


Boundary-Guided Semantic Context Network for Water Body Extraction from Remote Sensing Images

 , , ,
, , ,
Abstract
:1. Introduction
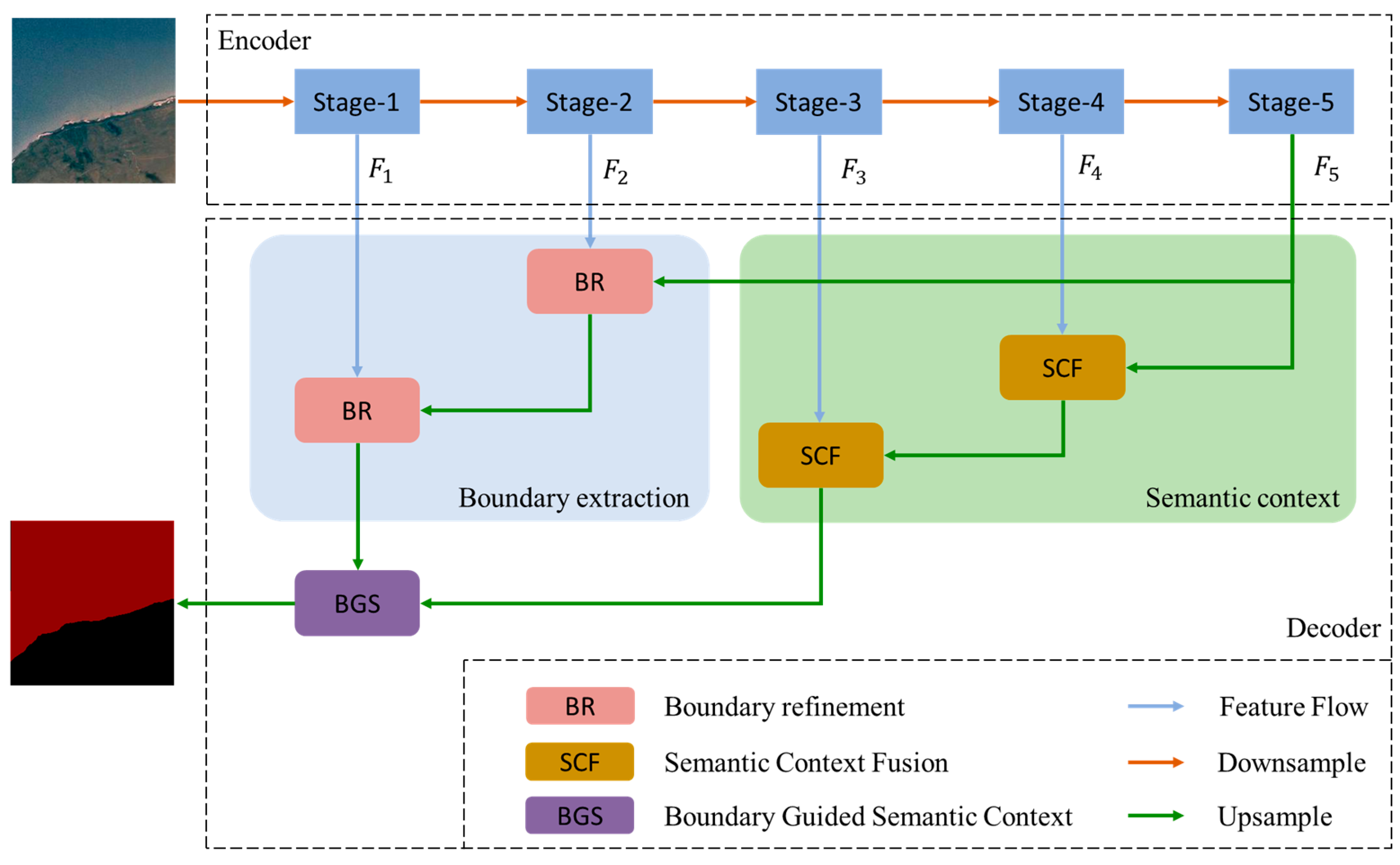
- Based on the encoder–decoder architecture, BGSNet is proposed for extracting water bodies from RSIs. BGSNet first captures boundary features and abstract semantics, and then leverages the boundary features as a guide for semantic context aggregation.
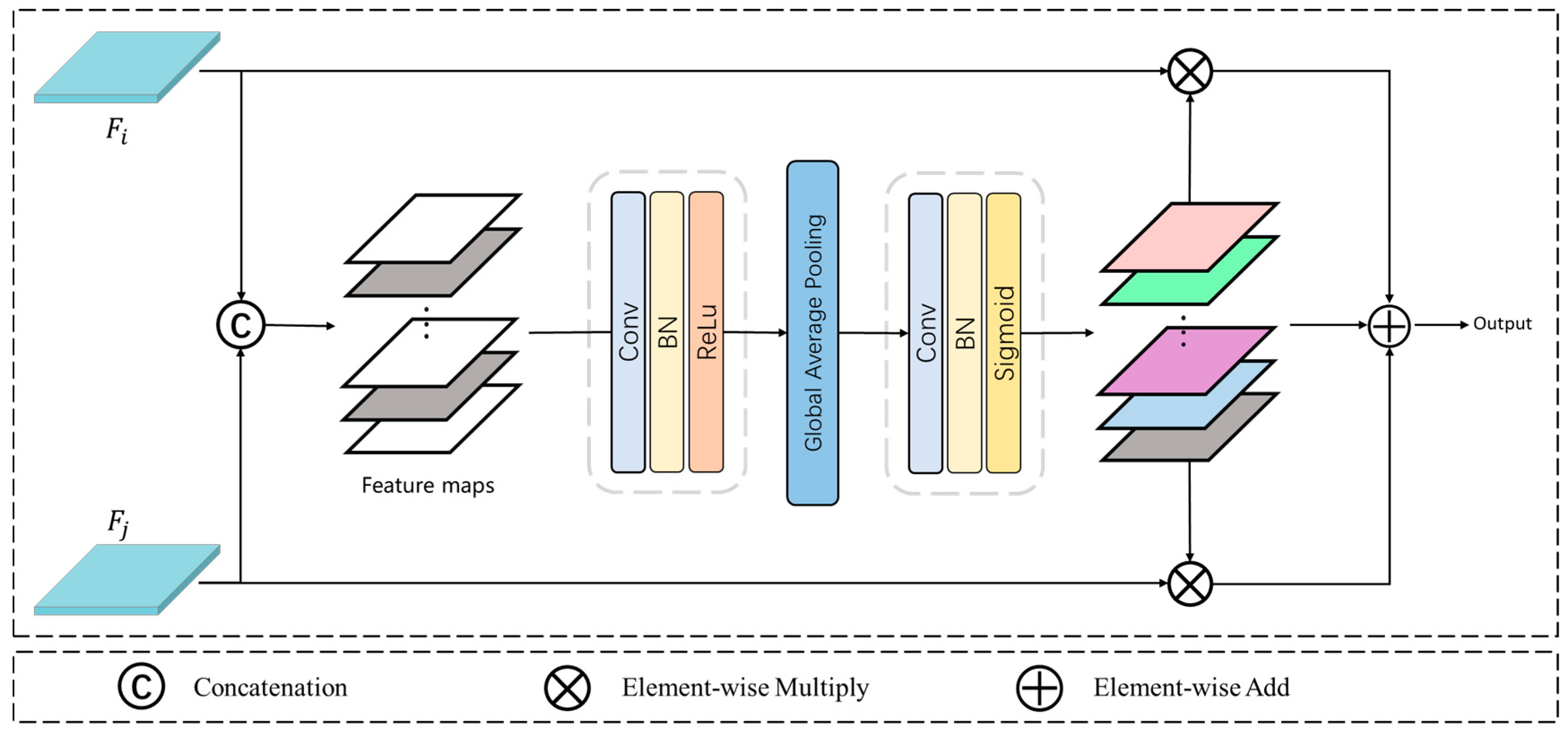
- To accurately locate water bodies, a boundary refinement (BR) module is proposed to preserve sufficient boundary distributions from shallow layer features. Additionally, a semantic context fusion (SCF) module is devised to capture semantic context for the generation of a coarse feature map.
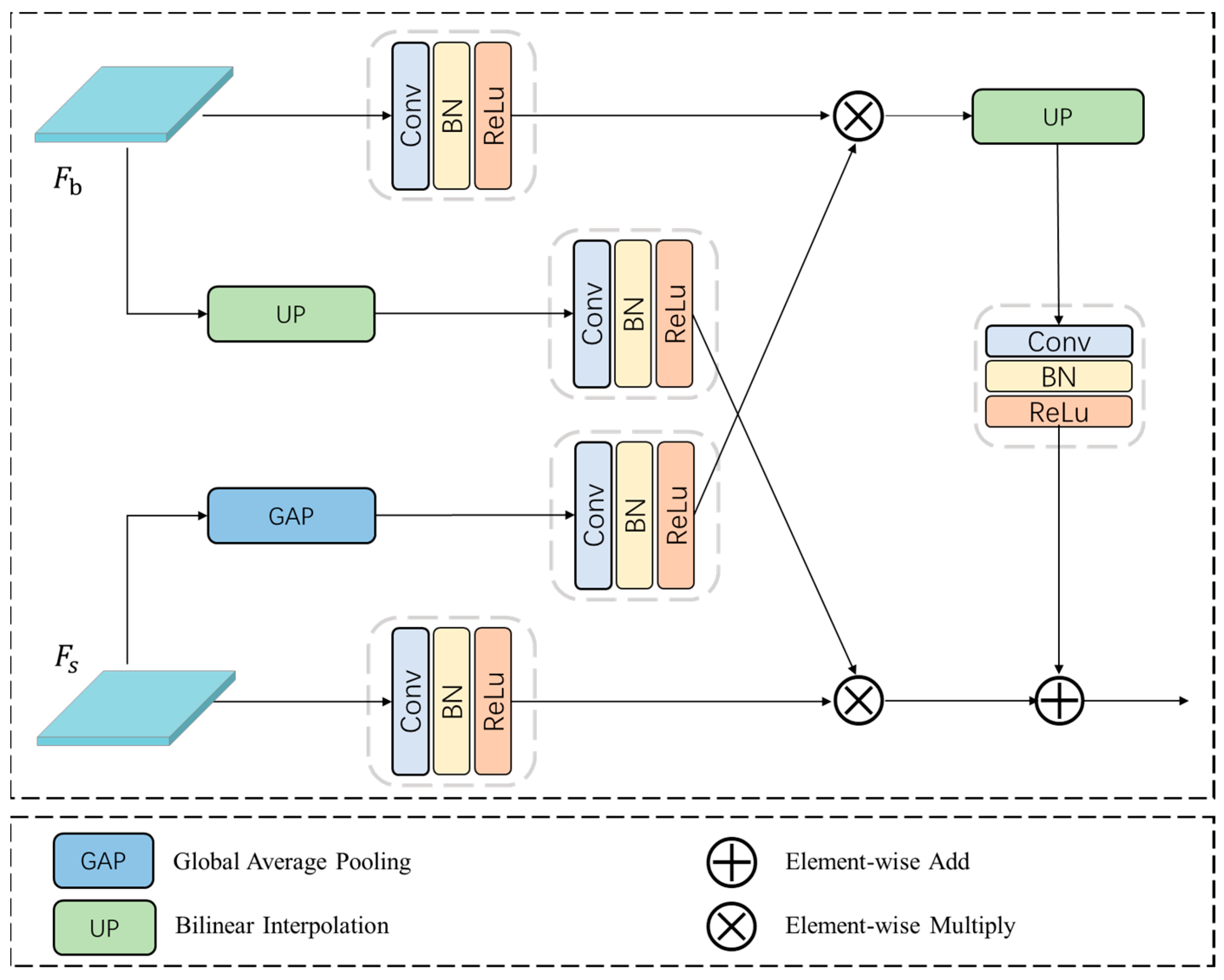
- To fully exploit the interdependence between the boundary and semantic context, a boundary-guided semantic context (BGS) module is designed. BGS aggregates context information along the boundaries to achieve the mutual enhancement of pixels belonging to the same class, thereby effectively improving intra-class consistency.
2. Related Work
2.1. Semantic Segmentation of RSIs
2.2. Water Body Detection of RSIs
3. Method
3.1. Architecture of BGSNet
3.2. Boundary Refinement Module
3.3. Semantic Context Fusion Module
3.4. Boundary-Guided Semantic Context Module
4. Experiment
4.1. Dataset
4.1.1. The QTPL Dataset
4.1.2. The LoveDA Dataset
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Comparative Analysis
4.4.1. Results on the QTPL Dataset
4.4.2. Results on the LoveDA dataset
4.5. Ablation Analysis
5. Conclusions
- (1)
- The BR module is designed to obtain prominent boundary information which is beneficial for localization.
- (2)
- The SCF module is embedded to capture semantic context for generating a coarse feature map.
- (3)
- The BGS module is devised to aggregate context information along the boundaries, facilitating the mutual enhancement of internal pixels belonging to the same class, thereby improving intra-class consistency.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oki, T.; Kanae, S. Global hydrological cycles and world water resources. Science 2006, 313, 1068–1072. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Zheng, L.; Jiang, L.; Liao, M. Forty-Year Water Body Changes in Poyang Lake and the Ecological Impacts Based on Landsat and HJ-1 A/B Observations. J. Hydrol. 2020, 589, 125161. [Google Scholar] [CrossRef]
- Xu, N.; Gong, P. Significant Coastline Changes in China during 1991–2015 Tracked by Landsat Data. Sci. Bull. 2018, 63, 883–886. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Fan, R.; Yang, X.; Wang, J.; Latif, A. Extraction of urban water bodies from high-resolution remote-sensing imagery using deep learning. Water 2018, 10, 585. [Google Scholar] [CrossRef]
- Xu, N.; Ma, Y.; Zhang, W.; Wang, X.H. Surface-Water-Level Changes During 2003–2019 in Australia Revealed by ICESat/ICESat-2 Altimetry and Landsat Imagery. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1129–1133. [Google Scholar] [CrossRef]
- Ovando, A.; Martinez, J.M.; Tomasella, J.; Rodriguez, D.A.; von Randow, C. Multi temporal flood mapping and satellite altimetry used to evaluate the flood dynamics of the Bolivian Amazon wetlands. Int. J. Appl. Earth Obs. Geoinf. 2018, 69, 27–40. [Google Scholar] [CrossRef]
- Ma, Y.; Xu, N.; Sun, J.; Wang, X.H.; Yang, F.; Li, S. Estimating Water Levels and Volumes of Lakes Dated Back to the 1980s Using Landsat Imagery and Photon-Counting Lidar Datasets. Remote Sens. Environ. 2019, 232, 111287. [Google Scholar] [CrossRef]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef]
- Ji, L.; Gong, P.; Wang, J.; Shi, J.; Zhu, Z. Construction of the 500-m Resolution Daily Global Surface Water Change Database (2001–2016). Water Resour. Res. 2018, 54, 10270–10292. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Xia, R.; Lyu, X.; Gao, H.; Tong, Y. Hybridizing Cross-Level Contextual and Attentive Representations for Remote Sensing Imagery Semantic Segmentation. Remote Sens. 2021, 13, 2986. [Google Scholar] [CrossRef]
- Hamm NA, S.; Atkinson, P.M.; Milton, E.J. A per-pixel, non-stationary mixed model for empirical line atmospheric correction in remote sensing. Remote Sens. Environ. 2012, 124, 666–678. [Google Scholar] [CrossRef]
- Li, Y.; Dang, B.; Zhang, Y.; Du, Z. Water body classification from high-resolution optical remote sensing imagery: Achievements and perspectives. ISPRS J. Photogramm. Remote Sens. 2022, 187, 306–327. [Google Scholar] [CrossRef]
- Xie, H.; Luo, X.; Xu, X.; Tong, X.; Jin, Y.; Pan, H.; Zhou, B. New hyperspectral difference water index for the extraction of urban water bodies by the use of airborne hyperspectral images. J. Appl. Remote Sens. 2014, 8, 085098. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Ji, L.; Zhang, L.; Wylie, B. Analysis of dynamic thresholds for the normalized difference water index. Photogramm. Eng. Remote Sens. 2009, 75, 1307–1317. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated Water Extraction Index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Guo, H.; He, G.; Jiang, W.; Yin, R.; Yan, L.; Leng, W. A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2020, 9, 189. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Li, X.; Xu, F.; Xia, R.; Li, T.; Chen, Z.; Wang, X.; Xu, Z.; Lyu, X. Encoding Contextual Information by Interlacing Transformer and Convolution for Remote Sensing Imagery Semantic Segmentation. Remote Sens. 2022, 14, 4065. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. Cfc-net: A critical feature capturing network for arbitrary-oriented object detection in remote sensing images. arXiv 2021, arXiv:2101.06849. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Miao, Z.; Fu, K.; Sun, H.; Sun, X.; Yan, M. Automatic water-body segmentation from high-resolution satellite images via deep networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 602–606. [Google Scholar] [CrossRef]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water Body Extraction from Very High-Resolution Remote Sensing Imagery Using Deep U-Net and a Superpixel-Based Conditional Random Field Model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 618–622. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Z.; Zeng, C.; Xia, G.-S.; Shen, H. An Urban Water Extraction Method Combining Deep Learning and Google Earth Engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 769–782. [Google Scholar] [CrossRef]
- Qin, P.; Cai, Y.; Wang, X. Small Waterbody Extraction with Improved U-Net Using Zhuhai-1 Hyperspectral Remote Sensing Images. IEEE Geosci. Remote Sensing Lett. 2022, 19, 5502705. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Xia, R.; Tong, Y.; Li, L.; Xu, Z.; Lyu, X. Hybridizing Euclidean and Hyperbolic Similarities for Attentively Refining Representations in Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sensing Lett. 2022, 19, 5003605. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Lyu, X.; Tong, Y.; Xu, Z.; Zhou, J. A Synergistical Attention Model for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sensing. 2023, 61, 5400916. [Google Scholar] [CrossRef]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive pyramid context network for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7519–7528. [Google Scholar]
- Ma, B.; Chang, C. Semantic Segmentation of High-Resolution Remote Sensing Images Using Multiscale Skip Connection Network. IEEE Sens. J. 2022, 22, 3745–3755. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Lyu, X.; Gao, H.; Tong, Y.; Cai, S.; Li, S.; Liu, D. Dual Attention Deep Fusion Semantic Segmentation Networks of Large-Scale Satellite Remote-Sensing Images. Int. J. Remote Sens. 2021, 42, 3583–3610. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607713. [Google Scholar] [CrossRef]
- Nong, Z.; Su, X.; Liu, Y.; Zhan, Z.; Yuan, Q. Boundary-Aware Dual-Stream Network for VHR Remote Sensing Images Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5260–5268. [Google Scholar] [CrossRef]
- Li, X.; Li, T.; Chen, Z.; Zhang, K.; Xia, R. Attentively Learning Edge Distributions for Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2022, 14, 102. [Google Scholar] [CrossRef]
- Bokhovkin, A.; Burnaev, E. Boundary loss for remote sensing imagery semantic segmentation. In International Symposium on Neural Networks; Springer: Cham, Switzerland, 2019; pp. 388–401. [Google Scholar]
- Yu, Y.; Huang, L.; Lu, W.; Guan, H.; Ma, L.; Jin, S.; Yu, C.; Zhang, Y.; Tang, P.; Liu, Z.; et al. WaterHRNet: A multibranch hierarchical attentive network for water body extraction with remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103103. [Google Scholar] [CrossRef]
- Kang, J.; Guan, H.; Peng, D.; Chen, Z. Multi-scale context extractor network for water-body extraction from high-resolution optical remotely sensed images. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102499. [Google Scholar] [CrossRef]
- Xia, M.; Cui, Y.; Zhang, Y.; Xu, Y.; Liu, J.; Xu, Y. DAU-Net: A novel water areas segmentation structure for remote sensing image. Int. J. Remote Sens. 2021, 42, 2594–2621. [Google Scholar] [CrossRef]
- Zhang, X.; Li, J.; Hua, Z. MRSE-Net: Multiscale Residuals and SE-Attention Network for Water Body Segmentation from Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5049–5064. [Google Scholar] [CrossRef]
- Yu, Y.; Yao, Y.; Guan, H.; Li, D.; Liu, Z.; Wang, L.; Yu, C.; Xiao, S.; Wang, W.; Chang, L. A self-attention capsule feature pyramid network for water body extraction from remote sensing imagery. Int. J. Remote Sens. 2021, 42, 1801–1822. [Google Scholar] [CrossRef]
- Krahenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. arXiv 2011, arXiv:1210.5644. [Google Scholar]
- Chu, Z.; Tian, T.; Feng, R.; Wang, L. Sea-Land Segmentation with Res-UNet and Fully Connected CRF. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3840–3843. [Google Scholar]
- Jin, Y.; Xu, W.; Zhang, C.; Luo, X.; Jia, H. Boundary-aware refined network for automatic building extraction in very high-resolution urban aerial images. Remote Sens. 2021, 13, 692. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, M.; Ji, S.; Yu, H.; Nie, C. Rich CNN Features for Water-Body Segmentation from Very High Resolution Aerial and Satellite Imagery. Remote Sens. 2021, 13, 1912. [Google Scholar] [CrossRef]
- Wang, B.; Chen, Z.; Wu, L.; Yang, X.; Zhou, Y. SADA-Net: A Shape Feature Optimization and Multiscale Context Information Based Water Body Extraction Method for High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1744–1759. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, X.; Zhang, Y.; Zhao, G. MSLWENet: A Novel Deep Learning Network for Lake Water Body Extraction of Google Remote Sensing Images. Remote Sens. 2020, 12, 4140. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. arXiv 2017, arXiv:1609.04747. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S. A Tutorial on the Cross-Entropy Method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 426–435. [Google Scholar] [CrossRef]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A Residual ASPP with Attention Framework for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Qin, X.; Fan, D.; Huang, C.; Diagne, C.; Zhang, Z. Boundary-Aware Segmentation Network for Mobile and Web Applications. arXiv 2021, arXiv:2101.04704. [Google Scholar]
- Li, X.; Li, X.; Li, Z.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving Semantic Segmentation via Decoupled Body and Edge Supervision. arXiv 2020, arXiv:2007.10035. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Settings |
|---|---|
| Max epoch | 200 |
| Batch Size | 8 |
| Optimizer | RMSProp |
| Momentum | 0.9 |
| Initial learning rate | 1 × 10−5 |
| Loss function | Cross-entropy loss |
| Method | OA (%) | MIoU (%) | F1-Score | Kappa |
|---|---|---|---|---|
| RAANet | 97.48 | 94.92 | 97.89 | 0.9478 |
| BASNet | 98.86 | 97.14 | 98.82 | 0.9709 |
| DecoupleSegNet | 98.89 | 97.37 | 98.92 | 0.9733 |
| DeeplabV3+ | 98.27 | 96.48 | 98.54 | 0.9642 |
| PSPNet | 98.74 | 97.43 | 98.95 | 0.9740 |
| LANet | 98.73 | 97.40 | 98.93 | 0.9737 |
| Attention UNet | 98.67 | 97.29 | 98.88 | 0.9725 |
| SENet | 98.65 | 97.24 | 98.86 | 0.9720 |
| UNet | 98.78 | 97.51 | 98.98 | 0.9747 |
| BGSNet | 98.97 | 97.89 | 99.14 | 0.9786 |
| Methods | Params (M) | Flops (G) |
|---|---|---|
| RAANet | 64.204 | 186.201 |
| BASNet | 87.080 | 1021.531 |
| DecoupleSegNet | 137.100 | 1457.126 |
| DeeplabV3+ | 54.608 | 166.053 |
| PSPNet | 46.707 | 368.898 |
| LANet | 23.792 | 66.475 |
| Attention UNet | 34.879 | 66.636 |
| SENet | 23.775 | 65.93 |
| UNet | 34.527 | 524.179 |
| BGSNet | 24.221 | 79.596 |
| Method | OA (%) | MIoU (%) | F1-Score | Kappa |
|---|---|---|---|---|
| RAANet | 93.11 | 71.69 | 96.15 | 0.6359 |
| BASNet | 93.07 | 71.86 | 96.45 | 0.6382 |
| DecoupleSegNet | 94.95 | 75.99 | 95.12 | 0.6366 |
| DeeplabV3+ | 92.45 | 71.84 | 95.71 | 0.5867 |
| PSPNet | 93.41 | 73.36 | 96.30 | 0.6634 |
| LANet | 95.47 | 79.71 | 97.47 | 0.7583 |
| Attention UNet | 94.27 | 73.92 | 96.83 | 0.6715 |
| SENet | 95.01 | 78.84 | 97.19 | 0.7463 |
| UNet | 94.62 | 75.95 | 97.01 | 0.7032 |
| BGSNet | 95.70 | 80.86 | 97.59 | 0.7745 |
| Dataset | Methods | OA (%) | MIoU (%) | F1-Score | Kappa | Params (M) |
|---|---|---|---|---|---|---|
| QTPL | Fusion () | 98.86 | 97.67 | 99.05 | 0.9765 | 24.147 |
| Fusion () | 98.93 | 97.81 | 99.10 | 0.9778 | 24.221 | |
| Fusion () | 98.96 | 97.86 | 99.12 | 0.9784 | 24.221 | |
| Fusion () | 98.97 | 97.89 | 99.14 | 0.9786 | 24.221 | |
| LoveDA | Fusion () | 95.37 | 79.25 | 97.42 | 0.7519 | 24.147 |
| Fusion () | 95.47 | 80.05 | 97.46 | 0.7633 | 24.221 | |
| Fusion () | 95.36 | 79.69 | 97.40 | 0.7582 | 24.221 | |
| Fusion () | 95.70 | 80.86 | 97.59 | 0.7745 | 24.221 |
| Dataset | Methods | OA (%) | MIoU (%) | F1-Score | Kappa | Params (M) |
|---|---|---|---|---|---|---|
| QTPL | BGSNet | 98.97 | 97.89 | 99.14 | 0.9786 | 24.221 |
| BGSNet (without BR) | 98.89 | 97.72 | 99.06 | 0.9769 | 24.073 | |
| BGSNet (without SCF) | 98.87 | 97.68 | 99.05 | 0.9765 | 24.131 | |
| BGSNet (without BGS) | 98.82 | 97.59 | 99.01 | 0.9756 | 23.999 | |
| LoveDA | BGSNet | 95.70 | 80.86 | 97.59 | 0.7745 | 24.221 |
| BGSNet (without BR) | 95.25 | 78.88 | 97.34 | 0.7465 | 24.073 | |
| BGSNet (without SCF) | 95.06 | 78.26 | 97.24 | 0.7376 | 24.131 | |
| BGSNet (without BGS) | 94.28 | 75.39 | 96.81 | 0.6947 | 23.999 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Cai, Y.; Lyu, X.; Xu, Z.; Wang, X.; Fang, Y.; Jiang, W.; Li, X. Boundary-Guided Semantic Context Network for Water Body Extraction from Remote Sensing Images. Remote Sens. 2023, 15, 4325. https://doi.org/10.3390/rs15174325
Yu J, Cai Y, Lyu X, Xu Z, Wang X, Fang Y, Jiang W, Li X. Boundary-Guided Semantic Context Network for Water Body Extraction from Remote Sensing Images. Remote Sensing. 2023; 15(17):4325. https://doi.org/10.3390/rs15174325
Chicago/Turabian StyleYu, Jie, Yang Cai, Xin Lyu, Zhennan Xu, Xinyuan Wang, Yiwei Fang, Wenxuan Jiang, and Xin Li. 2023. "Boundary-Guided Semantic Context Network for Water Body Extraction from Remote Sensing Images" Remote Sensing 15, no. 17: 4325. https://doi.org/10.3390/rs15174325
APA StyleYu, J., Cai, Y., Lyu, X., Xu, Z., Wang, X., Fang, Y., Jiang, W., & Li, X. (2023). Boundary-Guided Semantic Context Network for Water Body Extraction from Remote Sensing Images. Remote Sensing, 15(17), 4325. https://doi.org/10.3390/rs15174325