


Simulation-Based Self-Supervised Line Extraction for LiDAR Odometry in Urban Road Scenes
 , ,
, ,  and
and
Abstract
:1. Introduction
- (1)
- a heuristic simulated dataset construction strategy is proposed, with characteristics that are very similar to those of the real scenes;
- (2)
- a model transferring strategy is adopted to transfer the model from the simulated dataset to real scans;
- (3)
- experiments on the KITTI Odometry Dataset and the Apollo SouthBay show that this method can effectively extract reliable lines in road scenes by model transferring on few simulated data;
- (4)
- experiments show that using the extracted lines as input for LiDAR odometry in urban road scenes can greatly improve its accuracy and efficiency, especially cimbined with deep learning-based networks.
2. Related Works
2.1. LiDAR Odometry
2.2. Line Extraction
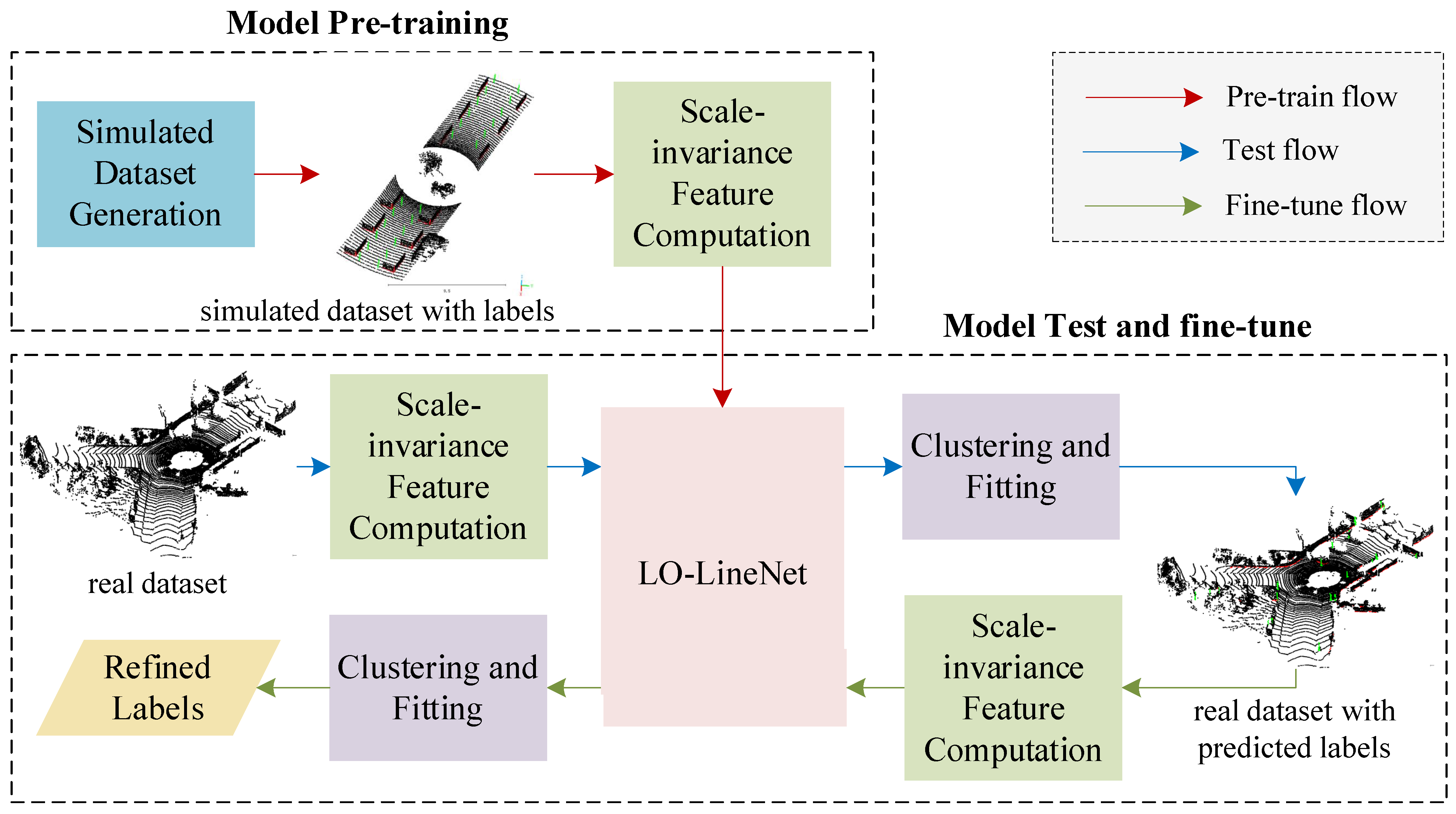
3. Methodology
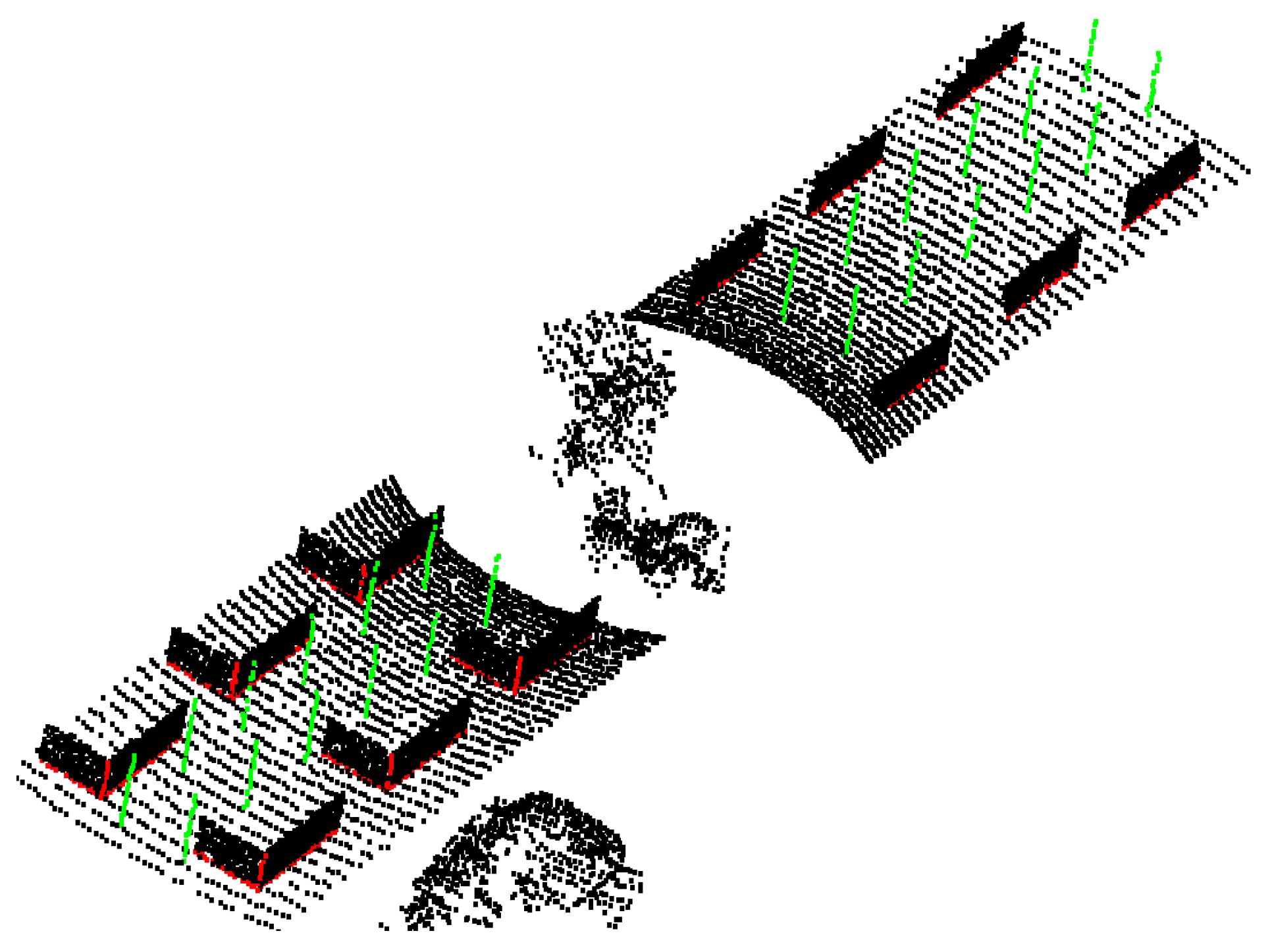
3.1. Simulated Dataset Construction
3.2. Scale-Invariant Feature Computation
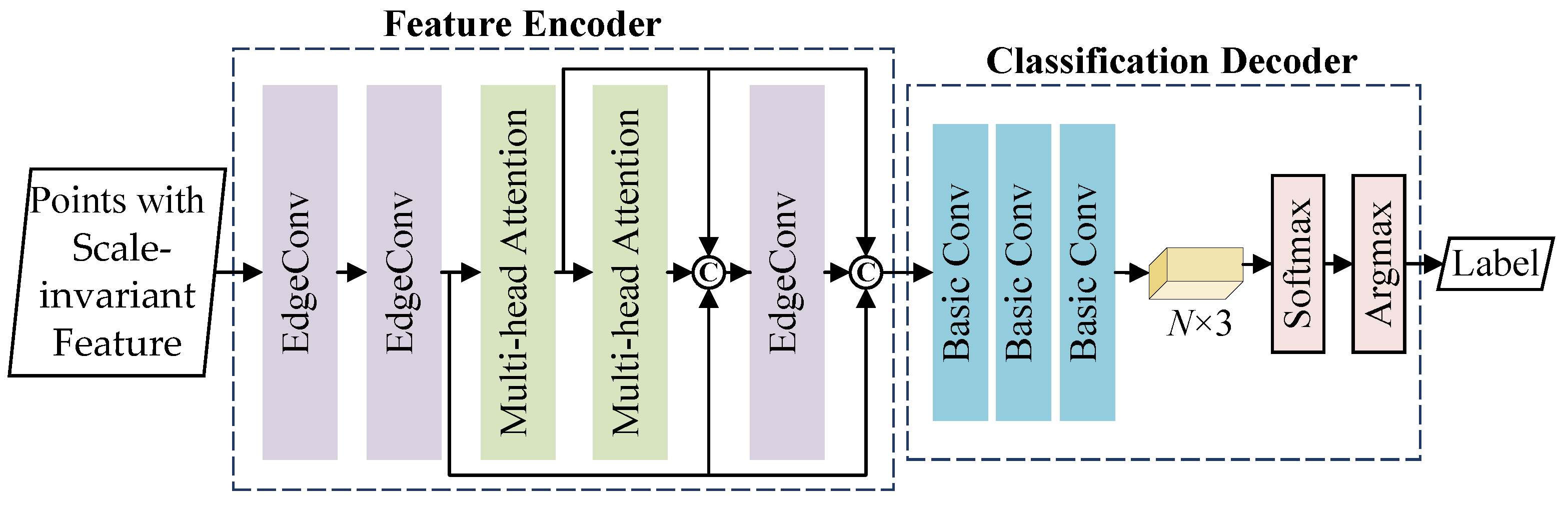
3.3. Network Architecture
3.4. Loss Function
3.5. Model Transferring
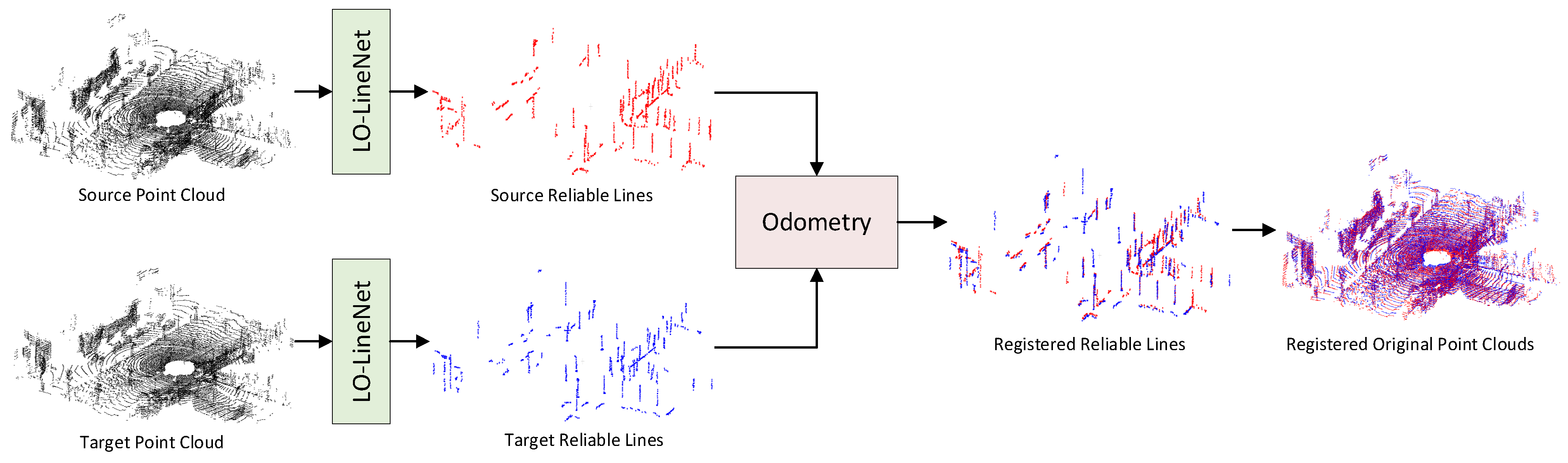
4. LiDAR Odometry
5. Dataset, Experimental Setting, and Metrics
6. Experimental Results
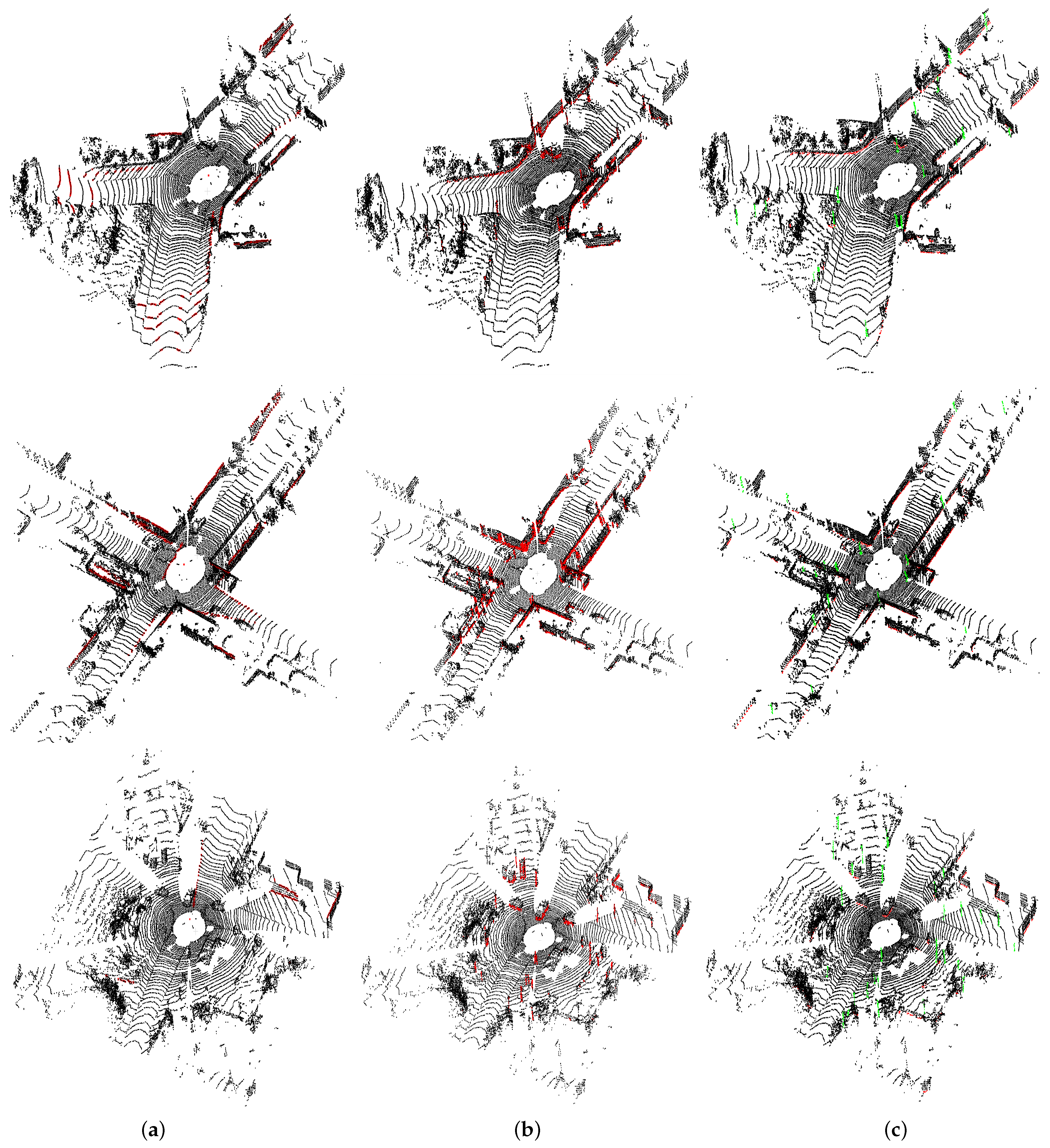
6.1. Results of Reliable Line Extraction
6.2. Effect of Model Transferring
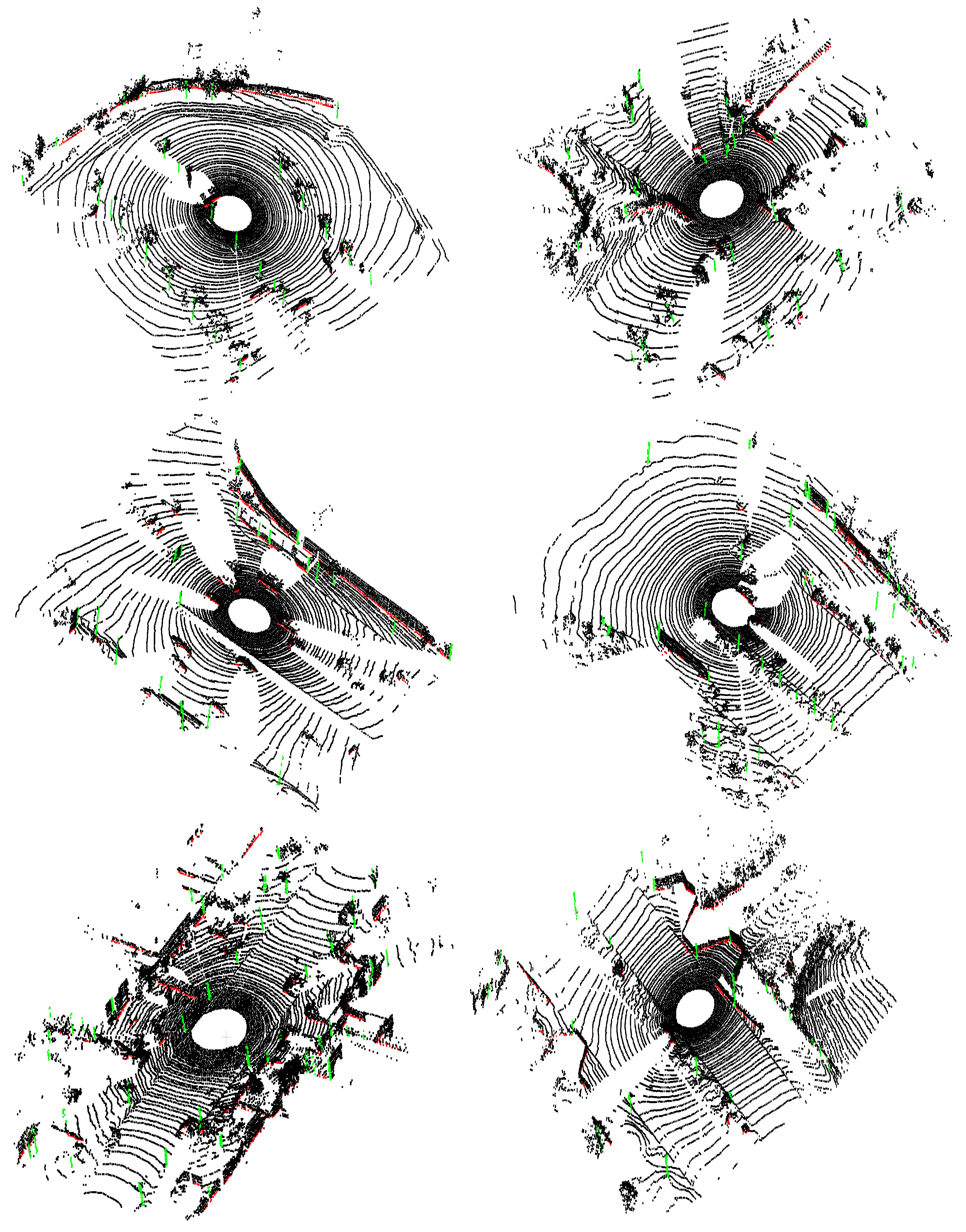
6.3. Generalization on Unseen Dataset
6.4. Accuracy of LiDAR Odometry
6.4.1. Accuracy of the KITTI Odometry Dataset
6.4.2. Accuracy of the Apollo SouthBay Dataset
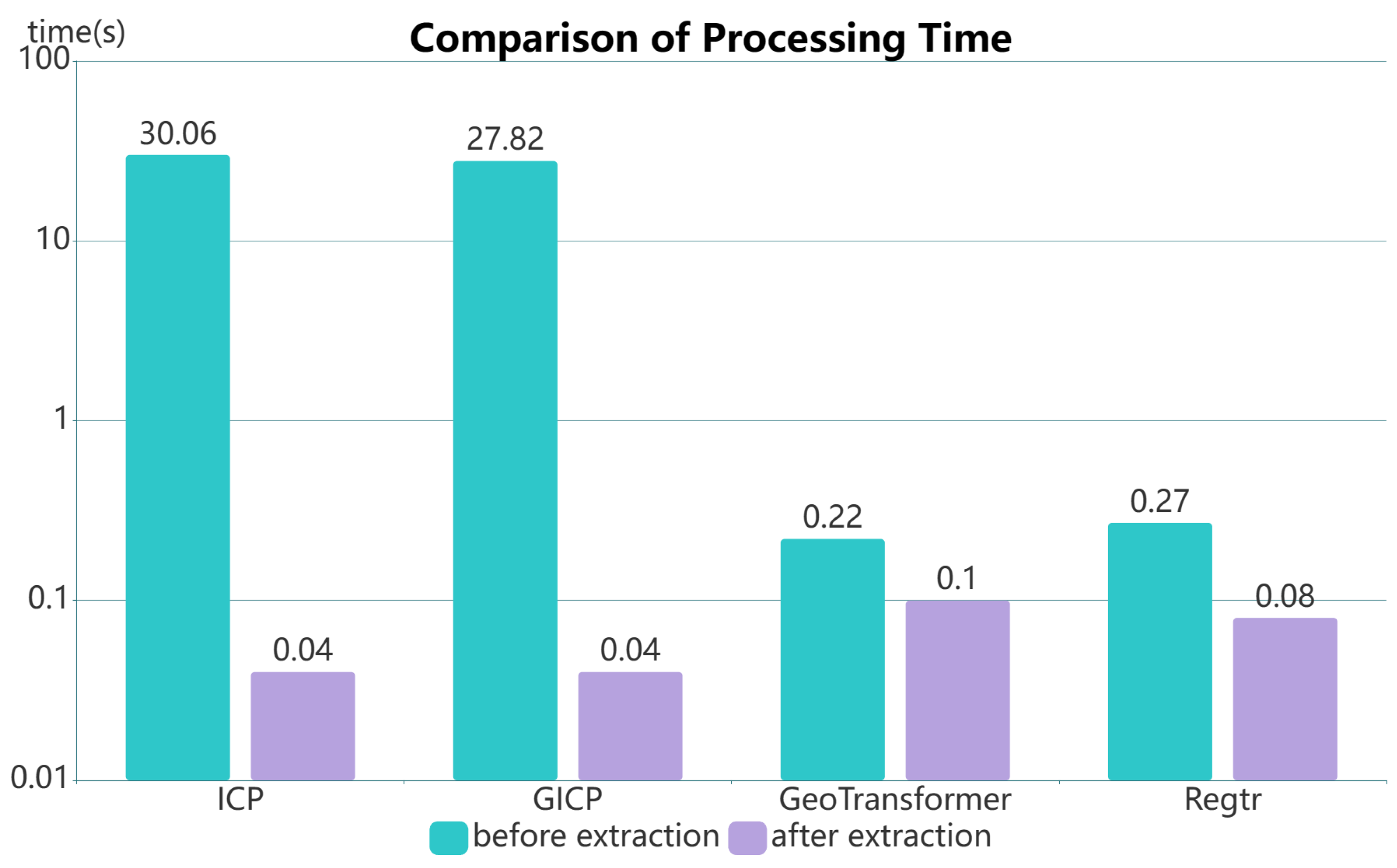
6.5. Running Memory and Efficiency of LiDAR Odometry
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Liu, Y.; Hu, Q.; Wang, B.; Chen, J.; Dong, Z.; Guo, Y.; Wang, W.; Yang, B. RoReg: Pairwise Point Cloud Registration With Oriented Descriptors and Local Rotations. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10376–10393. [Google Scholar] [CrossRef]
- Balsa-Barreiro, J.; Fritsch, D.; Bebis, G.; Boyle, R.; Parvin, B.; Koracin, D.; Pavlidis, I.; Feris, R.; McGraw, T.; Elendt, M.; et al. Generation of 3D/4D Photorealistic Building Models. The Testbed Area for 4D Cultural Heritage World Project: The Historical Center of Calw (Germany). Adv. Vis. Comput. 2015, 9474, 361–372. [Google Scholar] [CrossRef]
- Balsa-Barreiro, J.; Fritsch, D. Generation of visually aesthetic and detailed 3D models of historical cities by using laser scanning and digital photogrammetry. Digit. Appl. Archaeol. Cult. Herit. 2018, 8, 57–64. [Google Scholar] [CrossRef]
- Liu, S.; Wang, T.; Zhang, Y.; Zhou, R.; Dai, C.; Zhang, Y.; Lei, H.; Wang, H. Rethinking of learning-based 3D keypoints detection for large-scale point clouds registration. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102944. [Google Scholar] [CrossRef]
- Wei, H.; Qiao, Z.; Liu, Z.; Suo, C.; Yin, P.; Shen, Y.; Li, H.; Wang, H. End-to-End 3D Point Cloud Learning for Registration Task Using Virtual Correspondences. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 2678–2683. [Google Scholar] [CrossRef]
- Lu, W.; Wan, G.; Zhou, Y.; Fu, X.; Yuan, P.; Song, S. DeepVCP: An End-to-End Deep Neural Network for Point Cloud Registration. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 12–21. [Google Scholar] [CrossRef]
- Nubert, J.; Khattak, S.; Hutter, M. Self-supervised Learning of LiDAR Odometry for Robotic Applications. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 9601–9607. [Google Scholar] [CrossRef]
- Mi, X.; Yang, B.; Dong, Z. Fast Visibility Analysis and Application in Road Environment with Mobile Laser Scanning Data. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 258–264. [Google Scholar] [CrossRef]
- Wang, G.; Wu, X.; Jiang, S.; Liu, Z.; Wang, H. Efficient 3D Deep LiDAR Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5749–5765. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Chen, S.; Wang, C.; Li, X.; Wen, C.; Cheng, M.; Li, J. LO-Net: Deep Real-Time Lidar Odometry. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8465–8474. [Google Scholar] [CrossRef]
- Wang, G.; Wu, X.; Liu, Z.; Wang, H. PWCLO-Net: Deep LiDAR Odometry in 3D Point Clouds Using Hierarchical Embedding Mask Optimization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15905–15914. [Google Scholar] [CrossRef]
- Wang, Y.; Solomon, J. Deep Closest Point: Learning Representations for Point Cloud Registration. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3522–3531. [Google Scholar] [CrossRef]
- Choy, C.; Dong, W.; Koltun, V. Deep Global Registration. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2511–2520. [Google Scholar] [CrossRef]
- Bai, X.; Luo, Z.; Zhou, L.; Chen, H.; Li, L.; Hu, Z.; Fu, H.; Tai, C.L. PointDSC: Robust Point Cloud Registration using Deep Spatial Consistency. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15854–15864. [Google Scholar] [CrossRef]
- Yew, Z.J.; Lee, G.H. REGTR: End-to-end Point Cloud Correspondences with Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6667–6676. [Google Scholar] [CrossRef]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Xiaowei, Z. LoFTR: Detector-Free Local Feature Matching with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar] [CrossRef]
- Liu, L.; Xiao, J.; Wang, Y.; Lu, Z.; Wang, Y. A Novel Rock-Mass Point Cloud Registration Method Based on Feature Line Extraction and Feature Point Matching. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Liu, L.; Li, H.; Yao, H.; Zha, R. PlückerNet: Learn to Register 3D Line Reconstructions. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1842–1852. [Google Scholar] [CrossRef]
- Xu, E.; Xu, Z.; Yang, K. Using 2-Lines Congruent Sets for Coarse Registration of Terrestrial Point Clouds in Urban Scenes. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Lu, X.; Liu, Y.; Li, K. Fast 3D Line Segment Detection From Unorganized Point Cloud. arXiv 2019, arXiv:1901.02532. [Google Scholar]
- Zhao, X.; Yang, S.; Huang, T.; Chen, J.; Ma, T.; Li, M.; Liu, Y. SuperLine3D: Self-supervised Line Segmentation and Description for LiDAR Point Cloud. In Proceedings of the ECCV, 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Volume 13669, pp. 263–279. [Google Scholar] [CrossRef]
- Besl, P.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NeurIPS. Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Choy, C.; Park, J.; Koltun, V. Fully Convolutional Geometric Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8957–8965. [Google Scholar] [CrossRef]
- Yuan, W.; Eckart, B.; Kim, K.; Jampani, V.; Fox, D.; Kautz, J. DeepGMR: Learning Latent Gaussian Mixture Models for Registration. In Proceedings of the ECCV, 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 733–750. [Google Scholar] [CrossRef]
- Huang, S.; Gojcic, Z.; Usvyatsov, M.; Wieser, A.; Schindler, K. PREDATOR: Registration of 3D Point Clouds with Low Overlap. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4265–4274. [Google Scholar] [CrossRef]
- Fischer, K.; Simon, M.; Ölsner, F.; Milz, S.; Groß, H.M.; Mäder, P. StickyPillars: Robust and Efficient Feature Matching on Point Clouds using Graph Neural Networks. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 313–323. [Google Scholar] [CrossRef]
- Qin, Z.; Yu, H.; Wang, C.; Guo, Y.; Peng, Y.; Xu, K. Geometric Transformer for Fast and Robust Point Cloud Registration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11133–11142. [Google Scholar] [CrossRef]
- Wang, H.; Liu, X.; Kang, W.; Yan, Z.; Wang, B.; Ning, Q. Multi-features guidance network for partial-to-partial point cloud registration. Neural Comput. Appl. 2022, 34, 1623–1634. [Google Scholar] [CrossRef]
- Zhu, L.; Hyyppä, J. Fully-Automated Power Line Extraction from Airborne Laser Scanning Point Clouds in Forest Areas. Remote Sens. 2014, 6, 11267–11282. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Liu, L.; Zheng, D.; Li, C.; Li, K. Supervised Classification of Power Lines from Airborne LiDAR Data in Urban Areas. Remote Sens. 2017, 9, 771. [Google Scholar] [CrossRef]
- Zhou, R.; Jiang, W.; Jiang, S. A Novel Method for High-Voltage Bundle Conductor Reconstruction from Airborne LiDAR Data. Remote Sens. 2018, 10, 2051. [Google Scholar] [CrossRef]
- Jiang, T.; Wang, Y.; Zhang, Z.; Liu, S.; Dai, L.; Yang, Y.; Jin, X.; Zeng, W. Extracting 3-D Structural Lines of Building From ALS Point Clouds Using Graph Neural Network Embedded With Corner Information. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–28. [Google Scholar] [CrossRef]
- Fang, L.; Huang, Z.; Luo, H.; Chen, C. Solid Lanes Extraction from Mobile Laser Scanning Point CLouds. Acta Geod. Cartogr. Sin. 2019, 48, 960–974. [Google Scholar]
- Zhang, W.; Chen, L.; Xiong, Z.; Zang, Y.; Li, J.; Zhao, L. Large-scale point cloud contour extraction via 3D guided multi-conditional generative adversarial network. ISPRS J. Photogramm. Remote Sens. 2020, 164, 97–105. [Google Scholar] [CrossRef]
- Hu, Z.; Chen, C.; Yang, B.; Wang, Z.; Ma, R.; Wu, W.; Sun, W. Geometric feature enhanced line segment extraction from large-scale point clouds with hierarchical topological optimization. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102858. [Google Scholar] [CrossRef]
- Soria, X.; Riba, E.; Sappa, A. Dense Extreme Inception Network: Towards a Robust CNN Model for Edge Detection. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; pp. 1912–1921. [Google Scholar] [CrossRef]
- Almazàn, E.J.; Tal, R.; Qian, Y.; Elder, J.H. MCMLSD: A Dynamic Programming Approach to Line Segment Detection. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5854–5862. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NeurIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Segal, A.; Hähnel, D.; Thrun, S. Generalized-ICP. In Proceedings of the RSS, University of Washington, Seattle, WA, USA, 28 June–1 July 2009. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Lu, W.; Zhou, Y.; Wan, G.; Hou, S.; Song, S. L3-net: Towards learning based lidar localization for autonomous driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6389–6398. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Low-drift and real-time lidar odometry and mapping. Auton. Robot. 2017, 41, 401–416. [Google Scholar] [CrossRef]
- Velas, M.; Spanel, M.; Herout, A. Collar Line Segments for fast odometry estimation from Velodyne point clouds. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4486–4495. [Google Scholar] [CrossRef]
- Velas, M.; Spanel, M.; Hradis, M.; Herout, A. CNN for IMU assisted odometry estimation using velodyne LiDAR. In Proceedings of the 2018 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Torres Vedras, Portugal, 25–27 April 2018; pp. 71–77. [Google Scholar] [CrossRef]
- Low, K.L. Linear Least-Squares Optimization for Point-to-Plane ICP Surface Registration; University of North Carolina: Chapel Hill, NC, USA, 2004. [Google Scholar]
- Todor, S.; Martin, M.; Henrik, A.; Achim, J.L. Fast and accurate scan registration through minimization of the distance between compact 3D NDT representations. Int. J. Robot. Res. 2012, 31, 1377–1393. [Google Scholar] [CrossRef]
- Xu, Y.; Huang, Z.; Lin, K.; Zhu, X.; Shi, J.; Bao, H.; Zhang, G.; Li, H. SelfVoxeLO: Self-supervised LiDAR Odometry with Voxel-based Deep Neural Networks. In Proceedings of the 4th Conference on Robot Learning, PMLR, Cambridge, MA, USA, 16–18 November 2020; Volume 155, pp. 115–125. [Google Scholar]
- Xu, Y.; Lin, J.; Shi, J.; Zhang, G.; Wang, X.; Li, H. Robust Self-Supervised LiDAR Odometry Via Representative Structure Discovery and 3D Inherent Error Modeling. IEEE Robot. Autom. Lett. 2022, 7, 1651–1658. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Distances | 3714 | 4268 | 5075 | 563 | 397 | 2223 | 1239 | 695 | 3225 | 1717 | 919 |
| Frame | 4541 | 1101 | 4661 | 801 | 271 | 2761 | 1101 | 1101 | 4071 | 1591 | 1201 |
| Max speed | 46 | 96 | 49 | 31 | 56 | 48 | 51 | 39 | 43 | 52 | 51 |
| Environment | Urban | Highway | Mixed | Country | Country | Urban | Urban | Urban | Mixed | Mixed | Mixed |
| Route | Baylands to Seafood | Mathilda AVE | Columbia Park | San Jose Downtown | Highway 237 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Sequence | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 |
| Distance | 4435 | 6254 | 9990 | 9741 | 8825 | 14,675 | 3420 | 6285 | 3204 | 9695 | 12,175 |
| Frame | 6443 | 7538 | 10,903 | 11,846 | 14,014 | 20,801 | 9765 | 16,596 | 9868 | 4701 | 5677 |
| Max speed | 74 | 68 | 67 | 74 | 44 | 48 | 37 | 45 | 37 | 105 | 100 |
| Environment | Highway | Highway | Highway | Highway | Urban | Urban | Urban | Urban | Urban | Highway | Highway |
| Method | Metrics | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full LOAM [44] | 0.78 | 1.43 | 0.92 | 0.86 | 0.71 | 0.57 | 0.65 | 0.63 | 1.12 | 0.77 | 0.79 | 0.84 | |
| 0.53 | 0.55 | 0.55 | 0.65 | 0.50 | 0.38 | 0.39 | 0.50 | 0.44 | 0.48 | 0.57 | 0.50 | ||
| Full A-LOAM | 0.76 | 1.97 | 4.53 | 0.93 | 0.62 | 0.48 | 0.61 | 0.43 | 1.06 | 0.73 | 1.02 | 1.19 | |
| 0.31 | 0.50 | 1.45 | 0.49 | 0.39 | 0.25 | 0.28 | 0.26 | 0.32 | 0.31 | 0.40 | 0.45 | ||
| A-LOAM | 4.08 | 3.31 | 7.33 | 4.31 | 1.60 | 4.09 | 1.03 | 2.89 | 4.82 | 5.76 | 3.61 | 3.89 | |
| 1.69 | 0.92 | 2.51 | 2.11 | 1.13 | 1.68 | 0.52 | 1.80 | 2.08 | 1.85 | 1.76 | 1.64 | ||
| CLS [45] | 2.11 | 4.22 | 2.29 | 1.63 | 1.59 | 1.98 | 0.92 | 1.04 | 2.14 | 1.95 | 3.46 | 2.12 | |
| 0.95 | 1.05 | 0.86 | 1.09 | 0.71 | 0.92 | 0.46 | 0.73 | 1.05 | 0.92 | 1.28 | 0.91 | ||
| Velas et al. [46] | 3.02 | 4.44 | 3.42 | 4.94 | 1.77 | 2.35 | 1.88 | 1.77 | 2.89 | 4.94 | 3.27 | 3.15 | |
| NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | ||
| LO-Net [6] | 1.47 | 1.36 | 1.52 | 1.03 | 0.51 | 1.04 | 0.71 | 1.70 | 2.12 | 1.37 | 1.80 | 1.33 | |
| 0.72 | 0.47 | 0.71 | 0.66 | 0.65 | 0.69 | 0.50 | 0.89 | 0.77 | 0.58 | 0.93 | 0.69 | ||
| ICP-po2pl [47] | 3.80 | 13.53 | 9.00 | 2.72 | 2.96 | 2.29 | 1.77 | 1.55 | 4.42 | 3.95 | 6.13 | 4.74 | |
| 1.73 | 2.58 | 2.74 | 1.63 | 2.58 | 1.08 | 1.00 | 1.42 | 2.14 | 1.71 | 2.60 | 1.93 | ||
| ICP-po2po [22] | 6.88 | 11.21 | 8.21 | 11.07 | 6.64 | 3.97 | 1.95 | 5.17 | 10.04 | 6.92 | 8.91 | 7.36 | |
| 2.99 | 2.58 | 3.39 | 5.05 | 4.02 | 1.93 | 1.59 | 3.35 | 4.93 | 2.89 | 4.74 | 3.41 | ||
| ICP-po2po * [22] | 6.27 | 31.16 | 8.83 | 4.73 | 7.28 | 3.98 | 5.44 | 5.09 | 9.31 | 6.32 | 8.38 | 8.80 | |
| 2.76 | 3.18 | 3.15 | 4.26 | 4.88 | 1.83 | 1.97 | 2.27 | 3.07 | 2.30 | 3.64 | 3.03 | ||
| GICP [41] | 1.29 | 4.39 | 2.53 | 1.68 | 3.76 | 1.02 | 0.92 | 0.64 | 1.58 | 1.97 | 1.31 | 1.92 | |
| 0.64 | 0.91 | 0.77 | 1.08 | 1.07 | 0.54 | 0.46 | 0.45 | 0.75 | 0.77 | 0.62 | 0.73 | ||
| GICP * [41] | 2.96 | 19.77 | 3.59 | 2.80 | 3.59 | 2.23 | 2.31 | 1.82 | 3.33 | 4.25 | 2.88 | 4.50 | |
| 1.61 | 2.16 | 2.07 | 1.86 | 2.07 | 0.92 | 1.32 | 1.24 | 1.46 | 1.52 | 1.89 | 1.65 | ||
| GeoTransformer [28] | 2.20 | 3.23 | 7.42 | 4.99 | 3.30 | 2.11 | 3.00 | 2.52 | 2.52 | 3.58 | 3.29 | 3.47 | |
| 0.80 | 0.90 | 1.62 | 1.46 | 0.48 | 0.88 | 1.21 | 2.32 | 0.96 | 1.24 | 1.39 | 1.21 | ||
| GeoTransformer * [28] | 2.55 | 2.85 | 2.99 | 1.96 | 1.58 | 2.71 | 1.16 | 2.15 | 3.94 | 5.74 | 4.18 | 2.89 | |
| 1.42 | 2.29 | 1.26 | 0.98 | 0.94 | 1.46 | 0.71 | 1.40 | 1.83 | 5.23 | 1.77 | 1.76 | ||
| RegTR [15] | 2.23 | 5.03 | 3.19 | 1.92 | 2.40 | 3.24 | 1.51 | 11.33 | 5.13 | 7.42 | 5.55 | 4.45 | |
| 1.10 | 1.40 | 1.21 | 0.82 | 0.88 | 1.42 | 0.79 | 2.06 | 3.78 | 3.00 | 2.93 | 1.76 | ||
| RegTR * [15] | 1.46 | 2.29 | 1.55 | 1.31 | 0.48 | 0.99 | 1.03 | 1.13 | 2.04 | 2.36 | 1.86 | 1.50 | |
| 0.77 | 0.61 | 0.65 | 0.73 | 0.39 | 0.51 | 0.50 | 0.95 | 0.94 | 0.92 | 0.88 | 0.71 |
| Method | Metrics | Baylands ToSeafood | MathildaAVE | ColumbiaPark | SanJose Downtown | Highway237 | Average |
|---|---|---|---|---|---|---|---|
| ICP-po2pl [47] | NA | NA | NA | NA | NA | 7.75 | |
| NA | NA | NA | NA | NA | 1.20 | ||
| NDT-P2D [48] | NA | NA | NA | NA | NA | 52.70 | |
| NA | NA | NA | NA | NA | 9.40 | ||
| Full LOAM [44] | NA | NA | NA | NA | NA | 5.93 | |
| NA | NA | NA | NA | NA | 0.26 | ||
| Xu et al. [49] | NA | NA | NA | NA | NA | 6.42 | |
| NA | NA | NA | NA | NA | 1.65 | ||
| Xu et al. [49] | NA | NA | NA | NA | NA | 2.25 | |
| NA | NA | NA | NA | NA | 0.25 | ||
| RSLO [50] | NA | NA | NA | NA | NA | 5.99 | |
| NA | NA | NA | NA | NA | 1.58 | ||
| RSLO [50] | NA | NA | NA | NA | NA | 2.17 | |
| NA | NA | NA | NA | NA | 0.24 | ||
| ICP-po2po [22] | NA | NA | NA | NA | NA | 22.80 | |
| NA | NA | NA | NA | NA | 2.35 | ||
| ICP-po2po * [22] | 35.27 | 15.30 | 5.31 | 7.89 | 28.50 | 18.45 (6.60) | |
| 4.63 | 5.45 | 1.59 | 2.62 | 6.80 | 4.21 (2.10) | ||
| GICP [41] | NA | NA | NA | NA | NA | 4.55 | |
| NA | NA | NA | NA | NA | 0.76 | ||
| GICP * [41] | 16.96 | 12.16 | 5.63 | 5.91 | 12.02 | 10.53 (5.77) | |
| 3.29 | 3.37 | 2.08 | 2.53 | 1.98 | 2.65 (2.30) | ||
| GeoTransformer [28] | 26.83 | 16.78 | 4.82 | 8.44 | 9.65 | 13.30 | |
| 19.45 | 3.18 | 1.77 | 1.51 | 1.79 | 5.54 | ||
| GeoTransformer * [28] | 25.21 | 12.00 | 3.76 | 4.59 | 35.06 | 16.12 (4.17) | |
| 15.49 | 4.74 | 1.53 | 1.62 | 18.87 | 8.45 (1.57) | ||
| RegTR [15] | 63.07 | 61.52 | 31.56 | 75.21 | 71.26 | 60.52 | |
| 16.89 | 17.63 | 11.46 | 25.43 | 11.93 | 16.66 | ||
| RegTR * [15] | 14.11 | 3.86 | 2.44 | 2.59 | 12.06 | 7.01 (2.51) | |
| 3.03 | 1.06 | 0.90 | 0.89 | 1.55 | 1.48 (0.89) |
| Number of Points | Running Memory | |
|---|---|---|
| before extraction | 20,000 | 20,000 MiB |
| after extraction | 1000 | 2000 MiB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Zhou, R.; Dai, C.; Wang, H.; Jiang, W.; Zhang, Y. Simulation-Based Self-Supervised Line Extraction for LiDAR Odometry in Urban Road Scenes. Remote Sens. 2023, 15, 5322. https://doi.org/10.3390/rs15225322
Wang P, Zhou R, Dai C, Wang H, Jiang W, Zhang Y. Simulation-Based Self-Supervised Line Extraction for LiDAR Odometry in Urban Road Scenes. Remote Sensing. 2023; 15(22):5322. https://doi.org/10.3390/rs15225322
Chicago/Turabian StyleWang, Peng, Ruqin Zhou, Chenguang Dai, Hanyun Wang, Wanshou Jiang, and Yongsheng Zhang. 2023. "Simulation-Based Self-Supervised Line Extraction for LiDAR Odometry in Urban Road Scenes" Remote Sensing 15, no. 22: 5322. https://doi.org/10.3390/rs15225322
APA StyleWang, P., Zhou, R., Dai, C., Wang, H., Jiang, W., & Zhang, Y. (2023). Simulation-Based Self-Supervised Line Extraction for LiDAR Odometry in Urban Road Scenes. Remote Sensing, 15(22), 5322. https://doi.org/10.3390/rs15225322