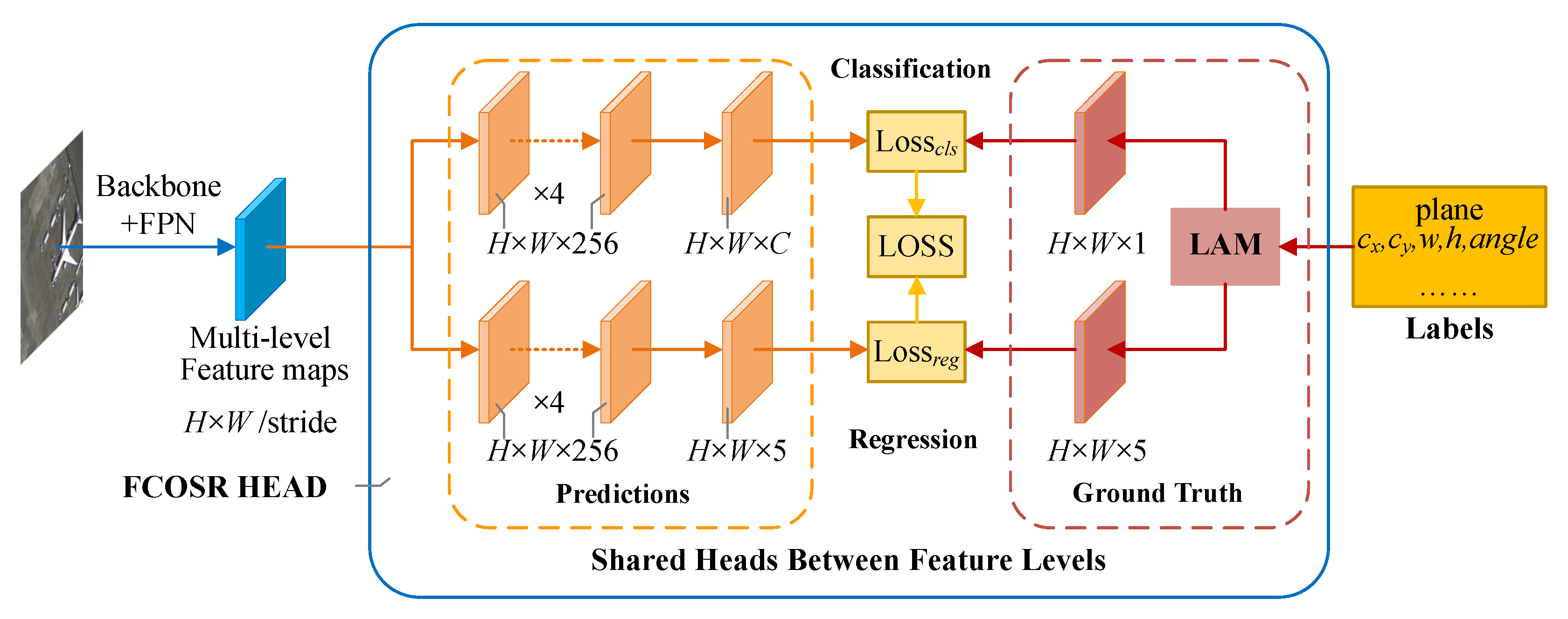
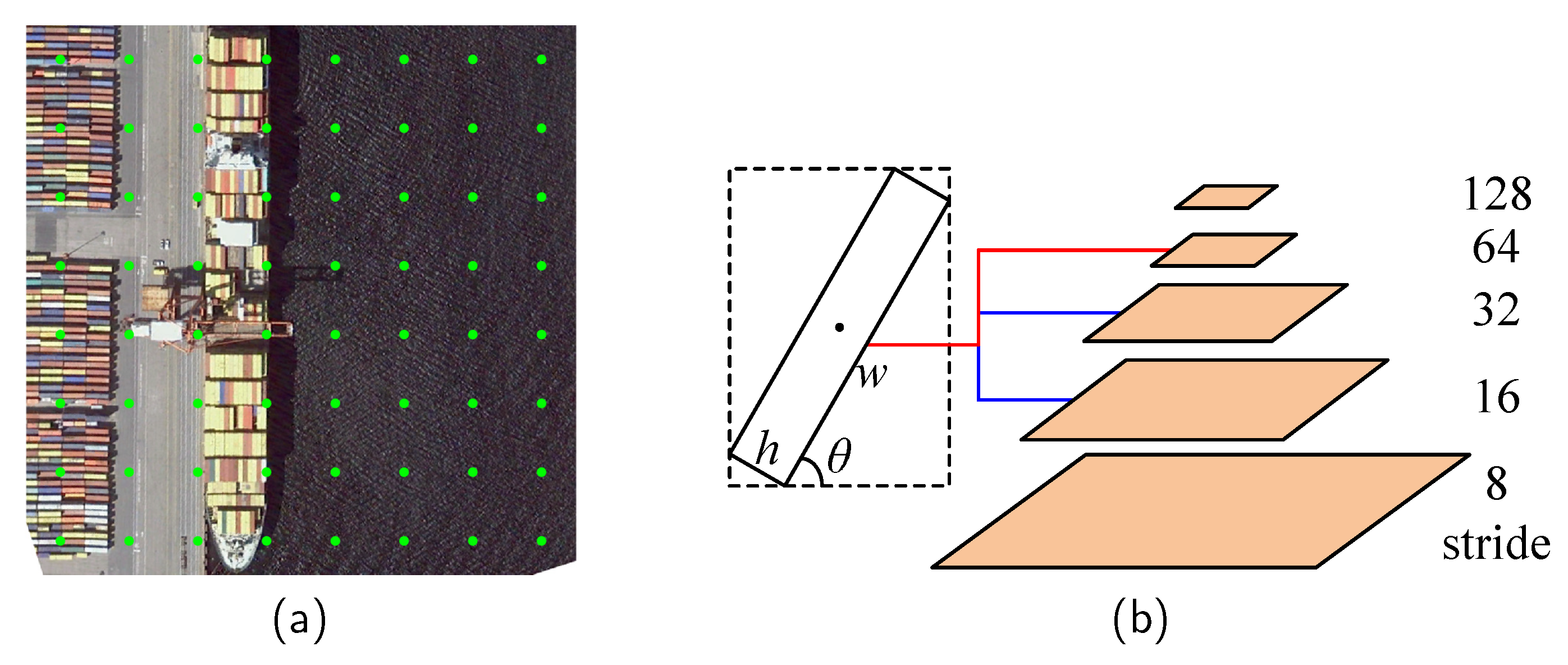
4.1. Datasets
We evaluated our method on the DOTA-v1.0, DOTA-v1.5, and HRSC2016 datasets.
DOTA [
21] is a large-scale dataset for aerial object detection. The data are collected from different sensors and platforms. DOTA-v1.0 contains 2806 large aerial images with size ranges from 800 × 800 to 4000 × 4000 and 188,282 instances among 15 common categories: Plane (PL), Baseball diamond (BD), Bridge (BR), Ground track field (GTF), Small vehicle (SV), Large vehicle (LV), Ship (SH), Tennis court (TC), Basketball court (BC), Storage tank (ST), Soccer-ball field (SBF), Roundabout (RA), Harbor (HA), Swimming pool (SP), and Helicopter (HC). DOTA-v1.5 adds the Container Crane (CC) class and instances smaller than 10 pixels on the basis of version 1.0. DOTA-v1.5, which contains 402,089 instances, is more challenging than DOTA-v1.0, but is stable during training. We used both the train and validation sets for training and used the test set for testing. All images were cropped into 1024 × 1024 patches with a gap of 512, and the multi-scale arguments of DOTA-v1.0 were {0.5, 1.0}, while those of DOTA-v1.5 were {0.5, 1.0, 1.5}. We also applied random flipping and the random rotation argument method during training.
HRSC2016 [
22] is a challenging ship detection dataset with OBB annotations, which contains 1061 aerial images with a size ranging from 300 × 300 to 1500 × 900. This includes 436, 181, and 444 images in the train, validation and test set, respectively. We used both the train and validation set for training and the test set for testing. All images were resized to 800 × 800 without changing the aspect ratio. Random flipping and random rotation were applied during training.
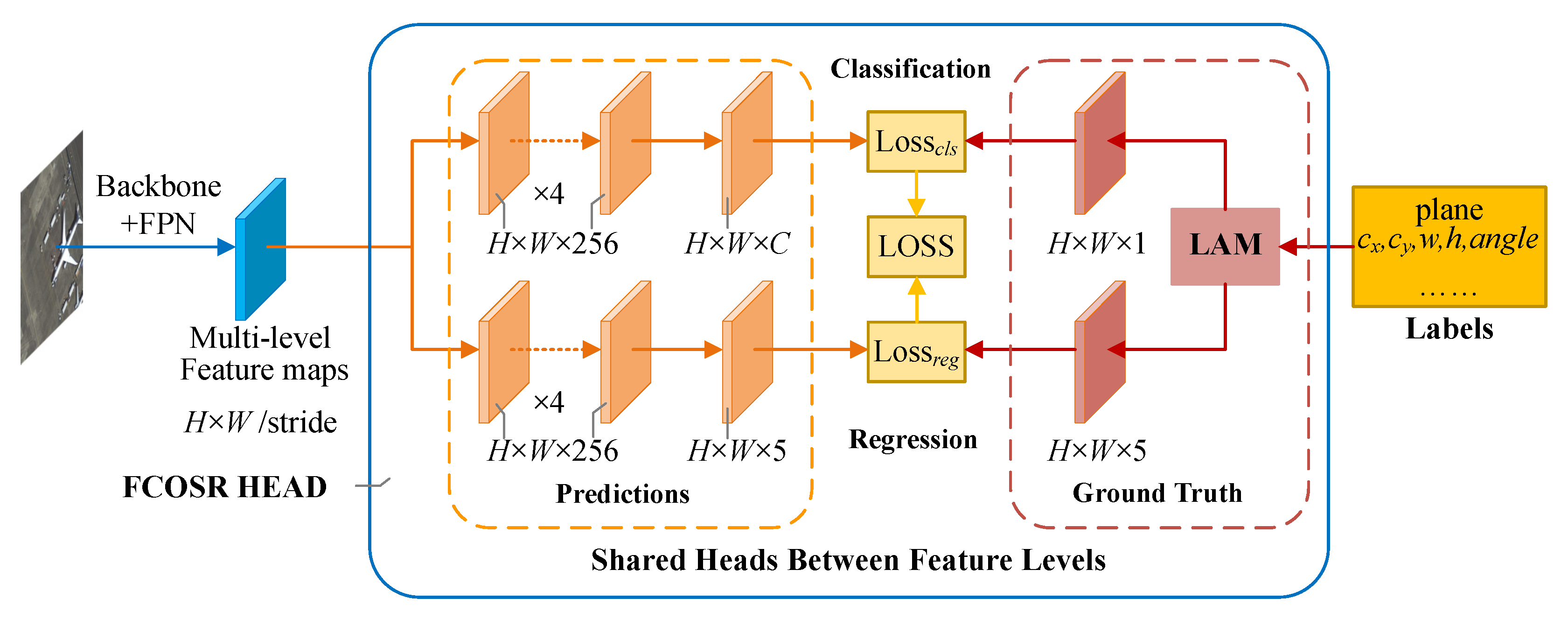
4.3. Lightweight and Embedded System
We adopted Mobilenet v2 [
45] as the backbone, and named it FCOSR-S (small). To deploy FCOSR on the embedded platform, we performed lightweight processing on the model. We adjusted the output stage of the backbone based on FCOSR-S, and replaced the extra convolutional layer of FPN with a pooling layer. We called it FCOSR-lite. On this basis, we further adjusted the feature channel of the head from 256 to 128, and named it FCOSR-tiny. These two models were then converted to the TensorRT 16-bit format and tested on the Nvidia Jetson platform.
Figure 5 illustrates a physical picture of the embedded object detection system. As the mainstream oriented object detectors are still designed to run on servers or PCs, we do not have a directly comparable method. Therefore, we compared it with other state-of-the-art (SOTA) methods.
Figure 5.
Physical picture of the embedded object detection system based on the Nvidia Jetson platform.
Figure 5.
Physical picture of the embedded object detection system based on the Nvidia Jetson platform.
The test was conducted on the DOTA-v1.0 single-scale test set at a 1024 × 1024 image scale. The results are shown in
Table 1, and the model size is the TensorRT engine file size (.trt). The FPS denotes the processing number of images by the detector within a one-second interval on Jetson NX and Jetson AGX Xavier devices. The lightweight FCOSR achieved an ideal balance between speed and accuracy on the Jetson device. The lightest tiny model achieved an mAP of
73.93 at
10.68/
17.76 FPS. On the Jetson AGX Xavier, it only takes about 2.3 s to process a 5000 × 5000 image.
Figure 6 shows the results of the tiny model running on the Jetson AGX Xavier. Our lightweight model quickly and accurately detected densely parked vehicles. This marked a successful attempt to deploy a high-performance oriented object detector on edge computing devices.
Figure 6.
The detection result of the entire aerial image on the Nvidia Jetson platform. We completed the detection of P2043 image from the DOTA-v1.0 test set in 1.4 s on a Jetson AGX Xavier device and visualized the results. The size of this large image was 4165 × 3438.
Figure 6.
The detection result of the entire aerial image on the Nvidia Jetson platform. We completed the detection of P2043 image from the DOTA-v1.0 test set in 1.4 s on a Jetson AGX Xavier device and visualized the results. The size of this large image was 4165 × 3438.
Table 1.
Lightweight FCOSR test results on Jetson platform.
Table 1.
Lightweight FCOSR test results on Jetson platform.
| Methods | Parameters | Model Size | Input Size | GFLOPs | FPS | mAP |
|---|
| FCOSR-lite | 6.9 M | 51.63 MB | 1024 × 1024 | 101.25 | 7.64/12.59 | 74.30 |
| FCOSR-tiny | 3.52 M | 23.2 MB | 1024 × 1024 | 35.89 | 10.68/17.76 | 73.93 |
4.4. Comparison with State-of-the-Art Methods
We used a variety of other backbones to replace ResNext50 [
43] to reconstruct the FCOSR model. We tested FCOSR on ResNext101 [
43] with 64 groups and 4 widths, and named this model FCOSR-L (large). The parameters, input patch size, FLOPs, FPS, and mAP on DOTA are shown in
Table 2. FPS represents the result tested on a single RTX 2080-Ti device. mAP is the result on DOTA-v1.0 with single-scale evaluation.
Table 2.
FCOSR series model size, FLOPs, FPS, and mAP comparison.
Table 2.
FCOSR series model size, FLOPs, FPS, and mAP comparison.
| Method | Backbone | Parameters | Input Size | GFLOPs | FPS | mAP |
|---|
| FCOSR-S | Mobilenet v2 | 7.32 M | 1024 × 1024 | 101.42 | 23.7 | 74.05 |
| FCOSR-M | ResNext50 | 31.4 M | 1024 × 1024 | 210.01 | 14.6 | 77.15 |
| FCOSR-L | ResNext101 | 89.64 M | 1024 × 1024 | 445.75 | 7.9 | 77.39 |
Results on DOTA-v1.0: As shown in
Table 3, we compared the FCOSR series with other SOTA methods on the DOTA-v1.0 OBB task. ROI-Trans. and BBAVec. indicate ROI-transformer and BBAVectors, respectively; R, RX, ReR, H, and Mobile indicate ResNet, ResNext, ReResNet, Hourglass, and MoblieNet v2, respectively; * indicates multi-scale training and testing. The results in
red and
blue indicate the best and second-best results in each column, respectively.
Our method enables a significant performance improvement over other anchor-based methods at the same model scale, namely ROI-transformer [
15], CenterMap [
46], SCRDet++ [
47], R
Det [
28], and CSL [
29]. It is only outperformed by S
ANet [
16] and ReDet [
20] in the multi-scale training and testing, while our medium and large models are more accurate than other methods in the single-scale evaluation.
Compared with other anchor-free methods, FCOSR-M achieved an mAP of 79.25 under multi-scale training and testing, and achieved the best or second-best accuracy in nine subcategories. Our small model showed competitive performance at multiple scales, and its accuracy was at the same level as that of most models. However, it is much smaller than other models and therefore faster. The results in
Section 4.6 also support this view.
We also note that FCOSR-L performed worse than the medium model at multiple scales, and the performance improvement at a single scale was small. From
Table 3, we can see that the performance improvement brought by ResNext101 was much smaller than that of other methods, but when tuning from the ResNext50 to Mobilenet backbone, FCOSR-S outperformed the other methods in both speed and accuracy. Therefore, we believe that the FCOSR series rapidly reaches peak performance as the trunk size increases, and is more suitable for small- and medium-sized models. From the overall results shown in
Table 3, although there is still a clear gap in speed and accuracy compared with the anchor-based model, our algorithm achieved better performance than other anchor-free methods. We visualized a part of the DOTA-v1.0 test set result in
Figure 7. The detection domain of our model covers various scales of targets, and it works well for dense vehicles in parking lots, stadiums, and runways (area overlap).
Results on DOTA-v1.5: As shown in
Table 4, we also conducted all experiments on the FCOSR series. RN-O., FR-O., and MR. indicate Retinanet-oriented, Faster-RCNN-oriented, and Mask RCNN, respectively; † and ‡ refer to one-stage and two-stage anchor-based methods, respectively; and * indicates multi-scale training and testing. There are currently only a few methods for evaluating the DOTA-v1.5 dataset, so we directly used some results in ReDet [
20] and the RotationDetection repository (
https://github.com/yangxue0827/RotationDetection (accessed on 1 August 2023)).
Table 3.
Comparison with state-of-the-art methods on the DOTA-v1.0 OBB task.
Table 3.
Comparison with state-of-the-art methods on the DOTA-v1.0 OBB task.
| Method | Backbone | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|
| Anchor-based, two-stage | | | | | | | | | | | | | | |
| ROI-Trans. * [15] | R101 | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| CenterMap * [46] | R101 | 89.83 | 84.41 | 54.60 | 70.25 | 77.66 | 78.32 | 87.19 | 90.66 | 84.89 | 85.27 | 56.46 | 69.23 | 74.13 | 71.56 | 66.06 | 76.03 |
| SCRDet++ * [47] | R101 | 90.05 | 84.39 | 55.44 | 73.99 | 77.54 | 71.11 | 86.05 | 90.67 | 87.32 | 87.08 | 69.62 | 68.90 | 73.74 | 71.29 | 65.08 | 76.81 |
| ReDet [20] | ReR50 | 88.79 | 82.64 | 53.97 | 74.00 | 78.13 | 84.06 | 88.04 | 90.89 | 87.78 | 85.75 | 61.76 | 60.39 | 75.96 | 68.07 | 63.59 | 76.25 |
| ReDet * [20] | ReR50 | 88.81 | 82.48 | 60.83 | 80.82 | 78.34 | 86.06 | 88.31 | 90.87 | 88.77 | 87.03 | 68.65 | 66.90 | 79.26 | 79.71 | 74.67 | 80.10 |
| Anchor-based, one-stage | | | | | | | | | | | | | | |
| RDet * [28] | R152 | 89.80 | 83.77 | 48.11 | 66.77 | 78.76 | 83.27 | 87.84 | 90.82 | 85.38 | 85.51 | 65.67 | 62.68 | 67.53 | 78.56 | 72.62 | 76.47 |
| CSL * [29] | R152 | 90.13 | 84.43 | 54.57 | 68.13 | 77.32 | 72.98 | 85.94 | 90.74 | 85.95 | 86.36 | 63.42 | 65.82 | 74.06 | 73.67 | 70.08 | 76.24 |
| SANet * [16] | R50 | 89.11 | 82.84 | 48.37 | 71.11 | 78.11 | 78.39 | 87.25 | 90.83 | 84.90 | 85.64 | 60.36 | 62.60 | 65.26 | 69.13 | 57.94 | 74.12 |
| SANet * [16] | R50 | 88.89 | 83.60 | 57.74 | 81.95 | 79.94 | 83.19 | 89.11 | 90.78 | 84.87 | 87.81 | 70.30 | 68.25 | 78.30 | 77.01 | 69.58 | 79.42 |
| Anchor-free, one-stage | | | | | | | | | | | | | | |
| BBAVec. * [17] | R101 | 88.63 | 84.06 | 52.13 | 69.56 | 78.26 | 80.40 | 88.06 | 90.87 | 87.23 | 86.39 | 56.11 | 65.62 | 67.10 | 72.08 | 63.96 | 75.36 |
| DRN * [48] | H104 | 89.45 | 83.16 | 48.98 | 62.24 | 70.63 | 74.25 | 83.99 | 90.73 | 84.60 | 85.35 | 55.76 | 60.79 | 71.56 | 68.82 | 63.92 | 72.95 |
| CFA [49] | R101 | 89.26 | 81.72 | 51.81 | 67.17 | 79.99 | 78.25 | 84.46 | 90.77 | 83.40 | 85.54 | 54.86 | 67.75 | 73.04 | 70.24 | 64.96 | 75.05 |
| PolarDet [18] | R50 | 89.73 | 87.05 | 45.30 | 63.32 | 78.44 | 76.65 | 87.13 | 90.79 | 80.58 | 85.89 | 60.97 | 67.94 | 68.20 | 74.63 | 68.67 | 75.02 |
| PolarDet * [18] | R101 | 89.65 | 87.07 | 48.14 | 70.97 | 78.53 | 80.34 | 87.45 | 90.76 | 85.63 | 86.87 | 61.64 | 70.32 | 71.92 | 73.09 | 67.15 | 76.64 |
| FCOSR-S | Mobile | 89.09 | 80.58 | 44.04 | 73.33 | 79.07 | 76.54 | 87.28 | 90.88 | 84.89 | 85.37 | 55.95 | 64.56 | 66.92 | 76.96 | 55.32 | 74.05 |
| FCOSR-S * | Mobile | 88.60 | 84.13 | 46.85 | 78.22 | 79.51 | 77.00 | 87.74 | 90.85 | 86.84 | 86.71 | 64.51 | 68.17 | 67.87 | 72.08 | 62.52 | 76.11 |
| FCOSR-M | RX50 | 88.88 | 82.68 | 50.10 | 71.34 | 81.09 | 77.40 | 88.32 | 90.80 | 86.03 | 85.23 | 61.32 | 68.07 | 75.19 | 80.37 | 70.48 | 77.15 |
| FCOSR-M * | RX50 | 89.06 | 84.93 | 52.81 | 76.32 | 81.54 | 81.81 | 88.27 | 90.86 | 85.20 | 87.58 | 68.63 | 70.38 | 75.95 | 79.73 | 75.67 | 79.25 |
| FCOSR-L | RX101 | 89.50 | 84.42 | 52.58 | 71.81 | 80.49 | 77.72 | 88.23 | 90.84 | 84.23 | 86.48 | 61.21 | 67.77 | 76.34 | 74.39 | 74.86 | 77.39 |
| FCOSR-L * | RX101 | 88.78 | 85.38 | 54.29 | 76.81 | 81.52 | 82.76 | 88.38 | 90.80 | 86.61 | 87.25 | 67.58 | 67.03 | 76.86 | 73.22 | 74.68 | 78.80 |
Table 4.
Comparison with state-of-the-art methods on the DOTA-v1.5 OBB task.
Table 4.
Comparison with state-of-the-art methods on the DOTA-v1.5 OBB task.
| Method | Backbone | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | CC | mAP |
|---|
| RN-O. † [10] | R50 | 71.43 | 77.64 | 42.12 | 64.65 | 44.53 | 56.79 | 73.31 | 90.84 | 76.02 | 59.96 | 46.95 | 69.24 | 59.65 | 64.52 | 48.06 | 0.83 | 59.16 |
| FR-O. ‡ [8] | R50 | 71.89 | 74.47 | 44.45 | 59.87 | 51.28 | 68.98 | 79.37 | 90.78 | 77.38 | 67.50 | 47.75 | 69.72 | 61.22 | 65.28 | 60.47 | 1.54 | 62.00 |
| MR. ‡ [9] | R50 | 76.84 | 73.51 | 49.90 | 57.80 | 51.31 | 71.34 | 79.75 | 90.46 | 74.21 | 66.07 | 46.21 | 70.61 | 63.07 | 64.46 | 57.81 | 9.42 | 62.67 |
| DAFNe * [50] | R101 | 80.69 | 86.38 | 52.14 | 62.88 | 67.03 | 76.71 | 88.99 | 90.84 | 77.29 | 83.41 | 51.74 | 74.60 | 75.98 | 75.78 | 72.46 | 34.84 | 71.99 |
| FCOS [11] | R50 | 78.67 | 72.50 | 44.31 | 59.57 | 56.25 | 64.03 | 78.06 | 89.40 | 71.45 | 73.32 | 49.51 | 66.47 | 55.78 | 63.26 | 44.76 | 9.44 | 61.05 |
| ReDet ‡ [20] | ReR50 | 79.20 | 82.81 | 51.92 | 71.41 | 52.38 | 75.73 | 80.92 | 90.83 | 75.81 | 68.64 | 49.29 | 72.03 | 73.36 | 70.55 | 63.33 | 11.53 | 66.86 |
| ReDet [20] | ReR50 | 88.51 | 86.45 | 61.23 | 81.20 | 67.60 | 83.65 | 90.00 | 90.86 | 84.30 | 75.33 | 71.49 | 72.06 | 78.32 | 74.73 | 76.10 | 46.98 | 76.80 |
| FCOSR-S | Mobile | 80.05 | 76.98 | 44.49 | 74.17 | 51.09 | 74.07 | 80.60 | 90.87 | 78.40 | 75.01 | 53.38 | 69.35 | 66.33 | 74.43 | 59.22 | 13.50 | 66.37 |
| FCOSR-S * | Mobile | 87.84 | 84.60 | 53.35 | 75.67 | 65.79 | 80.71 | 89.30 | 90.89 | 84.18 | 84.23 | 63.53 | 73.07 | 73.29 | 76.15 | 72.64 | 14.72 | 73.12 |
| FCOSR-M | RX50 | 80.48 | 81.90 | 50.02 | 72.32 | 56.82 | 76.37 | 81.06 | 90.86 | 78.62 | 77.32 | 53.63 | 66.92 | 73.78 | 74.20 | 69.80 | 15.73 | 68.74 |
| FCOSR-M * | RX50 | 80.85 | 83.89 | 53.36 | 76.24 | 66.85 | 82.54 | 89.61 | 90.87 | 80.11 | 84.27 | 61.72 | 72.90 | 76.23 | 75.28 | 70.01 | 35.87 | 73.79 |
| FCOSR-L | RX101 | 80.58 | 85.25 | 51.05 | 70.83 | 57.77 | 76.72 | 81.09 | 90.87 | 78.07 | 77.60 | 51.91 | 68.72 | 75.87 | 72.61 | 69.30 | 31.06 | 69.96 |
| FCOSR-L * | RX101 | 87.12 | 83.90 | 53.41 | 70.99 | 66.79 | 82.84 | 89.66 | 90.85 | 81.84 | 84.52 | 67.78 | 74.52 | 77.25 | 74.97 | 75.31 | 44.81 | 75.41 |
Figure 7.
The FCOSR-M detection result on the DOTA-v1.0 test set. The confidence threshold is set to 0.3 when showing these results.
Figure 7.
The FCOSR-M detection result on the DOTA-v1.0 test set. The confidence threshold is set to 0.3 when showing these results.
From a single-scale perspective, the medium-sized and large models achieved mAP values of 68.74 and 69.96, respectively, which were much higher than the results for other models. The small model achieved an mAP of 66.37, slightly lower than ReDet’s 66.86 mAP, while the Mobilenet v2 backbone used by the small model made it much faster than the other methods. As DOTA-v1.5 is only generated by adding a new category to version 1.0, the actual inference speed of the model was close to that of version 1.0. Referring to the results in
Section 4.6, we can see that the inference speed of the small model is 23.7 FPS at this time, while the speed of ReDet is only 8.8 FPS, and the medium-sized model of the same scale maintains 14.6 FPS.
Classical object detection algorithms such as Faster-RCNN-O can maintain the same speed as FCOSR, but with much less accuracy. Compared with the original FCOS model, our method has a redesigned label assignment strategy for the characteristics of aerial images, which is more suitable for oriented target detection. Our method maintains competitive results at multiple scales. Although the performance is still lower than that of two-stage anchor-based methods such as ReDet, our method shrinks the huge gap in performance between anchor-free and anchor-based methods.
Results on HRSC2016: We compared our method with other one-stage methods. We repeated the experiment 10 times and recorded the mean and standard deviation in
Table 5. FCOSR series models surpassed all anchor-free models and achieved an mAP of 95.70 under the VOC2012 metrics. FCOSR series models exceeded an mAP of 90 under the VOC2007 metrics. The large one even surpassed S
ANet [
16], which further proves that our proposed anchor-free method has a performance equivalent to that of the anchor-based method. The detection results are shown in
Figure 8. In complex background environments, our model accurately detected various scales of ship targets. The model displayed good detection of slender ships docked in ports, as well as ships in shipyards.
Table 5.
Comparison with state-of-the-art methods on HRSC2016.
Table 5.
Comparison with state-of-the-art methods on HRSC2016.
| Method | Backbone | mAP (07) | mAP (12) |
|---|
| PIoU [19] | DLA-34 | 89.20 | - |
| SANet [16] | ResNet101 | 90.17 | 95.01 |
| ProbIoU [34] | ResNet50 | 87.09 | - |
| DRN [48] | Hourglass104 | - | 92.70 |
| CenterMap [46] | ResNet50 | - | 92.80 |
| BBAVectors [17] | ResNet101 | 88.60 | - |
| PolarDet [18] | ResNet50 | 90.13 | - |
| FCOSR-S(ours) | Mobilenet v2 | 90.05 (±0.042) | 92.59 (±0.054) |
| FCOSR-M(ours) | ResNext50 | 90.12 (±0.034) | 94.81 (±0.030) |
| FCOSR-L(ours) | ResNext101 | 90.13 (±0.028) | 95.70 (±0.026) |
Figure 8.
The FCOSR-L detection result on HRSC2016. The confidence threshold is set to 0.3 when visualizing these results.
Figure 8.
The FCOSR-L detection result on HRSC2016. The confidence threshold is set to 0.3 when visualizing these results.
4.5. Ablation Experiments
We performed a series of experiments on the DOTA-v1.0 test set to evaluate the effectiveness of the proposed method. We used FCOSR-M (medium) as the baseline. We trained and tested the model at a single scale.
As shown in
Table 6, the mAP at the baseline for FCOS-M is 70.4, which increases by 4.03 with the addition of rotation augmentation. When QFL [
42] was used instead of focal loss, the detection result of the model gained an mAP of 0.91. Next, we tried to add ECS, FLA, and MLS modules and when used individually, the results were improved by 1.03, 0.58, and 0.34, respectively. Applying ECS and FLA at the same time, the detection result was improved to 76.80. Using all the modules brought the result up to 77.15. Through the use of multiple modules, FCOSR-M achieved a significant performance improvement over anchor-based methods. These modules do not have any additional calculations when making inferences, which makes FCOSR a simple, fast, and easy-to-deploy OBB detector.
Table 6.
Results of ablation experiments for FCOSR-M on single scale.
Table 6.
Results of ablation experiments for FCOSR-M on single scale.
| Method | Rotate Aug. | QFL | ECS | FLA | MLS | mAP |
|---|
| | | | | | | 70.40 |
| | ✓ | | | | | 74.43 |
| FCOSR-M | ✓ | ✓ | | | | 75.34 |
| | ✓ | ✓ | ✓ | | | 76.37 |
| | ✓ | ✓ | | ✓ | | 75.92 |
| | ✓ | ✓ | | | ✓ | 75.77 |
| | ✓ | ✓ | ✓ | ✓ | | 76.80 |
| | ✓ | ✓ | ✓ | ✓ | ✓ | 77.15 |
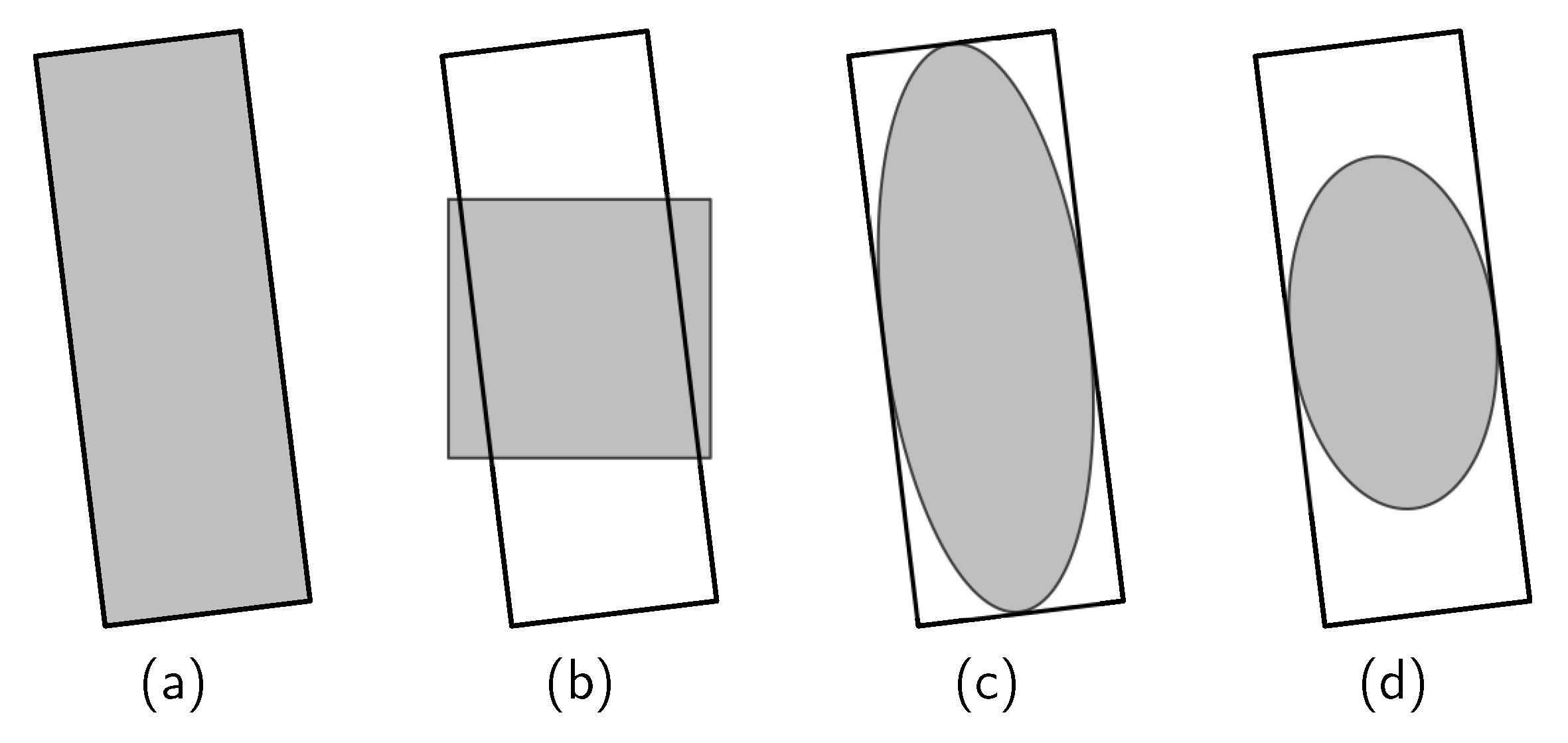
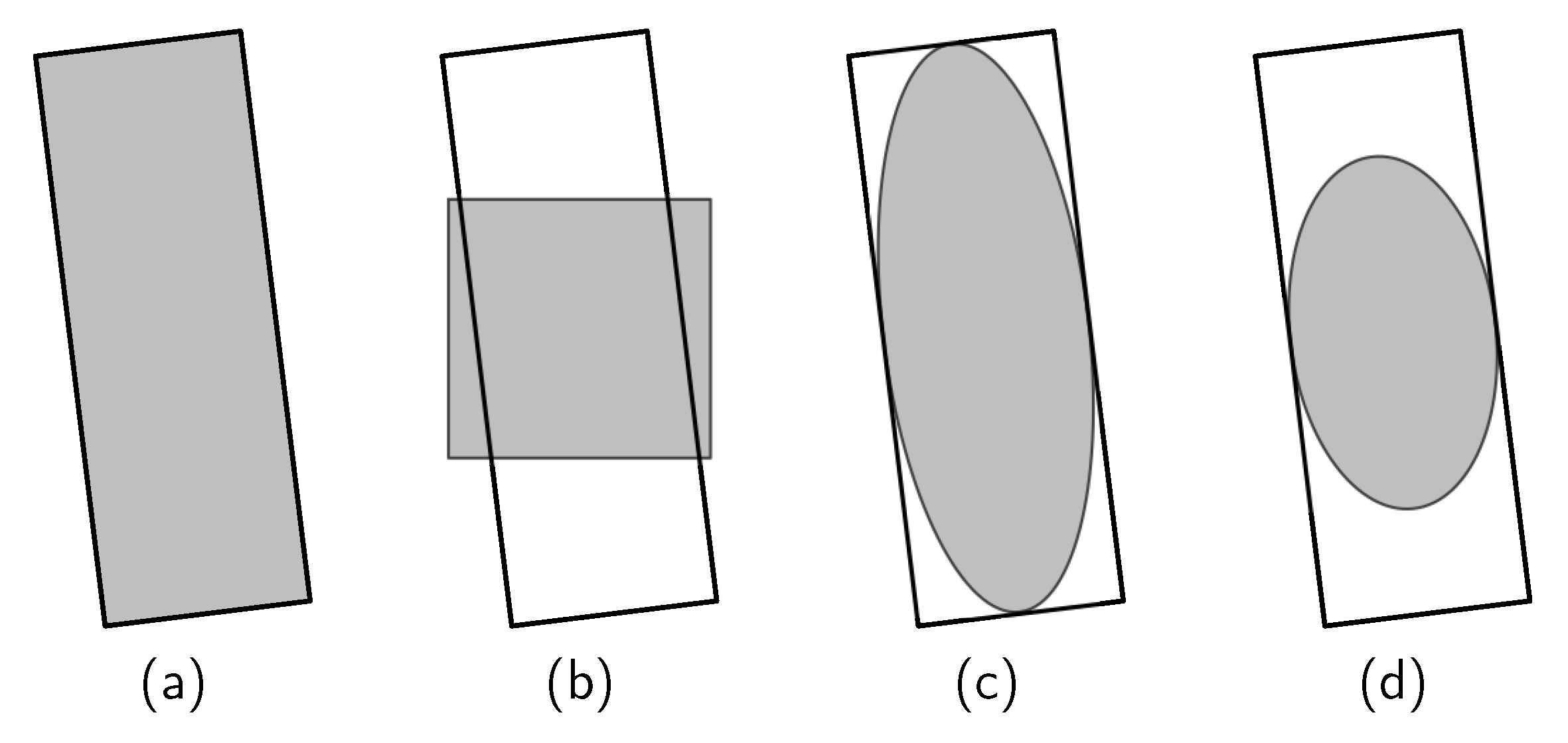
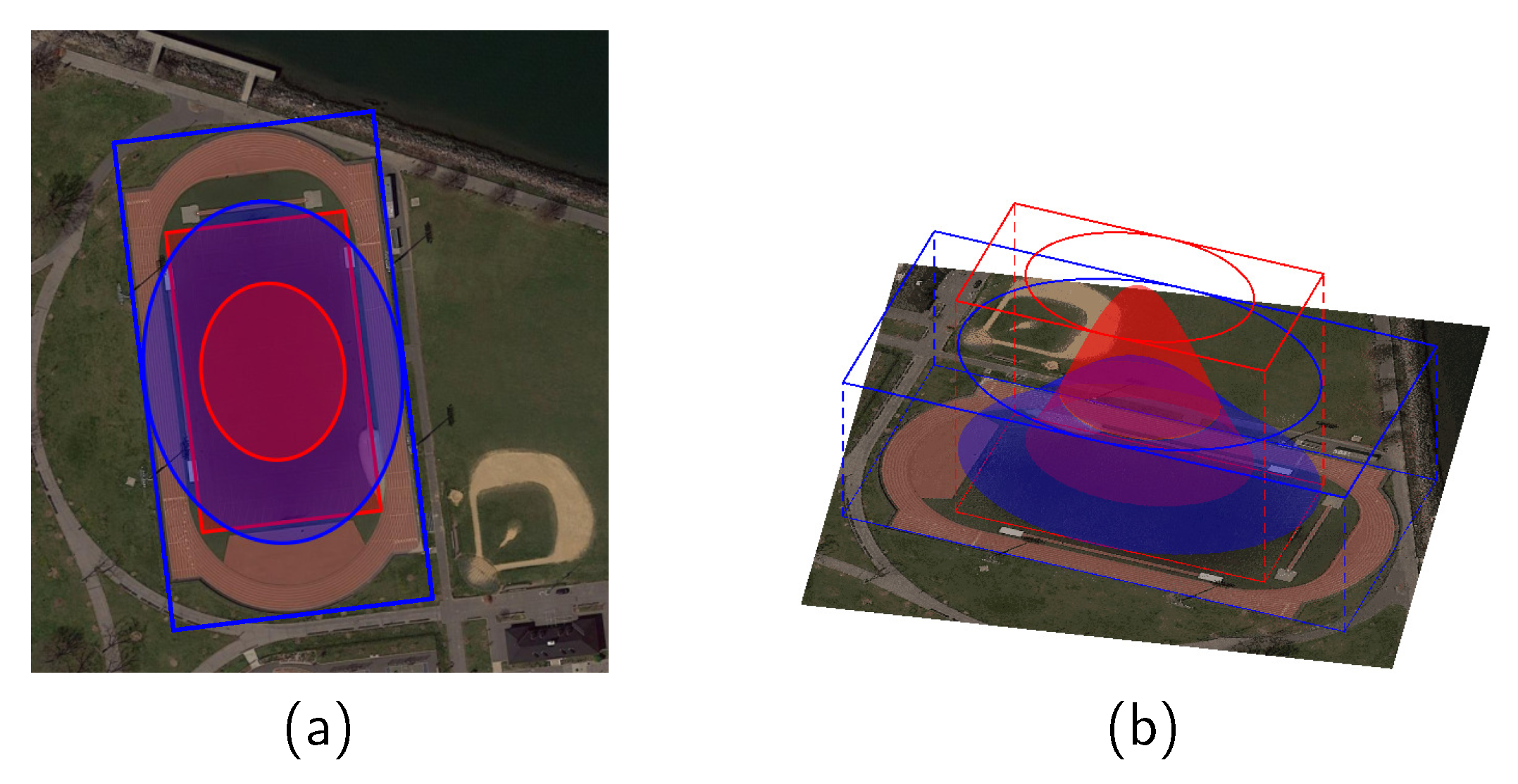
Effectiveness of ellipse center sampling: We changed the sampling regions of the FCOSR-M baseline to the shapes listed in
Figure 2.
Table 7 shows the results of the comparison experiments. The general sampling region (GS), horizontal center sampling region (HCS), and original elliptical sampling region (OES) achieved mAPs of 76.34, 75.48, and 76.70, respectively. These results are all lower than those of the standard FCOSR-M model. The HCS strategy is widely used in HBB detection. However, an OBB carries a rotation angle, so the horizontal fixed-scale sampling area does not match it effectively, further decreasing the number of positive samples. This makes the baseline performance of FCOSR with the HCS strategy lower than that of other strategies. The edge region of the OBB of many aerial targets is part of the background, such as aircraft, ships, and other targets. Directly applying the GS strategy tends to lead to incorrectly sampling the actual background area as a positive sample. The ellipse center sampling scheme removes part of the edge regions of the OBB. This effect is further enhanced by shrinking the long axis of the ellipse so that the SES-based FCOSR baseline has better overall performance. The difference between SES and HCS is that SES is not a fixed-scale sampling strategy, but calculates the range by using a 2D Gaussian function. Therefore, SES has the advantage of converting the Euclidean distance to Gaussian distance so that we can easily obtain an elliptical region matching the OBB.
The results for the elliptical shape sampling region are better than those of other schemes. The FCOSR based on the shrinking ellipse center sampling achieved an mAP of 77.15, demonstrating performance that is equivalent to that of other mainstream state-of-the-art models. The above experimental results validate the effectiveness of our proposed method.
Table 7.
Results of experiments comparing the different sampling ranges listed in
Figure 2.
Table 7.
Results of experiments comparing the different sampling ranges listed in
Figure 2.
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|
| GS | 89.40 | 83.73 | 50.97 | 71.42 | 80.87 | 77.81 | 88.49 | 90.76 | 85.36 | 85.45 | 60.12 | 62.98 | 76.22 | 75.64 | 65.93 | 76.34 |
| HCS | 88.09 | 79.57 | 55.31 | 63.63 | 81.13 | 77.67 | 88.11 | 90.80 | 84.85 | 84.11 | 58.75 | 62.29 | 74.29 | 80.51 | 63.11 | 75.48 |
| OES | 89.07 | 81.15 | 50.96 | 70.44 | 80.53 | 77.64 | 88.31 | 90.85 | 85.37 | 86.60 | 59.05 | 61.22 | 76.00 | 80.58 | 72.73 | 76.70 |
| SES | 88.88 | 82.68 | 50.10 | 71.34 | 81.09 | 77.40 | 88.32 | 90.80 | 86.03 | 85.23 | 61.32 | 68.07 | 75.19 | 80.37 | 70.48 | 77.15 |
Effectiveness of fuzzy sample label assignment: We used FCOSR-M as the baseline. Training and testing was performed on DOTA-v1.0, and all parts were unchanged except the label assignment method (LAM). We replaced our LAM with ATSS [
51] and simOTA [
3], and
Table 8 shows the results of the comparison experiments. ATSS [
51] and simOTA [
3] achieve an mAP of 76.60 and 72.63, respectively, both of which are lower than our reported mAP of 77.15. simOTA [
3] achieves strong results in the HBB object detection task, but the experimental results show that it may not be suitable for OBB object detection. Oriented objects have more difficulty converging than horizontal objects. Therefore, a small number of samples were actually used for the training, which directly affected the performance of the model. ATSS [
51] is designed based on the central sampling principle, which is similar to our method. However, both ATSS and simOTA are designed based on natural scenes, which do not match with the characteristics of remote sensing image objects. As a result, the actual effect is not as good as that of our proposed method.
Table 8.
Results of experiments comparing label assignment methods.
Table 8.
Results of experiments comparing label assignment methods.
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|
| ATSS [51] | 88.91 | 81.79 | 53.93 | 72.42 | 80.75 | 80.77 | 88.33 | 90.79 | 86.27 | 85.54 | 56.99 | 63.19 | 75.90 | 74.61 | 68.87 | 76.60 |
| simOTA [3] | 81.31 | 72.89 | 52.85 | 69.79 | 79.89 | 77.17 | 86.87 | 90.11 | 83.07 | 82.38 | 58.96 | 58.31 | 74.37 | 68.75 | 52.74 | 72.63 |
| Ours | 88.88 | 82.68 | 50.10 | 71.34 | 81.09 | 77.40 | 88.32 | 90.80 | 86.03 | 85.23 | 61.32 | 68.07 | 75.19 | 80.37 | 70.48 | 77.15 |
Effectiveness of multi-level sampling: As shown in
Table 6, the addition of the MLS module brings a 0.35–0.43 improvement in mAP. Targets in aerial image scenes are oriented arbitrarily, and there are many slender targets. This causes insufficient sampling of the target, which affects the performance for that type of target. The MLS module solves this problem by extending the sampling region for insufficiently sampled objects. Experimental results validate the effectiveness of the MLS method.
4.6. Speed versus Accuracy
We tested the inference speed of FCOSR series models and other open-source mainstream models, including R
Det [
28], ReDet [
20], S
ANet [
16], Faster-RCNN-O (FR-O) [
8], Oriented RCNN (O-RCNN) [
27], and RetinaNet-O (RN-O) [
10]. For convenience, we tested Faster-RCNN-O [
8] and RetinaNet-O models in the Oriented-RCNN repository (
https://github.com/jbwang1997/OBBDetection (accessed on 1 August 2023)). All tests were conducted on a single RTX 2080-Ti device at a 1024 × 1024 image scale.
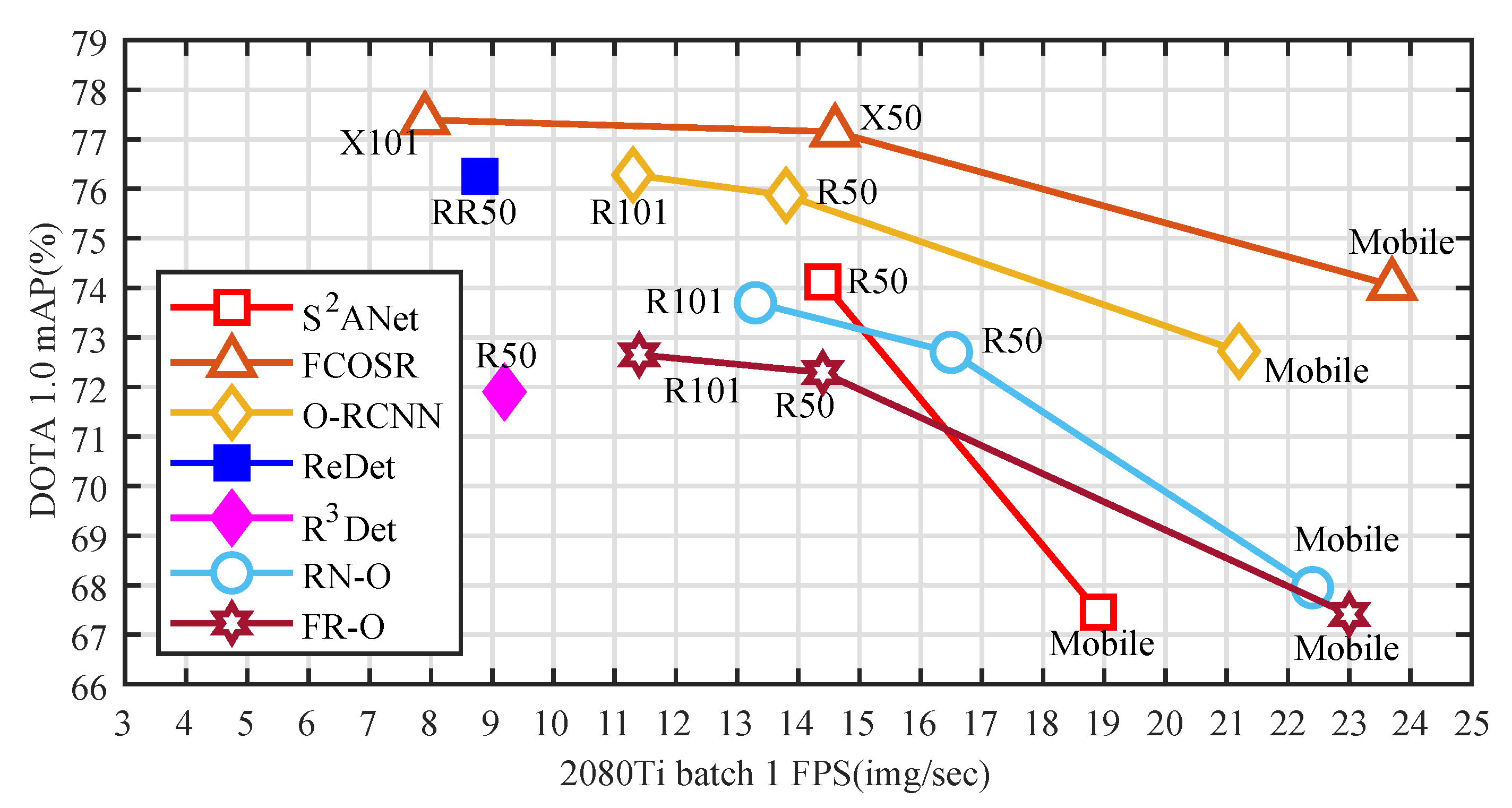
The test results are shown in
Figure 9. The accuracy of all models increased as the number of model parameters increased. FCOSR’s medium-sized and small models both outperformed other anchor-based methods with the same backbone size. FCOSR-M exceeded almost the same speed S
ANet [
16] and Oriented RCNN [
27] 3.03 mAP and 1.28 mAP, respectively. This is because of the simple and lightweight head structure and the well-designed label assignment strategy. FCOSR-S even achieved an mAP of
74.05 at a speed of
23.7 FPS, making it the fastest high-performance model currently. The FCOSR series models surpassed the existing mainstream models in speed and accuracy, which also proves that, through reasonable label assignment, even a simple model can achieve excellent performance.
Figure 9.
Speed versus accuracy on DOTA-v1.0 single-scale test set. X indicates the ResNext backbone. R indicates the ResNet backbone. RR indicates the ReResNet(ReDet) backbone. Mobile indicates the Mobilenet v2 backbone. We tested ReDet [
20], S
ANet [
16], and R
Det [
28] on a single RTX 2080-Ti device based on their source code. Faster-RCNN-O (FR-O) [
8], RetinaNet-O (RN-O) [
10], and Oriented RCNN (O-RCNN) [
27] test results are from the OBBDetection repository
2.
Figure 9.
Speed versus accuracy on DOTA-v1.0 single-scale test set. X indicates the ResNext backbone. R indicates the ResNet backbone. RR indicates the ReResNet(ReDet) backbone. Mobile indicates the Mobilenet v2 backbone. We tested ReDet [
20], S
ANet [
16], and R
Det [
28] on a single RTX 2080-Ti device based on their source code. Faster-RCNN-O (FR-O) [
8], RetinaNet-O (RN-O) [
10], and Oriented RCNN (O-RCNN) [
27] test results are from the OBBDetection repository
2.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}