



Ship Detection via Multi-Scale Deformation Modeling and Fine Region Highlight-Based Loss Function


Abstract
:1. Introduction
- A ship detection framework combining multi-scale saliency extraction with semantic consistency and loss function for fine region highlight is proposed, which can achieve a high-accuracy detection performance for typical ship targets in complex port and sea scenes.
- A deformable multi-scale convolutional saliency extraction network is proposed, which can jointly model the multi-scale and deformation characteristics of the target. The network combines multiple receptive fields to improve the ability to distinguish the difference between the target and the background and employs deformable convolution to extract the complete features of the target, thus enhancing the ability to characterize the target.
- A specialized loss function for fine and overall target region highlight is proposed, which comprehensively considers the brightness, contrast, and structure characteristics of the ship target, thus improving the classification performance in complex scenes such as port facilities, cloud and shadow interference.
2. Previous Related Research
2.1. Salient Object Extraction Model
2.2. Salient Region Highlighting Method
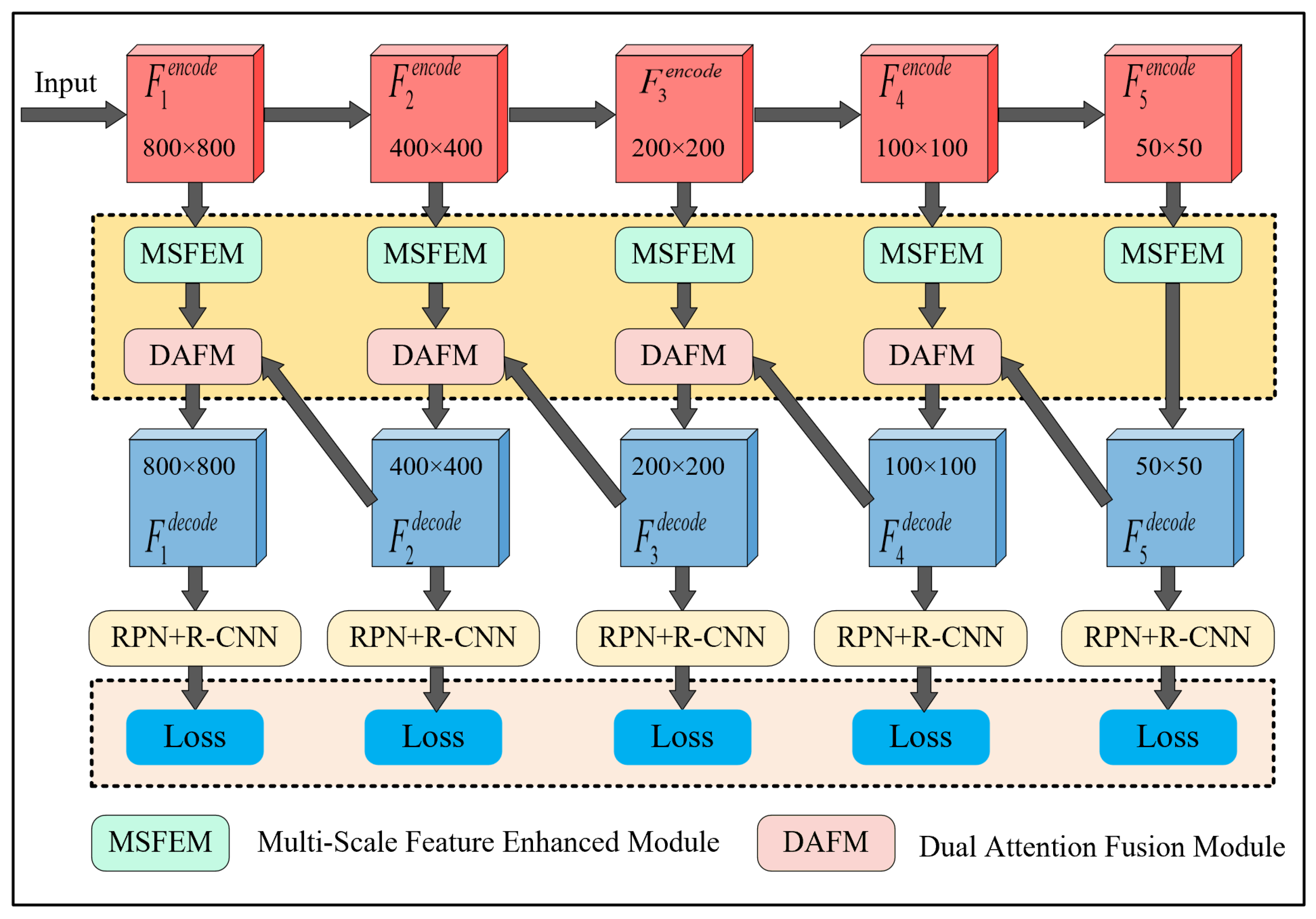
3. Proposed Method
3.1. Method Overview
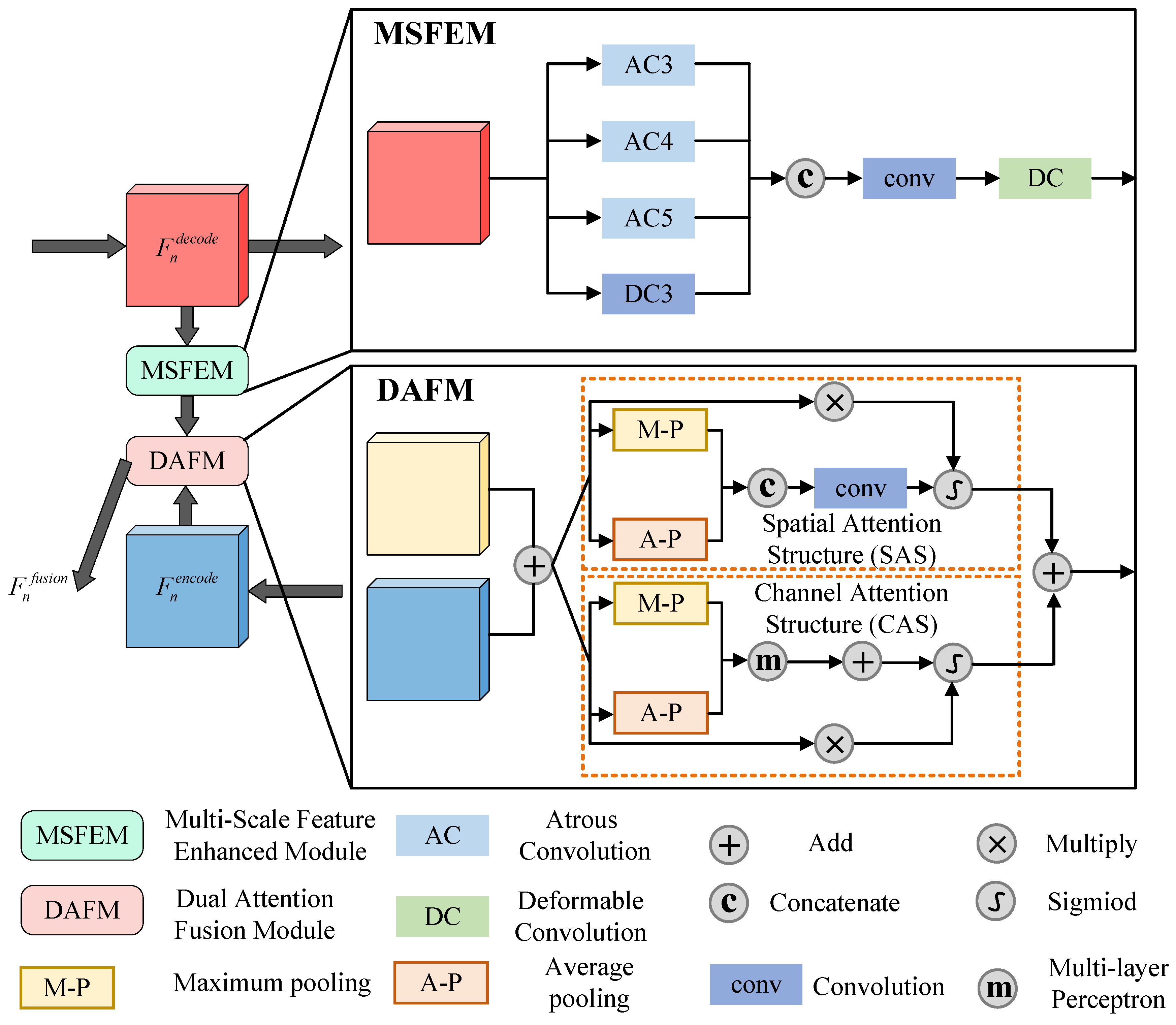
3.2. Multi-Scale Deformation Modeling Based Saliency Extraction
3.3. Loss Function for Fine Region Highlighting
4. Experimental Results
4.1. Experimental Settings
4.1.1. Datasets Description
4.1.2. Evaluation Metrics
4.2. Performance Analysis
4.2.1. Ablation Analysis
4.2.2. Implementation Details
4.2.3. Algorithm Performance Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, T.; Quan, S.; Yang, Z.; Guo, W.; Zhang, Z.; Gan, H. A two-stage method for ship detection using PolSAR image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Kanjir, U.; Greidanus, H.; Oštir, K. Vessel detection and classification from spaceborne optical images: A literature survey. Remote Sens. Environ. 2018, 207, 1–26. [Google Scholar] [CrossRef]
- Hu, J.; Zhi, X.; Zhang, W.; Ren, L.; Bruzzone, L. Salient Ship Detection via Background Prior and Foreground Constraint in Remote Sensing Images. Remote Sens. 2020, 12, 3370. [Google Scholar] [CrossRef]
- Nie, T.; Han, X.; He, B.; Li, X.; Liu, H.; Bi, G. Ship detection in panchromatic optical remote sensing images based on visual saliency and multi-dimensional feature description. Remote Sens. 2020, 12, 152. [Google Scholar] [CrossRef]
- Li, L.; Zhou, F.; Zheng, Y.; Bai, X. Saliency detection based on foreground appearance and background-prior. Neurocomputing 2018, 301, 46–61. [Google Scholar] [CrossRef]
- Song, S.; Jia, Z.; Yang, J.; Kasabov, N. Salient detection via the fusion of background-based and multiscale frequency-domain features. Inf. Sci. 2022, 618, 53–71. [Google Scholar] [CrossRef]
- Lv, P.; Yu, X.; Chi, J.; Wu, C. Saliency detection via absorbing Markov chain with multi-level cues. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2022, 105, 1010–1014. [Google Scholar] [CrossRef]
- Ma, F.; Sun, X.; Zhang, F.; Zhou, Y.; Li, H.C. What catch your attention in SAR images: Saliency detection based on Soft-Superpixel lacunarity cue. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–17. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, H.; Zhang, Z.; Liu, M. CNN-based encoder-decoder networks for salient object detection: A comprehensive review and recent advances. Inf. Sci. 2021, 546, 835–857. [Google Scholar] [CrossRef]
- Hu, J.; Zhi, X.; Shi, T.; Zhang, W.; Cui, Y.; Zhao, S. PAG-YOLO: A Portable Attention-Guided YOLO Network for Small Ship Detection. Remote Sens. 2021, 13, 3059. [Google Scholar] [CrossRef]
- Jiang, W.; Liu, M.; Peng, Y.; Wu, L.; Wang, Y. HDCB-Net: A Neural Network with the Hybrid Dilated Convolution for Pixel-Level Crack Detection on Concrete Bridges. IEEE Trans. Ind. Inform. 2020, 17, 5485–5494. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency optimization from robust background detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Liu, T.; Yuan, Z.; Sun, J.; Wang, J.; Zheng, N.; Tang, X.; Shum, H.Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 353–367. [Google Scholar]
- Wang, W.; Shen, J.; Shao, L. Video salient object detection via fully convolutional networks. IEEE Trans. Image Process. 2017, 27, 38–49. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Hu, J.; Zhi, X.; Jiang, S.; Tang, H.; Zhang, W.; Bruzzone, L. Supervised Multi-Scale Attention-Guided Ship Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Song, S.; Miao, Z.; Yu, H.; Fang, J.; Zheng, K.; Ma, C.; Wang, S. Deep domain adaptation based multi-spectral salient object detection. IEEE Trans. Multimed. 2020, 24, 128–140. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Ji, W.; Li, J.; Yu, S.; Zhang, M.; Piao, Y.; Yao, S.; Bi, Q.; Ma, K.; Zheng, Y.; Lu, H.; et al. Calibrated RGB-D salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 9471–9481. [Google Scholar]
- Wang, Y.; Zhao, X.; Hu, X.; Li, Y.; Huang, K. Focal boundary guided salient object detection. IEEE Trans. Image Process. 2019, 28, 2813–2824. [Google Scholar] [CrossRef] [PubMed]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The lovász-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4413–4421. [Google Scholar]
- Liu, N.; Han, J. Dhsnet: Deep hierarchical saliency network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 678–686. [Google Scholar]
- Wang, T.; Borji, A.; Zhang, L.; Zhang, P.; Lu, H. A stagewise refinement model for detecting salient objects in images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4019–4028. [Google Scholar]
- Islam, M.A.; Kalash, M.; Rochan, M.; Bruce, N.D.; Wang, Y. Salient Object Detection using a Context-Aware Refinement Network. In Proceedings of the BMVC, London, UK, 4–7 September 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017; Volume 2, pp. 324–331. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.; Borji, A. Salient object detection with pyramid attention and salient edges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1448–1457. [Google Scholar]
- Zhou, X.; Shen, K.; Weng, L.; Cong, R.; Zheng, B.; Zhang, J.; Yan, C. Edge-guided recurrent positioning network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2022, 53, 539–552. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R 2 cnn: Rotational region cnn for arbitrarily-oriented scene text detection. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3610–3615. [Google Scholar]
- Nabati, R.; Qi, H. Rrpn: Radar region proposal network for object detection in autonomous vehicles. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3093–3097. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yang, W.; Li, H.C.; Zhang, H.; Xia, G.S. Learning center probability map for detecting objects in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4307–4323. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y. Rotation-invariant task-aware spatial disentanglement in rotated ship detection based on the three-stage method. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Ren, Z.; Tang, Y.; He, Z.; Tian, L.; Yang, Y.; Zhang, W. Ship detection in high-resolution optical remote sensing images aided by saliency information. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Chen, W.; Han, B.; Yang, Z.; Gao, X. MSSDet: Multi-Scale Ship-Detection Framework in Optical Remote-Sensing Images and New Benchmark. Remote Sens. 2022, 14, 5460. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Loss Function | AP(%)@IOU0.5 (%) | AP(%)@IOU0.75 (%) |
|---|---|---|---|
| Faster R-CNN | The original function | 84.2 | 81.6 |
| Faster R-CNN + MDMFE | The original function | 88.7 (+4.5) | 85.4 (+3.8) |
| Faster R-CNN | The proposed loss function | 86.3 (+2.1) | 83.4 (+1.8) |
| Faster R-CNN + MDMFE | The proposed loss function | 91.2 (+7.0) | 87.9 (+6.3) |
| Methods | Backbone | AC(%) | FAR(%) |
|---|---|---|---|
| R2CNN | ResNet-101 | 68.35 | 13.73 |
| RRPN | ResNet-101 | 79.63 | 14.28 |
| Faster R-CNN | ResNet101 | 84.20 | 13.45 |
| YOLOv4 | CSPDarknet53 | 85.12 | 10.38 |
| YOLOv7 | ELAN-Net | 87.68 | 7.48 |
| Gliding Vertex | ResNet-101 | 88.22 | 8.53 |
| CenterMap-Net | ResNet-101 | 92.84 | 5.84 |
| RITSD | ResNet-101 | 92.92 | 6.36 |
| MSSDet | ResNet-101 | 93.05 | 9.43 |
| FES-SPB | ResNet-101 | 93.20 | 7.85 |
| R3Det | ResNet-101 | 94.61 | 5.50 |
| Proposed | ResNet101 | 94.89 | 5.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Hu, J.; Wang, D.; Li, H.; Wang, Z. Ship Detection via Multi-Scale Deformation Modeling and Fine Region Highlight-Based Loss Function. Remote Sens. 2023, 15, 4337. https://doi.org/10.3390/rs15174337
Li C, Hu J, Wang D, Li H, Wang Z. Ship Detection via Multi-Scale Deformation Modeling and Fine Region Highlight-Based Loss Function. Remote Sensing. 2023; 15(17):4337. https://doi.org/10.3390/rs15174337
Chicago/Turabian StyleLi, Chao, Jianming Hu, Dawei Wang, Hanfu Li, and Zhile Wang. 2023. "Ship Detection via Multi-Scale Deformation Modeling and Fine Region Highlight-Based Loss Function" Remote Sensing 15, no. 17: 4337. https://doi.org/10.3390/rs15174337
APA StyleLi, C., Hu, J., Wang, D., Li, H., & Wang, Z. (2023). Ship Detection via Multi-Scale Deformation Modeling and Fine Region Highlight-Based Loss Function. Remote Sensing, 15(17), 4337. https://doi.org/10.3390/rs15174337