


Hardware-Aware Design of Speed-Up Algorithms for Synthetic Aperture Radar Ship Target Detection Networks

 ,
, 
Abstract
:1. Introduction
- We propose a GPU-oriented model speed-up method for SAR ship target detection tasks and use this algorithm for yolov5n, yolov5s, yolov5m, and yolov5l. Then, the accelerated models are deployed on an NVIDIA AGX Xavier development board.
- This paper provides the first detailed analysis of the execution of the inference process for the SAR ship target detection task on a GPU. The results of the analysis give direction and provide a basis for subsequent optimization.
- To reduce the computation time on the GPU, SAR-aware model quantification is used. Firstly, we introduced a low-precision quantization method to improve the detection speed. After quantization, we used a SAR-adapting Calibration method to reduce the accuracy loss due to quantization while performing computational acceleration. At the same time, we used activation layer merging to reduce the number of memory readings to speed up the network.
- To further reduce the accuracy loss, the Precision-aware scheduling method is proposed. This method minimizes accuracy loss while guaranteeing speed-up by inverse quantization of layers unsuitable for quantization.
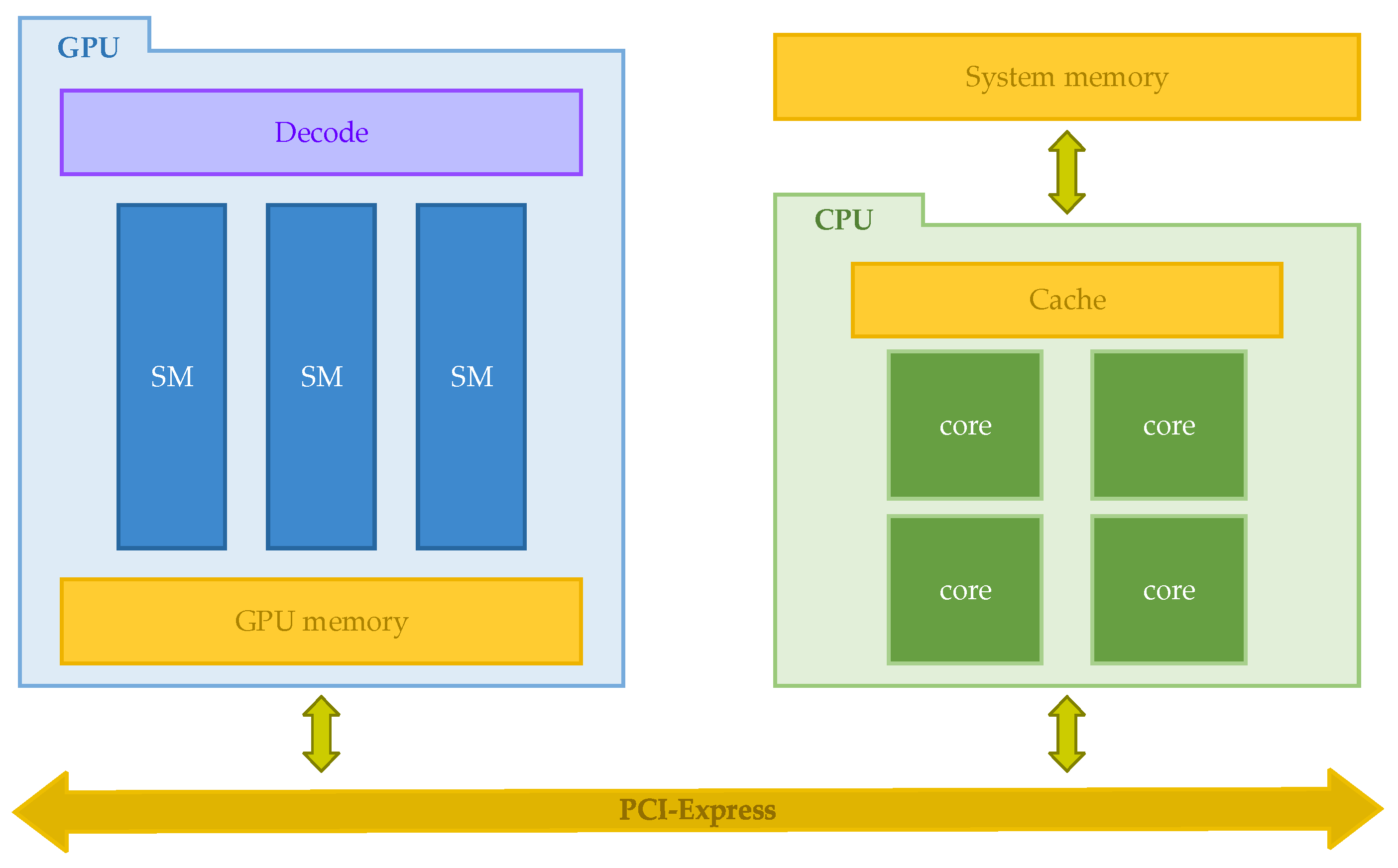
2. Analysis
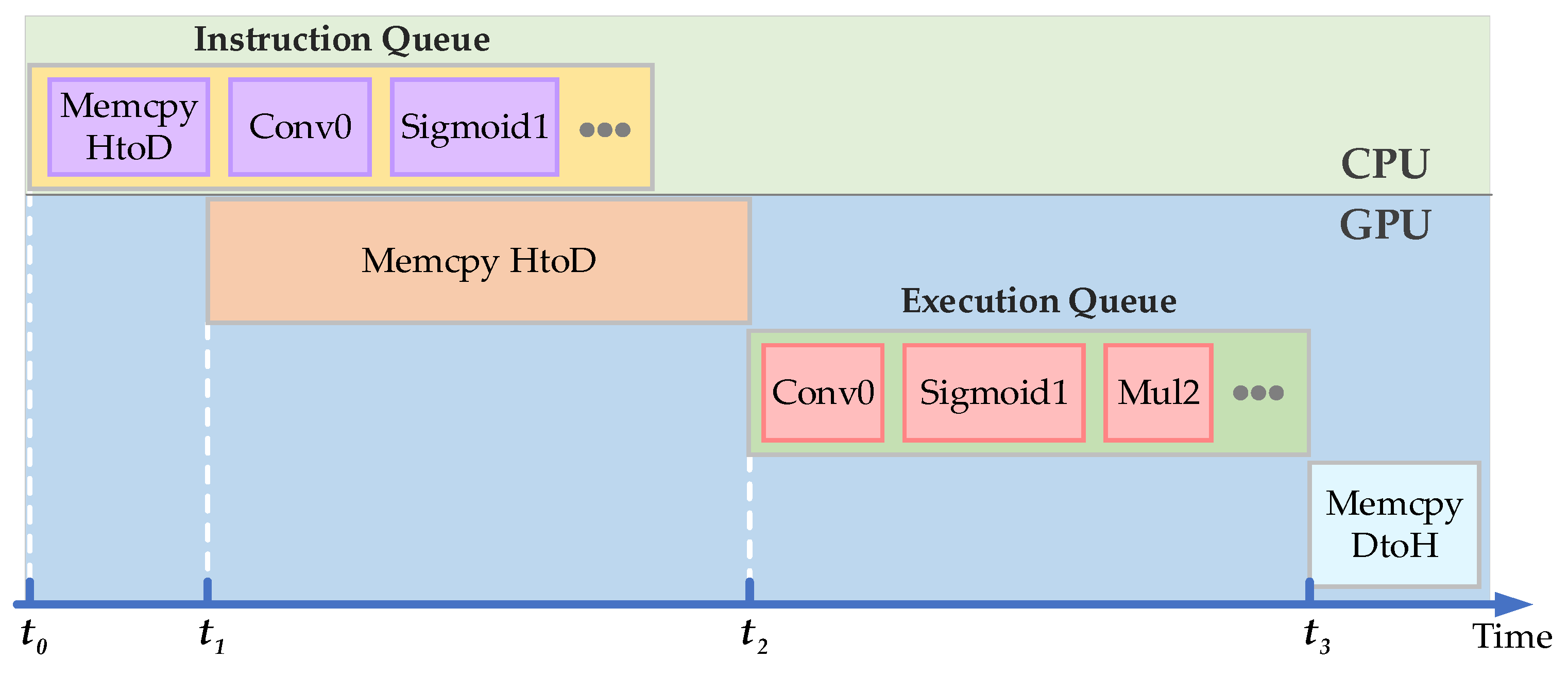
- The CPU compiles the executed code into instructions that can be executed by the GPU and sends them to the GPU through the instruction queue, including data loading instructions, arithmetic computation instructions, and data result transfer instructions.
- As shown in Figure 2, when the GPU receives the instruction of data loading, it starts the work of data loading and loads the image data saved in the system memory to the memory in the GPU at the moment of t1.
- Once the data and instructions are ready at the moment of t2., the arithmetic computation starts. In this process, the GPU reads the data from the GPU’s memory to start the operation of the convolution, activation, and other arithmetic operations. Each arithmetic operation reads input data from the memory on the GPU, and then saves the output data on the GPU’s memory after the computation is completed.
- When the above operations are finished at the moment of t3, the results will be saved in the memory of the GPU. Since the post-processing needs to be performed in the CPU, the results will be reloaded into the system memory.
3. Method
3.1. SAR-Aware Model Quantification
3.1.1. Low Precision Quantification
3.1.2. SAR-Adapting Calibration
- Prepare a trained SAR ship target detection model.
- Select a subset from the SAR image validation set as the calibration set.
- Inference is performed on the model of FP32 using the calibration dataset.
- The inference process traverses each layer of the network.
- The calibration set is deduced on the existing network and the histograms of activation values can be obtained which are further divided into 2048 intervals.
- The median of each of these intervals is chosen as the T-value.
- Iterate over different thresholds T and select the T that makes the MSE obtain the minimum value, which can be represented as
- 8.
- Return a series of T values, one for each layer T, creating the Calibration Table.
- 9.
- The quantization parameter S is calculated for each layer based on the value of T.
3.1.3. Arithmetic Operator Fusion
3.2. Precision-Aware Scheduling
- Insert the designed error detector into the detected network.
- The error detector is used to calculate the error in the feature map values before and after the quantization of each layer.
- Sort to select the top 5% of layers in the network with the largest errors.
- The selected layers are incremented layer by layer for the inverse quantization operation.
- The accuracy metrics and speed of detection are counted sequentially for each time as a Pareto solution set.
- The maximum value of the inference time metric was subtracted from the corresponding solution in the set of Pareto-optimal solutions to standardize all metrics to a larger value for better results. The normalization matrix is also normalized so that the scale of the three metrics does not affect the results. Assume that the forwarding matrix is written as . The standardized matrix is as follows:
- 7.
- Construct the judgment matrix A. The three optimization objectives, mAP@0.5, mAP@0.5:0.95, and are analyzed two by two, and their importance is judged by the 1~9 scale method [34]. The judgement matrix takes the value of
- 8.
- Consistency indicators and consistency ratios are calculated through the maximum eigenvalue of the matrix .
- 9.
- To calculate the relative approximation, the ideal and negative ideal solutions are first determined as
- 10.
- The Pareto solution corresponding to the scheme with the highest relative approximation is chosen as the final result.
4. Results
4.1. Experimental Platform
4.1.1. Training Platform
4.1.2. Testing Platform
4.2. Dataset
4.3. Model
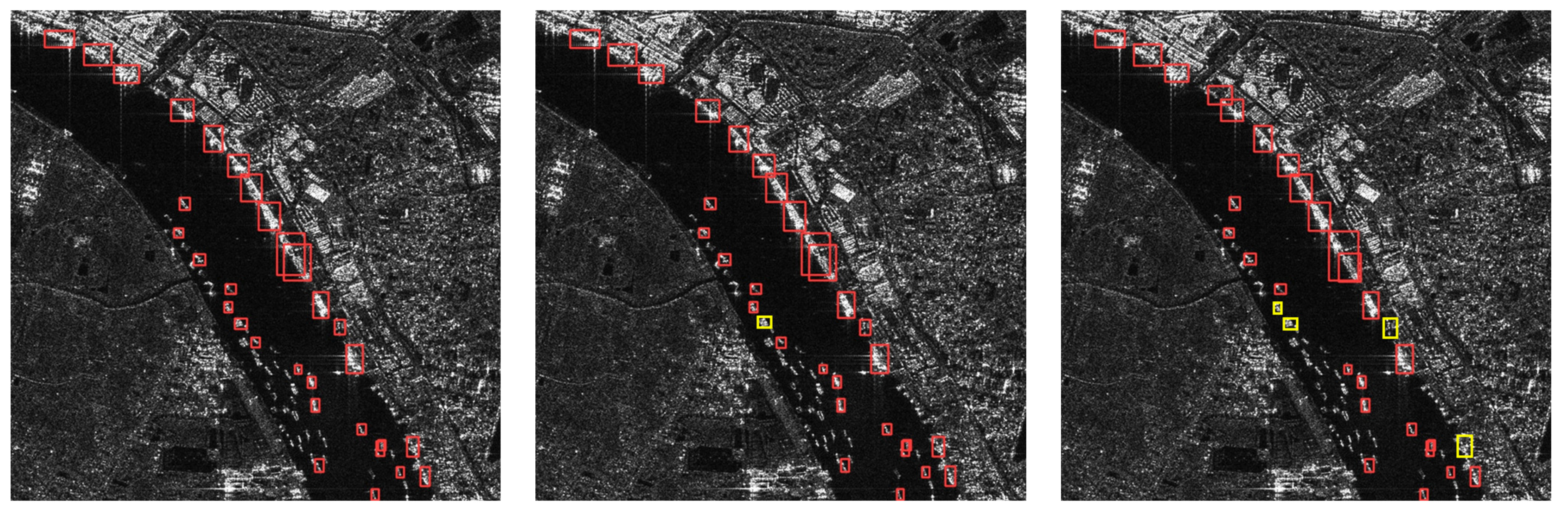
4.4. Result
4.4.1. Effect of Each Method
4.4.2. Comparison Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, W.; Wang, Z.; Li, J.; Luo, Y.; Yu, Z. A Lightweight Network Based on One-Level Feature for Ship Detection in SAR Images. Remote Sens. 2022, 14, 3321. [Google Scholar] [CrossRef]
- Zhang, J.; Xing, M.; Xie, Y. FEC: A Feature Fusion Framework for SAR Target Recognition Based on Electromagnetic Scattering Features and Deep CNN Features. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2174–2187. [Google Scholar] [CrossRef]
- Yang, M.; Guo, C. Ship Detection in SAR Images Based on Lognormal β-Metric. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1372–1376. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Zhou, S.; Zou, H. Noncircularity Parameters and Their Potential in Ship Detection from High Resolution SAR Imagery. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1876–1879. [Google Scholar]
- Copeland, A.C.; Ravichandran, G.; Trivedi, M.M. Localized Radon Transform-Based Detection of Ship Wakes in SAR Images. IEEE Trans. Geosci. Remote Sens. 1995, 33, 35–45. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Yang, K.; Zou, H. A Bilateral CFAR Algorithm for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1536–1540. [Google Scholar] [CrossRef]
- Jiaqiu, A.; Xiangyang, Q.; Weidong, Y.; Yunkai, D.; Fan, L.; Li, S.; Yafei, J. A Novel Ship Wake CFAR Detection Algorithm Based on SCR Enhancement and Normalized Hough Transform. IEEE Geosci. Remote Sens. Lett. 2011, 8, 681–685. [Google Scholar] [CrossRef]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Fu, K.; Sun, X. A Densely Connected End-to-End Neural Network for Multiscale and Multiscene SAR Ship Detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Nie, X.; Duan, M.; Ding, H.; Hu, B.; Wong, E.K. Attention Mask R-CNN for Ship Detection and Segmentation from Remote Sensing Images. IEEE Access 2020, 8, 9325–9334. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention Receptive Pyramid Network for Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense Attention Pyramid Networks for Multi-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S.; Wang, J.; Li, J. Balanced Feature Pyramid Network for Ship Detection in Synthetic Aperture Radar Images. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21 September 2020; pp. 1–5. [Google Scholar]
- Lv, Z.; Lu, J.; Wang, Q.; Guo, Z.; Li, N. ESP-LRSMD: A Two-Step Detector for Ship Detection Using SLC SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Ai, J.; Tian, R.; Luo, Q.; Jin, J.; Tang, B. Multi-Scale Rotation-Invariant Haar-Like Feature Integrated CNN-Based Ship Detection Algorithm of Multiple-Target Environment in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10070–10087. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship Detection in SAR Images Based on an Improved Faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Yang, X.; Zhang, X.; Wang, N.; Gao, X. A Robust One-Stage Detector for Multiscale Ship Detection with Complex Background in Massive SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Ge, J.; Zhang, B.; Wang, C.; Xu, C.; Tian, Z.; Xu, L. Azimuth-Sensitive Object Detection in Sar Images Using Improved Yolo V5 Model. In Proceedings of the IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17 July 2022; pp. 2171–2174. [Google Scholar]
- Chen, Y.; Duan, T.; Wang, C.; Zhang, Y.; Huang, M. End-to-End Ship Detection in SAR Images for Complex Scenes Based on Deep CNNs. J. Sens. 2021, 2021, 1–19. [Google Scholar] [CrossRef]
- Zhu, M.; Hu, G.; Zhou, H.; Lu, C.; Zhang, Y.; Yue, S.; Li, Y. Rapid Ship Detection in SAR Images Based on YOLOv3. In Proceedings of the 2020 5th International Conference on Communication, Image and Signal Processing (CCISP), Chengdu, China, 13–15 November 2020; pp. 214–218. [Google Scholar]
- Guo, Y.; Chen, S.; Zhan, R.; Wang, W.; Zhang, J. SAR Ship Detection Based on YOLOv5 Using CBAM and BiFPN. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17 July 2022; pp. 2147–2150. [Google Scholar]
- Cui, Z.; Wang, X.; Liu, N.; Cao, Z.; Yang, J. Ship Detection in Large-Scale SAR Images Via Spatial Shuffle-Group Enhance Attention. IEEE Trans. Geosci. Remote Sens. 2021, 59, 379–391. [Google Scholar] [CrossRef]
- Zhou, L.-Q.; Piao, J.-C. A Lightweight YOLOv4 Based SAR Image Ship Detection. In Proceedings of the 2021 IEEE 4th International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 13 August 2021; pp. 28–31. [Google Scholar]
- Jiang, J.; Fu, X.; Qin, R.; Wang, X.; Ma, Z. High-Speed Lightweight Ship Detection Algorithm Based on YOLO-V4 for Three-Channels RGB SAR Image. Remote Sens. 2021, 13, 1909. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, J.; Huang, Z.; Lv, J.; Song, J.; Luo, H.; Wu, B.; Li, Y.; Diniz, P.S.R. HRLE-SARDet: A Lightweight SAR Target Detection Algorithm Based on Hybrid Representation Learning Enhancement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–22. [Google Scholar] [CrossRef]
- Zheng, X.; Feng, Y.; Shi, H.; Zhang, B.; Chen, L. Lightweight Convolutional Neural Network for False Alarm Elimination in SAR Ship Detection. In Proceedings of the IET International Radar Conference (IET IRC 2020), Virtual; Institution of Engineering and Technology: Hong Kong, China, 2021; pp. 287–291. [Google Scholar]
- Long, Z.; Suyuan, W.; Zhongma, C.; Jiaqi, F.; Xiaoting, Y.; Wei, D. Lira-YOLO: A Lightweight Model for Ship Detection in Radar Images. J. Syst. Eng. Electron. 2020, 31, 950–956. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Zhang, T.; Shi, J.; Wei, S.; Li, J. On-Board Ship Detection in SAR Images Based on L-YOLO. In Proceedings of the 2022 IEEE Radar Conference (RadarConf22), New York City, NY, USA, 21 March 2022; pp. 1–5. [Google Scholar]
- Zhang, J.; Yang, J.; Li, X.; Fan, Z.; He, Z.; Ding, D. SAR Ship Target Detection Based on Lightweight YOLOv5 in Complex Environment. In Proceedings of the 2022 Cross Strait Radio Science & Wireless Technology Conference (CSRSWTC), Haidian, China, 17 December 2022; pp. 1–3. [Google Scholar]
- Ren, X.; Bai, Y.; Liu, G.; Zhang, P. YOLO-Lite: An Efficient Lightweight Network for SAR Ship Detection. Remote Sens. 2023, 15, 3771. [Google Scholar] [CrossRef]
- Banner, R.; Nahshan, Y.; Hoffer, E.; Soudry, D. Post-Training 4-Bit Quantization of Convolution Networks for Rapid-Deployment. arXiv 2019, arXiv:1810.05723. [Google Scholar]
- Nagel, M.; Fournarakis, M.; Amjad, R.A.; Bondarenko, Y.; van Baalen, M.; Blankevoort, T. A White Paper on Neural Network Quantization. arXiv 2021, arXiv:2106.08295. [Google Scholar]
- Wu, H.; Judd, P.; Zhang, X.; Isaev, M.; Micikevicius, P. Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation. arXiv 2020, arXiv:2004.09602. [Google Scholar]
- Yaraghi, N.; Tabesh, P.; Guan, P.; Zhuang, J. Comparison of AHP and Monte Carlo AHP Under Different Levels of Uncertainty. IEEE Trans. Eng. Manag. 2015, 62, 122–132. [Google Scholar] [CrossRef]
- Tompkins, M.; Iammartino, R.; Fossaceca, J. Multiattribute Framework for Requirements Elicitation in Phased Array Radar Systems. IEEE Trans. Eng. Manag. 2020, 67, 347–364. [Google Scholar] [CrossRef]

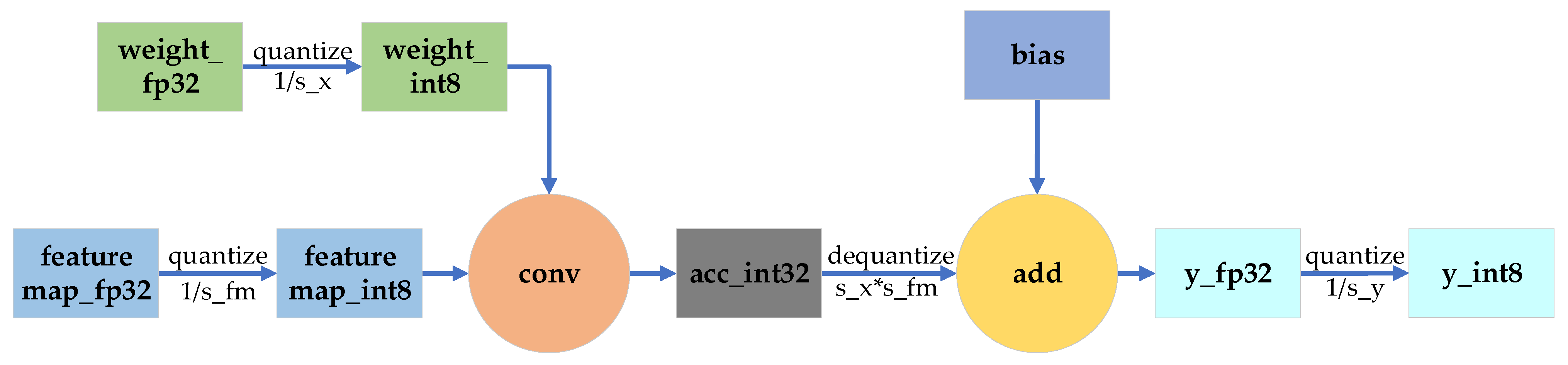

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Layers | Parameters | Flops |
|---|---|---|---|
| Yolov5n | 157 | 1,760,518 | 4.1 g |
| Yolov5s | 157 | 7,012,822 | 15.8 g |
| Yolov5m | 212 | 20,852,934 | 47.9 g |
| Yolov5l | 267 | 46,108,278 | 107.6 g |
| Model | Method | P | R | mAP@0.5 | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|---|
| Yolov5n | Baseline | 0.8906 | 0.7141 | 0.7965 | 0.5227 | 190.8484 |
| SAMQ | 0.8952 | 0.7123 | 0.7945 | 0.5077 | 237.5148 | |
| SAMQ + PAS | 0.8972 | 0.7145 | 0.7964 | 0.5155 | 234.7785 | |
| Yolov5s | Baseline | 0.8973 | 0.7499 | 0.8237 | 0.5531 | 144.8165 |
| SAMQ | 0.894 | 0.7506 | 0.8217 | 0.5438 | 218.2885 | |
| SAMQ + PAS | 0.8964 | 0.7516 | 0.8236 | 0.5438 | 212.8341 | |
| Yolov5m | Baseline | 0.9098 | 0.7615 | 0.8364 | 0.5693 | 84.7072 |
| SAMQ | 0.9012 | 0.7626 | 0.8289 | 0.5605 | 167.0161 | |
| SAMQ + PAS | 0.9096 | 0.7629 | 0.8363 | 0.5693 | 165.6523 | |
| Yolov5l | Baseline | 0.9123 | 0.7723 | 0.8469 | 0.5772 | 57.1275 |
| SAMQ | 0.8774 | 0.7699 | 0.8319 | 0.4605 | 140.4588 | |
| SAMQ + PAS | 0.9066 | 0.775 | 0.8467 | 0.5703 | 139.8758 |
| Model | Method | P | R | AP | FPS |
|---|---|---|---|---|---|
| Yolov5n | Baseline | 0.8906 | 0.7141 | 0.7965 | 190.8484 |
| TensorRT | 0.8771 | 0.7067 | 0.7896 | 235.6216 | |
| SAMQ + PAS | 0.8952 | 0.7123 | 0.7945 | 234.7785 | |
| Yolov5s | Baseline | 0.8973 | 0.7499 | 0.8237 | 144.8165 |
| TensorRT | 0.8789 | 0.7414 | 0.8171 | 212.2303 | |
| SAMQ + PAS | 0.8964 | 0.7516 | 0.8236 | 212.8341 | |
| Yolov5m | Baseline | 0.9098 | 0.7615 | 0.8364 | 84.7072 |
| TensorRT | 0.9028 | 0.7694 | 0.8352 | 93.2982 | |
| SAMQ + PAS | 0.9096 | 0.7629 | 0.8363 | 165.6523 | |
| Yolov5l | Baseline | 0.9123 | 0.7723 | 0.8469 | 57.1275 |
| TensorRT | 0.9069 | 0.774 | 0.846 | 60.8875 | |
| SAMQ + PAS | 0.9066 | 0.775 | 0.8467 | 139.8758 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Jiang, S.; Cao, Y.; Xiao, J.; Li, C.; Zhou, X.; Yu, Z. Hardware-Aware Design of Speed-Up Algorithms for Synthetic Aperture Radar Ship Target Detection Networks. Remote Sens. 2023, 15, 4995. https://doi.org/10.3390/rs15204995
Zhang Y, Jiang S, Cao Y, Xiao J, Li C, Zhou X, Yu Z. Hardware-Aware Design of Speed-Up Algorithms for Synthetic Aperture Radar Ship Target Detection Networks. Remote Sensing. 2023; 15(20):4995. https://doi.org/10.3390/rs15204995
Chicago/Turabian StyleZhang, Yue, Shuai Jiang, Yue Cao, Jiarong Xiao, Chengkun Li, Xuan Zhou, and Zhongjun Yu. 2023. "Hardware-Aware Design of Speed-Up Algorithms for Synthetic Aperture Radar Ship Target Detection Networks" Remote Sensing 15, no. 20: 4995. https://doi.org/10.3390/rs15204995
APA StyleZhang, Y., Jiang, S., Cao, Y., Xiao, J., Li, C., Zhou, X., & Yu, Z. (2023). Hardware-Aware Design of Speed-Up Algorithms for Synthetic Aperture Radar Ship Target Detection Networks. Remote Sensing, 15(20), 4995. https://doi.org/10.3390/rs15204995