
Multi-Stage Semantic Segmentation Quantifies Fragmentation of Small Habitats at a Landscape Scale


Abstract
:1. Introduction
2. Methods
2.1. Study Area
2.2. Image Data
2.3. Convolutional Neural Network
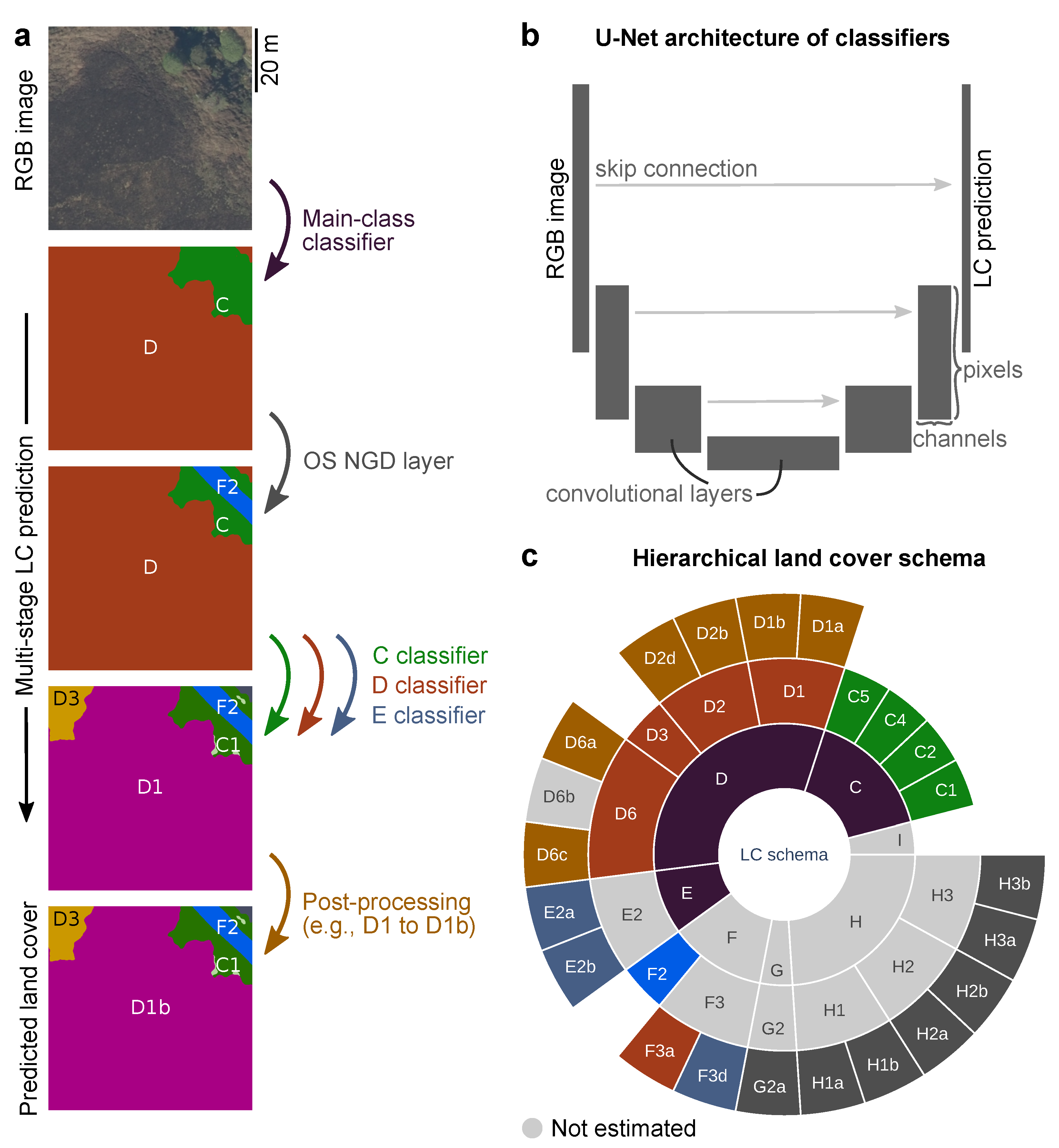
2.4. Land Cover Schema

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LC80-Main | LC80 | LC20 | Name | New? |
|---|---|---|---|---|
| C (Wood and forest land) | C1 | C1 | Broadleaved high forest | - |
| C | C2 | C2 | Coniferous high forest | - |
| C | C4 | C4 | Scrub | - |
| C | C5 | C5 | Clear felled/newly planted trees | - |
| D (Moor and heath land) | D1 | D1a | Upland heath | - |
| D | D1 | D1b | Upland heath, peaty soil | Yes |
| D | D2b | D2b | Upland grass moor | - |
| D | D2d | D2d | Blanket peat grass moor | - |
| D | D3 | D3 | Bracken | .. |
| D | D6a | D6a | Upland heath/grass mosaic | - |
| D | D6c | D6c | Upland heath/blanket peat mosaic | - |
| E (Agro-pastoral land) | E2a | E2a | Improved pasture | - |
| E | E2b | E2b | Rough pasture | - |
| F (Water and wetland) | F2 | F2 | Open water, inland | - |
| F | F3a | F3a | Peat bog | - |
| F | D2/E2 | F3d | Wet grassland and rush pasture | Yes |
| G (Rock and coastal land) | G2 | G2 | Inland bare rock | - |
| H (Developed land) | H1a | H1a | Urban area | - |
| H | H1b | H1b | Major transport route | - |
| H | H2a | H2a | Quarries and mineral working | - |
| H | H2b | H2b | Derelict land | - |
| H | H3a | H3a | Isolated farmsteads | - |
| H | H3b | H3b | Other developed land | - |
| I (Unclassified land) | I | I | Unclassified land | - |
- C3 (mixed high forest)—the aim of the new modelling was to resolve C1 (broadleaved) and C2 (coniferous) at the resolution of single trees, so it was decided to exclude C3 (which would normally consider large parcels of woodlands to be a mix of broadleaved and coniferous trees).
- D4 (unenclosed lowland areas)—the distinction between D4 and E classes is based on whether the land is “enclosed for stock control purposes” [29]. This cannot be done based on 64 m × 64 m image patches as used for input data by the CNNs. D4 was therefore excluded.
- D6b (upland mosaic heath/bracken)—although we have labelled these areas in the train/test data sets, we decided to merge these areas after classification into D3 (bracken). This was done because both D3 and D6b were relatively rare and therefore difficult to learn, while together they provided more data points (though combined, this was still one of the rarest classes).
- D7 (eroded areas)—the large areas of eroded peat (D7a) that were present in the Peak District in the 1991 census [9] have now been revegetated by the establishment of grasses and moorland plants in the past decades [20,40]. The few remaining patches of eroded peat are typically small patches or narrow strips in the bases of gullies.
- D8 (coastal heath)—not present in the Peak District.
- E1 (cultivated land)—this is barely present in the Peak District and was therefore excluded. (And where still present, it is relabelled to E2a).
- F1 (coastal open water), F3b (freshwater marsh), F3c (saltmarsh), G2b (coastal rock) and G3 (other coastal features)—all not present in the Peak District.
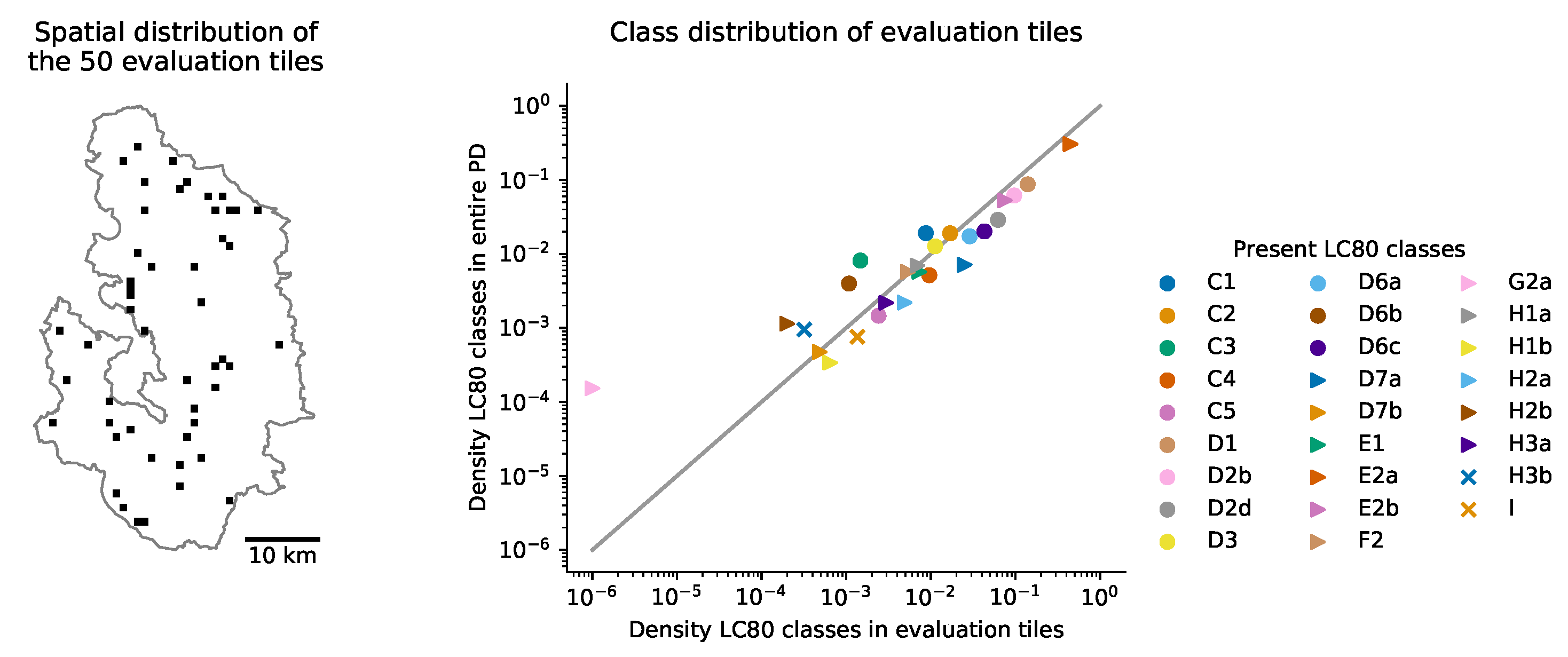
2.5. Selecting Image Patches for Training and Testing
- Training: (geospatial) data that are used to train the CNN classification models. These consist of both input data (aerial imagery) and land cover annotations.
- Testing: data that are used to evaluate the performance of trained CNNs. Importantly, these data are not used to further improve CNN performance nor to assess convergence but only to quantify its final performance. These consist of both input imagery and land cover annotations.
- Prediction: this is the entire area that is classified with the converged model (for further analysis). Only input imagery data are available a priori, from which the model predicts the land cover annotations.
2.6. Land Cover Annotation
2.7. Model Training
2.8. Multi-Stage Semantic Segmentation
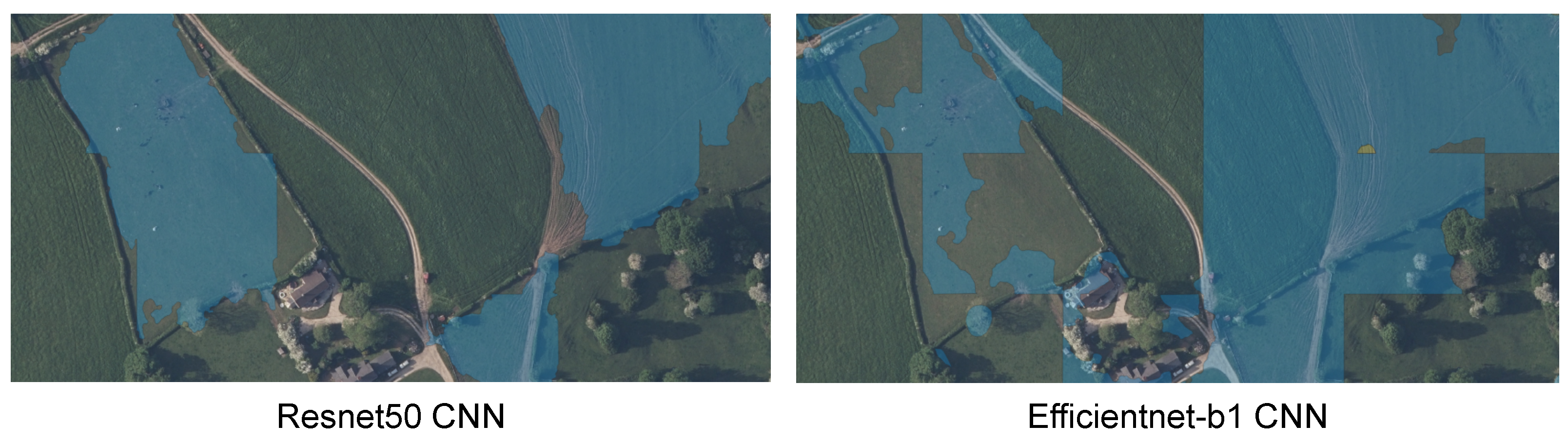
2.9. Single-Stage Semantic Segmentation
2.10. Merger with OS Layer for Developed Land
2.11. Post-Processing of Model Predictions
2.12. Statistics
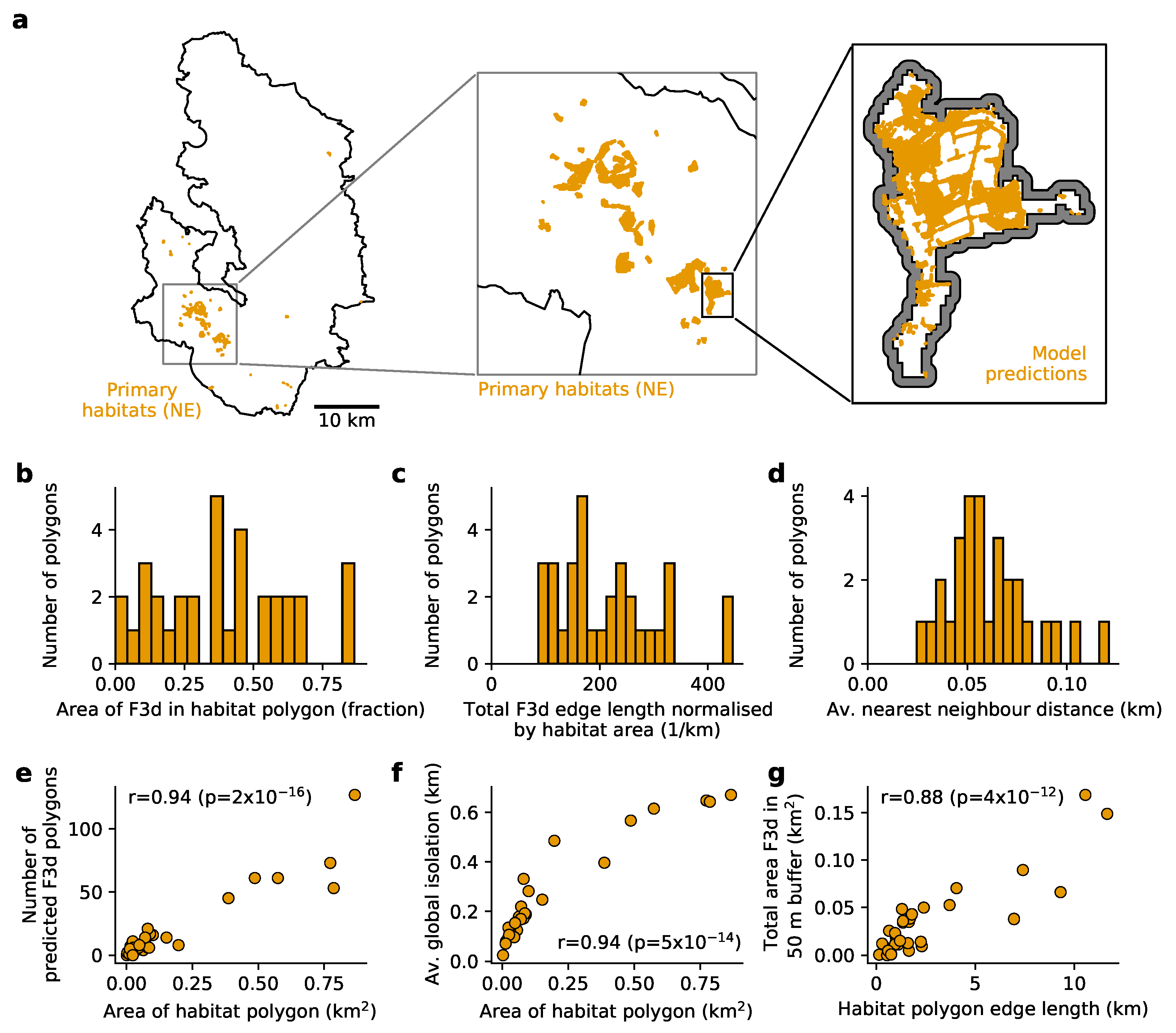
2.13. Habitat Fragmentation Indices
- Area of F3d in habitat polygon (fraction): total area of model-predicted F3d polygons inside one PH polygon.
- Total F3d edge length normalised by habitat area (1/km): sum of edge lengths of model-predicted F3d polygons inside one PH polygon divided by the area of that one PH polygon.
- Average nearest neighbour distance (km): average nearest-neighbour distance between model-predicted F3d polygons inside one PH polygon. PH polygons with fewer than two model-predicted F3d polygons were ignored.
- Number of predicted F3d polygons: number of model-predicted F3d polygons inside one PH polygon.
- Area of habitat polygon (km2): total area of one PH polygon.
- Average global isolation (km): average of global distance of all model-predicted F3d polygons inside one PH polygon, where global distance is the mean distance of the focal model-predicted F3d polygon to all other model-predicted F3d polygons (inside that PH polygon).
- Habitat polygon edge length (km): total edge length of one PH polygon.
- Total area F3d in 50 m buffer (km2): total area of model-predicted F3d within the 50 m buffer zone around one PH polygon.
2.14. Data and Software Availability
3. Results
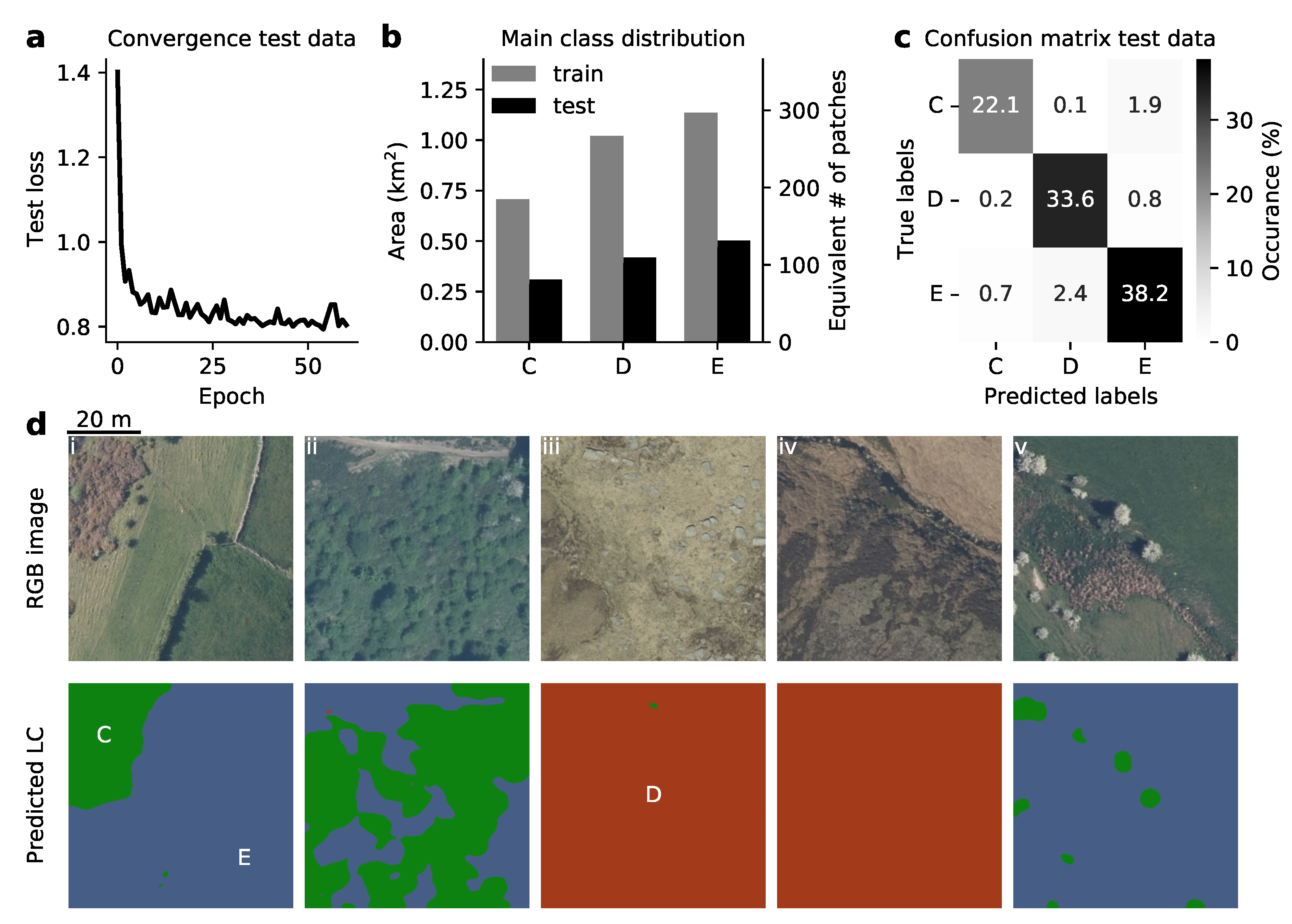
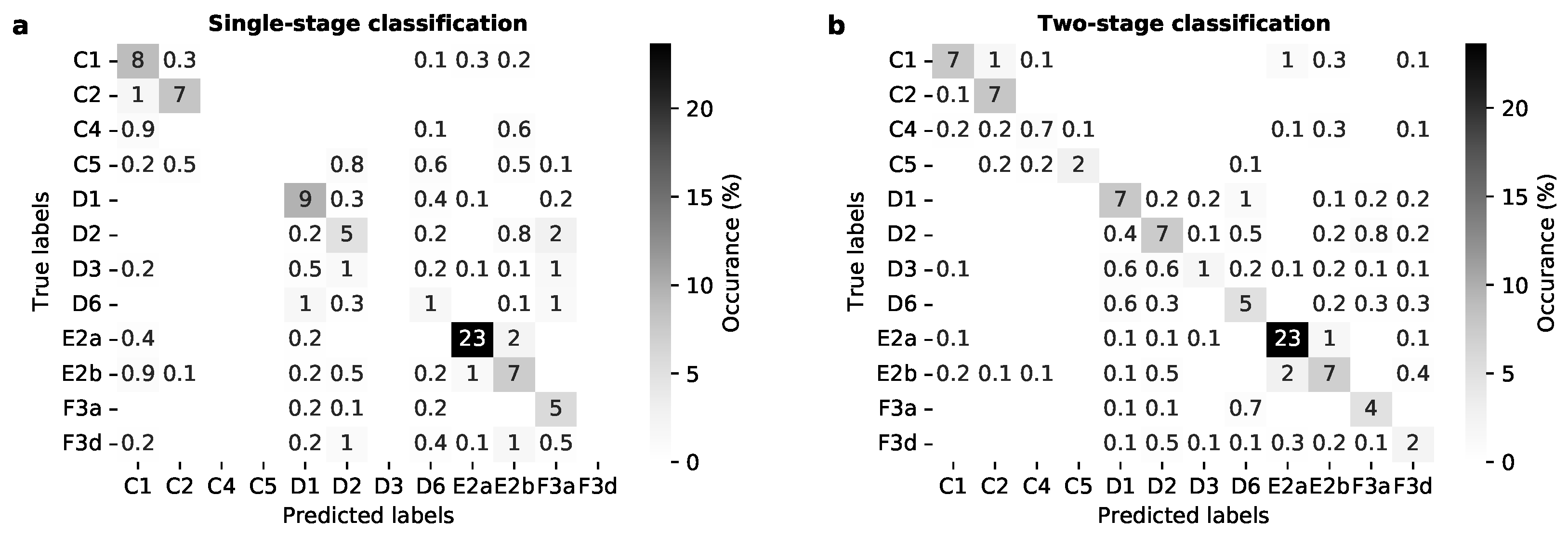
3.1. Multi-Stage Semantic Segmentation
3.2. Semantic Segmentation of Detailed Classes
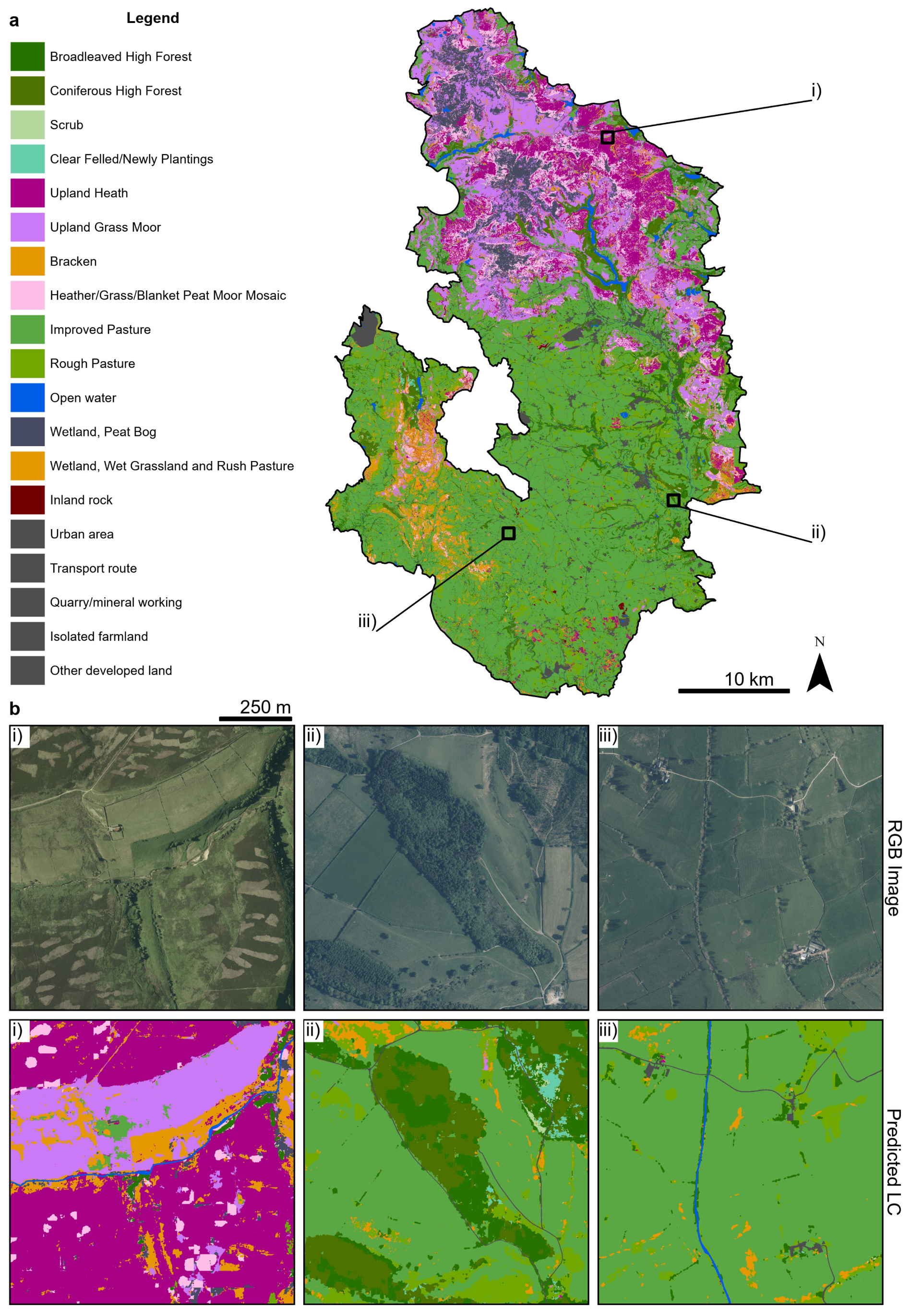
3.3. Land Cover Classification of PDNP
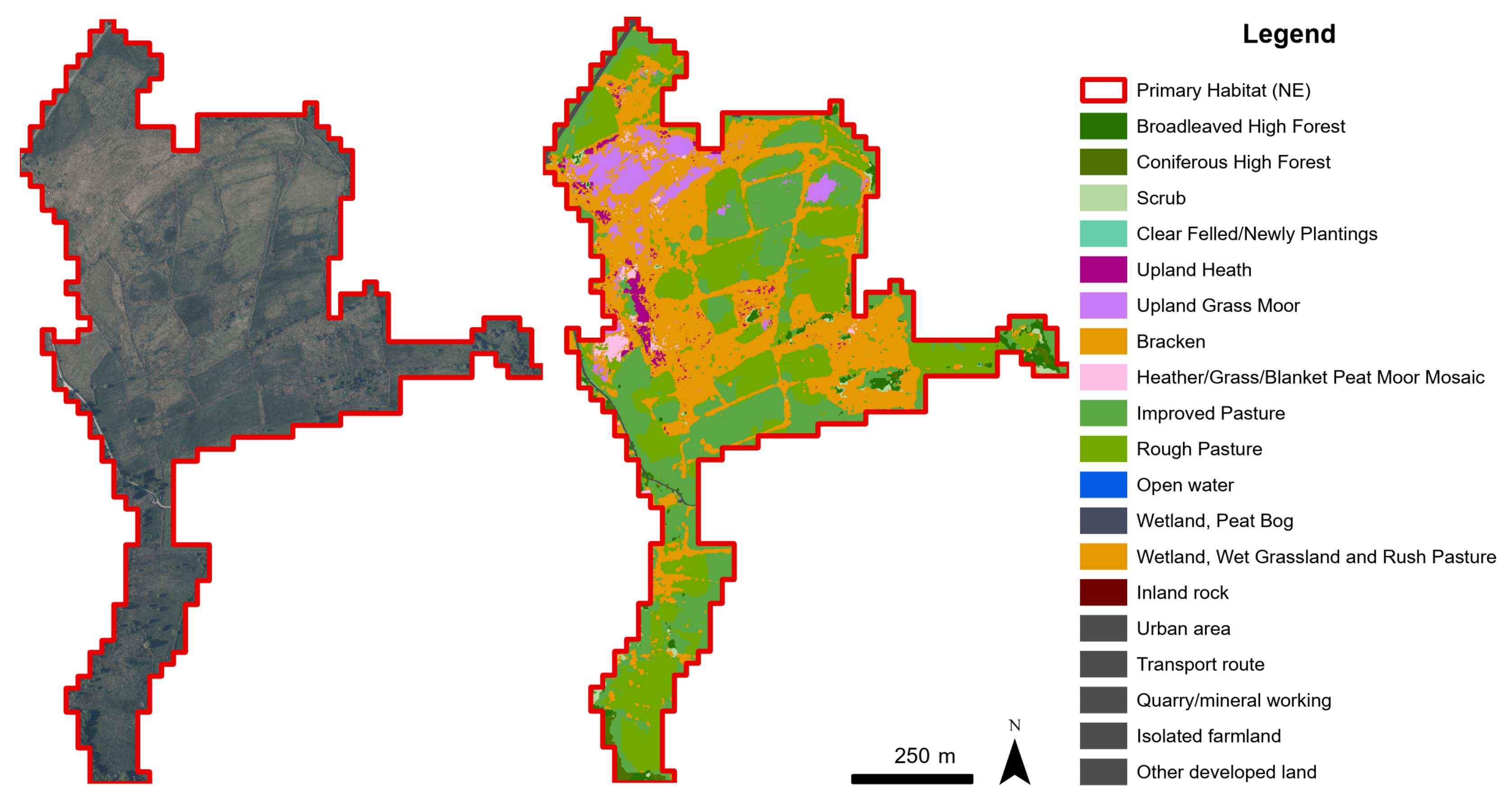
3.4. Wet Grassland and Rush Pasture Habitat Fragmentation at a Landscape Scale
4. Discussion
4.1. Multi-Stage Segmentation Approach
4.2. The Creation of a New LC Benchmark Data Set
4.3. Land Cover Prediction of a UK National Park
4.4. Quantifying Fragmentation of Patch Habitats at a Landscape Scale
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Szantoi, Z.; Geller, G.N.; Tsendbazar, N.E.; See, L.; Griffiths, P.; Fritz, S.; Gong, P.; Herold, M.; Mora, B.; Obregón, A. Addressing the need for improved land cover map products for policy support. Environ. Sci. Policy 2020, 112, 28–35. [Google Scholar] [CrossRef] [PubMed]
- Crowley, M.A.; Cardille, J.A. Remote sensing’s recent and future contributions to landscape ecology. Curr. Landsc. Ecol. Rep. 2020, 5, 45–57. [Google Scholar] [CrossRef]
- Halim, M.; Ahmad, A.; Rahman, M.; Amin, Z.; Khanan, M.; Musliman, I.; Kadir, W.; Jamal, M.; Maimunah, D.; Wahab, A.; et al. Land use/land cover mapping for conservation of UNESCO Global Geopark using object and pixel-based approaches. In The IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2018; Volume 169, p. 012075. [Google Scholar]
- Santos, M.J.; Smith, A.B.; Dekker, S.C.; Eppinga, M.B.; Leitão, P.J.; Moreno-Mateos, D.; Morueta-Holme, N.; Ruggeri, M. The role of land use and land cover change in climate change vulnerability assessments of biodiversity: A systematic review. Landsc. Ecol. 2021, 36, 3367–3382. [Google Scholar] [CrossRef]
- Roy, P.S.; Ramachandran, R.M.; Paul, O.; Thakur, P.K.; Ravan, S.; Behera, M.D.; Sarangi, C.; Kanawade, V.P. Anthropogenic land use and land cover changes—A review on its environmental consequences and climate change. J. Indian Soc. Remote Sens. 2022, 50, 1615–1640. [Google Scholar] [CrossRef]
- Rayner, M.; Balzter, H.; Jones, L.; Whelan, M.; Stoate, C. Effects of improved land-cover mapping on predicted ecosystem service outcomes in a lowland river catchment. Ecol. Indic. 2021, 133, 108463. [Google Scholar] [CrossRef]
- Burke, T.; Whyatt, J.D.; Rowland, C.; Blackburn, G.A.; Abbatt, J. The influence of land cover data on farm-scale valuations of natural capital. Ecosyst. Serv. 2020, 42, 101065. [Google Scholar] [CrossRef]
- Millin-Chalabi, G.; Labenski, P.; Pascagaza, A.M.P.; Clay, G.; Fassnacht, F.E. Dynamic fuel mapping in the South Pennines using a multitemporal intensity and coherence approach. In Proceedings of the European Space Agency-Fringe 2023, Leeds, UK, 11–15 September 2023. [Google Scholar]
- Taylor, J.; Bird, A.C.; Keech, M.; Stuttard, M. Landscape Change in the National Parks of England and Wales: Final Report, Volume I Main Report; Silsoe College: Bedford, UK, 1991; Available online: https://publications.naturalengland.org.uk/publication/5216333889273856 (accessed on 5 November 2023.).
- Taylor, J.C.; Brewer, T.R.; Bird, A.C. Monitoring landscape change in the National Parks of England and Wales using aerial photo interpretation and GIS. Int. J. Remote Sens. 2000, 21, 2737–2752. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Strager, M.P.; Warner, T.A.; Ramezan, C.A.; Morgan, A.N.; Pauley, C.E. Large-area, high spatial resolution land cover mapping using random forests, GEOBIA, and NAIP orthophotography: Findings and recommendations. Remote Sens. 2019, 11, 1409. [Google Scholar] [CrossRef]
- Witjes, M.; Parente, L.; van Diemen, C.J.; Hengl, T.; Landa, M.; Brodský, L.; Halounova, L.; Križan, J.; Antonić, L.; Ilie, C.M.; et al. A spatiotemporal ensemble machine learning framework for generating land use/land cover time-series maps for Europe (2000–2019) based on LUCAS, CORINE and GLAD Landsat. PeerJ 2022, 10, e13573. [Google Scholar] [CrossRef]
- Bradter, U.; Thom, T.J.; Altringham, J.D.; Kunin, W.E.; Benton, T.G. Prediction of National Vegetation Classification communities in the British uplands using environmental data at multiple spatial scales, aerial images and the classifier random forest. J. Appl. Ecol. 2011, 48, 1057–1065. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- García-Álvarez, D.; Nanu, S.F. Land Use Cover Datasets: A Review. In Land Use Cover Datasets and Validation Tools; Springer Nature: Cham, Switzerland, 2022; p. 47. [Google Scholar]
- Faccioli, M.; Zonneveld, S.; Tyler, C.R.; Day, B. Does local Natural Capital Accounting deliver useful policy and management information? A case study of Dartmoor and Exmoor National Parks. J. Environ. Manag. 2023, 327, 116272. [Google Scholar] [CrossRef] [PubMed]
- Horning, N. Land cover mapping with ultra-high-resolution aerial imagery. Remote Sens. Ecol. Conserv. 2020, 6, 429–430. [Google Scholar] [CrossRef]
- Kattenborn, T.; Eichel, J.; Wiser, S.; Burrows, L.; Fassnacht, F.E.; Schmidtlein, S. Convolutional Neural Networks accurately predict cover fractions of plant species and communities in Unmanned Aerial Vehicle imagery. Remote Sens. Ecol. Conserv. 2020, 6, 472–486. [Google Scholar] [CrossRef]
- Horning, N.; Fleishman, E.; Ersts, P.J.; Fogarty, F.A.; Wohlfeil Zillig, M. Mapping of land cover with open-source software and ultra-high-resolution imagery acquired with unmanned aerial vehicles. Remote Sens. Ecol. Conserv. 2020, 6, 487–497. [Google Scholar] [CrossRef]
- Clutterbuck, B.; Yallop, A.; Thacker, J. Monitoring the Impact of Blanket Bog Conservation in the South Pennine Moors Special Area of Conservation Using an Unmanned Aerial Vehicle; Nottingham Trent University & CS Conservation Survey: Notthingham, UK, 2021. [Google Scholar]
- García-Álvarez, D.; Lara Hinojosa, J.; Jurado Pérez, F.J.; Quintero Villaraso, J. General Land Use Cover Datasets for Europe. In Land Use Cover Datasets and Validation Tools: Validation Practices with QGIS; Springer International Publishing: Cham, Switzerland, 2022; pp. 313–345. [Google Scholar]
- Sertel, E.; Topaloğlu, R.H.; Şallı, B.; Yay Algan, I.; Aksu, G.A. Comparison of landscape metrics for three different level land cover/land use maps. ISPRS Int. J. Geo-Inf. 2018, 7, 408. [Google Scholar] [CrossRef]
- Marston, C.; Rowland, C.; O’Neil, A.; Morton, R. Land Cover Map 2021 (10 m classified pixels, GB). NERC EDS Environmental Information Data Centre. 2022. Available online: https://catalogue.ceh.ac.uk/documents/a22baa7c-5809-4a02-87e0-3cf87d4e223a (accessed on 6 November 2023).
- Kilcoyne, A.; Clement, M.; Moore, C.; Picton Phillipps, G.; Keane, R.; Woodget, A.; Potter, S.; Stefaniak, A.; Trippier, B. Living England: Satellite-Based Habitat Classification. Technical User Guide. 2022. Available online: http://nepubprod.appspot.com/publication/4918342350798848 (accessed on 11 November 2022).
- Tulbure, M.G.; Hostert, P.; Kuemmerle, T.; Broich, M. Regional matters: On the usefulness of regional land-cover datasets in times of global change. Remote Sens. Ecol. Conserv. 2022, 8, 272–283. [Google Scholar] [CrossRef]
- Dudley, N. Guidelines for Applying Protected Area Management Categories; IUCN: Gland, Switzerland, 2008. [Google Scholar]
- Starnes, T.; Beresford, A.E.; Buchanan, G.M.; Lewis, M.; Hughes, A.; Gregory, R.D. The extent and effectiveness of protected areas in the UK. Glob. Ecol. Conserv. 2021, 30, e01745. [Google Scholar] [CrossRef]
- Ahern, K.; Cole, L. Landscape scale–towards an integrated approach. Ecos 2012, 33, 6–12. [Google Scholar]
- Taylor, J.; Bird, A.C.; Brewer, T.; Keech, M.; Stuttard, M. Landscape Change in the National Parks of England and Wales: Final Report, Volume II Methodology; Silsoe College: Bedford, UK, 1991. [Google Scholar]
- Bluesky. Aerial Photography for Great Britain ©; Bluesky International Limited and Getmapping Plc.: Ashby-De-La-Zouch, UK, 2022; Available online: https://apgb.blueskymapshop.com/ (accessed on 6 November 2023).
- Ordnance Survey. OS National Geographic Database ©; Ordnance Survey: Southampton, UK, 2023; Available online: https://beta.ordnancesurvey.co.uk/products/os-ngd-api-features (accessed on 6 November 2023).
- Natural England. National Character Area Profiles. 2014. Available online: https://www.gov.uk/government/publications/national-character-area-profiles-data-for-local-decision-making/national-character-area-profiles (accessed on 27 September 2023).
- Brodrick, P.G.; Davies, A.B.; Asner, G.P. Uncovering ecological patterns with convolutional neural networks. Trends Ecol. Evol. 2019, 34, 734–745. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: New York, NY, USA, 2015; pp. 234–241. [Google Scholar]
- Simms, D.M. Fully convolutional neural nets in-the-wild. Remote Sens. Lett. 2020, 11, 1080–1089. [Google Scholar] [CrossRef]
- Lobo Torres, D.; Queiroz Feitosa, R.; Nigri Happ, P.; Elena Cué La Rosa, L.; Marcato Junior, J.; Martins, J.; Olã Bressan, P.; Gonçalves, W.N.; Liesenberg, V. Applying fully convolutional architectures for semantic segmentation of a single tree species in urban environment on high resolution UAV optical imagery. Sensors 2020, 20, 563. [Google Scholar] [CrossRef]
- Iakubovskii, P. Segmentation Models Pytorch. 2019. Available online: https://github.com/qubvel/segmentation_models.pytorch (accessed on 6 November 2023).
- Alexander, D.G.; Van der Plas, T.L.; Geikie, S.T. Interpretation Key of Peak District Land Cover Classes. 2023. Available online: https://reports.peakdistrict.gov.uk/interpretation-key/docs/introduction.html (accessed on 27 September 2023).
- Rodwell, J.S. British Plant Communities; Cambridge University Press: Cambridge, UK, 1998; Volume 2. [Google Scholar]
- Alderson, D.M.; Evans, M.G.; Shuttleworth, E.L.; Pilkington, M.; Spencer, T.; Walker, J.; Allott, T.E. Trajectories of ecosystem change in restored blanket peatlands. Sci. Total Environ. 2019, 665, 785–796. [Google Scholar] [CrossRef] [PubMed]
- Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy assessment in convolutional neural network-based deep learning remote sensing studies—Part 2: Recommendations and best practices. Remote Sens. 2021, 13, 2591. [Google Scholar] [CrossRef]
- Van der Plas, T.L.; Geikie, S.T.; Alexander, D.G.; Simms, D.M. Very High Resolution Aerial Photography and Annotated Land Cover Data of the Peak District [Dataset]. 2023. Available online: https://cord.cranfield.ac.uk/articles/dataset/Very_high_resolution_aerial_photography_and_annotated_land_cover_data_of_the_Peak_District_National_Park/24221314 (accessed on 9 October 2023).
- Forestry Commission. National Forest Inventory Woodland GB 2020; Forestry Commission Open Data Publication, Last Updated 30 June 2022; Forestry Commission: Bristol, UK, 2022. Available online: https://data-forestry.opendata.arcgis.com/datasets/eb05bd0be3b449459b9ad0692a8fc203_0/about (accessed on 6 November 2023).
- Natural England. Habitat Networks (England)—Purple Moor Grass & Rush Pasture; Natural England Open Data Publication, Last Updated 5 April 2022; Natural England: UK, 2022; Available online: https://naturalengland-defra.opendata.arcgis.com/datasets/Defra::habitat-networks-england-purple-moor-grass-rush-pasture (accessed on 6 November 2023).
- Natural England. Peaty Soils Location (England). 2022. Available online: https://naturalengland-defra.opendata.arcgis.com/datasets/1e5a1cdb2ab64b1a94852fb982c42b52_0/about (accessed on 27 September 2023).
- Stace, C. New Flora of the British Isles; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Ashby, M.A.; Whyatt, J.D.; Rogers, K.; Marrs, R.H.; Stevens, C.J. Quantifying the recent expansion of native invasive rush species in a UK upland environment. Ann. Appl. Biol. 2020, 177, 243–255. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems; NeurIPS: Vancouver, BC, Canada, 2019; Volume 32. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Wang, X.; Blanchet, F.G.; Koper, N. Measuring habitat fragmentation: An evaluation of landscape pattern metrics. Methods Ecol. Evol. 2014, 5, 634–646. [Google Scholar] [CrossRef]
- Watling, J.I.; Arroyo-Rodríguez, V.; Pfeifer, M.; Baeten, L.; Banks-Leite, C.; Cisneros, L.M.; Fang, R.; Hamel-Leigue, A.C.; Lachat, T.; Leal, I.R.; et al. Support for the habitat amount hypothesis from a global synthesis of species density studies. Ecol. Lett. 2020, 23, 674–681. [Google Scholar] [CrossRef]
- Loke, L.H.; Chisholm, R.A. Measuring habitat complexity and spatial heterogeneity in ecology. Ecol. Lett. 2022, 25, 2269–2288. [Google Scholar] [CrossRef]
- Gatis, N.; Carless, D.; Luscombe, D.J.; Brazier, R.E.; Anderson, K. An operational land cover and land cover change toolbox: Processing open-source data with open-source software. Ecol. Solut. Evid. 2022, 3, e12162. [Google Scholar] [CrossRef]
- Peak District National Park Authority. The Wooded Landscapes Plan: Increasing Tree and Scrub Cover in the Peak District National Park Landscapes (2022–2032). 2022. Available online: https://www.peakdistrict.gov.uk/__data/assets/pdf_file/0027/447255/Wooded-Landscapes-Plan-Final-Draft-July-22.pdf (accessed on 27 September 2023).
- Tuia, D.; Kellenberger, B.; Beery, S.; Costelloe, B.R.; Zuffi, S.; Risse, B.; Mathis, A.; Mathis, M.W.; van Langevelde, F.; Burghardt, T.; et al. Perspectives in machine learning for wildlife conservation. Nat. Commun. 2022, 13, 792. [Google Scholar] [CrossRef] [PubMed]
- Rolnick, D.; Donti, P.L.; Kaack, L.H.; Kochanski, K.; Lacoste, A.; Sankaran, K.; Ross, A.S.; Milojevic-Dupont, N.; Jaques, N.; Waldman-Brown, A.; et al. Tackling climate change with machine learning. ACM Comput. Surv. (CSUR) 2022, 55, 1–96. [Google Scholar] [CrossRef]
- O’Connell, J.; Bradter, U.; Benton, T.G. Wide-area mapping of small-scale features in agricultural landscapes using airborne remote sensing. ISPRS J. Photogramm. Remote Sens. 2015, 109, 165–177. [Google Scholar] [CrossRef] [PubMed]
- Bhatt, P.; Maclean, A.; Dickinson, Y.; Kumar, C. Fine-Scale Mapping of Natural Ecological Communities Using Machine Learning Approaches. Remote Sens. 2022, 14, 563. [Google Scholar] [CrossRef]
- Kubacka, M.; Żywica, P.; Subirós, J.V.; Bródka, S.; Macias, A. How do the surrounding areas of national parks work in the context of landscape fragmentation? A case study of 159 protected areas selected in 11 EU countries. Land Use Policy 2022, 113, 105910. [Google Scholar] [CrossRef]
- D’Urban Jackson, T.; Williams, G.J.; Walker-Springett, G.; Davies, A.J. Three-dimensional digital mapping of ecosystems: A new era in spatial ecology. Proc. R. Soc. B 2020, 287, 20192383. [Google Scholar] [CrossRef]
- Ridding, L.E.; Watson, S.C.; Newton, A.C.; Rowland, C.S.; Bullock, J.M. Ongoing, but slowing, habitat loss in a rural landscape over 85 years. Landsc. Ecol. 2020, 35, 257–273. [Google Scholar] [CrossRef]
- Fahrig, L. Ecological responses to habitat fragmentation per se. Annu. Rev. Ecol. Evol. Syst. 2017, 48, 1–23. [Google Scholar] [CrossRef]
- Chase, J.M.; Blowes, S.A.; Knight, T.M.; Gerstner, K.; May, F. Ecosystem decay exacerbates biodiversity loss with habitat loss. Nature 2020, 584, 238–243. [Google Scholar] [CrossRef]
- Riva, F.; Fahrig, L. Landscape-scale habitat fragmentation is positively related to biodiversity, despite patch-scale ecosystem decay. Ecol. Lett. 2023, 26, 268–277. [Google Scholar] [CrossRef]
- Natural England; RSPB. Climate Change Adaptation Manual—Evidence to Support Nature Conservation in a Changing Climate, 2nd ed.; Natural England: York, UK, 2019. [Google Scholar]
- Kelly, L.; Douglas, D.; Shurmer, M.; Evans, K. Upland rush management advocated by agri-environment schemes increases predation of artificial wader nests. Anim. Conserv. 2021, 24, 646–658. [Google Scholar] [CrossRef]
- UK Department for Environment, Food & Rural Affairs. A Green Future: Our 25 Year Plan to Improve the Environment. 2018. Available online: https://www.gov.uk/government/publications/25-year-environment-plan (accessed on 27 September 2023).
- United Nations Environment Programme. UN Biodiversity Conference (COP 15). 2022. Available online: https://www.unep.org/un-biodiversity-conference-cop-15 (accessed on 27 September 2023).
- Department for Environment, Food and Rural Affairs. Environmental Land Management Update: How Government Will Pay for Land-Based Environment and Climate Goods and Services. 2023. Available online: https://www.gov.uk/government/publications/environmental-land-management-update-how-government-will-pay-for-land-based-environment-and-climate-goods-and-services (accessed on 27 September 2023).
- Bailey, J.J.; Cunningham, C.A.; Griffin, D.C.; Hoppit, G.; Metcalfe, C.A.; Schéré, C.M.; Travers, T.J.P.; Turner, R.K.; Hill, J.K.; Sinnadurai, P.; et al. Protected Areas and Nature Recovery. Achieving the Goal to Protect 30% of UK Land and Seas for Nature by 2030; British Ecological Society: London, UK, 2022. [Google Scholar]


| Name | Description | Source | Used for | Total Area Used |
|---|---|---|---|---|
| National Forest Inventory (NFI) woodland map | Woodlands with an area over 0.5 ha with a minimum of 20% canopy cover and a minimum width of 20 m. Woodlands are classified similarly to C1–C5 in our LC schema. | Forestry Commission [43] | Training, testing | 4.2 km2 |
| OS NGD data | Topographical layer of developed land and waterways. Classes were aggregated to connect to our LC schema (F2, G2a and H classes). | Ordnance Survey © [31] | Testing, prediction | 1439 km2 |
| Habitat Networks (England)—Purple Moor Grass & Rush Pasture | Map of UK habitats | Natural England Open Data Publication [44] | Analysis | 1439 km2 |
| Peaty Soils Location (England) | Soil content | Natural England Open Data Publication, BGS, Cranfield University (NSRI) and OS [45] | Prediction | 1439 km2 |
| Classifier | Loss Function | Mean | Std | Max | Selected? |
|---|---|---|---|---|---|
| C | Cross entropy | 0.90 | 0.01 | 0.92 | Yes |
| C | Focal loss | 0.87 | 0.10 | 0.93 | - |
| D | Cross entropy | 0.67 | 0.03 | 0.72 | Yes |
| D | Focal loss | 0.70 | 0.02 | 0.72 | - |
| E | Cross entropy | 0.85 | 0.02 | 0.87 | Yes |
| E | Focal loss | 0.83 | 0.02 | 0.84 | - |
| Main | Cross entropy | 0.93 | 0.02 | 0.95 | Yes |
| Main | Focal loss | 0.92 | 0.01 | 0.94 | - |
| Single-stage | Cross entropy | 0.67 | 0.04 | 0.71 | N/A |
| Class Name | Code | Sensitivity | Precision | Density Test Set | Classifier |
|---|---|---|---|---|---|
| Wood and Forest Land | C | 0.91 | 0.96 | 24.2% | Main |
| Moor and Heath Land | D | 0.97 | 0.93 | 34.6% | Main |
| Agro-Pastoral Land | E | 0.93 | 0.93 | 41.3% | Main |
| Class Name | Code | Sensitivity | Precision | Density | Classifier |
|---|---|---|---|---|---|
| Broadleaved High Forest | C1 | 0.73 | 0.92 | 9.9% | C |
| Coniferous High Forest | C2 | 0.99 | 0.78 | 9.9% | C |
| Scrub | C4 | 0.46 | 0.77 | 1.7% | C |
| Clear Felled/New Plantings in Forest Areas | C5 | 0.96 | 0.92 | 2.7% | C |
| Upland Heath | D1 | 0.84 | 0.80 | 10.8% | D |
| Upland Grass Moor | D2 | 0.70 | 0.82 | 8.8% | D |
| Bracken | D3 | 0.52 | 0.83 | 3.6% | D |
| Heather/Grass/Blanket Peat Mosaic | D6 | 0.64 | 0.48 | 4.6% | D |
| Improved Pasture | E2a | 0.92 | 0.88 | 26.8% | E |
| Rough Pasture | E2b | 0.67 | 0.76 | 10.6% | E |
| Wetland, Peat Bog | F3a | 0.77 | 0.72 | 6.3% | D |
| Wetland, Wet Grassland and Rush Pasture | F3d | 0.85 | 0.86 | 4.1% | E |
| Class Name | Code | Sens. SS | Prec. SS | Sens. MS | Prec. MS |
|---|---|---|---|---|---|
| Broadleaved High Forest | C1 | 0.90 | 0.65 | 0.71 | 0.92 |
| Coniferous High Forest | C2 | 0.81 | 0.89 | 0.98 | 0.80 |
| Scrub | C4 | Not pred. | Not pred. | 0.42 | 0.63 |
| Clear Felled/New Plantings in Forest Areas | C5 | Not pred. | Not pred. | 0.84 | 0.92 |
| Upland Heath | D1 | 0.91 | 0.75 | 0.81 | 0.80 |
| Blanket Peat Grass Moor | D2 | 0.55 | 0.55 | 0.77 | 0.76 |
| Bracken | D3 | Not pred. | Not pred. | 0.48 | 0.81 |
| Upland Heath/Blanket Peat Mosaic | D6 | 0.33 | 0.38 | 0.75 | 0.66 |
| Improved Pasture | E2a | 0.89 | 0.93 | 0.92 | 0.85 |
| Rough Pasture | E2b | 0.70 | 0.53 | 0.62 | 0.70 |
| Wetland, Peat Bog | F3a | 0.92 | 0.48 | 0.84 | 0.76 |
| Wetland, Wet Grassland and Rush Pasture | F3d | Not pred. | Not pred. | 0.65 | 0.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van der Plas, T.L.; Geikie, S.T.; Alexander, D.G.; Simms, D.M. Multi-Stage Semantic Segmentation Quantifies Fragmentation of Small Habitats at a Landscape Scale. Remote Sens. 2023, 15, 5277. https://doi.org/10.3390/rs15225277
van der Plas TL, Geikie ST, Alexander DG, Simms DM. Multi-Stage Semantic Segmentation Quantifies Fragmentation of Small Habitats at a Landscape Scale. Remote Sensing. 2023; 15(22):5277. https://doi.org/10.3390/rs15225277
Chicago/Turabian Stylevan der Plas, Thijs L., Simon T. Geikie, David G. Alexander, and Daniel M. Simms. 2023. "Multi-Stage Semantic Segmentation Quantifies Fragmentation of Small Habitats at a Landscape Scale" Remote Sensing 15, no. 22: 5277. https://doi.org/10.3390/rs15225277
APA Stylevan der Plas, T. L., Geikie, S. T., Alexander, D. G., & Simms, D. M. (2023). Multi-Stage Semantic Segmentation Quantifies Fragmentation of Small Habitats at a Landscape Scale. Remote Sensing, 15(22), 5277. https://doi.org/10.3390/rs15225277