
Strip Attention Networks for Road Extraction


Abstract
:1. Introduction
- A novel encoder–decoder network has been designed and a SAM is proposed for extracting road features in row direction and column direction in images;
- A novel CAF is designed to extract the position information of roads in the low-level feature map and the category information in the high-level feature map, and to fuse them efficiently.
2. Materials and Methods
2.1. Datasets
2.2. Experimental Environment
2.3. Evaluation Metrics
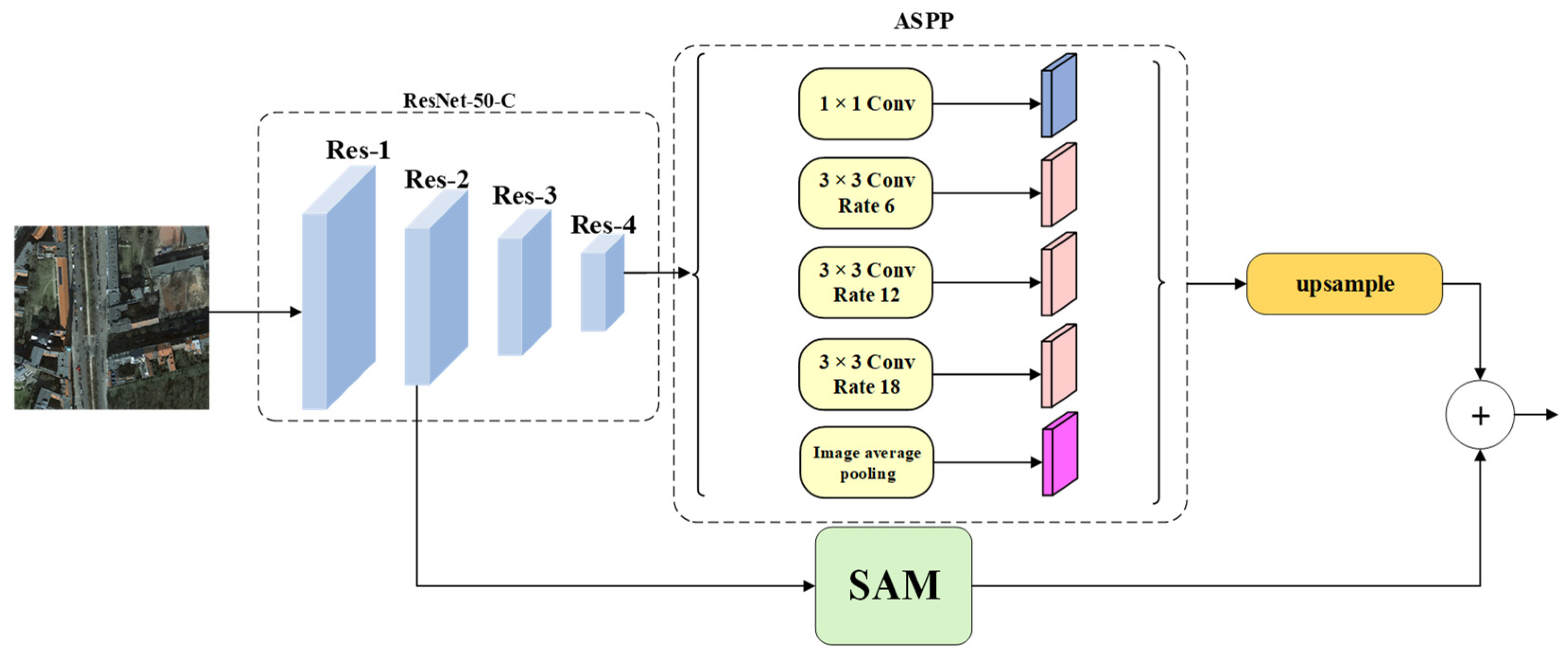
2.4. Strip Attention Net
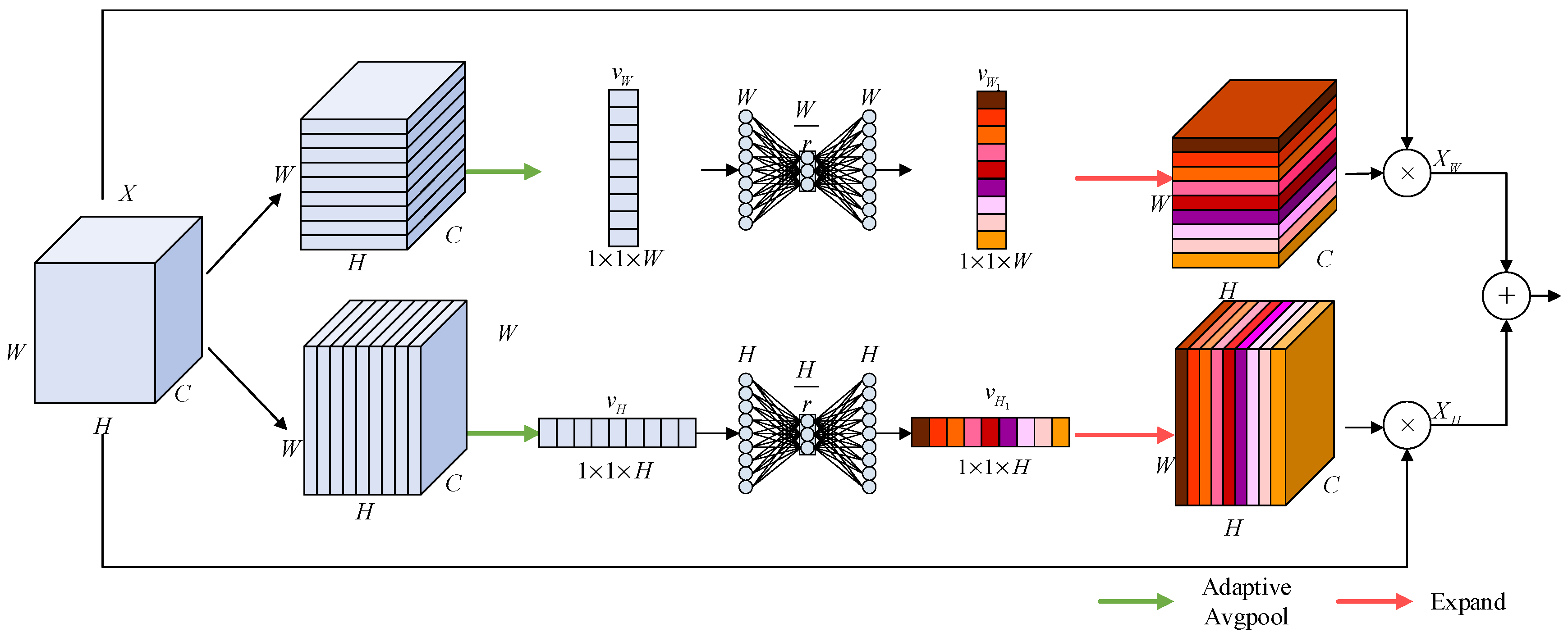
2.5. Strip Attention Module
2.6. Channel Attention Fusion Module
3. Results and Analysis
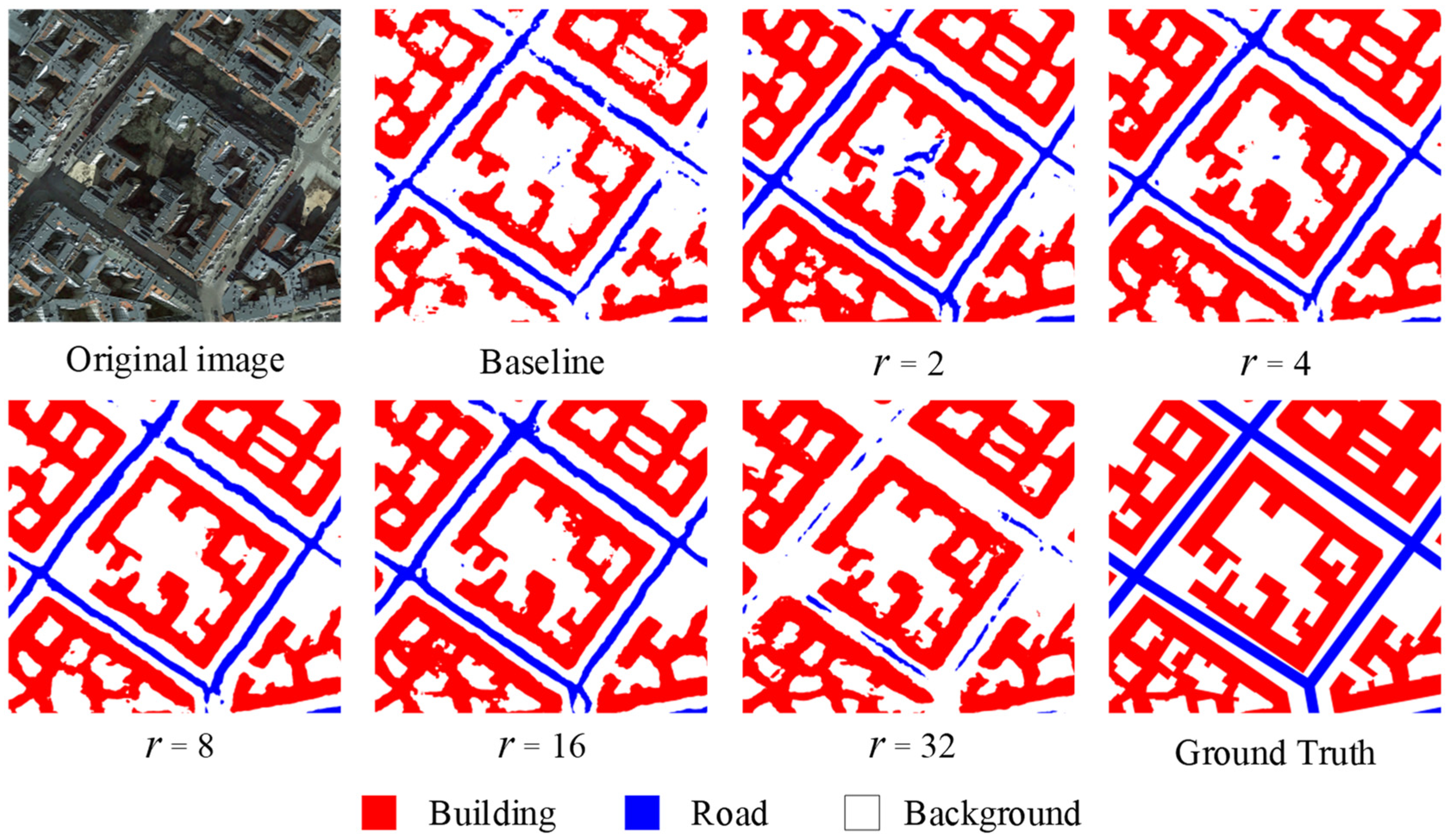
3.1. Comparison of the Reduction Rate
3.2. Module Validity Analysis
3.3. Comparison and Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, M.; Sui, H.; Chen, S.; Wang, J.; Chen, X. BT-RoadNet: A boundary and topologically-aware neural network for road extraction from high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 168, 288–306. [Google Scholar] [CrossRef]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of salient features for the design of a multistage framework to extract roads from high-resolution multispectral satellite images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Chen, Y.Y.; Wang, M. Very high resolution remote sensing image classification with SEEDS-CNN and scale effect analysis for superpixel CNN classification. Int. J. Remote Sens. 2019, 40, 506–531. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Lu, T.; Zhou, K.; Wang, M.; Bao, H. A new method for region-based majority voting CNNs for very high resolution image classification. Remote Sens. 2018, 10, 1946. [Google Scholar] [CrossRef]
- Sardar, A.; Mehrshad, N.; Mohammad, R.S. Efficient image segmentation method based on an adaptive selection of Gabor filters. IET Image Process. 2020, 14, 4198–4209. [Google Scholar] [CrossRef]
- Xu, D.; Zhao, Y.; Jiang, Y.; Zhang, C.; Sun, B.; He, X. Using Improved Edge Detection Method to Detect Mining-Induced Ground Fissures Identified by Unmanned Aerial Vehicle Remote Sensing. Remote Sens. 2021, 13, 3652. [Google Scholar] [CrossRef]
- Omati, M.; Sahebi, M.R. Change detection of polarimetric SAR images based on the integration of improved watershed and MRF segmentation approaches. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2018, 11, 4170–4179. [Google Scholar] [CrossRef]
- Song, M.J.; Civco, D. Road Extraction Using SVM and Image Segmentation. Photogramm. Eng. Remote Sens. 2004, 70, 1365–1371. [Google Scholar] [CrossRef]
- Jeong, M.; Nam, J.; Ko, B.C. Lightweight Multilayer Random Forests for Monitoring Driver Emotional Status. IEEE Access. 2020, 8, 60344–60354. [Google Scholar] [CrossRef]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Shi, W.; Miao, Z.; Wang, Q.; Zhang, H. Spectral-spatial classification and shape features for urban road centerline extraction. IEEE Geosci. Remote Sens. Lett. 2014, 11, 788–792. [Google Scholar]
- Ghaziani, M.; Mohamadi, Y.; Koku, A.B. Extraction of unstructured roads from satellite images using binary image segmentation. In Proceedings of the 2013 21st Signal Processing and Communications Applications Conference, Haspolat, Turkey, 24–26 April 2013; pp. 1–4. [Google Scholar]
- Sirmacek, B.; Unsalan, C. Road network extraction using edge detection and spatial voting. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3113–3116. [Google Scholar]
- Zhang, C.; Tang, Z.; Zhang, M.; Wang, B.; Hou, L. Developing a More Reliable Aerial Photography-Based Method for Acquiring Freeway Traffic Data. Remote Sens. 2022, 14, 2202. [Google Scholar] [CrossRef]
- Zhang, S.; Li, C.; Qiu, S.; Gao, C.; Zhang, F.; Du, Z.; Liu, R. EMMCNN: An ETPS-Based Multi-Scale and Multi-Feature Method Using CNN for High Spatial Resolution Image Land-Cover Classification. Remote Sens. 2020, 12, 66. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Shao, S.; Xiao, L.; Lin, L.; Ren, C.; Tian, J. Road Extraction Convolutional Neural Network with Embedded Attention Mechanism for Remote Sensing Imagery. Remote Sens. 2022, 14, 2061. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhang, Z.X.; Liu, Q.J.; Wang, Y.H. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the IEEE Visual Communications and Image Processing, St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Yu, C.; Wang, J.; Gao, C.; Yu, G.; Shen, C.; Sang, N. Context prior for scene segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12416–12425. [Google Scholar]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning aerial image segmentation from online maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A Global Context-aware and Batch-independent Network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- MMSegmentation Contributors. MMSegmentation: Openmmlab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 11 August 2020).
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive Pyramid Context Network for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7511–7520. [Google Scholar]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Huang, T.S. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-Maximization Attention Networks for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9167–9176. [Google Scholar]
- Yin, M.; Yao, Z.; Cao, Y.; Li, X.; Zhang, Z.; Lin, S.; Hu, H. Disentangled non-Local neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, KY, USA, 23–28 August 2020; pp. 191–207. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 7794–7803. [Google Scholar]
- Li, S.; Liao, C.; Ding, Y.; Hu, H.; Jia, Y.; Chen, M.; Xu, B.; Ge, X.; Liu, T.; Wu, D. Cascaded Residual Attention Enhanced Road Extraction from Remote Sensing Images. ISPRS Int. J. Geo.-Inf. 2022, 11, 9. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Per-Class IoU (%) | MIoU (%) | ||
|---|---|---|---|---|
| Background | Building | Road | ||
| Baseline | 83.44 | 48.61 | 76.3 | 69.45 |
| 83.54 | 52.74 | 76.93 | 71.07 | |
| 83.62 | 52.06 | 76.97 | 70.88 | |
| 83.58 | 52.43 | 77.0 | 71.01 | |
| 83.65 | 53.31 | 77.07 | 71.34 | |
| 82.78 | 46.32 | 76.05 | 68.39 | |
| Method | Per-Class IoU(%) | MIoU (%) | |
|---|---|---|---|
| Background | Road | ||
| Baseline | 98.06 | 62.24 | 80.15 |
| 98.10 | 62.43 | 80.27 | |
| 98.10 | 62.53 | 80.32 | |
| 98.07 | 62.67 | 80.37 | |
| 98.10 | 62.68 | 80.39 | |
| 98.10 | 62.36 | 80.23 | |
| Method | Per-class IoU (%) | MIoU (%) | |
|---|---|---|---|
| Background | Road | ||
| Baseline | 97.12 | 60.13 | 78.63 |
| 97.18 | 60.28 | 78.73 | |
| 97.23 | 60.71 | 78.97 | |
| 97.25 | 60.99 | 79.12 | |
| 97.26 | 61.73 | 79.50 | |
| 97.18 | 60.17 | 78.67 | |
| Method | Per-Class IoU (%) | MIoU (%) | ||
|---|---|---|---|---|
| Background | Building | Road | ||
| Baseline | 83.44 | 48.61 | 76.30 | 69.45 |
| Baseline+SAM (Res-1) | 83.42 | 51.28 | 76.51 | 70.40 |
| Baseline+SAM (Res-2) | 83.65 | 53.31 | 77.07 | 71.34 |
| Baseline+SAM (Res-3) | 83.29 | 50.64 | 76.58 | 70.17 |
| Baseline+SAM+CAF (average) | 83.96 | 50.72 | 77.13 | 70.60 |
| Baseline+SAM+CAF (max) | 83.53 | 52.45 | 77.10 | 71.03 |
| Baseline+SAM+CAF (Ours) | 84.26 | 54.78 | 77.55 | 72.20 |
| Method | Per-Class IoU (%) | MIoU (%) | |
|---|---|---|---|
| Background | Road | ||
| Baseline | 98.06 | 62.24 | 80.15 |
| Baseline + SAM (Res-1) | 98.11 | 62.45 | 80.28 |
| Baseline + SAM (Res-2) | 98.10 | 62.68 | 80.39 |
| Baseline + SAM (Res-3) | 98.10 | 62.58 | 80.34 |
| Baseline + SAM + CAF (average) | 98.14 | 62.72 | 80.43 |
| Baseline + SAM + CAF (max) | 98.09 | 62.66 | 80.37 |
| Baseline + SAM + CAF (Ours) | 98.15 | 63.05 | 80.60 |
| Method | Per-Class IoU (%) | MIoU (%) | |
|---|---|---|---|
| Background | Road | ||
| Baseline | 97.12 | 60.13 | 78.63 |
| Baseline + SAM (Res-1) | 97.11 | 61.29 | 79.20 |
| Baseline + SAM (Res-2) | 97.26 | 61.73 | 79.50 |
| Baseline + SAM (Res-3) | 97.26 | 61.58 | 79.42 |
| Baseline + SAM + CAF (average) | 97.32 | 62.50 | 79.91 |
| Baseline + SAM + CAF (max) | 97.18 | 62.04 | 79.61 |
| Baseline + SAM + CAF (Ours) | 97.35 | 63.08 | 80.22 |
| Method | Per-class IoU (%) | MIoU (%) | ||
|---|---|---|---|---|
| Background | Building | Road | ||
| DeepLabV3 [34] | 83.44 | 48.61 | 76.30 | 69.45 |
| APCNet [35] | 83.75 | 49.42 | 76.77 | 69.98 |
| CCNet [36] | 83.32 | 52.76 | 76.50 | 70.86 |
| DANet [28] | 81.76 | 47.61 | 73.04 | 67.47 |
| EMANet [37] | 83.76 | 53.34 | 77.03 | 71.38 |
| DNLNet [38] | 83.95 | 53.00 | 77.12 | 71.36 |
| CRANet [40] | 83.29 | 51.35 | 76.84 | 70.49 |
| SANet (Ours) | 84.26 | 54.78 | 77.55 | 72.20 |
| Method | Per-Class IoU (%) | MIoU (%) | |
|---|---|---|---|
| Background | Road | ||
| DeepLabV3 [34] | 98.06 | 62.24 | 80.15 |
| APCNet [35] | 98.03 | 59.78 | 78.91 |
| CCNet [36] | 98.09 | 61.77 | 79.93 |
| DANet [28] | 97.98 | 61.77 | 79.88 |
| EMANet [37] | 98.06 | 61.45 | 79.76 |
| DNLNet [38] | 98.10 | 62.19 | 80.15 |
| CRANet [40] | 98.05 | 62.04 | 80.04 |
| SANet (Ours) | 98.15 | 63.05 | 80.60 |
| Method | Per-Class IoU (%) | MIoU (%) | |
|---|---|---|---|
| Background | Road | ||
| DeepLabV3 [34] | 97.12 | 60.13 | 78.63 |
| APCNet [35] | 97.24 | 61.90 | 79.57 |
| CCNet [36] | 97.26 | 61.58 | 79.42 |
| DANet [28] | 97.23 | 60.44 | 78.83 |
| EMANet [37] | 97.18 | 62.04 | 79.61 |
| DNLNet [38] | 97.32 | 62.50 | 79.91 |
| CRANet [40] | 97.32 | 62.88 | 80.10 |
| SANet (Ours) | 97.35 | 63.08 | 80.22 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huan, H.; Sheng, Y.; Zhang, Y.; Liu, Y. Strip Attention Networks for Road Extraction. Remote Sens. 2022, 14, 4516. https://doi.org/10.3390/rs14184516
Huan H, Sheng Y, Zhang Y, Liu Y. Strip Attention Networks for Road Extraction. Remote Sensing. 2022; 14(18):4516. https://doi.org/10.3390/rs14184516
Chicago/Turabian StyleHuan, Hai, Yu Sheng, Yi Zhang, and Yuan Liu. 2022. "Strip Attention Networks for Road Extraction" Remote Sensing 14, no. 18: 4516. https://doi.org/10.3390/rs14184516
APA StyleHuan, H., Sheng, Y., Zhang, Y., & Liu, Y. (2022). Strip Attention Networks for Road Extraction. Remote Sensing, 14(18), 4516. https://doi.org/10.3390/rs14184516