


CD-MQANet: Enhancing Multi-Objective Semantic Segmentation of Remote Sensing Images through Channel Creation and Dual-Path Encoding

 ,
,
Abstract
:
1. Introduction
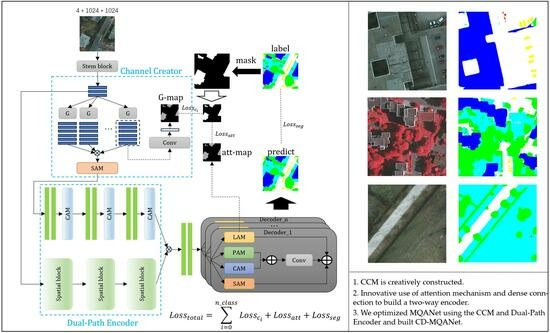
- The Channel Creator module (CCM) is creatively constructed. By imitating the means of image enhancement, an adaptive spectral enhancement method is introduced. CCM can expand the number of channels in the feature map and build spectral attention to give weight to the feature map, stimulate the channels containing useful information, suppress the channels with useless information, and enhance the ability of the network to extract and use the channel features.
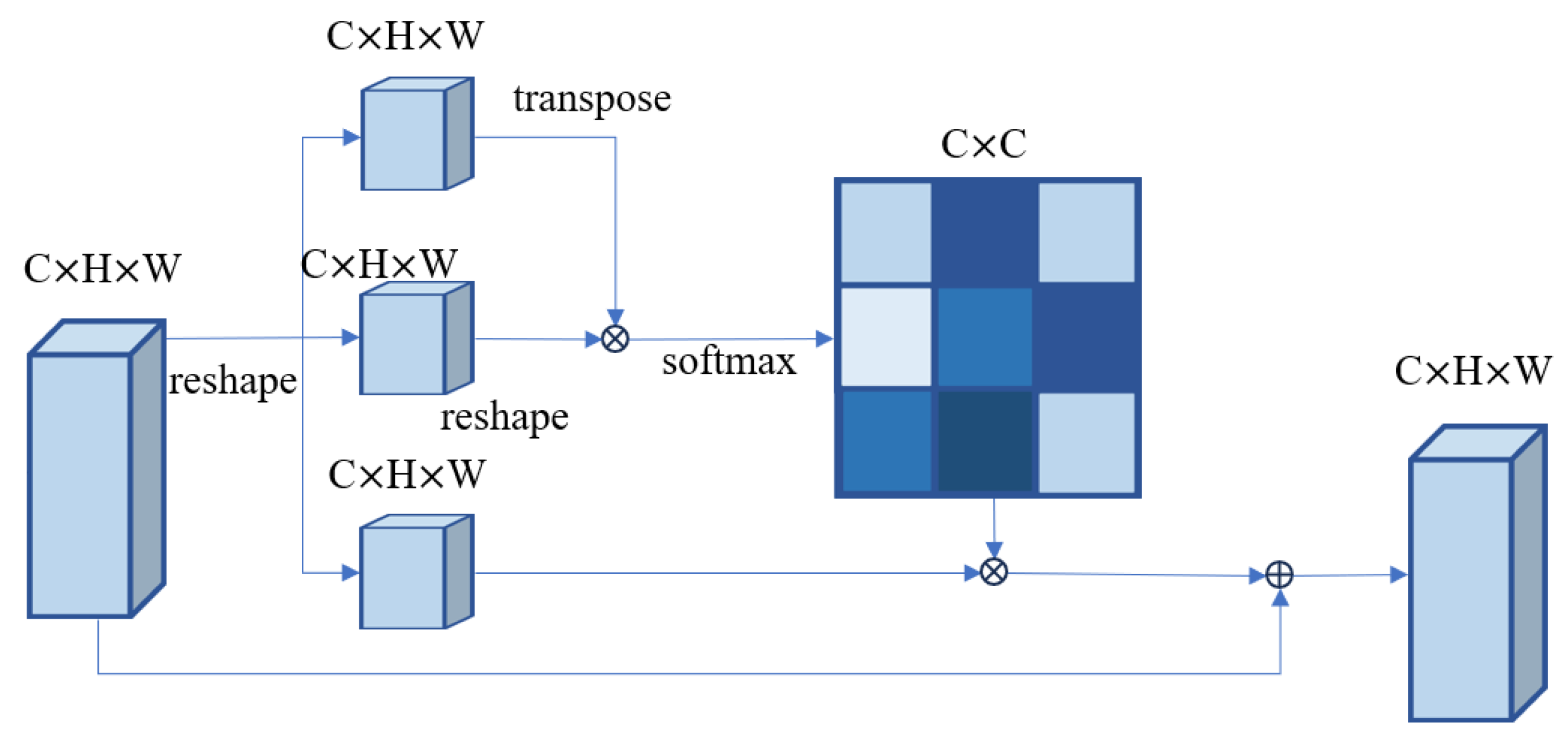
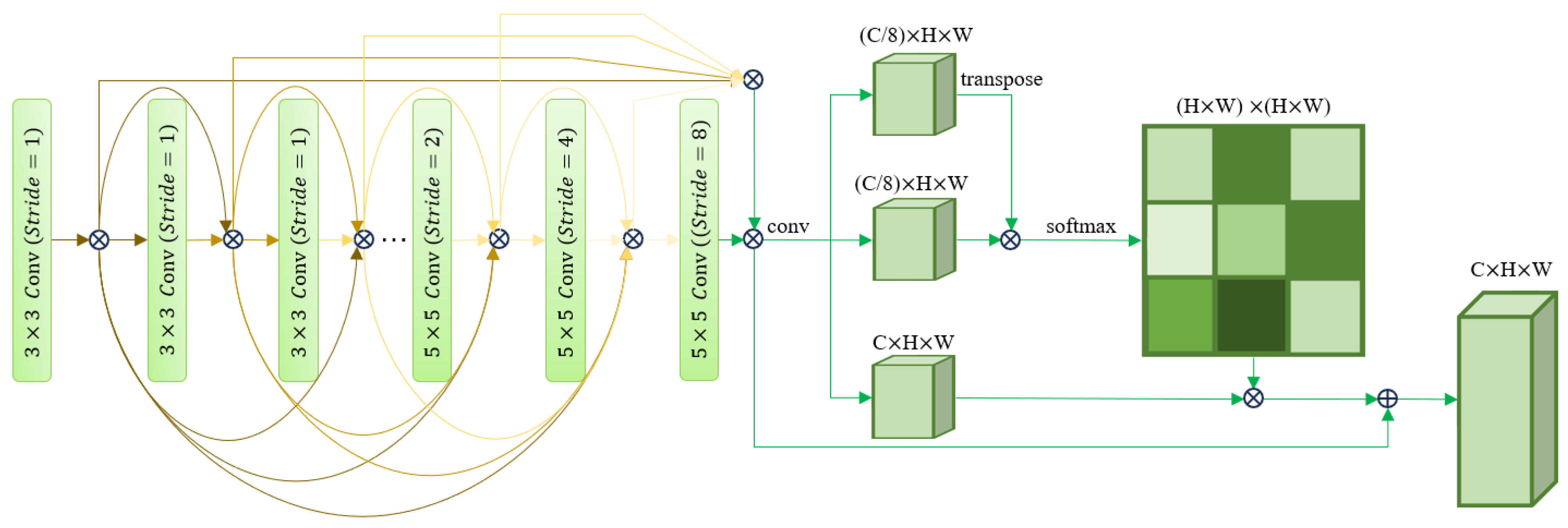
- Innovative use of attention mechanism and dense connection to build a two-way encoder. The Dual-Path Encoder is divided into two parts: channel encoder and spatial encoder. The channel encoder uses the channel attention mechanism to focus on the channel information of the feature map. The spatial encoder uses dense connection and spatial attention mechanism to extract multi-scale features. The two-way encoder improves the ability of the network to extract features of different scales and channels.
- We optimized MQANet using the CCM and Dual-Path Encoder and built CD-MQANet. We also tested CD-MQANet on two public datasets. The experiment shows that the evaluation metrics of CD-MQANet are greatly improved compared with the baseline model MQANet, especially for low vegetation and tree types. The attention mechanism of CD-MQANet and some intermediate results are also visualized and interpretable.
2. Methods
- MQANet did not address optimization in the encoder part of the network, leading to a mismatch in the scales of the encoder and decoder components. As a result, the encoder failed to fully extract information from the original image, indicating a pressing need to enhance the network’s ability to extract valuable information from the input image.
- The contribution of the edge attention mechanism in MQANet towards improving network accuracy was found to be relatively insignificant, and its implementation introduced complexity, requiring additional label preprocessing. Consequently, there is an urgent requirement for more effective attention mechanisms.
2.1. Architecture of CD-MQANet
2.2. Channel Creator Module
2.3. Dual-Path Encoder
2.4. Multi-Task Decoder and Label Attention
2.5. Loss Function
3. Experiments
3.1. Datasets
3.2. Metrics
4. Results
4.1. Ablation Study
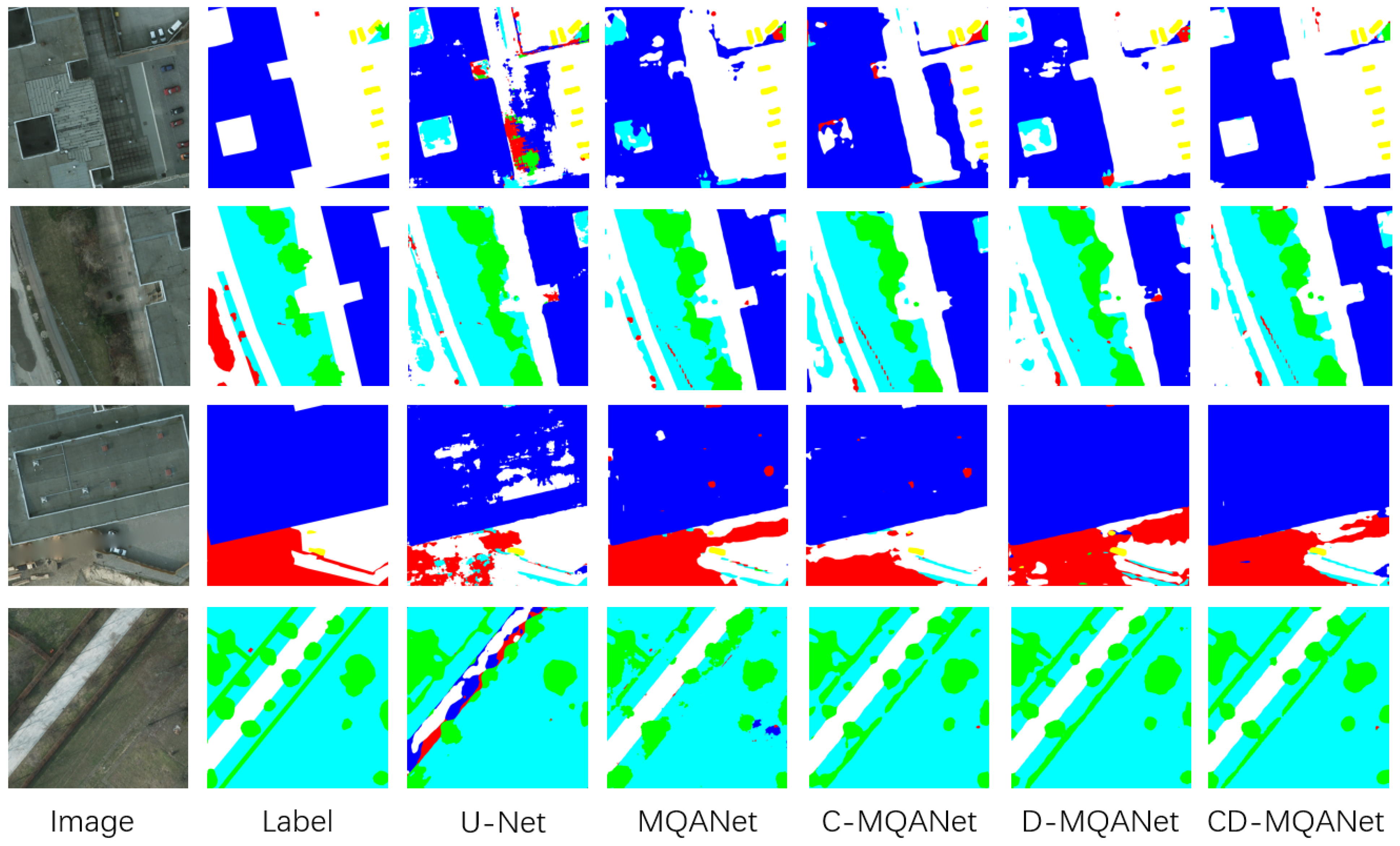
4.1.1. Experiments Results on Potsdam Datasets
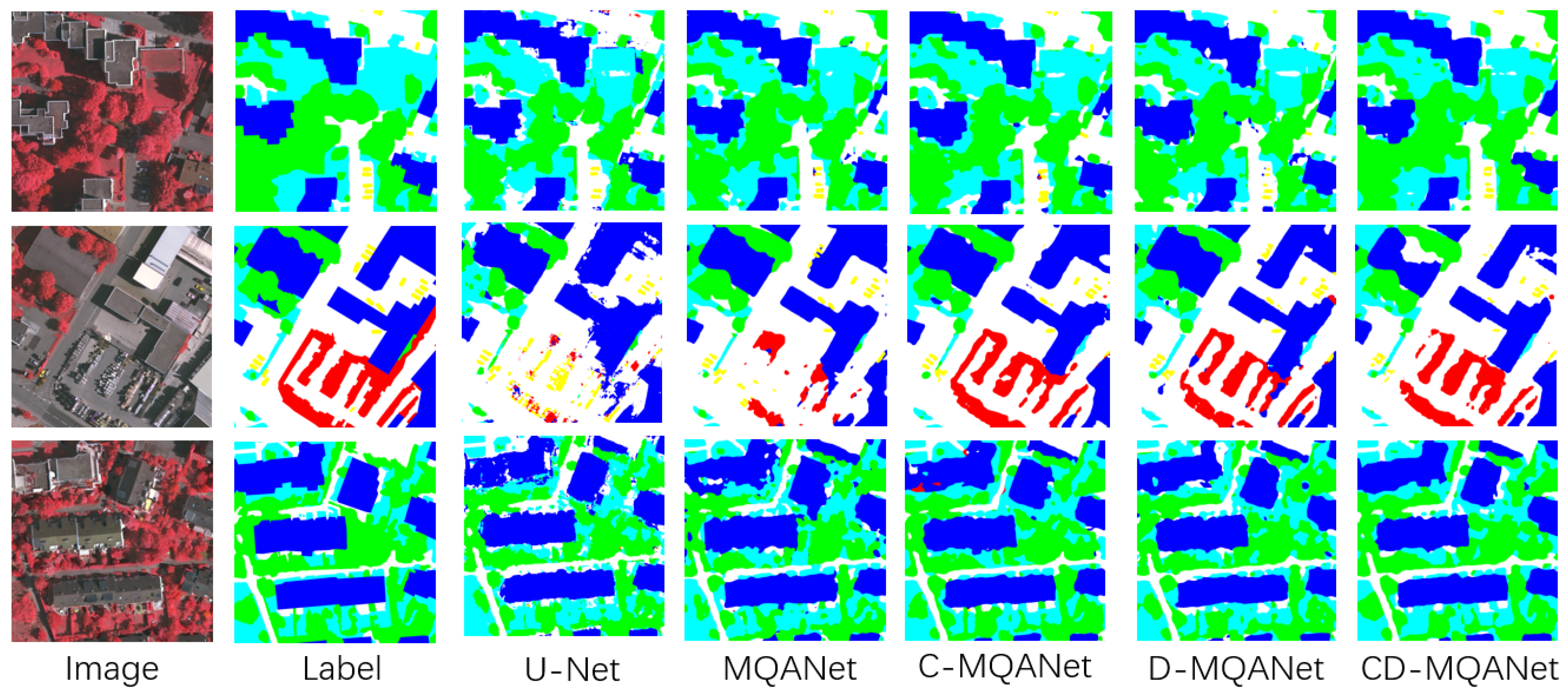
4.1.2. Experiment Results on Vaihingen Datasets
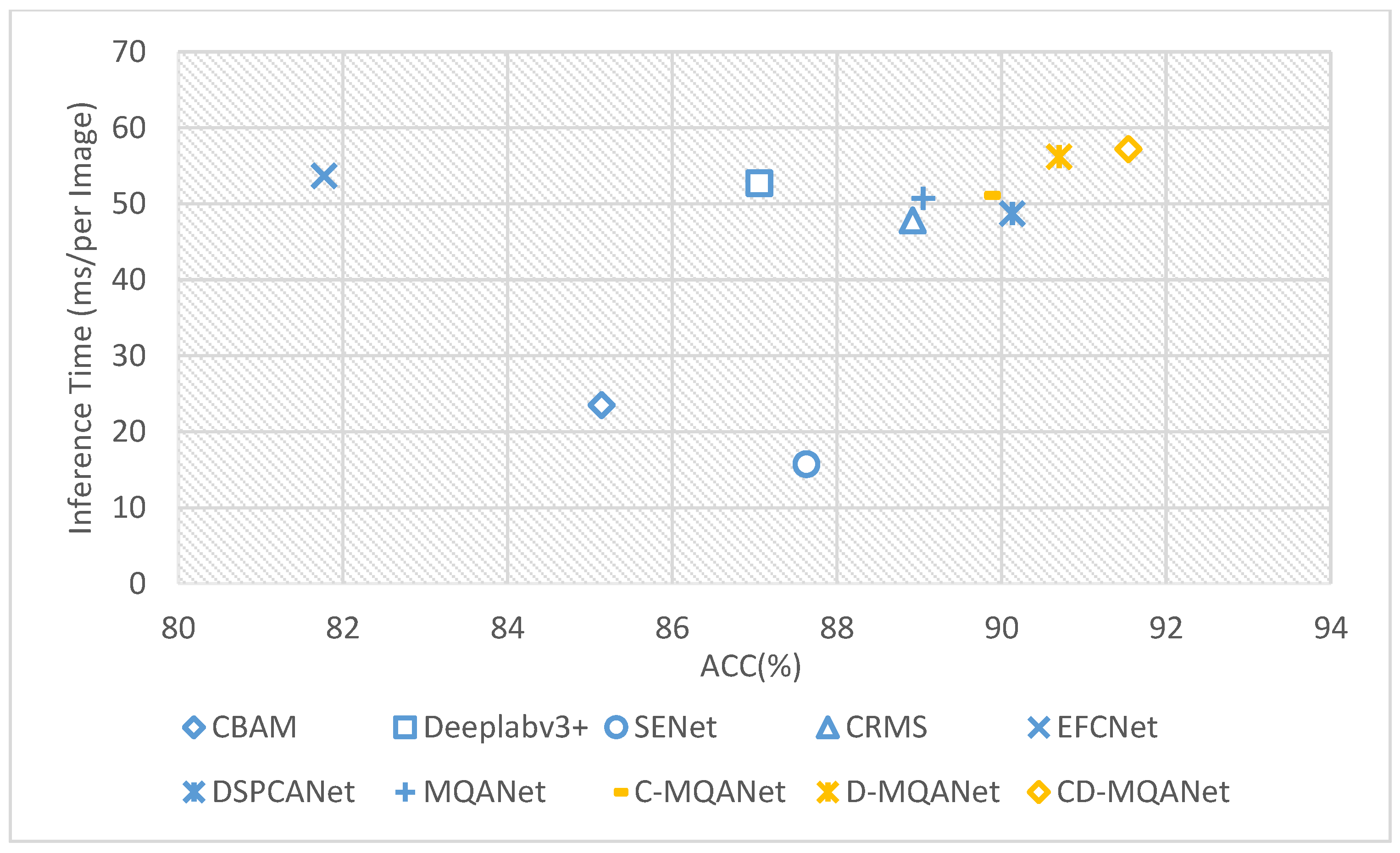
4.2. Comparative Experiment with Other Methods
- The latest CRMS [36] network adopts a multi-scale residual module for optimal feature extraction, and its performance in the field of image segmentation deserves attention.
- Deeplabv3 + [37], as a new network with a spatial feature pyramid structure, can better capture features at different scales and semantic levels in images to improve segmentation performance.
5. Discussion
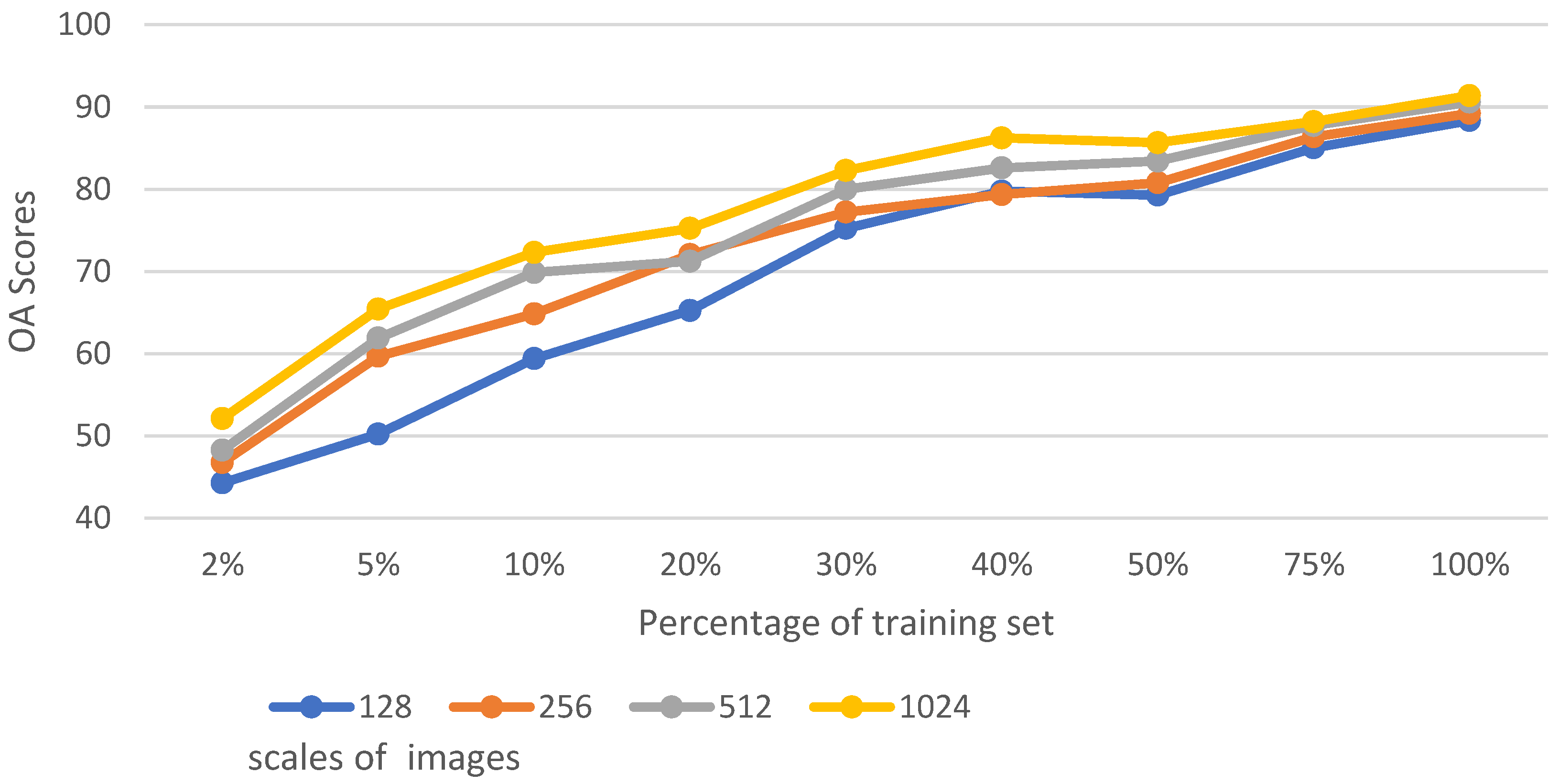
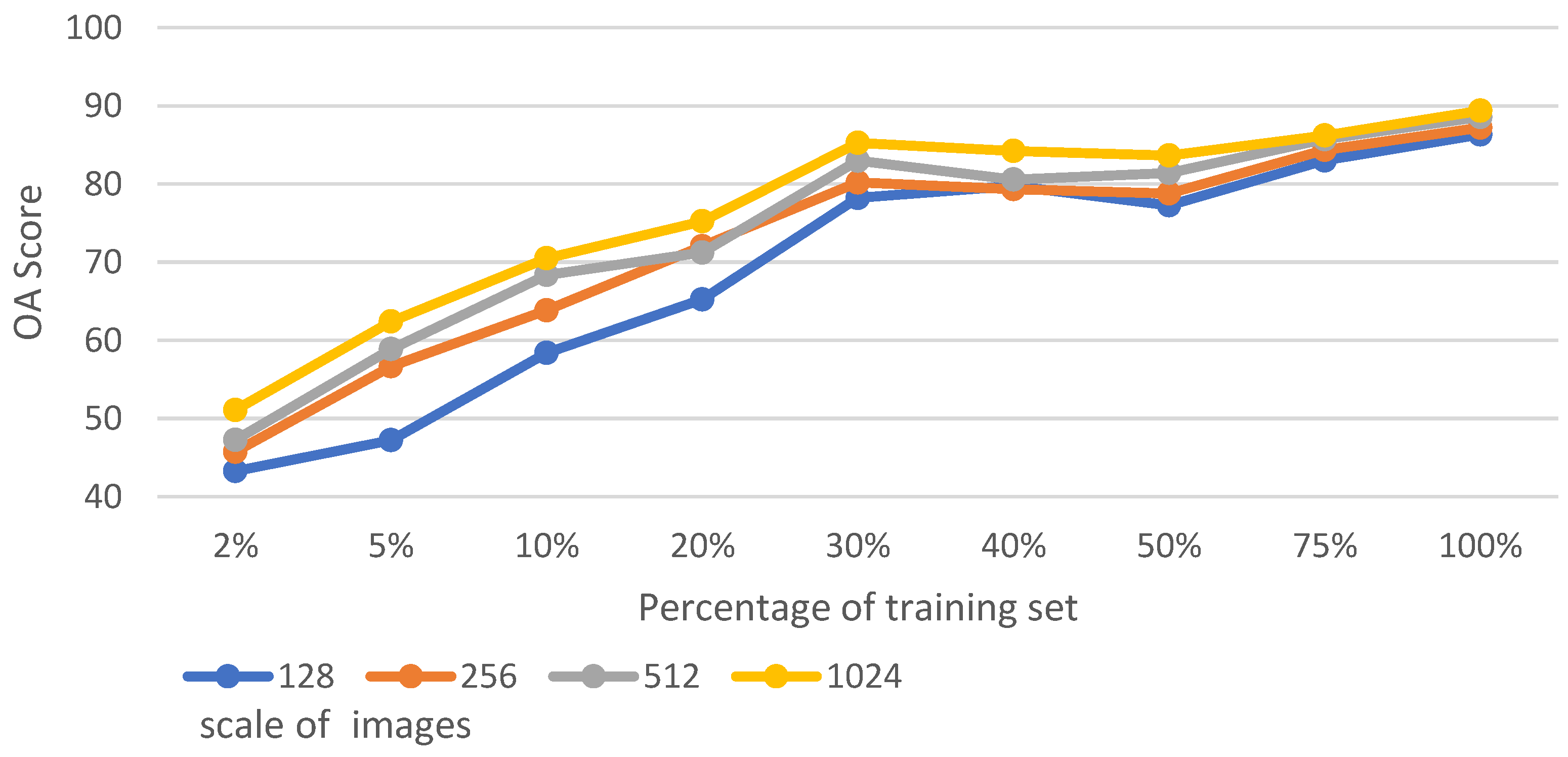
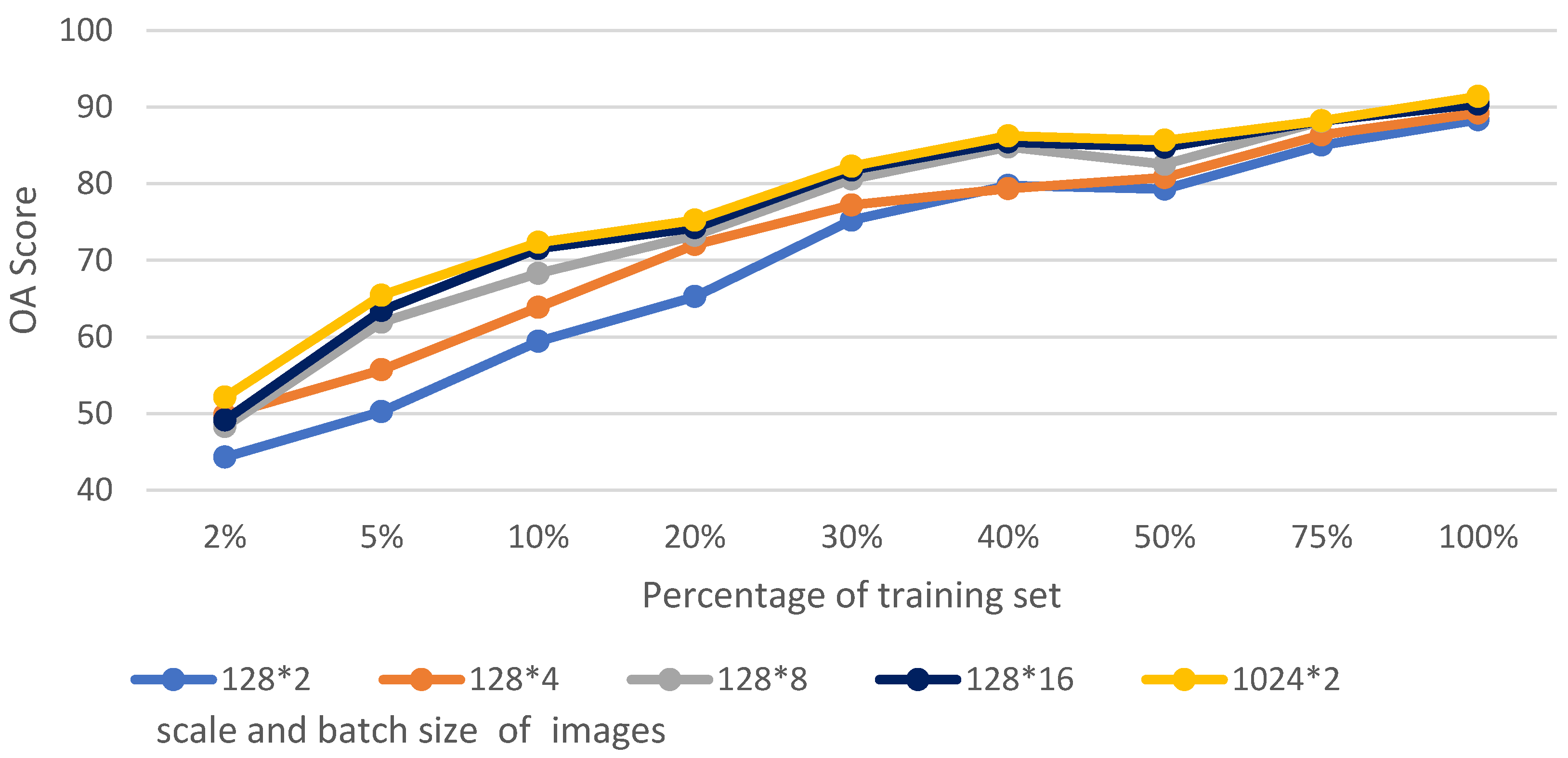
5.1. Analysis of Training Set Size and Image Scale
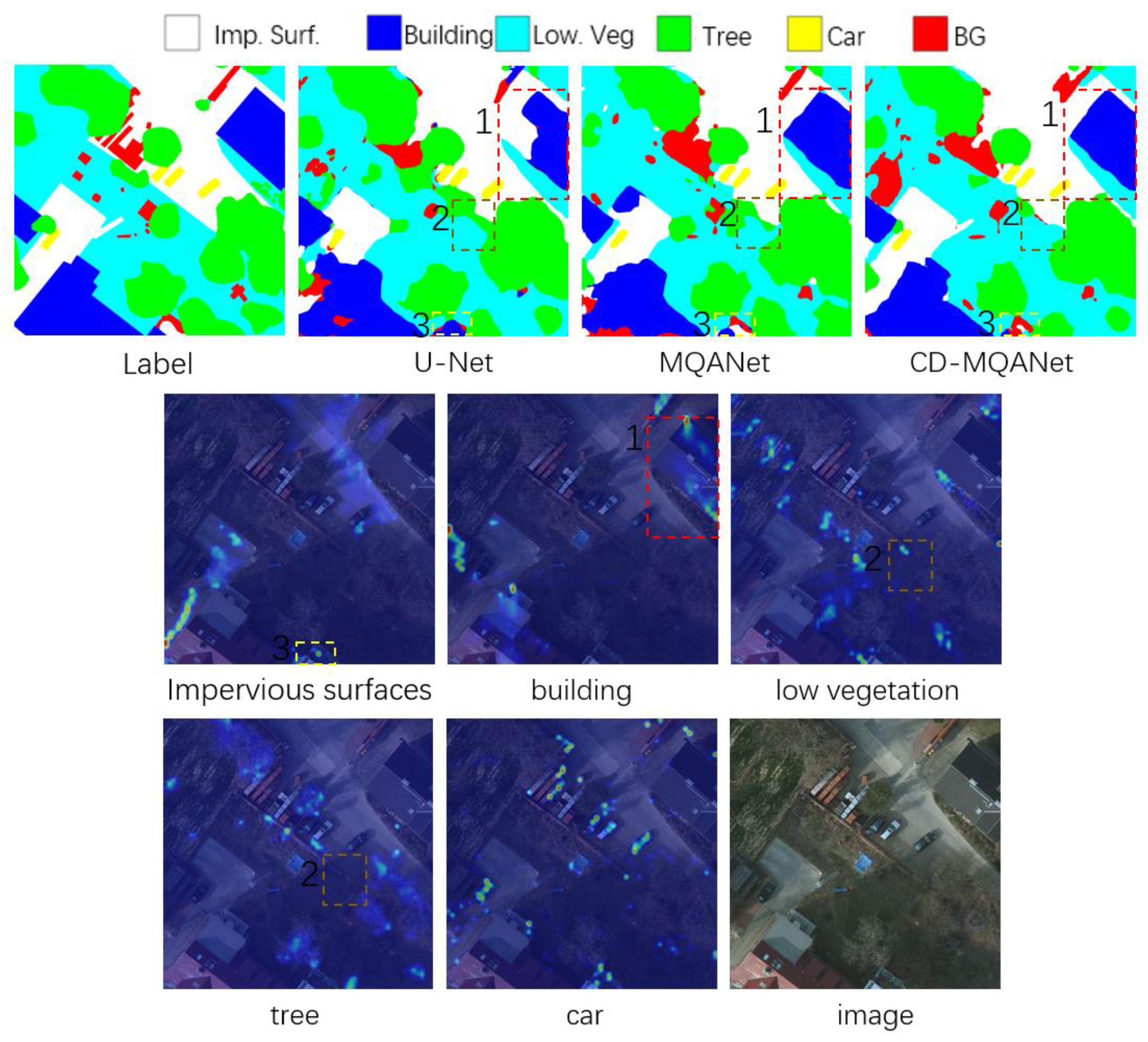
5.2. Class Activation Mapping
5.3. Analysis of CCM and LAM
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Elhag, M.; Psilovikos, A.; Sakellariou-Makrantonaki, M. Land Use Land Cover Changes and its Impacts on Water Resources in Nile Delta Region Using Remote Sensing Techniques. Environ. Dev. Sustain. 2013, 15, 1189–1204. [Google Scholar] [CrossRef]
- Zamari, M. A Proposal for a Wildfire Digital Twin Framework through Automatic Extraction of Remotely Sensed Data: The Italian Case Study of the Susa Valley. Master’s Thesis, Politecnico di Torino, Turin, Italy, 2023; 213p. [Google Scholar]
- Karamoutsou, L.; Psilovikos, A. Deep Learning in Water Resources Management: The Case Study of Kastoria Lake in Greece. Water 2021, 13, 3364. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Liu, F.; Wang, L. UNet-based model for crack detection integrating visual explanations. Constr. Build. Mater. 2022, 322, 126265. [Google Scholar] [CrossRef]
- Qiu, W.; Gu, L.; Gao, F.; Jiang, T. Building Extraction from Very High-Resolution Remote Sensing Images Using Refine-UNet. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6002905. [Google Scholar] [CrossRef]
- Jiao, L.; Huo, L.; Hu, C.; Tang, P.; Zhang, Z. Refined UNet V4: End-to-End Patch-Wise Network for Cloud and Shadow Segmentation with Bilateral Grid. Remote Sens. 2022, 14, 358. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, Q.; Zhang, G. SDSC-UNet: Dual Skip Connection ViT-Based U-Shaped Model for Building Extraction. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6005005. [Google Scholar] [CrossRef]
- Yan, X.; Tang, H.; Sun, S.; Ma, H.; Kong, D.; Xie, X. AFTer-UNet: Axial Fusion Transformer UNet for Medical Image Segmentation. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 3270–3280. [Google Scholar] [CrossRef]
- Fan, C.-M.; Liu, T.-J.; Liu, K.-H. SUNet: Swin Transformer UNet for Image Denoising. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 28 May–1 June 2022; pp. 2333–2337. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3146–3154. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11211. [Google Scholar]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A Dual-Attention Network for Road Extraction from High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Learning to Pay Attention on Spectral Domain: A Spectral Attention Module-Based Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 110–122. [Google Scholar] [CrossRef]
- Shi, Y.; Li, J.; Zheng, Y.; Xi, B.; Li, Y. Hyperspectral Target Detection with RoI Feature Transformation and Multiscale Spectral Attention. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5071–5084. [Google Scholar] [CrossRef]
- Hang, R.; Li, Z.; Liu, Q.; Ghamisi, P.; Bhattacharyya, S.S. Hyperspectral Image Classification with Attention-Aided CNNs. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2281–2293. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, G.; Jia, X.; Wu, L.; Zhang, A.; Ren, J.; Fu, H.; Yao, Y. Spectral–Spatial Self-Attention Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5512115. [Google Scholar] [CrossRef]
- Huang, W.; Zhao, Z.; Sun, L.; Ju, M. Dual-Branch Attention-Assisted CNN for Hyperspectral Image Classification. Remote Sens. 2022, 14, 6158. [Google Scholar] [CrossRef]
- Huang, X.; Zhou, Y.; Yang, X.; Zhu, X.; Wang, K. SS-TMNet: Spatial–Spectral Transformer Network with Multi-Scale Convolution for Hyperspectral Image Classification. Remote Sens. 2023, 15, 1206. [Google Scholar] [CrossRef]
- Shi, W.; Meng, Q.; Zhang, L.; Zhao, M.; Su, C.; Jancsó, T. DSANet: A Deep Supervision-Based Simple Attention Network for Efficient Semantic Segmentation in Remote Sensing Imagery. Remote Sens. 2022, 14, 5399. [Google Scholar] [CrossRef]
- Abadal, S.; Salgueiro, L.; Marcello, J.; Vilaplana, V. A Dual Network for Super-Resolution and Semantic Segmentation of Sentinel-2 Imagery. Remote Sens. 2021, 13, 4547. [Google Scholar] [CrossRef]
- Li, Z.; Cui, X.; Wang, L.; Zhang, H.; Zhu, X.; Zhang, Y. Spectral and Spatial Global Context Attention for Hyperspectral Image Classification. Remote Sens. 2021, 13, 771. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Gan, Y.; Zhang, W. Knowledge based domain adaptation for semantic segmentation. Knowl. Based Syst. 2020, 193, 105444. [Google Scholar] [CrossRef]
- Li, Y.; Si, Y.; Tong, Z.; He, L.; Zhang, J.; Luo, S.; Gong, Y. MQANet: Multi-Task Quadruple Attention Network of Multi-Object Semantic Segmentation from Remote Sensing Images. Remote Sens. 2022, 14, 6256. [Google Scholar] [CrossRef]
- Wang, D.; Liu, Z.; Gu, X.; Wu, W.; Chen, Y.; Wang, L. Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks. Remote Sens. 2022, 14, 3892. [Google Scholar] [CrossRef]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training Deep Convolutional Neural Networks for Land–Cover Classification of High-Resolution Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Zhang, Y.; Shen, Q. Spectral-spatial classification of hyperspectral imagery using a dual-channel convolutional neural network. Remote Sens. Lett. 2017, 8, 438–447. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- ISPRS. 2D Semantic Labeling Contest—Potsdam. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx (accessed on 4 September 2018).
- ISPRS. 2D Semantic Labeling Contest—Vaihingen. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx (accessed on 4 September 2018).
- Liu, Z. Semantic Segmentation of Remote sensing images via combining residuals and multi-scale modules. In Proceedings of the ICMLCA 2021: 2nd International Conference on Machine Learning and Computer Application, Shenyang, China, 17–19 December 2021; pp. 1–4. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, L.; Dou, X.; Peng, J.; Li, W.; Sun, B.; Li, H. EFCNet: Ensemble Full Convolutional Network for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8011705. [Google Scholar] [CrossRef]
- Li, Y.C.; Li, H.C.; Hu, W.S.; Yu, H.L. DSPCANet: Dual-Channel Scale-Aware Segmentation Network with Position and Channel Attentions for High-Resolution Aerial Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8552–8565. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Windows 10 |
|---|---|
| GPU | NVIDIA GeForce RTX 3090 Ti |
| CPU | Intel(R) Core (TM) i7-10700 CPU @ 2.90 GHz 2.90 GHz |
| DL Framework | Pytorch V1.11.0 |
| Compiler | Python V3.9.12 |
| Optimizer | AdamW |
| Learning Rate | 0.002 |
| Batch Size | 2 |
| Method | Per-Class F1-Scores (%) | Mean F1 (%) | OA (%) | ||||
|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low Veg. | Tree | Car | |||
| U-Net | 87.91 | 91.31 | 81.76 | 82.72 | 88.91 | 86.52 | 85.48 |
| MQANet (baseline) [29] | 91.34 | 95.40 | 84.80 | 85.67 | 90.78 | 89.35 | 89.05 |
| C-MQANet | 90.03 | 95.34 | 87.01 | 87.25 | 90.83 | 90.05 | 89.82 |
| D-MQANet | 92.11 | 95.87 | 85.81 | 84.12 | 90.97 | 90.57 | 90.70 |
| CD-MQANet | 92.30 | 96.56 | 87.69 | 87.39 | 91.08 | 91.38 | 91.54 |
| Method | Per-Class F1-Scores (%) | Mean F1 (%) | OA (%) | ||||
|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low Veg. | Tree | Car | |||
| U-Net | 84.45 | 87.32 | 69.77 | 83.16 | 63.12 | 77.56 | 81.27 |
| MQANet (baseline) [29] | 88.78 | 91.99 | 77.30 | 85.51 | 73.17 | 84.61 | 87.60 |
| C-MQANet | 88.52 | 91.63 | 81.42 | 86.63 | 73.33 | 85.01 | 87.97 |
| D-MQANet | 90.15 | 93.44 | 79.88 | 86.14 | 72.68 | 85.36 | 88.14 |
| CD-MQANet | 90.45 | 92.68 | 81.67 | 86.59 | 73.86 | 85.86 | 89.02 |
| Method | Potsdam Dataset | Vaihingen Dataset | ||
|---|---|---|---|---|
| Mean F1 (%) | OA (%) | Mean F1 (%) | OA (%) | |
| CBAMNet [17] | 86.04 | 85.14 | 83.77 | 86.47 |
| Deeplabv3+ [37] | 88.01 | 87.06 | 83.77 | 85.71 |
| SENet [14] | 87.97 | 87.63 | 82.85 | 85.26 |
| CRMS [36] | 89.02 | 88.92 | 83.25 | 86.40 |
| EFCNet [38] | 80.17 | 81.77 | 81.87 | 85.46 |
| DSPCANet [39] | 87.19 | 90.13 | 84.46 | 87.32 |
| MQANet | 89.35 | 89.05 | 84.61 | 87.60 |
| CD-MQANet | 91.38 | 91.54 | 85.86 | 89.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Li, Y.; Zhang, B.; He, L.; He, Y.; Deng, W.; Si, Y.; Tong, Z.; Gong, Y.; Liao, K. CD-MQANet: Enhancing Multi-Objective Semantic Segmentation of Remote Sensing Images through Channel Creation and Dual-Path Encoding. Remote Sens. 2023, 15, 4520. https://doi.org/10.3390/rs15184520
Zhang J, Li Y, Zhang B, He L, He Y, Deng W, Si Y, Tong Z, Gong Y, Liao K. CD-MQANet: Enhancing Multi-Objective Semantic Segmentation of Remote Sensing Images through Channel Creation and Dual-Path Encoding. Remote Sensing. 2023; 15(18):4520. https://doi.org/10.3390/rs15184520
Chicago/Turabian StyleZhang, Jinglin, Yuxia Li, Bowei Zhang, Lei He, Yuan He, Wantao Deng, Yu Si, Zhonggui Tong, Yushu Gong, and Kunwei Liao. 2023. "CD-MQANet: Enhancing Multi-Objective Semantic Segmentation of Remote Sensing Images through Channel Creation and Dual-Path Encoding" Remote Sensing 15, no. 18: 4520. https://doi.org/10.3390/rs15184520
APA StyleZhang, J., Li, Y., Zhang, B., He, L., He, Y., Deng, W., Si, Y., Tong, Z., Gong, Y., & Liao, K. (2023). CD-MQANet: Enhancing Multi-Objective Semantic Segmentation of Remote Sensing Images through Channel Creation and Dual-Path Encoding. Remote Sensing, 15(18), 4520. https://doi.org/10.3390/rs15184520