by the given field.
: Given a number and an array , return a logical value as true if is present in , and return a logical value as false otherwise.
4. Results
Table 2 presents the experimental statistical results of the six algorithms in terms of the total collision detection time
. In this table, Q1, Q2, and Q3 represent the first quartile, median, and third quartile of the data, respectively.
Figure 12 provides a visual representation of the distribution of the total collision detection time
in the form of a box plot. From the statistical information, it is evident that the TAOP algorithm requires significantly less computation time for collision detection when compared to directly using the RRT*, Q-RRT*, and DSFS algorithms, with average reduction percentages of approximately 94.85%, 83.78%, and 80.93%, respectively. In
Figure 12, the data points for the TAOP algorithm consistently appear at lower positions, significantly below their corresponding counterparts in the control algorithms, indicating a faster collision detection process for the TAOP algorithm.
Table 3 and
Table 4 present the statistical results for the initial cost
and initial path computation time
for six different algorithms.
Figure 13 and
Figure 14 display box plots for the initial cost and initial path computation time, respectively. When observing the statistical results, it is evident that the TAOP algorithm exhibits significant reductions in both the initial cost and initial path computation time. In
Figure 13, the data points for the TAOP algorithm are noticeably lower, with the upper and lower bounds of the box plot being lower than their corresponding parts for the control algorithms. This indicates that the TAOP algorithm generates paths with smaller costs compared to its control algorithms, effectively optimizing the planning results. In
Figure 14, fewer data points for the TAOP algorithm fall within higher time ranges, suggesting that the TAOP algorithm is more efficient in computing the initial path.
In the simulation results, there is a significant deviation between the mean and median of various statistical measures, indicating that the data do not follow a normal distribution. Therefore, we employed the Mann–Whitney U test to further validate the performance advantage of the TAOP algorithm statistically. In this test, the collision detection total time
, initial cost
, and initial path computation time
were used as evaluation metrics, and the corresponding p-values were calculated, as shown in
Table 5. From
Table 5, it can be observed that the p-values for all of test metrics are much smaller than the significance level of 0.05, indicating that the TAOP algorithm outperforms the RRT*, Q-RRT*, and DSFS algorithms in planning simulation experiments.
In addition, based on the mean initial cost and mean initial path computation time in
Table 3 and
Table 4, the average path planning efficiency for the six algorithms was calculated using Equation (8), as shown in
Table 6. It can be observed that, compared to the RRT*, Q-RRT*, and DSFS algorithms, the TAOP algorithm has improved the path planning efficiency by 15.6 times, 5.98 times, and 4.04 times, respectively.
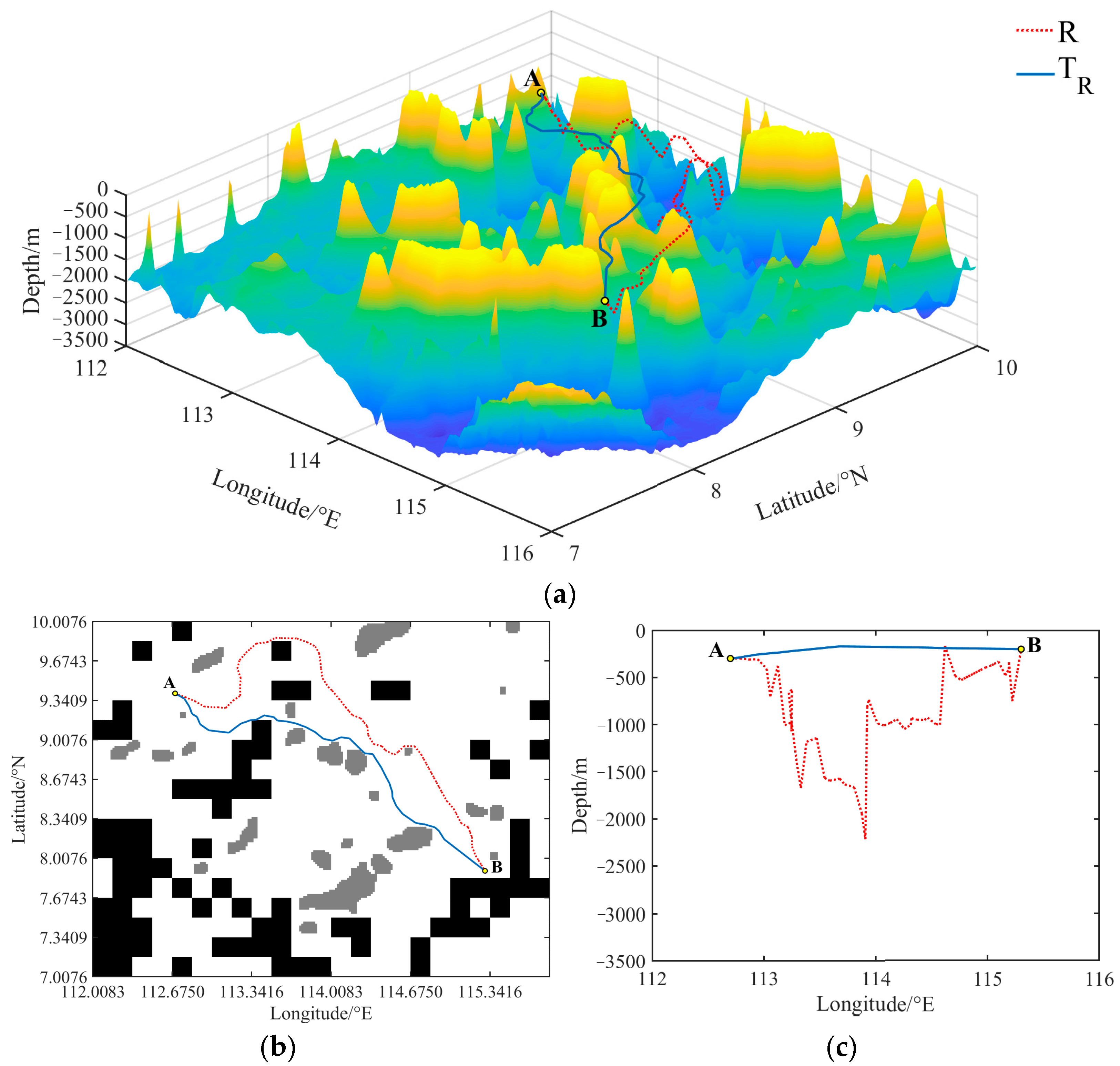
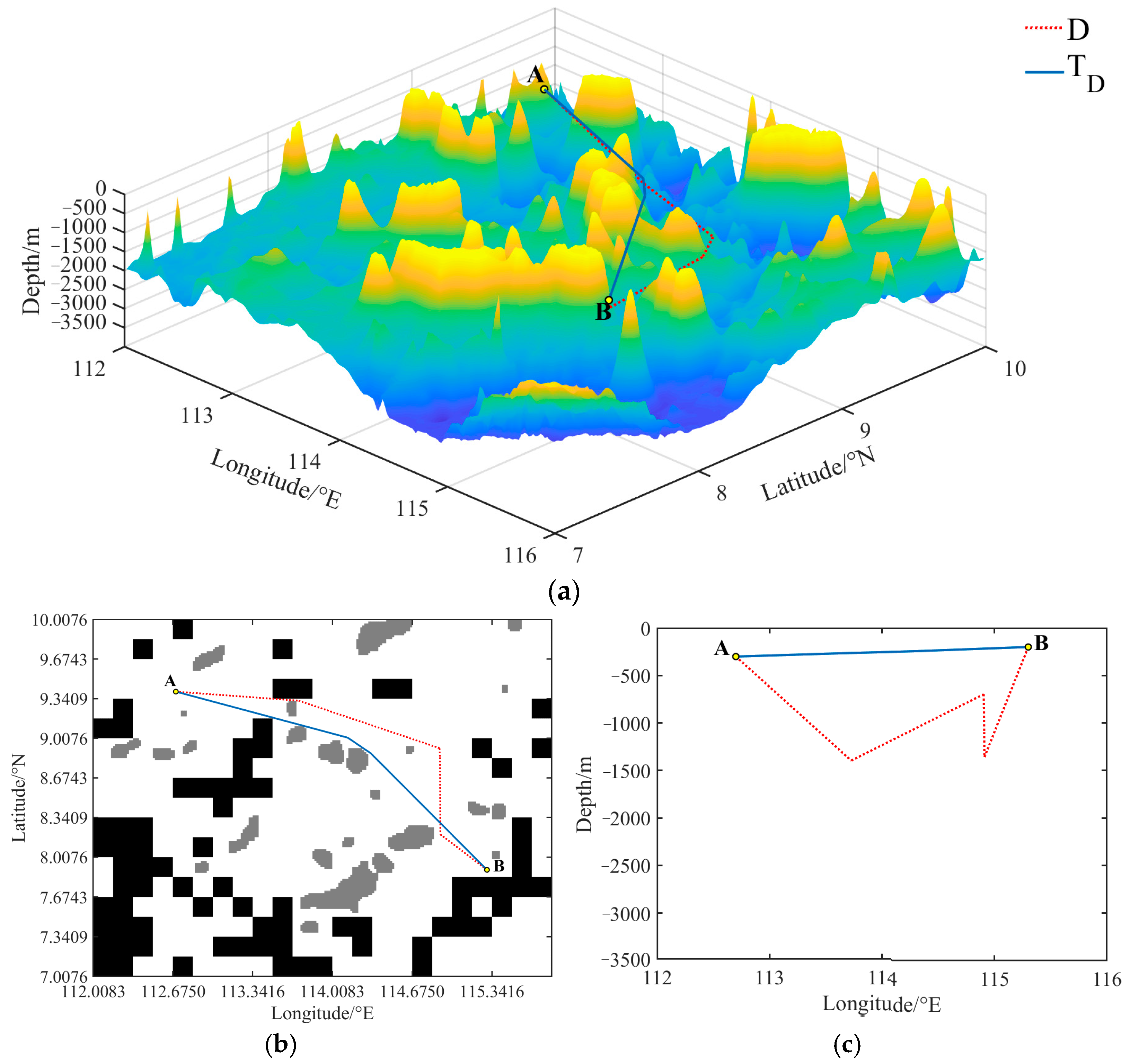
Figure 15,
Figure 16 and
Figure 17, respectively, present the initial path graphs generated using the R algorithm compared with the T
R algorithm, the Q algorithm compared with the T
Q algorithm, and the D algorithm compared with the T
D algorithm in a specific test scenario. Here, points A and B denote the starting and target points, respectively. Upon examination, it is evident that the paths generated using all six algorithms lie within the predefined suitable area, meeting the requirements for safe navigation. Additionally, in contrast to the RRT*, Q-RRT*, and DSFS algorithms, the TAOP algorithm produces initial paths with a lower cost. To offer a more intuitive portrayal of the variations in the planned paths in the vertical direction, the paths are projected onto the ‘longitude–depth’ plane, as depicted in
Figure 15c,
Figure 16c and
Figure 17c. From the perspective of the ‘longitude–depth’ plane, it is readily apparent that the initial paths generated using the TAOP algorithm exhibit greater smoothness, whereas the paths generated using the corresponding RRT*, Q-RRT*, and DSFS algorithms manifest pronounced undulations in the vertical direction, characterized by one or more conspicuous fluctuations. This divergence arises because the RRT*, Q-RRT*, and DSFS algorithms all engage in random sampling across the entire three-dimensional planning space, with sample points displaying significant randomness in the vertical dimension, thereby rendering them more likely to generate higher-cost paths. Conversely, the TAOP algorithm engages in judicious planning in the vertical dimension based on obstacle profiles, consequently optimizing the cost.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}