3.1. Results from Discussion
The results are shown in
Table 4, with values that are more than one standard deviation above the mean in blue and those more than one standard deviation below the mean in red. Similar processes were also carried out for Kappa and Z, as shown later in this section.
The least accurate year for the measurement of residue cover was 2013 with an accuracy of 45.79%. However, the best year, 2011, at 56.51%, was only 11% higher. This points to the difficulty of measuring residue cover using broadband spectral data. In 2011, classification techniques were more accurate than spectral indices, and this was partially true in 2013. In 2015 and 2018, spectral indices were more accurate than classification techniques. Of the classification techniques, SVMC and RANDTR were the most accurate and MINDIST and SAM were the least accurate. Overall, the spectral indices produced similar results, with four-year average accuracies ranging from 52.42 to 55.60%. STI, NDTI and MAXLI have at least one year where they are more than one standard deviation above the mean and at least one standard deviation below the mean. This shows that just because on a given year a spectral index or classification technique does well (badly), on a different year, they will perform the same.
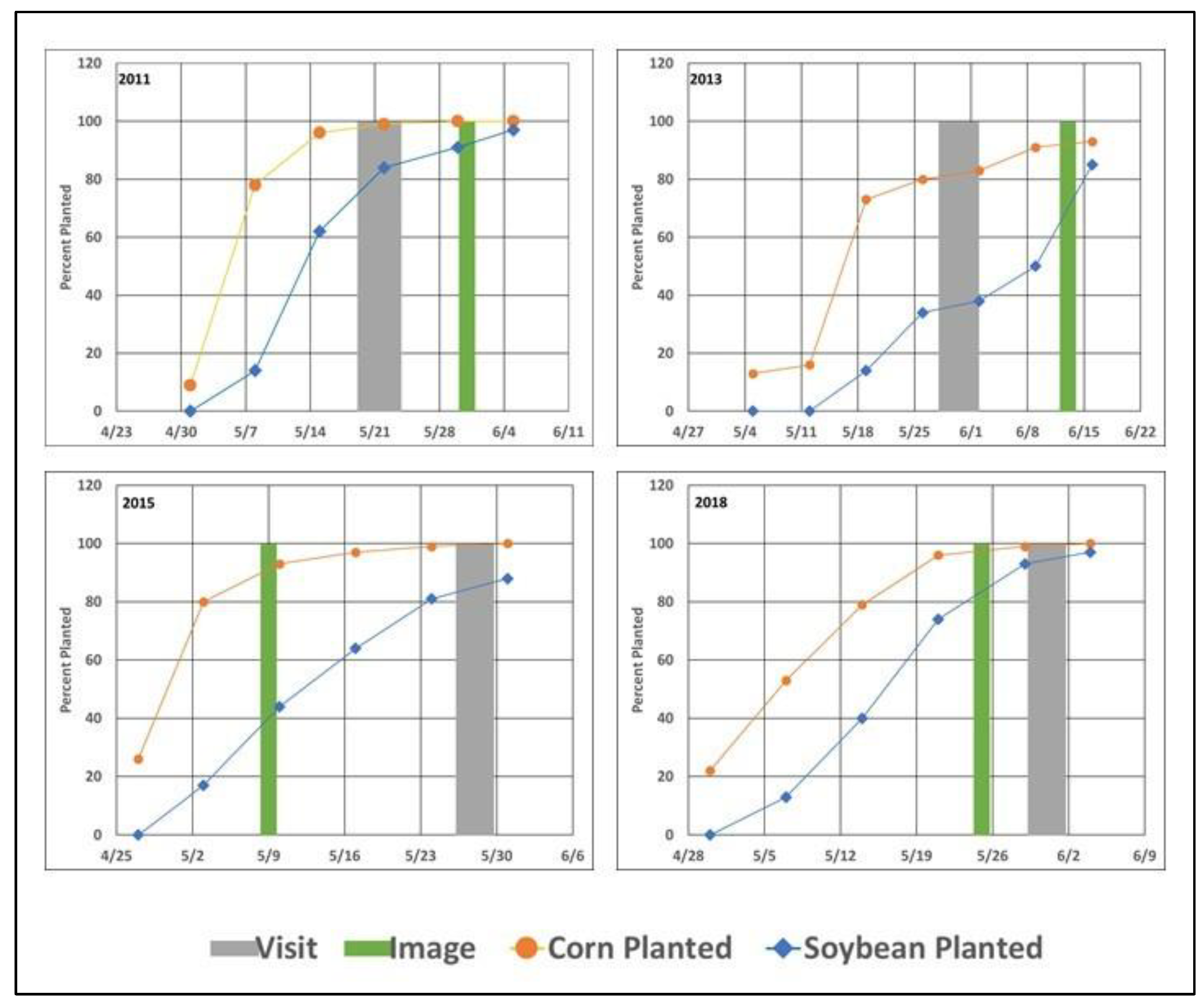
It is interesting to note that classification techniques were more accurate than spectral indices in years when the field visit preceded the image, while spectral indices were more accurate than classification techniques in years in which the image preceded the field visit. It is speculated that spectral indices are more resistant to changes in the residue levels between image and visit times. It is preferable/ideal to have both field visits and imagery shortly after most field activities have been completed. However, satellite revisit schedules and weather (cloud and rain) interfere with the ability to obtain images at the ideal time. In cases in which the image is after the visit, most field activities have finished, and there is no change in residue cover, which classification techniques perform well with. If the image preceded the field visit, it is possible field activities were still going on, changing the residue cover between the image and field visit, which are the circumstances that spectral indices perform better in.
The combination of ALL and FOUR performed very well. FOUR was more accurate than any of the individual spectral indices or classification techniques, ranking most accurate in 2011, 2013, 2015 and second highest in 2018. ALL performed slightly worse, ranking first in 2013, third in 2011 and 2015 and fourth in 2018. It should be noted that ALL and FOUR were ranked in comparison to the individual spectral indices/classification techniques and not to each other, hence both being ranked first in 2013.
To understand the importance of calculating Kappa and Z,
Table 5 shows results using data from 2013. In the example from 2013, NDI5 has an overall accuracy of 49.01%, but everything has been classified as class 3, which is not very meaningful. In comparison, NDTI has an accuracy of 39.25%, but the points are distributed more meaningfully, and the Kappa and Z are higher as a result. This shows the importance of using Kappa and Z in addition to accuracy. It is possible to have an accuracy near 50% simply by chance.
Table 6 and
Table 7 show Kappa and Z values for classification techniques and spectral indices associated with overall rank. Kappa and Z mimic each other and, similar to the accuracies (
Table 4), 2013 showed the worst performance. Like the accuracies, except for MINDIST, which was consistently bad, classification techniques performed better than spectral indices in 2011 and 2013 and spectral indices performed better in 2015 and 2018. For the classification techniques, the similarity with accuracy continued with SVMC performing the best and SAM and MINDIST performing the worst. The spectral index results departed from the pattern in accuracies. STI and NDTI performed the best, and NDI5 performed the worst.
FOUR is ranked highest for Kappa in 2011, 2015, and 2018 and second in 2013. ALL performed slightly worse. Only in Z does FOUR perform slightly worse, ranking second in 2011, third in 2015, and fourth in 2013 and 2018. ALL also shows a similar reduction in rank. It should be noted that because certain pixels do not have a most-frequent class, some pixels were lost in the combination process. ALL contained between 92.7 and 97.4% of the individual spectral indices/classification techniques. FOUR contained between 67.3 and 74.2% of the pixels. The reduction in pixels is probably shown in the rank decrease in Z, even though the accuracy and Kappa rated higher.
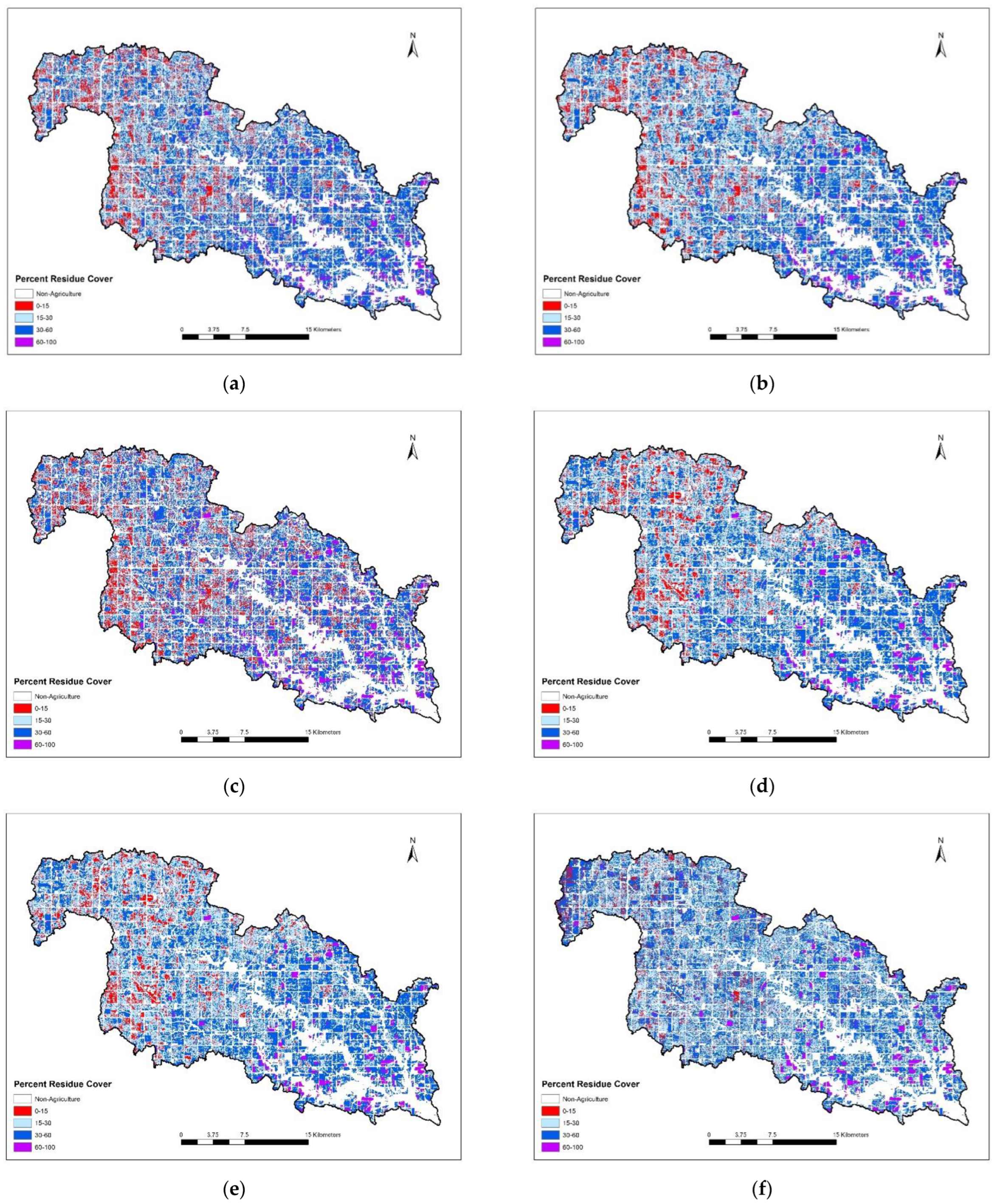
Figure 3 demonstrates a residue map created by using SVMC for 2011. Except for the very western edge of the watershed, there is a general increase in no-till toward the east (the mouth of the watershed), as the terrain becomes steeper.
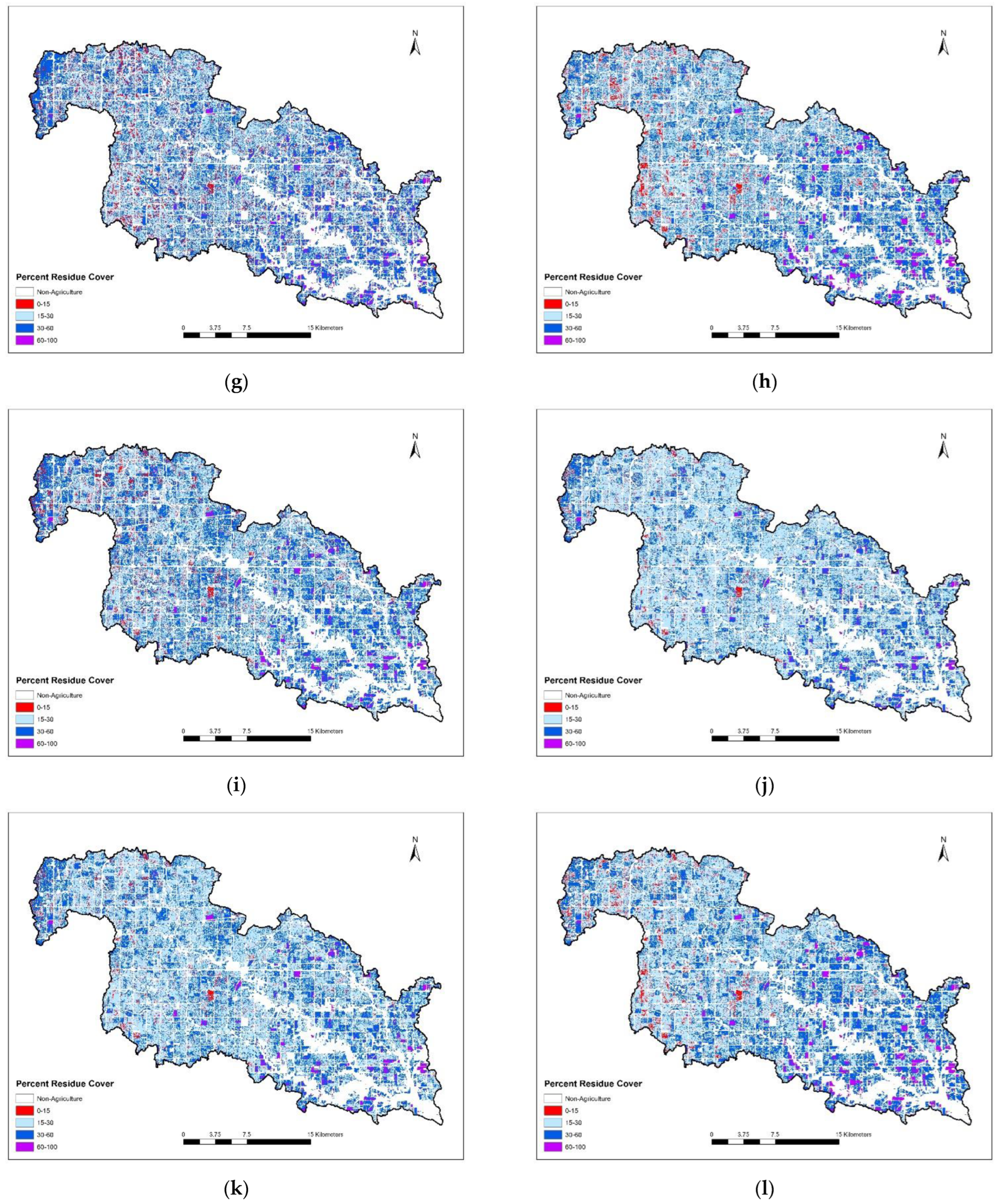
Figure A1 in
Appendix A show the residue cover maps of all spectral indices/classification techniques and the two combinations for 2011.
3.2. Appropriateness of Using Training R2 As a Surrogate for Validation Accuracy
To analyze the appropriateness of using R2 from training data as a surrogate for validation accuracy, the field-based R2 from training data were used. However, unlike the previous objective, the resulting residue image was averaged at the field level before being grouped into the four levels of residue. R2 and RMSE were calculated from the numeric average residue for each field, while accuracy, Kappa and Z were calculated based on the thematic level of residue cover (0–15, 15–30, 30–60, 60–100).
The process of calculating R
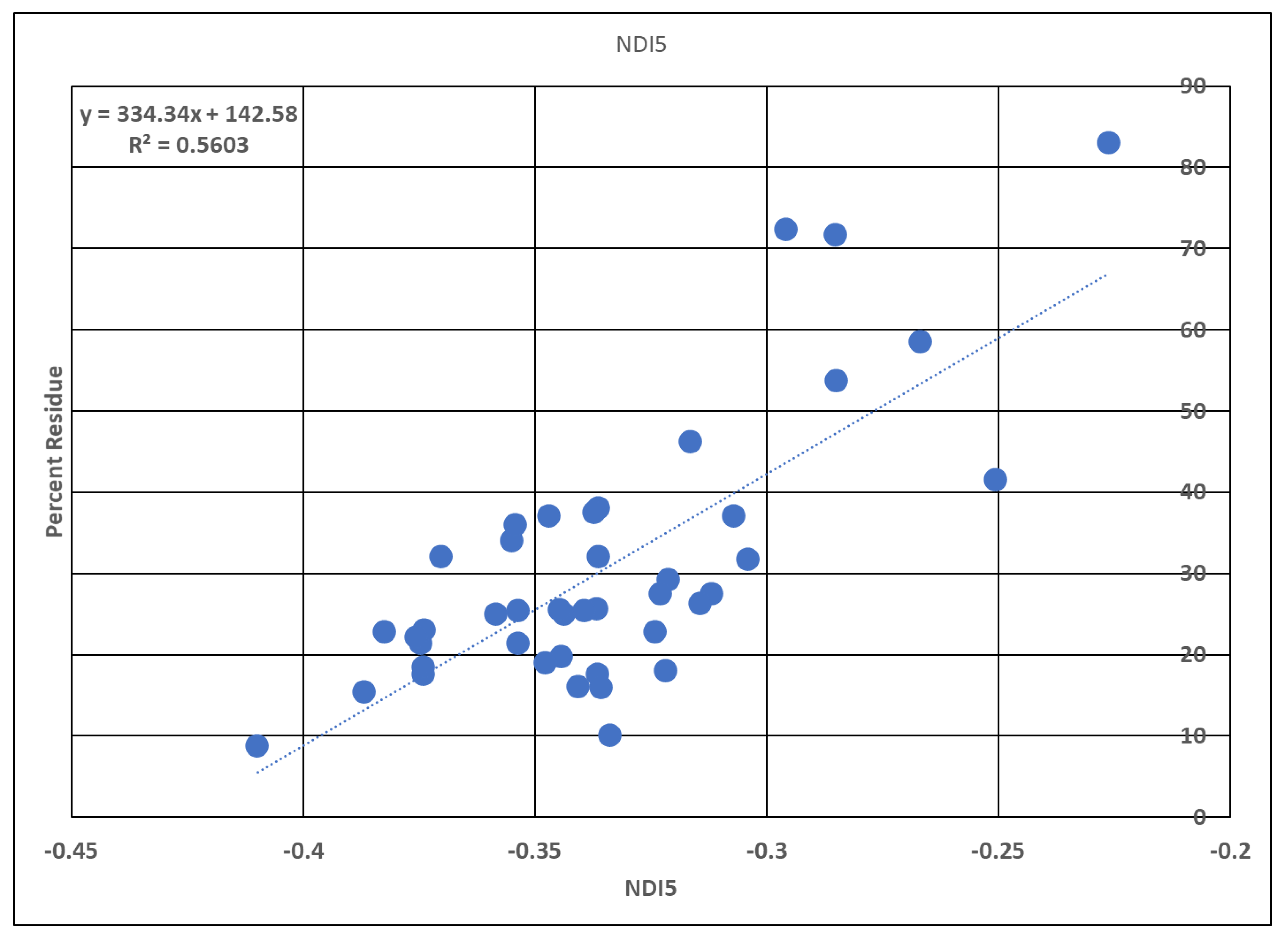
2 for the various spectral indices was conducted in several steps. To understand the process, NDI5 in 2011 will be used as an example. The training data in 2011 consisted of 43 fields. First, NDI5 and the sample residue data were averaged at the field level.
Figure 4 shows the results, with an R
2 of 0.5603. Second, the reference data and the created residue map were grouped into four groups (0–15, 15–30, 30–60, 60–100) and compared.
Table 8 shows the accuracy matrix and the results of the overall accuracy of 55.81%, Kappa of 0.227 and Z of 1.72. Third, the process was repeated for each year and each spectral index each created their own; see
Figure 4 and
Table 8.
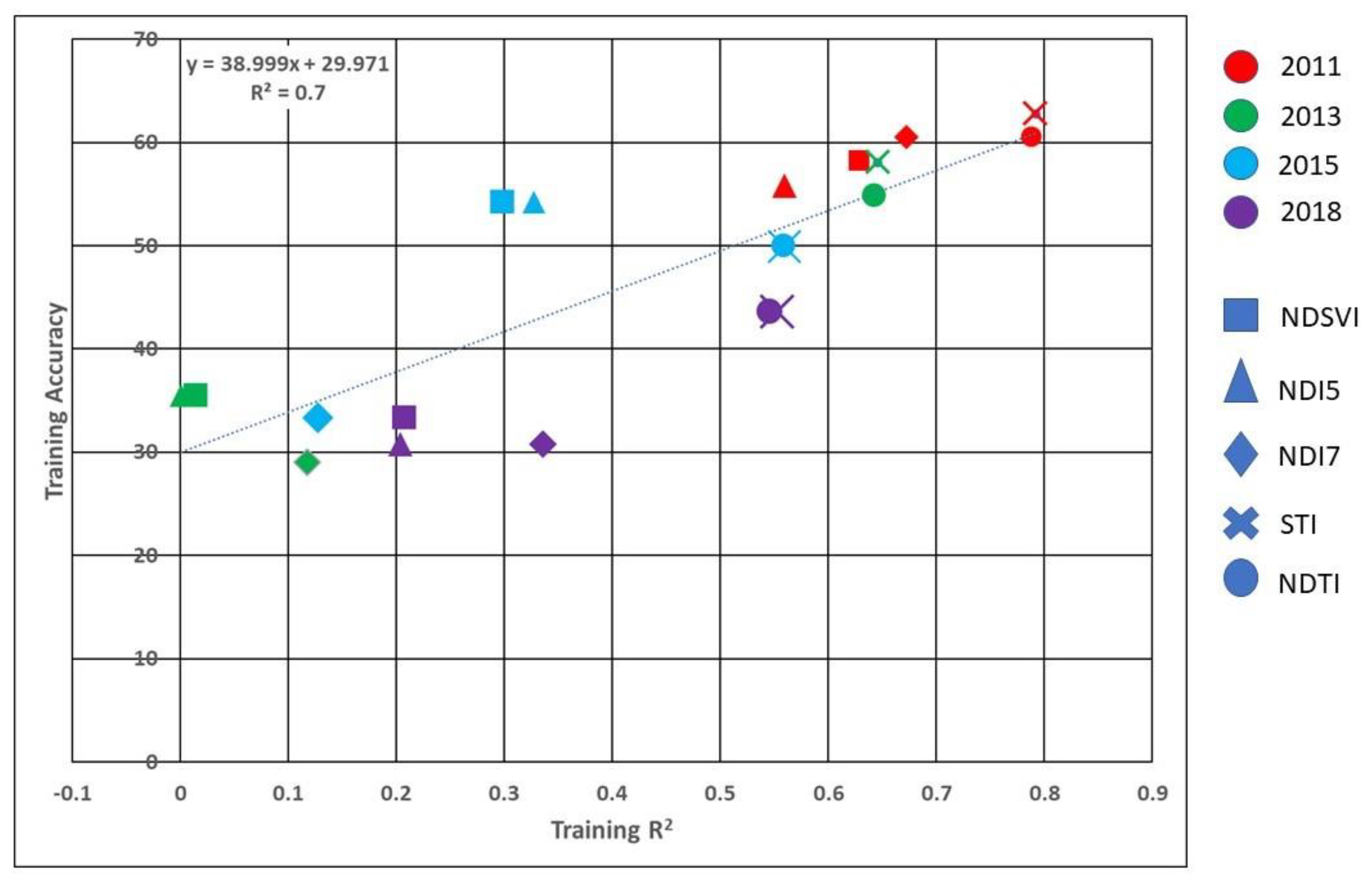
Figure 5 shows the result of R
2 and accuracy from training samples for five spectral indices and four years (20 points). The R
2 of the 20 points in
Figure 5 was computed (0.7). The red triangle at training R
2 of 0.5603 and training accuracy of 55.81% is the example. Finally,
Table 9 summarizes the R
2 of each combination tested with the R
2 from the example being on the first row (i.e., Training R
2 vs. Training Accuracy).
Table 9 shows that the R
2 varies when using different metrics to assess accuracy. Among combinations, the training data RMSE and training data accuracy have the highest R
2 of 0.758. While the training data R
2 shows a good correlation, it still would be best to simply calculate the accuracy. It should be noted that comparing training data R
2 and the accuracy from the validation data results in an R
2 of 0.528, which means training data R
2 is not a bad indicator of performance. However, the validation R
2 is poorly correlated to training accuracy (0.025) and validation accuracy (0.024). Like the training data, R
2 is slightly higher at 0.584 when comparing training data accuracy and the validation RMSE. The training accuracy and validation accuracy are not well correlated (R
2 = 0.237), which implies that the training accuracy may not be a good indicator of the validation accuracy. Validation samples must be reserved during experiment design for accuracy assessment.
3.3. Limitations
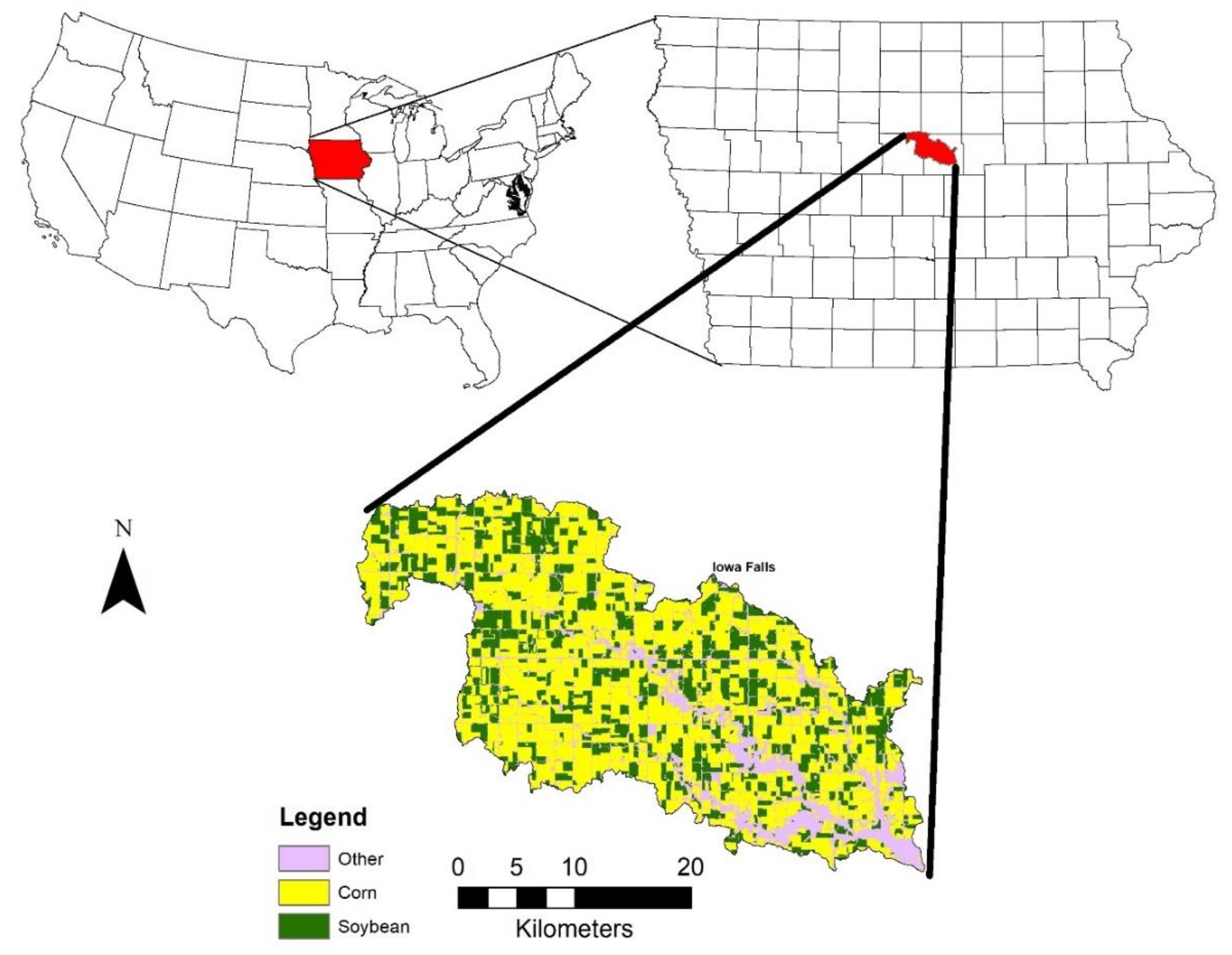
This study is based on the South Fork of the Iowa River situated in Central Iowa. The outcomes generated from this investigation are anticipated to have broad applicability across a significant portion of the corn belt region. However, it is essential to acknowledge that these findings might not directly translate to areas with diverse crops, soils, climates, and weather patterns.
The collection of field data was conducted over a span of four years (2011, 2013, 2015, and 2018). Although this timeframe offers insights, it is important to note that it does not encompass the full spectrum of potential weather variations and soil moisture levels. Thus, there is a need for further research to capture a more complete understanding.
The paper investigates five spectral indices and six classification techniques that are commonly used for crop residue cover mapping. It is worth noting that more advanced techniques may yield even more accurate results. It is expected that new satellite missions with more frequent observations (e.g., Sentinel-2) or additional narrow shortwave infrared reflectance bands (e.g., Landsat Next or Landsat 10) can provide a more accurate result in crop residue mapping.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}