1. Introduction
With the continuous improvement in the spatial resolution of remote sensing images (aerial images and satellite images), various application requirements for Earth observation are constantly being raised, especially for the observation of finer ground objects, such as buildings [
1,
2]. This is because buildings are among the essential products of human beings’ continuous transformation of the Earth’s surface for production and life [
3]. The changes in buildings in areas of interest are studied over time. Change detection (CD) is a technique that has been widely used in the field of remote sensing [
4,
5]. The purpose of CD is to obtain land cover changes by comparing and analyzing multi-temporal remote sensing images. In this context, building change detection (BCD) has received increasing attention in the past decade and can realize effective change monitoring for single-target buildings, including new buildings and disappearing buildings. Therefore, BCD has potential value in many practical applications, such as urban development planning [
6,
7], evaluation of the urbanization process [
8], and urban disaster prevention and mitigation [
9,
10].
In the past decade, many BCD methods have been proposed, and BCD has grown considerably as a result. Early on, scholars realized building extraction and change detection by designing hand-crafted features. Some studies have proposed that building recognition and change detection can be realized by using artificially designed building/shadow shape index, context, texture, and other information [
11,
12,
13]. The popularization of deep learning technology has led to remarkable results being achieved in remote sensing image interpretation [
14,
15,
16]. The deep network structure has strong multi-level feature extraction capability, which can automatically learn the complex features in the remote sensing imagery, including geometric information of ground objects, spectral information, and semantic information, avoiding the reliance on a priori knowledge and the laborious process of manually constructing features. Therefore, many deep-learning-based BCD methods have been proposed and have led to some achievements. Many methods based on semantic segmentation networks have been devised to improve the performance of BCD by designing and introducing various attention mechanisms [
17,
18], multi-scale networks [
19,
20,
21], etc. However, these networks have encountered new obstacles in further improving BCD performance. In recent years, some methods further introduced edge or contour information to enhance the performance of BCD. For instance, Bai et al. proposed an edge-guided recurrent convolutional neural network for BCD [
22]. Here, the recurrent convolutional neural network has been employed for change detection [
23]. The method can effectively enhance the building change extraction ability by introducing the edge of the building to guide the recurrent convolutional neural network. Yang et al. devised a multi-scale attention and edge-aware Siamese network in [
24] for BCD. These methods have proved that the introduction of edge information can improve the performance of BCD. In addition, Some approaches show that the introduction of frequency domain information can effectively enhance the building outline information, thereby significantly improving the accuracy of BCD. Recently, in [
25], an attention-guided high-frequency feature extraction module was proposed for BCD with the aim of enhancing the detailed feature representation of buildings. Zheng et al. proposed a high-frequency information attention-guided Siamese network for BCD. A built-in high-frequency information attention block was designed to improve the detection of building change [
26]. These methods have proved that high-frequency information can effectively enhance the details such as edges, thereby further elevating the performance of BCD.
High-frequency information corresponds to the rich edge detail of ground objects in remote sensing images, and low-frequency information contains more backbone features of ground objects. Although the above-mentioned recent research shows that the introduction of high-frequency information such as edges or outlines can help improve the accuracy of BCD, the utilization of frequency by these methods is obviously insufficient. This also shows that it is potentially valuable to improve building feature representation by fully mining frequency domain information, especially considering high frequency, low frequency, and other different frequencies at the same time. To this end, we proposed a multi-scale DCT network (MDNet) for BCD. Our motivation lies in the following two aspects.
On the one hand, according to the literature [
25,
26], most of the current BCD methods only use the high-frequency information in the frequency domain, without considering the effect of low-frequency information and other frequency information on the representation of building features. Moreover, Reference [
27] has proved that traditional global average pooling is a special case of frequency decomposition and proposed a frequency channel attention based on different frequencies to strengthen feature representation. This approach has been shown to achieve convincing performance in tasks such as image classification, object detection, and segmentation based on frequency channel attention at different frequencies. Hence, inspired by the literature [
27], we can simultaneously introduce information on different frequencies in the frequency domain from the two dimensions of channel and space in order to enhance the representation ability of building features.
On the other hand, compared with traditional CD, very-high-resolution remote sensing images can distinguish finer ground targets, which makes various scales of ground objects appear at the same time, and the scene is more complicated. In view of this, the existing multi-scale methods only extract multi-scale features through multi-scale operators in the spatial domain, such as spatial pyramid pooling [
28], atrous spatial pyramid pooling [
29], or pyramid pooling [
30]. These existing approaches lack the perception of information from the frequency domain. For this reason, introducing information on different frequencies in multi-scale operations may help to improve the multi-scale information representation ability of existing multi-scale methods, thus leading to new means of improving the performance of BCD.
Based on the above motivations, this paper proposes a multi-scale DCT network (MDNet) for BCD. In the proposed MDNet, two novel discrete cosine transform (DCT)-based modules are utilized, namely the dual-dimension DCT attention module (DAM) and multi-scale DCT pyramid (MDP). The proposed DAM can employ the DCT to obtain frequency information from both spatial and channel dimensions to refine building feature representation. In addition, the proposed MDP aims to enhance the multi-scale feature representation of buildings by utilizing multi-scale frequencies based on DCTs of different scales. The main contributions of this paper are as follows.
- (1)
We propose a novel multi-scale DCT network for BCD, which is composed of two new modules based on DCT. Our method demonstrates that using different frequencies in the frequency domain to refine features can further enhance the feature representation ability of the network.
- (2)
We designed a dual-dimension DCT attention module (DAM) in the proposed MDNet, which can effectively employ frequency domain information to enhance building feature representation from both spatial and channel dimensions.
- (3)
Different from the existing multi-scale methods, we constructed a novel multi-scale DCT pyramid (MDP) in the proposed MDNet. The proposed MDP aims to enhance the multi-scale feature representation of buildings by utilizing multi-scale DCT.
- (4)
The proposed MDNet achieves a more convincing performance for three publicly available BCD datasets compared with other methods. Moreover, extensive ablation experiments also demonstrate the effectiveness of the proposed DAM and MDP.
The remainder of this paper is arranged as follows.
Section 2 summarizes some related work.
Section 3 provides the proposed MDNet in detail. In
Section 4 and
Section 5, experimental results are presented and discussed. Finally, the conclusion and future work are in
Section 6.
3. Methodology
To better detect fine-grained multi-scale land cover objects, a new deep neural network, the multi-scale DCT network (MDNet), is proposed in this work. Different from conventional deep neural networks for CD, it has two novel modules, i.e., the dual-dimension DCT attention module (DAM) and multi-scale DCT pyramid (MDP), to better dig and utilize the information from frequency domain for better CD performance. The DAM employs the DCT to concurrently obtain frequency information from both spatial and channel dimensions to refine the feature maps in the network. Furthermore, the MDP can better recognize the objects with varied sizes through the information obtained by multi-scale DCT.
In this section, the overview of MDNet will be given briefly in
Section 3.1. Then, the D
AM and MDP will be introduced in detail in
Section 3.2 and
Section 3.3, respectively.
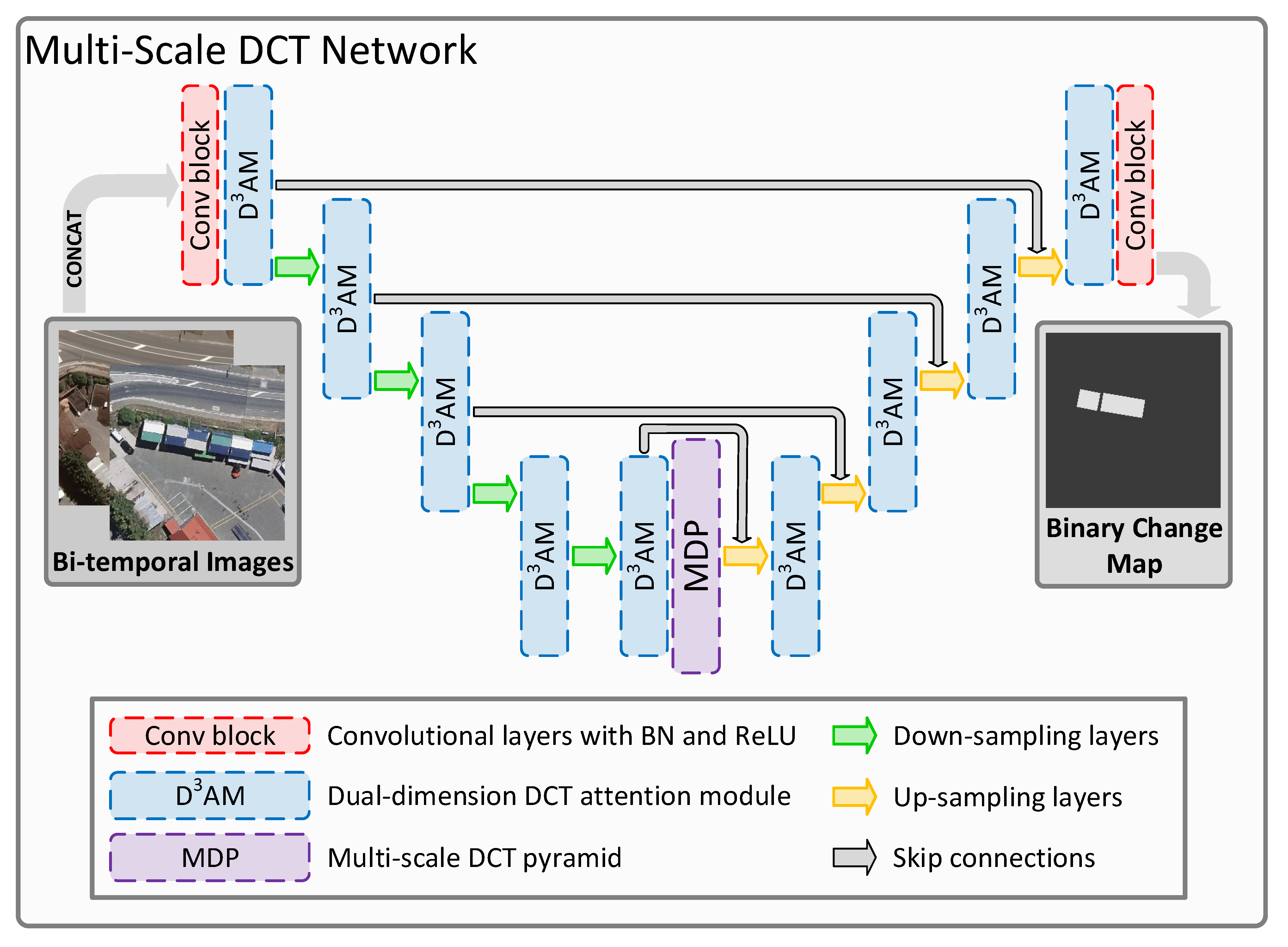
3.1. Overview
We employed a U-shaped [
67] network with skip connections as the backbone of the proposed MDNet as shown in
Figure 1. This backbone architecture can automatically acquire multi-scale feature representation and obtain hierarchical feature maps with varied sizes, which can be helpful for acquiring better cognition of multi-scale land cover objects in BCD. With these extracted multi-scale feature maps, we propose the D
AM to obtain extra information from the transformation domain, which is used to revalue the significance of feature maps from both spatial and channel dimensions for finer feature representation. We used the MDP to further dig multi-scale frequency information and built a feature pyramid through multi-scale DCT, which can acquire better recognition of multi-scale land cover objects. Apart from these modules, we used two conventional blocks, which contain several convolutional layers with batch normalization and rectified linear unit (ReLU) activation functions, to preliminarily process the input bi-temporal remote sensing images and generate the binary change maps, respectively. Moreover, to create hierarchical multi-scale features, down-sampling and up-sampling layers are utilized in MDNet. These layers have pooling layers and bi-linear interpolation with convolutional layers, respectively.
The proposed MDNet conducts the BCD in VHR bi-temporal remote sensing images as follows: Firstly, the bi-temporal remote sensing images are concatenated in the channel dimension and input into MDNet. Then, multi-scale features are extracted by up-sampling and down-sampling layers. These features are refined and enhanced by the D
AM and MDP. When features are processed by up-sampling layers, skip connections allow the features from the early stage to participate in the generation of the binary change maps, which provide more information to improve CD performance [
26]. Finally, the binary change maps are produced and output to indicate the change in land cover objects with pixel-wise results.
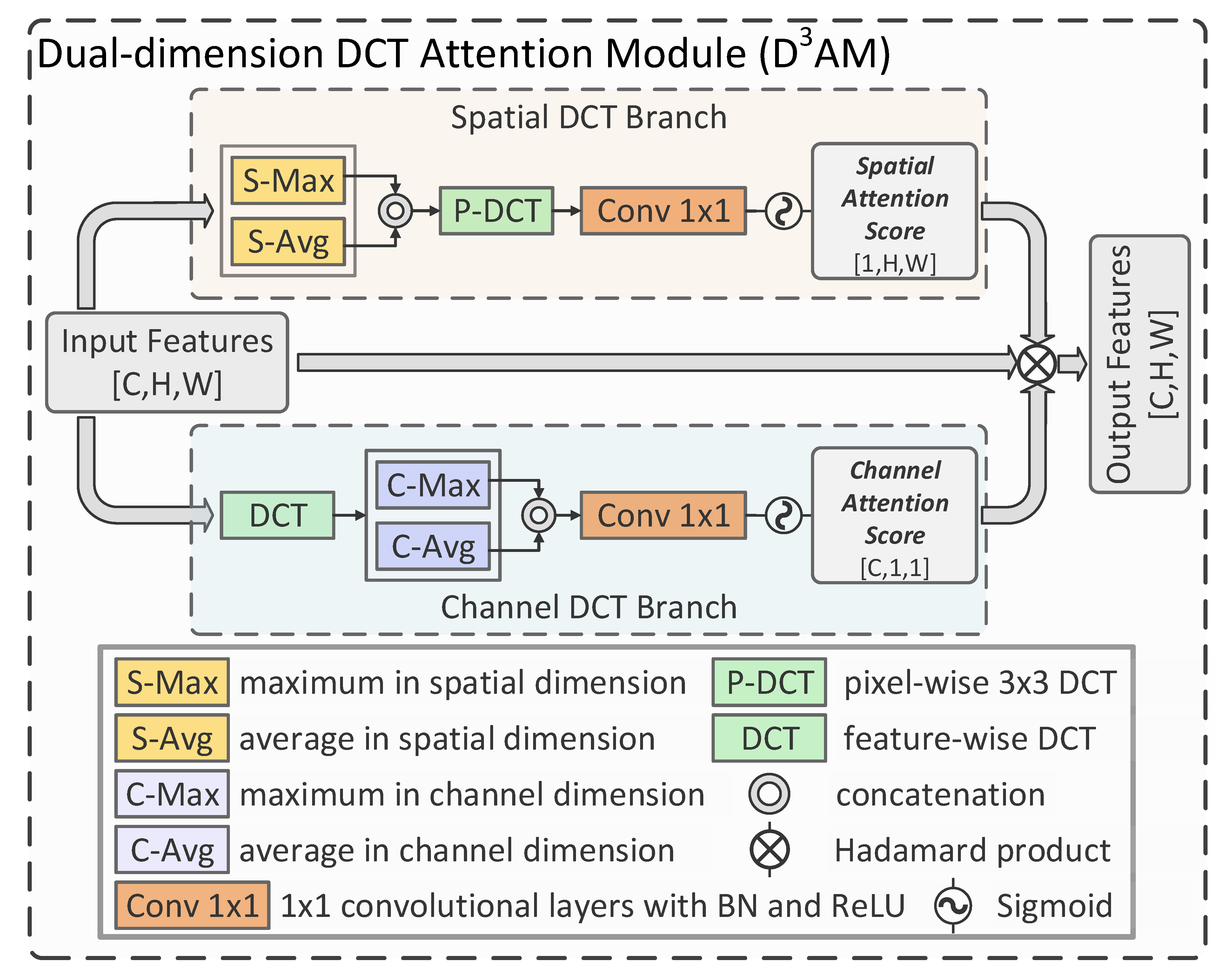
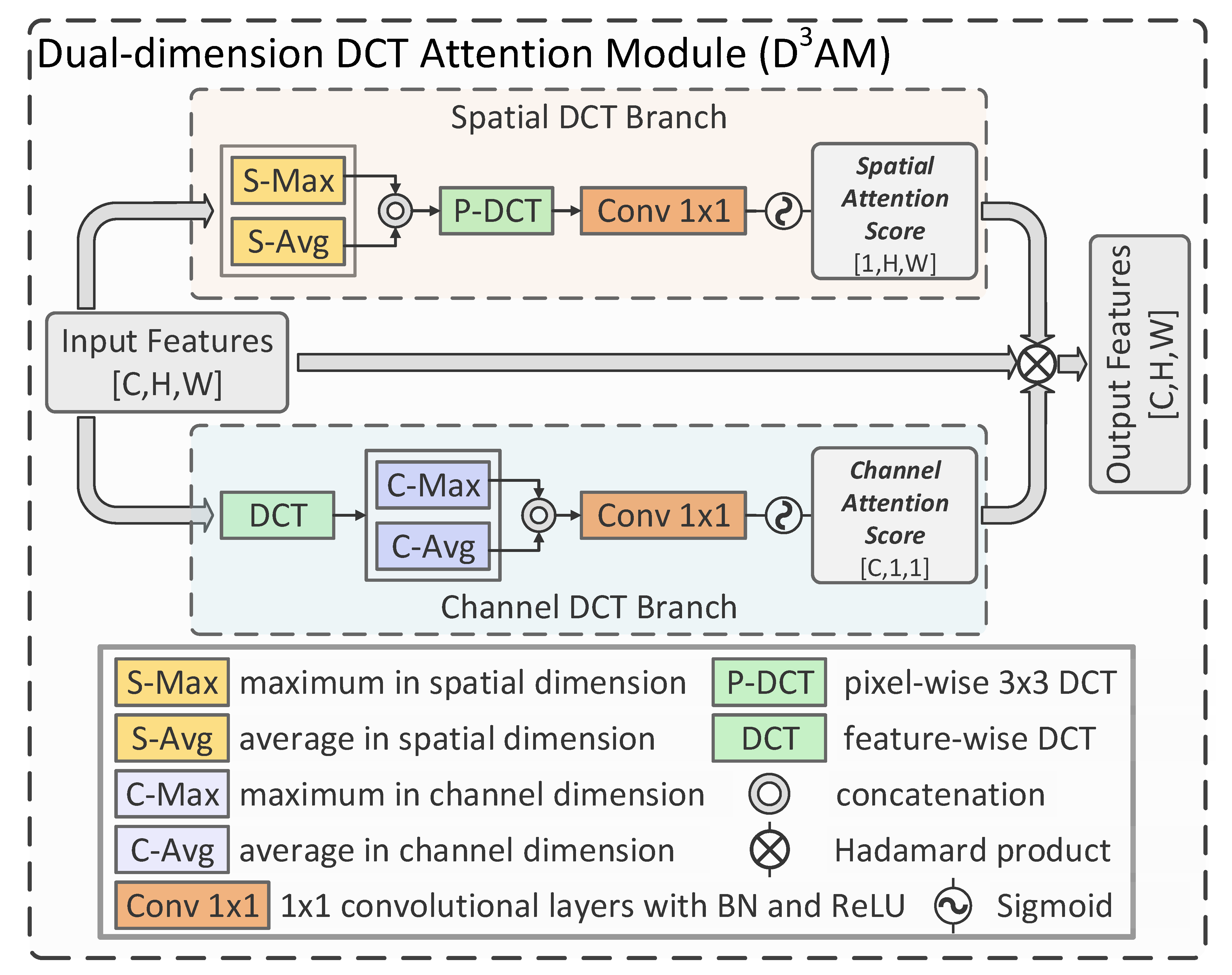
3.2. Dual-Dimension DCT Attention Module
In [
26], it has been demonstrated that frequency domain information can improve the performance of BCD. The researchers found that enhancing the high-frequency information can help the network better detect land cover objects with clearer boundaries, which improve CD performance. However, it is well recognized that most noise is concentrated in the high-frequency region. Individually enhancing the high-frequency information may enhance noise and cause performance loss for CD. High-frequency information is not the only significant aspect for image recognition [
27]; ignoring information from the lower frequency domain when building the attention mechanism can potentially decrease the BCD performance in complex scenes. Based on this, we utilize DCT to obtain more complete frequency information from both spatial and channel dimensions in the proposed D
AM. With the dual-dimension frequency information acquired, spatial and channel attention scores are generated to enhance useful information in the feature maps for better BCD performance. The process is illustrated in
Figure 2 and as follows:
Let the input of the DAM be represented as , where indicate the height, weight, and channel size, respectively. To acquire the information from both spatial and channel dimensions, the input feature maps are input into two different DCT attention paths concurrently, i.e., the (a) spatial DCT branch and (b) channel DCT branch.
3.2.1. (a) Spatial DCT Branch
In this path, the most representative spatial features are firstly extracted by the maximum and average in the spatial dimension [
68] and concatenated as
, which can be represented as follows:
where
and
indicate the procedures of taking the maximum and average in the spatial dimension, respectively. Furthermore,
represents the concatenation in the channel dimension. Then, we employ a pixel-wise DCT with a kernel size of 3 × 3 to acquire the fine-grained spatial frequency information
, which can be represented as:
where
is a pixel-wise DCT with a kernel size of 3 × 3. At the end of spatial DCT branch, the spatial attention mask
is obtained by several convolutional layers with a kernel size of 1 × 1 and a sigmoid function, which can be illustrated as:
where
indicates several 1 × 1 convolutional layers with BN and the ReLU, which are employed to evaluate the features in the spatial dimension through supervised learning. Furthermore, a sigmoid function,
, is employed to obtain a stable attention score.
3.2.2. (b) Channel DCT Branch
Different from the spatial branch, we firstly use a feature-wise DCT to acquire the channel-wise global frequency information
, which can be illustrated as:
To acquire the most representative channel-wise frequency information [
68]
, the global max pooling and global average pooling are employed, which can be represented as:
where
and
represent the global max pooling and global average pooling, respectively. Then, we train several 1 × 1 convolutional layers to generate channel-wise attention score
, which can be illustrated as follows:
where
indicates several convolutional layers with BN, the ReLU, and a kernel size of 1 × 1. Notably, a sigmoid function is also employed to acquire a stable output in this branch.
Through the spatial DCT branch and channel DCT branch, the dual-dimensional attention scores
and
are obtained. Then, the final output of the D
AM,
, can be obtained as follows:
where ⊗ indicates the Hadamard product. As shown in the equation, a residual link is utilized at this stage to keep the output stable and facilitate supervised learning.
In sum, in the proposed DAM, spatial and channel-wise frequency information can be exploited by using dual-dimensional DCT. Then the attention mechanisms are built around these information resources and refine the feature representation from both spatial and channel dimensions, which make the proposed DAM different from conventional frequency-analysis-based attention mechanisms.
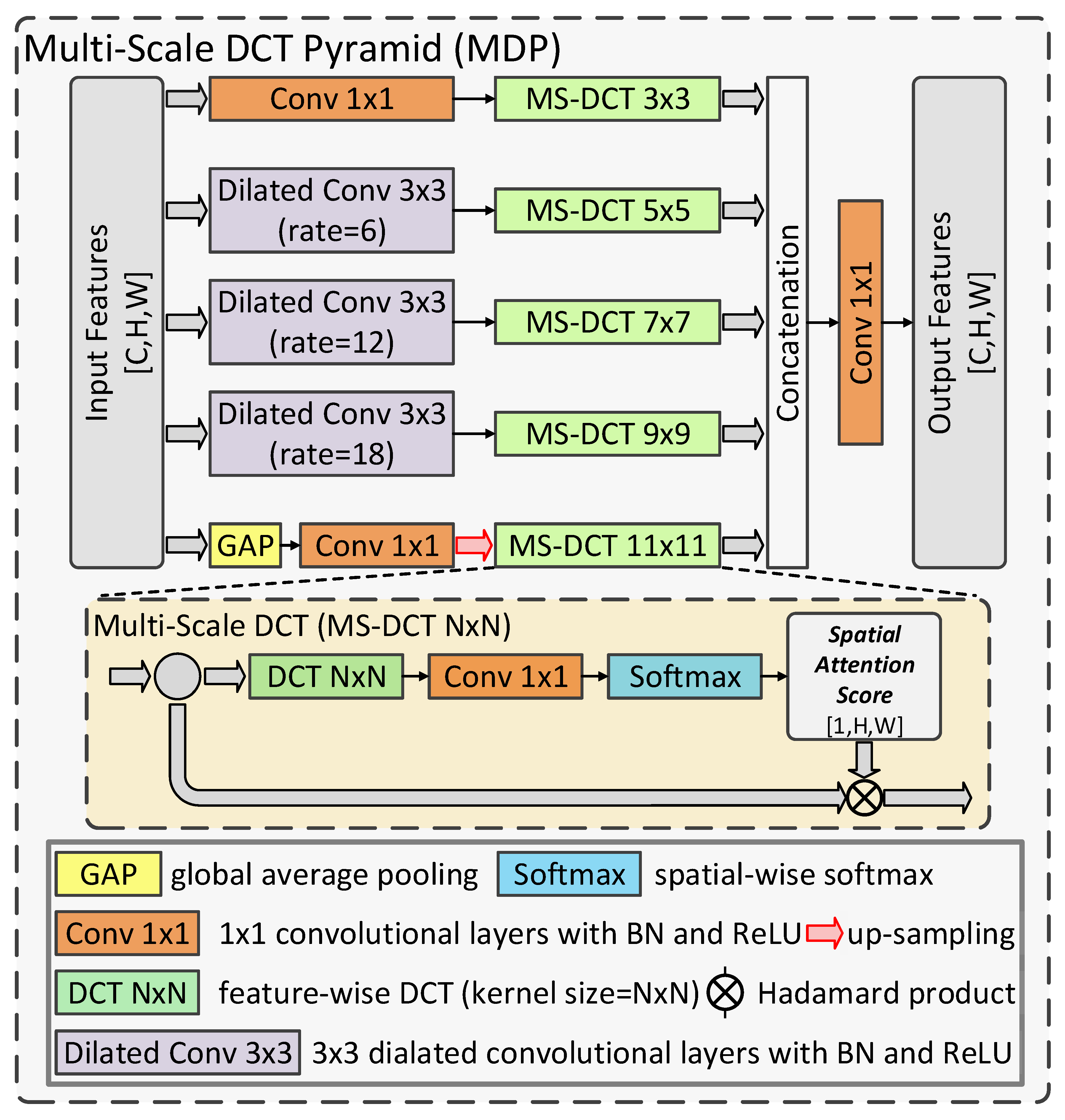
3.3. Multi-Scale DCT Pyramid
In the proposed MDNet, multi-scale feature representation is acquired not only from the hierarchical backbone but also in the proposed MDP. Multi-scale feature extraction has proven useful for obtaining finer pixel-wise annotation for CD tasks [
21]. Basically, the deepest feature maps have smaller spatial size compared to other features, thus making them lack precise spatial information. Based on this fact, it can be helpful to extract multi-scale features based on these deep features and improve the recognition of multi-scale land cover objects. Many conventional CD methods adopt adaptive pooling and atrous convolutional layers to extract multi-scale features for better cognition of varied land cover objects [
21], which is revealed to be helpful. However, these directly extracted features can be rough, since they are built over the features with minor spatial information. To overcome this problem, we utilized the spatial frequency analysis to refine the spatial information of multi-scale features in the proposed MDP, as shown in
Figure 3. Inspired by [
52], we firstly used dilated convolutional layers to build multi-scale features with different degrees of spatial detail information. Then, we used DCT with different scales to refine these multi-scale features. With finer multi-scale feature maps, the land cover objects with varied sizes can be better recognized and detected in the proposed MDNet. The detailed procedure of the proposed MDP is demonstrated as follows:
Firstly, let
be the input of the MDP. Then, the multi-scale feature maps
can be obtained as follows:
where
denotes a convolutional layer with a kernel size of 1 × 1, BN, and the ReLU.
represents the 3 × 3 dilated convolution with the dilated rate of n. Furthermore,
indicates global average pooling. Then, we use a multi-scale DCT process to extract multi-scale frequency information to refine these features as shown in
Figure 3, which can be denoted as:
where
indicates the multi-scale DCT with a kernel size of N × N
. Then, the spatially enhanced multi-scale features are fused to generate the output,
, as follows:
To sum up, the proposed MDP conducts frequency-based analysis over multi-scale feature maps to refine them in the spatial dimension, which can enhance their spatial information for better recognition of multi-scale land cover objects in remote sensing imagery.
5. Discussion
To further investigate the effectiveness of the framework and modules proposed in MDNet, we conducted extensive ablation experiments on MDNet across three benchmark datasets.
Table 4,
Table 5 and
Table 6 present the ablation experiments of the dual-dimension DCT attention module (D
AM) and multi-scale DCT pyramid (MDP) in MDNet for the WHU-CD, LEVIR-CD, and Google datasets, respectively. The best results are also indicated in bold for all the ablation experiments. Overall, the design of the D
AM and MDP in the backbone network has led to some improvement in the performance of building change detection. While combining both of them may not have better performance than individual methods for certain challenging datasets, the overall combination of the two proves to be complementary and beneficial. It is worth noting that the improvement in the D
AM is more significant than that of the MDP. This is because the D
AM uses DCT to obtain frequency information in both spatial and channel dimensions to refine the feature map, which is considered to be effective for high-frequency and low-frequency information in building distribution. Both provide better adaptive enhancement. The MDP, on the other hand, further captures multi-scale DCT information to better identify multi-scale land cover targets in VHR images.
To further demonstrate the effectiveness of our proposed MDP,
Figure 7 provides several heatmaps of the spatial attention masks from the proposed D
AM on three benchmark datasets. It can be seen from the figure that some of them can enhance the boundaries of the changed land cover objects; the others can globally depict the whole buildings. This suggests that the D
AM can utilize the DCT to capture global frequency information from low- to high-frequency regions, aiming to enhance feature maps in the network and help improve the recognition capability of land cover targets at multiple scales. Apart from that, MDNet exhibits remarkable extraction capability for the contour features of key changes in the scene with the help of the D
AM. It can be seen from the visualized results that the changed edges of buildings are clearly visible in the extracted features as a whole.
We also provide a comparison of the performance and computational cost of different models, as shown in
Table 7. Although the proposed MDNet cannot reach the SOTA in terms of model parameters (Param.) and floating point operations (FLOPs), our model has better performance than models with similar computational costs. Therefore, this compromise solution of sacrificing computational cost to obtain a high-performance model is ideal and has practical significance.
6. Conclusions
In this paper, a novel multi-scale DCT network (MDNet) is proposed for building change detection in VHR remote sensing imagery. Two crucial components were designed, namely the dual-dimension DCT attention module (DAM) and multi-scale DCT pyramid (MDP). Specifically, the DAM leverages DCT to simultaneously acquire frequency information in both spatial and channel dimensions to refine the feature maps, which is considered to provide better adaptive enhancement for both high-frequency and low-frequency information in building distribution. The MDP further captures multi-scale DCT information to better recognize the multi-scale land cover objects in VHR imagery. Experiments on benchmark datasets indicate that our method performs favorably against state-of-the-art algorithms on numerous benchmark datasets. In addition, the ablation analysis also demonstrates that our DAM and MDP modules improve both feature refinement and accurate segmentation of multi-scale targets.
However, the proposed method is built within a supervised learning framework and requires non-negligible time and annotated datasets to acquire the ability to automate building change detection. In this case, the untrained model may have unacceptable performance for change detection tasks. To deal with this problem, unsupervised and self-supervised learning-based techniques can be helpful for more flexible automated change detection. In future work, we will also actively explore accurate building feature extraction and change information analysis using high-resolution remote sensing data with limited quality, and cross-modal scenarios will also be further considered.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}