
SCDA: A Style and Content Domain Adaptive Semantic Segmentation Method for Remote Sensing Images


Abstract
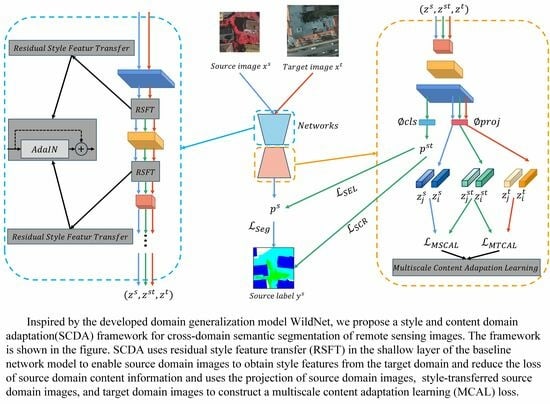
:
1. Introduction
- (1)
- This paper draws on the multiloss function architecture in WildNet to realize domain adaptation with regard to both the style and the content of different images. This domain adaption technology is then introduced into the semantic segmentation tasks of remote sensing images.
- (2)
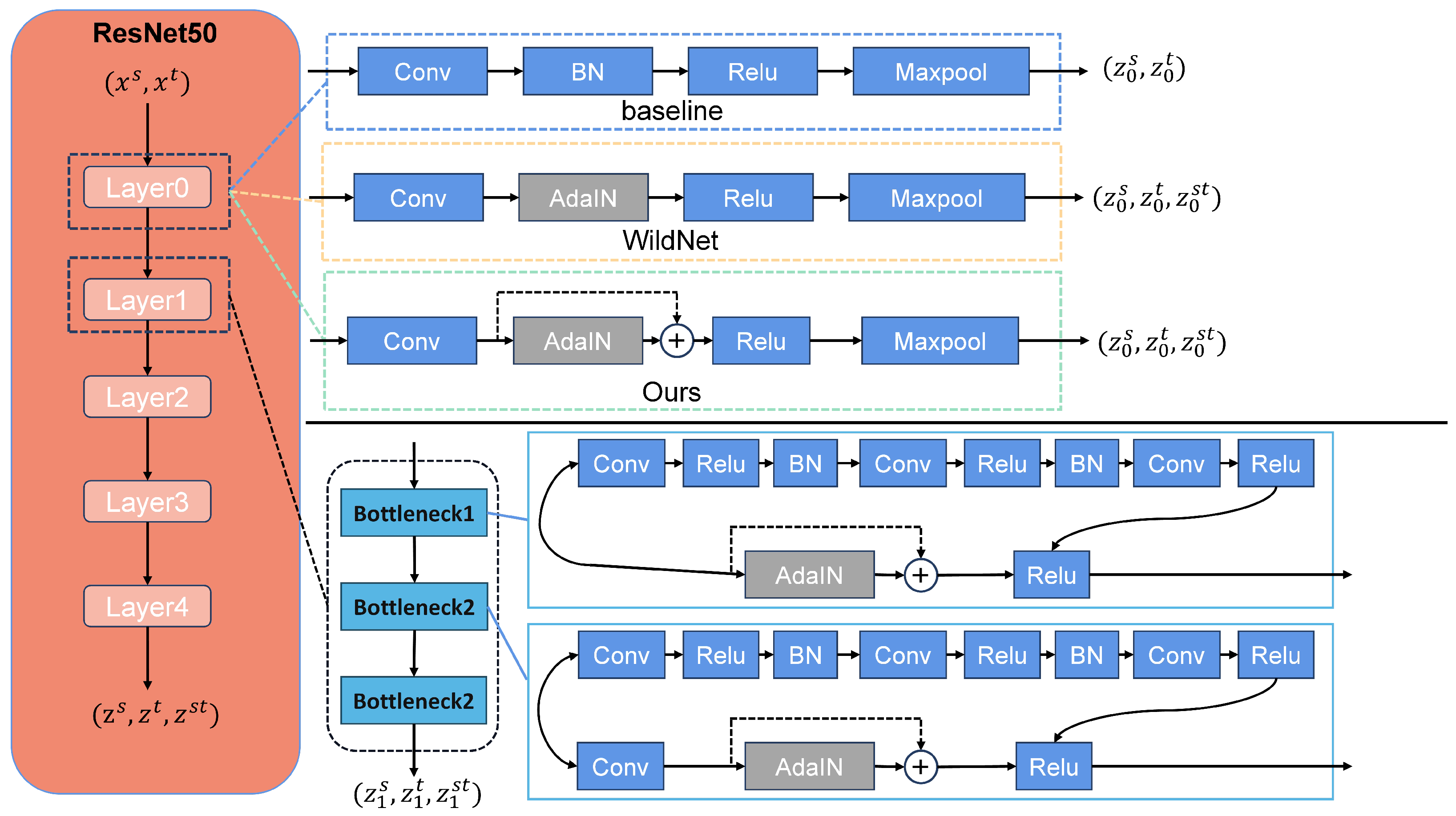
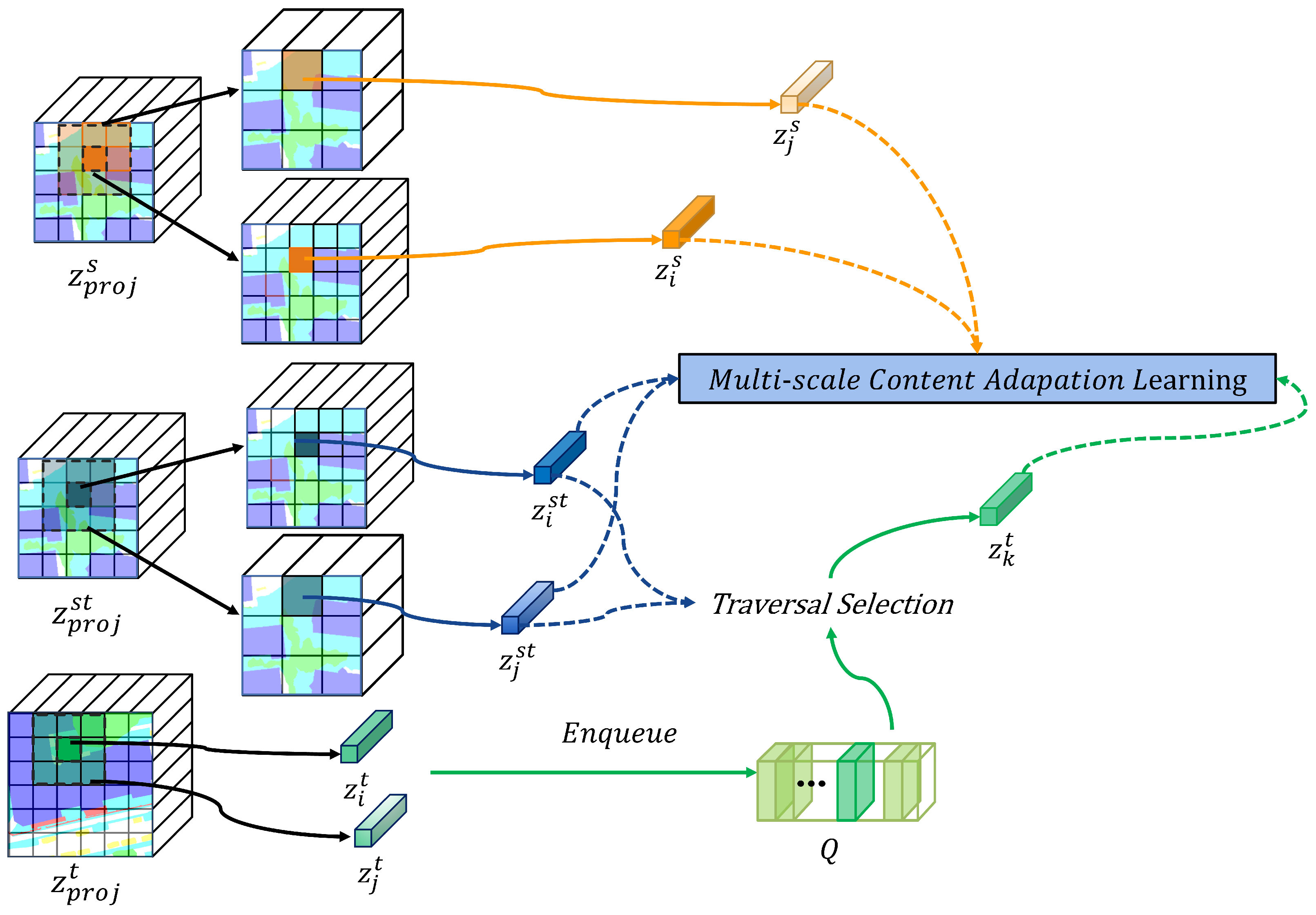
- As an improved model based on WildNet, a residual structure is added into the style transfer module, aiming to fully learn the style information of the target domain without losing the content information of the source domain data. Meanwhile, a multiscale model is added at the output end of the model to learn content information at different scales in the target domain.
- (3)
- In summary, we propose a novel end-to-end domain adaptive semantic segmentation framework SCDA for remote sensing images. The proposed method achieves state-of-the-art performance on cross-domain semantic segmentation tasks between two open-source datasets, Vaihingen and Potsdam. When performing cross-domain segmentation tasks from Vaihingen to Potsdam, mIOU is and , which is an improvement of and compared with the most advanced methods.
2. Related Work
2.1. Domain Adaptation Techniques Based on Style Transfer and Contrastive Learning
2.2. WildNet: A Domain Generalization Model Based on Multiple Loss Functions
3. Materials and Methods
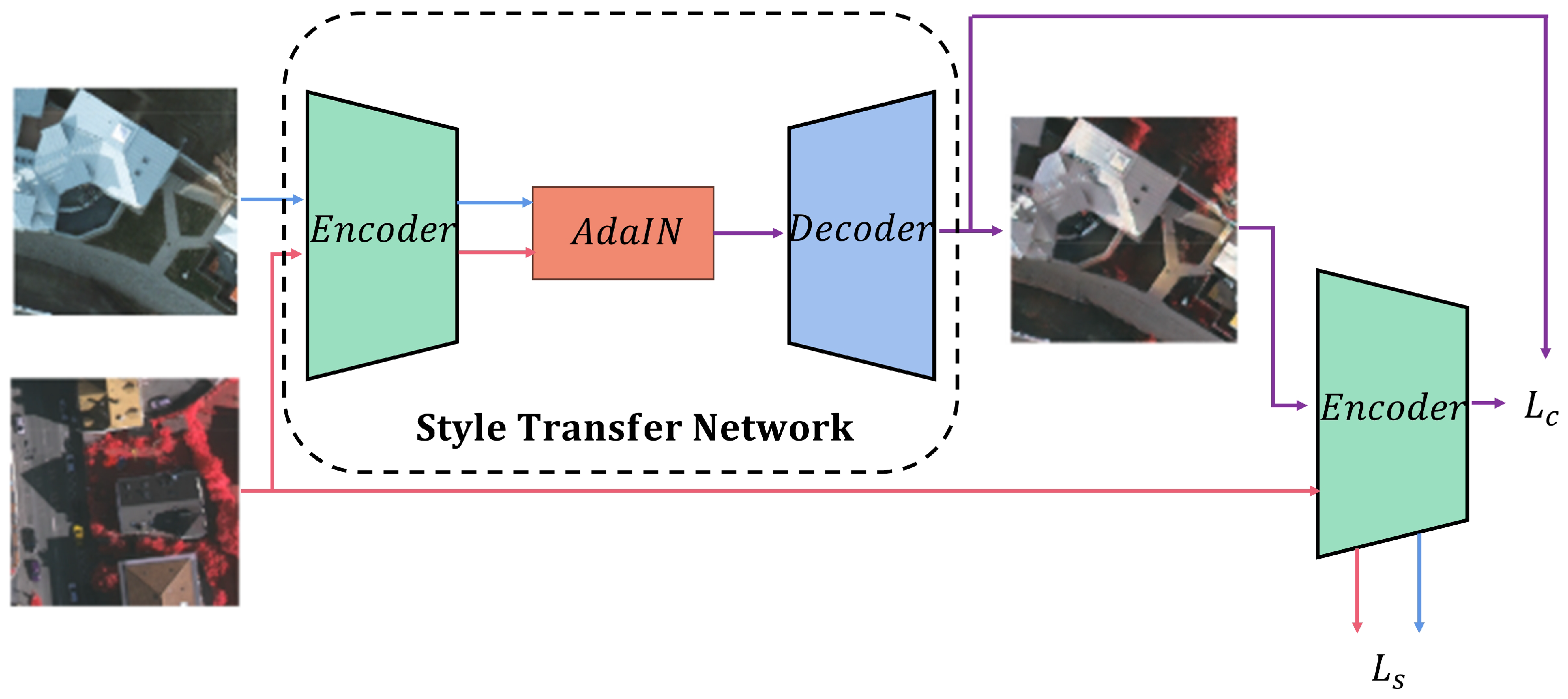
3.1. Preliminaries
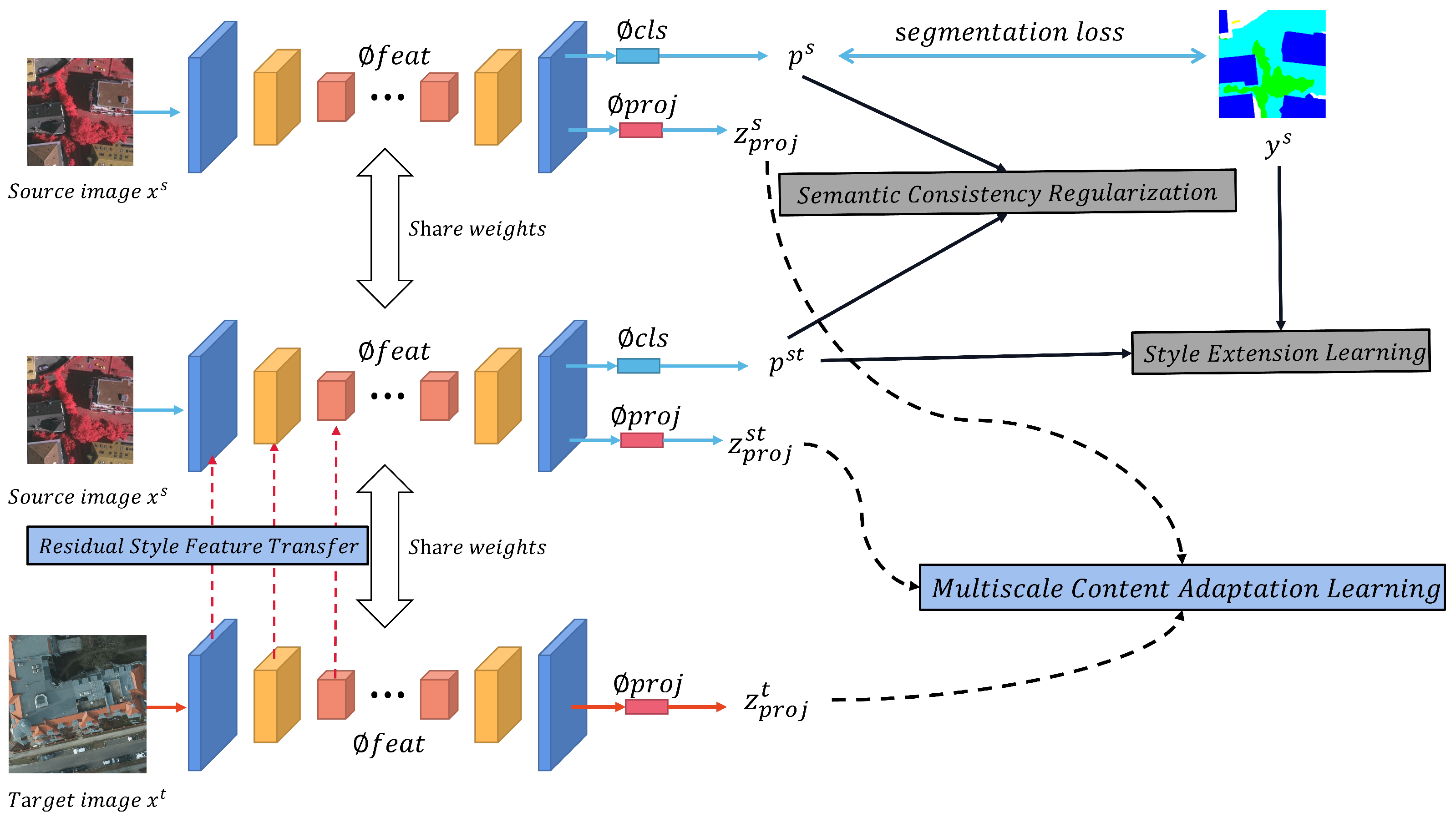
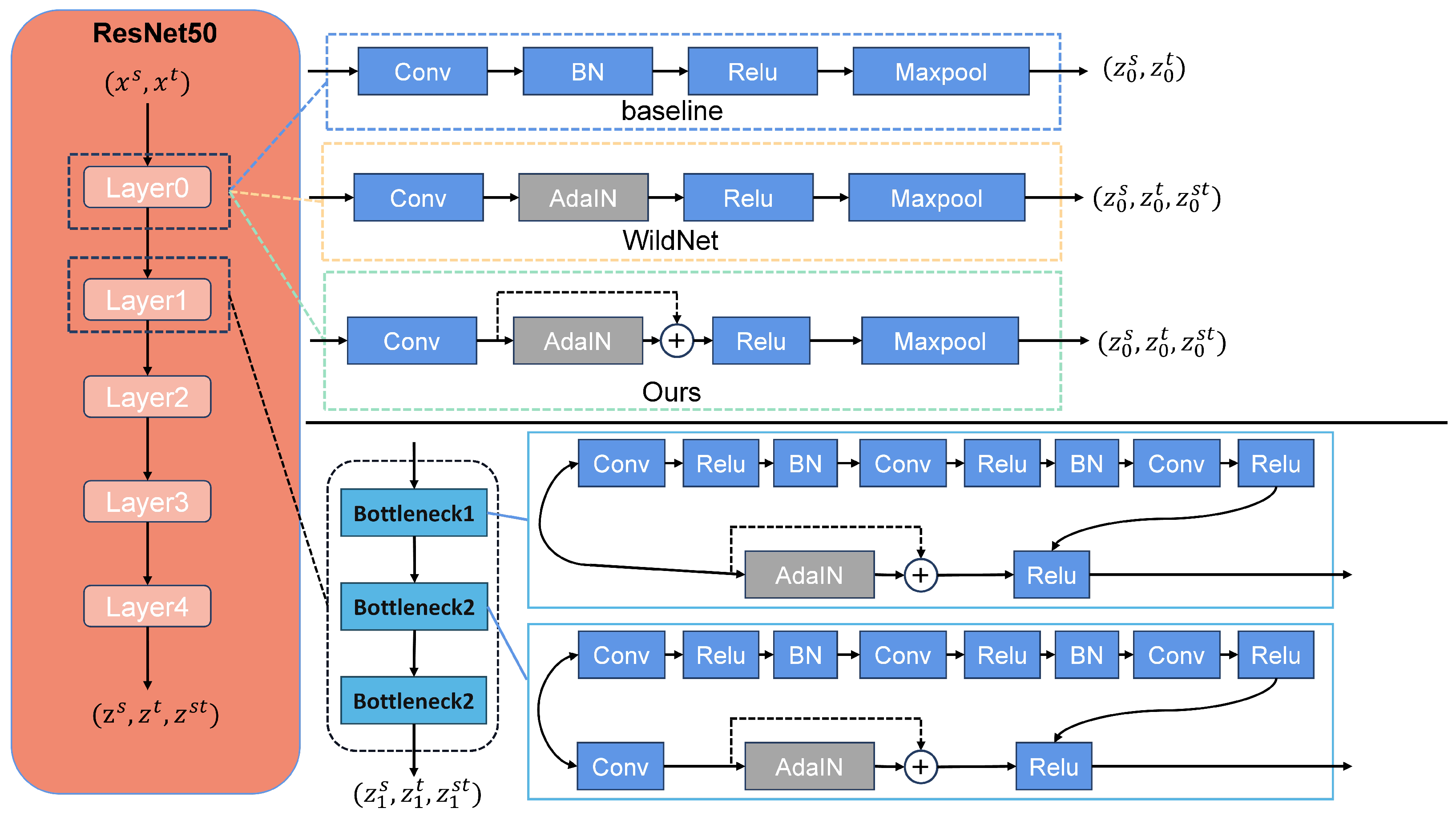
3.2. Residual Style Feature Transfer
3.3. Multiscale Content Adaptation Learning
4. Experiments and Discussion
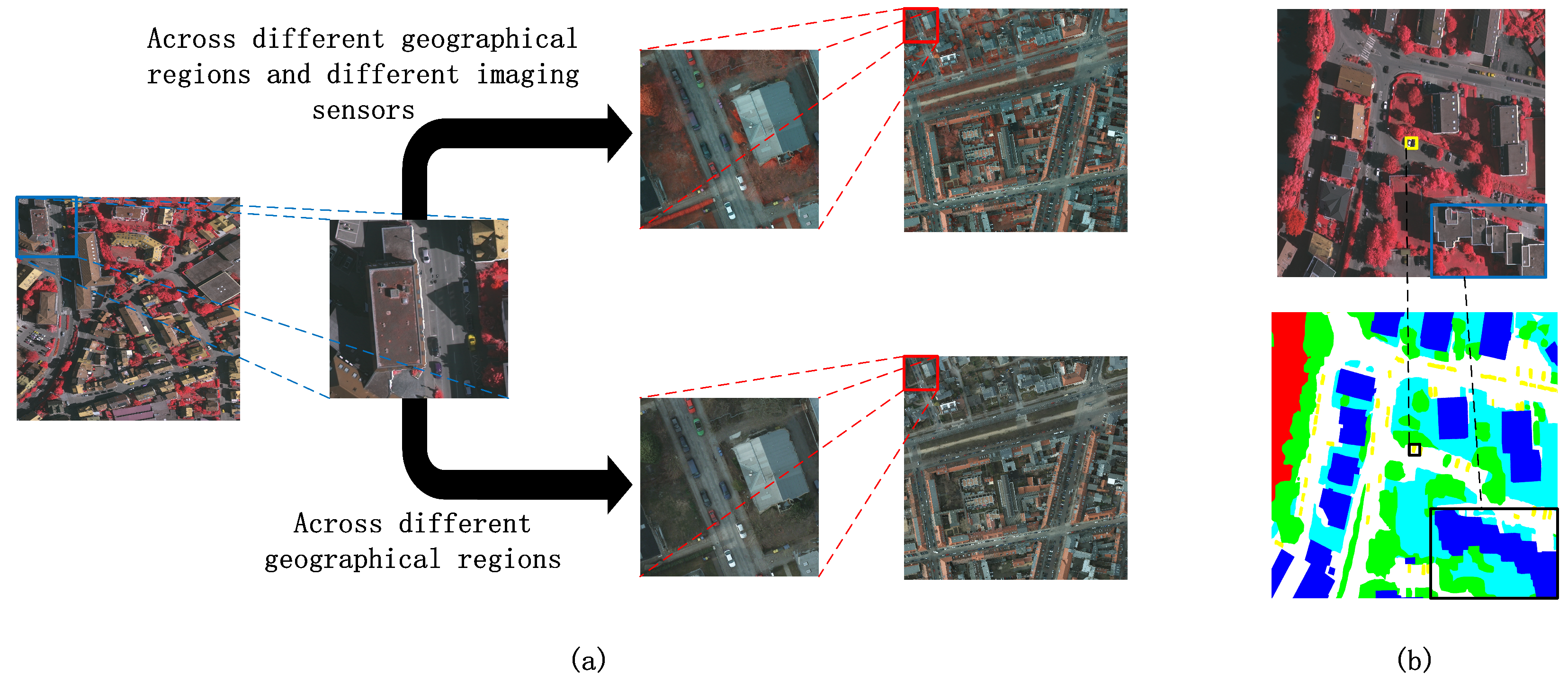
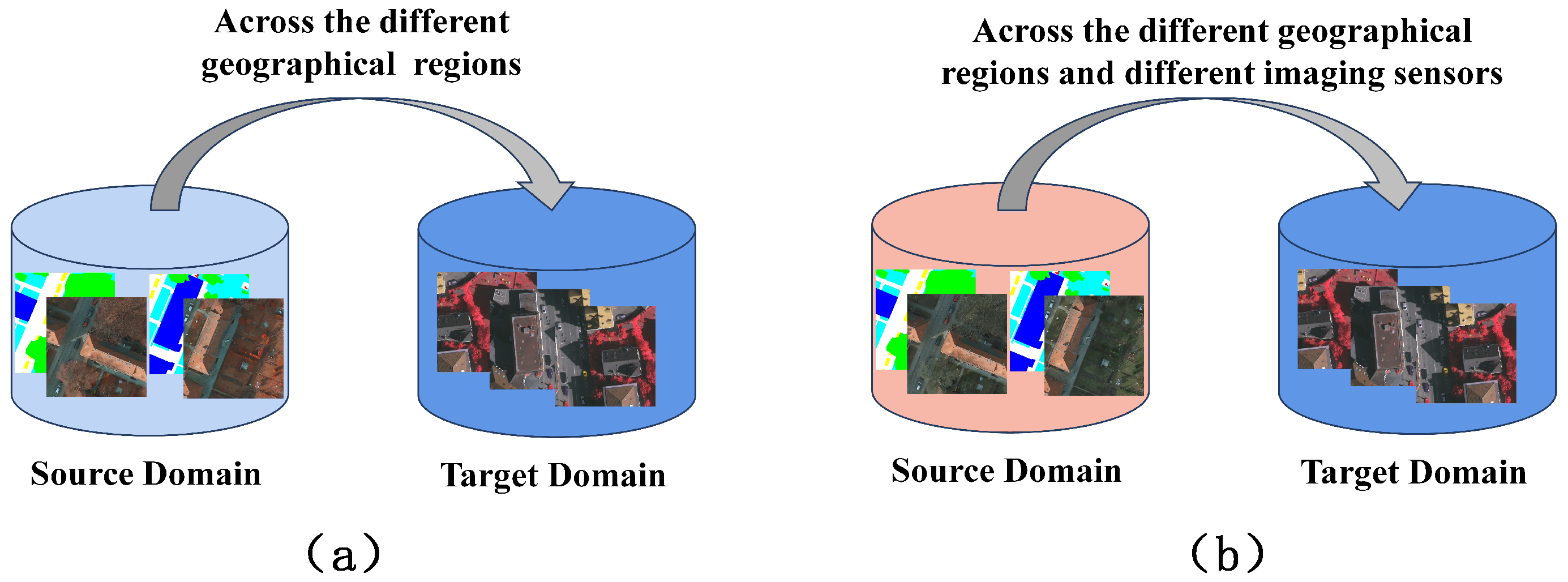
4.1. Datasets Description
4.2. Experiment Settings
4.3. Evaluation Metrics
4.4. Quantitative Results
4.5. Visualization Results
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lyu, Y.; Vosselman, G.; Xia, G.S.; Yilmaz, A.; Yang, M.Y. UAVid: A semantic segmentation dataset for UAV imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 108–119. [Google Scholar] [CrossRef]
- Shang, X.; Song, M.; Wang, Y.; Yu, C.; Yu, H.; Li, F.; Chang, C.I. Target-constrained interference-minimized band selection for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6044–6064. [Google Scholar] [CrossRef]
- Li, J.; Xu, Z.; Fu, L.; Zhou, X.; Yu, H. Domain adaptation from daytime to nighttime: A situation-sensitive vehicle detection and traffic flow parameter estimation framework. Transp. Res. Part Emerg. Technol. 2021, 124, 102946. [Google Scholar] [CrossRef]
- Vega, P.J.S. Deep Learning-Based Domain Adaptation for Change Detection in Tropical Forests. Ph.D. Thesis, PUC-Rio, Rio de Janeiro, Brazil, 2021. [Google Scholar]
- Wang, P.; Wang, L.; Leung, H.; Zhang, G. Super-resolution mapping based on spatial–spectral correlation for spectral imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2256–2268. [Google Scholar] [CrossRef]
- Zhang, W.; Chen, H.; Chen, W.; Yang, S. A Rooftop-Contour Guided 3D Reconstruction Texture Mapping Method for Building using Satellite Images. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, IEEE, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3456–3459. [Google Scholar]
- Ding, L.; Zhang, J.; Bruzzone, L. Semantic segmentation of large-size VHR remote sensing images using a two-stage multiscale training architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5367–5376. [Google Scholar] [CrossRef]
- Yang, H.L.; Crawford, M.M. Spectral and spatial proximity-based manifold alignment for multitemporal hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 54, 51–64. [Google Scholar] [CrossRef]
- Sun, W.; Wang, R. Fully convolutional networks for semantic segmentation of very high resolution remotely sensed images combined with DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Mou, L.; Hua, Y.; Zhu, X.X. Relation matters: Relational context-aware fully convolutional network for semantic segmentation of high-resolution aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7557–7569. [Google Scholar] [CrossRef]
- Yue, K.; Yang, L.; Li, R.; Hu, W.; Zhang, F.; Li, W. TreeUNet: Adaptive tree convolutional neural networks for subdecimeter aerial image segmentation. ISPRS J. Photogramm. Remote Sens. 2019, 156, 1–13. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Xu, M.; Wu, M.; Chen, K.; Zhang, C.; Guo, J. The eyes of the gods: A survey of unsupervised domain adaptation methods based on remote sensing data. Remote Sens. 2022, 14, 4380. [Google Scholar] [CrossRef]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Zou, Y.; Yu, Z.; Kumar, B.; Wang, J. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 289–305. [Google Scholar]
- Tasar, O.; Happy, S.; Tarabalka, Y.; Alliez, P. SemI2I: Semantically consistent image-to-image translation for domain adaptation of remote sensing data. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, IEEE, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1837–1840. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3722–3731. [Google Scholar]
- Shi, Y.; Du, L.; Guo, Y. Unsupervised domain adaptation for SAR target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6372–6385. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1180–1189. [Google Scholar]
- Long, M.; Cao, Y.; Cao, Z.; Wang, J.; Jordan, M.I. Transferable representation learning with deep adaptation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 3071–3085. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Yuan, B.; Gao, Y.; Qi, X.; Shi, Z. UGCNet: An Unsupervised Semantic Segmentation Network Embedded with Geometry Consistency for Remote-Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 5510005. [Google Scholar] [CrossRef]
- Zhao, D.; Li, J.; Yuan, B.; Shi, Z. V2RNet: An unsupervised semantic segmentation algorithm for remote sensing images via cross-domain transfer learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, IEEE, Brussels, Belgium, 11–16 July 2021; pp. 4676–4679. [Google Scholar]
- Cai, Y.; Yang, Y.; Zheng, Q.; Shen, Z.; Shang, Y.; Yin, J.; Shi, Z. BiFDANet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 190. [Google Scholar] [CrossRef]
- Liu, W.; Su, F.; Jin, X.; Li, H.; Qin, R. Bispace Domain Adaptation Network for Remotely Sensed Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5600211. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, T.; Wang, B. Curriculum-style local-to-global adaptation for cross-domain remote sensing image segmentation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Zhao, Y.; Guo, P.; Sun, Z.; Chen, X.; Gao, H. ResiDualGAN: Resize-residual DualGAN for cross-domain remote sensing images semantic segmentation. Remote Sens. 2023, 15, 1428. [Google Scholar] [CrossRef]
- Chen, X.; Pan, S.; Chong, Y. Unsupervised domain adaptation for remote sensing image semantic segmentation using region and category adaptive domain discriminator. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Lee, S.; Seong, H.; Lee, S.; Kim, E. WildNet: Learning domain generalized semantic segmentation from the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9936–9946. [Google Scholar]
- Marsden, R.A.; Wiewel, F.; Döbler, M.; Yang, Y.; Yang, B. Continual unsupervised domain adaptation for semantic segmentation using a class-specific transfer. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Wang, R.; Wu, Z.; Weng, Z.; Chen, J.; Qi, G.J.; Jiang, Y.G. Cross-domain contrastive learning for unsupervised domain adaptation. IEEE Trans. Multimed. 2022, 25, 1665–1673. [Google Scholar] [CrossRef]
- Kang, G.; Jiang, L.; Yang, Y.; Hauptmann, A.G. Contrastive adaptation network for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4893–4902. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Dwibedi, D.; Aytar, Y.; Tompson, J.; Sermanet, P.; Zisserman, A. With a little help from my friends: Nearest-neighbor contrastive learning of visual representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9588–9597. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, K.; Yang, Y.; Qiao, Y.; Xiang, T. Domain generalization with mixstyle. arXiv 2021, arXiv:2104.02008. [Google Scholar]
- Park, K.; Woo, S.; Shin, I.; Kweon, I.S. Discover, hallucinate, and adapt: Open compound domain adaptation for semantic segmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 10869–10880. [Google Scholar]
- Rottensteiner, F.; Sohn, G.; Gerke, M.; Wegner, J.D. ISPRS Semantic Labeling Contest; ISPRS: Leopoldshöhe, Germany, 2014; Volume 1. [Google Scholar]
- Wang, Q.; Gao, J.; Li, X. Weakly supervised adversarial domain adaptation for semantic segmentation in urban scenes. IEEE Trans. Image Process. 2019, 28, 4376–4386. [Google Scholar] [CrossRef] [PubMed]
- Ji, S.; Wang, D.; Luo, M. Generative adversarial network-based full-space domain adaptation for land cover classification from multiple-source remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3816–3828. [Google Scholar] [CrossRef]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Datasets | |
|---|---|---|
| Vaihingen | Potsdam | |
| Sensor | Leica ADS80 | Leica ADS80 |
| Pixel | 2000 × 3000 | 6000 × 6000 |
| GSD | 5 cm/pixel | 9 cm/pixel |
| Processed size | 512 × 512 | 896 × 896 |
| Channel compositions | IR-R-G | R-G-B/IR-R-G/IR-R-G-B |
| Clutter/background samples | 0.70% | 4.80% |
| Impervious surface samples | 29.30% | 29.80% |
| Car samples | 1.40% | 1.80% |
| Tree samples | 22.50% | 14.50% |
| Low-vegetation samples | 19.30% | 21.00% |
| Buildings samples | 26.80% | 28.10% |
| Description | Across the Different Region | Across the Different Region and Imaging Sensors | ||
|---|---|---|---|---|
| Domain | Source | Target | Source | Target |
| Location | Vaihingen | Potsdam | Vaihingen | Potsdam |
| Imaging mode | IR-R-G | IR-R-G | IR-R-G | R-G-B |
| Labeled | ✓ | ✓ | ||
| Methods | Background/ Clutter | Impervious Surface | Car | Tree | Low Vegetation | Buildings | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | |
| Deeplabv3 [40] | 9.3 | 16.86 | 49.18 | 65.93 | 38.51 | 55.6 | 7.67 | 14.24 | 29.32 | 45.34 | 36.96 | 53.97 | 28.49 | 41.99 |
| BiSeNet [48] | 29.01 | 44.97 | 22.70 | 36.99 | 0.69 | 1.36 | 41.56 | 58.71 | 26.12 | 41.42 | 39.61 | 34.61 | 23.5 | 36.34 |
| AdaptSegNet [15] | 8.36 | 15.33 | 49.55 | 64.64 | 40.95 | 58.11 | 22.59 | 36.79 | 34.43 | 61.5 | 48.01 | 63.41 | 33.98 | 49.96 |
| MUCSS [28] | 33.48 | 50.24 | 50.78 | 67.35 | 36.93 | 54.08 | 58.69 | 73.97 | 40.84 | 58.00 | 63.20 | 77.45 | 46.36 | 62.46 |
| CCDA_LGFA [27] | 12.31 | 24.59 | 64.39 | 78.59 | 59.35 | 75.08 | 37.55 | 54.60 | 47.17 | 63.27 | 66.44 | 79.84 | 47.87 | 62.66 |
| Ours | 19.68 | 33.88 | 66.91 | 81.17 | 70.90 | 83.97 | 15.23 | 28.44 | 48.79 | 66.58 | 70.34 | 84.59 | 48.64 | 63.11 |
| Methods | Clutter/ Background | Impervious Surface | Car | Tree | Low Vegetation | Buildings | Overall | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | |
| Deeplabv3 [40] | 6.99 | 13.04 | 42.98 | 60.12 | 38.01 | 55.08 | 0.53 | 1.06 | 1.59 | 3.13 | 29.09 | 45.05 | 19.86 | 29.58 |
| BiSeNet [48] | 23.66 | 38.26 | 17.74 | 30.12 | 0.99 | 1.95 | 32.67 | 49.24 | 18.42 | 31.11 | 12.64 | 22.43 | 17.69 | 28.85 |
| AdaptSegNet [15] | 6.11 | 11.5 | 37.66 | 59.55 | 42.31 | 55.95 | 30.71 | 45.41 | 15.1 | 25.81 | 54.25 | 70.31 | 31.02 | 44.75 |
| MUCSS [28] | 16.09 | 27.76 | 47.28 | 64.21 | 40.71 | 57.87 | 28.96 | 44.97 | 43.66 | 60.79 | 59.84 | 74.88 | 38.06 | 53.81 |
| CCDA_LGFA [27] | 13.27 | 23.43 | 57.65 | 73.14 | 56.99 | 72.27 | 35.87 | 52.80 | 29.77 | 45.88 | 65.44 | 79.11 | 43.17 | 57.77 |
| Ours | 15.76 | 26.73 | 63.31 | 76.02 | 66.57 | 80.77 | 12.63 | 21.8 | 40.89 | 58.22 | 67.63 | 81.01 | 44.38 | 57.43 |
| Experiment | Vaihingen IRRG to Potsdam RGB | Vaihingen IRRG to Potsdam IRRG | ||
|---|---|---|---|---|
| mIou | F1 | mIou | F1 | |
| baseline [32] | 35.54 | 52.86 | 40.25 | 57.79 |
| resize images | 39.32 | 55.21 | 45.68 | 61.56 |
| with RSFT | 40.76 | 55.36 | 44.98 | 60.67 |
| with MCAL | 42.49 | 55.92 | 48.64 | 63.11 |
| with RSFT and MACL | 44.38 | 57.43 | 50.59 | 66.42 |
| Hyperparameters Settings | Vaihingen IRRG to Potsdam RGB | Vaihingen IRRG to Potsdam IRRG | |||
|---|---|---|---|---|---|
| mIou | F1 | mIou | F1 | ||
| RSFT = [1,0,0,0,0] | 43.71 | 53.29 | 47.15 | 58.98 | |
| RSFT = [1,1,0,0,0] | 41.46 | 52.12 | 48.96 | 65.13 | |
| RSFT = [1,1,1,0,0] | k = 1.0 | 44.38 | 57.43 | 50.59 | 66.42 |
| RSFT = [1,1,1,1,0] | 43.33 | 52.51 | 47.40 | 59.21 | |
| RSFT = [1,1,1,1,1] | 42.53 | 52.26 | 46.33 | 58.78 | |
| RSFT = [1,1,1,0,0] | k = 0 | 39.32 | 55.21 | 45.68 | 61.56 |
| k = 0.5 | 38.14 | 53.37 | 46.30 | 62.56 | |
| k = 1.0 | 44.38 | 57.43 | 50.59 | 66.42 | |
| k = 1.5 | 40.76 | 54.22 | 49.02 | 65.67 | |
| k = 2.0 | 41.10 | 55.79 | 49.43 | 65.90 | |
| Hyperparameter Settings | Vaihingen IRRG to Potsdam IRRG | Vaihingen IRRG to Potsdam RGB | ||
|---|---|---|---|---|
| mIou | F1 | mIou | F1 | |
| = 0 | 48.00 | 62.80 | 41.71 | 52.99 |
| = 0.5 | 50.59 | 66.42 | 44.38 | 57.43 |
| = 1 | 48.84 | 63.00 | 42.06 | 54.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, H.; Yao, W.; Chen, H.; Cheng, L.; Li, B.; Ren, L. SCDA: A Style and Content Domain Adaptive Semantic Segmentation Method for Remote Sensing Images. Remote Sens. 2023, 15, 4668. https://doi.org/10.3390/rs15194668
Xiao H, Yao W, Chen H, Cheng L, Li B, Ren L. SCDA: A Style and Content Domain Adaptive Semantic Segmentation Method for Remote Sensing Images. Remote Sensing. 2023; 15(19):4668. https://doi.org/10.3390/rs15194668
Chicago/Turabian StyleXiao, Hongfeng, Wei Yao, Haobin Chen, Li Cheng, Bo Li, and Longfei Ren. 2023. "SCDA: A Style and Content Domain Adaptive Semantic Segmentation Method for Remote Sensing Images" Remote Sensing 15, no. 19: 4668. https://doi.org/10.3390/rs15194668
APA StyleXiao, H., Yao, W., Chen, H., Cheng, L., Li, B., & Ren, L. (2023). SCDA: A Style and Content Domain Adaptive Semantic Segmentation Method for Remote Sensing Images. Remote Sensing, 15(19), 4668. https://doi.org/10.3390/rs15194668