1. Introduction
Image quality is affected by numerous factors, both in everyday life and in space remote sensing imaging. These factors encompass the light intensity of the imaging device as well as the imaging environment itself. For this purpose, low illumination enhancement techniques have been widely used to improve the quality of captured images. Recently, several types of methods have been proposed by scholars to deal with dark images, including histogram equalization, Retinex decomposition, and deep learning, among others. Histogram equalization uses a histogram to count the gray level distribution of the image, show the gray level of each pixel in the image in the form of occurrence frequency or number, and evenly distribute the gray level of the image with dense distribution, so as to improve the image contrast and information. Kim et al. [
1] proposed adaptive histogram equalization (AHE), an algorithm with higher complexity. In addition, Reza et al. [
2] presented an algorithm using contrast-limited adaptive histogram equalization (CLAHE), which solves the problem of noise and excessive contrast enhancement by limiting the height of each sub-block histogram. Kang et al. [
3] proposed the adaptive height modified histogram equalization algorithm (AHMHE), which aims to establish the mapping function of the adaptive height correction histogram and enhance the local contrast by combining the relationship between adjacent pixels. Chang et al. [
4] introduced a technique known as automatic contrast finite adaptive histogram equalization with double gamma correction, which reassigns the histogram of CLAHE [
2] blocks according to the dynamic range of each block, and performs double gamma correction to enhance brightness. This approach is more suitable for image enhancement in dark regions and can reduce artifacts due to over-enhancement. Pankaj Kandhway et al. [
5] introduced a novel sub-histogram equalization method based on adaptive thresholds, which can enhance contrast and brightness while preserving basic image features.
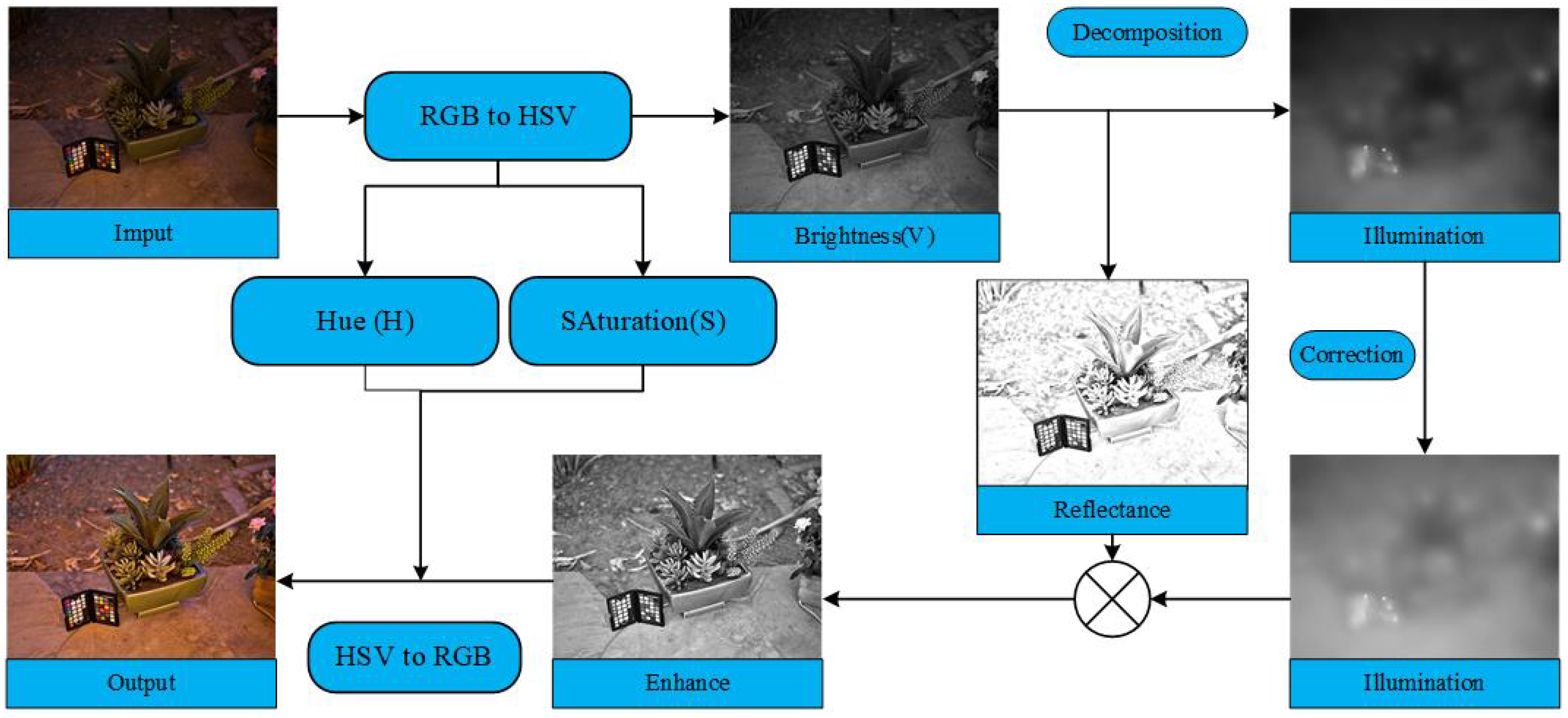
In Retinex theory, the image is obtained via the combined action of the illuminance component and the object reflectance component (
, which references the observed image
S, illuminance component
L, and reflectance component
R, where ∘ represents element multiplication). The image enhancement algorithm rooted in the Retinex theory involves decomposing the image into two distinct components, the object reflection component and the illumination component. then applying a gamma function to the illumination component, and, finally, combining the two layers to obtain the enhancement result. Jobson et al. [
6] proposed the center/surround model using a Gaussian low-pass filter and a logarithmic method. The model included a single-scale Retinex model (SSR) and a multi-scale color restoration Retinex model (MSRCR). The Retinex theory addresses the problem of image separation into object reflectance and illumination components. However, this problem is usually undetermined. Therefore, the variational model was proposed by Kimmel et al. [
7]. There is a spatial correlation between the object reflectance and the illuminance component, which can have an effect on the object reflectance during image decomposition. Fu et al. believed that both of them should be estimated at the same time [
8]. Based on this, Fu et al. [
9] introduced the weighted variational model.
For images with uneven lighting, Wang et al. [
10] presented the natural retention enhancement algorithm. Based on the traditional Retinex theory, Guo et al. [
11] proposed an image enhancement method by estimating an illuminance map. In this method, the goal is to identify the highest value in the RGB channel and create an illumination map by extracting the maximum grayscale value from the color image across the three channels. By rectifying the initial illumination map using this technique, an improved image can be achieved. Dong et al. [
12] proposed a low-illumination enhancement algorithm based on dark channel de-fogging. This method enhanced the image by using de-fogging processing method by taking advantage of the grayscale intensity of a low illumination image after inversion and the approximate gray value of image with fog. Hao et al. [
13] proposed an improved model based on the semi-decoupling decomposition (SDD) method. In this model, the decomposition is completed by using the pseudo-decoupling mode. The illuminance component is calculated based on the Gaussian variation of the image, while the reflectivity is calculated jointly from the input image and the illuminance component. Cai et al. [
14] proposed the Joint Internal and External Prior (JieP) model based on Retinex. However, the model tends to over-smooth the illumination and reflectivity components of the scene. Li et al. [
15] proposed a Retinex enhancement method based on robust structure. The objective of the Retinex theory of robust structure is to enhance the effectiveness of algorithms for improving low-illumination images by considering noisy maps.
Ren et al. [
16] proposed the joint enhancement and denoising model based on sequence decomposition (JED). The Retinex model is used to sequentially decompose the images to obtain uniform illumination components and noiseless reflectance components. Xu et al. [
17] presented a model of structure and texture perceptual reconstruction (STAR) for enhancing low illumination images. The approach of STAR incorporates an exponential filter that is specifically designed to extract accurate structure and texture from the image, utilizing specific parameters. The plug-and-play Retinex low-light enhancement model, proposed by Lin in 2022 [
18], takes a non-convex
constraint and applies a contractive mapping to the illumination layer.
The development of deep learning techniques has spawned a wide range of techniques specifically designed to enhance low-illumination images. The LLNet [
19] method uses a dark image with added noise and enhanced image pairs as training. Method [
20] is an unsupervised Gan network method. The network of this method is trained in the absence of image pairs. Global–local processing refers to the approach used to handle various illumination conditions present in the input image. Both Retinex network [
21] and DeepUPE [
22] embrace the principles of the Retinex theory and utilize them as the foundation for their network architectures. Nevertheless, the deep learning approaches necessitate an extensive volume of training data, and the illumination layer can generate artifacts when confronted with test images exhibiting distinct characteristics compared to the training data.
This manuscript introduces an innovative optimization model for Retinex. In this model, from the perspective of texture and structure, the local gradient relative deviation is used as a constraint term in the horizontal and vertical directions, to, respectively, highlight texture and structure. In addition, we incorporate a noise component into the model to enhance its robustness. The features of ambient illumination and object reflectivity are considered in this paper. Ideally, the illumination should be overall smooth, with more detail in the object’s reflectivity. When compared to the widely employed and norms, the norm exhibits superior sparsity characteristics, particularly for piecewise smoothing. Therefore, norm is adopted in this paper to constrain the local gradient deviation of the object reflectance and the local gradient deviation of the illuminance component, respectively, to better retain the reflectance information while smoothing the illuminance component. Innovations in the research content of this paper come from the literature we have read. According to the analytical quantitative evaluation, the performance of the proposed method surpasses that of the aforementioned methods. The proposed technique has shown promising results in remote sensing. The following list outlines the various innovations presented in this paper:
- 1.
In this paper, from the perspective of texture and structure, we highlight texture and structure by using local gradient relative deviations in horizontal and vertical directions, respectively, as constraint terms. Furthermore, to enhance the robustness of the model, we introduce a noise term into the equation;
- 2.
This paper takes into account the attributes of the illumination component as well as the reflectance properties of the object, and uses the norm for constraint to smooth the illumination component while better preserving the details of the reflectance component.
- 3.
The experimental results demonstrate that the proposed method exhibits excellent stability and convergence, making it particularly beneficial for remote sensing images.
The remaining sections of the paper are outlined below.
Section 2 of the paper is devoted to the exposition of Retinex theory and its closely related analysis.
Section 3 presents a comprehensive exposition of the methodological principles employed in this paper.
Section 4 describes the methodology and experimental results of the subjective and objective analyses.
Section 5 is dedicated to the presentation of the conclusions of the paper, summarizing the main findings and outcomes of the study.
4. Experimental Results
In this section, the performance of the proposed method is evaluated. First, we present the experimental empirical parameters of the ensemble. Second, we compare the performance of the proposed method with state-of-the-art low-illumination image enhancement techniques and analyze the results obtained from the comparison. To fully evaluate the methods presented in this paper, all experiments were performed on MATLAB R2019a and the program was run on a Windows 7 server with 8 GB of memory and a 3.5 GHz CPU. Meanwhile, to fully evaluate the proposed method, this paper takes images of different scenarios for testing. Image data include LOL dataset [
21], AID dataset [
25], VV dataset [
26], SCIE dataset [
27], and TGRS-HRRSD dataset [
28].
In this trial, after both qualitative and quantitative analyses, the values of the experimental encounter factors have been established as follows: at 0.001, at 0.0001, at 2.2, at 1.5, at 0.05, at 0.001, at 0.0001. When the magnitude of becomes excessively high, the separated component L lacks information or experiences partial loss of contour details. Conversely, when takes on excessively low values, component L exhibits inadequate smoothness. At considerably elevated values of , the resolved component R appears to be over-smoothed, causing the finer details of R to become blurred. In turn, when an excessively small value of is assumed, the decomposition results are similar to the case where is set to 0.0001.
When assumes excessively small values, the smoothness of the separated component L diminishes; conversely, when becomes overly large, contour information within the decomposed L component becomes absent. A significantly elevated value of results in an excessively smooth decomposed component R, leading to the loss of detailed information. When takes on excessively small values, the effect of decomposed component R remains similar to that when is set to 0.05. The solution for N is linked to the values of R, L, and . Larger values introduce noticeable noise into the decomposed R. Conversely, smaller values yield R outcomes with reduced noise, although some noise remains due to the relatively greater influence of R and L within the N solution.
The presence of in the denominator serves to prevent division by zero. Consequently, minimizing is preferable. Excessively large values impact the denominator and directly alter the decomposition results. Conversely, when becomes exceedingly small, the outcome is akin to using values of 0.0001, and the solution process converges.
In this article, the proposed method was compared with the Joint Internal and External Prior (JieP) model based on Retinex [
14], the Retinex enhancement method (SEM) based on robustness [
15], the improved model based on semi-decoupling-decomposition (SDD) [
13], the joint enhancement and denoising model based on sequence decomposition (JED) [
16], and the low-light enhancement plug-and-play Retinex Model (LUPP) [
18], and other methods.
4.1. Decomposition Evaluation
In
Figure 2, the reflectance of objects resolved by Method 5 [
18] is generally dark and many details are lost. According to the decomposition results of Method 1 [
16] and Method 2 [
15], a part of the reflectance information of the object is lost and the color is significantly excessive. In contrast to methods 3 [
14] and 4 [
13], the proposed method can ensure maximum color information while highlighting reflectivity details. By comprehensive comparison, the method in this paper has advantages.
In
Figure 3, the illumination component decomposed by the proposed method is significantly smoother, while the illumination components decomposed by Methods 1 [
16], 2 [
15], and 3 [
14] are weaker than the other Methods. The intensity of the illuminant component of the decomposition by Method 5 [
18] is low, and the error of the illuminant component is large. Compared to Method 4 [
13], the proposed method has better smoothness. By comprehensive comparison, the method in this paper shows clear advantages.
4.2. Objective Evaluation
To conduct an objective evaluation of the quality of the enhanced results, this paper employed five widely recognized image quality assessment (IQA) metrics.
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 present the average values of the IQA metrics for the four datasets(The bold data in tables represents the best value for its corresponding metric in that data set). The five IQAs include unreferenced/blind assessment methods and fully referenced assessment methods.
In the natural image quality evaluator (NIQE) [
29] approach, some image patches are selected as training data based on local features, and the model parameters are obtained by fitting a generalized Gaussian model to the features, which are described by a multivariate Gaussian model. During the evaluation process, the distance between the parameters of the image feature model to be evaluated and the parameters of the pre-established model are used to determine the image quality. AutoRegressive-based image sharpness metric (ARISM) [
30] works by separately measuring the energy and contrast differences of the AR model coefficients at each pixel and then computing the image sharpness with percentile pooling to infer the overall quality score. Colorfulness-based PCQI (CPCQI) [
31] evaluates the perceptual distortion between the enhanced image and the input image via three aspects: mean intensity, signal strength, and signal structure. Visual information fidelity (VIF) [
32] combines the natural image statistical model, image distortion model, and human visual system model to calculate the mutual information between the image to be evaluated and the reference image, to measure the quality of the image to be evaluated. Lightness order error (LOE) [
10] evaluates the image quality by separately extracting the brightness of the original image and the enhanced image, and then calculating the relative magnitude difference in brightness from each pixel. The higher the values of CPCQI and VIF, the better the image quality. Lower values of NIQE, LOE, and ARISM indicate better image quality.
In the data in
Table 1, the proposed method demonstrates superior performance compared to other algorithms in terms of CPCQI, NIQE, and VIF. On the other hand, both ARISM and LOE exhibit better results than Method 5 [
18]. In the data in
Table 2, the proposed algorithm’s NIQE and ARISM outperform the other methods, while CPCQI and VIF are only second to Methods 3 [
14] and 5 [
18], respectively, and the LOE method is also second to Method 3 [
14]. In the data in
Table 3, the CPCQI, VIF, and ARISM metrics of the introduced algorithm are slightly better than the other methods; In terms of NIQE, the algorithm is better than Methods 1 [
16], 2 [
15], and 4 [
13], close to Method 3 [
14], and slightly weaker than Method 5 [
18]. It is second only to Method 3 [
14] in terms of LOE. In the data in
Table 4, NIQE, LOE and ARISM demonstrate superior performance compared to the remaining methods, whereas CPCQI exhibits slightly lower performance than Method 5 [
18]. In
Table 5, the proposed method outperforms the other algorithms in NIQE, VIF, and ARISM, with LOE second only to Method 5 [
18], and CPCQI slightly weaker than Method 5 [
18]. After comparison on four datasets, the proposed method outperforms the others.
4.3. Subjective Evaluation
In the improved outcomes presented in
Figure 4, the central lines of the illustrations and the books, as enhanced through techniques 1 [
16] and 2 [
15], exhibit excessive brightness (contained within the left-hand rectangular enclosure). Nonetheless, these enhancements lack a sense of naturalness and display an overly pronounced smoothness, leading to a loss of sharp details in both the lines and the intricate features of the doll’s nose (as depicted within the right-hand rectangular enclosure). The overall tone of the resulting image from the application of Method 3 [
14] appears significantly darker, whereas the enhancement achieved by the method introduced in this paper renders the cartoon doll significantly superior in terms of overall textural quality, surpassing the results of Method 3 [
14], Method 4 [
13], and Method 5 [
18]. It is important to note that, in contrast to method 5 [
18], the technique presented in this study exhibits a discernible noise reduction effect while still preserving intricate textural details (as is evident within the restricted region of the small red rectangle on the right).
Within the enhancement outcomes depicted in
Figure 5, the evident smoothing effects from Methods 1 [
16], 2 [
15], and 4 [
13] lead to a conspicuous blurring of intricate flower textures and chair details, observable within the two highlighted red rectangular sections within the illustration. In addition, the enhancement results of Method 2 [
15] show a slight color distortion. In contrast, the augmentation of Method 3 [
14] exhibits a relatively darker appearance among the various techniques. Contrasting with the approach introduced in this paper, the enhancement results of Method 5 [
18] distinctly reveal noticeable noise within the chair segment (as indicated by the red rectangular region on the right). It is worth noting that the method presented in this study demonstrates a discernible noise reduction capability while preserving intricate details.
Displayed in
Figure 6, the enhanced outcomes arising from Method 1 [
16] and Method 2 [
15], although yielding a heightened overall luminosity in comparison to alternative techniques, suffer from an excess of smoothing that detrimentally affects the intricate details within the scenery, leading to a loss of clarity as demonstrated within the enclosed red rectangular region on the right. The combined visual impact of Methods 4 [
13] and 5 [
18] closely approximates that of the algorithm introduced herein, yet the latter significantly outperforms the former two in low-light scenarios, as evidenced by the red rectangle on the left. In turn, the enhancement results stemming from Method 3 [
14] are biased towards general darkness and exhibit weaker refinement compared to the other algorithms. Through a comprehensive evaluation, it becomes clear that the proposed method exhibits superior performance when measured against alternatives.
As illustrated in
Figure 7, the treatment of the shopping mall staircases and signage using Methods 1 [
16] and 2 [
15] yields an overly conspicuous smoothness, resulting in obscured stairway details and blurred representations of store signboards—both instances can be observed within the enclosed red rectangular compartment in figure. Simultaneously, the interiors of the stores in the enhancement outcomes of Methods 1 [
16] and 2 [
15] suffer from pronounced blurring, resulting in reduced sharpness when compared to the alternative techniques. In addition, the overall contrast of store details within Methods 1 [
16] and 2 [
15] falls short when compared to other approaches. The enhanced outcome of Method 3 [
14] tends to exhibit an overall darker appearance. In the case of Method 4 [
13], detail retention slightly lags behind that of Algorithm 5 [
18] and the approximations delineated in this paper, which is particularly evident within the upper left stairway region enclosed by the red rectangle. Moreover, in terms of intricate color processing, the method presented in this paper triumphs over Methods 4 [
13] and 5 [
18]. This triumph is particularly evident in the color preservation of detailed elements, such as the signboard depicted within the figure. In the enhancement results of the other methods, the right segment of the signboard experiences color distortion, while the method introduced in this paper remarkably preserves the original image color.
In the results shown in
Figure 8, the overall enhancement in image brightness achieved by employing Methods 1 [
16] and 2 [
15] surpasses the performance of alternative approaches. Nonetheless, these methods fall short in terms of visual dynamic range when compared to other algorithms. Additionally, an excess of smoothing is evident in the images, leading to a lack of emphasis on intricate details within the components like trees, squares, and houses (marked by three red rectangular boxes). Method 3 [
14], although it manages to maintain these fine details, results in an overall darker image. In contrast, when measured against Methods 4 [
13] and 5 [
18], the proposed method in this study strikes a balance by maintaining a certain level of smoothness while preserving crucial details. It is notable that the detail preservation achieved by Method 4 [
13] is not as potent as that of Method 5 [
18] or the technique introduced in this paper (highlighted in the upper left red rectangular box). Comparatively, Method 5 [
18] displays evident noise in specific portions of the image (as seen in the middle red rectangular frame containing trees). Therefore, the method proposed in this paper demonstrates an ability to mitigate noise to a considerable extent. Moreover, when stacked against alternative algorithms, the proposed method exhibits superior detail retention while effectively suppressing noise. As a result, the proposed algorithm boasts an overall advantage in this context.
In
Figure 9,
Figure 10 and
Figure 11, the enhancement of image dynamic range achieved through Methods 1 [
16] and 2 [
15] falls behind that of alternative algorithms. Moreover, an excessive application of image smoothing leads to the unfortunate consequence of losing intricate details within the images. When juxtaposed against Methods 3 [
14], 4 [
13], and 5 [
18], the method proposed in this study adeptly maintains a certain degree of smoothness while safeguarding essential details. Comparatively, Method 3 [
14] results in darker enhanced images when contrasted with Methods 4 [
13], 5 [
18], and the techniques introduced within this paper. Method 5 [
18], however, reveals conspicuous noise in specific regions of the images (highlighted by red rectangular boxes in the upper left of
Figure 9, upper right of
Figure 10, and other sections in
Figure 11). In light of this, the approach outlined in this paper demonstrates a noteworthy capability in mitigating noise to a certain extent.
4.4. Real Remote Sensing Image Data
To assess the effectiveness of the proposed algorithm in practical scenarios, real images taken in the laboratory are used for validation and the average IQA values are listed in
Table 6.
In
Table 6, NIQE, VIF, and CPCQI of the proposed method outperform the other methods, while LOE and ARISM are slightly weaker.
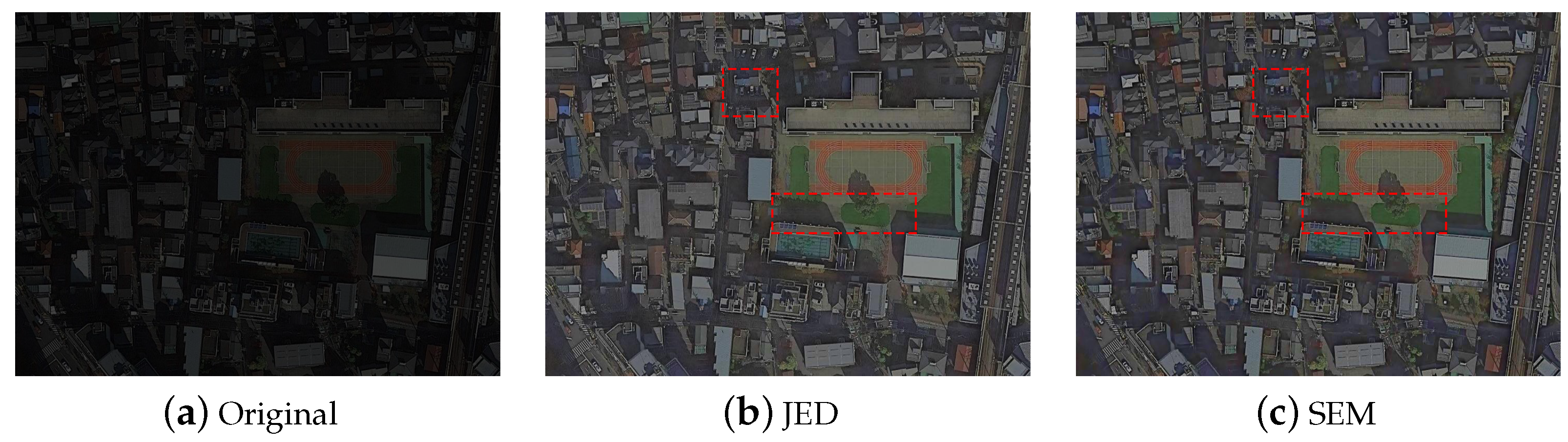
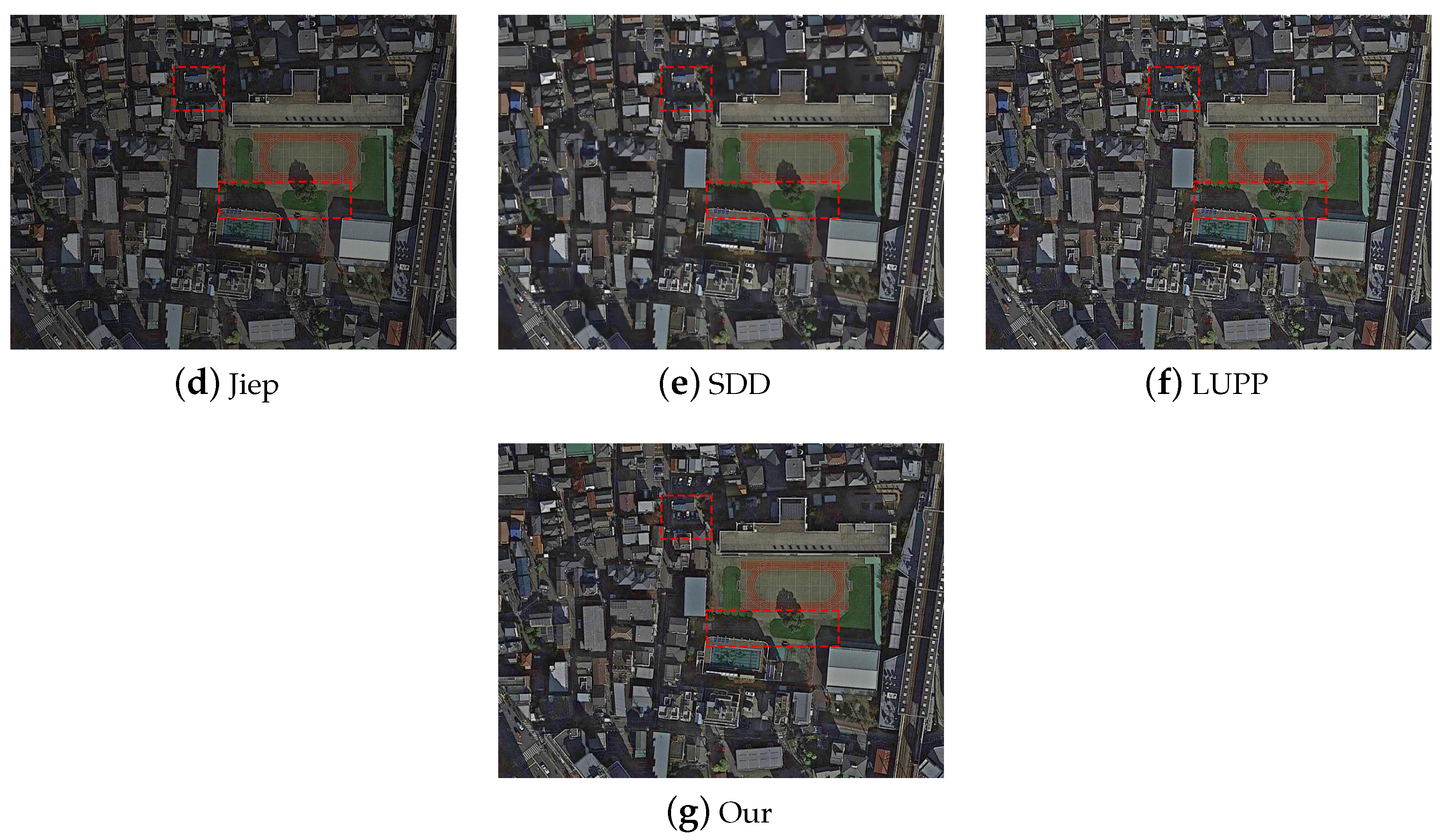
To assess the visual outcomes achieved by implementing the proposed algorithm in real-world applications, this article adopt real images taken in the laboratory for validation and present the enhancement results of the different methods in
Figure 12 and
Figure 13.
In the enhancement results of Methods 1 [
16] and 2 [
15] in
Figure 12 and
Figure 13, the visual impact of the images is low and the images are over-smoothed so that the image information is not effectively presented. In
Figure 12, the visual effect of Method 5 [
18] is close to that of the present paper, while the result of Method 4 [
13] is slightly weaker than that of the present paper in terms of detail (The red rectangle box is shown in
Figure 12). The overall brightness of Method 3 [
14] is slightly fainter than that of Method 4 [
13] and Method 5 [
18] in this paper. In
Figure 13, the results of Method 5 [
18] show artifacts in some dark regions(The red rectangle box is shown in
Figure 13), and the overall brightness of Method 3 [
14] is slightly fainter than that of Method 4 [
13] and Method 5 [
18] in this paper.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}