
A Multi-Stream Attention-Aware Convolutional Neural Network: Monitoring of Sand and Dust Storms from Ordinary Urban Surveillance Cameras



Abstract
:1. Introduction
- (1)
- Traditional ground-based methods, like lookout towers, are considered more objective and directed observations. With advances in industrial manufacturing and sensing technologies, ground radars, lidars, and wireless sensor networks become essential options for SDS monitoring tasks while being irreplaceable parts in the calibration and integration of remote sensing-based measurements [2,5,6]. Limited by cost, operating requirements, and deployment conditions, these ground-based observations usually cannot be deployed at a high density over a large spatial scale, resulting in a lack of spatial representation of observation results.
- (2)
- Space-based technologies mainly refer to satellite-based remote sensing methods, which are important in monitoring, assessing, and predicting SDS events. The well-known Moderate Resolution Imaging Spectroradiometer (MODIS) and Total Ozone Mapping Spectrometer (TOMS) satellites [7] enable passive detection of the occurrence and transportation of an SDS on the vertical distribution, while Cloud-Aerosol Lidar and Infrared Pathfinder Satellite Observation (CALIPSO) satellites [8] can actively sense the vertical profile of cloud aerosols and inverse the vertical information of SDSs. However, the satellite is more suitable for large-scale and long-term SDS monitoring tasks. With the enhancement of satellite imagery resolution and the number of satellites, the problem of insufficient spatial and temporal resolution has been gradually alleviated. However, rapid sensing of small-scale dust storm events still needs to be improved.
- (1)
- The designed monitoring system is deployed on existing urban surveillance resources rather than specifically deploying cameras, thus having higher reliability and obvious low-cost advantages. To the best of our knowledge, prior efforts did not use ordinary urban surveillance cameras for such a task.
- (2)
- A novel Multi-Stream Attention-aware Convolutional Neural Network (MA-CNN) is proposed, which learns SDS image features at different scales through a multi-stream structure and employs the attention mechanism to achieve satisfactory performance for accurate and automatic SDS identification from complex and dynamic surveillance scenarios.
- (3)
- For deep learning model training and testing, sand and dust storm image (SDSI), a new dataset consisting of 13,216 images (6578 SDS images and 6638 non-SDS images taken from scenes similar to SDS scenarios), was constructed.
2. Methodology
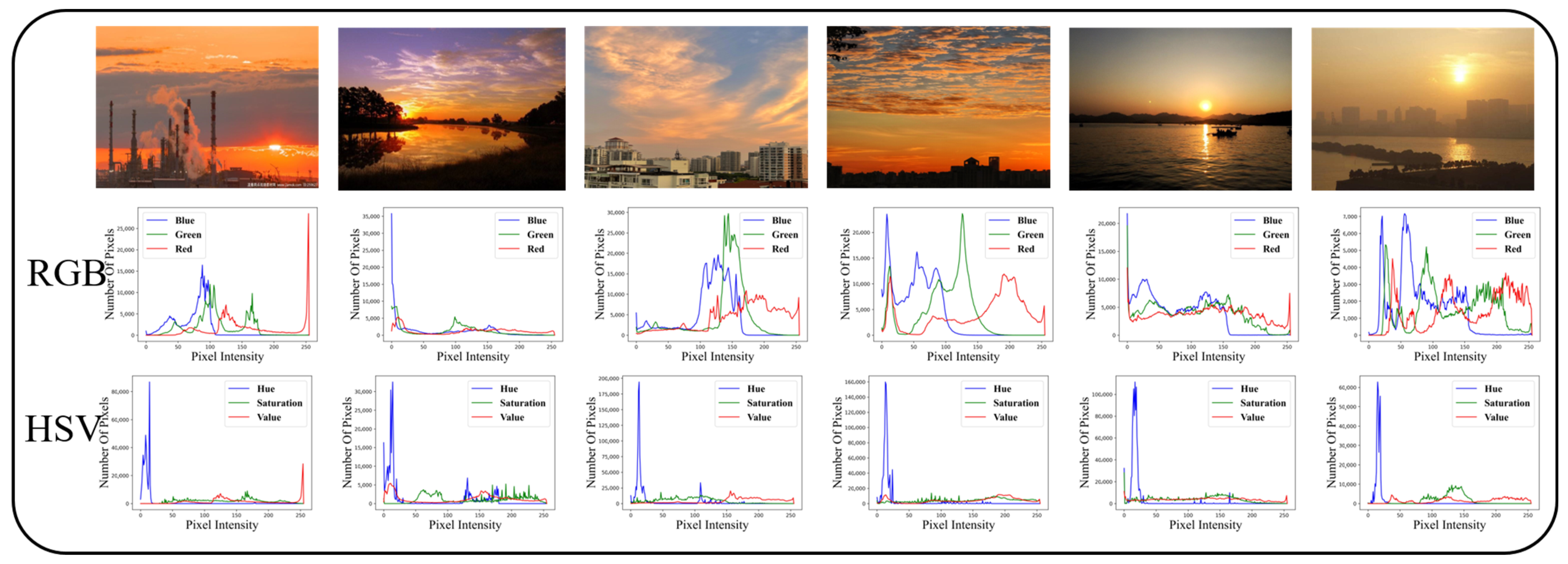
2.1. Image Features Selection
2.2. Multi-Stream Attention-Aware CNN Network
2.3. Experiment Setup
2.3.1. Experimental Environment
- 2× Intel Xeon Silver 4216 CPU@2.10 GHz (32 cores);
- 8×NVIDIA GEFORCE GTX2080Ti graphics cards equipped with 11 GB GDDR6 memory;
- 188 GB RAM;
- Python 3.9.16;
- TensorFlow 2.4.1, Scikit-learn 1.2.1, and Keras 2.4.3 libraries;
- CUDA 11.8 and CUDNN 8.
2.3.2. Evaluation Metrics
2.3.3. Dataset Building
2.3.4. Model Training
3. Results
3.1. Experiments in SDSI Dataset
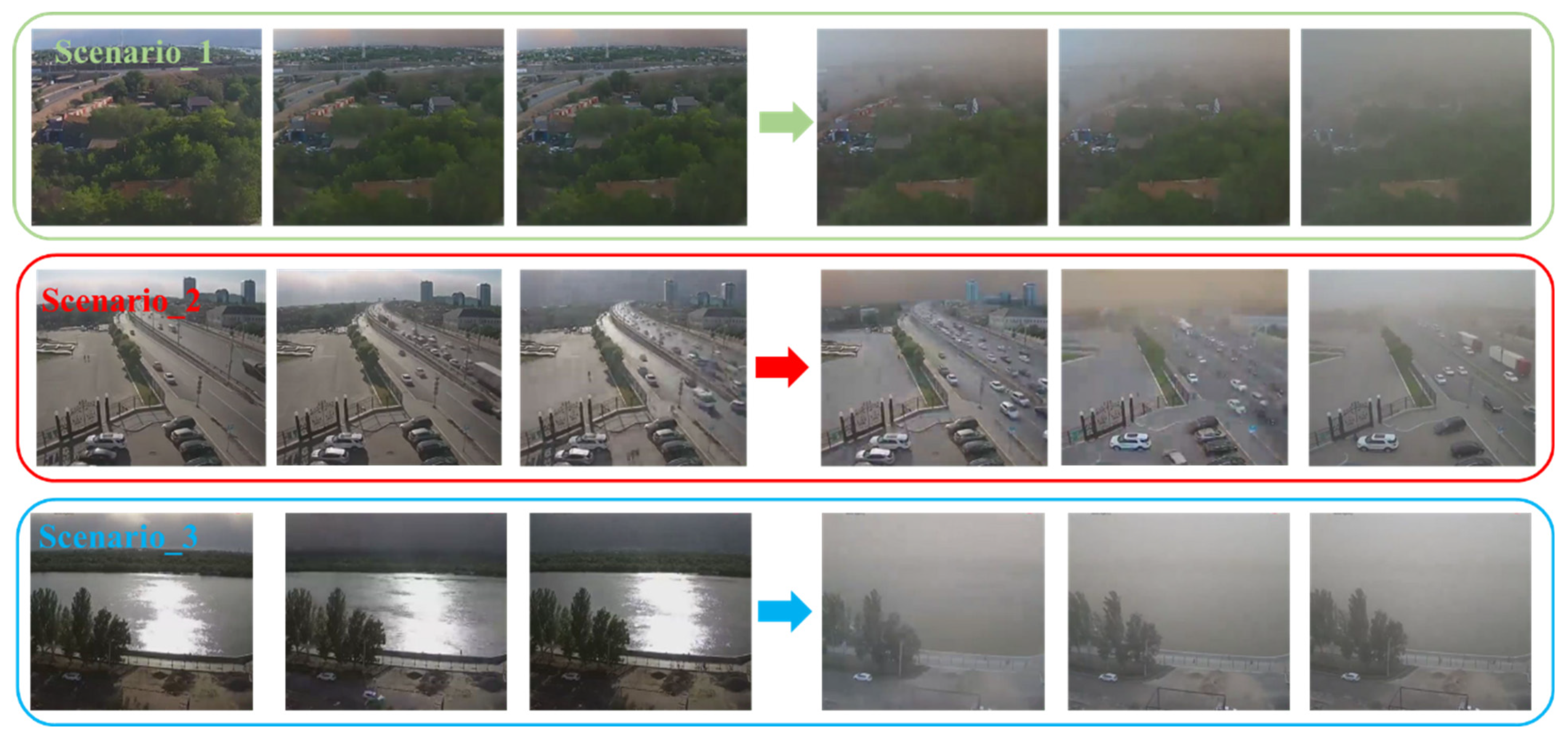
3.2. Experiments in Real-World Scenarios
4. Discussion
- (1)
- Although the proposed MA-CNN model brings an improvement in SDS accuracy, it suffers from a long computational delay due to a relatively large number of parameters (as presented in Table 2 and Table 3). Taking the experimental platform shown in Section 2.3.1 as an example, the MA-CNN algorithm costs 0.78 s to judge whether an SDS appears in a surveillance image with a resolution of 1920 × 1080, whereas VGG16, VGG19, NasNetMobile, Xception, ResNet50, Mobile Net V1, Mobile Net V2, InceptionV3, and DenseNet121 take 0.39 s, 0.52 s, 0.27 s, 0.54 s, 0.65 s, 0.25 s, 0.21 s, 0.62 s, and 0.44 s, respectively. In practical applications, increasing the computational capability of the hardware devices or adopting a distributed computing manner are alternative solutions to reduce the abovementioned latency.
- (2)
- In this study, we detect SDSs in visible light surveillance video captured during the daytime, while in low-light scenarios such as nighttime, it is difficult to capture the appearance of an SDS in visible light surveillance video, and the MA-CNN method will on not work. Extensive research has shown that ordinary surveillance cameras can have “night vision” through near-infrared (NIR) video to perceive low-light scenarios [39], which provides the opportunity to monitor SDSs at night. Research on NIR video-based SDS monitoring, thereby constructing an all-weather observation system, will be the focus of the next step.
- (3)
- Rapid changes over time are an important distinction between SDSs and similar weather events (e.g., fog, haze, and smoke). Understanding SDSs from both temporal and spatial dimensions is an effective strategy to improve SDS monitoring accuracy. The proposed MA-CNN algorithm can mine the image features of SDSs from the spatial dimension, and the patterns of SDSs in the temporal dimension are not utilized. The main reason is that few dust storm videos can be collected currently, making it challenging to build a deep learning dataset for describing an SDS’s spatial and temporal features. Therefore, more SDS and similar weather video data should be collected in the future, which is the basis for the study of more accurate SDS monitoring methods.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images from scenario_1 |  |
| VGG16 |  |
| VGG19 |  |
| NasNet |  |
| Xception |  |
| ResNet50 |  |
| Mobile Net V1 |  |
| MobileNet V2 |  |
| InceptionV3 |  |
| DenseNet121 |  |
| MA-CNN (Ours) |  |
 | |
| Images from scenario_1 |  |
| VGG16 |  |
| VGG19 |  |
| NasNet |  |
| Xception |  |
| ResNet50 |  |
| Mobile Net V1 |  |
| MobileNet V2 |  |
| InceptionV3 |  |
| DenseNet121 |  |
| MA-CNN (Ours) |  |
 | |
References
- Shepherd, G.; Terradellas, E.; Baklanov, A.; Kang, U.; Sprigg, W.; Nickovic, S.; Boloorani, A.D.; Al-Dousari, A.; Basart, S.; Benedetti, A. Global Assessment of Sand and Dust Storms; United Nations Environment Programme: Nairobi, Kenya, 2016. [Google Scholar]
- Jiao, P.; Wang, J.; Chen, X.; Ruan, J.; Ye, X.; Alavi, A.H. Next-Generation Remote Sensing and Prediction of Sand and Dust Storms: State-of-the-Art and Future Trends. Int. J. Remote Sens. 2021, 42, 5277–5316. [Google Scholar]
- Nickovic, S.; Agulló, E.C.; Baldasano, J.M.; Terradellas, E.; Nakazawa, T.; Baklanov, A. Sand and Dust Storm Warning Advisory and Assessment System (Sds-Was) Science and Implementation Plan: 2015–2020; World Meteorological Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Behzad, R.; Barati, S.; Goshtasb, H.; Gachpaz, S.; Ramezani, J.; Sarkheil, H. Sand and Dust Storm Sources Identification: A Remote Sensing Approach. Ecol. Indic. 2020, 112, 106099. [Google Scholar]
- Muhammad, A.; Sheltami, T.R.; Mouftah, H.T. A Review of Techniques and Technologies for Sand and Dust Storm Detection. Rev. Environ. Sci. Bio Technol. 2012, 11, 305–322. [Google Scholar]
- Gutierrez, J. Automated Detection of Dust Storms from Ground-Based Weather Station Imagery Using Neural Network Classification. Ph.D. Thesis, New Mexico State University, Las Cruces, NM, USA, 2020. [Google Scholar]
- McPeters, R.D. Nimbus-7 Total Ozone Mapping Spectrometer (Toms) Data Products User’s Guide; National Aeronautics and Space Administration, Scientific and Technical: Washington, DC, USA, 1996; Volume 1384. [Google Scholar]
- Sassen, K.; Wang, Z.; Liu, D. Global Distribution of Cirrus Clouds from Cloudsat/Cloud-Aerosol Lidar and Infrared Pathfinder Satellite Observations (Calipso) Measurements. J. Geophys. Res. Atmos. 2008, 113, D00A12. [Google Scholar]
- Bukhari, S.A. Depicting Dust and Sand Storm Signatures through the Means of Satellite Images and Ground-Based Observations for Saudi Arabia. PhD Thesis, University of Colorado at Boulder, Boulder, CO, USA, 1993. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Vision and the Atmosphere. Int. J. Comput. Vis. 2002, 48, 233. [Google Scholar] [CrossRef]
- Jr, C.; Pat, S.; Mackinnon, D.J.; Reynolds, R.L.; Velasco, M. Monitoring Dust Storms and Mapping Landscape Vulnerability to Wind Erosion Using Satellite and Ground-Based Digital Images. Arid. Lands. Newsl. 2002, 51, 1–8. [Google Scholar]
- Dagsson-Waldhauserova, P.; Magnusdottir, A.Ö.; Olafsson, H.; Arnalds, O. The Spatial Variation of Dust Particulate Matter Concentrations During Two Icelandic Dust Storms in 2015. Atmosphere 2016, 7, 77. [Google Scholar] [CrossRef]
- Urban, F.E.; Goldstein, H.L.; Fulton, R.; Reynolds, R.L. Unseen Dust Emission and Global Dust Abundance: Documenting Dust Emission from the Mojave Desert (USA) by Daily Remote Camera Imagery and Wind-Erosion Measurements. J. Geophys. Res. Atmos. 2018, 123, 8735–8753. [Google Scholar]
- Abdulameer, F.S. Using Color Spaces Hsv, Yiq and Comparison in Analysis Hazy Image Quality. Adv. Phys. Theor. Appl 2019, 76, 15–23. [Google Scholar]
- Fattal, R. Single Image Dehazing. ACM Trans. Graph. (TOG) 2008, 27, 1–9. [Google Scholar] [CrossRef]
- Narasimhan, S.G.; Nayar, S.K. Chromatic Framework for Vision in Bad Weather. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2000 (Cat. No. PR00662), Hilton Head, SC, USA, 15 June 2000. [Google Scholar]
- Xu, G.; Wang, X.; Xu, X. Single Image Enhancement in Sandstorm Weather Via Tensor Least Square. IEEE/CAA J. Autom. Sin. 2020, 7, 1649–1661. [Google Scholar] [CrossRef]
- Sun, K.J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Cheng, Y.; Jia, Z.; Lai, H.; Yang, J.; Kasabov, N.K. Blue Channel and Fusion for Sandstorm Image Enhancement. IEEE Access 2020, 8, 66931–66940. [Google Scholar] [CrossRef]
- Shi, F.; Jia, Z.; Lai, H.; Kasabov, N.K.; Song, S.; Wang, J. Sand-Dust Image Enhancement Based on Light Attenuation and Transmission Compensation. Multimed. Tools Appl. 2023, 82, 7055–7077. [Google Scholar] [CrossRef]
- Fu, X.; Huang, Y.; Zeng, D.; Zhang, X.-P.; Ding, X. A Fusion-Based Enhancing Approach for Single Sandstorm Image. In Proceedings of the 2014 IEEE 16th International Workshop on Multimedia Signal Processing (MMSP), Jakarta, Indonesia, 22–24 September 2014. [Google Scholar]
- Lee, H.S. Efficient Sandstorm Image Enhancement Using the Normalized Eigenvalue and Adaptive Dark Channel Prior. Technologies 2021, 9, 101. [Google Scholar] [CrossRef]
- Ding, B.; Zhang, R.; Xu, L.; Cheng, H. Sand-Dust Image Restoration Based on Gray Compensation and Feature Fusion. Acta Armamentarii 2022. [Google Scholar] [CrossRef]
- Gao, G.; Lai, H.; Liu, Y.; Wang, L.; Jia, Z. Sandstorm Image Enhancement Based on Yuv Space. Optik 2021, 226, 165659. [Google Scholar] [CrossRef]
- Brauwers, G.; Frasincar, F. A General Survey on Attention Mechanisms in Deep Learning. IEEE Trans. Knowl. Data Eng. 2021, 35, 3279–3298. [Google Scholar]
- Hassanin, M.; Anwar, S.; Radwan, I.; Khan, F.S.; Mian, A. Visual Attention Methods in Deep Learning: An in-Depth Survey. arXiv 2022, arXiv:2204.07756. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A Review on the Attention Mechanism of Deep Learning. Neurocomputing 2021, 452, 48–62. [Google Scholar]
- Hafiz, M.A.; Parah, S.A.; Bhat, R.U.A. Attention Mechanisms and Deep Learning for Machine Vision: A Survey of the State of the Art. arXiv 2021, arXiv:2106.07550. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient Object Localization Using Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, K.X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Wang, M.; Liu, X.; Zhu, L.; Shi, S.; Glade, T.; Chen, M.; Xie, Y.; Wu, Y.; He, Y. Near-Infrared Surveillance Video-Based Rain Gauge. J. Hydrol. 2023, 618, 129173. [Google Scholar] [CrossRef]







| Training Dataset | Validation Dataset | Test Dataset | Total | |
|---|---|---|---|---|
| Other | 4431 | 1029 | 1178 | 6638 |
| Sandstorm | 4425 | 1028 | 1125 | 6578 |
| Total | 8856 | 2057 | 2303 | 13,216 |
| Precision | F1_Score | Recall | Parameters | |
|---|---|---|---|---|
| VGG16 | 0.830 | 0.864 | 0.858 | 14,715,714 |
| VGG19 | 0.834 | 0.829 | 0.830 | 20,025,410 |
| NasNetMobile | 0.778 | 0.833 | 0.820 | 4,271,830 |
| Xception | 0.771 | 0.852 | 0.834 | 20,865,578 |
| ResNet50 | 0.736 | 0.633 | 0.677 | 23,591,810 |
| Mobile Net V1 | 0.693 | 0.814 | 0.774 | 3,230,914 |
| Mobile Net V2 | 0.788 | 0.854 | 0.840 | 2,260,546 |
| InceptionV3 | 0.800 | 0.850 | 0.840 | 21,806,882 |
| DenseNet121 | 0.802 | 0.867 | 0.855 | 7,039,554 |
| MA-CNN (Ours) | 0.857 | 0.868 | 0.866 | 28,171,314 |
| Precision | F1_Score | Recall | Parameters | |
|---|---|---|---|---|
| VGG16 | 0.812 | 0.855 | 0.847 | 14,781,924 |
| VGG19 | 0.821 | 0.847 | 0.842 | 20,091,620 |
| NasNetMobile | 0.801 | 0.861 | 0.861 | 4,551,802 |
| Xception | 0.774 | 0.844 | 0.828 | 21,916,458 |
| ResNet50 | 0.704 | 0.642 | 0.670 | 24,642,690 |
| Mobile Net V1 | 0.799 | 0.854 | 0.852 | 3,494,210 |
| Mobile Net V2 | 0.732 | 0.822 | 0.796 | 2,671,586 |
| InceptionV3 | 0.786 | 0.835 | 0.824 | 22,857,762 |
| DenseNet121 | 0.790 | 0.858 | 0.845 | 7,039,554 |
| MA-CNN (Ours) | 0.857 | 0.868 | 0.866 | 28,171,314 |
| Precision | F1_Score | Recall | |
|---|---|---|---|
| VGG16 | 0.86 | 0.883 | 0.902 |
| VGG19 | 0.891 | 0.912 | 0.925 |
| NasNetMobile | 0.925 | 0.936 | 0.957 |
| Xception | 0.887 | 0.892 | 0.865 |
| ResNet50 | 0.785 | 0.832 | 0.804 |
| Mobile Net V1 | 0.742 | 0.788 | 0.769 |
| Mobile Net V2 | 0.924 | 0.939 | 0.94 |
| InceptionV3 | 0.879 | 0.886 | 0.897 |
| DenseNet121 | 0.897 | 0.913 | 0.944 |
| MA-CNN (Ours) | 0.945 | 0.967 | 0.956 |
| Precision | F1_Score | Recall | |
|---|---|---|---|
| VGG16 | 0.823 | 0.835 | 0.870 |
| VGG19 | 0.856 | 0.894 | 0.908 |
| NasNetMobile | 0.842 | 0.851 | 0.850 |
| Xception | 0.822 | 0.817 | 0.834 |
| ResNet50 | 0.771 | 0.820 | 0.799 |
| Mobile Net V1 | 0.692 | 0.722 | 0.743 |
| Mobile Net V2 | 0.870 | 0.895 | 0.913 |
| InceptionV3 | 0.887 | 0.913 | 0.920 |
| DenseNet121 | 0.906 | 0.923 | 0.926 |
| MA-CNN (Ours) | 0.919 | 0.936 | 0.934 |
| Precision | F1_Score | Recall | |
|---|---|---|---|
| VGG16 | 0.764 | 0.792 | 0.800 |
| VGG19 | 0.902 | 0.933 | 0.941 |
| NasNetMobile | 0.910 | 0.934 | 0.922 |
| Xception | 0.861 | 0.823 | 0.842 |
| ResNet50 | 0.845 | 0.883 | 0.871 |
| Mobile Net V1 | 0.797 | 0.811 | 0.826 |
| Mobile Net V2 | 0.853 | 0.892 | 0.887 |
| InceptionV3 | 0.915 | 0.935 | 0.946 |
| DenseNet121 | 0.922 | 0.971 | 0.957 |
| MA-CNN (Ours) | 0.953 | 0.967 | 0.948 |
| Precision | F1_Score | Recall | |
|---|---|---|---|
| VGG16 | 0.875 | 0.891 | 0.884 |
| VGG19 | 0.912 | 0.918 | 0.914 |
| NasNetMobile | 0.864 | 0.859 | 0.862 |
| Xception | 0.824 | 0.83 | 0.832 |
| ResNet50 | 0.812 | 0.809 | 0.822 |
| Mobile Net V1 | 0.787 | 0.789 | 0.792 |
| Mobile Net V2 | 0.933 | 0.944 | 0.938 |
| InceptionV3 | 0.902 | 0.911 | 0.907 |
| DenseNet121 | 0.919 | 0.923 | 0.954 |
| MA-CNN (Ours) | 0.945 | 0.967 | 0.956 |
| Precision | F1_Score | Recall | |
|---|---|---|---|
| VGG16 | 0.852 | 0.859 | 0.862 |
| VGG19 | 0.873 | 0.889 | 0.878 |
| NasNetMobile | 0.792 | 0.783 | 0.801 |
| Xception | 0.754 | 0.753 | 0.759 |
| ResNet50 | 0.742 | 0.732 | 0.753 |
| Mobile Net V1 | 0.725 | 0.737 | 0.734 |
| Mobile Net V2 | 0.798 | 0.803 | 0.808 |
| InceptionV3 | 0.907 | 0.915 | 0.918 |
| DenseNet121 | 0.916 | 0.917 | 0.917 |
| MA-CNN (Ours) | 0.919 | 0.936 | 0.934 |
| Precision | F1_Score | Recall | |
|---|---|---|---|
| VGG16 | 0.814 | 0.807 | 0.815 |
| VGG19 | 0.917 | 0.923 | 0.921 |
| NasNetMobile | 0.922 | 0.913 | 0.917 |
| Xception | 0.87 | 0.863 | 0.872 |
| ResNet50 | 0.817 | 0.823 | 0.821 |
| Mobile Net V1 | 0.825 | 0.818 | 0.834 |
| Mobile Net V2 | 0.914 | 0.925 | 0.917 |
| InceptionV3 | 0.929 | 0.933 | 0.952 |
| DenseNet121 | 0.928 | 0.944 | 0.953 |
| MA-CNN (Ours) | 0.953 | 0.967 | 0.948 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Yang, Z.; Feng, H.; Zhao, J.; Shi, S.; Cheng, L. A Multi-Stream Attention-Aware Convolutional Neural Network: Monitoring of Sand and Dust Storms from Ordinary Urban Surveillance Cameras. Remote Sens. 2023, 15, 5227. https://doi.org/10.3390/rs15215227
Wang X, Yang Z, Feng H, Zhao J, Shi S, Cheng L. A Multi-Stream Attention-Aware Convolutional Neural Network: Monitoring of Sand and Dust Storms from Ordinary Urban Surveillance Cameras. Remote Sensing. 2023; 15(21):5227. https://doi.org/10.3390/rs15215227
Chicago/Turabian StyleWang, Xing, Zhengwei Yang, Huihui Feng, Jiuwei Zhao, Shuaiyi Shi, and Lu Cheng. 2023. "A Multi-Stream Attention-Aware Convolutional Neural Network: Monitoring of Sand and Dust Storms from Ordinary Urban Surveillance Cameras" Remote Sensing 15, no. 21: 5227. https://doi.org/10.3390/rs15215227
APA StyleWang, X., Yang, Z., Feng, H., Zhao, J., Shi, S., & Cheng, L. (2023). A Multi-Stream Attention-Aware Convolutional Neural Network: Monitoring of Sand and Dust Storms from Ordinary Urban Surveillance Cameras. Remote Sensing, 15(21), 5227. https://doi.org/10.3390/rs15215227