
Ensemble Learning for Blending Gridded Satellite and Gauge-Measured Precipitation Data



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Ensemble Learners and Combiners
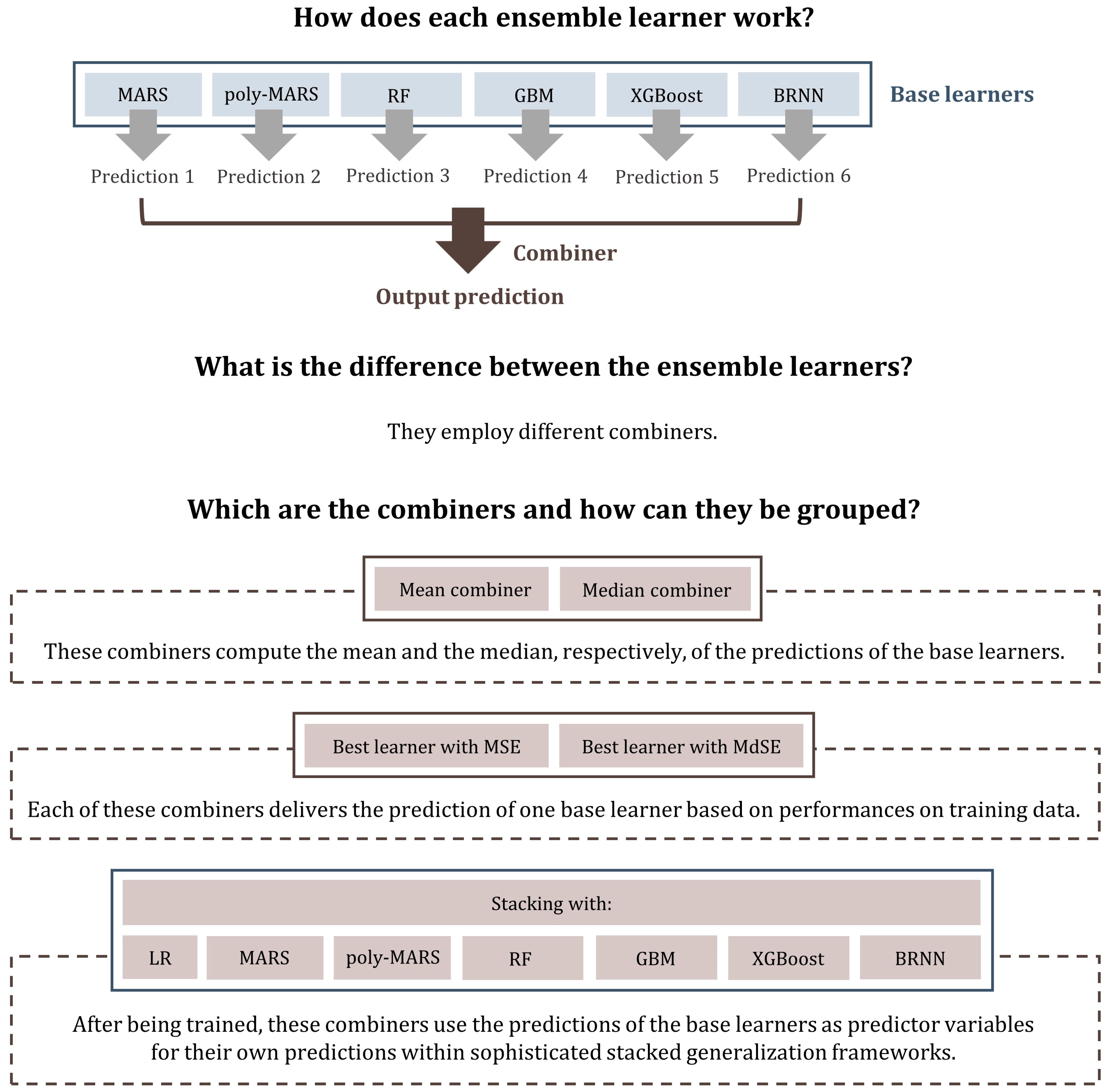
2.1. Ensemble Learners
2.2. Mean Combiner
2.3. Median Combiner
2.4. Best Learners
2.5. Stacking of Regression Algorithms
3. Data and Application
3.1. Data
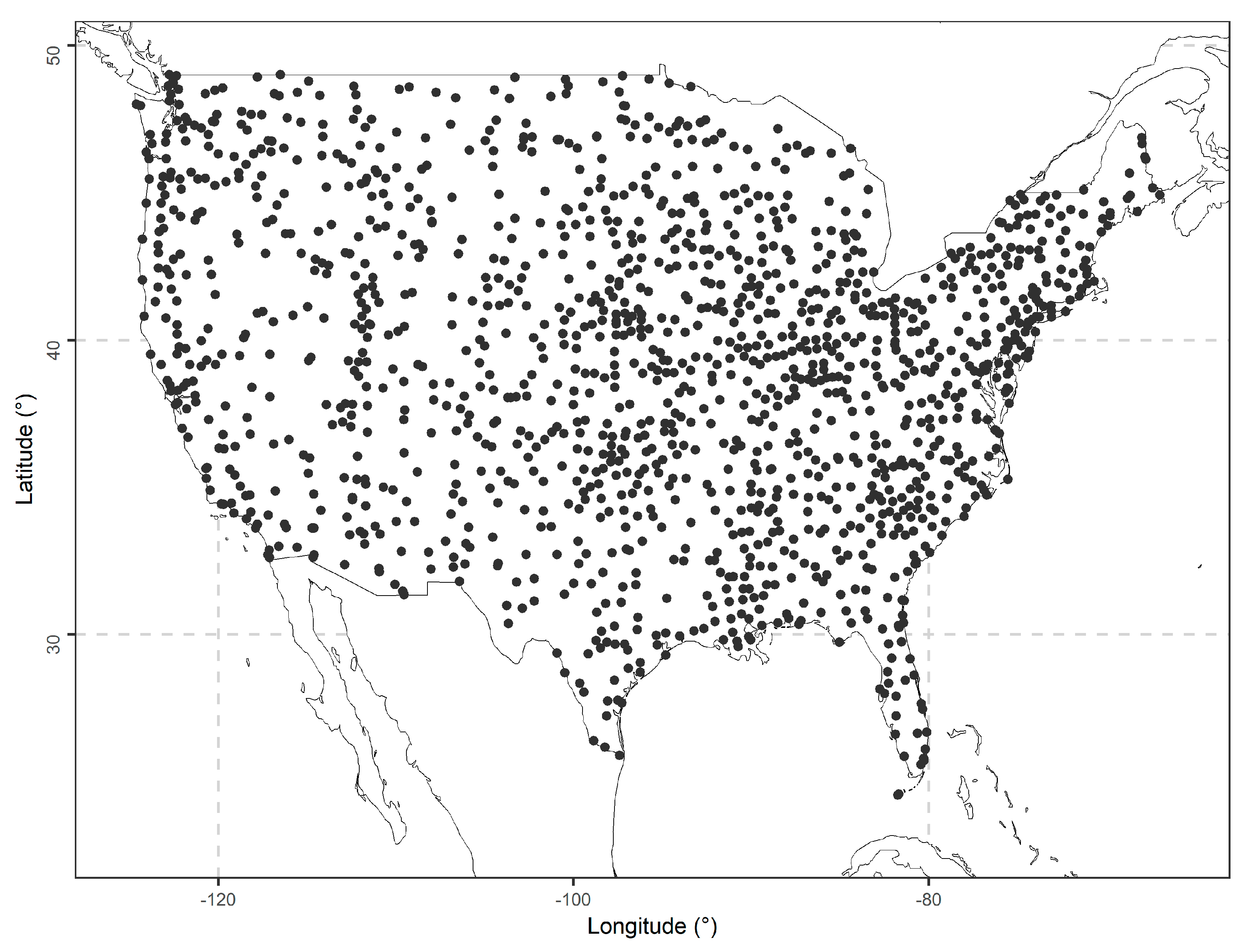
3.1.1. Gauge-Measured Precipitation Data
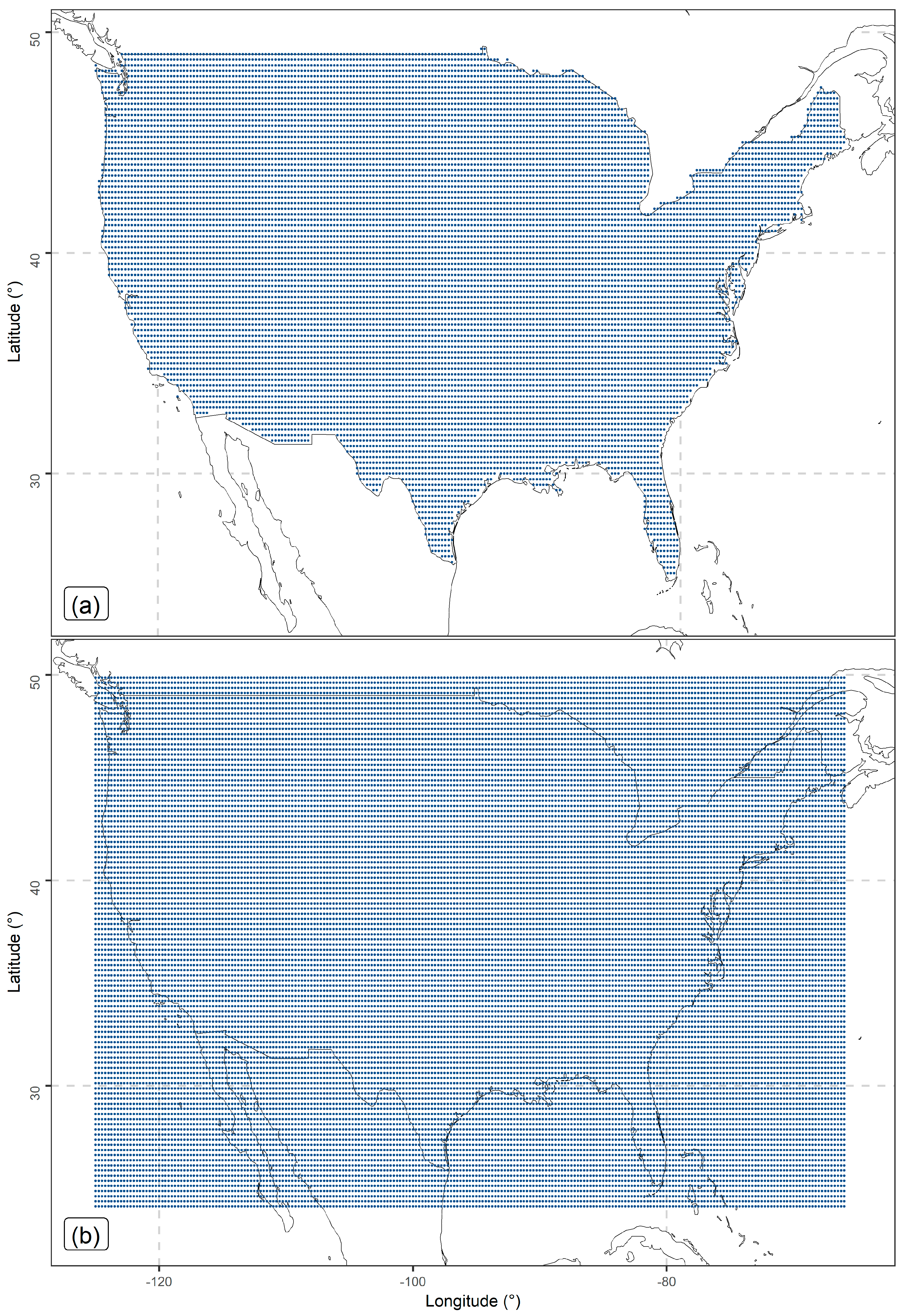
3.1.2. Satellite Precipitation Data
3.1.3. Elevation Data
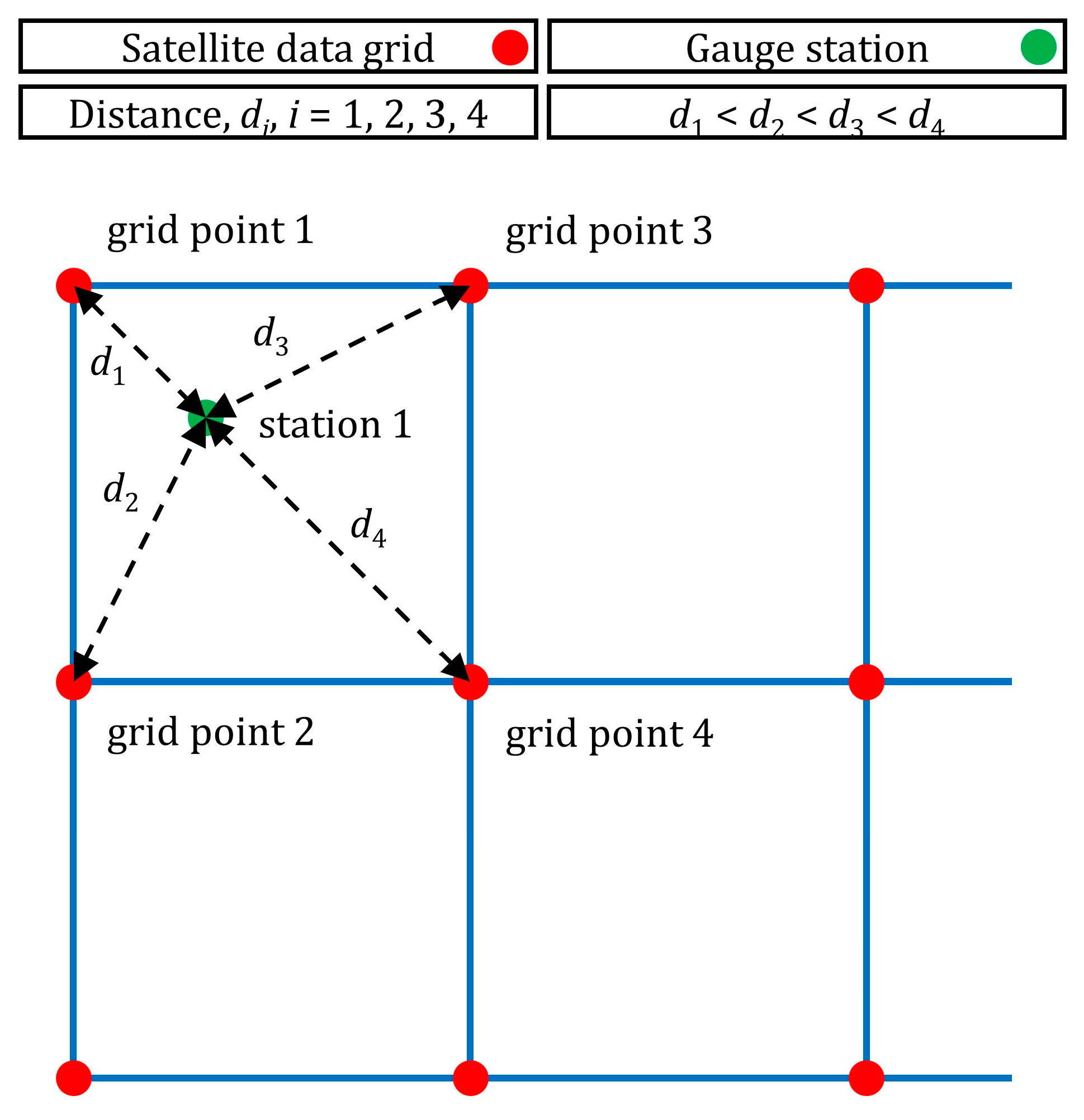
3.2. Regression Settings and Validation Procedure
3.3. Predictive Performance Comparison
3.4. Additional Investigations
4. Results
4.1. Predictive Performance
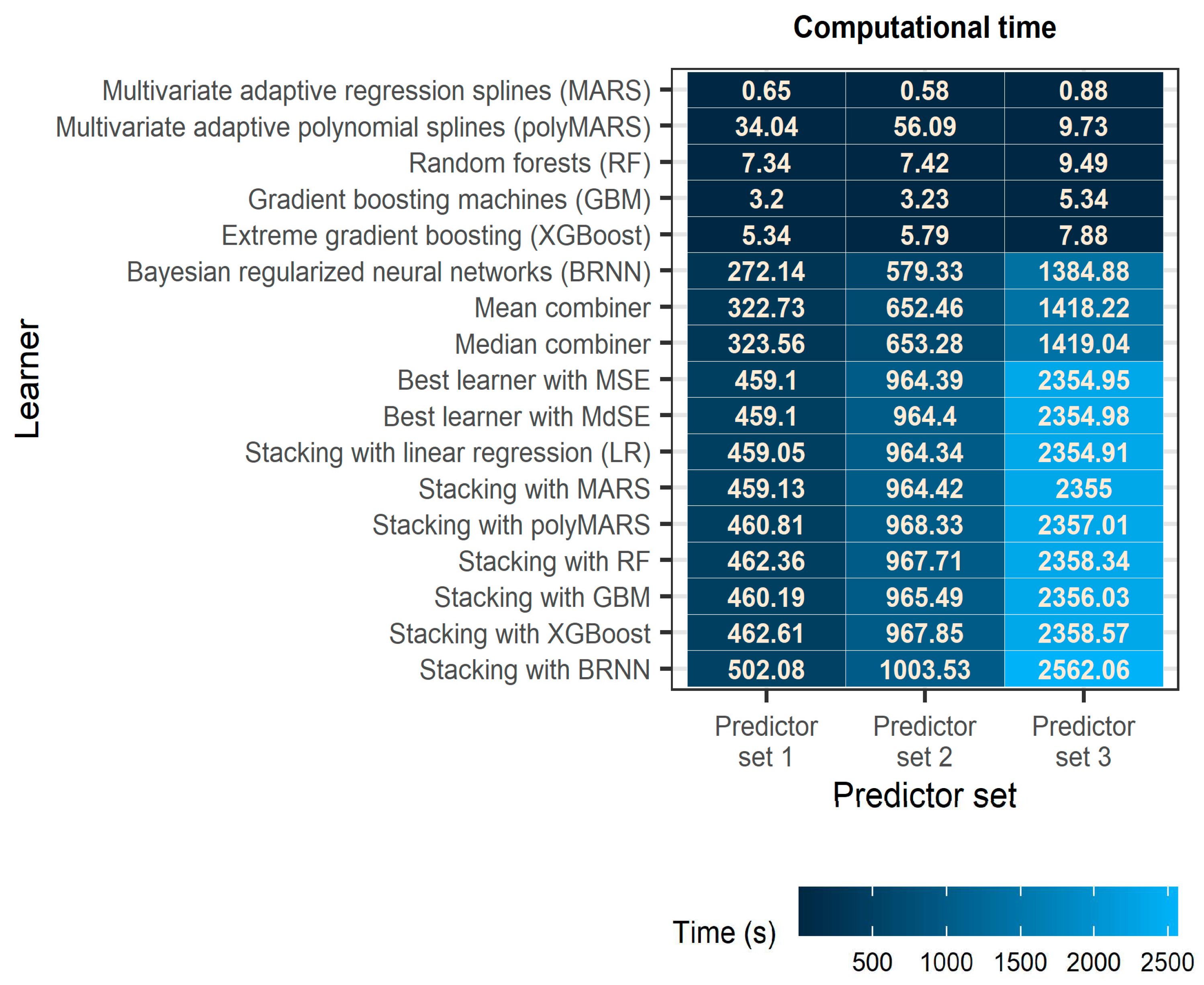
4.2. Computational Time
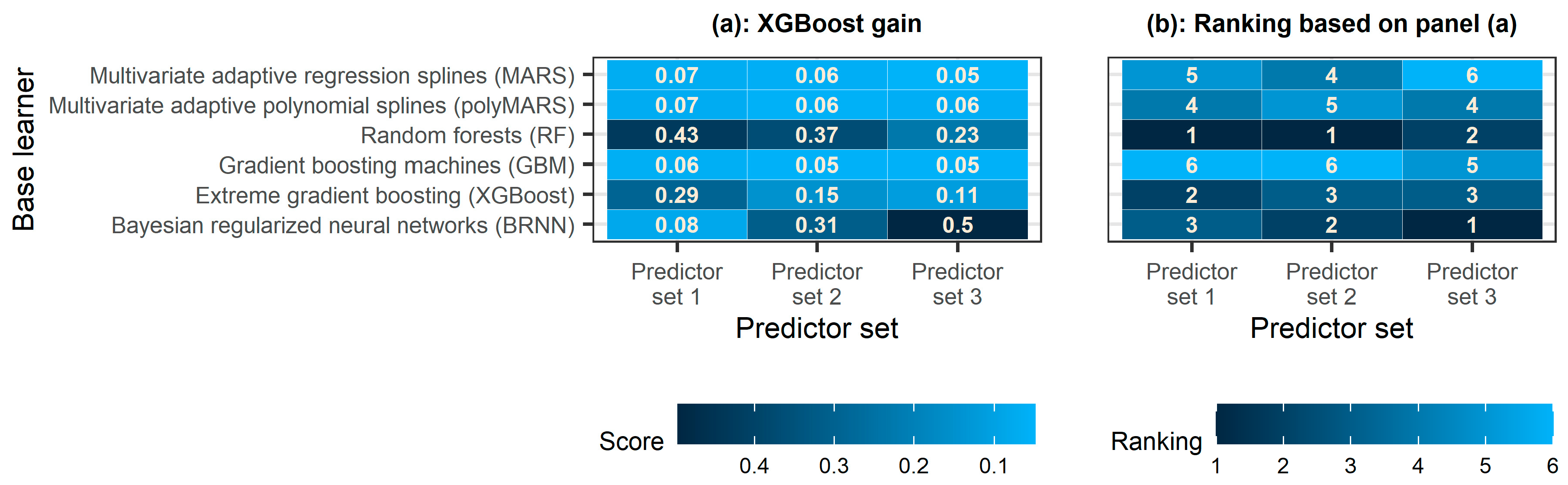
4.3. Contribution of Base Learners
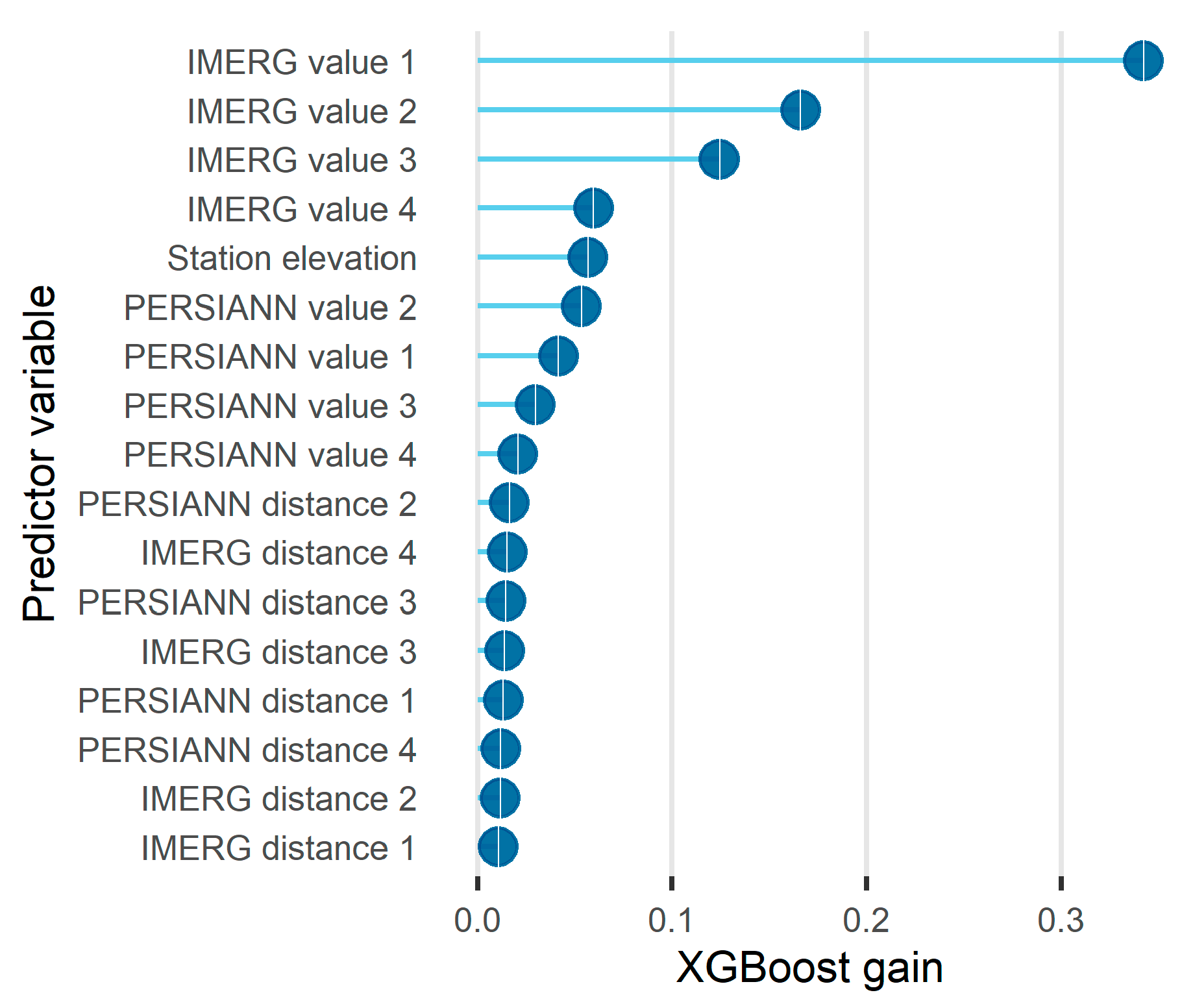
4.4. Importance of Predictor Variables
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Linear regression (LR): In LR, the dependent variable is a function of a linear weighted sum of the predictors ([17], pp. 43–55). The weights are estimated by minimizing the mean squared error.
- Multivariate adaptive regression splines (MARS): In MARS ([84,85]), the dependent variable is a function of a weighted sum of basis functions. Important parameters are the product degree (i.e., the total number of basis functions) and the knot locations. These parameters are estimated in an automatic way. In our study, we used an additive model and hinge basis functions. We used the default parameters of the R package, as suggested in the respective R package implementation.
- Multivariate adaptive polynomial splines (poly-MARS): In poly-MARS ([86,87]), the dependent variable is a function of piecewise linear splines within an adaptive regression framework. MARS and poly-MARS differ in the sense that the latter necessitates the existence of linear terms of a predictor variable to be included in the model prior to adding predictor’s nonlinear terms, combined with including a univariate basis function in the model prior to including a tensor-product basis function that contains the univariate basis function [88]. The application was made with the default parameters, as suggested in the respective R package implementation.
- Random forests (RF): RF [34] is an ensemble learning algorithm. The ensemble is constructed by decision trees. The construction procedure is based on bootstrap aggregation (also termed as “bagging”) with some additional randomization. The latter is based on a random selection of predictors as candidates in the notes of the decision tree. A summary of the benefits of the algorithm can be found in [89], a study that also comments on the utility of the algorithm in hydrological sciences. The application was made with 500 trees. The remaining parameters of the algorithm were kept equal to their defaults in the respective R package implementation.
- Gradient boosting machines (GBM): GBM is an ensemble learning algorithm that trains iteratively new learners on the errors of previously trained learners ([35,90,91,92]). In our case, these learners were decision trees; yet, it is also possible to use other types of learners. The trained algorithm is practically the sum of the trained decision trees. A gradient descent algorithm was used for the optimization. As it is possible to tailor the loss function of GBM to the user’s needs, we selected the squared error loss function. We also used 500 trees to be consistent with the implementation of RF. The remaining parameters of GBM were kept equal to their defaults in the respective R package implementation.
- Extreme gradient boosting (XGBoost): XGBoost [36] is a boosting algorithm that improves over GBM in certain conditions. These conditions are mostly related to data availability. Furthermore, XGBoost is an order of magnitude faster compared to earlier boosting implementations and uses a type of regularization to control overfitting. In our study, we set the number of maximum boosting iterations equal to 500. The remaining parameters were kept equal to their defaults in the respective R package implementation.
- Feed-forward neural networks with Bayesian regularization (BRNN): Artificial neural networks model the dependent variable as a nonlinear function of features that were previously extracted through linear combinations of the predictors ([17], p 389). In this work, we applied BRNN ([93], pp 143–180, [94]) that are particularly useful to avoid overfitting. We set the number of neurons equal to 20 and kept the remaining parameters of the algorithm equal to their defaults in the respective R package implementation.
Appendix B
References
- Kopsiaftis, G.; Mantoglou, A. Seawater intrusion in coastal aquifers under drought and transient conditions. In Environmental Hydraulics; Christodoulou, G.C., Stamou, A.I., Eds.; Two Volume Set; CRC Press: Boca Raton, FL, USA, 2010; pp. 637–642. [Google Scholar]
- Dogulu, N.; López López, P.; Solomatine, D.P.; Weerts, A.H.; Shrestha, D.L. Estimation of predictive hydrologic uncertainty using the quantile regression and UNEEC methods and their comparison on contrasting catchments. Hydrol. Earth Syst. Sci. 2015, 19, 3181–3201. [Google Scholar] [CrossRef]
- Granata, F.; Gargano, R.; De Marinis, G. Support vector regression for rainfall-runoff modeling in urban drainage: A comparison with the EPA’s storm water management model. Water 2016, 8, 69. [Google Scholar] [CrossRef]
- Széles, B.; Broer, M.; Parajka, J.; Hogan, P.; Eder, A.; Strauss, P.; Blöschl, G. Separation of scales in transpiration effects on low flows: A spatial analysis in the Hydrological Open Air Laboratory. Water Resour. Res. 2018, 54, 6168–6188. [Google Scholar] [CrossRef] [PubMed]
- Curceac, S.; Atkinson, P.M.; Milne, A.; Wu, L.; Harris, P. Adjusting for conditional bias in process model simulations of hydrological extremes: An experiment using the North Wyke Farm Platform. Front. Artif. Intell. 2020, 3, 565859. [Google Scholar] [CrossRef] [PubMed]
- Curceac, S.; Milne, A.; Atkinson, P.M.; Wu, L.; Harris, P. Elucidating the performance of hybrid models for predicting extreme water flow events through variography and wavelet analyses. J. Hydrol. 2021, 598, 126442. [Google Scholar] [CrossRef]
- Di Nunno, F.; Granata, F.; Pham, Q.B.; de Marinis, G. Precipitation forecasting in Northern Bangladesh using a hybrid machine learning model. Sustainability 2022, 14, 2663. [Google Scholar] [CrossRef]
- Sun, Q.; Miao, C.; Duan, Q.; Ashouri, H.; Sorooshian, S.; Hsu, K.-L. A review of global precipitation data sets: Data sources, estimation, and intercomparisons. Rev. Geophys. 2018, 56, 79–107. [Google Scholar] [CrossRef]
- Mega, T.; Ushio, T.; Matsuda, T.; Kubota, T.; Kachi, M.; Oki, R. Gauge-adjusted global satellite mapping of precipitation. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1928–1935. [Google Scholar] [CrossRef]
- Salmani-Dehaghi, N.; Samani, N. Development of bias-correction PERSIANN-CDR models for the simulation and completion of precipitation time series. Atmos. Environ. 2021, 246, 117981. [Google Scholar] [CrossRef]
- Li, W.; Jiang, Q.; He, X.; Sun, H.; Sun, W.; Scaioni, M.; Chen, S.; Li, X.; Gao, J.; Hong, Y. Effective multi-satellite precipitation fusion procedure conditioned by gauge background fields over the Chinese mainland. J. Hydrol. 2022, 610, 127783. [Google Scholar] [CrossRef]
- Tang, T.; Chen, T.; Gui, G. A comparative evaluation of gauge-satellite-based merging products over multiregional complex terrain basin. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5275–5287. [Google Scholar] [CrossRef]
- Gohin, F.; Langlois, G. Using geostatistics to merge in situ measurements and remotely-sensed observations of sea surface temperature. Int. J. Remote Sens. 1993, 14, 9–19. [Google Scholar] [CrossRef]
- Journée, M.; Bertrand, C. Improving the spatio-temporal distribution of surface solar radiation data by merging ground and satellite measurements. Remote Sens. Environ. 2010, 114, 2692–2704. [Google Scholar] [CrossRef]
- Peng, J.; Tanguy, M.; Robinson, E.L.; Pinnington, E.; Evans, J.; Ellis, R.; Cooper, E.; Hannaford, J.; Blyth, E.; Dadson, S. Estimation and evaluation of high-resolution soil moisture from merged model and Earth observation data in the Great Britain. Remote Sens. Environ. 2021, 264, 112610. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.A.; Doulamis, N.; Doulamis, A. Merging satellite and gauge-measured precipitation using LightGBM with an emphasis on extreme quantiles. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6969–6979. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T. Computer Age Statistical Inference; Cambridge University Press: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Hu, Q.; Li, Z.; Wang, L.; Huang, Y.; Wang, Y.; Li, L. Rainfall spatial estimations: A review from spatial interpolation to multi-source data merging. Water 2019, 11, 579. [Google Scholar] [CrossRef]
- Abdollahipour, A.; Ahmadi, H.; Aminnejad, B. A review of downscaling methods of satellite-based precipitation estimates. Earth Sci. Inform. 2022, 15, 1–20. [Google Scholar] [CrossRef]
- Tao, Y.; Gao, X.; Hsu, K.; Sorooshian, S.; Ihler, A. A deep neural network modeling framework to reduce bias in satellite precipitation products. J. Hydrometeorol. 2016, 17, 931–945. [Google Scholar] [CrossRef]
- Baez-Villanueva, O.M.; Zambrano-Bigiarini, M.; Beck, H.E.; McNamara, I.; Ribbe, L.; Nauditt, A.; Birkel, C.; Verbist, K.; Giraldo-Osorio, J.D.; Xuan Thinh, N. RF-MEP: A novel random forest method for merging gridded precipitation products and ground-based measurements. Remote Sens. Environ. 2020, 239, 111606. [Google Scholar] [CrossRef]
- Chen, S.; Xiong, L.; Ma, Q.; Kim, J.-S.; Chen, J.; Xu, C.-Y. Improving daily spatial precipitation estimates by merging gauge observation with multiple satellite-based precipitation products based on the geographically weighted ridge regression method. J. Hydrol. 2020, 589, 125156. [Google Scholar] [CrossRef]
- Chen, C.; Hu, B.; Li, Y. Easy-to-use spatial random-forest-based downscaling-calibration method for producing precipitation data with high resolution and high accuracy. Hydrol. Earth Syst. Sci. 2021, 25, 5667–5682. [Google Scholar] [CrossRef]
- Shen, Z.; Yong, B. Downscaling the GPM-based satellite precipitation retrievals using gradient boosting decision tree approach over Mainland China. J. Hydrol. 2021, 602, 126803. [Google Scholar] [CrossRef]
- Zhang, L.; Li, X.; Zheng, D.; Zhang, K.; Ma, Q.; Zhao, Y.; Ge, Y. Merging multiple satellite-based precipitation products and gauge observations using a novel double machine learning approach. J. Hydrol. 2021, 594, 125969. [Google Scholar] [CrossRef]
- Chen, H.; Sun, L.; Cifelli, R.; Xie, P. Deep learning for bias correction of satellite retrievals of orographic precipitation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4104611. [Google Scholar] [CrossRef]
- Lin, Q.; Peng, T.; Wu, Z.; Guo, J.; Chang, W.; Xu, Z. Performance evaluation, error decomposition and tree-based machine learning error correction of GPM IMERG and TRMM 3B42 products in the Three Gorges reservoir area. Atmos. Res. 2022, 268, 105988. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Doulamis, A.; Doulamis, N. Comparison of machine learning algorithms for merging gridded satellite and earth-observed precipitation data. Water 2023, 15, 634. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H. A review of machine learning concepts and methods for addressing challenges in probabilistic hydrological post-processing and forecasting. Front. Water 2022, 4, 961954. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Wang, X.; Hyndman, R.J.; Li, F.; Kang, Y. Forecast combinations: An over 50-year review. Int. J. Forecast. 2022, 39, 1518–1547. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Bates, J.M.; Granger, C.W.J. The combination of forecasts. J. Oper. Res. Soc. 1969, 20, 451–468. [Google Scholar] [CrossRef]
- Petropoulos, F.; Svetunkov, I. A simple combination of univariate models. Int. J. Forecast. 2020, 36, 110–115. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H.; Langousis, A.; Jayawardena, A.W.; Sivakumar, B.; Mamassis, N.; Montanari, A.; Koutsoyiannis, D. Probabilistic hydrological post-processing at scale: Why and how to apply machine-learning quantile regression algorithms. Water 2019, 11, 2126. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H. Hydrological time series forecasting using simple combinations: Big data testing and investigations on one-year ahead river flow predictability. J. Hydrol. 2020, 590, 125205. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Divina, F.; Gilson, A.; Goméz-Vela, F.; García Torres, M.; Torres, J.F. Stacking ensemble learning for short-term electricity consumption forecasting. Energies 2018, 11, 949. [Google Scholar] [CrossRef]
- Yao, Y.; Vehtari, A.; Simpson, D.; Gelman, A. Using stacking to average Bayesian predictive distributions. Bayesian Anal. 2018, 13, 917–1003. [Google Scholar] [CrossRef]
- Alobaidi, M.H.; Meguid, M.A.; Chebana, F. Predicting seismic-induced liquefaction through ensemble learning frameworks. Sci. Rep. 2019, 9, 11786. [Google Scholar] [CrossRef]
- Cui, S.; Yin, Y.; Wang, D.; Li, Z.; Wang, Y. A stacking-based ensemble learning method for earthquake casualty prediction. Appl. Soft Comput. 2021, 101, 107038. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.; Langousis, A. Super ensemble learning for daily streamflow forecasting: Large-scale demonstration and comparison with multiple machine learning algorithms. Neural Comput. Appl. 2021, 33, 3053–3068. [Google Scholar] [CrossRef]
- Wu, T.; Zhang, W.; Jiao, X.; Guo, W.; Hamoud, Y.A. Evaluation of stacking and blending ensemble learning methods for estimating daily reference evapotranspiration. Comput. Electron. Agric. 2021, 184, 106039. [Google Scholar] [CrossRef]
- Hwangbo, L.; Kang, Y.J.; Kwon, H.; Lee, J.I.; Cho, H.J.; Ko, J.K.; Sung, S.M.; Lee, T.H. Stacking ensemble learning model to predict 6-month mortality in ischemic stroke patients. Sci. Rep. 2022, 12, 17389. [Google Scholar] [CrossRef] [PubMed]
- Zandi, O.; Zahraie, B.; Nasseri, M.; Behrangi, A. Stacking machine learning models versus a locally weighted linear model to generate high-resolution monthly precipitation over a topographically complex area. Atmos. Res. 2022, 272, 106159. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Rezaali, M.; Quilty, J.; Karimi, A. Probabilistic urban water demand forecasting using wavelet-based machine learning models. J. Hydrol. 2021, 600, 126358. [Google Scholar] [CrossRef]
- Granata, F.; Di Nunno, F.; Modoni, G. Hybrid machine learning models for soil saturated conductivity prediction. Water 2022, 14, 1729. [Google Scholar] [CrossRef]
- Quilty, J.M.; Sikorska-Senoner, A.E.; Hah, D. A stochastic conceptual-data-driven approach for improved hydrological simulations. Environ. Model. Softw. 2022, 149, 105326. [Google Scholar] [CrossRef]
- Kopsiaftis, G.; Kaselimi, M.; Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Doulamis, N.; Mantoglou, A. Performance comparison of physics-based and machine learning assisted multi-fidelity methods for the management of coastal aquifer systems. Front. Water 2023, 5, 1195029. [Google Scholar] [CrossRef]
- Peterson, T.C.; Vose, R.S. An overview of the Global Historical Climatology Network temperature database. Bull. Am. Meteorol. Soc. 1997, 78, 2837–2849. [Google Scholar] [CrossRef]
- Hsu, K.-L.; Gao, X.; Sorooshian, S.; Gupta, H.V. Precipitation estimation from remotely sensed information using artificial neural networks. J. Appl. Meteorol. 1997, 36, 1176–1190. [Google Scholar] [CrossRef]
- Nguyen, P.; Ombadi, M.; Sorooshian, S.; Hsu, K.; AghaKouchak, A.; Braithwaite, D.; Ashouri, H.; Thorstensen, A.R. The PERSIANN family of global satellite precipitation data: A review and evaluation of products. Hydrol. Earth Syst. Sci. 2018, 22, 5801–5816. [Google Scholar] [CrossRef]
- Nguyen, P.; Shearer, E.J.; Tran, H.; Ombadi, M.; Hayatbini, N.; Palacios, T.; Huynh, P.; Braithwaite, D.; Updegraff, G.; Hsu, K.; et al. The CHRS data portal, an easily accessible public repository for PERSIANN global satellite precipitation data. Sci. Data 2019, 6, 180296. [Google Scholar] [CrossRef]
- Huffman, G.J.; Stocker, E.F.; Bolvin, D.T.; Nelkin, E.J.; Tan, J. GPM IMERG Late Precipitation L3 1 day 0.1 degree × 0.1 degree V06, Edited by Andrey Savtchenko, Greenbelt, MD, Goddard Earth Sciences Data and Information Services Center (GES DISC). 2019. Available online: https://disc.gsfc.nasa.gov/datasets/GPM_3IMERGDL_06/summary (accessed on 12 October 2022).
- Wang, Z.; Zhong, R.; Lai, C.; Chen, J. Evaluation of the GPM IMERG satellite-based precipitation products and the hydrological utility. Atmos. Res. 2017, 196, 151–163. [Google Scholar] [CrossRef]
- Akbari Asanjan, A.; Yang, T.; Hsu, K.; Sorooshian, S.; Lin, J.; Peng, Q. Short-term precipitation forecast based on the PERSIANN system and LSTM recurrent neural networks. J. Geophys. Res. Atmos. 2018, 123, 12543–12563. [Google Scholar] [CrossRef]
- Jiang, S.; Ren, L.; Xu, C.Y.; Yong, B.; Yuan, F.; Liu, Y.; Yang, X.; Zeng, X. Statistical and hydrological evaluation of the latest Integrated Multi-satellitE Retrievals for GPM (IMERG) over a midlatitude humid basin in South China. Atmos. Res. 2018, 214, 418–429. [Google Scholar] [CrossRef]
- Tan, M.L.; Santo, H. Comparison of GPM IMERG, TMPA 3B42 and PERSIANN-CDR satellite precipitation products over Malaysia. Atmos. Res. 2018, 202, 63–76. [Google Scholar] [CrossRef]
- Moazami, S.; Na, W.; Najafi, M.R.; de Souza, C. Spatiotemporal bias adjustment of IMERG satellite precipitation data across Canada. Adv. Water Resour. 2022, 168, 104300. [Google Scholar] [CrossRef]
- Pradhan, R.K.; Markonis, Y.; Godoy, M.R.V.; Villalba-Pradas, A.; Andreadis, K.M.; Nikolopoulos, E.I.; Papalexiou, S.M.; Rahim, A.; Tapiador, F.J.; Hanel, M. Review of GPM IMERG performance: A global perspective. Remote Sens. Environ. 2022, 268, 112754. [Google Scholar] [CrossRef]
- Salehi, H.; Sadeghi, M.; Golian, S.; Nguyen, P.; Murphy, C.; Sorooshian, S. The Application of PERSIANN Family Datasets for Hydrological Modeling. Remote Sens. 2022, 14, 3675. [Google Scholar] [CrossRef]
- Xiong, L.; Li, S.; Tang, G.; Strobl, J. Geomorphometry and terrain analysis: Data, methods, platforms and applications. Earth-Sci. Rev. 2022, 233, 104191. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Doulamis, A.; Doulamis, N. Comparison of tree-based ensemble algorithms for merging satellite and earth-observed precipitation data at the daily time scale. Hydrology 2023, 10, 50. [Google Scholar] [CrossRef]
- Gneiting, T. Making and evaluating point forecasts. J. Am. Stat. Assoc. 2011, 106, 746–762. [Google Scholar] [CrossRef]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable machine learning for scientific insights and discoveries. IEEE Access 2020, 8, 42200–42216. [Google Scholar] [CrossRef]
- Belle, V.; Papantonis, I. Principles and practice of explainable machine learning. Front. Big Data 2021, 4, 688969. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef]
- Smith, J.; Wallis, K.F. A simple explanation of the forecast combination puzzle. Oxf. Bull. Econ. Stat. 2009, 71, 331–355. [Google Scholar] [CrossRef]
- Lichtendahl, K.C., Jr.; Grushka-Cockayne, Y.; Winkler, R.L. Is it better to average probabilities or quantiles? Manag. Sci. 2013, 59, 1594–1611. [Google Scholar] [CrossRef]
- Winkler, R.L. Equal versus differential weighting in combining forecasts. Risk Anal. 2015, 35, 16–18. [Google Scholar] [CrossRef]
- Claeskens, G.; Magnus, J.R.; Vasnev, A.L.; Wang, W. The forecast combination puzzle: A simple theoretical explanation. Int. J. Forecast. 2016, 32, 754–762. [Google Scholar] [CrossRef]
- Winkler, R.L.; Grushka-Cockayne, Y.; Lichtendahl, K.C.; Jose, V.R.R. Probability forecasts and their combination: A research perspective. Decis. Anal. 2019, 16, 239–260. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G. A review of probabilistic forecasting and prediction with machine learning. arXiv 2022, arXiv:2209.08307. [Google Scholar]
- Kang, Y.; Hyndman, R.J.; Smith-Miles, K. Visualising forecasting algorithm performance using time series instance spaces. Int. J. Forecast. 2017, 33, 345–358. [Google Scholar] [CrossRef]
- Montero-Manso, P.; Athanasopoulos, G.; Hyndman, R.J.; Talagala, T.S. FFORMA: Feature-based forecast model averaging. Int. J. Forecast. 2020, 36, 86–92. [Google Scholar] [CrossRef]
- Talagala, T.S.; Li, F.; Kang, Y. FFORMPP: Feature-based forecast model performance prediction. Int. J. Forecast. 2021, 38, 920–943. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023; Available online: https://www.R-project.org (accessed on 17 August 2023).
- Friedman, J.H. Multivariate adaptive regression splines. Ann. Stat. 1991, 19, 1–67. [Google Scholar] [CrossRef]
- Friedman, J.H. Fast MARS. Stanford University, Department of Statistics. Technical Report 110. 1993. Available online: https://statistics.stanford.edu/sites/g/files/sbiybj6031/f/LCS%20110.pdf (accessed on 17 December 2022).
- Kooperberg, C.; Bose, S.; Stone, C.J. Polychotomous regression. J. Am. Stat. Assoc. 1997, 92, 117–127. [Google Scholar] [CrossRef]
- Stone, C.J.; Hansen, M.H.; Kooperberg, C.; Truong, Y.K. Polynomial splines and their tensor products in extended linear modeling. Ann. Stat. 1997, 25, 1371–1470. [Google Scholar] [CrossRef]
- Kooperberg, C. polspline: Polynomial Spline Routines. R Package Version 1.1.22. 2022. Available online: https://CRAN.R-project.org/package=polspline (accessed on 17 August 2023).
- Tyralis, H.; Papacharalampous, G.; Langousis, A. A brief review of random forests for water scientists and practitioners and their recent history in water resources. Water 2019, 11, 910. [Google Scholar] [CrossRef]
- Mayr, A.; Binder, H.; Gefeller, O.; Schmid, M. The evolution of boosting algorithms: From machine learning to statistical modelling. Methods Inf. Med. 2014, 53, 419–427. [Google Scholar] [CrossRef] [PubMed]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed]
- Tyralis, H.; Papacharalampous, G. Boosting algorithms in energy research: A systematic review. Neural Comput. Appl. 2021, 33, 14101–14117. [Google Scholar] [CrossRef]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar] [CrossRef]
- MacKay, D.J.C. Bayesian interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Kuhn, M. caret: Classification and Regression Training. R Package Version 6.0-94. 2023. Available online: https://CRAN.R-project.org/package=caret (accessed on 17 August 2023).
- Dowle, M.; Srinivasan, A. data.table: Extension of ‘data.frame’. R Package Version 1.14.8. 2023. Available online: https://CRAN.R-project.org/package=data.table (accessed on 17 August 2023).
- Hollister, J.W. elevatr: Access Elevation Data from Various APIs. R Package Version 0.4.2. 2022. Available online: https://CRAN.R-project.org/package=elevatr (accessed on 17 August 2023).
- Pierce, D. ncdf4: Interface to Unidata netCDF (Version 4 or Earlier) Format Data Files. R Package Version 1.21. 2023. Available online: https://CRAN.R-project.org/package=ncdf4 (accessed on 17 August 2023).
- Bivand, R.S.; Keitt, T.; Rowlingson, B. rgdal: Bindings for the ‘Geospatial’ Data Abstraction Library. R Package Version 1.6-6. 2023. Available online: https://CRAN.R-project.org/package=rgdal (accessed on 17 August 2023).
- Pebesma, E. Simple features for R: Standardized support for spatial vector data. R J. 2018, 10, 439–446. [Google Scholar] [CrossRef]
- Pebesma, E. sf: Simple Features for R. R Package Version 1.0-13. 2023. Available online: https://CRAN.R-project.org/package=sf (accessed on 17 August 2023).
- Bivand, R.S. spdep: Spatial Dependence: Weighting Schemes, Statistics. R Package Version 1.2-8. 2023. Available online: https://CRAN.R-project.org/package=spdep (accessed on 17 August 2023).
- Bivand, R.S.; Wong, D.W.S. Comparing implementations of global and local indicators of spatial association. TEST 2018, 27, 716–748. [Google Scholar] [CrossRef]
- Bivand, R.S.; Pebesma, E.; Gómez-Rubio, V. Applied Spatial Data Analysis with R, 2nd ed.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J.; et al. Welcome to the tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef]
- Wickham, H. tidyverse: Easily Install and Load the ‘Tidyverse’. R Package Version 2.0.0. 2023. Available online: https://CRAN.R-project.org/package=tidyverse (accessed on 17 August 2023).
- Rodriguez, P.P.; Gianola, D. brnn: Bayesian Regularization for Feed-Forward Neural Networks. R Package Version 0.9.2. 2022. Available online: https://CRAN.R-project.org/package=brnn (accessed on 17 August 2023).
- Milborrow, S. earth: Multivariate Adaptive Regression Splines. R Package Version 5.3.2. 2023. Available online: https://CRAN.R-project.org/package=earth (accessed on 17 August 2023).
- Greenwell, B.; Boehmke, B.; Cunningham, J.; GBM Developers. gbm: Generalized Boosted Regression Models. R package version 2.1.8.1. 2022. Available online: https://CRAN.R-project.org/package=gbm (accessed on 17 August 2023).
- Ripley, B.D. nnet: Feed-Forward Neural Networks and Multinomial Log-Linear Models. R Package Version 7.3-19. 2023. Available online: https://CRAN.R-project.org/package=nnet (accessed on 17 August 2023).
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; ISBN 0-387-95457-0. [Google Scholar]
- Wright, M.N. Ranger: A Fast Implementation of Random Forests. R Package Version 0.15.1. 2023. Available online: https://CRAN.R-project.org/package=ranger (accessed on 17 August 2023).
- Wright, M.N.; Ziegler, A. ranger: A fast implementation of random forests for high dimensional data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. xgboost: Extreme Gradient Boosting. R Package Version 1.7.5.1. 2023. Available online: https://CRAN.R-project.org/package=xgboost (accessed on 17 August 2023).
- Tyralis, H.; Papacharalampous, G. scoringfunctions: A Collection of Scoring Functions for Assessing Point Forecasts. 2022. Available online: https://CRAN.R-project.org/package=scoringfunctions (accessed on 17 August 2023).
- Wickham, H.; Hester, J.; Chang, W.; Bryan, J. devtools: Tools to Make Developing R Packages Easier. R Package Version 2.4.5. 2022. Available online: https://CRAN.R-project.org/package=devtools (accessed on 17 August 2023).
- Xie, Y. knitr: A Comprehensive Tool for Reproducible Research in R. In Implementing Reproducible Computational Research; Stodden, V., Leisch, F., Peng, R.D., Eds.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2014. [Google Scholar]
- Xie, Y. Dynamic Documents with R and knitr, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2015. [Google Scholar]
- Xie, Y. knitr: A General-Purpose Package for Dynamic Report Generation in R. R Package Version 1.43. 2023. Available online: https://CRAN.R-project.org/package=knitr (accessed on 17 August 2023).
- Allaire, J.J.; Xie, Y.; McPherson, J.; Luraschi, J.; Ushey, K.; Atkins, A.; Wickham, H.; Cheng, J.; Chang, W.; Iannone, R. Rmarkdown: Dynamic Documents for R. R Package Version 2.21. 2023. Available online: https://CRAN.R-project.org/package=rmarkdown (accessed on 17 August 2023).
- Xie, Y.; Allaire, J.J.; Grolemund, G. R Markdown: The Definitive Guide; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; ISBN 9781138359338. Available online: https://bookdown.org/yihui/rmarkdown (accessed on 17 August 2023).
- Xie, Y.; Dervieux, C.; Riederer, E. R Markdown Cookbook; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020; ISBN 9780367563837. Available online: https://bookdown.org/yihui/rmarkdown-cookbook (accessed on 17 August 2023).




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papacharalampous, G.; Tyralis, H.; Doulamis, N.; Doulamis, A. Ensemble Learning for Blending Gridded Satellite and Gauge-Measured Precipitation Data. Remote Sens. 2023, 15, 4912. https://doi.org/10.3390/rs15204912
Papacharalampous G, Tyralis H, Doulamis N, Doulamis A. Ensemble Learning for Blending Gridded Satellite and Gauge-Measured Precipitation Data. Remote Sensing. 2023; 15(20):4912. https://doi.org/10.3390/rs15204912
Chicago/Turabian StylePapacharalampous, Georgia, Hristos Tyralis, Nikolaos Doulamis, and Anastasios Doulamis. 2023. "Ensemble Learning for Blending Gridded Satellite and Gauge-Measured Precipitation Data" Remote Sensing 15, no. 20: 4912. https://doi.org/10.3390/rs15204912
APA StylePapacharalampous, G., Tyralis, H., Doulamis, N., & Doulamis, A. (2023). Ensemble Learning for Blending Gridded Satellite and Gauge-Measured Precipitation Data. Remote Sensing, 15(20), 4912. https://doi.org/10.3390/rs15204912