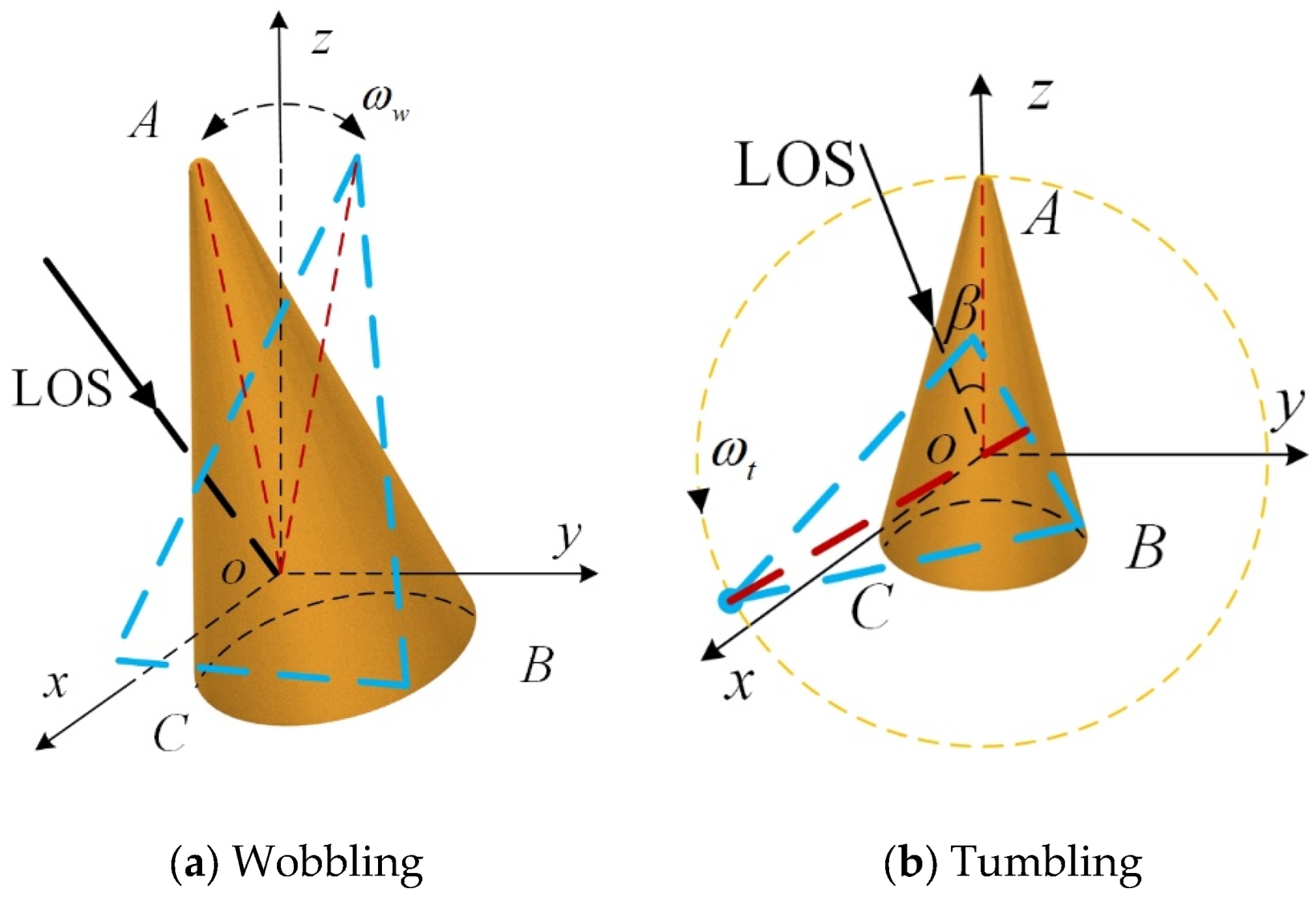
2. Space Target Micro-Motion Characteristics Analysis
Here, the representative micro-motions for space targets are considered: (1) Wobbling, see
Figure 1a. (2) Tumbling, see
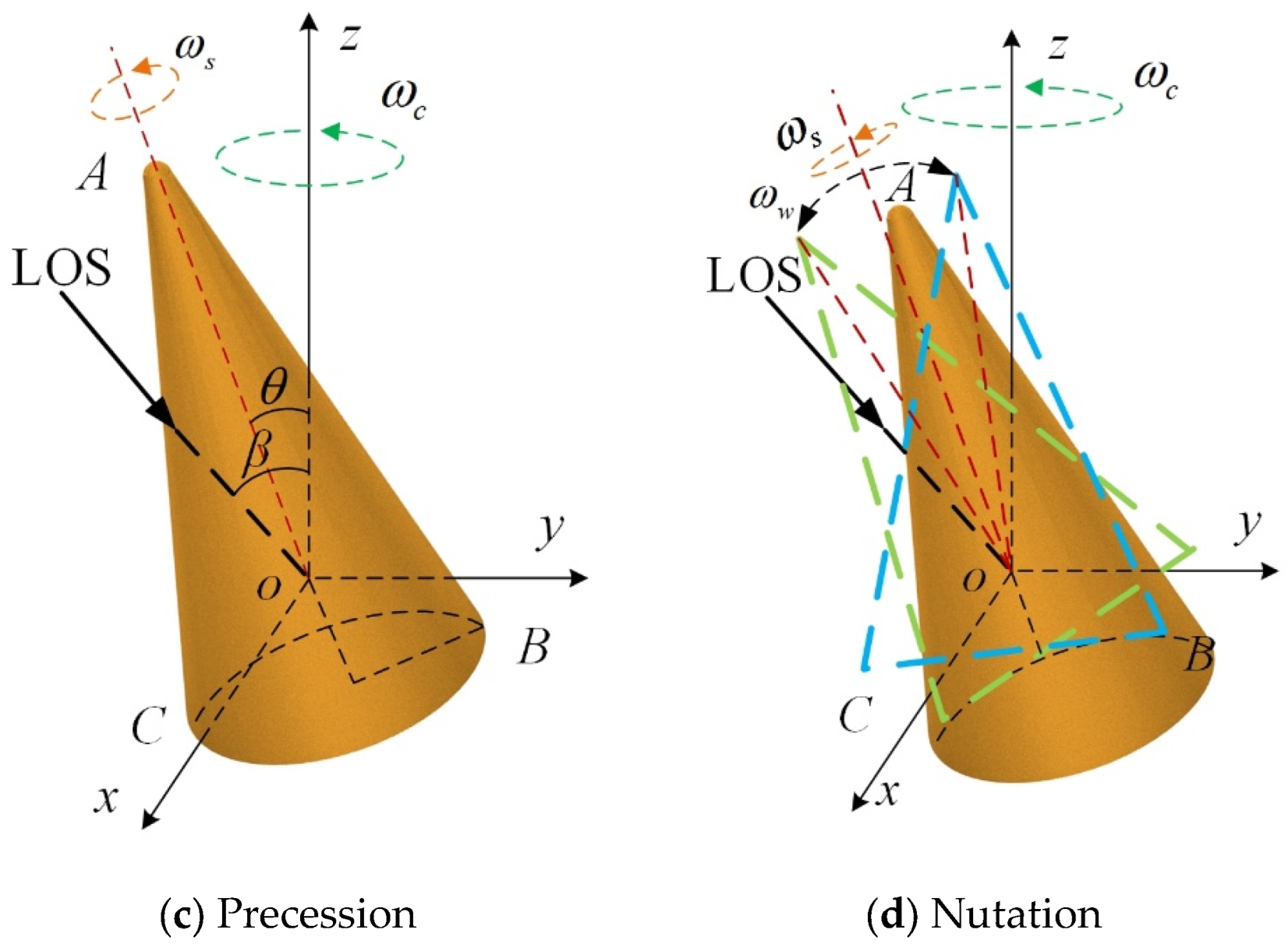
Figure 1b. (3) Precession, see
Figure 1c. and (4) nutation, see
Figure 1d [
24]. The mass of the cone-shaped space target is set at the origin of the
coordinate system, the elevation angle of the target symmetry axis is
, the angle between the radar line-of-sight (LOS) and the
axis is
. The initial coning matrix can be expressed as:
Taking the wobbling motion as an example to analyze, assuming
represents the wobbling angular velocity, the micro-motion matrix at time
is
where
is the identity matrix and
represents the wobble angular velocity. The skew-symmetric matrix
can be defined by
where
,
, and
are the projection of
onto the
,
, and
, respectively.
Then, the micro-range of scattering centers by wobbling are
where
is the initial position of scattering centers and
is the unit vector of LOS.
Similarly, at time
, the tumbling matrix can be expressed as
where
represents the tumble angular velocity.
represents the skew-symmetric matrix of tumbling angular velocity
.
Precession can be considered as the combination of spinning and coning motion, and nutation can be considered as the combination of spinning, coning, and wobbling [
25].
Assume
and
represent the coning matrix and the spinning matrix, respectively. Then, the precession matrix and nutation matrix can be expressed as
Then, the micro-range of scattering centers by tumbling, precession, and nutation are
In conclusion, the micro-range characteristics of the wobbling target conform to the law of sinusoidal modulation. If the wobbling angle exceeds , the target will rotate in a specific direction around its center of mass, entering the tumbling state. Precession and nutation belong to compound micro-motions which can be regarded as a composite of multiple primary micro-motions. Consequently, the micro-range characteristics of the precession and nutation target will undergo additional modulation on a sinusoidal basis.
Given that the wideband radar emits a linear frequency-modulated (LFM) signal, consequently, the echo signal may be defined as follows
where
and
represent the fast time and slow time, respectively.
is the frequency modulation slope of LFM signal,
denotes the wideband radar carrier frequency,
is the time duration, and
represents the speed of light.
and
denote the scattering coefficient and the echo delay time at
of the
kth scattering center, respectively.
After applying the “dechirp” processing and compensating for the residual video phase, a Fourier transform (FT) is performed on the echo in the fast time domain [
26]. Subsequently,
is substituted to obtain the expression for the echo in the domain of the time-range, which can be defined as follows:
where
is the radar bandwidth, and
denotes the motion range.
; symbol
is reference range.
represents the sinc function.
In simulation, the time-range maps can be obtained by Equation (9). Assuming the wideband radar carrier frequency is 10 GHz, the bandwidth is 2 GHz, and the radar observation time is 2 s. The height and radius of the cone target are 3 m and 0.64 m, respectively.
Figure 2 presents simulation time-range maps of the four micro-motion forms including wobbling, tumbling, precession, and nutation. In wobbling state, the wobble angular velocity
rad/s, the maximum angle of wobbling is
, and the simulation result is shown in
Figure 2a. In the tumbling state, the tumble angular velocity
rad/s, which is the simulation result, as shown in
Figure 2b. The cone rotation angular velocity of precession state is
rad/s, and the angle
is
. The simulation result of the precession as shown in
Figure 2c. For nutation target, the cone rotation angular velocity, wobble angular velocity,
and maximum wobbling angle are
rad/s,
rad/s,
and
, respectively. The simulation result of nutation is shown in
Figure 2a.
As shown in
Figure 2, the time-range maps of different micro-motion forms have obvious periodicity, but their variation laws are different, which can be used as an important basis for distinguishing different targets.
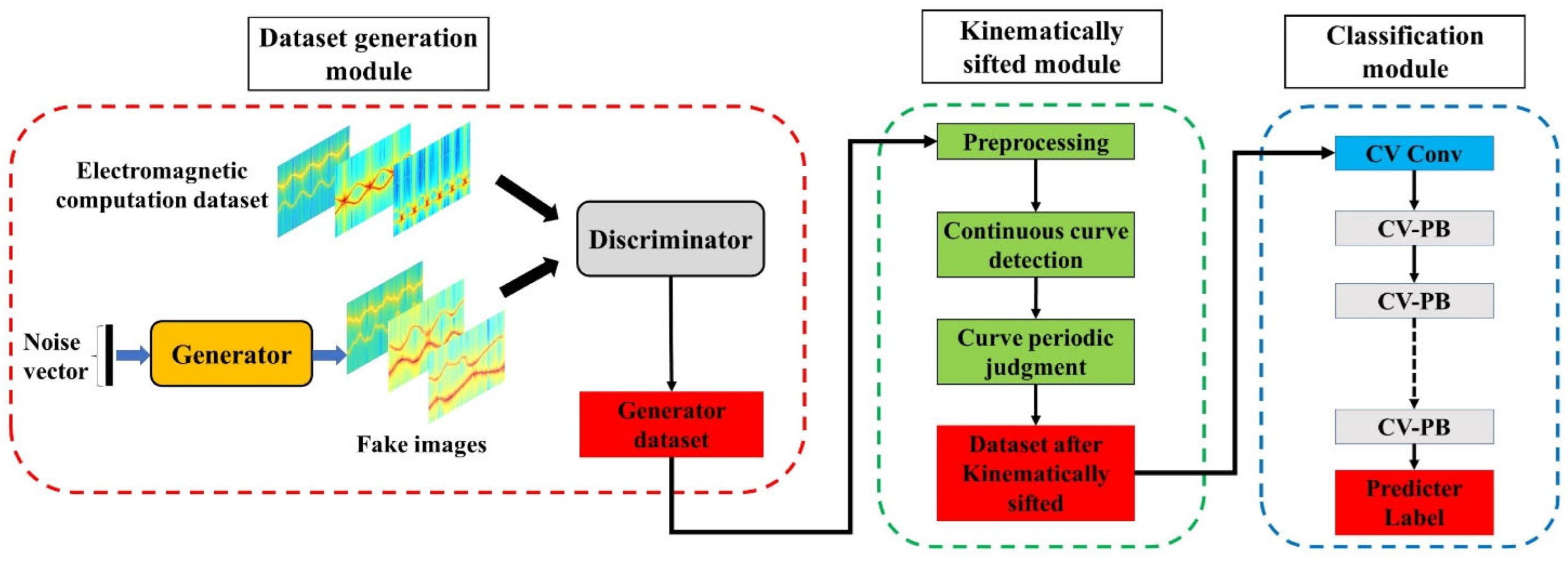
3. Proposed Framework
Figure 3 is the schematic diagram of the proposed framework. The basic structure of our proposed framework includes a dataset generation module, a kinematically sifted module, and a classification module. The dataset generation module uses a complex-valued generative adversarial network (CV-GAN) to generator dataset. The module for the kinematic sifted module verifies the compliance of the generated images with the kinematic laws and eliminates any images that violate these laws. The classification module implements target recognition function based on time-range maps. Below are the implementation methods of the three modules.
3.1. Dataset Generation Module
GAN is commonly utilized for various tasks such as generating images, style conversion, and achieving image super-resolution capabilities. Unlike traditional networks, GAN consists of two connected parts, including the generator and the discriminator. The generator is responsible for creating new data samples from random noise. Its role is to generate different but highly similar samples compared to real samples. On the other hand, the discriminator is employed to differentiate between real and generated samples. The generator and the discriminator play a min-max game, and the final optimization goal is to reach Nash equilibrium [
27]. The process can be defined as:
where
is the samples input, and
is the noise vector.
and
defined the generator and the discriminator, respectively.
and
defined the distribution of real data and generated data, respectively.
In the objective function, the discriminator manages to maximize its ability to distinguish between fake and real images. The generator aims to minimize the JS divergence between the distribution of generated data and real data.
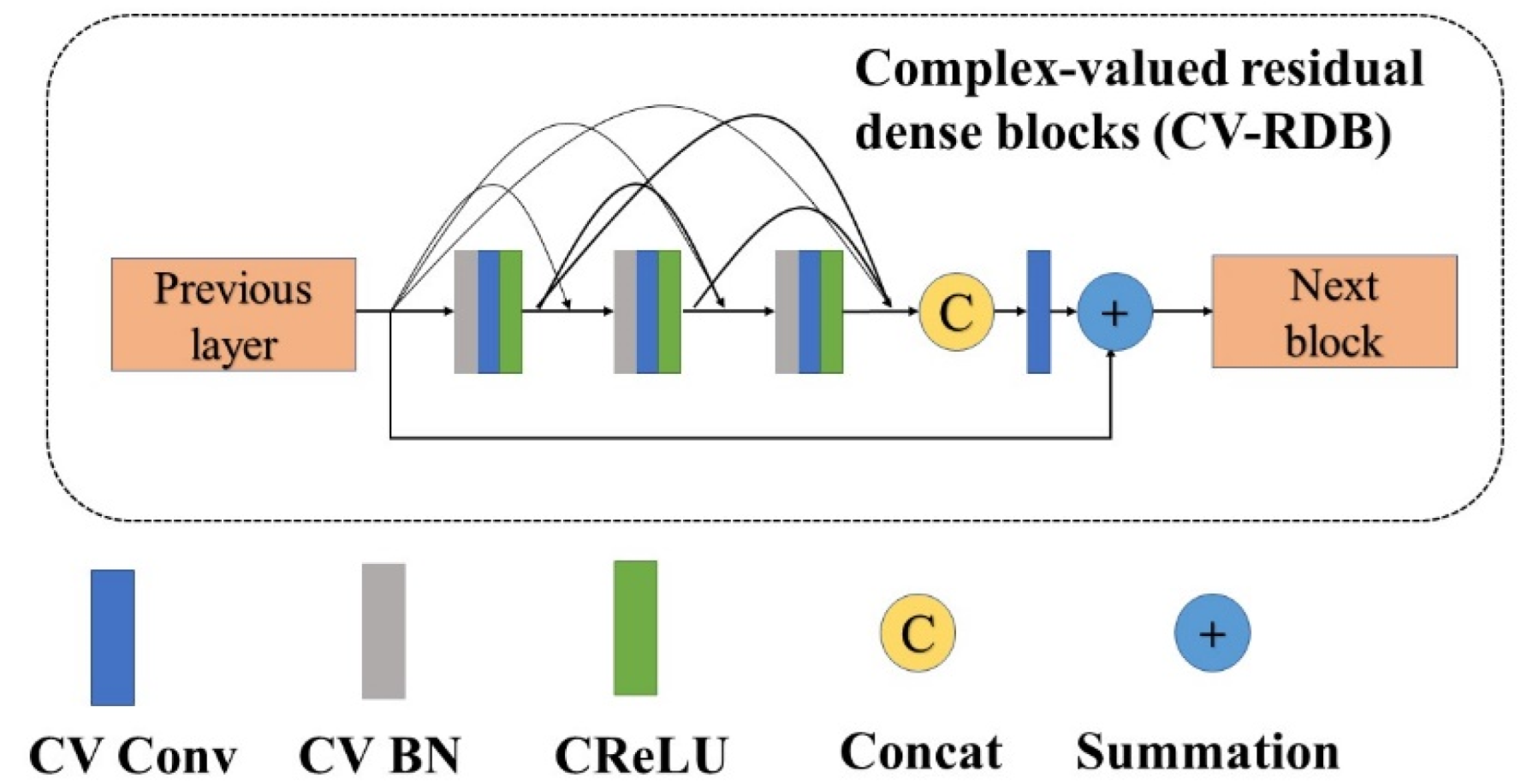
In this paper, this is the first time that the concept of complex values has been used in GAN construction. We use the complex-valued generative adversarial network (CV-GAN) to generate large time-range maps. Similarly, CV-GAN consists of two parts. The generator and discriminator in this paper were composed of complex-valued residual dense blocks (CV-RDB). The structure of CV-RDB is shown in
Figure 4.
Figure 4 illustrates the architecture of the CV-RDB, with blue blocks representing the complex-valued convolution layer, gray blocks representing the complex-valued batch normalization (CV BN) layer, green blocks representing the complex-valued activation function, “C” denoting the concatenation operator, and “+” indicating the summation. CV-RDB can be considered as a combination of the residual block and dense block, which can fully extract features and widen the network.
Complex-valued convolution can be defined as
where
and subscript “
” represents the real part of complex values,
and subscript “
” represents the imaginary part of the complex value.
is a complex filter matrix,
is a complex vector, and
denotes the convolution operation.
According to Liouville’s theory [
28], bounded entire functions must be constants. In a real-valued network, the activation function is often required to be a differentiable function, but in the complex-valued field, a bounded complex activation function cannot be complexly differentiable at the same time. Hence, it is not possible to use the real-valued activation function in a complex-valued network. There is still no agreed consensus on the use of complex-valued activation functions. In this paper, we use complex-valued ReLU (CReLU) [
29] as activation function, which can be defined as
where
,
represents the rectified linear unit.
is the phase of
. When
or
, real and imaginary parts are either strictly positive or strictly negative at the same time.
Complex-valued networks generally rely upon the CV BN process to accelerate learning. The CV BN can be written as
where
is complex-valued data,
represents normalized complex-valued data, and
is a covariance matrix, which is given by:
where
represents the covariance operation.
The generator and the discriminator in a dynamic process of continuous confrontation, and finally, CV-GAN can produce many fake images which are sufficiently close to real images. The optimization function of CV-GAN is defined as follows:
3.2. Kinematically Sifted Module
It is important to note that the phenomenology of radar data exhibits different properties from optical imagery. In GAN synthetic image conventional evaluation, the visual effect is often regarded as the main evaluation metric. Visual effect evaluation involves assessing the quality of generated images in terms of details, colors, textures, clarity, and other aspects through subjectively judging their visual impact. However, some of the authentic synthetic images may be visually similar, but kinematically impossible. Therefore, using visual effects as the sole evaluation metric for synthetic images may not be accurate.
In this paper, it is necessary to observe the targets continuously over one micro-motion periodic to obtain the periodic and continuous curve images of the targets. We proposed a generation data-sifted method based on physics and kinematics, which can be described as follows:
- (1)
Preprocessing: The pixel-wise adaptive Wiener filter [
15] was used to preprocess.
- (2)
Continuous Curve Detection: Due to the constraints of the radar line of sight, the number of scattering points of cone-shaped targets should not exceed three, which is also reflected in the time-range map, indicating that the number of continuous curves should be no more than three. This paper uses the ShuffleNet [
30] to recognize the number of scattering point curves, as shown in
Figure 5. The basic unit of the ShuffleNet consists of a group convolution with channel shuffling, as depicted in
Figure 5a. Specifically, the original group is divided into multiple subgroups, which are then recombined to form new groups and subsequently undergo group convolution. As illustrated in
Figure 5b, the number of groups after channel shuffle is three. The main branch of the basic unit first performs channel-level signal convolution via a 1 × 1 group convolution to the feature map, followed by shuffling the obtained feature map with channel shuffling technology. Subsequently, a 3 × 3 convolution kernel is used to additionally learn the target feature map, and a 1 × 1 group convolution is used to learn the obtained feature map. Moreover, a direct connection structure is adopted in the residual block to guarantee that the quality of the features produced by the next layer of the network does not fall below the quality of the features produced by the previous layer.
To train the network, time-range maps with different numbers of scattering points were generated according to the motion characteristics of different micro-motion targets presented in
Section 2. Four labels were constructed to represent images containing one, two, three, and more than three scattering point curves, respectively. The network is trained using the simulation database, and then the generated database is classified to remove images with labels indicating more than three scattering point curves, thus enabling a screening of the number of scattering point curves.
- (3)
Curve periodic judgment. We choose as the initial time point. Time-range map sequence at as the reference sequence. Then, we calculate the value of the correlation coefficient between and other sequence , which can be described as:
where
and
denote the average of
and
, respectively.
3.3. Classification Module
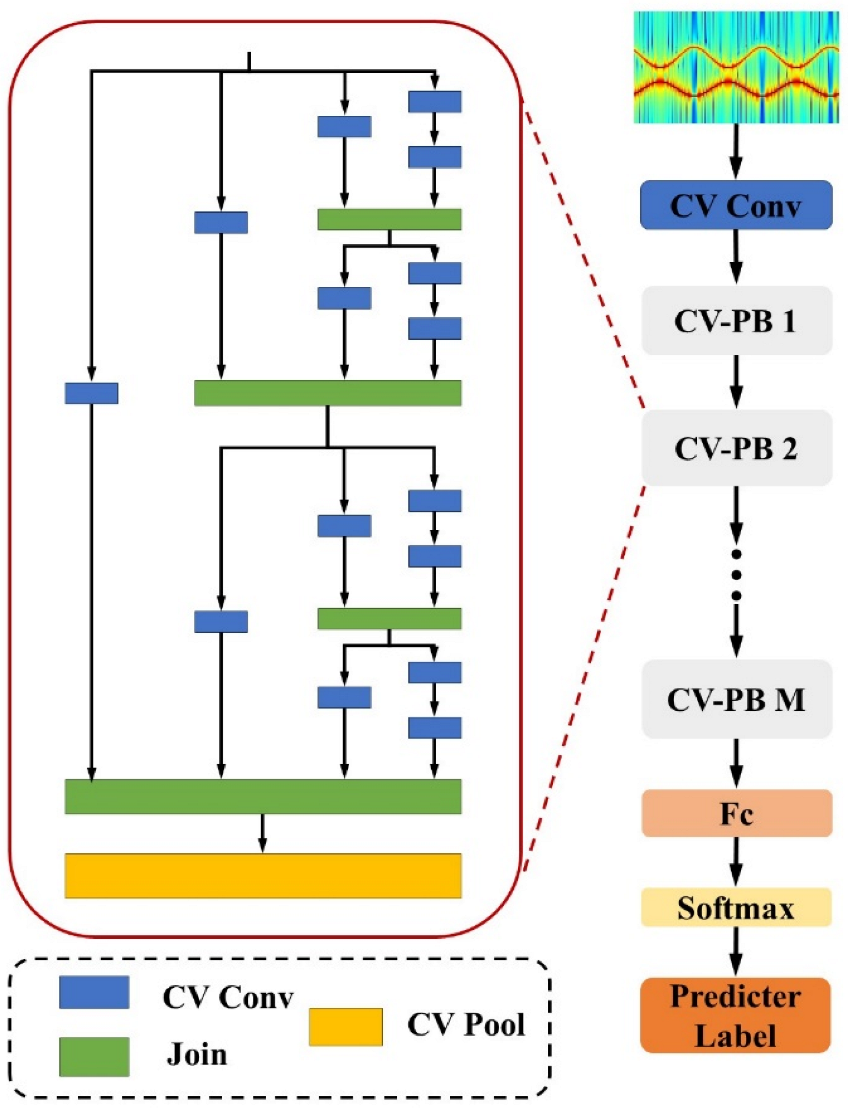
Based on the characteristics of the time-range maps, we use a series of complex-valued parallel block (CV-PB) structures to construct a complex-valued parallel network (CV-PNet). The overall architecture of the CV-PNet is shown in
Figure 4.
Assuming the parallel blocks have
parallel branches, the parallel block contains
convolutional blocks. In
Figure 6, where
, it contains 15 convolutional blocks. Stacking
parallel block and a complex-valued convolution layer yields the parallel network whose total depth, measured in terms of convolution layers, is
.
There are different types of complex-valued convolutional layers in the parallel block, which are, respectively, , , , . In order to reduce computational complexity and expand the network depth, the structural design of parallel blocks follows fractal thinking. First, the complex-valued convolutional layer was used as the initial layer. Then, we connect two complex-valued convolutional layers in series and combine them with complex-valued convolutional layers to obtain the second framework. Then, concatenating two second layer frameworks with complex-valued convolutional layers yields the third framework. This continues until two frameworks are concatenated and then combined with complex-valued convolutional layers to obtain the framework.
Parallel structures, as opposed to independent convolutional kernels that learn a single feature, have the ability to automatically extract diverse features and demonstrate an increased capacity for handling complex tasks. Different processing branches sample different convolutional kernels, enabling the module to capture features at different scales.
4. Simulation Results and Discussion
4.1. Electromagnetic Computation Dataset
It is technically very hard to obtain real radar echo data of the space cone-shaped target [
15,
31]. Therefore, to acquire a sufficiently large dataset to drive the synthetic radar image generation with CV-GAN, the electromagnetic computation data was used as the CV-GAN training dataset. The steps for obtaining the CV-GAN training dataset are as follows:
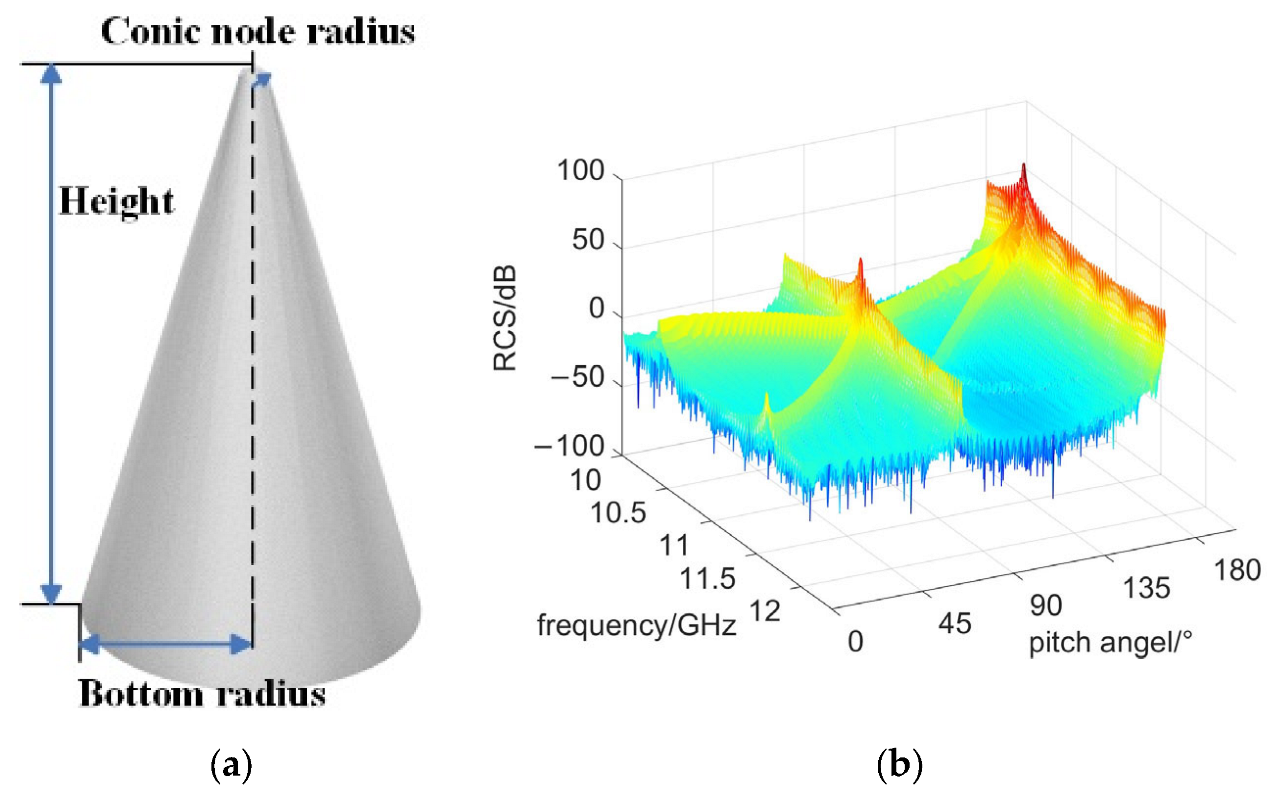
Step 1: Calculation of the radar cross-section (RCS) value for the space target, as shown in
Figure 7. Begin by creating a simulation model of the space target. The geometric structure is illustrated in
Figure 7a. Next, the simulation model is imported into the FEKO 2019 software, and the Physical Optics (PO) method is applied to calculate the RCS of the target. The parameters used for electromagnetic computation are provided in
Table 3.
Figure 7b demonstrates the RCS effect.
The RCS value of the target experiences a sudden change at pitch angles of approximately and . This phenomenon occurs due to the mirror reflection between the generatrix and the base of the cone target, resulting in a significant increase in RCS. Furthermore, due to the occlusion effect, the cone target comprises three scattering centers, and the visibility of these centers is dependent on the pitch angle.
Step 2: Micro-motion parameter setting. According to the RCS of the target, we can obtain the CV-GAN training dataset by setting different target motion parameters, an initial angle, and LOS.
Table 4 presents the settings of the micro-motion parameters.
Step 3: Acquire the echo signal of the space target. Integrate the expressions for the target micro-range under different micro-motions and place the echo expression into the time-range domain in order to generate the time-range maps.
Finally, there are 3840 samples in this EM computation dataset.
4.2. Dataset Generation and Kinematically Sifted Module
The structure of CV-RDB is shown in
Table 5. For a simple presentation, the CV BN layer and CReLU layer are not represented.
The network structure of CV-GAN is shown in
Table 6.
In this paper, the adaptive moment estimation (Adam) algorithm is employed as the CV-GAN optimizer method, with an exponential decay of 0.5 for the first-order momentum and 0.999 for the second-order momentum. The learning rate is 0.0002. The size of complex-valued convolutional layers in CV-RDB is , and the step size is 1. The CV BN with the momentum of 0.8.
In this paper, the CV-GAN experiments were implemented using PyCharm, while the kinematically sifted experiments were implemented using MATLAB. The configuration details of the PC platform were as follows: CPU Intel(R) Xeon(R) Gold 6246@3.30 Ghz and RAM 256 GB, and the GPU was an NVIDIA Quadro GV100.
Each training image in CV-GAN is scaled to . The minibatch size is 16, and the noise vector of the generator is (dimensionality of the latent space). Each time the number of channels in a CV-RDB layer is halved, the length and width are doubled.
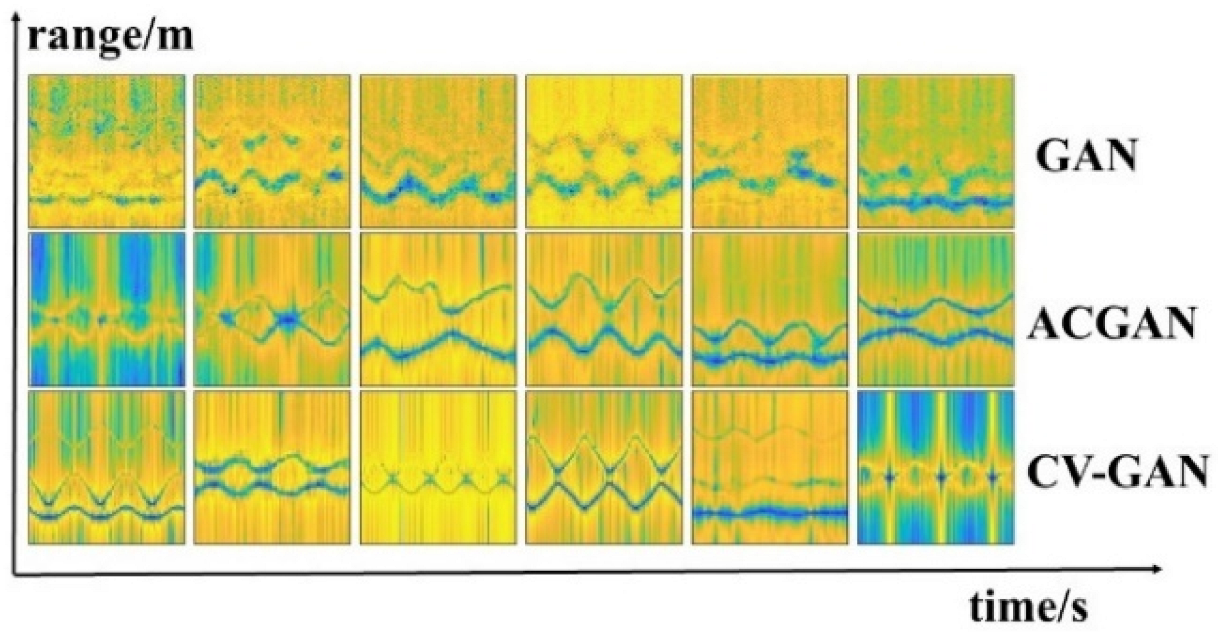
A sample of six time-range maps generated by GAN [
19], ACGAN [
20], and CV-GAN are depicted in
Figure 8. It can be observed that the GAN-generated images appear to be blurry, the ACGAN-generated images are comparatively clear, and the images generated by CV-GAN have the highest imaging quality.
In our evaluation of the quality of generated images, we employed Peak Signal to Noise Ratio (PSNR), an objective evaluation indicator for evaluating noise levels or image distortion that plays a crucial role in ensuring the quality of generated images. PSNR can be defined as:
where
defined the maximum value of image color and
is the error of the mean square.
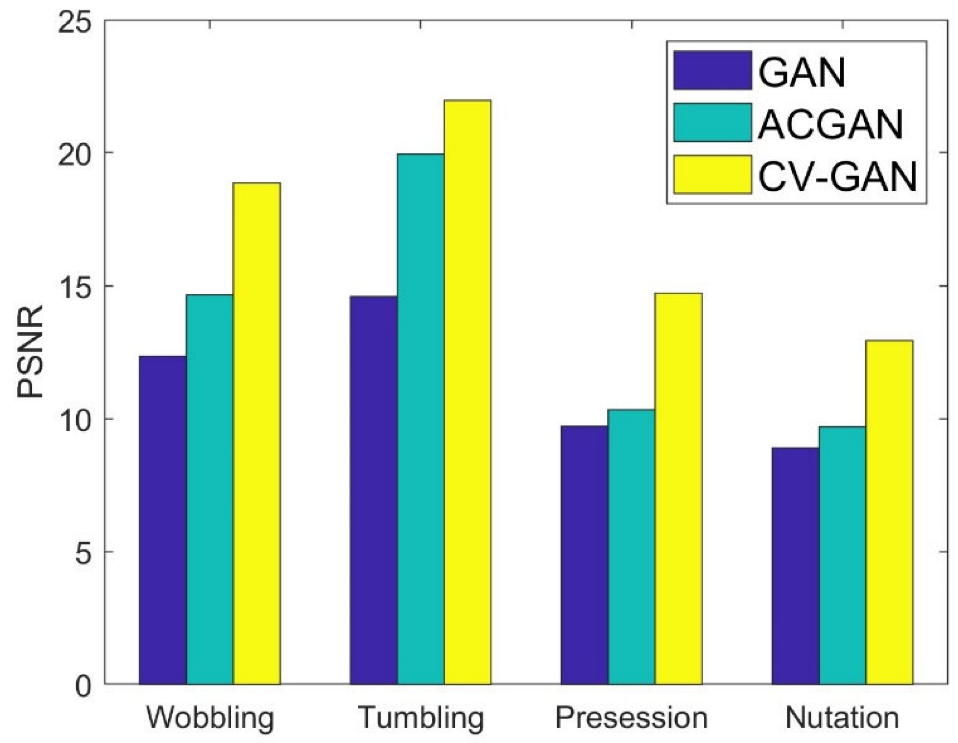
The larger the PSNR, the less distortion and the better the quality of the generated image. In
Figure 9, we observe that the images generated using CV-GAN exhibit significantly larger PSNR values, indicating superior image quality compared to other methods.
To quantitatively assess the performance of different methods, Fréchet inception distance (FID) is employed to measure the quality of generated data [
32]. FID is mathematically formulated as
where
and
denote the distribution of the electromagnetic computation image and synthetic image, respectively. The value of FID is dependent on means
,
, and covariances
,
.
represents the trace of the matrix.
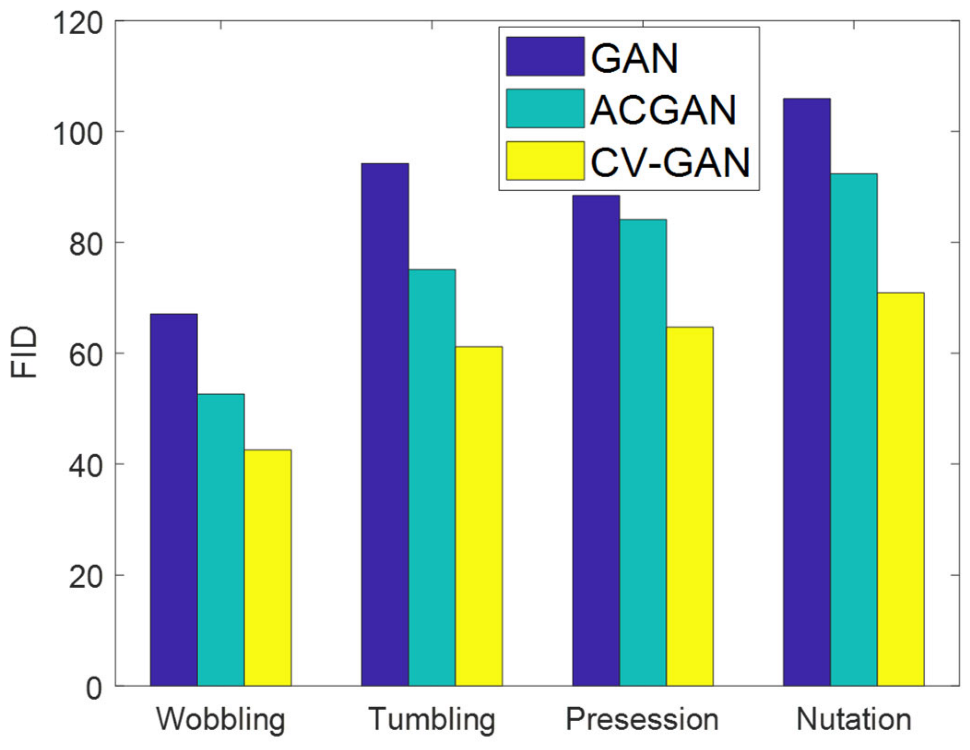
The FID of the time-range maps generated by different methods was calculated. As shown in
Figure 10, the generated images based on CV-GAN have a lower FID value, indicating an improved diversity of the images.
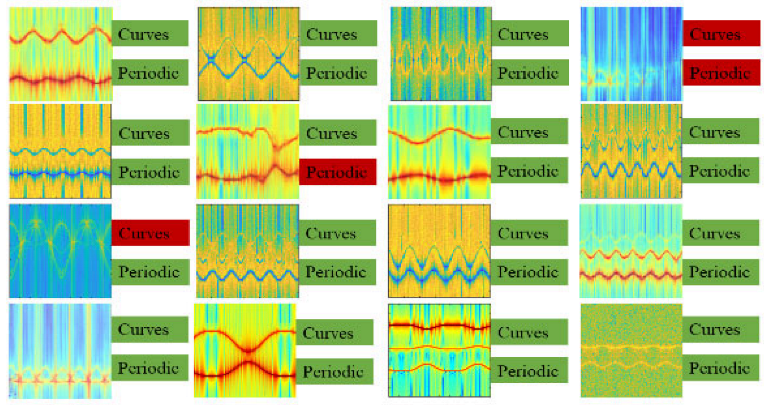
To demonstrate the kinematic sifting method presented in this paper, we randomly selected 16 synthetic images generated by CV-GAN. As illustrated in
Figure 11, the green label indicates that the generated image adheres to the motion law, while the red label indicates that the generated image is unsuccessful.
Upon examining this random selection of 16 synthetic images, we discovered that three images did not adhere to the kinematic laws and should be excluded from the generated database. This process was repeated to filter all generated data. As a result, 1273 images of wobbling, 1360 images of tumbling, 1185 images of precession, and 977 images of nutation that did not meet the criteria were eliminated.
4.3. Classification Result
The structure and hyperparameters of the CV-PNet are shown in
Table 7.
The number of parallel branches is 4 and the size of complex-valued convolutional layers in CV-PB are , , , and . The step size of all complex-valued convolutional layers is 1.
The performance of the network can be assessed using the classification accuracy, F1 [
33], and kappa coefficient [
16], which are all values between 0 and 1, with higher values indicating better performance. The definition of the evaluation metric is as follows
where
is the number of categories. The abbreviations are as follows: TP (true positive), TN (true negative), FN (false negative), and FP (false positive).
is the relative misclassification number. Assuming that the total number of samples is
, then
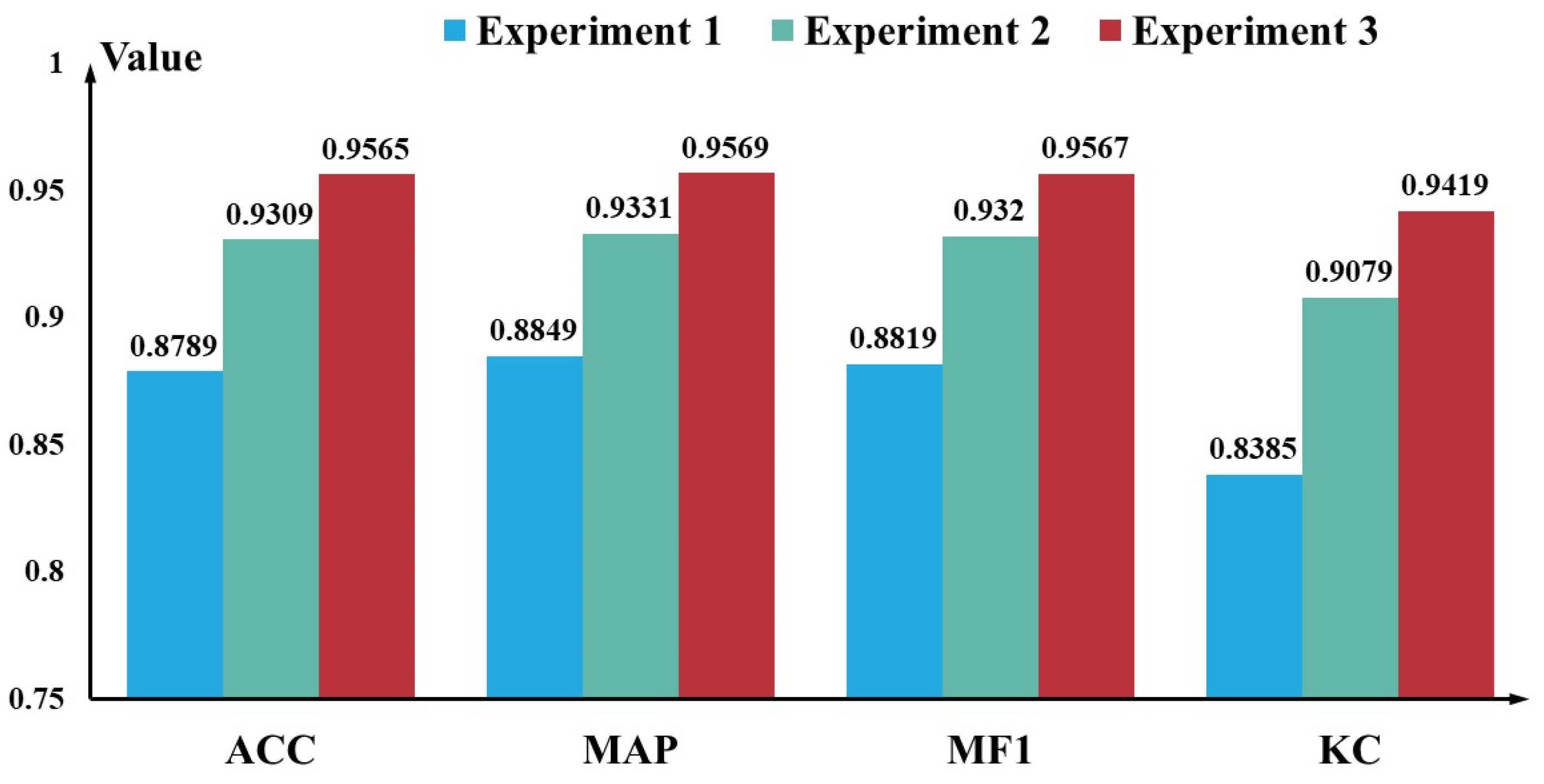
We set the electromagnetic computation dataset as Data1, the generated dataset as Data2, and the generated dataset after sifting as Data3. To ensure the preciseness of the experiment, we set the database size of each target micro-motion type in Data2 and Data3 to 8640. The following experiments were designed to verify the effectiveness of the proposed method:
- (1)
Experiment 1: We used Data1 as the network training database, with 20% of Data2 allocated as the classification validation database and 20% as the classification testing database.
- (2)
Experiment 2: We used Data1 and 60% of Data2 as the classification training database. The settings of the validation database and testing database are kept consistent with Experiment 1.
- (3)
Experiment 3: We used Data1 and 60% of Data3 as the classification training database. The settings of the validation database and testing database are kept consistent with Experiment 1.
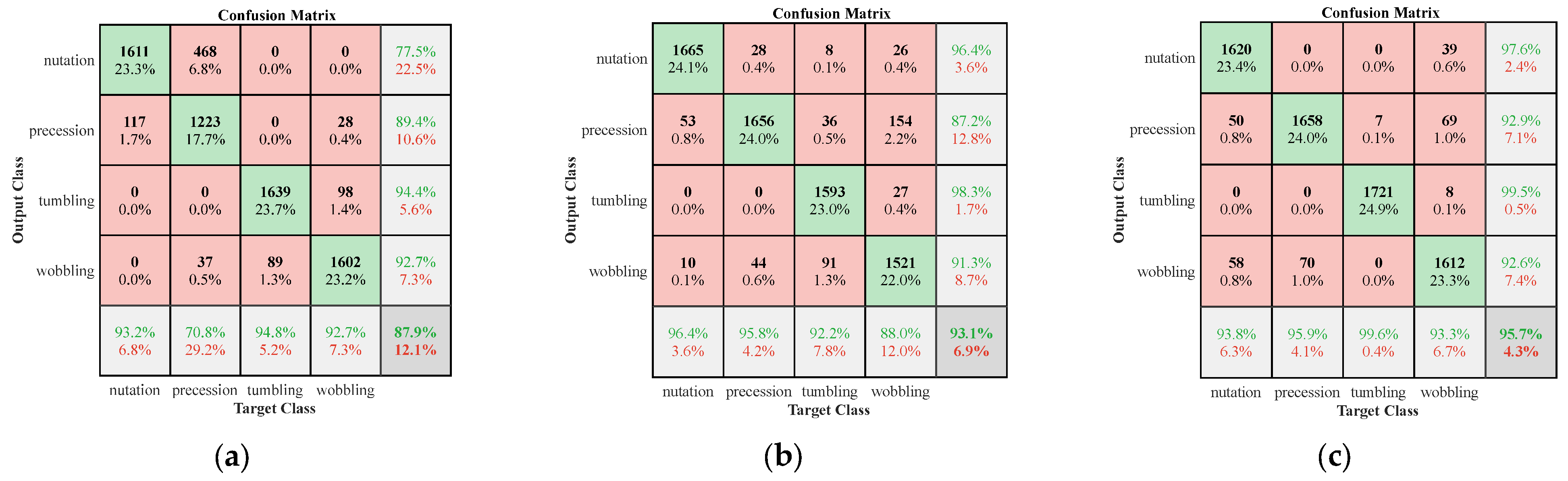
The test confusion matrixes are depicted in
Figure 12.
Then, we compute the value of the evaluation metric based on the confusion matrix. The confusion matrix of experiment 1, experiment 2 and experiment 3 is shown in
Figure 12a–c.
Figure 13 illustrates that the four indicators of the experiment 3 are the best and the experiment 2 is slightly inferior, whereas experiment 1 is poor. The worst recognition performance of experiment 1 was attributed to the small number of samples in the electromagnetic dataset, while the best performance accuracy of experiment 3 verified the importance of kinematically sifted experiments.
To further verify the effectiveness of the method, we compared the proposed networks with the following state-of-the-art target recognition algorithms. (1) TARAN [
14]; (2) 2D CNN [
15]; (3) 19-layer CNN [
19].
Table 8 shows that under the same dataset, the proposed networks achieve a better performance in terms of ACC, MAP, MF1, and KC.
Then, based on the initial network structure, we studied the influence of the number of parallel blocks (
M) and the number of parallel branches (
N) in the proposed CV-PNet. The Data3 dataset for each class was randomly divided into 60% for training, 20% for validation, and 20% for testing. The comparison results are illustrated in
Table 9 and
Table 10.
As shown in
Table 9, the number of parallel blocks (
M) is increased from 4 to 12 in an interval of 2. As the value of
M increased, the evaluation metric values gradually increased. It is noteworthy that the recognition effect of CV-PNet significantly improved when
M was between 4 and 10. However, beyond
M = 10, the recognition effect showed a slower improvement. One can observe from
Table 10 that as the number of parallel branches increases, so does the recognition ability of CV-PNet.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}