
Efficient Detection of Forest Fire Smoke in UAV Aerial Imagery Based on an Improved Yolov5 Model and Transfer Learning


Abstract
:1. Introduction
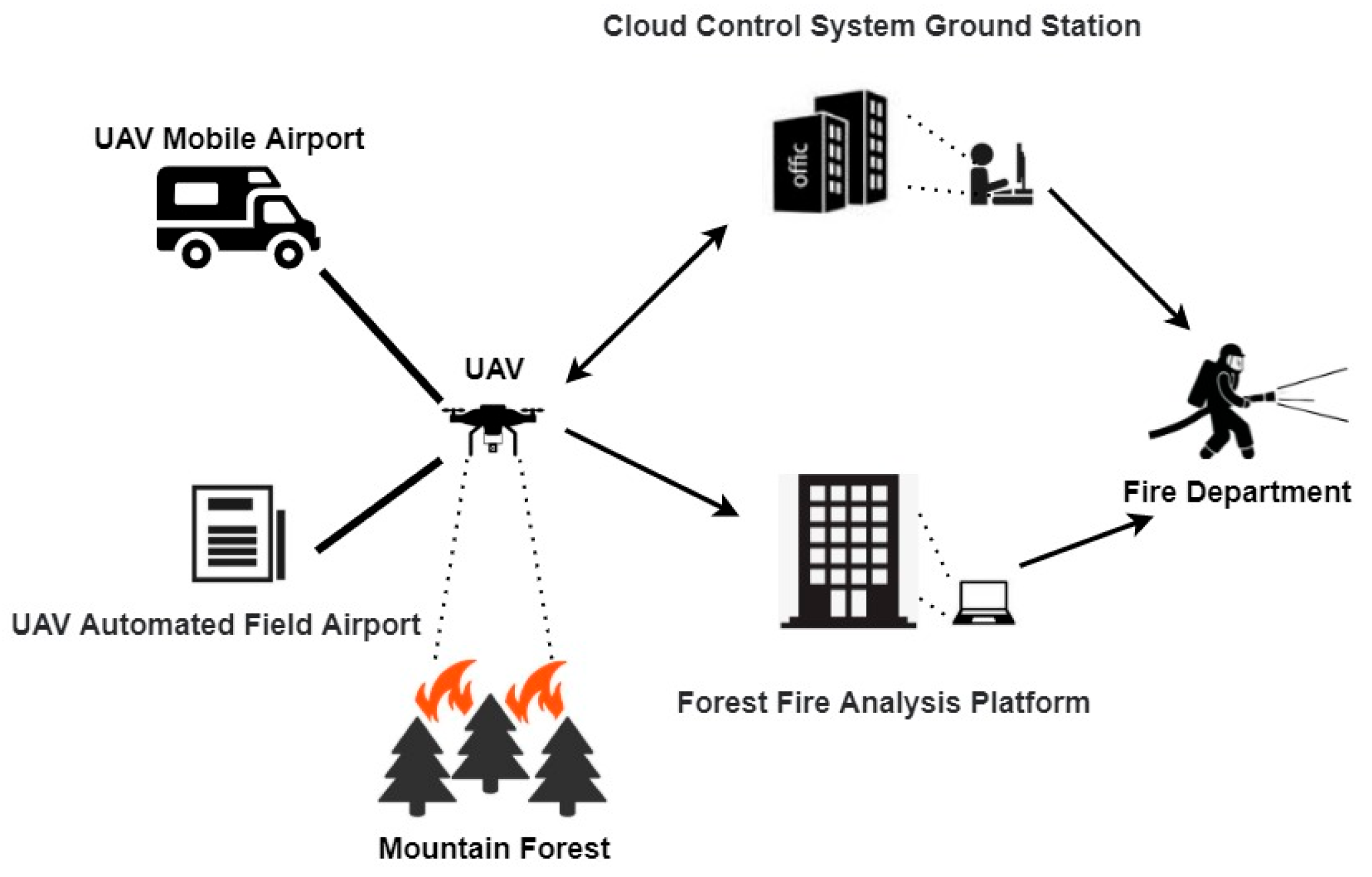
- We formulate the framework of a fully automated system for forest fire smoke detection, which is based on UAV images and deep learning network;
- We use the K-mean++ method to improve the clustering of anchor boxes, substantially diminishing the categorization error;
- We enhance the YOLOv5s model by introducing an extra prediction head tailored for small-scale smoke target detection, swapping out the original backbone with a novel partial convolution (PConv) to improve computational efficiency, and by incorporating Coordinate Attention, which enables the model to pinpoint regions of interest in wide-ranging images, effectively filtering out clouds and similar distractors;
- We employ data augmentation and transfer learning strategy to refine the model construction and speed up the convergence of model training.
2. Related Works
2.1. Comprehensive Approaches for Forest Fire Smoke Detection
2.2. Image Processing Approaches for Smoke Detection
2.2.1. Conventional Image Processing Approaches
2.2.2. Deep Learning-Based Image Processing Approaches
2.2.3. Deep Learning-Based Approaches for UAV-Based Smoke Detection
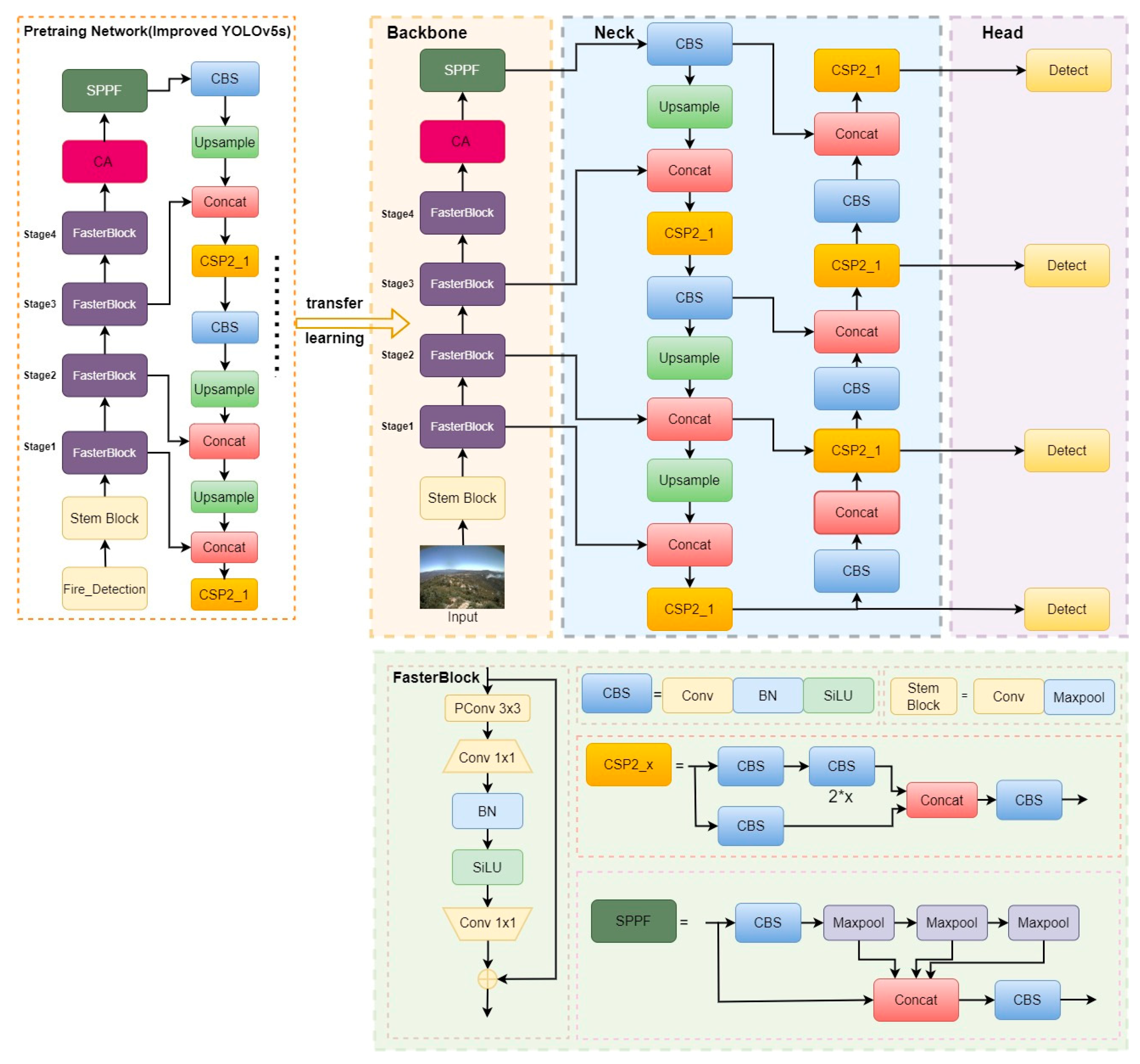
3. Proposed Forest Fire Smoke Detection Model and Algorithm
3.1. Proposed Forest Fire Smoke Detection Model
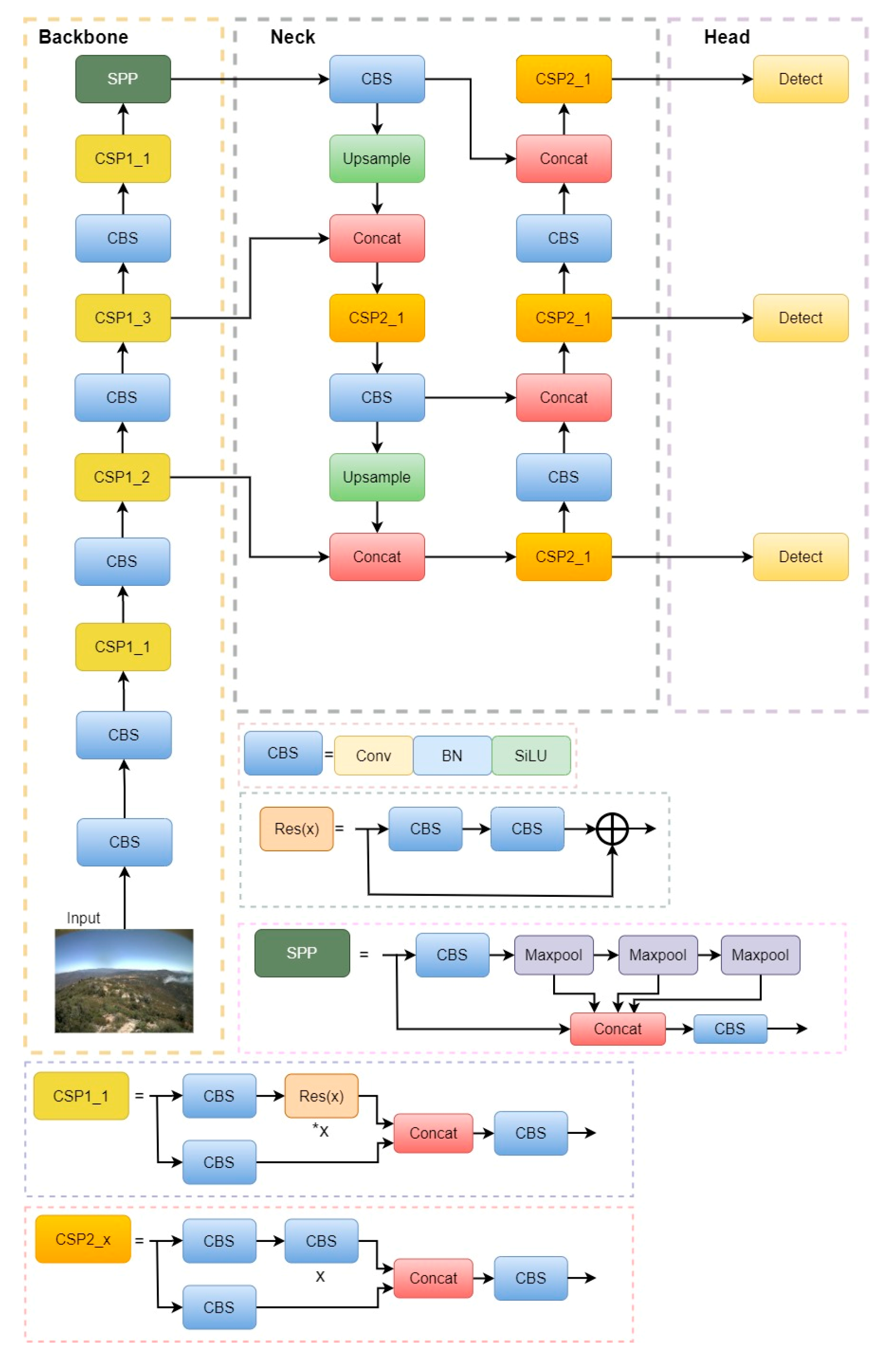
3.1.1. Original YOLOv5
3.1.2. K-Means++ Methodology
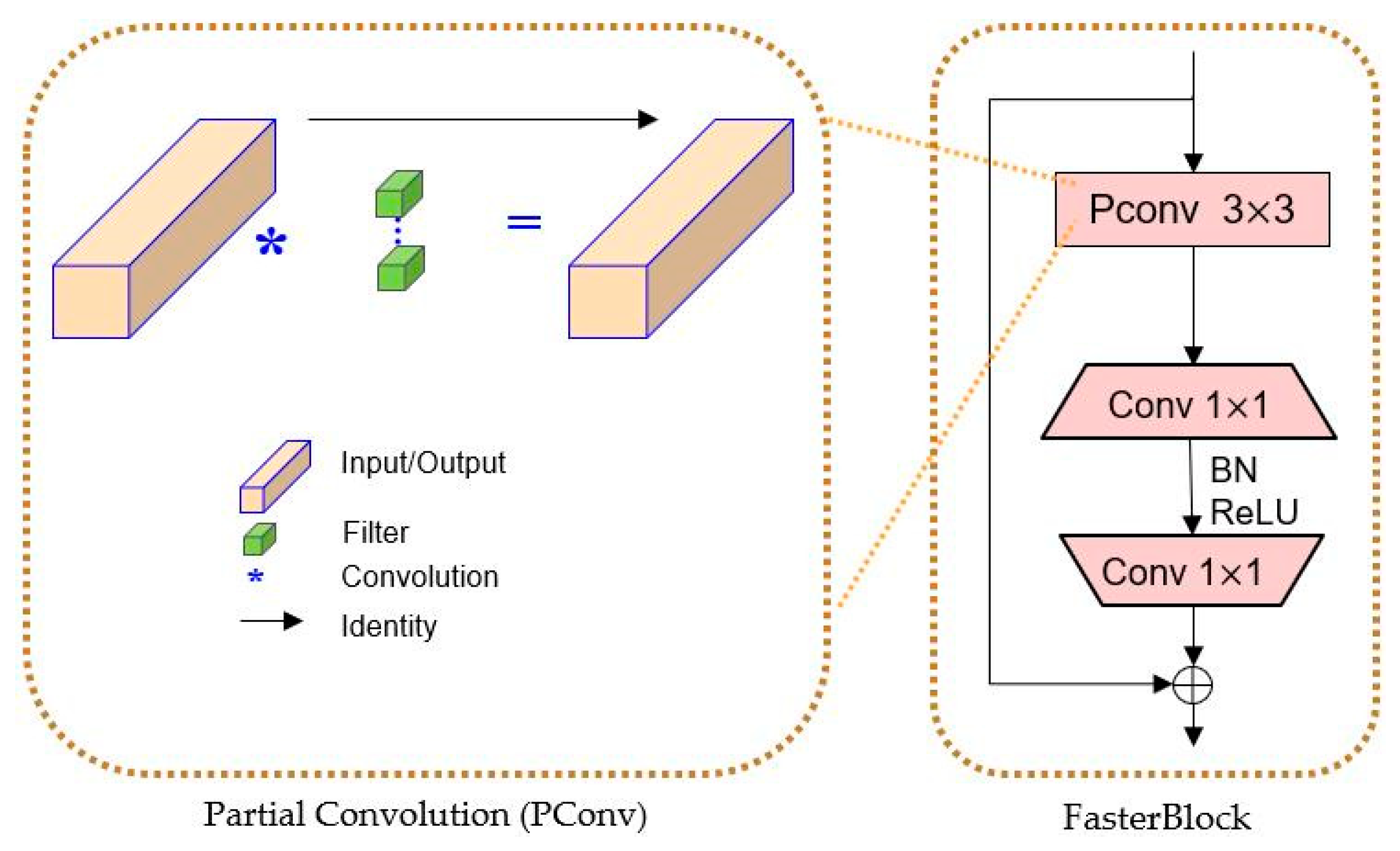
3.1.3. The Design of Backbone
3.1.4. Detection Head for Small Smoke Objects
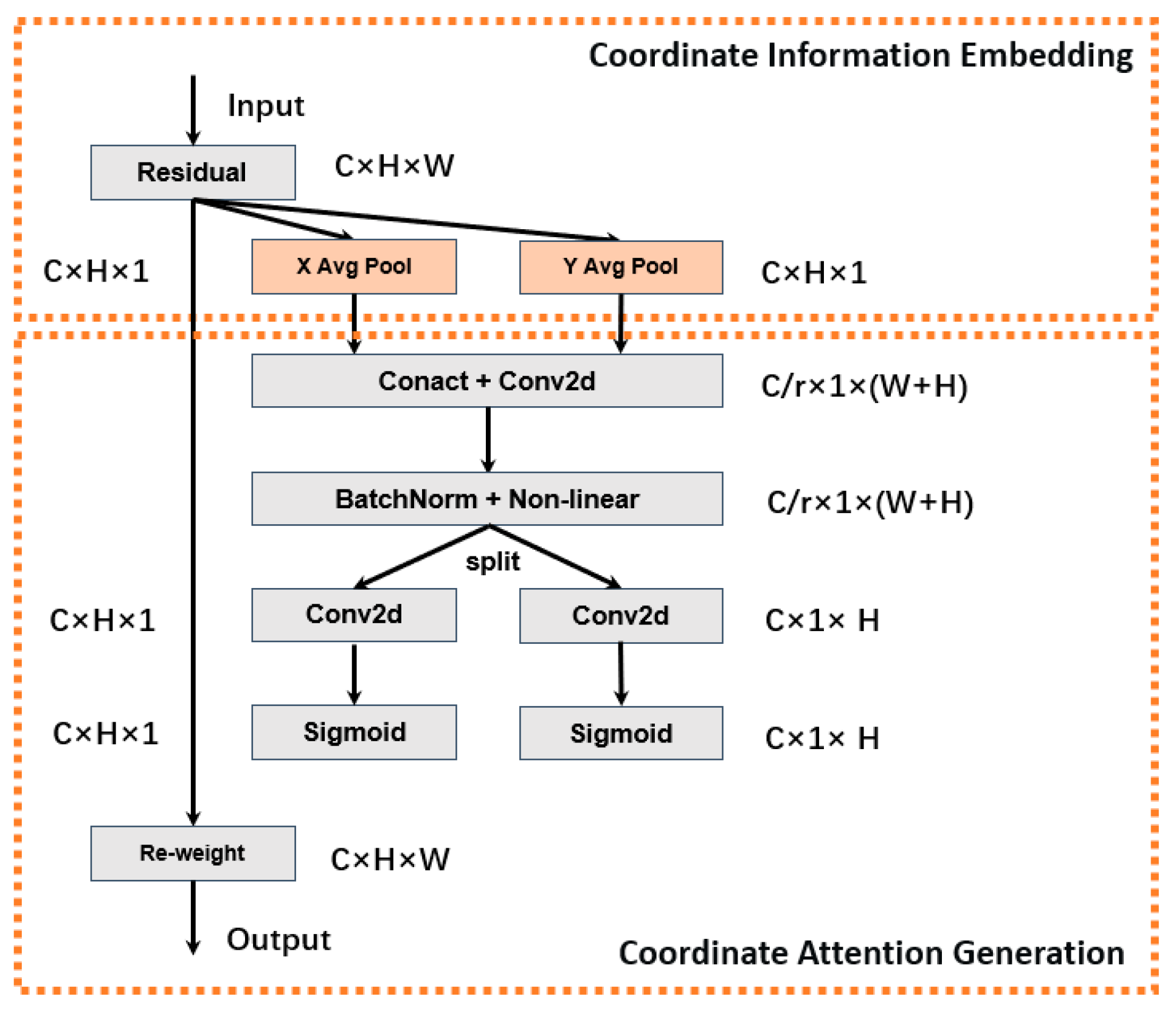
3.1.5. Coordinate Attention Mechanism
3.2. Transfer Learning and Overview of the Algorithm Flow
4. Dataset and Model Evaluation
4.1. Dataset
4.1.1. Data Acquisition
4.1.2. Data Augmentation
4.2. Model Evaluation Metrics
5. Experimental Results and Discussion
5.1. Model Training Environment
5.2. Qualitative Visualization of the Detection Results
5.3. Comparative Experiments
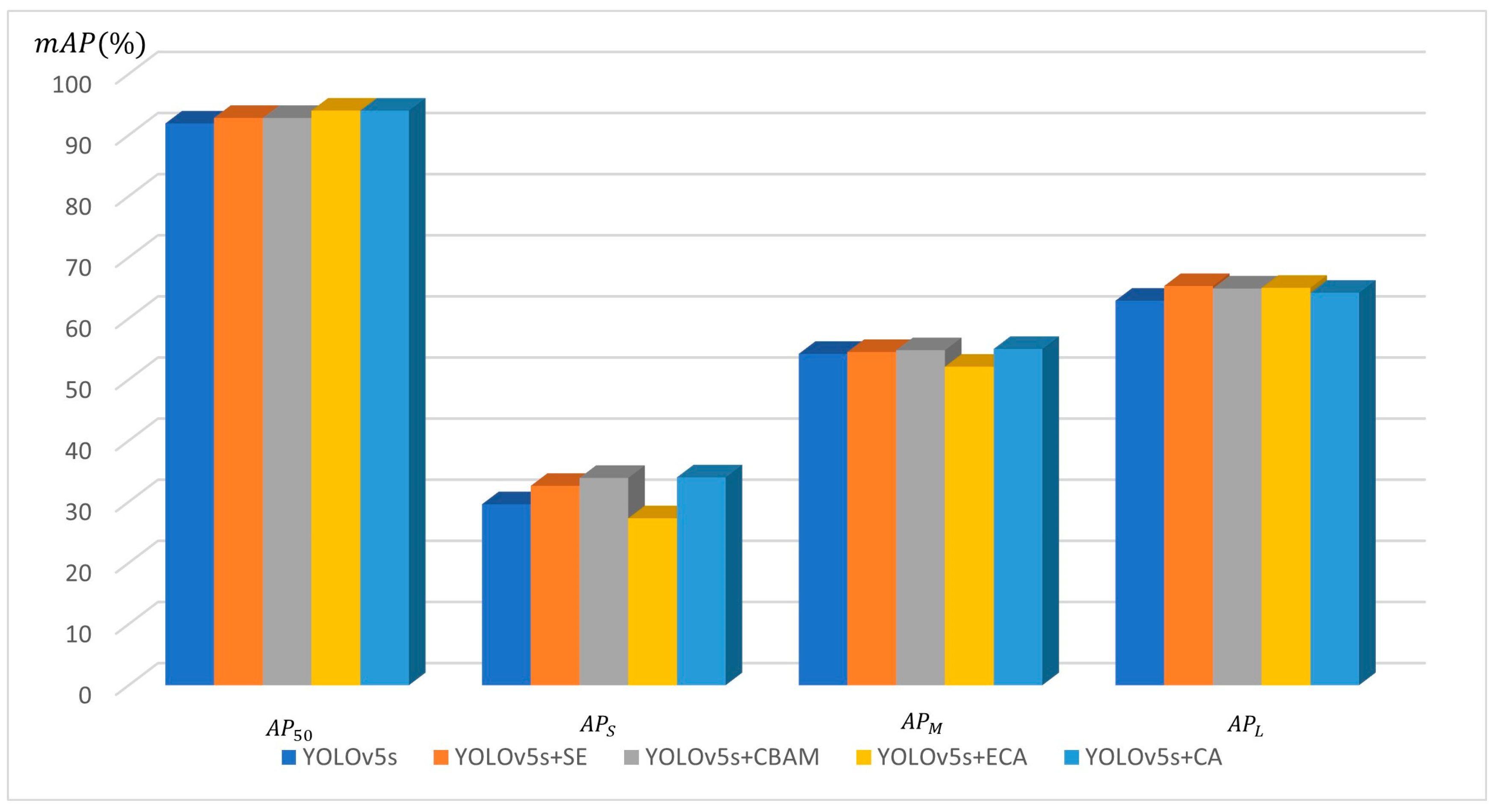
5.3.1. Comparative Experiments on Attention Mechanisms
5.3.2. Comparative Experiments on Backbone Design
5.3.3. Comparative Experiments of Different Models
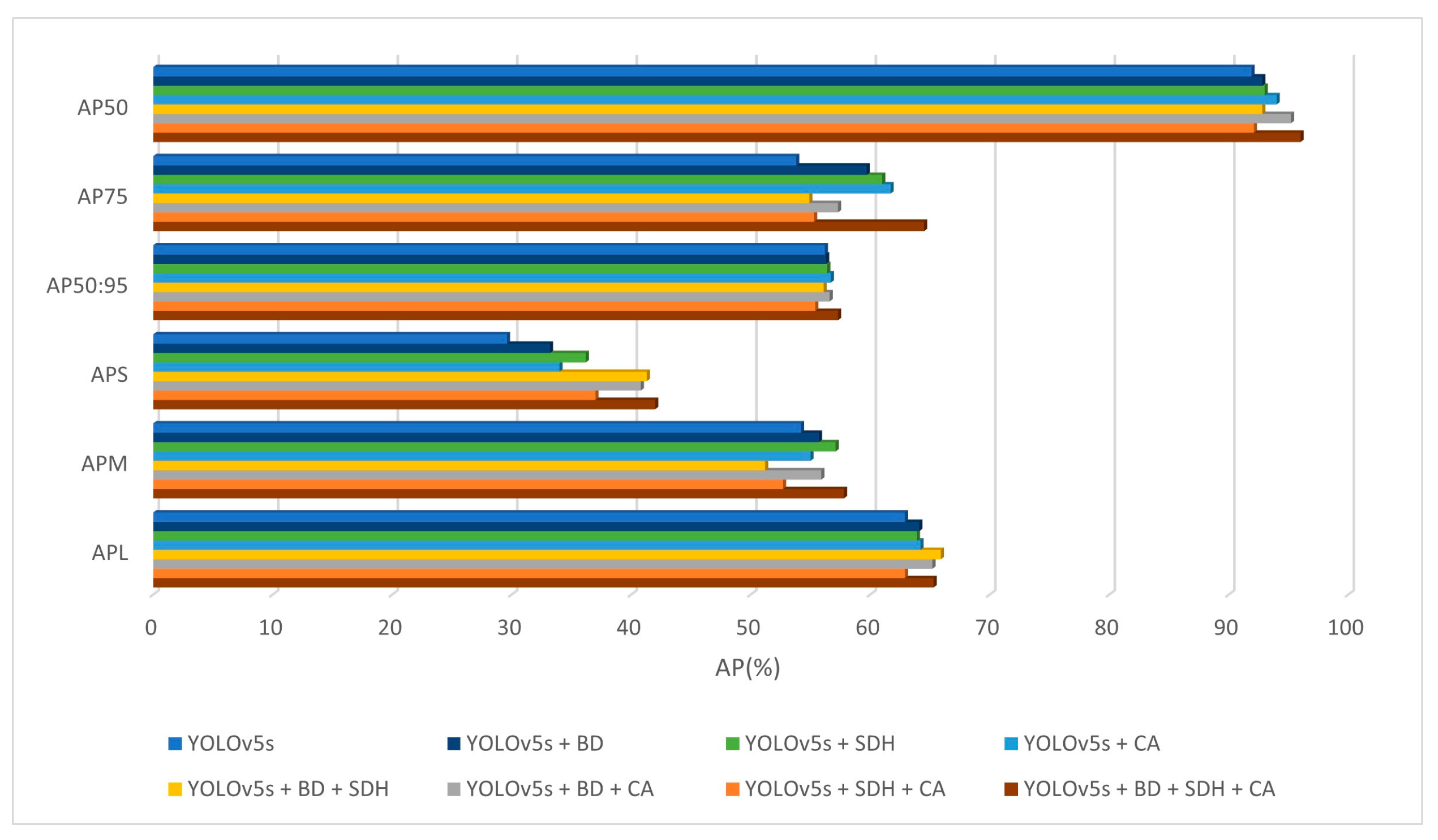
5.4. Ablation Experiments
5.5. Extended Experiments
5.6. Discussion
6. Conclusions and Future Work
- (1)
- The results of the controlled experiments on different attention mechanisms modules show that the model with CA performed the best in almost all the evaluation metrics, with a , , and reaching 0.94, 0.34, and 0.55, respectively. was also improved by 1.3 points compared to the original model. Additionally, heatmap experiments with various attention mechanisms indicated that the CA module possesses superior foreground-background differentiation capabilities and heightened accuracy in the detection of forest fire smoke.
- (2)
- The results of the controlled experiments on different backbone architectures show that, by employing our custom-designed backbone, the model’s parameters were reduced from 6.11 M to 6.02 M, GFLOPS decreased from 15.8 to 12.8, and the image detection time was diminished from 12.7 ms to 12.3 ms, with the FPS increasing from 78.7 to 81.3. Moreover, relative to the CSPDarknet53 of the original YOLOv5s, our backbone network model achieved enhancements of 0.9, 3.6, 1.5, and 1.2 percentage points in the evaluation metrics , , , and , respectively. Our designed backbone not only elevated the AP metrics, but also compacted the model size and expedited processing speed.
- (3)
- The results of the controlled experiments on different state-of-the-art models show that our model, with a total of 11.1 M parameters, is marginally larger than the fastest YOLOv5s, which has 6.11 M parameters. However, thanks to the backbone designed for more efficient memory access, our model secured a notable advantage in terms of laudable inference speed (13 ms) and the minimal quantity of floating-point operations (13.3 GFLOPS), marking an improvement over SSD, YOLOv3, YOLOv4, YOLOv5, YOLOv7, and YOLOv8s. Moreover, our model achieved exhilarating accuracy results, leading the pack with the highest recorded 96% in and 57.3% in . While the proposed approach may not surpass YOLOv5s in terms of model parameters and inference speed, it successfully achieved a favorable balance between speed of inference and accuracy of detection. From the detection experiments conducted on three actual instances of forest fire smoke, it is evident that our model possesses the highest accuracy for small target smoke detection, along with the greatest confidence. Our model stands superior to the current leading detection frameworks, including YOLOv7 and YOLOv8.
- (4)
- The ablation study results indicate that the inclusion of a backbone design, CA module, and small target detection head module enhanced the accuracy of the original YOLOv5s model. Among these, the YOLOv5s + BD + SDH + CA (the model we proposed in this paper) exhibited the most significant improvements, increasing by 4.1%, by 1.1%, by 12.4%, by 3.6%, and by 2.4%.
- (5)
- In conclusion, the experimental results demonstrate a significant improvement in the performance of our model compared to YOLOv5s and other commonly used models, highlighting the potential of our approach for forest fire smoke detection. Additionally, the results of extended experiments indicate that our approach also possesses certain universality and superiority in other small object detection tasks.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Adachi, J.K.; Li, L. The impact of wildfire on property prices: An analysis of the 2015 Sampson Flat Bushfire in South Australia. Cities 2023, 136, 104255. [Google Scholar] [CrossRef]
- Fantina, T.; Vittorio, L. The Dilemma of Wildfire Definition: What It Reveals and What It Implies. Front. For. Glob. Change 2020, 3, 553116. [Google Scholar]
- Tang, C.Y.; Zhang, H.W.; Liu, S.Z.; Zhu, G.L.; Sun, M.H.; Wu, Y.S.; Gan, Y.D. Research on the Setting of Australian Mountain Fire Emergency Center Based on -Means Algorithm. Math. Probl. Eng. 2021, 2021, 5783713. [Google Scholar] [CrossRef]
- Saffre, F.; Hildmann, H.; Karvonen, H.; Lind, T. Monitoring and Cordoning Wildfires with an Autonomous Swarm of Unmanned Aerial Vehicles. Drones 2022, 6, 301. [Google Scholar] [CrossRef]
- Kantarcioglu, O.; Kocaman, S.; Schindler, K. Artificial neural networks for assessing forest fire susceptibility in Türkiye. Ecol. Inform. 2023, 75, 102034. [Google Scholar] [CrossRef]
- Lertsinsrubtavee, A.; Kanabkaew, T.; Raksakietisak, S. Detection of forest fires and pollutant plume dispersion using IoT air quality sensors. Environ. Pollut. 2023, 338, 122701. [Google Scholar] [CrossRef] [PubMed]
- Javadi, S.H.; Mohammadi, A. Fire detection by fusing correlated measurements. J. Ambient Intell. Hum. Comput. 2019, 10, 1443–1451. [Google Scholar] [CrossRef]
- Ertugrul, M.; Varol, T.; Ozel, H.B.; Mehmet, C.; Hakan, S. Influence of climatic factor of changes in forest fire danger and fire season length in Turkey. Environ. Monit. Assess. 2021, 193, 28. [Google Scholar] [CrossRef]
- Jiao, Q.; Fan, M.; Tao, J.; Wang, W.; Liu, D.; Wang, P. Forest Fire Patterns and Lightning-Caused Forest Fire Detection in Heilongjiang Province of China Using Satellite Data. Fire 2023, 6, 166. [Google Scholar] [CrossRef]
- Xue, Z.; Lin, H.; Wang, F. A Small Target Forest Fire Detection Model Based on YOLOv5 Improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Wang, K.; Yuan, Y.; Chen, M.; Lou, Z.; Zhu, Z.; Li, R. A Study of Fire Drone Extinguishing System in High-Rise Buildings. Fire 2022, 5, 75. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, M.; Ding, Y.; Bu, X. MS-FRCNN: A Multi-Scale Faster RCNN Model for Small Target Forest Fire Detection. Forests 2023, 14, 616. [Google Scholar] [CrossRef]
- Al-Smadi, Y.; Alauthman, M.; Al-Qerem, A.; Aldweesh, A.; Quaddoura, R.; Aburub, F.; Mansour, K.; Alhmiedat, T. Early Wildfire Smoke Detection Using Different YOLO Models. Machines 2023, 11, 246. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, J.; Peters, S.; Li, J.; Oliver, S.; Mueller, N. Investigating the Impact of Using IR Bands on Early Fire Smoke Detection from Landsat Imagery with a Lightweight CNN Model. Remote Sens. 2022, 14, 3047. [Google Scholar] [CrossRef]
- Lu, K.; Xu, R.; Li, J.; Lv, Y.; Lin, H.; Liu, Y. A Vision-Based Detection and Spatial Localization Scheme for Forest Fire Inspection from UAV. Forests 2022, 13, 383. [Google Scholar] [CrossRef]
- Kim, S.-Y.; Muminov, A. Forest Fire Smoke Detection Based on Deep Learning Approaches and Unmanned Aerial Vehicle Images. Sensors 2023, 23, 5702. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency Detection and Deep Learning-Based Wildfire Identification in UAV Imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Zhao, E.; Zhang, J.; Hu, C. Detection of Wildfire Smoke Images Based on a Densely Dilated Convolutional Network. Electronics 2019, 8, 1131. [Google Scholar] [CrossRef]
- Zhou, P.; Liu, G.; Wang, J.; Weng, Q.; Zhang, K.; Zhou, Z. Lightweight unmanned aerial vehicle video object detection based on spatial-temporal correlation. Int. J. Commun. Syst. 2022, 35, 5334. [Google Scholar] [CrossRef]
- Hu, B.; Wang, J. Deep learning based hand gesture recognition and UAV flight controls. Int. J. Autom. Comput. 2020, 17, 17–29. [Google Scholar] [CrossRef]
- Almeida, J.S.; Jagatheesaperumal, S.K.; Nogueira, F.G.; de Albuquerque, V.H.C. EdgeFireSmoke++: A novel lightweight algorithm for real-time forest fire detection and visualization using internet of things-human machine interface. Expert Syst. Appl. 2023, 221, 119747. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, S.; Wang, W.; Zhang, W.; Zhang, L. Pyramid Attention Based Early Forest Fire Detection Using UAV Imagery. J. Phys. Conf. Ser. 2022, 2363, 012021. [Google Scholar] [CrossRef]
- Lee, S.J.; Lee, Y.W. Detection of Wildfire-Damaged Areas Using Kompsat-3 Image: A Case of the 2019 Unbong Mountain Fire in Busan, South Korea. Korean J. Remote Sens. 2020, 36, 29–39. [Google Scholar]
- Imran; Ahmad, S.; Kim, D.H. A task orchestration approach for efficient mountain fire detection based on microservice and predictive analysis in IoT environment. J. Intell. Fuzzy Syst. 2021, 40, 5681–5696. [Google Scholar] [CrossRef]
- Yang, X.; Wang, Y.; Liu, X.; Liu, Y. High-Precision Real-Time Forest Fire Video Detection Using One-Class Model. Forests 2022, 13, 1826. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. Car Detection from Low-Altitude UAV Imagery with the Faster R-CNN. J. Adv. Transp. 2017, 2017, 2823617. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vsion (ECCV 2016), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. YOLOv5. Ultralytics: Github. 2023. Available online: https://github.com/ultralytics/yolov5 (accessed on 12 May 2023).
- Marsha, A.L.; Larkin, N.K. Evaluating Satellite Fire Detection Products and an Ensemble Approach for Estimating Burned Area in the United States. Fire 2022, 5, 147. [Google Scholar] [CrossRef]
- Singh, N.; Chatterjee, R.S.; Kumar, D.; Panigrahi, D.C. Spatio-temporal variation and propagation direction of coal fire in Jharia Coalfield, India by satellite-based multi-temporal night-time land surface temperature imaging. Int. J. Min. Sci. Technol. 2021, 31, 765–778. [Google Scholar] [CrossRef]
- Zheng, R.; Zhang, D.; Lu, S.; Yang, S.L. Discrimination Between Fire Smokes and Nuisance Aerosols Using Asymmetry Ratio and Two Wavelengths. Fire Technol. 2019, 55, 1753–1770. [Google Scholar] [CrossRef]
- Tu, R.; Zeng, Y.; Fang, J.; Zhang, Y.M. Influence ofhigh altitude on the burning behaviour of typical combustibles and the related responses of smoke detectors in compartments. R. Soc. Open Sci. 2018, 5, 180188. [Google Scholar] [CrossRef] [PubMed]
- Reddy, P.R.; Kalyanasundaram, P. Novel Detection of Forest Fire Using Temperature and Carbon Dioxide Sensors with Improved Accuracy in Comparison between Two Different Zones. In Proceedings of the International Conference on Intelligent Engineering and Management (ICIEM 2022), London, UK, 27–29 April 2022; pp. 524–527. [Google Scholar]
- Kadir, E.A.; Rahim, S.K.A.; Rosa, S.L. Multi-sensor system for land and forest fire detection application in Peatland Area. Indones. J. Electr. Eng. Inform. (IJEEI) 2019, 7, 789–799. [Google Scholar]
- Benzekri, W.; Moussati, A.E.; Moussaoui, O.; Berrajaa, M. Early Forest Fire Detection System using Wireless Sensor Network and Deep Learning. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 5. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, Z.; Zhang, Y. Fire Detection Using Infrared Images for UAV-Based Forest Fire Surveillance. In Proceedings of the International Conference on Unmanned Aircraft Systems (ICUAS), Miami, FL, USA, 13–16 June 2017; pp. 567–572. [Google Scholar]
- Yuan, H.W.; Xiao, C.S.; Wang, Y.F.; Peng, X.; Wen, Y.Q.; Li, Q.L. Maritime vessel emission monitoring by an UAV gas sensor system. Ocean Eng. 2020, 218, 108206. [Google Scholar] [CrossRef]
- Yuan, H.; Xiao, C.; Zhan, W.; Wang, Y.F.; Shi, C.; Ye, H.X.; Jiang, K.; Ye, Z.Y.; Zhou, C.H.; Wen, Y.Q.; et al. Target Detection, Positioning and Tracking Using New UAV Gas Sensor Systems: Simulation and Analysis. J. Intell. Robot. Syst. 2019, 94, 871–882. [Google Scholar] [CrossRef]
- Peruzzi, G.; Pozzebon, A.; Van Der Meer, M. Fight Fire with Fire: Detecting Forest Fires with Embedded Machine Learning Models Dealing with Audio and Images on Low Power IoT Devices. Sensors 2023, 23, 783. [Google Scholar] [CrossRef]
- Muid, A.; Kane, H.; Sarasawita, I.K.A.; Evita, M.; Aminah, N.S.; Budiman, M.; Djamal, M. Potential of UAV Application for Forest Fire Detection. J. Phys. Conf. Ser. 2022, 2243, 012041. [Google Scholar] [CrossRef]
- Ba, R.; Song, W.; Li, X.; Xie, Z.; Lo, S. Integration of Multiple Spectral Indices and a Neural Network for Burned Area Mapping Based on MODIS Data. Remote Sens. 2019, 11, 326. [Google Scholar] [CrossRef]
- Li, B.; Lu, S.Q.; Wang, F.; Sun, X.L.; Zhang, Y.J. Fog Detection by Multi-threshold and DistanceWeights of Connected Component. Remote Sens. Inf. 2022, 37, 41–47. [Google Scholar]
- Jang, H.-Y.; Hwang, C.-H. Preliminary Study for Smoke Color Classification of Combustibles Using the Distribution of Light Scattering by Smoke Particles. Appl. Sci. 2023, 13, 669. [Google Scholar] [CrossRef]
- Asiri, N.; Bchir, O.; Ismail, M.M.B.; Zakariah, M.; Alotaibi, Y.A. Image-based smoke detection using feature mapping and discrimination. Soft Comput. 2021, 25, 3665–3674. [Google Scholar] [CrossRef]
- Alexandrov, D.; Pertseva, E.; Berman, I.; Pantiukhin, I.; Kapitonov, A. Analysis of Machine Learning Methods for Wildfire Security Monitoring with an Unmanned Aerial Vehicles. Proceedings of 2019 24th Conference of Open Innovations Association (FRUCT), Moscow, Russia, 8–12 April 2019; pp. 3–9. [Google Scholar]
- Ghali, R.; Akhloufi, M.A.; Mseddi, W.S. Deep Learning and Transformer Approaches for UAV-Based Wildfire Detection and Segmentation. Sensors 2022, 22, 1977. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. A Wildfire Smoke Detection System Using Unmanned Aerial Vehicle Images Based on the Optimized YOLOv5. Sensors 2022, 22, 9384. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Ma, A.; Niu, Y.; Ma, Z. Small-Object Detection for UAV-Based Images Using a Distance Metric Method. Drones 2022, 6, 308. [Google Scholar] [CrossRef]
- Jiao, Z.T.; Zhang, Y.M.; Xin, J.; Mu, L.X.; Yi, Y.M.; Liu, H.; Liu, D. A Deep Learning Based Forest Fire Detection Approach Using UAV and YOLOv3. In Proceedings of the International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 23–27 July 2019; pp. 1–5. [Google Scholar]
- Xiao, Z.; Wan, F.; Lei, G.; Xiong, Y.; Xu, L.; Ye, Z.; Liu, W.; Zhou, W.; Xu, C. FL-YOLOv7: A Lightweight Small Object Detection Algorithm in Forest Fire Detection. Forests 2023, 14, 1812. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.; He, H.; Zhou, W.; Lee, C.H.; Chan, S.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. arXiv 2023, arXiv:2303.03667. [Google Scholar]
- Hu, J.; Shen, L.; Sun, J. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Z.; Wang, M. Convolutional Neural Network with Convolutional Block Attention Module for Finger Vein Identification. arXiv 2022, arXiv:2202.06673. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Malaysia, 18–20 December 2021; pp. 13713–13722. [Google Scholar]
- Fire_Detection Dataset. Available online: https://aistudio.baidu.com/aistudio/datasetdetail/90352/0 (accessed on 12 May 2023).
- High Performance Wireless Research and Education Network (HPWREN). Education Network University of California San Diego. HPWREN Dataset. 2020. Available online: http://hpwren.ucsd.edu/HPWREN-FIgLib/ (accessed on 12 May 2023).
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 11534–11542. [Google Scholar]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | SPPF | PAN | FPN | Lightweight Backbone Design | Coordinate Attention | Small-Scale Detection Head |
|---|---|---|---|---|---|---|
| YOLOv5s | √ | √ | √ | |||
| Ours | √ | √ | √ | √ | √ | √ |
| Metrics | Details |
|---|---|
| Precision | TP/(TP+FP) TP/(TP+FN) |
| Recall | |
| AP at IoU = 0.5 | |
| AP at IoU = 0.75 | |
| AP mean values for different IoU thresholds between 0.5 and 0.95 | |
| for small objects: area < | |
| for medium objects: < area < | |
| for large objects: area > |
| Experimental Environment | Details |
|---|---|
| Operating system | Windows 10 Pycharm 2022.1.3 |
| Compiler | |
| Programming language | Python 3.6 |
| Deep Learning Framework | Pytorch 1.5.1 |
| GPU model | NVIDIA GeForce RTX2070 8 GB |
| CUDA version | |
| Central Processing Unit | Intel(R) Core(TM) i7-10750H CPU |
| Training Parameters | Details |
|---|---|
| Epochs | 300 8 |
| Batch size | |
| Image size | 640 × 640 |
| Optimizer | SGD |
| Number of workers | 0 |
| Dataset | Number of Images | ||
|---|---|---|---|
| Train | Val | Test | |
| Forest fire Smoke | 1180 | 147 | 147 |
| Non-Smoke | 864 | 108 | 108 |
| Model | SE | CBAM | ECA | CA | Precision | Recall | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 88.2 | 90.5 | 91.9 | 29.6 | 54.2 | 62.9 | ||||
| √ | 89.3 | 90.5 | 92.8 | 32.6 | 54.5 | 65.3 64.9 | ||||
| √ | 89.6 | 93 | 92.8 | 33.9 | 54.8 | |||||
| √ | 93.7 | 93.2 | 94 | 27.3 | 52.1 | 65 | ||||
| √ | 94.5 | 92.6 | 94 | 34 | 55 | 64.2 |
| Baseline | Backbone | Param/M | GFLOPs | Speed GPU (ms) | FPS | ||||
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | CSPDarknet-53 | 6.11 | 15.8 | 12.7 | 78.7 | 91.9 | 29.6 | 54.2 | 62.9 |
| Ours | 6.02 | 12.8 | 12.3 | 81.3 | 92.8 | 33.2 | 55.7 | 64.1 |
| Model | Param/M | GFLOPs | Speed GPU (ms) | FPS | ||
|---|---|---|---|---|---|---|
| SSD | 86.2 | 52.4 | 26.15 | 294.8 | 24 | 41.7 |
| YOLOv3 | 90.2 | 54.4 | 61.5 | 154.5 | 41.8 | 23.9 |
| YOLOv4 | 91.1 | 56.6 | 64.36 | 148.2 | 44.5 | 22.5 |
| YOLOv5s | 91.9 | 56.2 | 6.11 | 15.8 | 12.7 | 78.7 |
| YOLOv7 | 95.1 | 57.1 | 37.2 | 105.1 | 28.4 | 35.2 |
| YOLOv8s | 94.2 | 57 | 11.2 | 28.3 | 13.8 | 72.4 |
| Ours | 96 | 57.3 | 11.1 | 13.3 | 13 | 76.9 |
| Experiment Number | Model | ||||||
|---|---|---|---|---|---|---|---|
| 1 | YOLOv5s | 91.9 | 53.8 | 56.2 | 29.6 | 54.2 | 62.9 |
| 2 | YOLOv5s + BD | 92.8 | 59.7 | 56.3 | 33.2 | 55.7 | 64.1 |
| 3 | YOLOv5s + SDH | 93 | 61 | 56.4 | 36.2 | 57.1 | 63.9 |
| 4 | YOLOv5s + CA | 94 | 61.7 | 56.7 | 34 | 55 | 64.2 |
| 5 | YOLOv5s + BD + SDH | 92.8 | 54.9 | 56.1 | 41.3 | 51.2 | 65.9 |
| 6 | YOLOv5s + BD + CA | 95.2 | 57.3 | 56.6 | 40.8 | 55.9 | 65.2 |
| 7 | YOLOv5s + SDH + CA | 92.1 | 55.3 | 55.4 | 37 | 52.7 | 62.9 |
| 8 | YOLOv5s + BD + SDH + CA | 96 | 64.5 | 57.3 | 42 | 57.8 | 65.3 |
| Model | mAP | Param/M |
|---|---|---|
| RetinaNet | 65.6 | 37.8 |
| YOLOv5s | 65.8 | 7.4 |
| YOLOv5m | 66.3 | 22.3 |
| YOLOX | 69.6 | 25.8 |
| Ours | 71.4 | 11.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Wang, J.; Wang, J. Efficient Detection of Forest Fire Smoke in UAV Aerial Imagery Based on an Improved Yolov5 Model and Transfer Learning. Remote Sens. 2023, 15, 5527. https://doi.org/10.3390/rs15235527
Yang H, Wang J, Wang J. Efficient Detection of Forest Fire Smoke in UAV Aerial Imagery Based on an Improved Yolov5 Model and Transfer Learning. Remote Sensing. 2023; 15(23):5527. https://doi.org/10.3390/rs15235527
Chicago/Turabian StyleYang, Huanyu, Jun Wang, and Jiacun Wang. 2023. "Efficient Detection of Forest Fire Smoke in UAV Aerial Imagery Based on an Improved Yolov5 Model and Transfer Learning" Remote Sensing 15, no. 23: 5527. https://doi.org/10.3390/rs15235527
APA StyleYang, H., Wang, J., & Wang, J. (2023). Efficient Detection of Forest Fire Smoke in UAV Aerial Imagery Based on an Improved Yolov5 Model and Transfer Learning. Remote Sensing, 15(23), 5527. https://doi.org/10.3390/rs15235527