
An Improved U-Net Network for Sandy Road Extraction from Remote Sensing Imagery

 ,
,  ,
, 
Abstract
:1. Introduction
- (a)
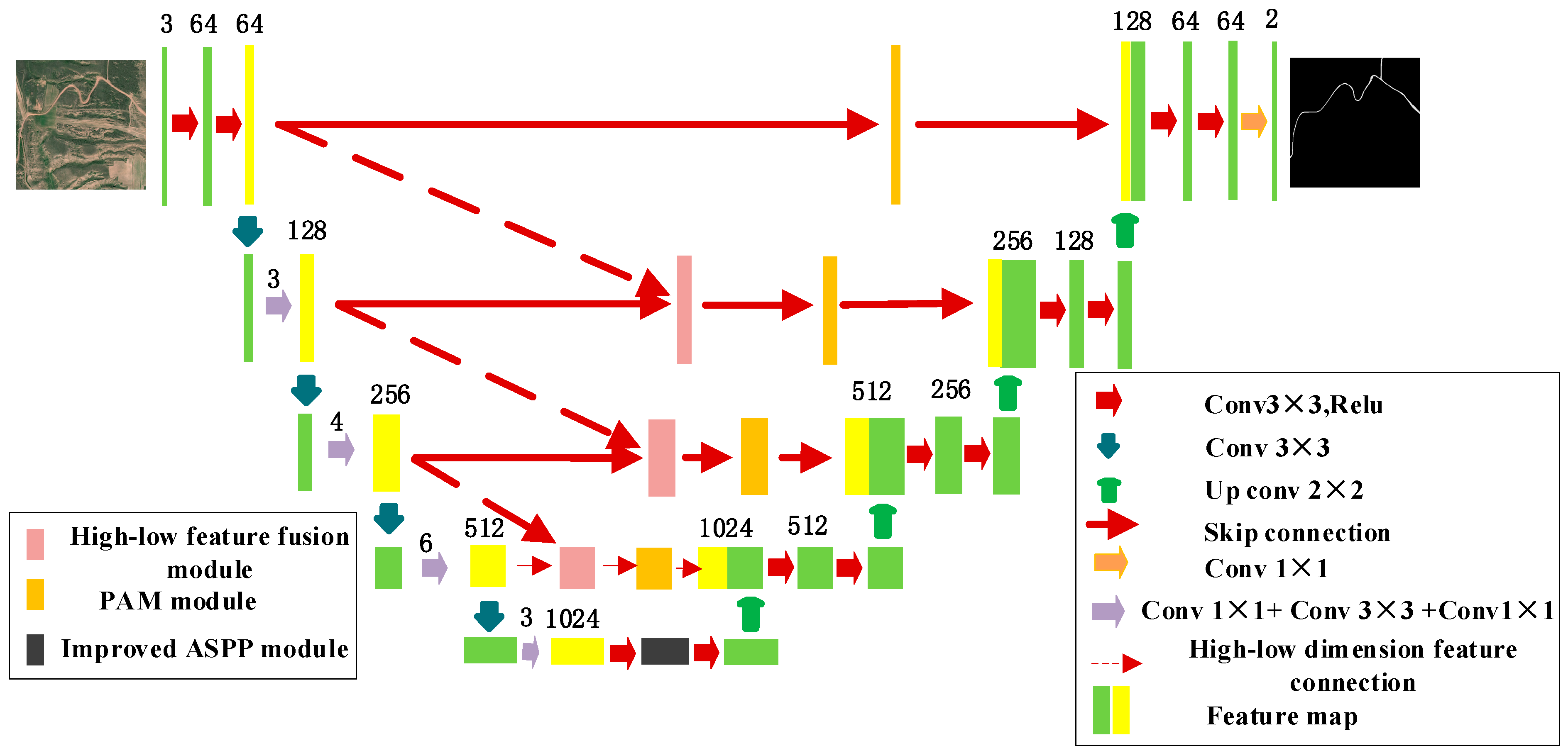
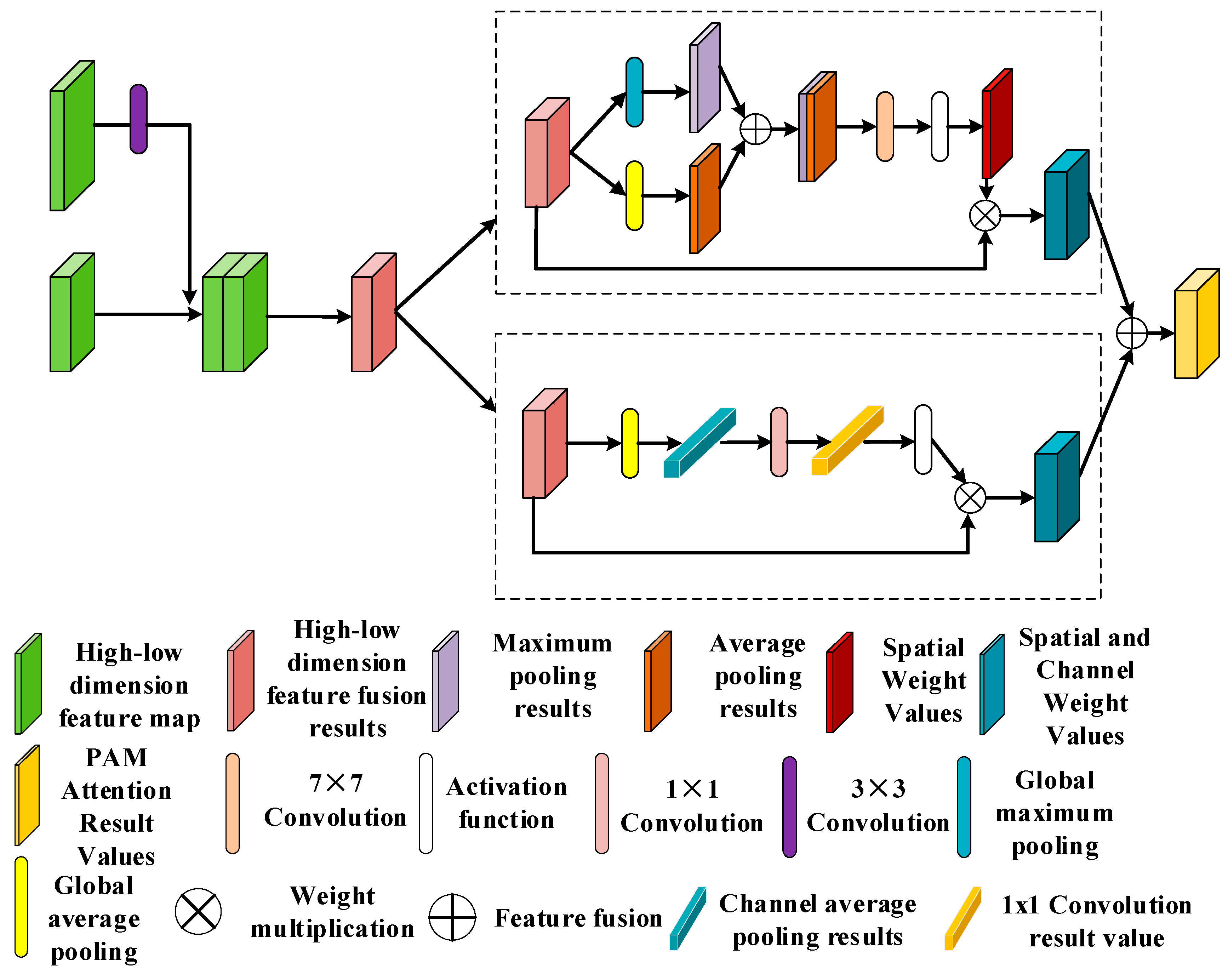
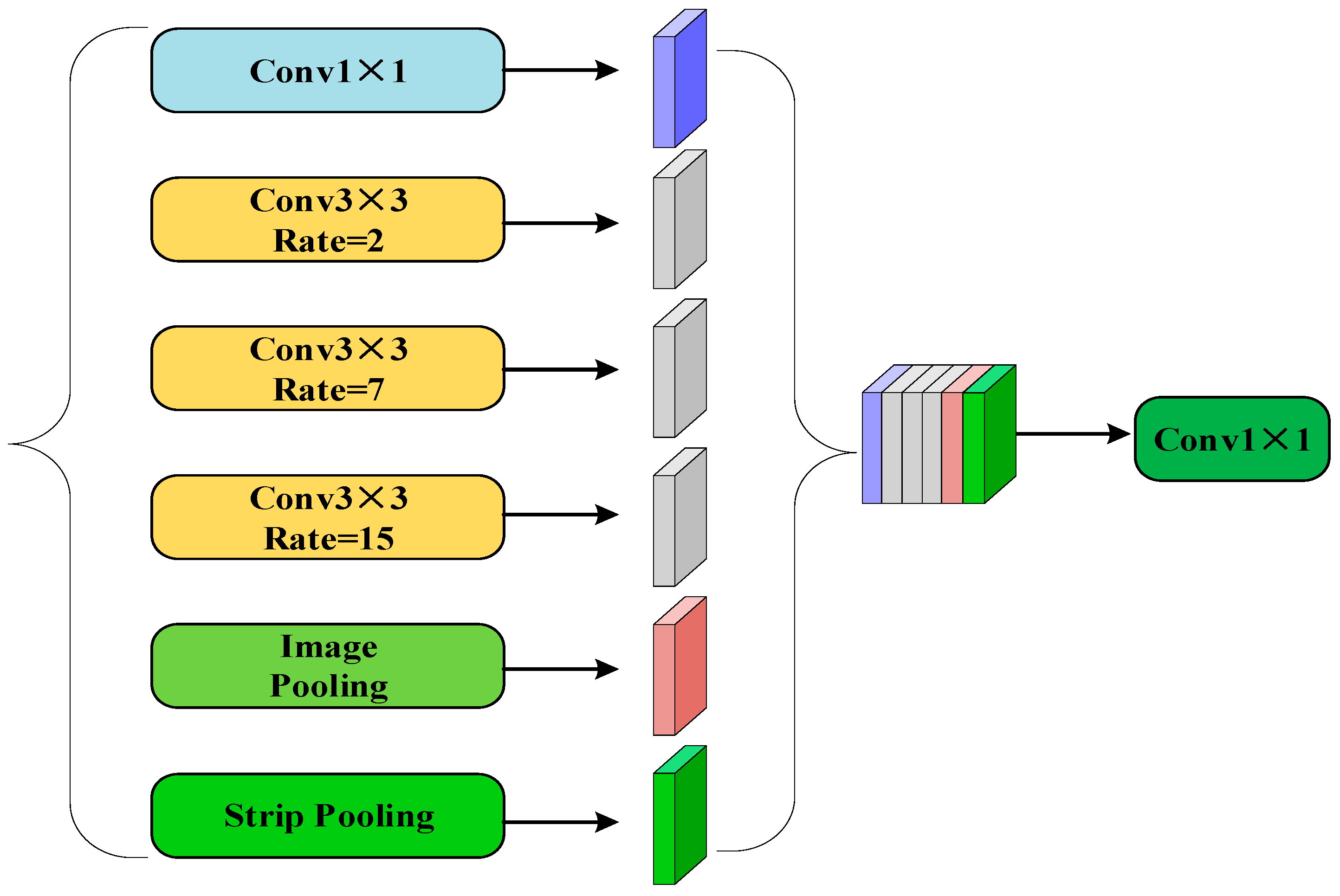
- This study proposes a sandy road extraction model PAM-Unet based on an improved U-Net [34,35,36,37]. To address the issue of poor continuity in sandy roads, PAM-Unet employs stacked residual modules in the encoder section to enhance the model’s feature extraction capability. Meanwhile, at the end of the model encoder, the ASPP module proposed in the DeepLab series of models [38,39,40,41] is combined with the stripe pooling module [42] to better perceive the multi-scale features [43]and to adapt to the sandy roads’ long-range banded features. For the occlusion of other targets in the field environment, the parallel attention mechanism (PAM) is proposed and adopted in the feature fusion part of the process to enhance the reducibility of the feature map.
- (b)
- This study proposes the RSISR dataset, which covers a variety of complex sandy road scenarios including bare soil, grassland, forests, etc. For this dataset, 12,252 data samples were finally obtained. The construction of this dataset provides strong support and a reliable baseline for this study and analysis of sandy roads.
- (c)
- The PAM-Unet model was tested and analyzed several times on the RSISR dataset and DeepGlobe dataset, which proved that the PAM-Unet model is effective in terms of the extraction of qualitative roads and the improvement of modules. The results showed that the PAM-Unet achieved the ideal extraction results on the sandy road dataset, with an IoU value of 0.762, and obtained a high F1 value and recall, while on the DeepGlobe dataset, the results further demonstrated the positive effects of the model’s modules.
2. Research Methodology
2.1. Basic U-Net Structure
2.2. PAM-Unet Structure
2.3. Parallel Attention Mechanism (PAM)
2.4. Improved ASPP Module
3. Dataset and Experimental Setup
3.1. Sandy Road Dataset Construction
3.2. DeepGlobe Dataset
3.3. Experimental Setup
3.4. Evaluation Indicators
4. Experimental Results and Analysis
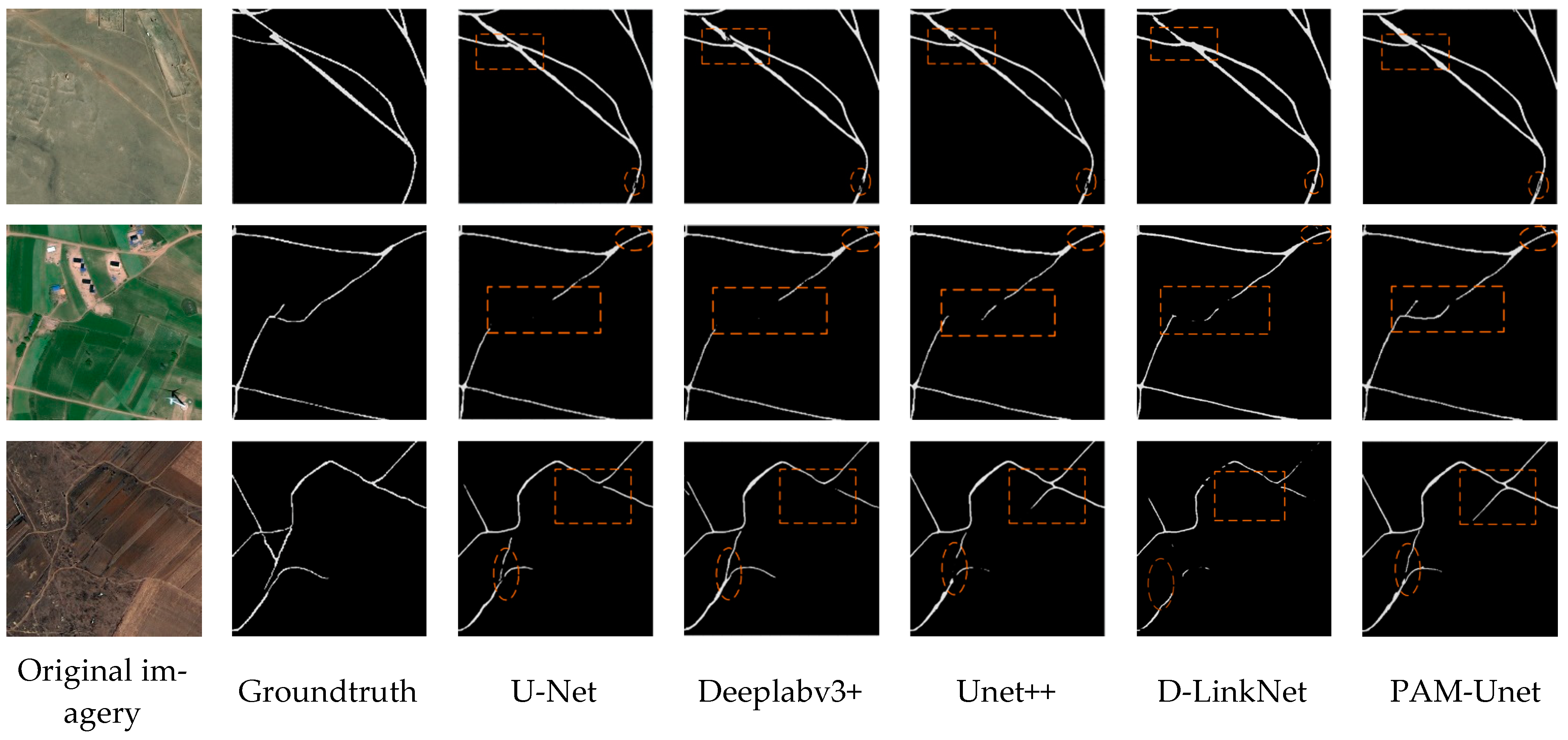
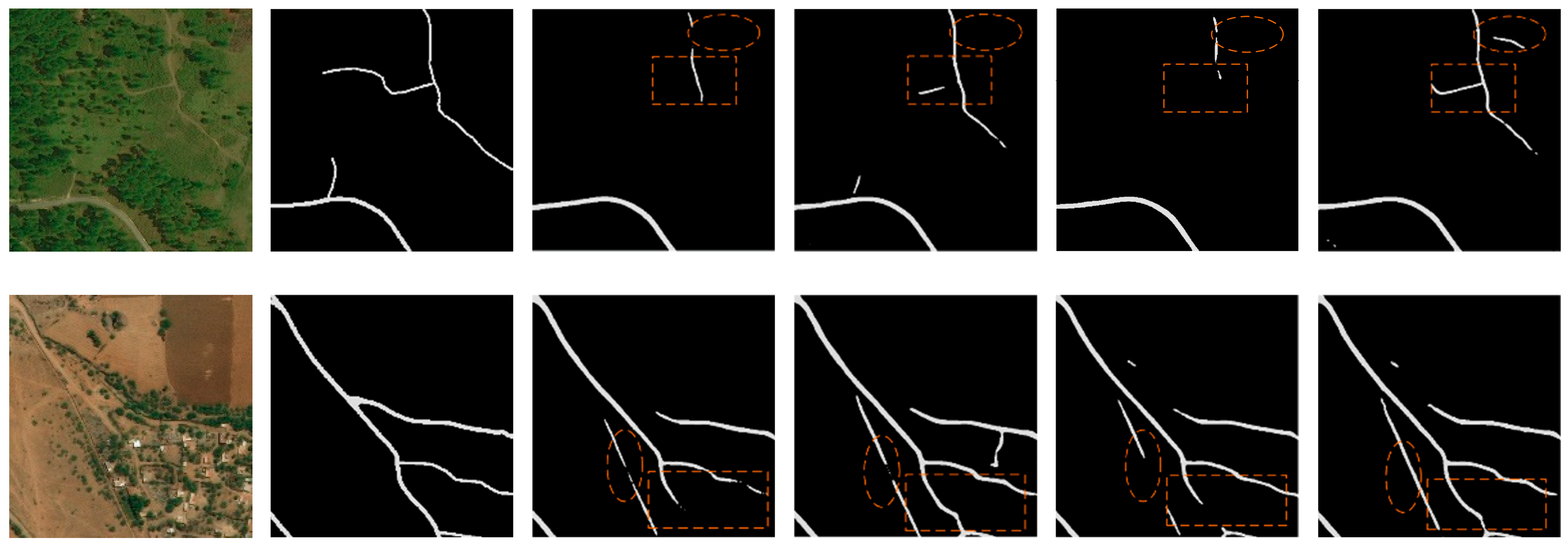
4.1. Road Extraction Results and Experiments on RSISR Dataset
4.2. Road Extraction Results and Experiments on DeepGlobe Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, S.F.; Liao, C.; Ding, Y.L.; Hu, H.; Jia, Y.; Chen, M.; Xu, B.; Ge, X.M.; Liu, T.Y.; Wu, D. Cascaded residual attention enhanced road extraction from remote sensing images. ISPRS Int. J. Geo-Inf. 2022, 11, 9. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep learning approaches applied to remote sensing datasets for road extraction: A state-of-the-art review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Deng, L.A.; Luo, Y.H.; Li, D.L.; Junior, J.M.; Goncalves, W.N.; Nurunnabi, A.A.M.; Li, J.; Wang, C.; Li, D. Road extraction in remote sensing data: A survey. Int. J. Appl. Earth Obs. 2022, 112, 102833. [Google Scholar] [CrossRef]
- Zhao, Y.Y.; Zhang, Y.; Yuan, M.T.; Yang, M.; Deng, J.Y. Estimation of initiation thresholds and soil loss from gully erosion on unpaved roads on China’s Loess Plateau. Earth Surf. Proc. Land 2021, 46, 1713–1724. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Li, C.K.; Zeng, Q.G.; Fang, J.; Wu, N.; Wu, K.H. Road extraction in rural areas from high resolution remote sensing image using an improved Full Convolution Network. Nat. Remote Sens. Bull. 2021, 25, 1978–1988. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Zhou, H.Y.; Wang, R.L.; Yang, J. Road segmentation for remote sensing images using adversarial spatial pyramid networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4673–4688. [Google Scholar] [CrossRef]
- Wei, Y.; Ji, S. Scribble-based weakly supervised deep learning for road surface extraction from remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602312. [Google Scholar] [CrossRef]
- Hou, Y.W.; Liu, Z.Y.; Zhang, T.; Li, Y.J. C-UNet: Complement UNet for remote sensing road extraction. Sensors 2021, 21, 2153. [Google Scholar] [CrossRef]
- Zhu, Q.Q.; Zhang, Y.N.; Wang, L.Z.; Zhong, Y.F.; Guan, Q.F.; Lu, X.Y.; Zhang, L.P.; Li, D. A global context-aware and batch-independent network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Lin, S.F.; Yao, X.; Liu, X.L.; Wang, S.H.; Chen, H.M.; Ding, L.; Zhang, J.; Chen, G.H.; Mei, Q. MS-AGAN: Road Extraction via Multi-Scale Information Fusion and Asymmetric Generative Adversarial Networks from High-Resolution Remote Sensing Images under Complex Backgrounds. Remote Sens. 2023, 15, 3367. [Google Scholar] [CrossRef]
- Zhang, Y.C.; Yang, H.L.; Xin, Z.B.; Lu, L.L. Extraction of Small Watershed Terraces in the Hilly Areas of Loess Plateau through UAV Images with Object-oriented Approach. J. Soil Water Conserv. 2023, 37, 139–146. [Google Scholar]
- Sun, Y.X.; Zhou, L.P.; Pi, Y.Z. Object-oriented classification based on high resolution UCE aerial images. Survey World 2022, 1, 55–58. [Google Scholar]
- Li, Y.; Han, X.; Ma, H.; Deng, L.; Sun, Y. Road image segmentation based on threshold watershed algorithm. J. Nonlinear Convex A 2019, 20, 1453–1463. [Google Scholar]
- Zhou, A.X.; Yu, L.; Feng, J.; Zhang, X.Y. Road Information Extraction from High-Resolution Remote Sensing Image Based on Object-Oriented Image Analysis Method. Geomat. Spat. Inf. Technol. 2017, 40, 1–4. [Google Scholar]
- Wu, Z.H.; Pan, S.R.; Chen, F.W.; Long, G.D.; Zhang, C.Q.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef]
- Goswami, A.; Sharma, D.; Mathuku, H.; Gangadharan, S.M.P.; Yadav, C.S.; Sahu, S.K.; Pradhan, M.K.; Singh, J.; Imran, H. Change detection in remote sensing image data comparing algebraic and machine learning methods. Electronics 2022, 11, 431. [Google Scholar] [CrossRef]
- Wang, G.H.; Li, B.; Zhang, T.; Zhang, S.B. A network combining a transformer and a convolutional neural network for remote sensing image change detection. Remote Sens. 2022, 14, 2228. [Google Scholar] [CrossRef]
- Feng, J.N.; Jiang, Q.; Tseng, C.H.; Jin, X.; Liu, L.; Zhou, W.; Yao, S.W. A deep multitask convolutional neural network for remote sensing image super-resolution and colorization. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5407915. [Google Scholar] [CrossRef]
- Cheng, X.J.; He, X.H.; Qiao, M.J.; Li, P.L.; Hu, S.K.; Chang, P.; Tian, Z.H. Enhanced contextual representation with deep neural networks for land cover classification based on remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102706. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N. Road extraction from high-resolution orthophoto images using convolutional neural network. J. Indian Soc. Remote 2021, 49, 569–583. [Google Scholar] [CrossRef]
- Zhou, G.D.; Chen, W.T.; Gui, Q.S.; Li, X.J.; Wang, L.Z. Split depth-wise separable graph-convolution network for road extraction in complex environments from high-resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5614115. [Google Scholar] [CrossRef]
- Wang, B.; Chen, Z.L.; Wu, L.; Xie, P.; Fan, D.L.; Fu, B.L. Road extraction of high-resolution satellite remote sensing images in U-Net network with consideration of connectivity. Remote Sens. Bull. 2020, 24, 1488–1499. [Google Scholar] [CrossRef]
- Xie, T.Y.; Liang, X.W.; Xu, S. Research on Urban Road Extraction Method Based on Improved U-Net Network. Comput. Digit. Eng. 2023, 51, 650–656. [Google Scholar]
- Zhang, K.; Chen, Z.J.; Qiao, D.; Zhang, Y. Real-Time Image Detection via Remote Sensing Based on Receptive Field and Feature Enhancement. Laser Optoelectron. Prog. 2023, 60, 0228001-1–0228001-10. [Google Scholar]
- Li, M.; Hsu, W.; Xie, X.D.; Cong, J.; Gao, W. SACNN: Self-attention convolutional neural network for low-dose CT denoising with self-supervised perceptual loss network. IEEE Trans. Med. Imaging 2020, 39, 2289–2301. [Google Scholar] [CrossRef]
- Jing, P.; Yu, H.Y.; Hua, Z.H.; Xie, S.F.; Song, C.Y. Road Crack Detection Using Deep Neural Network Based on Attention Mechanism and Residual Structure. IEEE Access 2022, 11, 919–929. [Google Scholar] [CrossRef]
- Wu, Q.Q.; Luo, F.; Wu, P.H.; Wang, B.; Yang, H.; Wu, Y.L. Automatic road extraction from high-resolution remote sensing images using a method based on densely connected spatial feature-enhanced pyramid. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens. 2020, 14, 3–17. [Google Scholar] [CrossRef]
- Qi, X.Q.; Li, K.Q.; Liu, P.K.; Zhou, X.G.; Sun, M.Y. Deep attention and multi-scale networks for accurate remote sensing image segmentation. IEEE Access 2020, 8, 146627–146639. [Google Scholar] [CrossRef]
- Liu, B.; Ding, J.L.; Zou, J.; Wang, J.J.; Huang, S.A. LDANet: A Lightweight Dynamic Addition Network for Rural Road Extraction from Remote Sensing Images. Remote Sens. 2023, 15, 1829. [Google Scholar] [CrossRef]
- Luo, Y.B.; Chen, J.X.; Shi, Z.; Li, J.Z.; Liu, W.W. Mechanical characteristics of primary support of large span loess highway tunnel: A case study in Shaanxi Province, Loess Plateau, NW China primary. Tunn. Undergr. Space Technol. 2020, 104, 103532. [Google Scholar] [CrossRef]
- Diaz-Gonzalez, F.A.; Vuelvas, J.; Correa, C.A.; Vallejo, V.E.; Patino, D. Machine learning and remote sensing techniques applied to estimate soil indicators—Review. Ecol. Indic. 2022, 135, 108517. [Google Scholar] [CrossRef]
- Liu, W.Q.; Wang, C.; Zang, Y.; Hu, Q.; Yu, S.S.; Lai, B.Q. A survey on information extraction technology based on remote sensing big data. Big Data Res. 2022, 8, 28–57. [Google Scholar]
- Kong, J.Y.; Zhang, H.S. Improved U-Net network and its application of road extraction in remote sensing image. Chin. Space Sci. Techn. 2022, 42, 105. [Google Scholar]
- Xu, L.L.; Liu, Y.J.; Yang, P.; Chen, H.; Zhang, H.Y.; Wang, D.; Zhang, X. HA U-Net: Improved model for building extraction from high resolution remote sensing imagery. IEEE Access 2021, 9, 101972–101984. [Google Scholar] [CrossRef]
- Ma, Y. Research Review of Image Semantic Segmentation Method in High-Resolution Remote Sensing Image Interpretation. J. Front. Comput. Sci. Technol. 2023, 1, 4200153. [Google Scholar]
- He, C.; Liu, Y.L.; Wang, D.C.; Liu, S.F.; Yu, L.J.; Ren, Y.H. Automatic Extraction of Bare Soil Land from High-Resolution Remote Sensing Images Based on Semantic Segmentation with Deep Learning. Remote Sens. 2023, 15, 1646. [Google Scholar] [CrossRef]
- Wang, J.X.; Feng, Z.X.; Jiang, Y.; Yang, S.Y.; Meng, H.X. Orientation Attention Network for semantic segmentation of remote sensing images. Knowl. Based Syst. 2023, 267, 110415. [Google Scholar] [CrossRef]
- Mahmud, M.N.; Azim, M.H.; Hisham, M.; Osman, M.K.; Ismail, A.P.; Ahmad, F.; Ahmad, K.A.; Ibrahim, A.; Rabiani, A.H. Altitude Analysis of Road Segmentation from UAV Images with DeepLab V3+. In Proceedings of the 2022 IEEE 12th International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 21–22 October 2022; pp. 219–223. [Google Scholar]
- Yan, Y.T.; Gao, Y.; Shao, L.W.; Yu, L.Q.; Zeng, W.T. Cultivated land recognition from remote sensing images based on improved deeplabv3 model. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; pp. 2535–2540. [Google Scholar]
- Hou, Q.B.; Zhang, L.; Cheng, M.M.; Feng, J.S. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Wulamu, A.; Shi, Z.X.; Zhang, D.Z.; He, Z.Y. Multiscale road extraction in remote sensing images. Comput. Intell. Neurosci. 2019, 2019, 2373798. [Google Scholar] [CrossRef]
- Abderrahim, N.Y.Q.; Abderrahim, S.; Rida, A. Road segmentation using u-net architecture. In Proceedings of the 2020 IEEE International Conference of Moroccan Geomatics (Morgeo), Casablanca, Morocco, 11–13 May 2020; pp. 1–4. [Google Scholar]
- Xiao, B.; Yang, Z.Y.; Qiu, X.M.; Xiao, J.J.; Wang, G.Y.; Zeng, W.B.; Li, W.S.; Nian, Y.J.; Chen, W. PAM-DenseNet: A deep convolutional neural network for computer-aided COVID-19 diagnosis. IEEE Trans. Cybern. 2021, 52, 12163–12174. [Google Scholar] [CrossRef] [PubMed]
- Ye, H.R.; Zhou, R.; Wang, J.H.; Huang, Z.L. FMAM-Net: Fusion Multi-Scale Attention Mechanism Network for Building Segmentation in Remote Sensing Images. IEEE Access 2022, 10, 134241–134251. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.R.; Tao, F.; Liu, X.T.; Na, J.M.; Leng, H.J.; Wu, J.J.; Zhou, T. RAANet: A residual ASPP with attention framework for semantic segmentation of high-resolution remote sensing images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Li, Y.Z.; Cheng, Z.Y.; Wang, C.J.; Zhao, J.L.; Huang, L.S. RCCT-ASPPNet: Dual-Encoder Remote Image Segmentation Based on Transformer and ASPP. Remote Sens. 2023, 15, 379. [Google Scholar] [CrossRef]
- Shin, T.; Jeong, S.; Ko, J. Development of a Radiometric Calibration Method for Multispectral Images of Croplands Obtained with a Remote-Controlled Aerial System. Remote Sens. 2023, 15, 1408. [Google Scholar] [CrossRef]
- Wang, C.S.; Wang, L.H.; Zhang, J.; Ye, A.W.; Zhong, G.X.; Wang, Y.Q.; Cui, H.X.; Li, Q.Q. Remote Sensing Video Production and Traffic Information Extraction Based on Urban Skyline. Geomat. Inf. Sci. Wuhan Univ. 2023, 48, 1490–1498. [Google Scholar]
- Kong, Z.; Yang, H.T.; Zheng, F.J.; Li, Y.; Qi, J.; Zhu, Q.Y.; Yang, Z.L. Research advances in atmospheric correction of hyperspectral remote sensing images. Remote Sens. Nat. Resour. 2022, 34, 1–10. [Google Scholar]
- Xu, H.; Yuan, J.; Ma, J. MURF: Mutually Reinforcing Multi-modal Image Registration and Fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12148–12166. [Google Scholar] [CrossRef]
- Lu, X.Y.; Zhong, Y.F.; Zheng, Z.; Chen, D.Y. GRE and Beyond: A Global Road Extraction Dataset. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3035–3038. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoder | Type | Input | Output | Kernel | Stride | Padding |
|---|---|---|---|---|---|---|
| Encoder0 | Conv | 512 × 512 × 3 | 256 × 256 × 64 | 7 | 2 | 3 |
| max pooling | 256 × 256 × 64 | 128 × 128 × 64 | 3 | 2 | 1 | |
| Encoder1 | 3 × res_block | 128 × 128 × 64 | 128 × 128 × 128 | 3 | 1 | 1 |
| Encoder2 | Conv | 128 × 128 × 128 | 64 × 64 × 256 | 1 | 2 | 0 |
| 4 × res_block | 64 × 64 × 256 | 64 × 64 × 256 | 3 | 1 | 1 | |
| Encoder3 | Conv | 64 × 64 × 256 | 32 × 32 × 512 | 1 | 2 | 0 |
| 6 × res_block | 32 × 32 × 512 | 32 × 32 × 512 | 3 | 1 | 1 | |
| Encoder4 | Conv | 32 × 32 × 512 | 16 × 16 × 1024 | 1 | 2 | 0 |
| 3 × res_block | 16 × 16 × 1024 | 16 × 16 × 1024 | 3 | 1 | 1 |
| Name of the Parameter | Parameter Value |
|---|---|
| learning rate | 0.001 |
| optimizer | Adam |
| loss function | binary cross entropy |
| batch size | 8 |
| epochs | 150 |
| weight_decay | 0.0005 |
| momentum | 0.9 |
| gamma | 0.98 |
| Method | IoU | Precision | Recall | F1 Score | Running Time |
|---|---|---|---|---|---|
| Unet++ | 0.726 | 0.832 | 0.851 | 0.841 | 70 s |
| Deeplabv3+ | 0.709 | 0.814 | 0.847 | 0.830 | 68 s |
| Unet | 0.721 | 0.831 | 0.844 | 0.838 | 66 s |
| D-LinkNet | 0.721 | 0.822 | 0.854 | 0.838 | 67 s |
| PAM-Unet | 0.762 | 0.863 | 0.868 | 0.865 | 72 s |
| Method | IoU | Precision | Recall | F1 Score | Running Time |
|---|---|---|---|---|---|
| Unet | 0.721 | 0.831 | 0.844 | 0.838 | 66 s |
| PA-Unet | 0.746 | 0.851 | 0.858 | 0.854 | 67 s |
| AS-Unet | 0.733 | 0.843 | 0.849 | 0.846 | 69 s |
| PAM-Unet | 0.762 | 0.863 | 0.868 | 0.865 | 72 s |
| Method | IoU | Precision | Recall | F1 Score | Running Time |
|---|---|---|---|---|---|
| U-Net | 0.627 | 0.758 | 0.781 | 0.769 | 64 s |
| PA-Unet | 0.651 | 0.789 | 0.789 | 0.789 | 65 s |
| AS-Unet | 0.644 | 0.780 | 0.787 | 0.783 | 67 s |
| PAM-Unet | 0.658 | 0.799 | 0.789 | 0.794 | 70 s |
| Method | IoU | Precision | Recall | F1 Score | Running Time |
|---|---|---|---|---|---|
| Unet++ | 0.643 | 0.791 | 0.774 | 0.782 | 68 s |
| Deeplabv3+ | 0.636 | 0.770 | 0.786 | 0.778 | 66 s |
| U-Net | 0.627 | 0.758 | 0.781 | 0.769 | 64 s |
| SegNet | 0.629 | 0.765 | 0.779 | 0.771 | 65 s |
| PAM-Unet | 0.658 | 0.799 | 0.789 | 0.794 | 70 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, Y.; An, K.; Chen, X.; Zhao, L.; Liu, W.; Wang, X.; Yu, Y.; Luo, W.; Li, K.; Zhang, Z. An Improved U-Net Network for Sandy Road Extraction from Remote Sensing Imagery. Remote Sens. 2023, 15, 4899. https://doi.org/10.3390/rs15204899
Nie Y, An K, Chen X, Zhao L, Liu W, Wang X, Yu Y, Luo W, Li K, Zhang Z. An Improved U-Net Network for Sandy Road Extraction from Remote Sensing Imagery. Remote Sensing. 2023; 15(20):4899. https://doi.org/10.3390/rs15204899
Chicago/Turabian StyleNie, Yunfeng, Kang An, Xingfeng Chen, Limin Zhao, Wantao Liu, Xing Wang, Yihao Yu, Wenyi Luo, Kewei Li, and Zhaozhong Zhang. 2023. "An Improved U-Net Network for Sandy Road Extraction from Remote Sensing Imagery" Remote Sensing 15, no. 20: 4899. https://doi.org/10.3390/rs15204899
APA StyleNie, Y., An, K., Chen, X., Zhao, L., Liu, W., Wang, X., Yu, Y., Luo, W., Li, K., & Zhang, Z. (2023). An Improved U-Net Network for Sandy Road Extraction from Remote Sensing Imagery. Remote Sensing, 15(20), 4899. https://doi.org/10.3390/rs15204899