
A Decompressed Spectral-Spatial Multiscale Semantic Feature Network for Hyperspectral Image Classification




Abstract
:1. Introduction
- (1)
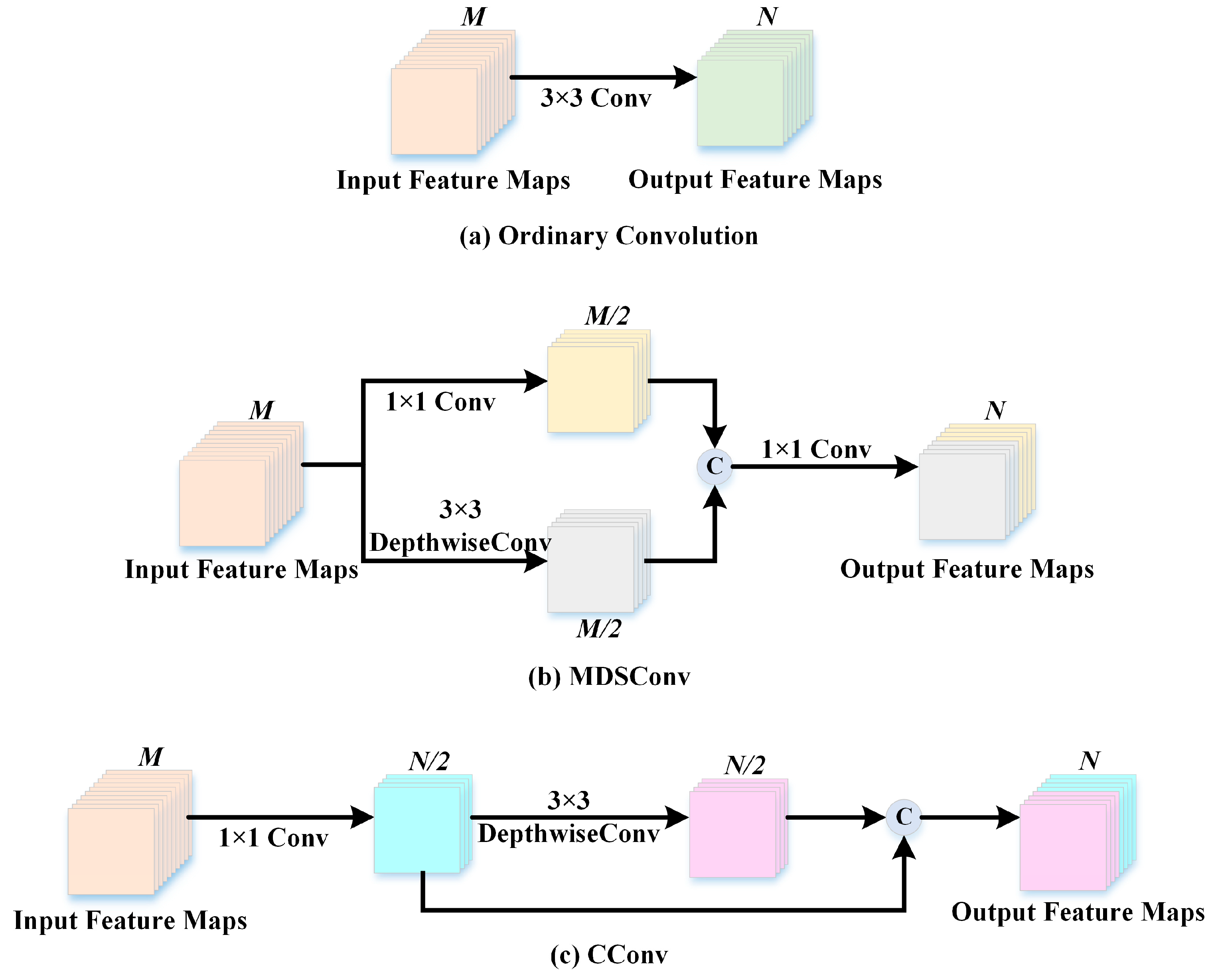
- To decrease the training parameters and computational complexity, we devise a compressed-weight convolutional (CConv) layer, which takes the place of the traditional 2D convolutional layer, to extract spatial and spectral information through cheap operations.
- (2)
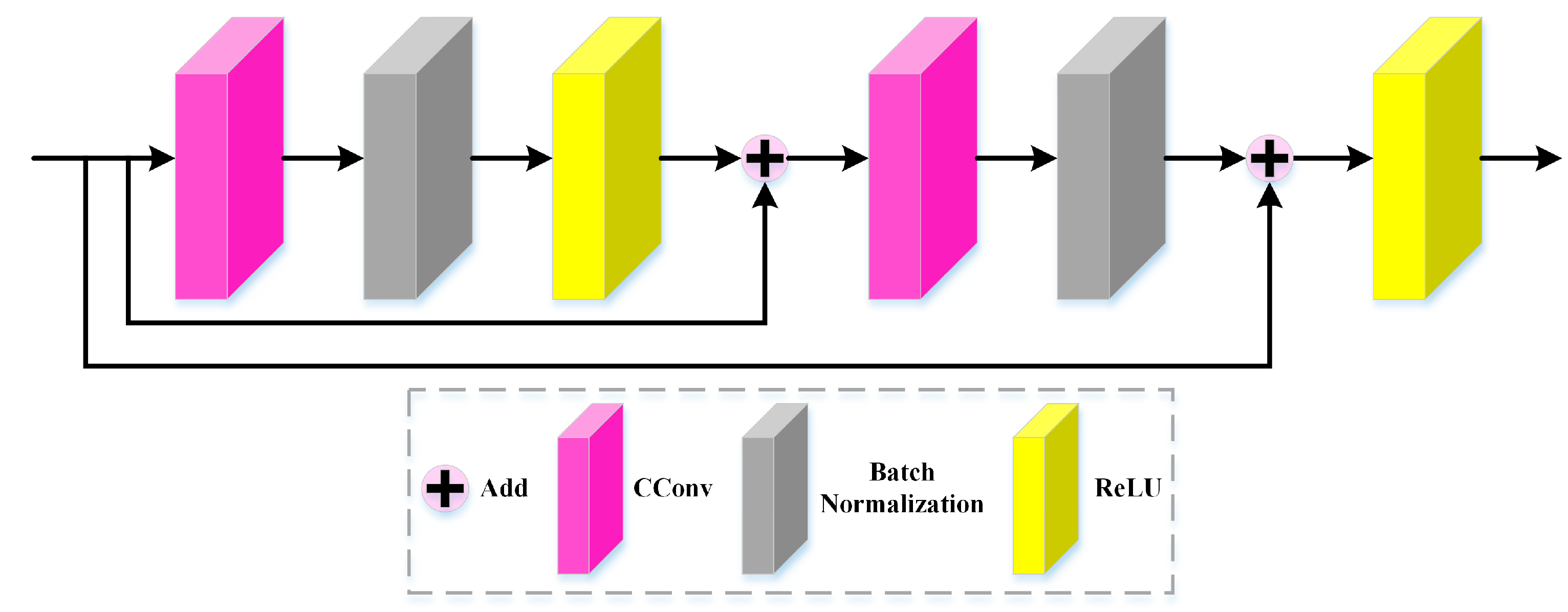
- To conduct an efficient and lightweight spectral-spatial feature extraction, we construct a compressed residual block (CRB), embedding the CConv layer into a residual block, to alleviate the overfitting and achieve spectral-spatial feature reuse effectively.
- (3)
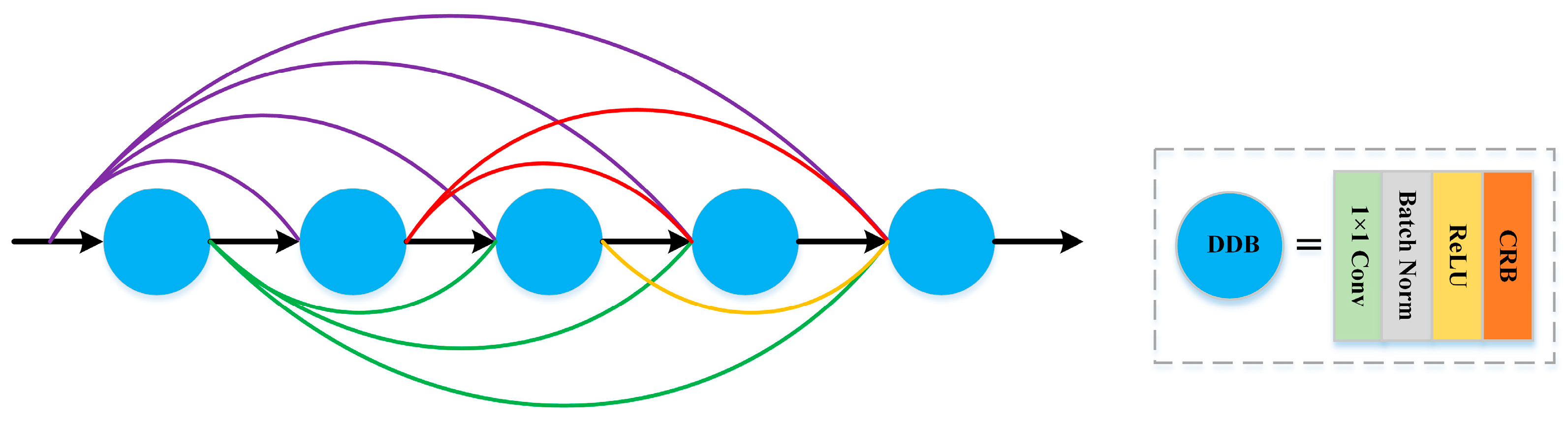
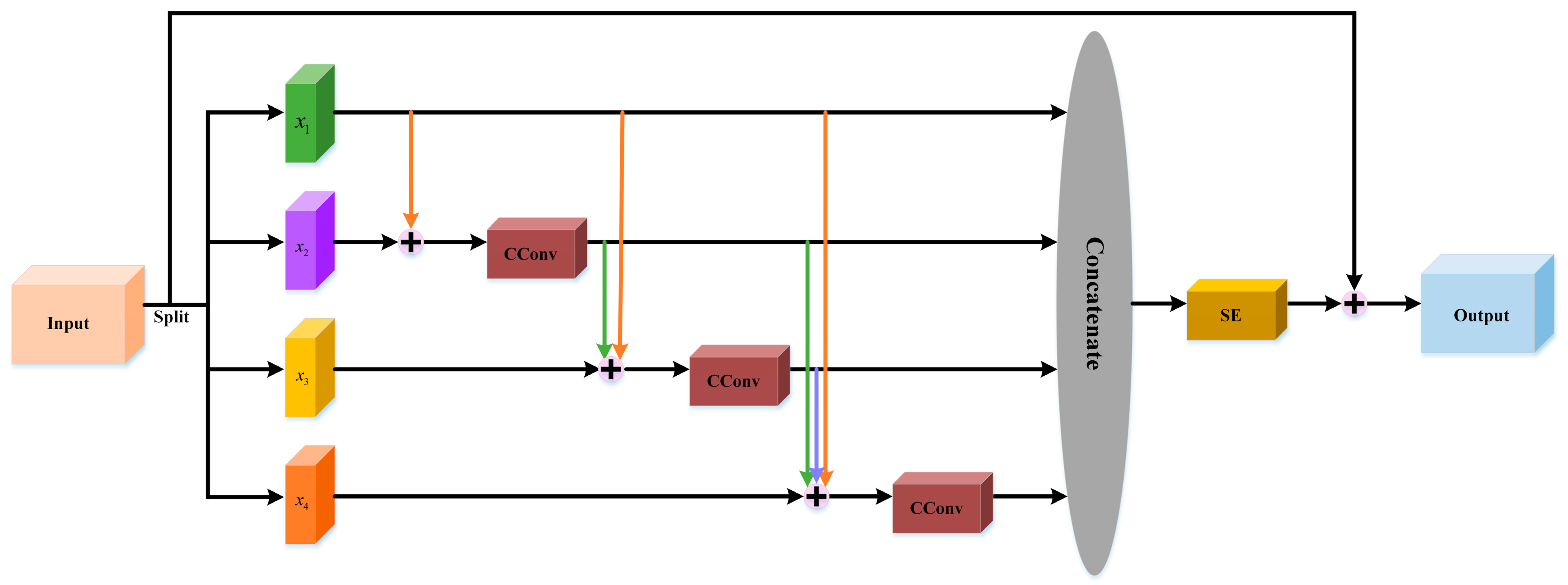
- To obtain more representative and discriminative global decompressed spectral-spatial features, we build a decompressed spectral-spatial feature extraction module (DSFEM) in a lightweight extraction manner. For one thing, DSFEM is composed of multiple decompressed dense blocks (DDBs), which provide abundant local decompressed spectral-spatial features. For another thing, the dense connection is introduced into DSFEM to integrate features from shallow and deep layers, thereby acquiring robust complementary information.
- (4)
- To further enhance the classification performance, we raise a multiscale semantic feature extraction module (MSFEM). The MSFEM can not only expand the range of available receptive fields but also generate clean multiscale semantic features for classification tasks at a granular level.
2. Method
2.1. Decompressed Spectral-Spatial Feature Extraction Module
2.1.1. Compressed-Weight Convolution Layer
2.1.2. Compressed Residual Block
2.1.3. Decompressed Dense Block
2.2. Multiscale Semantic Feature Extraction Module
2.3. The Overall Framework of the Proposed DSMSFNet
3. Experimental Results and Discussion
3.1. Datasets Description
3.2. Experimental Setup
3.3. Comparison Methods
3.4. Discussion
3.4.1. Influence of Different Spatial Sizes
3.4.2. Influence of Diverse Training Percentage
3.4.3. Influence of Different Numbers of Principal Components
3.4.4. Influence of Diverse Compressed Ratio in the MSFEM
3.4.5. Influence of Different L2 Regularization Parameters
3.4.6. Influence of Diverse Convolutional Kernel Numbers of DDBs
3.4.7. Influence of Various Numbers of DDBs in the DSFEM
3.5. Ablation Study
3.5.1. The Effect of Constructed CConv Layer
3.5.2. The Effect of the Designed DSMSFNet Model
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Landgrebe, D. Hyperspectral image data analysis. IEEE Signal Process. Mag. 2002, 19, 17–28. [Google Scholar] [CrossRef]
- Han, X.; Yu, J.; Xue, J.-H.; Sun, W. Hyperspectral and multispectral image fusion using optimized twin dictionaries. IEEE Trans. Image Process. 2020, 29, 4709–4720. [Google Scholar] [CrossRef]
- Gu, Y.; Chanussot, J.; Jia, X.; Benediktsson, J.A. Multiple Kernel learning for hyperspectral image classification: A review. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6547–6565. [Google Scholar] [CrossRef]
- Li, S.; Zhu, X.; Liu, Y.; Bao, J. Adaptive spatial–spectral feature learning for hyperspectral image classification. IEEE Access 2019, 7, 61534–61547. [Google Scholar] [CrossRef]
- Ghamisi, P.; Yokoya, N.; Li, J.; Liao, W.; Liu, S.; Plaza, J.; Rasti, B.; Plaza, A. Advances in hyperspectral image and signal processing: A comprehensive overview of the state of the art. IEEE Geosci. Remote Sens. Mag. 2017, 5, 37–78. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5966–5978. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More diverse means better: Multimodal deep learning meets remote sensing imagery classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Wu, Z.; Zhu, W.; Chanussot, J.; Xu, Y.; Osher, S. Hyperspectral anomaly detection via global and local joint modeling of background. IEEE Trans. Signal Process. 2019, 67, 3858–3869. [Google Scholar] [CrossRef]
- Vaglio Laurin, G.; Chan, J.C.; Chen, Q.; Lindsell, J.A.; Coomes, D.A.; Guerriero, L.; Frate, F.D.; Miglietta, F.; Valentini, R. Biodiversity Mapping in a Tropical West African Forest with Airborne Hyperspectral Data. PLoS ONE 2014, 9, e97910. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Zhang, N.; Xu, D.; Luo, H.; Chen, B.; Ben, G. SSDANet: Spectral-spatial three-dimensional convolutional neural network for hyperspectral image classification. IEEE Access 2020, 8, 127167–127180. [Google Scholar] [CrossRef]
- Lin, C.; Wang, T.; Dong, S.; Zhang, Q.; Yang, Z.; Gao, F. Hybrid Convolutional Network Combining 3D Depthwise Separable Convolution and Receptive Field Control for Hyperspectral Image Classification. Electronics 2022, 11, 3992. [Google Scholar] [CrossRef]
- Savelonas, M.A.; Veinidis, C.V.; Bartsokas, T.K. Computer Vision and Pattern Recognition for the Analysis of 2D/3D Remote Sensing Data in Geoscience: A Survey. Remote Sens. 2022, 14, 6017. [Google Scholar] [CrossRef]
- Gong, H.; Li, Q.; Li, C.; Dai, H.; He, Z.; Wang, W.; Li, H.; Han, F.; Tuniyazi, A.; Mu, T. Multiscale information fusion for hyperspectral image classification based on hybrid 2D-3D CNN. Remote Sens. 2021, 13, 2268. [Google Scholar] [CrossRef]
- Ghaderizadeh, S.; Abbasi-Moghadam, D.; Sharifi, A.; Zhao, N.; Tariq, A. Hyperspectral image classification using a hybrid 3D-2D convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7570–7588. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Q.; Li, X. Exploring the relationship between 2D/3D convolution for hyperspectral image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8693–8703. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, C.; Wang, H.; Li, J. Learn multiple-kernel SVMs domain adaptation in hyperspectral data. IEEE Geosci. Remote Sens. 2013, 10, 1224–1228. [Google Scholar]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral–spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2012, 50, 809–823. [Google Scholar] [CrossRef]
- Meng, Z.; Jiao, L.; Liang, M.; Zhao, F. A Lightweight SpectralSpatial Convolution Module for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5504205. [Google Scholar]
- Zhang, C.; Zheng, Y. Hyperspectral remote sensing image classification based on combined SVM and LDA. In Proceedings of the SPIE Asia Pacific Remote Sensing 2014, Beijing, China, 13–16 October 2014; p. 92632P. [Google Scholar]
- Licciardi, G.; Marpu, P.; Chanussot, J.; Benediktsson, J. Linear versus nonlinear pca for the classification of hyperspectral data based on the extended morphological profiles. IEEE Geosci. Remote Sens. Lett. 2011, 9, 447–451. [Google Scholar] [CrossRef]
- Villa, A.; Chanussot, J.; Jutten, C.; Benediktsson, J.; Moussaoui, S. On the use of ICA for hyperspectral image analysis. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; pp. IV-97–IV-100. [Google Scholar]
- Li, S.; Jia, X.; Zhang, B. Superpixel-based Markov random field for classification of hyperspectral images. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Melbourne, Australia, 21–26 July 2013; pp. 3491–3494. [Google Scholar]
- Jiang, J.; Ma, J.; Wang, Z.; Chen, C.; Liu, X. Hyperspectral image classification in the presence of noisy labels. IEEE Trans. Geosci. Remote Sens. 2019, 57, 851–865. [Google Scholar] [CrossRef]
- Chne, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sensors 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Li, W.; Wu, G.; Zhang, F.; Du, Q. Hyperspectral Image Classification Using Deep Pixel-Pair Features. IEEE Trans. Geosci. Remote Sens. 2017, 55, 844–853. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.; Chan, J.C.; Yi, C. Hyperspectral image classification using two-channel deep convolutional neural network. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 5079–5082. [Google Scholar]
- Li, X.; Ding, M.; Pižurica, A. Deep Feature Fusion via Two-Stream Convolutional Neural Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2615–2629. [Google Scholar] [CrossRef]
- Zhu, M.; Jiao, L.; Yang, S.; Wang, J. Residual Spectral-spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 449–462. [Google Scholar] [CrossRef]
- Zhang, X.; Shang, S.; Tang, X.; Feng, J.; Jiao, L. Spectral Partitioning Residual Network with Spatial Attention Mechanism for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5507714. [Google Scholar] [CrossRef]
- Wang, W.; Dou, S.; Jiang, Z.; Sun, L. A fast dense spectral–spatial convolution network framework for hyperspectral images classification. Remote Sens. 2018, 10, 1068. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67–87. [Google Scholar] [CrossRef]
- Lin, J.; Mou, L.; Zhu, X.; Ji, X.; Wang, Z.J. Attention-Aware Pseudo-3-D Convolutional Neural Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7790–7802. [Google Scholar] [CrossRef]
- Zhao, S.; Li, W.; Du, Q.; Ran, Q. Hyperspectral classification based on Siamese neural network using spectral–spatial feature. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2087–2090. [Google Scholar]
- He, M.; Li, B.; Chen, H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3904–3908. [Google Scholar]
- Gao, H.; Miao, Y.; Cao, X.; Li, C. Densely Connected Multiscale Attention Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2563–2576. [Google Scholar] [CrossRef]
- Xue, Y.; Zeng, D.; Chen, F.; Wang, Y.; Zhang, Z. A new dataset and deep residual spectral spatial network for hyperspectral image classification. Symmetry 2020, 12, 561. [Google Scholar] [CrossRef]
- Safari, K.; Prasad, S.; Labate, D. A multiscale deep learning approach for high-resolution hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2021, 18, 167–171. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral image classification with deep feature fusion network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep & dense convolutional neural network for hyperspectral image classification. Remote Sens. 2018, 10, 1454. [Google Scholar]
- Li, Z.; Zhao, X.; Xu, Y.; Li, W.; Shi, X. Hyperspectral Image Classification With Multiattention Fusion Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5503305. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Gao, H.; Yang, Y.; Li, C.; Gao, L.; Zhang, B. Multiscale Residual Network with Mixed Depthwise Convolution for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3396–3408. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Gao, H.; Zhang, Y.; Chen, Z.; Li, C. A Multiscale Dual-Branch Feature Fusion and Attention Network for Hyperspectral Images Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8180–8192. [Google Scholar] [CrossRef]
- Xu, Q.; Xiao, Y.; Wang, D.; Luo, B. CSA-MSO3DCNN: Multiscale Octave 3D CNN with Channel and Spatial Attention for Hyperspectral Image Classification. Remote Sens. 2020, 12, 188. [Google Scholar] [CrossRef]
- Acito, N.; Matteoli, S.; Rossi, A.; Diani, M.; Corsini, G. Hyperspectral airborne “Viareggio 2013 Trial” data collection for detection algorithm assessment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2365–2376. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, T.; Yang, Y. Hyperspectral image classification based on multi-scale residual network with attention mechanism. arXiv 2020, arXiv:2004.12381. [Google Scholar]
- Ahmad, M.; Shabbir, S.; Raza, R.A.; Mazzara, M.; Distefano, S.; Khan, A.M. Hyperspectral Image Classification: Artifacts of Dimension Reduction on Hybrid CNN. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Xiang, J.; Wei, C.; Wang, M.; Teng, L. End-to-End Multilevel Hybrid Attention Framework for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5511305. [Google Scholar] [CrossRef]
- Wang, X.; Fan, Y. Multiscale Densely Connected Attention Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1617–1628. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Color | Class | Train | Test |
|---|---|---|---|---|
| 1 |  | Water | 10 | 85 |
| 2 |  | Hippo grass | 27 | 241 |
| 3 |  | Floodplain grasses 1 | 19 | 162 |
| 4 |  | Floodplain grasses 2 | 31 | 274 |
| 5 |  | Reeds | 25 | 223 |
| 6 |  | Riparian | 32 | 282 |
| 7 |  | Fires car | 21 | 182 |
| 8 |  | Island interior | 26 | 233 |
| 9 |  | Acacia woodlands | 27 | 242 |
| 10 |  | Acacia shrub lands | 27 | 242 |
| 11 |  | Acacia grasslands | 22 | 193 |
| 12 |  | short mopane | 26 | 225 |
| 13 |  | Mixed mopane | 11 | 90 |
| 14 |  | Exposed soils | 27 | 243 |
| Total | 331 | 2917 | ||
| No. | Color | Class | Train | Test |
|---|---|---|---|---|
| 1 |  | Alfalfa | 10 | 36 |
| 2 |  | Corn-notill | 286 | 1142 |
| 3 |  | Corn-mintill | 166 | 664 |
| 4 |  | Corn | 48 | 189 |
| 5 |  | Grass-pasture | 97 | 386 |
| 6 |  | Grass-trees | 146 | 584 |
| 7 |  | Grass-pasture-mowed | 6 | 22 |
| 8 |  | Hay-windrowed | 96 | 382 |
| 9 |  | Oats | 4 | 16 |
| 10 |  | Soybean-notill | 195 | 777 |
| 11 |  | Soybean-mintill | 491 | 1964 |
| 12 |  | Soybean-clean | 119 | 474 |
| 13 |  | Wheat | 41 | 164 |
| 14 |  | Woods | 253 | 1012 |
| 15 |  | Buildings-Grass-Tree | 78 | 308 |
| 16 |  | Stone-Steel-Towers | 19 | 74 |
| Total | 2055 | 8194 | ||
| No. | Color | Class | Train | Test |
|---|---|---|---|---|
| 1 |  | Healthy grass | 239 | 1125 |
| 2 |  | Stressed grass | 126 | 1128 |
| 3 |  | Synthetic grass | 70 | 627 |
| 4 |  | Trees | 125 | 1119 |
| 5 |  | Soil | 125 | 1117 |
| 6 |  | Water | 33 | 292 |
| 7 |  | Residential | 127 | 1141 |
| 8 |  | Commercial | 125 | 1119 |
| 9 |  | Road | 126 | 1126 |
| 10 |  | Highway | 123 | 1104 |
| 11 |  | Railway | 124 | 1111 |
| 12 |  | Parking Lot 1 | 124 | 1109 |
| 13 |  | Parking Lot 2 | 47 | 422 |
| 14 |  | Tennis Court | 43 | 385 |
| 15 |  | Running Track | 66 | 594 |
| Total | 1510 | 13519 | ||
| No. | SVM | RF | KNN | GaussianNB | HybridSN | MSRN_A | 3D_2D_CNN | RSSAN | MSRN_B | DMCN | MSDAN | DSMSFNet |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 100.00 | 97.89 | 99.59 | 98.37 | 87.82 | 96.05 | 92.75 | 100.00 | 98.78 | 91.01 | 95.29 | 97.59 |
| 2 | 98.11 | 98.81 | 92.13 | 67.74 | 100.00 | 100.00 | 96.77 | 100.00 | 100.00 | 88.24 | 100.00 | 100.00 |
| 3 | 78.65 | 90.25 | 93.62 | 80.58 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 4 | 100.00 | 83.64 | 87.25 | 65.02 | 98.47 | 100.00 | 99.47 | 100.00 | 100.00 | 96.48 | 96.41 | 100.00 |
| 5 | 80.59 | 72.66 | 82.33 | 71.90 | 88.24 | 97.05 | 95.90 | 87.08 | 92.37 | 100.00 | 96.54 | 100.00 |
| 6 | 50.00 | 76.34 | 60.00 | 57.23 | 97.78 | 100.00 | 97.51 | 93.53 | 100.00 | 100.00 | 97.10 | 100.00 |
| 7 | 100.00 | 98.67 | 99.55 | 97.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 99.57 | 100.00 | 100.00 |
| 8 | 84.90 | 88.02 | 77.53 | 82.84 | 99.44 | 100.00 | 100.00 | 100.00 | 91.92 | 94.49 | 100.00 | 100.00 |
| 9 | 68.48 | 80.14 | 78.23 | 71.43 | 98.26 | 100.00 | 100.00 | 97.45 | 100.00 | 100.00 | 100.00 | 100.00 |
| 10 | 75.62 | 76.83 | 88.02 | 67.83 | 98.67 | 100.00 | 98.67 | 98.22 | 96.96 | 97.80 | 100.00 | 100.00 |
| 11 | 86.24 | 89.53 | 91.49 | 88.85 | 97.51 | 96.48 | 99.64 | 99.27 | 100.00 | 99.63 | 100.00 | 100.00 |
| 12 | 89.60 | 91.57 | 93.49 | 91.61 | 97.59 | 100.00 | 100.00 | 97.44 | 46.55 | 96.41 | 100.00 | 100.00 |
| 13 | 90.77 | 79.76 | 93.06 | 70.97 | 100.00 | 100.00 | 100.00 | 94.88 | 100.00 | 98.77 | 97.97 | 100.00 |
| 14 | 100.00 | 98.80 | 97.59 | 93.62 | 100.00 | 97.70 | 100.00 | 95.31 | 83.33 | 97.18 | 100.00 | 100.00 |
| OA (%) | 82.05 | 85.98 | 87.04 | 78.83 | 96.95 | 99.01 | 98.53 | 97.15 | 91.50 | 97.57 | 98.66 | 99.79 |
| AA (%) | 81.82 | 86.95 | 87.87 | 81.06 | 95.87 | 99.12 | 98.13 | 96.16 | 92.21 | 97.02 | 98.71 | 99.82 |
| Kappa × 100 | 80.53 | 84.81 | 85.96 | 77.10 | 96.69 | 98.92 | 98.40 | 96.92 | 90.81 | 97.36 | 98.55 | 99.78 |
| Complexity (G) | — | — | — | — | 0.0102 | 0.0011 | 0.0005 | 0.0002 | 0.0003 | 0.0045 | 0.0025 | 0.0003 |
| Parameter (M) | — | — | — | — | 9.2252 | 0.1965 | 0.2579 | 0.1159 | 0.1637 | 2.2292 | 1.2638 | 0.1628 |
| No. | SVM | RF | KNN | GaussianNB | HybridSN | MSRN_A | 3D_2D_CNN | RSSAN | MSRN_B | DMCN | MSDAN | DSMSFNet |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.00 | 86.67 | 36.36 | 31.07 | 97.06 | 100.00 | 100.00 | 97.30 | 90.32 | 100.00 | 100.00 | 94.59 |
| 2 | 61.51 | 82.02 | 50.38 | 45.54 | 98.86 | 99.73 | 95.79 | 98.00 | 97.45 | 97.46 | 98.95 | 98.70 |
| 3 | 84.04 | 78.66 | 61.95 | 35.92 | 97.04 | 100.00 | 95.99 | 99.54 | 98.74 | 93.50 | 99.54 | 100.00 |
| 4 | 46.43 | 72.87 | 53.26 | 15.31 | 98.86 | 98.38 | 92.94 | 99.46 | 99.39 | 96.81 | 98.85 | 97.42 |
| 5 | 88.82 | 90.16 | 84.71 | 3.57 | 98.47 | 97.72 | 99.47 | 98.22 | 92.54 | 98.69 | 98.70 | 99.48 |
| 6 | 76.72 | 82.61 | 78.08 | 67.87 | 100.00 | 100.00 | 100.00 | 99.83 | 99.65 | 100.00 | 99.49 | 100.00 |
| 7 | 0.00 | 83.33 | 68.42 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 86.96 | 100.00 |
| 8 | 83.49 | 87.16 | 88.55 | 83.78 | 96.46 | 100.00 | 100.00 | 99.48 | 80.08 | 98.70 | 99.74 | 100.00 |
| 9 | 0.00 | 100.00 | 40.00 | 11.02 | 76.19 | 100.00 | 100.00 | 100.00 | 0.00 | 100.00 | 100.00 | 100.00 |
| 10 | 70.89 | 83.61 | 69.40 | 27.07 | 99.74 | 97.72 | 97.48 | 99.48 | 88.93 | 99.87 | 98.46 | 100.00 |
| 11 | 58.51 | 75.16 | 69.49 | 60.60 | 98.77 | 98.94 | 97.48 | 99.19 | 97.57 | 99.69 | 99.74 | 100.00 |
| 12 | 59.38 | 66.74 | 62.13 | 23.95 | 98.34 | 92.40 | 91.19 | 98.13 | 91.52 | 92.74 | 91.30 | 98.95 |
| 13 | 82.23 | 92.53 | 86.70 | 84.38 | 100.00 | 89.62 | 99.38 | 99.39 | 94.58 | 96.91 | 97.02 | 100.00 |
| 14 | 87.39 | 89.78 | 91.76 | 75.08 | 99.90 | 99.51 | 97.47 | 99.80 | 100.00 | 99.40 | 99.90 | 100.00 |
| 15 | 86.30 | 72.00 | 64.127 | 53.17 | 94.12 | 98.09 | 90.88 | 98.72 | 100.00 | 92.92 | 95.00 | 99.68 |
| 16 | 98.36 | 100.00 | 100.00 | 98.44 | 98.67 | 100.00 | 100.00 | 97.33 | 94.37 | 91.14 | 98.53 | 98.67 |
| OA (%) | 70.21 | 89.91 | 70.95 | 50.88 | 98.58 | 98.50 | 96.85 | 99.07 | 95.56 | 97.86 | 98.61 | 99.62 |
| AA (%) | 53.06 | 66.77 | 62.39 | 52.65 | 96.87 | 96.56 | 94.34 | 96.53 | 86.25 | 93.47 | 94.85 | 99.26 |
| Kappa × 100 | 65.07 | 78.01 | 66.63 | 44.07 | 98.39 | 98.29 | 96.41 | 98.94 | 94.94 | 97.57 | 98.41 | 99.57 |
| Complexity (G) | — | — | — | — | 0.0102 | 0.0011 | 0.0005 | 0.0002 | 0.0003 | 0.0045 | 0.0025 | 0.0003 |
| Parameter (M) | — | — | — | — | 9.2258 | 0.1981 | 0.2582 | 0.1164 | 0.1642 | 2.2295 | 1.2640 | 0.1327 |
| No. | SVM | RF | KNN | GaussianNB | HybridSN | MSRN_A | 3D_2D_CNN | RSSAN | MSRN_B | DMCN | MSDAN | DSMSFNet |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 82.38 | 95.64 | 98.29 | 90.78 | 97.64 | 98.85 | 98.16 | 98.75 | 99.11 | 99.01 | 99.20 | 100.00 |
| 2 | 98.46 | 95.44 | 95.70 | 98.80 | 99.73 | 99.65 | 99.19 | 97.98 | 99.73 | 98.17 | 99.56 | 99.82 |
| 3 | 97.72 | 100.00 | 97.29 | 93.09 | 99.68 | 100.00 | 99.84 | 99.52 | 100.00 | 98.12 | 100.00 | 100.00 |
| 4 | 98.76 | 99.55 | 98.11 | 99.01 | 93.25 | 99.91 | 99.82 | 99.29 | 99.46 | 98.89 | 99.28 | 100.00 |
| 5 | 86.86 | 93.36 | 93.00 | 73.96 | 99.91 | 100.00 | 100.00 | 99.73 | 100.00 | 99.64 | 99.37 | 99.73 |
| 6 | 100.00 | 100.00 | 100.00 | 31.00 | 100.00 | 100.00 | 100.00 | 98.29 | 100.00 | 100.00 | 100.00 | 100.00 |
| 7 | 64.91 | 79.15 | 87.83 | 63.06 | 97.77 | 100.00 | 96.32 | 96.96 | 98.79 | 99.43 | 95.66 | 99.91 |
| 8 | 86.03 | 87.95 | 82.05 | 70.03 | 98.32 | 100.00 | 96.61 | 93.64 | 100.00 | 97.52 | 90.71 | 100.00 |
| 9 | 61.38 | 75.59 | 76.07 | 42.67 | 93.82 | 99.11 | 95.96 | 89.75 | 95.58 | 92.70 | 91.22 | 99.82 |
| 10 | 51.36 | 84.43 | 79.24 | 0.00 | 98.57 | 96.76 | 97.68 | 94.35 | 98.22 | 95.76 | 100.00 | 99.91 |
| 11 | 45.16 | 76.50 | 79.76 | 34.42 | 97.99 | 99.73 | 98.92 | 96.75 | 100.00 | 93.28 | 96.39 | 99.46 |
| 12 | 60.82 | 72.16 | 70.67 | 21.08 | 98.92 | 99.91 | 98.84 | 90.84 | 99.73 | 91.79 | 98.83 | 100.00 |
| 13 | 100.00 | 79.72 | 88.89 | 15.61 | 100.00 | 97.32 | 99.20 | 95.55 | 99.01 | 96.50 | 98.41 | 100.00 |
| 14 | 79.39 | 96.68 | 95.17 | 67.40 | 98.97 | 100.00 | 99.74 | 100.00 | 100.00 | 99.74 | 99.23 | 100.00 |
| 15 | 99.66 | 99.64 | 99.13 | 99.08 | 99.83 | 99.00 | 100.00 | 100.00 | 99.83 | 100.00 | 99.83 | 99.83 |
| OA (%) | 75.17 | 87.47 | 87.51 | 60.82 | 97.91 | 99.36 | 99.41 | 96.31 | 99.17 | 96.82 | 97.33 | 99.88 |
| AA (%) | 74.91 | 86.09 | 85.77 | 63.10 | 97.33 | 99.07 | 98.03 | 96.37 | 98.83 | 95.88 | 97.21 | 99.83 |
| Kappa × 100 | 73.11 | 86.43 | 86.47 | 57.73 | 97.74 | 99.31 | 98.28 | 96.01 | 99.10 | 96.56 | 97.11 | 99.87 |
| Complexity (G) | — | — | — | — | 0.0102 | 0.0011 | 0.0005 | 0.0002 | 0.0003 | 0.0045 | 0.0025 | 0.0003 |
| Parameter (M) | — | — | — | — | 5.1220 | 0.1973 | 0.2580 | 0.1162 | 0.1639 | 2.2293 | 1.2639 | 0.1557 |
| Datasets | Case | Location of DDB | Metrics | ||||||
|---|---|---|---|---|---|---|---|---|---|
| DDB1 | DDB2 | DDB3 | DDB4 | DDB5 | Parameters (M) | Time (s) | OA (%) | ||
| BOW | case1 | × | × | × | × | × | 0.522850 | 0.84 | 99.59 |
| case2 | √ | × | × | × | × | 0.451093 | 0.82 | 98.97 | |
| case3 | √ | √ | × | × | × | 0.389381 | 0.77 | 99.42 | |
| case4 | √ | √ | √ | × | × | 0.307669 | 0.77 | 99.42 | |
| case5 | √ | √ | √ | √ | × | 0.235957 | 0.76 | 99.49 | |
| case6 | √ | √ | √ | √ | √ | 0.162785 | 0.72 | 99.79 | |
| IP | case1 | × | × | × | × | × | 0.319609 | 1.22 | 99.54 |
| case2 | √ | × | × | × | × | 0.279361 | 1.19 | 98.89 | |
| case3 | √ | √ | × | × | × | 0.240493 | 1.15 | 99.67 | |
| case4 | √ | √ | √ | × | × | 0.200149 | 1.12 | 98.77 | |
| case5 | √ | √ | √ | √ | × | 0.159805 | 1.04 | 95.86 | |
| case6 | √ | √ | √ | √ | √ | 0.118369 | 1.02 | 99.62 | |
| Houston 2013 | case1 | × | × | × | × | × | 0.356989 | 2.26 | 99.68 |
| case2 | √ | × | × | × | × | 0.316650 | 2.20 | 99.64 | |
| case3 | √ | √ | × | × | × | 0.276402 | 2.10 | 99.55 | |
| case4 | √ | √ | √ | × | × | 0.236154 | 1.99 | 99.56 | |
| case5 | √ | √ | √ | √ | × | 0.195906 | 1.88 | 99.62 | |
| case6 | √ | √ | √ | √ | √ | 0.155658 | 1.78 | 99.88 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.; Li, Q.; Li, M.; Zhang, J. A Decompressed Spectral-Spatial Multiscale Semantic Feature Network for Hyperspectral Image Classification. Remote Sens. 2023, 15, 4642. https://doi.org/10.3390/rs15184642
Liu D, Li Q, Li M, Zhang J. A Decompressed Spectral-Spatial Multiscale Semantic Feature Network for Hyperspectral Image Classification. Remote Sensing. 2023; 15(18):4642. https://doi.org/10.3390/rs15184642
Chicago/Turabian StyleLiu, Dongxu, Qingqing Li, Meihui Li, and Jianlin Zhang. 2023. "A Decompressed Spectral-Spatial Multiscale Semantic Feature Network for Hyperspectral Image Classification" Remote Sensing 15, no. 18: 4642. https://doi.org/10.3390/rs15184642
APA StyleLiu, D., Li, Q., Li, M., & Zhang, J. (2023). A Decompressed Spectral-Spatial Multiscale Semantic Feature Network for Hyperspectral Image Classification. Remote Sensing, 15(18), 4642. https://doi.org/10.3390/rs15184642