1. Introduction
The progression of information technology has led to the gradual transformation of scene detection from single-sensor to multi-sensor systems. This transition is necessitated by the images acquired by single sensors being inadequate to effectively address the requirements of practical tasks. Image fusion is a crucial technology for achieving multi-sensor information fusion [
1]. In comparison to a single image, a fused image incorporates abundant and complementary information from different sensors. This enhanced amalgamation is particularly beneficial for environmental perception and facilitates the processing of high-level visual tasks. Typically, common image fusion techniques include multi-focus fusion and multi-sensor fusion. As an important branch of multi-sensor fusion, infrared and visible image fusion is widely applied in the computer vision field, such as in target detection [
2], video security surveillance [
3], remote sensing image processing [
4,
5,
6,
7], and military reconnaissance [
8].
Due to the different imaging mechanisms used, the difference between images captured by various imaging systems is huge in terms of contrast, color, and texture. Visible images have a high spatial resolution, rich color, and detailed textures; however, their imaging quality is dependent on illumination conditions. Therefore, in low light or adverse weather conditions, the use of visible imaging is not ideal. In comparison to visible imaging, infrared imaging captures the thermal radiation information of the target and provides good discrimination between warmer targets and backgrounds. Consequently, infrared imaging is well-suited for use in challenging conditions, such as weak light environments, strong winds, dense fog, rain, and snow. Moreover, it remains relatively unaffected by light and weather interference, making it a reliable choice for such situations. However, infrared imagery is not well suited to human visual perception due to its low spatial resolution, limited textural detail, and poor clarity. Therefore, fusion of the images from these two types of sensors may help to achieve a more adaptive scene perception of the environment.
Over the past decade, extensive research in image fusion has yielded numerous methods, broadly categorized into traditional and deep learning-based approaches. Traditional methods, like multi-scale transform (MST) [
9,
10,
11], sparse representation (SR) [
12,
13], low-rank representation [
14,
15,
16], and saliency-based approaches [
17,
18], employ various techniques for fusion. However, they suffer from drawbacks such as operator dependency and computational intensity. In recent years, deep learning (DL) has emerged as a superior alternative, offering high adaptability and robustness. Depending on the training methods and network architecture, deep learning-based fusion methods can be broadly classified into two primary categories: non-end-to-end image fusion methods and end-to-end image fusion methods. In the case of non-end-to-end methods, pre-trained neural networks are commonly utilized to extract image features. Subsequently, these extracted features undergo fusion using predefined rules and are reconstructed to yield the ultimate fused image.
Unlike the non-end-to-end methods, end-to-end image fusion techniques simplify the fusion process and improve performance. Xu et al. [
19] introduced FusionDN, a versatile network trained using a resilient weight-connection algorithm. Ma et al. [
20] pioneered the use of generative adversarial networks (GANs) in image fusion. However, since these methods do not fully consider the illumination factor and cannot adapt to different light intensity distributions, they may sometimes produce distorted fusion results [
21]. Meanwhile, although existing deep learning-based methods achieve high efficiency and good fusion quality, most of them highlight local features and lack consideration of global features during image fusion.
Despite achieving competitive performance, deep learning-based methods still exhibit certain drawbacks, including the following disadvantages:
Shallow features tend to have only local information and lack global information and cannot include contextual information from features at all scales;
In the feature fusion stage, convolutional layers are initially employed to integrate the features, followed by their fusion. This process involves local and global interactions solely within the domain, with no cross-domain contextual interactions being executed.
To address the above drawbacks, we propose a hybrid attention Transformer fusion model (HATF). The main contributions of the proposed method can be summarized as follows:
A residual U-Net block (RUB) is utilized in each encoding block. The integration of a U-shaped structure nested within the RUB allows the network to capture richer local and global information simultaneously across all scales.
Hybrid attention mechanisms are constructed within and between domains. Intra-domain self-attention is first adopted to extract global information from single-mode images. Subsequently, inter-domain cross-attention is applied to obtain interaction information of the dual-mode images. With the hybrid attention mechanism, the complementary information of the infrared and visible features is seamlessly integrated to yield a more informative fused image.
We designed an adaptive fusion loss function based on different modal features, combined with a saliency loss, to achieve high-quality fusion of infrared and visible light images. Extensive experiments conclusively demonstrate the effectiveness of the proposed approach in significantly improving the quality of the fused images. Compared to state-of-the-art fusion methods, the proposed approach exhibits superior fusion performance.
The subsequent sections of this paper are organized as follows:
Section 2 offers an extensive review of related work on visible and infrared image fusion, emphasizing the development and advantages of the Transformer.
Section 3 provides a detailed description of HATF. Comparative experiments are conducted and their results analyzed in
Section 4. The paper concludes with a summary in
Section 5.
3. Methodology
The fusion network incorporating the hybrid attention mechanism is described in detail in this section.
Section 3.1 provides an introduction to the architecture of the fusion framework. Then, the residual U-Net feature extraction block is built in
Section 3.2, and the Transformer module with hybrid attention is constructed in
Section 3.3. Finally, the loss function and the training strategy are presented in
Section 3.4.
3.1. Overall Network Structure
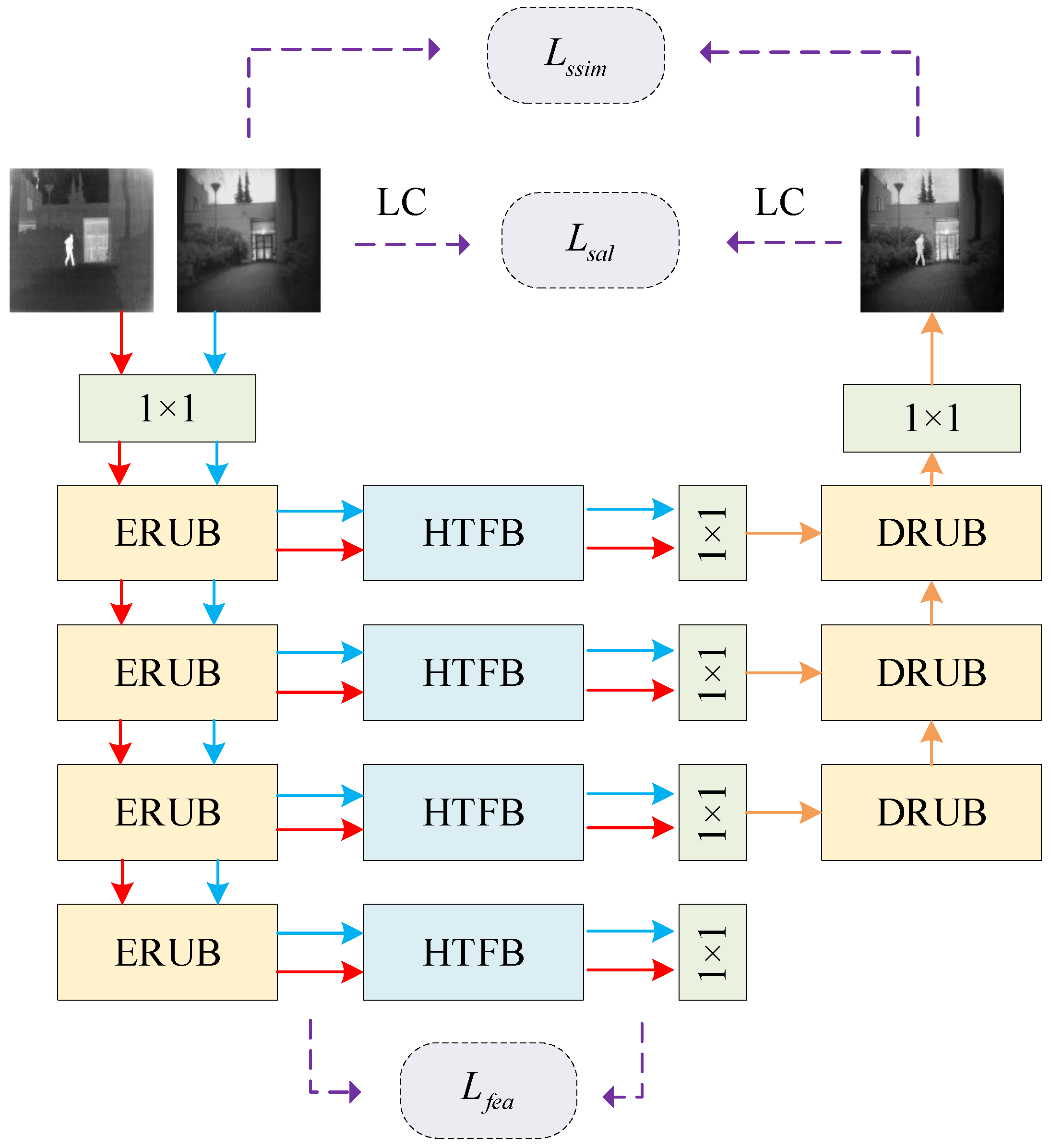
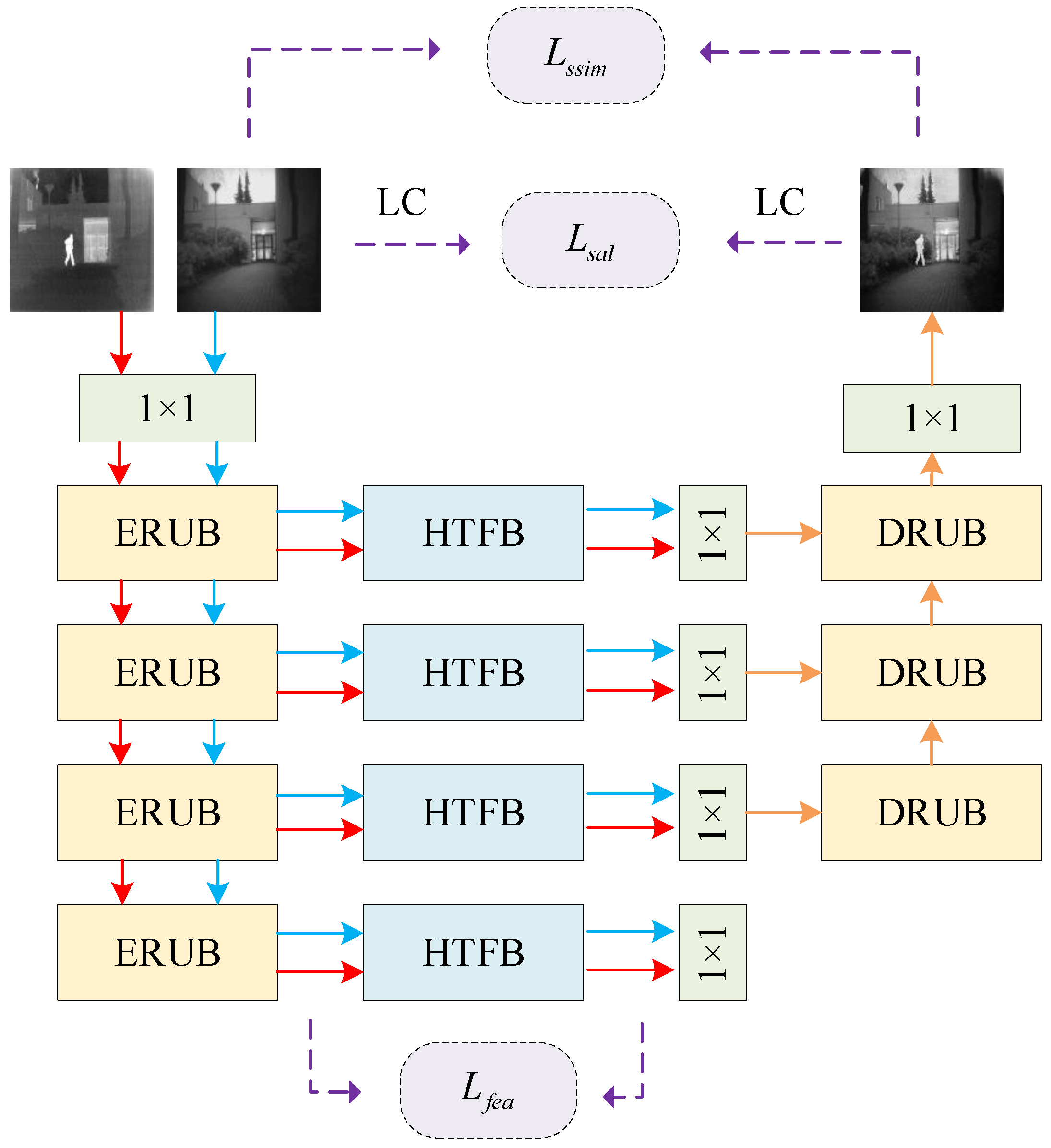
The HATF model is composed of three pivotal components: an encoder, a fusion module, and a decoder. The overall model structure is depicted in
Figure 2, and detailed descriptions of each component as given below:
(1) Encoder: The encoder adopts U2-Net as the backbone network for extracting multimodal features, which contain structural information at different granularities from shallow to deep. The multi-scale encoder is composed of 1 convolutional layer and 4 encoder residual U-Net blocks (ERUBs). To diminish the spatial resolution of the features, a max pooling layer is inserted between each ERUB.
(2) Hybrid Attention Transformer Fusion Block (HTFB): This block is constructed on Swin-Transformer with a hybrid attention mechanism. The hybrid attention mechanism is constructed from intra-domain self-attention units and inter-domain cross-attention units, which enables long-range dependency modeling and global interaction of features. The fusion features are obtained from the HTFBs, which are able to fully retain complementary infrared and visible information and better integrate multimodal features.
(3) Decoder: The decoder is made up of one convolutional layer and three decoder U-Net blocks (DRUBs). It reconstructs fusion features to generate the fused image. With the help of DRUBs, the reconstruction ability of the model for global information has been improved.
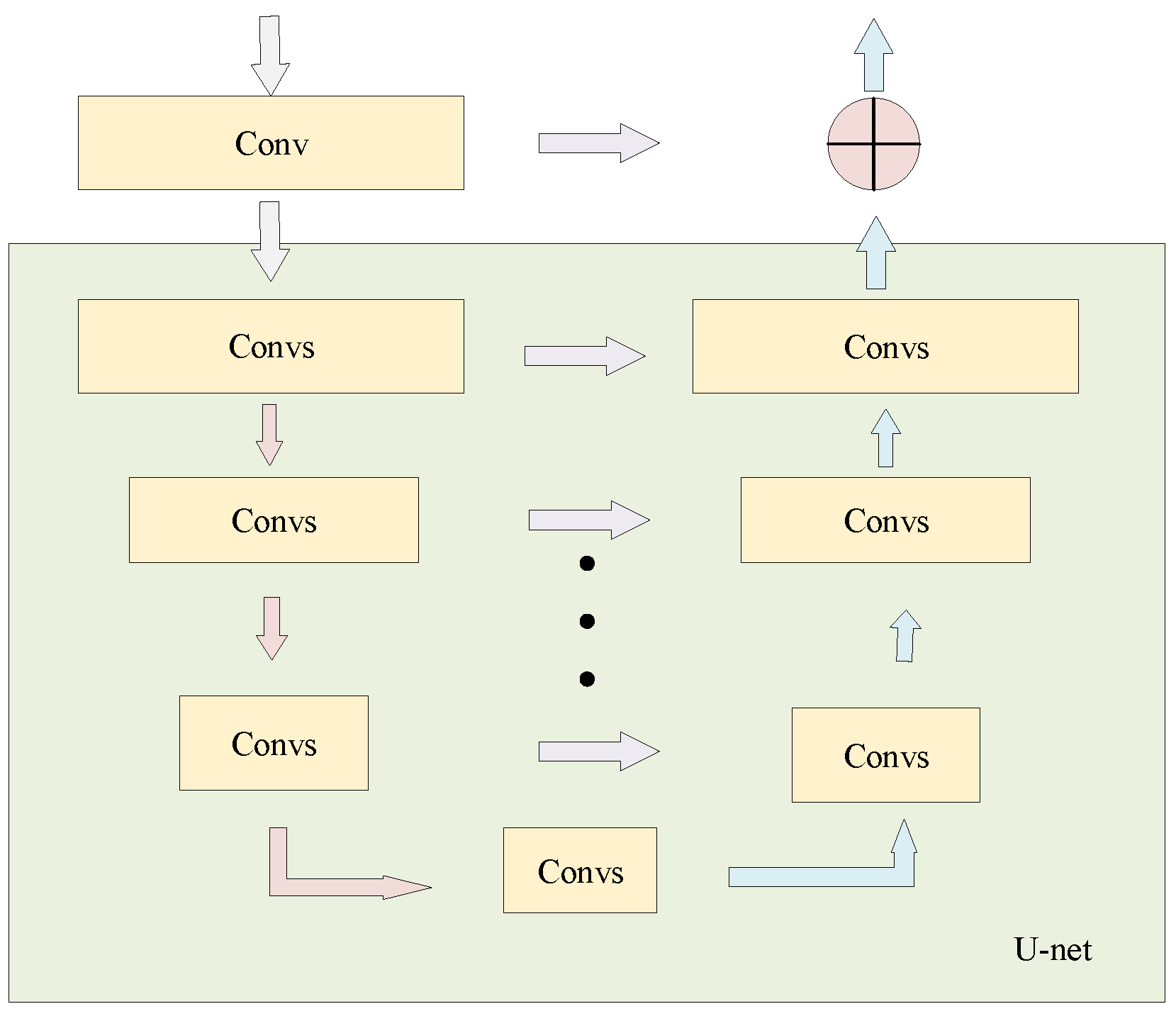
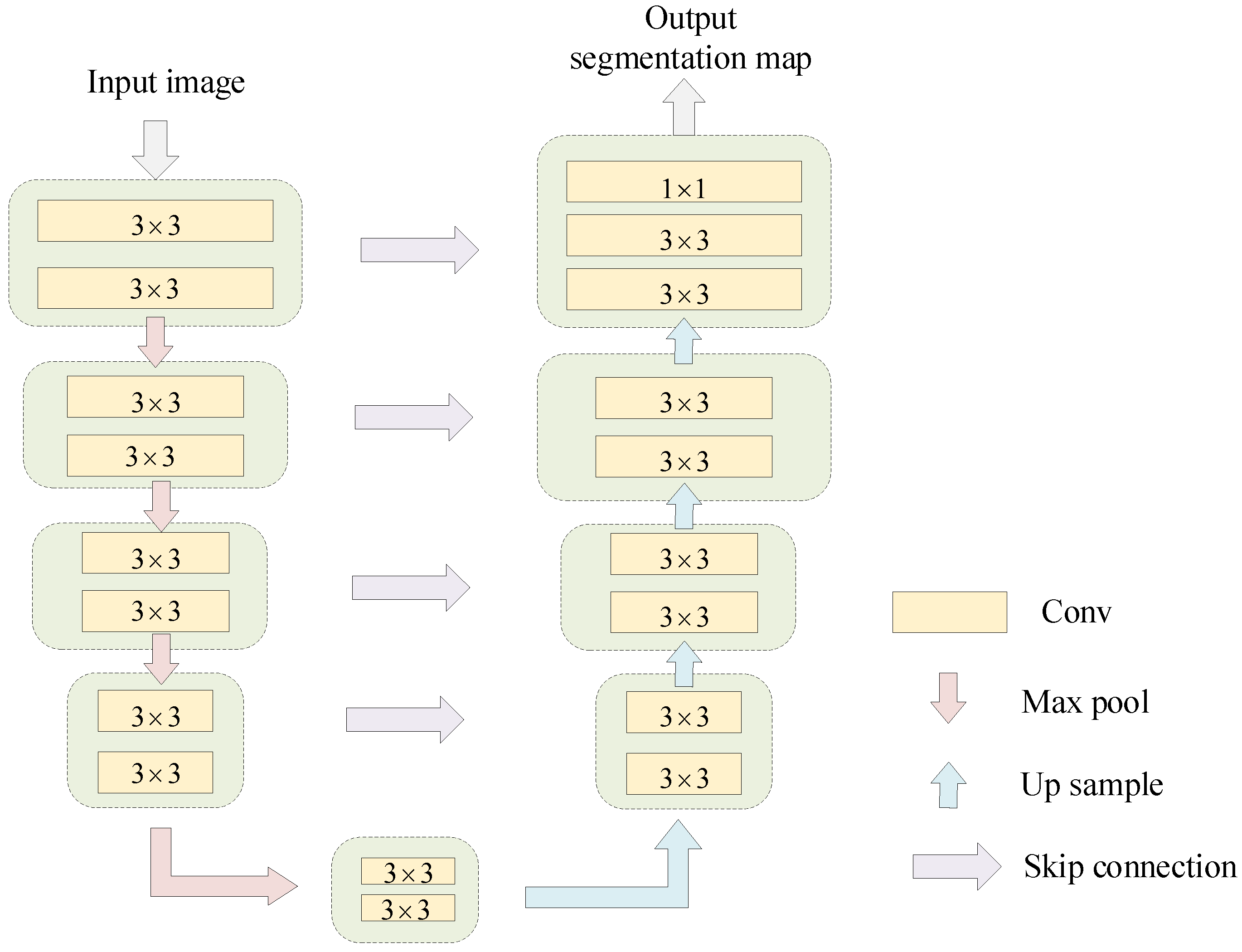
3.2. RUB-Based Feature Extraction
Feature extraction that encompasses both local and global information is crucial for image fusion. In the design of CNNs, the convolutional kernel size is typically
or
, leading to a perceptual field that is too small to capture global information. On the other hand, the residual U-Net block (RUB) is adapted to extract global features across all scales. Therefore, we employ RUBs to extract more global information from the shallow, high-resolution feature maps. The residual U-Net block can be defined as
, where
L is the number of U-Net layers;
and
represent the input and output channels, respectively; and
M represents the number of internal channels. The composition of the RUB, as shown in
Figure 3, can thus be described in three parts:
(1) Input layer: It conducts local feature extraction and transforms the input feature map into an intermediate feature with channels. The convolution kernel size is , and the activation function used is ReLU.
(2) U-Net encoder–decoder: Similar to U-Net, this structure encodes multi-scale context information from and acquires decoder features , where U represents the U-Net-like structure. A larger L implies a deeper residual U-Net module. The module initially extracts multi-scale features from multiple downsamples and subsequently encodes them into a high-resolution feature map through successive upsampling, concatenation, and convolution. This approach helps alleviate the loss of detail associated with direct upsampling.
(3) Residual connection: It combines local features with multi-scale depth features to achieve improved preservation of structural information:
where
is the output of RUB.
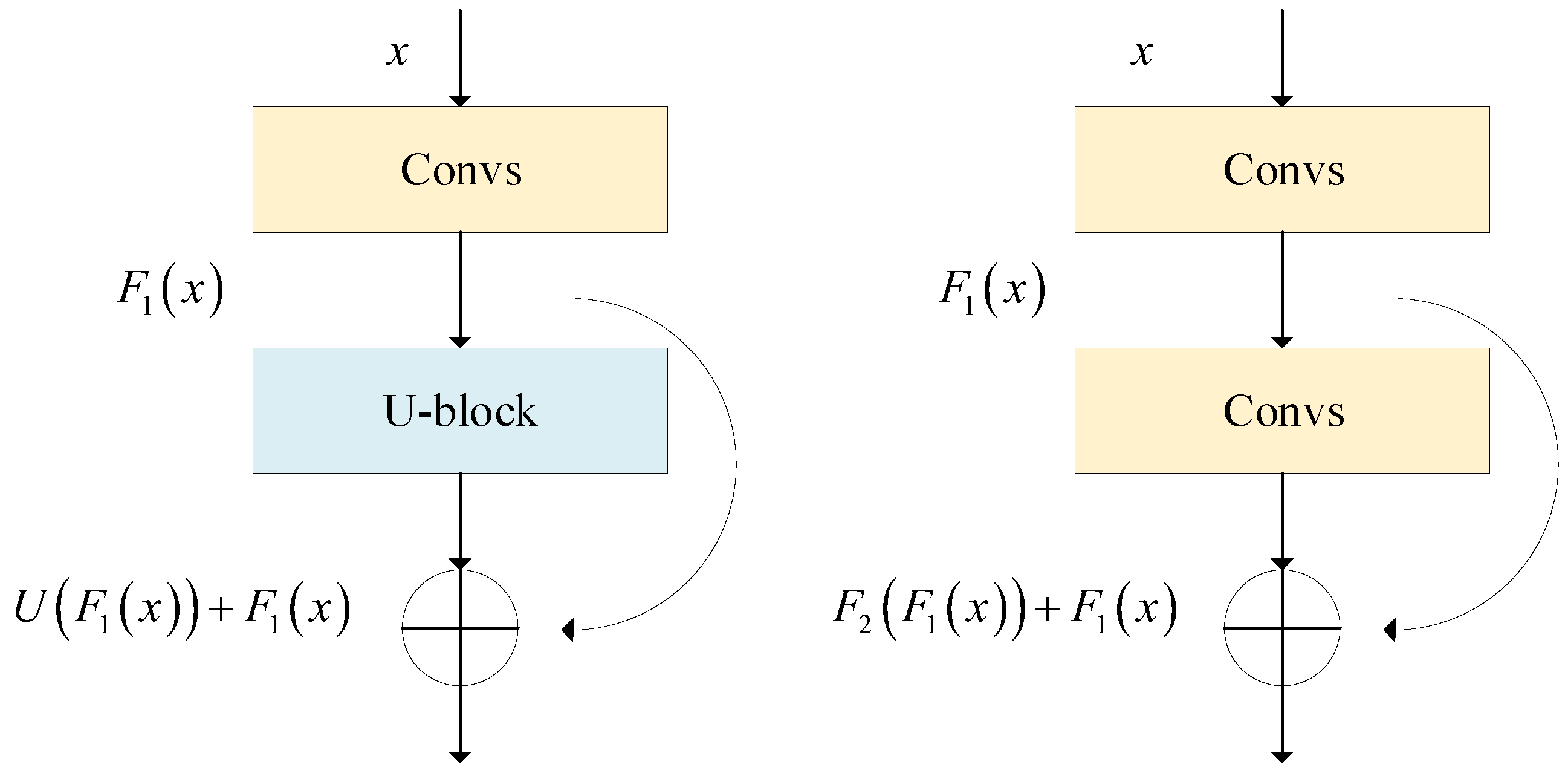
The comparison between normal residual blocks and RUBs is shown in
Figure 4. The extraction operations in normal residual blocks usually consist of one or more convolutional layers, which can be represented as
where
is the expected output. The main difference between RUBs and normal residual blocks is the replacement of the single-flow convolution with a U-Net structure. This makes it possible for the network to extract global information directly with very low computational overhead. In view of this, we employ a RUB as an encoder for the proposed method to thoroughly extract essential features at each scale.
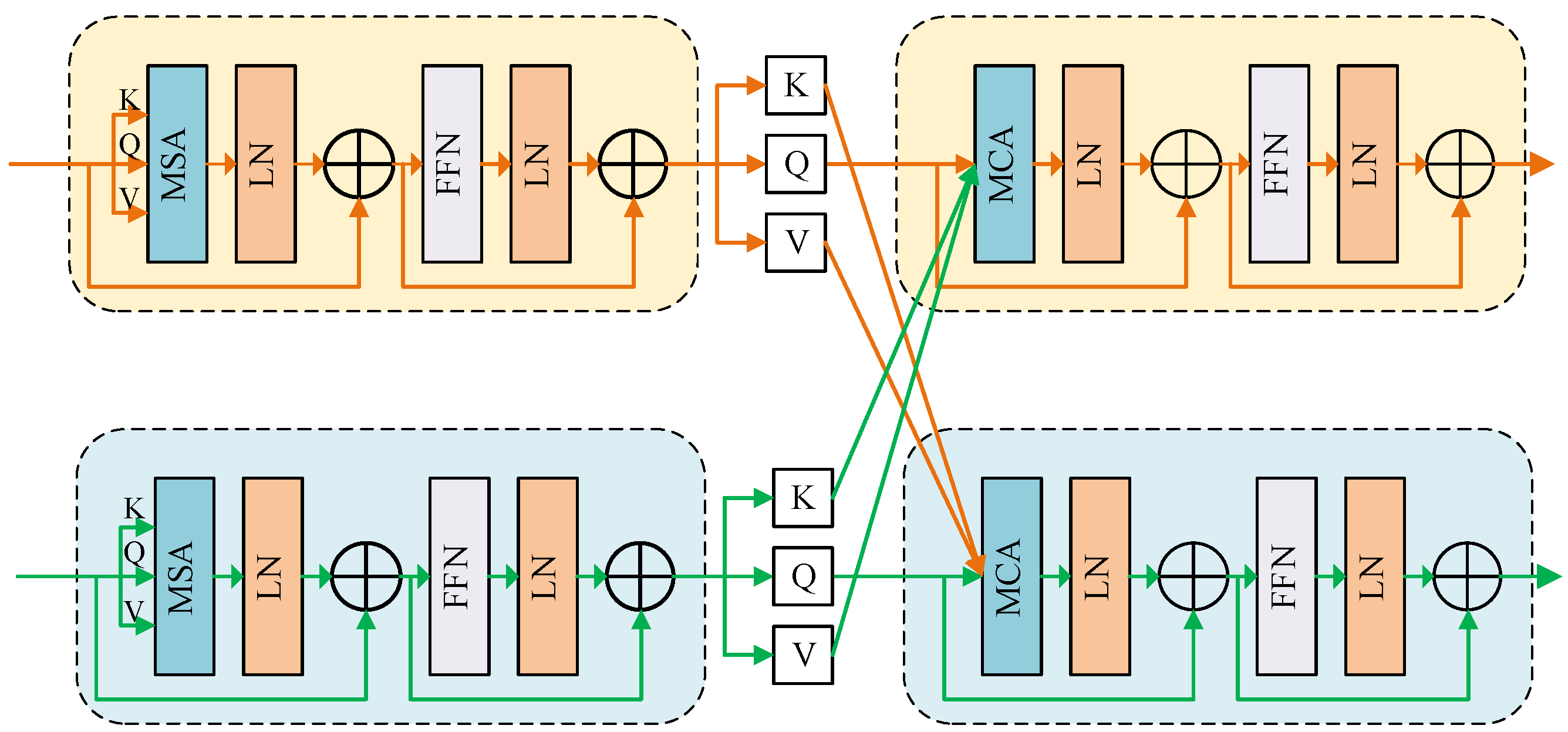
3.3. Hybrid Attention Transformer Fusion Block
After the extraction of multimodal features by the RUB, an HTFB is constructed to fuse these features using intra-domain self-attention and inter-domain cross-attention mechanisms. Firstly, multi-headed self-attentiveness (MSA) takes into account the global feature distribution, which helps the model capture information from multiple encoding subspaces. Then, to improve the feature tokens generated by MSA, a feedforward network (FFN) consisting of two multilayer perceptron (MLP) layers and a GELU activation layer is applied. Subsequently, layer normalization (LN) is implemented after the the MSA and FFN are run, and finally the residuals are deployed after being processed by these two modules. The process of intra-domain self-attention can be expressed as
Following intra-domain perception, inter-domain cross-attention interaction is implemented to further explore information common to different domains. As can be seen in
Figure 5, the basic modules of inter-domain and intra-domain awareness are similar, the main difference being that inter-domain awareness adopts multi-headed cross-attention (MCA) to achieve global content interaction. The whole process of inter-domain cross-attention interaction can be defined as below:
As shown in Formulas (
5)–(
8),
are querying features from domain2 that are similar to
in domain1, and similarly,
are querying features from domain1 that are similar to
in domain2, thus enabling the interaction between the two domains. Following the HTFB, a convolutional layer is adopted to integrate local information from different domains. Ultimately, the effective fusion of complementary multimodal features can be realized by cascading intra- and inter-domain hybrid attention.
3.4. Loss Function for HATF
In deep learning-based methods, the choice of the loss function is pivotal to fusion performance. To bolster feature extraction and fusion capabilities, we employ a two-stage training strategy and devise an adaptive loss function for the fusion of multimodal features. During the initial training stage, the encoder and decoder are directly connected to enhance feature extraction. In this stage, the loss function of the auto-encoder network (
) comprises two terms: the content loss (
) and the structural similarity loss (
).
is calculated as follows:
where
is a hyperparameter controlling the balance between the two terms. The content loss
facilitates the preservation of more details from the source image in the reconstructed image and can be expressed as follows:
where
represents the Frobenius norm, and
O and
I represent the output and input images, respectively. The structural similarity loss
is calculated to incorporate more structural features from the input images into the results and is defined as follows:
where
denotes structural similarity between two images, considering brightness, contrast, and structure. The inclusion of structural similarity loss aims to enhance the structural similarity of the results to the source images. In the second stage, HTFB undergoes training to augment the fusion feature’s capability. For more effective fusion of multimodal features, an adaptive fusion loss function is devised for this stage. The total fusion loss
encompasses three components: structural similarity loss
, multimodal feature loss
, and saliency loss
. The comprehensive loss is calculated as follows:
where
and
are hyperparameters that balance the three terms.
is calculated as in Equation (
11).
The multimodal deep features extracted by the encoder encompass diverse information, with shallow features being rich in detail, intermediate features representing structural information, and deep features primarily capturing regional features. To maximize the transfer of feature information to the fusion images, specific loss functions are designed for different modal features. The multimodal feature
consists of three parts: detail features loss
, structural feature loss
, and regional feature loss
; they are formulated as follows:
where
represents the features of each layer,
and
are hyperparameters,
and
denote masks to remove noise from features,
and
are self-adapting weights,
denotes the covariance function, and
denotes the standard deviation function.
,
,
, and
can be defined as follows:
where
is a constant set controlling the degree of noise removal.
To maintain the saliency of the thermal objects, the training process is supplemented with salient object detection information. During the fusion procedure, salient object regions are masked and an adaptive loss function is developed to drive feature extraction and reconstruction according to the masks. By selectively increasing the weights of salient objects and background textures, the fused images have high-quality texture details and clear saliency targets. Firstly, the LC [
41] saliency extraction algorithm is applied to extract the saliency map from the infrared image. The saliency map is then normalized to obtain
. Finally, the saliency loss is calculated as follows:
4. Experiments and Analysis
In this section, we perform comparative experiments to assess the performance of the proposed method against state-of-the-art methods. The experiments begin with an introduction to the evaluation metrics and datasets used. Subsequently, details about the training process are provided. Finally, the results of ablation experiments and comparison tests are presented to demonstrate the effectiveness of the proposed method.
Objective evaluation is employed to quantitatively assess the quality of the fusion results, aligning with the human visual system. In this section, five representative evaluation metrics are selected: entropy (EN), standard deviation (SD), mutual information (MI), structural similarity (SSIM) [
42], and root mean square error (RMSE). EN and SD provide insights into the amount of information present in the fused image. MI quantifies the information conveyed from the input image to the output image. SSIM and RMSE assess the similarity of structures and the level of distortion in the fused image, respectively. The better the fusion method, the higher the values of EN, SD, MI, and SSIM, and the lower the value for RMSE.
Five datasets were employed for training and testing: [
43] COCO datasets with rich scenes were selected to train the encoders. The TNO [
44], FLIR, and LLVIP [
45] datasets are infrared and visible image datasets containing various scenes, which are suitable for training and testing the proposed framework. In addition, supplementary experiments have been conducted on remote sense images to verify the generalizability of the proposed method. To assess the superiority of the proposed methods, we compared them with nine state-of-the-art fusion methods. These methods includes three traditional methods (DWT [
46], DTCWT [
47], and CVT [
48]) and five deep learning methods (DenseFuse [
23], FusionGAN [
20], IFCNN [
49], RFN-Nest [
25], Swin-F [
50], and MFST [
51]). To be fair, the comparative experiments were implemented employing the code and parameters provided in the corresponding papers.
4.1. Training Details
The proposed method was trained using Python 3.8, and all experiments were conducted on a system equipped with an RTX 2080Ti GPU and an Intel i7-7700 CPU. The detailed settings of each module are shown in
Table 1 and
Table 2. In the first stage, the encoder and decoder are trained by 80,000 images chosen from the MS-COCO dataset, which are first converted to greyscale and normalized to
. In the second stage, CTFBs are mainly trained. One CTFB contains four Transformer modules, two for intra-domain self-attention and the other two for inter-domain cross-attention. In Transformer, both the partition window size and the number of heads are set to eight. In this stage, 12,000 pairs of images from the LLVIP dataset are selected for training, which are converted to greyscale and resized to
. In addition, we give information on the computational and parametric quantities of HATF in
Table 3.
4.2. Ablation Study
To validate the feasibility of the model’s design, two ablation experiments are implemented in this section. First, the importance of RUBs in extracting multimodal features is discussed. Then, the effectiveness of the hybrid attention Transformer for feature fusion is verified.
4.2.1. Effect of RUBs on Extracting Multimodal Features
To confirm the effectiveness of the RUBs for feature extraction, the image reconstruction experiment was performed on the encoder. The performance of feature extraction and fusion on the TNO dataset was compared, with 2convs and RUBs as the encoders, respectively. As can be seen from
Table 4, both models have advantages in the reconstruction of infrared and visible images, respectively, while the average error of the RUBs is smaller than that of 2convs, indicating that the RUBs can transfer more information during the fusion process, leading to an increase in the image quality.
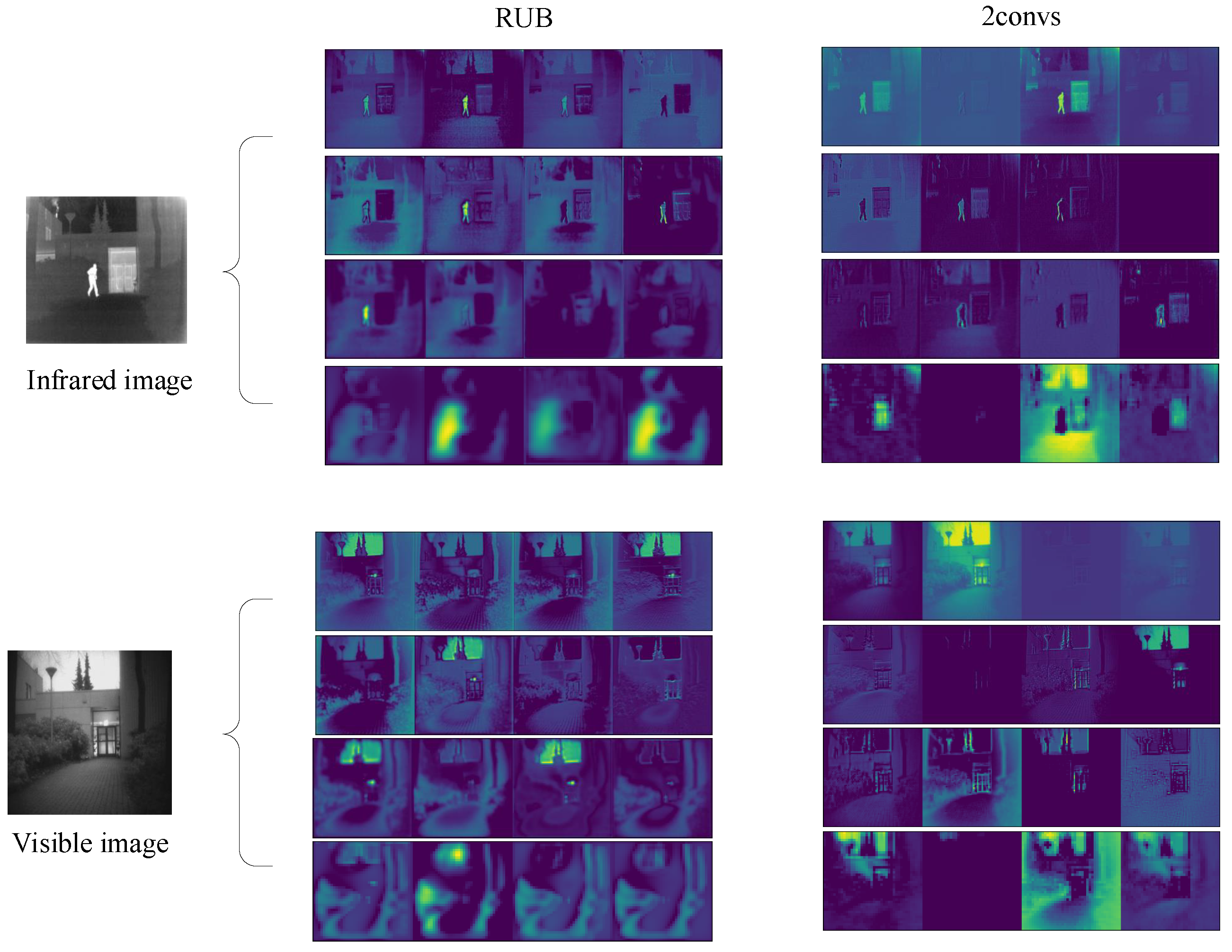
To provide a more intuitive understanding of the effectiveness of RUBs, the multimodal features extracted by the two networks are visualized in
Figure 6. For the infrared image, the shallow features extracted by the RUBs have more edge features, and the human target is more distinct when compared to the background. The RUBs effectively integrate local and global features in the shallow feature maps of visible images, showcasing their ability to capture clear structural information.
Finally, to indicate the role of RUBs in the overall fusion process, the 2convs and the RUBs encoders are separately connected to a hybrid attention Transformer to construct the fusion network. The same loss function and datasets are adopted to train the two networks, and the results of their comparison are depicted in
Figure 7. It is clear that the sky in
Figure 7c is unnatural and artifacts exist, whereas in
Figure 7d, the overall scene is blended more naturally.
Figure 7g shows a higher overall brightness but insufficient resolution. In
Figure 7h, the RUBs effectively combine shallow local features with deep features, improve the transmission efficiency of important information, and suppress noise to avoid artifacts.
Table 5 presents the objective metric comparison results for the two encoders. The RUBs achieve the best performance, demonstrating that they are superior to 2convs in terms of maintaining the richness of an image’s content and improving the visual quality of fused images.
4.2.2. The Impact of HTFBs on Feature Fusion
To check the efficiency of HTFBs, the fusion results of the HTFBs and the ordinary Swin-Transformer (swin-T) are compared, which can be seen in
Figure 8. For the first group of images, both fusion modules are able to produce satisfactory fusion results. In the case of the second group of images, the image fused by swin-T is relatively blurry, with glowing branches in the air, while the image obtained by the HTFBs has clearer door frames and renders people without artifacts. These results indicate that the hybrid attention mechanism can effectively integrate multimodal features, enhancing the complementarity of information.
Table 6 presents the comparative results of objective evaluation on the TNO dataset. As we can see, the HTFBs are superior to swin-T in five metrics, which is attributed to the fact that the hybrid attention Transformer not only improves the fusion of intra-domain local features but also the fusion of inter-domain complementary features.
4.3. Comparative Experiments and Analysis
To offer a comprehensive evaluation of the proposed method, nine different methods are compared based on five evaluation metrics using the TNO, FLIR, and LLVIP datasets. To further validate the generalization of the method, we tested it on remote sensing images and provided visualization results.
4.3.1. Results on TNO Dataset
To assess the performance of various methods in fusing infrared and visible images, we initially focused on the TNO dataset, which is a well-established benchmark used for evaluations.
Figure 9 displays the fusion results of six image pairs using the proposed method as well as nine other methods. Among them, DWT, CVT, and DTCWT can effectively preserve the content of both the infrared and visible images. However, their fusion results suffer from blurred textures because the weighted averaging strategy leads to the loss of detailed information. Although FusionGan mainly preserves the pixel distribution in infrared images, it ignores the texture details in visible images. RFN-Nest does a good job of preserving the texture information and the greyscale distribution in the visible images, while also making thermal objects appear blurred. The results of DenseFuse are relatively low in brightness, while those of IFCNN are relatively high in brightness. The fused images of swin-F and MFST are visually good, but their contrast is low. Compared to the above methods, HATF achieved higher contrast and better visual results and is able to balance important object and background texture information well.
Table 7 showcases the quantitative comparison results among the relevant methods. The best values, second-best values, and third-best values are highlighted in bold, red, and blue, respectively. Overall, deep learning-based methods outperform traditional methods in all metrics, mainly because neural networks transmit information significantly more efficiently than traditional methods. Among them, Swin-F and MFST exhibit significant advantages, which can be attributed to the adoption of Transformer as the feature fusion module. This allows for enhanced fusion efficiency and better utilization of complementary information, leading to improved performance. The proposed method outperforms other methods in four metrics (EN, SD, SSIM, MI), and achieves sub-optimal performance on RMSE. The comparative results reveal that the proposed method generates fused images with enhanced information and textural detail and improved visual effects.
4.3.2. Results on FLIR Dataset
To confirm the fusion capability of HATF for complicated scenes, further experiments were performed on the FLIR dataset. Intuitive comparison results of night and day scenes are presented in
Figure 10 and
Figure 11. As can be seen in
Figure 10, the results obtained by DWT, CVT, DTCWT, and DenseFuse preserve primary pixel distribution well; nevertheless, they lack the detailed information contained in visible images. FusionGan and RFN-Nest do not perform well on night scenes and produce results with poor visual effects. It is observed that IFCNN preserves infrared details well; however, there are significant contrast differences compared to the original image. Swin-F and MFST demonstrate strong performances on the FLIR dataset, producing fused images with enhanced backgrounds and salient object edges. In contrast to those methods, the proposed method does not only maintains the rich background texture and clear edge contours but also integrates salient thermal objects to produce images suitable for human visual perception. For the daytime scene (
Figure 11), our fusion framework also produces a high-contrast image by achieving a balance between infrared and visible information.
The quantitative evaluation of the fusion capability of the ten methods on the FLIR dataset is presented in
Table 8. From the table, it can be observed that the proposed method achieved the highest MI, the second-best results in terms of SSIM and SD, and the third-best results in terms of EN. RFN-Nest mainly focuses on constraining the pixel values between the fusion image and the input images, considering mainly local information during the fusion, which results in improved fusion performance in EN and SD. Our method is comparable to SWIN-F on SSIM and has significant advantages on EN, SD, and MI. Compared to MFST, the proposed method has advantages in all metrics except for a slightly lower EN and RMSE. In general, the proposed method excels in fusing images comprehensively, considering both structural features and saliency features. It performs particularly well in processing images with distinct structures and clear edges, showcasing its advantages in such scenarios.
4.3.3. Results on LLVIP Dataset
In addition, further comparison experiments were carried out on the LLVIP dataset, which was captured by surveillance cameras and has high-resolution and rich texture information.
Figure 12 shows the comparison fusion results of the related methods for a typical surveillance scene with clear objects. Results obtained by traditional methods have more artifacts and noise, resulting in poor image quality. FusionGan and RFN-nest are not good enough at keeping the edges of thermal objects. Although IFCNN and Swin-F perform the fusion task better, they do not employ a multi-scale network to extract features, which results in the loss of structural information like contours. Meanwhile, the results obtained by MFST have lower contrast and less visible texture details. In comparison, the proposed method generates images with clear objects, sharp edges, and the best visual effects, demonstrating that it also provides better fusion performance on the LLVIP dataset.
The quantitative comparison of the fusion performance for the ten methods on the LLVIP dataset is presented in
Table 9. As can be seen from the table, the overall performance of IFCNN and RFN-nest are similar. Swin-F has a good performance on EN and SD and a poor performance on the other three metrics. MFST outperforms traditional methods in terms of SSIM and MI due to the more efficient information transfer in Transformer. HATF achieved optimal scores in three metrics: SSIM, MI, and RMSE. This shows that our method produces fused images of high quality on the LLVIP dataset, which can be attributed to the effective extraction and fusion of complementary features by the RUBs and HTFBs.
4.4. Generalization Experiments on Remote Sensing Images
To validate the generalization of the proposed method, extensive experiments on remote sensing images are conducted in this section. Near-infrared (NIR) and visible image datasets to be fused are chosen from multimodal remote sensing images.
Figure 13 showcases the remote sensing fusion images obtained by the proposed method. The images from the first to the third column represent the NIR, visible, and fused images, respectively. The fusion results achieved by the proposed method demonstrate a notable enhancement of salient information from the NIR image while preserving color texture. Consequently, the proposed method significantly improves the information richness and visual impact of the fused image, affirming its robust generalization capability on remote sensing images.
5. Conclusions
In this paper, we present a hybrid attention Transformer fusion model (HATF) for infrared and visible image fusion task. The proposed method effectively improves the extraction efficiency of multimodal features and the fusion quality of images.
The innovations of our model are presented in three parts. Firstly, a residual U-Net block (RUB) is adopted to obtain more local and global information from shallow and deep layers. Secondly, the hybrid attention Transformer is constructed to fully retain complementary information and better integrate multimodal features. Finally, the adaptive loss function of multimodal features is designed to realize the high-quality fusion of infrared and visible images. Extensive comparative experiments on three datasets were conducted, and HATF achieved competitive results on several performance metrics. The experimental results demonstrate that the proposed method is effective at fusing various scene images and that it outperforms related popular methods, thus verifying the superiority of HATF.
Our experiments on satellite images validate that HATF can be applied to remote sensing image fusion scenarios. In our future work, we will further verify the performance of HATF in several potential application scenarios, such as medical image fusion, multi-exposure image fusion, and multi-focus image fusion. In addition, we will also focus on the use of fused image techniques to enhance the performance of other visual tasks, such as target detection and image segmentation.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}