
Learning Implicit Neural Representation for Satellite Object Mesh Reconstruction


Abstract
:1. Introduction
- 1
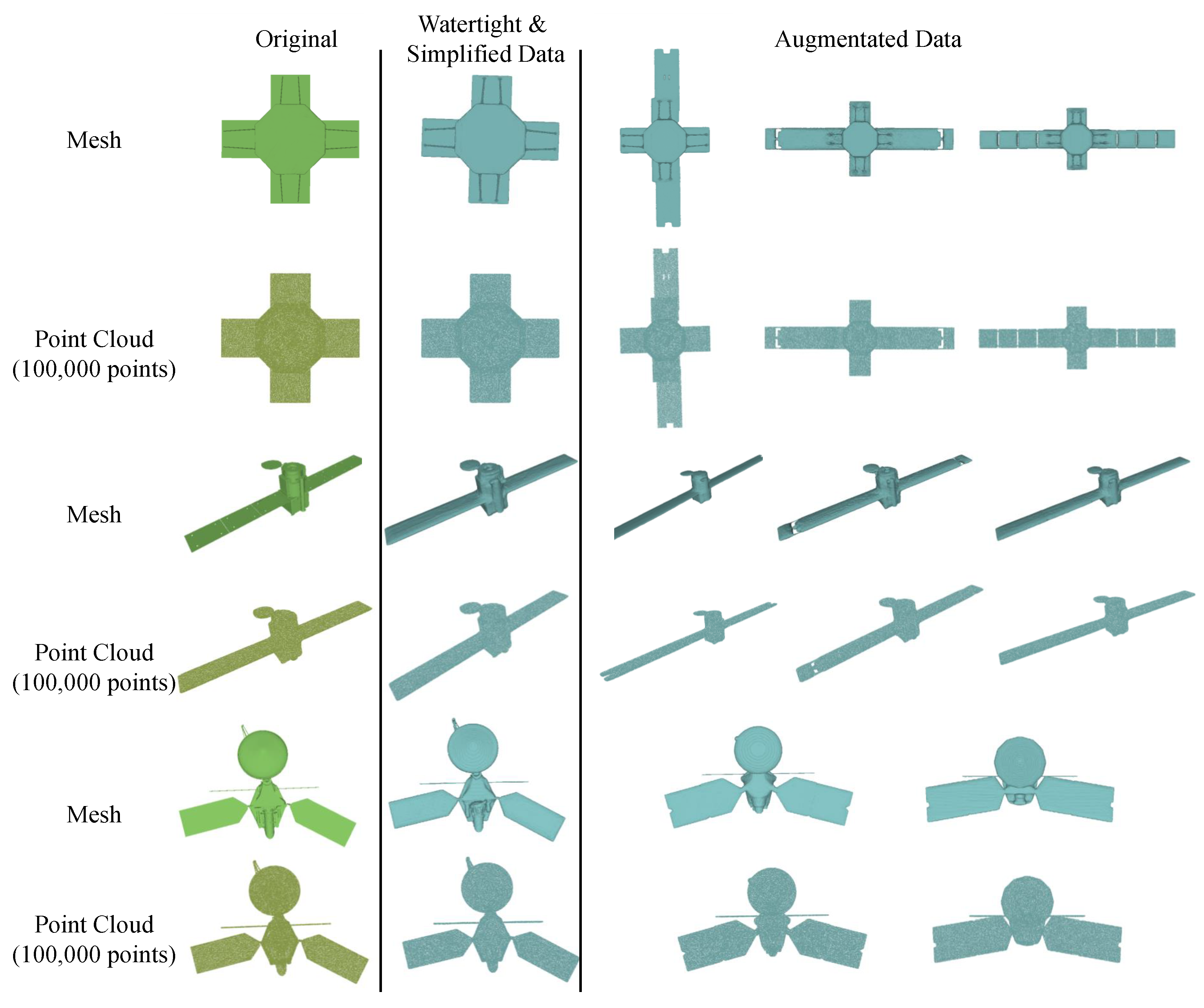
- We build a dataset for tackling satellite mesh reconstruction from sparse point cloud tasks through learning-based methods. Moreover, we are the first to utilize implicit neural representation to reconstruct meshes from sparse point clouds.
- 2
- We propose a Grid Occupancy Network (GONet), introducing the Grid Occupancy Field (GOF), an explicit-driven implicit representation in ConvONet. Our GOF enables a semi-explicit supervision of 3D surfaces, and we demonstrate that the additional supervision on GOF improves the reconstruction quality of satellite meshes.
- 3
- We design a learning-based Adaptive Feature Aggregation (AFA) module to adaptively aggregate the features on multi-planes and volume, which enhances GONet on implicit feature learning. Furthermore, extensive experiments, including visual and quantitative experiments, demonstrate that our GONet can handle 3D satellite reconstruction work and outperform existing SOTAs.
2. Related Work
3. Methodology
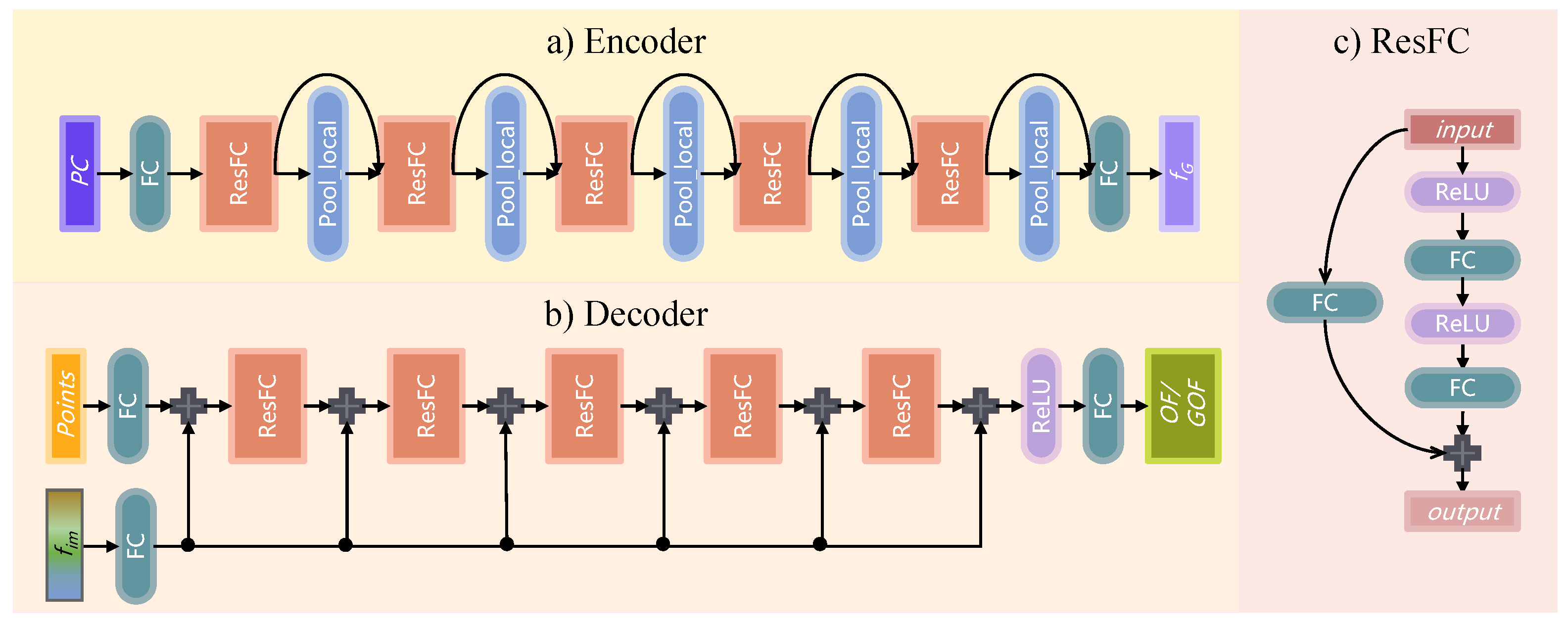
3.1. Method Overview
| Algorithm 1: Surface Reconstruction using GONet |
| Input :Point cloud (P), randomly sampled points (R), and uniformly sampled points (U) Output:Reconstruction mesh
|
3.2. Grid Occupancy Field
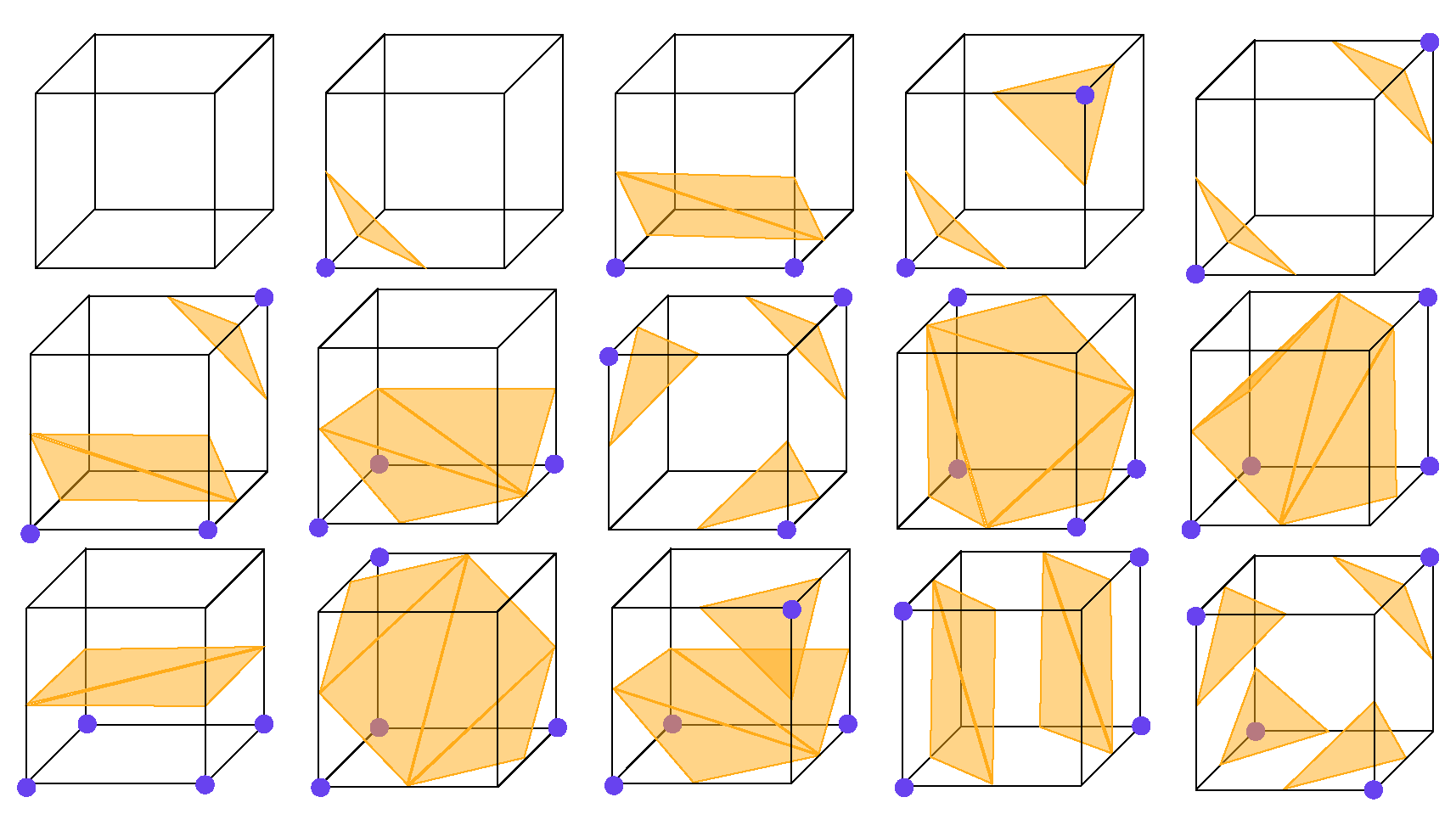
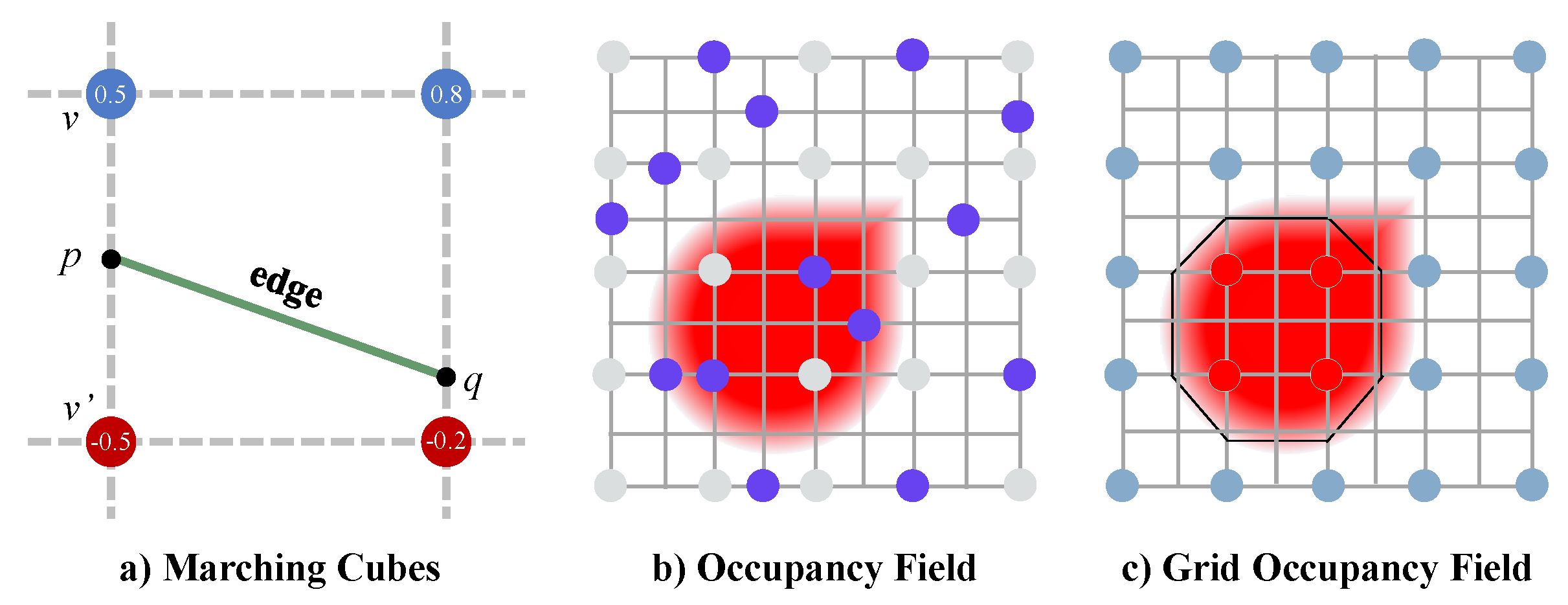
3.2.1. Marching Cubes
3.2.2. GOF
3.3. Adaptive Feature Aggregation Module
3.4. Training and Inference
4. Experiments
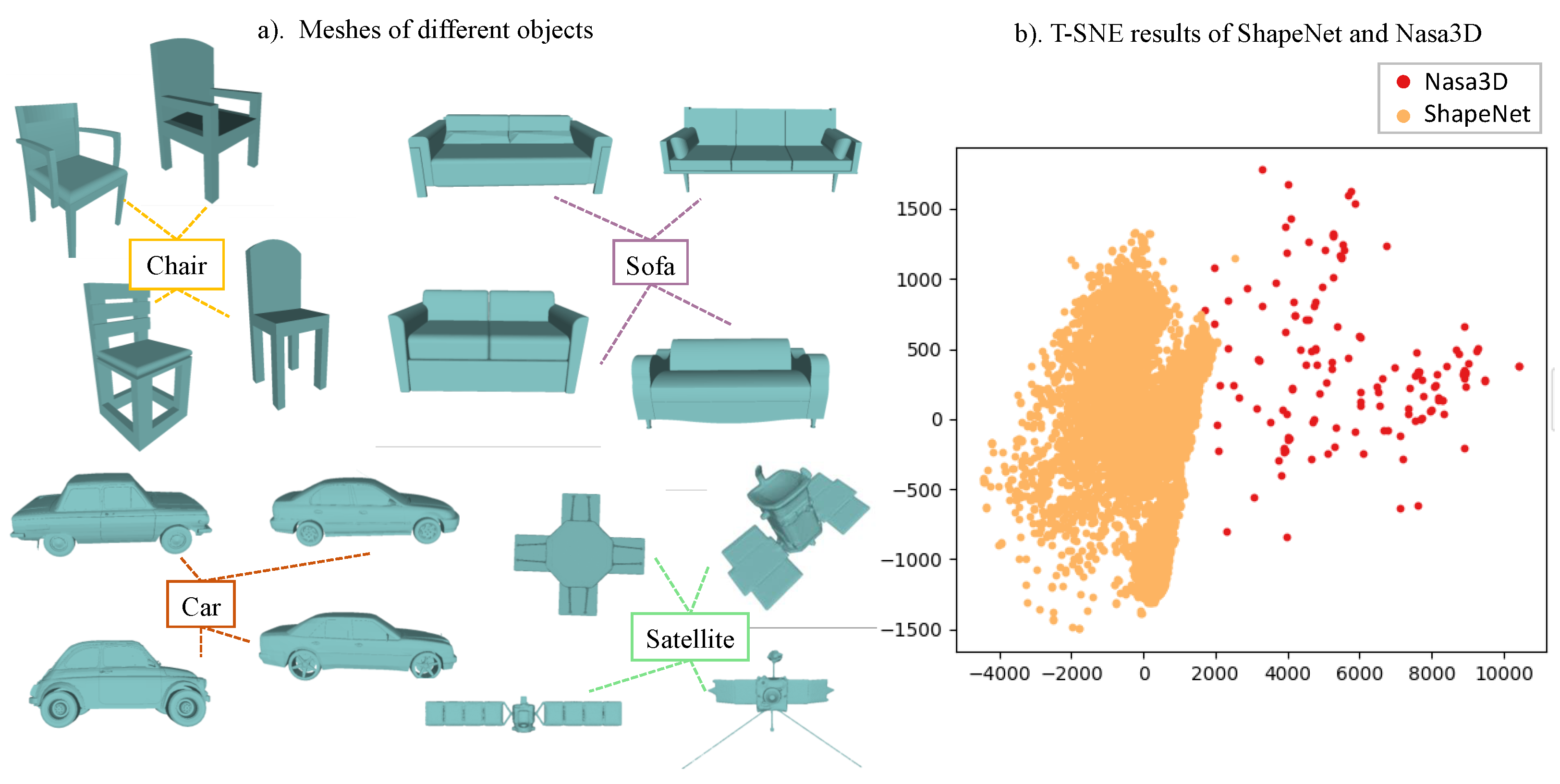
4.1. NASA3D Dataset
4.2. Metrics
4.3. Implementation Details
4.4. Ablation Studies
4.5. Reconstruction Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the 4th Eurographics Symposium on Geometry Processing, Cagliari, Italy, 26–28 June 2006; Volume 7. [Google Scholar]
- Kazhdan, M.; Hoppe, H. Screened poisson surface reconstruction. ACM Trans. Graph. 2013, 32, 1–13. [Google Scholar] [CrossRef]
- Erler, P.; Guerrero, P.; Ohrhallinger, S.; Mitra, N.J.; Wimmer, M. Points2surf learning implicit surfaces from point clouds. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 108–124. [Google Scholar]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4460–4470. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Boulch, A.; Marlet, R. POCO: Point Convolution for Surface Reconstruction. arXiv 2022, arXiv:2201.01831. [Google Scholar]
- Peng, S.; Niemeyer, M.; Mescheder, L.; Pollefeys, M.; Geiger, A. Convolutional occupancy networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 523–540. [Google Scholar]
- Tang, Y.; Qian, Y.; Zhang, Q.; Zeng, Y.; Hou, J.; Zhe, X. WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation. In Proceedings of the of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6397–6405. [Google Scholar]
- Liu, Z.; Zhang, C.; Cai, H.; Qv, W.; Zhang, S. A Model Simplification Algorithm for 3D Reconstruction. Remote Sens. 2022, 14, 4216. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, C.; Yan, Y.; Su, N. A 3D Reconstruction Framework of Buildings Using Single Off-Nadir Satellite Image. Remote Sens. 2021, 13, 4434. [Google Scholar] [CrossRef]
- Wang, Q.; Zhu, Z.; Chen, R.; Xia, W.; Yan, C. Building Floorplan Reconstruction Based on Integer Linear Programming. Remote Sens. 2022, 14, 4675. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 405–421. [Google Scholar]
- Yariv, L.; Gu, J.; Kasten, Y.; Lipman, Y. Volume rendering of neural implicit surfaces. Adv. Neural Inf. Process. Syst. 2021, 34, 4805–4815. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. 2022, 41, 102. [Google Scholar] [CrossRef]
- Saito, S.; Huang, Z.; Natsume, R.; Morishima, S.; Kanazawa, A.; Li, H. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2304–2314. [Google Scholar]
- Chen, Z.; Zhang, H. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5939–5948. [Google Scholar]
- Chen, Z.; Tagliasacchi, A.; Zhang, H. Bsp-net: Generating compact meshes via binary space partitioning. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2020; pp. 45–54. [Google Scholar]
- Remelli, E.; Lukoianov, A.; Richter, S.; Guillard, B.; Bagautdinov, T.; Baque, P.; Fua, P. Meshsdf: Differentiable iso-surface extraction. Adv. Neural Inf. Process. Syst. 2020, 33, 22468–22478. [Google Scholar]
- Liao, Y.; Donne, S.; Geiger, A. Deep marching cubes: Learning explicit surface representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2916–2925. [Google Scholar]
- Rao, Y.; Lu, J.; Zhou, J. Global-local bidirectional reasoning for unsupervised representation learning of 3D point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5376–5385. [Google Scholar]
- Rozsa, Z.; Sziranyi, T. Optical Flow and Expansion Based Deep Temporal Up-Sampling of LIDAR Point Clouds. Remote Sens. 2023, 15, 2487. [Google Scholar] [CrossRef]
- Huang, Z.; Yu, Y.; Xu, J.; Ni, F.; Le, X. Pf-net: Point fractal network for 3d point cloud completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7662–7670. [Google Scholar]
- Fei, B.; Yang, W.; Ma, L.; Chen, W.M. DcTr: Noise-robust point cloud completion by dual-channel transformer with cross-attention. Pattern Recognit. 2023, 133, 109051. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, J.; Zou, Y.; Liu, P.X.; Liu, J. PS-Net: Point Shift Network for 3-D Point Cloud Completion. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5704313. [Google Scholar] [CrossRef]
- Zhang, R.; Gao, W.; Li, G.; Li, T.H. QINet: Decision Surface Learning and Adversarial Enhancement for Quasi-Immune Completion of Diverse Corrupted Point Clouds. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5705314. [Google Scholar] [CrossRef]
- Cheng, M.; Li, G.; Chen, Y.; Chen, J.; Wang, C.; Li, J. Dense point cloud completion based on generative adversarial network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5701310. [Google Scholar] [CrossRef]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 628–644. [Google Scholar]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. A papier-mâché approach to learning 3d surface generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 216–224. [Google Scholar]
- Gkioxari, G.; Malik, J.; Johnson, J. Mesh r-cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 6 June 2019; pp. 9785–9795. [Google Scholar]
- Luo, Y.; Mi, Z.; Tao, W. Deepdt: Learning geometry from delaunay triangulation for surface reconstruction. In Proceedings of the AAAI Conference on Artificial Intelligence, online, 2–9 February 2021; Volume 35, pp. 2277–2285. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2mesh: Generating 3d mesh models from single rgb images. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 52–67. [Google Scholar]
- Tang, J.; Lei, J.; Xu, D.; Ma, F.; Jia, K.; Zhang, L. Sa-convonet: Sign-agnostic optimization of convolutional occupancy networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6504–6513. [Google Scholar]
- Liu, Q.; Xiao, J.; Liu, L.; Wang, Y.; Wang, Y. High-Resolution and Efficient Neural Dual Contouring for Surface Reconstruction from Point Clouds. Remote Sens. 2023, 15, 2267. [Google Scholar] [CrossRef]
- Sclaroff, S.; Pentland, A. Generalized implicit functions for computer graphics. ACM Siggraph Comput. Graph. 1991, 25, 247–250. [Google Scholar] [CrossRef]
- Stutz, D.; Geiger, A. Learning 3d shape completion under weak supervision. Int. J. Comput. Vis. 2020, 128, 1162–1181. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Meagher, D. Geometric modeling using octree encoding. Comput. Graph. Image Process. 1982, 19, 129–147. [Google Scholar] [CrossRef]
- Jackins, C.L.; Tanimoto, S.L. Oct-trees and their use in representing three-dimensional objects. Comput. Graph. Image Process. 1980, 14, 249–270. [Google Scholar] [CrossRef]
- Tatarchenko, M.; Richter, S.R.; Ranftl, R.; Li, Z.; Koltun, V.; Brox, T. What do single-view 3d reconstruction networks learn? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3405–3414. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | AFA with | AFA with | GOF | CD-L1(× 1000, ↓) | F-Score ↑ | IoU (%, ↑) |
|---|---|---|---|---|---|---|
| ConvONet | 7.287 | 0.8150 | 63.30 | |||
| ConvONet + AFA | ✓ | 6.990 | 0.8309 | 65.01 | ||
| ConvONet + AFA | ✓ | 6.903 | 0.8015 | 62.51 | ||
| ConvONet + AFA | ✓ | ✓ | 6.043 | 0.8617 | 67.70 | |
| GONet | ✓ | ✓ | ✓ | 5.507 | 0.8821 | 68.86 |
| w | CD-L1(×1000, ↓) | F-Score ↑ | IoU (%, ↑) |
|---|---|---|---|
| 0.1 | 6.390 | 0.8728 | 68.48 |
| 0.2 | 5.973 | 0.8712 | 67.88 |
| 0.3 | 5.782 | 0.8746 | 68.30 |
| 0.4 | 5.507 | 0.8821 | 68.86 |
| 0.5 | 5.943 | 0.8611 | 68.22 |
| 0.6 | 6.231 | 0.8722 | 67.41 |
| 0.7 | 6.459 | 0.8786 | 69.12 |
| 0.8 | 5.641 | 0.8732 | 68.18 |
| 0.9 | 6.914 | 0.8622 | 67.79 |
| 1.0 | 6.662 | 0.8614 | 68.02 |
| Metrics | PSGN | DMC | OccNet | POCO | ConvONet | SAConvONet | GONet | |
|---|---|---|---|---|---|---|---|---|
| Methods | ||||||||
| CD-L1(×1000, ↓) | 27.747 | 10.626 | 28.005 | 8.784 | 7.287 | 6.884 | 5.507 | |
| F-score ↑ | - | 0.5756 | 0.4326 | 0.7545 | 0.815 | 0.8355 | 0.8821 | |
| IoU (%, ↑) | - | 42.23 | 31.74 | 58.61 | 63.30 | 65.27 | 68.86 | |
| run time(s, ↓) | 0.0085 | 0.1575 | 0.6166 | 11.8741 | 0.5723 | 0.6346 | 1.0121 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Cao, M.; Li, C.; Zhao, H.; Yang, D. Learning Implicit Neural Representation for Satellite Object Mesh Reconstruction. Remote Sens. 2023, 15, 4163. https://doi.org/10.3390/rs15174163
Yang X, Cao M, Li C, Zhao H, Yang D. Learning Implicit Neural Representation for Satellite Object Mesh Reconstruction. Remote Sensing. 2023; 15(17):4163. https://doi.org/10.3390/rs15174163
Chicago/Turabian StyleYang, Xi, Mengqing Cao, Cong Li, Hua Zhao, and Dong Yang. 2023. "Learning Implicit Neural Representation for Satellite Object Mesh Reconstruction" Remote Sensing 15, no. 17: 4163. https://doi.org/10.3390/rs15174163
APA StyleYang, X., Cao, M., Li, C., Zhao, H., & Yang, D. (2023). Learning Implicit Neural Representation for Satellite Object Mesh Reconstruction. Remote Sensing, 15(17), 4163. https://doi.org/10.3390/rs15174163