This section presents the results of tests performed on the algorithm technique for recognizing transfer in underwater SSS by using the crossed PPCSSA model. The experiments were conducted on a computer system using the Microsoft Windows 10 operating system with 64 GB memory and an NVIDIA GTX TITAN-XP GPU. The network architecture was developed using Python version 3.6.8. The reliability and efficacy of the proposed method were assessed through comparative analysis and experiments. The recognition accuracy improvement of the proposed method was evaluated by comparing it with various conventional DL-based recognition techniques. Moreover, the effectiveness of the self-attention TL algorithm in target recognition was examined by contrasting it with related TL algorithms.
4.3. Performance Analysis
The performance of the proposed method was assessed by analyzing the OA index on the test set and comparing it to several state-of-the-art (SOTA) methods.
- (1)
Comparison with traditional deep models
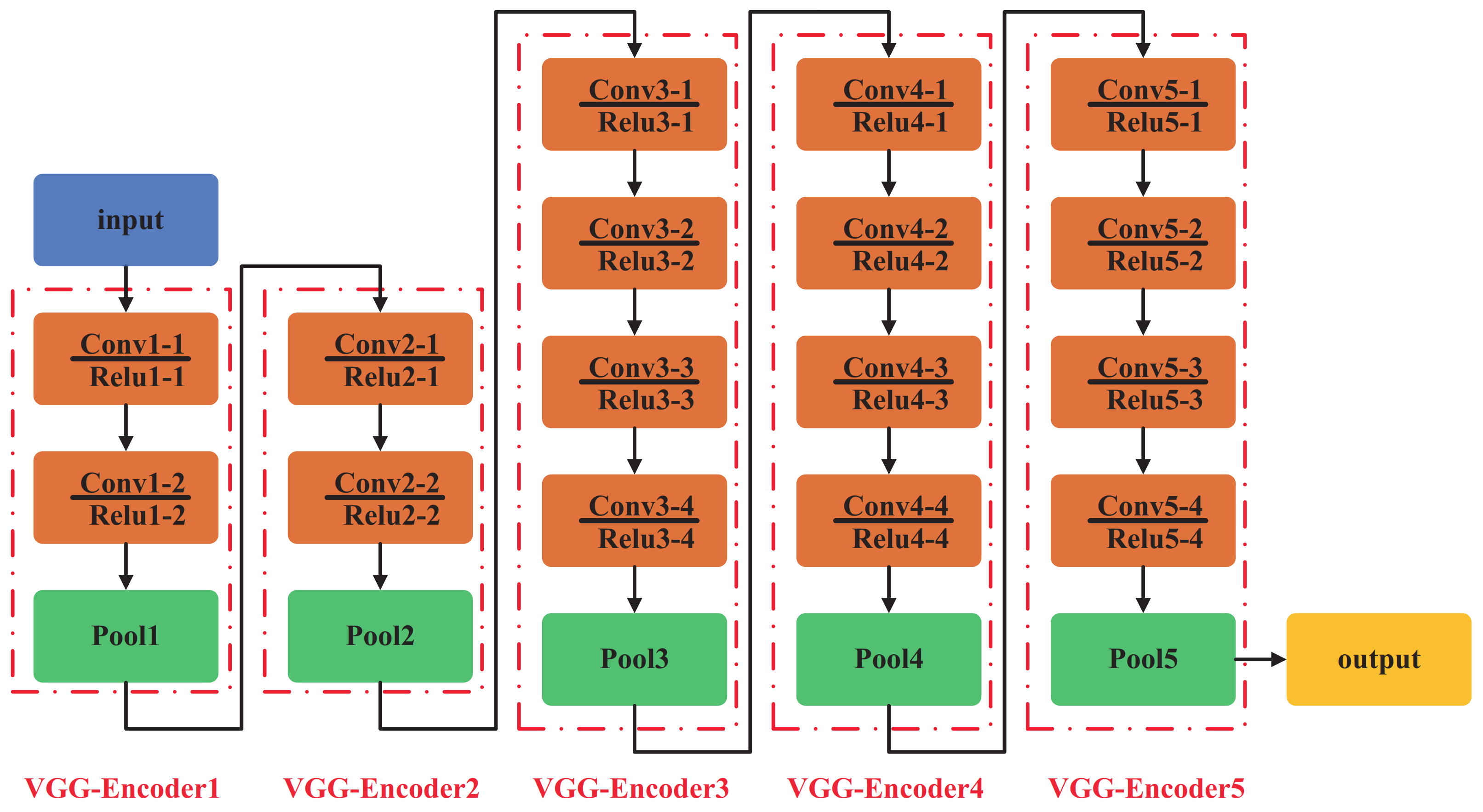
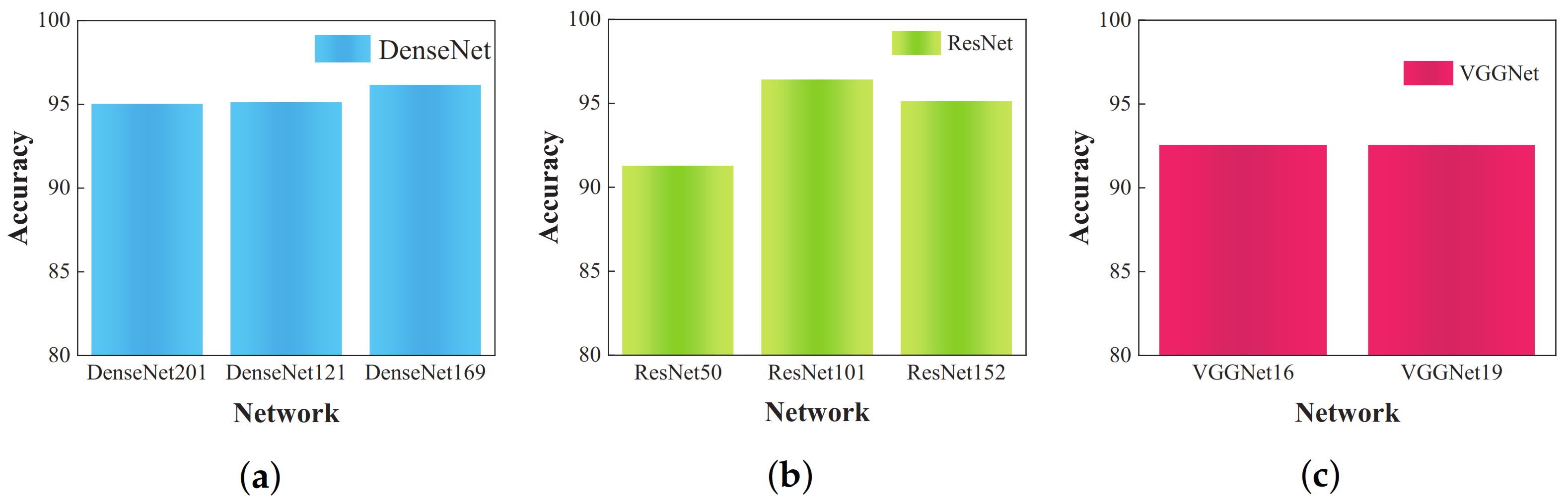
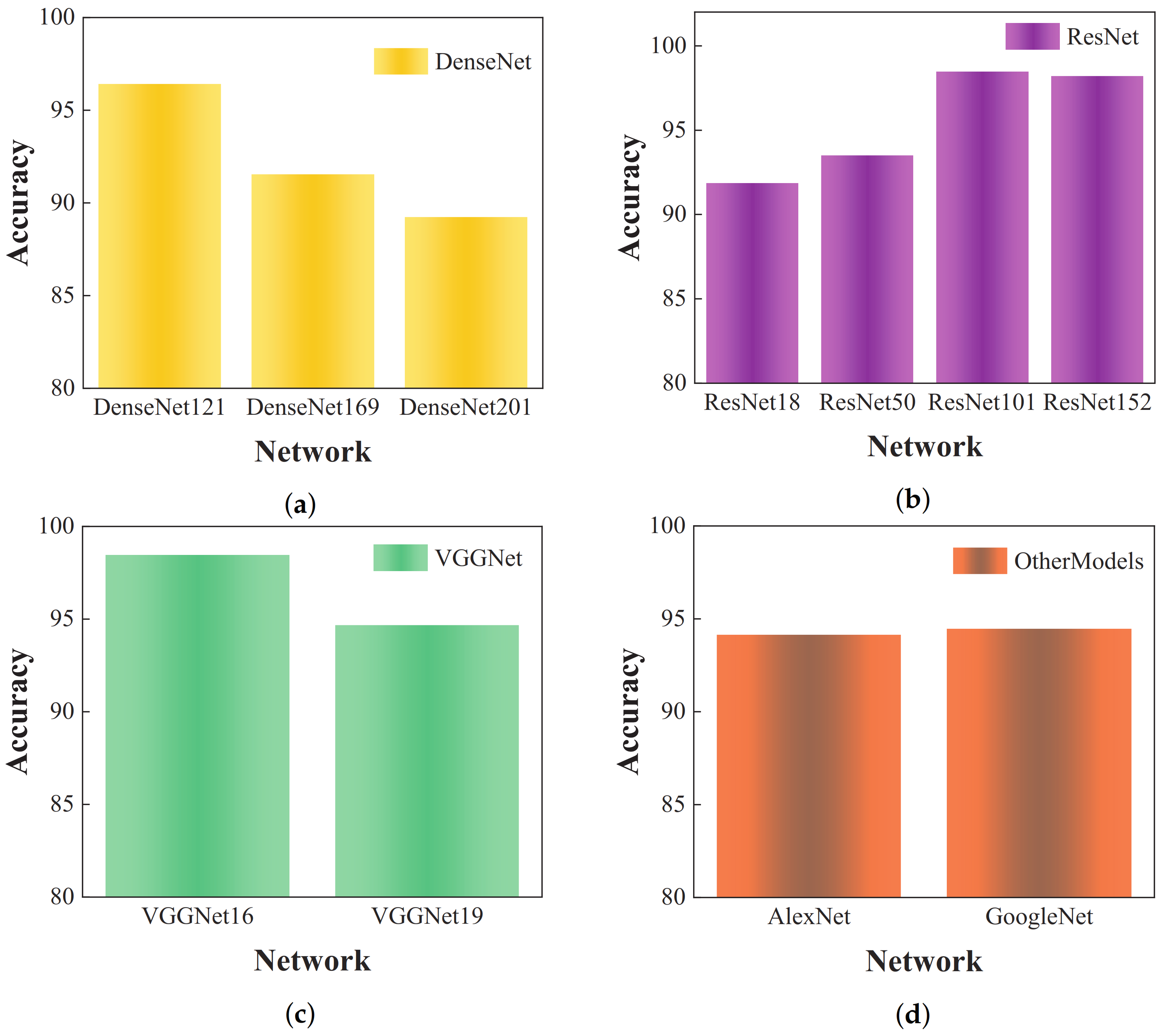
DenseNet (201, 121, 169), ResNet (50, 101, 152), and VGGNet (16, 19) are among the most frequently employed network architectures for object recognition in recent research. Therefore, in this study, the above-mentioned methods were selected for comparative analysis. All these models utilized a standard open network structure. In order to maintain recognition accuracy, input images were consistently resized to 224 × 244 pixels, ensuring alignment between learning rate and batch size.
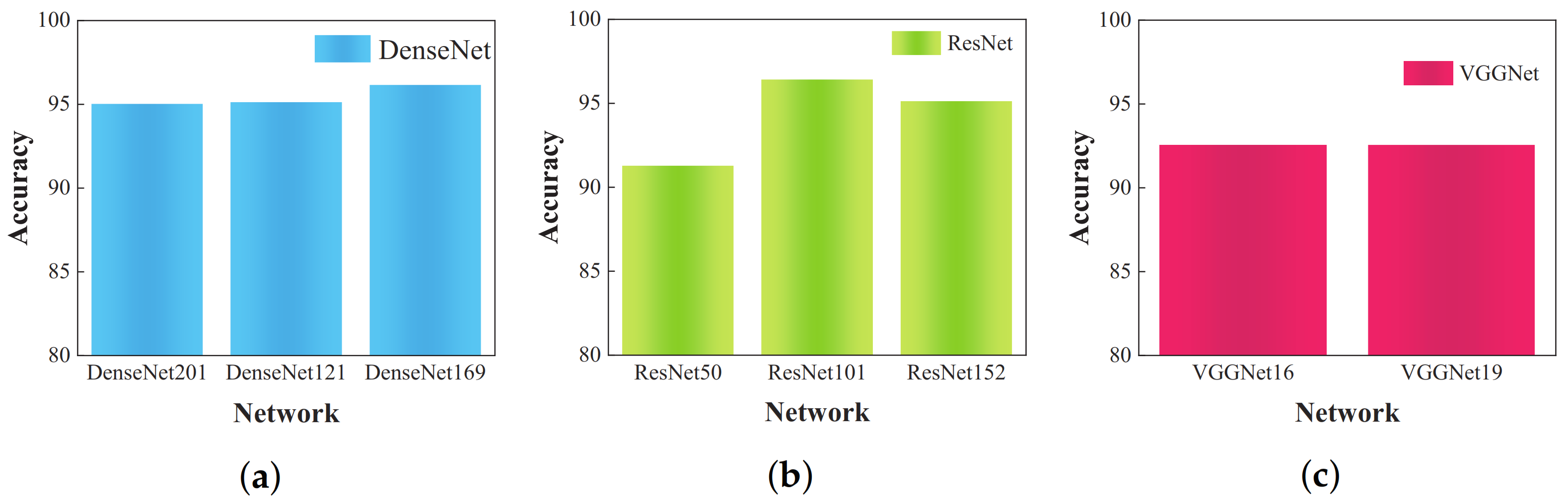
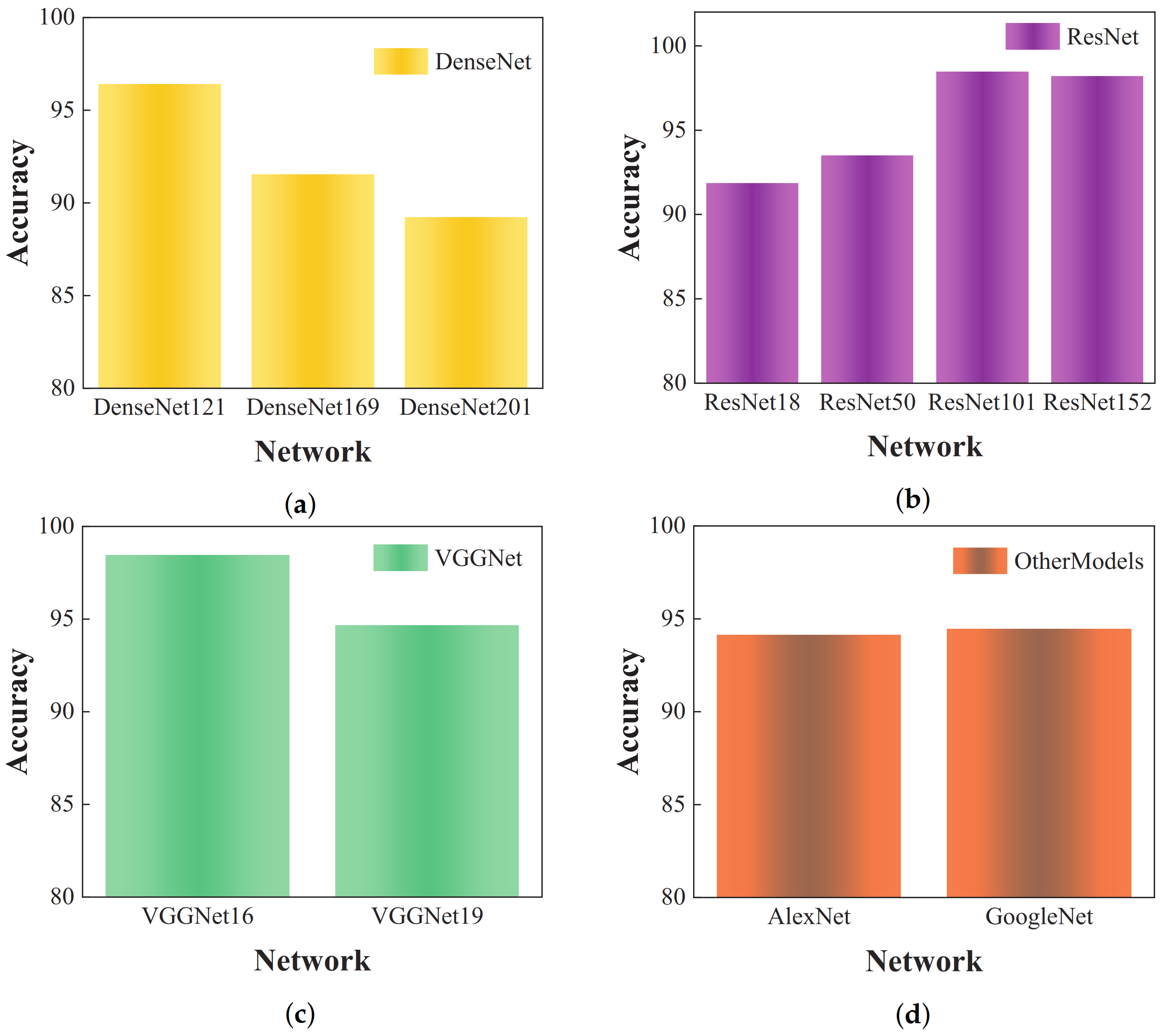
Figure 8 displays the experimental outcomes.
Table 4 reveals that, while the VGG-16 and VGG-19 models exhibit simpler architectures, their recognition performance, with an accuracy of 92.56%, does not meet the set standards. In contrast, the DenseNet (201, 121, 169) models represent DenseNet architectures with 201, 121, and 169 layers, respectively. Their recognition accuracies are comparable, with DenseNet-169 achieving the highest accuracy of 96.15% and DenseNet-201 registering 95.02%. The recognition accuracy of the ResNet model varies based on its layer count, with the ResNet-50 model achieving 91.28% and the ResNet-101 model peaking at 96.41%. Analysis of the recognition results from these models reveals that DenseNet and ResNet outperform VGGNet. This superior performance is attributed to the more intricate connections between convolutional layers in DenseNet and ResNet compared to those in VGGNet. Thus, utilization of the less complex VGG-19 model can enhance the recognition abilities of the algorithm.
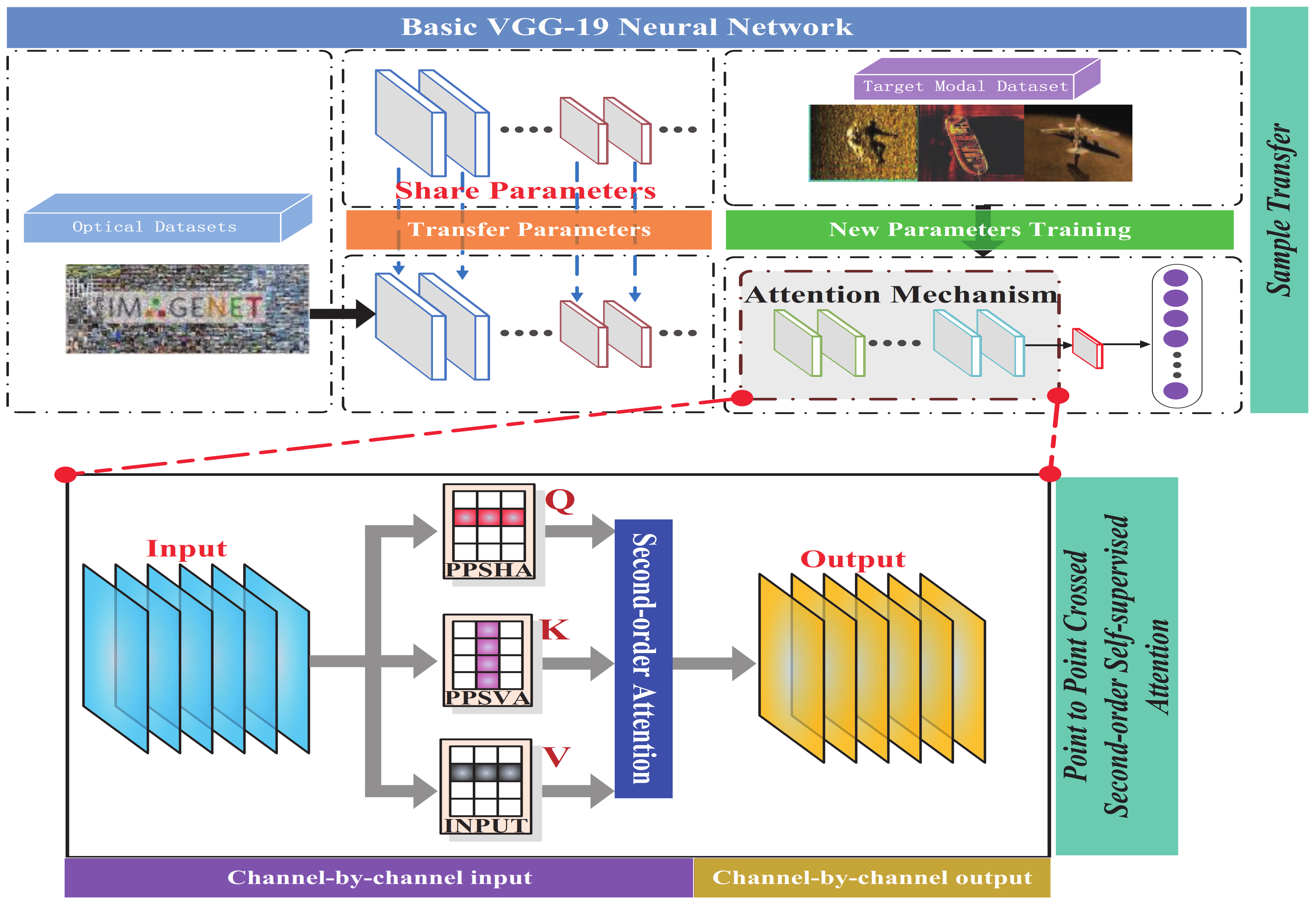
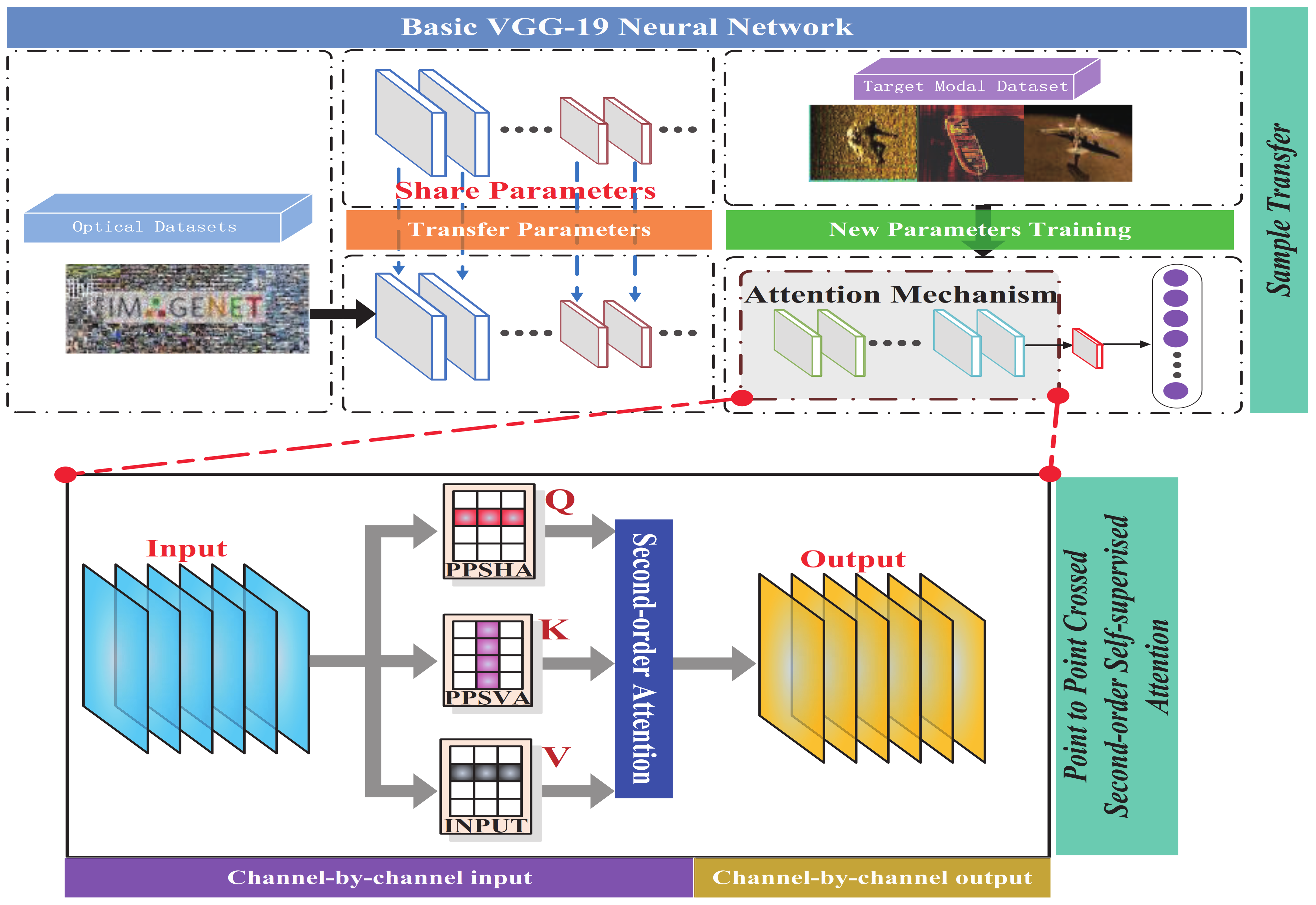
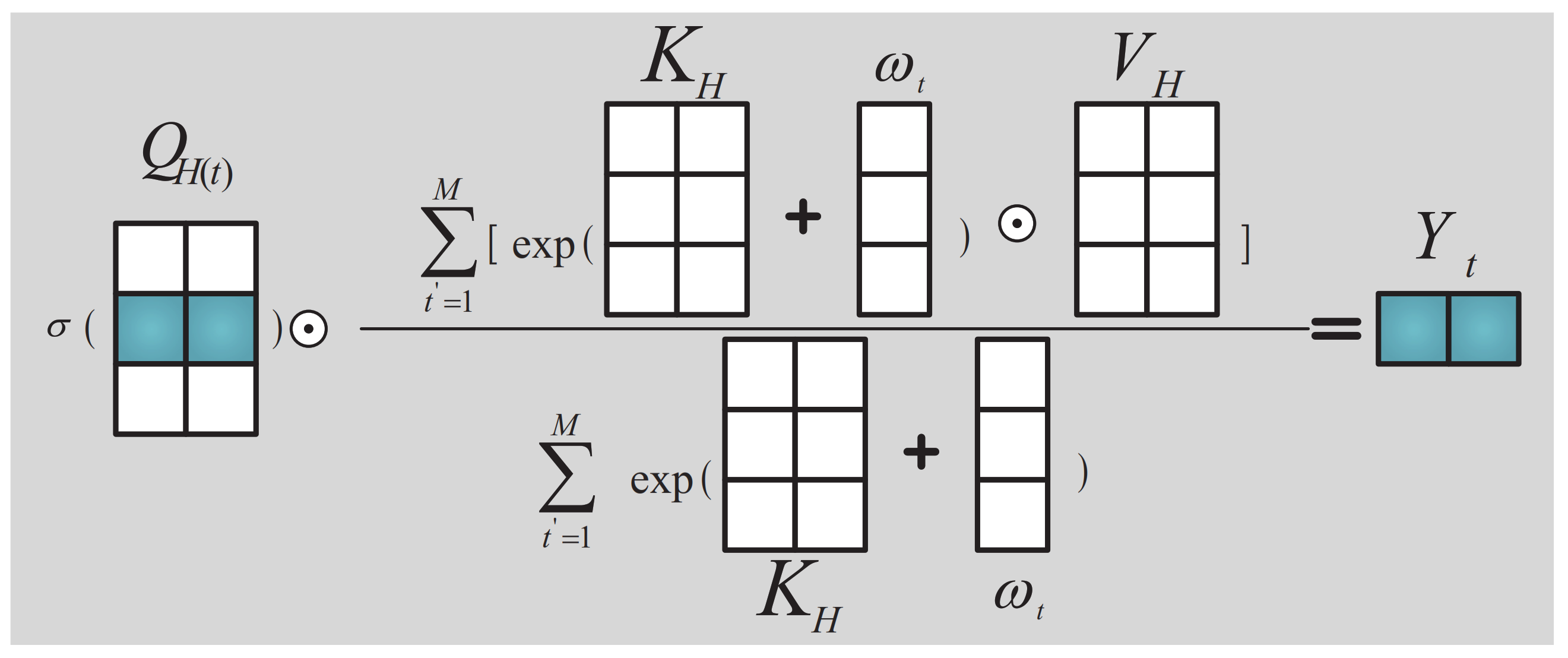
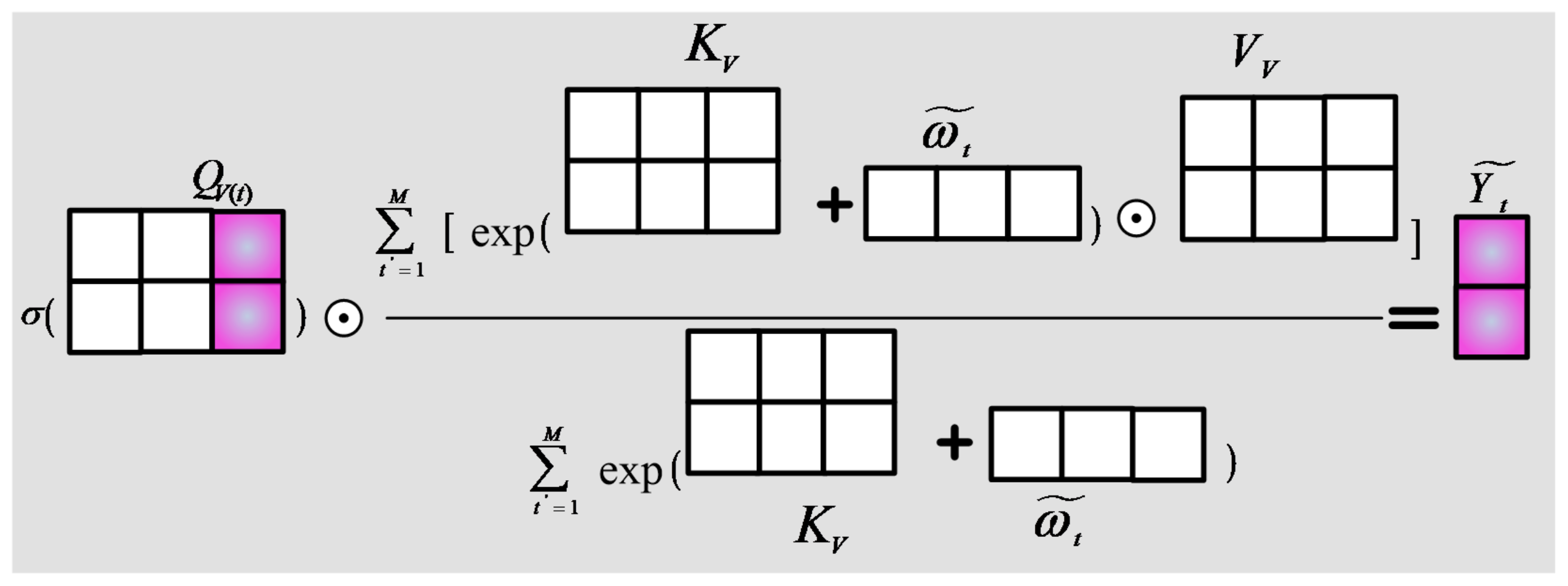
In the process of target recognition training in deep networks, the number of network parameters is relatively large, and a large number of data samples is required for good training of network parameters. If the data sample size is insufficient, the “overfitting” problem with a large training recognition rate and a low test recognition rate is expected to occur in the process of network training. Sonar image corresponds to a typical small data sample. Therefore, sonar images also offer the drawback that a deep network is not effective in target recognition. In this study, the network parameters requiring sonar image training are reduced by the transfer recognition strategy. Simultaneously, the importance features of images are extracted by the PPCSSA mechanism, and the target is accurately identified under the support of the importance features.
Figure 9 illustrates that, due to the large noise of underwater images, the classical deep network used for optical target recognition causes serious interference in the process of image feature extraction, in particular, for target images with small scale, low contrast, and fuzzy nature.
Figure 9a,b show the crashed aircraft; however,
Figure 9a presents the small scale, and
Figure 9b shows the problem of ambiguity, so the classical depth recognition method can easily misidentify the target as the seabed.
Figure 9c–f show a shipwreck. Nonetheless,
Figure 9c is ambiguous,
Figure 9d,e have the problem of low contrast,
Figure 9f faces the problem of a small scale, and the classical depth recognition method can easily misidentify the target as the seabed. In this study, the key features identified in the image are extracted in the process of feature extraction to reduce the noise interference, with the objective of improving the recognition accuracy of the target.
- (2)
SSS image classification results for different backbone networks
In this study, the most widely used models in the field of transfer recognition were adopted as backbone network models to analyze the transfer performance of the proposed transfer identification method. Specifically, the DenseNet, ResNet, VGGNet, AlexNet, and GoogleNet models were employed. The backbone network was trained on the ImageNet optical dataset, while the head network was trained on the SSS data. The sample transfer strategy was used for the transfer identification of SSS targets. The recognition accuracy results are presented in
Figure 10 and
Table 5.
Figure 10 and
Table 5 present the recognition accuracy values of the ResNet-18, ResNet-50, ResNet-152, and ResNet-101 models as 91.86%, 93.50%, 98.21%, and 98.46%, respectively, with the ResNet-101 model demonstrating optimal recognition. Recognition accuracy results for the DenseNet models, including DenseNet-121, DenseNet-169, and DenseNet-201, are 96.41%, 91.54%, and 89.23%, respectively. Thus, the recognition rate appears to decrease with the addition of network layers. Notably, more layers indicate that more detailed information can be extracted; therefore, the distinct feature data distributions between the optical and SSS data indicate that the backbone network trained on optical data is used directly for feature extraction. This information regarding extracted features includes both target feature information and noise feature information, with the latter potentially affecting the recognition performance of the head network, leading to a sharp decrease in recognition accuracy. Among the VGGNet models, VGG-19 demonstrates a lower recognition accuracy. Both the AlexNet and GoogleNet models achieve a recognition accuracy of above 94%. The proposed method trained the head network by using the SSS data, which were then applied for transfer recognition and incorporated into the PPCSSA model to capture the essential low-redundancy image features.
Compared to the other models, the proposed method exhibits superior recognition accuracy, achieving 99.28%, which is 4.61% higher than that of the VGG-19 model. This highlights that the proposed method enhances the recognition performance, notably improving upon the VGG-19 transfer recognition method that utilizes the same backbone model.
- (3)
SSS image classification results for different methods
Subsequently, this method was compared to several advanced sample transfer recognition methods, such as the shallow CNN network, the semi-synthetic transfer recognition method, the regularization transfer recognition method, and the self-supervised training recognition method, all tested on the same SSS dataset.
Table 6 presents the comparison results.
The proposed method was compared with several common SSS identification methods.
Table 6 presents that, by increasing the complexity of the model structure, the recognition accuracy of the method proposed in the literature studies [
16,
17,
18] was improved. The recognition accuracy rate increased from 83.19% to 94.46% and 94.67%, indicating that deepening the network layers or using a more complex network structure was conducive to improving the recognition performance. Moreover, compared with the results of these studies [
16,
18], under the condition of complex network structure, the recognition accuracy improves from 94.46% to 94.67%, and the accuracy increases by 0.21%. Thus, the sample transfer recognition method can improve the performance of small sample target recognition. Moreover, based on the recognition results of methods proposed in literature studies [
15,
16], by employing semi-synthetic data, the sample transfer identification method could successfully address the problem of inadequate recognition accuracy caused by the limited number of data samples. This led to a remarkable improvement of 3% in recognition accuracy, from 94.67% to 97.76%. Furthermore, Huo et al. [
16] reported that, under the condition of VGG-19 as the backbone network, semi-synthetic data were used for sample transfer recognition, and the recognition accuracy exhibited a significant change, from 94.67% to 97.76%, corresponding to an increase of 3.09%. In the process of network parameter transfer recognition by using semi-synthetic data, the distribution difference between synthetic data and SSS data is smaller than that between optical data and SSS data, which reduces the possibility of negative transfer in the process of network parameter training. Therefore, reduction in the distribution difference between different modal data can improve the accuracy of TL target recognition. The SPDRDL and FL-DARTS methods proposed by Gerg and Monga [
19] and Zhang et al. [
20] used self-supervision and empirical regularization knowledge to reduce the distribution differences among different modal data and to improve the accuracy of target recognition to 96.38% and 99.07%, respectively. However, the network structure used in these two methods faced data noise and other interference in the process of feature extraction, which made the recognition effect of the algorithm less suitable compared with that of the proposed method. The results of comparative analysis show that the proposed method uses only optical and SSS image data for model parameter training, which reduces the computational complexity of the multi-modal sample transfer recognition method and solves the problem of small sample target recognition based on the deep network mechanism. Furthermore, the proposed method starts from the key feature extraction and considers that the image dataset is 2D in nature. First, the image is divided into horizontal and vertical directions, and the main features of each row and column in the image can be obtained by the location importance feature extraction method, while the redundant features in each row and column of the image can be eliminated. Then, through the self-supervised second-order key feature extraction method, each row and column of key features in the image are connected with the original features by dot product, and the key features are further enhanced by the multiplicity correlation enhancement method, which considers the interference features and global redundancy features caused by large differences in data distribution during sample transfer. The negative transfer phenomenon in the sample transfer is reduced, and the accuracy of SSS target recognition is improved. Experimental results show that the performance of this method is superior to that of other methods.
- (4)
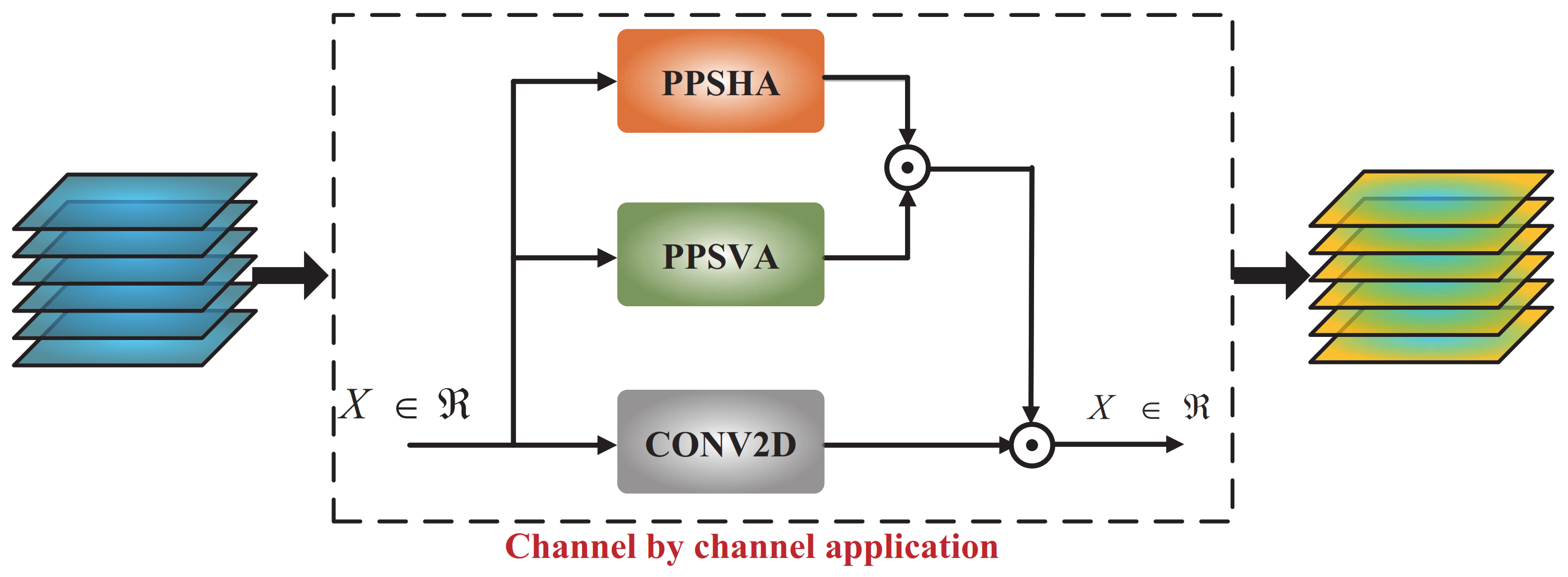
Ablation experiments on PPSHA, PPSVA, and PPCSSA
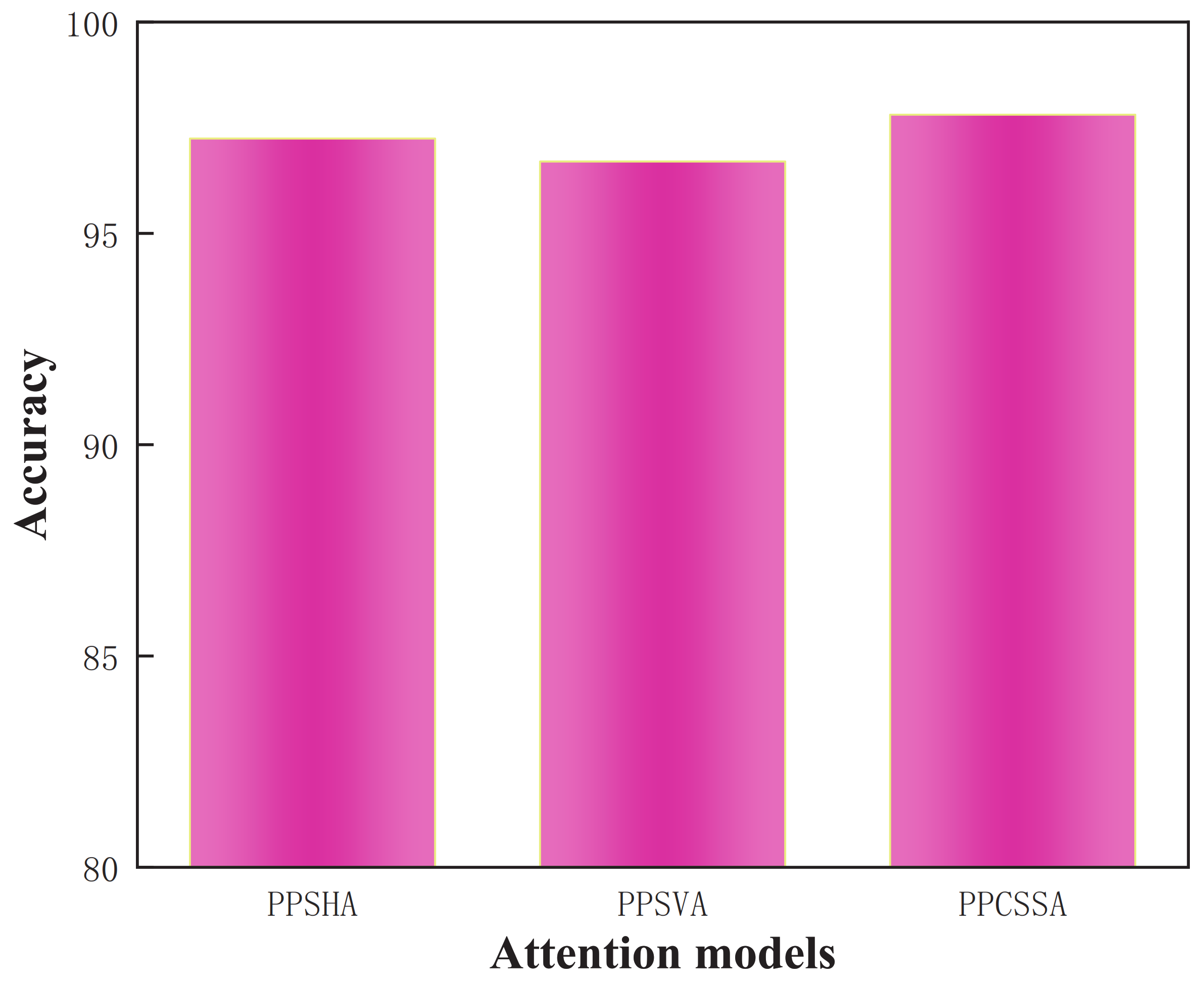
Furthermore, to validate the efficacy of the PPCSSA model, in this study, several attention mechanism-based ablation experiments were conducted. These experiments focused on three methods, the PPSHA, the PPSVA, and the PPCSSA, all utilizing the VGG-19 model as their backbone network.
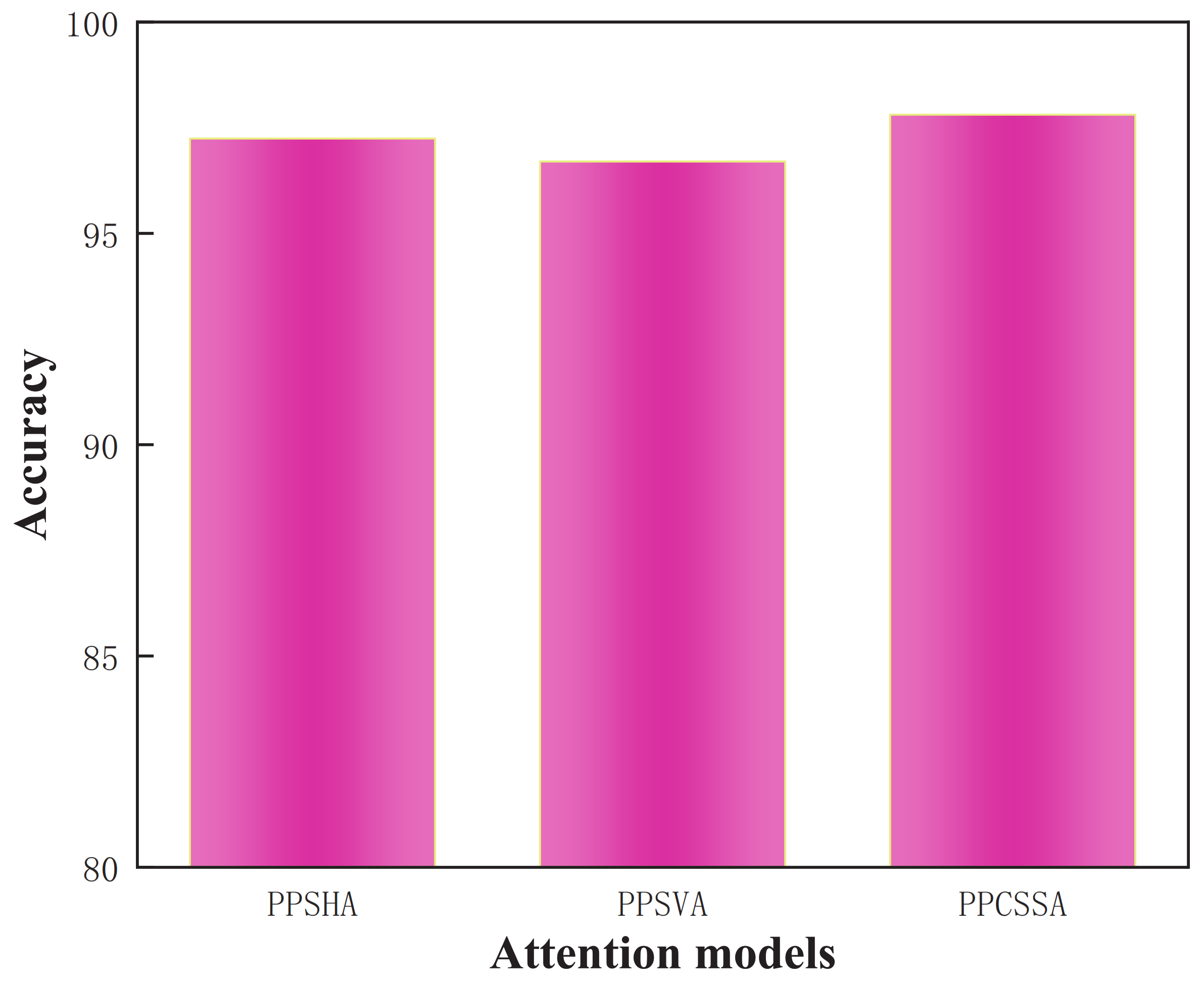
Table 7 provides the results from these ablation experiments.
Table 6 shows that the OA values for the PPSHA and PPSVA models are 98.51% and 98.01%, respectively. The PPCSSA model achieves an OA value of 99.28%, enhancing its recognition accuracy by 0.77% and 1.27% compared to the PPSHA and PPSVA models. Therefore, the PPCSSA model holds the potential for augmenting recognition performance.
- (5)
Comparison of different attention mechanisms in transfer recognition
Under identical conditions using the SSS dataset, this study analyzes the performance of the point-to-point crossover second-order attention mechanism in detail and compares it with the other representative attention mechanism methods. These attention mechanisms include location attention, channel attention, and location channel fusion attention mechanisms. The comparison results are presented in
Table 8.
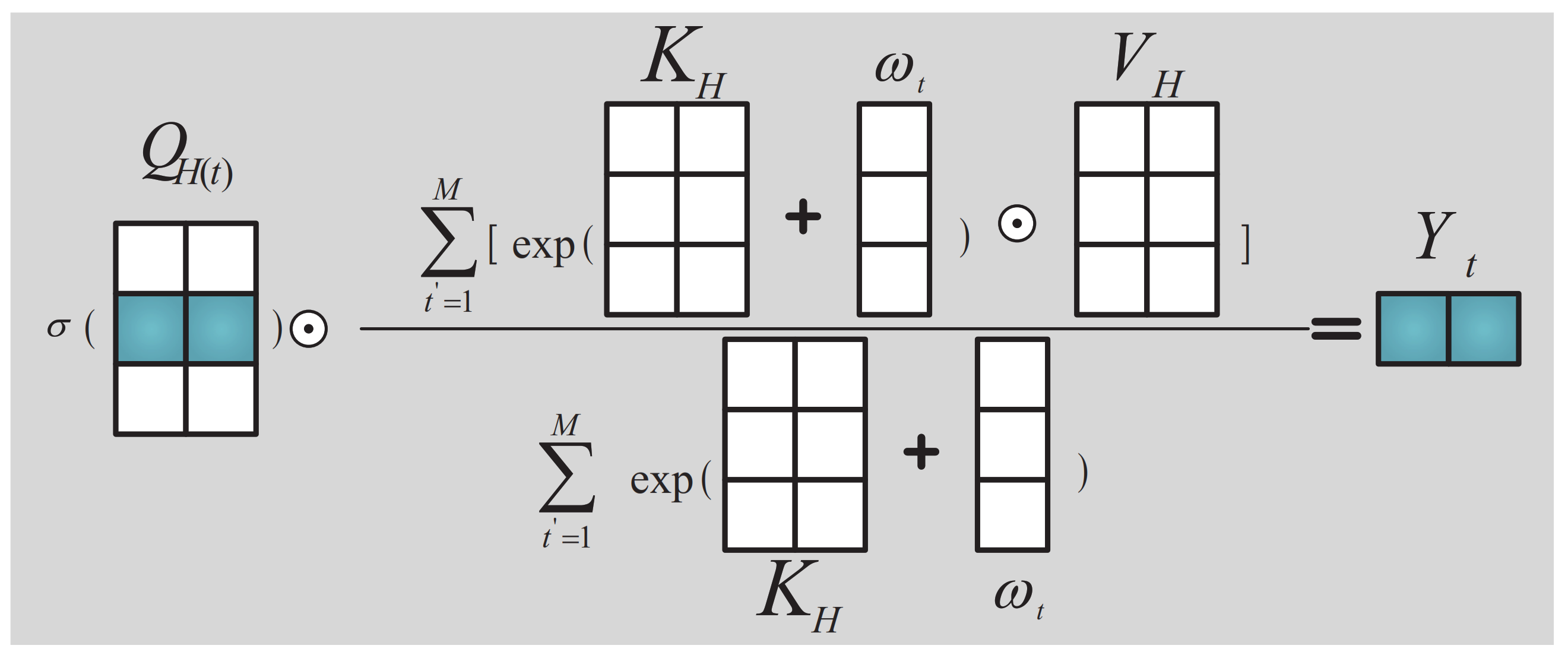
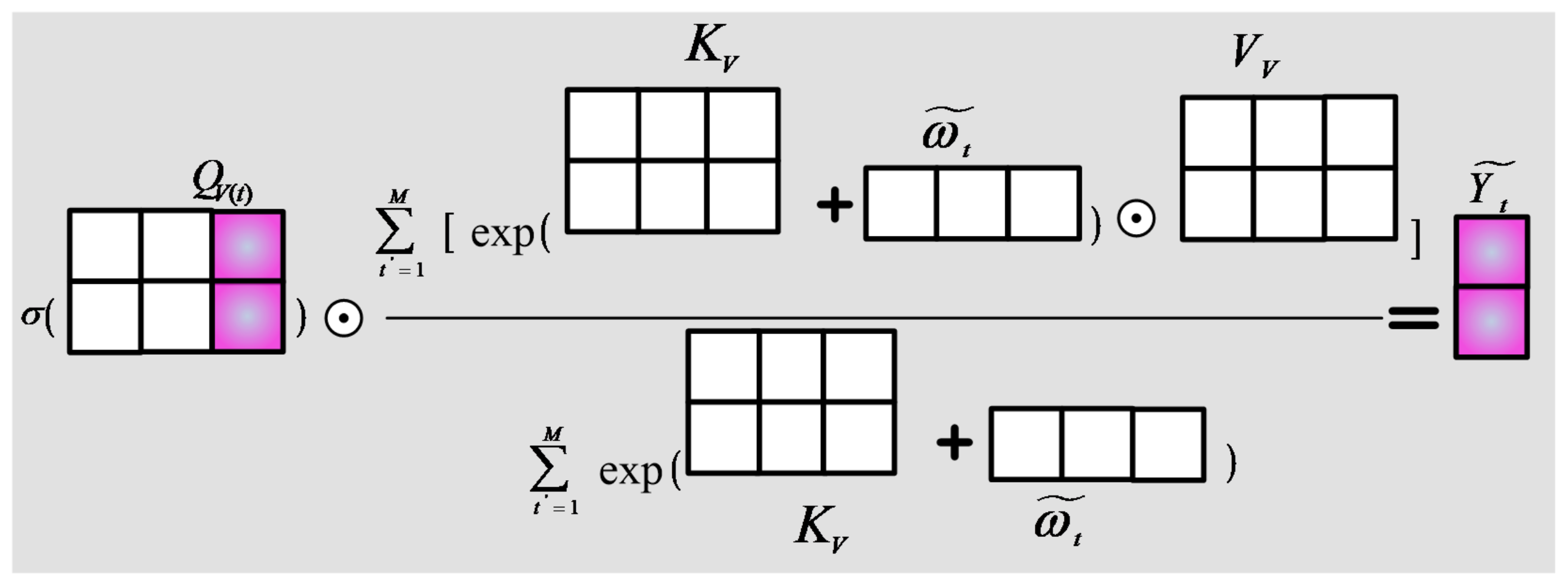
Table 8 presents the comparative experimental results, revealing that the point-to-point crossover second-order attention mechanism proposed in this study offers distinct performance advantages on the SSS datasets. Compared to the location attention mechanism, the point-to-point crossover second-order attention mechanism more precisely captures the essential feature information of the target object by the second-order key feature extraction method. This enhances the key features, suppresses redundant and interference features, and thus improves the target recognition accuracy. The recognition accuracy rate is 2.1% above 97.18%. Compared to the channel attention mechanism, the point-to-point crossover second-order attention mechanism can extract key features in each channel layer through the second-order key feature extraction approach, thus reducing the interference between channel layers and thereby increasing the target recognition accuracy by 1.59% over 97.69%. The point-to-point crossover second-order attention mechanism derives higher-order key features utilizing the second-order key feature extraction and channel-by-channel analysis methods. Compared to the rigid fusion of the two attention mechanisms, the location and channel features can fully emerge while mitigating the interference feature effects. The recognition performance is improved compared to the integrated attention mechanism, leading to an improvement in accuracy from 98.72% to 99.28%. Therefore, the proposed method excels in extracting key features and exhibits superior recognition performance.
- (6)
Comparison of methods with different backbones in SSS noisy image classification
The primary distinction between the SSS data and optical images stems from the low signal-to-noise ratio in underwater images due to intricate underwater conditions. Moreover, underwater noise interference directly impacts the performance of the recognition network. Thus, Gaussian, speckle, multiplicative, and Poisson noise were added to the original SSS images. These types of noise epitomize typical interference in underwater images, effectively emulating a high-noise environment. In order to evaluate and compare the efficacy of various models, in this study, the VGGNet, ResNet, and DenseNet network architectures were selected, which are well-recognized and widely utilized in contemporary research, as the backbone networks for the comparative experiment. The numerical results are listed in
Table 9.
Table 9 shows that the proposed method registers a recognition accuracy of 98.16%. DenseNet recorded the lowest recognition accuracy of 91.63% among all models, while VGGNet showcased the highest accuracy at 95.5%. The recognition accuracy of the proposed method exceeded those of VGGNet, ResNet, and DenseNet by 2.66%, 5.48%, and 6.53%, respectively. Therefore, the proposed method demonstrates commendable recognition capabilities even amidst significant noise interference.
- (7)
Target recognition performance analysis of forward-looking sonar images
FLS, synthetic aperture sonar (SAS), and side-scan sonar data differ significantly in imaging mechanism, resolution performance, detection range, and application scenarios compared to other common marine sonar equipment. The FLS determines the location and shape of underwater targets by measuring the travel time and intensity of sound waves and echoes. The sound wave is reflected, scattered, and refracted when it encounters an underwater target or terrain. The echo signal of the FLS can be reconstructed in the underwater image through signal processing and algorithms. The resolution of an FLS image is affected by acoustic frequency, beam width, signal processing method, etc. It is suitable for underwater navigation and for avoiding obstacles [
3,
38,
42,
43]. SAS receives and synthesizes the amplitude and phase information of a series of echo signals through a receiver traveling a relatively short distance and generates high-resolution images with an increase in the imaging aperture, making it suitable for remote detection tasks [
44,
45,
46,
47]. The SSS transmits an acoustic signal to the seafloor, measures and records the echo data, calculates the received echo signal amplitude, and creates a bilateral coverage image centered on the seafloor. SSS images rely primarily on the amplitude difference of the echo signal to determine the characteristics of the external environment, which is appropriate for the close-range detection task. Accordingly, FLS, SSS, and SAS perform image processing differently. The SSS image processing is relatively simple; however, the resolution is low, making it suitable for locating and detecting short-distance seabed targets. SAS is well-suited for remote target detection and high-precision imaging due to its complex image processing and high resolution.
In order to verify the efficacy of the proposed method for target recognition of additional categories and generalization of recognition performance across multiple sonar datasets, the FLS dataset was selected to validate the proposed method. FLS datasets include image data acquired by forward sonar equipment for detecting and imaging target objects. The dataset contains multiple sonar images from various scenes, encompassing the shape, size, and physical property parameters of different targets, and can comprehensively evaluate the performance of the proposed approach. This study uses FLS datasets for training and testing and divides the dataset into training and test sets. The training set is utilized to train the model during the training stage, and then the model’s recognition accuracy performance index is evaluated on the test set by using the trained model. The FLS dataset contains 3192 samples representing 10 distinct target categories. The training set includes 2231 samples, while the test set contains 961 samples.
Figure 11 depicts a data sample graph to facilitate a more intuitive presentation of the FLS dataset sample information. Moreover,
Table 10 shows the identification outcomes for 10 categories of FLS dataset objects.
Table 10 shows that the recognition rates of DenseNet-201, DenseNet-121, and DenseNet-169 are 89.07%, 88.87%, and 89.91%, respectively, slightly higher than those obtained with the ResNet series algorithms. DenseNet and ResNet algorithms exhibit recognition rates above 88%. Among the reference algorithms, VGG-16 achieves the highest OA = 90.63%, and VGG-19 performs the lowest, with OA = 85.22%. However, from an image quality perspective, the signal-to-noise ratio of FLS images is low, and noise interference is substantial, resulting in a downward trend in the overall effect of target recognition. The intersection point-to-point key feature extraction method adopted in this approach can extract the most critical features in the target image via two key feature extraction methods, improving the robustness of the recognition impact. The proposed method outperforms all comparison algorithms with an OA = 97.80%, demonstrating its good FLS target recognition behavior.
In order to further analyze the recognition performance of the proposed network model on the FLS dataset, the network model was decomposed into three important feature extraction models (PPSHA, PPSVA, and PPCSSA). Next, the advantages of the proposed model in FLS target recognition were analyzed through ablation experiments on the three models. The experimental results are presented in
Table 11 and
Figure 12.
Table 11 and
Figure 12 show that, with the VGG-19 network as the backbone network, only the key features in the horizontal direction of the image were extracted, the recognition accuracy was found to be 97.24%, and the key features in the vertical direction were extracted with the recognition accuracy of 96.70%. The second-order key feature extraction method with point-to-point crossover was adopted, and the recognition accuracy was 97.80%. This shows that this method can extract the key features in all directions, reduce the influence of interference features, and exhibit the best recognition effect.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}