
Radar Timing Range–Doppler Spectral Target Detection Based on Attention ConvLSTM in Traffic Scenes





Abstract
:
1. Introduction
- According to the characteristics of the dataset itself, due to the time–spatial relationship between the consecutive range–Doppler spectral frames in the dataset, we innovatively designed a backbone network (ConvLSTM) with a time series prediction function to enhance the ability of the network to extract time series features;
- For the characteristics of the range–Doppler spectrum, since the targets in the RD spectrum are very small, they are easily lost in the network detection process, so we introduce an improved lightweight and efficient channel attention mechanism (ECA) in the backbone and feature fusion parts, which improves the ability of the network to focus on key features;
- The feature extraction network that combines timing prediction and attention enhancement shows good generalization ability in radar target detection tasks, and the detection performance on public datasets CARRADA and RADDet is better than other algorithms.
2. Background and Related Work
2.1. Radar Sensor-Related Knowledge
2.2. Traditional Approach Object Detection
2.3. Deep Learning Object Detection
3. Object Detection Method Based on Radar Range–Doppler Spectrum
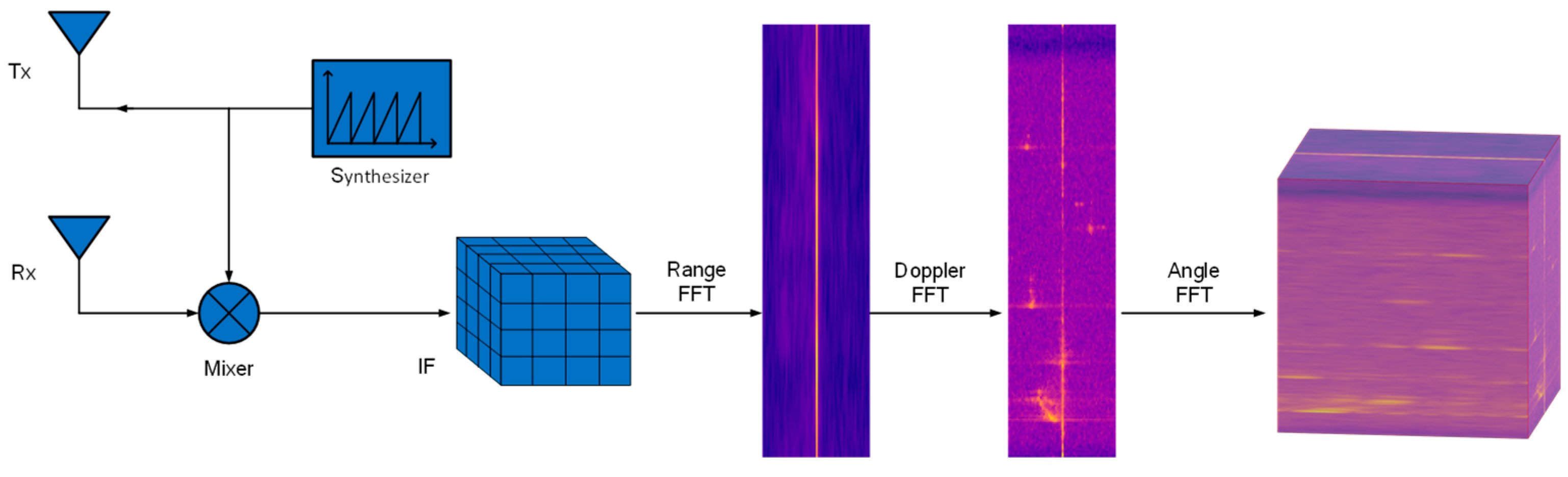
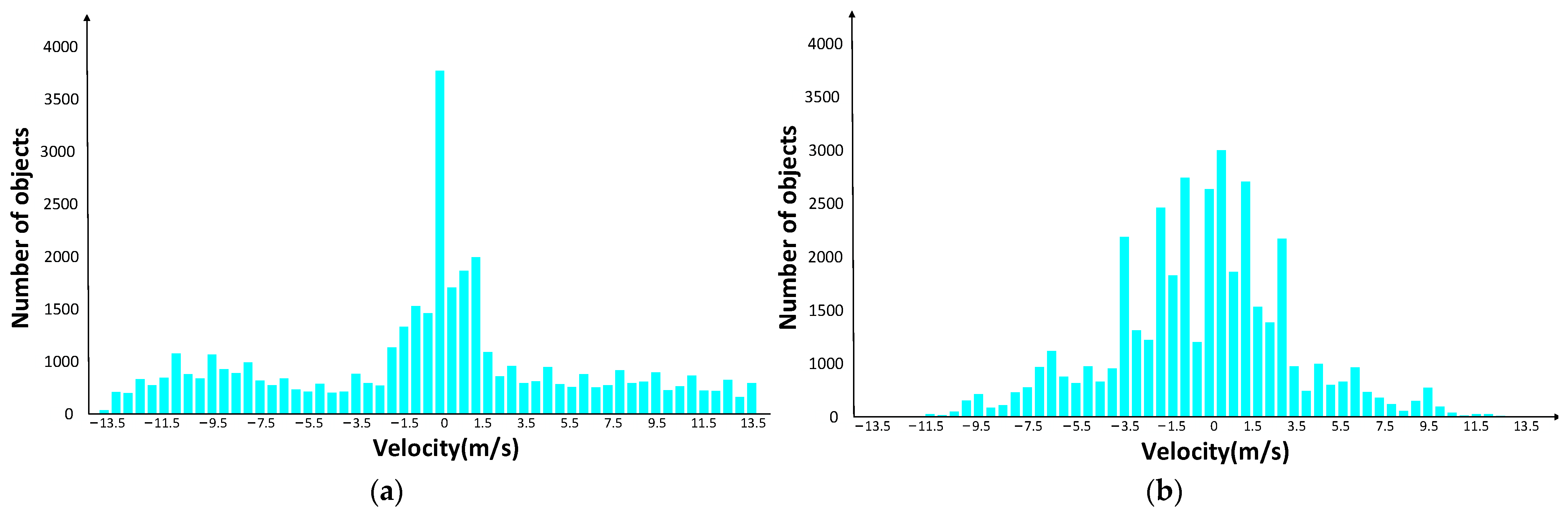
3.1. Data Preprocessing
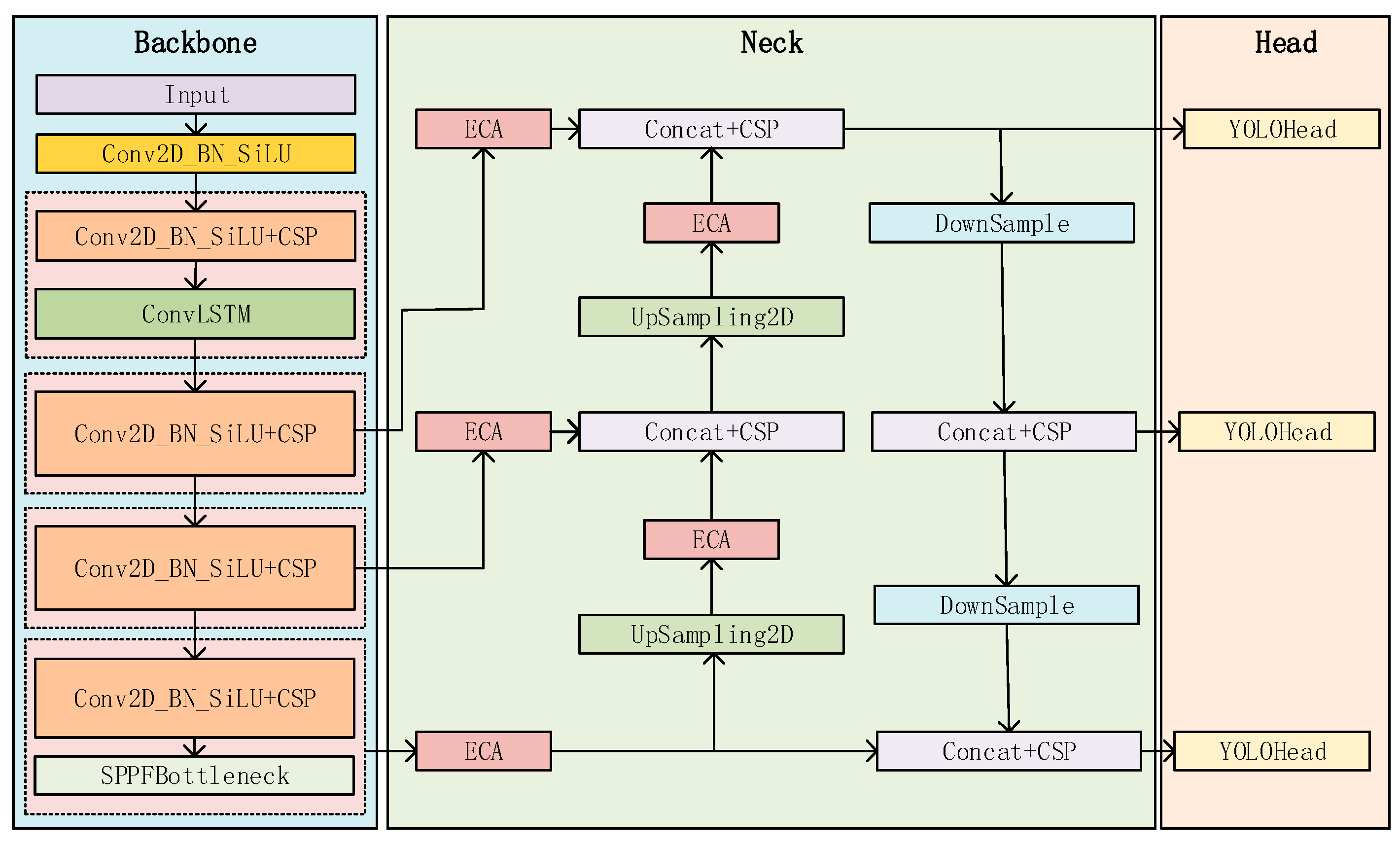
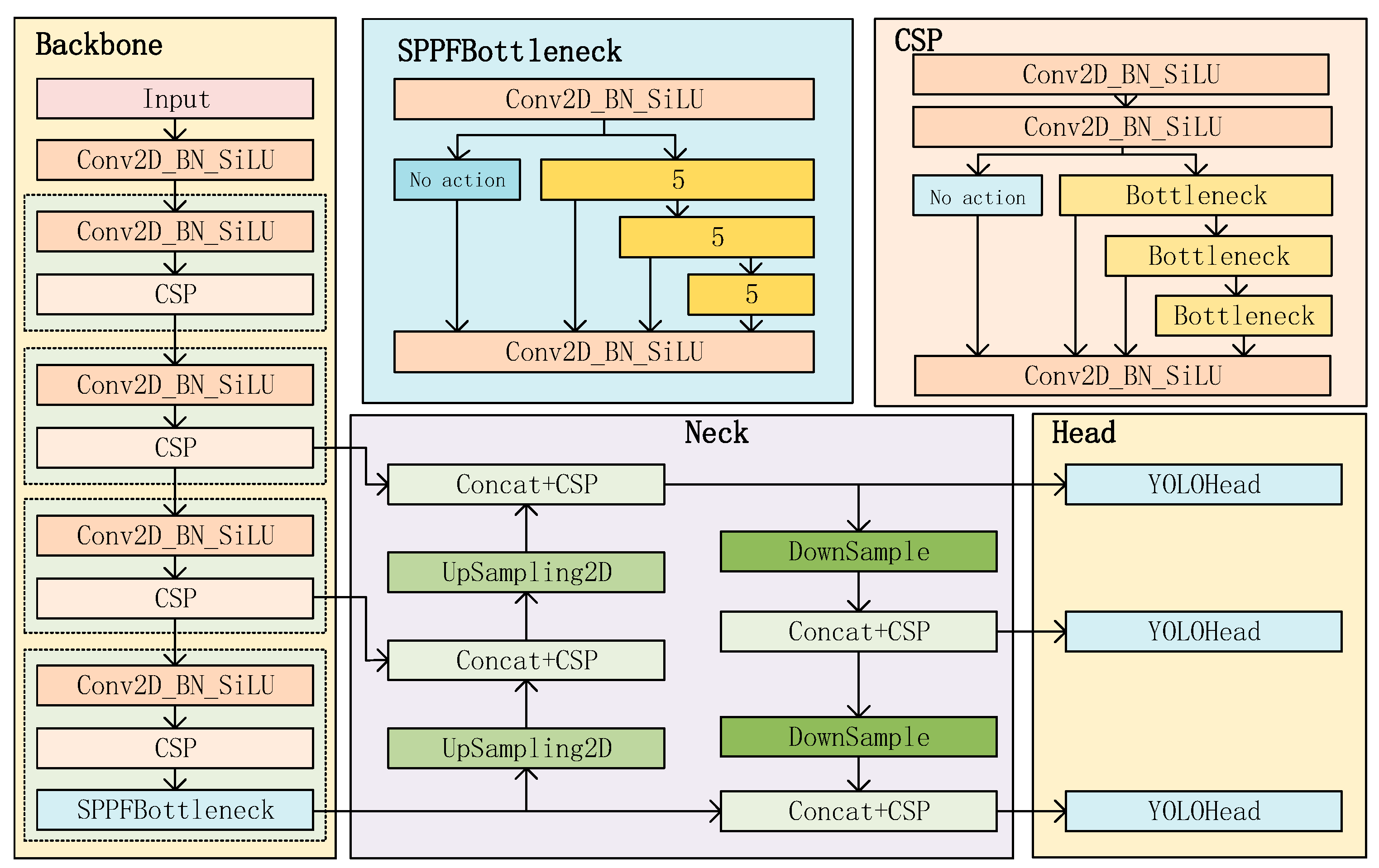
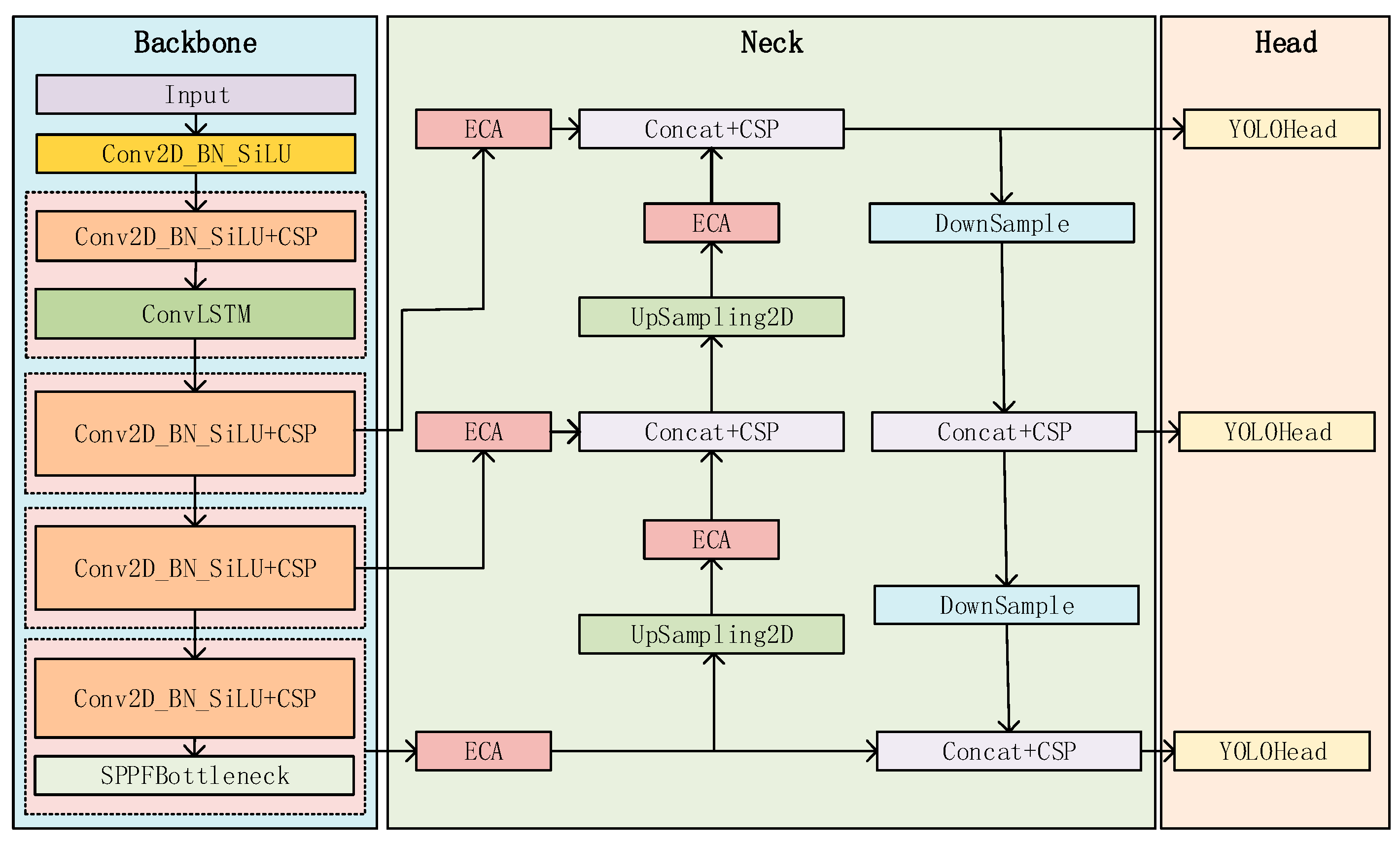
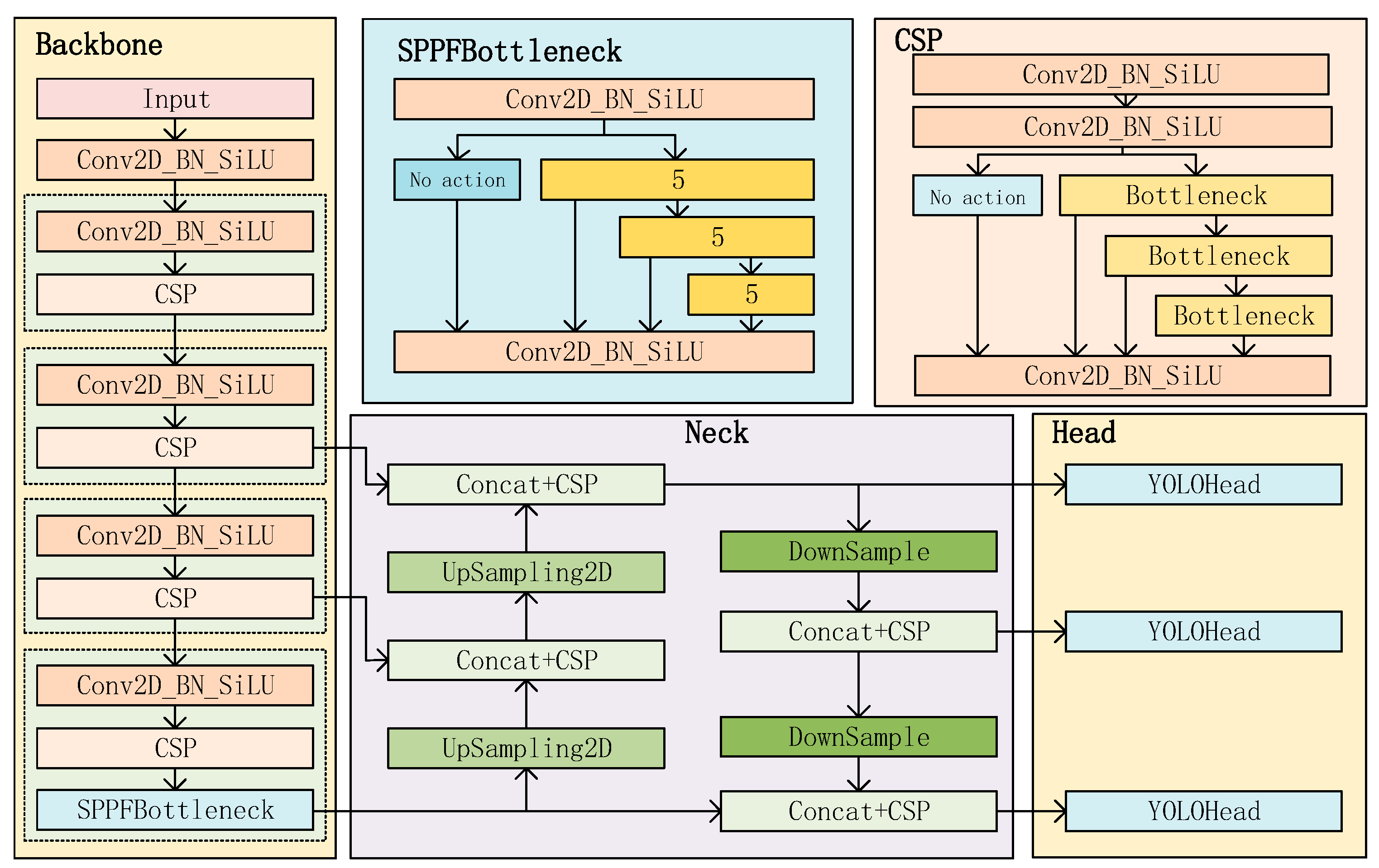
3.2. Object Detection Network Model
3.2.1. YOLOv8 Algorithm Description
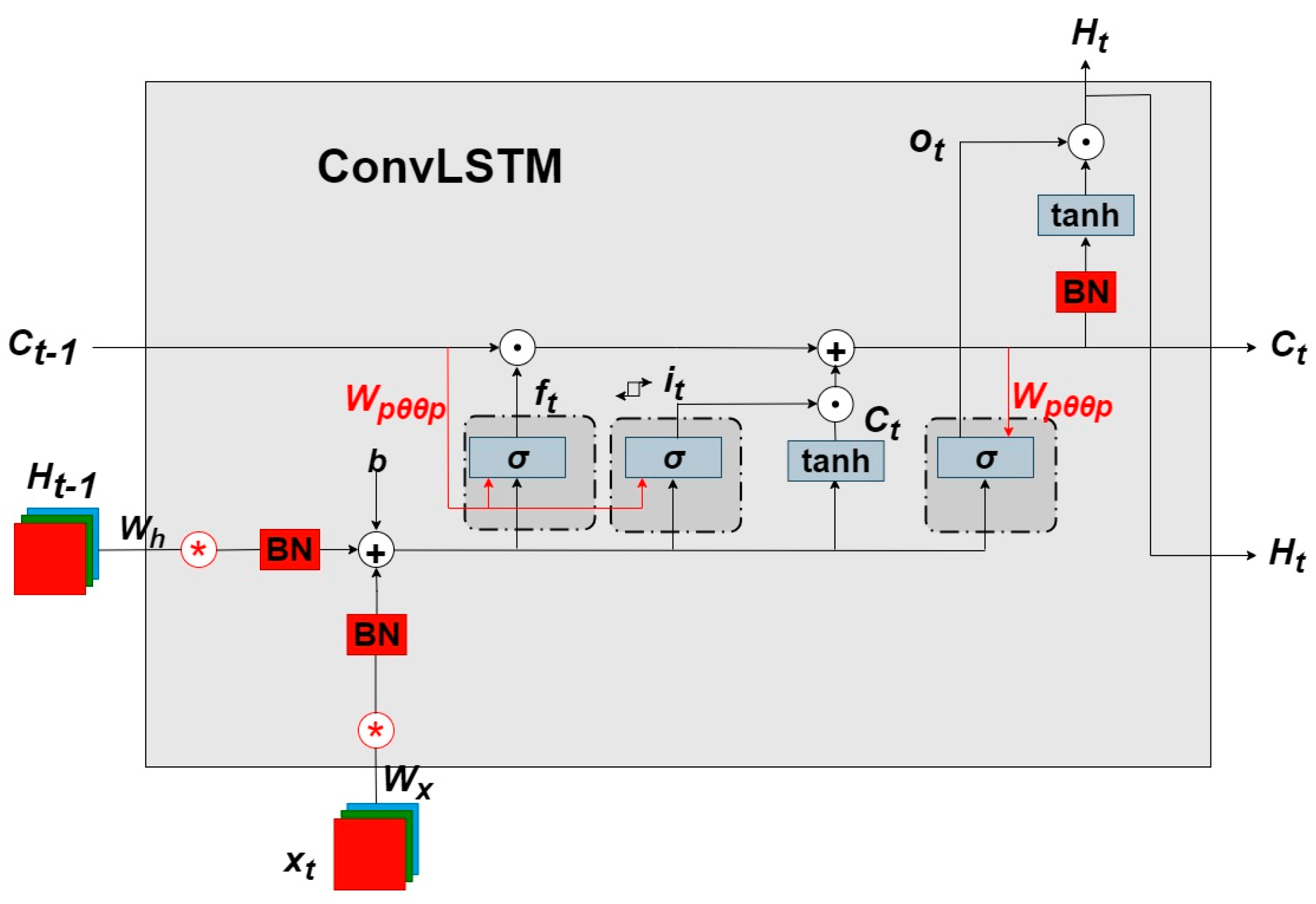
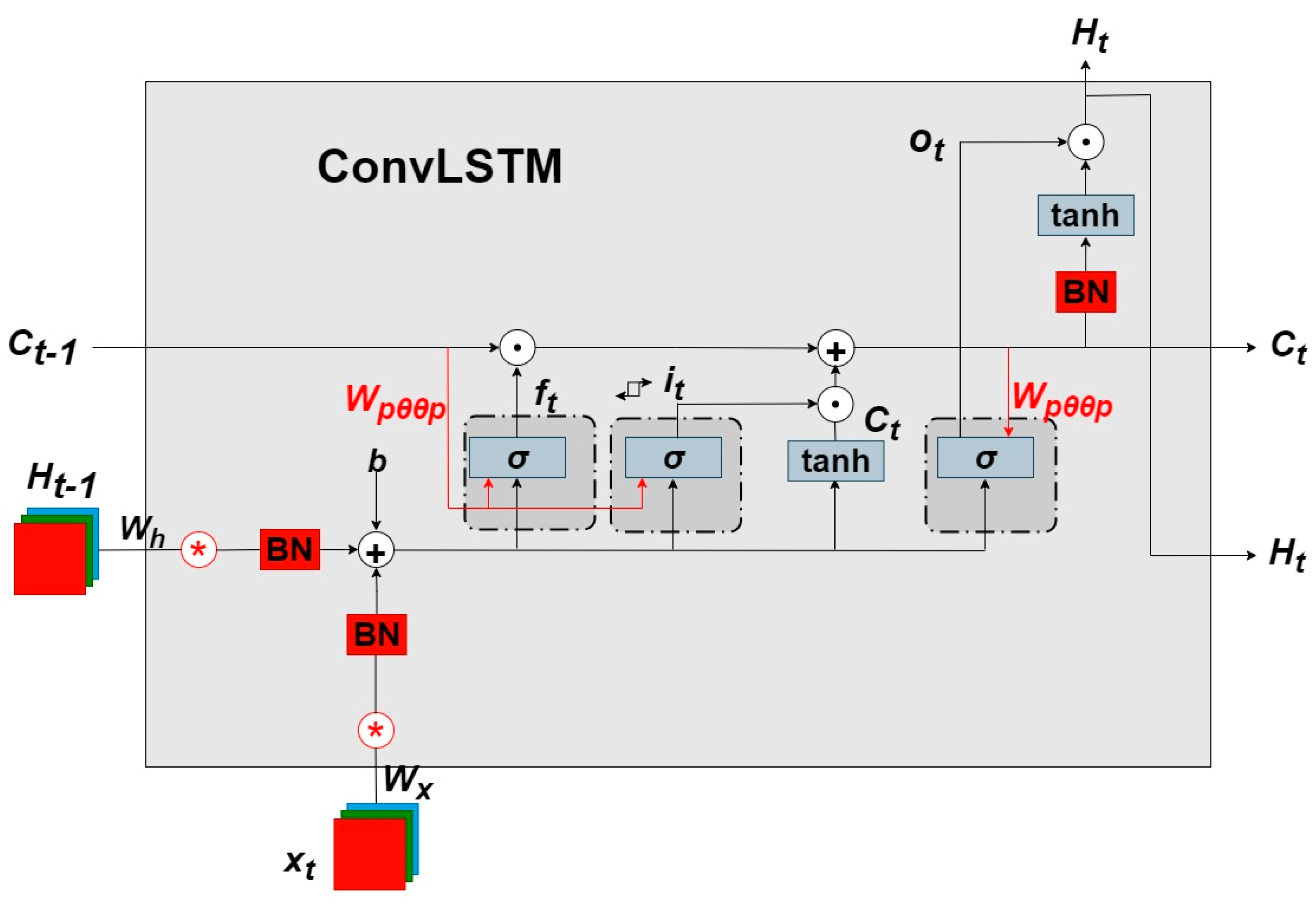
3.2.2. ConvLSTM
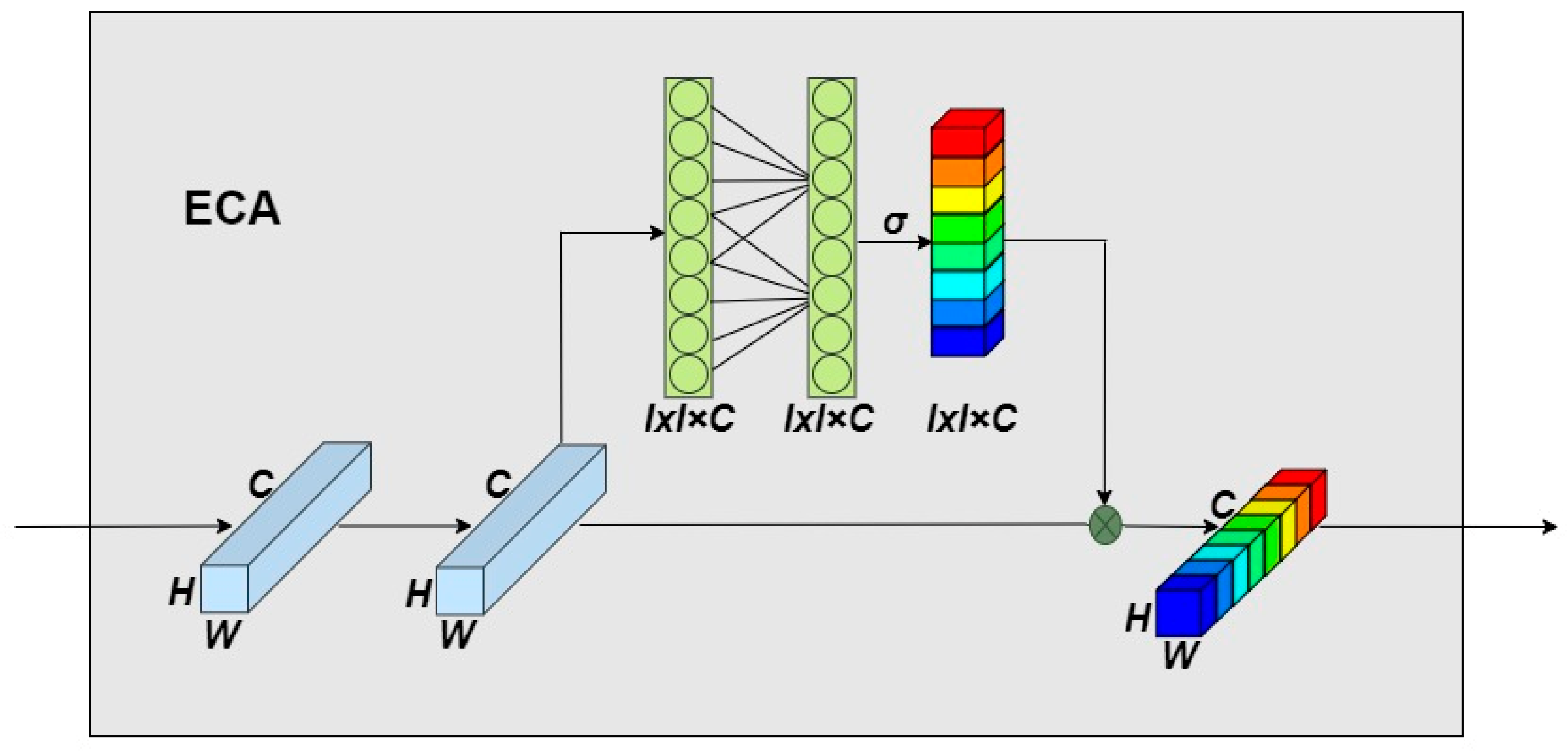
3.2.3. Add Efficient Channel Attention (ECA) Module
4. Experiments
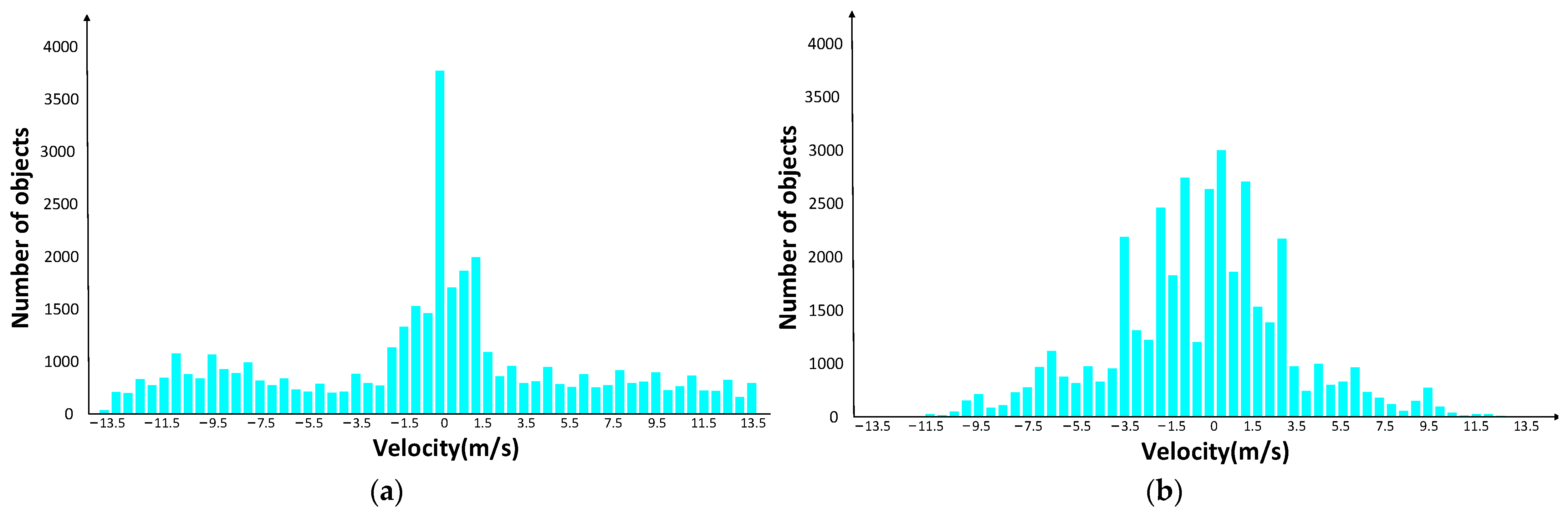
4.1. Experimental Data
4.2. Evaluation Indicators
- Accuracy: Refers to the probability of detecting the correct value among all detected targets:
- Recall rate: Refers to the probability of correct identification in all positive samples:
- AP: Refers to the average value of the detector in each Recall case, corresponding to the area under the PR curve:
- mAP: The average evaluation of AP from the category dimension, so the performance of multi-classifiers can be evaluated:
4.3. Comparison Method and Training Details
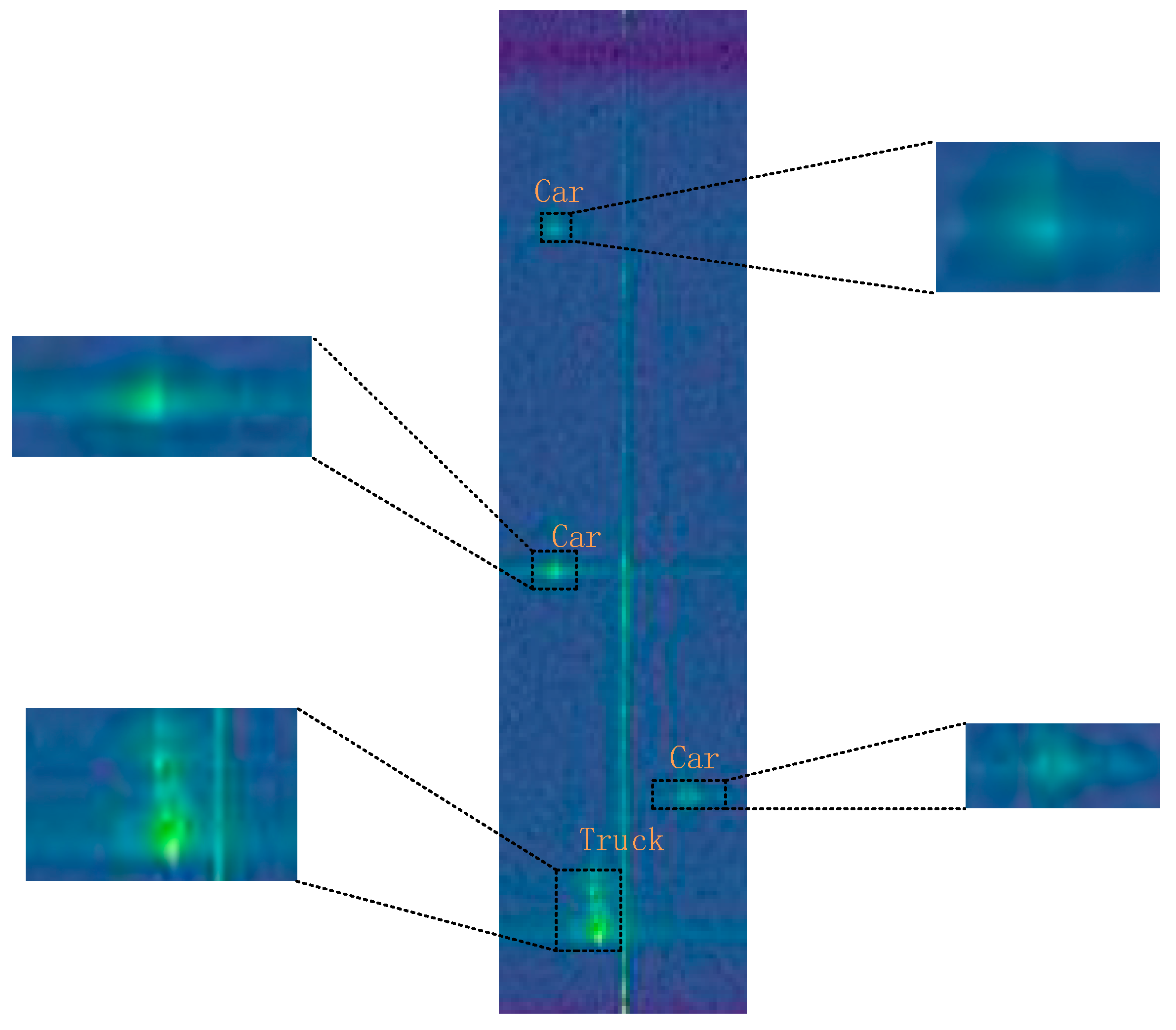
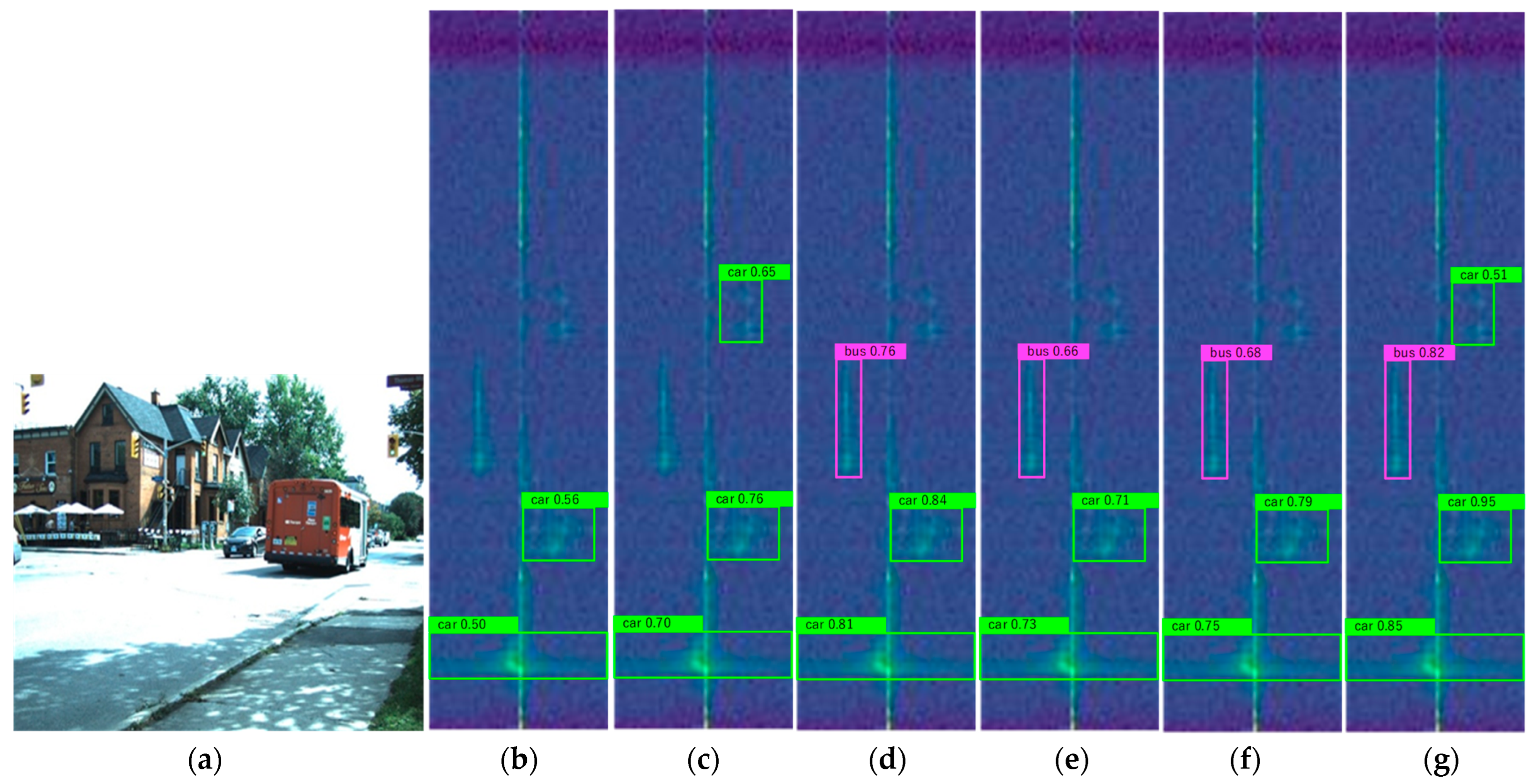
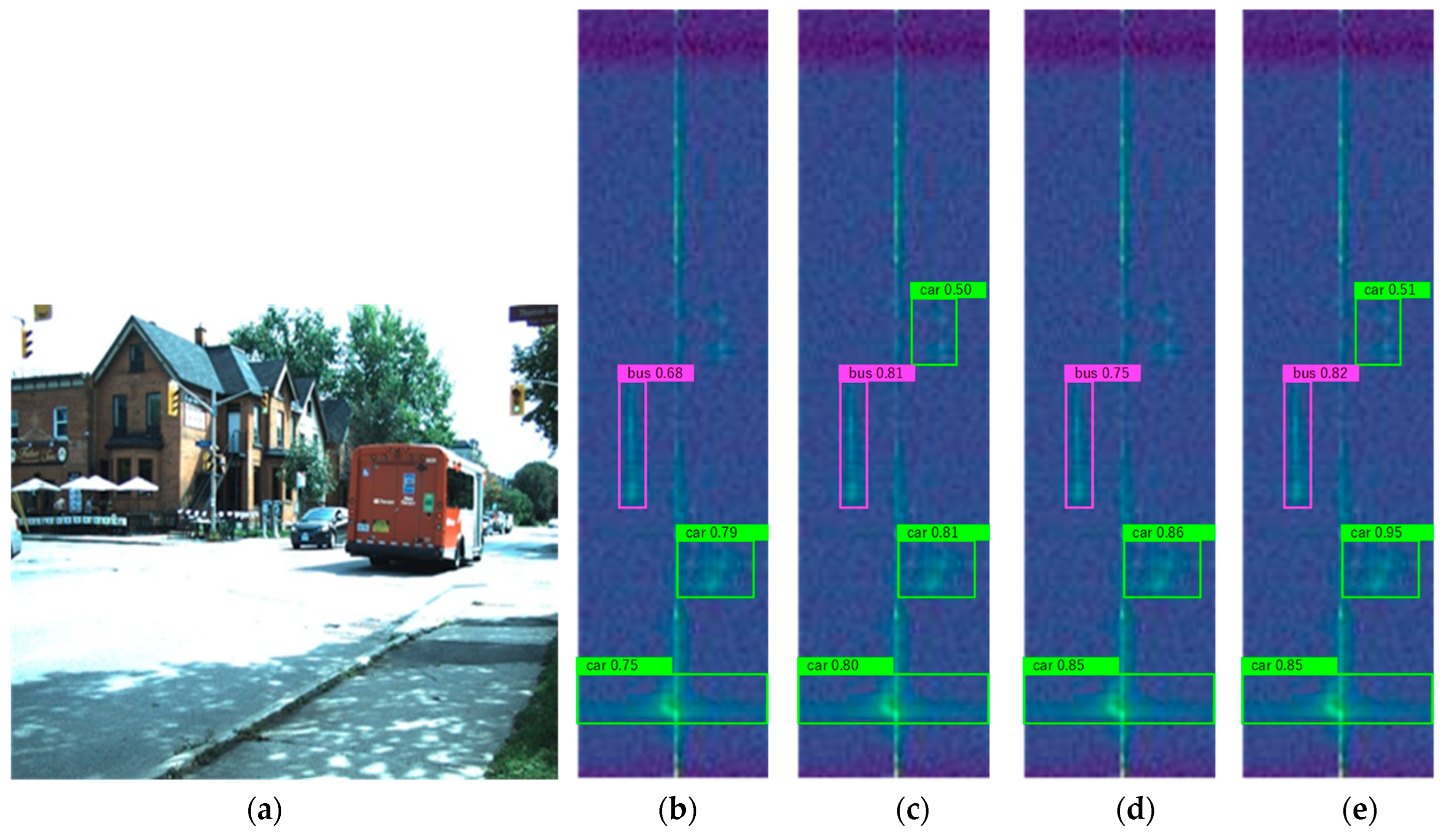
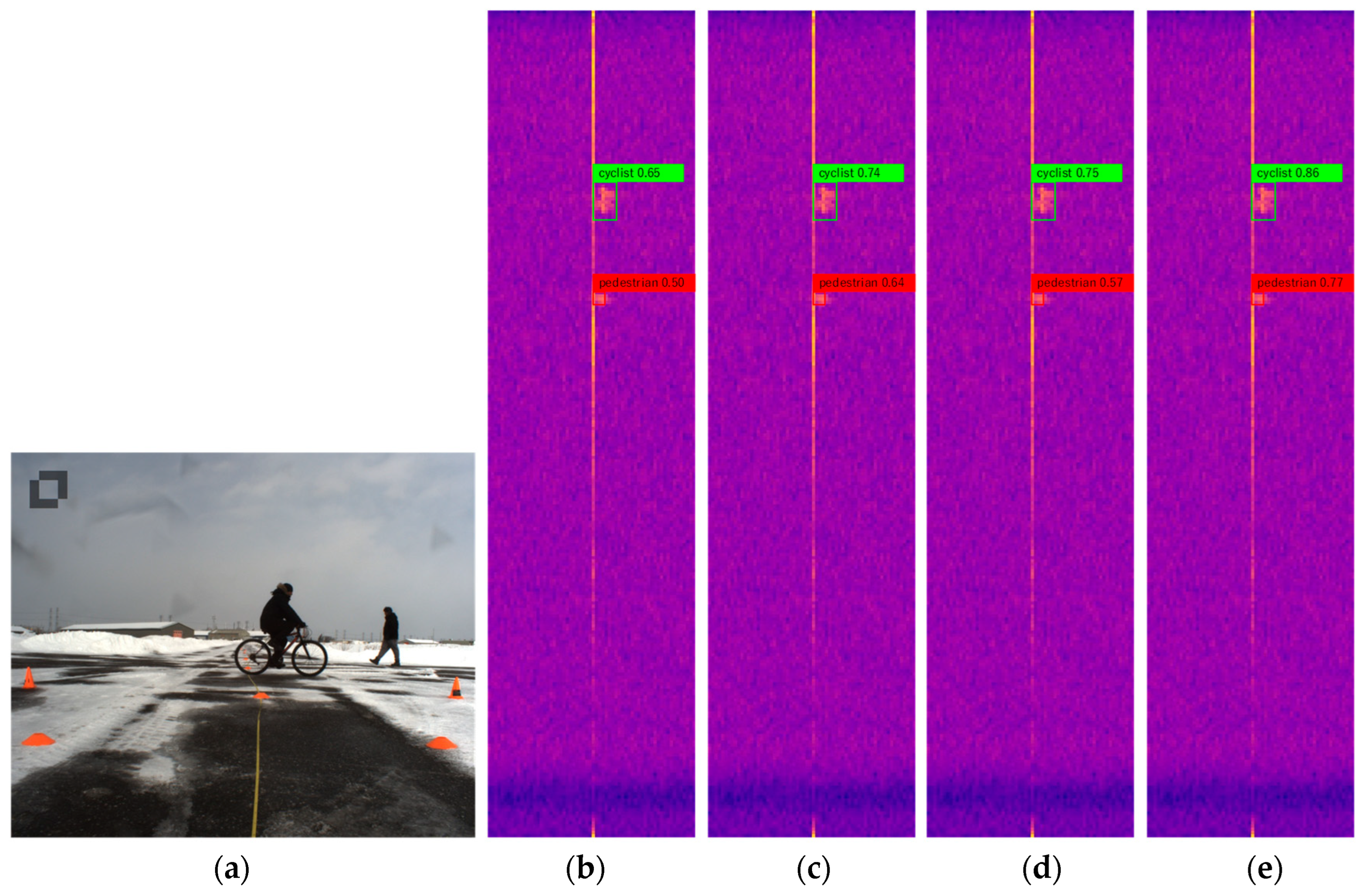
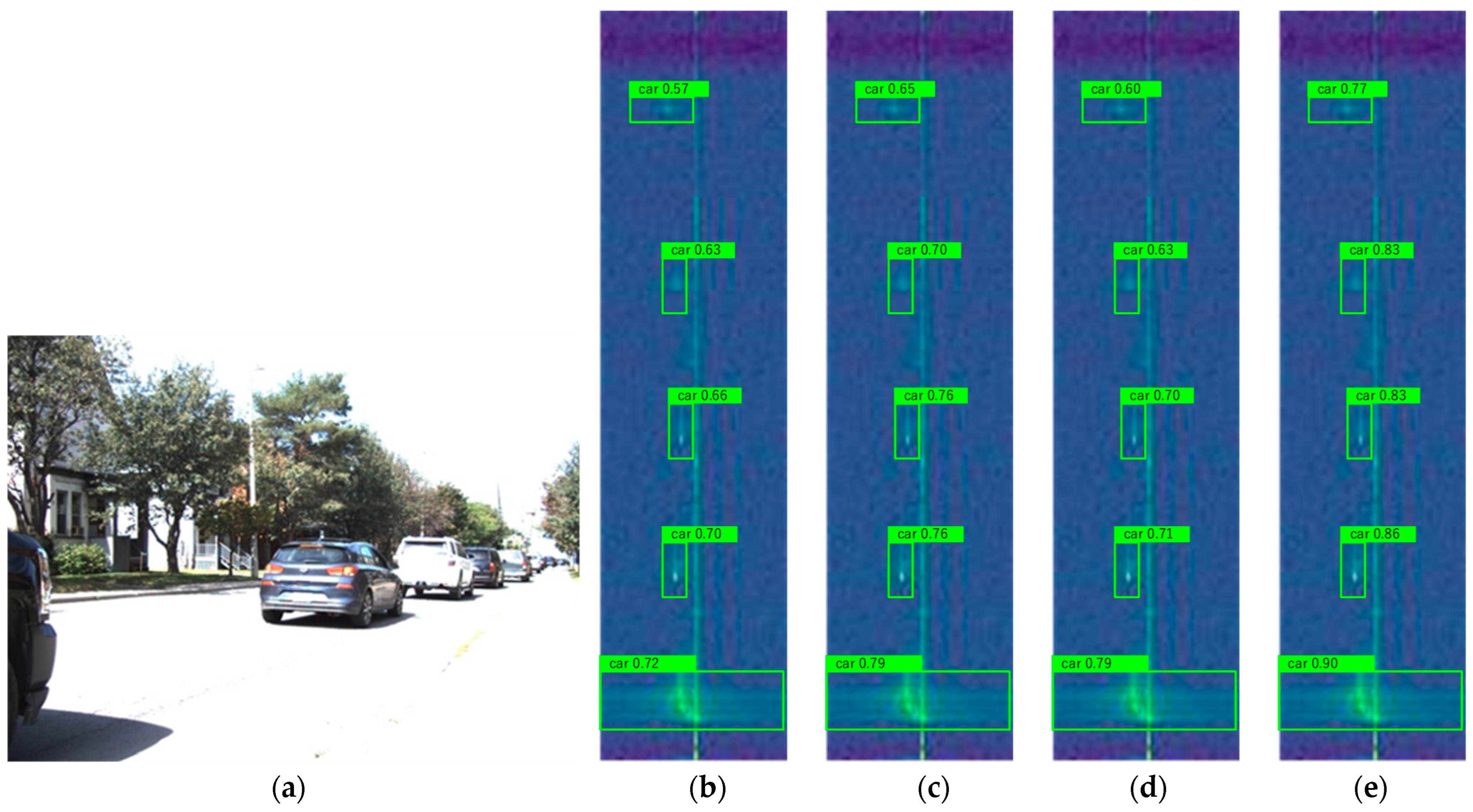
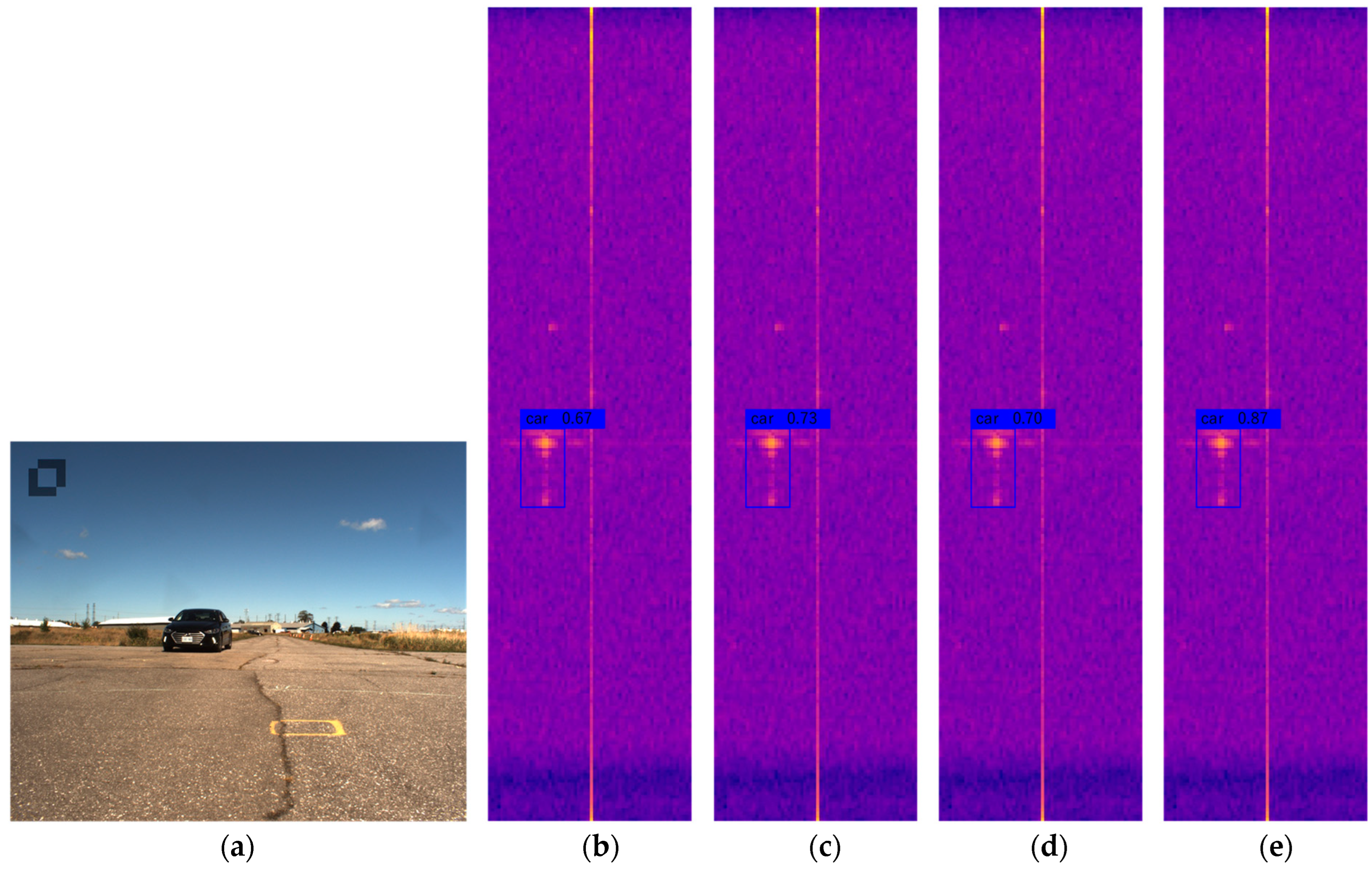
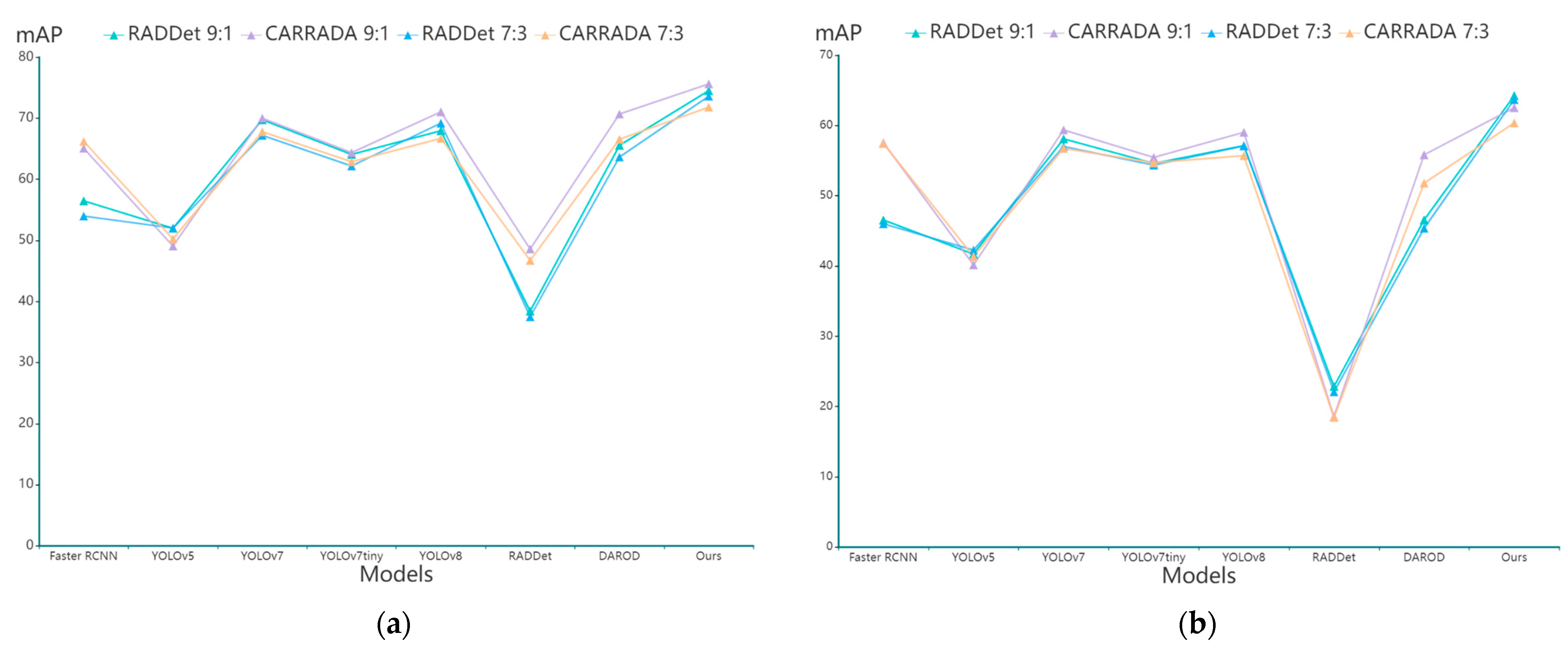
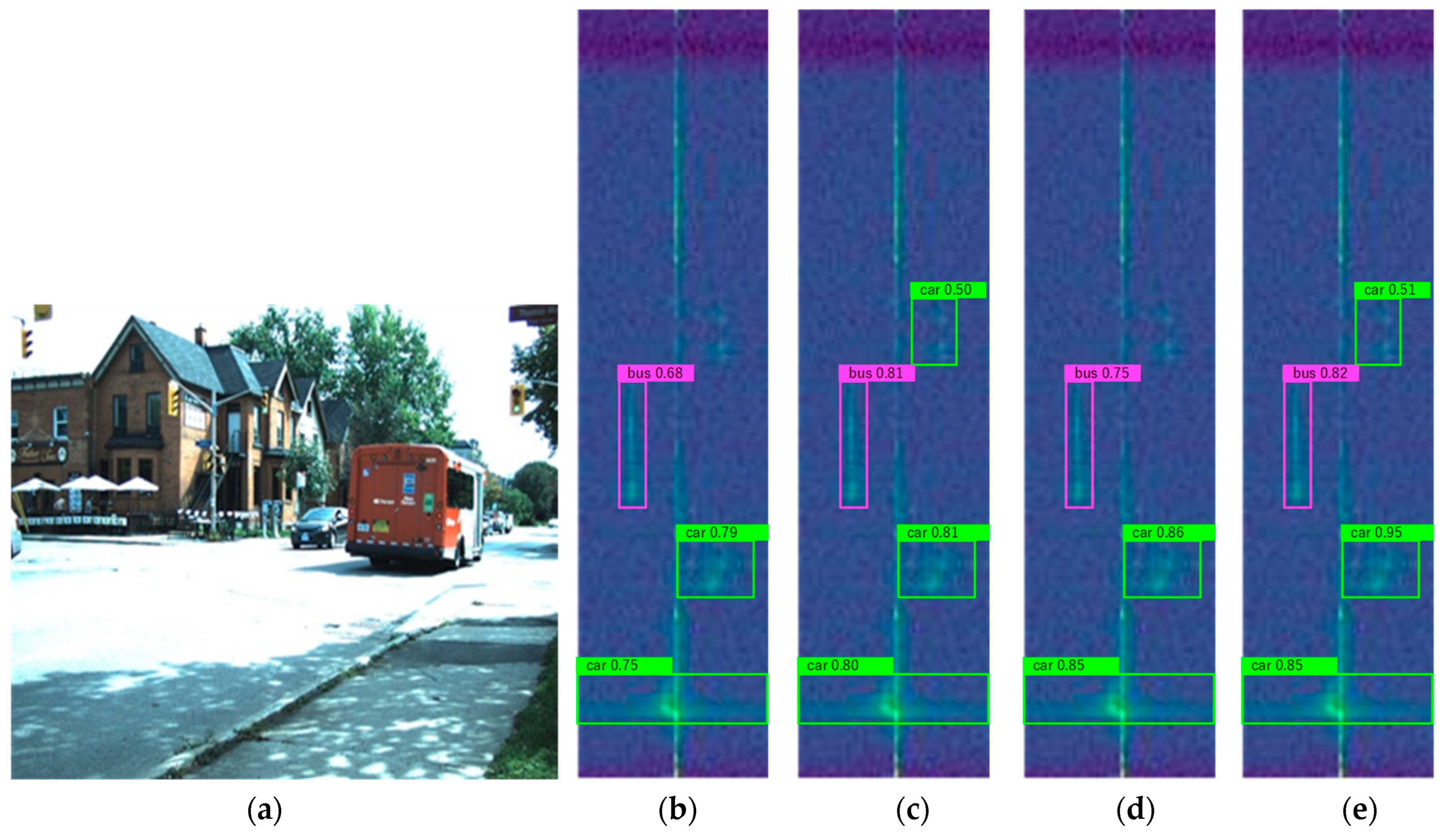
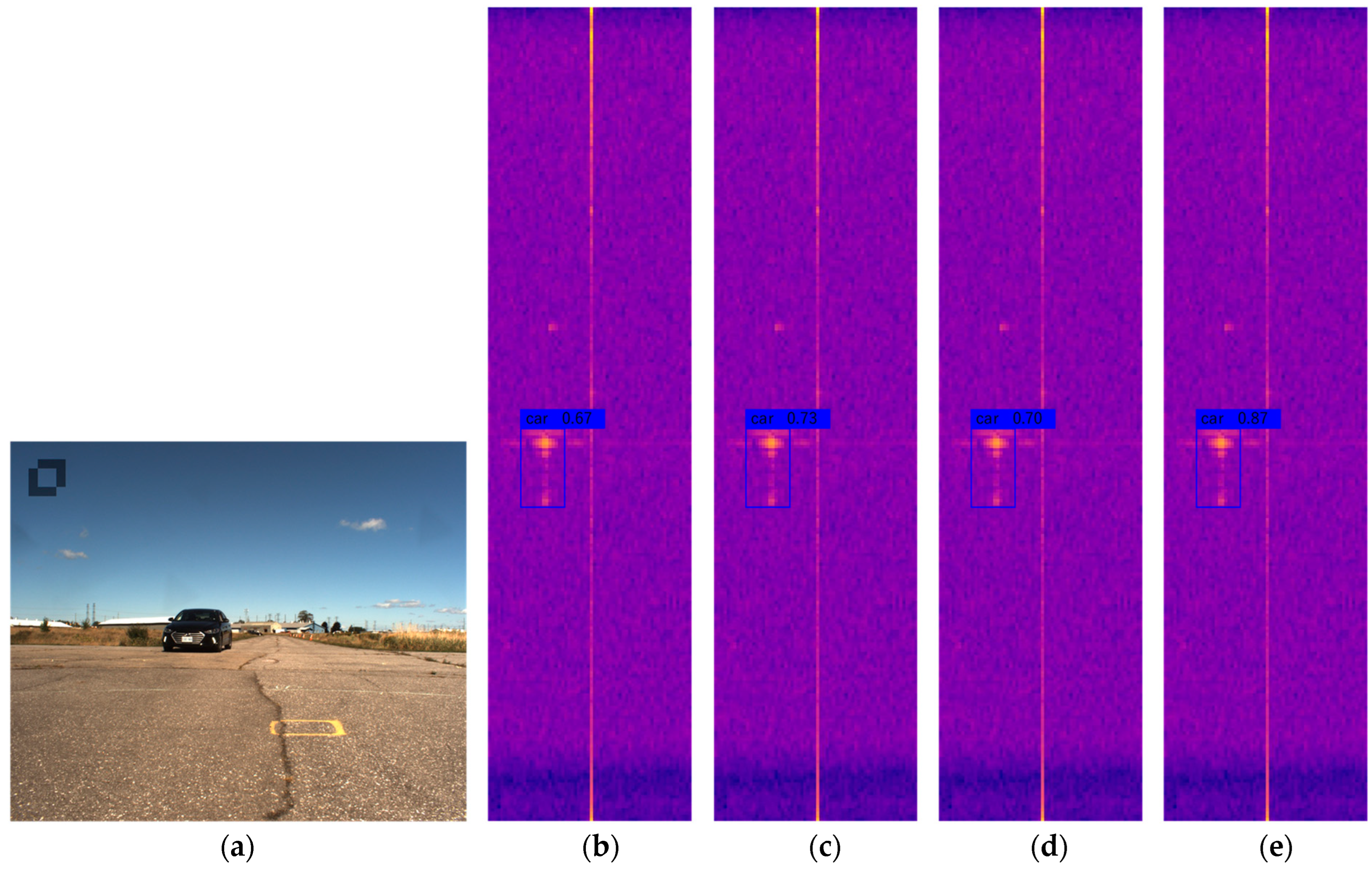
4.4. Analysis of Results
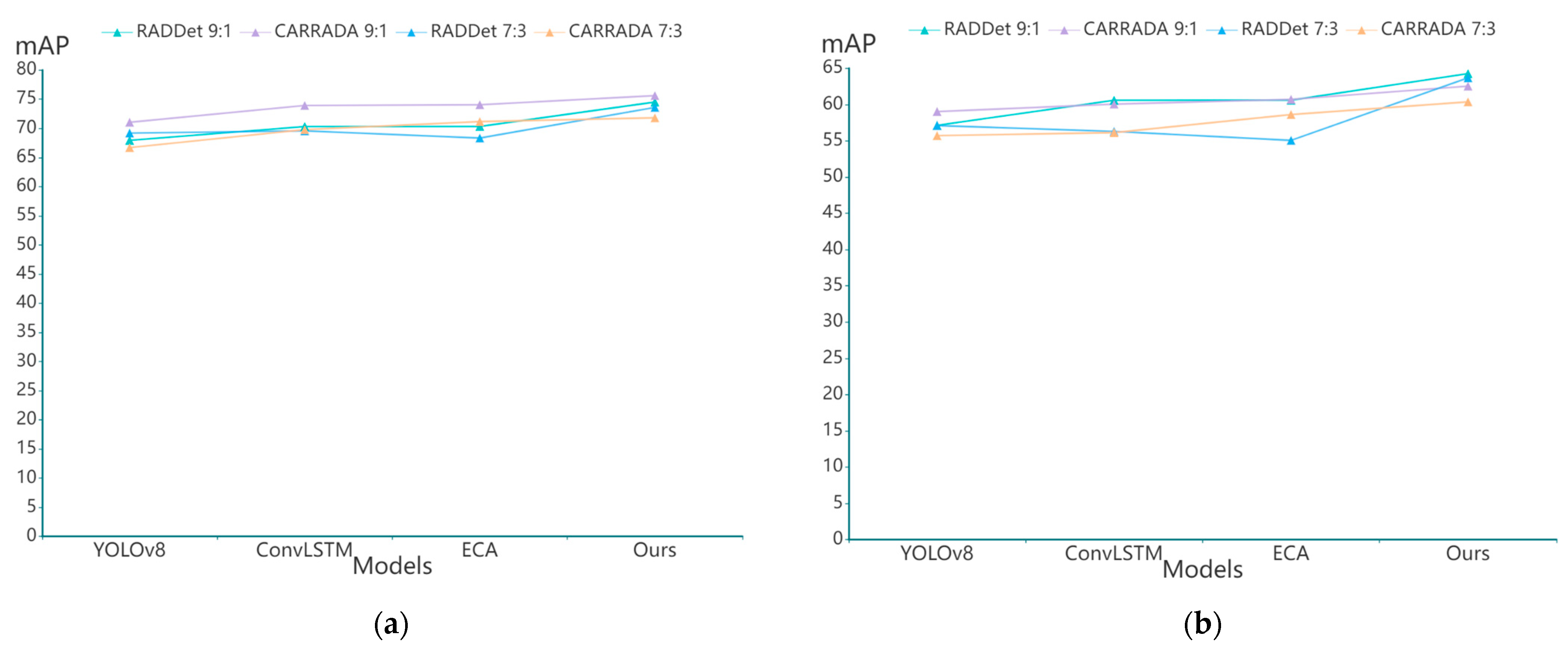
4.5. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gharineiat, Z.; Tarsha Kurdi, F.; Campbell, G. Review of Automatic Processing of Topography and Surface Feature Identification LiDAR Data Using Machine Learning Techniques. Remote Sens. 2022, 14, 4685. [Google Scholar] [CrossRef]
- Alaba, S.Y.; Ball, J.E. A Survey on Deep-Learning-Based LiDAR 3D Object Detection for Autonomous Driving. Sensors 2022, 22, 9577. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2022; pp. 4490–4499. [Google Scholar]
- Decourt, C.; VanRullen, R.; Salle, D. DAROD: A Deep Automotive Radar Object Detector on Range-Doppler maps. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium, Aachen, Germany, 5–9 June 2022; pp. 112–118. [Google Scholar]
- Zhang, A.; Nowruzi, F.E.; Laganiere, R. RADDet: Range-Azimuth-Doppler based radar object detection for dynamic road users. In Proceedings of the 2021 18th Conference on Robots and Vision, Beijing, China, 18–22 August 2021; pp. 95–102. [Google Scholar]
- Ouaknine, A.; Newson, A.; Rebut, J.; Tupin, F.; Pérez, P. CARRADA Dataset: Camera and Automotive Radar with Range-Angle-Doppler Annotations. In Proceedings of the 2020 25th International Conference on Pattern Recognition, Milan, Italy, 13–18 September 2020; pp. 5068–5075. [Google Scholar]
- Liu, Y.; Zhang, S.; Suo, J.; Zhang, J.; Yao, T. Research on a new comprehensive CFAR (comp-CFAR) processing method. IEEE Access 2019, 7, 19401–19413. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Samaras, S.; Diamantidou, E.; Ataloglou, D.; Sakellariou, N.; Vafeiadis, A.; Magoulianitis, V.; Lalas, A.; Dimou, A.; Zarpalas, D.; Votis, K.; et al. Deep Learning on Multi Sensor Data for Counter UAV Applications—A Systematic Review. Sensors 2019, 19, 4837. [Google Scholar] [CrossRef]
- Kronauge, M.; Rohling, H. Fast two-dimensional CFAR procedure. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 1817–1823. [Google Scholar] [CrossRef]
- El-Darymli, K.; McGuire, P.; Power, D.; Moloney, C. Target detection in synthetic aperture radar imagery: A state-of-the-art survey. Remote Sens. 2013, 7, 071598. [Google Scholar]
- Kulpa, K.S.; Czekała, Z. Masking effect and its removal in PCL radar. IEE Proc.-Radar Sonar Navig. 2005, 152, 174–178. [Google Scholar] [CrossRef]
- Hansen, V.; Sawyers, J. Detectability loss due to “greatest of” selection in a cell-averaging CFAR. IEEE Trans. Aerosp. Electron. Syst. 1980, 16, 115–118. [Google Scholar] [CrossRef]
- Trunk, G. Range resolution of targets using automatic detectors. IEEE Trans. Aerosp. Electron. Syst. 1978, 14, 750–755. [Google Scholar] [CrossRef]
- Smith, M.; Varshney, P. Intelligent CFAR processor based on data variability. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 837–847. [Google Scholar] [CrossRef]
- Blake, S. OS-CFAR theory for multiple targets and nonuniform clutter. IEEE Trans. Aerosp. Electron. Syst. 1988, 24, 785–790. [Google Scholar] [CrossRef]
- Gandhi, P.; Kassam, S. Analysis of CFAR processors in homogeneous background. IEEE Trans. Aerosp. Electron. Syst. 1988, 24, 427–445. [Google Scholar] [CrossRef]
- Wang, P.; Wang, L.; Leung, H.; Zhang, G. Super-resolution mapping based on spatial–spectral correlation for spectral imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2256–2268. [Google Scholar] [CrossRef]
- Shang, X.; Song, M.; Wang, Y.; Yu, C.; Yu, H.; Li, F.; Chang, C.I. Target-constrained interference-minimized band selection for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6044–6064. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, J.; Yang, D.; Xu, L.; Jia, F. Cascaded Convolutional Neural Network-Based Hyperspectral Image Resolution Enhancement via an Auxiliary Panchromatic Image. IEEE Trans. Image Process. 2021, 30, 6815–6828. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A.J. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M.J. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Li, C.; Li, L.; Jiang, H. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Hsu, H.W.; Lin, Y.C.; Lee, M.C.; Lin, C.H.; Lee, T.S. Deep learning-based range-doppler map reconstruction in automotive radar systems. In Proceedings of the IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–7. [Google Scholar]
- Su, N.; Chen, X.; Guan, J.; Huang, Y. Maritime target detection based on radar graph data and graph convolutional network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4019705. [Google Scholar] [CrossRef]
- Wang, C.; Tian, J.; Cao, J.; Wang, X. Deep learning-based UAV detection in pulse-Doppler radar. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5105612. [Google Scholar] [CrossRef]
- Jing, H.; Cheng, Y.; Wu, H.; Wang, H. Radar target detection with multi-task learning in heterogeneous environment. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4021405. [Google Scholar] [CrossRef]
- Wen, L.; Ding, J.; Xu, Z. Multiframe detection of sea-surface small target using deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5107116. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, L.; Xie, Y.; Li, J.; Hu, T.; Zhu, J.; Song, C.; Xu, Z. A target detection scheme with decreased complexity and enhanced performance for range-Doppler FMCW radar. IEEE Trans. Instrum. Meas. 2020, 70, 8001113. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, Z.; Li, Y.; Hwang, J.N.; Xing, G.; Liu, H. RODNet: A real-time radar object detection network cross-supervised by camera-radar fused object 3D localization. IEEE J. Sel. Top. Signal Process. 2021, 15, 954–967. [Google Scholar] [CrossRef]
- Ng, W.; Wang, G.; Lin, Z.; Dutta, B.J. Range-Doppler detection in automotive radar with deep learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19 July 2020; pp. 1–8. [Google Scholar]
- Pérez, R.; Schubert, F.; Rasshofer, R.; Biebl, E. Deep learning radar object detection and classification for urban automotive scenarios. In Proceedings of the 2019 Kleinheubach Conference, Kleinheubach, Germany, 4 November 2019; pp. 1–4. [Google Scholar]
- Franceschi, R.; Rachkov, D. Deep learning-based radar detector for complex automotive scenarios. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 5–9 June 202; pp. 303–308.
- Decourt, C.; VanRullen, R.; Salle, D.; Oberlin, T. A recurrent CNN for online object detection on raw radar frames. arXiv 2022, arXiv:2212.11172. [Google Scholar]
- Lin, Z.; Li, M.; Zheng, Z.; Chen, Y.; Yuan, C. Self-attention convlstm for spatiotemporal prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11531–11538. [Google Scholar]
- Song, H.; Wang, W.; Zhao, S.; Shen, J.; Lam, K.M. Pyramid dilated deeper convlstm for video salient object detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 715–731. [Google Scholar]
- Islam, Z.; Rukonuzzaman, M.; Ahmed, R.; Kabir, M.H.; Farazi, M. Efficient two-stream network for violence detection using separable convolutional lstm. In Proceedings of the 2021 International Joint Conference on Neural Networks, Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE/CVF CVPR 2020, Seattle, WA, USA, 14–18 June 2020; pp. 11534–11542. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Categories | Quantity | Train | 9:1 Validation | Test | Train | 7:3 Validation | Test |
|---|---|---|---|---|---|---|---|---|
| RADDet | person | 4707 | ||||||
| bicycle | 654 | |||||||
| car | 12,179 | |||||||
| truck | 2764 | 8227 | 915 | 1016 | 6399 | 711 | 3048 | |
| motorcycle | 56 | |||||||
| bus | 154 | |||||||
| CARRADA | pedestrian | 2908 | ||||||
| cyclist | 1595 | 5826 | 647 | 720 | 4531 | 504 | 2158 | |
| car | 3375 |
| Environment | Versions or Model Number |
|---|---|
| CPU | i7-1165G7 |
| GPU | RTX 2080Ti |
| OS | Windows 10 |
| Python | 3.6.13 |
| Pytorch | 1.10.2 |
| Torchvision | 0.11.3 |
| OpenCV-Python | 4.1.2.30 |
| Input Size | Optimizer | Momentum | Batch Size | Epoch | Learning Rate | Training and Test Set Radio |
|---|---|---|---|---|---|---|
| 640 × 640 | SGD | 0.937 | 4 | 300 | 1 × 10−3 | 9:1 |
| 640 × 640 | SGD | 0.937 | 4 | 300 | 1 × 10−3 | 7:3 |
| Dataset | Model | mAP | IOU 0.3 P | R | mAP | IOU 0.5 P | R | Paras (M) | GFLOPs (G) | FPS (ms) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RADDet | Faster RCNN | 56.47 | 52.17 | 56.92 | 49.55 | 47.78 | 51.77 | 41.3 | 60.1 | 26.9 | 607 | 68 |
| YOLOv5 | 51.98 | 75.57 | 33.5 | 41.71 | 66.21 | 30.21 | 7.1 | 16.5 | 41.6 | 223 | 15 | |
| YOLOv7 | 69.76 | 85.69 | 45.68 | 58.1 | 75.67 | 46.62 | 37.2 | 105.2 | 34.4 | 457 | 32 | |
| YOLOv7tiny | 64.07 | 83.8 | 42.46 | 54.62 | 80.57 | 39.36 | 6.0 | 13.2 | 66.2 | 236 | 12 | |
| YOLOv8 | 67.94 | 94.26 | 29.76 | 57.13 | 91.56 | 29.13 | 25.9 | 79.1 | 41.1 | 294 | 31 | |
| RADDet | 38.42 | 78.2 | 29.77 | 22.87 | 60.41 | 20.55 | 7.8 | 5.0 | 13.5 | 621 | 54 | |
| DAROD | 65.56 | 82.31 | 47.78 | 46.57 | 68.23 | 38.74 | 3.4 | 6.8 | 39.5 | 286 | 20 | |
| Ours | 74.51 | 89.94 | 45.95 | 64.26 | 86.63 | 44.46 | 25.9 | 82 | 29.8 | 291 | 20 | |
| CARRADA | Faster RCNN | 65.08 | 51.7 | 72.97 | 61.56 | 47.86 | 67.21 | 41.3 | 60.1 | 26.9 | 596 | 57 |
| YOLOv5 | 49.08 | 76.69 | 31.11 | 40.16 | 65.68 | 29.76 | 7.1 | 16.5 | 41.6 | 199 | 14 | |
| YOLOv7 | 70.0 | 82.98 | 28.21 | 59.38 | 78.68 | 21.86 | 37.2 | 105.2 | 34.3 | 442 | 29 | |
| YOLOv7tiny | 64.37 | 86.32 | 26.66 | 55.46 | 77.88 | 34.36 | 6.0 | 13.2 | 66.2 | 230 | 20 | |
| YOLOv8 | 71.04 | 88.05 | 27.34 | 59.03 | 91.25 | 26.68 | 25.9 | 79.1 | 46.2 | 280 | 23 | |
| RADDet | 48.59 | 61.31 | 42.56 | 18.57 | 36.73 | 25.5 | 7.8 | 5.0 | 13.5 | 615 | 47 | |
| DAROD | 70.68 | 76.73 | 52.52 | 55.83 | 68.34 | 46.03 | 3.4 | 6.8 | 39.5 | 272 | 19 | |
| Ours | 75.62 | 94.54 | 38.29 | 62.54 | 90.55 | 33.47 | 25.9 | 82 | 30.6 | 253 | 18 |
| Dataset | Model | mAP | IOU 0.3 P | R | mAP | IOU 0.5 P | R | Paras (M) | GFLOPs (G) | FPS (ms) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RADDet | Faster RCNN | 53.99 | 50.53 | 55.67 | 49.01 | 47.92 | 50.65 | 41.3 | 60.1 | 26.9 | 636 | 73 |
| YOLOv5 | 52.02 | 74.86 | 33.35 | 42.27 | 63.67 | 31.51 | 7.1 | 16.5 | 41.6 | 194 | 16 | |
| YOLOv7 | 67.19 | 82.96 | 46.83 | 57.01 | 73.7 | 48.52 | 37.2 | 105.2 | 34.4 | 426 | 35 | |
| YOLOv7tiny | 62.18 | 83.6 | 40.13 | 54.36 | 79.1 | 38.96 | 6.0 | 13.2 | 66.2 | 264 | 29 | |
| YOLOv8 | 69.19 | 86.81 | 37.6 | 57.1 | 83.44 | 39.86 | 25.9 | 79.1 | 41.1 | 294 | 31 | |
| RADDet | 37.5 | 77.42 | 28.79 | 22.1 | 58.87 | 21.63 | 7.8 | 5.0 | 13.5 | 618 | 55 | |
| DAROD | 63.65 | 79.1 | 45.19 | 45.38 | 66.8 | 37.04 | 3.4 | 6.8 | 39.5 | 281 | 23 | |
| Ours | 73.6 | 89.17 | 44.21 | 63.68 | 83.09 | 46.52 | 25.9 | 82 | 29.8 | 283 | 24 | |
| CARRADA | Faster RCNN | 66.21 | 46.98 | 69.15 | 61.44 | 45.38 | 63.86 | 41.3 | 60.1 | 26.9 | 587 | 62 |
| YOLOv5 | 50.24 | 75.35 | 34.07 | 41.36 | 65.99 | 28.81 | 7.1 | 16.5 | 41.6 | 179 | 15 | |
| YOLOv7 | 67.8 | 81.61 | 29.04 | 56.75 | 77.92 | 20.11 | 37.2 | 105.2 | 34.3 | 399 | 32 | |
| YOLOv7tiny | 62.89 | 81.57 | 24.16 | 54.71 | 74.61 | 30.1 | 6.0 | 13.2 | 66.2 | 190 | 18 | |
| YOLOv8 | 66.7 | 75.8 | 31.37 | 55.71 | 86.08 | 27.53 | 25.9 | 79.1 | 46.2 | 282 | 25 | |
| RADDet | 46.72 | 60.27 | 40.3 | 18.46 | 35.19 | 24.44 | 7.8 | 5.0 | 13.5 | 609 | 45 | |
| DAROD | 66.56 | 74.31 | 50.68 | 51.8 | 65.34 | 46.62 | 3.4 | 6.8 | 39.5 | 257 | 19 | |
| Ours | 71.81 | 92.9 | 37.54 | 60.37 | 88.19 | 32.17 | 25.9 | 82 | 30.6 | 260 | 22 |
| Dataset | Model | mAP | IOU 0.3 P | R | mAP | IOU 0.5 P | R | Paras (M) | GFLOPs (G) | FPS (ms) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RADDet | YOLOv8 | 67.94 | 94.26 | 29.76 | 57.13 | 91.56 | 29.13 | 25.86 | 79.08 | 41.12 | 294 | 31 |
| ConvLSTM | 70.32 | 92.32 | 44.5 | 60.59 | 93.86 | 36.36 | 25.92 | 82.01 | 29.99 | 287 | 18 | |
| ECA | 70.33 | 95.67 | 41.12 | 60.6 | 92.39 | 39.99 | 25.86 | 79.09 | 39.56 | 300 | 19 | |
| Ours | 74.51 | 89.94 | 45.95 | 64.26 | 86.63 | 44.46 | 25.92 | 82.01 | 29.81 | 291 | 20 | |
| CARRADA | YOLOv8 | 71.04 | 88.05 | 27.34 | 59.03 | 91.25 | 26.68 | 25.86 | 79.08 | 46.17 | 280 | 23 |
| ConvLSTM | 73.93 | 93.35 | 32.57 | 60.06 | 88 | 24.53 | 25.92 | 82.01 | 29.96 | 254 | 18 | |
| ECA | 74.05 | 93.08 | 32.29 | 60.71 | 89.75 | 31.04 | 25.86 | 79.09 | 41.68 | 260 | 18 | |
| Ours | 75.62 | 94.54 | 38.29 | 62.54 | 90.55 | 33.47 | 25.92 | 82.01 | 30.62 | 253 | 18 |
| Dataset | Model | mAP | IOU 0.3 P | R | mAP | IOU 0.5 P | R | Paras (M) | GFLOPs (G) | FPS (ms) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RADDet | YOLOv8 | 69.19 | 86.81 | 37.6 | 57.1 | 83.44 | 39.86 | 25.86 | 79.08 | 41.12 | 294 | 31 |
| ConvLSTM | 69.57 | 90.8 | 43.03 | 56.29 | 83.65 | 40.24 | 25.92 | 82.01 | 29.99 | 285 | 26 | |
| ECA | 68.34 | 92.08 | 46.59 | 55.06 | 86.06 | 43.58 | 25.86 | 79.09 | 39.56 | 287 | 29 | |
| Ours | 73.6 | 89.17 | 44.21 | 63.68 | 83.09 | 46.52 | 25.92 | 82.01 | 29.81 | 283 | 24 | |
| CARRADA | YOLOv8 | 66.7 | 75.8 | 31.37 | 55.71 | 86.08 | 27.53 | 25.86 | 79.08 | 46.17 | 282 | 25 |
| ConvLSTM | 69.79 | 89.82 | 30.91 | 56.13 | 86.65 | 23.19 | 25.92 | 82.01 | 29.96 | 247 | 24 | |
| ECA | 71.16 | 90.66 | 33.29 | 58.62 | 91.91 | 30.8 | 25.86 | 79.09 | 41.68 | 256 | 20 | |
| Ours | 71.81 | 92.9 | 37.54 | 60.37 | 88.19 | 32.17 | 25.92 | 82.01 | 30.62 | 260 | 22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, F.; Tan, J.; Lu, X.; Qian, J. Radar Timing Range–Doppler Spectral Target Detection Based on Attention ConvLSTM in Traffic Scenes. Remote Sens. 2023, 15, 4150. https://doi.org/10.3390/rs15174150
Jia F, Tan J, Lu X, Qian J. Radar Timing Range–Doppler Spectral Target Detection Based on Attention ConvLSTM in Traffic Scenes. Remote Sensing. 2023; 15(17):4150. https://doi.org/10.3390/rs15174150
Chicago/Turabian StyleJia, Fengde, Jihong Tan, Xiaochen Lu, and Junhui Qian. 2023. "Radar Timing Range–Doppler Spectral Target Detection Based on Attention ConvLSTM in Traffic Scenes" Remote Sensing 15, no. 17: 4150. https://doi.org/10.3390/rs15174150
APA StyleJia, F., Tan, J., Lu, X., & Qian, J. (2023). Radar Timing Range–Doppler Spectral Target Detection Based on Attention ConvLSTM in Traffic Scenes. Remote Sensing, 15(17), 4150. https://doi.org/10.3390/rs15174150