
Unified Transformer with Cross-Modal Mixture Experts for Remote-Sensing Visual Question Answering

 , , , ,
, , , ,
Abstract
:1. Introduction
- Most existing methods utilize basic fusion strategies, like concatenation or element-wise operations, to combine visual and language features. However, these approaches inadequately capture the complex interactions between the two modalities, resulting in fused features with limited information richness;
- The existing models do not adequately model cross-modal attention, whereas cross-modal attention mechanisms can assist the model in better attending to the correlation between visual and language features, enabling accurate determination of which features to focus on in specific questions and images;
- The task of RSVQA requires the model to comprehend the semantic essence of the posed question and reason with the relevant content in the image to generate accurate answers. However, existing models may struggle to effectively model and capture the intricate semantic relationship between the question and the image.
- We propose a novel TCMME model to address the RSVQA tasks;
- We design the cross-modal mixture expert module to facilitate the interaction between visual and language features and effectively model the cross-modal attention, which enables effectively modeling and capturing the intricate semantic relationship between the image and question;
- The experimental results unequivocally validate the efficacy of our proposed methodology. Compared to existing approaches, our model attains state-of-the-art (SOTA) performance on both the RSVQA-LR and RSVQA-HR datasets.
2. Related Work
2.1. Visual Question Answering
2.2. Remote-Sensing Visual Question Answering
2.3. Transformers in Remote Sensing
3. Methodology
3.1. Problem Definition
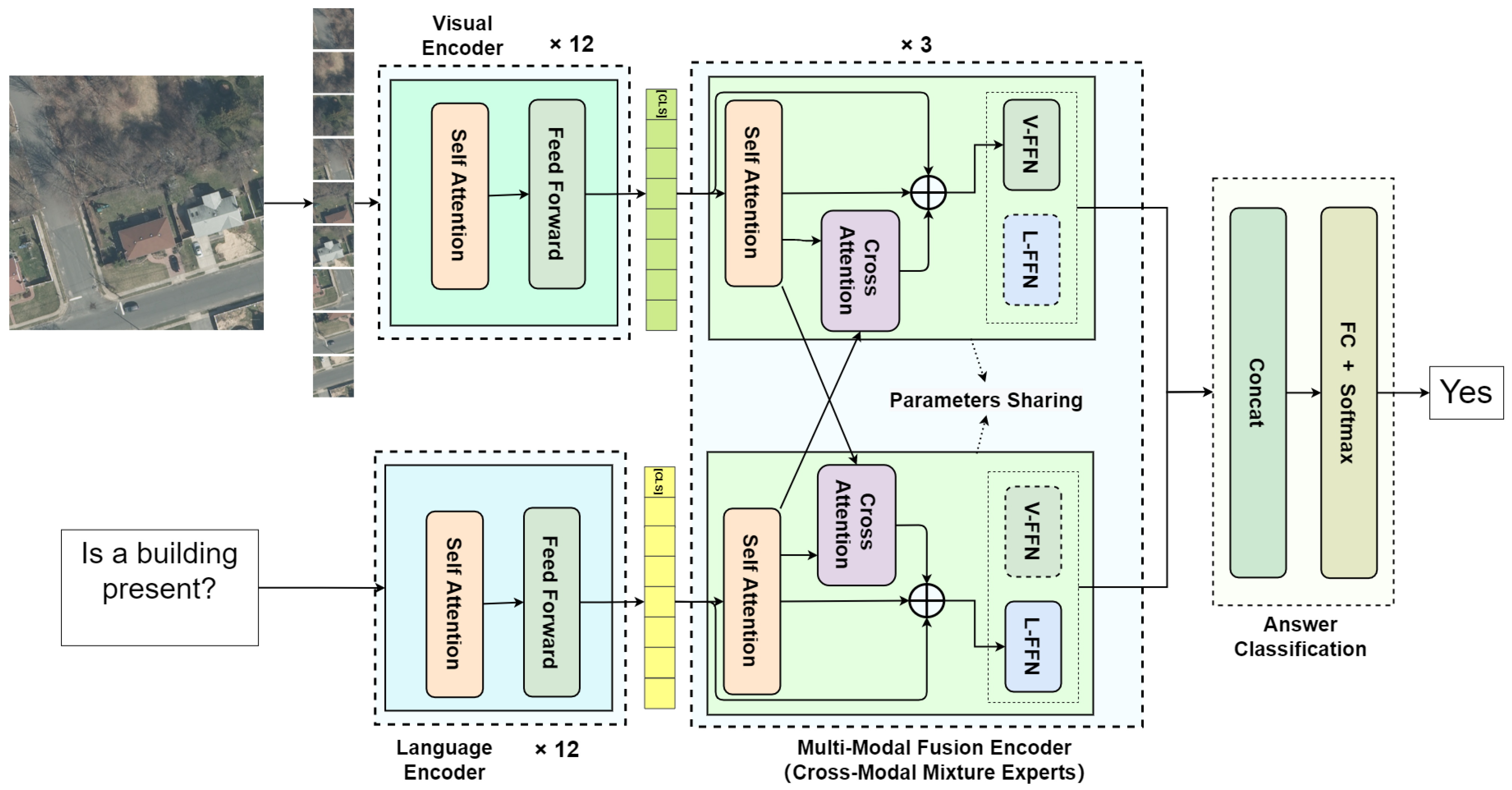
3.2. Model Architecture
3.2.1. Visual Encoder
3.2.2. Language Encoder
3.2.3. Multimodal Fusion Encoder
3.2.4. Answer Prediction
4. Experiment Results and Discussion
4.1. Datasets
4.1.1. RSVQA-LR
4.1.2. RSVQA-HR
4.2. Implementation Details
4.3. Comparison Results and Analysis
4.3.1. Accuracy Comparison on RSVQA-LR Dataset
4.3.2. Accuracy Comparison on RSVQA-HR Dataset
4.4. Discussion
4.5. Ablation Study
4.5.1. Ablation Study on the Effectiveness of Different Components
- TCMME w/o CMME: We remove the CMME module, which renders the model incapable of performing multimodal interaction, and directly concatenate the encoded visual representations with the language representations for answer prediction.
- TCMME w/o ME: We remove the modality experts within the CMME module, which is replaced by a layer FFN, allowing the FFN outputs both the fused visual features and the fused language features.
- TCMME w/o CA: We remove the cross-attention layer from the CMME module and utilize the remaining self-attention and modality experts components in CMME to fuse the visual and language features.
4.5.2. Ablation Study on the Optimal Number of Layers in the CMME Module
4.5.3. Ablation Study on the Sensitivity to the Training Set Size
4.6. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, X.; Gong, T.; Li, X.; Lu, X. Generalized Scene Classification From Small-Scale Datasets with Multitask Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5609311. [Google Scholar] [CrossRef]
- Ye, Y.; Bruzzone, L.; Shan, J.; Bovolo, F.; Zhu, Q. Fast and Robust Matching for Multimodal Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9059–9070. [Google Scholar] [CrossRef]
- Pham, H.M.; Yamaguchi, Y.; Bui, T.Q. A case study on the relation between city planning and urban growth using remote sensing and spatial metrics. Landsc. Urban Plan. 2011, 100, 223–230. [Google Scholar] [CrossRef]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Jahromi, M.N.; Jahromi, M.N.; Pourghasemi, H.R.; Zand-Parsa, S.; Jamshidi, S. Accuracy assessment of forest mapping in MODIS land cover dataset using fuzzy set theory. In Forest Resources Resilience and Conflicts; Elsevier: Amsterdam, The Netherlands, 2021; pp. 165–183. [Google Scholar]
- Li, Y.; Yang, J. Meta-learning baselines and database for few-shot classification in agriculture. Comput. Electron. Agric. 2021, 182, 106055. [Google Scholar] [CrossRef]
- Li, X.; Shao, G. Object-based urban vegetation mapping with high-resolution aerial photography as a single data source. Int. J. Remote Sens. 2013, 34, 771–789. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Feng, X.; Han, J.; Yao, X.; Cheng, G. TCANet: Triple Context-Aware Network for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6946–6955. [Google Scholar] [CrossRef]
- Qian, X.; Lin, S.; Cheng, G.; Yao, X.; Ren, H.; Wang, W. Object Detection in Remote Sensing Images Based on Improved Bounding Box Regression and Multi-Level Features Fusion. Remote Sens. 2020, 12, 143. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y. Airport Detection and Aircraft Recognition Based on Two-Layer Saliency Model in High Spatial Resolution Remote-Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1511–1524. [Google Scholar] [CrossRef]
- Yao, X.; Cao, Q.; Feng, X.; Cheng, G.; Han, J. Scale-Aware Detailed Matching for Few-Shot Aerial Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5611711. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A. Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation: New York, NY, USA, 2020; pp. 4095–4104. [Google Scholar] [CrossRef]
- Xu, P.; Li, Q.; Zhang, B.; Wu, F.; Zhao, K.; Du, X.; Yang, C.; Zhong, R. On-Board Real-Time Ship Detection in HISEA-1 SAR Images Based on CFAR and Lightweight Deep Learning. Remote Sens. 2021, 13, 1995. [Google Scholar] [CrossRef]
- Noothout, J.M.H.; de Vos, B.D.; Wolterink, J.M.; Postma, E.M.; Smeets, P.A.M.; Takx, R.A.P.; Leiner, T.; Viergever, M.A.; Isgum, I. Deep Learning-Based Regression and Classification for Automatic Landmark Localization in Medical Images. IEEE Trans. Med. Imaging 2020, 39, 4011–4022. [Google Scholar] [CrossRef] [PubMed]
- Cen, F.; Wang, G. Boosting Occluded Image Classification via Subspace Decomposition-Based Estimation of Deep Features. IEEE Trans. Cybern. 2020, 50, 3409–3422. [Google Scholar] [CrossRef] [PubMed]
- Zheng, G.; Li, X.; Zhou, L.; Yang, J.; Ren, L.; Chen, P.; Zhang, H.; Lou, X. Development of a Gray-Level Co-Occurrence Matrix-Based Texture Orientation Estimation Method and Its Application in Sea Surface Wind Direction Retrieval From SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5244–5260. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, W.; Rong, X.; Li, X.; Chen, J.; Wang, H.; Fu, K.; Sun, X. A Lightweight Multi-Scale Crossmodal Text-Image Retrieval Method in Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar] [CrossRef]
- Cheng, Q.; Zhou, Y.; Fu, P.; Xu, Y.; Zhang, L. A Deep Semantic Alignment Network for the Cross-Modal Image-Text Retrieval in Remote Sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4284–4297. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, W.; Tian, C.; Rong, X.; Zhang, Z.; Wang, H.; Fu, K.; Sun, X. Remote Sensing Cross-Modal Text-Image Retrieval Based on Global and Local Information. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Gu, J.; Li, C.; Wang, X.; Tang, X.; Jiao, L. Recurrent Attention and Semantic Gate for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5608816. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, W.; Yan, M.; Gao, X.; Fu, K.; Sun, X. Global Visual Feature and Linguistic State Guided Attention for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5615216. [Google Scholar] [CrossRef]
- Zhao, R.; Shi, Z.; Zou, Z. High-Resolution Remote Sensing Image Captioning Based on Structured Attention. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5603814. [Google Scholar] [CrossRef]
- Lobry, S.; Marcos, D.; Murray, J.; Tuia, D. RSVQA: Visual Question Answering for Remote Sensing Data. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8555–8566. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, B.; Du, X.; Lu, X. Mutual Attention Inception Network for Remote Sensing Visual Question Answering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5606514. [Google Scholar] [CrossRef]
- Yuan, Z.; Mou, L.; Wang, Q.; Zhu, X.X. From Easy to Hard: Learning Language-Guided Curriculum for Visual Question Answering on Remote Sensing Data. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML 2021), Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: Sydney, Australia, 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Bazi, Y.; Rahhal, M.M.A.; Mekhalfi, M.L.; Zuair, M.A.A.; Melgani, F. Bi-Modal Transformer-Based Approach for Visual Question Answering in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4708011. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiao, L.; Li, L.; Liu, X.; Chen, P.; Liu, F.; Li, Y.; Guo, Z. A Spatial Hierarchical Reasoning Network for Remote Sensing Visual Question Answering. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4400815. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Virtual Event, 3–7 May 2021. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 2425–2433. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; A Meeting of SIGDAT, a Special Interest Group of the ACL. Moschitti, A., Pang, B., Daelemans, W., Eds.; ACL: Toronto, ON, Canada, 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP 2016), Austin, TX, USA, 1–4 November 2016; Su, J., Carreras, X., Duh, K., Eds.; The Association for Computational Linguistics: Toronto, ON, Canada, 2016; pp. 457–468. [Google Scholar] [CrossRef]
- Yu, Z.; Yu, J.; Fan, J.; Tao, D. Multi-modal Factorized Bilinear Pooling with Co-attention Learning for Visual Question Answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 1839–1848. [Google Scholar] [CrossRef]
- Kim, J.; On, K.W.; Lim, W.; Kim, J.; Ha, J.; Zhang, B. Hadamard Product for Low-rank Bilinear Pooling. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation: New York, NY, USA; IEEE Computer Society: Washington, DC, USA, 2018; pp. 6077–6086. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A.J. Stacked Attention Networks for Image Question Answering. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 21–29. [Google Scholar] [CrossRef]
- Kim, J.; Jun, J.; Zhang, B. Bilinear Attention Networks. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; 2018; pp. 1571–1581. [Google Scholar]
- Peng, L.; Yang, Y.; Wang, Z.; Wu, X.; Huang, Z. CRA-Net: Composed Relation Attention Network for Visual Question Answering. In Proceedings of the 27th ACM International Conference on Multimedia (MM 2019), Nice, France, 21–25 October 2019; Amsaleg, L., Huet, B., Larson, M.A., Gravier, G., Hung, H., Ngo, C., Ooi, W.T., Eds.; ACM: New York, NY, USA, 2019; pp. 1202–1210. [Google Scholar] [CrossRef]
- Chappuis, C.; Zermatten, V.; Lobry, S.; Le Saux, B.; Tuia, D. Prompt-RSVQA: Prompting visual context to a language model for remote sensing visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1372–1381. [Google Scholar]
- Yuan, Z.; Mou, L.; Xiong, Z.; Zhu, X.X. Change Detection Meets Visual Question Answering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5630613. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Deng, P.; Xu, K.; Huang, H. When CNNs Meet Vision Transformer: A Joint Framework for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8020305. [Google Scholar] [CrossRef]
- Ma, J.; Li, M.; Tang, X.; Zhang, X.; Liu, F.; Jiao, L. Homo-Heterogenous Transformer Learning Framework for RS Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2223–2239. [Google Scholar] [CrossRef]
- Xu, X.; Feng, Z.; Cao, C.; Li, M.; Wu, J.; Wu, Z.; Shang, Y.; Ye, S. An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, W.; Liu, H.; Yang, M.; Jiang, B.; Hu, G.; Bai, X. Few Could Be Better Than All: Feature Sampling and Grouping for Scene Text Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), New Orleans, LA, USA, 18–24 June 2022; pp. 4553–4562. [Google Scholar] [CrossRef]
- Dai, L.; Liu, H.; Tang, H.; Wu, Z.; Song, P. AO2-DETR: Arbitrary-Oriented Object Detection Transformer. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 2342–2356. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection With Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607514. [Google Scholar] [CrossRef]
- Wang, G.; Li, B.; Zhang, T.; Zhang, S. A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection. Remote Sens. 2022, 14, 2228. [Google Scholar] [CrossRef]
- Ke, Q.; Zhang, P. Hybrid-TransCD: A Hybrid Transformer Remote Sensing Image Change Detection Network via Token Aggregation. ISPRS Int. J. Geo Inf. 2022, 11, 263. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient Transformer for Remote Sensing Image Segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Transformer-Based Decoder Designs for Semantic Segmentation on Remotely Sensed Images. Remote Sens. 2021, 13, 5100. [Google Scholar] [CrossRef]
- Xiao, X.; Guo, W.; Chen, R.; Hui, Y.; Wang, J.; Zhao, H. A Swin Transformer-Based Encoding Booster Integrated in U-Shaped Network for Building Extraction. Remote Sens. 2022, 14, 2611. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; IEEE Computer Society: Washington, DC, USA, 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.; Hinton, G.; Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv 2017, arXiv:1701.06538. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. J. Mach. Learn. Res. 2022, 23, 120. [Google Scholar]
- Bao, H.; Wang, W.; Dong, L.; Liu, Q.; Mohammed, O.K.; Aggarwal, K.; Som, S.; Piao, S.; Wei, F. VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts. In Proceedings of the NeurIPS, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR Workshops 2020), Seattle, WA, USA, 14–19 June 2020; Computer Vision Foundation: New York, NY, USA, 2020; pp. 3008–3017. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations (ICLR 2019), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Abnar, S.; Zuidema, W.H. Quantifying Attention Flow in Transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020), Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 4190–4197. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | RSVQA-LR | ||||
|---|---|---|---|---|---|
| RSVQA [25] | EasyToHard [27] | Bi-Modal [30] | SHRNet [31] | TCMME (Ours) | |
| Count | 67.01% (0.59%) | 69.22% (0.33%) | 72.22% (0.57%) | 73.87% (0.22%) | 74.08% (0.35%) |
| Presence | 87.46% (0.06%) | 90.66% (0.24%) | 91.06% (0.17%) | 91.03% (0.13%) | 91.64% (0.13%) |
| Comparison | 81.50% (0.03%) | 87.49% (0.10%) | 91.16% (0.09%) | 90.48% (0.05%) | 92.10% (0.06%) |
| Rural/Urban | 90.00% (1.41%) | 91.67% (1.53%) | 92.66% (1.52%) | 94.00% (0.87%) | 95.00% (0.93%) |
| Average Accuracy | 81.49% (0.49%) | 84.76% (0.35%) | 86.78% (0.28%) | 87.34% (0.13%) | 88.21% (0.24%) |
| Overall Accuracy | 79.08% (0.20%) | 83.09% (0.15%) | 85.56% (0.16%) | 85.85% (0.28%) | 86.69% (0.21%) |
| Types | RSVQA-HR Test Set 1 | ||||
|---|---|---|---|---|---|
| RSVQA [25] | EasyToHard [27] | Bi-Modal [30] | SHRNet [31] | TCMME (Ours) | |
| Count | 68.63% (0.11%) | 69.06% (0.13%) | 69.80% (0.09%) | 70.04% (0.15%) | 69.43% (0.11%) |
| Presence | 90.43% (0.04%) | 91.39% (0.15%) | 92.03% (0.08%) | 92.45% (0.11%) | 91.97% (0.07%) |
| Comparison | 88.19% (0.08%) | 89.75% (0.10%) | 91.83% (0.00%) | 91.68% (0.09%) | 91.99% (0.03%) |
| Area | 85.24% (0.05%) | 85.92% (0.19%) | 86.27% (0.05%) | 86.35% (0.13%) | 91.08% (0.09%) |
| Average Accuracy | 83.12% (0.03%) | 83.97% (0.06%) | 84.98% (0.05%) | 85.13% (0.08%) | 86.12% (0.05%) |
| Overall Accuracy | 83.23% (0.02%) | 84.16% (0.05%) | 85.30% (0.05%) | 85.39% (0.05%) | 85.96% (0.06%) |
| Types | RSVQA-HR Test Set 2 | ||||
|---|---|---|---|---|---|
| RSVQA [25] | EasyToHard [27] | Bi-Modal [30] | SHRNet [31] | TCMME (Ours) | |
| Count | 61.47% (0.08%) | 61.95% (0.08%) | 63.06% (0.11%) | 63.42% (0.14%) | 62.13% (0.10%) |
| Presence | 86.26% (0.47%) | 87.97% (0.06%) | 89.37% (0.21%) | 89.81% (0.27%) | 88.93% (0.19%) |
| Comparison | 85.94% (0.12%) | 87.68% (0.23%) | 89.62% (0.29%) | 89.44% (0.23%) | 89.89% (0.22%) |
| Area | 76.33% (0.50%) | 78.62% (0.23%) | 80.12% (0.39%) | 80.37% (0.16%) | 88.22% (0.33%) |
| Average Accuracy | 77.50% (0.29%) | 79.06% (0.15%) | 80.54% (0.16%) | 80.76% (0.21%) | 82.29% (0.16%) |
| Overall Accuracy | 78.23% (0.25%) | 79.29% (0.15%) | 81.23% (0.15%) | 81.37% (0.19%) | 82.15% (0.18%) |
| Variant | RSVQA-LR | RSVQA-HR (Test Set 1) | RSVQA-HR (Test Set 2) | |||
|---|---|---|---|---|---|---|
|
Overall Accuracy |
Average Accuracy |
Overall Accuracy |
Average Accuracy |
Overall Accuracy |
Average Accuracy | |
| w/o CMME | 85.37% | 86.20% | 84.95% | 85.01% | 81.03% | 81.04% |
| w/o ME | 86.29% | 87.67% | 85.51% | 85.60% | 81.93% | 82.02% |
| w/o CA | 86.12% | 87.53% | 85.42% | 85.55% | 81.65% | 81.71% |
| TCMME (full) | 86.69% | 88.21% | 85.96% | 86.12% | 82.15% | 82.29% |
| Number of Layers in the CMME | RSVQA-LR | RSVQA-HR (Test Set 1) | RSVQA-HR (Test Set 2) | |||
|---|---|---|---|---|---|---|
| Overall Accuracy | Average Accuracy | Overall Accuracy | Average Accuracy | Overall Accuracy | Average Accuracy | |
| 1 | 86.05% | 87.47% | 85.36% | 85.47% | 81.62% | 81.63% |
| 2 | 86.23% | 87.65% | 85.77% | 85.95% | 82.06% | 82.01% |
| 3 | 86.69% | 88.21% | 85.96% | 86.12% | 82.15% | 82.29% |
| 4 | 86.36% | 87.19% | 85.78% | 85.98% | 82.12% | 82.22% |
| 5 | 86.21% | 88.02% | 85.91% | 86.06% | 81.94% | 81.91% |
| 6 | 86.09% | 86.52% | 85.53% | 85.64% | 82.08% | 82.00% |
| Types | RSVQA-LR | ||||
|---|---|---|---|---|---|
| Train (10%) | Train (20%) | Train (30%) | Train (40%) | Train (100%) | |
| Count | 66.98% | 70.21% | 71.50% | 72.38% | 74.08% |
| Presence | 90.93% | 90.46% | 90.66% | 90.59% | 91.64% |
| Comparison | 88.93% | 90.08% | 90.70% | 92.15% | 92.10% |
| Rural/Urban | 90.00% | 88.00% | 92.00% | 93.00% | 95.00% |
| Average Accuracy | 84.21% | 84.69% | 86.22% | 87.03% | 88.21% |
| Overall Accuracy | 83.07% | 84.32% | 85.05% | 85.88% | 86.69% |
| Types | RSVQA-HR Test Set 1 | RSVQA-HR Test Set 2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Train (10%) |
Train (20%) |
Train (30%) |
Train (40%) |
Train (100%) |
Train (10%) |
Train (20%) |
Train (30%) |
Train (40%) |
Train (100%) | |
| Count | 68.60% | 68.82% | 68.85% | 69.68% | 69.43% | 62.41% | 62.02% | 61.67% | 62.42% | 62.13% |
| Presence | 90.91% | 91.24% | 91.89% | 91.87% | 91.97% | 88.11% | 88.63% | 89.06% | 89.43% | 88.93% |
| Comparison | 90.63% | 91.34% | 91.45% | 91.53% | 91.99% | 88.79% | 89.09% | 89.25% | 89.24% | 89.89% |
| Area | 90.13% | 90.63% | 90.73% | 90.89% | 91.08% | 86.31% | 86.78% | 87.54% | 87.33% | 88.22% |
| Average Accuracy | 85.07% | 85.51% | 85.73% | 85.99% | 86.12% | 81.41% | 81.63% | 81.88% | 80.10% | 82.29% |
| Overall Accuracy | 84.88% | 85.33% | 85.55% | 85.82% | 85.96% | 81.37% | 81.57% | 81.76% | 82.01% | 82.15% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, G.; He, J.; Li, P.; Zhong, S.; Li, H.; He, G. Unified Transformer with Cross-Modal Mixture Experts for Remote-Sensing Visual Question Answering. Remote Sens. 2023, 15, 4682. https://doi.org/10.3390/rs15194682
Liu G, He J, Li P, Zhong S, Li H, He G. Unified Transformer with Cross-Modal Mixture Experts for Remote-Sensing Visual Question Answering. Remote Sensing. 2023; 15(19):4682. https://doi.org/10.3390/rs15194682
Chicago/Turabian StyleLiu, Gang, Jinlong He, Pengfei Li, Shenjun Zhong, Hongyang Li, and Genrong He. 2023. "Unified Transformer with Cross-Modal Mixture Experts for Remote-Sensing Visual Question Answering" Remote Sensing 15, no. 19: 4682. https://doi.org/10.3390/rs15194682
APA StyleLiu, G., He, J., Li, P., Zhong, S., Li, H., & He, G. (2023). Unified Transformer with Cross-Modal Mixture Experts for Remote-Sensing Visual Question Answering. Remote Sensing, 15(19), 4682. https://doi.org/10.3390/rs15194682