
LMSD-Net: A Lightweight and High-Performance Ship Detection Network for Optical Remote Sensing Images


Abstract
:1. Introduction
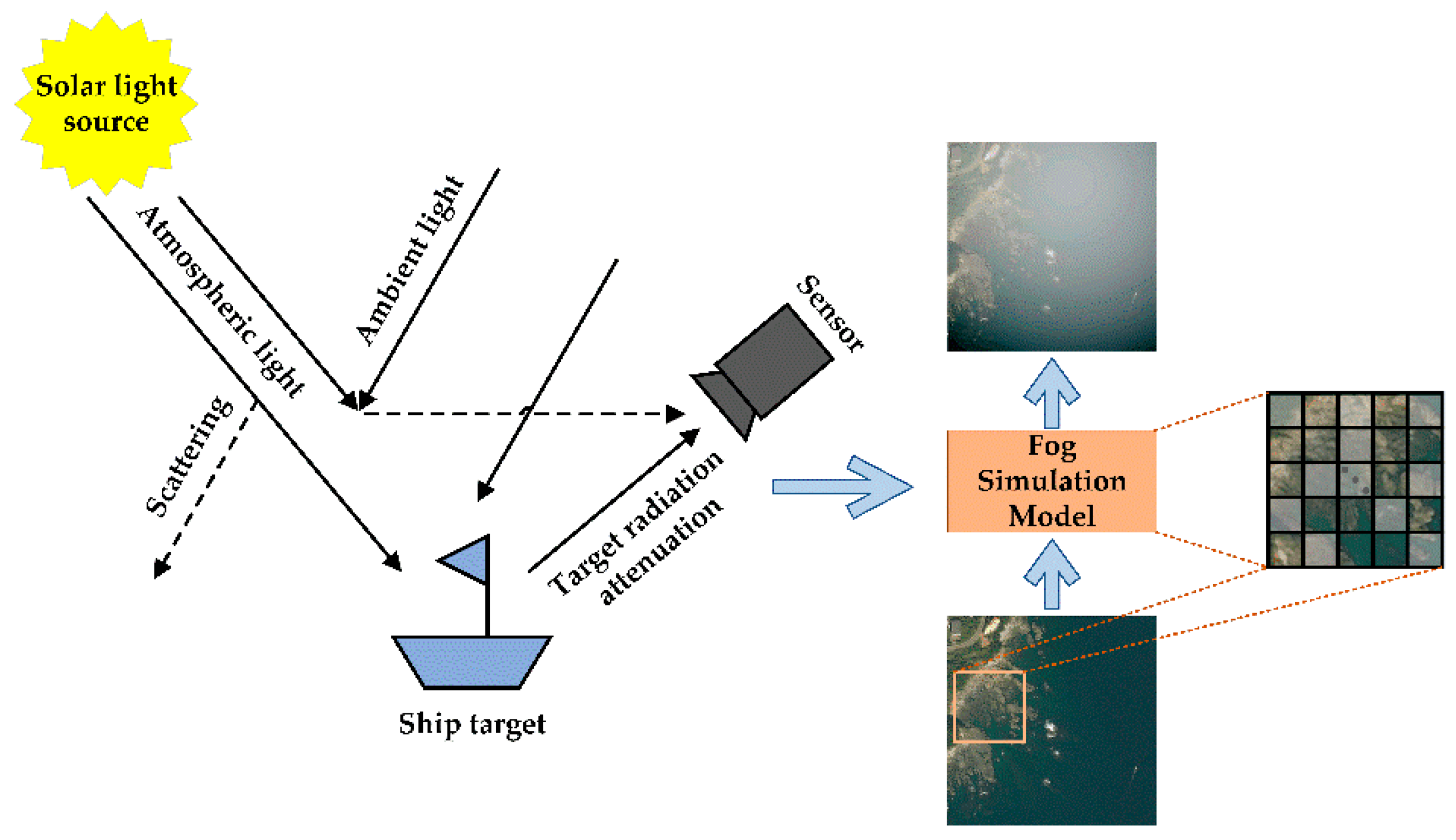
- We propose a method to generate fog images in remote sensing datasets to simulate actual background disturbances and compensate for the lack of images with extreme weather. From the perspective of data augmentation and data driven, fog simulation indirectly improves the model’s robustness and detection performance.
- Based on the analysis of the difficulties in optical remote sensing, we have designed a lightweight and layered detection framework (LMSD-Net). Inspired by the detection paradigm of “backbone–neck–head”, in LMSD-Net, an improved module (ELA-C3) is proposed for efficient feature extraction. In the neck, we design a weighted fusion connection (WFC-PANet) to compress the network neck and enhance the representation ability of channel features. In the prediction, we introduce a Contextual Transformer (CoT) to improve the accuracy of dense targets in complex offshore scenes. During the training process, we discovered the degradation problem of CIoU in dealing with small ships and proposed V-CIoU to improve the detection performance of vessels marked by small boxes.
- Based on the VRS ship dataset [54], we added more nearshore images to construct a new ship dataset (VRS-SD v2). The dataset covers different nearshore and offshore scenes, multiple potential disturbances, different target scales, and more dense distributions of tiny ships. Then, we used the proposed fog simulation to process the dataset and obtained the dataset for the actual scenes.
2. Methods
2.1. Data Augmentation–Fog Simulation on Actual Remote Sensing Scenes
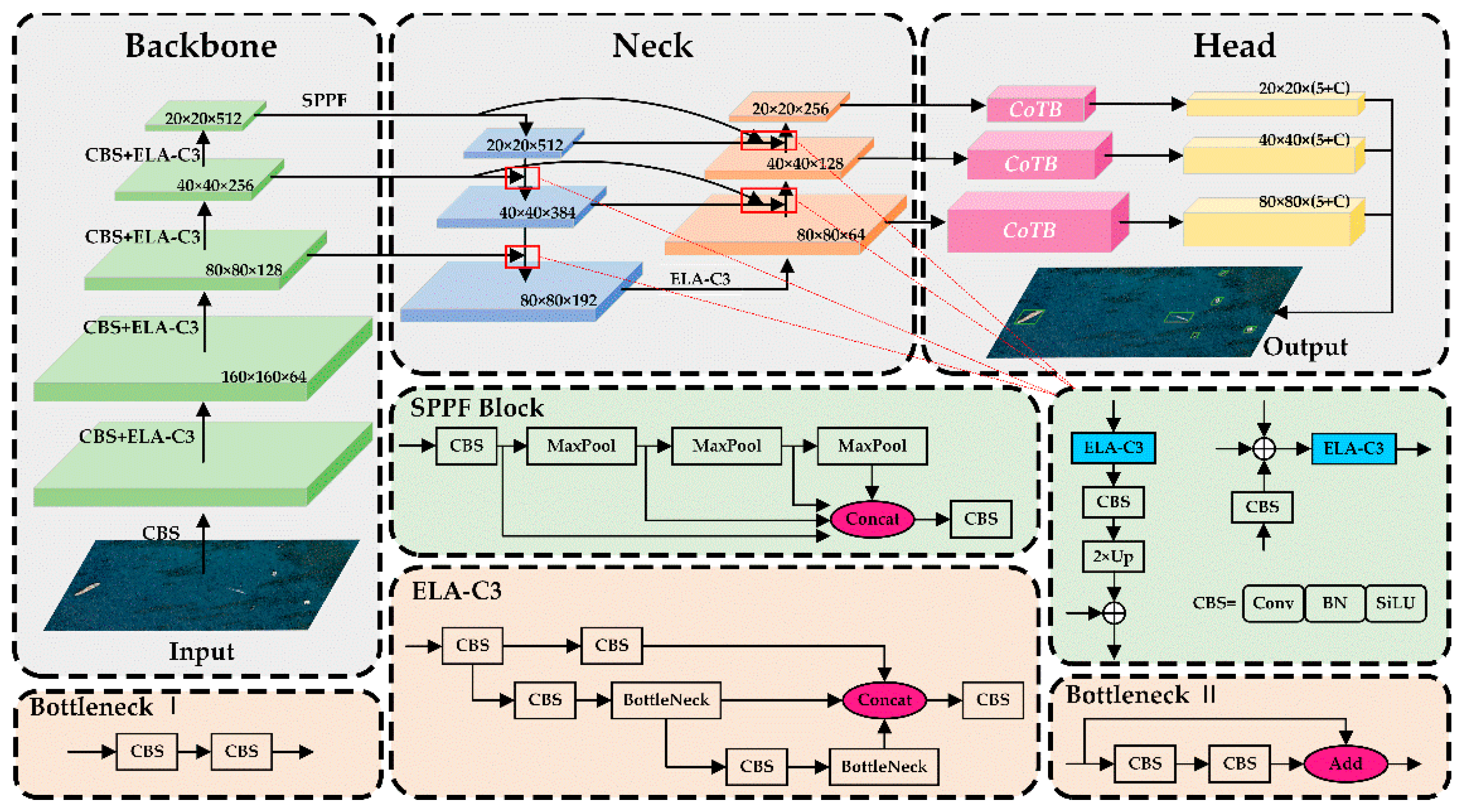
2.2. The Proposed LMSD-Net
2.2.1. Overall Architecture
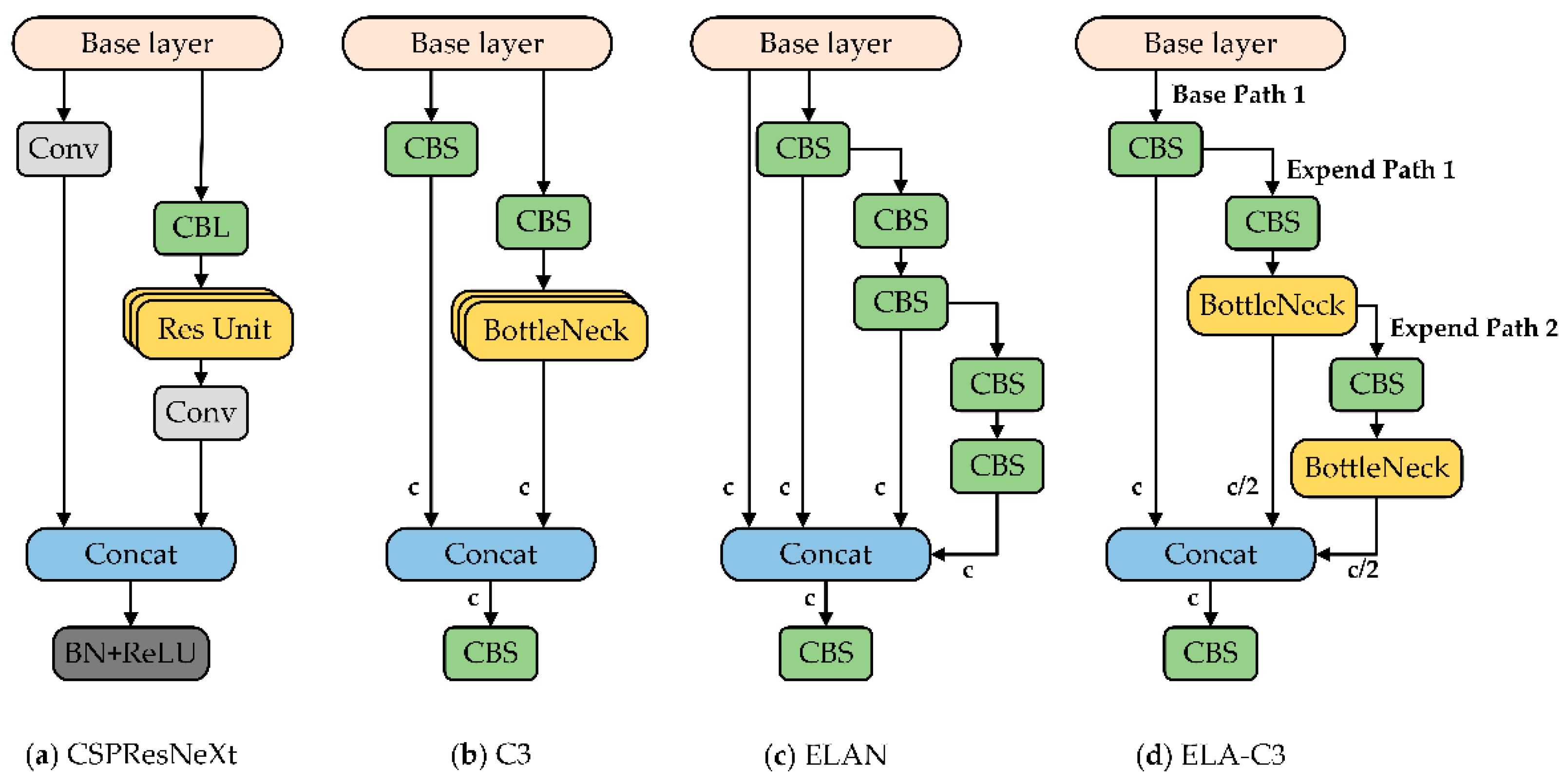
2.2.2. Efficient Layer Aggregation Block
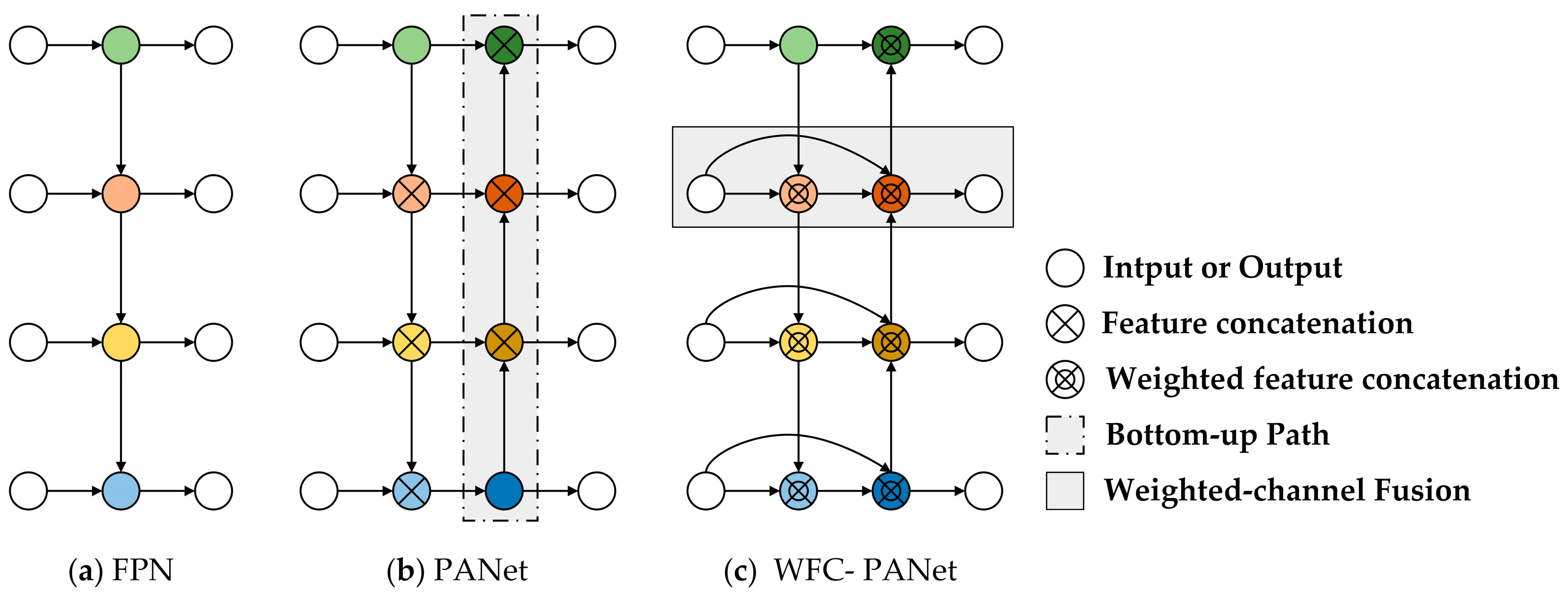
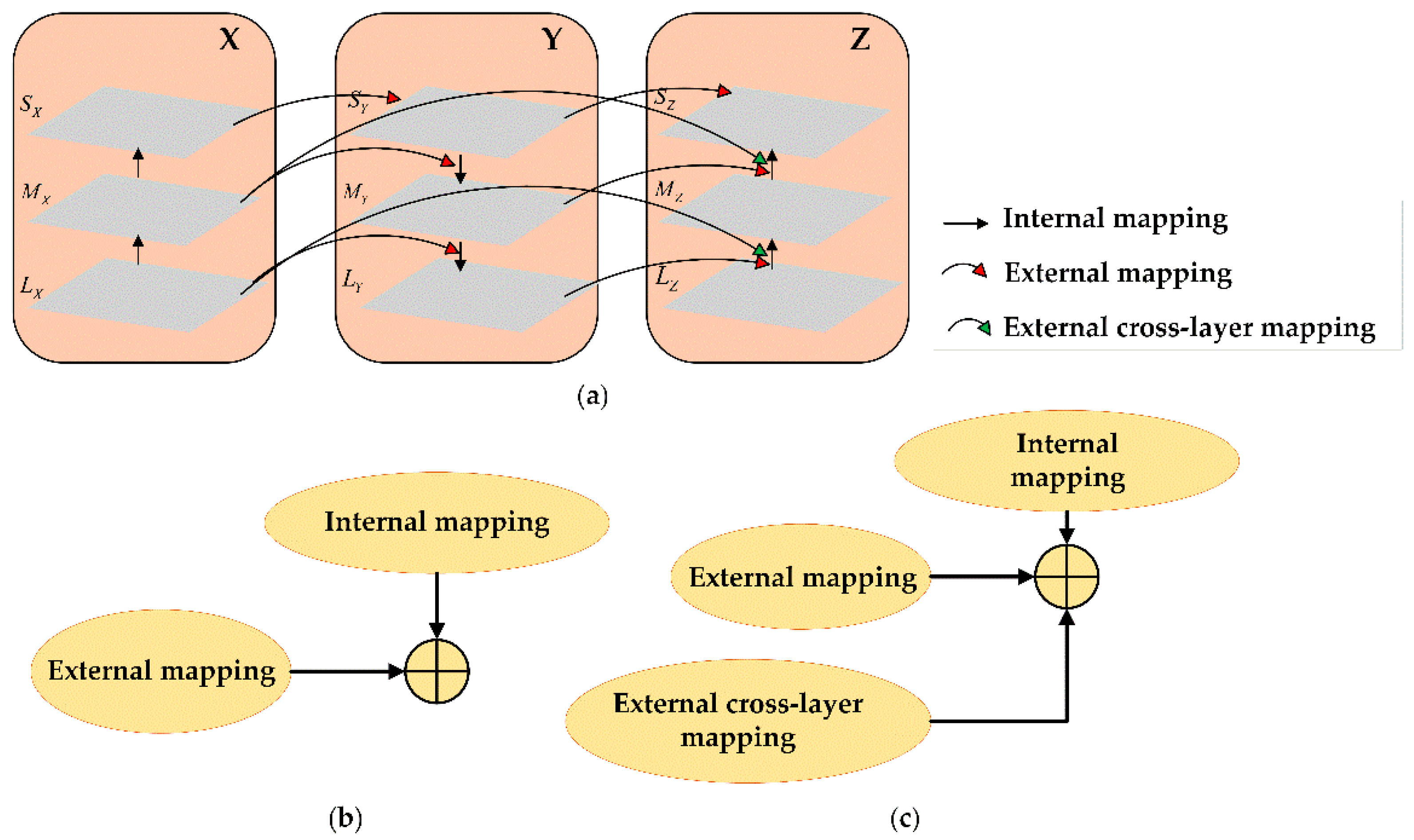
2.2.3. Lightweight Fusion with Weighted-Channel Concatenation
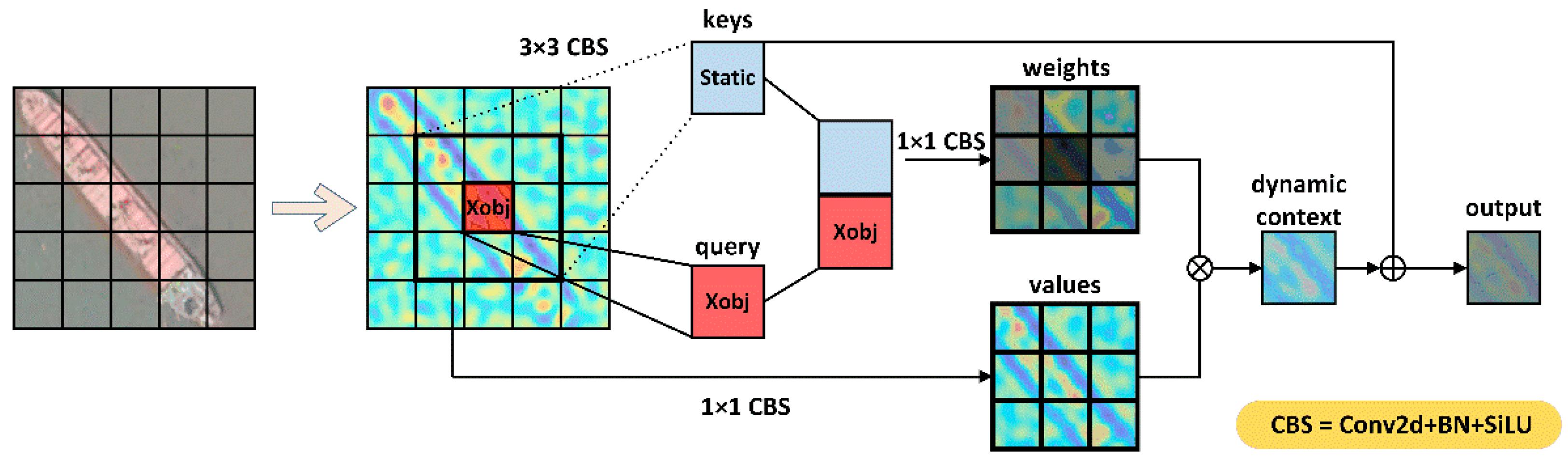
2.2.4. Contextual Transformer Block for the Detection Head
2.2.5. Prediction
| Algorithm 1. V-CIoU computation | |
| 1: | Input: Bounding box of ground truth |
| 2: | Input: Bounding box of prediction |
| 3: | Output: VCIoU between the ground-truth box and the prediction boxes |
| 4: | If do |
| 5: | For A and B, find the smallest enclosing convex object C. |
| 6: | within C, calculate . |
| 7: | If : |
| 8: | then , |
| 9: | , |
| 10: | . |
| 11: | else |
| 12: | then . |
| 13: | else |
| 14: | . |
3. Results and Experiments
3.1. Dataset
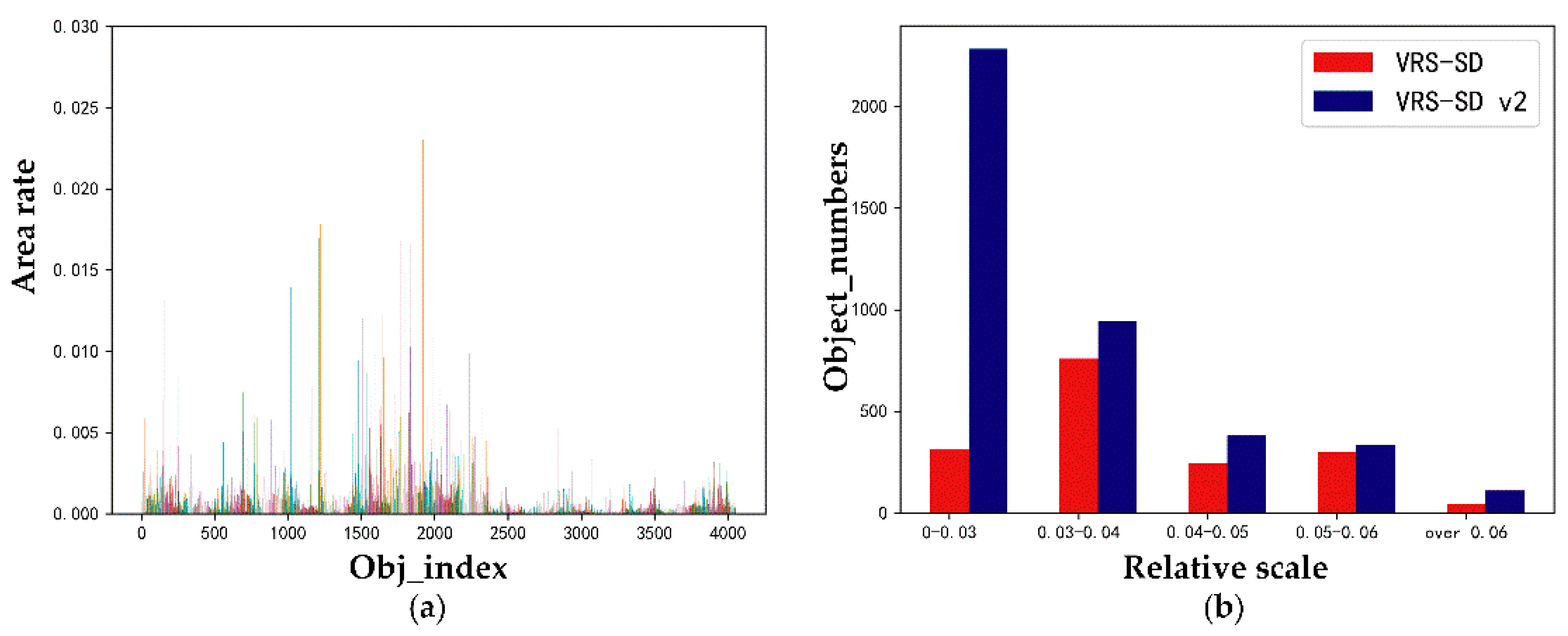
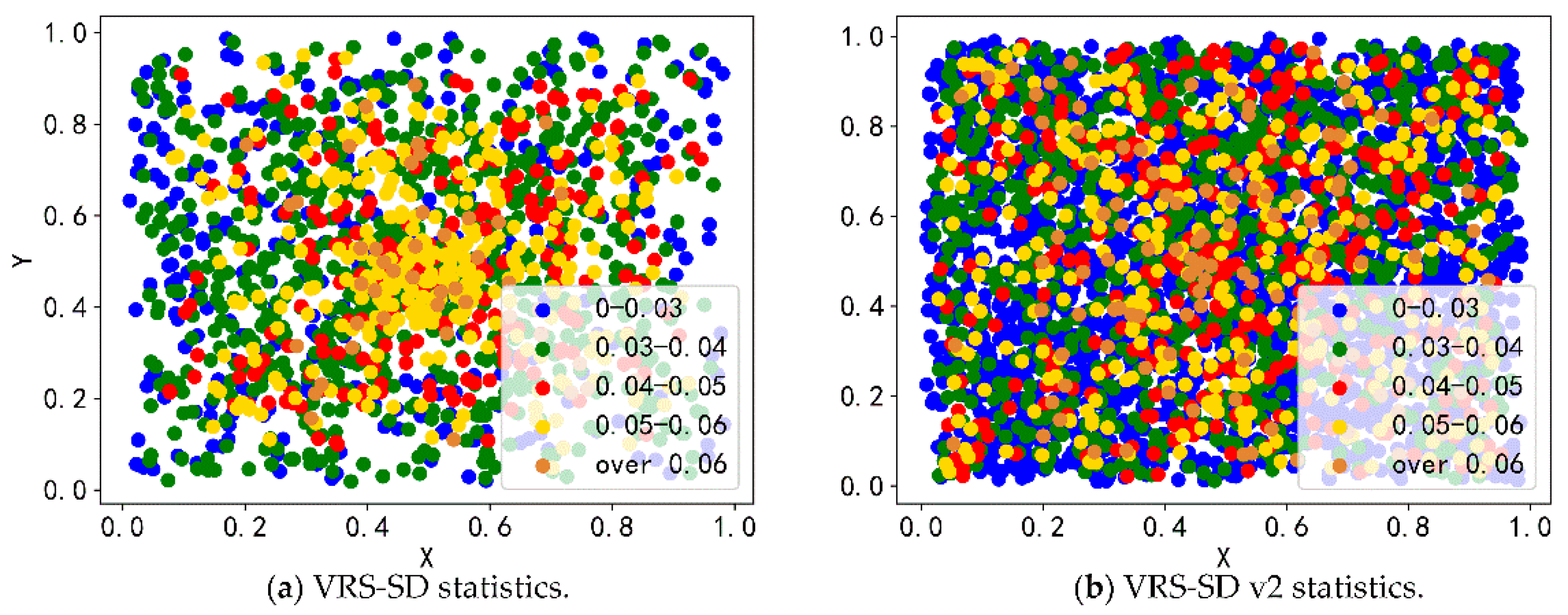
3.1.1. The Analysis of VRS-SD v2
3.1.2. Fog Simulation
3.2. Evaluation Metrics
3.3. Ablation Study
3.3.1. Effect of Fog Simulation
3.3.2. Effect of ELA-C3
3.3.3. Effect of WFC-PANet
3.3.4. Structure Exploration of the Detection Head
3.3.5. Validation of Regression Loss Function
3.3.6. Multi-Scale Performance of the Model
3.4. Overall Detection Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zou, H.; He, S.; Wang, Y.; Li, R.; Cheng, F.; Cao, X. Ship detection based on medium-low resolution remote sensing data and super-resolved feature representation. Remote Sens. Lett. 2022, 13, 323–333. [Google Scholar] [CrossRef]
- Cui, D.; Guo, L.; Zhang, Y. Research on the development of ship target detection based on deep learning technology. In Proceedings of the ACM International Conference on Frontier Computing (FC), Turin, Italy, 17–19 May 2022. [Google Scholar]
- Wu, J.; Li, J.; Li, R.; Xi, X. A fast maritime target identification algorithm for offshore ship detection. Appl. Sci. 2022, 12, 4938. [Google Scholar] [CrossRef]
- Yue, T.; Yang, Y.; Niu, J. A Light-weight Ship Detection and Recognition Method Based on YOLOv4. In Proceedings of the 2021 International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), Changsha, China, 26–28 March 2021. [Google Scholar]
- Joseph, S.I.T.; Karunakaran, V.; Sujatha, T.; Rai, S.B.E.; Velliangiri, S. Investigation of deep learning methodologies in satellite image based ship detection. In Proceedings of the International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 7–9 April 2022. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI transformer for detecting oriented objects in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Wu, X.; Hong, D.; Tian, J.; Chanussot, J.; Li, W.; Tao, R. ORSIm Detector: A Novel Object Detection Framework in Optical Remote Sensing Imagery Using Spatial-Frequency Channel Features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5146–5158. [Google Scholar] [CrossRef]
- Shi, Z.; Yu, X.; Jiang, Z.; Li, B. Ship Detection in High-Resolution Optical Imagery Based on Anomaly Detector and Local Shape Feature. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4511–4523. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.; Zhao, B. Compressed-Domain Ship Detection on Spaceborne Optical Image Using Deep Neural Network and Extreme Learning Machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Ship Detection in Spaceborne Optical Image with SVD Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Nie, T.; Han, X.; He, B.; Li, X.; Liu, H.; Bi, G. Ship Detection in Panchromatic Optical Remote Sensing Images Based on Visual Saliency and Multi-Dimensional Feature Description. Remote Sens. 2020, 12, 152. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami Beach, FL, USA, 20–25 June 2009. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Zhi, X.; Jiang, S.; Tang, H. Supervised Multi-Scale Attention-Guided Ship Detection in Optical Remote Sensing Images. IEEE Trans Geosci Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krhenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2020, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- GitHub: Ultralytics. YOLOv5-v 6.1. 2022. Available online: https://github.com/ultralytics/yolov5 (accessed on 23 December 2022).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- GitHub: Airockchip. YOLOv8. 2023. Available online: https://github.com/airockchip/ultralytics_yolov8. (accessed on 10 February 2023).
- Wang, B.; Han, B.; Yang, L. Accurate Real-time Ship Target detection Using Yolov4. In Proceedings of the International Conference on Transportation Information and Safety (ICTIS), Wuhan, China, 27 June 2022. [Google Scholar]
- Ye, Y.; Ren, X.; Zhu, B.; Tang, T.; Tan, X.; Gui, Y.; Yao, Q. An Adaptive Attention Fusion Mechanism Convolutional Network for Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 516. [Google Scholar] [CrossRef]
- Xu, Q.; Li, Y.; Shi, Z. LMO-YOLO: A Ship Detection Model for Low-Resolution Optical Satellite Imagery. IEEE J-STARS 2022, 15, 4117–4131. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (2021), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. arXiv 2020, arXiv:1911.09070. [Google Scholar]
- Gholami, A.; Kwon, K.; Wu, B.; Tai, Z.; Yue, X.; Jin, P.; Zhao, S.; Keutzer, K. SqueezeNext: Hardware-Aware Neural Network Design. arXiv 2018, arXiv:1803.10615. [Google Scholar]
- Huang, G.; Liu, S.; Maaten, L.; Weinberger, K.Q. CondenseNet: An Efficient DenseNet using Learned Group Convolutions. arXiv 2017, arXiv:1711.09224. [Google Scholar]
- Zhang, T.; Qi, G.; Xiao, B.; Wang, J. Interleaved Group Convolutions for Deep Neural Networks. arXiv 2017, arXiv:1707.02725. [Google Scholar]
- Xie, G.; Wang, J.; Zhang, T.; Lai, J.; Hong, R.; Qi, G. IGCV2: Interleaved Structured Sparse Convolutional Neural Networks. arXiv 2018, arXiv:1804.06202. [Google Scholar]
- Sun, K.; Li, M.; Liu, D.; Wang, J. IGCV3: Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks. arXiv 2018, arXiv:1806.00178. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE /CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, GA, USA, 21–26 July 2017. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. arXiv 2018, arXiv:1803.01534. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Pang, R.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. arXiv 2019, arXiv:1904.07392. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network. arXiv 2018, arXiv:1811.04533. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. arXiv 2021, arXiv:2108.11539. [Google Scholar]
- Tian, Y.; Liu, J.; Zhu, S.; Xu, F.; Bai, G.; Liu, C. Ship Detection in Visible Remote Sensing Image Based on Saliency Extraction and Modified Channel Features. Remote Sens. 2022, 14, 3347. [Google Scholar] [CrossRef]
- Sakaridis, C.; Dai, D.; Gool, L.V. Semantic Foggy Scene Understanding with Synthetic Data. arXiv 2019, arXiv:1708.07819. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2019, arXiv:1801.04381. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Cot Contextual Transformer Networks for Visual Recognition. arXiv 2021, arXiv:2107.12292. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. arXiv 2021, arXiv:2005.03572. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods (ICPRAM), Porto, Portugal, 24–26 February 2017. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-Class Geospatial Object Detection and Geographic Image Classification Based on Collection of Part Detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Al-Saad, M.; Aburaed, N.; Panthakkan, A.; Al Mansoori, S.; Al Ahmad, H.; Marshall, S. Airbus Ship Detection from Satellite Imagery using Frequency Domain Learning. In Proceedings of the Conference on Image and Signal Processing for Remote Sensing XXVII, online, Spain, 13–17 September 2021. [Google Scholar]
- Gallego, A.J.; Pertusa, A.; Gil, P. Automatic Ship Classification from Optical Aerial Images with Convolutional Neural Networks. Remote Sens. 2018, 10, 511. [Google Scholar] [CrossRef]
- Chen, K.; Wu, M.; Liu, J.; Zhang, C. FGSD: A Dataset for Fine-grained Ship Detection in High Resolution Satellite Images. arXiv 2021, arXiv:2003.06832. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A Normalized Gaussian Wasserstein Distance for Tiny Object Detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale Match for Tiny Person Detection. arXiv 2020, arXiv:1912.10664. [Google Scholar]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. arXiv 2019, arXiv:1711.10398. [Google Scholar]
- Chen, C.; Liu, M.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Proceedings of the 13th Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, 20–24 November 2016. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. arXiv 2021, arXiv:2101.08158. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- GitHub: RangiLyu. NonoDet-Plus. 2021. Available online: https://github.com/RangiLyu/nanodet (accessed on 12 February 2023).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. YOLOv6 v3.0: A Full-Scale Reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The nth Layer | From | Module | Num | Output Shape | Params |
|---|---|---|---|---|---|
| / | Input | / | [640,640,3] | / | |
| 0 | −1 | Convolution | 1 | [320,320,32] | 3520 |
| 1 | −1 | Convolution | 1 | [160,160,64] | 18,560 |
| 2 | −1 | ELA-C3 Block | 1 | [160,160,64] | 18,816 |
| 3 | −1 | Convolution | 1 | [80,80,128] | 73,984 |
| 4 | −1 | ELA-C3 Block | 2 | [80,80,128] | 115,712 |
| 5 | −1 | Convolution | 1 | [40,40,256] | 295,424 |
| 6 | −1 | ELA-C3 Block | 3 | [40,40,256] | 625,152 |
| 7 | −1 | Convolution | 1 | [20,20,512] | 1,180,672 |
| 8 | −1 | ELA-C3 Block | 1 | [20,20,512] | 1,182,720 |
| 9 | −1 | SPPF | 1 | [20,20,512] | 656,896 |
| 10 | −1 | Convolution | 1 | [20,20,128] | 65,792 |
| 11 | −1 | Nearest Upsample | 1 | [40,40,128] | - |
| 12 | −1,6 | WFC_Concat_2 | 1 | [40,40,384] | 2 |
| 13 | −1 | ELA-C3 Block | 1 | [40,40,128] | 107,264 |
| 14 | −1 | Convolution | 1 | [40,40,64] | 8320 |
| 15 | −1 | Nearest Upsample | 1 | [80,80,64] | - |
| 16 | −1,4 | WFC_Concat_2 | 1 | [80,80,192] | 2 |
| 17 | −1 | ELA-C3 Block | 1 | [80,80,64] | 27,008 |
| 18 | −1 | Convolution | 1 | [40,40,64] | 36,992 |
| 19 | −1,14,6 | WFC_Concat_3 | 1 | [40,40,384] | 3 |
| 20 | −1 | ELA-C3 Block | 1 | [40,40,128] | 107,264 |
| 21 | −1 | Convolution | 1 | [20,20,128] | 147,712 |
| 22 | −1,10,8 | WFC_Concat_3 | 1 | [20,20,768] | 3 |
| 23 | −1 | ELA-C3 Block | 1 | [20,20,256] | 427,520 |
| 24 | 17 | CoTB | 3 | [80,80,64] | 18,944 |
| 25 | 20 | CoTB | 3 | [40,40,128] | 74,240 |
| 26 | 23 | CoTB | 3 | [20,20,256] | 293,888 |
| 27 | 24,25,26 | Detect | 1 | / | 8118 |
| 366 Conv layers | 12.8 GFLOPs | parameters | |||
| Dataset | Images | Class | Ship Instances | Image Size | Source | Fog |
|---|---|---|---|---|---|---|
| NWPU VHR-10 | 800 | 10 | 302 | / | Google Earth | × |
| HRSC2016 | 1061 | 3 | 2976 | 300 × 300~1500 × 1900 | Google Earth | × |
| Airbus ship dataset | 192,570 | 2 | / | 768 × 768 | Google Earth | × |
| MASATI [62] | 6212 | 7 | 7389 | 512 × 512 | Aircraft | × |
| FGSD2021 [63] | 636 | 20 | 5274 | 157 × 224~6506 × 7789 | Google Earth | × |
| AI-TOD [64] | 28,036 | 8 | 700,621 | / | Google Earth | √ |
| VRS-SD | 893 | 6 | 1162 | 512 × 512 | Google Earth | √ |
| VRS-SD v2 | 2368 | 8 | 4054 | 512 × 512 | Google Earth and Aircraft | √ |
| Relative Scales | Relative Area Rates | VRS-SD/pcs | VRS-SD v2/pcs |
|---|---|---|---|
| Tiny ship | (0, 0.0008) | 312 | 2284 |
| Small ship | (0.0008, 0.0016) | 761 | 943 |
| (0.0016–0.0025) | 244 | 381 | |
| (0.0025–0.0058) | 300 | 335 | |
| Medium ship | (0.0058–0.04) | 46 | 111 |
| Dataset | Train/Val Set With Fog | Test Set with Fog | Recall | Precision | F1 | AP@0.5 | AP@0.5:0.95 |
|---|---|---|---|---|---|---|---|
| MASATI | × | × | 0.813 | 0.825 | 0.82 | 0.813 | 0.407 |
| × | √ (100%) | 0.609 | 0.679 | 0.64 | 0.587 | 0.264 | |
| √ (100%) | √ (100%) | 0.738 | 0.766 | 0.75 | 0.758 | 0.345 | |
| √ (50%) | √ (50%) | 0.731 | 0.833 | 0.78 | 0.783 | 0.358 | |
| VRS-SOD v2 | × | × | 0.771 | 0.832 | 0.80 | 0.817 | 0.395 |
| × | √ (100%) | 0.612 | 0.718 | 0.66 | 0.615 | 0.283 | |
| √ (100%) | √ (100%) | 0.650 | 0.744 | 0.69 | 0.718 | 0.32 | |
| √ (50%) | √ (50%) | 0.662 | 0.848 | 0.74 | 0.741 | 0.342 |
| Input Size | Backbone + ELA-C3 | Neck + ELA-C3 | AP@0.5 | AP@0.5:0.95 | FPS bs@16 | Params (M) | GFLOPs (G) |
|---|---|---|---|---|---|---|---|
| 640 × 640 | × | × | 0.782 | 0.363 | 126 | 6.97 | 17.3 |
| 640 × 640 | √ | × | 0.821 (+3.9%) | 0.381 (+1.8%) | 204 | 5.09 | 12.1 |
| 640 × 640 | × | √ | 0.797 (+1.5%) | 0.382 (+1.9%) | 161 | 6.51 | 16.5 |
| 640 × 640 | √ | √ | 0.837 (+5.5%) | 0.396 (+3.3%) | 181 | 5.5 | 12.8 |
| Neck | Recall | Precision | AP@0.5 | AP@0.5:0.95 | FPS bs@16 | Params (M) | GFLOPs (G) |
|---|---|---|---|---|---|---|---|
| PANet | 0.811 | 0.823 | 0.831 | 0.41 | 181 | 7.02 | 15.8 |
| BiFPN_Add | 0.783 | 0.789 | 0.809 | 0.38 | 169 | 9.32 | 22.9 |
| BiFPN_Concat | 0.771 | 0.844 | 0.823 | 0.404 | 181 | 7.08 | 16.0 |
| WFC-PANet(ours) | 0.790 | 0.832 | 0.817 | 0.39 | 208 | 5.10 | 12.1 |
| Detection Head | Recall | Precision | AP@0.5 | AP@0.5:0.95 | FPS (bs@16) | Params (M) | GFLOPs (G) |
|---|---|---|---|---|---|---|---|
| YOLO head | 0.743 | 0.784 | 0.793 | 0.368 | 208 | 5.10 | 12.1 |
| Decoupled head [28] | 0.792 | 0.821 | 0.800 | 0.386 | 188 | 6.09 | 13.9 |
| Swin+ YOLO head [53] | 0.773 | 0.804 | 0.796 | 0.392 | 181 | 5.54 | 25.7 |
| CoT_1+ YOLO head | 0.756 | 0.837 | 0.817 | 0.375 | 208 | 4.97 | 12.1 |
| CoT_2+ YOLO head | 0.787 | 0.821 | 0.831 | 0.384 | 185 | 5.18 | 12.5 |
| CoT_3+ YOLO head | 0.781 | 0.847 | 0.837 | 0.396 | 171 | 5.49 | 12.8 |
| CoT_4+ YOLO head | 0.784 | 0.850 | 0.839 | 0.398 | 162 | 5.90 | 13.2 |
| Regression Loss | |||
|---|---|---|---|
| CIoU | 0.821 | 0.309 | 0.382 |
| DIoU [68] | 0.817 | 0.293 | 0.371 |
| EIoU [69] | 0.796 | 0.294 | 0.375 |
| SIoU [70] | 0.787 | 0.318 | 0.379 |
| Wise-IoU [71] | 0.817 | 0.326 | 0.378 |
| V-CIoU | 0.823 | 0.338 | 0.404 |
| Model | Params (M) | GFLOPs(G) | Size | ||||
|---|---|---|---|---|---|---|---|
| Yolov7-tiny | 6.01 | 13.2 | 640 | 0.208 | 0.211 | 0.149 | 0.342 |
| Yolov5s-6.1 | 7.03 | 15.9 | 640 | 0.376 | 0.369 | 0.549 | 0.581 |
| Yolov6n-3.0 | 4.63 | 11.34 | 640 | 0.323 | 0.316 | 0.513 | 0.604 |
| Yolov8s | 11.1 | 28.6 | 640 | 0.380 | 0.360 | 0.595 | 0.683 |
| LMSD-Net | 5.50 | 12.8 | 640 | 0.392 | 0.372 | 0.591 | 0.644 |
| Method | Backbone | Input Size | Recall | Precision | F1 | AP@0.5 | AP@0.5:0.95 | FPS (bs@1) | Params (M) | GFLOPs (G) |
|---|---|---|---|---|---|---|---|---|---|---|
| EfficientDet-D0 [39] | Efficient-B0 | 512 | 0.233 | 0.766 | 0.36 | 0.291 | 0.125 | 23 | 3.83 | 4.7 |
| EfficientDet-D1 [39] | Efficient-B1 | 640 | 0.404 | 0.833 | 0.54 | 0.444 | 0.213 | 19 | 6.56 | 11.5 |
| EfficientDet-D2 [39] | Efficient-B2 | 768 | 0.458 | 0.842 | 0.59 | 0.561 | 0.266 | 16 | 8.01 | 20.5 |
| EfficientDet-D3 [39] | Efficient-B3 | 896 | 0.671 | 0.780 | 0.72 | 0.638 | 0.300 | 13 | 11.90 | 46.9 |
| Nanodet-m [72] | ShuffleNetV2 1.0x | 320 | 0.355 | 0.879 | 0.51 | 0.420 | 0.162 | 78 | 0.94 | 0.72 |
| Nanodet-plus-m [72] | ShuffleNetV2 1.5x | 416 | 0.556 | 0.656 | 0.60 | 0.585 | 0.278 | 67 | 2.44 | 2.97 |
| Nanodet-EfficientLite [72] | EfficientNet-Lite1 | 416 | 0.586 | 0.677 | 0.63 | 0.578 | 0.288 | 59 | 4.00 | 4.06 |
| Nanodet-EfficientLite [72] | EfficientNet-Lite2 | 512 | 0.635 | 0.691 | 0.66 | 0.596 | 0.284 | 48 | 4.70 | 7.12 |
| Yolov4-tiny [26] | CSPDarknet53-tiny | 640 | 0.576 | 0.751 | 0.65 | 0.683 | 0.235 | 130 | 5.87 | 16.2 |
| Yolov7-tiny [29] | CSP-ELAN | 640 | 0.699 | 0.891 | 0.78 | 0.731 | 0.282 | 80 | 6.01 | 13.2 |
| Yolox-nano [73] | CSPDarknet-C3 | 640 | 0.689 | 0.661 | 0.67 | 0.705 | 0.283 | 57 | 0.90 | 2.5 |
| Yolox-tiny [73] | CSPDarknet-C3 | 640 | 0.763 | 0.827 | 0.79 | 0.782 | 0.324 | 53 | 5.06 | 15.4 |
| Yolov5n6 [27] | CSPDarknet-C3 | 640 | 0.665 | 0.842 | 0.74 | 0.756 | 0.329 | 91 | 1.77 | 4.2 |
| Yolov5s6 [27] | CSPDarknet-C3 | 640 | 0.724 | 0.856 | 0.78 | 0.787 | 0.370 | 79 | 7.03 | 15.9 |
| Yolov5-Ghost [27] | CSPDarknet-C3Ghost | 640 | 0.725 | 0.781 | 0.75 | 0.771 | 0.347 | 84 | 4.90 | 10.6 |
| Yolov6-3.0-nano [74] | EfficientRep | 640 | 0.726 | 0.829 | 0.77 | 0.744 | 0.380 | 81 | 4.63 | 11.34 |
| Yolov6-3.0-s [74] | EfficientRep | 640 | 0.743 | 0.884 | 0.81 | 0.789 | 0.392 | 73 | 18.50 | 45.17 |
| Yolov8n [30] | CSPDarknet-C2f | 640 | 0.716 | 0.877 | 0.79 | 0.772 | 0.345 | 82 | 3.1 | 8.2 |
| Yolov8s [30] | CSPDarknet-C2f | 640 | 0.760 | 0.886 | 0.82 | 0.809 | 0.358 | 79 | 11.1 | 28.6 |
| LMSD-Net(ours) | CSPDarknet- ELA-C3 (ours) | 640 | 0.790 | 0.824 | 0.81 | 0.813 | 0.384 | 68 | 5.50 | 12.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Wang, X.; Zhu, S.; Xu, F.; Liu, J. LMSD-Net: A Lightweight and High-Performance Ship Detection Network for Optical Remote Sensing Images. Remote Sens. 2023, 15, 4358. https://doi.org/10.3390/rs15174358
Tian Y, Wang X, Zhu S, Xu F, Liu J. LMSD-Net: A Lightweight and High-Performance Ship Detection Network for Optical Remote Sensing Images. Remote Sensing. 2023; 15(17):4358. https://doi.org/10.3390/rs15174358
Chicago/Turabian StyleTian, Yang, Xuan Wang, Shengjie Zhu, Fang Xu, and Jinghong Liu. 2023. "LMSD-Net: A Lightweight and High-Performance Ship Detection Network for Optical Remote Sensing Images" Remote Sensing 15, no. 17: 4358. https://doi.org/10.3390/rs15174358
APA StyleTian, Y., Wang, X., Zhu, S., Xu, F., & Liu, J. (2023). LMSD-Net: A Lightweight and High-Performance Ship Detection Network for Optical Remote Sensing Images. Remote Sensing, 15(17), 4358. https://doi.org/10.3390/rs15174358