


Improving the Spatial Prediction of Sand Content in Forest Soils Using a Multivariate Geostatistical Analysis of LiDAR and Hyperspectral Data

 ,
,  ,
,  ,
,  , and
, and
Abstract
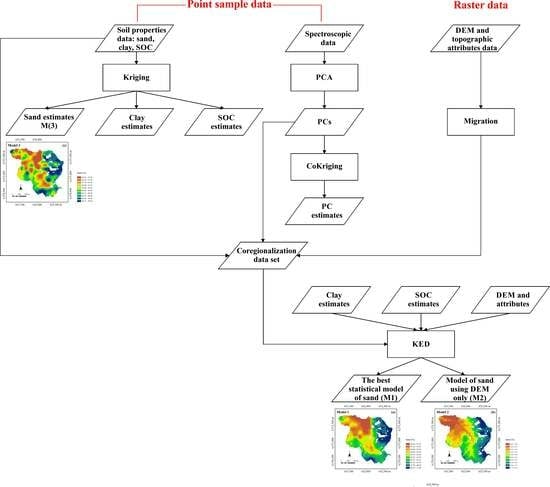
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Remote Sensing (LiDAR) Data Acquisition and Processing
2.3. Topographic Attributes
2.4. Field Soil Sampling and Laboratory Analysis
2.5. Hyperspectral Spectroscopy Measurements
2.6. Preliminary Statistical Data Analysis and Non-Stationary Geostatistical Approach
2.6.1. Principal Component Analysis
2.6.2. Fusion of Heterogeneous Spatial Data
2.6.3. Kriging with External Drift
- (1)
- Determination of the order k of the trend;
- (2)
- Calculation of the generalized covariance function K(h) of the module of the distance vector (h) and fitting of an authorized parametric model to it.
2.7. Mapping Methods Comparison
3. Results
3.1. Exploratory Data Analysis
3.1.1. LiDAR Data
3.1.2. Soil Properties Data
3.1.3. Spectroscopic Data
3.2. Coregionalization Data Set
3.3. Kriging with External Drift
3.3.1. Trend Estimation
3.3.2. Generalized Covariance Function (GCf) Identification
3.4. Comparison among the Three Approaches
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Silvero, N.E.Q.; Demattê, J.A.M.; Minasny, B.; Rosin, N.A.; Nascimento, J.G.; Rodríguez Albarracín, H.S.; Bellinaso, H.; Gómez, A.M.R. Sensing Technologies for Characterizing and Monitoring Soil Functions: A Review. Adv. Agron. 2023, 177, 125–168. [Google Scholar]
- Ciampalini, R.; Follain, S.; Cheviron, B.; Le Bissonnais, Y.; Couturier, A.; Moussa, R.; Walter, C. Local Sensitivity Analysis of the LandSoil Erosion Model Applied to a Virtual Catchment. In Sensitivity Analysis in Earth Observation Modelling; Elsevier: Amsterdam, The Netherlands, 2017; pp. 55–73. [Google Scholar]
- Yost, J.L.; Hartemink, A.E. Chapter Four—Soil Organic Carbon in Sandy Soils: A Review. In Advances in Agronomy; Sparks, D.L., Ed.; Academic Press: Cambridge, MA, USA, 2019; Volume 158, pp. 217–310. [Google Scholar]
- Thomas, D.S.G. 11.18 Aeolian Paleoenvironments of Desert Landscapes. In Treatise on Geomorphology; Shroder, J.F., Ed.; Academic Press: San Diego, CA, USA, 2013; pp. 356–374. ISBN 978-0-08-088522-3. [Google Scholar]
- McBratney, A.B.; Minasny, B.; Whelan, B. Defining Proximal Soil Sensing. In Proceedings of the Second Global Workshop on Proximal Soil Sensing, Montreal, QC, Canada, 15–18 May 2011; Adamchuk, V.I., Viscarra Rossel, R.A., Eds.; McGill University: Montreal, QC, Canada, 2011; pp. 144–146. [Google Scholar]
- Viscarra Rossel, R.A.; Adamchuk, V.I.; Sudduth, K.A.; McKenzie, N.J.; Lobsey, C. Proximal Soil Sensing. An Effective Approach for Soil Measurements in Space and Time. Adv. Agron. 2011, 113, 237–282. [Google Scholar] [CrossRef]
- Mouazen, A.M.; Alexandridis, T.; Buddenbaum, H.; Cohen, Y.; Moshou, D.; Mulla, D.; Nawar, S.; Sudduth, K.A. Monitoring. In Agricultural Internet of Things and Decision Support for Precision Smart Farming; Castrignanò, A., Buttafuoco, G., Khosla, R., Mouazen, A., Moshou, D., Naud, O., Eds.; Elsevier: London, UK, 2020; pp. 35–138. ISBN 978-0-12-818373-1. [Google Scholar]
- Castrignanò, A.; Buttafuoco, G. Data Processing. In Agricultural Internet of Things and Decision Support for Precision Smart Farming; Castrignanò, A., Buttafuoco, G., Khosla, R., Mouazen, A., Moshou, D., Naud, O., Eds.; Elsevier Academic Press: London, UK, 2020; pp. 139–182. ISBN 9780128183731. [Google Scholar]
- Deutsch, C.V. A Review of Geostatistical Approaches to Data Fusion. In Geophysical Monograph Series; American Geophysical Union (AGU): Washington, DC, USA, 2007; Volume 171, pp. 7–18. ISBN 9781118666463. [Google Scholar]
- Nguyen, H.; Cressie, N.; Braverman, A. Spatial Statistical Data Fusion for Remote Sensing Applications. J. Am. Stat. Assoc. 2012, 107, 1004–1018. [Google Scholar] [CrossRef]
- Pickett, S.; Kolasa, J.; Jones, C. Ecological Understanding. The Nature of Theory and the Theory of Nature, 2nd ed.; Academic Press: New York, NY, USA, 2010; ISBN 9780125545228. [Google Scholar]
- Carpenter, S.R.; Armbrust, E.V.; Arzberger, P.W.; Chapin, F.S.; Elser, J.J.; Hackett, E.J.; Ives, A.R.; Kareiva, P.M.; Leibold, M.A.; Lundberg, P.; et al. Accelerate Synthesis in Ecology and Environmental Sciences. Bioscience 2009, 59, 699–701. [Google Scholar] [CrossRef]
- Peters, D.P.C. Accessible Ecology: Synthesis of the Long, Deep, and Broad. Trends Ecol. Evol. 2010, 25, 592–601. [Google Scholar] [CrossRef] [PubMed]
- Prince, A.; Franssen, J.; Lapierre, J.-F.; Maranger, R. High-Resolution Broad-Scale Mapping of Soil Parent Material Using Object-Based Image Analysis (OBIA) of LiDAR Elevation Data. Catena 2020, 188, 104422. [Google Scholar] [CrossRef]
- Banwart, S.A.; Nikolaidis, N.P.; Zhu, Y.-G.; Peacock, C.L.; Sparks, D.L. Soil Functions: Connecting Earth’s Critical Zone. Annu. Rev. Earth Planet. Sci. 2019, 47, 333–359. [Google Scholar] [CrossRef]
- Gillin, C.P.; Bailey, S.W.; McGuire, K.J.; Gannon, J.P. Mapping of Hydropedologic Spatial Patterns in a Steep Headwater Catchment. Soil Sci. Soc. Am. J. 2015, 79, 440–453. [Google Scholar] [CrossRef]
- Grebby, S.; Field, E.; Tansey, K. Evaluating the Use of an Object-Based Approach to Lithological Mapping in Vegetated Terrain. Remote Sens. 2016, 8, 843. [Google Scholar] [CrossRef]
- Soares, M.F.; Timm, L.C.; Siqueira, T.M.; dos Santos, R.C.V.; Reichardt, K. Assessing the Spatial Variability of Saturated Soil Hydraulic Conductivity at the Watershed Scale Using the Sequential Gaussian Co-Simulation Method. Catena 2023, 221, 106756. [Google Scholar] [CrossRef]
- Räsänen, A.; Virtanen, T. Data and Resolution Requirements in Mapping Vegetation in Spatially Heterogeneous Landscapes. Remote Sens. Environ. 2019, 230, 111207. [Google Scholar] [CrossRef]
- Maesano, M.; Santopuoli, G.; Moresi, F.; Matteucci, G.; Lasserre, B.; Scarascia Mugnozza, G. Above Ground Biomass Estimation from UAV High Resolution RGB Images and LiDAR Data in a Pine Forest in Southern Italy. IForest 2022, 15, 451–457. [Google Scholar] [CrossRef]
- Mendonça, R.L.; Paz, A.R.d. LiDAR Data for Topographical and River Drainage Characterization: Capabilities and Shortcomings. RBRH 2022, 27, e42. [Google Scholar]
- Debnath, S.; Paul, M.; Debnath, T. Applications of LiDAR in Agriculture and Future Research Directions. J. Imaging 2023, 9, 57. [Google Scholar] [CrossRef]
- Tarolli, P. High-Resolution Topography for Understanding Earth Surface Processes: Opportunities and Challenges. Geomorphology 2014, 216, 295–312. [Google Scholar] [CrossRef]
- Leempoel, K.; Parisod, C.; Geiser, C.; Daprà, L.; Vittoz, P.; Joost, S. Very High-resolution Digital Elevation Models: Are Multi-scale Derived Variables Ecologically Relevant? Methods Ecol. Evol. 2015, 6, 1373–1383. [Google Scholar] [CrossRef]
- Curcio, A.C.; Peralta, G.; Aranda, M.; Barbero, L. Evaluating the Performance of High Spatial Resolution UAV-Photogrammetry and UAV-LiDAR for Salt Marshes: The Cádiz Bay Study Case. Remote Sens. 2022, 14, 3582. [Google Scholar] [CrossRef]
- Riefolo, C.; Castrignanò, A.; Colombo, C.; Conforti, M.; Ruggieri, S.; Vitti, C.; Buttafuoco, G. Investigation of Soil Surface Organic and Inorganic Carbon Contents in a Low-Intensity Farming System Using Laboratory Visible and near-Infrared Spectroscopy. Arch. Agron. Soil Sci. 2020, 66, 1436–1448. [Google Scholar] [CrossRef]
- Demattê, J.; Morgan, C.; Chabrillat, S.; Rizzo, R.; Franceschini, M.; da Silva Terra, F.; Vasques, G.; Wetterlind, J. Spectral Sensing from Ground to Space in Soil Science: State of the Art, Applications, Potential, and Perspectives. In Land Resources Monitoring, Modeling, and Mapping with Remote Sensing; Thenkabail, P.S., Ed.; CRC Press: Boca Raton, FL, USA, 2015; pp. 661–732. ISBN 9780429089442. [Google Scholar]
- Viscarra Rossel, R.A.; Walvoort, D.J.J.; McBratney, A.B.; Janik, L.J.; Skjemstad, J.O. Visible, near Infrared, Mid Infrared or Combined Diffuse Reflectance Spectroscopy for Simultaneous Assessment of Various Soil Properties. Geoderma 2006, 131, 59–75. [Google Scholar] [CrossRef]
- Gozukara, G.; Zhang, Y.; Hartemink, A.E. Using PXRF and Vis-NIR Spectra for Predicting Properties of Soils Developed in Loess. Pedosphere 2022, 32, 602–615. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. Digital Soil Mapping: A Brief History and Some Lessons. Geoderma 2016, 264, 301–311. [Google Scholar] [CrossRef]
- Arrouays, D.; McBratney, A.; Bouma, J.; Libohova, Z.; Richer-de-Forges, A.C.; Morgan, C.L.S.; Roudier, P.; Poggio, L.; Mulder, V.L. Impressions of Digital Soil Maps: The Good, the Not so Good, and Making Them Ever Better. Geoderma Reg. 2020, 20, e00255. [Google Scholar] [CrossRef]
- Chen, S.; Arrouays, D.; Leatitia Mulder, V.; Poggio, L.; Minasny, B.; Roudier, P.; Libohova, Z.; Lagacherie, P.; Shi, Z.; Hannam, J.; et al. Digital Mapping of GlobalSoilMap Soil Properties at a Broad Scale: A Review. Geoderma 2022, 409, 115567. [Google Scholar] [CrossRef]
- Burrough, P.A. Principles of Geographical Information Systems for Land Resources Assessment; Oxford University Press: Oxford, UK, 1986; ISBN 0198545630. [Google Scholar]
- Matheron, G. The Theory of Regionalized Variables and Its Applications; Ecole Nationale Superieure des Mines de Paris: Paris, France, 1971; Volume 5. [Google Scholar]
- Chilès, J.-P.; Delfiner, P. Geostatistics: Modeling Spatial Uncertainty, 2nd ed.; Wiley Series in Probability and Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2012; ISBN 9781118136188. [Google Scholar]
- Wadoux, A.M.J.C.; Román-Dobarco, M.; McBratney, A.B. Perspectives on Data-Driven Soil Research. Eur. J. Soil Sci. 2020, 72, 1675–1689. [Google Scholar] [CrossRef]
- Wackernagel, H. Multivariate Geostatistics: An Introduction with Applications; Springer: Berlin/Heidelberg, Germany, 2003; ISBN 3540441425. [Google Scholar]
- Hudson, G.; Wackernagel, H. Mapping Temperature Using Kriging with External Drift: Theory and an Example from Scotland. Int. J. Climatol. 1994, 14, 77–91. [Google Scholar] [CrossRef]
- Moresi, F.V.; Maesano, M.; Collalti, A.; Sidle, R.C.; Matteucci, G.; Scarascia Mugnozza, G. Mapping Landslide Prediction through a GIS-Based Model: A Case Study in a Catchment in Southern Italy. Geosciences 2020, 10, 309. [Google Scholar] [CrossRef]
- Buttafuoco, G.; Castrignanò, A. Study of the Spatio-Temporal Variation of Soil Moisture under Forest Using Intrinsic Random Functions of Order k. Geoderma 2005, 128, 208–220. [Google Scholar] [CrossRef]
- Conforti, M.; Buttafuoco, G. Insights into the Effects of Study Area Size and Soil Sampling Density in the Prediction of Soil Organic Carbon by Vis-NIR Diffuse Reflectance Spectroscopy in Two Forest Areas. Land 2023, 12, 44. [Google Scholar] [CrossRef]
- ARSSA. Carta Dei Suoli Della Regione Calabria—Scala 1:250000. In Monografia Divulgativa; Servizio Agropedologia; Agenzia Regionale per Lo Sviluppo e per i Servizi in Agricoltura: Soveria Mannelli, Italy, 2003. [Google Scholar]
- Soil Survey Staff. Keys to Soil Taxonomy, 12th ed.; USDA-Natural Resources Conservation Service: Washington, DC, USA, 2014.
- Olaya, V. A Gentle Introduction to SAGA GIS; The SAGA User Group Ev: Gottingen, Germany, 2004; Volume 208. [Google Scholar]
- Wilson, J.P.; Gallant, J.C. Terrain Analysis: Principles and Applications; John Wiley & Sons, Inc.: New York, NY, USA, 2000; ISBN 978-0-471-32188-0. [Google Scholar]
- Florinsky, I.V. Digital Terrain Analysis in Soil Science and Geology, 2nd ed.; Academic Press Inc.: Cambridge, MA, USA, 2016; ISBN 9780128046326. [Google Scholar]
- Sidari, M.; Ronzello, G.; Vecchio, G.; Muscolo, A. Influence of Slope Aspects on Soil Chemical and Biochemical Properties in a Pinus Laricio Forest Ecosystem of Aspromonte (Southern Italy). Eur. J. Soil Biol. 2008, 44, 364–372. [Google Scholar] [CrossRef]
- Conforti, M.; Longobucco, T.; Scarciglia, F.; Niceforo, G.; Matteucci, G.; Buttafuoco, G. Interplay between Soil Formation and Geomorphic Processes along a Soil Catena in a Mediterranean Mountain Landscape: An Integrated Pedological and Geophysical Approach. Environ. Earth Sci. 2020, 79, 59. [Google Scholar] [CrossRef]
- Conforti, M.; Lucà, F.; Scarciglia, F.; Matteucci, G.; Buttafuoco, G. Soil Carbon Stock in Relation to Soil Properties and Landscape Position in a Forest Ecosystem of Southern Italy (Calabria Region). Catena 2016, 144, 23–33. [Google Scholar] [CrossRef]
- Renard, K.G.; Foster, G.R.; Weesies, G.A.; McCool, D.K.; Yoder, D.C. Predicting Soil Erosion by Water: A Guide to Conservation Planning with the Revised Universal Soil Loss Equation (RUSLE); Agriculture Handbook No. 703; US Department of Agriculture: Washington, DC, USA, 1997; ISBN 0160489385.
- Moore, I.D.; Gessler, P.E.; Nielsen, G.A.; Peterson, G.A. Soil Attribute Prediction Using Terrain Analysis. Soil Sci. Soc. Am. J. 1993, 57, 443–452. [Google Scholar] [CrossRef]
- Sequi, P.; De Nobili, M. Determinazione Del Carbonio Organico. In Metodi di Analisi Chimica del Suolo; Violante, P., Ed.; Franco Angeli: Roma, Italy, 2000; pp. 18–25. [Google Scholar]
- Soil Science Division Staff. Soil Survey Manual. USDA Handbook 18; Ditzler, C., Scheffe, K., Monger, H.C., Eds.; Government Printing Office: Washington, DC, USA, 2017.
- Rock, B.N.; Williams, D.L.; Moss, D.M.; Lauten, G.N.; Kim, M. High-Spectral Resolution Field and Laboratory Optical Reflectance Measurements of Red Spruce and Eastern Hemlock Needles and Branches. Remote Sens. Environ. 1994, 47, 176–189. [Google Scholar] [CrossRef]
- Shepherd, K.D.; Walsh, M.G. Development of Reflectance Spectral Libraries for Characterization of Soil Properties. Soil Sci. Soc. Am. J. 2002, 66, 988. [Google Scholar] [CrossRef]
- Castrignanò, A.; Quarto, R.; Venezia, A.; Buttafuoco, G. A Comparison between Mixed Support Kriging and Block Cokriging for Modelling and Combining Spatial Data with Different Support. Precis. Agric. 2019, 20, 193–213. [Google Scholar] [CrossRef]
- Jackson, J.E. User’s Guide to Principal Components; John Wiley & Sons: New York, NY, USA, 2003; ISBN 978-0-471-47134-9. [Google Scholar]
- Cattell, R.B. The Scientific Use of Factor Analysis in Behavioral and Life Sciences; Springer: Boston, MA, USA, 1978; ISBN 978-1-4684-2264-1. [Google Scholar]
- Yong, A.G.; Pearce, S. A Beginner’s Guide to Factor Analysis: Focusing on Exploratory Factor Analysis. Tutor Quant. Methods Psychol. 2013, 9, 79–94. [Google Scholar] [CrossRef]
- SAS (Statistical Analysis System). Software Package Version 9.2; SAS Institute Inc.: Cary, NC, USA, 2017. [Google Scholar]
- Webster, R.; Oliver, M.A. Geostatistics for Environmental Scientists; Statistics in Practice; John Wiley & Sons, Ltd.: Chichester, UK, 2007; ISBN 9780470517277. [Google Scholar]
- Matheron, G. The Intrinsic Random Functions and Their Applications. Adv. Appl. Probab. 1973, 5, 439–468. [Google Scholar] [CrossRef]
- Carroll, S.S.; Cressie, N. A Comparison of Geostatistical Methodologies Used to Estimate Snow Water Equivalent. J. Am. Water Resour. Assoc. 1996, 32, 267–278. [Google Scholar] [CrossRef]
- Heege, H.J. Sensing of Natural Soil Properties. In Precision in Crop Farming: Site Specific Concepts and Sensing Methods: Applications and Results; Heege, H.J., Ed.; Springer: Dordrecht, The Netherlands, 2013; pp. 51–102. ISBN 978-94-007-6760-7. [Google Scholar]
- Telles, E.d.C.C.; de Camargo, P.B.; Martinelli, L.A.; Trumbore, S.E.; da Costa, E.S.; Santos, J.; Higuchi, N.; Oliveira, R.C. Influence of Soil Texture on Carbon Dynamics and Storage Potential in Tropical Forest Soils of Amazonia. Glob. Biogeochem. Cycles 2003, 17, 1040. [Google Scholar] [CrossRef]
- Lucà, F.; Robustelli, G.; Conforti, M.; Fabbricatore, D. Geomorphological Map of the Crotone Province (Calabria, South Italy). J. Maps 2011, 7, 375–390. [Google Scholar] [CrossRef][Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Sand | Silt | Clay | SOC |
|---|---|---|---|---|
| Minimum (%) | 39.00 | 1.00 | 7.00 | 0.67 |
| Median (%) | 63.00 | 22.00 | 15.00 | 2.38 |
| Mean (%) | 62.63 | 21.34 | 16.03 | 2.66 |
| Maximum (%) | 86.00 | 40.00 | 29.00 | 11.02 |
| Stand. Dev. (%) | 9.73 | 6.72 | 5.04 | 1.30 |
| Skewness (-) | −0.26 | 0.00 | 0.72 | 2.69 |
| Kurtosis (-) | 2.86 | 3.01 | 3.11 | 15.58 |
| PC | Eigenvalue | Difference | Explained Variance (%) | Cumulative Explained Variance (%) |
|---|---|---|---|---|
| 1 | 186.61 | 166.34 | 85.21 | 85.21 |
| 2 | 20.27 | 15.89 | 9.26 | 94.47 |
| 3 | 4.38 | 0.81 | 2.00 | 96.47 |
| 4 | 3.57 | 2.05 | 1.63 | 98.10 |
| 5 | 1.52 | 0.40 | 0.69 | 98.79 |
| 6 | 1.12 | 0.61 | 0.51 | 99.31 |
| Statistics | Elevation | Slope | Aspect | LS | SPI | TRI | TWI | Curvature |
|---|---|---|---|---|---|---|---|---|
| (m) | (°) | (-) | (-) | (-) | (-) | (-) | (-) | |
| Minimum | 1020.53 | 0.00 | −1.00 | 0.00 | 0.00 | 0.00 | 0.00 | −84.37 |
| Median | 1168.26 | 22.45 | 245.52 | 4.60 | 0.01 | 0.28 | 5.90 | 0.16 |
| Mean | 1171.02 | 23.40 | 213.27 | 5.05 | 0.23 | 0.31 | 5.98 | −0.02 |
| Maximum | 1340.83 | 72.86 | 360.00 | 112.63 | 1131.30 | 7.23 | 24.03 | 89.76 |
| Stand. Dev. | 65.79 | 11.44 | 104.17 | 3.36 | 5.74 | 0.19 | 1.65 | 4.47 |
| Skewness (-) | 0.18 | 0.45 | −0.60 | 2.23 | 65.10 | 1.49 | 1.74 | −1.61 |
| Kurtosis (-) | 2.27 | 2.90 | 2.04 | 24.17 | 6394.88 | 8.71 | 12.44 | 40.59 |
| Variables | Sand | Clay | SOC | PC1 | PC2 | Elevation | Slope | Aspect | LS | SPI | TRI | TWI | Curvature |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sand | 1 | ||||||||||||
| Clay | −0.76 | 1 | |||||||||||
| SOC | −0.08 | 0.02 | 1 | ||||||||||
| PC1 | −0.05 | 0.07 | −0.59 | 1 | |||||||||
| PC2 | −0.19 | 0.28 | −0.13 | −0.04 | 1 | ||||||||
| Elevation | 0.42 | −0.37 | 0.26 | −0.36 | −0.18 | 1 | |||||||
| Slope | −0.17 | 0.08 | 0.10 | −0.19 | 0.03 | −0.17 | 1 | ||||||
| Aspect | 0.18 | −0.10 | −0.01 | −0.06 | −0.04 | 0.20 | 0.05 | 1 | |||||
| LS | −0.15 | 0.05 | 0.00 | −0.18 | −0.03 | −0.14 | 0.85 | 0.04 | 1 | ||||
| SPI | −0.04 | 0.06 | −0.06 | 0.07 | −0.09 | −0.06 | −0.13 | −0.16 | 0.04 | 1 | |||
| TRI | −0.19 | 0.09 | 0.10 | −0.16 | 0.14 | −0.23 | 0.89 | 0.01 | 0.75 | −0.08 | 1 | ||
| TWI | −0.02 | 0.02 | −0.21 | 0.11 | −0.17 | 0.11 | −0.48 | −0.13 | −0.08 | 0.60 | −0.43 | 1 | |
| Curvature | −0.08 | 0.21 | 0.08 | −0.05 | 0.30 | 0.02 | −0.06 | 0.07 | −0.33 | −0.25 | −0.07 | −0.37 | 1 |
| (a) Identification of the Order k | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Mean Error | Mean Squared Error | Mean Rank | |||||||
| Trial | Ring 1 | Ring 2 | Total | Ring 1 | Ring 2 | Total | Ring 1 | Ring 2 | Total |
| T1: 1 f1 | 0.260 | −0.645 | −0.197 | 44.020 | 49.220 | 46.640 | 7.043 | 6.924 | 6.983 |
| T7: 1 f1 f2 | 0.256 | −0.654 | −0.203 | 47.210 | 51.990 | 49.620 | 7.137 | 7.127 | 7.132 |
| T9: 1 f1 f2 f3 | 0.529 | −0.676 | −0.079 | 55.440 | 58.050 | 56.760 | 7.933 | 7.574 | 7.752 |
| T11: 1 f1 f2 f3 f4 | 0.576 | −0.601 | −0.018 | 61.680 | 63.080 | 62.380 | 8.309 | 8.052 | 8.179 |
| T12: 1 f1 f2 f3 f4 f5 | 0.382 | −0.632 | −0.129 | 64.530 | 69.020 | 66.790 | 8.359 | 8.054 | 8.205 |
| T2: 1 x y f1 | 0.600 | −1.021 | −0.217 | 48.780 | 65.710 | 57.320 | 7.301 | 8.265 | 7.787 |
| T8: 1 x y f1 f2 | 0.745 | −0.934 | −0.102 | 52.060 | 67.750 | 59.970 | 7.568 | 8.392 | 7.983 |
| T10: 1 x y f1 f2 f3 | 0.770 | −0.889 | −0.067 | 64.920 | 74.870 | 69.940 | 8.418 | 8.571 | 8.495 |
| T13: 1 f1 f2 f3 f4 f5 f6 | 0.734 | −1.036 | −0.158 | 77.280 | 80.660 | 78.990 | 8.967 | 8.754 | 8.860 |
| T14: 1 f1 f2 f3 f4 f5 f6 f7 | 0.884 | −0.888 | −0.009 | 86.140 | 96.730 | 91.480 | 9.466 | 9.244 | 9.354 |
| T15: 1 f1 f2 f3 f4 f5 f6 f7 f8 | 0.748 | −0.871 | −0.068 | 102.200 | 103.600 | 102.900 | 9.917 | 9.576 | 9.745 |
| T16: 1 f1 f2 f3 f4 f5 f6 f7 f8 f9 | 1.008 | −0.783 | 0.105 | 136.400 | 121.700 | 129.000 | 10.328 | 9.663 | 9.993 |
| T3: 1 f2 | 0.769 | −1.257 | −0.253 | 108.500 | 115.700 | 112.100 | 10.104 | 10.137 | 10.121 |
| T17: 1 f1 f2 f3 f4 f5 f6 f7 f8 f9 f10 | 1.588 | −0.874 | 0.347 | 204.800 | 163.000 | 183.700 | 11.029 | 10.188 | 10.605 |
| T5: 1 f3 | 1.118 | −0.735 | 0.184 | 112.900 | 119.100 | 116.000 | 10.297 | 10.476 | 10.387 |
| T4: 1 x y f2 | 1.408 | −1.137 | 0.125 | 116.400 | 163.900 | 140.300 | 10.510 | 10.922 | 10.717 |
| T6: 1 x y f3 | 1.518 | −0.531 | 0.485 | 117.900 | 158.400 | 138.300 | 10.316 | 11.080 | 10.701 |
| Count of measures: Ring 1 = 1260; Ring 2 = 1281; Total = 2541 Average Neighborhood Radius: 386.57 m | |||||||||
| (b) Covariance Identification S1 = Nugget effect; S2 = Order 1 Generalized Covariance (G.C.), Scale = 200 m | |||||||||
| Explained/Theorical Variance Ratios | Generalized covariance | ||||||||
| Mean square error (Q) | Ring 1 | Ring 2 | Rings | Jackknife test | S1 | S2 | |||
| 0.701 | 0.959 | 1.007 | 0.984 | 0.985 | 32.380 | 5.021 | |||
| 0.703 | 0.923 | 1.040 | 0.983 | 0.983 | 41.350 | 0.000 | |||
| 0.717 | 1.026 | 0.831 | 0.910 | 0.894 | 0.000 | 25.150 | |||
| (a) Identification of the Order k | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Mean Error | Mean Squared Error | Mean Rank | |||||||
| Trial | Ring 1 | Ring 2 | Total | Ring 1 | Ring 2 | Total | Ring 1 | Ring 2 | Total |
| T1: 1 f1 | 0.525 | −0.188 | 0.165 | 89.660 | 100.500 | 95.150 | 89.660 | 100.500 | 95.150 |
| T2: 1 f1 f2 | 0.873 | 0.137 | 0.501 | 109.100 | 113.500 | 111.300 | 109.100 | 113.500 | 111.300 |
| T3: 1 f1 f2 f3 | 0.791 | 0.008 | 0.395 | 116.000 | 115.900 | 116.000 | 116.000 | 115.900 | 116.000 |
| T4: 1 f1 f2 f3 f4 | 0.710 | −0.011 | 0.345 | 163.300 | 142.300 | 152.700 | 163.300 | 142.300 | 152.700 |
| T5: 1 f1 f2 f3 f4 f5 | 0.749 | 0.080 | 0.410 | 155.400 | 141.700 | 148.500 | 155.400 | 141.700 | 148.500 |
| T6: 1 f1 f2 f3 f4 f5 f6 | 0.770 | 0.030 | 0.396 | 132.700 | 126.800 | 129.700 | 132.700 | 126.800 | 129.700 |
| T7: 1 f1 f2 f3 f4 f5 f6 f7 | 0.421 | 0.173 | 0.295 | 176.500 | 163.200 | 169.800 | 176.500 | 163.200 | 169.800 |
| T8: 1 f1 f2 f3 f4 f5 f6 f7 f8 | 0.179 | 0.080 | 0.129 | 204.400 | 186.800 | 195.500 | 204.400 | 186.800 | 195.500 |
| Count of measures: Ring 1 = 3271; Ring 2 = 3343; Total = 6614 Average Neighborhood Radius: 493.06 m | |||||||||
| (b) Covariance Identification S1 = Nugget effect; S2 = Order 1 Generalized Covariance (G.C.), Scale = 200 m; S3 = Spline G.C., Scale = 200 m; S4 = Order 3 G.C., Scale = 200 m | |||||||||
| Explained/Theorical Variance Ratios | Generalized covariance | ||||||||
| Mean square error (Q) | Ring 1 | Ring 2 | Rings | Jackknife test | S1 | S2 | S3 | S4 | |
| 0.629 | 0.989 | 1.014 | 1.002 | 1.003 | 82.470 | 0.826 | 0.000 | 0.000 | |
| 0.629 | 0.987 | 1.016 | 1.002 | 1.003 | 84.120 | 0.000 | 0.000 | 0.000 | |
| 0.677 | 0.956 | 0.821 | 0.879 | 0.870 | 0.000 | 47.980 | 0.000 | 0.000 | |
| Model | Mean Error | RMSSE | r | ρ |
|---|---|---|---|---|
| 1 | −0.0215 | 0.97 | 0.78 | 0.02 |
| 2 | 0.0252 | 0.90 | 0.38 | 0.02 |
| 3 | −0.1398 | 1.13 | 0.35 | 0.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castrignanò, A.; Buttafuoco, G.; Conforti, M.; Maesano, M.; Moresi, F.V.; Mugnozza, G.S. Improving the Spatial Prediction of Sand Content in Forest Soils Using a Multivariate Geostatistical Analysis of LiDAR and Hyperspectral Data. Remote Sens. 2023, 15, 4416. https://doi.org/10.3390/rs15184416
Castrignanò A, Buttafuoco G, Conforti M, Maesano M, Moresi FV, Mugnozza GS. Improving the Spatial Prediction of Sand Content in Forest Soils Using a Multivariate Geostatistical Analysis of LiDAR and Hyperspectral Data. Remote Sensing. 2023; 15(18):4416. https://doi.org/10.3390/rs15184416
Chicago/Turabian StyleCastrignanò, Annamaria, Gabriele Buttafuoco, Massimo Conforti, Mauro Maesano, Federico Valerio Moresi, and Giuseppe Scarascia Mugnozza. 2023. "Improving the Spatial Prediction of Sand Content in Forest Soils Using a Multivariate Geostatistical Analysis of LiDAR and Hyperspectral Data" Remote Sensing 15, no. 18: 4416. https://doi.org/10.3390/rs15184416
APA StyleCastrignanò, A., Buttafuoco, G., Conforti, M., Maesano, M., Moresi, F. V., & Mugnozza, G. S. (2023). Improving the Spatial Prediction of Sand Content in Forest Soils Using a Multivariate Geostatistical Analysis of LiDAR and Hyperspectral Data. Remote Sensing, 15(18), 4416. https://doi.org/10.3390/rs15184416