




High-Quality Object Detection Method for UAV Images Based on Improved DINO and Masked Image Modeling

 , ,
, ,
Abstract
:1. Introduction
- (1)
- A high-quality UAV image object detection method was developed using the SOTA object detection method as the baseline network;
- (2)
- A global–local hybrid backbone for feature extraction that combines the advantages of CNN and ViT was built for the baseline network;
- (3)
- AdaBelief, an optimizer with better stability and generalizability, was used to achieve faster convergence and higher training accuracy by reasonably adjusting the learning rate;
- (4)
- A pre-training model that better meets the downstream task requirements of UAV images was obtained using the MIM method and an aerospace image dataset with a much lower data volume than current mainstream natural scene datasets. This model further improved the object detection performance of UAV images.
2. Related Work
2.1. Object Detection Methods
2.1.1. CNN-Based Methods
2.1.2. ViT-Based Method
2.1.3. Hybrid Methods
2.2. Masked Modeling Methods
3. Proposed Method
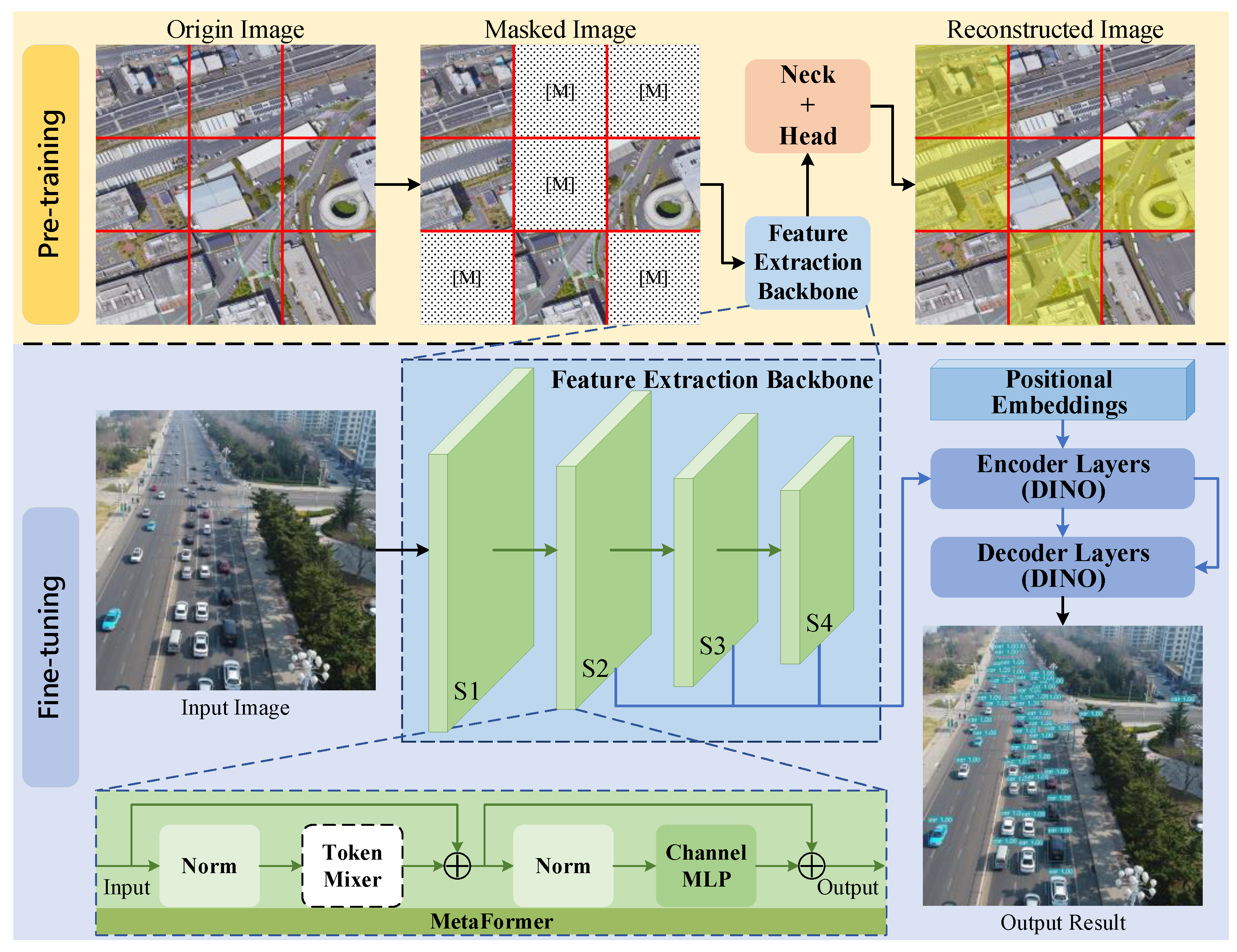
3.1. Overall Framework
- (1)
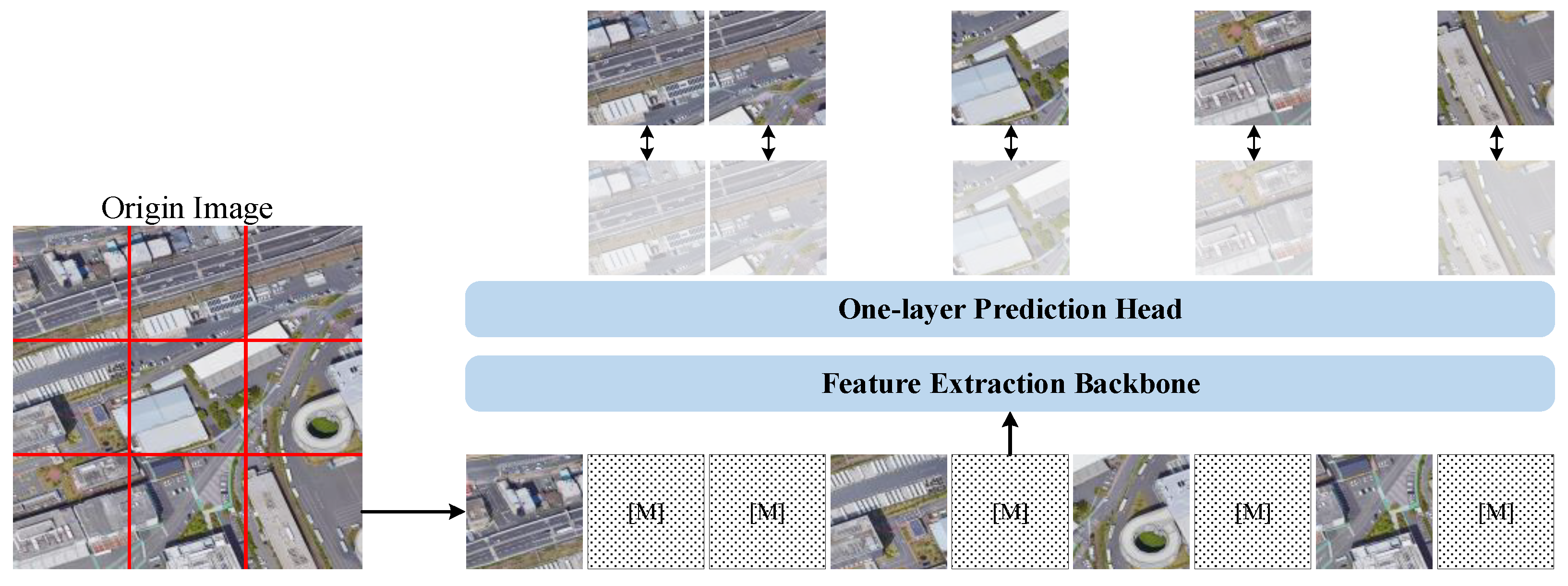
- In the pre-training step, a self-supervised training method based on SIMMIM was adopted. With the help of the significant similarity between the aerospace remote sensing images and UAV images, an aerospace remote sensing dataset, which has a much lower volume than the mainstream natural scene dataset, was applied to obtain the pre-training model of the proposed feature extraction backbone; thus, the pre-training model can better adapt to object detection in UAV images.
- (2)
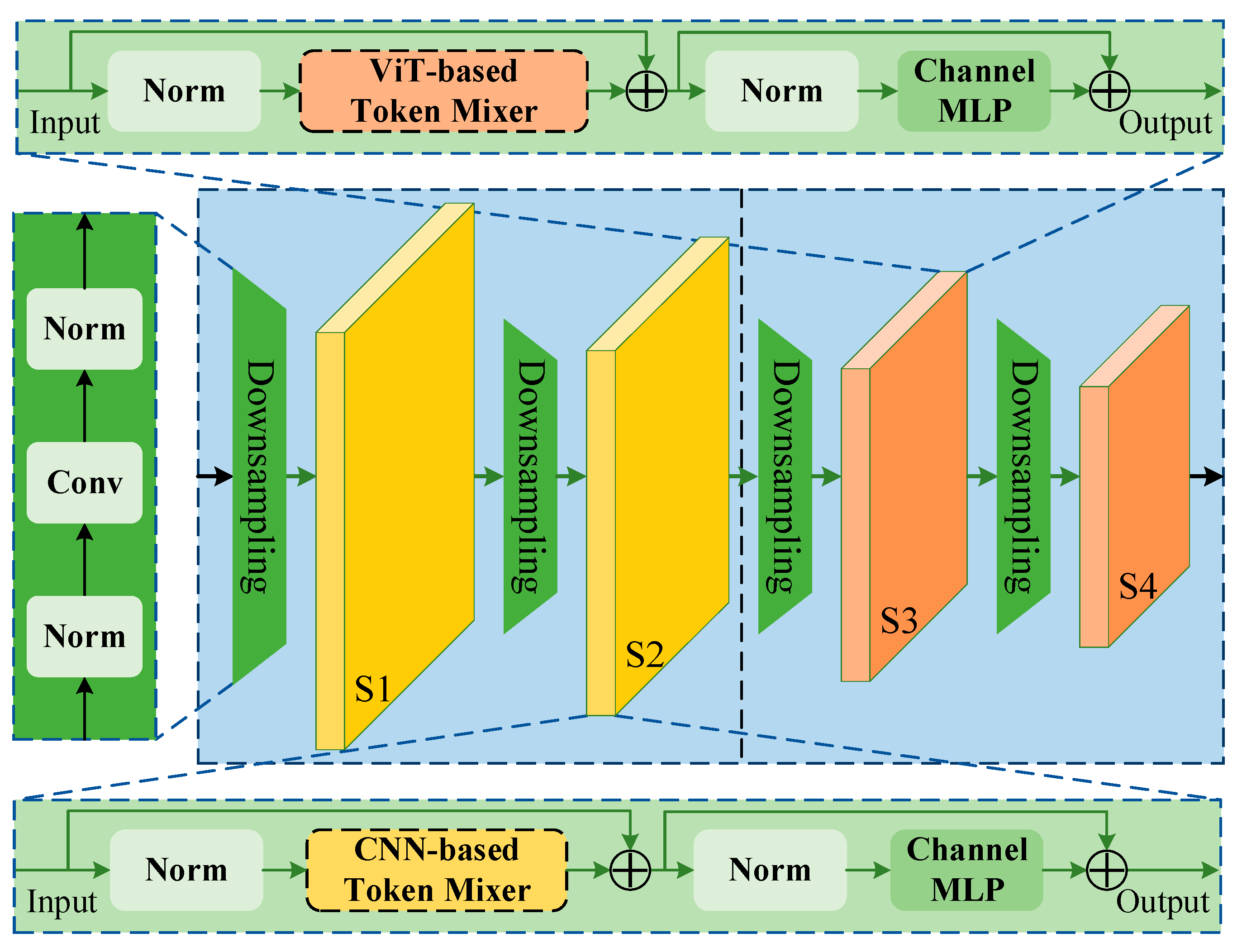
- In the fine-tuning step, DINO, which utilizes denoising methods to achieve high-precision object-detection accuracy, was used as the baseline network. In this study, we designed a backbone based on MetaFormer, as shown in Figure 1, and embedded a token mixer suitable for masked image training by combining the CNN and ViT to extract features, which will be transmitted to the encoder layers. The feature extraction backbone has four stages: S1, S2, S3, and S4, with each containing one downsampling module that was not presented and several MetaFormer blocks, introduced in Section 3.2 in detail. Notably, only the extraction features of stages of S2, S3, and S4 in the backbone are input to the encoder layers, which can further reduce computational complexity while maintaining a high performance. After that, the model used the optimizer AdaBelief, which has better stability and generalizability, to further improve network performance.
3.2. Global–Local Hybrid Feature Extraction Backbone
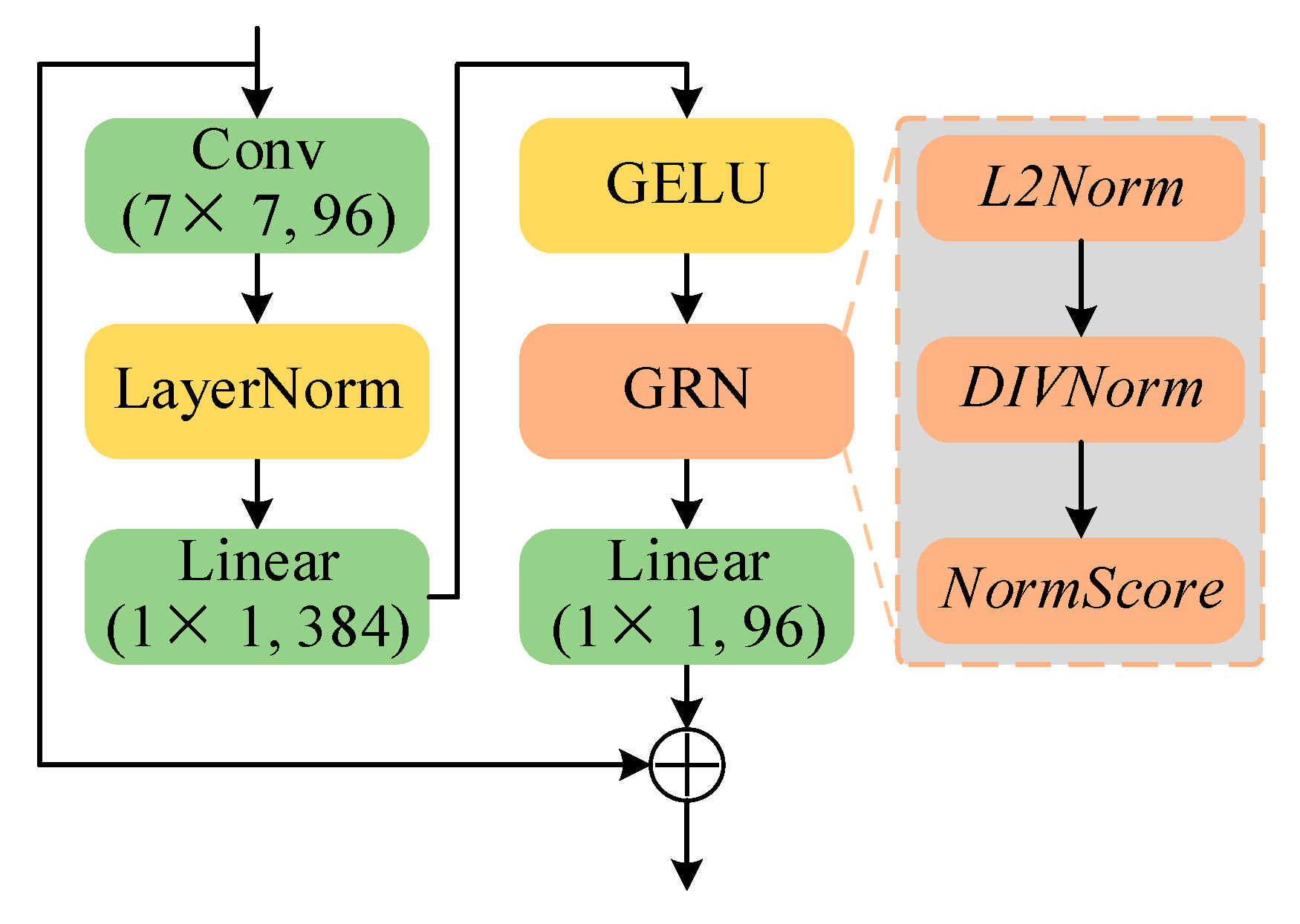
3.2.1. CNN-Based Token Mixer
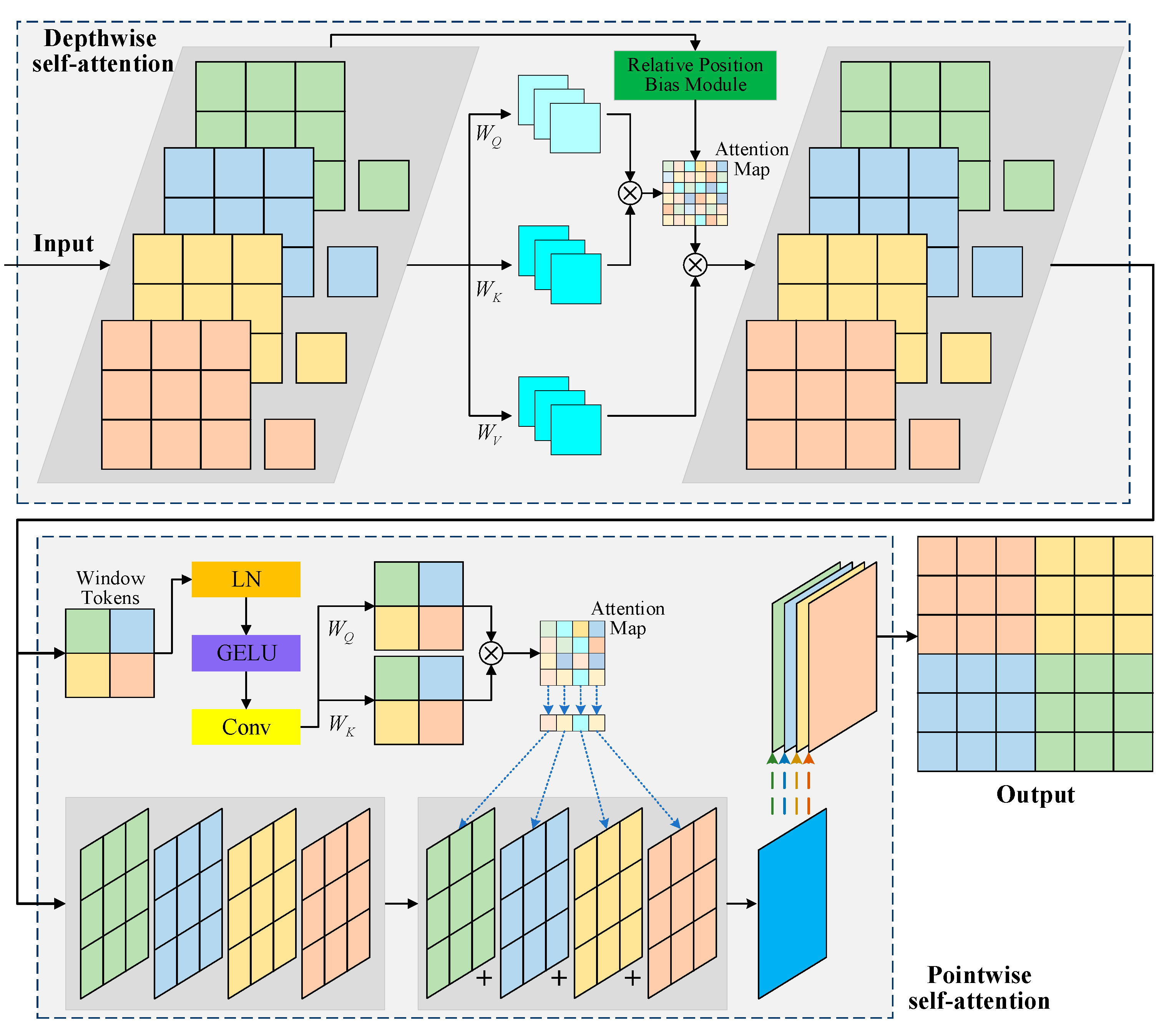
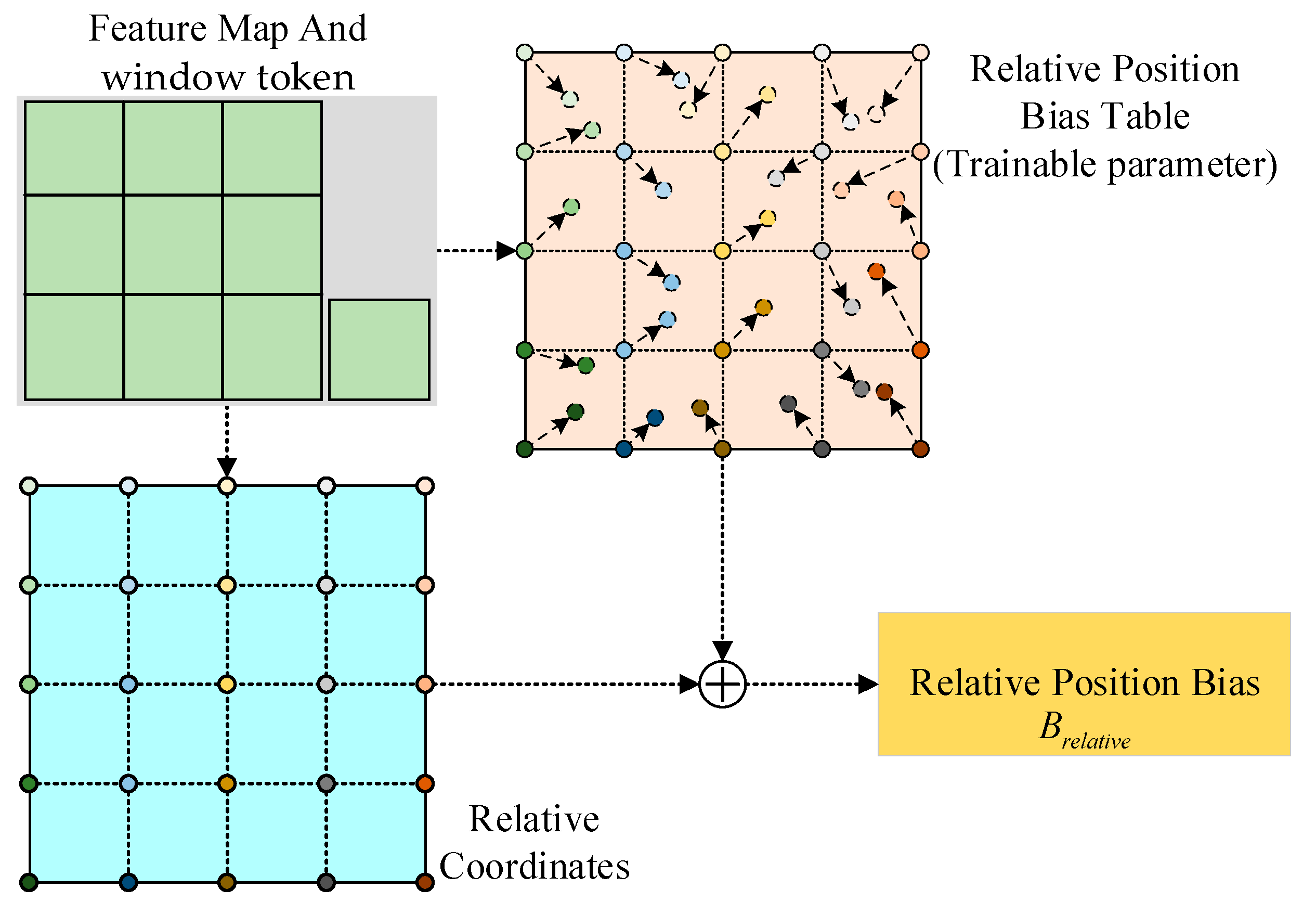
3.2.2. ViT-Based Token Mixer
3.3. Efficient Optimizer for Training
3.4. Masked-Based Pretraining Model
4. Experiments and Results
4.1. Experiments Setting
4.1.1. Pre-Training Datasets
4.1.2. Fine-Tuning Datasets
4.1.3. Implementation Details
4.1.4. Evaluation Metrics
4.2. Ablation Study
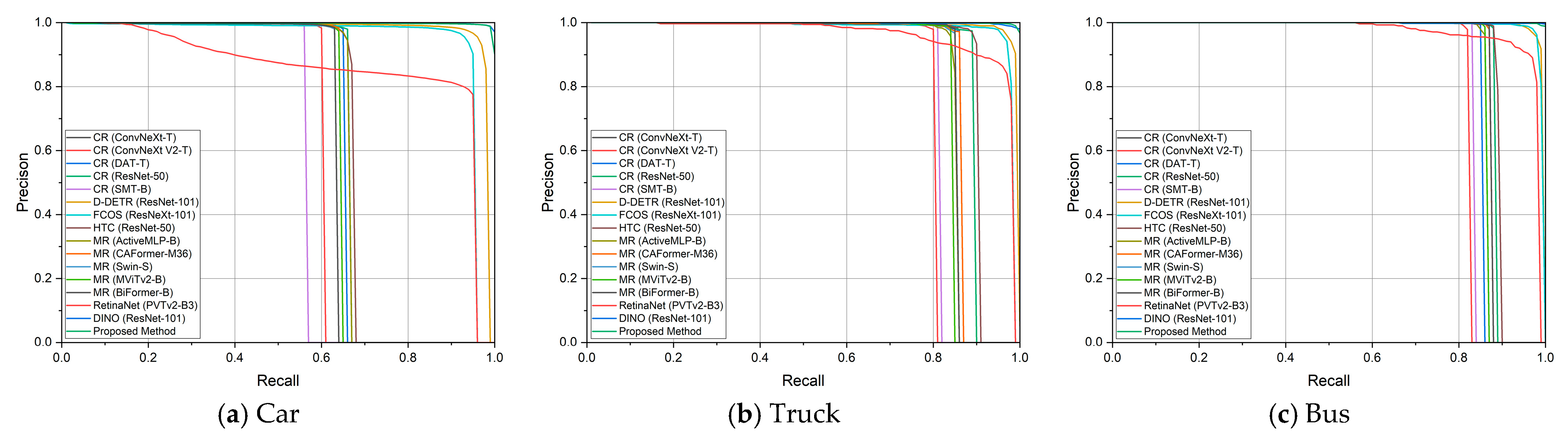
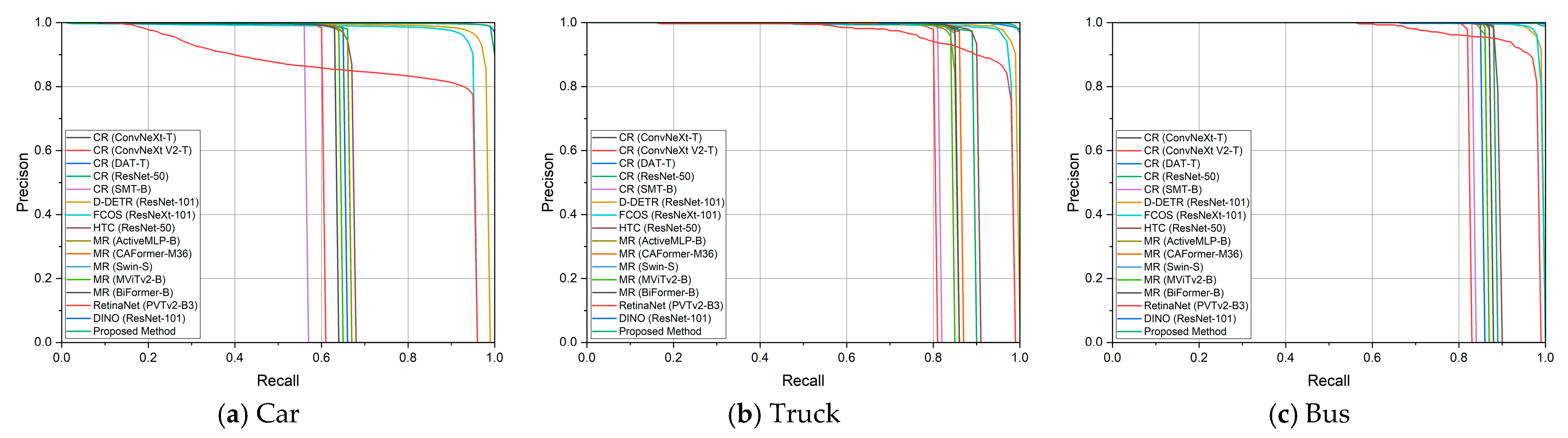
4.3. Experiment Results
4.3.1. Experimental Results for UAVDT
4.3.2. Experimental Results for AFO
4.4. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Adrian, C.; Carlos, S.; Alejandro, R.R.; Pascual, C. A review of deep learning methods and applications for unmanned aerial vehicles. J. Sens. 2017, 2017, 3296874. [Google Scholar]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep learning for unmanned aerial vehicle-based object detection and tracking: A survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 91–124. [Google Scholar] [CrossRef]
- Fan, Z.; Liu, Y.; Liu, Y.; Zhang, L.; Zhang, J.; Sun, Y.; Ai, H. 3mrs: An effective coarse-to-fine matching method for multimodal remote sensing imagery. Remote Sens. 2022, 14, 478. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2013; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-Cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-Cnn: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2017; pp. 6154–6162. [Google Scholar]
- Zhang, H.; Chang, H.; Ma, B.; Wang, N.; Chen, X. Dynamic R-Cnn: Towards high quality object detection via dynamic training. In Proceedings of the 2020 European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 260–275. [Google Scholar]
- Wang, S. Research towards YOLO-series algorithms: Comparison and analysis of object detection models for real-time UAV applications. In Proceedings of the 2021 2nd International Conference on Internet of Things, Artificial Intelligence and Mechanical Automation, Hangzhou, China, 14–16 May 2021; p. 012021. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2015; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2020; pp. 9626–9635. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the Ninth International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the 2020 European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. In Proceedings of the 10th International Conference on Learning Representations, Virtually, 25–29 April 2021. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. Dn-Detr: Accelerate detr training by introducing query denoising. In Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13619–13627. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. Dab-detr: Dynamic anchor boxes are better queries for detr. In Proceedings of the 10th International Conference on Learning Representations, Virtually, 25–29 April 2022. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 548–558. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P. PVT v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 2022, 415–424. [Google Scholar] [CrossRef]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A Global-local self-adaptive network for drone-view object detection. IEEE Trans. Image Process. 2021, 30, 1556–1569. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-scale feature fusion for object detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 431–435. [Google Scholar] [CrossRef]
- Li, J.; Chen, L.; Shen, J.; Xiao, X.; Liu, X.; Sun, X.; Wang, X.; Li, D. Improved neural network with spatial pyramid pooling and online datasets preprocessing for underwater target detection based on side scan sonar imagery. Remote Sens. 2023, 15, 440. [Google Scholar] [CrossRef]
- Xu, B.; Zhang, L.; Liu, Y.; Ai, H.; Wang, B.; Sun, Y.; Fan, Z. Robust hierarchical structure from motion for large-scale unstructured image sets. ISPRS J. Photogramm. Remote Sens. 2021, 181, 367–384. [Google Scholar] [CrossRef]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10809–10819. [Google Scholar]
- Zhuang, J.; Tang, T.; Ding, Y.; Tatikonda, S.C.; Dvornek, N.; Papademetris, X.; Duncan, J. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. In Proceedings of the 34th Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 18795–18806. [Google Scholar]
- Liu, Y.; Mo, F.; Tao, P. Matching multi-source optical satellite imagery exploiting a multi-stage approach. Remote Sens. 2017, 9, 1249. [Google Scholar] [CrossRef]
- Fan, Z.; Zhang, L.; Liu, Y.; Wang, Q.; Zlatanova, S. Exploiting high geopositioning accuracy of sar data to obtain accurate geometric orientation of optical satellite images. Remote Sens. 2021, 13, 3535. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Jie, Z.; Zhang, T.; Yang, J. learning object-wise semantic representation for detection in remote sensing imagery. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 15–20 June 2019; pp. 20–27. [Google Scholar]
- Chen, X.; Li, H.; Wu, Q.; Ngan, K.N.; Xu, L. High-quality R-Cnn object detection using multi-path detection calibration network. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 715–727. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A Convnet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext V2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16133–16142. [Google Scholar]
- Wang, G.; Zhuang, Y.; Chen, H.; Liu, X.; Zhang, T.; Li, L.; Dong, S.; Sang, Q. Fsod-net: Full-scale object detection from optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5602918. [Google Scholar] [CrossRef]
- Ma, W.; Li, N.; Zhu, H.; Jiao, L.; Tang, X.; Guo, Y.; Hou, B. Feature split–merge–enhancement network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5616217. [Google Scholar] [CrossRef]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer V2: Scaling up capacity and resolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11999–12009. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12114–12124. [Google Scholar]
- Li, W.; Wang, X.; Xia, X.; Wu, J.; Xiao, X.; Zheng, M.; Wen, S. Sepvit: Separable vision transformer. arXiv 2022, arXiv:2203.15380. [Google Scholar]
- Wang, W.; Yao, L.; Chen, L.; Lin, B.; Cai, D.; He, X.; Liu, W. Crossformer: A versatile vision transformer hinging on cross-scale attention. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4784–4793. [Google Scholar]
- Wei, Z.; Liang, D.; Zhang, D.; Zhang, L.; Geng, Q.; Wei, M.; Zhou, H. Learning calibrated-guidance for object detection in aerial images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2721–2733. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Q.; Xu, Y.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Advancing plain vision transformer towards remote sensing foundation model. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5607315. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. Abnet: Adaptive balanced network for multiscale object detection in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614914. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. Unetformer: A unet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12165–12175. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-former: Bridging mobilenet and transformer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5260–5269. [Google Scholar]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. Mpvit: Multi-path vision transformer for dense prediction. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7277–7286. [Google Scholar]
- Peng, Z.; Guo, Z.; Huang, W.; Wang, Y.; Xie, L.; Jiao, J.; Tian, Q.; Ye, Q. Conformer: Local features coupling global representations for recognition and detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9454–9468. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, Y.; Wu, Y.; Zhang, K.; Wang, Q. Frpnet: A feature-reflowing pyramid network for object detection of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8004405. [Google Scholar] [CrossRef]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the integration of self-attention and convolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 805–815. [Google Scholar]
- Li, G.; Liu, Z.; Lin, W.; Ling, H. Multi-content complementation network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614513. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 2014 European Conference on Computer Vision, Zurich, Switzerland, 8–10 October 2014; pp. 740–755. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, J.; Du, B.; Xia, G.S.; Tao, D. An empirical study of remote sensing pretraining. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5608020. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15979–15988. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9643–9653. [Google Scholar]
- Zhang, Q.; Xu, Y.; Zhang, J.; Tao, D. Vitaev2: Vision transformer advanced by exploring inductive bias for image recognition and beyond. Int. J. Comput. Vis. 2023, 131, 1141–1162. [Google Scholar] [CrossRef]
- Gao, P.; Ma, T.; Li, H.; Lin, Z.; Dai, J.; Qiao, Y. Mcmae: Masked convolution meets masked autoencoders. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA; 2022; pp. 35632–35644. [Google Scholar]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. Fair1m: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8429–8438. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. Dota: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Yu, H.; Li, G.; Zhang, W.; Huang, Q.; Du, D.; Tian, Q.; Sebe, N. The unmanned aerial vehicle benchmark: Object detection and tracking. Int. J. Comput. Vis. 2018, 2020, 1141–1159. [Google Scholar] [CrossRef]
- Gasienica-Józkowy, J.; Knapik, M.; Cyganek, B. An ensemble deep learning method with optimized weights for drone-based water rescue and surveillance. Integr. Comput. Aided Eng. 2021, 28, 221–235. [Google Scholar] [CrossRef]
- Wei, G.; Zhang, Z.; Lan, C.; Lu, Y.; Chen, Z. ActiveMLP: An MLP-like architecture with active token mixer. arXiv 2022, arXiv:2203.06108. [Google Scholar]
- Li, Y.; Wu, C.Y.; Fan, H.; Mangalam, K.; Xiong, B.; Malik, J.; Feichtenhofer, C. Mvitv2: Improved multiscale vision transformers for classification and detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4804. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R. Biformer: Vision transformer with Bi-level routing attention. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, W.; Wu, Z.; Chen, J.; Huang, J.; Jin, L. Scale-aware modulation meet transformer. arXiv 2023, arXiv:2307.08579. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 15–20 June 2019; pp. 4969–4978. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Images (k) | Instances (M) | Categories | Volume (GB) |
|---|---|---|---|---|
| COCO 2017 [58] | 328 | 2.5 | 91 | 25 |
| ImageNet-1k [57] | 1430 | 1.28 | 1000 | 144 |
| Objects365 [66] | 630 | 29 | 365 | 48 |
| DOTA v2.0 [67] | 11.3 | 1.79 | 18 | 138 |
| FAIR1M | 42.8 | 1.02 | 37 | 43 |
| Item | Parameter | Value |
|---|---|---|
| Pre-training hyperparameter | Epochs | 300 |
| Batch size | 12 | |
| Optimizer | AdamW | |
| Learning rate | 0.0008 | |
| Weight decay | 0.05 | |
| Random crop size | 448 | |
| Random crop scale | (0.67, 1.0) | |
| Random crop ratio | (0.75, 1.33) | |
| Random flip | 0.5 | |
| Mask generator | Input size | 448 |
| Mask patch size | 32 | |
| Model patch size | 1 | |
| Mask ratio | 0.6 |
| Method | Dataset | Backbone | Optimizer | Params (M) | FLOPs (G) | (%) |
|---|---|---|---|---|---|---|
| DINO | UAVDT | ResNet-101 | AdamW | 66.21 | 79.72 | 82.3 |
| Proposed Backbone | AdamW | 57.69 | 80.47 | 82.2 | ||
| AdaBelief | 57.68 | 80.47 | 82.2 | |||
| AFO | ResNet-101 | AdamW | 66.21 | 79.72 | 56.3 | |
| Proposed Backbone | AdamW | 57.69 | 80.47 | 56.7 | ||
| AdaBelief | 57.68 | 80.47 | 57.6 |
| Methods | Backbone | Params (M) | FLOPs (G) | mAP (%) | AP50 (%) | AP75 (%) | APS (%) | APM (%) | APL (%) |
|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN [7] | Swin-S [20] | 66.07 | 55.46 | 65.2 | 76.7 | 75.6 | 38.6 | 85.7 | 91.3 |
| ActiveMLP-B [70] | 69.21 | 56.32 | 63.4 | 77.3 | 73.9 | 36.8 | 83.4 | 85.8 | |
| CAFormer-M36 [27] | 69.75 | 72.24 | 66.4 | 77.8 | 76.0 | 41.7 | 86.3 | 89.6 | |
| MViTv2-B [71] | 67.94 | 56.89 | 65.0 | 76.5 | 74.6 | 38.1 | 85.3 | 90.6 | |
| BiFormer-B [72] | 73.29 | 58.76 | 67.6 | 76.8 | 76.3 | 41.4 | 88.4 | 92.5 | |
| Cascade R-CNN [8] | ResNet-50 [73] | 68.94 | 40.83 | 68.1 | 78.7 | 77.6 | 44.2 | 86.8 | 94.1 |
| DAT-T [44] | 76.64 | 385.00 | 66.3 | 76.8 | 75.4 | 37.7 | 87.3 | 92.2 | |
| ConvNeXt-T [35] | 76.82 | 385.37 | 65.3 | 76.5 | 75.0 | 38.7 | 85.9 | 93.9 | |
| ConvNeXt V2-T [36] | 63.92 | 377.23 | 62.1 | 70.9 | 69.8 | 26.0 | 87.4 | 93.0 | |
| SMT-B [74] | 80.44 | 398.33 | 63.3 | 71.5 | 70.8 | 30.4 | 88.4 | 94.6 | |
| HTC [75] | ResNet-50 [73] | 68.93 | 40.84 | 66.5 | 79.6 | 75.2 | 40.5 | 86.4 | 93.0 |
| FCOS [13] | ResNeXt-101 [76] | 89.63 | 85.22 | 79.3 | 95.3 | 90.6 | 67.0 | 86.8 | 92.6 |
| Deformable DETR [17] | ResNet-101 [73] | 58.76 | 54.38 | 74.5 | 97.1 | 88.9 | 65.4 | 80.9 | 86.4 |
| RetinaNet [22] | PVTv2-B3 [22] | 70.70 | 55.20 | 68.7 | 90.7 | 76.7 | 41.0 | 83.0 | 92.5 |
| DINO [39] | ResNet-101 [73] | 66.21 | 79.72 | 82.3 | 98.9 | 95.4 | 75.1 | 87.1 | 92.8 |
| Proposed Method | 57.68 | 80.47 | 82.2 | 98.8 | 95.7 | 74.6 | 87.1 | 93.5 | |
| Methods | Backbone | Params (M) | FLOPs (G) | mAP (%) | AP50 (%) | AP75 (%) | APS (%) | APM (%) | APL (%) |
|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN [7] | Swin-S [20] | 66.07 | 55.46 | 47.4 | 66.2 | 55.3 | 0.0 | 37.8 | 66.6 |
| ActiveMLP-B [70] | 69.21 | 56.32 | 43.3 | 62.3 | 50.9 | 0.4 | 28.0 | 61.8 | |
| CAFormer-M36 [27] | 69.75 | 72.24 | 41.6 | 62.9 | 46.3 | 0.3 | 31.9 | 59.0 | |
| MViTv2-B [71] | 67.94 | 56.89 | 43.0 | 63.5 | 50.0 | 0.1 | 33.6 | 61.6 | |
| BiFormer-B [72] | 73.29 | 58.76 | 48.6 | 67.1 | 56.7 | 0.0 | 36.3 | 68.0 | |
| Cascade R-CNN [8] | ResNet-50 [73] | 68.94 | 40.83 | 50.0 | 67.9 | 59.2 | 1.5 | 36.8 | 69.4 |
| DAT-T [44] | 76.64 | 385.00 | 46.8 | 66.7 | 55.3 | 0.3 | 35.5 | 65.2 | |
| ConvNeXt-T [35] | 76.82 | 385.37 | 51.7 | 71.3 | 61.4 | 0.6 | 40.3 | 71.0 | |
| ConvNeXt V2-T [36] | 63.92 | 377.23 | 38.9 | 57.2 | 45.0 | 0.0 | 24.8 | 56.7 | |
| SMT-B [74] | 80.44 | 398.33 | 48.4 | 63.7 | 57.9 | 0.0 | 28.3 | 69.6 | |
| HTC [75] | ResNet-50 [73] | 68.93 | 40.84 | 49.0 | 68.2 | 56.4 | 0.5 | 35.4 | 68.7 |
| FCOS [13] | ResNeXt-101 [76] | 89.63 | 85.22 | 54.5 | 83.0 | 60.8 | 21.8 | 42.8 | 67.9 |
| Deformable DETR [17] | ResNet-101 [73] | 58.76 | 54.38 | 48.2 | 82.9 | 49.9 | 10.0 | 43.0 | 58.3 |
| RetinaNet [22] | PVTv2-B3 [22] | 70.70 | 55.20 | 46.2 | 76.8 | 48.5 | 13.6 | 32.0 | 59.3 |
| DINO [39] | ResNet-101 [73] | 66.21 | 79.72 | 56.3 | 90.9 | 62.4 | 29.9 | 54.0 | 66.1 |
| Proposed Method | 57.68 | 80.47 | 57.6 | 89.7 | 62.5 | 30.3 | 51.7 | 67.9 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, W.; Niu, C.; Lan, C.; Liu, W.; Wang, S.; Yu, J.; Hu, T. High-Quality Object Detection Method for UAV Images Based on Improved DINO and Masked Image Modeling. Remote Sens. 2023, 15, 4740. https://doi.org/10.3390/rs15194740
Lu W, Niu C, Lan C, Liu W, Wang S, Yu J, Hu T. High-Quality Object Detection Method for UAV Images Based on Improved DINO and Masked Image Modeling. Remote Sensing. 2023; 15(19):4740. https://doi.org/10.3390/rs15194740
Chicago/Turabian StyleLu, Wanjie, Chaoyang Niu, Chaozhen Lan, Wei Liu, Shiju Wang, Junming Yu, and Tao Hu. 2023. "High-Quality Object Detection Method for UAV Images Based on Improved DINO and Masked Image Modeling" Remote Sensing 15, no. 19: 4740. https://doi.org/10.3390/rs15194740
APA StyleLu, W., Niu, C., Lan, C., Liu, W., Wang, S., Yu, J., & Hu, T. (2023). High-Quality Object Detection Method for UAV Images Based on Improved DINO and Masked Image Modeling. Remote Sensing, 15(19), 4740. https://doi.org/10.3390/rs15194740