
A Siamese Multiscale Attention Decoding Network for Building Change Detection on High-Resolution Remote Sensing Images

 ,
,
Abstract
:1. Introduction
- (1)
- We introduce SMADNet, employing the Multiscale Context Feature Fusion Module (MCFFM) and integrating the Dual Contextual Attention Decoding Module (CADM). In addition, it incorporates the Deep Supervision (DS) strategy in the middle layers of the decoder to assist in training network parameters, thus improving the generalization ability and detection accuracy.
- (2)
- We propose a novel Dual Contextual Attention Decoding Module (CADM). The combination of a parallel structure and CADM can effectively suppress pseudo-changes and leads to better integration of raw image feature and difference features, achieving information retention.
- (3)
- We perform rigorous experiments using widely recognized change detection datasets, further buttressed by comprehensive ablation studies. The subsequent qualitative and quantitative evaluations reinforce the proposed method’s preeminence, underscoring its potential for building change detection applications.
2. Methods
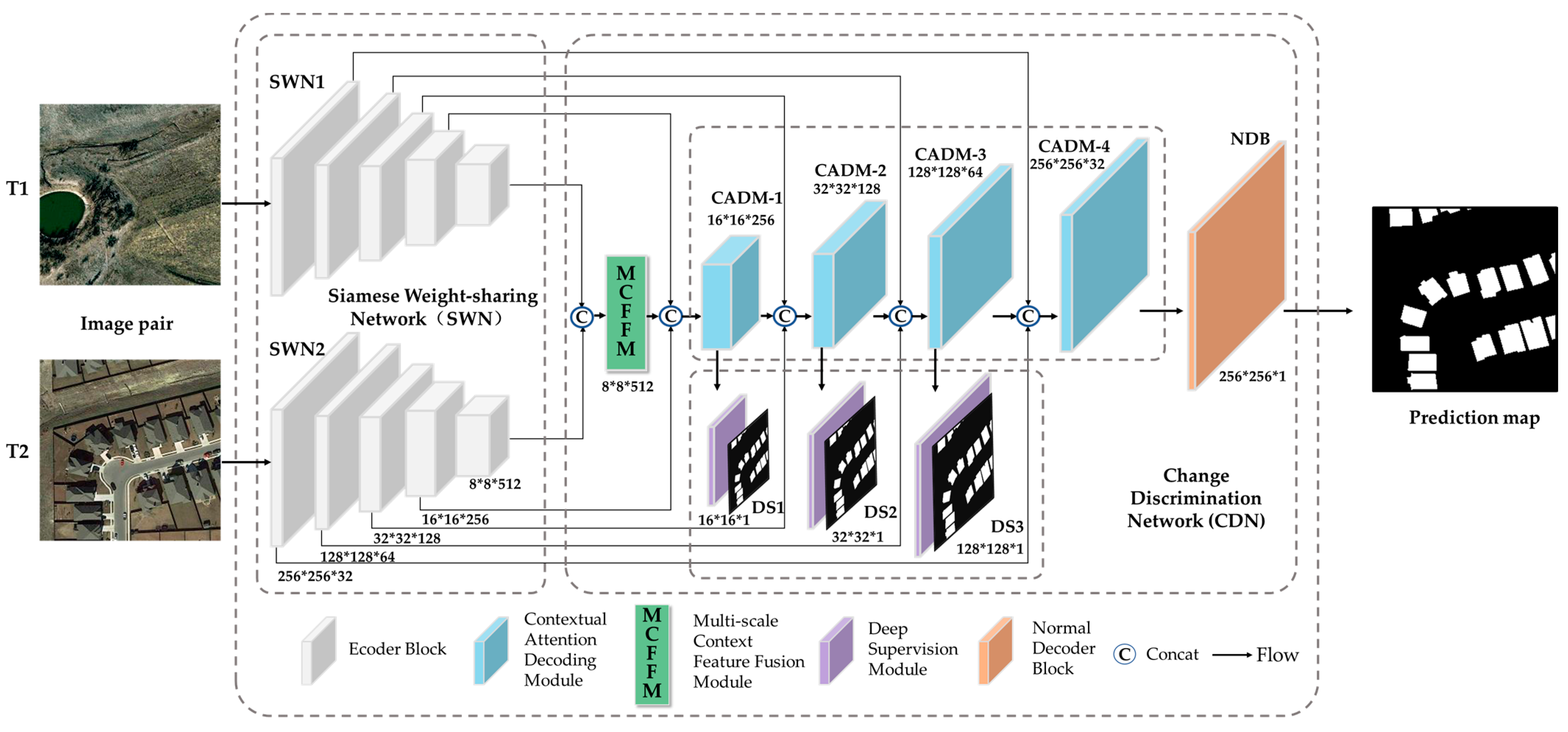
2.1. Overview
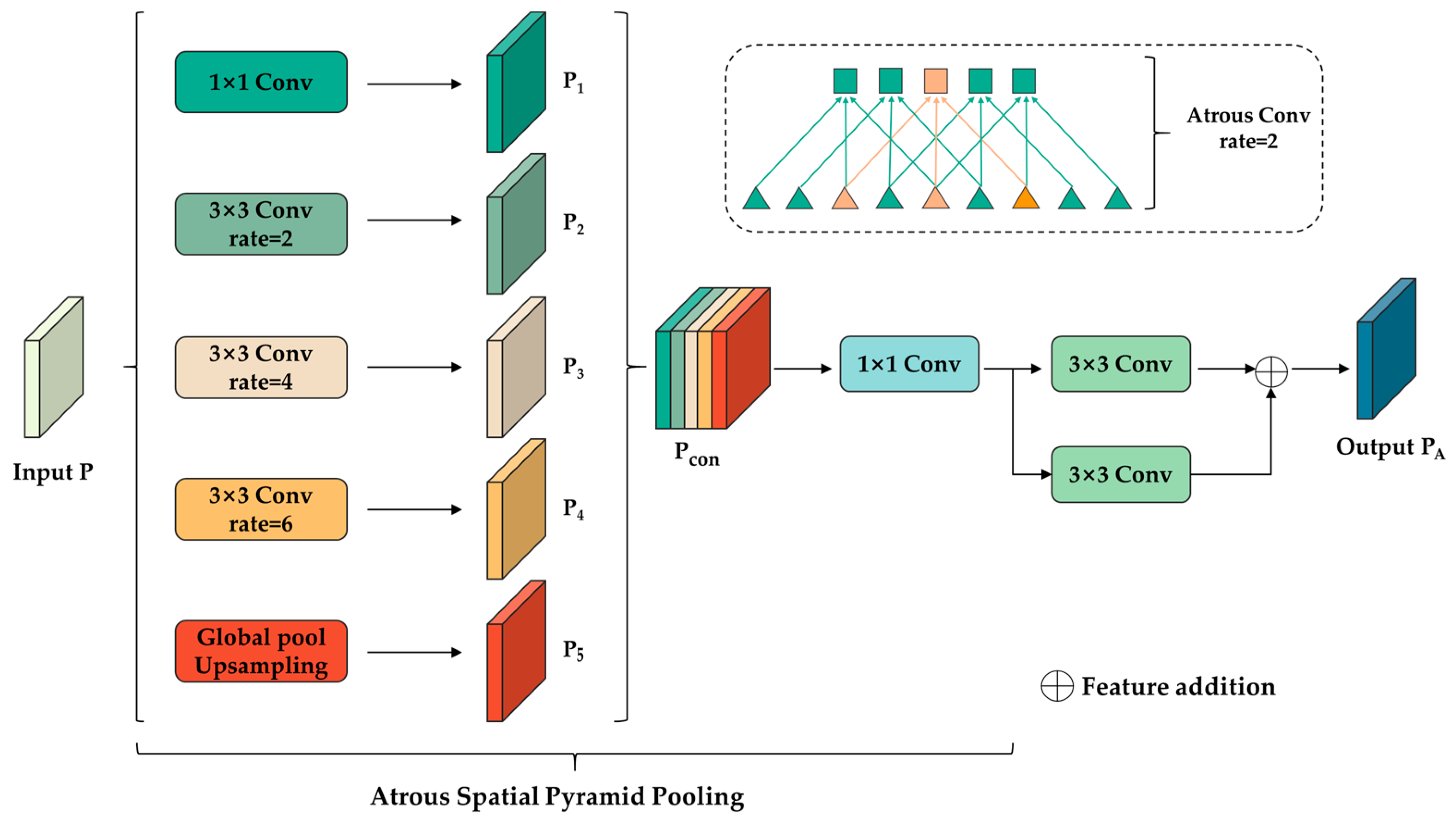
2.2. Multiscale Context Feature Fusion Module
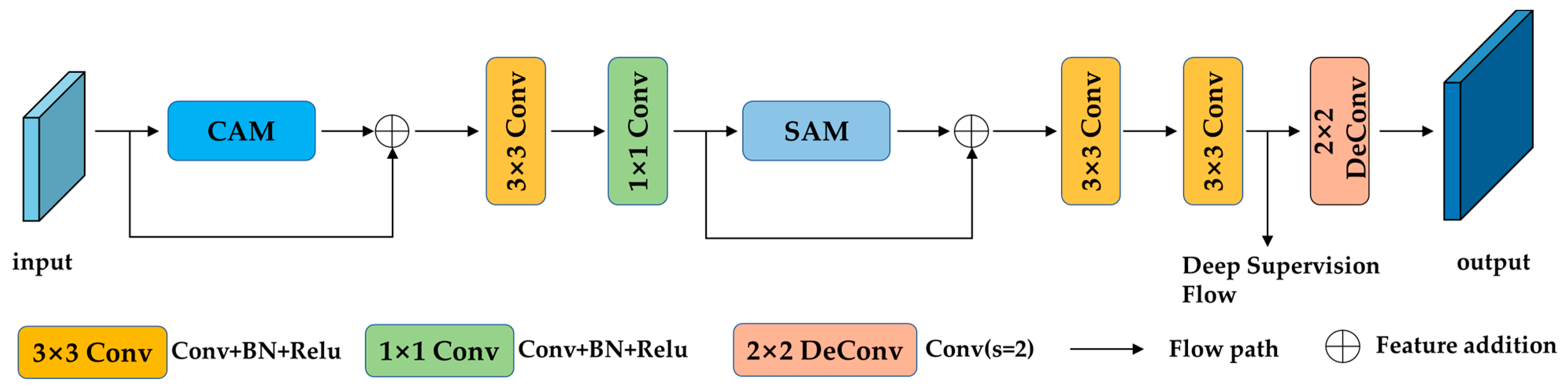
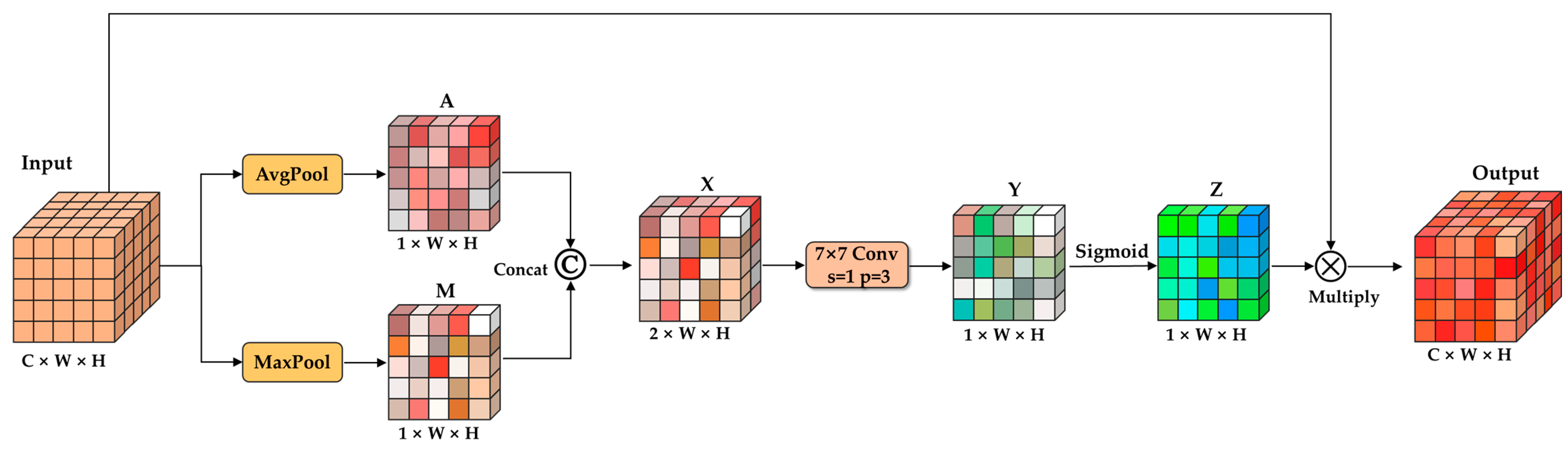
2.3. Contextual Attention Decoding Module
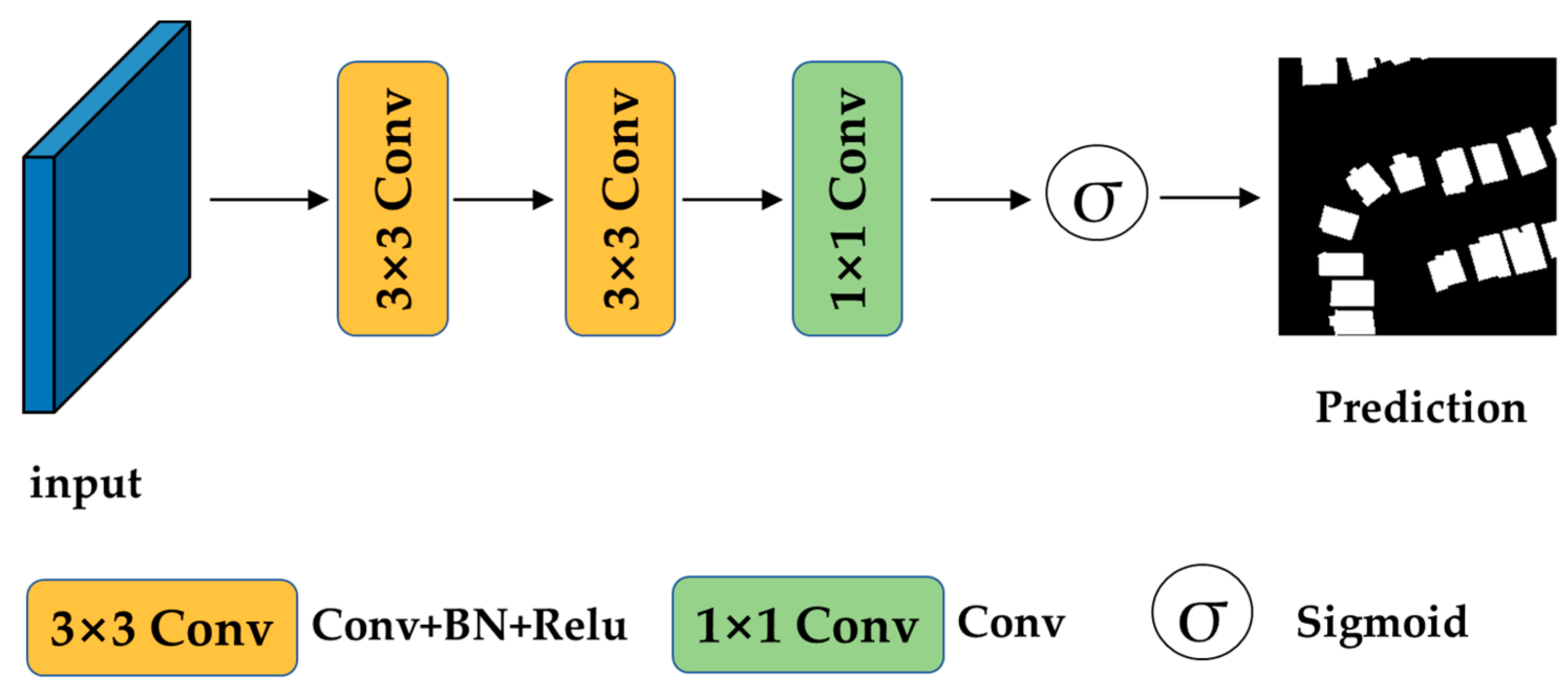
2.4. Deep Supervision
2.5. Loss Function
3. Results
3.1. Data Description
3.2. Metrics
3.3. Experimental Platform and Parameter Configuration
3.4. Experimental Results and Analysis
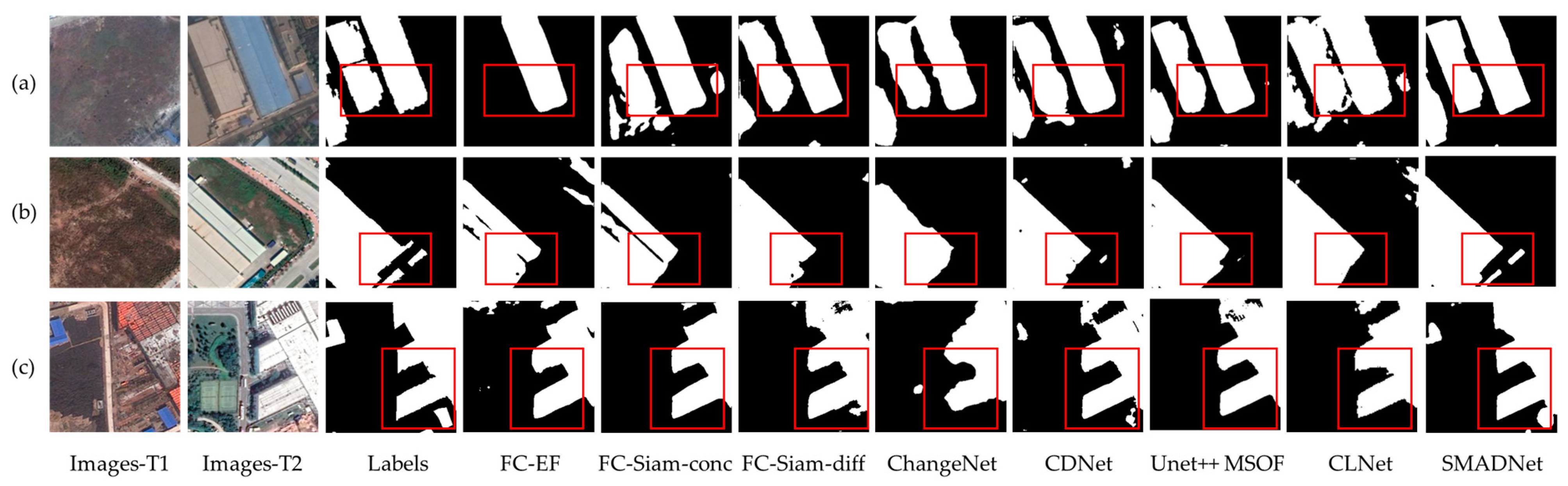
3.4.1. Experiments on GDSCD
3.4.2. Experiments on LEVIR-CD
3.4.3. Experiments on HRCUS-CD
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Demir, B.; Bovolo, F.; Bruzzone, L. Updating land-cover maps by classification of image time series: A novel change-detection-driven transfer learning approach. IEEE Trans. Geosci. Remote Sens. 2012, 51, 300–312. [Google Scholar] [CrossRef]
- Walter, V. Object-based classification of remote sensing data for change detection. ISPRS J. Photogramm. Remote Sens. 2004, 58, 225–238. [Google Scholar] [CrossRef]
- Jimenez-Sierra, D.A.; Benítez-Restrepo, H.D.; Vargas-Cardona, H.D.; Chanussot, J. Graph-based data fusion applied to: Change detection and biomass estimation in rice crops. Remote Sens. 2020, 12, 2683. [Google Scholar] [CrossRef]
- Gong, M.; Zhao, J.; Liu, J.; Miao, Q.; Jiao, L. Change detection in synthetic aperture radar images based on deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 125–138. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Zheng, H.; Gong, M.; Liu, T.; Jiang, F.; Zhan, T.; Lu, D.; Zhang, M. HFA-Net: High frequency attention siamese network for building change detection in VHR remote sensing images. Pattern Recognit. 2022, 129, 108717. [Google Scholar] [CrossRef]
- Asokan, A.; Anitha, J.J. Change detection techniques for remote sensing applications: A survey. Earth Sci. Inform. 2019, 12, 143–160. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Gilani, S.A.N.; Siddiqui, F.U. An effective data-driven method for 3-d building roof reconstruction and robust change detection. Remote Sens. 2018, 10, 1512. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, X.; Li, Z.; Li, D. A review of multi-class change detection for satellite remote sensing imagery. Geo-Spat. Inf. Sci. 2022, 1–15. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Zhang, Y.; Peng, D.; Huang, X. Object-based change detection for VHR images based on multiscale uncertainty analysis. IEEE Geosci. Remote Sens. Lett. 2017, 15, 13–17. [Google Scholar] [CrossRef]
- Zhang, C.; Li, G.; Cui, W. High-resolution remote sensing image change detection by statistical-object-based method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2440–2447. [Google Scholar] [CrossRef]
- Gil-Yepes, J.L.; Ruiz, L.A.; Recio, J.A.; Balaguer-Beser, Á.; Hermosilla, T. Description and validation of a new set of object-based temporal geostatistical features for land-use/land-cover change detection. ISPRS J. Photogramm. Remote Sens. 2016, 121, 77–91. [Google Scholar] [CrossRef]
- Qin, Y.; Niu, Z.; Chen, F.; Li, B.; Ban, Y. Object-based land cover change detection for cross-sensor images. Int. J. Remote Sens. 2013, 34, 6723–6737. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Blaschke, T.; Ma, X.; Tiede, D.; Cheng, L.; Chen, Z.; Chen, D. Object-based change detection in urban areas: The effects of segmentation strategy, scale, and feature space on unsupervised methods. Remote Sens. 2016, 8, 761. [Google Scholar] [CrossRef]
- Bai, T.; Wang, L.; Yin, D.; Sun, K.; Chen, Y.; Li, W.; Li, D. Deep learning for change detection in remote sensing: A review. Geo-Spat. Inf. Sci. 2022, 1–27. [Google Scholar] [CrossRef]
- Deng, J.S.; Wang, K.; Deng, Y.H.; Qi, G.J. PCA-based land-use change detection and analysis using multitemporal and multisensor satellite data. Int. J. Remote Sens. 2008, 29, 4823–4838. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Cui, X.; Zhang, L. A post-classification change detection method based on iterative slow feature analysis and Bayesian soft fusion. Remote Sens. Environ. 2017, 199, 241–255. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, X.; Chen, G.; Dai, F.; Gong, Y.; Zhu, K. Change detection based on Faster R-CNN for high-resolution remote sensing images. Remote Sens. Lett. 2018, 9, 923–932. [Google Scholar] [CrossRef]
- Long, Y.; Xia, G.S.; Li, S.; Yang, W.; Yang, M.Y.; Zhu, X.X.; Zhang, L.; Li, D. On creating benchmark dataset for aerial image interpretation: Reviews, guidances, and million-aid. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4205–4230. [Google Scholar] [CrossRef]
- Ding, Q.; Shao, Z.; Huang, X.; Altan, O. DSA-Net: A novel deeply supervised attention-guided network for building change detection in high-resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102591. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Urban change detection for multispectral earth observation using convolutional neural networks. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2115–2118. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Ji, S.; Shen, Y.; Lu, M.; Zhang, Y. Building instance change detection from large-scale aerial images using convolutional neural networks and simulated samples. Remote Sens. 2019, 11, 1343. [Google Scholar] [CrossRef]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change detection based on deep siamese convolutional network for optical aerial images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building change detection for remote sensing images using a dual-task constrained deep siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Varghese, A.; Gubbi, J.; Ramaswamy, A.; Balamuralidhar, P. ChangeNet: A deep learning architecture for visual change detection. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Jin, W.D.; Xu, J.; Han, Q.; Zhang, Y.; Cheng, M.M. CDNet: Complementary depth network for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 3376–3390. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Proceedings of the 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional Siamese networks for change detection in high-resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1194–1206. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Bandara, W.G.C.; Patel, V.M. A transformer-based siamese network for change detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Wang, D.; Chen, X.; Guo, N.; Yi, H.; Li, Y. STCD: Efficient Siamese transformers-based change detection method for remote sensing images. Geo-Spat. Inf. Sci. 2023, 1–20. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Dong, H.; Ma, W.; Wu, Y.; Gong, M.; Jiao, L. Local descriptor learning for change detection in synthetic aperture radar images via convolutional neural networks. IEEE Access 2018, 7, 15389–15403. [Google Scholar] [CrossRef]
- Gong, M.; Yang, H.; Zhang, P. Feature learning and change feature classification based on deep learning for ternary change detection in SAR images. ISPRS J. Photogramm. Remote Sens. 2017, 129, 212–225. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A semisupervised convolutional neural network for change detection in high resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5891–5906. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Zhang, J.; Shao, Z.; Ding, Q.; Huang, X.; Wang, Y.; Zhou, X.; Li, D. AERNet: An attention-guided edge refinement network and a dataset for remote sensing building change detection. IEEE Trans. Geosci. Remote Sensing 2023, 61, 5617116. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | P | R | F1 | OA | IoU | MIoU | Kappa |
|---|---|---|---|---|---|---|---|
| FC-EF | 61.50 | 78.70 | 69.05 | 96.27 | 52.72 | 74.41 | 67.09 |
| FC-Siam-conc | 62.17 | 82.50 | 70.90 | 96.54 | 54.92 | 75.66 | 69.10 |
| FC-Siam-diff | 77.16 | 80.15 | 78.63 | 97.16 | 64.78 | 80.89 | 77.11 |
| ChangeNet | 79.67 | 84.71 | 82.11 | 97.65 | 69.65 | 83.58 | 80.86 |
| CDNet | 74.07 | 81.59 | 77.65 | 97.11 | 63.46 | 80.21 | 76.11 |
| Unet++MSOF | 69.29 | 88.76 | 77.83 | 97.33 | 63.70 | 80.45 | 76.43 |
| CLNet | 71.63 | 79.41 | 75.32 | 96.82 | 60.41 | 78.54 | 73.63 |
| SMADNet | 88.64 | 87.35 | 87.99 | 98.36 | 78.56 | 88.41 | 87.11 |
| Methods | P | R | F1 | OA | IoU | MIoU | Kappa |
|---|---|---|---|---|---|---|---|
| FC-EF | 78.72 | 85.43 | 81.94 | 98.23 | 69.40 | 83.78 | 81.01 |
| FC-Siam-conc | 83.02 | 87.47 | 85.19 | 98.53 | 74.20 | 86.33 | 84.41 |
| FC-Siam-diff | 81.65 | 90.88 | 86.02 | 98.65 | 75.47 | 87.03 | 85.31 |
| ChangeNet | 82.56 | 84.40 | 83.47 | 98.33 | 76.30 | 84.95 | 82.59 |
| CDNet | 84.99 | 88.99 | 86.94 | 98.70 | 76.90 | 87.77 | 86.26 |
| Unet++MSOF | 86.26 | 90.23 | 88.20 | 98.87 | 79.50 | 89.16 | 87.99 |
| CLNet | 87.94 | 90.49 | 89.20 | 98.92 | 80.50 | 89.68 | 88.63 |
| SMADNet | 88.97 | 92.49 | 90.70 | 99.07 | 82.98 | 91.00 | 90.21 |
| Methods | P | R | F1 | OA | IoU | MIoU | Kappa |
|---|---|---|---|---|---|---|---|
| FC-EF | 42.26 | 64.28 | 50.99 | 98.48 | 34.22 | 66.34 | 50.25 |
| FC-Siam-conc | 53.95 | 66.95 | 59.75 | 98.64 | 42.61 | 70.61 | 59.07 |
| FC-Siam-diff | 64.29 | 67.76 | 65.98 | 98.76 | 49.23 | 73.99 | 65.34 |
| ChangeNet | 55.24 | 67.09 | 60.59 | 98.65 | 43.46 | 71.05 | 59.91 |
| CDNet | 55.74 | 67.95 | 61.24 | 98.68 | 44.14 | 71.40 | 60.58 |
| Unet++MSOF | 61.10 | 70.06 | 65.27 | 98.78 | 48.45 | 73.61 | 64.65 |
| CLNet | 67.67 | 61.07 | 64.20 | 98.59 | 47.28 | 72.92 | 63.48 |
| Datasets | Baseline | MCFFM | CADM | DS | IoU | OA | F1 | Kappa |
|---|---|---|---|---|---|---|---|---|
| GDSCD | ✓ | 72.61 | 97.85 | 84.13 | 82.98 | |||
| ✓ | ✓ | 74.01 | 97.97 | 85.07 | 83.98 | |||
| ✓ | ✓ | ✓ | 76.13 | 98.25 | 86.45 | 85.52 | ||
| ✓ | ✓ | ✓ | ✓ | 78.56 | 98.36 | 87.99 | 87.11 | |
| LEVIR-CD | ✓ | 78.95 | 98.77 | 88.24 | 87.59 | |||
| ✓ | ✓ | 79.82 | 98.90 | 88.78 | 88.2 | |||
| ✓ | ✓ | ✓ | 81.93 | 99.01 | 90.07 | 89.55 | ||
| ✓ | ✓ | ✓ | ✓ | 82.98 | 99.07 | 90.70 | 90.21 | |
| HRCUS-CD | ✓ | 54.96 | 98.85 | 70.93 | 70.35 | |||
| ✓ | ✓ | 56.84 | 98.98 | 72.48 | 71.96 | |||
| ✓ | ✓ | ✓ | 57.08 | 98.96 | 72.68 | 72.15 | ||
| ✓ | ✓ | ✓ | ✓ | 59.36 | 99.02 | 74.50 | 74.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Zhang, J.; Shao, Z.; Huang, X.; Ding, Q.; Li, X.; Huang, Y. A Siamese Multiscale Attention Decoding Network for Building Change Detection on High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 5127. https://doi.org/10.3390/rs15215127
Chen Y, Zhang J, Shao Z, Huang X, Ding Q, Li X, Huang Y. A Siamese Multiscale Attention Decoding Network for Building Change Detection on High-Resolution Remote Sensing Images. Remote Sensing. 2023; 15(21):5127. https://doi.org/10.3390/rs15215127
Chicago/Turabian StyleChen, Yao, Jindou Zhang, Zhenfeng Shao, Xiao Huang, Qing Ding, Xianyi Li, and Youju Huang. 2023. "A Siamese Multiscale Attention Decoding Network for Building Change Detection on High-Resolution Remote Sensing Images" Remote Sensing 15, no. 21: 5127. https://doi.org/10.3390/rs15215127
APA StyleChen, Y., Zhang, J., Shao, Z., Huang, X., Ding, Q., Li, X., & Huang, Y. (2023). A Siamese Multiscale Attention Decoding Network for Building Change Detection on High-Resolution Remote Sensing Images. Remote Sensing, 15(21), 5127. https://doi.org/10.3390/rs15215127