
UniRender: Reconstructing 3D Surfaces from Aerial Images with a Unified Rendering Scheme




Abstract
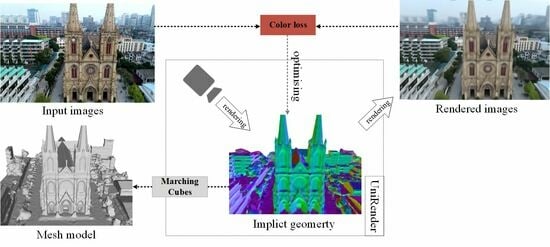
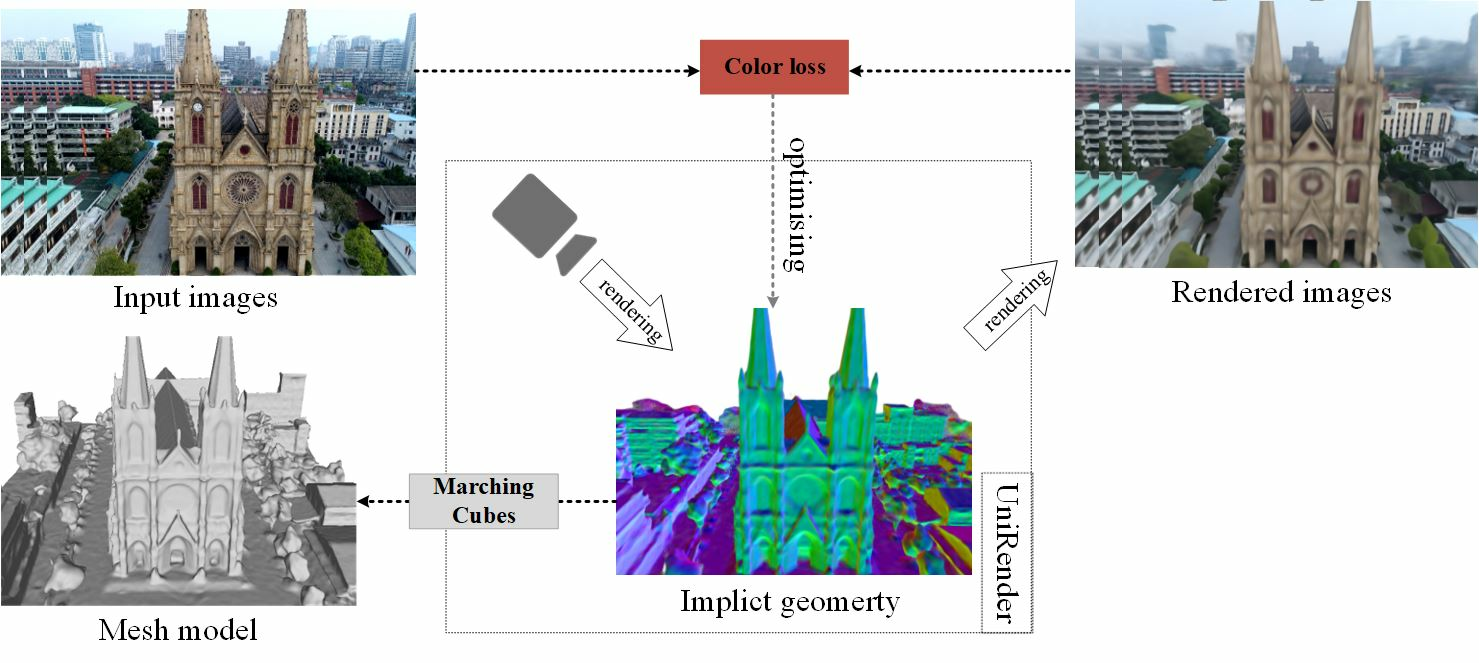
:
1. Introduction
- A qualitative and quantitative analysis of the biases that exist in the current volume rendering paradigm.
- An approximately unbiased rendering scheme.
- A novel geometric constraint mechanism.
- A novel spherical sampling algorithm.
2. Related Work
2.1. Neural Implicit Representation
2.2. 3D Reconstruction with Differentiable Rendering
2.2.1. Surface Rendering
2.2.2. Density-Field-Based Volume Rendering
2.2.3. SDF-Based Volume Rendering
2.3. Issues Existing in Volume Rendering
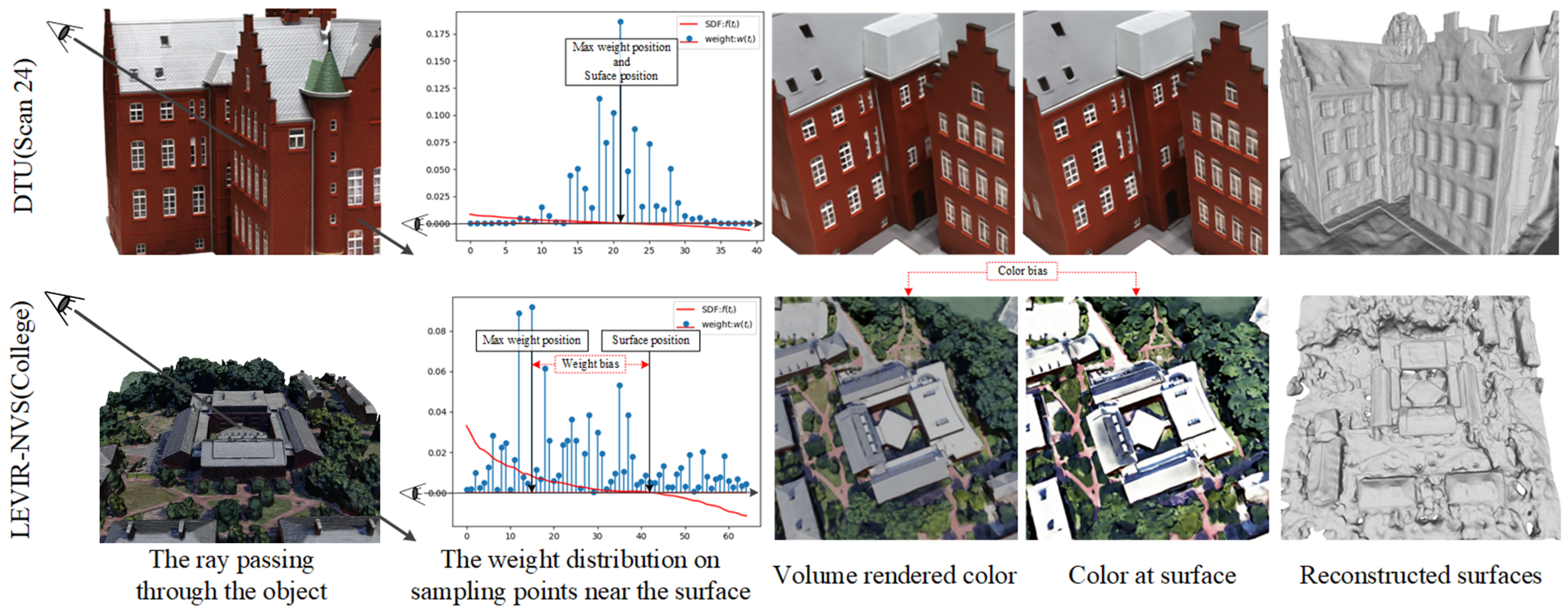
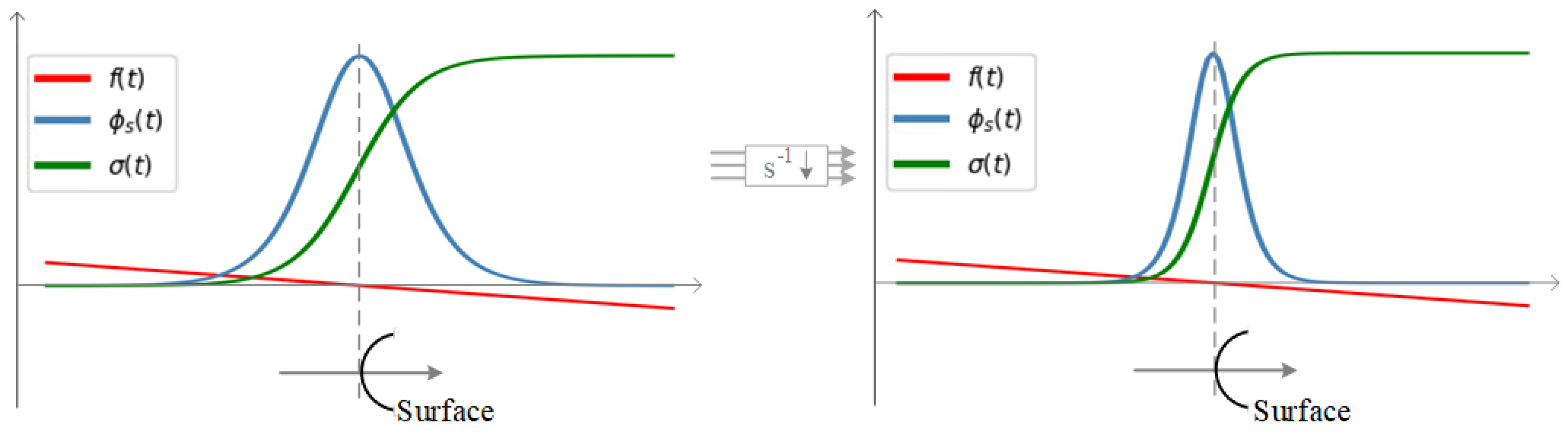
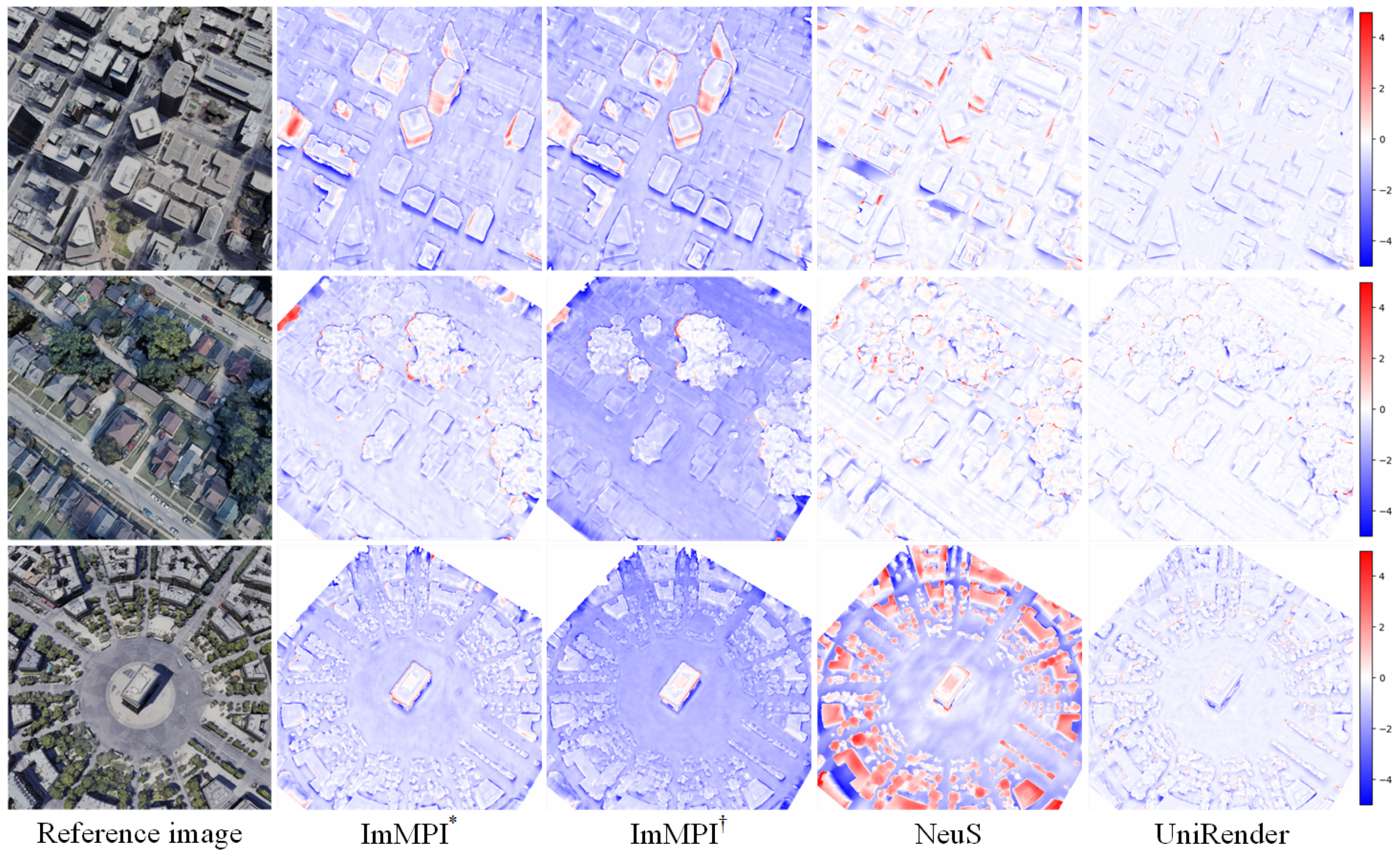
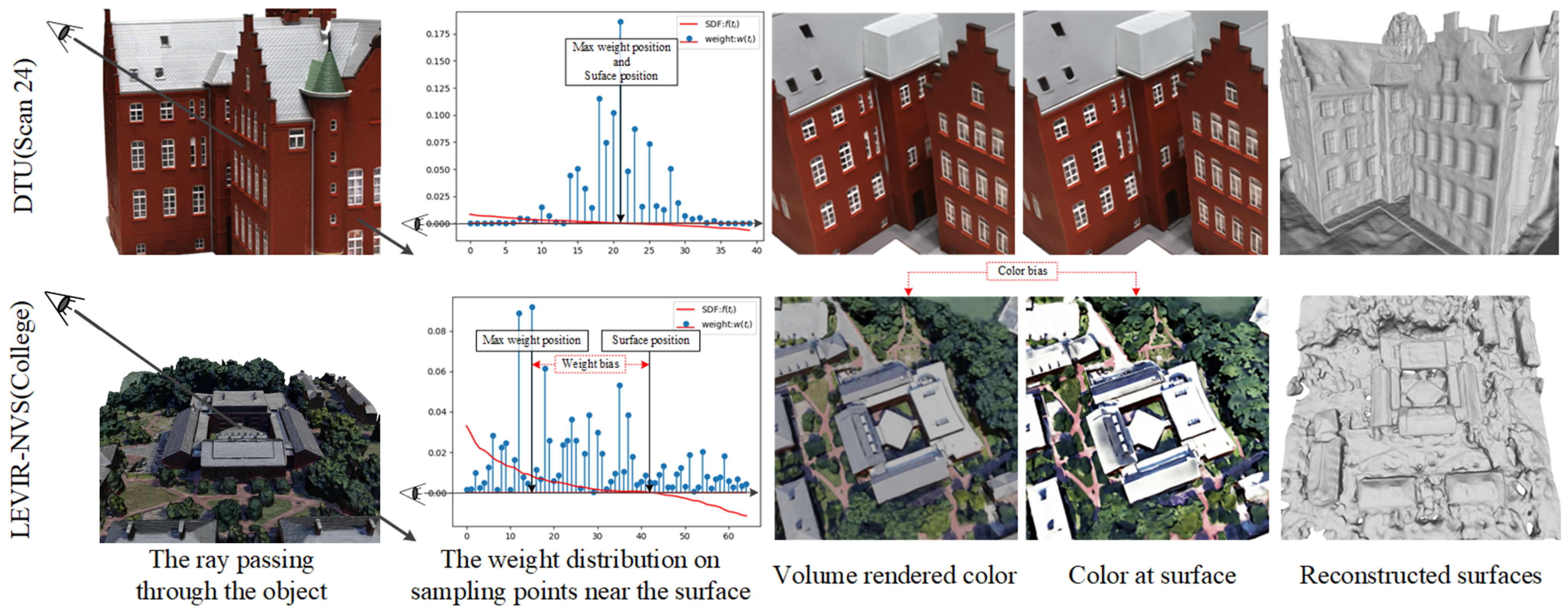
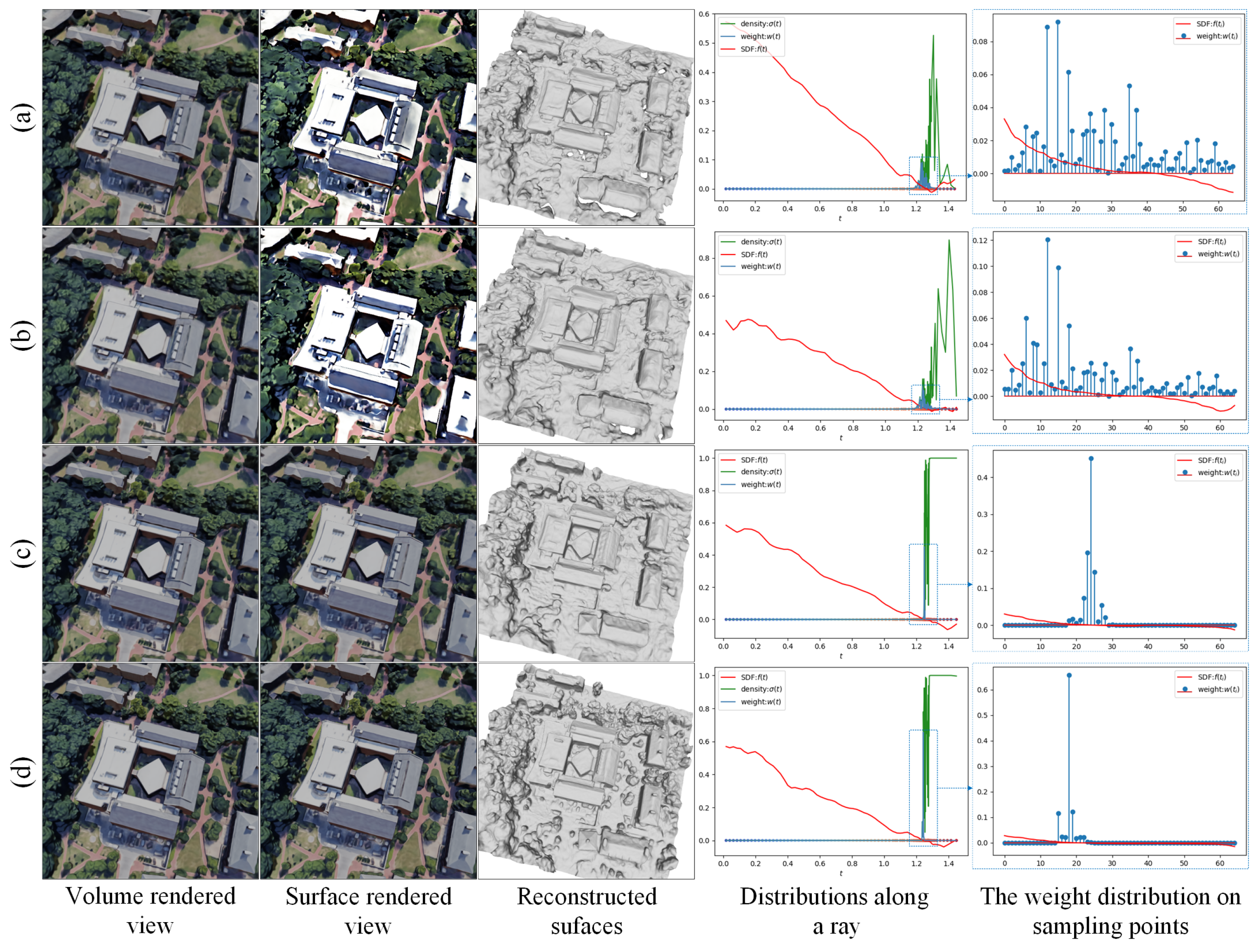
- Color bias: Given a ray, volume rendering directly optimizes the color integration along the ray rather than the surface color where the ray intersects the surface; therefore, the estimated color at the surface, i.e., the surface-rendered color, may deviate from the volume-rendered color. We note this color bias phenomenon is particularly evident in remote sensing scenes, as shown in Figure 1 (2nd row, 2nd column and 3rd column). For methods that rely on color to optimize geometry, color bias will inevitably erode their geometric constraint ability.
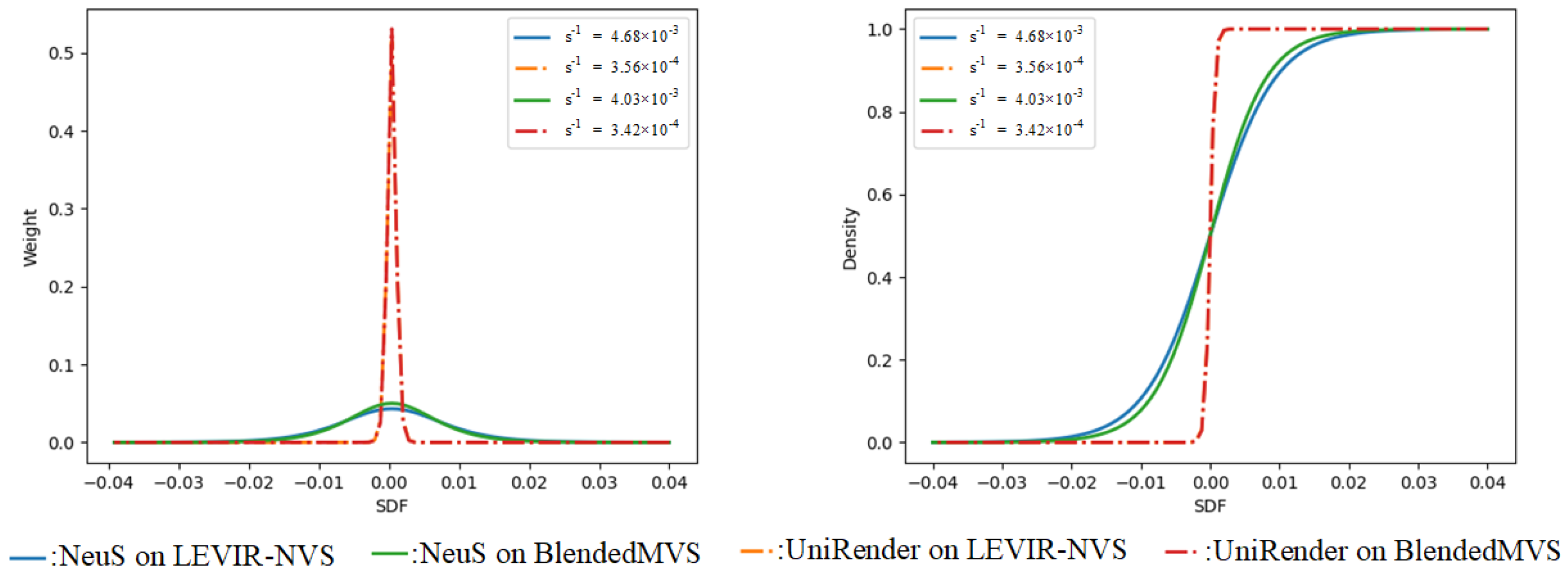
- Weight bias: Take the volume rendering method NeuS [13], as an example. This assumes that when approaching the surface along the ray, the weight distribution of color used to compute the color integration will reach its maximum at the position of the zero signed distance field (SDF) value, i.e., the surface position, as shown in Figure 1 (1st row, 2nd column). This assumption often holds for datasets with close-up dense views and simple geometry, such as a DTU dataset [22]. However, things are different on remote sensing datasets, in which the position with the maximum weight value usually deviates from the position with the zero SDF value, as shown in Figure 1 (2nd row, 2nd column). Such a weight bias phenomenon results in a misalignment between color and geometry, and prevents volume rendering from capturing the correct geometry.
- Geometric ambiguity: For most neural rendering pipelines [11,12,13,14], the geometry is only constrained by the color loss from a single view in each iteration, which cannot guarantee consistency across different views in the direction of geometric optimization, thus leading to ambiguity. When the input views become sparse, this ambiguity increases and results in inaccurate geometry. For remote sensing scenes, in which views are often sparse, this inherent ambiguity is undoubtedly a challenging issue.
- UNISURF [18] represents the scene geometry by occupancy values, while we use SDF representation and, thus, produce a higher-quality surface.
- UNISURF [18] makes a transition from volume rendering to surface rendering by gradually narrowing the sampling intervals during optimization. But the sampling interval is manually defined and controlled by hyperparameters, such as iteration steps, while our method spontaneously completes this transition along with the convergence process of the networks.
3. Preliminaries
3.1. Scene Representation
3.2. Paradigm of Volume Rendering
3.3. SDF-Induced Volume Density
4. Method
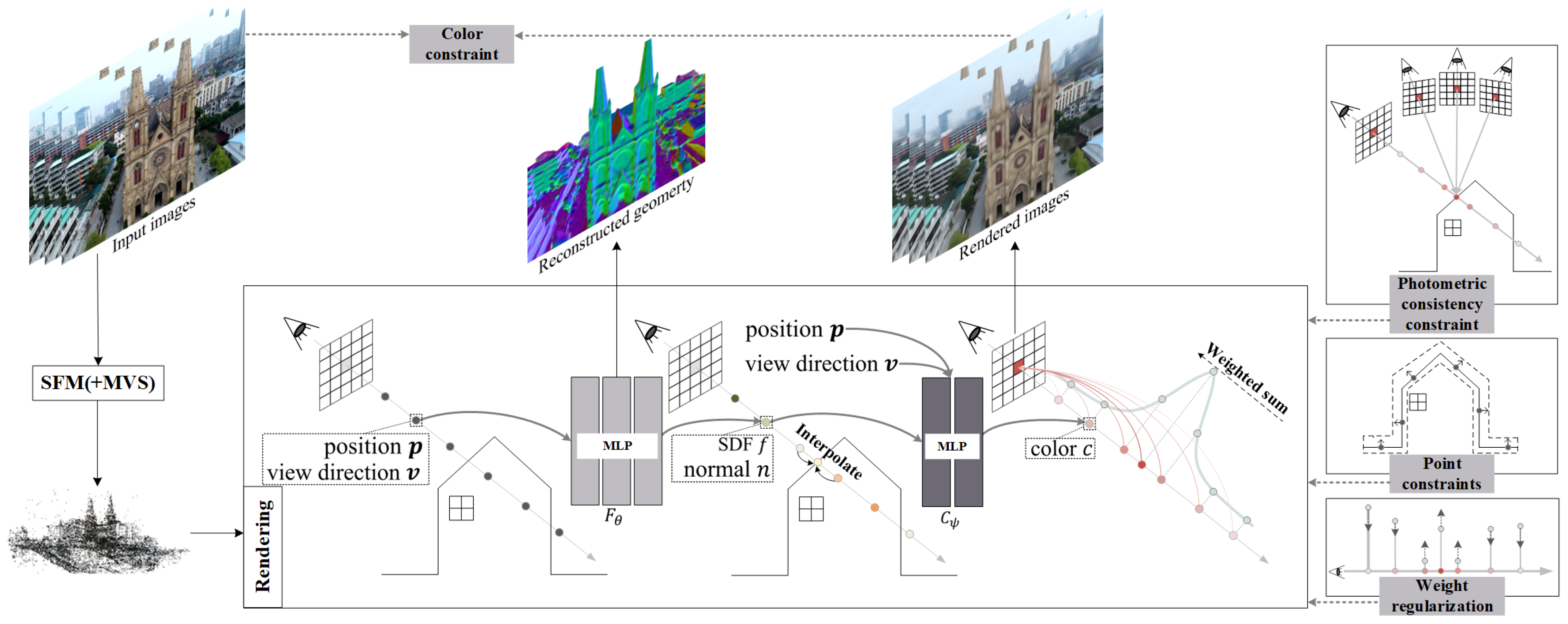
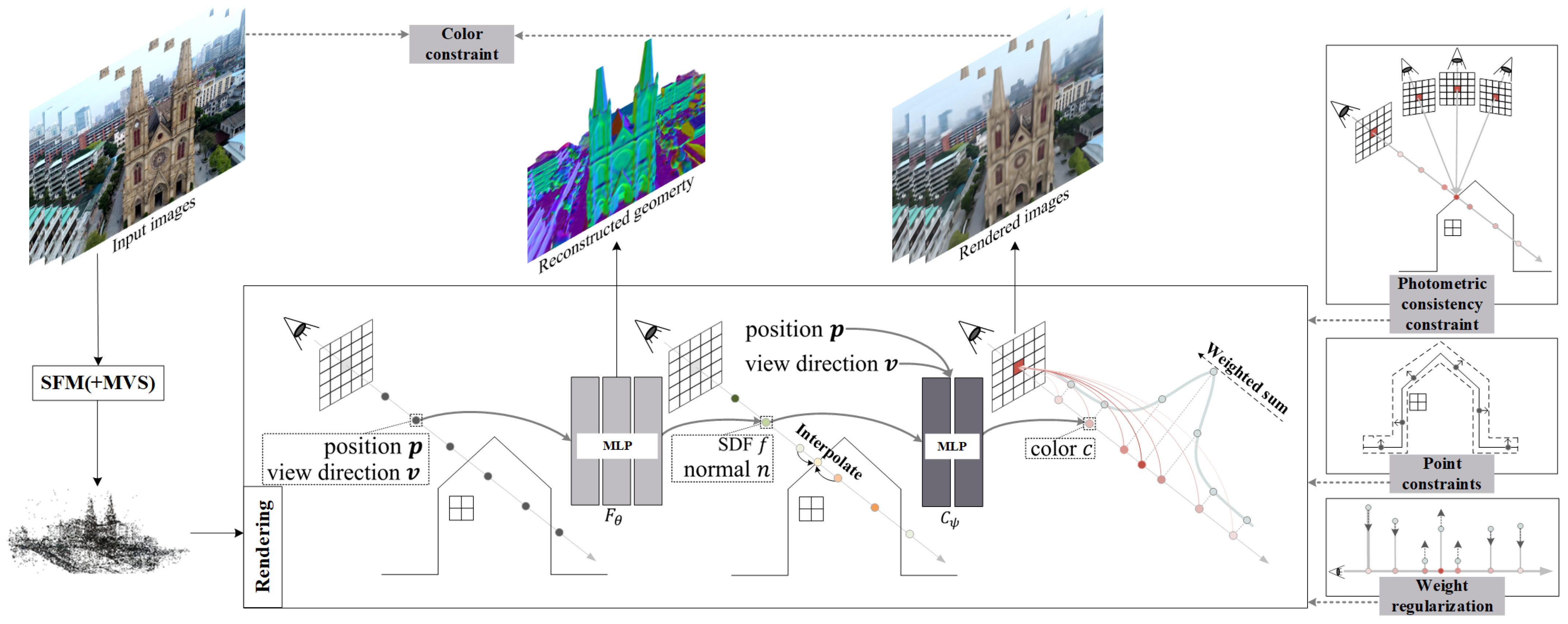
4.1. Unified Rendering Scheme
4.1.1. Interpolated Volume Rendering
4.1.2. Weight Regularization
4.1.3. Color Constraints
4.2. Geometric Constraints
4.2.1. Photometric Consistency Constraints
4.2.2. Point Constraints
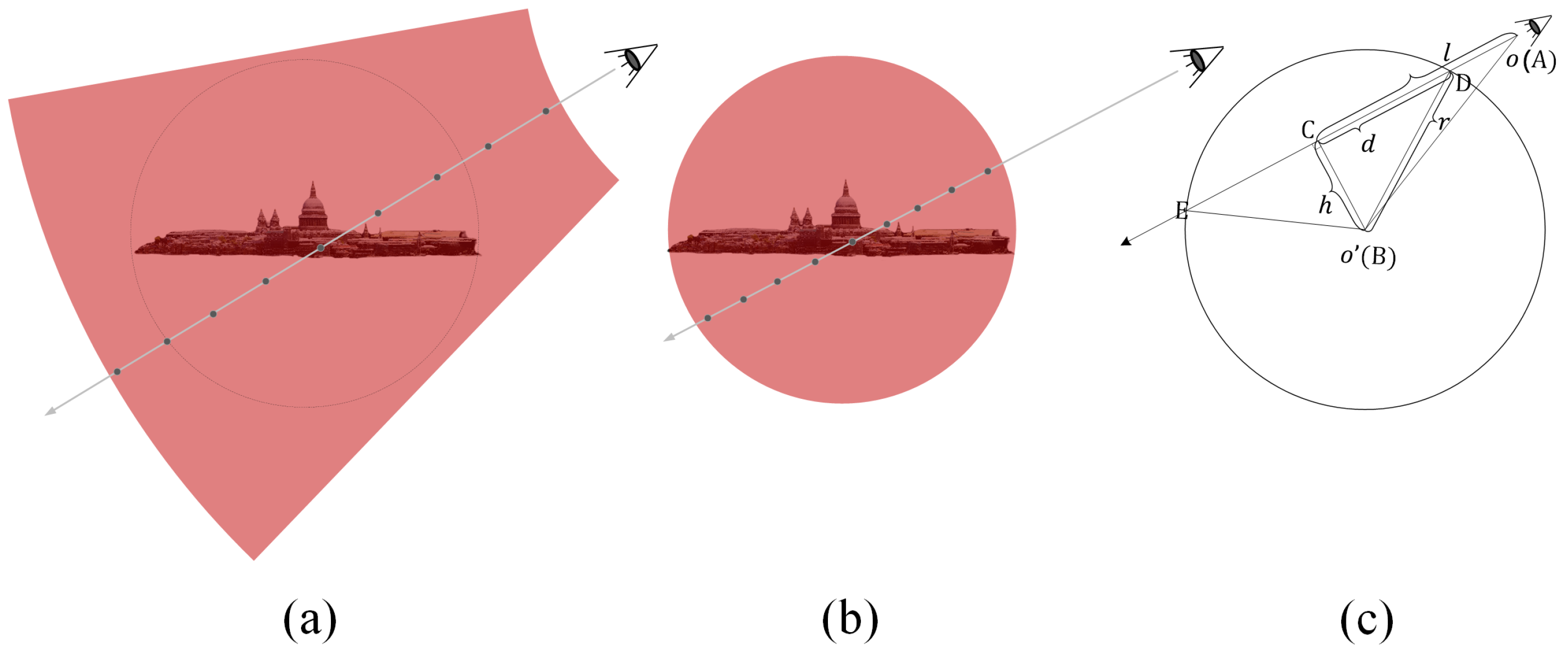
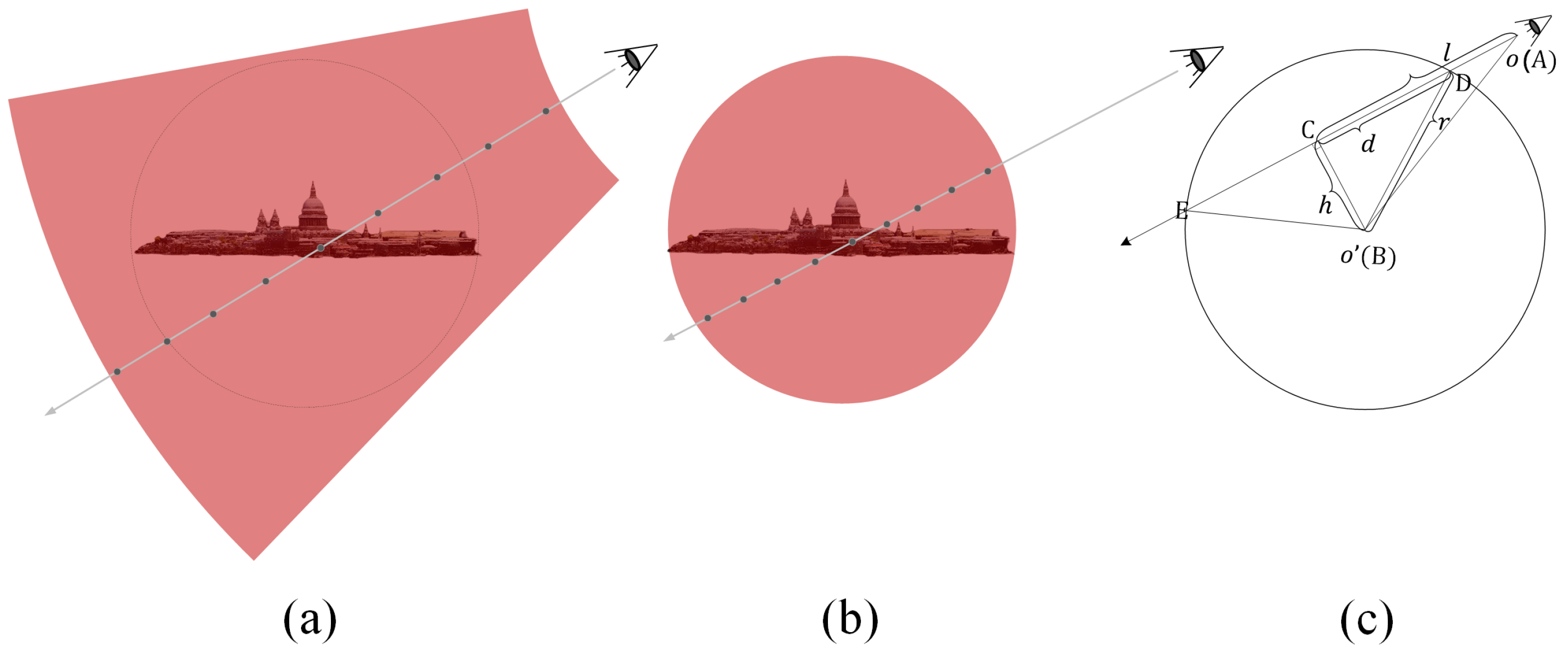
4.3. Spherical Sampling
| Algorithm 1: Spherical sampling algorithm |
| Input: the camera position , i.e., the starting point of the ray |
| the view direction along the ray |
| the spatial origin position |
| the radius of the inner space r |
| Output: the depth range to sample along the ray |
| 1: Calculate the projection length of the vector in the ray direction: . |
| 2: Calculate the length of the right-side BC of the right triangle △ABC: . |
| 3: Calculate the length of the right-side CD of the right triangle △ABC: . |
| 4: Determine the sampling range along the ray : . |
Implementation Details
5. Experiments
5.1. Exp Setting
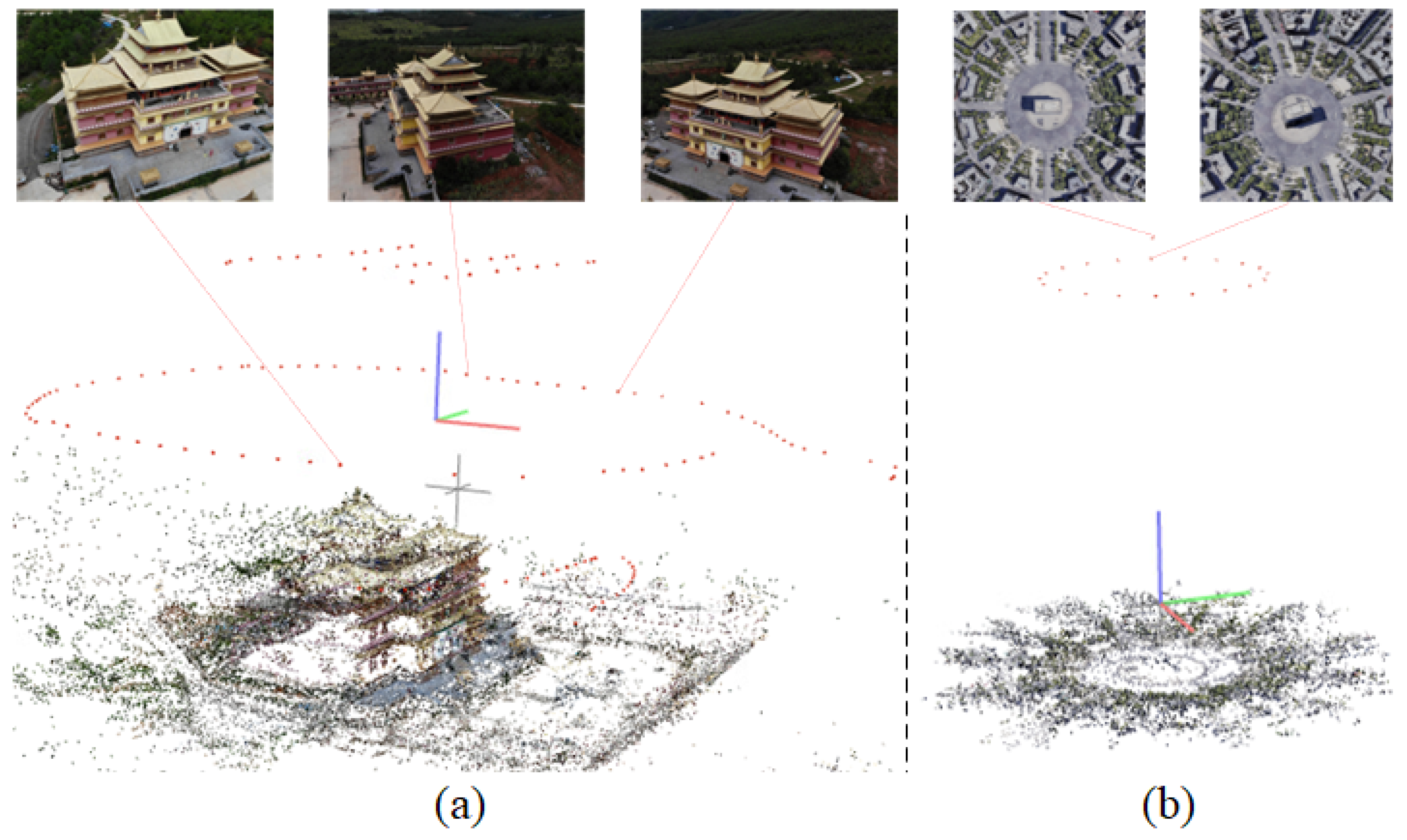
5.1.1. Dataset
5.1.2. Baseline
5.1.3. Evaluation Metrics
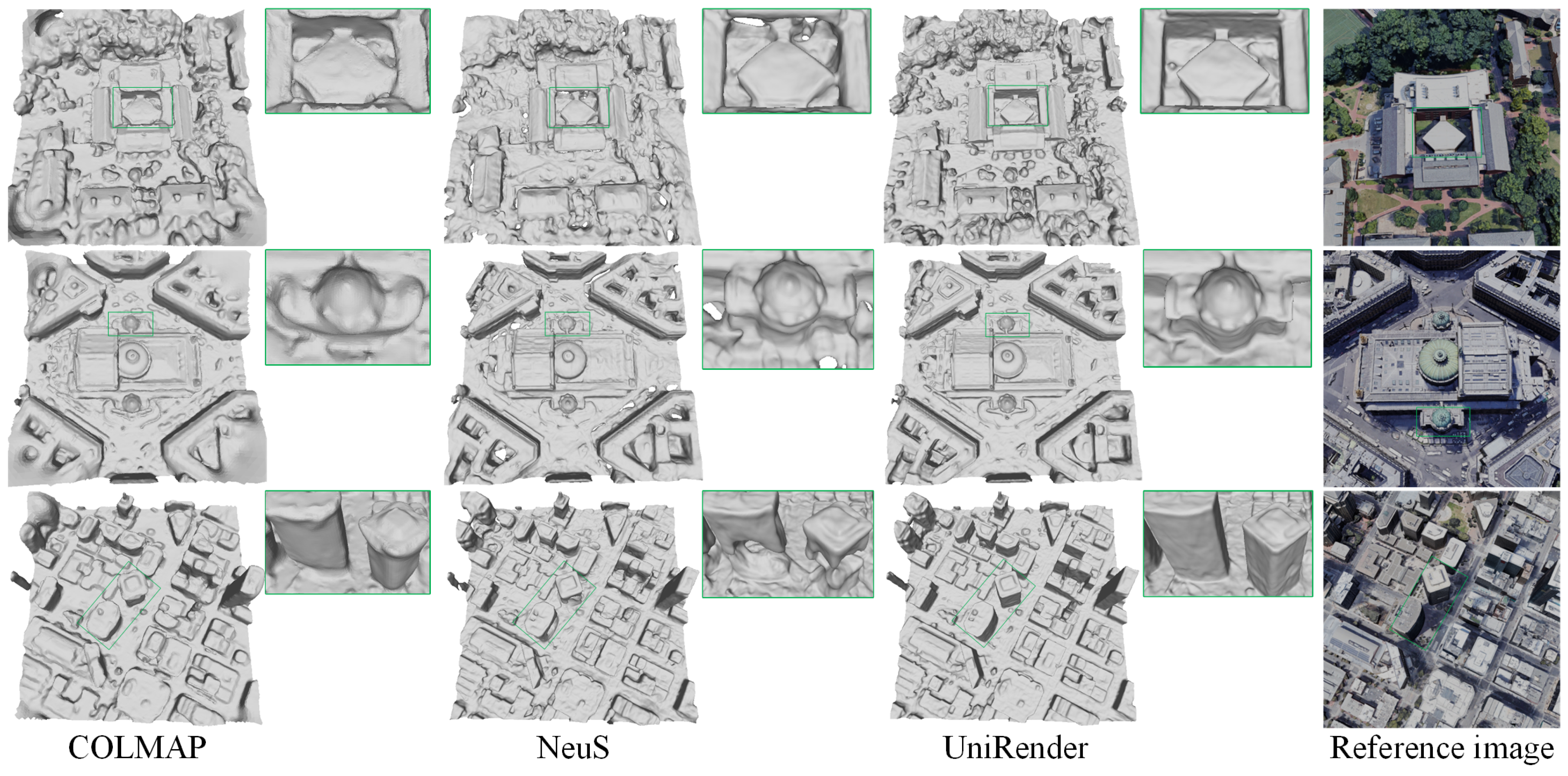
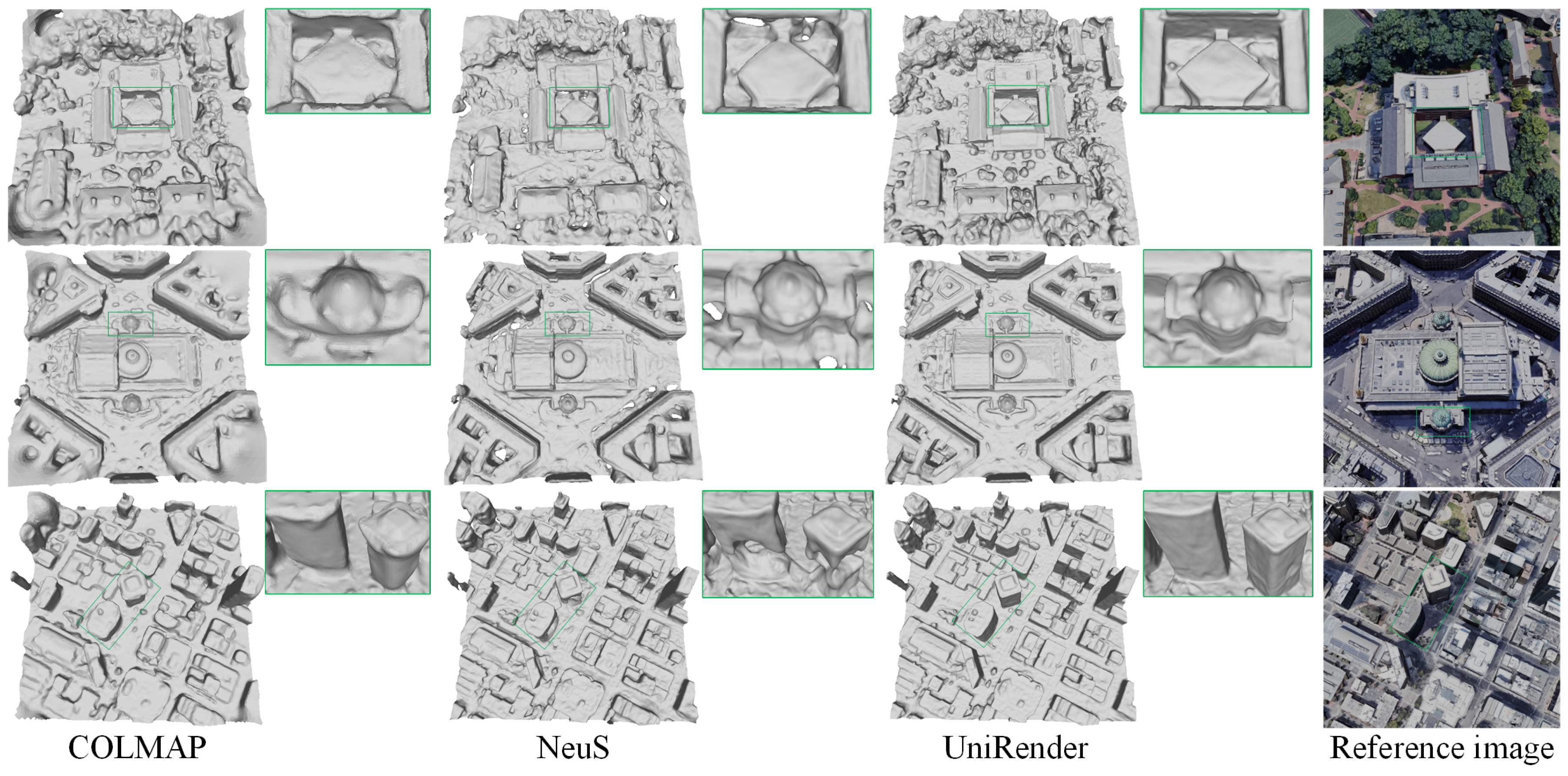
5.2. Results
5.3. Discussion
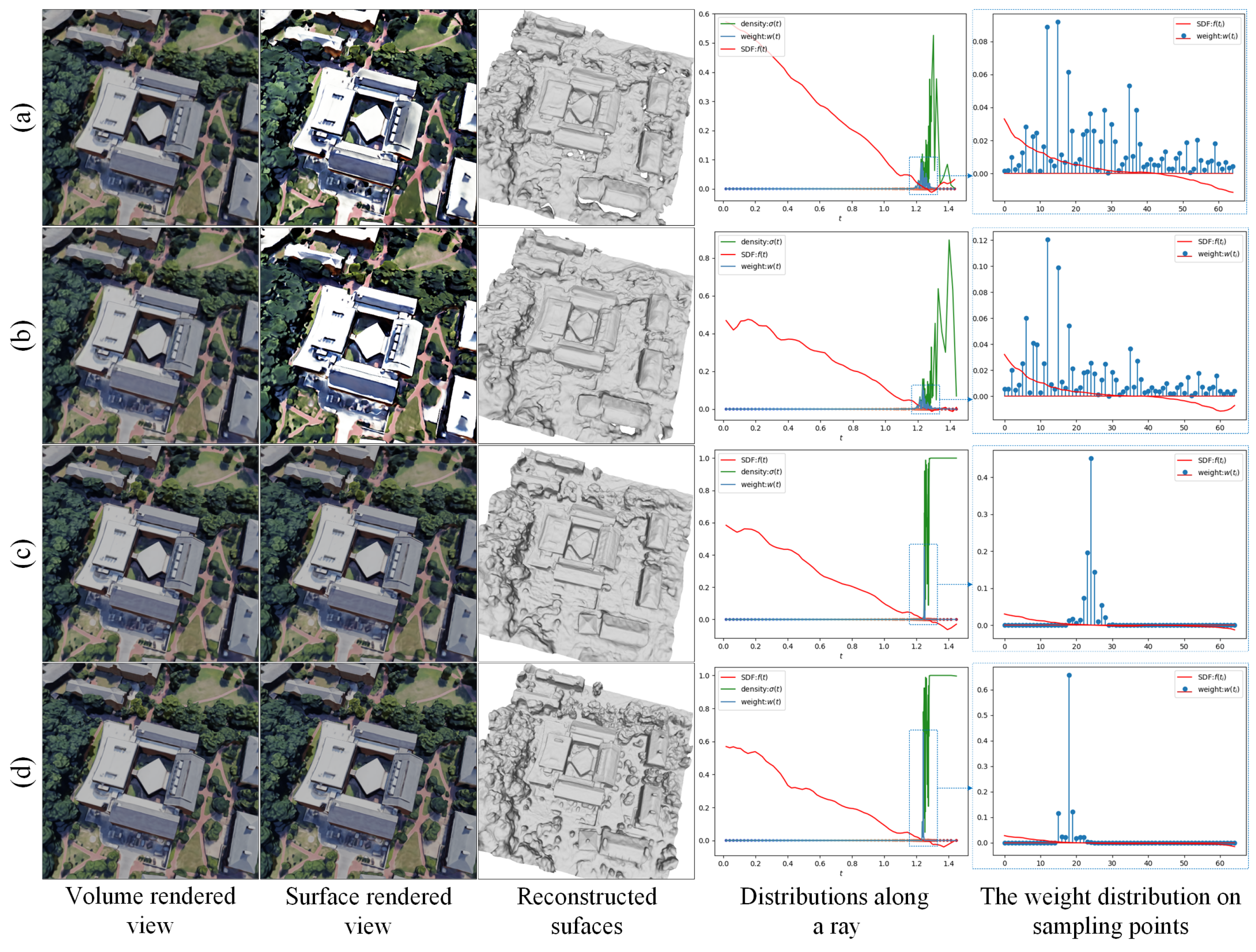
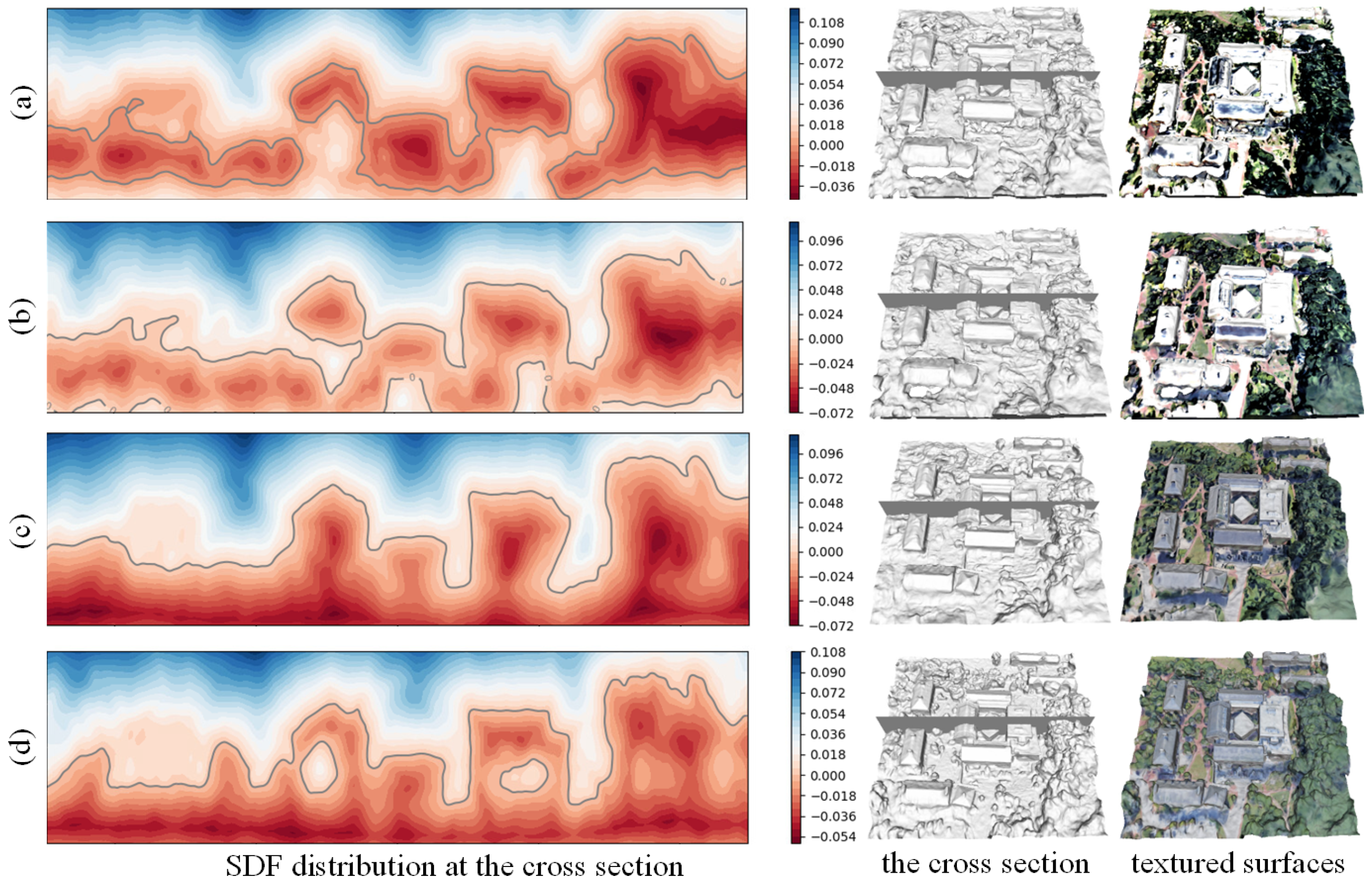
5.3.1. Biases Elimination Verification
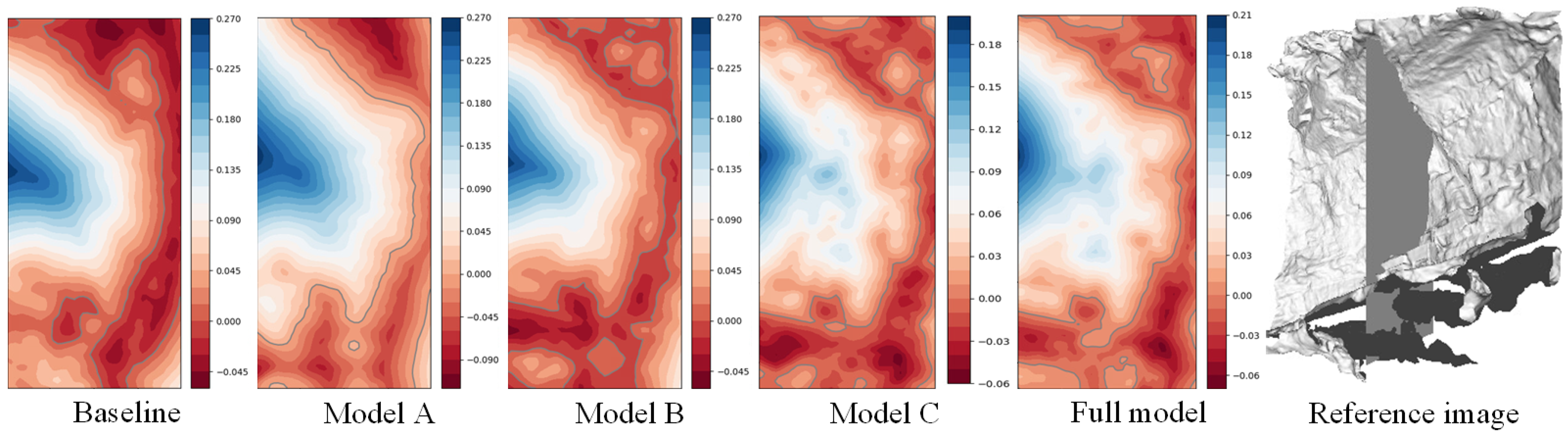
- (a) using a sampling strategy that first sampled 64 points uniformly and then sampled 64 points hierarchically.
- (b) using a sampling strategy that first sampled 32 points uniformly and then sampled 96 points hierarchically.
- (c) replacing the rendering scheme of NeuS [13] with our proposed rendering scheme, and using the same sampling strategy as (b).
- (d) adding all the geometric constraints based on (c).
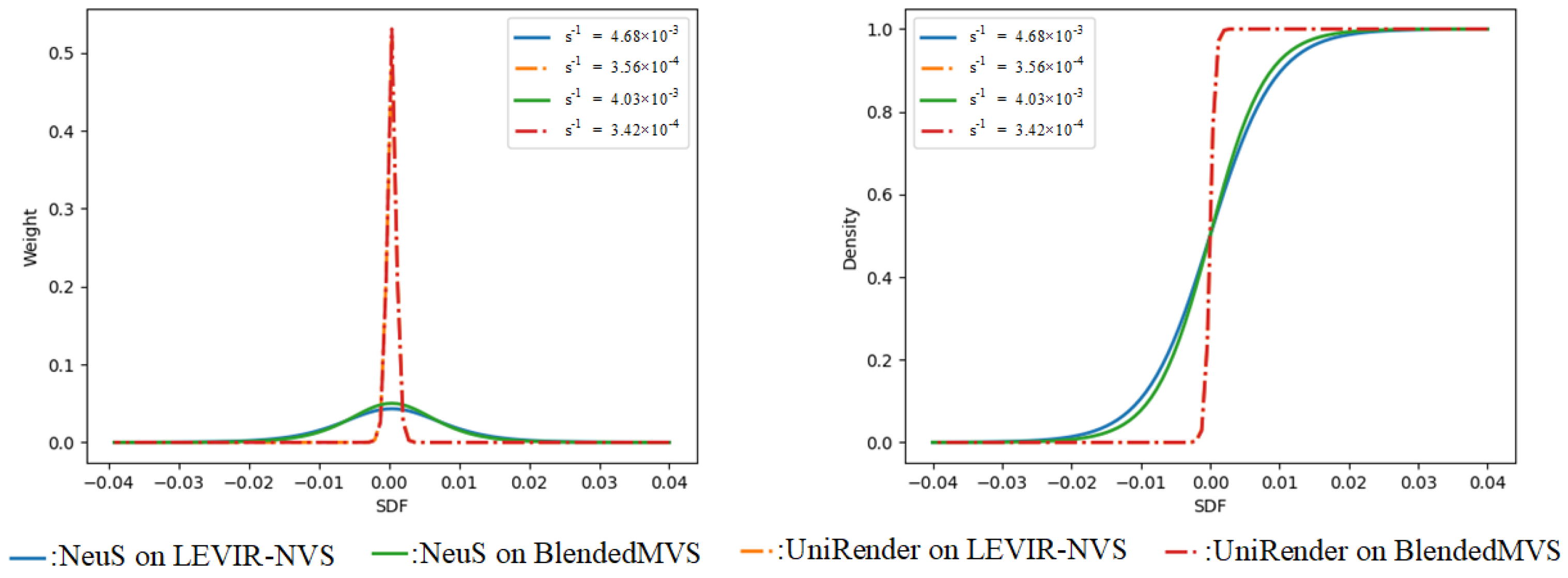
5.3.2. Optimization of the Parameters
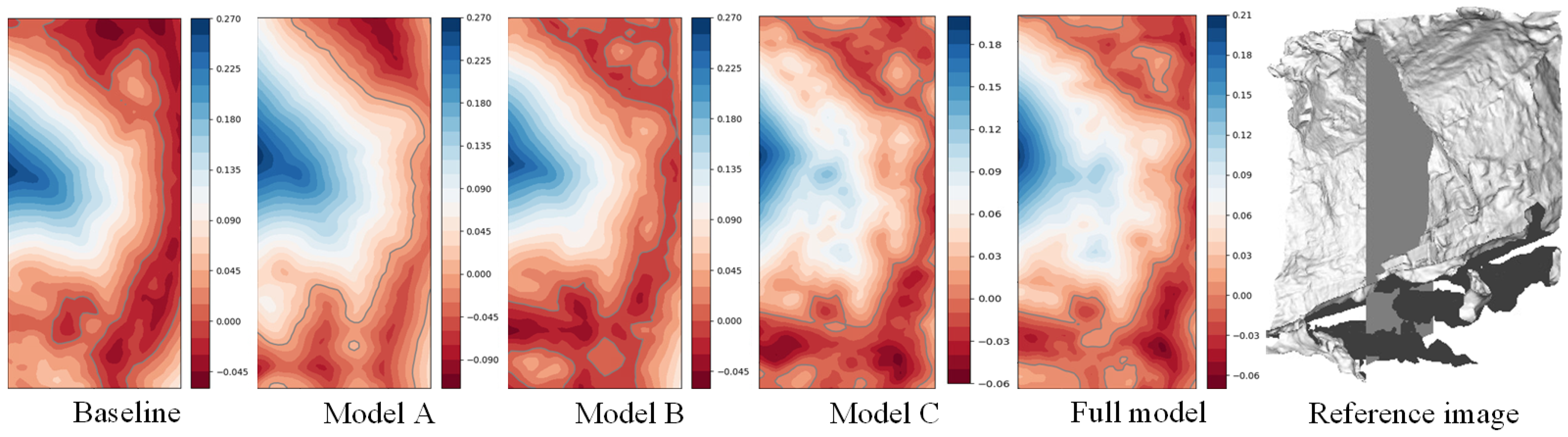
5.3.3. Ablation Study
- The unified rendering scheme tends to produce smooth and continuous surfaces, and improves geometric accuracy to some extent.
- The geometric constraint mechanisms are effective in improving the quality of geometric reconstruction.
- The spherical sampling strategy can facilitate the capture of detail.
6. Conclusions and Outlook
6.1. Conclusions
6.2. Outlook
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene | Distance | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| COLMAP | NeuS | UniRender | |||||||
| Acc↓ | Comp↓ | Overall↓ | Acc↓ | Comp↓ | Overall↓ | Acc↓ | Comp↓ | Overall↓ | |
| scene1, 5bf18642c50e6f7f8bdbd492 | 0.2087 | 0.2763 | 0.2425 | 0.2765 | 0.2207 | 0.2486 | 0.1751 | 0.1046 | 0.1398 |
| scene2, 58eaf1513353456af3a1682a | 0.2281 | 0.5860 | 0.4071 | 0.2933 | 0.2613 | 0.2773 | 0.1975 | 0.1252 | 0.1613 |
| scene3, 5b558a928bbfb62204e77ba2 | 0.2581 | 0.3027 | 0.2804 | 0.5262 | 0.5168 | 0.5215 | 0.2427 | 0.2086 | 0.2256 |
| scene4, 5b6eff8b67b396324c5b2672 | 0.1746 | 0.6420 | 0.4083 | 0.3049 | 0.2608 | 0.2829 | 0.1276 | 0.0708 | 0.0992 |
| scene5, 58c4bb4f4a69c55606122be4 | 0.0951 | 0.0020 | 0.0485 | 0.1995 | 0.0114 | 0.1055 | 0.1015 | 0.0015 | 0.0515 |
| scene6, 5bd43b4ba6b28b1ee86b92dd | 0.0996 | 0.0267 | 0.0631 | 0.0044 | 0.0035 | 0.0039 | 0.0031 | 0.0023 | 0.0027 |
| scene7, 5b62647143840965efc0dbde | 0.2200 | 0.1599 | 0.1899 | 0.5461 | 0.5257 | 0.5359 | 0.2000 | 0.1245 | 0.1623 |
| scene8, 5ba75d79d76ffa2c86cf2f05 | 0.1739 | 0.2826 | 0.2282 | 0.5253 | 0.5393 | 0.5323 | 0.2008 | 0.1476 | 0.1742 |
| mean | 0.1823 | 0.2848 | 0.2335 | 0.3345 | 0.2924 | 0.3135 | 0.1560 | 0.0981 | 0.1271 |
| Scene | Distance | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| COLMAP | NeuS | UniRender | |||||||
| Acc↓ | Comp↓ | Overall↓ | Acc↓ | Comp↓ | Overall↓ | Acc↓ | Comp↓ | Overall↓ | |
| scene00, Building#1 | 0.2900 | 0.3456 | 0.3178 | 0.5010 | 0.6288 | 0.5649 | 0.2648 | 0.3249 | 0.2948 |
| scene01, Church | 0.2261 | 0.2151 | 0.2206 | 0.1859 | 0.1959 | 0.1909 | 0.1616 | 0.1666 | 0.1641 |
| scene02, College | 0.3011 | 0.2722 | 0.2867 | 0.3658 | 0.3515 | 0.3587 | 0.2681 | 0.2748 | 0.2714 |
| scene03, Mountain#1 | 0.0894 | 0.0954 | 0.0924 | 0.0822 | 0.0981 | 0.0901 | 0.0907 | 0.1123 | 0.1015 |
| scene04, Mountain#2 | 0.0895 | 0.1151 | 0.1023 | 0.0744 | 0.0943 | 0.0843 | 0.0730 | 0.0977 | 0.0854 |
| scene05, Observation | 0.2570 | 0.2218 | 0.2394 | 0.3362 | 0.2865 | 0.3114 | 0.2005 | 0.1608 | 0.1806 |
| scene06, Building#2 | 0.2851 | 0.2784 | 0.2817 | 0.2912 | 0.2554 | 0.2733 | 0.2698 | 0.2753 | 0.2725 |
| scene07, Town#1 | 0.2334 | 0.2368 | 0.2351 | 0.2964 | 0.2211 | 0.2588 | 0.1762 | 0.1581 | 0.1671 |
| scene08, Stadium | 0.1634 | 0.1572 | 0.1603 | 0.2320 | 0.1909 | 0.2114 | 0.1377 | 0.1543 | 0.1460 |
| scene09, Town#2 | 0.1608 | 0.1749 | 0.1679 | 0.3309 | 0.3684 | 0.3497 | 0.1539 | 0.1753 | 0.1646 |
| scene10, Mountain#3 | 0.0835 | 0.1037 | 0.0936 | 0.0729 | 0.0885 | 0.0807 | 0.0692 | 0.0861 | 0.0776 |
| scene11, Town#3 | 0.1818 | 0.1479 | 0.1648 | 0.1669 | 0.1248 | 0.1459 | 0.1633 | 0.1403 | 0.1518 |
| scene12, Factory | 0.2566 | 0.3111 | 0.2839 | 0.3917 | 0.4597 | 0.4257 | 0.2395 | 0.2953 | 0.2674 |
| scene13, Park | 0.1791 | 0.2448 | 0.2119 | 0.3356 | 0.3233 | 0.3294 | 0.1941 | 0.2628 | 0.2284 |
| scene14, School | 0.1875 | 0.1910 | 0.1892 | 0.2016 | 0.2164 | 0.2090 | 0.1532 | 0.1567 | 0.1549 |
| scene15, Downtown | 0.2593 | 0.2748 | 0.2671 | 0.2153 | 0.2273 | 0.2213 | 0.1835 | 0.2405 | 0.2120 |
| mean | 0.2116 | 0.2027 | 0.2072 | 0.2582 | 0.2550 | 0.25664 | 0.1926 | 0.1749 | 0.1838 |
References
- Griwodz, C.; Gasparini, S.; Calvet, L.; Gurdjos, P.; Castan, F.; Maujean, B.; Lillo, G.D.; Lanthony, Y. AliceVision Meshroom: An open-source 3D reconstruction pipeline. In Proceedings of the 12th ACM Multimedia Systems Conference, Istanbul, Turkey, 28 September–1 October 2021. [Google Scholar]
- Rupnik, E.; Daakir, M.; Deseilligny, M.P. MicMac—A free, open-source solution for photogrammetry. Open Geospat. Data Softw. Stand. 2017, 2, 14. [Google Scholar] [CrossRef]
- Labatut, P.; Pons, J.P.; Keriven, R. Efficient Multi-View Reconstruction of Large-Scale Scenes using Interest Points, Delaunay Triangulation and Graph Cuts. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate, Dense, and Robust Multiview Stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Schönberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Schönberger, J.L.; Zheng, E.; Frahm, J.M.; Pollefeys, M. Pixelwise View Selection for Unstructured Multi-View Stereo. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Kazhdan, M.M.; Hoppe, H. Screened poisson surface reconstruction. ACM Trans. Graph. 2013, 32, 1–13. [Google Scholar] [CrossRef]
- Yariv, L.; Kasten, Y.; Moran, D.; Galun, M.; Atzmon, M.; Basri, R.; Lipman, Y. Multiview Neural Surface Reconstruction by Disentangling Geometry and Appearance. arXiv 2020, arXiv:2003.09852. [Google Scholar]
- Long, X.; Lin, C.H.; Wang, P.; Komura, T.; Wang, W. SparseNeuS: Fast Generalizable Neural Surface Reconstruction from Sparse views. arXiv 2022, arXiv:2206.05737. [Google Scholar]
- Tewari, A.; Fried, O.; Thies, J.; Sitzmann, V.; Lombardi, S.; Xu, Z.; Simon, T.; Nießner, M.; Tretschk, E.; Liu, L.; et al. Advances in Neural Rendering. Comput. Graph. Forum 2021, 41, 703–735. [Google Scholar] [CrossRef]
- Mar’i, R.; Facciolo, G.; Ehret, T. Sat-NeRF: Learning Multi-View Satellite Photogrammetry with Transient Objects and Shadow Modeling Using RPC Cameras. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 1310–1320. [Google Scholar]
- Derksen, D.; Izzo, D. Shadow Neural Radiance Fields for Multi-view Satellite Photogrammetry. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 1152–1161. [Google Scholar]
- Wang, P.; Liu, L.; Liu, Y.; Theobalt, C.; Komura, T.; Wang, W. NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction. In Proceedings of the Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Yariv, L.; Gu, J.; Kasten, Y.; Lipman, Y. Volume Rendering of Neural Implicit Surfaces. arXiv 2021, arXiv:2106.12052. [Google Scholar]
- Zhang, J.; Yao, Y.; Quan, L. Learning Signed Distance Field for Multi-view Surface Reconstruction. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 6505–6514. [Google Scholar]
- Zhang, J.; Yao, Y.; Li, S.; Fang, T.; McKinnon, D.N.R.; Tsin, Y.; Quan, L. Critical Regularizations for Neural Surface Reconstruction in the Wild. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6260–6269. [Google Scholar]
- Niemeyer, M.; Mescheder, L.M.; Oechsle, M.; Geiger, A. Differentiable Volumetric Rendering: Learning Implicit 3D Representations Without 3D Supervision. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3501–3512. [Google Scholar]
- Oechsle, M.; Peng, S.; Geiger, A. UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 5569–5579. [Google Scholar]
- Sun, J.; Chen, X.; Wang, Q.; Li, Z.; Averbuch-Elor, H.; Zhou, X.; Snavely, N. Neural 3D Reconstruction in the Wild. In ACM SIGGRAPH 2022 Conference Proceedings; Association for Computing Machinery: New York, NY, USA, 2022. [Google Scholar]
- Wu, Y.; Zou, Z.; Shi, Z. Remote Sensing Novel View Synthesis with Implicit Multiplane Representations. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. arXiv 2020, arXiv:2003.08934. [Google Scholar] [CrossRef]
- Aanæs, H.; Jensen, R.R.; Vogiatzis, G.; Tola, E.; Dahl, A.B. Large-Scale Data for Multiple-View Stereopsis. Int. J. Comput. Vis. 2016, 120, 153–168. [Google Scholar] [CrossRef]
- Park, J.J.; Florence, P.R.; Straub, J.; Newcombe, R.A.; Lovegrove, S. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Fu, Q.; Xu, Q.; Ong, Y.; Tao, W. Geo-Neus: Geometry-Consistent Neural Implicit Surfaces Learning for Multi-view Reconstruction. arXiv 2022, arXiv:2205.15848. [Google Scholar]
- Mescheder, L.M.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy Networks: Learning 3D Reconstruction in Function Space. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4455–4465. [Google Scholar]
- Li, J.; Feng, Z.; She, Q.; Ding, H.; Wang, C.; Lee, G.H. MINE: Towards Continuous Depth MPI with NeRF for Novel View Synthesis. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 12558–12568. [Google Scholar]
- Goesele, M.; Curless, B.; Seitz, S.M. Multi-View Stereo Revisited. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2402–2409. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, Y.; Peng, S.; Shi, B.; Pollefeys, M.; Cui, Z. DIST: Rendering Deep Implicit Signed Distance Function with Differentiable Sphere Tracing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2016–2025. [Google Scholar]
- Darmon, F.; Bascle, B.; Devaux, J.C.; Monasse, P.; Aubry, M. Improving neural implicit surfaces geometry with patch warping. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6250–6259. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Verbin, D.; Srinivasan, P.P.; Hedman, P. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5460–5469. [Google Scholar]
- Zhang, K.; Riegler, G.; Snavely, N.; Koltun, V. NeRF++: Analyzing and Improving Neural Radiance Fields. arXiv 2020, arXiv:2010.07492. [Google Scholar]
- Gropp, A.; Yariv, L.; Haim, N.; Atzmon, M.; Lipman, Y. Implicit Geometric Regularization for Learning Shapes. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. In Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Technique, Anaheim, CA, USA, 27–31 July 1987. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Zhang, J.; Ren, Y.; Zhou, L.; Fang, T.; Quan, L. BlendedMVS: A Large-Scale Dataset for Generalized Multi-View Stereo Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1787–1796. [Google Scholar]
- Li, S.; He, S.F.; Jiang, S.; Jiang, W.; Zhang, L. WHU-Stereo: A Challenging Benchmark for Stereo Matching of High-Resolution Satellite Images. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–14. [Google Scholar] [CrossRef]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. MVSNet: Depth Inference for Unstructured Multi-view Stereo. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Knapitsch, A.; Park, J.; Zhou, Q.Y.; Koltun, V. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Trans. Graph. (TOG) 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Sun, C.; Sun, M.; Chen, H.T. Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5449–5459. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. (TOG) 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Turki, H.; Ramanan, D.; Satyanarayanan, M. Mega-NeRF: Scalable Construction of Large-Scale NeRFs for Virtual Fly- Throughs. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12912–12921. [Google Scholar]
- Tancik, M.; Casser, V.; Yan, X.; Pradhan, S.; Mildenhall, B.; Srinivasan, P.P.; Barron, J.T.; Kretzschmar, H. Block-NeRF: Scalable Large Scene Neural View Synthesis. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8238–8248. [Google Scholar]






| Method | Distance | Threshold = 0.5 | ||||
|---|---|---|---|---|---|---|
| Acc↓ | Comp↓ | Overall↓ | Acc↑ | Comp↑ | F-Score↑ | |
| COLMAP | 0.182 | 0.284 | 0.233 | 78.62 | 77.53 | 72.33 |
| NeuS | 0.334 | 0.292 | 0.313 | 46.37 | 59.79 | 50.86 |
| UniRender | 0.156 | 0.098 | 0.127 | 82.70 | 96.86 | 88.87 |
| Method | Distance | Threshold = 0.5 | ||||
|---|---|---|---|---|---|---|
| Acc↓ | Comp↓ | Overall↓ | Acc↑ | Comp↑ | F-Score↑ | |
| COLMAP | 0.202 | 0.211 | 0.207 | 86.79 | 91.15 | 88.79 |
| NeuS | 0.255 | 0.258 | 0.256 | 62.68 | 81.43 | 68.50 |
| UniRender | 0.174 | 0.192 | 0.183 | 90.39 | 95.17 | 92.50 |
| ImMPI | ImMPI | NeuS | UniRender | |
|---|---|---|---|---|
| MAE↓ | 0.832 | 1.027 | 0.650 | 0.254 |
| Scene | Distance | |||||
|---|---|---|---|---|---|---|
| UNISURF | UniRender | |||||
| Acc↓ | Comp↓ | Overall↓ | Acc↓ | Comp↓ | Overall↓ | |
| scene1 of BlendedMVS | 0.593 | 0.583 | 0.587 | 0.265 | 0.325 | 0.295 |
| scene02 of LEVIR-NVS | 0.543 | 0.509 | 0.526 | 0.268 | 0.275 | 0.271 |
| Method | Unified Rendering | Geometric Constraints | Sphere Sampling | Acc↓ | Comp↓ | Overall↓ |
|---|---|---|---|---|---|---|
| Baseline | 0.19959 | 0.01143 | 0.10551 | |||
| Model A | ✓ | ✓ | 0.08909 | 0.00666 | 0.04787 | |
| Model B | ✓ | ✓ | 0.12987 | 0.00163 | 0.06575 | |
| Model C | ✓ | ✓ | 0.11727 | 0.00171 | 0.05949 | |
| Full model | ✓ | ✓ | ✓ | 0.10151 | 0.00154 | 0.05153 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Y.; Zhou, W.; Su, N.; Zhang, C. UniRender: Reconstructing 3D Surfaces from Aerial Images with a Unified Rendering Scheme. Remote Sens. 2023, 15, 4634. https://doi.org/10.3390/rs15184634
Yan Y, Zhou W, Su N, Zhang C. UniRender: Reconstructing 3D Surfaces from Aerial Images with a Unified Rendering Scheme. Remote Sensing. 2023; 15(18):4634. https://doi.org/10.3390/rs15184634
Chicago/Turabian StyleYan, Yiming, Weikun Zhou, Nan Su, and Chi Zhang. 2023. "UniRender: Reconstructing 3D Surfaces from Aerial Images with a Unified Rendering Scheme" Remote Sensing 15, no. 18: 4634. https://doi.org/10.3390/rs15184634
APA StyleYan, Y., Zhou, W., Su, N., & Zhang, C. (2023). UniRender: Reconstructing 3D Surfaces from Aerial Images with a Unified Rendering Scheme. Remote Sensing, 15(18), 4634. https://doi.org/10.3390/rs15184634