1. Introduction
As an integral part of the Earth’s ecosystem, forests possess immeasurable natural and social value and are recognized as the “lungs of the Earth”. However, due to the impacts of global climate change and human activities, forest fires are becoming increasingly frequent, causing significant losses [
1,
2,
3] and becoming one of the greatest threats to forest security.
Traditional forest fire monitoring is typically conducted through manual patrols, lookout towers, and satellite technologies. However, manual patrols and lookout towers require significant manpower and resources [
4]. In recent decades, multi-source satellite remote sensing data with varying spatial resolutions have shown great potential in the detection and monitoring of forest fires, including MODIS (Moderate-resolution Imaging Spectroradiometer), VIIRS (Visible infrared Imaging Radiometer), Landsat 8, Sentinel-2A/B, and so on. Pourshakouri et al. [
5] proposed an improved contextual algorithm for detecting small and low-intensity fires based on the MODIS Level 1B Radiance Product, which outperforms the contextual traditional algorithms and has potential for global applications. Comparing the 1-km MODIS and 375-m VIIRS fire products, Fu et al. [
6] found that VIIRS outperformed MODIS in detecting forest fires, and showed higher detection accuracy. Ding et al. [
7] proposed a deep learning algorithm for wildfire detection based on Himawari-8 data, which greatly improves the detection accuracy compared to traditional machine learning algorithms. However, these higher than 100-m remote sensing data may be more suitable for large-scale fire detection, and showed poor performance for accurately detecting small fires. With 10-m Sentinel-2A\B and 30-m Landsat 8 imageries, Achour et al. [
8] mapped the summer forest fires in Tunisia in 2017. The results showed that Sentinel-2 performed better than Landsat 8 in characterizing the forest fires because of its higher spatial resolution. Furthermore, Waigl et al. [
9] evaluated three fire detection methods using EO-1 (Earth Observing-1) Hyperion data, which can detect up to 5 m
2 high-temperature fires. However, this remote sensing imagery may be difficult to detect small fires because of coarse resolution and cloud cover [
10]. In addition, since forest fires often occur in remote mountainous areas, the aforementioned methods face significant challenges in accurately monitoring and responding to fires on time [
11].
In recent years, with the rapid development of unmanned aerial vehicle (UAV) technology, monitoring and response efforts for forest fires have greatly improved [
4,
12,
13]. By leveraging the UAV’s maneuverability, high resolution, and fast information transmission capabilities, the comprehensive, real-time, and efficient monitoring of forest fires can be achieved.
Traditional methods for forest fire detection rely on image-processing techniques, which primarily detect the occurrence of fires based on features such as smoke and flame color, shape, and texture. Celik et al. [
14] proposed a color model for smoke detection based on the YCbCr (Luminance, Chrominance-Blue, Chrominance-Red) color space, but this method had a high false detection rate. Chen et al. [
15] analyzed the dynamic patterns of fire growth and disorder using the RGB (Red, Green, Blue) model, ultimately achieving fire detection based on the RGB color space, which involved simpler calculations than other color spaces. Toreyin et al. [
16] used spatial wavelet transform of the current image and background image to monitor the reduction in high-frequency energy in the scene, thus detecting smoke. However, this method’s accuracy may be affected by cloud cover. Borges et al. [
17] extracted features such as flame color, surface roughness, centroid height ratio, and flame flicker frequency and used a Bayesian classifier for discrimination, achieving good classification results. Gubbi et al. [
18] proposed smoke detection based on a wavelet transform and support vector machine classifier, which yielded satisfactory results but had a slower processing speed.
Throughout its development, deep learning has been applied to forest fire detection in three main ways: image classification, object detection, and image segmentation. Among these techniques, the methods based on object detection are the most commonly used because they offer higher accuracy and ease of use compared to image classification and segmentation. Object detection methods can be categorized into two-stage detection models, represented by the R-CNN (Region-based Convolutional Neural Networks) series [
19,
20], and one-stage detection models, represented by the YOLO (You Only Look Once) series [
21] and SSD (Single Shot Multibox Detector) [
22]. Compared to two-stage detection models, one-stage detection models achieve faster detection speeds while maintaining excellent accuracy, and among the one-stage detection models, the YOLO series outperforms SSD [
23,
24,
25]. Srinivas et al. [
26] proposed the application of a basic CNN (Convolutional Neural Networks) architecture for classifying forest fire images, achieving a classification accuracy of 95%. Kinaneva et al. [
27] and Barmpoutis et al. [
24] used the Faster R-CNN algorithm to detect smoke and flames in UAV images. Jiao et al. [
28,
29] proposed modified versions of YOLOv3-tiny and YOLOv3 for the real-time detection of flames and smoke in drone images.
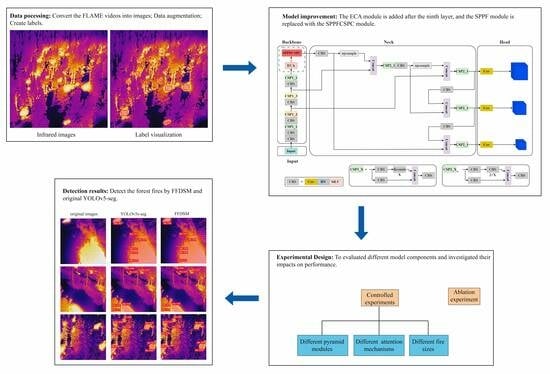
However, the aforementioned forest fire detection methods are based on optical images. Although detection methods based on such images are widely used, they have limitations in fog and low-light conditions and are prone to obstruction. Therefore, in this study, UAV infrared images are adopted to detect the obstructed forest fire. A Forest Fire Detection and Segmentation Model (FFDSM) is proposed based on the YOLOv5s-seg model. The FFDSM model incorporates the Efficient Channel Attention (ECA) [
30] module and the Spatial Pyramid Pooling Fast Cross-Stage Partial Channel (SPPFCSPC) [
31] module, enhancing the accuracy of fire detection and the capability to extract forest fire features. This model addresses the issue of the poor adaptability of traditional methods.
3. Results
3.1. Ablation Experiments
In order to validate the impacts of the different improvement modules on the performance of the forest fire detection model, the trained model was tested on the test set to obtain the corresponding evaluation metrics, and the results were analyzed. The results are shown in
Table 7.
According to the results in
Table 7, the models with the ECA module and SPPFCSPC module outperform the YOLOv5s-seg baseline. Among them, the FFDSM model performs the best, with a P of 0.959, R of 0.870, mAP@0.5 of 0.907, and mAP@0.5:0.95 of 0.711. Compared to YOLOv5s-seg, FFDSM shows improvements of 2.1% in P, 2.7% in R, 2.3% in mAP@0.5, and 4.2% in mAP@0.5:0.95. FFDSM achieves the most significant improvement in mAP@0.5:0.95.
Additionally, the model with the SPPFCSPC module performs better in P and R compared to the model with the ECA module. However, these models show opposite performances in terms of mAP@0.5, and both models perform similarly in terms of mAP@0.5:0.95.
3.2. Comparison of Different Attention Mechanisms
By introducing attention mechanisms, one can better focus on crucial information, thereby improving detection efficiency and accuracy. In order to select the optimal attention mechanism to enhance the detection performance, we considered several commonly used attention mechanism modules, including CA, CBAM, SE, and ECA. The results are shown in
Table 8.
According to
Table 8, among the four attention modules, CBAM+SPPFCSPC performs the worst. On the other hand, ECA+SPPFCSPC performs the best, achieving a P of 0.959, R of 0.870, mAP@0.5 of 0.907, and mAP@0.5:0.95 of 0.711. The next best-performing module is SE+SPPFCSPC, which has the same P as ECA+SPPFCSPC but a slightly lower R, mAP@0.5, and mAP@0.5:0.95. Additionally, CA+SPPFCSPC has the highest recall, reaching 0.871.
3.3. Comparison of Different Spatial Pyramid Pooling Modules
In this study, we replaced the SPPF module with the SPPFCSPC module, which is an improvement on the SPPCSPC module. Therefore, we compared the SPPF, SPPFCSPC, and SPPCSPC. The results are shown in
Table 9.
Table 9 shows that ECA+SPPFCSPC performs the best across all the evaluation metrics, with a P, R, mAP@0.5, and mAP@0.5:0.95 reaching 0.959, 0.870, 0.907, and 0.711, respectively. Although ECA+SPPCSPC does not perform as well as ECA+SPPFCSPC, it still shows some improvement compared to ECA+SPPF, while ECA+SPPF performs the worst.
3.4. Comparison of Different Forest Fire Sizes
In order to assess the suitability of the FFDSM for different fire sizes in the images, we selected images from the test set containing large fires (210 images), small fires (180 images), and a mixture of both large and small fires (150 images). The results are shown in
Table 10.
For all three fire sizes, the FFDSM outperforms YOLOv5s-seg. Specifically, in the case of small fires, both YOLOv5s-seg and FFDSM perform the best across all the evaluation metrics. The FFDSM achieves a P of 0.989, R of 0.938, mAP@0.5 of 0.964, and mAP@0.5:0.95 of 0.769. In the case of a mixture of large and small fires, YOLOv5s-seg and the FFDSM demonstrate a better P than they do for large fires. However, in terms of R, mAP@0.5, and mAP@0.5:0.95, the performance is inferior to that in the scenario with large fires.
Furthermore, the FFDSM achieves significant improvements compared to YOLOv5s-seg. In the case of a mixture of large and small fires, the most significant improvement is observed in P, with an increase of 2.1%. In the case of large fires, the most significant improvements are seen in R and mAP@0.5, with increases of 2.6% and 2.0%, respectively. In the scenario with small fires, the most significant improvement is observed in mAP@0.5:0.95, with an increase of 5.3%.
Overall, the FFDSM shows significant improvements over YOLOv5s-seg across different evaluation metrics for different fire sizes. Specifically, the FFDSM performs the best in the case of small fires, achieving excellent results in terms of P, R, mAP@0.5, and mAP@0.5:0.95.
4. Discussion
Forest fires are prone to obstruction by trees. In the case of latent fires, smoldering conditions may be caused by forest litter [
45]; these fires do not involve open flames or dense smoke and are difficult to detect through optical images. In contrast, infrared cameras measure the thermal radiation emitted by objects, and the captured infrared images can effectively complement optical images. In the optical image (
Figure 7a), the forest fire within the red box is obscured by trees or smoke, making it difficult to detect its exact location. In the infrared image (
Figure 7b), although the forest fire within the target box is partially obstructed, it can still be captured and detected (
Figure 7c).
While some researchers have used infrared images for forest fire detection in recent years, most of them have employed traditional image processing methods [
46] or used infrared images as an aid in conjunction with optical images for forest fire discrimination [
47,
48,
49], making it challenging to achieve accurate real-time detection. Based on deep learning methods, the above problems can be effectively solved through direct learning from infrared images in different scenarios. Among the different deep-learning-based forest fire detection methods, object-detection-based methods are the most commonly used due to their high accuracy and usability compared to object classification and segmentation methods [
50]. Among the single-stage detection models, YOLOv5 stands out, as it has a small model size, high detection accuracy, and fast detection speed, making it suitable for real-time forest fire detection [
10,
43,
51,
52].
In order to further verify the superiority of the FFDSM model, we compared the FFDSM model with several improved forest fire detection methods based on YOLOv5. According to
Table 11, Model1 performed the best in terms of P, reaching a value of 0.961. However, it showed the worst performance in terms of R, mAP@0.5, and mAP@0.5:0.95. On the other hand, Model2 had the lowest P (0.947), but it outperformed Model1 in terms of R, mAP@0.5, and mAP@0.5:0.95. Model3 demonstrated a better performance in terms of R, mAP@0.5, and mAP@0.5:0.95 compared to both Model1 and Model2. Model4, while having a slightly lower P than Model1, showed the best performance in terms of R, mAP@0.5, and mAP@0.5:0.95. Model1 achieved the best P due to its use of the SIOU (Scale Sensitive Intersection over Union) loss function [
53] instead of the original CIOU loss function. The SIOU loss function introduces vector angles between the desired regressions, redefines the distance loss, effectively reduces the degree of regression freedom, accelerates network convergence, and improves the regression accuracy. In the future, we will introduce SIOU into our model for further improvement.
However, the selection of appropriate improvement modules is also crucial for improving the original deep learning models. Therefore, in this study, we conducted experiments to assess the suitability of the selected ECA and SPPFCSPC modules.
The results of the ablation experiments show that the models with the ECA module and SPPFCSPC module which were introduced both improve on the performance of the original YOLOv5s-seg model. The FFDSM significantly improves performance over the baseline YOLOv5s-seg model in object detection and segmentation tasks. It performs excellently across different evaluation metrics, with the most notable improvement observed in mAP@0.5:0.95, which is increased by 4.2%. This indicates that the combination of the introduced modules effectively enhances the model’s performance.
The controlled experiments of the different attention modules and pyramid modules show that ECA+SPPFCSPC outperforms the other combinations of attention mechanisms and pyramid pooling modules, achieving the highest scores across multiple evaluation metrics. It achieves a P of 0.959, R of 0.870, mAP@0.5 of 0.907, and mAP@0.5:0.95 of 0.711. This indicates that ECA+SPPFCSPC has significant advantages in object detection and segmentation tasks, as it can better extract features, utilize the contextual information in images, and demonstrate superior contextual modeling capabilities.
The controlled experiments on different fire sizes show that the FFDSM consistently outperforms the original YOLOv5s-seg model for all three fire sizes, with a P reaching above 0.95. This demonstrates that the FFDSM is well-suited for detecting fires of different sizes. Additionally, the FFDSM performs best in detecting small fires, indicating its superior applicability in early forest fire detection, allowing for the more accurate detection and localization of small fires.
According to the ablation and controlled experiments, we noticed that the FFDSM has the highest improvement in mAP@0.5:0.95 and also shows improvements for different fire sizes. This can be attributed to the SPPFCSPC module, which performs four different MaxPool operations representing different scales of receptive fields. This enables the model to better distinguish between large and small objects, resulting in improved generalization. In addition, the ECA module uses a 1 × 1 convolutional layer after the global average pooling layer and removes the fully connected layer. This module avoids dimensionality reduction and efficiently captures cross-channel interactions. In addition, the ECA module completes cross-channel information interactions through one-dimensional convolution. The size of the convolution kernel adapts to changes through a function so that layers with a larger number of channels can perform more cross-channel interactions.
As shown in
Figure 8, both YOLOv5s-seg and the FFDSM accurately detect large fires. However, the FFDSM outperforms YOLOv5s-seg in terms of accuracy, especially in the case of small fires. This high-precision detection, specifically for small fires, is crucial for fire detection and response. Small fires often serve as the first sign of a fire in its early stages. Identifying and locating these small fires promptly can facilitate the rapid implementation of effective firefighting measures, preventing further escalation and spread of the fire. Therefore, the high-precision detection capability of the FFDSM model holds significance for enhancing fire detection capabilities.
While using infrared imagery for forest fire detection can effectively address the limitations of optical imagery, there is currently a scarcity of forest fire datasets based on infrared imagery, and the available datasets often represent limited forest fire scenarios [
56,
57]. Therefore, we will conduct UAV experiments in the future to obtain forest fire optical and infrared images in different scenarios and further improve the detection accuracy of forest fires in different scenarios through the fusion of visible light and infrared images. In particular, for small fires, we will further optimize the FFDSM model to achieve the small target detection of forest fires.




 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}