1. Introduction
Object detection technology is a prominent area of research in computer vision, widely applied in autonomous vehicles (AVs), security, and medicine fields. The rapid advancement of deep learning has promoted the presence of many excellent object-detection works [
1,
2]. For instance, Yang et al. utilized a Dense Feature Pyramid Network (DFPN) to enhance detection [
3], and Yao et al. introduced an anchor-free two-stage detection method [
4]. Object detection works based on RGB exhibit good performance in ordinary surroundings [
5,
6]. However, the natural environment is open and dynamic. Existing RGB-based works have found it hard to cope with the challenges brought by some harsh environments [
7,
8], such as rain, fog occlusion, and low-light conditions. Meanwhile, some works [
9,
10] have studied infrared-based object-detection methods because infrared has good penetrating ability and works well in low-light conditions [
11,
12]. However, infrared-based detectors are susceptible to interference from heat and highlight sources [
13]. There are some object-detection works based on hyperspectral images [
14]. Yan et al. designed an SSD-based variant network with 3D convolution for hyperspectral image object detection [
15], and Li et al. proposed a spectral self-expressive model guided deep ensemble network for hyperspectral image tracking [
16]. Although they can utilize dense and rich spectral signatures beyond the visible wavelengths, it is relatively difficult to obtain hyperspectral images due to the high cost of the sensor. Therefore, object detection based on RGB-Infrared has become a research focus. Owing to the complementary advantages of RGB and infrared modalities, RGB-Infrared object-detection methods [
17,
18,
19,
20] have more robust performance under complex natural scenes. However, there exist spatial-misalignment and domain-discrepancy issues between RGB and infrared modalities, which will adversely impact object detection based on RGB-Infrared.
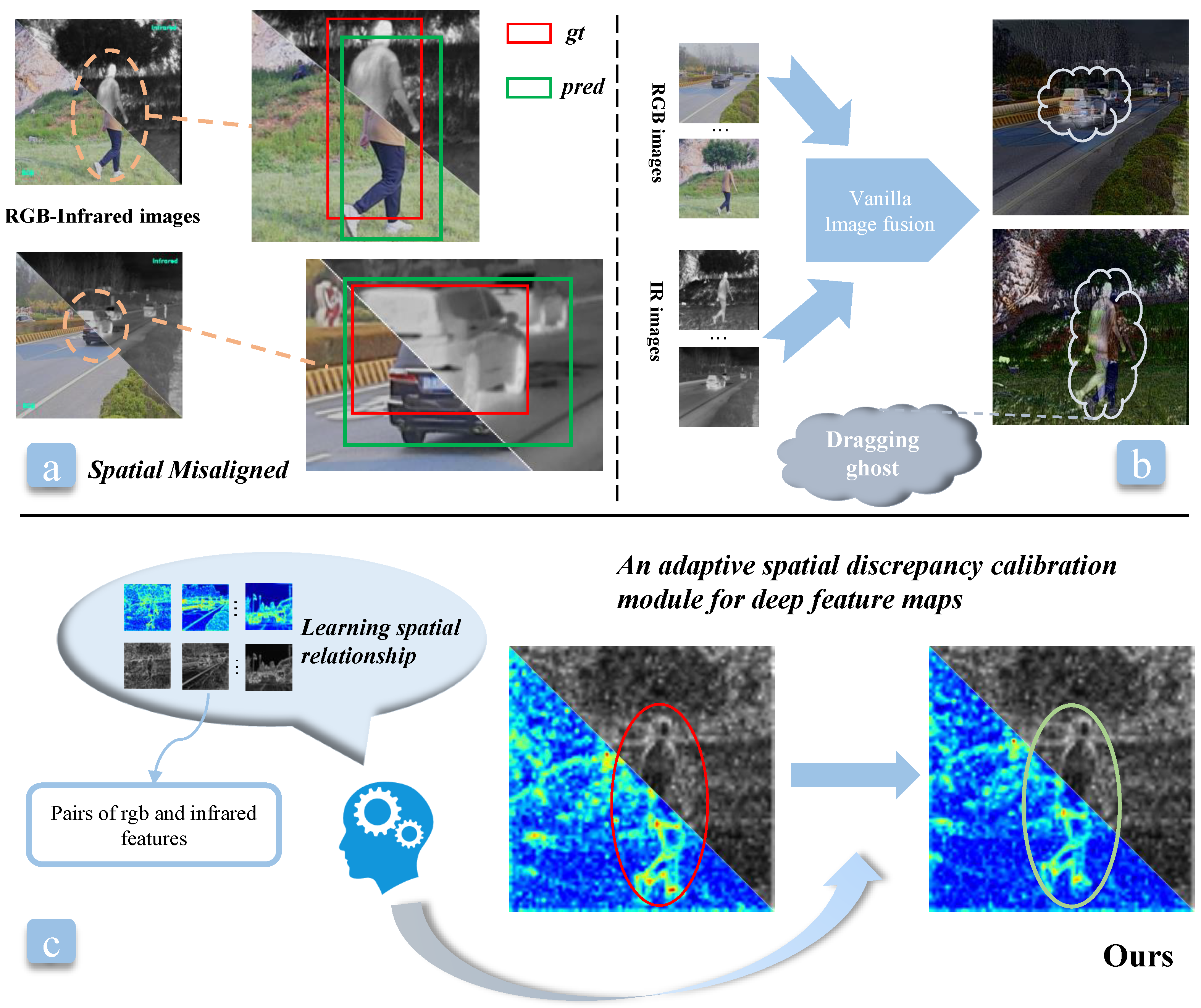
Spatial misalignment: Since RGB and infrared sensors have different coordinate systems, fields of view, and sampling frequencies, pairs of RGB and infrared images usually are spatial misaligned [
21], resulting in low-quality bounding boxes predicted by RGB and infrared fusion object detection, as shown in
Figure 1a.
Figure 1b indicates that the fusion of original RGB and infrared images via the image fusion algorithm [
22] will take in a significantly misaligned ghost, which will also disturb localization. The downsampling may decrease the degree of misalignment [
8], yet the situation still exists, as shown in
Figure 1c. The performance of RGB and infrared fusion detection methods that directly fuse misaligned features is not ideal. Therefore, achieving spatial alignment between RGB and infrared modalities is crucial. The training process of existing RGB and infrared fusion object-detection networks [
7,
19] relies on manually aligned datasets in advance. However, manual alignment is a labor-intensive task [
13,
23], and there will still be subtle misalignments after manual processing, such as the FLIR dataset [
24]. A more feasible way is to take misaligned RGB and infrared images as input directly, and how to adaptively perform spatial alignment at the feature level is the concern of our work. Furthermore, RGB and infrared images usually have different resolutions. Existing works [
22,
25] directly resize different modal images to the same size through downscaling or upscaling, either dropping beneficial information or introducing redundancy and increasing computational overhead.
Domain discrepancy: RGB and infrared images come from distinct sensors, and the deep feature maps extracted by convolutional neural networks (CNN) have apparent domain discrepancies [
26,
27]. As shown in
Figure 2, there is a notable disparity in the distribution of deep features from the two modalities when projected onto the same feature space. Although the object and background distributions of both modalities can be distinguished, the projected points of RGB and infrared features are also clearly divided into two clusters for the same object. Directly fusing the domain-discrepant features from RGB and infrared images will result in overlapping distributions of the object and background, which brings disturbance to the detection head [
28,
29]. The domain discrepancy makes it challenging to learn object and background distribution from the fusion feature of multi-modal [
30,
31]. Therefore, domain alignment is necessary before fusing RGB and infrared features. Existing RGB-Infrared object-detection works [
19,
32] emphasize designing the interaction structure of RGB and infrared, such as various attention mechanisms, ignoring the impact of domain discrepancy between RGB and infrared modalities on object detection.
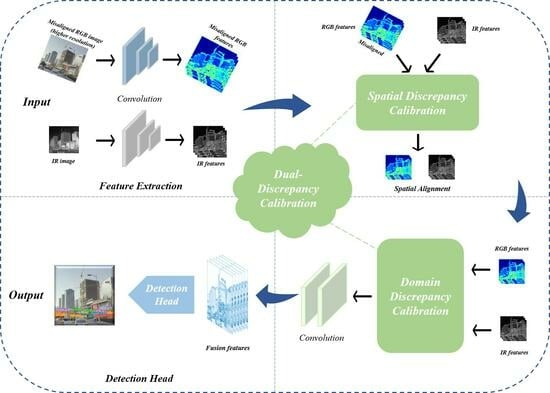
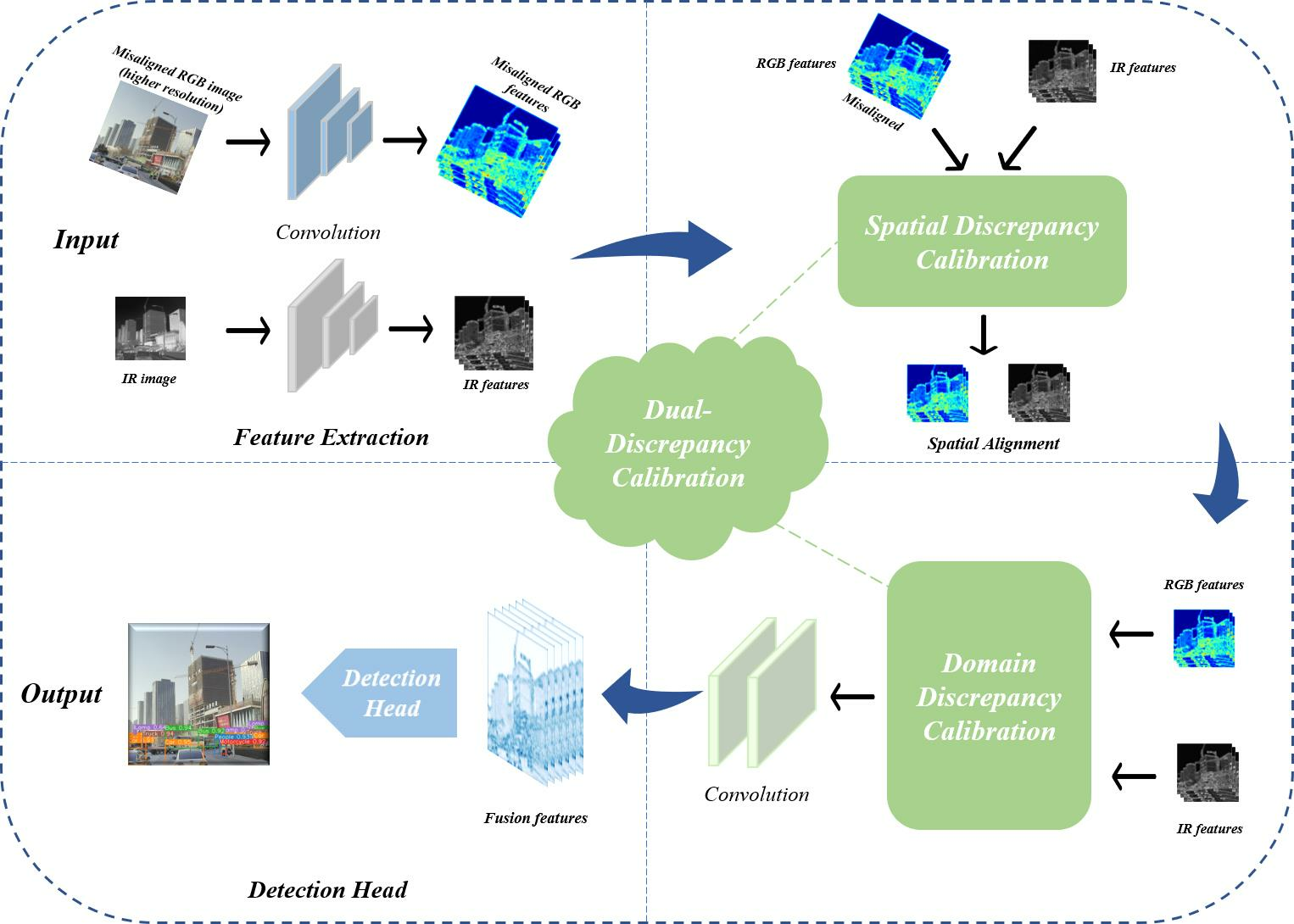
To address the above problems, we propose an adaptive dual-discrepancy calibration network (ADCNet) for misaligned RGB-Infrared object detection. We adopt a dual-branch network structure, including two feature extractors and a detection head. A size adaptation process is adopted so that our network can directly take RGB and IR images with different resolutions as network input. For the spatial-misalignment issue of RGB and infrared modalities, we append an adaptive spatial discrepancy calibration module in the detection network to achieve spatial alignment before feature fusion. Furthermore, we design a domain discrepancy calibration module to perform domain alignment to make the object and background features of various modalities more distinguishable to facilitate the downstream object-detection task.
Overall, the main contributions of this paper are summarized as follows:
This paper proposes a misaligned RGB and infrared object-detection network, which can adaptively tackle misalignment with variable degrees of rotation, translation, and scale between RGB and infrared images.
We use a spatial discrepancy calibration module to achieve spatial alignment, and a domain-discrepancy calibration module is designed to achieve domain alignment that enhances the fusion effectiveness for object detection.
Our method is validated on two misaligned RGB and infrared object-detection datasets and achieves state-of-the-art performance.
The rest of this paper is scheduled as follows:
Section 2 introduces the related work of RGB and infrared fusion object detection.
Section 3 elaborates on our method and network structure.
Section 4 gives the details of our experiment and a comparison of results to verify the effectiveness of our methodology. Finally, we discuss further and summarize this paper in
Section 5. Our code is available at
https://github.com/Hiram1026/misaligned_RGB-IR_detection (accessed on 5 October 2023).
2. Related Work
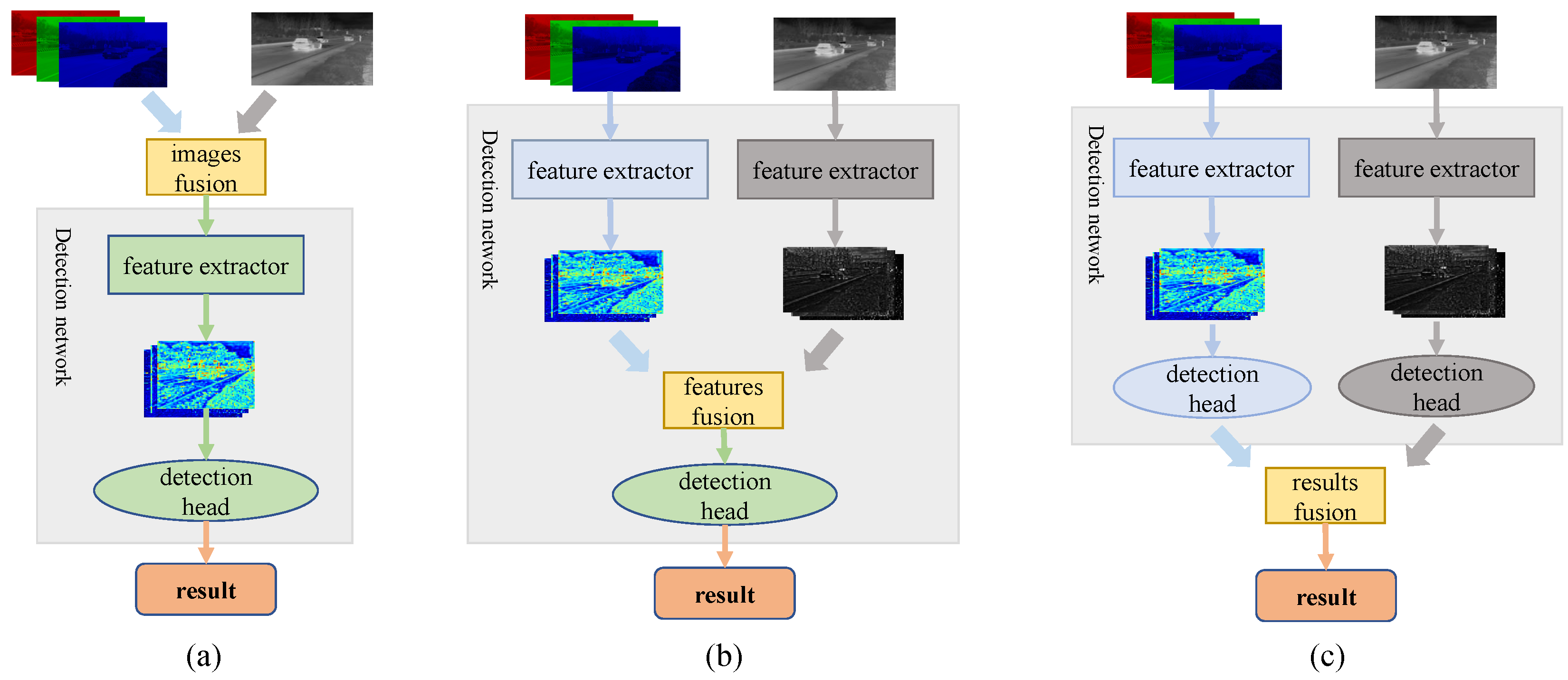
Multi-modal fusion object detection based on RGB and infrared images has rapidly developed thanks to the open source of some RGB and infrared image datasets, e.g., FLIR [
13], M3FD [
22], LLVIP [
33], and VEDAI [
34]. The significant challenge for the cooperative detection of RGB and infrared is how to fuse the two modalities’ information effectively. Previous works have explored fusion strategies at different stages, which can be mainly divided into early fusion, mid-fusion, and late fusion [
18,
20,
35,
36], as illustrated in
Figure 3.
Early fusion is designed to fuse RGB and infrared images before feeding pictures into the object-detection network (cf.
Figure 3a). A native way is to concatenate the pair RGB and IR images into a four-channel input [
37], but this fusion method is too rough. A high-level approach is intended to fuse RGB and infrared images into a new picture. Fu et al. [
38] decomposed RGB and infrared images into multiple sets of high-frequency and low-frequency features by training a neural network, then added the corresponding features of the two modalities to form a fusion image. Zhao et al. [
39] implements a fusion network for RGB and infrared images based on an auto-encoder (AE). Liu et al. [
22] adopt a generative adversarial network (GAN) for image fusion, where an object discriminator distinguishes foreground objects from the infrared image, and a detail discriminator extracts background texture from the RGB image. However, early fusion is not an end-to-end strategy, and the image generated by fusion is not necessarily beneficial for the object-detection task. In addition, as shown in
Figure 1b, it is more complicated to troubleshoot the misaligned issue for fused images.
Mid-fusion is designed to feed RGB and infrared images into dual-branch feature extraction networks, then fuse their features downstream of the network [
40], as shown in
Figure 3b. Zhang et al. [
7] proposed a guided attention feature fusion (GAFF) method, which takes the prediction of the targets’ mask as a subtask and regards the two modalities’ masks as guidance for the attention of intra- and inter-modal. F et al. [
19] designed a cross-modal feature fusion structure based on the transformer, the network can naturally perform intra- and inter-modal fusion because of the self-attention [
41] mechanism. Mid-fusion works mainly focused on where to fuse multi-modal features and the structure of fusion modules [
32,
42], ignoring the problem of misalignment and domain discrepancy, which limited the fusion effect. The misaligned RGB-Infrared object detection via adaptive dual-discrepancy calibration, which is our proposed methodology, belongs to the category of mid-fusion.
Late fusion is designed to post-process outputs of two independent object-detection networks to obtain the final result, as illustrated in
Figure 3c. Actually, it is ensemble technology. The ensemble is a well-proven method, which is commonly used in engineering to improve performance [
43,
44,
45]. A straightforward manner of the ensemble is intended to pool the results of multiple detectors and then use non-maximum suppression (NMS) [
46,
47] to conceal overlapping detections. However, the NMS method fails to gain helpful information from the low-scoring modality. A recent work (ProbEn [
8]) explores this issue, considering that the suppressed bounding box should enhance the confidence of the preferred bounding box, in turn [
48]. Based on this assumption, Chen et al. [
8] proposed a probabilistic ensembling technique and achieved excellent performance. Nevertheless, the misaligned image pair is still a challenge. The method ProbEn relies on the performance of multiple detectors, and the misaligned modality cannot train a well-performing detector, which will drag down the result of the ensemble. Some ensemble methods are proposed in earlier studies, such as score-averaging [
49] and max-voting [
50], which also suffer from the same problem. In addition, late fusion requires more computational resources and more time on inferencing than mid-fusion.
Domain discrepancy: The works discussed above are all based on supervised learning. There are some unsupervised domain adaptation works that have studied the issue of domain discrepancy [
51,
52]. For instance, Kan et al. proposed a bi-shifting auto-encoder network that exploits the nonlinearity of the encoder network to enable it to transform samples between domains that may be far apart, while sparse representation constraints ensure semantic consistency [
53]. Ye et al. proposed a domain adaption model for SAR image retrieval by learning the domain-invariant feature between SAR images and optical aerial images [
54]. Jiang et al. proposed an adversarial regressive domain adaptation approach to achieve infrared thermography-based cross-domain remaining useful life prediction by effectively aligning marginal and conditional distributions [
55]. The above works mainly discover commonalities between the source and target domains. However, the fusion detection based on RGB-IR aims to extract their complementary information.
5. Conclusions and Discussion
In this paper, we propose an adaptive dual-discrepancy calibration network (ADCNet) for misaligned RGB-Infrared object detection to address the issues of spatial misalignment and domain discrepancies between RGB and infrared modalities. Specifically, the adaptive spatial discrepancy calibration module drives the spatial alignment of RGB and infrared features to alleviate the localization error introduced by misaligned images. Then, we design a domain-discrepancy calibration module, which separately aligns object and background features from different modalities, making the fusion features easier for the network to distinguish the object and background to improve the performance of object detection. Comprehensive experimental results on two misaligned RGB-Infrared detection datasets demonstrate the effectiveness of our proposed method. In addition, ablation experiments of the hyperparameters and variance reports of multiple experiments verify that our proposed method has stable performance. The migration experiment between datasets verified that our method has good transferability. At the same time, our method is not heavily dependent on the amount of training data. The above performance further demonstrates the superiority of our ADCNet.
Manual calibration of misalignment between RGB and infrared images is a labor-intensive task, making adaptive calibration methods crucial in the field of RGB-Infrared object detection. In future work, we will broaden the research scope to encompass additional modalities, including LiDAR, SAR, and text, aiming to enhance object-detection performance by leveraging the synergistic potential of more modalities. Additionally, the employment of large language models has demonstrated remarkable performance in various object-detection tasks, such as CLIP-based open vocabulary object detection, text-guided object detection, etc. We believe that introducing CLIP into fusion detection based on RGB-IR would be a promising research avenue.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}