1. Introduction
Remote sensing image scene classification (RSISC) is a significant undertaking that has attracted considerable interest across diverse domains and use cases [
1,
2,
3]. The continuous evolution of imaging technology has resulted in notable advancements, contributing to the progressive enhancement of resolution in remote sensing images (RSI) [
4,
5,
6]. This encompasses a wide array of intricate land cover characteristics, including terrain, mountains, and bodies of water. The processing of RSI varies depending on the specific characteristics exhibited by the scenes they depict [
1]. Assigning semantic labels to RSI holds immense importance as this facilitates the unified management and analysis of remote sensing data. Semantic labels aid in organizing and analyzing these data in a consistent manner. Thus, the primary objective of scene classification is to categorize RSI based on similar scene characteristics using extracted features [
7,
8,
9]. Presently, the usage of scene classification technology extends across a wide range of domains, including but not limited to natural disaster evaluation, vegetation mapping, geological surveying, urban planning, environmental monitoring, object detection, and various other disciplines [
10,
11,
12,
13,
14,
15,
16,
17].
In recent years, deep learning techniques have gained substantial traction as highly prospective methodologies for RSISC [
18], showcasing notable achievements with models like VGG16 [
19], GoogLeNet [
20], AlexNet [
21], and ResNet [
22]. Deep learning has revolutionized RSISC by eliminating the need for manual feature retrieval [
23,
24,
25,
26]. This approach holds immense significance in remote sensing applications. Recently, Zhai et al. [
27] introduced a highly efficient model that addresses the issue of lifelong learning, which incorporates prior knowledge to enable rapid generalization to new datasets. In line with this objective, Zhang et al. [
28] incorporated the remote sensing transformer (TRS) into the realm of RSISC, with the primary goal of capturing long-range dependencies and acquiring comprehensive global features from the images. To further enhance the extraction of semantic features from different classes, Tang et al. [
29] conducted spatial rotation on RSI based on previous studies. This creative approach helps capture additional valuable information and reduces the potential for misclassification by improving feature discriminability. Harnessing these breakthroughs resulted in substantial improvements in the accuracy and resilience of RSISC, leading to enhanced performance in various applications.
From another perspective, the effectiveness of deep learning approaches is often greatly influenced by the quality and quantity of the available training set. This implies that a substantial amount of human and material resources must be invested in acquiring labeled image data. Additionally, well trained deep learning models are only effective for the scenes included in the training dataset and cannot accurately classify scenes not present in the training set. To incorporate new scenes, it is necessary to include them in the training set and retrain the model.
Therefore, for the problem of scene classification in RSI, few-shot learning becomes highly meaningful. The core issue of few-shot learning revolves around exploring methods to rapidly acquire knowledge from a limited set of annotated samples, with the aim of enabling the model to exhibit rapid learning capabilities [
30,
31,
32]. Given the possibility of utilizing prior knowledge to address this core issue, few-shot learning methods can be classified from three standpoints: (i) data, where prior knowledge enriches the supervised learning process; (ii) model, where prior knowledge diminishes the complexity of the hypothesis space; and (iii) algorithm, where prior knowledge modifies the search for the optimal hypothesis within the provided hypothesis space [
30,
31,
32]. For example, Cheng et al. introduced a Siamese-prototype network (SPNet) with prototype self-calibration (SC) and intercalibration (IC) to tackle the few-shot problem [
33]. SC utilizes supervision information from support labels to calibrate prototypes generated from support features, while IC leverages the confidence scores of query samples as additional prototypes to predict support samples, further improving prototype calibration. Chen et al. proposed a novel method named multiorder graph convolutional network (MGCN) [
34], which tackles the few-shot scene classification challenge by employing two approaches: mitigating interdomain differences through a domain adaptation technique that adjusts feature dispersion based on their weights, and decreasing the dispersion degree of node features. Therefore, in the few-shot task, the deep features learned by the model should not only have good separability, but also have strong discriminability, so that new classes can be recognized with a limited set of annotated samples. Vin et al. [
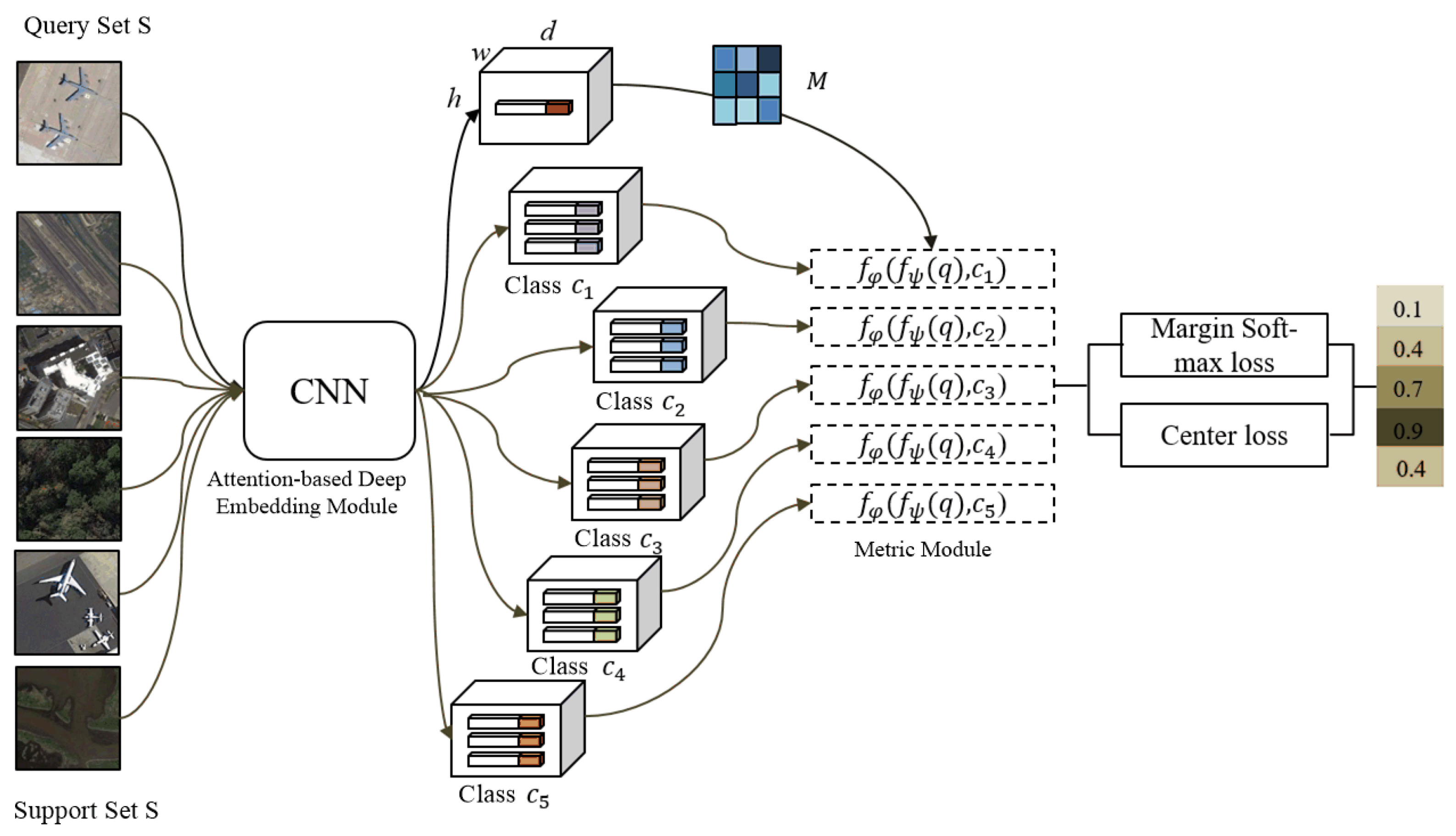
35] introduced an episodic training approach as a solution to tackle the challenges associated with few-shot learning. In the training stage, a support set is created by randomly selecting
K images for each of the
C classes that are sampled from the dataset, resulting in a total of
images. Subsequently,
N images are chosen from the remaining dataset for each class among the selected
C classes, forming a query set. An episode is formed by combining one support set with one query set. Multiple iterations of training using different episodes are performed until convergence, enabling the network to provide the class labels of query set images based on their resemblance to the support set. The predominant approach in metric learning-based few-shot methods entails the direct computation of the distance between support samples and query samples, enabling the subsequent learning of a classifier based on this measured distance. They do not fully exploit the network’s robustness in extracting features, resulting in the reduced discriminability of the model’s output features and consequently hindering the overall performance of few-shot models.
Moreover, RSI frequently presents significant intra-class variations and noticeable inter-class similarities, posing challenges for precise scene image classification. The substantial intra-class variance pertains to the assortment of visual attributes exhibited by objects belonging to the same semantic class. Certain ground-level entities demonstrate variations in terms of style, shape, and spatial distribution. For example, as shown in
Figure 1a, churches exhibit diverse architectural styles, while airports and railway stations display notable differences in their distinct shapes. Furthermore, when an airplane or space platform captures a RSI, due to different imaging conditions, the color and radiation intensity in the identical category may be significantly different due to weather, cloud, fog and other factors. For example, beach scenes exhibit significant differences under different imaging conditions. The notable similarities across distinct classes in RSI is primarily due to the presence of similar objects or semantic overlap among different scene classes. For example, in
Figure 1b, both bridge and overpass scenes contain the same objects, and basketball court and tennis court exhibit a high degree of semantic information overlap. In addition, the vague definition of scene classes can also lead to reduced inter-class differences, resulting in visually similar appearances for some complex scenes. Therefore, distinguishing between these scene classes can be extremely challenging, which is attributable to the extensive intra-class variations and pronounced inter-class resemblance. For example, images that do not belong to the same class are classified into one class, and different classes may be assigned to images that actually belong to the same class due to the diversity of samples. For this reason, the acquisition of a classifier capable of extracting discriminative features from RSI significantly contributes to enhancing the performance of RSISC.
To solve the few-shot RSISC, Chen et al. [
36] proposed the deep nearest neighbor neural network based on attention mechanism (DN4AM). DN4AM employs an episodic training technique for network training and performs evaluations on novel classes to enhance few-shot learning. In addition, DN4AM integrates a channel attention mechanism to craft attention maps that are tailored to scene classes, harnessing global information to mitigate the influence of unimportant regions. Furthermore, DN4AM employs the scene class-related attention maps to measure the resemblance of descriptors between query images and support images. By employing this strategy, DN4AM is able to compute a metric score for each image-to-class comparison, effectively mitigating the impact of irrelevant scene-semantic objects and elevating the classification accuracy. However, DN4AM does not address the challenge of significant intra-class variations and substantial inter-class similarities in RSI scenes.
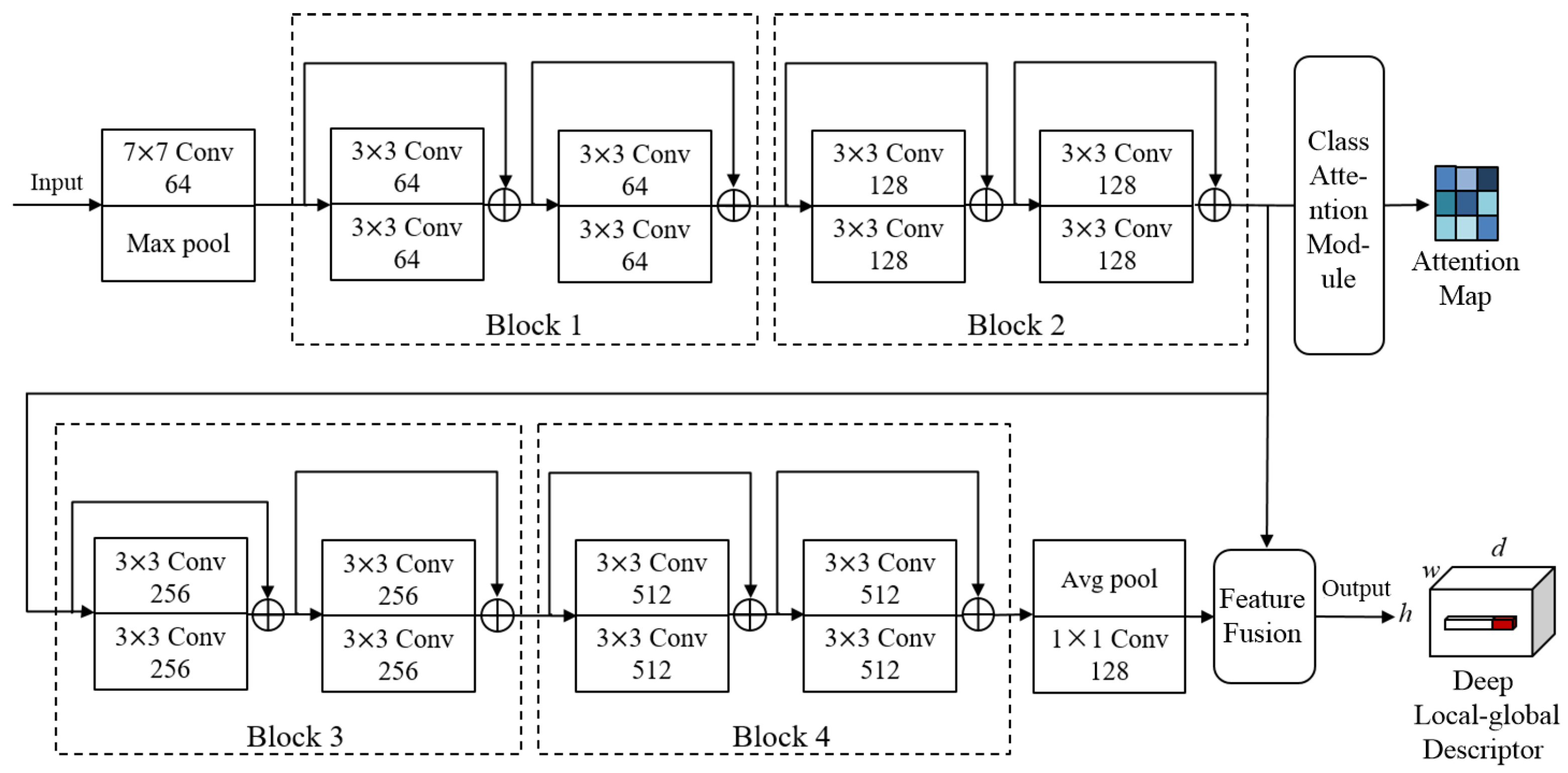
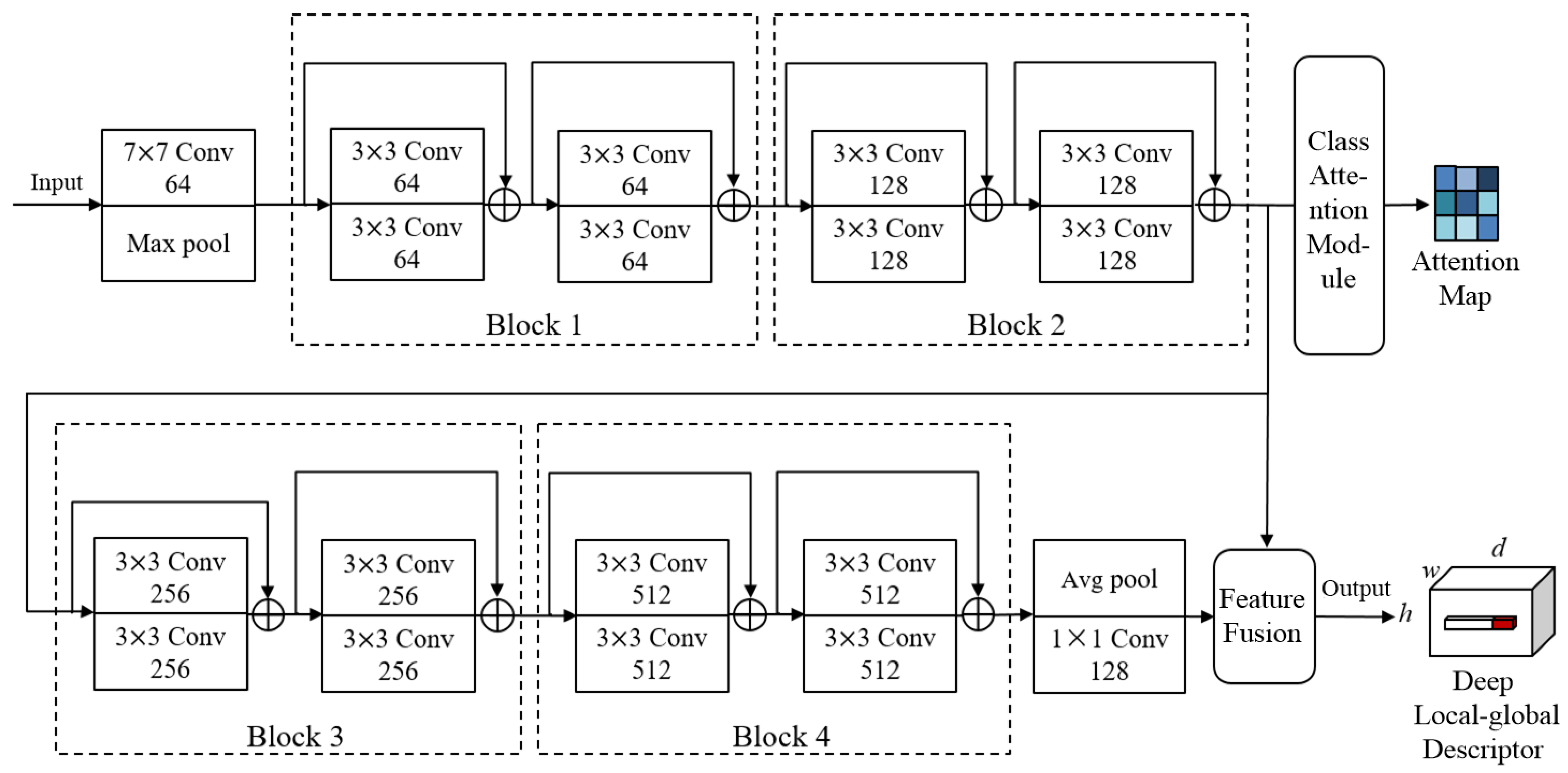
In this paper, we propose the discriminative enhanced attention-based deep nearest neighbor neural network (DEADN4) based on the DN4AM model. While retaining the advantages of DN4AM, DEADN4 model has three additional advantages. Firstly, incorporating both local and global information, the DEADN4 model employs the deep local-global descriptor (DLGD) for classification, enhancing the differentiation between different classes’ descriptors. Secondly, to enhance the intra-class compactness, DEADN4 introduces the center loss to optimize global information. By using the center loss, it effectively increases the intra-class compactness by pulling features of the same class towards their centers, mitigating significant intra-class diversity. Finally, DEADN4 improves the Softmax loss function in the classification module by incorporating the cosine margin, encouraging larger inter-class distances between learned features. These advantages contribute to improving the few-shot RSISC results. In
Section 2, we delve into the existing research in the domain. In
Section 3, we unveil our proposed method. The outcomes of our experiments and corresponding discussion are elucidated in
Section 4. Lastly, in
Section 5, we draw definitive conclusions based on our findings.
2. Related Work
Deep convolutional neural network (CNN) is capable of extracting abundant semantic features and distinguishing diverse classes of deep features in the final fully connected layer of the network, enabling the accurate prediction of test samples. Nevertheless, research has found that traditional Softmax loss can disperse features belonging to different classes as much as possible, but it overlooks the intra-class compactness of features, leading to a deficiency in the discriminability of the learned features. Therefore, many researchers started studying how more discriminative features could be extracted to further enhance the performance of CNN. Intuitively, if the close clustering within classes and the distinct differentiation across classes are maximized simultaneously, the learned features will have excellent separability and discriminability. Although learning good features is not easy for many tasks due to significant inter-class differences, considering the powerful representational capacity of CNN, it is possible to learn features that exhibit both good separability and strong discriminability. At present, the work related to the discriminative enhancement of CNN can be roughly divided into two classes: class-center method and improved loss function. Since our method is based on DN4AM, this section will include a concise overview of the DN4AM model.
2.1. Class-Center Method
The method of using the class-center usually defines a center for each class, and then increases the distinguishability of the model’s extracted features by increasing the intra-class compactness [
37,
38,
39]. The class-center is defined by researchers, and a commonly used definition for the class-center is the average of the characteristics found in training samples belonging to the identical category. Wen et al. [
37] believe that CNN can complete classification tasks by using Softmax loss training until the network converges. However, an observation can be made that the acquired features through the network still exhibit significant intra-class variance, indicating that the network’s acquired deep features are separable through solely using Softmax loss but lack sufficient discriminability. Thus, Wen et al. proposed the center loss to augment the distinctiveness of the acquired features within the neural network, which can be formulated as:
where
represents the
class-center of the deep feature,
m denotes the population size of the current training dataset. The combination of Softmax loss and center loss in training the CNN achieves exceptional accuracy on various significant face recognition datasets. The experiments demonstrate that, through the aforementioned joint supervision, a more robust neural network can be trained, obtaining deep features that aim to achieve both the dispersion between different classes and the compactness within same class. This significantly enhances the distinguishability of the extracted features through the deep learning model.
2.2. Improved Loss Function
The loss function is a pivotal area of study in machine learning, greatly influencing the development and enhancement of various machine learning techniques. For classification and recognition tasks, the deep CNN is employed to extract critical information from face images, ensuring that samples within the same class exhibit similarity whereas samples belonging to different classes display pronounced dissimilarity. Softmax loss is commonly used to solve multi-class classification problems, which are widely adopted in practical scenarios like image recognition, face recognition, and semantic segmentation. Although the Softmax loss function is concise and has probabilistic semantics, making it one of the frequently employed elements in CNN models, some scholars argue that it does not overtly advocate for compactness within the same class and distinctiveness between different classes [
40,
41]. In order to tackle this problem, based on their work [
40,
41], the loss function of Softmax can be modified as follows:
where
N is the quantity belonging to the training samples,
is the class information of the
ith sample,
denotes the deviation angle between the weight vector of the
jth class and the
ith sample,
is a constant employed to regulate the cosine margin,
s is a fixed value. In this way, the Softmax loss is formulated in terms of cosine, and the cosine margin is utilized to maximize the distance between features in the cosine decision space. As a result, the objective of reducing variability within classes while increasing dissimilarity between classes has been successfully accomplished.
2.3. DN4AM
DN4AM is a model designed to address the problem of few-shot RSISCs. It consists of two main parts: attention-based deep embedding module and the metric module .
The module is responsible for capturing the deep local descriptor (DLD) within images and generating attention maps that are closely associated with scene classes. For each input image X, represents a feature map of size , which can be seen as containing DLD of dimension . The DLD captures the features in different regions of the image.
Additionally, the module incorporates a class-relevant attention learning module. This module partitions the DLD into relevant and irrelevant parts to the scene classification. The primary purpose of this is to minimize the impact of ambient noise and prioritize the characteristics associated with the scene class.
Finally, in the module, the class of a query image is determined by comparing the similarity between the DLDs of the query and support images.
In summary, DN4AM utilizes the module to learn the features about scene classes in images. The module then compares the similarities between query and support images’ DLDs to perform few-shot RSISC. This approach provides more accurate classification results while reducing interference from background noise.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}