Abstract
In order to effectively utilize acquired remote sensing imagery and improve the completeness of information extraction, we propose a new road extraction model called C2S-RoadNet. C2S-RoadNet was designed to enhance the feature extraction capability by combining depth-wise separable convolution with lightweight asymmetric self-attention based on encoder and decoder structures. C2S-RoadNet is able to establish long-distance dependencies and fully utilize global information, and it better extracts road information. Based on the lightweight asymmetric self-attention network, a multi-scale adaptive weight module was designed to aggregate information at different scales. The use of adaptive weights can fully harness features at different scales to improve the model’s extraction performance. The strengthening of backbone information plays an important role in the extraction of road main branch information, which can effectively improve the integrity of road information. Compared with existing deep learning algorithms based on encoder–decoder, experimental results on various public road datasets show that the C2S-RoadNet model can produce more complete road extraction, especially when faced with scenarios involving occluded roads or complex lighting conditions. On the Massachusetts road dataset, the PA, F1 score, and IoU reached 98%, 77%, and 72%, respectively. Furthermore, on the DeepGlobe dataset, the PA, F1 score, and IoU reached 98%, 78%, and 64%, respectively. The objective performance evaluation indicators also significantly improved on the LSRV dataset, and the PA, F1 score, and IoU reached 96%, 82%, and 71%, respectively.
1. Introduction
With the rapid development of remote sensing technology, the application of ultra-high-resolution remote sensing imagery has garnered widespread attention. Road extraction has several applications such as city planning, traffic management, GPS navigation, land cover, and land use analysis [1]. It is a significant research direction in the field of remote sensing and artificial intelligence, and many researchers have studied it.
The methods of road extraction can be divided into two stages with the 2012 ImageNet Challenge as the watershed. These stages include the road extraction stage based on traditional methods and the road extraction stage based on deep learning. The traditional method stage mainly uses template matching approaches, knowledge-driven approaches, object-oriented approaches, path morphology approaches [2], etc. Hu [3] proposed a road extraction algorithm that consists of two steps: detection and pruning. This algorithm utilizes the shape of a locally homogeneous region around a pixel for pixel classification. It uses the footprints generated by the classification results and then employs a rectangle approximated automatic road-seeding method along with a Bayesian decision model to obtain road information. Jing [4] utilized the spectral, geometric, and texture features of roads in high-resolution remote sensing images. Through the effective combination of these features, they generate multi-scale integrated features to enhance road characteristics. This approach successfully facilitated road extraction on islands. Das [5] utilized the conspicuous spectral contrast of roads along with local linear trajectory features. The study devised a multi-stage framework incorporating probabilistic SVM and dominant singular value decomposition methods to extract roads from high-resolution multispectral satellite images. Additionally, curvature information was leveraged to effectively filter out disconnected non-road structures. Li et al. [6] introduced an unsupervised road-detection method involving five main stages: superpixel segmentation, feature description, homogeneity region merging, Gaussian mixture model clustering, and outlier filtering. They utilized transparency, color, and texture to define two shape features—parallelism deviation and narrowness ratio—to automatically identify road layers and filter out anomalies. Traditional algorithms primarily rely on manually designed road features for road extraction. While they perform well in extracting straightforward features from simple and small-scale areas with uncomplicated ground texture, traditional algorithms exhibit low automation and limited generalization capabilities due to their heavy reliance on manual design. Deep learning algorithms improve the accuracy of road extraction through hierarchical and convolutional operations and show good performance for complex features. Deep learning is data-driven, with automatic feature learning and strong feature extraction capabilities. It can fully exploit the high-level and low-level features of high-resolution remote sensing imagery. It realizes the full utilization of spectral information, geometric information, and texture information of remote sensing imagery. Road information constitutes only a fraction of the entire high-resolution remote sensing image. The improvement of the resolution of remote sensing images not only provides more detailed information for road extraction but also provides a lot of interference information. To make full use of the automatic learning ability of deep learning, it is particularly important to design deep learning algorithms that are suitable for high-resolution remote sensing images in road extraction [7,8,9,10,11].
The fully convolutional neural network (FCN) demonstrates good performance when applied to semantic segmentation. However, its upsampling results are not sufficiently refined, and it is not sensitive enough to detect road details in remote sensing images. Each pixel is isolated from the others, global information is not considered, and there is a lack of spatial consistency that leads to road extraction fragmentation. U-Net [12] is a convolutional neural network structure with encoders and decoders. It uses skip connections to directly transmit low-level feature information to the corresponding high level for feature information connection. Skip connections actually create a propagation channel between low-level information and high-level information, allowing feature information to be transmitted on the channel effectively. After upsampling four times, more detailed road information is restored. The use of skip connections allows the fusion of road feature maps at different scales, showing superior performance in road extraction from remote sensing images. Limited by the receptive field of the convolution operation, the long-distance information of the road is not fully utilized. In order to fully utilize the global information to improve the integrity of the road, F. Yu et al. [13] initially proposed dilated convolution in 2016 to achieve the purpose of expanding the receptive field without increasing parameters. He effectively used contextual information to solve the problem of spatial information loss in semantic segmentation. Later, inspired by dilated convolution, Chen [14] et al. proposed the famous DeepLab series model with dilated convolution as the core. Res-Net [15] uses residual connections to integrate more feature information without increasing the number of parameters and calculations, effectively improving the accuracy of road extraction from high-resolution remote sensing images. Zhang [9] et al. proposed a deep residual U-Net for road extraction, which greatly reduced information loss and effectively improved the accuracy of road extraction. DeepLabV3 [16] belongs to the typical Dilated FCN. DeepLabv3+ introduces the decoder module, which further integrates low-level features and high-level features to improve the accuracy of segmentation boundaries [17]. The attention mechanism provides huge benefits in the task of semantic segmentation [18]. The self-attention mechanism is equivalent to the model deciding the shape and type of the receptive field. Woo et al. proposed the convolutional block attention module (CBAM) based on the attention mechanism in 2018, which is a lightweight module that pays attention to the importance of both space and channel [19]. Zhigang Yang et al. [20] combined high-level semantic features and foreground context information and proposed to use priority-designed location attention to enhance the expression ability of road features. In order to capture the road context information in the image, a context information extraction module was constructed. In the recovery stage of the decoder, foreground context information was provided, and a foreground context information supplement module was proposed, which effectively improved the inference ability of the occluded area. The transformer [21] used as the main network for feature extraction in the task of road remote sensing images achieved good results. Alshaikhli [22] effectively obtained pixel values and optimized prediction results by combining residual blocks and attention. Cheng GL et al. [23] proposed a cascaded end-to-end convolutional neural network so that the network can obtain more consistent road detection results in complex backgrounds, e.g., vehicles and tree occlusion, and realize smooth, complete, single-pixel-width road centerline network. Qiqi Zhu et al. [24] proposed a global context-aware and batch-independent network using a global context-aware network embedded in the encoder–decoder structure to extract complete and continuous road networks. Panle Li et al. [25] proposed a remote context-aware road extraction neural network using strip pooling to capture remote context, improving the continuity and completeness of road extraction results and introducing a structural similarity (SS) loss function to optimize the road structure of the LR road network. Shao Z et al. [26] proposed a dual-task end-to-end convolutional neural network using cumulative convolution and pyramid scene parsing pool module, expanding the network reception field, integrating multi-level features, and obtaining richer road information. Yu Rong et al. [27] proposed a new context-enhanced and self-attention capsule feature pyramid network, which integrates context enhancement and self-attention modules, uses multi-scale context attributes and channel information feature enhancement, and enhances the robustness of feature representation. Li J. et al. [28] obtained the context information of the road through global attention, used core attention to obtain multi-scale information, improved the connectivity of road extraction, restored the information at the occlusion place, and improved the cross-entropy function to propose an adaptive loss function, effectively solving the ratio problem of road and non-road areas in training samples. A series of satisfactory results was achieved in the effective information extraction of remote sensing images based on the combination of convolutional networks and transformer, and a series of explorations were made in extraction accuracy and integrity [29,30,31,32,33].
Although these deep learning methods have achieved impressive results in road-related tasks, they typically focus on the local information of the images and often struggle to effectively utilize global information. In order to tackle these challenges, this paper proposes a road extraction model, C2S-RoadNet, that combines depth-wise separable convolution and self-attention based on encoder and decoder structures. This model uses depth-wise separable convolution to replace ordinary convolution structures to maintain road spatial information details and improve computer speed. At the same time, it adds a lightweight asymmetric self-attention module to further strengthen feature extraction, and it can fully utilize remote context information and obtain long-distance information. The backbone information and extracted road features are more obvious. Finally, the adaptive feature fusion module can fuse the feature information of roads at different scales and improve road extraction effects. The method proposed in this paper has the following contributions:
- By combining depth-wise separable convolution residual unit and self-attention, the authors propose a deep separable residual asymmetric self-attention network for road extraction tasks, which can obtain more complete road information in complex scenes;
- Lightweight asymmetric self-attention effectively reduces the computational complexity of self-attention while effectively utilizing global information, enhancing the model’s robustness to image flipping and rotation, and improving the extraction effect of roads under occlusion;
- The use of a multi-scale module with adaptive weights can fuse features at different scales, utilizing trainable parameters to fully fuse the available information of different features;
- C2S-RoadNet is evaluated by using two challenging road datasets. It achieves better performance than other state-of-the-art road extraction methods.
The rest of this paper is structured as follows. Section 2 describes the proposed new algorithm. Section 3 introduces the experimental data and preprocessing. Section 4 introduces the experimental results of three challenging road datasets. Section 5 analyzes the results of experiment. Section 6 draws the conclusions of this study.
2. Materials and Methods
In this study, we introduce an asymmetric convolutional neural network with adaptive multi-scale feature fusion. The network architecture is based on an encoder–decoder model. It incorporates depth-wise separable convolutions with lower computational demands and asymmetric convolution modules that employ parallel one-dimensional horizontal and vertical convolutions to enhance skeleton information. A deep separable symmetric convolutional block is constructed. Finally, the output features of the last enhanced residual block in the encoder are inputted into the adaptive multi-scale feature fusion module. This approach preserves resolution while increasing receptive fields to precisely locate targets and resolves the issue of local information loss by incorporating adaptive multi-scale feature fusion.
2.1. Lightweight Asymmetric Self-Attention Module
This section introduces the depth-wise separable convolution module and the asymmetric convolution module, which are less computationally intensive. It uses parallel one-dimensional horizontal and vertical convolutions to enhance backbone information and adds an adaptive feature fusion module. Based on the encoder–decoder structure of the U-Net model, the C2S-RoadNet algorithm proposed in this chapter is presented. To verify the effectiveness and applicability of the algorithm in this chapter, parameter tuning and training were carried out on three classic public datasets. According to the quantitative and qualitative analysis on the three validation datasets, the usefulness of enhancing backbone information in extracting main trunk road information was verified, effectively improving the completeness of road information extraction.
2.1.1. Depth-Wise Separable Convolution
Depth-wise separable convolution [34] (DSC) is composed of depth-wise convolution and pointwise convolution. Depth-wise convolution uses a convolution kernel for each channel of the input feature map separately, with one convolution kernel responsible for one channel, and then concatenates the outputs of all convolution kernels to obtain its final output. This step reduces the number of multiplication operations. Pointwise convolution convolves the feature map of each channel with a pointwise convolutional kernel to produce the final output channels. The operation of pointwise convolution is highly lightweight, involving only element-wise multiplication and summation, as the feature map of each output channel is computed by operating with the corresponding weights of the pointwise convolutional kernel. The computationally intensive nature of pointwise convolution is lower, which results in a relatively lower overall computational complexity. This makes depth-wise separable convolution highly beneficial in lightweight models and environments with limited computational resources. The structure diagram is shown in Figure 1.
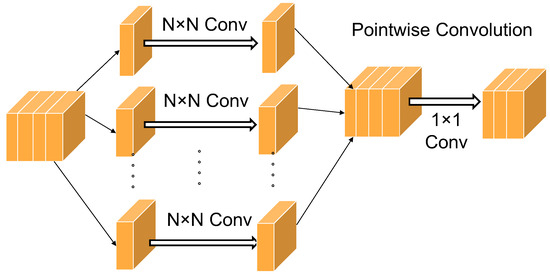
Figure 1.
Structure diagram of depth-separable convolution.
If we disregard convolutional stride, padding, and other potential operations, we can roughly estimate the total number of multiplication and addition operations required in a convolutional layer. Given an input image with size of and a kernel of size , resulting in an output of , the computational complexity of the standard convolution is as follows:
The calculational complexity of depth-wise convolution is as follows:
The calculational complexity of pointwise convolution is shown below:
The total calculational complexity of depth-wise separable convolution is calculated as shown below:
The ratio of the calculational complexity of depth-wise separable convolution to the calculational complexity of standard convolution is shown below:
In summary, the calculation efficiency of depth-wise separable convolution is much higher than that of standard convolution. Incorporating it into the model can improve the speed of model training and inference.
2.1.2. Asymmetric Convolution Blocks
The improvement in computational efficiency of depth-wise separable convolution comes at the cost of sacrificing training accuracy. Therefore, it is designed to combine the inverse bottleneck depth-wise separable convolution with the residual structure to make up for its shortcomings.
Asymmetric structures can enhance the recognition robustness of rotated targets and significantly improve the accuracy of image classification. The asymmetric convolution block (ACB) uses one-dimensional asymmetric convolution kernels to enhance square convolution kernels. It uses parallel d × d, 1 × d, and d × 1 convolution kernel to replace the basic d × d convolution kernel. The convolution kernel is split into several different shaped convolution kernels for training. Without increasing the computationally intensive, it enhances feature extraction efficiency and increases the model’s robustness to image flipping and rotation, and the cross-shaped receptive field can reduce the impact of redundant information on capturing representative features. This paper designs an asymmetric convolution to enhance the features of edge information. Given an input feature map of a certain size (), calculating the new feature map requires the use of three distinct convolutional filters.: , , and . Finally, averaging the results of these three convolutional operations enhances the expressive capacity of feature representation. The structure diagram is shown in Figure 2. The calculation equations are as follows:
where is the output of ACB, and is the input of ACB. and represent the variance function and expectation of the input. is a small constant that maintains numerical stability. and are the two trainable parameters of the BN layer, and the normalized results can be scaled by and shifted by .
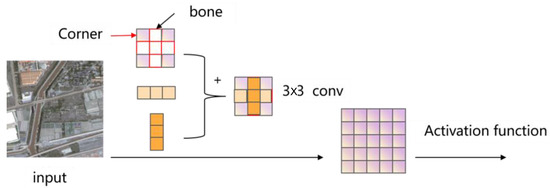
Figure 2.
Structure diagram of asymmetric convolution.
2.1.3. Self-Attentive Mechanism
Limited by the receptive field, a CNN will only model the relationship between neighboring pixels and lacks global information. However, transformers can model the relationship between all pixels in a single layer, focusing on global information. Since self-attention does not have spatial invariance, it requires more data for learning and a large amount of data for feature learning and computationally intensive. Therefore, this paper combines convolutional neural design to create a lightweight self-attention module, establishing long-distance dependencies while reducing computational complexity and improving training inference speed.
The self-attention mechanism proposed by Vaswani et al. [20] originates from the transformer network in natural language processing (NLP) and has superior performance. As a result, the self-attention mechanism has been widely applied. The standard self-attention formula is defined as shown below:
The standard self-attention mechanism linearly transforms the input features to obtain variables query (), key (), and value () with the same dimension (), then normalizes the result of the vector dot product of and to obtain the potential relationship between every two features. Subsequently, this potential relationship is used to recombine features to obtain the output features, and feature fusion is performed on this basis. In order ensure that the model pays more attention to the information at different positions in different representation subspaces, we embed the multi-head attention mechanism into self-attention. The calculation equations of multi-head self-attention are as follows:
where
where
where
Each head uses different weight transformations, calculates all heads in parallel, and subsequently combines the computed results to obtain the final output. The output ratio is adjusted by controlling the V value. Usually, the dimension of the V value is consistent with the input features. After the complete multi-head attention calculation, the size of the input and output can be the same, which is convenient for embedding into various networks to achieve multi-head attention.
The characteristic of self-attention is that it does not consider the distance between features and directly calculates dependencies, which has a strong semantic feature extraction ability and performs parallel calculations. The image has two sources of dimensional information, which gives visual transformer (ViT) have a high computational complexity, and the diversity of image feature information makes the training of ViT difficult. The self-attention mechanism does not have to keep the dimensions of query, key, and V values consistent. Excessive dimensions of query and key will not only lead to data redundancy in the model but even have a negative impact on the final performance of the model. In order to make self-attention better applicable to semantic segmentation, it is considered necessary to perform convolution operations on the input reduce the image scale; and thus reduce the computational complexity of dot multiplication.
The efficient transformer [35] relies on the idea of group convolution: it breaks down large matrices into smaller one, performs calculation, and finally merges them, thereby achieving the purpose of reducing computational intensity.
2.2. Multi-Scale Adaptive Weighting Module
Shallow neural networks have a small receptive field and strong ability to express detail features. Because they undergo fewer convolutions, their semantics are lower and have more noise. The semantics of the extracted features are weaker. In CNNs, continuous pooling operations are used to reduce the resolution of features. As the depth of the network increases, the receptive field of the network gradually enlarges, and the ability to express semantics is enhanced. However, it reduces the resolution of the image and causes the detail features to be blurred after multiple layers of network convolution operations, losing the feature information of the image; moreover, the ability to perceive details is poor. In order to obtain strong semantic features, traditional deep learning models usually only use the feature map output by the last layer of the feature extraction network for object classification and positioning. However, the downsampling rate corresponding to the last feature map is relatively large. It causes small targets to have less-effective information on the last feature map, and the ability to extract features of small targets is reduced. The purpose of feature fusion is to merge the features extracted from the image into a feature that is more discriminative than the input feature. The fusion of multi-scale features makes full use of multi-scale information. The fusion of multi-scale features is no longer just using the last layer of feature maps for detection but choosing multiple layers of features for fusion and then detection. This process can be summarized into four types of methods:
- (1)
- Early fusion: It is a classic feature fusion method. Existing networks (such as VGG19) use concat or add to fuse some layers;
- (2)
- Late fusion: This adopts a similar idea as feature pyramid network (FPN) and makes predictions after feature fusion;
- (3)
- One method uses a network with high and low feature fusion capabilities to replace ordinary networks, such as Densenet;
- (4)
- The last method adjusts the prediction results based on the prediction of high-layer features.
Image pyramid scales the original image at different ratios to obtain input images of different sizes, extract features, and predict outputs for the obtained images separately. The image pyramid algorithm improves the accuracy of target detection, but the disadvantages are also very obvious. The image pyramid actually trains multiple models at different scales. Although it can solve the multi-scale problem, it increases the memory space for storing images of different scales and the cost of training time. The algorithm in this paper is mainly based on the image pyramid for improvement. Using depth-wise separable convolution to replace convolution and pooling operations can retain more feature details. Because different scale information plays different roles in the effect of the model, this paper uses adaptive weights to make full use of effective scale features. Before different scale features, a learnable parameter is added as a weight coefficient. The initial weight coefficients are all set to 1. During the network training process, the weight coefficients are taught to adjust the importance of different scale features during the training process, save the memory occupied by training, and improve the training efficiency. The structure diagram of the adaptive feature fusion module is shown in Figure 3.
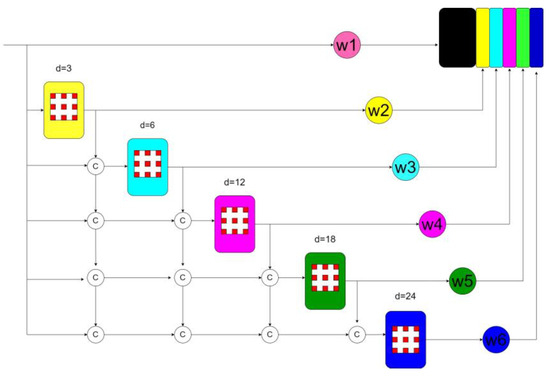
Figure 3.
Structure diagram of adaptive weighting module. d is the downsampling rate we set, and c represents feature map fusion.
2.3. Asymmetric Convolutional Neural Network with Adaptive Multiscale Feature Fusion
The depth-wise separable asymmetric convolution neural network with adaptive multi-scale feature fusion is based on the encoder–decoder network model. U-Net with a typical encoder–decoder structure, and a more intuitive description is shown in Figure 4.
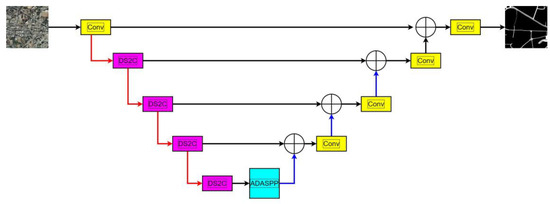
Figure 4.
The schematic diagram of the network model proposed in this paper, in which the red arrow represents the downsampling operation, DS2C represents the depth separable asymmetric convolution block, ADASPP represents the adaptive feature fusion module, the plus sign represents the feature fusion, and the blue arrow represents the upsampling operation.
In the encoder, there are four convolution modules and four pooling modules. The convolution modules are used to extract image features and double the number of feature channels. Each convolution module consists of two 3 × 3 convolutions, each followed by a BN layer and a ReLU function. After each convolution module, a max pooling operation with a size of 2 × 2 and a stride of 2 is used for downsampling, reducing the resolution of the feature map by half, and the number of feature channels remains consistent with the number of channels after convolution.
In the decoder, before the feature map enters the convolution module, a transposed convolution with a size of 2 × 2 and a stride of 2 is first used for upsampling, doubling its spatial resolution. Then, it is concatenated with the feature map of the corresponding resolution in the encoder with a skip connection to mitigate the loss of spatial information caused by downsampling. After the feature map passes through the convolution module, the number of its channels is halved. In the final layer of the network, a 1 × 1 convolution is used to map the extracted feature vector to the required number of classes, using Softmax to complete the classification.
Combining depth-wise separable convolution with asymmetric convolution, we construct a deep separable symmetric convolution block. The 3 × 3 convolution in the asymmetric convolution is replaced with a 3 × 3 depth-wise separable convolution, which is then paralleled with a horizontal 1 × 3 convolution and a vertical 3 × 1 convolution. The additivity of convolution is used to add the three convolution structures and output the feature map.
In the feature extraction phase, based on ResNet101 with the last two layers removed, the ResNet101 network is built into a depth-wise separable asymmetric encoding block by replacing the ordinary convolution with a depth-wise separable asymmetric convolution. The output feature of the last improved residual block of the encoder is input into the ASPP module of the adaptive feature fusion. The ASPP uses five different dilation rates (3, 6, 12, 18, and 24). The input with a dilation rate of 3 is the output of the encoder; the input with a dilation rate of 6 is the sum of the output of the encoder and the output with a dilation rate of 3; the input with a dilation rate of 12 is the sum of the output of the encoder, the output with a dilation rate of 3, and the output with a dilation rate of 6; the input with a dilation rate of 18 is the sum of the output of the encoder, the output with a dilation rate of 3, the output with a dilation rate of 6, and the output with a dilation rate of 12. The input with a dilation rate of 24 is the sum of the output of the encoder, the output with a dilation rate of 3, the output with a dilation rate of 6, the output with a dilation rate of 12, and the output with a dilation rate of 18. Finally, the results of the five outputs are concatenated after being multiplied by an initial learnable parameter.
The output result is input into the decoder module, and each feature size map uses a skip connection with the same size map in the encoder, gradually restoring the size of the feature map and reducing the number of channels, and finally outputting the feature map.
3. Experimental Data and Preprocessing
3.1. Datasets and Pre-Processing
3.1.1. Datasets
The datasets used in this study come from the Massachusetts Road dataset [36], the DeepGlobe dataset [37], and the LSRV dataset [38].
(1) The Massachusetts Road dataset is an aerial dataset collected in the state of Massachusetts, USA, covering an area of 2.25 km2. The spatial resolution is 1.2 m. There are a total of 1171 images, of which 1108 are used for training, 14 for validation, and the remaining 49 for testing. Each image comes with binary segmentation labels (black represents non-road areas; white represents road areas), with pixels of 1500 × 1500. Figure 5 shows some examples from the Massachusetts Road dataset. The dataset covers a variety of typical urban, suburban, and rural areas, making it a challenging road extraction dataset.
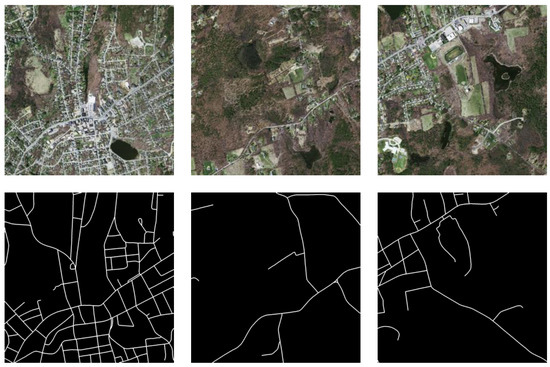
Figure 5.
Massachusetts Road Dataset.
(2) The DeepGlobe dataset is a satellite dataset that includes images collected in Thailand, Indonesia, and India. It covers a total area of 2220 square kilometers, including urban and suburban areas. The spatial resolution is 0.5 m. Each image is 1024 × 1024 pixels in size. The original dataset contains 8570 images, of which 6226 training images publicly provide ground-truth data. Therefore, we further divided the accessible data into training and testing sets at a ratio of 5 to 1. We chose 5189 images for training and the remaining 1037 images for testing. Figure 6 shows some examples from the DeepGlobe dataset. Compared to the Massachusetts dataset, it contains more types of road surfaces, making road extraction more challenging in this dataset.

Figure 6.
DeepGlobe dataset.
(3) The LSRV dataset includes three large-scale images, which were collected from Google Earth and accurately labeled for evaluation. Table 1 provides details of the large-scale images.

Table 1.
LSRV Dataset Details.
Figure 7 shows the distribution of features in the Shanghai image, which is significantly different from the distribution in the Boston and Birmingham images. Moreover, the buildings in Shanghai are relatively taller and denser, with many narrow roads.

Figure 7.
LSRV dataset.
The C2S-RoadNet proposed in this paper requires a large amount of remote sensing imagery with road labels as support. The mainstream remote sensing road data currently in use are wide-format images. Direct training can lead to excessive memory usage, resulting in memory overflow and a slower training rate, while the amount of image data is insufficient for vision transformer tasks. In this section, we consider using image cropping and image augmentation to process and expand the original images.
3.1.2. Pre-Processing
- Image cropping: The original images were cropped using a sliding window technique, with a pixel value of 256 for the sliding window and a stride of 256. There was no overlap between adjacent windows. If the length and width of the large images in the dataset could not be divided evenly by 256, zero padding was used to make them multiples of 256 before sliding and cutting. After cropping, the Massachusetts Road dataset contained a total of 39,888 training images of size 256 and 504 validation images. The DeepGlobe training dataset, after cropping, yielded 83,168 images. The images obtained after cropping were divided into training and validation sets at a ratio of 8 to 2, resulting in a total of 66,532 training images and 16,634 validation images. The LSRV dataset includes three regions, each of which was cropped using a 1024 sliding window on three large images. If the images could not be divided evenly by 1024, zero padding was used to make them multiples of 1024 before sliding and cutting. The Boston area yielded 529 images of size 1024. The Birmingham area yielded 484 images of size 1024. The Shanghai area yielded 289 images of size 1024. The three regions were divided into training, validation, and test sets. The training set accounts for 70% of the total, the validation set accounts for 20%, and the test set accounts for 10%. The training and validation sets obtained from the three regions were each organized into a total training set and a total validation set. The training and validation sets were then cropped using a 256 sliding window, ultimately yielding a total of 14,584 training images of sizes 256 and 4167 validation images of size 256.
- Image augmentation: Image augmentation can effectively avoid overfitting, improve the robustness of the model, improve the generalization ability of the model, and avoid the problem of sample imbalance. Therefore, this paper adopts the following data enhancement methods to expand the dataset:
- Random flipping: There are three main options, namely horizontal, vertical, and both horizontal and vertical flipping;
- Random rotation of 90°, where ranges from 0 to 4;
- Center rotation: This method rotates the image by a certain angle with the center of the image as the rotation point;
- Translation: The image is shifted a certain distance in the vertical and horizontal directions;
- Random scaling: If the scaling size is larger than the original size, the image is randomly cropped to the original size; if the scaling size is smaller than the original size, the image is extended to the original size by mirror padding;
- Cutout: In addition to solving the occlusion problem, cutout is also inspired by dropout. As is well known, dropout randomly hides some neurons, and the final network model is equivalent to an ensemble of multiple models.
3.2. Model Evaluation Criteria
In this paper, we use a confusion matrix to evaluate the performance of models in binary classification problems. Labels are divided into positive samples and negative samples, and prediction results are divided into positive results (true) and negative results (false). We use (true positive) and (true negative) to represent correct predictions and (false positive) and (false negative) to represent incorrect predictions. To evaluate the performance of the proposed model in extracting roads, we use three evaluation metrics: pixel accuracy (PA), score, and .
Pixel accuracy: Pixel accuracy is the simplest evaluation metric in the pixel-level classification task, indicating how many positive samples are predicted is positive. It represents the scale of marked roads extracted from the model.
score: score is the harmonic mean of precision and recall, and it is a widely used metric for measuring the accuracy of a binary classification model.
Intersection of Union: is used to describe the accuracy of the detected object and quantify the degree of fit between the extraction results and the true labels. The larger the value, the more overlap there is in the results.
3.3. Experimental Settings
In this section, we introduce the public dataset used in the experiment. Then, we provide the implementation details and evaluation metrics. Next, we conduct ablation experiments to validate the effectiveness of the model and its modules. Finally, we compare our model with the latest models to demonstrate the superiority of our method. All experiments were implemented under the Pytorch framework (version 1.11.0) and conducted on Nvidia GeForce RTX 3060, with a memory size of 12 GB, a CPU of Intel Core i5-9400F, and an operating system of Windows 10. Each batch processed eight images. The learning rate was initially set to 0.01, and a learning rate multiplier factor was returned according to the number of steps, using the learning rate multiplier factor to adjust the learning rate during training. The number of training times was set to 50. The AdamW function was used for parameter optimization, with the sizes of the momentum parameters β1 and β2 set to 0.9 and 0.999, respectively.
4. Experimental Results
In this investigation, our proposed algorithm is benchmarked against a selection of notable architectures, each contributing unique strengths to the field of semantic segmentation. U-Net serves as the foundational model, combining local and global contextual features for segmentation tasks. ACNet enriches this paradigm by utilizing asymmetric convolutions, focusing on capturing more distinct features. DeeplabV3+ amplifies semantic discrimination through its atrous spatial pyramid pooling, capturing contextual information at multiple scales. DDU-Net, a dual-encoder network initially optimized for medical image segmentation, integrates semantic features at different levels to offer a more nuanced approach to segmentation [39]. The experimental results on the three datasets are shown in Table 2. In the context of road extraction, each model exhibited distinct strengths and weaknesses, as confirmed by the experimental results tabulated in Table 3. U-Net, although groundbreaking in its time, shows limitations evidenced by the conspicuous discontinuities in the segmented road networks. ACNet mitigated this issue somewhat, enhancing feature completeness through asymmetric convolutions. DeeplabV3+ exceled in the accurate capturing of road features but lacked in delivering contiguous road networks. Surpassing DeeplabV3+ in this regard, DDU-Net leveraged its dual-encoder architecture for a more harmonious fusion of semantic features at varying scales, thereby achieving superior road extraction quality. The standout performer is C2S-RoadNet, which incorporates depth-wise separable convolutions and self-attention mechanisms to deliver unparalleled road extraction fidelity. This comparative analysis serves not only to validate the proposed algorithm’s efficacy but also sets a robust benchmark that points toward potential avenues for further research in this area.
Table 2.
The dataset consisting of the images after cropping.
Table 3.
Extraction indicators of the algorithm in this section on three datasets.
4.1. Experimental Results on the Massachusetts Roads Dataset
The visualization results of C2S-RoadNet and the other four comparison algorithms on the test set of the Massachusetts Roads dataset are shown in Figure 8.

Figure 8.
Experimental extraction effect of algorithms and comparison algorithms in this section on the Massachusetts dataset test set.
4.2. Experimental Results on the DeepGlobe Dataset
The visualization results of the four comparison algorithms on the DeepGlobe dataset are shown in Figure 9.

Figure 9.
Experimental extraction effect of algorithm and its comparison algorithm in this section on DeepGlobe dataset test set.
4.3. Experimental Results on the LSRV Dataset
The visualization results of C2S-RoadNet and the other three algorithms on the DeepGlobe dataset are shown in Figure 10.
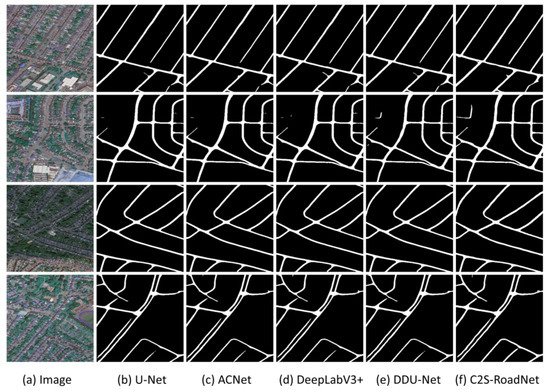
Figure 10.
Experimental extraction effect of algorithm and its comparison algorithm in this section on LSRV dataset test set.
5. Discussion
5.1. Comparative Test Discussion
5.1.1. Analysis of the Extraction Results of Massachusetts Road Dataset
In the Massachusetts Road dataset, C2S-RoadNet demonstrated a commanding lead with a pixel accuracy (PA) of 0.9813, F1 score of 0.7732, and intersection over union (IoU) of 0.7218, outperforming the closest competitor, DDU-Net, by approximately 1.1% in IoU. U-Net, a seminal work in the field, fell notably behind, particularly in F1 and IoU metrics, suggesting limitations in capturing complex road networks. As illustrated in Figure 8, focusing primarily on the Massachusetts Road dataset, it is evident that C2S-RoadNet sets a new benchmark in road extraction, outperforming all evaluated models under various complexities. While all models, including DDU-Net, are competent in simpler settings with distinct road features, their performance diverges in more complex environments. U-Net exhibited pronounced fragmentation in extracted roads, and while ACNet mitigated this to some extent, it sacrificed model robustness. DeepLab v3+ overlooked minor features during downsampling, and its single skip connection inadequately captured finer details. DDU-Net performed admirably but fell short in delineating minor roads with high fidelity. In contrast, C2S-RoadNet exceled consistently, leveraging deep separable asymmetric convolution blocks and an adaptive atrous spatial pyramid pooling (ASPP) feature fusion module. This not only enhanced the model’s sensitivity to finer road structures but also ensured superior road feature extraction under challenging conditions such as occlusion and lighting variations.
5.1.2. Analysis of the Extraction Results of DeepGlobe Road Dataset
Consistently, C2S-RoadNet maintained its preeminence across all performance indicators in the DeepGlobe dataset, achieving an IoU of 0.6398, which is 0.7% higher than its nearest rival, DDU-Net. DeeplabV3+ trailed behind with an F1 score of 0.7626, failing to match DDU-Net and C2S-RoadNet in their robustness. ACNet and U-Net brought up the rear, indicating limitations in their architectures for adapting to this dataset’s diversity. As Figure 9 illustrates, across the DeepGlobe dataset, marked disparities emerged among the performance of evaluated models, with C2S-RoadNet standing as the most proficient in road extraction tasks. U-Net and DeepLab v3+ displayed evident fracture phenomena, with U-Net further marred by omissions in occluded regions. ACNet demonstrated a partial remedy to these issues through its deep separable asymmetric convolution module but still fell short in complex environments. While DDU-Net provided commendable results, particularly in reducing fractures at road intersections, it nevertheless exhibited limitations when confronted with occlusion or complex pixel interplay. In contrast, C2S-RoadNet exceled significantly in these challenging conditions. It employs a multi-faceted approach, leveraging adaptive feature fusion and deep separable convolutions, to ameliorate fracture phenomena at road intersections substantially better than all compared models, including DDU-Net. Despite this, C2S-RoadNet is not entirely free from limitations; complexities at intersections induce some remaining fractures.
5.1.3. Analysis of the Extraction Results of LSRV Road Dataset
For the LSRV dataset, C2S-RoadNet and DDU-Net are the unequivocal frontrunners, with IoUs of 0.7131 and 0.7083, respectively. Notably, C2S-RoadNet edged out DDU-Net by approximately 0.48% in IoU. DeeplabV3+ and ACNet follow closely in F1 scores but displayed limitations in the granularity of road extraction, as evidenced by lower IoU scores. U-Net continued to lag, revealing its inherent shortcomings in intricate road extraction tasks. As evident in Figure 10, the LSRV dataset, featuring road data from large urban areas like Boston, Birmingham, and Shanghai, exhibited a higher proportion of main roads, a factor that naturally influences the accuracy of road extraction across different algorithms. While ACNet partially ameliorated U-Net’s coarse boundary delineation by integrating multi-scale information, it nonetheless faced challenges in avoiding mis-extraction due to spectral and topological interference. DeepLab v3+ gained a more nuanced extraction capability through its atrous spatial pyramid pooling, allowing it to account for roads of varying hierarchical levels with appreciable accuracy. DDU-Net, although proficient in multi-scale encoding, delivered a performance analogous to ACNet and DeepLab v3+ in these urban settings, only slight improvement. However, it is C2S-RoadNet that elevated the state of the art. Armed with asymmetric convolution and adaptive ASPP mechanisms, C2S-RoadNet not only improved spectral information extraction but also provided a more astute interpretation of both global and local contextual information. Consequently, the overall accuracy of road extraction experienced a measurable uplift, and the visual outcomes were particularly satisfying.
5.2. Ablation Test Analysis
To rigorously evaluate the efficacy of our newly introduced depth-wise separable asymmetric convolution (DS2C) blocks and the atrous spatial pyramid pooling with adaptive feature fusion (ADASPP) modules, we designed a systematic series of ablation studies. These studies were conducted on two challenging road segmentation datasets: the Massachusetts Roads dataset and the DeepGlobe Roads dataset. The experimental paradigm included four configurations: a baseline model utilizing a standard U-Net architecture, model A augmented with DS2C blocks, model B enhanced with ADASPP modules, and model C that amalgamates features from both DS2C and ADASPP modules. All configurations were optimized under uniform hyperparameter settings. The ensuing performance metrics are delineated in the supplemental Table 4.
Table 4.
In the ablation test, the four models tested the evaluation indicators on the Massachusetts Road dataset and the DeepGlobe road dataset. Among them, Baseline represents the baseline model U-Net, Model A represents the U-Net model combined with adding depth separable asymmetric convolution blocks, Model B represents the U-Net model combined with the ASPP module of adaptive feature fusion, and Model C represents the model proposed in this paper.
Our ablation studies quantitatively substantiated that both DS2C and ADASPP modules contributed significantly to model performance. Specifically, the integration of DS2C blocks in model A resulted in improvements of 4.24%, 7.00%, and 3.08% in pixel accuracy (PA), F1 score, and intersection over union (IoU) on the Massachusetts dataset and respective gains of 1.86%, 2.48%, and 6.97% on the DeepGlobe dataset. In parallel, the incorporation of ADASPP modules in model B elevated PA, F1, and IoU by 5.06%, 7.91%, and 5.68% on the Massachusetts dataset and 1.98%, 4.43%, and 7.34% on the DeepGlobe dataset. Most saliently, the fusion of DS2C and ADASPP in model C outperformed the baseline, marking increases of 6.29%, 10.27%, and 8.74% on the Massachusetts dataset and 2.93%, 5.34%, and 10.10% on the DeepGlobe dataset. These results not only validate the independent effectiveness of each module but also underscore their synergistic potential.
Building upon our quantitative metrics, we conducted a qualitative analysis to substantiate the efficacy and robustness of the introduced modules. For this analysis, representative images were meticulously selected from both the Massachusetts Roads dataset and the DeepGlobe Roads dataset. The qualitative outcomes of the ablation studies are delineated in Figure 11.

Figure 11.
The test results of the four test schemes of the ablation test on the Massachusetts Road dataset and the DeepGlobe Road dataset. In the image, the upper two images are from the Massachusetts Road dataset, and the lower two images are from the DeepGlobe Road dataset. Among them, Image represents the remote sensing image from the dataset, Baseline represents the baseline model U-Net, Model A represents the U-Net model combined with adding depth separable asymmetric convolution blocks, Model B represents the ASPP of the U-Net model combined with adaptive feature fusion module, and Model C represents the model proposed in this paper.
Upon scrutinizing the segmentation outcomes of the selected images, it becomes unequivocally evident that models incorporating the deep separable asymmetric convolution block (model A) and the adaptive feature fusion ASPP module (model B) outperform the baseline U-Net model in capturing intricate road structures, corners, and intersections. This observed qualitative improvement aligns consistently with the quantified performance metrics, reinforcing the utility of these modular enhancements. Notably, when these two modules are synergistically integrated into a comprehensive model (model C), it exhibits a heightened ability to discern complex details within road networks, including minor road segments and intersections that are typically overlooked by conventional U-Net models. This not only intuitively corroborates the complementary nature of these technological advancements but also fortifies the empirical findings of our ablation studies.
In summary, through both qualitative and quantitative analyses, we rigorously validated the substantial performance gains achieved by the deep separable asymmetric convolution block and the adaptive feature fusion ASPP module in tasks of complex road network segmentation. This opens new avenues for applications in road detection and autonomous driving. These discoveries not only deepen our understanding of these advanced techniques but also affirm their practical value in addressing real-world challenges.
5.3. Integrated Summary
Section 5.1 and Section 5.2 of the manuscript comprehensively evaluate the performance of our proposed C2S-RoadNet model across multiple datasets while also examining the impact of its two key modules: DS2C and ADASPP. Synthesizing these analyses, we arrive at the following salient conclusions:
- Superior Performance: The C2S-RoadNet model exhibits significant advantages in performance across diverse test scenarios and datasets. This assertion is substantiated by both quantitative metrics and qualitative analyses;
- Module Efficacy: Our ablation studies confirm that the DS2C and ADASPP modules are instrumental in enhancing the model’s performance. Their inclusion endows the model with increased flexibility and accuracy when navigating complex scenarios and varying road conditions;
- Holistic Utility: The newly incorporated modules demonstrate exemplary performance not only in quantitative metrics but also in qualitative evaluations, such as result visualization.
Collectively, these findings underscore the robust capabilities and extensive applicability of the C2S-RoadNet model and its constituent modules. This amplifies the significance and innovative aspects of the present research, thereby laying a robust foundation for future explorations in this field. This succinctly integrated summary facilitates quick comprehension of the study’s primary contributions and potential practical applications.
6. Conclusions
High-resolution remote sensing images contain rich ground object information, and roads of different levels have significant differences in pixels and structure, which have an important impact on the integrity of road information extraction. We propose a road extraction model, C2S-RoadNet, that combines depth-wise separable convolution with self-attention based on the encoder–decoder structure. This model can effectively reduce the computational complexity of self-attention and improve inference speed. At the same time, it establishes long-distance dependencies, makes full use of global information, enhances the model’s robustness to image flipping and rotation, and effectively improves the extraction effect of roads under occlusion. The fusion of the adaptive weight multi-scale module uses trainable parameters to fully integrate the available information of different scale features. The effectiveness of C2S-RoadNet was confirmed by comparing it with some advanced approaches on three open accessible datasets. The findings suggest that the presented approach holds greater potential compared to other methods.
Convolutional and transformer parallel structures demonstrated excellent performance in extracting features from roads of different levels. Therefore, in the future, further exploration will be conducted using concatenated structures or hybrid structures with dynamic selection capabilities as feature extraction modules. We will simultaneously explore the integration of traditional road extraction methods with deep learning, utilizing images processed with conventional techniques for training and extraction and continuously improving the completeness, accuracy, resistance to interference, and overall applicability of road extraction from high-resolution remote sensing images. Deep learning models’ demand for large-scale labeled training data is continuously increasing. If the data are insufficient or of poor quality, the model may struggle to achieve good performance. Therefore, the next step in research will focus on exploring semi-supervised or weakly supervised methods to train localization models, aiming to better utilize vast amounts of unlabeled data.
Author Contributions
Conceptualization, X.X.; Methodology, C.R. and Z.Y.; Software, Z.Y.; Validation, A.Y.; Formal analysis, A.Y.; Investigation, A.Y.; Resources, Z.Y., Y.Z., Y.L., J.L. and C.D.; Data curation, A.Y.; Writing—original draft, X.X.; Writing—review & editing, A.Y.; Visualization, Y.Z., Y.L., J.L. and C.D.; Supervision, C.R.; Project administration, C.R.; Funding acquisition, C.R. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 42064003). The author is located at the Guilin University of Technology.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Schubert, H.; van de Gronde, J.J.; Roerdink, J.B. Efficient computation of greyscale path openings. Math. Morphol.-Theory Appl. 2016, 1, 189–202. [Google Scholar] [CrossRef][Green Version]
- Hu, J.; Razdan, A.; Femiani, J.C.; Cui, M.; Wonka, P. Road Network Extraction and Intersection Detection from Aerial Images by Tracking Road Footprints. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4144–4157. [Google Scholar] [CrossRef]
- Jing, R.; Gong, Z.; Zhu, W.; Guan, H.; Zhao, W. Island Road Centerline Extraction Based on a Multiscale United Feature. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3940–3953. [Google Scholar] [CrossRef]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of Salient Features for the Design of a Multistage Framework to Extract Roads From High Resolution Multispectral Satellite Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. Unsupervised road extraction via a Gaussian 56 mixture model with object-based features. Int. J. Remote Sens. 2018, 39, 2421–2440. [Google Scholar] [CrossRef]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road Extraction from High-Resolution Remote Sensing Imagery Using Refined Deep Residual Convolutional Neural Network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, L.; Wang, C.; Zhuo, L.; Tian, Q.; Liang, X. Road Recognition from Remote Sensing Imagery Using Incremental Learning. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2993–3005. [Google Scholar] [CrossRef]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. Electron. Imag. 2016, 60, 1–9. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation 2015. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Se-mantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Peng, X.; Yin, Z.; Yang, Z. Deeplab_v3_plus-net for Image Semantic Segmentation with Channel Compression. In Proceedings of the 2020 IEEE 20th International Conference on Communication Technology (ICCT), Nanning, China, 28–31 October 2020. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yang, Z.; Zhou, D.; Yang, Y.; Zhang, J.; Chen, Z. TransRoadNet: A Novel Road Extraction Method for Remote Sensing Images via Combining High-Level Semantic Feature and Context. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Alshaikhli, T.; Liu, W.; Maruyama, Y. Simultaneous Extraction of Road and Centerline from Aerial Images Using a Deep Convolutional Neural Network. ISPRS Int. J. Geo-Inf. 2021, 10, 147. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A Global Context-aware and Batchin dependent Network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Li, P.; Tian, Z.; He, X.; Qiao, M.; Cheng, X.; Song, D.; Chen, M.; Li, J.; Zhou, T.; Guo, X.; et al. LR-RoadNet: A long-range context-aware neural network for road extraction via high resolution remote sensing images. IET Image Process. 2021, 15, 3239–3253. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High Resolution Images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Rong, Y.; Zhuang, Z.; He, Z.; Wang, X. A Maritime Traffic Network Mining Method Based on Massive Trajectory Data. Electronics 2022, 11, 987. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y.; Zhang, Y.; Zhang, Y. Cascaded Attention DenseUNet (CADUNet) for Road Extraction from Very-High-Resolution Images. ISPRS Int. J. Geo-Inf. 2021, 10, 329. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Transformer-Based Decoder Designs for Semantic Segmentation on Remotely Sensed Images. Remote Sens. 2021, 13, 5100. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient Transformer for Remote Sensing Image Segmentation. Remote. Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, H.; Chen, X.; Zhang, T.; Xu, Z.; Li, J. CCTNet: Coupled CNN and Transformer Network for Crop Segmentation of Remote Sensing Images. Remote. Sens. 2022, 14, 1956. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing Swin Transformer and Convolutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 1800–1807. [Google Scholar]
- Xu, G.; Li, J.; Gao, G.; Lu, H.; Yang, J.; Yue, D. Lightweight Real-time Semantic Segmentation Network with Efficient Transformer and CNN. arXiv 2023, arXiv:2302.10484. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road Segmentation of Remotely-Sensed Images Using Deep Convolutional Neural Networks with Landscape Metrics and Conditional Random Fields. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deep Globe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Lu, X.; Zhong, Y.; Zheng, Z.; Zhang, L. GAMSNet: Globally aware road detection network with multi-scale residual learning. ISPRS J. Photogramm. Remote Sens. 2021, 175, 340–352. [Google Scholar] [CrossRef]
- Cheng, J.; Tian, S.; Yu, L.; Liu, S.; Wang, C.; Ren, Y.; Lu, H.; Zhu, M. DDU-Net: A Dual Dense U-Structure Network for Medi-cal Image Segmentation. Appl. Soft Comput. 2022, 126, 109297. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).